capbtabboxtable[][\FBwidth]
\datasetname: A Minimally Contrastive Benchmark for Grounding Spatial Relations in 3D
Abstract
Understanding spatial relations (e.g., “laptop on table”) in visual input is important for both humans and robots. Existing datasets are insufficient as they lack large-scale, high-quality 3D ground truth information, which is critical for learning spatial relations. In this paper, we fill this gap by constructing \datasetname: the first large-scale, human-annotated dataset for grounding spatial relations in 3D. \datasetname enables quantifying the effectiveness of 3D information in predicting spatial relations on large-scale human data. Moreover, we propose minimally contrastive data collection—a novel crowdsourcing method for reducing dataset bias. The 3D scenes in our dataset come in minimally contrastive pairs: two scenes in a pair are almost identical, but a spatial relation holds in one and fails in the other. We empirically validate that minimally contrastive examples can diagnose issues with current relation detection models as well as lead to sample-efficient training. Code and data are available at https://github.com/princeton-vl/Rel3D.
1 Introduction
Spatial relations such as “laptop on table” are ubiquitous in our environment, and understanding them is vital for both humans and intelligent agents like robots. As humans, we use spatial relations for perceiving and building knowledge of the surrounding environment and supporting our daily activities such as moving around and finding objects [1, 2]. Spatial relations play an important role in communication for describing to others where objects are located [3, 4, 5, 6].
Likewise, for robots, understanding spatial relations is necessary for navigation [7], object manipulation [8, 9], and human-robot interaction [10, 11]. For a robot to complete a task such as “put the bottle in the box”, it is necessary to first understand the relation “bottle in the box”.
A spatial relation is defined as a subject-predicate-object triplet, where predicate describes the spatial configuration between subject and object, such as painting-over-bed. Understanding spatial relations may seem an easy task at first glance, and a plausible model could be a set of hand-crafted rules for each predicate based on the spatial properties of subject and object, like their relative position [12, 13, 14, 15]. However, just like many other rule-based systems, this approach works for a small set of carefully curated examples, but fails for wider real-world examples consistent with human judgment [16].
The failure results from the rich and complex semantics of spatial predicates, which depend on various factors beyond relative positions. For example, they depend on frames of reference (Is “left to the car” relative to the observer or relative to the car?), object properties (For “in front of the house”, what is the frontal side of a house? Is there still a frontal side if the object were a tree?), and also commonsense (“painting over bed” is not touching while “blanket over bed” is). With all these subtleties, any set of hand-crafted rules is likely to be inadequate, so researchers have applied data-driven approaches to learn spatial relations from visual data [17, 18, 11, 7, 8, 19, 20].

Benchmarking spatial relations in 3D. Benchmark datasets have been proposed for training and evaluating a system’s understanding of spatial relations [6, 19, 20]. However, existing datasets either have limited scale and variety [6, 19] or contain human-annotated relations only on 2D images [19, 20]. Prior research suggests that 3D information may play a critical role in spatial relations [20, 21, 11, 9]. With only 2D images, the model has to implicitly learn the mapping to 3D, which is itself an unsolved problem. Instead of developing an accurate 3D understanding of spatial relations, models tend to utilize superficial 2D cues [20]. More importantly, in robotics, 3D information is often readily available, making it valuable to study spatial relation recognition using 3D information.
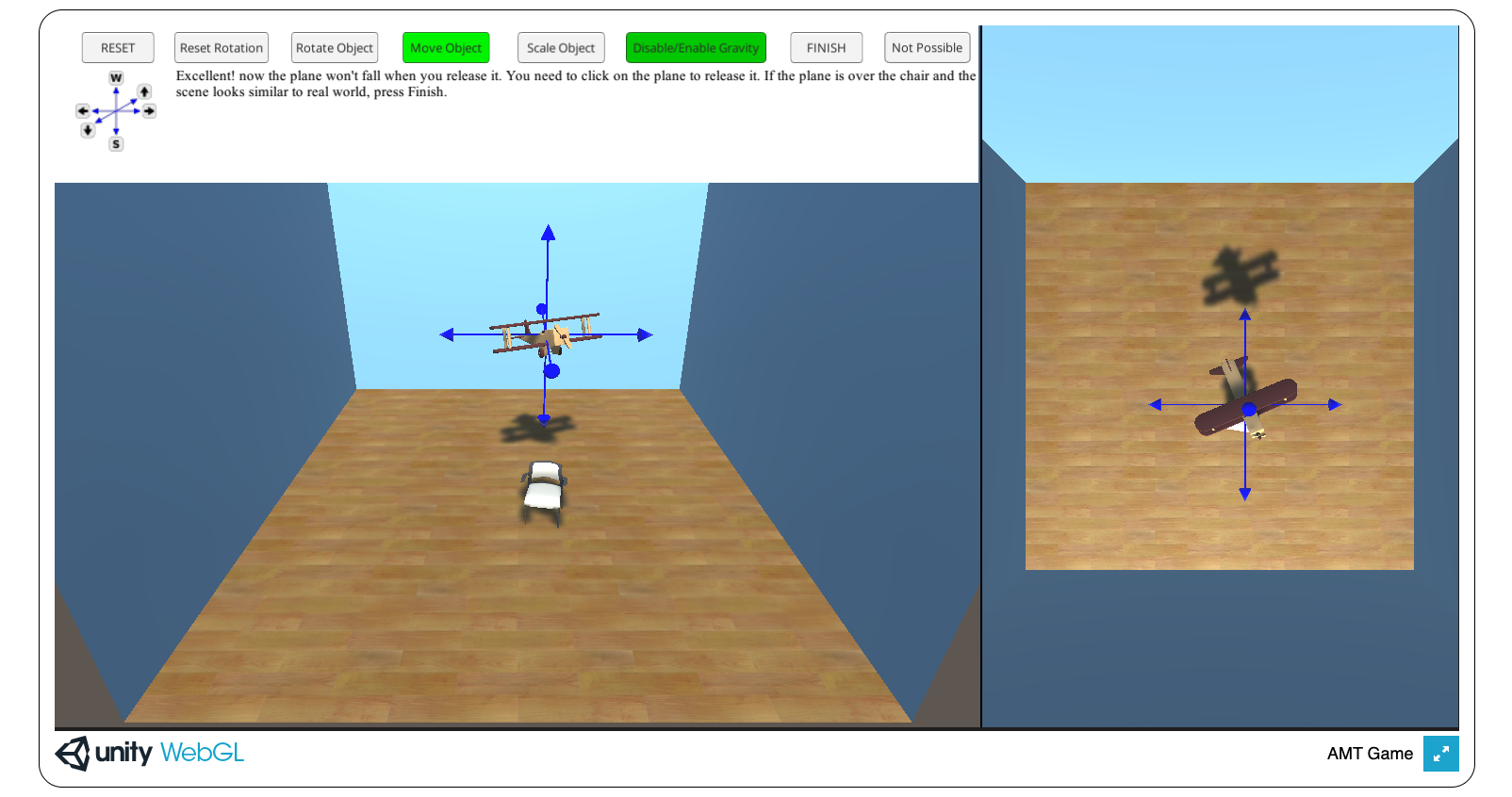
In this work, we propose \datasetname—the first large-scale dataset of human-annotated spatial relations in 3D (Fig. 1). It consists of spatial relations situated in synthetic 3D scenes, making it possible to extract rich and accurate geometric and semantic information, including depth, segmentation mask, object positions, poses, and scales. The scenes in \datasetname are created by crowd workers on Amazon Mechanical Turk (Fig. 3). Workers manipulate objects according to instructions, and independent workers are asked to verify whether a given spatial relation holds in the 3D scene. We choose to use synthetic scenes because they give us complete control over various factors, e.g., objects, positions, camera poses, etc. Such flexibility is important for datasets specializing in spatial relations, enabling us to study the grounding of spatial relations with respect to these factors.
is the first to provide rich geometric and semantic information in 3D for the task of spatial relation understanding. It enables the exploration of problems that were out of reach before. Specifically, we study how ground truth object 3D positions, scales, and poses (including frontal and upright orientation) can be used to train neural networks to predict spatial relations with high accuracy. Further, our experiments suggest that estimating 3D configurations is a promising step towards understanding spatial relations in 2D images.
Reducing dataset bias through minimally contrastive examples. Besides promoting 3D understanding of spatial relations, \datasetname also addresses a fundamental issue with existing datasets—biases in language and 2D spatial cues. Despite prior efforts in mitigating bias [22, 23, 20], state-of-the-art models achieve superficially high performance by exploiting bias, without much understanding [20].
We propose minimally contrastive data collection for spatial relations—a novel crowdsourcing method that significantly reduces dataset bias. \datasetname consists of minimally contrastive scenes: pairs of scenes with minimal differences, so that the spatial relation holds in one but fails in the other (Fig. 1). The task for the model is to classify whether the given relation holds. This minimally contrastive construction makes it unlikely for a model to exploit bias, including language bias (“cup on table” is more likely than not) and other spurious correlations with factors like the color of the background or the texture of an object. If a model attempts to associate the background with a relation, it cannot succeed in both instances of a minimally contrastive pair with identical backgrounds.
Through our experiments, we demonstrate how \datasetname can be used as an effective tool for diagnosing models that rely heavily on 2D bias as well as Language bias for making predictions. We show that a simple 2D baseline outperforms more sophisticated models, implying that these models lack 3D understanding for recognizing spatial relations. Further, we empirically demonstrate that training models on minimally contrastive examples leads to better sample efficiency.
Our contributions are as follows:
-
•
We construct \datasetname: the first large-scale dataset of human-annotated spatial relations in 3D
-
•
\datasetname
is the first benchmark for spatial relation understanding that contains minimally contrastive examples, alleviating bias and leading to sample-efficient training
-
•
With \datasetname, we demonstrate how 3D positions, scales, and poses of objects can be used to predict spatial relations with high accuracy
2 Related Work
Spatial relations. Research in psycholinguistics has studied how humans perceive spatial relations and use them in natural language. Landau & Jackendoff [5] have argued that natural languages use a surprisingly small set of predicates (less than 100 in English) for spatial relations, which forms the basis of how we select predicates in \datasetname. Some researchers have investigated the semantics of spatial predicates from views of human language and cognition [2, 3, 4, 16]. Others have attempted to build computational models [12, 17, 13, 15, 14]. However, these models are often based on hand-crafted rules and they are validated only on a handful of toy examples (e.g., treating objects as 2D shapes). We differ from this body of research as ours is a data-driven approach. Instead of hand-designing rules for spatial relations using a small set of curated examples, we develop machine learning models to recognize spatial relations from large-scale human-annotated visual data. We also show that our data can be potentially used to provide empirical evidence for some prior observations.
Many data-driven approaches for spatial relations have been developed in robotics, including applications in navigation [7], object manipulation [8, 18, 9] and human-robot interaction [10, 24, 11, 25, 26]. Zeng et al. [9] designed a robot to manipulate objects given visual observations of the initial state and the goal. A core intermediate step in their method is to predict spatial relations. Guadarrama et al. [11] built a robot to respond to spatial queries in natural language (e.g., “What is the object in front of the cup?”). To answer the query, the robot needs to predict spatial relations in the scene. These spatial relation modules in robotics are usually developed on small-scale datasets specific to each robotic system, making it hard to compare different methods. Also, many systems rely on hand-crafted rules that are not applicable universally [10, 24, 9]. In contrast, we build a large-scale benchmark that facilitates a common base for training and evaluating different methods.
Visual relationship detection. Recognizing relations in images has become a frontier of computer vision beyond object recognition. Lu et al. [27] introduced the task of visual relationship detection: the model takes an image as input and detects subject-predicate-object triplets by localizing pairs of objects and classifying the predicates. Since then, several datasets containing visual relations have been proposed, such as VRD [27], Visual Genome [28], and Open Images [29]. The relations in these are not necessarily spatial (e.g., “person drink tea”). We focus on spatial relations, which is an important class of visual relations; 66.0% of relations in VRD and 51.5% in Visual Genome are spatial. Unlike them, our dataset contains rich and accurate information about the 3D scene like object locations, orientation, surface normal, and depth. Further, we alleviate bias in language and 2D cues that are present in VRD and Visual Genome [20]. Many model architectures [30, 31, 32, 33, 34, 35, 36, 37, 38] have been developed on these datasets. We adapt and benchmark some recent works on \datasetname.
Closest to our work is SpatialSense [20], which consists of K relations on K images from NYU Depth [39] and Flickr. SpatialSense proposed adversarial crowd-sourcing to reduce language and 2D spatial bias. \datasetname differs from SpatialSense in two ways. First, \datasetname contains rich and accurate geometric and semantic information like depth, surface normal, segmentation mask, object positions, poses, and scale; while SpatialSense only contains bounding box annotations and noisy depth for some images. Rich 3d information enables analysis that is not possible with SpatialSense (see Sec.6). Second, scenes in \datasetname occur in minimally contrastive pairs. Not only does this eliminate language bias and reduce 2D bias, but it also controls for any spurious correlations with factors like background, texture, and lighting, which are not considered in SpatialSense.
Language and 3D. Similar to our work, prior works have also explored grounding language in 3D. Notably, Chang et al. [40] model spatial knowledge by leveraging statistics in 3D scenes. For spatial relations, they create a dataset with 609 annotations between 131 object pairs in 17 scenes. Also, Chang et al. [41] create a model for generating 3D scenes from text, and create a dataset of 1129 scenes from 60 seed sentences. Concurrent to our work, Panos et al. [42] proposed ReferIt3D, a benchmark for contrasting objects in 3D using natural and synthetic language. However, unlike in prior works [40, 41, 42], scenes in Rel3D occur in minimally contrastive pairs which control for potential biases like language bias. Also, the objects in prior works [40, 41, 42] are limited to those found in indoor scenes like chairs and tables, while Rel3D also considers outdoor objects like trees, planes, cars and birds, and hence it covers a wider array of spatial relations.
Dataset bias. The issue of dataset bias has plagued many machine learning tasks both within computer vision [22, 23, 20] and beyond [43, 44, 45, 46]. Zhang et al. [22] address language bias in answering yes/no questions on clipart images. They collect pairs of images with the same question but different answers by showing the image and the question to crowd workers and asking them to modify the image so that the answer changes. Goyal et al. [23] extend this idea to real images. Unlike them, we ask for minimal modifications to input, and hence reduce bias by a much larger extent, not only in language but also in a variety of factors, including texture, color, and lighting.
“something-something” [47] is a video action recognition dataset that reduces bias by having a large number of classes. Hence, a model has to learn the action nuances (e.g., “folding something” vs. “unfolding something”). However, unlike \datasetname, it does not contain minimally contrastive pairs.
Generating synthetic 3D data. Our work is also related to prior works in generating synthetic 3D data using graphics engines or simulators [48, 49, 50, 51, 52, 53, 54]. This approach can produce massive data at low cost, and 3D information is readily available. It also gives us the flexibility to control various factors in the scene, such as object categories, shapes, and positions. Note that the relations in our dataset are annotated by humans rather than generated automatically.
