Data-driven Koopman Operator-based Prediction and Control
Using Model Averaging
Abstract
This work presents a data-driven Koopman operator-based modeling method using a model averaging technique. While the Koopman operator has been used for data-driven modeling and control of nonlinear dynamics, it is challenging to accurately reconstruct unknown dynamics from data and perform different decision-making tasks, mainly due to its infinite dimensionality and difficulty of finding invariant subspaces. We utilize ideas from a Bayesian inference-based model averaging technique to devise a data-driven method that first populates multiple Koopman models starting with a feature extraction using neural networks and then computes point estimates of the posterior of predicted variables. Although each model in the ensemble is not likely to be accurate enough for a wide range of operating points or unseen data, the proposed weighted linear embedding model combines the outputs of model ensemble aiming at compensating the modeling error of each model so that the overall performance will be improved.
I INTRODUCTION
While conventional systems modeling methods describe the dynamics on a state-space, operator theoretic approaches offer an alternative view of the system behaviors through the lens of functions, often called feature maps or observables. The Koopman operator, a linear operator acting on a space of feature maps, has been widely used in the context of data-driven modeling, analysis, and control of nonlinear dynamical systems[1, 2]. It allows linear evolution of the embedded systems on a function space even if the original dynamics is nonlinear in the state-space. Also, it can be approximated numerically from data using either linear regression or neural network training. The Koopman operator framework is especially appealing when applied to controller synthesis since linear controller designs such as Linear Quadratic Regulator (LQR) and linear Model Predictive Control (MPC) can be utilized with the obtained linear embedding model.
However, obtaining accurate and reliable Koopman operator-based models that can be successfully applied to decision-making tasks is still challenging. Specifically, it is known that the convergence property of EDMD does not hold for control systems[3], which implies that Koopman operator-based models may fail to accurately describe control systems even if the training data is sufficiently rich and unbiased. To overcome the modeling error of such Koopman operator-based models for control applications, several data-driven controller designs have been proposed that take model uncertainty into account[4, 5, 6, 7]. Also, if one restricts the attention to control affine systems instead of general nonlinear dynamics, finite-data error bounds are available and stability guarantees may be established on the basis of robust control theories[8, 9]. While many efforts have been made on the model uncertainty of Koopman operator-based models from a controller design perspective, it is also of great importance to devise a modeling method that can yield accurate and generalizable models for control systems. In [10], a model refinement technique is proposed to incorporate data from closed-loop dynamics into model learning so that the modeling error when applied to controller design problems can be directly mitigated. To improve the generalizability of the Koopman operator-based models for a wide range of applications, [11] develops a two-stage learning method utilizing the oblique projection in the context of linear operator learning in a Hilbert space.
In this paper, we adopt a Bayesian approach to learn unknown control systems with the use of the Koopman operator, which takes into consideration that a single Koopman operator-based model is not likely to be accurate and reliable for a wide range of operating points and it will be beneficial to aggregate an ensemble of models and utilize them to find the most useful output. Ensemble approaches are a popular class of methods that aim to improve the accuracy in learning problems by combining predictions of multiple models[12, 13]. We show that the Bayesian Model Averaging (BMA)[14], a Bayesian inference-based model averaging technique, yields a Koopman operator-based model whose parameters are represented as sums of corresponding parameters of individual models weighted by the posterior model evidence. The proposed Koopman Model Averaging (KMA) first populates multiple models, starting from a base model whose feature maps are parameterized by a neural network. Computing point estimates of the original state and the embedded state then results in the same type of linear embedding model while being model-uncertainty aware. The outputs of the individual models are incorporated into this uncertainty-aware model and the overall performance is expected to be improved.
II Koopman Operator Framework
Consider a discrete-time, non-autonomous dynamical system:
| (1) |
where , , and are the state, the input, and the (possibly nonlinear) state-transition mapping, respectively. It is assumed throughout the paper that the dynamics (1) is unknown while we have access to data of the form .
