DANNet: A One-Stage Domain Adaptation Network for Unsupervised
Nighttime Semantic Segmentation
Abstract
Semantic segmentation of nighttime images plays an equally important role as that of daytime images in autonomous driving, but the former is much more challenging due to poor illuminations and arduous human annotations. In this paper, we propose a novel domain adaptation network (DANNet) for nighttime semantic segmentation without using labeled nighttime image data. It employs an adversarial training with a labeled daytime dataset and an unlabeled dataset that contains coarsely aligned day-night image pairs. Specifically, for the unlabeled day-night image pairs, we use the pixel-level predictions of static object categories on a daytime image as a pseudo supervision to segment its counterpart nighttime image. We further design a re-weighting strategy to handle the inaccuracy caused by misalignment between day-night image pairs and wrong predictions of daytime images, as well as boost the prediction accuracy of small objects. The proposed DANNet is the first one-stage adaptation framework for nighttime semantic segmentation, which does not train additional day-night image transfer models as a separate pre-processing stage. Extensive experiments on Dark Zurich and Nighttime Driving datasets show that our method achieves state-of-the-art performance for nighttime semantic segmentation.
1 Introduction
 |

|
| Input image | Ground truth |
 |

|
| MGCDA | DANNet (Ours) |
Aiming to label each pixel of a given image to an object category, semantic segmentation is a fundamental computer vision task and plays an important role in many applications such as autonomous driving [11], medical imaging [5] and human parsing [49]. With the advancement of deep learning and computing power, the state-of-the-art performance of semantic segmentation for natural scene images taken at the daytime has been significantly improved in recent years [10, 17]. Many researchers have started to segment more challenging images under various kinds of degradations, such as those taken in foggy weather [34] or at the nighttime [33]. In this paper, we focus on semantic segmentation of nighttime images, which has wide and important applications in autonomous driving.
With many indiscernible regions and visual hazards [47], e.g., under/over exposure and motion blur, it is usually difficult even for human to build high-quality pixel-level annotations of the nighttime scene images as ground truth, which, however, is a prerequisite for training many deep neural networks for semantic image segmentation. To handle this problem, several domain adaptation methods have been proposed to transfer the semantic segmentation models from daytime to nighttime without using labels in the nighttime domain. For example, in [8, 33, 35], an intermediate twilight domain is taken as a bridge to build the adaptation between daytime to nighttime. In [33, 30, 37, 26, 35], an image transferring network is trained to stylize nighttime or daytime images and construct synthetic datasets. All these methods require an additional pre-processing stage of training an image transfer model between daytime and nighttime. This is not only time-consuming but also making the second stage closely rely on the first one. Especially, it is difficult to generate a transferred image that shares the exactly same semantic information with the original images when the domain gap is large.
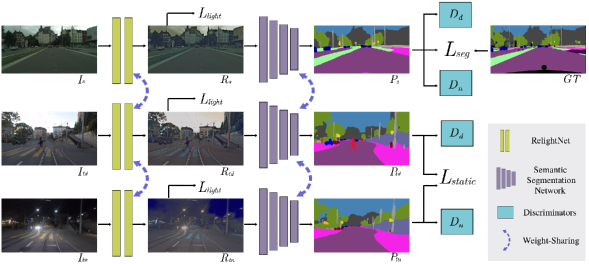
In this paper, we propose a novel one-stage domain adaptation network (DANNet) based on adversarial learning for nighttime semantic segmentation (shown in Figure 1) by using the newly released Dark Zurich dataset [33], which contains unlabeled day-night scene image pairs that are coarsely aligned using GPS recordings. The proposed DANNet performs a multi-target adaptation from Cityscapes data to Dark Zurich daytime (Dark Zurich-D) and nighttime data (Dark Zurich-N). Specifically, we first adapt the model from Cityscapes, which contains large-scale training data with labels, to Dark Zurich-D since they are all taken at the daytime. Then, the prediction of Dark Zurich-D is used as a pseudo supervision for Dark Zurich-N in the network training. We apply an image relighting subnetwork to make the intensity distribution of the images from different domains to be close. Following [38], we incorporate a weight-sharing semantic segmentation network to make predictions for the relighted images and perform an adversarial learning in the output space to ensure very close layout across different domains. We further design a re-weighting strategy to handle the inaccuracy caused by misalignment between day-night image pairs and wrong predictions of daytime images, as well as boost the prediction accuracy of small objects. We conduct extensive experiments on Dark Zurich and Nighttime Driving datasets to justify the effectiveness of the proposed DANNet for nighttime semantic segmentation. The main contributions of our work are summarized in the following:
-
•
We propose a multi-target domain adaptation network, DANNet, for nighttime semantic segmentation via adversarial learning. DANNet consists of an image relighting network and a semantic segmentation network, as well as two discriminators. To the best of our knowledge, the proposed DANNet is the first one-stage adaptation framework for nighttime semantic segmentation.
