Decentralized Optimization Over the Stiefel Manifold by an Approximate Augmented Lagrangian Function
Abstract
In this paper, we focus on the decentralized optimization problem over the Stiefel manifold, which is defined on a connected network of agents. The objective is an average of local functions, and each function is privately held by an agent and encodes its data. The agents can only communicate with their neighbors in a collaborative effort to solve this problem. In existing methods, multiple rounds of communications are required to guarantee the convergence, giving rise to high communication costs. In contrast, this paper proposes a decentralized algorithm, called DESTINY, which only invokes a single round of communications per iteration. DESTINY combines gradient tracking techniques with a novel approximate augmented Lagrangian function. The global convergence to stationary points is rigorously established. Comprehensive numerical experiments demonstrate that DESTINY has a strong potential to deliver a cutting-edge performance in solving a variety of testing problems.
1 Introduction
This paper is dedicated to providing an efficient approach to the decentralized optimization with orthogonality constraints, a problem defined on a connected network and solved by agents cooperatively.
| (1.1) | ||||
where is the identity matrix, and is a local function privately known by the -th agent. The set of all orthogonal matrices is referred to as Stiefel manifold [37], which is denoted by . Throughout this paper, we make the following blanket assumptions about these local functions.
Assumption 1.
Each local objective function is smooth and its gradient is locally Lipschitz continuous.
We consider the scenario that the agents can only exchange information with their immediate neighbors through the network, which is modeled as a connected undirected graph . Here, is composed of all the agents and denotes the set of all the communication links. Let be the local copy of the common variable kept by the -th agent. Then the optimization problem (1.1) over the Stiefel manifold can be equivalently recast as the following decentralized formulation.
| (1.2a) | ||||
| (1.2b) | ||||
| (1.2c) | ||||
Since the graph is assumed to be connected, the constraints (1.2b) enforce the consensus condition , which guarantees the equivalence between (1.1) and (1.2). Due to the nonconvexity of Stiefel manifolds, it is challenging to design efficient algorithms to solve (1.2).
1.1 Broad applications
Problems of the form (1.1) that require decentralized computations are found widely in various scientific and engineering areas. We briefly describe several representative applications of it below.
Application 1: Principal Component Analysis.
The principal component analysis (PCA) is a basic and ubiquitous tool for dimensionality reduction serving as a critical procedure or preprocessing step in numerous statistical and machine learning tasks. Mathematically, PCA amounts to solving the following optimization problem.
| (1.3) | ||||
where is the data matrix consisting of samples with features. In the decentralized setting, represents the local data stored in the -th agent such that . This is a natural scenario since each sample is a column of .
Application 2: Orthogonal Least Squares Regression.
The orthogonal least squares regression (OLSR) proposed in [52] is a supervised learning method for feature extraction in linear discriminant analysis. Suppose we have samples with features drawn from classes. Then OLSR identifies an orthogonal transformation by solving the following problem.
| (1.4) | ||||
where and are two matrices constructed by samples. Under the decentralized scenario, and are local data and corresponding class indicator matrix stored in the -th agent, respectively. Here, . As claimed in [52], enforcing the orthogonality on transformation matrices is conducive to preserve local structure and discriminant information.
Application 3: Sparse Dictionary Learning.
Sparse dictionary learning (SDL) is a classical unsupervised representation learning method, which finds wide applications in signal and image processing due to its powerful capability of exploiting low-dimensional structures in high-dimensional data. Motivated by the fact that maximizing a high-order norm promotes spikiness and sparsity simultaneously, the authors of [50] introduce the following -norm maximization problem with orthogonality constraints for SDL.
| (1.5) | ||||
where is the data matrix consisting of samples with features, and the -norm is defined as . In the decentralized setting, is the local data stored in the -th agent such that .
1.2 Literature survey
Recent years have witnessed the development of algorithms for optimization problems over the Stiefel manifold, including gradient descent approaches [24, 28, 1, 3], conjugate gradient approaches [9, 33, 53], constraint preserving updating schemes [41, 20], Newton methods [19, 18], trust-region methods [2], multipliers correction frameworks [13, 38], augmented Lagrangian methods [14], sequential linearized proximal gradient algorithms [45], and so on. Moreover, exact penalty models are constructed for this special type of problems, such as PenC [44] and ExPen [43]. Efficient infeasible algorithms can be designed based on these two models. Unfortunately, none of the above algorithms take the decentralized optimization into account.
Recently, several distributed ADMM algorithms designed for centralized networks have emerged to solve various variants of PCA problems [39, 40], which pursue a consensus on the subspaces spanned by splitting variables. This strategy relaxes feasibility restrictions and significantly improves the convergence. However, these algorithms can not be straightforwardly extended to the decentralized setting.