We embed the state into a latent space by applying feature maps, or observables, . Let denote the function space to which the feature maps belong. If the input is constant s.t. , , (1) induces autonomous dynamics:
| (2) |
The state transition through is then represented by
| (3) |
where the composition operator is called the Koopman operator associated with the autonomous dynamics (2). It is obvious from (3) that is a linear operator and it describes the possibly nonlinear dynamics (2) linearly in the latent space . Since is infinite dimensional acting on the function space , its finite dimensional approximation is often considered for the purpose of dynamical systems modeling. Given feature maps (), there exists a matrix s.t.
| (4) |
if and only if is an invariant subspace, i.e., for . Note that finding feature maps that form an invariant subspace may be challenging in practice. In the data-driven setting, one can approximately obtain by solving the following linear regression problem:
| (5) |
where and the training data is given as . It admits the unique analytical solution with the use of pseudo inverse and this procedure is called Extended Dynamic Mode Decomposition (EDMD)[15]. Note that the design of the feature maps needs to be pre-specified in EDMD. The finite dimensional approximation then yields a linear embedding model of the form:
| (8) |
where is the predicted state at the next time step and the decoder is similarly obtained by solving linear regression on the given data set. The decoder can be also introduced as a nonlinear mapping depending on the problem.
For general non-autonomous dynamics (1) with control inputs , the corresponding Koopman operator can be defined as follows[3]. For the space of input sequences: , consider a mapping . Also, let be an embedding feature map from an extended space to . Then, the Koopman operator associated with the non-autonomous dynamics (1) is defined as a linear operator s.t. is a function space to which feature maps belong and the dynamics (1) along with a sequence of future inputs is represented by
The argument on the subspace invariance of the Koopman operator (eq. (4)) also holds for the non-autonomous case, which is written as
| (9) |
where and denotes the number of feature maps. In analogous to (8), if we consider feature maps () of the form:
| (10) |
the first rows of (9) reads , where denotes the first rows of . Similar to (8), this yields a linear embedding model:
| (13) |
in which the parameters , and may be obtained by EDMD with training data , i.e.,
| (16) | ||||
| (17) |
A notable feature of the model (13) is that the model dynamics in the embedded space is given as a linear time-invariant system and linear controller designs can be utilized to control the possibly nonlinear dynamics (1). For instance, with the parameters and in (13), one can compute an LQR gain that stabilizes the following virtual system:
| (18) |
Note that if span an invariant subspace, we have the exact relation: . Since the model (13) has a linear decoder, the quadratic loss of the LQR problem ( is a weight matrix) can be associated with the original state by .
While we adopt linear embedding models represented in the form (13), which is a common choice in the literature, more expressive ones such as bilinear models are also available if the strict linearity w.r.t. in (13) is not enough to reconstruct the target dynamics[16, 17]. Also, it is noted that in addition to the extension of the Koopman operator framework to control systems reviewed in this section[3], there are other formalisms to utilize the Koopman operator for modeling non-autonomous systems[18].
III Learning Models from Data
The accuracy of the linear embedding model (13) depends on the design of the feature maps as well as how the model dynamics parameters , , and are obtained. While EDMD provides a simple model learning procedure with the analytic solution, the design of feature maps needs to be user-specified such as monomials and Fourier basis functions and it may not be sufficiently expressive for complex nonlinear dynamics. Neural networks, on the other hand, are a popular choice of the feature map design since they allow greater expressivity of the model compared to EDMD (e.g., [19, 20, 21]). With the feature maps characterized by a neural network, both the model dynamics parameters and the feature maps can be learned simultaneously, which is formulated as the following problem:
Problem 1
Let be a neural network characterized by parameters . Find , , , and that minimize the loss function:
| (19) |
where the data set is given in the form and are hyperparameters.
Although neural network-based models are expected to be more expressive and accurate than EDMD-based ones, Problem 1 is typically a high-dimensional non-convex problem and the resulting models may suffer from overfitting or poor learning. For instance, solving Problem 1 can lead to inaccurate models if the optimization is terminated at a local minimum with a high loss value, or if the quantity and/or quality of training data are not sufficient to reconstruct the target dynamics for a wide range of operating points. Therefore, one may need to repeat the data-collection and learning processes multiple times to obtain a satisfying model in practice, which often takes a long time and consumes a large amount of computational resources.