-
•
We demonstrate that the segmentation of Dark Zurich-D images can provide pseudo supervision for segmenting the corresponding Dark Zurich-N images, by considering only static object categories. In particular, it is shown that the specially designed probability re-weighting strategy can significantly enhance the segmentation of small objects.
-
•
Experiments on Dark Zurich-test and Nighttime Driving datasets show that the proposed DANNet achieves a new state-of-the-art performance of nighttime semantic segmentation. Ablation study also verifies the effectiveness of each component in DANNet.
2 Related Work
Domain adaptation for semantic segmentation Domain adaptation methods are developed to transfer knowledge learned from source domains to target domains which share similar objects yet different data distributions. Recently, domain adaptation has been applied to help semantic segmentation. In [16], Hoffman et al.proposed a novel fully convolutional domain adversarial learning approach with category constraints [27] for semantic segmentation. Tsai et al. [38] later developed a multi-level adversarial network to perform domain adaptation in the output space.
Instead of using adversarial learning techniques, image translation and style transfer [52] from source images to target ones, or vice versa, have been widely used for domain adaptation [15, 44]. Previous works have shown that domain-invariant representations can be obtained in the process of image translation between the source and target domains [36, 53, 1]. Several recent works [21, 43, 19] made use of self-training strategies by iteratively predicting and fine-tuning a set of pseudo labels in multiple rounds of network training. Another line of researches [50, 22] adopted the curriculum-style learning by first learning easy properties in the target domain and then using it to regularize the semantic segmentation model. However, most of these general-purpose domain adaptation approaches cannot handle well the significant adaptation gap between the daytime and the nighttime images and therefore could not achieve satisfactory performance in nighttime semantic segmentation [33]. Specifically, all the above methods focus on the domain adaptation for synthetic-to-real (i.e., GTA5 [29] or SYNTHIA [31] to Cityscapes) or cross-city images (i.e., Cityscapes to Cross-City [6]), which are all daytime to daytime adaptations. In this paper, we instead focus on the adaptation between the daytime and the nighttime domains with significantly different illumination patterns [33].
Nighttime semantic segmentation Recently, Dai et al. [8] leveraged an intermediate twilight domain to progressively adapt semantic models trained in daytime scenes to nighttime. Sakaridis et al. [33, 35] further extended it to a guided curriculum adaptation framework, which uses both the stylized synthetic images and the unlabeled real images to exploit the cross-time-of-day correspondence of the scene images. However, such gradual adaptation approaches usually need to train multiple semantic segmentation models, e.g., three models in [33] for three different domains respectively, which is highly inefficient. Following works along this line [30, 37, 26] also train some additional image transfer models, e.g., CycleGAN [52], to perform the day-to-night or night-to-day image transfer before training the semantic segmentation models. For these methods, the performance of later adaptation and semantic segmentation is highly dependent on the image transfer model pre-trained in the pre-processing stage.
Vertens et al. [39] proposed to leverage the thermal infrared images as a complementary input to the RGB images for nighttime semantic segmentation since thermal radiation is not very sensitive to the illumination changes. In [9], a two-stage adversarial training method was proposed for semantic segmentation of rainy night scenes by performing domain adaptation between day-night near scene pairs. Different from all the above methods, the DANNet proposed in this paper performs a one-stage end-to-end adversarial learning for training the nighttime semantic segmentation network without using any other image modalities.