3 Dataset
consists of spatial relations situated in 3D scenes, from which one can extract rich and accurate information, such as depth, object positions, poses, and scales. Each scene contains two objects (subject and object), that either satisfy a spatial relation (subject-predicate-object) or not (Fig. 1). Objects in \datasetname come from multiple sources, including ShapeNet [55], and YCB [56]. We use predicates based on prior work [5] and aim to cover most of the common spatial relations. Given the vocabulary of objects and predicates, we remove triplets that are unlikely to occur in the real world (e.g. “laptop in cup”). We design an interface for crowd workers to compose 3D scenes for a given spatial relation by manipulating objects (Fig. 3). We collect instances as pairs of minimally contrastive scenes in two stages. First, we collect positive scenes wherein the spatial relation is true. Next, we give a positive scene and ask them to move the objects just enough to falsify the relation.
After collecting the 3D scenes, we render images from multiple views and conduct a final round of verification by independent crowd workers. As a result, we collect 9,990 3D scenes ( 4,995 positive, 4,995 negative) and 27336 images. The objects come from 67 categories, with 30 different spatial predicates. Below, we detail each component of our data collection pipeline.
Object vocabulary. The objects in our dataset are from three sources: ShapeNet [55]: It is a large-scale dataset of 3D shapes. We use the ShapeNetSem subset [57], which contains rich annotations such as the frontal side, upright orientation, and real-world scale of objects. These annotations are important because, for instance, the frontal side of an object affects the configuration for the spatial predicate ‘‘in front of’’ when considered from the object’s frame. There are 270 object categories in ShapeNetSem. We remove categories with too few shapes, as well as group similar ones (e.g. different types of chairs), and end up with 48 categories.
YCB [56]: It is a dataset for benchmarking object manipulation, consisting of everyday objects that can be manipulated on a table. These are included because object manipulation requires understanding spatial relations, and \datasetname can potentially be used for object manipulation in simulation engines. There are 77 shapes in YCB, which we manually filter and merge with ShapeNet to get 53 object categories from YCB+ShapeNet.
Manual collection: We collect a set of objects manually. These are from the word list of the Thing Explainer book [58]. We add 14 categories from this, including house, mountain, wall, and stick. For each category, we download five to six 3D shapes from open-source shape repositories.
In summary, the objects in \datasetname comprise of 358 shapes from categories. They cover a wide range of everyday objects and are annotated with real-world scales and pose information (frontal side, upright orientation). The 3D shapes are manually reviewed to ensure quality. The train and test data contain mutually exclusive sets of 3D shapes. The supplementary material has more details.
Predicate vocabulary. As argued by Landau & Jackendoff [5], the space of spatial predicates is surprisingly small (less than 100 in English). We start with the list of spatial predicates in [5] and group those with similar semantic meaning (e.g., nearby and near). Next, we add multi-word prepositional phrases that describe spatial relations, such as facing towards and leaning against. We end up with 30 spatial predicates, which is a superset of those in SpatialSense [20].
Some predicates like to the left of are ambiguous and depend on the reference frame. For example, “person in front of the car” can be interpreted with respect to the observer or the car. If it is relative to the car, and the car is facing away from the observer, then the person would be behind the car in the frame of reference of the observer. Unlike prior work [20], we resolve this ambiguity by splitting such predicates into two: one relative to the observer and the other relative to the object. We ask crowd workers to complete the task without mentioning frames, and later ask which reference frame was used. This also captures real-world frequencies of frames of reference (refer to Sec. 4 for details). As a result, the spatial predicates in \datasetname are not ambiguous with respect to reference frames. However, if one wishes to retain the ambiguity, our data still captures the real-world frequencies of different reference frames.
Relation vocabulary. Given 67 object categories and 30 predicates, there are 67 30 67 = 134,670 possible relations. However, not all relations are likely to happen in the real world (e.g., “laptop in cup”). In \datasetname, we only include relations that can occur naturally. We randomly sample about th of all relations which then are examined by 6 expert annotators to select natural relations.