Decentralized optimization in the Euclidean space has been adequately investigated in recent decades. Most existing algorithms adapt classical Euclidean methods to the decentralized setting. For instance, in the decentralized gradient descent (DGD) method [27], each agent combines the average of its neighbors with a local negative gradient step. DGD can only converge to a neighborhood of a solution with a constant stepsize, and it has to employ diminishing stepsizes to obtain an exact solution at the cost of slow convergence [48, 49]. To cope with this speed-accuracy dilemma of DGD, EXTRA [36] corrects the convergence error by introducing two different mixing matrices (to be defined in Subsection 2.1) for two consecutive iterations and leveraging their difference to update local variables. And decentralized gradient tracking (DGT) algorithms [46, 30, 26] introduce an auxiliary variable to maintain a local estimate of the global gradient descent direction. Both EXTRA and DGT permit the use of a constant stepsize to attain an exact solution without sacrificing the convergence rate. The above three types of algorithms are originally tailored for unconstrained problems. Their constrained versions, such as [31, 8, 35], are still incapable of solving (1.2) since they can only deal with convex constraints. Another category of methods is based on the primal-dual framework, including decentralized augmented Lagrangian methods [17, 16] and decentralized ADMM methods [4, 22, 23]. In the presence of nonconvex constraints, these algorithms are not applicable to (1.2) either.
As a special case of (1.2), a considerable amount of effort has been devoted to developing algorithms for decentralized PCA problems. For instance, a decentralized ADMM algorithm is proposed in [34] based on the low-rank matrix approximation model. And [12] develops a decentralized algorithm called DSA and its accelerated version ADSA by adopting a similar update formula of DGD to an early work of training neural networks [32]. The linear convergence of DSA to a neighborhood of a solution is established in [11], but ADSA does not yet have theoretical guarantees. Moreover, [10] further introduces a decentralized version of an early work for online PCA [21], which enjoys the exact and linear convergence. Recently, [47] combines gradient tracking techniques with subspace iterations to develop an exact algorithm DeEPCA with a linear convergence rate. Generally speaking, it is intractable to extend these algorithms to generic cases.
In a word, all the aforementioned approaches can not be employed to solve (1.2). In fact, the investigation of decentralized optimization over the Stiefel manifold is relatively limited. To the best of our knowledge, there is only one work [5] targeting at this specific type of problem, which extends DGD and DGT from the Euclidean space to the Stiefel manifold. The resulting algorithms are called DRSGD and DRGTA, respectively. Analogous to the Euclidean setting, DRGTA can achieve the exact convergence with constant stepsizes, but DRSGD can not. For these two algorithms, a communication bottleneck arises from multiple consensus steps, namely, multiple rounds of communications per iteration, making them difficult to acquire a practical application in large-scale networks. As illustrated in [6], one local consensus step requires approximately one-third or one-half the communication overheads of a global averaging operation under a certain practical scenario. Consequently, multiple consensus steps will incur intolerably high communication budgets, thereby hindering the scalability of decentralized algorithms. Furthermore, an extra consensus stepsize, which is less than , is introduced in DRSGD and DRGTA, significantly slowing down the convergence. In fact, the above two requirements are imposed to control the consensus error on Stiefel manifolds. The nonconvexity of triggers off an enormous difficulty in seeking a consensus on it.
1.3 Contributions
This paper develops an infeasible decentralized approach, called DESTINY, to the problem (1.2), which invokes only a single round of communications per iteration and gets rid of small consensus stepsizes. These two goals are achieved with the help of a novel approximate augmented Lagrangian function. It enables us to use unconstrained algorithms to solve the problem (1.2) and hence tides us over the obstacle to reaching a consensus on Stiefel manifolds. The potential of this function is not limited to the decentralized setting. It can serve as a penalty function for optimization problems over the Stiefel manifold, which is of independent interest.
Although DESTINY is based on the gradient tracking technique, existing convergence results are not applicable. We rigorously establish the global convergence to stationary points with the worst case complexity under rather mild conditions. All the theoretical analysis is applicable to the special case of . Therefore, as a by-product, DESTINY boils down to a new algorithm in the non-distributed setting.
Preliminary numerical experiments, conducted under the distributed environment, validate the effectiveness of our approximate augmented Lagrangian function and demonstrate the robustness to penalty parameters. In addition, for the first time, we find that BB stepsizes can accelerate the convergence of decentralized algorithms for optimization problems over the Stiefel manifold. Finally, extensive experimental results indicate that our algorithm requires far fewer rounds of communications than what are required by existing peer methods.
1.4 Notations
The Euclidean inner product of two matrices with the same size is defined as , where stands for the trace of a square matrix . And the notation represents the symmetric part of . The Frobenius norm and 2-norm of a given matrix is denoted by and , respectively. The -th entry of a matrix is represented by . The notation stands for the -dimensional vector of all ones. The Kronecker product is denoted by . Given a differentiable function , the gradient of with respect to is represented by . Further notation will be introduced wherever it occurs.
