DDN-SLAM: Real-time Dense Dynamic Neural Implicit SLAM
Abstract
SLAM systems based on NeRF have demonstrated superior performance in rendering quality and scene reconstruction for static environments compared to traditional dense SLAM. However, they encounter tracking drift and mapping errors in real-world scenarios with dynamic interferences. To address these issues, we introduce DDN-SLAM, the first real-time dense dynamic neural implicit SLAM system integrating semantic features. To address dynamic tracking interferences, we propose a feature point segmentation method that combines semantic features with a mixed Gaussian distribution model. To avoid incorrect background removal, we propose a mapping strategy based on sparse point cloud sampling and background restoration. We propose a dynamic semantic loss to eliminate dynamic occlusions. Experimental results demonstrate that DDN-SLAM is capable of robustly tracking and producing high-quality reconstructions in dynamic environments, while appropriately preserving potential dynamic objects. Compared to existing neural implicit SLAM systems, the tracking results on dynamic datasets indicate an average 90% improvement in Average Trajectory Error (ATE) accuracy.
1 Introduction
In the fields of robotics and virtual reality, the Neural Radiance Fields (NeRF) [73, 70, 69, 68, 74, 75, 9] have shown tremendous potential. There is a significant focus on real-time dense SLAM (Simultaneous Localization and Mapping) systems [53, 42, 63, 22, 24, 50] to combine with NeRF. Dense reconstruction [68, 71, 76] is crucial for scene perception and understanding, providing improvements over sparse reconstruction [16, 17, 61, 10, 13, 8]. While traditional SLAM systems have achieved remarkable results in tracking and sparse reconstruction [14, 23], low-resolution and discontinuous surface reconstruction fails to meet the requirements [11, 15, 49]. Recently, neural implicit SLAM methods [45, 47, 21, 20, 19, 7] have demonstrated excellent performance, with systems capable of real-time reconstruction [26, 27, 46] and inference in large-scale virtual/real scenes. These SLAM systems outperform traditional SLAM methods in terms of texture details, memory consumption, noise handling, and outlier processing.
Although current neural implicit SLAM systems have achieved good reconstruction results in static scenes [27, 81, 12, 43], many real-world environments are often affected by dynamic objects, especially in applications such as robotics or autonomous driving, which involve complex physical environments and may also have low-texture areas or significant changes in lighting and viewing angles. Current neural implicit SLAM systems are unable to achieve effective tracking and reliable reconstruction in such environments. The depth information and pixel interference caused by dynamic objects lead to inaccurate tracking results, while severe occlusions result in distorted reconstructions and ghosting artifacts. In addition, traditional dynamic semantic SLAM systems [1, 4, 2, 3, 5] often treat potential dynamic objects as dynamic objects to be removed, resulting in holes. In the real world, foreground objects segmented by semantics often lie between dynamic and static states, rather than constantly in motion. These objects in potential motion do not interfere with the operation of the SLAM system and are of significant importance for the complete reconstruction of the scene. Traditional semantic SLAM systems also struggle to effectively differentiate between high-dynamic objects (involving significant human movement and high speed) and low-dynamic objects (involving minimal human movement and slower speed) and adopt different mapping strategies for them.
To address these challenges, we propose DDN-SLAM, which is able to accurately differentiate between dynamic, static, and potentially static objects, instead of simply removing all foregrounds segmented by semantics. It utilizes the prior information provided by the semantic framework to constrain the segmentation range of dynamic object masks and performs feature point segmentation based on a mixture of Gaussian distributions. To improve the robustness of segmentation, we propose a reprojection error check to provide long-term data association, restoring features points that have been incorrectly removed. To accurately preserve potential static objects and achieve a complete reconstruction of the scene, we propose a mixed background restoration and rendering strategy. To fully utilize the results of static segmentation, we use map points guided by static sparse point cloud mapping to guide ray sampling. To prevent excessive removal, we use optical flow to distinguish low dynamic foreground constructed from sparse static feature points for background restoration. To constrain the impact of high-dynamic occlusion on rendering, we propese the motion consistency, depth, and color losses. Compared to other neural implicit SLAM systems[45, 21, 20], we achieve a balance between real-time performance, low memory consumption, and high-quality geometric and texture details. In contrast to traditional dense semantic SLAM methods, our approach incorporates potential static objects into the scene representation, leading to high-quality rendering results. Our method can stably track and reconstruct in dynamic and challenging scenarios at a speed of 20Hz, supporting monocular, stereo, and RGB-D inputs. In summary, our contributions can be summarized as follows:
-
•
We propose DDN-SLAM, the first dynamic SLAM system based on semantic features. By combining semantic detection framework and a Gaussian Mixture Model background depth probability check method, we distinguish foreground from background to eliminate interfering dynamic feature points. Long-term data association is established through a secondary check of reprojection errors of dynamic points and adjusting the Bundle Adjustment (BA) process.
-
•
We propose a mixed background restoration and rendering strategy, which includes using feature-based optical flow to differentiate dynamic masks for background restoration. We also propose a sampling strategy guided by static sparse point clouds to enhance the reconstruction of the static surface.
-
•
We propose a rendering loss based on dynamic masks, including motion consistency loss, depth loss, and color loss, to constrain rendering artifacts of dynamic objects and remove occlusions.
2 Related works
2.1 Traditional Dynamic Visual SLAM
In most SLAM systems [36, 42, 53, 54], eliminating false data from dynamic objects [55, 56] that are commonly present in the real world is an important problem. It holds significant implications for both camera tracking and dense reconstruction [62, 63, 65]. Early researchers often used reliable constraints or multi-view geometric methods for feature matching, but they often failed to accurately segment subtly moving objects. Additionally, there was a lack of viable solutions for handling potential moving objects. Methods relying on optical flow consistency [57, 58, 59, 60] could differentiate by detecting inconsistent optical flow generated by moving objects, but with lower accuracy.