Crowdsourcing 3D scenes. We ask crowd workers on Amazon Mechanical Turk to compose 3D scenes by manipulating objects (Fig. 3). We create a Unity WebGL interface that renders two objects placed in an empty scene with walls and a floor. Workers can manipulate the 3D position, pose, and scale of the objects. Gravity is enabled by default but can be turned off by the worker for an object (e.g. an airplane). First, we collect positive samples. Given a spatial relation subject-predicate-object, the worker has to manipulate objects so that the relation holds. We ask workers to re-scale objects to resemble their real-world scales. Next, we collect minimally contrastive negative samples. Recall that a pair of minimally contrastive scenes are almost identical, but the spatial relation holds in one while fails in the other. Given a positive scene, workers are asked to move objects minimally to make the relation invalid. To simplify the task and ensure diversity, we allow them to move/rotate only one of the objects, along a randomly chosen predefined axis. If the relation cannot be invalidated by movement/rotation along the chosen axis, they can select “Not Possible”, and a new axis is provided.
We find that for about 20% of negative samples, movement along the axis leads to an unnatural scene. For example, a chair could be in the air when moved along the vertical axis. While collecting negative samples, we ask AMT workers to identify these examples. Although unnatural, these are valid negative samples for the spatial relation, hence are included in the dataset. If one wishes, they can be removed using our annotations. During both the stages, we control the quality by inspecting random samples and removing annotations coming from workers with several low-quality annotations.
Rendering and human verification. After collecting scenes, we render images and ask independent crowd workers to verify them. For each pair of minimally contrastive scenes, we sample 12 camera views111For directional relations that depend on the view of the observer, we use 3 views along the front plane. and perform photo-realistic rendering using Blender [59]. The same set of camera views are used for positive and negative scenes in a pair. We show the images to crowd workers and ask them to verify whether the spatial relation holds. Each image is reviewed by three workers and we take the majority vote. We include only those image pairs for which the original labels are corroborated by the workers. This also provides us the views from which humans could distinguish whether the spatial relation holds or not. Finally, we end up with 27336 human-verified images, which we use for our experiments. Note that, by using the 3D scene and the view information in Rel3D, one can potentially render infinitely many images by modifying factors like 3D context, background, and lighting.
Distribution of Samples per Predicate Class. \datasetname poses a binary classification problem where given a relation, the task is to classify whether or not the objects satisfy the relation. \datasetname has variable number of instances per predicate, as some predicates, like on, occur more frequently than others, like passing through (exact distribution in supplementary material). However, as \datasetname has each predicate represented by an equal number of positive and negative samples, the imbalance in predicate counts does not bias a model to predict one more than another. Also, \datasetname poses an independent binary classification task for each predicate and uses average class accuracy as the metric which is robust to the number of samples per predicate. Unlike \datasetname, VRD and Visual Genome use Recall@K (the recall of ground truth relations given K predicted relations), which fails to identify if a system is producing valid but unannotated predictions or false positives [20].
4 Dataset Analysis
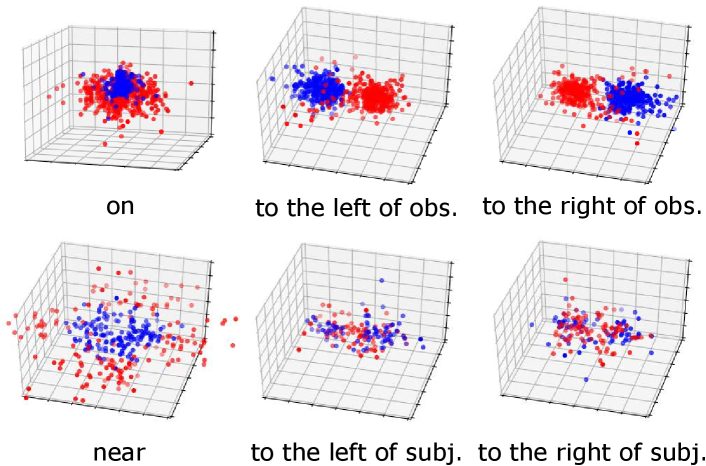
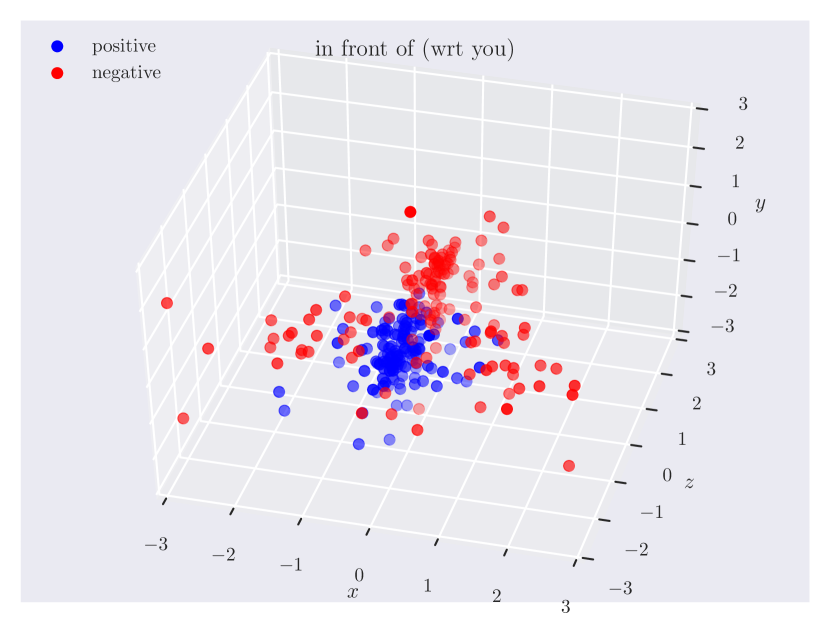
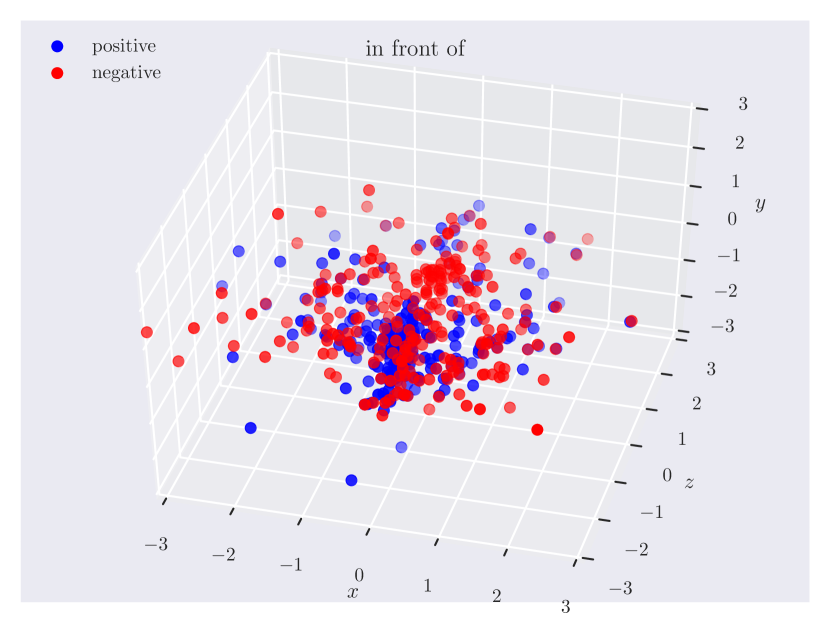
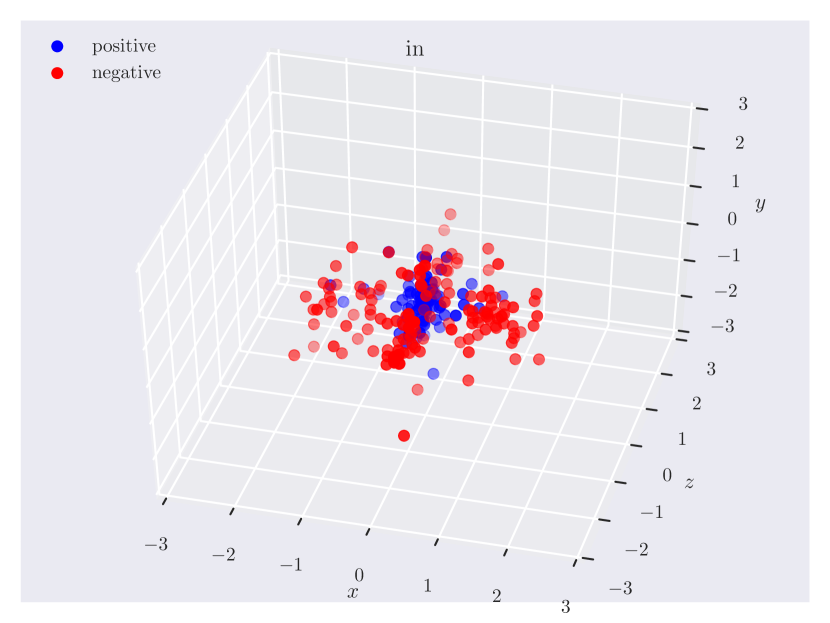
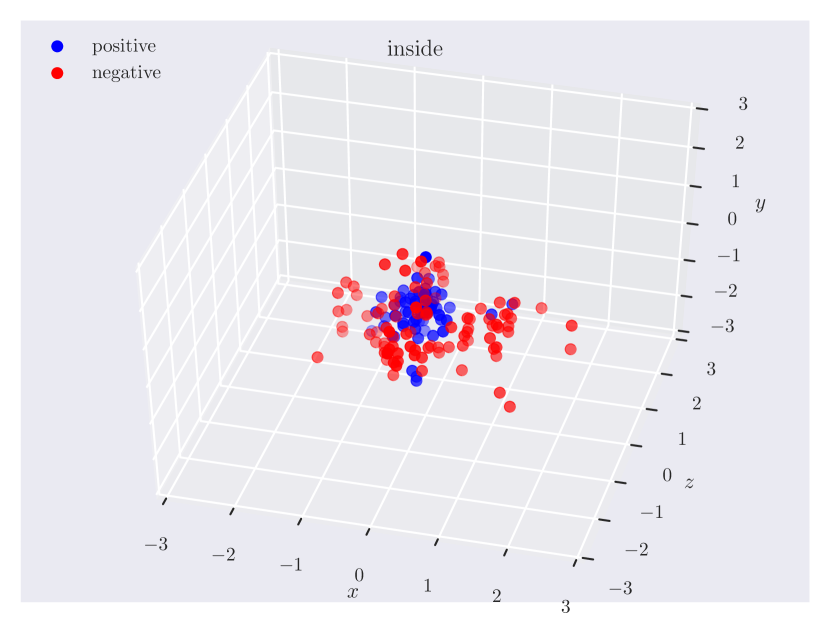
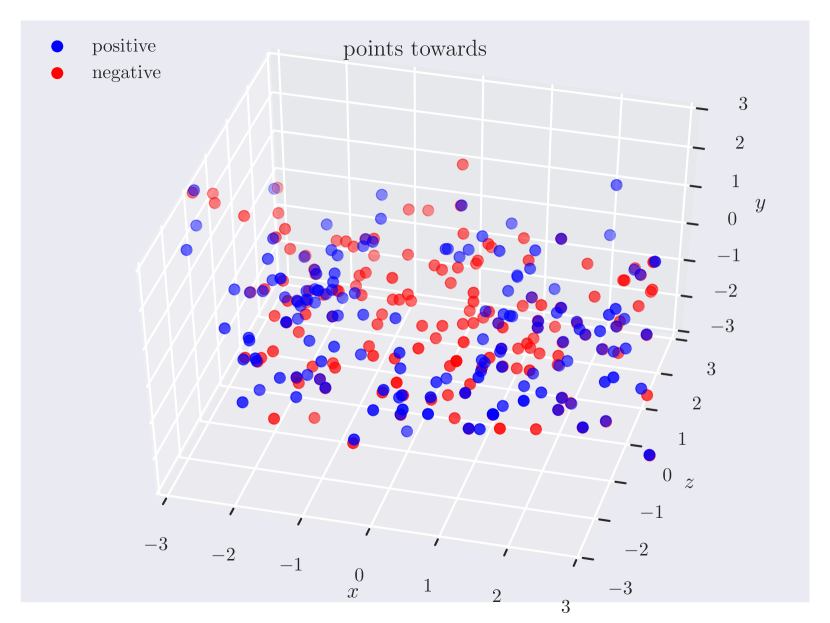
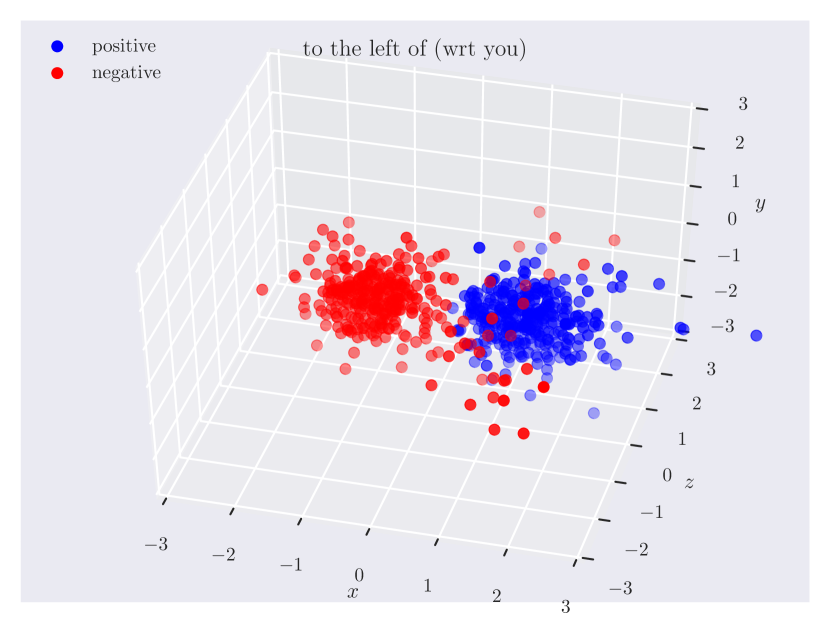
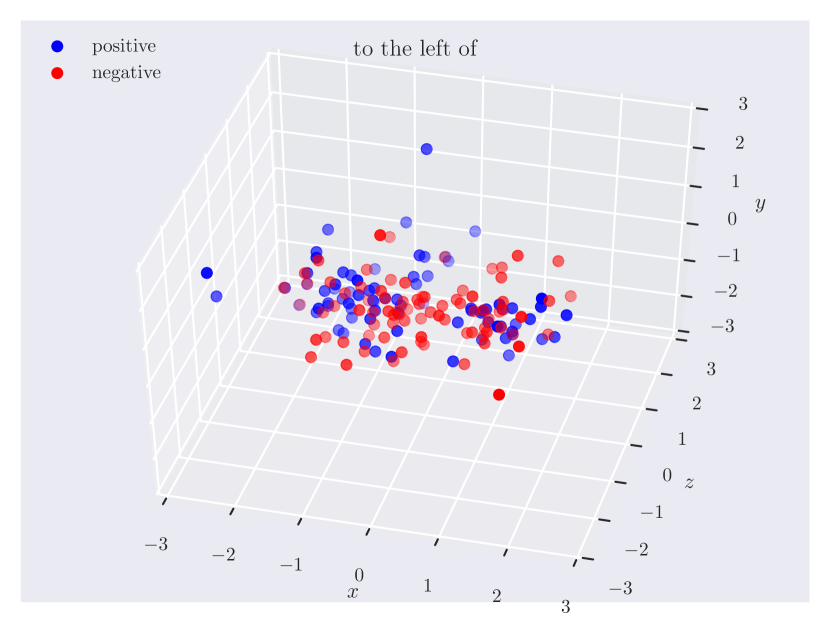
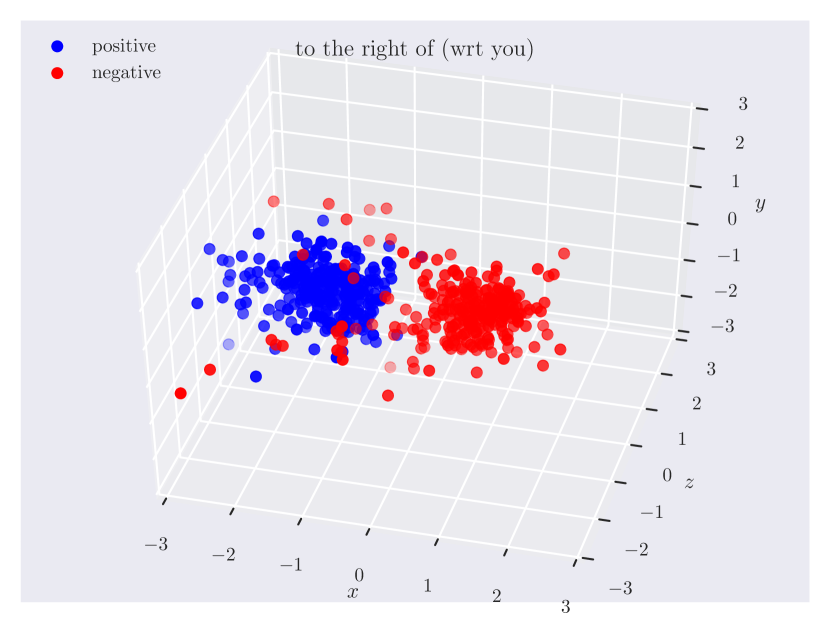
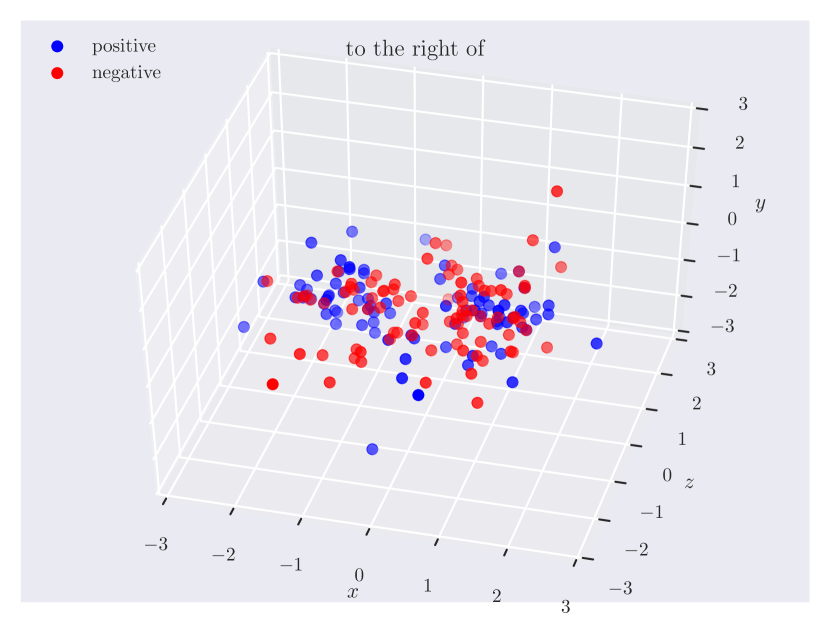
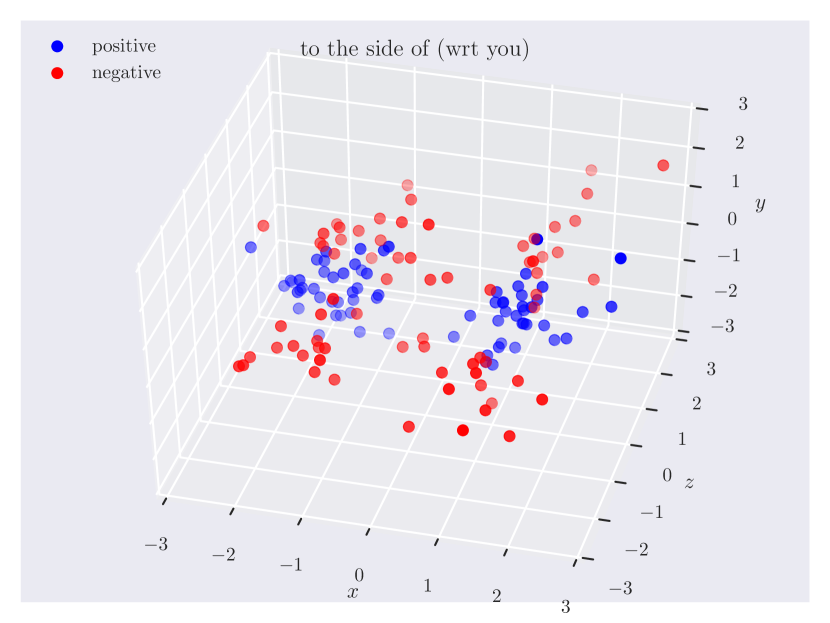
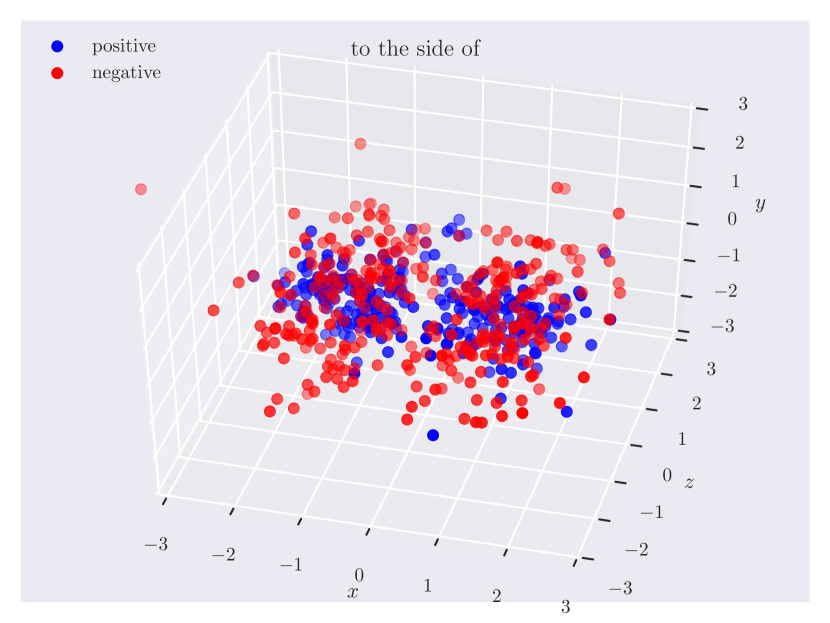
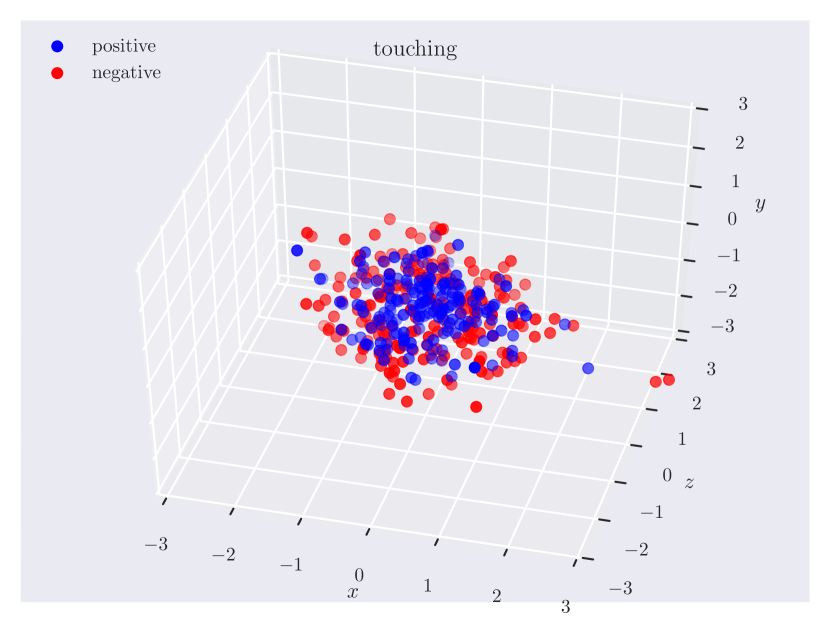
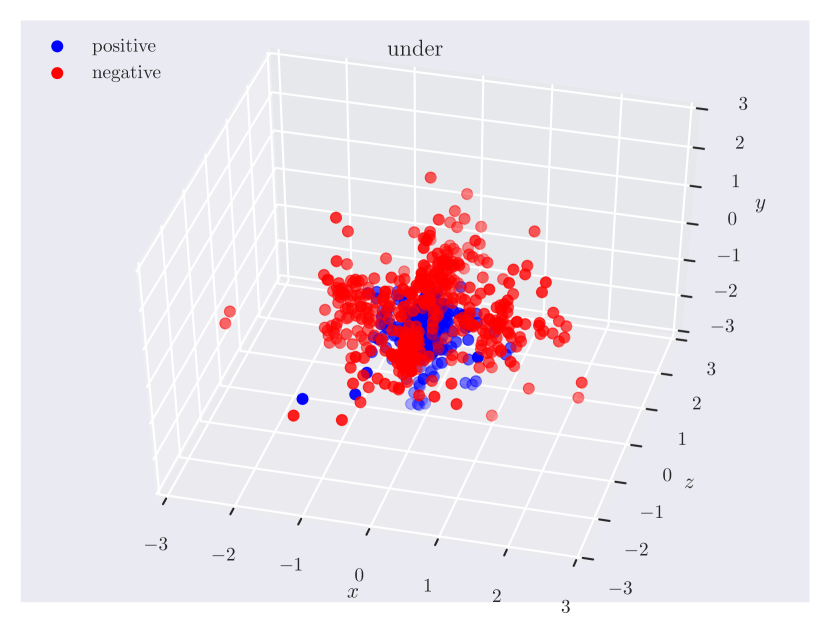
Distribution of objects in 3D space. Since our dataset has ground truth 3D positions, it can provide insights into which regions of 3D space do humans consider as ‘‘to the left of’’ something, or how close the objects should be for them to be ‘‘near’’. In Fig. 3, we plot the relative position of the subject w.r.t. the object. Note how the directional predicate to the left of has different distributions depending on frames of reference. When relative to the observer, there exists a cleaner boundary of separation in the reference frame of the observer, while no such boundary exists relative to the object, as the object could have any orientation in the scene. Plots for other relations can be found in the supplementary material.