1.5 Outline
The rest of this paper is organized as follows. In Section 2, we introduce an approximate augmented Lagrangian function and devise a novel decentralized algorithm for (1.2). Moreover, Section 3 is dedicated to investigating the convergence properties of the proposed algorithm. Numerical experiments on a variety of test problems are presented in Section 4 to evaluate the performance of the proposed algorithm. We draw final conclusions and discuss some possible future developments in the last section.
2 Algorithm Development
In this section, some preliminaries are first introduced, including first-order stationarity conditions and mixing matrices. Then we propose a novel approximate augmented Lagrangian function to deal with nonconvex orthogonality constraints. From this foundation, we further devise an efficient infeasible decentralized approach to optimization problems over the Stiefel manifold.
2.1 Preliminaries
To facilitate the narrative, we first introduce the stationarity conditions. As discussed in [3, 38], the definition of first-order stationary points of (1.1) can be stated as follows.
Definition 2.1.
In addition, the structure of the communication network is associated with a mixing matrix , which conforms to the underlying graph topology. The mixing matrix plays an essential role in the development of decentralized algorithms. We assume that satisfies the following properties, which are standard in the literature.
Assumption 2.
The mixing matrix satisfies the following conditions.
-
(i)
is symmetric.
-
(ii)
is doubly stochastic, namely, is nonnegative and .
-
(iii)
if and .
Typically, decentralized algorithms rely on the mixing matrix to diffuse information throughout the network, which has a few common choices. We refer interested readers to [42, 36] for more details. According to the Perron-Frobenius Theorem [29], we know that the eigenvalues of lie in and
| (2.1) |
The parameter measures the connectedness of networks and plays a prominent part in the analysis of gradient tracking based methods.
2.2 Approximate augmented Lagrangian function
As mentioned earlier, it is quite difficult to seek a consensus on the Stiefel manifold, which motivates us to devise an infeasible decentralized algorithm for the problem (1.2). The renowned augmented Lagrangian method is a natural choice. Therefore, the story behind our algorithm starts from the augmented Lagrangian function of optimization problems over the Stiefel manifold, which is of the following form.
where consists of the corresponding Lagrangian multipliers and is the penalty parameter. However, the presence of multipliers brings the difficulties in both algorithmic design and theoretical analysis.
In fact, the Lagrangian multipliers , as discussed in [38], admit the following closed-form expression at any first-order stationary point of (1.1).
| (2.2) |
The second term of with the above expression of can be rewritten as the following form.
Then in light of the Taylor expansion, we have the following approximation.
| (2.3) |
Now we replace the second term of with the left hand side of (2.3), and then obtain the following function.
where
We call it approximate augmented Lagrangian function. The multiplier is updated implicitly by the closed form expression (2.2) in this function , and hence, we can design an infeasible algorithm entirely in the primal formulation.
Now we discuss the gradient of that can be easily computed as follows.
where
Clearly, the gradient of should be evaluated twice at different points and in , which gives rise to additional computational costs. In order to alleviate this difficulty, we use the following direction to approximate .
For convenience, we denote
As an approximation of , possesses the following desirable properties.
Lemma 2.2.
Let be a bounded region and be a positive constant. Then if , we have
for any .
Proof.
Suppose is the smallest singular value of . Then for any , we have and , and hence,
Moreover, simple algebraic manipulations give us
which yields that
Now it can be readily verifies that
which together with completes the proof. ∎
Lemma 2.2 reveals that the orthogonality violation of is controlled by the squared norm of as long as and is sufficiently large. And it is worthy of mentioning that when . In fact, can play the part of a penalty function for optimization problems over the Stiefel manifold, which is of interest for a future investigation.
2.3 Algorithm description
Inspired by Lemma 2.2, we can devise a decentralized algorithm such that the iterates are restricted in the bounded region and asymptotically vanishes.
Under the decentralized setting, the computation of can be distributed into agents as follows.
where , and
Clearly, only local gradient is involved in the expression of , which signifies that the evaluation of can be accomplished by the -th agent individually. Consequently, can act as a local descent direction. We can employ gradient tracking techniques to estimate the average of these local descent directions. The resulting algorithm is summarized in Algorithm 1, named decentralized Stiefel algorithm by an approximate augmented Lagrangian penalty function and abbreviated to DESTINY.
Our algorithm consists of two procedures, namely, updating local variables and tracking global descent directions. Unlike DRGTA [5], in each procedure, our algorithm only performs one consensus step per iteration. These two operations can be realized in a single round of communications to reduce the latency. In addition, our algorithm does not involve an extra consensus stepsize.
For the sake of convenience, we now define the following averages of local variables.