In recent years, deep object detection networks that incorporate semantic information have been employed for pixel-level segmentation to more accurately deal with dynamic objects in real-world environments [25]. However, the depth models used in traditional SLAM methods often incur high computational costs, impacting real-time performance. Moreover, traditional methods suffer from an inability to perform scene representation and reasonable hole filling for complex textures and geometric details due to discrete or incomplete surface structures. Moreover, traditional dynamic semantic SLAM methods cannot accurately distinguish between dynamic, static, and potentially dynamic objects, leading to excessive removal after semantic segmentation, failing to preserve potentially dynamic objects that do not affect the mapping process.
2.2 NERF-BASED SLAM
The achievements of NeRF [28, 29, 86, 31, 32, 33, 69] in 3D scene representation [35, 37, 38, 39, 40, 41] have attracted widespread attention. In recent work, neural implicit SLAM systems and similar work [64, 66] have shown impressive performance in high-quality rendering and accurate 3D reconstruction. iMAP [26] proposes a real-time updating system using a single MLP decoder, and NICE-SLAM [45] extends the system to achieve larger scene representation, addressing the scene limitations of iMAP [26]. ESLAM [21] uses multi-scale vertically aligned feature planes for representation and decodes compact features directly into TSDF. Co-SLAM [47] adopts a joint encoding method based on coordinates and one-blob to balance geometric accuracy and inference speed. GO-SLAM [34] introduces an effective loop closure strategy that enables global correction but may impact tracking speed and efficiency. However, these methods result in severe errors in reconstruction and tracking in dynamic scenes due to interference from high/low dynamic objects. That leads to incorrect data association and cumulative drift amplification in pose estimation. The dynamic objects as interference information affecting the reconstruction results, causing artifacts or catastrophic forgetting issues. Although NICE-SLAM [45] proposes a pixel filtering method based on depth threshold to achieve effective tracking and reconstruction in low dynamic scenes, its inference speed and tracking accuracy decrease significantly in high-dynamic(involving significant human movement and high speed) scenes with occlusion and interference. Meanwhile, in challenging scenarios [80], neural implicit SLAM systems often get weak in pose estimation, resulting in tracking loss or significant pose drift. Neural implicit SLAM methods usually cannot match traditional methods in tracking accuracy due to the lack of loop detection and global BA. We combine the advantages of traditional methods and neural implicit methods, using semantic constraints to limit the impact of dynamic objects during tracking. We segment the dynamic, static, and potentially dynamic objects to achieve adaptive background restoration. In the rendering process, we also utilize semantic information as an additional constraint loss to restrict high-dynamic occlusion and artifacts. We are able to adaptively remove high-dynamic objects during the rendering process and retain potential dynamic objects to enhance the completeness of scene reconstruction.
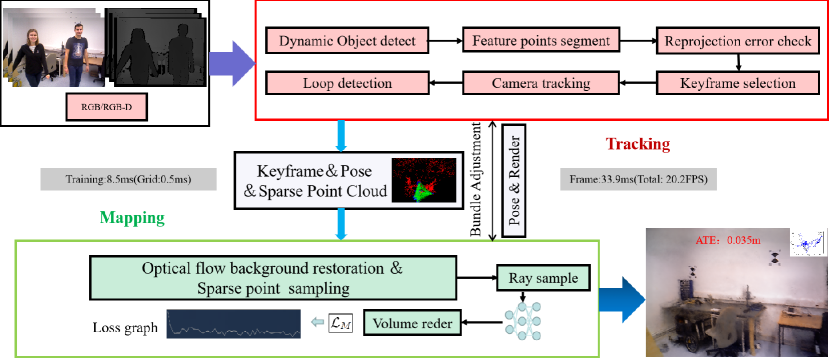
3 Method
Our system framework is shown in Figure 1. We introduce our method in three parts: Sec.3.1 presents our foreground segmentation technique based on semantic understanding and Gaussian distribution assumptions. We employ feature points that exclude dynamic disturbances for tracking and utilize a secondary verification of reprojection errors to re-establish long-term data associations. Sec.3.2 introduce our mixed method to background restoration, where we utilize sparse static optical flow to segment low-dynamic pixels and employ background inpainting to address occlusion issues caused by dynamic objects. We enhance the quality of static reconstruction by incorporating jump sampling guided by sparse feature points. In Sec. 3.3, we introduced our mapping method where we represent the scene using NeRF. We proposed a dynamic loss based on motion consistency and the color and depth of dynamic pixels, which can effectively reduce the impact of highly dynamic pixels.
3.1 Foreground and Background Segmentation
Based on ORBSLAM3[77], we have constructed a feature point tracking system. Unlike other neural implicit SLAM systems, to address the interference introduced by dynamic objects in the real world, we incorporate prior semantic information through YOLOv9[84] to obtain dynamic bounding box priors and form a set of dynamic points. To segment the dynamic feature points within the bounding box in a limited manner, we introduce a background hypothesis based on a Gaussian mixture distribution. Given that the bounding boxes constrained by semantic information contain dynamic objects, we set the collection of depth values for all pixels as . We define the average depth value of the four corners of the Yolo box as , and we use two Gaussian distributions, and , to represent the depth value distributions of the foreground and background, respectively, where the subscripts fg and bg denote foreground and background. We introduce prior probabilities, assuming pixels with depth greater than as background, and those with lesser depth as foreground. For depth values greater than , the background prior probability and the foreground prior probability .