As the first step of the proposed method, we execute Step 1 to obtain a base model. Considering that the base model may not be perfect, we aim to improve its accuracy further by combining multiple models in the second step. Specifically, an ensemble of linear embedding models (13) is generated using additional data points with the design of feature maps fixed to that of the base model. These models, including the base model, share the same model structure but are trained on different data sets and their predictive capabilities vary. Therefore, even if some model is most accurate for certain unseen data among the model ensemble, others may show better accuracy for different data. To handle this lack of generalizability of individual models, we use all the models so that the accuracy for unknown regimes of dynamics will be improved. Specifically, a Bayesian inference-based model averaging technique is utilized to merge the individual models into a new linear embedding model.
IV Weighted Koopman Operator-based Models
In this section, we first outline the Bayesian Model Averaging (BMA). It is then followed by the formulation of the proposed Koopman operator-based model averaging method.
IV-A Bayesian Model Averaging
Given data and an ensemble of models denoted by (), the posterior distribution of a quantity of interest is represented as
| (20) |
where the posterior model evidence is given by
| (21) |
The marginal likelihood of model is represented by
| (22) |
where are the parameters of model .
As a point estimate, consider the expectation of :
| (23) |
The equation (23) may be viewed as a superposition of individual predictions of the model ensemble, each of which is weighted by , so that
| (24) |
Computing the exact is difficult in general since it involves the marginalization (22). Therefore, BMA may be approximately implemented in practice, e.g., using the Expectation Maximization (EM) algorithm[22, 23], Markov Chain Monte Carlo (MCMC) methods[24], and Akaike Information Criterion (AIC)-type weighting[25, 26]. In this paper, we adopt an AIC-type weighting method, also called pseudo-BMA, which approximates the weight as
| (25) |
where denotes the expected log pointwise predictive density of model , where are unseen new data points and is the true distribution of the data. In practice, may be also approximated by the Leave-One-Out (LOO) predictor. For details, refer to [25]. To compute the weights , PyMC[27] is used in the numerical simulations in Section V.
IV-B Koopman Model Averaging
Given a data set , consider an ensemble of linear embedding models with the common feature maps :
| (26) | |||||
| (27) |
where . In the proposed algorithm, a base model is trained first by solving Problem 1 on a subset of the entire date set to obtain the feature maps and matrices . The remaining model parameters are obtained by EDMD, each of which is trained on another subset of the data:
| (30) | ||||
| (31) |
where corresponds to the parameters of model in Section IV-A.
Given a state and an input , we assume that both and have Gaussian distributions conditioned on the -th model:
| (32) | |||
| (33) |
where and are covariance matrices of the distributions.
Taking the expectation (24) w.r.t. and , we have:
| (34) | ||||
| (35) |
The weight is then approximately computed according to (25). Finally, equations (34) and (35) yield a new weighted linear embedding model:
| (36) | |||||
| (37) |
The outputs of this model are point estimates of the posterior that take the models’ possible outputs into account and are expected to possess a better predictive capability as well as generalizability compared to obtaining a single model only. The proposed method yields a linear embedding model, which can be used for not only prediction but also other decision-making tasks such as controller designs while it is still model-uncertainty aware by computing the point estimates of the posterior. The proposed Koopman Model Averaging (KMA) is summarized in Algorithm 1.
V Numerical evaluations
V-A Duffing Oscillator
We first evaluate the proposed model averaging method using the Duffing oscillator with a control input, which is given by:
| (38) |
where the state and the input are continuous variables. It is assumed that the time-series data , () is available to train models, where is the sampling period. Equation (38) yields a difference equation of the same form as (1) with a first-order time discretization so that we can relate the time-series data and the discrete-time dynamics (1) as , . The sampling period is set to in the simulations.
To train a base model, 300 trajectories of the state are generated, each of which has a length of 50 steps and starts from an initial condition sampled from . This corresponds to the data in Algorithm 1. Inputs are sampled from a uniform distribution , . Following a common practice in the literature, we adopt a specific structure of feature maps of the form:
| (39) |
where the first components are the state itself. This allows an analytic expression of the decoder, i.e., with in (13), we can recover the original state without learning the parameter . We have one additional feature map in (39), which is a neural network with a single hidden layer consisting of 10 neurons.