-
•
.
-
•
.
-
•
.
Then it is not difficult to check that, for any , the following relationships hold.
| (2.4) |
Moreover, we denote , , and . The following stacked notations are also used in the sequel.
-
•
, .
-
•
, .
-
•
, .
By virtue of the above notations, we have . And the main iteration loop of Algorithm 1 can be summarized as the following compact form.
3 Convergence Analysis
Existing convergence guarantees of gradient tracking based algorithms, such as [7], are constructed for globally Lipschitz smooth and coercive functions, which are restrictive for (1.2) since is compact. In this section, the global convergence of Algorithm 1 is rigorously established under rather mild conditions. The objective function is only assumed to be locally Lipschitz smooth (see Assumption 1). The worst case complexity is also provided.
All the special constants to be used in this section are listed below. We divide these constants into two categories. Recall that is a bounded set defined in Lemma 2.2 and is a constant defined in (2.1). And we define .
-
•
Category I:
(3.1) -
•
Category II:
(3.2)
The first category of constants defined in (3.1) is independent of , while the second category in (3.2) is not. In order to establish the global convergence of Algorithm 1, we need to impose several mild conditions on and . To facilitate the narrative, we first state all these conditions here.
Assumption 3.
We make the following assumptions about and .
-
(i)
The penalty parameter satisfies
-
(ii)
The stepsize satisfies
where
The conditions in Assumption 3 are introduced for theoretical analysis. The parameters and satisfying these conditions are usually restrictive in practical use.
3.1 Boundedness of iterates
The purpose of this subsection is to show that the sequence generated by Algorithm 1 is bounded and is restricted in the bounded region . We first prove the following technical lemma.
Lemma 3.1.
Proof.
Since , we have . Then it can be readily verified that
Moreover, it follows from (2.4) that
where and satisfies
Then by straightforward calculations, we can obtain that
This further implies that
where the last equality follows from . Now we consider the above relationship in the following two cases.
Case I: .
Since , we have
Case II: .
It can be readily verified that
which together with and yields that
Hence, we arrive at . Combing the above two cases, we complete the proof. ∎
Based on Lemma 3.1, we can prove the main results of this subsection.
Proposition 3.2.
Proof.
We use mathematical induction to prove this proposition. The argument (3.3) directly holds at resulting from the initialization. Now, we assume that this argument holds at , and investigate the situation at .
Our first purpose is to show that . By straightforward calculations, we can attain that
which together with implies that
Then we aim to prove that and . According to Lemma 3.1, we have . And it follows that
as a result of the condition .
In order to finish the proof, we still have to show that . In fact, we have
which implies that
Moreover, it can be readily verified that
where the last inequality follows from . Combing the above two relationships, we can obtain that
which is followed by
Therefore, we can obtain that
The proof is completed. ∎
3.2 Sufficient descent of the merit function
In this subsection, we aim to prove the sufficient descent property of the merit function (to be defined later). Towards this end, we first build the upper bound of consensus error and gradient tracking error .
Lemma 3.3.
Proof.
By straightforward calculations, we can attain that
where is a constant defined in (3.1). This completes the proof since and . ∎
Lemma 3.4.
Proof.
At first, it is straightforward to verify that
| (3.4) | ||||
which further implies that
| (3.5) | ||||
We complete the proof since . ∎
Lemma 3.5.
Proof.
By straightforward calculations, we can attain that
where is a constant defined in (3.1). According to Proposition 3.2, the inequality holds for all . Hence, it follows that
Moreover, it can be readily verified that
According to Lemma 3.4, we have
where the last inequality follows from the condition . Combing the above relationships, we can obtain that
Moreover, it follows from the condition that the inequality
holds. The proof is completed. ∎
Next, we evaluate the descent property of the sequence .
Lemma 3.6.
Proof.
According to Proposition 3.2, we know that the inequality holds for any . Then it follows from the local Lipschitz continuity of that
where the last inequality follows from (3.5) and the condition . Moreover, we have
where the last inequality results from (3.5) and the condition . And straightforward manipulations give us
and
where the last inequality is implied by (3.4) and the condition . Combing the above relationships, we finally arrive at the assertion of this lemma. ∎
Proposition 3.7.
3.3 Global convergence
Finally, we can establish the global convergence of Algorithm 1 together with the worst case complexity.
Theorem 3.8.
Suppose the conditions in Assumptions 1, 2, and 3 hold. Let be the iterate sequence generated by Algorithm 1 with . Then has at least one accumulation point. Moreover, for any accumulation point , we have , where is a first-order stationary point of the problem (1.1). Finally, the following relationships hold, which results in the global sublinear convergence rate of Algorithm 1.
| (3.7) |
| (3.8) |
and
| (3.9) |
where is a constant.
Proof.