The probability density function (PDF) of the Gaussian Mixture Model(GMM) for a depth value is defined as:
| (1) |
where and are the mixing coefficients, satisfying .
Based on the current parameter estimates, we calculate the expected value of the latent variables or the expected distribution. We obtain the posterior probability of each depth value belonging to the foreground or background, denoted as and , respectively:
| (2) |
| (3) |

Parameters are updated based on the expected values to maximize the likelihood function. We update the model parameters, including the means, variances, and mixing coefficients of the two Gaussian distributions:
| (4) |
| (5) |
Based on the convergence results of the EM (Expectation-Maximization) algorithm, we can assign the most likely distribution to each pixel. If , then is classified as foreground; otherwise, it is considered background. Thus, we can obtain the set of static feature points and the set of dynamic feature points . If more than 10% of points within a box are dynamic, we consider the bounding box to contain a dynamic object. This ensures the consistency of object motion in the scene. The depth segmentation results after segmenting foreground and background on the Bonn[88] dataset are shown in Figure 2.
To avoid excluding potential static points, we introduce the mean reprojection error as a check before bundle adjustment (BA). Consequently, we assign weights to static and dynamic points as follows:
| (6) |
Where, is directly assigned based on the posterior probability of point belonging to the background, ensuring that the weights reflect the likelihood of each point being a static feature point.

The reprojection error based on features classified as static, whose positions are more likely to represent the camera’s true movement relative to the environment. Specifically, we disable the function of eliminating potential feature points in static scenes. Therefore, we define the translation vector optimization process in pose estimation as follows:
| (7) |
| (8) |
where is the projection transformation from the camera coordinate system to the plane coordinate system, and and are the rotation matrix vector of the frame. and represent the translation vectors of the frame adjusted based on the static point set.
In pose estimation, the optimization process should focus more on static feature points. We use the translation vector , derived from static feature points, to minimize the reprojection error. We jointly optimize the rotation matrix , the translation vector , the mapping of 3D map points to image coordinates , and the weights of each map point. We obtain the minimum reprojection error as follows:
| (9) |
where is the information matrix related to the scale of the feature points, is the robust Huber loss function. We performed BA to optimize the keyframes and camera poses as well as the observed map points in these keyframes. Foreground points within dynamic boxes are considered as dynamic points and excluded during pose initialization. The optimized keyframes and mapped points were then passed to NeRF for further processing. The feature point segmentation results are shown in Figure 3.
3.2 Mixed Background Restoration
To eliminate ghosting artifacts caused by dynamic occlusions while preserving potential dynamic objects, we optimize both the input rendering and the rendering process. We propose a mixed background restoration strategy. This allows us to reduce dynamic interference and enhance static reconstruction.
Optical flow-based background restoration: Inspired by [1], [79], and [87], we combine optical flow-based dynamic judgment with background completion for background restoration. Different from traditional dynamic SLAM methods, which require complete traversal and completion of all input frames, resulting in extremely high computational costs. We only need to perform optical flow-based dynamic pixel segmentation for the keyframes involved in NeRF mapping, dividing the image into high-dynamic, low-dynamic, and static regions. We then fill in the low-dynamic pixels, thereby improving sampling efficiency and reducing memory consumption. We retain static pixels that do not interfere with the tracking process to ensure that our method can accurately distinguish dynamic and static information without interference. We retain static pixels that do not interfere with the tracking process to ensure that our method can correctly distinguish dynamic and static information without interference. We use the pixel mask obtained from the Gaussian mixture distribution clustering within the bounding box in Sec. 3.1, as well as the filtered static feature points. We construct the sparse optical flow vector between adjacent frames as follows.
| (10) |
Where refers to the static optical flow, which is the difference between the scene-induced optical flow and the observed optical flow caused by camera motion. Based on temporal consistency, we calculate the dynamic optical flow vector for each pixel in between two consecutive frames. In the mapping process, the high-dynamic parts of objects are removed due to the constraints we imposed in Sec.3.3. Therefore, we only need to restoration the low-dynamic pixels to avoid interference caused by them. We can further refine by dividing it into low-dynamic and high-dynamic pixels to reduce its occupancy. We establish a threshold that defines pixels with optical flow. We obtain the low-dynamic pixel optical flow set , high-dynamic pixel optical flow set , and static pixel optical flow set , with the partition formula as follows:
| (11) |
Then, we establish a sliding window that bundles the latest 20 keyframes into a keyframe group and calculate the relative poses between each keyframe and the current frame. We fill in the color image and depth map corresponding to the low dynamic part mask . For RGB mode, we fill in the depth map obtained from[78]. We use the repaired keyframe image as the final mapping frame.
Sparse point cloud-guided skip sampling: Inspired by [20], we input the static sparse point cloud acquired by our system into the backend NeRF mapping thread, considering the corresponding map points of the sparse point cloud. We obtain the spatial position of map points in the density grid through their poses. Given the correlation between map points and feature points, the surroundings of the map points are closer to the surface of static objects. Therefore, we apply sampling adjustment to the filtered static point cloud. We use the sample counter of the density network to calculate the relationship between the sampling rays and the map points. When a voxel in the density grid intersects with a map point, we mark that voxel as 1; otherwise, it is marked as 0. Each voxel marked as 1 indicates that the corresponding voxel should have an additional 10 ray samples. We set the upper limit of the sampling threshold as . This method allows for a more complete reconstruction of static surfaces, increasing the proportion of static pixels and better filling in the gaps.
