Data-driven MPC with stability guarantees using extended dynamic mode decomposition††thanks: K. Worthmann gratefully acknowledges funding by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 507037103
2Chair of Applied Mathematics, University of Bayreuth, Germany
July 2024 )
Abstract: For nonlinear (control) systems, extended dynamic mode decomposition (EDMD) is a popular method to obtain data-driven surrogate models. Its theoretical foundation is the Koopman framework, in which one propagates observable functions of the state to obtain a linear representation in an infinite-dimensional space. In this work, we prove practical asymptotic stability of a (controlled) equilibrium for EDMD-based model predictive control, in which the optimization step is conducted using the data-based surrogate model. To this end, we derive novel bounds on the estimation error that are proportional to the norm of state and control. This enables us to show that, if the underlying system is cost controllable, this stabilizablility property is preserved. We conduct numerical simulations illustrating the proven practical asymptotic stability.
1 Introduction
Model Predictive Control (MPC; [9]) is a well-established feedback control technique. In each iteration, an optimal control problem is solved, and a first portion of the optimal control is applied [4]. This process is then repeated at the successor time instant after measuring (or estimating) the resulting state of the system. The popularity of MPC is mainly due to its solid mathematical foundation and the ability to cope with nonlinear constrained multi-input systems. In the optimization step, it is, however, necessary to predict the cost functional and/or constraints along the flow of the underlying system, which requires a model, e.g., based on first principles.
Due to recent progress in data-driven methods, there are several works considering MPC and other model-based controllers using data-driven surrogate models. A popular approach is based on extended dynamic mode decomposition (EDMD [37]) as an approximation technique in the Koopman framework. The key idea is to lift a nonlinear (control) system to a linear, but infinite-dimensional one and, then, employ EDMD to generate a data-driven finite-dimensional approximation [24]. Convergence of EDMD in the infinite-data limit was shown in [14]. Generally speaking, the Koopman framework can be utilized for data-driven predictions of so-called observables (quantities of interest, e.g., the stage cost in MPC) along the flow of the dynamical (control) system. For control systems there are two popular approaches: The first seeks a linear surrogate and is widely called (e)DMDc [28, 13]. The second approach yields a bi-linear representation [36] and performs particularly well for systems with direct state-control coupling. For this approach also finite-data error bounds for ordinary and stochastic differential equations with i.i.d. and ergodic sampling were recently shown in [30, 23].
In [19], an LQR-based approach to control unconstrained systems by means of a linear surrogate model using Taylor arguments is proposed. The performance was further assessed in [18] using a simulation study. Recently, robust control of bi-linear Koopman models with guarantees was proposed in [32] or, using Lyapunov-based arguments, in [31, 22]. However, without rigorously linking the analysis to verifiable error bounds. EDMD-based surrogate models were further applied in the prediction step of MPC [25, 13] and [40] for a robust tube-based approach. Simulation-based case studies can be found in [39] for Koopman-based MPC and in [12] for the bi-linear approach. Whereas many of the proposed approaches are shown to perform well in examples, no rigorous guarantees for closed-loop stability of Koopman-based MPC are given.
The main contribution of this work is threefold. First, we propose and prove novel error bounds, which are proportional to the distance from the desired set point rather than uniform in the state, building upon the error bounds derived in [23]. Second, we show that cost controllability (roughly speaking asymptotic null controllability in terms of the stage costs, see [4] for details), i.e., a key property to establish asymptotic stability in MPC without terminal conditions, is preserved using the EDMD-based surrogat. Third, we establish semi-global practical asymptotic stability of the original system if the feedback law is computed using the data-driven surrogate model only. To this end, we recall a key result from [9] on practical asymptotic stability for numerical approximations and verify the assumptions based on the novel proportional error bounds and the maintained cost controllability.
The manuscript is organized as follows. In Section 2, we recap EDMD within the Koopman framework. Then, we introduce MPC, before we derive the novel proportional error bound and provide the problem formulation. In Section 4, we present our main results, i.e., the preservation of cost controllability for the EDMD-based surrogate and practical asymptotic stability of the EDMD-based MPC closed loop. Then, we illustrate our findings by means of a simulation study. Finally, conclusions are drawn in Section 6.