According to Lemma 3.2, we know that the sequence is bounded. Hence, the lower boundedness of is owing to the continuity of . Namely, there exists a constant such that for any . Then, it follows from Proposition 3.7 that the sequence is convergent and the following relationships hold.
| (3.10) |
According to the Bolzano-Weierstrass theorem, it follows that exists an accumulation point, say . The relationships in (3.10) imply that for some . Moreover, we have
which implies that is a first-order stationary point of (1.1). Finally, we prove that the relationships (3.7)-(3.9) hold. Indeed, it follows from Proposition 3.7 that
which implies the relationship (3.7). The other two relationships can be proved similarly. Therefore, we complete the proof. ∎
4 Numerical Simulations
In this section, the numerical performance of DESTINY is evaluated through comprehensive numerical experiments in comparison to state-of-the-art algorithms. The corresponding experiments are performed on a workstation with two Intel Xeon Gold 6242R CPU processors (at GHz) and 510GB of RAM under Ubuntu 20.04. All the tested algorithms are implemented in the Python language, and the communication is realized via the package mpi4py.
4.1 Test problems
In the numerical experiments, we test three types of problems, including PCA, OLSR and SDL, which are introduced in Subsection 1.1.
In the PCA problem (1.3), we construct the global data matrix (assuming without loss of generality) by its (economy-form) singular value decomposition as follows.
| (4.1) |
where both and are orthogonal matrices orthonormalized from randomly generated matrices, and is a diagonal matrix with diagonal entries
| (4.2) |
for a parameter that determines the decay rate of the singular values of . In general, smaller decay rates (with closer to 1) correspond to more difficult cases. Finally, the global data matrix is uniformly distributed into agents.
As for the OLSR problem (1.4) and SDL problem (1.5), we use real-world text and image datasets to construct the global data matrix, respectively.
Unless otherwise specified, the network is randomly generated based on the Erdos-Renyi graph with a fixed probability in the following experiments. And we select the mixing matrix to be the Metroplis constant edge weight matrix [36].
In our experiments, we collect and compare two performance measurements: (relative) substationarity violation defined by
and consensus error defined by
When presenting numerical results, we plot the decay of the above two measurements versus the round of communications.
4.2 Default settings
In this subsection, we determine the default settings for our algorithm. The corresponding experiments are performed on an Erdos-Renyi network with .
In the first experiment, we test the performances of DESTINY with different choices of stepsizes. Classical strategies for choosing stepsizes, such as line search, are not applicable in the decentralized setting. Recently, BB stepsizes have been introduced to the decentralized optimization for strongly convex problems [15]. In order to improve the performance of DESTINY, we intend to apply the following BB stepsizes.
where , and . As illustrated in Figure 1, the above BB stepsizes can significantly enhance the efficiency of DESTINY. Hence, in subsequent experiments, we equip DESTINY with BB stepsizes by default. To the best of our knowledge, this is the first attempt, for nonconvex optimization problems, to accelerate the convergence of decentralized algorithms by BB stepsizes.


Next, we present that our algorithm is not sensitive to the penalty parameter . Figure 2 depicts the performances of DESTINY with different values of which are distinguished by colors. In Figure 2(c), the y-axis depicts the feasibility violation in the logarithmic scale, which is defined by:
We can observe that the curves of substationarity violations, consensus errors, and feasibility violations almost coincide with each other, which indicates that DESTINY has almost the same performance in a wide range of penalty parameters. This observation validates the robustness of our algorithm to penalty parameters. Therefore, we fix by default in the subsequent experiments.



4.3 Comparison on decentralized PCA
In this subsection, we compare the performance of DESTINY in solving decentralized PCA problems (1.3) with some other state-of-the-art methods, including ADSA[12], DRGTA [5], and DeEPCA [47]. Among these three algorithms, ADSA and DRGTA require to choose the stepsize. In the empirical experiments, we find that DRGTA also benefits from the BB stepsizes, but ADSA can not converge with it. Hence, DRGTA is equipped with the same BB stepsizes as DESTINY, while the stepsize of ADSA is fixed as a hand-optimized constant. In the following experiments, for fair comparisons, both DRGTA and DeEPCA perform only one round of communications per iteration.
In order to assess the quality of the above four solvers, we perform a set of experiments on randomly generated matrices as described in Subsection 4.1. The network is built based on an Erdos-Renyi graph with ranging from to with increment . Other experimental settings are , , , , and . The numerical results are illustrated in Figure 3. It can be observed that DeEPCA and DRGTA can not converge when , which signifies that a single consensus step per iteration is not sufficient for these two algorithms to converge in sparse networks. Apart from this special case, DeEPCA has the best performance among all the algorithms. Moreover, DESTINY is competitive with ADSA and significantly outperforms DRGTA in all cases. It should be noted that DeEPCA and ADSA are tailored for decentralized PCA problems and can not be extended to generic cases.