3.3 Dynamic Volume Rendering
For representing 3D scenes in the presence of occlusion, we employ a volumetric rendering process combined with multi-resolution hash encoding [28]. The given position can be mapped to the respective positions on each resolution grid, and trilinear interpolation is performed on the grid cell corners to obtain concatenated encoding feature vectors . After feature concatenation, we input them into an MLP. More specifically, our SDF network is composed of a single MLP, with learnable parameters . It takes the point position and the corresponding hash encoding as inputs and predicts the signed distance field (SDF) as:
| (12) |
To estimate the color , we utilize a color network that processes the learned geometric feature vector , position , and SDF gradient with respect to :
| (13) |
We adopt hierarchical sampling to obtain samples on each ray, and additionally sample points near the surface. For all points on the ray. We sampled N and denoted as . This process represents the projection of a ray from the camera center through a pixel along its normalized viewing direction . We adopt the SDF representation and express its opacity as .
| (14) |
where is the sigmoid function. denotes the cumulative transmission rate, which represents the proportion of light reaching the camera. With the weight We use MLP predictions to render the color and depth for each ray:
| (15) |
The definitions of color and depth rendering losses are as follows:
| (16) |
where represents the set of rays with valid depths, corresponds to the filtered set of pixel depths, and is the batch of rays contributing to depth. In monocular mode, supervision is performed using predicted depths from [78]. To effectively reduce the impact of dynamic pixels and improve the accuracy of depth and color predictions, we construct a dynamic rendering loss. Our loss function consists of three parts: the basic loss (including depth loss and color loss), the motion consistency loss, the dynamic area penalty loss (). The basic loss evaluates the overall accuracy of the prediction, while the additional depth and color penalty items are specifically aimed at dynamic pixel areas to constrain the occlusion impact of dynamic objects. We construct the motion consistency loss () as follows:
| (17) |
where is the predicted motion distance for the th dynamic pixel, is its actual motion distance, and is the number of dynamic pixels. We construct the dynamic area penalty item () as:
| (18) |
where is the number of pixels in the dynamic area, and respectively represent the predicted and actual depth values. Combining the above losses, we define the rendering loss as:
| (19) |
where and are initialized to 0.001.
4 Experiment
4.1 Experimental Setup
Implementation Details. Our system is implemented on a system with a NVIDIA RTX 3090ti GPU and an Intel Core i7-12700K CPU operating at 3.60 GHz. We use the YOLOv9[84] network pre-trained on the COCO dataset[72] as the backbone of our object detection system. We initialize the optical flow threshold to 5, and the sampling threshold to 500. Due to the page limit the more parameter settings and detailed ablation experiments can be found in the supplementary materials.
Dataset. We evaluated our system on a total of 2 dynamic datasets, 1 challenging dataset with large viewpoints and weak textures, and 3 static datasets. The datasets used for evaluation include TUM RGB-D [52], Bonn [88], OpenLORIS-Scene [80], Replica[51], ScanNet[48], and EuRoC [44]. The TUM RGB-D [52] dataset consists of 6 high-dynamic sequences, 2 low-dynamic sequences, and 3 static sequences. The Bonn [88] dataset includes 6 high-dynamic range sequences and 2 sequences with complex occlusions. The challenging scenes dataset consists of 7 indoor sequences from the OpenLORIS-Scene dataset [80], demonstrating large changes in viewpoint, variations in lighting, and sudden dynamic interferences. The static datasets consist of 6 sequences from the ScanNet [48] dataset, 8 sequences from the high-quality virtual scene dataset Replica[51], and 3 Sequences on the EuRoC [44] Dataset. Due to the page limit, we include more experimental results in the supplemental material.
Metrics and Baseline. We evaluate the reconstruction quality using {Depth L1} (cm), {Accuracy} (cm), {Completion} (cm), {Completion Ratio} (%), and {PSNR} (dB). For assessing camera tracking quality in dynamic scenes, we use {ATE RMSE}. Our main baselines for reconstruction quality and camera tracking include iMAP [26], NICE-SLAM [45], ESLAM [63], GO-SLAM [34], Orbeez-SLAM[20]and Co-SLAM [47]. We utilized the replication code provided by [81] to achieve better performance reproduction for iMAP [26]. For a fair comparison, we introduce classical traditional dynamic SLAM methods for tracking results in dynamic scenes, including LC-CRF SLAM [57], Crowd-SLAM [58], ElasticFusion [4], ORB-SLAM2 [14], and DS-SLAM [23].
4.2 Evaluation in Dynamic Scenes

TUM RGB-D [52] Dynamic Sequence Evaluation. To evaluate our system on TUM RGB-D [52] dynamic sequences, we compare it with LC-CRF SLAM [57], Crowd-SLAM [58], ORB-SLAM2 [14], NICE-SLAM [45], ESLAM [21] and Co-SLAM [47]. Our method achieves effective rendering, effectively avoids occlusion interference caused by high-dynamic human subjects, reasonably fills scene holes, and achieves high-precision geometric detail reconstruction with minimal artifacts. Our method preserves the potential dynamic objects and enhances the integrity of the reconstruction. as shown in Figure 4. We have achieved tracking results that are competitive with traditional methods, as shown in Table 2. Due to severe accumulated drift, current neural implicit SLAM methods are unable to complete reliable mapping.