Notation: We use the following comparison functions: is said to be of class if it is strictly increasing with and of class if it, in addition, grows unboundedly. A function is of class if it is strictly decreasing with . Moreover, is said to be of class if and hold. For integers , we set . The -th standard unit vector in is denoted by , . For a matrix , denotes the squared Frobenius norm. For a set , we denote the interior by .
2 Koopman-based prediction and control
In this section, we recap the basics of surrogate modeling of nonlinear control systems within the Koopman framework. The underlying idea is to exploit an identity between the nonlinear flow and a linear, but infinite-dimensional operator. Then, a compression of this operator onto a finite-dimensional subspace is approximated by extended dynamic mode decomposition (EDMD) using finitely many samples of the system.
First, we consider the autonomous dynamical system governed by the nonlinear ordinary differential equation (ODE)
| (2.1) |
with locally-Lipschitz continuous map . For initial condition , we denote the unique solution of System (2.1) at time by . We consider the ODE (2.1) on a compact and non-empty set . Then, to avoid technical difficulties in this introductory section, forward invariance of the set w.r.t. the dynamics (2.1) is assumed, i.e., , , holds for all . This may be ensured, e.g., by some inward-pointing condition and guarantees existence of the solution on . Then, the Koopman semigroup of bounded linear operators is defined by the identity
| (2.2) |
see, e.g., [20, Prop. 2.4] or [17, Chapter 7]. Here, the real-valued functions are called observables. The identity (2.2) states that, instead of evaluating the observable at the solution of the nonlinear system (2.1) emanating from initial state at time , one may also apply the linear, infinite-dimensional Koopman operator to the observable and, then, evaluate at .
Since the flow of System (2.1) is continuous, is a strongly-continuous semigroup of bounded linear operators. Correspondingly, we can define the, in general, unbounded infinitesimal generator of this semigroup by
| (2.3) |
where the domain consists of all -functions, for which the above limit exists. Using this generator, we may formulate the equivalent evolution equation for
| (2.4) |
Next, we recap the extension of the Koopman approach to control-affine systems, i.e., systems governed by the dynamics
| (2.5) |
where the control function serves as an input and the input maps , , are locally Lipschitz continuous. A popular approach to obtain a data-based surrogate model is DMDc [28] or c [13], where one seeks a linear control system. In this paper, we pursue an alternative bi-linear approach, which exploits the control-affine structure of system (2.5) and was – to the best of our knowledge – proposed by [36, 35]. This approach shows a superior performance for systems with state-control coupling [2, 6]. For the flow of the control system (2.5) with constant control input , the Koopman operator is defined analogously to (2.2). A straightforward computation shows that its generator preserves control affinity, i.e.,
| (2.6) |
holds for , where and , , are the generators of the Koopman semigroups corresponding to the constant controls and , , respectively. For general control functions , one can now state the respective abstract Cauchy problem analogously to (2.4) replacing the generator by its time-varying counterpart defined by (2.6), see [23] for details.
The success of the Koopman approach in recent years is due to its linear nature such that the compression of the Koopman operator or its generator (2.6) to a finite-dimensional subspace – called dictionary – leads to matrix representations. Being finite-dimensional objects, these matrices can then be approximated by a finite amount of data. Let the dictionary be the -dimensional subspace spanned by the chosen observables . We denote the -orthogonal projection onto by . Further, using i.i.d. data points , the -matrices
are defined, where holds for and . Then, the empirical estimator of the compressed Koopman generator is given by
We have to repeat this step for , , based on the identity
to construct the data-driven approximation of according to (2.6). Consequently, for and control function , a data-driven predictor is given as the solution of the linear time-varying Cauchy problem (2.4), where the unbounded operator is replaced by . The convergence of this estimator was shown in [14] if both the dictionary size and the number of data points goes to infinity. Finite-data bounds typically split the error into two sources: A projection error stemming from the finite dictionary and an estimation error resulting from a finite amount of data. A bound on the estimation error for control systems was derived in [23], where, in addition to i.i.d. sampling of ODEs, also SDEs and ergodic sampling, i.e. sampling along one sufficiently-long trajectory, were considered. A full approximation error bound for control systems was provided in [30] using a dictionary of finite elements. We provide an error bound tailored to the sampled-data setting used in this work in Subsection 3.1.