3 Proposed Method
3.1 Framework overview
Our method involves a source domain and two target domains and , where , , and represent Cityscapes (daytime), Dark Zurich-D (daytime), and Dark Zurich-N (nighttime), respectively. Note that only the source domain of Cityscapes has ground-truth semantic segmentation in training. The proposed DANNet proceeds the domain adaptation from to and to simultaneously and it consists of three different modules: an image relighting network, a semantic segmentation network, and two discriminators, as illustrated in Figure 2.
3.2 Network architecture

All modules of the proposed DANNet are elaborated in detail below.
Image relighting network Inspired by [18], we design an image relighting network to make the intensity distributions of the images from different domains to be close such that the later semantic segmentation network is less sensitive to illumination changes. The relighting network takes the scene images , and from the three domains, and generates the relighted images , and , respectively. The relighting network shares weights for all input images from the three domains, see Figure 3 for the detailed structure of this network.
Semantic segmentation network We select and test three popular semantic segmentation networks in our method: Deeplab-v2 [3], RefineNet [23] and PSPNet [51]. Note that the common backbone is ResNet-101 [14] in all of them. For this module, we share weights for all the input images from the three domains. The semantic segmentation network takes , and as the inputs and produces segmentation predictions (category-likelihood map) , and for the three domains, respectively. The composition of the image relighting network and the semantic segmentation network forms the generator of the proposed DANNet.
Discriminators As done in [38], the discriminators are designed to distinguish whether the segmentation prediction comes from the source domain or either of the target domains by performing adversarial learning in the output space. We modified the architecture in [28] following [38] by utilizing all fully convolutional layers. Particularly, it includes 5 convolutional layers with the channel numbers of , and a kernel size of . The stride is 2 for the first two convolutional layers and 1 for the rest. Since we have two target domains and , we design two discriminators and to distinguish whether the output is from or and from or , respectively. The two discriminators share the same structures yet the weights and are jointly trained.
3.3 Probability re-weighting
Due to the fact that the numbers of pixels for different object categories are imbalanced in the source domain, network training can usually converge more easily by predicting a pixel to be a category of large-size object, such as road, building, and tree, in training discriminators. In this case, it is quite difficult to correctly predict the pixels of small objects which have relatively fewer annotations in the dataset, such as pole, sign, and light. To address this problem, we propose a re-weighting strategy to the predicted category-likelihood maps. Specifically, for each category , we first define a weight
| (1) |
where is the proportion of all the valid pixels that are labeled as category in the source domain. Clearly the smaller the value of , the larger the value of and the use of such a weight can help segment the categories of smaller-size objects. We use the logarithm to prevent from overweighting small-size object categories. In our experiment, we further normalize this weight by
| (2) |
where and are the mean and standard deviation of , respectively. The parameters and are two positive constants we pre-select to shift the value range of to be mainly positive. During training, we set and empirically. We then multiply each normalized weight with the corresponding category channel of the predicted likelihood map , where . Thus, the final semantic segmentation result is obtained by employing an argmax operation on the multiplication result.
3.4 Objective functions
In this subsection, we introduce all the objective functions involved in the proposed end-to-end DANNet training, including the light loss, the semantic segmentation loss, the static loss, and the adversarial loss.
Light Loss The light loss is proposed to ensure that the intensity distributions of the outputs , and after the image relighting network are close to each other. The light loss is a combination of three loss functions: the total variation loss , the exposure control loss , and the structural similarity loss .
The total variation loss [32] is widely used in image denoising [48] and image synthesis [41] to make images smoother. In this paper, we apply such a loss function to remove rough textures such as noises to facilitate the semantic segmentation. The loss is defined by
| (3) |
where represents the input images, is the output of the relighting network, is the number of pixels in , and represent intensity gradients between neighboring pixels along the and directions, respectively, and is the norm that sums up over all the pixels.