4.4 Comparison on decentralized OLSR
In this subsection, the abilities of DESTINY and DRGTA [5] are examined in solving decentralized OLSR problems (1.4) on the real-world text dataset Cora [25]. For our testing in this case, we select a subset of Cora and extract the first features to use, which contains research papers from three subfields, including data structure (DS), hardware and architecture (HA), and programming language (PL). The number of samples and classes are summarized as follows.
-
•
Cora-DS: , .
-
•
Cora-HA: , .
-
•
Cora-PL: , .
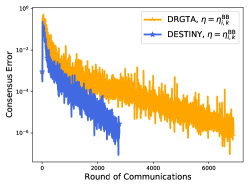
The detailed descriptions and download links of this dataset can be found in [51]. The number of agents is set to in this experiment. We provide the numerical results in Figure 4, which demonstrates that DESTINY attains better performances than DRGTA in terms of both substationarity violations and consensus errors. Therefore, our algorithm manifests its efficiency in dealing with real-world datasets.





4.5 Comparison on decentralized SDL
In this subsection, we evaluate the performance on decentralized SDL problems (1.5) of DESTINY and DRGTA [5]. Three image datasets popular in machine learning research are tested in the following experiments, including MNIST111Available from http://yann.lecun.com/exdb/mnist/ , CIFAR-10222Available from https://www.cs.toronto.edu/~kriz/cifar.html , and CIFAR-100. We summarize the numbers of features and samples as follows.
-
•
MNIST: , .
-
•
CIFAR-10: , .
-
•
CIFAR-100: , .
For our testing, the numbers of computed bases and agents are set to and , respectively. Numerical results from this experiment are given in Figure 5. It can be observed that DESTINY always dominates DRGTA in terms of both substationarity violations and consensus errors. These results indicate that the observed superior performance of our algorithm is not just limited to PCA and OLSR problems.






5 Conclusions
As a powerful and fundamental tool, Riemannian optimization has been adapted to solving consensus problems on a multi-agent network, giving rise to the decentralized Riemannian gradient tracking algorithm (DRGTA) on the Stiefel manifold. In order to guarantee the convergence, DRGTA requires multiple rounds of communications per iteration, and hence, the communication overheads are very high. In this paper, we propose an infeasible decentralized algorithm, called DESTINY, which only invokes a single round of communications per iteration. DESTINY seeks a consensus in the Euclidean space directly by resorting to an elegant approximate augmented Lagrangian function. Even in the non-distributed setting, the proposed algorithm is still new for optimization problems over the Stiefel manifold.
Most existing works on analyzing the convergence of gradient tracking based algorithms impose stringent assumptions on objective functions, such as global Lipschitz smoothness and coerciveness. In our case of DESTINY which tackles decentralized optimization problems with nonconvex constraints, we are able to derive the global convergence and worst case complexity under rather mild conditions. The objective function is only assumed to be locally Lipschitz smooth.
Comprehensive numerical comparisons are carried out under the distributed setting with test results strongly in favor of DESTINY. Most notably, the rounds of communications required by DESTINY are significantly fewer than what are required by DRGTA.
Finally, some topics are worthy of future studies to fully understand the behavior and realize the potential of DESTINY and its variants. For example, the asynchronous version of DESTINY is worthy of investigating to address the load balance issues in the distributed environments. And more work is needed to adapt DESTINY to the dynamic network settings so that it can find a wider range of applications.
Acknowledgment
The authors would like to thank Prof. Lei-Hong Zhang for sharing the Cora dataset, and Prof. Qing Ling and Dr. Nachuan Xiao for their insightful discussions.
References
- [1] T. E. Abrudan, J. Eriksson, and V. Koivunen, Steepest descent algorithms for optimization under unitary matrix constraint, IEEE Transactions on Signal Processing, 56 (2008), pp. 1134–1147.
- [2] P.-A. Absil, C. G. Baker, and K. A. Gallivan, Trust-region methods on Riemannian manifolds, Foundations of Computational Mathematics, 7 (2006), pp. 303–330.
- [3] P.-A. Absil, R. Mahony, and R. Sepulchre, Optimization algorithms on matrix manifolds, Princeton University Press, 2008.
- [4] T.-H. Chang, M. Hong, and X. Wang, Multi-agent distributed optimization via inexact consensus ADMM, IEEE Transactions on Signal Processing, 63 (2015), pp. 482–497.
- [5] S. Chen, A. Garcia, M. Hong, and S. Shahrampour, Decentralized Riemannian gradient descent on the Stiefel manifold, in Proceedings of the 38th International Conference on Machine Learning, vol. 139, PMLR, 2021, pp. 1594–1605.