3 Proportional error bound for EDMD-based MPC and problem formulation
We consider the discrete-time control system given by
| (3.1) |
with nonlinear map . Then, for initial state and sequence of control values , denotes the solution at time , which is recursively defined by (3.1) and . In the following, is assumed, i.e., the origin is a controlled equilibrium for . After reviewing the basics of model predictive control, we derive a sampled-data representation of the continuous-time dynamics (2.5) and the corresponding abstract Cauchy problem, i.e., (2.4) with including its -based surrogate in Subsection 3.1. Then, we provide the problem formulation in Subsection 3.2.
We impose state and control constraints using the compact sets and with , respectively. Next, we define admissibility of a sequence of control values.
Definition 1.
A sequence of control values of length is said to be admissible for state , if holds for all . For , the set of admissible control sequences is denoted by . If, for , holds for the restriction of for all , we write .
We introduce the quadratic stage cost ,
| (3.2) |
for symmetric and positive definite matrices and . Next, based on Definition 1, we introduce the MPC Algorithm, where we tacitly assume existence of an optimal sequence of control values in Step (2) along the MPC closed-loop dynamics and full-state measurement.
Algorithm 2 (Model Predictive Control with horizon ).
At each time :
-
(1)
Measure the state and set .
-
(2)
Solve the optimization problem
subject to and the dynamics , .
-
(3)
Apply the feedback value .
Overall, Algorithm 2 yields the MPC closed-loop dynamics
| (3.3) |
where the feedback law is well defined at if holds. We emphasize that this condition holds if, e.g., is controlled forward invariant and refer to [1] and [5] for sufficient condition to ensure recursive feasibility without requiring controlled forward invariance of (and without terminal conditions) for discrete and continuous-time systems, respectively. The closed-loop solution resulting from the dynamics (3.3) is denoted by , where holds. Moreover, we define the (optimal) value function as .
3.1 Proportional error bound for sampled-data systems
We consider the nonlinear continuous-time control system given by (2.5). Equidistantly discretizing the time axis , i.e., using the partition with sampling period , and using a (piecewise) constant control function on each sampling interval, i.e., on , we generate the discrete-time system
| (3.4) |
We emphasize that the drift does not exhibit an offset independently of the state variable in view of our assumption . We define the vector-valued observable
| (3.5) | ||||
where , , , and , , are locally-Lipschitz continuous functions satisfying and . Hence, is Lipschitz continuous with constant such that holds. A straightforward calculation then shows , , which we impose for the data-driven approximation to ensure consistency, i.e., that is preserved. For , , the first (constant) observable enables us to approximate components of the control maps, which do not depend on the state , separately.
In this note, we make use of the following Assumption 3, which ensures that no projection error occurs. This assumption is common in systems and control when the Koopman framework is used, see, e.g., [29, 13]. The construction of suitable dictionaries ensuring this assumption is discussed in [3, 15]. A condition ensuring this invariance is provided, e.g., in [7, Theorem 1], where even a method for the construction of a suitable dictionary is discussed.
Assumption 3 (Invariance of ).
For any , the relation holds for all .
We note that if this invariance assumption does not hold, and in order mitigate the projection error, subspace identification methods may be employed to (approximately) ensure invariance of the dictionary, i.e., the space spanned by the choosen observables, see, e.g., [11, 16].
Next, we deduce an error bound adapted to our sampled-data setting. Assumption 3 implies that the compression of the generator coincides with its restriction onto , i.e., . Thus, for , the Koopman operator is the matrix exponential of the generator, i.e., holds.
Proposition 4.
Suppose that Assumption 3 holds. For every error bound and probabilistic tolerance , there is an amount of data such that with probability , the error bound
| (3.6) |
holds for all and all for the Koopman operator .
Proof.
For , we have
Since , we have . Then, plugging in the expression for , the triangle inequality yields
with the constant and
for all , where maximizes w.r.t. the compact set . Then, Gronwall’s inequality with replaced by yields
Invoking [30, Theorem 3] yields, for any , a sufficient amount of data such that holds for all and . Hence, setting such that the inequality
| (3.7) |
holds and using the definitions of and ensures Inequality (3.6). Since the left hand side is monotonically increasing in and zero for , this is always possible, which completes the proof. ∎
We briefly quantify the sufficient amount of data in view of the dictionary size and the parameters and . First, by a standard Chebychev inequality, one obtains the dependency , cf. [30, 23]. This can be improved in reproducing kernel Hilbert spaces, where the dictionary is given by feature maps given by the kernel evaluated at the samples. Here a scaling depending logarithmically on was shown in [27, Proposition 3.4] using Hoeffding’s inequality, see also [26]. In the latter reference, invariance conditions were discussed, which may allow to relax Assumption 3. Otherwise, only bounds on the projection error w.r.t. the -norm are available [30], which does not yield pointwise bounds.