To obtain the similar lighting effects in the day and night scenarios, we apply the following exposure loss proposed in [13] to control the exposure level:
| (4) |
where is a average pooling function and represents the number of pixels in . Different from [13], the value of is dynamically set to be the average intensity value of the nighttime image for each training iteration.
The structural similarity loss [42] is widely used for image reconstruction [12, 2]. Here we apply this loss function to ensure that the generated relighted images could maintain the structure of original images . The loss is defined by
| (5) |
As in [12], we use a simplified SSIM (structural similarity index measure) with a block filter in this loss function.
Finally, by combining all the three loss terms, our light loss is defined by
| (6) |
where , and are set to 10, 1, and 1, respectively in all experiments.
Semantic segmentation loss We adopt the widely used weighted cross-entropy loss for training the semantic image segmentation in the source domain:
| (7) |
where is the -th channel of the prediction from the source images, is the weight defined in Eq. (2), and is the one-hot encoding of the ground truth for the -th category.
Static loss Based on the fact that the daytime image share similarities with its corresponding nighttime counterpart when considering only the static object categories, we here introduce a static loss to provide pixel-level pseudo supervision for the static object categories, e.g., road, sidewalk, wall, fence, pole, light, sign, vegetation, terrain and sky, in the nighttime images.
Given the segmentation predictions and , we only consider the channels corresponding to the static categories for calculating this loss. Let us denote as the total number of the categories of static objects, then it holds that and .
We first apply Eq. (2) to calculate the re-weighted prediction as the pseudo label. Following [45, 4], we then employ the focal loss [24] to remedy the imbalance among different categories of training samples. Finally, the static loss is defined by
| (8) |
where is the total number of valid pixels in the segmentation ground truth, is the focusing parameter (set to 1 in all experiments), and is the likelihood map for the correct category. Different from the focal loss in [24], we compute at each pixel in a local region for category by
| (9) |
where is the one-hot encoding of the semantic pseudo ground truth , and represents each position of the region centered at .
Adversarial loss We employ two discriminators for adversarial learning, which are used to distinguish whether the output is from the source domain or one of the two target domains, i.e., or and or . We adopt the least-squares loss function [25] to make both predictions and to be close to . Specifically, we define the combination of these two adversarial losses () as:
| (10) |
where , , and is the label for the source domain which has the same resolution as the output of discriminators. Thus, the total loss of the generator (G) is defined by combining , , and :
| (11) |
where , and are set to 0.01, 1, 1 and 0.01 respectively in all experiments.
The generator and the corresponding discriminators are trained alternatively and the objective functions of the discriminators and are defined respectively by:
| (12) |
| (13) |
where is the label for the target domains with the same resolution as the output of discriminators.
4 Experiments
4.1 Datasets and evaluation metrics
For all experiments, we use the mean of category-wise intersection-over-union (mIoU) as the evaluation metric, and the higher the better. The following datasets are used for model training and performance evaluation:
Cityscapes [7] The Cityscapes dataset contains 5,000 frames taken in street scenes with pixel-level annotations of a total of 19 categories, and both the original images and annotations have a resolution of pixels. In total, there are 2,975 images for training, 500 images for validation and 1,525 images for testing. In this paper, we use the Cityscapes training set in the training stage of the proposed DANNet for adversarial learning.
Dark Zurich [33] The Dark Zurich dataset consists of 2,416 nighttime images, 2,920 twilight images and 3,041 daytime images for training, which are all unlabeled with a resolution of . Images in these three domains can be coarsely aligned by using GPS-based nearest neighbor assignment to compensate the translation in each direction and the zoom in/out factors. In this paper, we only use 2,416 night-day image pairs in training of the proposed DANNet (without using the twilight images). The Dark Zurich dataset also contains another 201 annotated nighttime images including 50 for validation (Dark Zurich-val) and 151 for testing (Dark Zurich-test), for quantitative evaluation. Note that the Dark Zurich-test serves as an online benchmark whose ground truth are not publicly available. In our experiments, by submitting the segmentation results to the online evaluation website we get the performance of the proposed DANNet on Dark Zurich-test against the annotated ground truths.