Directional spatial relations. Directional relations are spatial relations whose semantics depend on frame of reference. There are 5 directional relations in \datasetname: to the left of, to the right of, to the side of, in front of, and behind. They have different spatial groundings in the two frames: relative (relative to the observer) and intrinsic (relative to the object). Prior research in psycho-linguistics has studied the problem of how humans choose between different frames of reference [60, 12, 61, 16]. However, there aren’t any empirical results based on large-scale data of human judgments. With \datasetname, we are able to shed light on this problem.
When collecting positive samples, we give the workers a relation (e.g., “person to the left of car”) and ask them to manipulate objects to make the relation hold. We intentionally do not specify the frame of reference and let them decide. After the task, we display an image of the scene from a different viewpoint and ask if the relation remains valid. If the answer is “Yes”, the worker is using intrinsic frame of reference (relative to the car). Otherwise, the worker is using relative frame of reference (relative to the observer). Based on responses from workers, our data reflects a natural distribution of how different reference frames are used.
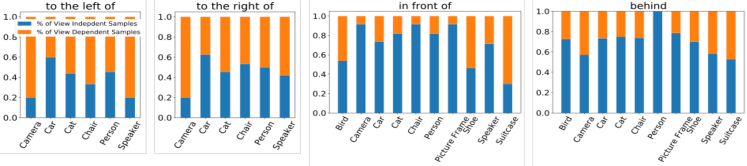
Fig. 4 shows the percentage of intrinsic reference frames (view-independent) and relative reference frames (view-dependent) for each directional relation in \datasetname. We show the plots for objects-predicate combinations with more than 10 samples for both to the left of and to the right of or both in front of and behind. We find that human choices of reference frames depend on the object as well as the predicate.
To the left and to the right have highly-correlated responses (), showing that humans make similar choices for both. The correlation between in front of and behind is 0.4, showing that they are not as symmetric as to the left of and to the right of. In fact, for some object categories like “Camera”, the responses for in front of and behind are very different. This suggests that the choice of reference frames may also depend on object affordances.
5 Experiments
Baselines for spatial relation recognition. We benchmark state-of-the-art visual relationship detection models [33, 30, 31, 34] on \datasetname. They are outperformed by a simple baseline based solely on 2D bounding boxes, demonstrating that \datasetname is a challenging benchmark, and existing methods are unable to truly understand spatial relations.
Experimental setup. For benchmarking, we follow an approach similar to SpatialSense [20]. The task is spatial relation recognition: Input is an RGB image, two object bounding boxes, their category labels, and a spatial relation between them. The model predicts whether the spatial relation triplet holds in the image or not. We compute the accuracy for each of the 30 predicates separately and then report the average of those 30 values. This ensures that the reported metric reflects models’ overall performance, unaffected by the variability in the number of samples per predicate.
Model architectures. Similar to SpatialSense, we evaluate 2D-only and language-only baselines. The 2D-only baseline takes as input the predicate and the coordinates of two bounding boxes; while the language-only baseline takes the predicate and the object categories. They output a scalar indicating whether the spatial relation holds. Similar to SpatialSense, we also adapt four state-of-the-art visual relationship detection models for our task, namely DRNet [33], Vip-CNN [30], VTransE [31] and PPR-FCN [34]. Please refer to the supplementary for more details.
Implementation details. All images are resized to before feeding into the model. We perform random cropping and color jittering on training data. Hyper-parameters for each model are tuned separately using validation data, and the best-performing model on the validation set is used for testing. Please refer to the supplementary material for more details.
Results. Table 6 shows the performance of the baselines for spatial relation recognition on \datasetname. Accuracy for each relation can be found in the supplementary material. The dataset does not contain any language bias since each triplet (subject-predicate-object) has both positive and minimally contrastive negative examples. So, the language-only model does no well than a random baseline (50%). All state-of-the-art models fail to outperform the simple 2D baseline, emphasizing that the current models rely on language and 2D bias to achieve high performance on existing benchmarks. Thus, \datasetname can serve as a tool for diagnosing issues in models. Also, human performance on the dataset is around 94%. This confirms the quality of the dataset and the scope for improvement for models. The 6% errors demonstrate that some spatial relations are inherently fuzzy and subjective.
[\FBwidth][][] \capbtabbox
Model
Input
Avg. Acc.
Random
—
50.00%
Lang Only [20]
class
50.00%
BBox Only [20]
bbox
74.14%
DRNet [33]
RGB + bbox
73.25%
+ class
Vip-CNN [30]
RGB + bbox
72.32%
+ class
VTransE [31]
RGB + bbox
72.27%
PPR-FCN [34]
RGB + bbox
73.30%
MLP
Raw Features
81.24%
MLP
Aligned Features
85.03%
Human
RGB + phrase
94.25%
\capbtabbox
Model
Input
Avg. Acc.
Random
—
50.00%
Lang Only [20]
class
50.00%
BBox Only [20]
bbox
74.14%
DRNet [33]
RGB + bbox
73.25%
+ class
Vip-CNN [30]
RGB + bbox
72.32%
+ class
VTransE [31]
RGB + bbox
72.27%
PPR-FCN [34]
RGB + bbox
73.30%
MLP
Raw Features
81.24%
MLP
Aligned Features
85.03%
Human
RGB + phrase
94.25%
Using 3D information for spatial relations. A reasonable hypothesis is that the 3D configuration between objects is important in determining their spatial relation. Prior works have built computational models for spatial relations based on hand-crafted features such as angle and distance [12, 17, 13, 15, 14]. However, they are unable to provide a quantitative evaluation on large-scale natural data. \datasetname makes it possible to quantify the predictive power of 3D information for spatial relations.
To explore this, for each object in a scene, we define three reference frames: the camera reference frame , the object’s raw reference frame , and the object’s aligned reference frame . In the , the camera is at origin and points towards axis, and up direction is . The object’s raw reference frame is the reference frame wherein the axes correspond to the raw CAD mesh. These axes might not be aligned for their front and up direction. If we align the axis to the mesh’s frontal direction and axis to the mesh’s up direction, we obtain the aligned reference frame . We use the following two mechanisms for encoding this information:
Raw features. For each object, we encode its centroid in , rotation angles between and , and scale along in . Since raw mesh is not aligned for the frontal and top directions, we encode this information by finding the relative rotation between and . The final raw feature has 24 dimensions (each object: 3-centroids, 3-rotation from to , 3-sizes, 3-rotation between and ).
Aligned features. Here we directly encode the positions, rotation angles, and scale of the object’s aligned mesh. In this way the front and up directions are implicitly encoded. We represent each object with a 9-d vector (3 - centroid in , 3 - rotation from to , 3 - sizes in directions in ). The final aligned features have dimensions. Note that these features do not encode information about the exact geometry of objects. They are approximating each object as cuboids in the 3D space. We use these features to train a 5-layer Multi-layer perceptron (MLP) with skip connections for classifying spatial relations.
[5pt] Animal to the left of Bird
Animal to the left of Bird
[5pt] Bottle passing through tire
Bottle passing through tire
[5pt] Ball under TV
Ball under TV
[5pt] Radio in front of Man
Radio in front of Man
Results. The performance of different models is reported in Table 6. Further, Fig. 8a shows how our model effectively learns the decision boundary for spatial relations. Note that directly comparing these models to those using only 2D information is unfair. However, our analysis reveals how much one can gain by utilizing the 3D information. This suggests that learning to predict 3D information like pose and orientation could be an effective intermediate strategy for spatial predicate grounding.
Our results show that the 3D features alone are not sufficient to solve the relation recognition problem. In Fig. 8b, we visualize some cases where the model fails. One reason for failure is that aligned features do not encode information about the geometry of objects (refer to Sec. 6) but approximates each object as a cuboid. In Ball under TV, it approximates the TV as a cuboid and predicts some regions underneath the screen as not being under the TV. Radio in front of Man shows an ambiguous case where there is fuzziness whether the front of a person is defined w.r.t to their face or torso. It is important to emphasize that this study becomes possible as we have access to accurate 3D data information of the scene; and it is not possible in benchmarks that operate only in 2D images.
Minimally Contrastive Examples Improve Sample Efficiency. we hypothesize that minimally contrastive examples lead to sample-efficient training as they reduce bias for a network to overfit. To verify this hypothesis, we construct subsets of training data with only contrastive and only non-contrastive samples.
We construct the contrastive subset by randomly sampling minimally contrastive pairs. For the non-contrastive subset, we first sample twice as many contrastive pairs and then choose one sample from each pair. Thus the total number of training samples remains the same between contrastive and non-contrastive subsets. Fig. 6 show that training on minimally contrastive examples is much more sample efficient than on non-contrastive examples. Models trained on contrastive subsets outperform those trained on non-contrastive subsets using only about training data. This trend holds for models that use RGB input (DRNet and VtransE) as well as for models using 3D information. This demonstrates that minimally contrastive examples lead to sample efficient training.
6 Conclusion
Understanding spatial relations is an important task that requires reasoning in 3D. But existing datasets for the task lack large-scale, high-quality 3D ground truth. In this paper, we constructed \datasetname: the first large-scale dataset with human-annotated spatial relations in 3D. To reduce bias, we collected minimally contrastive pairs. Our experiments confirmed the utility of 3D information for spatial relations and the effectiveness of minimally contrastive samples for reducing bias.
7 Broader Impact
This work contributes to improve the understanding of spatial relations, which in turn is a critical piece of the giant puzzle on language understanding. Our work could potentially lead to better language understanding and scene comprehension for intelligent systems like robots. This can eventually help the intelligent systems to communicate better with humans. Depending on how these intelligent systems are used, the society could gain positively as well as negatively from the existence of such systems.
Acknowledgement. This work is partially supported by the National Science Foundation under Grant IIS-1734266 and the Office of Naval Research under Grant N00014-20-1-2634. We would like to thank Alexander Strzalkowski, Pranay Manocha and Shruti Bhargava for their help with data collection.
Appendices
Appendix A Predicate Vocabulary
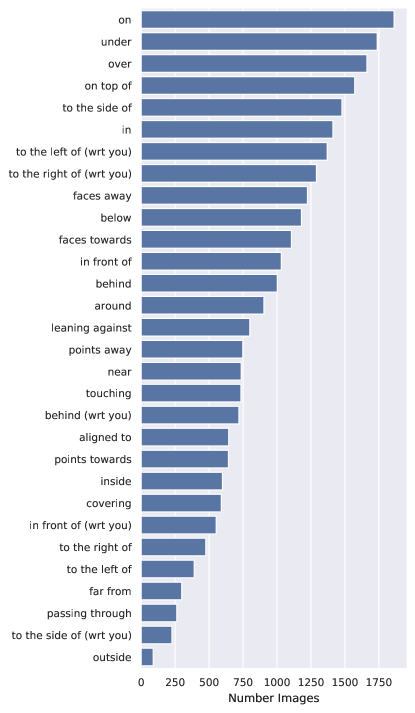
There are in total 27336 images in Rel3D. Figure. 9 plots the number of images per predicate.