For the discrete-time dynamics (3.4), we get the identity
| (3.8) |
resulting from sampling with zero-order hold in view of Assumption 3, where is the projection onto the first components. Further, based on the bi-linear -based surrogate model of Subsection 2 for data points, we define the data-driven surrogate model
| (3.9) |
Next, we derive a novel error bound that is proportional to the norm of the state and the control and, thus, ensures that the error becomes small close to the origin.
Proposition 5.
Let be the Lipschitz constant of on the set . Then, for every error bound , the inequality
| (3.10) |
holds for all and with some constant if (3.6) holds provided .
Proof.
By local Lipschitz continuity of , and we compute
Then, Taylor series expansion of , , with leads to the representation
For a sufficient amount of data , we have . Then, the second summand can be estimated by
with with from Proposition 4, where maximizes w.r.t. the compact set and we have used that the contributions of and cancel out thanks to and the control value acts as a factor. The same argument yields . Combining the derived estimates yields the assertion, i.e., Inequality (3.10) with . ∎
In [32], a bound of the form (3.10) was assumed in the lifted space, i.e., without the projector . Therein, the bound was used to construct a feedback controller achieving robust local stability using a finite gain argument. However, the bound was not established, but rather assumed – in addition to the invariance in Assumption 3.
3.2 Problem statement
We will leverage the error bound of Proposition 5 to provide a stability result when using the surrogate dynamics in Step (2) of the MPC Algorithm 2 to stabilize the original system. The main result shows that, if the nominal MPC controller is asymptotically stabilizing, the data-based controller with ensures convergence to a neighborhood of the origin, whose size depends on , i.e., practical asymptotic stability.
Definition 6 (Practical asymptotic stability).
For , let be the feedback law defined in Algorithm 2 with , where admissibility of control sequences at , i.e., , is defined w.r.t. the tightened set . Let be given such that for all . Then, the origin is said to be semi-globally practically asymptotically stable (PAS) on if there exists such that for each and there is such that for each with and all such that (3.10) holds, the solution of
| (3.11) |
with satisfies and
The incorporation of the Pontryagin difference in the admissibility of control sequences for the surrogate model ensures that the original system evolves in the compact set , i.e., that every optimal control function is, in particular, admissible for the original system in view of the error bound of Proposition 4. In the following section, we will show that the error bound shown in Proposition 5 and cost-controllability of the original dynamics imply practical asymptotic stability of the closed-loop using EDMD-based MPC.
4 Practical asymptotic stability of surrogate-based MPC
In this section, we prove our main result, i.e., practical asymptotic stability of the data-based MPC Algorithm 2 using the surrogate as defined in (3.9) to stabilize the original system with given by (3.4) or, equivalently, (3.8).
We follow the line of reasoning outlined in [9, Section 11.5]. To this end, we recall [9, Theorem 11.10] regarding stability for perturbed solutions in Proposition 7, which is a key tool for our analysis. We define
where and for .
Proposition 7.
Consider the MPC-feedback law of Algorithm 2 with , where satisfies Condition (3.10) and let be a forward-invariant set w.r.t. . Further, let the following assumptions hold:
(i) There is and such that for all the relaxed dynamic programming inequality
holds on . In addition, there exist such that
hold for all , , and .
(ii) is uniformly continuous and is uniformly continuous in on closed balls , i.e., there is such that, for each , there exists :
for all and . Then the exact closed-loop system with perturbed feedback defined in (3.11) is semiglobally practically asymptotically stable on in the sense of Definition 6.
We first verify the condition of Proposition 7 considering uniform continuity of the surrogate model.
Lemma 8.
Let be given. Then, is uniform continuous in with , , i.e.,
| (4.1) |
holds for all , , and provided that the error bound (3.6) is satisfied.
Proof.