Nighttime Driving [8] The Nighttime Driving test set contains 50 nighttime images of resolution from diverse visual scenes. All these 50 images have been annotated at the pixel level using the same 19 Cityscapes category labels. In our experiments, we only use Nighttime Driving test set for method evaluation.
4.2 Experimental settings
We implement the proposed DANNet using PyTorch on a single Nvidia 2080Ti GPU. Following [3], we train our network using the Stochastic Gradient Descent (SGD) optimizer with a momentum of 0.9 and a weight decay of . The base learning rate is set to and then we employ the poly learning rate policy to decrease it with a power of 0.9. The batch size is set to 2. We use Adam optimizer [20] for training the discriminators with being set to . The learning rate of the discriminators is set to and follows the same decay strategy as for the generator. In addition, we apply random cropping with the crop size of 512 on the scale between 0.5 and 1.0 for Cityscapes dataset, with the crop size of 960 on the scale between 0.9 and 1.1 on Dark Zurich dataset, and random horizontal flipping in the training. To make the training easier to converge, we use the semantic segmentation models that are pre-trained on Cityscapes for 150,000 epochs and report the performance of different segmentation models on the validation set of Cityscapes and Dark Zurich in Table 1.
| Method | Cityscapes-val | Dark Zurich-val |
|---|---|---|
| RefineNet [23] | 65.20 | 15.16 |
| DeepLab-v2 [3] | 65.67 | 12.14 |
| PSPNet [51] | 63.37 | 12.28 |
| Method |
road |
sidewalk |
building |
wall |
fence |
pole |
traffic light |
traffic sign |
vegetation |
terrain |
sky |
person |
rider |
car |
truck |
bus |
train |
motorcycle |
bicycle |
mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RefineNet [23]-Cityscapes | 68.8 | 23.2 | 46.8 | 20.8 | 12.6 | 29.8 | 30.4 | 26.9 | 43.1 | 14.3 | 0.3 | 36.9 | 49.7 | 63.6 | 6.8 | 0.2 | 24.0 | 33.6 | 9.3 | 28.5 |
| DeepLab-v2 [3]-Cityscapes | 79.0 | 21.8 | 53.0 | 13.3 | 11.2 | 22.5 | 20.2 | 22.1 | 43.5 | 10.4 | 18.0 | 37.4 | 33.8 | 64.1 | 6.4 | 0.0 | 52.3 | 30.4 | 7.4 | 28.8 |
| PSPNet [51]-Cityscapes | 78.2 | 19.0 | 51.2 | 15.5 | 10.6 | 30.3 | 28.9 | 22.0 | 56.7 | 13.3 | 20.8 | 38.2 | 21.8 | 52.1 | 1.6 | 0.0 | 53.2 | 23.2 | 10.7 | 28.8 |
| AdaptSegNet-CityscapesDZ-night [38] | 86.1 | 44.2 | 55.1 | 22.2 | 4.8 | 21.1 | 5.6 | 16.7 | 37.2 | 8.4 | 1.2 | 35.9 | 26.7 | 68.2 | 45.1 | 0.0 | 50.1 | 33.9 | 15.6 | 30.4 |
| ADVENT-CityscapesDZ-night [40] | 85.8 | 37.9 | 55.5 | 27.7 | 14.5 | 23.1 | 14.0 | 21.1 | 32.1 | 8.7 | 2.0 | 39.9 | 16.6 | 64.0 | 13.8 | 0.0 | 58.8 | 28.5 | 20.7 | 29.7 |
| BDL-CityscapesDZ-night [21] | 85.3 | 41.1 | 61.9 | 32.7 | 17.4 | 20.6 | 11.4 | 21.3 | 29.4 | 8.9 | 1.1 | 37.4 | 22.1 | 63.2 | 28.2 | 0.0 | 47.7 | 39.4 | 15.7 | 30.8 |