| Completion Rate | walking/xyz | walking/half | walking/static | walking/rpy | sitting-xyz | sitting-half | AVG | |
| LC-CRF SLAM [57] | 100% | 0.020 | 0.030 | 0.028 | 0.051 | 0.013 | 0.026 | 0.028 |
| Crowd-SLAM [58] | 100% | 0.019 | 0.036 | 0.007 | 0.044 | 0.017 | 0.025 | 0.027 |
| ORB-SLAM2 [14] | 93% | 0.721 | 0.462 | 0.386 | 0.785 | 0.009 | 0.026 | 0.373 |
| NICE-SLAM [45] | 79% | 0.420 | 0.732 | 0.491 | N/A | 0.029 | 0.134 | 0.362 |
| ESLAM [63] | 61% | 0.432 | N/A | 0.075 | N/A | 0.034 | 0.063 | 0.151 |
| Co-SLAM [47] | 44% | 0.714 | N/A | 0.499 | N/A | 0.065 | 0.023 | 0.325 |
| DDN-SLAM(RGB) | 100% | 0.028 | 0.041 | 0.025 | 0.089 | 0.013 | 0.031 | 0.037 |
| DDN-SLAM | 100% | 0.014 | 0.023 | 0.010 | 0.039 | 0.010 | 0.017 | 0.020 |
Bonn [88] Dynamic Sequence Evaluation. Our tracking method demonstrates robustness and achieves competitive tracking results, as demonstrated in Table 3. Compared to the TUM RGB-D [52] dataset, the Bonn [88] dataset exhibits more complex dynamic scenes, severe occlusions, and the presence of multiple moving objects simultaneously. The reconstruction results are shown in Fig. 5. In comparison to traditional dynamic SLAM methods, our approach achieves better results. The current neural implicit systems have shown significant drift or tracking failures in most scenarios.
| Completion Rate | balloon | balloon2 | move | move2 | crowd | crowd2 | person | person2 | AVG | |
| LC-CRF SLAM [57] | 100% | 0.027 | 0.024 | 0.079 | 0.186 | 0.027 | 0.098 | 0.046 | 0.041 | 0.066 |
| Crowd-SLAM [58] | 100% | 0.037 | 0.014 | 0.026 | 0.029 | 0.019 | 0.035 | 0.046 | 0.099 | 0.038 |
| ORB-SLAM2 [14] | 91% | 0.065 | 0.230 | 0.320 | 0.039 | 0.496 | 0.989 | 0.692 | 0.079 | 0.363 |
| NICE-SLAM [45] | 87% | 2.442 | 2.018 | 0.177 | 0.832 | 1.934 | 3.582 | 0.245 | 0.536 | 1.470 |
| ESLAM [63] | 64% | 0.203 | 0.235 | 0.190 | 0.129 | 0.416 | 1.142 | 0.845 | 7.441 | 1.325 |
| Co-SLAM [47] | 100% | 0.211 | 0.480 | 0.076 | 0.200 | 51.983 | 2.019 | 0.695 | 0.758 | 7.052 |
| DDN-SLAM | 100% | 0.018 | 0.041 | 0.020 | 0.032 | 0.018 | 0.023 | 0.043 | 0.038 | 0.029 |
4.3 Evaluation in Challenging Scenes
Openloris-Scene [80] Dataset Experimental Results. We conducted reconstruction and tracking evaluation on the challenging Openloris-Scene [80] dataset. Our method significantly outperforms existing neural implicit methods and traditional approaches. Benefite from accurate feature point segmentation, and there is no significant drift as in NICE-SLAM [45] and Co-SLAM [47], as shown in Table 5. Our method is capable of tracking in highly challenging scenarios, and improving tracking completion rates.
| Completion Rate | office1-1 | office1-2 | office1-3 | office1-4 | office1-5 | office1-6 | office1-7 | AVG | |
| ORB-SLAM2 [14] | 100%↑ | 0.074 | 0.072 | 0.015 | 0.077 | 0.161 | 0.080 | 0.100 | 0.082 |
| ElasticFusion [4] | 100%↑ | 0.112 | 0.118 | 0.022 | 0.100 | 0.144 | 0.113 | 0.192 | 0.114 |
| DS-SLAM [23] | 77%↑ | 0.089 | 0.101 | 0.016 | 0.021 | 0.052 | 0.129 | 0.077 | 0.069 |
| NICE-SLAM [45] | 100%↑ | 0.110 | 0.142 | 0.040 | 0.232 | 0.130 | 0.104 | 0.251 | 0.144 |
| ESLAM [63] | 100%↑ | 0.101 | 0.152 | 0.010 | 0.235 | 0.151 | 0.101 | 0.201 | 0.150 |
| Co-SLAM[47] | 99%↑ | 0.112 | 0.173 | 0.043 | 0.141 | 0.174 | 0.134 | 0.186 | 0.138 |
| GO-SLAM [34] | 100%↑ | 0.120 | 0.160 | 0.033 | 0.183 | 0.942 | 0.092 | 0.142 | 0.239 |
| DDN-SLAM | 100%↑ | 0.058 | 0.071 | 0.011 | 0.056 | 0.120 | 0.050 | 0.105 | 0.067 |
ScanNet [48] Dataset Experimental Results. Our evaluation results are based on the ScanNet[48] dataset(RGB-D), which contains large-scale scenes. We assessed the average running speed, memory usage, mapping time, and GPU memory usage across six scenes. The results indicate that our method achieves higher running speed and reduces memory consumption.
5 Conclusion
We propose DDN-SLAM, a neural implicit semantic SLAM system that enables stable tracking in complex occlusion and challenging environments. Through 2D-3D scene understanding, it achieves dense indoor scene reconstruction. Our system is more aligned with real-world requirements, capable of flexibly supporting various inputs while demonstrating superior performance. It addresses occlusion from complex moving objects, retains and reconstructs potential moving objects in the scene, all while balancing computational memory and running speed. Our experiments demonstrate that our method effectively avoids interference from severe occlusion on mapping and tracking, and achieves state-of-the-art performance on various datasets.
References
- [1] T. Zhang, H. Zhang, Y. Li, Y. Nakamura, and L. Zhang, "FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow," in 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2020, pp. 7322–7328.