To populate the model ensemble, we use 4 data subsets (so that in Algorithm 1). Each consists of 100 trajectories, each of which is a length of 50 steps. Data set consists of 50 trajectories with a length of 20 steps, each of which is sampled from the same distributions of that of . We use Pytorch to solve Problem 1. PyMC[27] is used to compute in (25).
To compare with the proposed method, we also train two models: an EDMD model and a neural network-based model obtained by Problem 1. The neural network-based model is labeled normal NN model in the sequel. Pre-specified feature maps for the EDMD model are monomials up to the second order. Both the EDMD and the normal NN models are trained on the entire data set used for learning the proposed model.
We consider two control applications in addition to the state prediction: stabilization by LQR and linear MPC. The objective of the LQR problem is to have the state converge to . In the MPC design, we define a cost function so that the first component of the state will follow a reference signal:
| (42) |
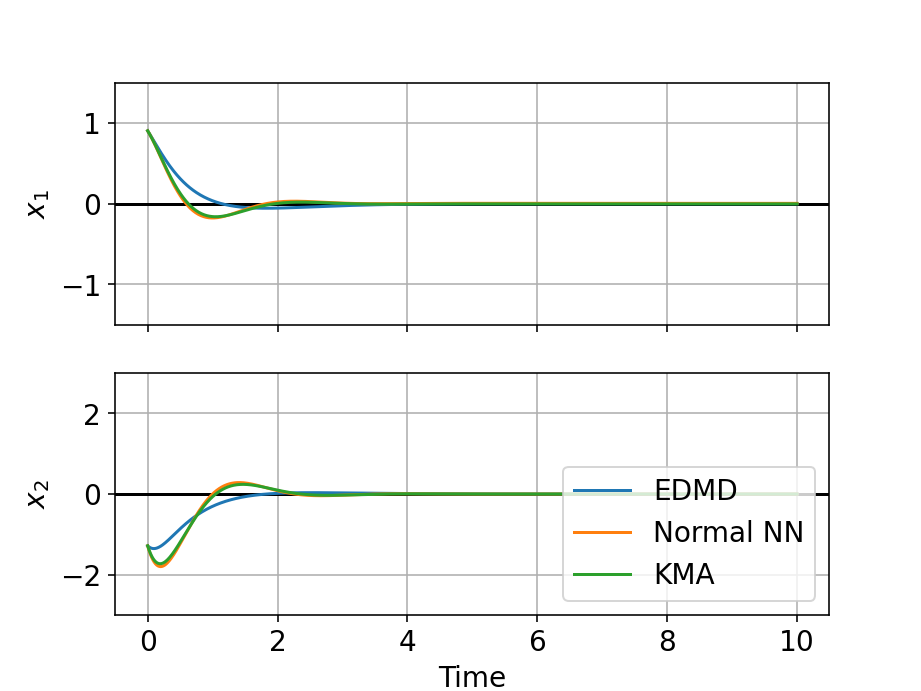
The results are shown in Fig. 1. Figures 1(a) and 1(b) are the results of state prediction, where two initial conditions are randomly selected and labeled IC 1 and IC 2, respectively. Since the EDMD model has a simpler feature map design than the other two neural network-based models, it fails to reconstruct the target dynamics. On the other hand, both the normal NN and the proposed models show comparable performance and they successfully predict the future states. Figures 1(c) and 1(d) are the LQR simulation results with randomly selected initial conditions labeled IC 1 and IC 2, respectively. All the controllers designed for the three models achieve the control objective in this task. On the contrary, MPC with the EDMD model fails to track the reference signal as shown in Fig. 1(e). The normal NN model also has a slight steady state error, whereas the proposed weighted model perfectly tracks the reference signal. The validation loss of the normal NN model is , which is smaller by one order of magnitude than that of the base model of the proposed method, which is . However, the proposed model outperforms in the MPC task, which implies the effectiveness of aggregating an ensemble of models to find more accurate model outputs.