| DMAda [8] | 75.5 | 29.1 | 48.6 | 21.3 | 14.3 | 34.3 | 36.8 | 29.9 | 49.4 | 13.8 | 0.4 | 43.3 | 50.2 | 69.4 | 18.4 | 0.0 | 27.6 | 34.9 | 11.9 | 32.1 |
| GCMA [33] | 81.7 | 46.9 | 58.8 | 22.0 | 20.0 | 41.2 | 40.5 | 41.6 | 64.8 | 31.0 | 32.1 | 53.5 | 47.5 | 75.5 | 39.2 | 0.0 | 49.6 | 30.7 | 21.0 | 42.0 |
| MGCDA [35] | 80.3 | 49.3 | 66.2 | 7.8 | 11.0 | 41.4 | 38.9 | 39.0 | 64.1 | 18.0 | 55.8 | 52.1 | 53.5 | 74.7 | 66.0 | 0.0 | 37.5 | 29.1 | 22.7 | 42.5 |
| DANNet (DeepLab-v2) | 88.6 | 53.4 | 69.8 | 34.0 | 20.0 | 25.0 | 31.5 | 35.9 | 69.5 | 32.2 | 82.3 | 44.2 | 43.7 | 54.1 | 22.0 | 0.1 | 40.9 | 36.0 | 24.1 | 42.5 |
| DANNet (RefineNet) | 90.0 | 54.0 | 74.8 | 41.0 | 21.1 | 25.0 | 26.8 | 30.2 | 72.0 | 26.2 | 84.0 | 47.0 | 33.9 | 68.2 | 19.0 | 0.3 | 66.4 | 38.3 | 23.6 | 44.3 |
| DANNet (PSPNet) | 90.4 | 60.1 | 71.0 | 33.6 | 22.9 | 30.6 | 34.3 | 33.7 | 70.5 | 31.8 | 80.2 | 45.7 | 41.6 | 67.4 | 16.8 | 0.0 | 73.0 | 31.6 | 22.9 | 45.2 |















4.3 Comparison with state-of-the-art methods
Comparison on Dark Zurich-test We first compare our DANNet with some existing state-of-the-art methods, including MGCDA [35], GCMA [33], DMAda [8] and several other domain adaptation approaches [38, 40, 21] on Dark Zurich-test, and the results on the mIoU performance are reported in Table 2. Among these methods, MGCDA, GCMA, and DMAda share the same baseline RefineNet while the rest are based on Deeplab-v2 and they use the common ResNet-101 backbone [14] and the nighttime images in Dark Zurich-test as inputs during testing. Our DANNets with either DeepLab-v2, RefineNet or PSPNet all perform better than or tie to existing methods on this dataset, and the one with PSPNet achieves the best performance among all, with a 2.7% improvement of the overall mIoU over the highest score obtained by all existing methods (by MGCDA). We also observe that our DANNet significantly outperforms other methods on quite a few categories, such as road, sidewalk, and sky, which indicates that our method handles the large day-to-night domain gap very well even in discernible regions. Sample visualization results on Dark Zurich-val in Figure 4 also verify such observation.
Comparison on Night Driving We report the performance of the proposed DANNet and the same set of comparison methods on Night Driving test set in Table 3, with sample visualization results presented in Figure 5. It is worth to mention that Night Driving dataset is not labeled as elaborately as Dark Zurich-test as shown in Figure 5, and many categories that our DANNet predicts well (see Table 2), such as building and vegetation, are not annotated in this test set. We also notice that the category of sky is only labeled in 2 out of the 50 images in Night Driving test set. Even with these issues, our DANNet with PSPNet still achieves the second best performance (MGCDA gets the best) on this dataset.