The error bound (3.6) and imply
where maximizes w.r.t. the compact set . This completes the proof with . ∎
Using the novel proportional error bound of Proposition 5 we rigorously show that cost controllability as defined in [4] and [38] for continuous- and discrete-time systems, respectively, is inherited by the EDMD-based surrogate model. Cost controllability links stabilizability with the stage cost employed in MPC, see, e.g., [10, 38]. The only additional requirement is that optimal control sequences have to be admissible also for the surrogate model. While this may be a severe restriction close to the boundary of the set , it is typically satisfied on a suitably chosen sub-level set of the optimal value function in view of the finite prediction horizon .
Proposition 9.
Let the error bound (3.6) hold with and the stage cost be given by (3.2). Suppose existence of a monotonically increasing and bounded sequence and a set such that the growth bound
| (4.2) |
with holds for all and some . Then, there exists a monotonically increasing and bounded sequence such that Inequality (4.2) holds for and instead of and , respectively. Moreover, we have for , .
Proof.
Let and denote the trajectories generated by and , , with , respectively. Set and . Then, we have
| (4.3) | ||||
If (3.6) holds, then Proposition 5 yields the bound (3.10) on the difference of and . Thus, we may estimate the term by
with and . Hence,
Summing up the resulting inequalities for over and using that the first summands in and coincide, we get
with constants and , where we have invoked the imposed cost controllability multiple times. ∎
Finally, invoking our findings on cost controllability, we verify the remaining conditions of Proposition 7 to show the main result.
Theorem 10 (PAS of EDMD-based MPC).
Let the error bound (3.6), , for some , Assumption 3 and cost controllability of the dynamics (3.4) and the stage cost (3.2), i.e., Condition (4.2), hold. Let the prediction horizon be chosen such that holds with
| (4.4) |
and .111The performance index or degree of suboptimality was proposed in [8] and [10, Theorem 5.4] and updated to (4.4) in [38]. Further, let contain the origin in its interior and be chosen such that, for all , an optimal control function exists satisfying , . Then the EDMD-based MPC controller ensures semi-global practical asymptotic stability of the origin w.r.t. on the set .
Proof.
First, we show condition (i) of Proposition 7 for the system dynamics (3.9). To this end, note that the lower bound on the optimal value function can be inferred by
with defined as in the proof of Proposition 9. Then, defining analogously (4.4) using the sequence instead and invoking yields for sufficiently small . This ensures the relaxed Lyapunov inequality for all , by applying [8, Theorem 5.2]. Further, the upper bound on the value function directly follows from the imposed (and preserved) cost controllability. Hence, we established the value function as a Lyapunov function for the closed loop of the surrogate dynamics .
It remains to show for all and , i.e., uniform continuity of with , for some . Then, the condition of Proposition 7 hold and the assertion follows.
In combination with the uniform continuity of proven in Lemma 8, the assumption for all implies the existence of such that, for each , the respective optimal control remains admissible for all initial values from . Then, is uniformly bounded on . This immediately shows the assertion for with , see, e.g., [1] for a detailed outline of the construction. Hence, it remains to show the assumption for satisfying . Based on our assumption that an optimal sequence of control values exists, for every there is such that . Then, invoking admissibility of for , uniform Lipschitz continuity of on in and , we get
with for all . Then, using that is uniformly bounded on the compact set , we have derived . Analogously,
on . Combining both inequalities yields the assertion. ∎
The assumption that the minimum exists may be completely dropped and is only imposed to streamline the presentation, see, e.g., [9, p. 59] for details. The imposed (technical) condition w.r.t. can, e.g., be ensured by choosing a sufficiently small sub-level set such that for some yields a contradiction in view of the quadratic penalization of that state in the stage cost and the assumed bound on the sub-level set – similar to the construction used in [1].
The assumed bound (3.6) of Theorem 10 and cost controllability of the original system are the key ingredients for PAS of EDMD-based MPC. In Proposition 4 we proved that such a bound can be guaranteed with probability . This allows to also deduce PAS with probability . Increasing the number of samples can then be used to either increase the confidence (that is, to reduce ), or reduce . The latter allows to shrink the set of PAS, i.e., reduce the radius in Definition 6.
5 Numerical simulations
In this section we conduct numerical simulations to validate practical asymptotic stability of the origin for EDMD-based MPC as rigorously shown in Theorem 10.