- [2] J. He, M. Li, Y. Wang, et al., “OVD-SLAM: An Online Visual SLAM for Dynamic Environments,” IEEE Sensors Journal, 2023.
- [3] Z. Lv, K. Kim, A. Troccoli, D. Sun, J. M. Rehg, and J. Kautz, "Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation," in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 468–484.
- [4] T. Whelan, S. Leutenegger, R. Salas-Moreno, B. Glocker, and A. Davison, "ElasticFusion: Dense SLAM without a pose graph," in Robotics: Science and Systems2015,pp. 1-2.
- [5] T. Whelan, M. Kaess, M. Fallon, H. Johannsson, J. Leonard, and J. McDonald, "Kintinuous: Spatially extended kinectfusion," in Proc. Workshop RGB-D, Adv. Reason. Depth Cameras, 2012, article 4.
- [6] T. Deng, H. Xie, J. Wang, W. Chen. "Long-Term Visual Simultaneous Localization and Mapping: Using a Bayesian Persistence Filter-Based Global Map Prediction," IEEE Robotics & Automation Magazine, vol. 30, no. 1, pp. 36-49, 2023.
- [7] T. Deng, G. Shen, T. Qin, J. Wang, W. Zhao, J. Wang, D. Wang, W. Chen. "PLGSLAM: Progressive Neural Scene Representation with Local to Global Bundle Adjustment," arXiv preprint arXiv:2312.09866, 2023.
- [8] H. Xie, T. Deng, J. Wang, W. Chen. "Robust Incremental Long-Term Visual Topological Localization in Changing Environments," IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1-14, 2022.
- [9] T. Deng, S. Liu, X. Wang, Y. Liu, D. Wang, W. Chen. "ProSGNeRF: Progressive Dynamic Neural Scene Graph with Frequency Modulated Auto-Encoder in Urban Scenes," arXiv preprint arXiv:2312.09076, 2023.
- [10] T. Qin, P. Li, S. Shen. "Vins-mono: A robust and versatile monocular visual-inertial state estimator," IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004-1020, 2018.
- [11] T. Whelan, M. Kaess, H. Johannsson, et al. "Real-time large-scale dense RGB-D SLAM with volumetric fusion," The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 598-626, 2015.
- [12] X. Yang, H. Li, H. Zhai, et al., “Vox-Fusion: Dense tracking and map with voxel-based neural implicit representation,” in 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), IEEE, 2022, pp. 499-507.
- [13] M. Hosseinzadeh, K. Li, Y. Latif, et al. "Real-time monocular object-model aware sparse SLAM," in 2019 International Conference on Robotics and Automation (ICRA), IEEE, 2019, pp. 7123-7129.
- [14] R. Mur-Artal and J. D. Tard’os, "ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras," IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017, IEEE.
- [15] J. McCormac, A. Handa, A. Davison, et al. "Semanticfusion: Dense 3D semantic map with convolutional neural networks," in 2017 IEEE International Conference on Robotics and automation (ICRA), IEEE, 2017, pp. 4628-4635.
- [16] T. Qin, P. Li, S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE Transactions on Robotics, 34(4): 1004-1020, 2018.
- [17] R. Wang, M. Schworer, D. Cremers, “Stereo DSO: Large-scale direct sparse visual odometry with stereo cameras,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 3903-3911.
- [18] X. Kong, S. Liu, M. Taher, et al., “vmap: Vectorised object map for neural field slam,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 952-961.
- [19] M. Li, J. He, Y. Wang, et al. "End-to-End RGB-D SLAM With Multi-MLPs Dense Neural Implicit Representations," IEEE Robotics and Automation Letters, 2023.
- [20] C. M. Chung, Y. C. Tseng, Y. C. Hsu, et al., “Orbeez-SLAM: A Real-Time Monocular Visual SLAM with ORB Features and NeRF-Realized Map,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2023, pp. 9400-9406.
- [21] Johari M M, Carta C, Fleuret F. , "Eslam: Efficient dense slam system based on hybrid representation of signed distance fields[," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17408-17419.
- [22] Jan Czarnowski, Tristan Laidlow, Ronald Clark, and Andrew J. Davison, "DeepFactors: Real-Time Probabilistic Dense Monocular SLAM," IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 721–728, 2020.
- [23] C. Yu, Z. Liu, X. Liu, F. Xie, Y. Yang, Q. Wei, and Q. Fei, "DS-SLAM: A semantic visual SLAM towards dynamic environments," in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 1168-1174.
- [24] R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohi, J. Shotton, S. Hodges, and A. Fitzgibbon, "Kinectfusion: Real-time dense surface mapping and tracking," in 2011 10th IEEE international symposium on mixed and augmented reality, 2011, pp. 127-136.
- [25] M. Strecke and J. Stuckler, "Em-fusion: Dynamic object-level slam with probabilistic data association," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5865-5874.
- [26] E. Sucar, S. Liu, J. Ortiz, and A. J. Davison, "iMAP: Implicit mapping and positioning in real-time," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6229–6238.
- [27] A. Rosinol, J. J. Leonard, and L. Carlone, "NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields," arXiv preprint arXiv:2210.13641, 2022.
- [28] T. Müller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,” ACM Transactions on Graphics (ToG), vol. 41, no. 4, pp. 1–15, 2022.
- [29] T. Wu, F. Zhong, A. Tagliasacchi, F. Cole, and C. Oztireli, “D2NeRF: Self-Supervised Decoupling of Dynamic and Static Objects from a Monocular Video,” arXiv preprint arXiv:2205.15838, 2022.