V-B Cartpole
As a more complex nonlinear system, the cartpole is considered as the second example, whose dynamics is given as follows[2]:
| (49) |
where , , , , , and . Data collecting procedures and model learning conditions are the same as the first example except for the number of hidden layers of the neural network, which is two for the cartpole system.
The results are shown in Fig. 2. In this example, all the models are successfully applied to the MPC task as in Fig. 2(e). On the other hand, the EDMD model fails in the LQR design problem (Figs. 2(c) and 2(d)), which is considered as a result of too simple feature map design for the four dimensional dynamics of the cartpole. The results of the state prediction are shown in Figs. 2(a) and 2(b). The EDMD model also has difficulty in this task. Both the normal NN and the proposed models show reasonable predictions with the initial condition IC 1 (Fig. 2(a)). However, the prediction of the normal NN model starts deviating from the true values at around with the second initial condition (Fig. 2(b)). The proposed model, on the other hand, shows better accuracy and its prediction follows the true values until the end of the simulation. It is noted that the validation loss of the normal NN model () is smaller than that of the proposed method (). This result implies that the proposed model effectively combines the model ensemble into a new weighted model to acquire high predictive accuracy with respect to wider range of regimes of dynamics than the normal NN model.
VI CONCLUSION
We propose a model averaging method for learning Koopman operator-based models for prediction and control utilizing the Bayesian model averaging. While the Koopman operator framework allows to obtain linear embedding models from data so that linear systems theories can be applied to control possibly nonlinear dynamics, it is challenging to accurately reconstruct the dynamics and deploy the learned model in several applications. Considering that training a single model only may not be sufficient to obtain model predictions that are accurate enough for a wide range of operating points even if the model possesses high accuracy w.r.t. a certain regime of dynamics such as training data, the proposed method first trains a base model with the use of neural networks and then populates an ensemble of models on different data points. Based on the ideas of the Bayesian model averaging, these models are merged into a new weighted linear embedding model, in which individual outputs of the model ensemble are weighted according to the posterior model evidence. This model explicitly takes uncertainty into account and the overall performance is expected to be improved. Using numerical simulations, it is shown that the proposed weighted model achieves better state predictive accuracy as well as greater generalizability to different control applications compared to other Koopman operator-based models.
References
- [1] A. Mauroy, I. Mezić, and Y. Susuki, The Koopman Operator in Systems and Control. Springer International Publishing, 2020.
- [2] S. L. Brunton and J. N. Kutz, Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control. Cambridge University Press, 2019.
- [3] M. Korda and I. Mezić, “Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control,” Automatica, vol. 93, pp. 149–160, 2018.
- [4] X. Zhang, W. Pan, R. Scattolini, S. Yu, and X. Xu, “Robust tube-based model predictive control with Koopman operators,” Automatica, vol. 137, p. 110114, 2022.
- [5] M. Han, J. Euler-Rolle, and R. K. Katzschmann, “DeSKO: Stability-assured robust control with a deep stochastic Koopman operator,” in The Tenth International Conference on Learning Representations, ICLR, 2022.
- [6] D. Uchida, A. Yamashita, and H. Asama, “Data-driven Koopman controller synthesis based on the extended norm characterization,” IEEE Control Systems Letters, vol. 5, no. 5, pp. 1795–1800, 2021.
- [7] S. H. Son, A. Narasingam, and J. Sang-Il Kwon, “Handling plant-model mismatch in Koopman Lyapunov-based model predictive control via offset-free control framework,” arXiv e-prints, p. arXiv:2010.07239, 2020.
- [8] F. Nüske, S. Peitz, F. Philipp, M. Schaller, and K. Worthmann, “Finite-data error bounds for Koopman-based prediction and control,” Journal of Nonlinear Science, vol. 33, no. 14, 2022.
- [9] R. Strässer, M. Schaller, K. Worthmann, J. Berberich, and F. Allgöwer, “Koopman-based feedback design with stability guarantees,” arXiv e-prints, p. arXiv:2312.01441, 2023.
- [10] D. Uchida and K. Duraisamy, “Control-aware learning of Koopman embedding models,” in 2023 American Control Conference (ACC), pp. 941–948, 2023.