First, we consider the van-der-Pol oscillator given by
| (5.1) |
for . Since the linearization at the origin is controllable, cost controllablility holds for the quadratic stage cost (3.2), see, e.g., [38]. We consider the ODE (5.1) as a sampled-data system with zero-order hold as introduced in (3.4), where the integrals are numerically solved using the Runge-Kutta-Fehlberg method (RK45) with step-size control (Python function scipy.integrate.solve_ivp). For the approximation of the Koopman operator on the set , EDMD as described in Section 2 is used. As dictionary of observables we choose all -variate monomials of degree less or equal than three, resulting in a dictionary size of . The step size is set to .
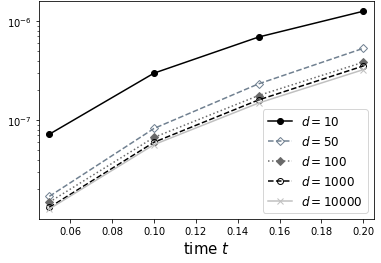
First, we inspect the open-loop error of the EDMD-based surrogate for a random but fixed control sequence and different numbers of data points , cf. Figure 1, which shows the average norm of the error for initial conditions distributed uniformly over the set . As to be expected from Proposition 5, the open-loop error decreases for increased number of samples.
Next, we inspect the MPC closed-loop while imposing the constraints for and for , respectively. We compare the closed-loop performance resulting from nominal MPC denoted by as defined in (3.3) and EDMD-based MPC defined in (3.11) for and optimization horizons . The Koopman approximation is performed using EDMD with i.i.d. data points. For small control penalization parameter , the norm of the closed-loop state corresponding to nominal MPC decays until the precision of the optimization solver is reached. As to be expected, this decay is faster for a longer prediction horizon. As proven in Theorem 10, the EDMD-based surrogate only enjoys practical asymptotic stability. More precisely, increasing the horizon only increases the convergence speed, but does not lead to a lower norm at the end of the considered simulation horizon.
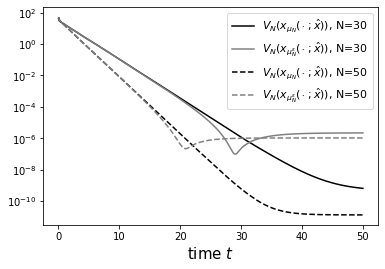
In Figure 2, we illustrate the decrease of the optimal value function along the closed-loop trajectories. The observed stagnation indicates that the bottleneck is the approximation quality of the EDMD-based surrogate. The behavior is qualitatively very similar to the norm of the solution. Moreover, we observe a strict decrease of the value function over time. This is not the case for the EDMD-based MPC, for which we only have practical asymptotic stability of the origin. Correspondingly, only decreases outside of a neighboorhood of the origin.
The next example is taken from [21], where the parameter values can be found. Here, describes an exothermic reaction that converts reactant to product and is given by
| (5.2) |
with state , where is the concentration of , the reactor temperature, and the control input is the heat supplied to the reactor. Since we want to stabilize the controlled steady state (), we consider the shifted dynamics, for which is origin is a steady state.
For EDMD, we use i.i.d. data points drawn from the state-constrained set and propagate them by time units for control input and , respectively. The dictionary consists of observables . We consider the respective OCP subject to with weighting and for control and state.
Figure 3 shows the numerical simulations emanating from the initial condition . The decay in norm of the closed-loop state corresponding to the EDMD-based surrogate stagnates around , i.e., practical asymptotic stability can be observed in this example, too. For the considered horizons, the decreasing behavior in the beginning until the point of stagnation is reached is similar to that of nominal MPC. The fact that the convergence stagnates earlier for larger is not unexpected, because in Proposition 7(ii) may deteriorate since larger may render the optimal values more sensitive w.r.t. the initial condition.
6 Conclusions
We proved practical asymptotic stability of data-driven MPC for nonlinear systems using EDMD embedded in the Koopman framework. To this end, we established a novel bound on the estimation error, which scales proportional to the norm of the state and the control. The underlying idea of imposing a certain structure in EDMD and, then, deriving proportional bounds was also key in follow-up work for controller design using the Koopman generator [33] and operator [34]. Then, we showed that cost controllability of the original model is preserved for the proposed data-based surrogate. Last, we provided two numerical examples to illustrate our findings and, in particular, the practical asymptotic stability of the origin.