- [6] Y. Chen, K. Yuan, Y. Zhang, P. Pan, Y. Xu, and W. Yin, Accelerating gossip SGD with periodic global averaging, in Proceedings of the 38th International Conference on Machine Learning, vol. 139, PMLR, 2021, pp. 1791–1802.
- [7] A. Daneshmand, G. Scutari, and V. Kungurtsev, Second-order guarantees of distributed gradient algorithms, SIAM Journal on Optimization, 30 (2020), pp. 3029–3068.
- [8] P. Di Lorenzo and G. Scutari, Next: In-network nonconvex optimization, IEEE Transactions on Signal and Information Processing over Networks, 2 (2016), pp. 120–136.
- [9] A. Edelman, T. A. Arias, and S. T. Smith, The geometry of algorithms with orthogonality constraints, SIAM Journal on Matrix Analysis and Applications, 20 (1998), pp. 303–353.
- [10] A. Gang and W. U. Bajwa, FAST-PCA: A fast and exact algorithm for distributed principal component analysis, arXiv:2108.12373, (2021).
- [11] A. Gang and W. U. Bajwa, A linearly convergent algorithm for distributed principal component analysis, Signal Processing, 193 (2022), p. 108408.
- [12] A. Gang, H. Raja, and W. U. Bajwa, Fast and communication-efficient distributed PCA, in Proceedings of the 2019 International Conference on Acoustics, Speech and Signal Processing, IEEE, 2019, pp. 7450–7454.
- [13] B. Gao, X. Liu, X. Chen, and Y.-X. Yuan, A new first-order algorithmic framework for optimization problems with orthogonality constraints, SIAM Journal on Optimization, 28 (2018), pp. 302–332.
- [14] B. Gao, X. Liu, and Y.-X. Yuan, Parallelizable algorithms for optimization problems with orthogonality constraints, SIAM Journal on Scientific Computing, 41 (2019), pp. A1949–A1983.
- [15] J. Gao, X.-W. Liu, Y.-H. Dai, Y. Huang, and P. Yang, Achieving geometric convergence for distributed optimization with Barzilai-Borwein step sizes, Science China Information Sciences, 65 (2022), pp. 1–2.
- [16] D. Hajinezhad and M. Hong, Perturbed proximal primal–dual algorithm for nonconvex nonsmooth optimization, Mathematical Programming, 176 (2019), pp. 207–245.
- [17] M. Hong, D. Hajinezhad, and M.-M. Zhao, Prox-PDA: The proximal primal-dual algorithm for fast distributed nonconvex optimization and learning over networks, in International Conference on Machine Learning, PMLR, 2017, pp. 1529–1538.
- [18] J. Hu, B. Jiang, L. Lin, Z. Wen, and Y.-X. Yuan, Structured quasi-Newton methods for optimization with orthogonality constraints, SIAM Journal on Scientific Computing, 41 (2019), pp. A2239–A2269.
- [19] J. Hu, A. Milzarek, Z. Wen, and Y. Yuan, Adaptive quadratically regularized Newton method for Riemannian optimization, SIAM Journal on Matrix Analysis and Applications, 39 (2018), pp. 1181–1207.
- [20] B. Jiang and Y.-H. Dai, A framework of constraint preserving update schemes for optimization on Stiefel manifold, Mathematical Programming, 153 (2015), pp. 535–575.
- [21] T. Krasulina, Method of stochastic approximation in the determination of the largest eigenvalue of the mathematical expectation of random matrices, Automatation and Remote Control, 2 (1970), pp. 50–56.
- [22] Q. Ling, W. Shi, G. Wu, and A. Ribeiro, DLM: Decentralized linearized alternating direction method of multipliers, IEEE Transactions on Signal Processing, 63 (2015), pp. 4051–4064.
- [23] Y. Liu, W. Xu, G. Wu, Z. Tian, and Q. Ling, Communication-censored ADMM for decentralized consensus optimization, IEEE Transactions on Signal Processing, 67 (2019), pp. 2565–2579.
- [24] J. H. Manton, Optimization algorithms exploiting unitary constraints, IEEE Transactions on Signal Processing, 50 (2002), pp. 635–650.
- [25] A. K. McCallum, K. Nigam, J. Rennie, and K. Seymore, Automating the construction of internet portals with machine learning, Information Retrieval, 3 (2000), pp. 127–163.
- [26] A. Nedic, A. Olshevsky, and W. Shi, Achieving geometric convergence for distributed optimization over time-varying graphs, SIAM Journal on Optimization, 27 (2017), pp. 2597–2633.
- [27] A. Nedic and A. Ozdaglar, Distributed subgradient methods for multi-agent optimization, IEEE Transactions on Automatic Control, 54 (2009), pp. 48–61.