Appendix B Object Vocabulary
| ShapeNetSem Only | YCB Only | Both in YCB and ShapeNetSem | SimpleWord |
| Speaker | Can | Cereal Box | Building |
| Computer | Fruits | Bottle | Mountain |
| Picture Frame | Cup | Glasses | |
| Desk | Block | Radio | |
| TV | Ball | Stick | |
| Mirror | Stone | ||
| Person | House | ||
| Picture | Wheel | ||
| Book | Shoe | ||
| Chair | Door | ||
| Rug | Tire | ||
| Bed | Tree | ||
| Camera | Wall | ||
| Media Storage | Bag | ||
| Table | |||
| Plant | |||
| Gun | |||
| CellPhone | |||
| Plate | |||
| Cat | |||
| Controller | |||
| Knife | |||
| Cap | |||
| Animal | |||
| Clock | |||
| Ladder | |||
| Car | |||
| Washer | |||
| Bus | |||
| Boat | |||
| Fish | |||
| Ring | |||
| Truck | |||
| Bird | |||
| Teapot | |||
| Airplane | |||
| Bowl | |||
| Fork | |||
| Spoon | |||
| Couch | |||
| Child Bed | |||
| Vase | |||
| Toilet | |||
| Sink | |||
| Suitcase | |||
| Bike |
| ShapeNetSem Cat. | In Rel3D | < 5 shapes | Rel3D Cat. | Similar Cat. in Rel3D |
| WallArt | Yes | Picture | ||
| Chair,Recliner | Yes | Chair | ||
| Speaker | Yes | Speaker | ||
| Lamp,DeskLamp | No | Plant | ||
| Chair,OfficeChair | Yes | Chair | ||
| Chair,rankChairs,OfficeSideChair | Yes | Chair | ||
| Computer | Yes | Computer | ||
| Chair,rankChairs | Yes | Chair | ||
| Table,RoundTable,AccentTable | Yes | Table | ||
| Picture Frame | Yes | Picture Frame | ||
| Couch | Yes | Couch | ||
| Candle | No | Bottle | ||
| Dresser,ChestOfDrawers | Yes | Media Storage | ||
| Desk | Yes | Desk | ||
| Helicopter | Yes | Airplane | ||
| Bottle,WineBottle | Yes | Bottle | ||
| Clock,StandingClock | Yes | Clock | ||
| Bench | Yes | Table | ||
| TV | Yes | TV | ||
| Mirror | Yes | Mirror | ||
| Person | Yes | Person | ||
| Picture | Yes | Picture | ||
| Bottle | Yes | Bottle | ||
| Shelves,Bookcase | Yes | Media Storage | ||
| TrashBin | No | Cup | ||
| Bed,LoftBed | No | Bed | ||
| Books | Yes | Book | ||
| Chair,OfficeSideChair | Yes | Chair | ||
| Book | Yes | Book | ||
| Chair | Yes | Chair | ||
| Lamp,FloorLamp | No | Plant | ||
| Laptop,Computer | Yes | Computer | ||
| FoodItem,MilkCarton | Yes | Cereal Box | ||
| Oven,Counter | No | Yes | Washer | |
| Fireplace | No | |||
| Lamp,TableLamp | No | Plant | ||
| Rug | Yes | Rug | ||
| ArcadeMachine | No | Yes | ||
| Monitor | Yes | TV | ||
| LightSwitch | No | Block | ||
| OutdoorTable | Yes | Table | ||
| Bed | Yes | Bed | ||
| Chair,rankChairs,OfficeChair | Yes | Chair | ||
| Table,AccentTable | Yes | Table | ||
| Camera | Yes | Camera | ||
| Media Storage | Yes | Media Storage | ||
| Table | Yes | Table | ||
| Plant | Yes | Plant | ||
| Gun | Yes | Gun | ||
| Dresser,ChestOfDrawers,DresserWithMirror | Yes | Media Storage | ||
| Child Bed | Yes | Child Bed | ||
| Cabinet | Yes | Media Storage | ||
| Vase | Yes | Vase | ||
| Cabinet,Sideboard | Yes | Media Storage | ||
| Chair,Recliner,rankChairs | Yes | Chair | ||
| Lamp,WallLamp | No | Plant | ||
| TvStand,Media Storage | Yes | Media Storage | ||
| Window | No | Picture | ||
| Stapler | No | Block | ||
| Microwave | No | Washer | ||
| Violin | No | Knife | ||
| TvStand,MediaStorage | Yes | Media Storage | ||
| Table,DiningTable | Yes | Table | ||
| Table,RoundTable | Yes | Table | ||
| CellPhone | Yes | CellPhone | ||
| Chair,SideChair | Yes | Chair | ||
| Plate | Yes | Plate | ||
| Teapot | Yes | Teapot | ||
| Cat | Yes | Cat | ||
| Lamp,CeilingLamp | No | Plant | ||
| Controller | Yes | Controller | ||
| Armoire,ChestOfDrawers | Yes | Media Storage | ||
| Chair,ChairWithOttoman | Yes | Chair | ||
| Lamp,LampPost | No | Plant | ||
| Armoire,Dresser,Wardrobe,ChestOfDrawers | Yes | Media Storage | ||
| Armoire,Wardrobe,ChestOfDrawers | Yes | Media Storage | ||
| Picture Frame | Yes | Picture Frame | ||
| Bookcase | Yes | Media Storage | ||
| Oven | No | Washer | ||
| Refrigerator | No | Washer | ||
| Table,EndTable | Yes | Table | ||
| Table,RoundTable,DiningTable | Yes | Table | ||
| Lamp,DeskLamp,FloorLamp | No | Plant | ||
| Piano | No | Table | ||
| Bathtub | No | Yes | ||
| Stool | Yes | Table | ||
| Whiteboard | No | Picture | ||
| Knife | Yes | Knife | ||
| Lamp | No | Plant | ||
| Donut,FoodItem | No | Ring | ||
| Cap | Yes | Cap | ||
| GameTable | Yes | Table | ||
| Chair,Couch | Yes | Chair | ||
| ChestOfDrawers | Yes | Media Storage | ||
| Table,EndTable,RoundTable | Yes | Table | ||
| Table,CoffeeTable | Yes | Table | ||
| MediaPlayer | No | Washer | ||
| MousePad | No | Yes | ||
| Animal | Yes | Animal | ||
| Picture,Painting | Yes | Picture | ||
| Airplane | Yes | Airplane | ||
| Toilet | Yes | Toilet | ||
| Chair,AccentChair | Yes | Chair | ||
| FoodItem | No | Yes | ||
| Computer | Yes | Computer | ||
| Printer | No | Washer | ||
| DartBoard | No | WallArt | ||
| Curtain | No | Door | ||
| Booth | No | Yes | ||
| SpaceShip | Yes | Airplane | ||
| Horse | Yes | Animal | ||
| Nightstand,ChestOfDrawers | Yes | Media Storage | ||
| Tank | No | Truck | ||
| FileCabinet | Yes | Media Storage | ||
| Bed,PosterBed | Yes | Bed | ||
| Cabinet,CurioCabinet | Yes | Media Storage | ||
| Table,RoundTable,CoffeeTable | Yes | Table | ||
| Sink | Yes | Sink | ||
| Ipod | Yes | CellPhone | ||
| Bed,SingleBed | Yes | Bed | ||
| Animal,PlushToy | Yes | Animal | ||
| ToyFigure | No | Block, Person | ||
| Bed,KingBed | Yes | Bed | ||
| TvStand | No | Yes | ||
| Notepad | Yes | Book | ||
| Dryer | Yes | Washer | ||
| WallArt,Painting | Yes | Picture | ||
| Bottle,BeerBottle | Yes | Bottle | ||
| NintendoDS,VideoGameController | Yes | Controller | ||
| BarTable | Yes | Table | ||
| Bowl | Yes | Bowl | ||
| Chair,Chaise,rankChairs | Yes | Chair | ||
| Clock | Yes | Clock | ||
| Stool,Barstool | Yes | Table | ||
| Toy | No | Yes | ||
| Clock,WallClock | Yes | Clock | ||
| Rock | Yes | Stone | ||
| Bottle,DrinkBottle | Yes | Bottle | ||
| Dart | No | Yes | ||
| Fork | Yes | Fork | ||
| Cabinet,FileCabinet | No | Media Storage | ||
| CoffeeMaker | No | Sink | ||
| DresserWithMirror | Yes | Mirror | ||
| Ladder | Yes | Ladder | ||
| Chair,Chaise | Yes | Chair | ||