- [11] D. Uchida and K. Duraisamy, “Extracting Koopman Operators for Prediction and Control of Non-linear Dynamics Using Two-stage Learning and Oblique Projections,” arXiv e-prints, p. arXiv:2308.13051, 2023.
- [12] O. Sagi and L. Rokach, “Ensemble learning: A survey,” WIREs Data Mining and Knowledge Discovery, vol. 8, no. 4, p. e1249, 2018.
- [13] J. a. Mendes-Moreira, C. Soares, A. M. Jorge, and J. F. D. Sousa, “Ensemble approaches for regression: A survey,” ACM Comput. Surv., vol. 45, no. 1, 2012.
- [14] T. M. Fragoso, W. Bertoli, and F. Louzada, “Bayesian model averaging: A systematic review and conceptual classification,” International Statistical Review, vol. 86, no. 1, pp. 1–28, 2018.
- [15] M. Williams, I. Kevrekidis, and C. Rowley, “A data driven approximation of the Koopman operator: Extending dynamic mode decomposition,” Journal of Nonlinear Science, vol. 25, no. 6, pp. 1307–1346, 2015.
- [16] D. Goswami and D. A. Paley, “Global bilinearization and controllability of control-affine nonlinear systems: A Koopman spectral approach,” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pp. 6107–6112, 2017.
- [17] D. Bruder, X. Fu, and R. Vasudevan, “Advantages of bilinear Koopman realizations for the modeling and control of systems with unknown dynamics,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4369–4376, 2021.
- [18] M. Haseli and J. Cortés, “Modeling Nonlinear Control Systems via Koopman Control Family: Universal Forms and Subspace Invariance Proximity,” arXiv e-prints, p. arXiv:2307.15368, 2023.
- [19] S. Pan and K. Duraisamy, “Physics-informed probabilistic learning of linear embeddings of nonlinear dynamics with guaranteed stability,” SIAM Journal on Applied Dynamical Systems, vol. 19, no. 1, pp. 480–509, 2020.
- [20] N. Takeishi, Y. Kawahara, and T. Yairi, “Learning Koopman invariant subspaces for dynamic mode decomposition,” Advances in Neural Information Processing Systems, vol. 30, pp. 1130–1140, 12 2017.
- [21] Y. Han, W. Hao, and U. Vaidya, “Deep learning of Koopman representation for control,” in 2020 59th IEEE Conference on Decision and Control (CDC), pp. 1890–1895, 2020.
- [22] A. E. Raftery, T. Gneiting, F. Balabdaoui, and M. Polakowski, “Using Bayesian model averaging to calibrate forecast ensembles,” Monthly Weather Review, vol. 133, no. 5, pp. 1155–1174, 2005.
- [23] Q. Duan, N. K. Ajami, X. Gao, and S. Sorooshian, “Multi-model ensemble hydrologic prediction using Bayesian model averaging,” Advances in Water Resources, vol. 30, no. 5, pp. 1371–1386, 2007.
- [24] G. Li and J. Shi, “Application of bayesian model averaging in modeling long-term wind speed distributions,” Renewable Energy, vol. 35, no. 6, pp. 1192–1202, 2010.
- [25] Y. Yao, A. Vehtari, D. Simpson, and A. Gelman, “Using Stacking to Average Bayesian Predictive Distributions (with Discussion),” Bayesian Analysis, vol. 13, no. 3, pp. 917 – 1007, 2018.
- [26] K. Barigou, P.-O. Goffard, S. Loisel, and Y. Salhi, “Bayesian model averaging for mortality forecasting using leave-future-out validation,” International Journal of Forecasting, vol. 39, no. 2, pp. 674–690, 2023.
- [27] O. Abril-Pla, V. Andreani, C. Carroll, L. Dong, C. Fonnesbeck, M. Kochurov, R. Kumar, J. Lao, C. Luhmann, O. Martin, M. Osthege, R. Vieira, T. Wiecki, and R. Zinkov, “PyMC: A modern and comprehensive probabilistic programming framework in Python,” PeerJ Computer Science, vol. 9, p. e1516, 2023.