- [30] P. Wang, L. Liu, Y. Liu, C. Theobalt, T. Komura, and W. Wang, “Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction,” arXiv preprint arXiv:2106.10689, 2021.
- [31] C.-Y. Weng, B. Curless, P. P. Srinivasan, J. T. Barron, and I. Kemelmacher-Shlizerman, “Humannerf: Free-viewpoint rendering of moving people from monocular video,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16210–16220.
- [32] H. Turki, D. Ramanan, and M. Satyanarayanan, “Mega-nerf: Scalable construction of large-scale nerfs for virtual fly-throughs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12922–12931.
- [33] D. Rebain, M. Matthews, K. M. Yi, D. Lagun, and A. Tagliasacchi. Lolnerf: Learn from one look. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1558–1567, 2022.
- [34] Y. Zhang, F. Tosi, S. Mattoccia, et al. "Go-slam: Global optimization for consistent 3D instant reconstruction," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3727-3737.
- [35] N. Pearl, T. Treibitz, and S. Korman. Nan: Noise-aware nerfs for burst-denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12672–12681, 2022.
- [36] T. Pire, T. Fischer, G. Castro, P. De Crist’oforis, J. Civera, and J. J. Berlles. S-PTAM: Stereo parallel tracking and mapping. Robotics and Autonomous Systems, 93:27–42, 2017.
- [37] S. Zakharov, W. Kehl, A. Bhargava, and A. Gaidon. Autolabeling 3d objects with differentiable rendering of sdf shape priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12224–12233, 2020.
- [38] Chen Wang, Xian Wu, Yuan-Chen Guo, Song-Hai Zhang, Yu-Wing Tai, and Shi-Min Hu. NeRF-SR: High Quality Neural Radiance Fields using Supersampling. In Proceedings of the 30th ACM International Conference on Multimedia, pages=6445–6454, 2022.
- [39] Jeffrey Ichnowski, Yahav Avigal, Justin Kerr, and Ken Goldberg. Dex-nerf: Using a neural radiance field to grasp transparent objects. arXiv preprint arXiv:2110.14217, 2021.
- [40] Zehao Yu, Songyou Peng, Michael Niemeyer, Torsten Sattler, and Andreas Geiger. Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction. arXiv preprint arXiv:2206.00665, 2022.
- [41] Benran Hu, Junkai Huang, Yichen Liu, Yu-Wing Tai, and Chi-Keung Tang. NeRF-RPN: A general framework for object detection in NeRFs. arXiv preprint arXiv:2211.11646, 2022.
- [42] Thomas Schops, Torsten Sattler, and Marc Pollefeys. Bad slam: Bundle adjusted direct RGB-D slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages=134–144, 2019.
- [43] Z. Zhu, S. Peng, V. Larsson, et al., “Nicer-slam: Neural implicit scene encoding for RGB SLAM,” arXiv preprint arXiv:2302.03594, 2023.
- [44] M. Burri, J. Nikolic, P. Gohl, et al. "The EuRoC micro aerial vehicle datasets," The International Journal of Robotics Research, vol. 35, no. 10, pp. 1157-1163, 2016.
- [45] Z. Zhu, S. Peng, V. Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, and M. Pollefeys, "Nice-slam: Neural implicit scalable encoding for slam," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12786–12796.
- [46] Y. Ming, W. Ye, and A. Calway, "iDF-SLAM: End-to-End RGB-D SLAM with Neural Implicit Mapping and Deep Feature Tracking," arXiv preprint arXiv:2209.07919, 2022.
- [47] Hengyi Wang, Jingwen Wang, Lourdes Agapito. "Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM,"in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 13293-13302.
- [48] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, "Scannet: Richly-annotated 3d reconstructions of indoor scenes," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5828–5839.
- [49] K. Li, Y. Tang, V.A. Prisacariu, and P.H.S. Torr. "Bnv-fusion: dense 3D reconstruction using bi-level neural volume fusion," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6166–6175.
- [50] J. Huang, S.-S. Huang, H. Song, and S.-M. Hu. "Di-fusion: Online implicit 3d reconstruction with deep priors," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8932–8941.
- [51] J. Straub, T. Whelan, L. Ma, Y. Chen, E. Wijmans, S. Green, J.J. Engel, R. Mur-Artal, C. Ren, S. Verma, et al. "The Replica Dataset: A digital replica of indoor spaces," arXiv preprint arXiv:1906.05797, 2019.
- [52] J. Sturm, W. Burgard, and D. Cremers. "Evaluating egomotion and structure-from-motion approaches using the TUM RGB-D benchmark," in Proc. of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), 2012, pp. 1–7.
- [53] R.A. Newcombe, S.J. Lovegrove, and A.J. Davison. "DTAM: Dense tracking and mapping in real-time," in 2011 International Conference on Computer Vision, IEEE, 2011, pp. 2320–2327.
- [54] R. Mur-Artal, J.M.M. Montiel, and J.D. Tardos. "ORB-SLAM: a versatile and accurate monocular SLAM system," IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
- [55] Z. Liao, Y. Hu, J. Zhang, X. Qi, X. Zhang, and W. Wang. "So-slam: Semantic object slam with scale proportional and symmetrical texture constraints," IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4008–4015, 2022.
- [56] R. Tian, Y. Zhang, Y. Feng, L. Yang, Z. Cao, S. Coleman, and D. Kerr. "Accurate and Robust Object SLAM with 3D Quadric Landmark Reconstruction in Outdoor Environment," in IEEE Robotics and Automation Letters, pp. 1534-1541, 2022.