| Poster,WallArt | Yes | Picture | ||
| Couch,Loveseat | Yes | Couch | ||
| Chair,BeanBag | Yes | Chair | ||
| Suitcase | Yes | Suitcase | ||
| Wii,VideoGameConsole | Yes | Controller | ||
| Dog | Yes | Animal | ||
| PianoKeyboard | No | Controller, Block | ||
| PSP,VideoGameController | Yes | Controller | ||
| Snowman | No | Yes | ||
| Cabinet,Sideboard,CurioCabinet | No | Yes | ||
| Dishwasher | Yes | Washer | ||
| Spoon | Yes | Spoon | ||
| Horse,ToyFigure | Yes | Animal | ||
| Radio | Yes | Radio | ||
| Car | Yes | Car | ||
| FoodItem,Cereal Box | Yes | Cereal Box | ||
| Painting | Yes | Picture | ||
| Washer | Yes | Washer | ||
| Bus | Yes | Bus | ||
| Bed,DoubleBed | Yes | Bed | ||
| Cereal Box | Yes | Cereal Box | ||
| ComputerMouse | Yes | |||
| ToyFigure,SpaceShip | No | |||
| Bowl,FoodItem | No | Bowl | ||
| SodaCan | Yes | Can | ||
| Boat | Yes | Boat | ||
| Fish | Yes | Fish | ||
| GameTable,RoundTable | Yes | Table | ||
| Coin | No | Plate, Ring | ||
| Picture,WallArt,Painting | Yes | Picture | ||
| Airplane,ToyFigure,rankAirplanes | Yes | Airplane | ||
| MediaDiscs | No | Yes | ||
| Ipad | Yes | CellPhone | ||
| Ring | Yes | Ring | ||
| PowerSocket | No | Yes | ||
| Ipod,Cabling | No | Yes | ||
| _StanfordSceneDBModels | No | |||
| Couch,Sectional | Yes | Couch | ||
| Backpack | Yes | Bag | ||
| Truck | Yes | Truck | ||
| Lamp,DeskLamp,TableLamp | No | Yes | ||
| Elephant | Yes | Animal | ||
| Bed | Yes | Bed | ||
| Desk,DraftingTable | Yes | Desk | ||
| Bed,RoundBed | Yes | Bed | ||
| Pen | No | Yes | ||
| Chair,SideChair,rankChairs | Yes | Chair | ||
| Board | Yes | Picture | ||
| Bowl,FruitBowl | Yes | Bowl | ||
| Keyboard | No | Block, Book | ||
| Door | Yes | Door | ||
| Chair,rankChairs,AccentChair | Yes | Chair | ||
| ChestOfDrawers,DresserWithMirror | Yes | Media Storage | ||
| Ipod,Headphones | No | Yes | ||
| DiscCase | No | Yes | ||
| Tank,ToyFigure | No | Yes | ||
| Headphones | Yes | |||
| LDesk | No | Desk | ||
| Counter | No | Table | ||
| Nightstand | No | Yes | ||
| Rack,Shelves,CoatRack | Yes | Media Storage | ||
| Sword | Yes | Knife | ||
| Ship | Yes | Boat | ||
| Hanger | No | Yes | ||
| Easel | No | Yes | ||
| Bed,CanopyBed,PosterBed | No | Bed | ||
| Armoire,Wardrobe | No | Yes | ||
| Vanity | No | Yes | ||
| SkateBoard | No | Yes | ||
| Bird | Yes | Bird | ||
| BedWithNightstand | Yes | Bed | ||
| Toy,Clock | Yes | Clock | ||
| Car,ToyFigure | Yes | Car | ||
| Cow | Yes | Animal | ||
| Shelves | Yes | Media Storage | ||
| Camera,DSLRCamera | Yes | Camera | ||
| Bike | Yes | Bike | ||
| Bicycle | Yes | Bike | ||
| Thumbtack | No | Yes | ||
| Picture,WallArt | No | Picture | ||
| Shirt | No | Yes | ||
| _OIMwhitelist | No | Yes | ||
| Rack | No | Yes | ||
| Fries,FoodItem | No | Yes | ||
| Hat | Yes | Cap | ||
| Bowl,FoodItem,FruitBowl | Yes | Yes | Bowl | |
| Armoire | Yes | Media Storage | ||
| PowerStrip | No | Yes | ||
| Chair,KneelingChair | Yes | Chair | ||
| Harp | No | Yes | ||
| Rack,Shelves | Yes | Media Storage | ||
| Armoire,Dresser,ChestOfDrawers | Yes | Media Storage | ||
| Table,ChestOfDrawers | Yes | Table | ||
| Toy,Horse | Yes | Yes | Animal | |
| Knife,Utensils | Yes | Knife | ||
| Ipod,CellPhone | Yes | CellPhone | ||
| Gamecube,VideoGameConsole | Yes | Controller | ||
| StaplerWithStaples | No | Yes | ||
| Cabinet,ChestOfDrawers | Yes | Media Storage | ||
| Toy,Truck | Yes | Truck | ||
| Bowl,Plate | Yes | Bowl | ||
| Faucet | Yes | Yes | Sink | |
| Kettle | Yes | Teapot | ||
| Toy,Animal,PlushToy | Yes | Animal | ||
| VideoGameConsole | Yes | Controller | ||
| Bed,Crib | Yes | Child Bed | ||
| ToiletPaper | No | |||
| WasherDryerSet | Yes | Washer | ||
| Donkey | Yes | Animal | ||
| TissueBox | No | Yes | ||
| RiceCooker | No | Yes | ||
| Credenza | No | Yes | ||
| Bed,KingBed | Yes | Bed | ||
| Plate,FoodItem,FoodPlate | Yes | Plate | ||
| Poster | Yes | Picture | ||
| Shower | No | Yes | ||
| Lectern | No | Yes | ||
| Cassette | No | Yes | ||
| WallArtWithFigurine | Yes | Picture | ||
| Glasses | Yes | Glasses | ||
| TvStand,RoundTable,MediaStorage | Yes | Table | ||
| Xbox,VideoGameConsole | No | Yes | ||
| GuitarStand | No | Yes | ||
| _BAD | No | Yes | ||
| Telephone | No | Yes | ||
| Bed,Cradle | Yes | Child Bed | ||
| Toy,Elephant,PlushToy,ToyFigure | Yes | Animal | ||
| Bidet | No | Yes | ||
| DeskLamp | No | Plant | ||
| TV,TvStand | No | Yes | ||
| Radio,Clock | Yes | Clock | ||
| Bed,Dresser,DoubleBed,ChestOfDrawers | Yes | Bed | ||
| Room | No | |||
| Calculator | No | Block, Controller | ||
| Toy,Airplane | No | Airplane |
| Object ID | Rel3D Category | Reason for not including in Rel3D |
| 001_chips_can | Can | |
| 002_master_chef_can | Can | |
| 003_cracker_box | Cereal Box | |
| 004_sugar_box | Cereal Box | |
| 005_tomato_soup_can | Can | |
| 006_mustard_bottle | Bottle | |
| 007_tuna_fish_can | Can | |
| 008_pudding_box | Cereal Box | |
| 009_gelatin_box | Cereal Box | |
| 010_potted_meat_can | Can | |
| 011_banana | Fruits | |
| 012_strawberry | Fruits | |
| 013_apple | Fruits | |
| 014_lemon | Fruits | |
| 015_peach | Bad reconstruction | |
| 016_pear | Fruits | |
| 017_orange | Fruits | |
| 018_plum | Bad reconstuction | |
| 019_pitcher_base | Bad reconstuction | |
| 021_bleach_cleanser | Bottle | |
| 022_windex_bottle | Largely distorted | |
| 023_wine_glass | Missing Object | |
| 024_bowl | Bad reconstuction | |
| 025_mug | Cup | |
| 026_sponge | Block | |
| 027_skillet | Bad reconstuction | |
| 028_skillet_lid | Missing object | |
| 029_plate | Bad reconstuction | |
| 030_fork | Bad reconstuction | |
| 031_spoon | Bad reconstuction | |
| 032_knife | Bad reconstuction | |
| 033_spatula | Missing object | |
| 035_power_drill | Only 1 shape | |
| 036_wood_block | Block | |
| 037_scissors | Only 1 shape | |
| 038_padlock | Bad reconstruction | |
| 039_key | Missing object | |
| 040_large_marker | Only 1 shape | |
| 041_small_marker | Bad reconstuction | |
| 042_adjustable_wrench | Bad reconstuction | |
| 043_phillips_screwdriver | Bad reconstuction | |