- [28] Y. Nishimori and S. Akaho, Learning algorithms utilizing quasi-geodesic flows on the Stiefel manifold, Neurocomputing, 67 (2005), pp. 106–135.
- [29] S. U. Pillai, T. Suel, and S. Cha, The Perron-Frobenius theorem: some of its applications, IEEE Signal Processing Magazine, 22 (2005), pp. 62–75.
- [30] G. Qu and N. Li, Harnessing smoothness to accelerate distributed optimization, IEEE Transactions on Control of Network Systems, 5 (2017), pp. 1245–1260.
- [31] S. S. Ram, A. Nedić, and V. V. Veeravalli, Distributed stochastic subgradient projection algorithms for convex optimization, Journal of Optimization Theory and Applications, 147 (2010), pp. 516–545.
- [32] T. D. Sanger, Optimal unsupervised learning in a single-layer linear feedforward neural network, Neural Networks, 2 (1989), pp. 459–473.
- [33] H. Sato, A Dai–Yuan-type Riemannian conjugate gradient method with the weak Wolfe conditions, Computational Optimization and Applications, 64 (2016), pp. 101–118.
- [34] I. D. Schizas and A. Aduroja, A distributed framework for dimensionality reduction and denoising, IEEE Transactions on Signal Processing, 63 (2015), pp. 6379–6394.
- [35] G. Scutari and Y. Sun, Distributed nonconvex constrained optimization over time-varying digraphs, Mathematical Programming, 176 (2019), pp. 497–544.
- [36] W. Shi, Q. Ling, G. Wu, and W. Yin, EXTRA: An exact first-order algorithm for decentralized consensus optimization, SIAM Journal on Optimization, 25 (2015), pp. 944–966.
- [37] E. Stiefel, Richtungsfelder und fernparallelismus in n-dimensionalen mannigfaltigkeiten, Commentarii Mathematici Helvetici, 8 (1935), pp. 305–353.
- [38] L. Wang, B. Gao, and X. Liu, Multipliers correction methods for optimization problems over the Stiefel manifold, CSIAM Transactions on Applied Mathematics, 2 (2021), pp. 508–531.
- [39] L. Wang, X. Liu, and Y. Zhang, A distributed and secure algorithm for computing dominant SVD based on projection splitting, arXiv:2012.03461, (2020).
- [40] , A communication-efficient and privacy-aware distributed algorithm for sparse PCA, arXiv:2106.03320, (2021).
- [41] Z. Wen and W. Yin, A feasible method for optimization with orthogonality constraints, Mathematical Programming, 142 (2013), pp. 397–434.
- [42] L. Xiao and S. Boyd, Fast linear iterations for distributed averaging, Systems & Control Letters, 53 (2004), pp. 65–78.
- [43] N. Xiao and X. Liu, Solving optimization problems over the Stiefel manifold by smooth exact penalty function, arXiv:2110.08986, (2021).
- [44] N. Xiao, X. Liu, and Y.-X. Yuan, A class of smooth exact penalty function methods for optimization problems with orthogonality constraints, Optimization Methods and Software, (2020), pp. 1–37.
- [45] , A penalty-free infeasible approach for a class of nonsmooth optimization problems over the Stiefel manifold, arXiv:2103.03514, (2021).
- [46] J. Xu, S. Zhu, Y. C. Soh, and L. Xie, Augmented distributed gradient methods for multi-agent optimization under uncoordinated constant stepsizes, in 54th IEEE Conference on Decision and Control, IEEE, 2015, pp. 2055–2060.
- [47] H. Ye and T. Zhang, DeEPCA: Decentralized exact PCA with linear convergence rate, Journal of Machine Learning Research, 22 (2021), pp. 1–27.
- [48] K. Yuan, Q. Ling, and W. Yin, On the convergence of decentralized gradient descent, SIAM Journal on Optimization, 26 (2016), pp. 1835–1854.
- [49] J. Zeng and W. Yin, On nonconvex decentralized gradient descent, IEEE Transactions on Signal Processing, 66 (2018), pp. 2834–2848.
- [50] Y. Zhai, Z. Yang, Z. Liao, J. Wright, and Y. Ma, Complete dictionary learning via -norm maximization over the orthogonal group, Journal of Machine Learning Research, 21 (2020), pp. 1–68.
- [51] L.-H. Zhang, W. H. Yang, C. Shen, and J. Ying, An eigenvalue-based method for the unbalanced Procrustes problem, SIAM Journal on Matrix Analysis and Applications, 41 (2020), pp. 957–983.
- [52] H. Zhao, Z. Wang, and F. Nie, Orthogonal least squares regression for feature extraction, Neurocomputing, 216 (2016), pp. 200–207.
- [53] X. Zhu, A Riemannian conjugate gradient method for optimization on the Stiefel manifold, Computational Optimization and Applications, 67 (2017), pp. 73–110.