- [57] Z. J. Du, S. S. Huang, T. J. Mu, et al., “Accurate dynamic SLAM using CRF-based long-term consistency,” IEEE Transactions on Visualization and Computer Graphics, 2020, 28(4), 1745-1757.
- [58] J. C. V. Soares, M. Gattass, M. A. Meggiolaro, “Crowd-SLAM: visual SLAM towards crowded environments using object detection,” Journal of Intelligent & Robotic Systems, 2021, 102(2), 50.
- [59] Y. Wang, K. Xu, Y. Tian, et al., “DRG-SLAM: A Semantic RGB-D SLAM using Geometric Features for Indoor Dynamic Scene,” In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2022, pp. 1352-1359.
- [60] B. Bescos, C. Campos, J.D. Tard’os, and J. Neira. "DynaSLAM II: Tightly-coupled multi-object tracking and SLAM," IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5191–5198, 2021.
- [61] Y. Ling and S. Shen, “Building maps for autonomous navigation using sparse visual SLAM features,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 1374–1381.
- [62] M. R"unz and L. Agapito, “Co-fusion: Real-time segmentation, tracking and fusion of multiple objects,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 4471–4478.
- [63] Michael Bloesch, Jan Czarnowski, Ronald Clark, Stefan Leutenegger, and Andrew J Davison. "CodeSLAM—learning a compact, optimisable representation for dense visual SLAM." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2560-2568. 2018.
- [64] C.-H. Lin, W.-C. Ma, A. Torralba, and S. Lucey, "Barf: Bundle-adjusting neural radiance fields," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5741–5751.
- [65] R. Craig and R. C. Beavis, “TANDEM: matching proteins with tandem mass spectra,” Bioinformatics, vol. 20, no. 9, pp. 1466–1467, 2004.
- [66] Y. Yao, Z. Luo, S. Li, T. Shen, T. Fang, and L. Quan, “Recurrent MVSNet for high-resolution multi-view stereo depth inference,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5525–5534.
- [67] Z. Teed and J. Deng, "Droid-slam: Deep visual slam for monocular, stereo, and RGB-D cameras," Advances in Neural Information Processing Systems, vol. 34, pp. 16558-16569, 2021.
- [68] Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su, "MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14124-14133.
- [69] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, "Nerf: Representing scenes as neural radiance fields for view synthesis," Communications of the ACM, vol. 65, no. 1, pp. 99-106, 2021.
- [70] A. Yu, V. Ye, M. Tancik, and A. Kanazawa, "Pixelnerf: Neural radiance fields from one or few images," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4578-4587.
- [71] Kangle Deng, Andrew Liu, Jun-Yan Zhu, and Deva Ramanan, "Depth-supervised NeRF: Fewer views and faster training for free," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12882-12891.
- [72] T. Y. Lin, M. Maire, S. Belongie, et al., "Microsoft COCO: Common Objects in Context," in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, vol. 13, Springer International Publishing, 2014, pp. 740-755.
- [73] Y.-C. Guo, D. Kang, L. Bao, Y. He, and S.-H. Zhang, "Nerfren: Neural radiance fields with reflections," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18409-18418.
- [74] Q. Xu, Z. Xu, J. Philip, S. Bi, Z. Shu, K. Sunkavalli, and U. Neumann. "Point-nerf: Point-based neural radiance fields," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5438-5448.
- [75] J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin-Brualla, and P. P. Srinivasan, “Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5855–5864.
- [76] Bernhard Kerbl, et al., "3D Gaussian Splatting for Real-Time Radiance Field Rendering," ACM Transactions on Graphics (ToG), 42.4 (2023): 1-14.
- [77] C. Campos, R. Elvira, J. J. G. Rodríguez, J. M. M. Montiel, and J. D. Tardós, "ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial, and Multimap SLAM," IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021.
- [78] Bhat, S. F., Birkl, R., Wofk, D., et al., “Zoedepth: Zero-shot transfer by combining relative and metric depth,” arXiv preprint arXiv:2302.12288,2023.
- [79] B. Bescos, J. M. M. Montiel, and D. Scaramuzza, “DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 4076-4083, 2018.
- [80] Shi, X., Li, D., Zhao, P., et al., “Are we ready for service robots? The OpenLORIS-Scene datasets for lifelong SLAM,” In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2020, pp. 3139-3145.
- [81] X. Kong, S. Liu, M. Taher, et al., “vmap: Vectorised object map** for neural field slam,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 952-961.
- [82] G. Jocher, A. Chaurasia, A. Stoken, et al., "ultralytics/yolov5: v6.1-TensorRT, TensorFlow edge TPU and OpenVINO export and inference," Zenodo, 2022.
- [83] Chen, J., Xu, Y., “DynamicVINS: Visual-Inertial Localization and Dynamic Object Tracking,” In Proceedings of the 2022 China Automation Congress (CAC), IEEE, 2022, pp. 6861-6866.
- [84] Ultralytics YOLOv9 GitHub repository, https://github.com/WongKinYiu/yolov9, Accessed 2024.
- [85] Cheng, S., Sun, C., Zhang, S., et al., “SG-SLAM: a real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information,” IEEE Transactions on Instrumentation and Measurement, 2022, 72: 1-12.
- [86] Wang, P., Liu, L., Liu, Y., et al., “Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction,” arXiv preprint arXiv:2106.10689, 2021.
- [87] Ye, W., Yu, X., Lan, X., et al., “DeFlowSLAM: Self-supervised scene motion decomposition for dynamic dense SLAM,” arXiv preprint arXiv:2207.08794, 2022.
- [88] Palazzolo, E., Behley, J., Lottes, P., Giguere, P., Stachniss, C., “ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals,” In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Nov. 2019, pp. 7855-7862.