| 044_flat_screwdriver | Bad reconstuction | |
| 048_hammer | Only 1 shape | |
| 049_small_clamp | Missing .obj file | |
| 050_medium_clamp | Bad reconstuction | |
| 051_large_clamp | Bad reconstuction | |
| 052_extra_large_clamp | Only 1 Shape | |
| 053_mini_soccer_ball | Bad reconstuction | |
| 054_softball | Ball | |
| 055_baseball | Ball | |
| 056_tennis_ball | Ball | |
| 057_racquetball | Ball | |
| 058_golf_ball | Ball | |
| 059_chain | Bad reconstruction | |
| 061_foam_brick | Block | |
| 062_dice | Bad reconstruction | |
| 063-a_marbles | Bad reconstruction | |
| 063-b_marbles | Missing objects | |
| 063-c_marbles | Missing objects | |
| 063-d_marbles | Missing objects | |
| 063-e_marbles | Missing objects | |
| 063-f_marbles | Missing objects | |
| 065-a_cups | Bad reconstruction, looks like a blob | |
| 065-b_cups | Bad reconstruction | |
| 065-c_cups | Bad reconstruction | |
| 065-d_cups | Cup | |
| 065-e_cups | Cup | |
| 065-f_cups | Cup | |
| 065-g_cups | Cup | |
| 065-h_cups | Bad reconstruction | |
| 065-i_cups | Cup | |
| 065-j_cups | Cup | |
| 070-a_colored_wood_blocks | Bad reconstruction | |
| 070-b_colored_wood_blocks | Missing objects | |
| 071_nine_hole_peg_test | Block | |
| 072-a_toy_airplane | Small Object Part | |
| 072-b_toy_airplane | Small Object Part | |
| 072-c_toy_airplane | Small Object Part | |
| 072-d_toy_airplane | Small Object Part | |
| 072-e_toy_airplane | Small Object Part | |
| 072-f_toy_airplane | Small Object Part | |
| 072-g_toy_airplane | Small Object Part | |
| 072-h_toy_airplane | Small Object Part | |
| 072-i_toy_airplane | Small Object Part | |
| 072-j_toy_airplane | Small Object Part | |
| 072-k_toy_airplane | Small Object Part | |
| 073-a_lego_duplo | Small Object Part | |
| 073-b_lego_duplo | Small Object Part | |
| 073-c_lego_duplo | Small Object Part | |
| 073-d_lego_duplo | Small Object Part | |
| 073-e_lego_duplo | Small Object Part | |
| 073-f_lego_duplo | Small Object Part | |
| 073-g_lego_duplo | Small Object Part | |
| 073-h_lego_duplo | Small Object Part | |
| 073-i_lego_duplo | Small Object Part | |
| 073-j_lego_duplo | Small Object Part | |
| 073-k_lego_duplo | Small Object Part | |
| 073-l_lego_duplo | Small Object Part | |
| 073-m_lego_duplo | Small Object Part | |
| 076_timer | Only 1 shape | |
| 077_rubiks_cube | Block | |
| 078_tshirt | No obj model |
Appendix C Relation Plots
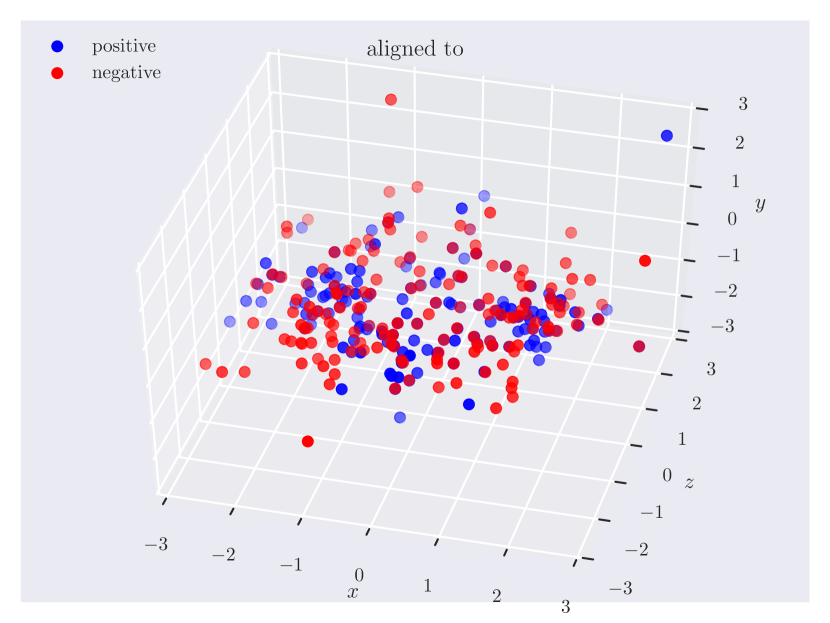
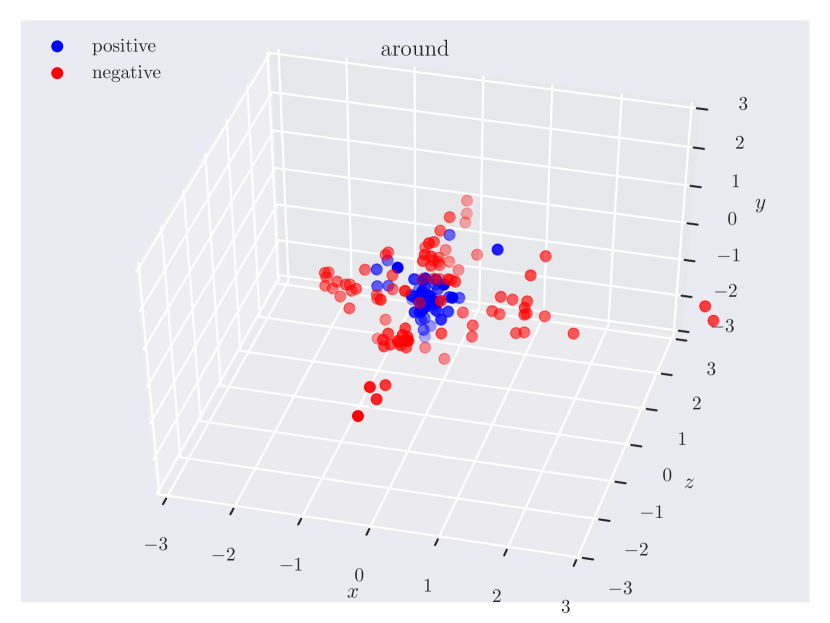
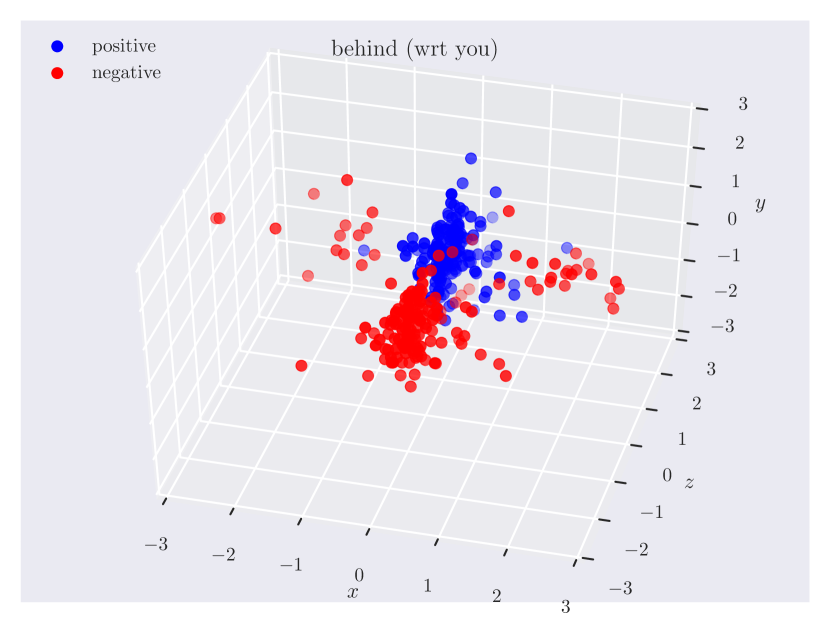
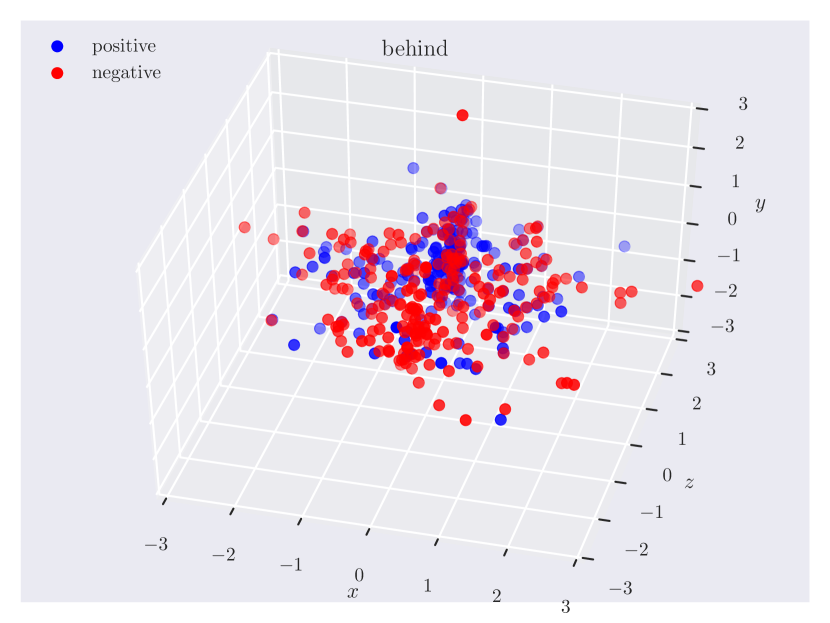
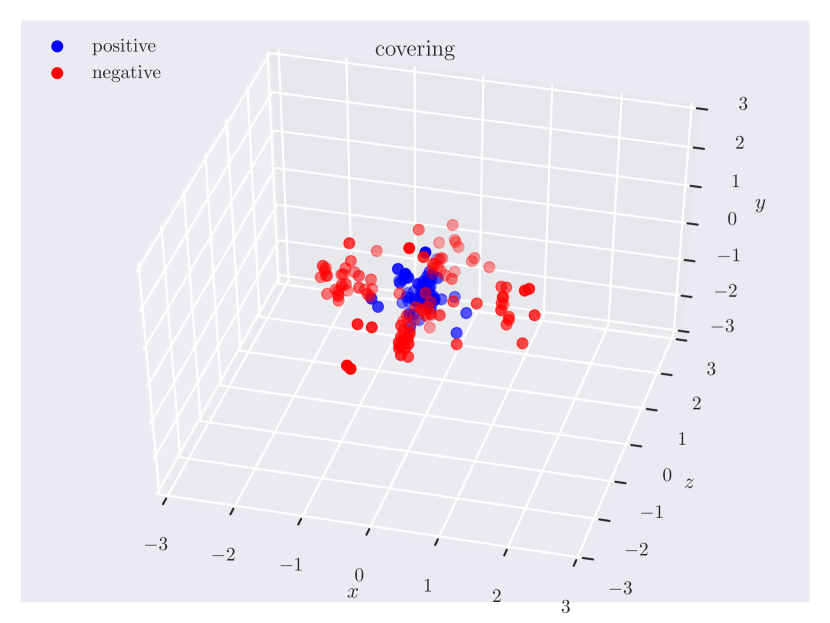
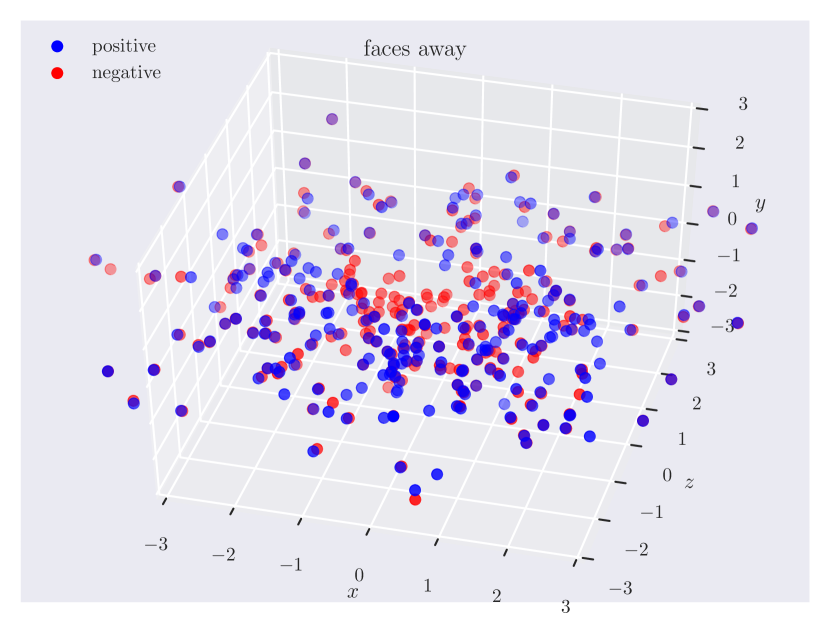
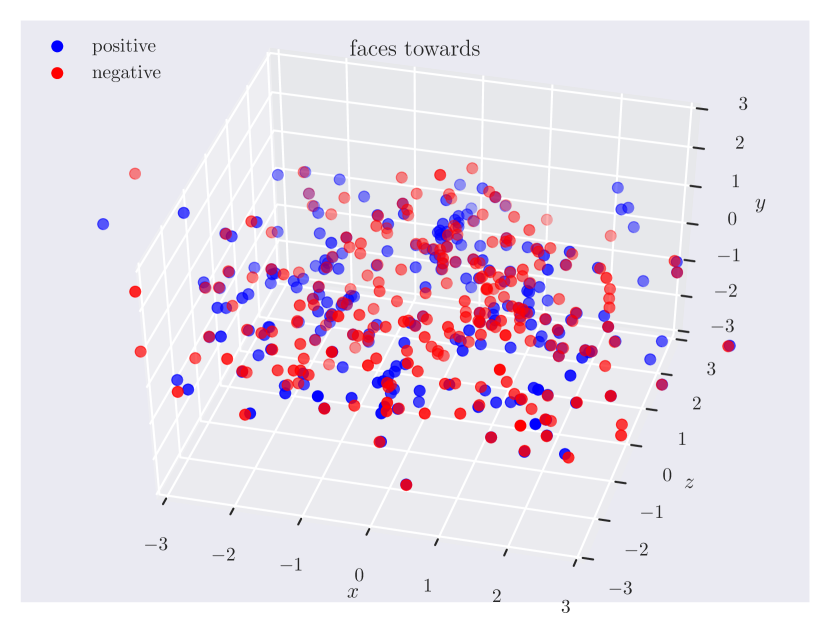
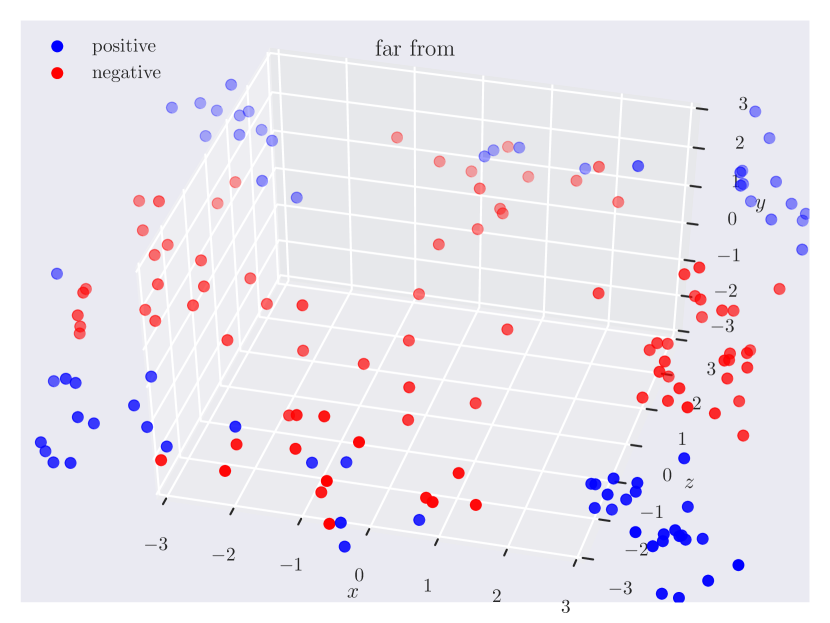
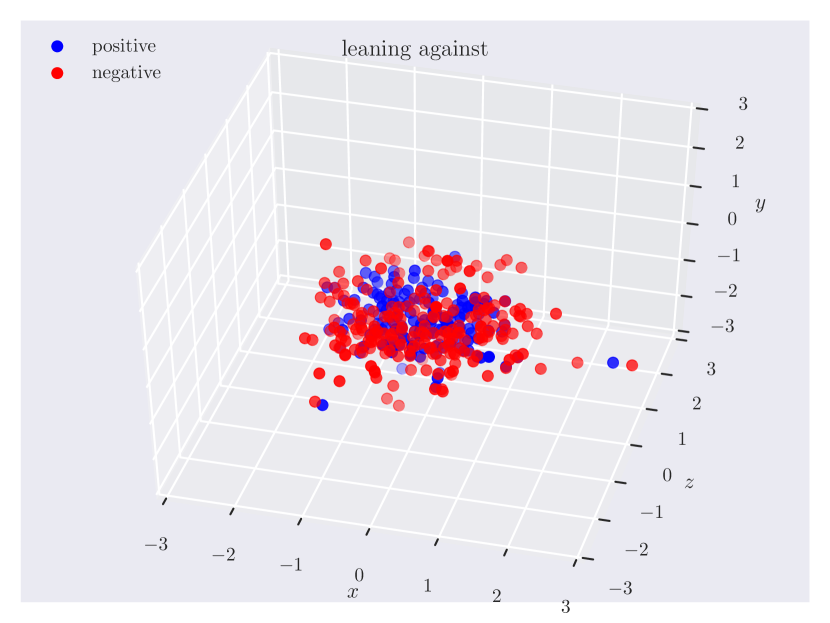
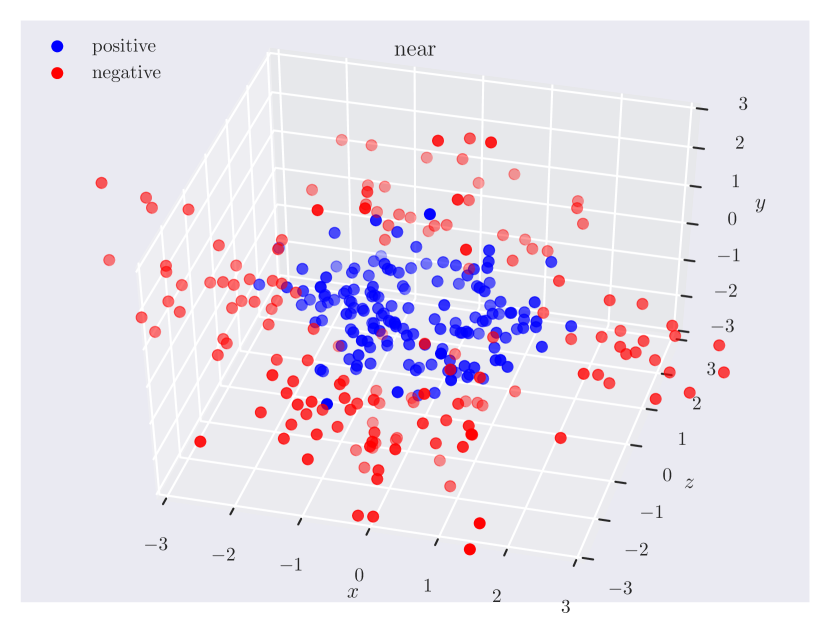
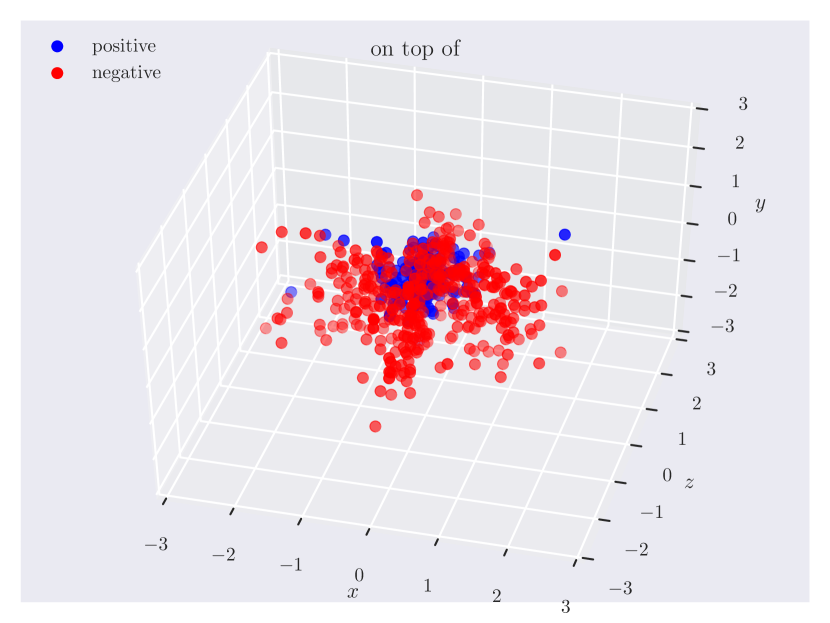
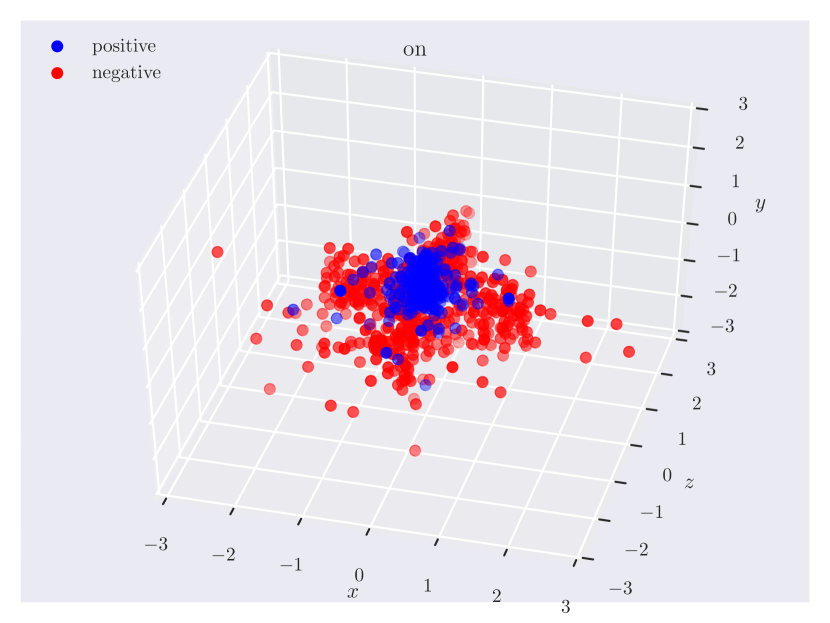
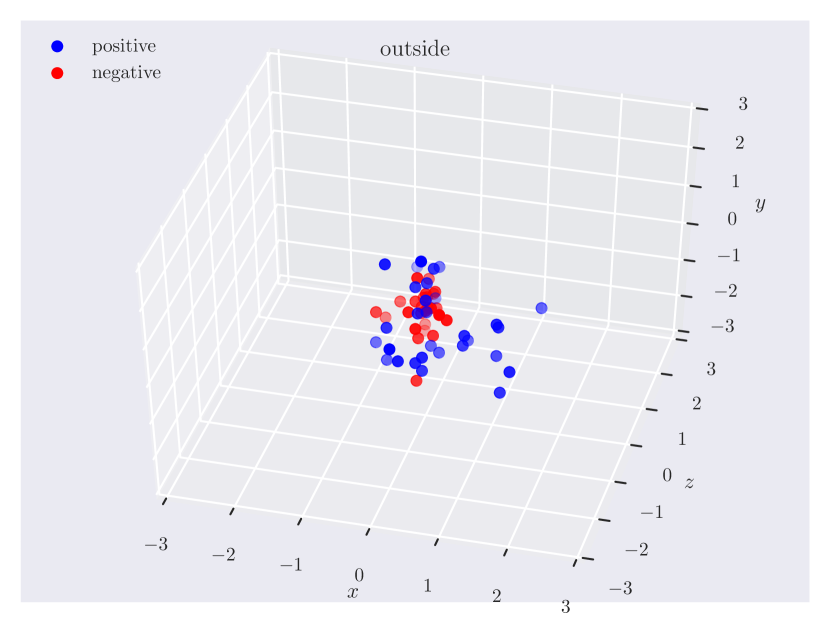
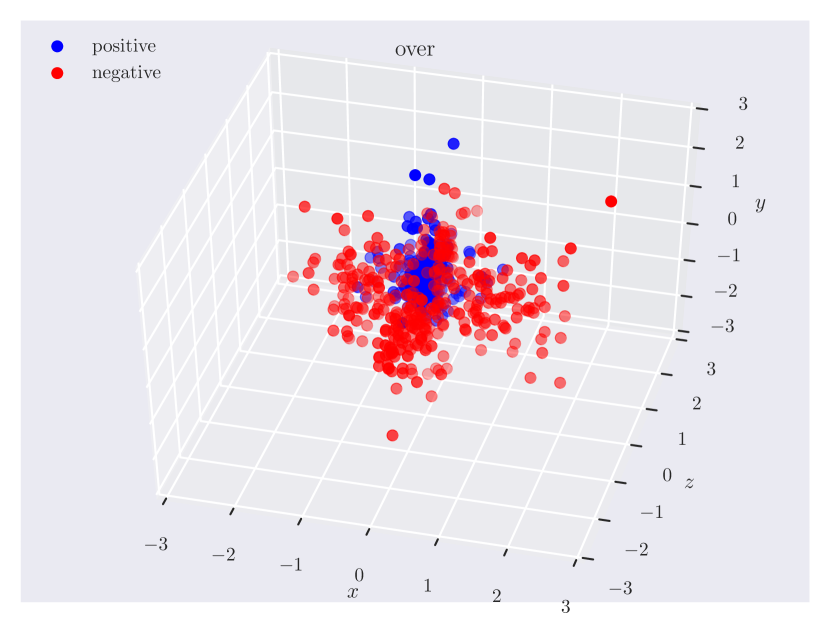
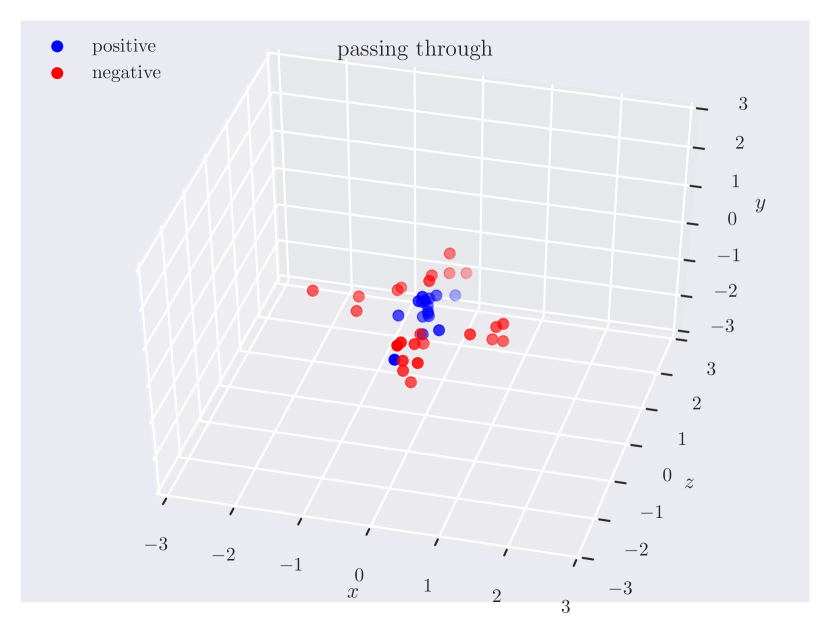
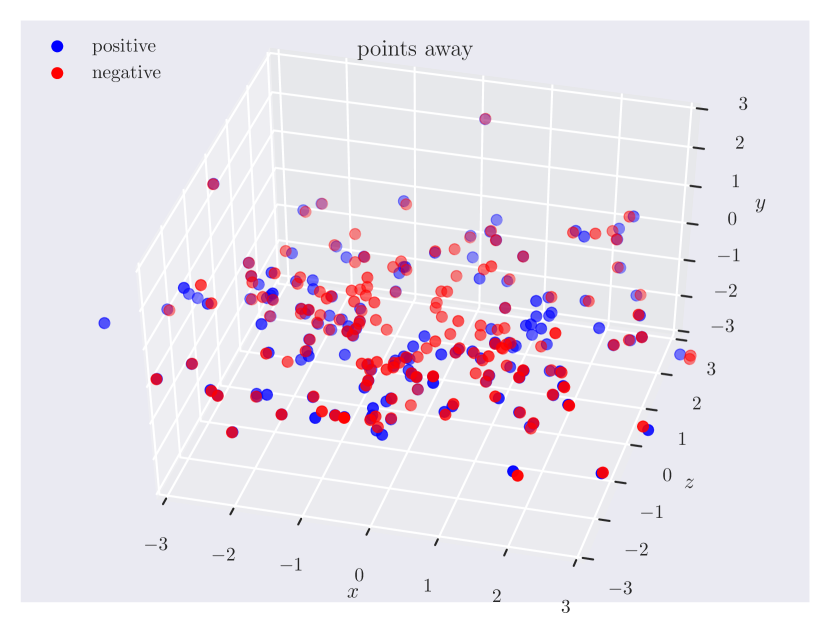
Appendix D Model Hyperparameters
| Model | l2 regularization | Feature dim | Roi size | Back-bone |
| 2D | 0, 1e-4, 1e-3 | 64, 128, 256, 512 | ||
| VtranE | 0, 1e-6, 1e-4, 1e-2 | 128, 256, 512, 1024, 2048, 4096 | 1, 3, 5 | resnet18 |
| VipCNN | 0, 1e-6, 1e-4 | 3, 5, 7, 9 | resnet18, resnet101 | |
| DRNet | 0, 1e-6, 1e-4, 1e-3 | 64, 128, 256, 512 | ||
| PPFRCN | 0, 1e-6, 1e-4 | 3 | resnet18, resnet101 |
Appendix E Results Predicate-wise
| Model | aligned to | around | behind | behind (wrt you) | below | covering | faces away | faces towards | far from | in | in front of | in front of (wrt you) | inside | leaning against | near | on | on top of | outside | over | passing through | points away | points towards | to the left of | to the left of (wrt you) | to the right of | to the right of (wrt you) | to the side of | to the side of (wrt you) | touching |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2d | 0.578 | 0.817 | 0.576 | 0.945 | 0.845 | 0.873 | 0.513 | 0.5 | 0.872 | 0.762 | 0.625 | 0.931 | 0.717 | 0.757 | 0.916 | 0.845 | 0.831 | 0.667 | 0.798 | 0.67 | 0.516 | 0.551 | 0.717 | 0.948 | 0.517 | 0.935 | 0.661 | 0.889 | 0.674 |
| VtranE | 0.612 | 0.768 | 0.53 | 0.961 | 0.818 | 0.822 | 0.526 | 0.55 | 0.723 | 0.766 | 0.578 | 0.944 | 0.692 | 0.716 | 0.878 | 0.849 | 0.838 | 0.667 | 0.805 | 0.717 | 0.548 | 0.543 | 0.667 | 0.933 | 0.542 | 0.952 | 0.641 | 0.792 | 0.667 |
| VipCNN | 0.647 | 0.774 | 0.606 | 0.914 | 0.75 | 0.803 | 0.545 | 0.567 | 0.872 | 0.703 | 0.602 | 0.889 | 0.725 | 0.662 | 0.882 | 0.797 | 0.77 | 0.583 | 0.743 | 0.594 | 0.492 | 0.623 | 0.5 | 0.881 | 0.592 | 0.917 | 0.713 | 0.889 | 0.727 |
| DRNet | 0.612 | 0.848 | 0.576 | 0.961 | 0.777 | 0.866 | 0.539 | 0.558 | 0.723 | 0.752 | 0.625 | 0.958 | 0.75 | 0.676 | 0.849 | 0.832 | 0.858 | 0.708 | 0.775 | 0.689 | 0.5 | 0.529 | 0.6 | 0.952 | 0.475 | 0.957 | 0.67 | 0.875 | 0.667 |
| PPFRCN | 0.647 | 0.811 | 0.606 | 0.844 | 0.777 | 0.793 | 0.513 | 0.567 | 0.83 | 0.752 | 0.633 | 0.889 | 0.7 | 0.635 | 0.857 | 0.828 | 0.791 | 0.542 | 0.741 | 0.66 | 0.516 | 0.601 | 0.817 | 0.913 | 0.558 | 0.939 | 0.69 | 0.903 | 0.667 |
| MLP (Aligned Absolute) | 0.672 | 0.945 | 0.803 | 0.977 | 0.946 | 0.904 | 0.955 | 0.783 | 0.787 | 0.841 | 0.891 | 0.944 | 0.817 | 0.797 | 0.929 | 0.909 | 0.824 | 0.792 | 0.869 | 0.698 | 0.913 | 0.703 | 0.817 | 0.956 | 0.808 | 0.965 | 0.796 | 0.889 | 0.674 |
| MLP (Raw Absolute) | 0.672 | 0.915 | 0.682 | 0.977 | 0.946 | 0.889 | 0.818 | 0.608 | 0.862 | 0.831 | 0.742 | 0.903 | 0.85 | 0.743 | 0.933 | 0.888 | 0.845 | 0.833 | 0.874 | 0.708 | 0.786 | 0.652 | 0.717 | 0.94 | 0.567 | 0.987 | 0.716 | 0.917 | 0.659 |
| Human | 0.888 | 0.982 | 0.97 | 0.961 | 0.946 | 0.965 | 0.968 | 0.925 | 0.777 | 0.955 | 0.938 | 0.958 | 0.933 | 0.932 | 0.966 | 0.983 | 0.973 | 0.75 | 0.982 | 0.972 | 0.9682 | 0.986 | 0.95 | 0.988 | 0.958 | 0.983 | 0.951 | 0.986 | 0.932 |
References
- Brooks [1968] Lee R Brooks. Spatial and verbal components of the act of recall. Canadian Journal of Psychology/Revue canadienne de psychologie, 22(5):349, 1968.