References
- [1] A. Boccia, L. Grüne, and K. Worthmann. Stability and feasibility of state constrained MPC without stabilizing terminal constraints. Systems & Control letters, 72:14–21, 2014.
- [2] D. Bruder, X. Fu, and R. Vasudevan. Advantages of bilinear Koopman realizations for the modeling and control of systems with unknown dynamics. IEEE Robotics Automat. Lett., 6(3):4369–4376, 2021.
- [3] S. L. Brunton, B. W. Brunton, J. L. Proctor, and J. N. Kutz. Koopman invariant subspaces and finite linear representations of nonlinear dynamical systems for control. PloS one, 11(2):e0150171, 2016.
- [4] J.-M. Coron, L. Grüne, and K. Worthmann. Model predictive control, cost controllability, and homogeneity. SIAM Journal on Control and Optimization, 58(5):2979–2996, 2020.
- [5] W. Esterhuizen, K. Worthmann, and S. Streif. Recursive feasibility of continuous-time model predictive control without stabilising constraints. IEEE Control Systems Letters, 5(1):265–270, 2020.
- [6] C. Folkestad and J. W. Burdick. Koopman NMPC: Koopman-based learning and nonlinear model predictive control of control-affine systems. In IEEE International Conference on Robotics and Automation (ICRA), pages 7350–7356, 2021.
- [7] D. Goswami and D. A. Paley. Bilinearization, reachability, and optimal control of control-affine nonlinear systems: A Koopman spectral approach. IEEE Trans. Automat. Control, 67(6):2715–2728, 2021.
- [8] L. Grüne. Analysis and design of unconstrained nonlinear MPC schemes for finite and infinite dimensional systems. SIAM Journal on Control and Optimization, 48(2):1206–1228, 2009.
- [9] L. Grüne and J. Pannek. Nonlinear model predictive control. Springer Cham, 2017.
- [10] L. Grüne, J. Pannek, M. Seehafer, and K. Worthmann. Analysis of unconstrained nonlinear MPC schemes with time varying control horizon. SIAM Journal on Control and Optimization, 48(8):4938–4962, 2010.
- [11] M. Haseli and J. Cortés. Learning Koopman eigenfunctions and invariant subspaces from data: Symmetric subspace decomposition. IEEE Transactions on Automatic Control, 67(7):3442–3457, 2021.
- [12] M. Kanai and M. Yamakita. Linear model predictive control with lifted bilinear models by Koopman-based approach. SICE Journal of Control, Measurement, and System Integration, 15(2):162–171, 2022.
- [13] M. Korda and I. Mezić. Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control. Automatica, 93:149–160, 2018.
- [14] M. Korda and I. Mezić. On convergence of extended dynamic mode decomposition to the Koopman operator. Journal of Nonlinear Science, 28(2):687–710, 2018.
- [15] M. Korda and I. Mezić. Optimal construction of Koopman eigenfunctions for prediction and control. IEEE Transactions on Automatic Control, 65(12):5114–5129, 2020.
- [16] A. Krolicki, D. Tellez-Castro, and U. Vaidya. Nonlinear dual-mode model predictive control using Koopman eigenfunctions. In 61st IEEE Conference on Decision and Control (CDC), pages 3074–3079, 2022.
- [17] A. Lasota and M. C. Mackey. Chaos, fractals, and noise: stochastic aspects of dynamics. Springer New York, 2013.
- [18] X. Ma, B. Huang, and U. Vaidya. Optimal quadratic regulation of nonlinear system using Koopman operator. In Proceedings of the 2019 IEEE American Control Conference (ACC), pages 4911–4916, 2019.
- [19] G. Mamakoukas, M. L. Castano, X. Tan, and T. D. Murphey. Derivative-based Koopman operators for real-time control of robotic systems. IEEE Transactions on Robotics, 37(6):2173–2192, 2021.
- [20] A. Mauroy, Y. Susuki, and I. Mezić. Koopman operator in systems and control. Springer Cham, 2020.
- [21] A. Narasingam and J. S.-I. Kwon. Koopman lyapunov-based model predictive control of nonlinear chemical process systems. AIChE Journal, 65(11):e16743, 2019.