- Freeman [1975] John Freeman. The modelling of spatial relations. Computer graphics and image processing, 4(2):156–171, 1975.
- Talmy [1983] Leonard Talmy. How language structures space. In Spatial orientation, pages 225–282. Springer, 1983.
- Herskovits [1985] Annette Herskovits. Semantics and pragmatics of locative expressions. Cognitive Science, 9(3):341–378, 1985.
- Landau and Jackendoff [1993] Barbara Landau and Ray Jackendoff. “what” and “where” in spatial language and spatial cognition. Behavioral and brain sciences, 16(2):217–238, 1993.
- Golland et al. [2010] Dave Golland, Percy Liang, and Dan Klein. A game-theoretic approach to generating spatial descriptions. In Proceedings of the 2010 conference on empirical methods in natural language processing, pages 410–419. Association for Computational Linguistics, 2010.
- Boularias et al. [2015] Abdeslam Boularias, Felix Duvallet, Jean Oh, and Anthony Stentz. Grounding spatial relations for outdoor robot navigation. In 2015 IEEE International Conference on Robotics and Automation (ICRA), pages 1976–1982. IEEE, 2015.
- Zampogiannis et al. [2015] Konstantinos Zampogiannis, Yezhou Yang, Cornelia Fermüller, and Yiannis Aloimonos. Learning the spatial semantics of manipulation actions through preposition grounding. In 2015 IEEE international conference on robotics and automation (ICRA), pages 1389–1396. IEEE, 2015.
- Zeng et al. [2018] Zhen Zeng, Zheming Zhou, Zhiqiang Sui, and Odest Chadwicke Jenkins. Semantic robot programming for goal-directed manipulation in cluttered scenes. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 7462–7469. IEEE, 2018.
- Skubic et al. [2004] Marjorie Skubic, Dennis Perzanowski, Samuel Blisard, Alan Schultz, William Adams, Magda Bugajska, and Derek Brock. Spatial language for human-robot dialogs. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 34(2):154–167, 2004.
- Guadarrama et al. [2013] Sergio Guadarrama, Lorenzo Riano, Dave Golland, Daniel Go, Yangqing Jia, Dan Klein, Pieter Abbeel, and Trevor Darrell. Grounding spatial relations for human-robot interaction. In 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1640–1647. IEEE, 2013.
- Gapp [1995] Klaus-Peter Gapp. Angle, distance, shape, and their relationship to projective relations. In Proceedings of the 17th annual conference of the cognitive science society, pages 112–117, 1995.
- Bloch [1999] Isabelle Bloch. Fuzzy relative position between objects in image processing: a morphological approach. IEEE transactions on pattern analysis and machine intelligence, 21(7):657–664, 1999.
- Matsakis et al. [2001] Pascal Matsakis, James M Keller, Laurent Wendling, Jonathon Marjamaa, and Ozy Sjahputera. Linguistic description of relative positions in images. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 31(4):573–588, 2001.
- Kelleher et al. [2006] John D Kelleher, Geert-Jan M Kruijff, and Fintan J Costello. Proximity in context: an empirically grounded computational model of proximity for processing topological spatial expressions. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, pages 745–752. Association for Computational Linguistics, 2006.
- Coventry and Garrod [2004] Kenny R Coventry and Simon C Garrod. Saying, seeing and acting: The psychological semantics of spatial prepositions. Psychology Press, 2004.
- Keller and Wang [1996] James M Keller and Xiaomei Wang. Learning spatial relationships in computer vision. In Proceedings of IEEE 5th International Fuzzy Systems, volume 1, pages 118–124. IEEE, 1996.
- Rosman and Ramamoorthy [2011] Benjamin Rosman and Subramanian Ramamoorthy. Learning spatial relationships between objects. The International Journal of Robotics Research, 30(11):1328–1342, 2011.
- Mota and Sridharan [2018] Tiago Mota and Mohan Sridharan. Incrementally grounding expressions for spatial relations between objects. In IJCAI, pages 1928–1934, 2018.
- Yang et al. [2019] Kaiyu Yang, Olga Russakovsky, and Jia Deng. Spatialsense: An adversarially crowdsourced benchmark for spatial relation recognition. In International Conference on Computer Vision, 2019.
- Ye and Hua [2013] Jun Ye and Kien A Hua. Exploiting depth camera for 3d spatial relationship interpretation. In Proceedings of the 4th ACM Multimedia Systems Conference, pages 151–161, 2013.
- Zhang et al. [2016] Peng Zhang, Yash Goyal, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Yin and yang: Balancing and answering binary visual questions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5014–5022, 2016.
- Goyal et al. [2017a] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017a.
- Moratz and Tenbrink [2006] Reinhard Moratz and Thora Tenbrink. Spatial reference in linguistic human-robot interaction: Iterative, empirically supported development of a model of projective relations. Spatial cognition and computation, 6(1):63–107, 2006.
- Tan et al. [2014] Jiacheng Tan, Zhaojie Ju, and Honghai Liu. Grounding spatial relations in natural language by fuzzy representation for human-robot interaction. In 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), pages 1743–1750. IEEE, 2014.
- Shridhar and Hsu [2017] Mohit Shridhar and David Hsu. Grounding spatio-semantic referring expressions for human-robot interaction. arXiv preprint arXiv:1707.05720, 2017.
- Lu et al. [2016] Cewu Lu, Ranjay Krishna, Michael Bernstein, and Li Fei-Fei. Visual relationship detection with language priors. In European Conference on Computer Vision, pages 852–869. Springer, 2016.
- Krishna et al. [2017] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 2017.
- Kuznetsova et al. [2018] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Tom Duerig, and Vittorio Ferrari. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv:1811.00982, 2018.
- Li et al. [2017] Yikang Li, Wanli Ouyang, Xiaogang Wang, and Xiao’ou Tang. Vip-cnn: Visual phrase guided convolutional neural network. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Zhang et al. [2017a] Hanwang Zhang, Zawlin Kyaw, Shih-Fu Chang, and Tat-Seng Chua. Visual translation embedding network for visual relation detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017a.
- Liang et al. [2017] Xiaodan Liang, Lisa Lee, and Eric P. Xing. Deep variation-structured reinforcement learning for visual relationship and attribute detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Dai et al. [2017] Bo Dai, Yuqi Zhang, and Dahua Lin. Detecting visual relationships with deep relational networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Zhuang et al. [2017] Bohan Zhuang, Lingqiao Liu, Chunhua Shen, and Ian Reid. Towards context-aware interaction recognition for visual relationship detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 589–598, 2017.
- Yu et al. [2017] Ruichi Yu, Ang Li, Vlad I. Morariu, and Larry S. Davis. Visual relationship detection with internal and external linguistic knowledge distillation. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- Peyre et al. [2017] Julia Peyre, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Weakly-supervised learning of visual relations. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- Zhang et al. [2017b] Hanwang Zhang, Zawlin Kyaw, Jinyang Yu, and Shih-Fu Chang. Ppr-fcn: Weakly supervised visual relation detection via parallel pairwise r-fcn. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017b.
- Yang et al. [2018] Xu Yang, Hanwang Zhang, and Jianfei Cai. Shuffle-then-assemble: Learning object-agnostic visual relationship features. In Proceedings of the European Conference on Computer Vision (ECCV), pages 36–52, 2018.
- Silberman et al. [2012] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. In European conference on computer vision, pages 746–760. Springer, 2012.
- Chang et al. [2014] Angel Chang, Manolis Savva, and Christopher D Manning. Learning spatial knowledge for text to 3d scene generation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2028–2038, 2014.
- Chang et al. [2015a] Angel Chang, Will Monroe, Manolis Savva, Christopher Potts, and Christopher D Manning. Text to 3d scene generation with rich lexical grounding. arXiv preprint arXiv:1505.06289, 2015a.
- Achlioptas et al. [2020] Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. 16th European Conference on Computer Vision (ECCV), 2020.
- Zellers et al. [2018] Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. Swag: A large-scale adversarial dataset for grounded commonsense inference. arXiv preprint arXiv:1808.05326, 2018.
- He et al. [2019] He He, Sheng Zha, and Haohan Wang. Unlearn dataset bias in natural language inference by fitting the residual. arXiv preprint arXiv:1908.10763, 2019.
- Clark et al. [2019] Christopher Clark, Mark Yatskar, and Luke Zettlemoyer. Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases. arXiv preprint arXiv:1909.03683, 2019.
- Le Bras et al. [2020] Ronan Le Bras, Swabha Swayamdipta, Chandra Bhagavatula, Rowan Zellers, Matthew E Peters, Ashish Sabharwal, and Yejin Choi. Adversarial filters of dataset biases. arXiv, pages arXiv–2002, 2020.
- Goyal et al. [2017b] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. In ICCV, volume 1, page 5, 2017b.
- Richter et al. [2016] Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In European conference on computer vision, pages 102–118. Springer, 2016.
- Shafaei et al. [2016] Alireza Shafaei, James J Little, and Mark Schmidt. Play and learn: Using video games to train computer vision models. arXiv preprint arXiv:1608.01745, 2016.
- Kolve et al. [2017] Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Daniel Gordon, Yuke Zhu, Abhinav Gupta, and Ali Farhadi. Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474, 2017.
- Johnson et al. [2017] Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2901–2910, 2017.
- McCormac et al. [2017] John McCormac, Ankur Handa, Stefan Leutenegger, and Andrew J Davison. Scenenet rgb-d: Can 5m synthetic images beat generic imagenet pre-training on indoor segmentation? In Proceedings of the IEEE International Conference on Computer Vision, pages 2678–2687, 2017.
- Dosovitskiy et al. [2017] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. arXiv preprint arXiv:1711.03938, 2017.
- Goyal and Deng [2020] Ankit Goyal and Jia Deng. Packit: A virtual environment for geometric planning. In International Conference on Machine Learning, 2020.
- Chang et al. [2015b] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago, 2015b.
- Calli et al. [2015] Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M Dollar. The ycb object and model set: Towards common benchmarks for manipulation research. In 2015 international conference on advanced robotics (ICAR), pages 510–517. IEEE, 2015.
- Savva et al. [2015] Manolis Savva, Angel X Chang, and Pat Hanrahan. Semantically-enriched 3d models for common-sense knowledge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 24–31, 2015.
- Munroe [2015] Randall Munroe. Thing explainer: complicated stuff in simple words. Hachette UK, 2015.
- Community [2017] Blender Online Community. Blender-a 3d modelling and rendering package, 2017.
- Garnham [1989] Alan Garnham. A unified theory of the meaning of some spatial relational terms. Cognition, 31(1):45–60, 1989.
- Jackendoff [1996] Ray Jackendoff. The architecture of the linguistic-spatial interface. Language and space, 1:30, 1996.