- [22] A. Narasingam, S. H. Son, and J. S.-I. Kwon. Data-driven feedback stabilisation of nonlinear systems: Koopman-based model predictive control. International Journal of Control, 96(3):770–781, 2023.
- [23] F. Nüske, S. Peitz, F. Philipp, M. Schaller, and K. Worthmann. Finite-data error bounds for Koopman-based prediction and control. Journal of Nonlinear Science, 33:14, 2023.
- [24] S. E. Otto and C. W. Rowley. Koopman operators for estimation and control of dynamical systems. Annual Review of Control, Robotics, and Autonomous Systems, 4:59–87, 2021.
- [25] S. Peitz, S. E. Otto, and C. W. Rowley. Data-driven model predictive control using interpolated Koopman generators. SIAM Journal on Applied Dynamical Systems, 19(3):2162–2193, 2020.
- [26] F. M. Philipp, M. Schaller, K. Worthmann, S. Peitz, and F. Nüske. Error analysis of kernel EDMD for prediction and control in the Koopman framework. Preprint arXiv:2312.10460, 2024.
- [27] F. M. Philipp, M. Schaller, K. Worthmann, S. Peitz, and F. Nüske. Error bounds for kernel-based approximations of the Koopman operator. Applied and Computational Harmonic Analysis, 71:101657, 2024.
- [28] J. L. Proctor, S. L. Brunton, and J. N. Kutz. Dynamic mode decomposition with control. SIAM J. Appl. Dynam. Syst., 15(1):142–161, 2016.
- [29] J. L. Proctor, S. L. Brunton, and J. N. Kutz. Generalizing Koopman theory to allow for inputs and control. SIAM Journal on Applied Dynamical Systems, 17(1):909–930, 2018.
- [30] M. Schaller, K. Worthmann, F. Philipp, S. Peitz, and F. Nüske. Towards reliable data-based optimal and predictive control using extended DMD. IFAC-PapersOnLine, 56(1):169–174, 2023.
- [31] S. H. Son, A. Narasingam, and J. S.-I. Kwon. Development of offset-free Koopman Lyapunov-based model predictive control and mathematical analysis for zero steady-state offset condition considering influence of Lyapunov constraints on equilibrium point. Journal of Process Control, 118:26–36, 2022.
- [32] R. Strässer, J. Berberich, and F. Allgöwer. Control of bilinear systems using gain-scheduling: Stability and performance guarantees. In 62nd IEEE Conference on Decision and Control (CDC), pages 4674–4681, 2023.
- [33] R. Strässer, M. Schaller, K. Worthmann, J. Berberich, and F. Allgöwer. Koopman-based feedback design with stability guarantees. IEEE Transactions on Automatic Control, 2024.
- [34] R. Strässer, M. Schaller, K. Worthmann, J. Berberich, and F. Allgöwer. SafEDMD: A certified learning architecture tailored to data-driven control of nonlinear dynamical systems. Preprint arXiv:2402.03145, 2024.
- [35] A. Surana. Koopman operator based observer synthesis for control-affine nonlinear systems. In 55th IEEE Conference on Decision and Control (CDC), pages 6492–6499, 2016.
- [36] M. O. Williams, M. S. Hemati, S. T. Dawson, I. G. Kevrekidis, and C. W. Rowley. Extending data-driven Koopman analysis to actuated systems. IFAC-PapersOnLine, 49(18):704–709, 2016.
- [37] M. O. Williams, I. G. Kevrekidis, and C. W. Rowley. A data–driven approximation of the Koopman operator: Extending dynamic mode decomposition. Journal of Nonlinear Science, 25:1307–1346, 2015.
- [38] K. Worthmann. Stability analysis of unconstrained receding horizon control schemes. PhD thesis, University of Bayreuth, 2011. https://epub.uni-bayreuth.de/id/eprint/273/1/Dissertation_KarlWorthmann.pdf.
- [39] S. Yu, C. Shen, and T. Ersal. Autonomous driving using linear model predictive control with a Koopman operator based bilinear vehicle model. IFAC-PapersOnLine, 55(24):254–259, 2022.
- [40] X. Zhang, W. Pan, R. Scattolini, S. Yu, and X. Xu. Robust tube-based model predictive control with Koopman operators. Automatica, 137:110114, 2022.