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
| Input image | GCMA [33] | MGCDA [35] | DANNet (PSPNet) | Semantic GT |
| Method | mIoU |
|---|---|
| RefineNet [23]-Cityscapes | 32.75 |
| DeepLab-v2 [3]-Cityscapes | 25.44 |
| PSPNet [51]-Cityscapes | 27.65 |
| AdaptSegNet-CityscapesDZ-night [38] | 34.5 |
| ADVENT-CityscapesDZ-night [40] | 34.7 |
| BDL-CityscapesDZ-night [21] | 34.7 |
| DMAda [8] | 36.1 |
| GCMA [33] | 45.6 |
| MGCDA [35] | 49.4 |
| DANNet (RefineNet) | 42.36 |
| DANNet (DeepLab-v2) | 44.98 |
| DANNet (PSPNet) | 47.70 |
4.4 Ablation study
To demonstrate the effectiveness of different components of the proposed DANNet, we train several model variants for 35,000 epochs and test them on Dark Zurich-val. The performance results are reported in Table 4. Adaptation to Dark Zurich-N using AdaptSegNet [38] serves as the baseline and DANNet is the full model. We observe that coarsely aligned Dark Zurich-D is quite important although it is unlabeled, and the pseudo labels drawn from the predictions on Dark Zurich-D also play a key role in our network, without which the mIoU decreases by 13.78%. Both the image relighting network and the corresponding loss can enhance the performance. We also see that the specially designed loss is better than directly applying the cross entropy or focal loss to calculate the static loss.
| Method | mIoU |
|---|---|
| GCMA [33] | 26.65 |
| MGCDA [35] | 26.10 |
| AdaptSegNet-CityscapesDZ-night [38] | 20.19 |
| w/o Dark Zurich-D | 22.78 |
| w/o relighting network & | 34.14 |
| w/o | 35.05 |
| w/o | 20.48 |
| w/ Cross Entropy Loss in | 33.61 |
| w/ Focal Loss in | 36.49 |
| w/o re-weighting on pseudo labels | 32.71 |
| w/o re-weighting on prediction | 32.22 |
| w/o pretrained segmentation model | 30.74 |
| DANNet | 36.76 |

|

|
| Image | Semantic GT |

|

|
| w/o re-weighting | w/ re-weighting |

In addition, the re-weighting strategy is verified to be useful and can further boost the performance. As shown in Figure 6, this strategy helps segment the small objects. We find that the selection of the value is also important in applying the re-weighting strategy. We test different values and the performance curve of the proposed DANNet on Dark Zurich-val is shown in Figure 7, and the quantitative comparison result for each category is provided in the supplemental material. The optimal performance is achieved when setting during testing. By directly applying the commonly-used weights provided by OCNet [46], it only achieves 35.05 mIoU on DZ-val dataset, which is less than that of our DANNet. In general, the full settings of our DANNet bring about an additional 10% performance increase over the state-of-the-art approaches on Dark Zurich-val.
5 Conclusion
In this paper, we have proposed a novel end-to-end neural network DANNet for unsupervised nighttime semantic segmentation, which performs an adaptation from a labeled daytime dataset to unlabeled day-night image pairs. In our DANNet, an image relighting network with a special light loss function is first used to make the intensity distributions of the images from different domains to be close to each other. Then the unlabeled Dark Zurich-D data is used to bridge the domain gap between the labeled daytime images (Cityscapes) and the unlabeled nighttime images (Dark Zurich-N). By leveraging the similar illumination patterns between Dark Zurich-D and Cityscapes and coarse alignment of static categories between Dark Zurich-D and Dark Zurich-N, our DANNet performs multi-target domain adaptation as well as a re-weighting strategy to boost the performance for small objects. Experimental results demonstrated the effectiveness of each of the designed components and showed that our DANNet achieves the state-of-the-art performance on Dark-Zurich and Night Driving test datasets.
References
- [1] Wei-Lun Chang, Hui-Po Wang, Wen-Hsiao Peng, and Wei-Chen Chiu. All about structure: Adapting structural information across domains for boosting semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1900–1909, 2019.
- [2] Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. Learning to see in the dark. In IEEE Conf. Comput. Vis. Pattern Recog., pages 3291–3300, 2018.
- [3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell., 40(4):834–848, 2017.
- [4] Minghao Chen, Hongyang Xue, and Deng Cai. Domain adaptation for semantic segmentation with maximum squares loss. In IEEE Conf. Comput. Vis. Pattern Recog., pages 2090–2099, 2019.
- [5] Xu Chen, Bryan M Williams, Srinivasa R Vallabhaneni, Gabriela Czanner, Rachel Williams, and Yalin Zheng. Learning active contour models for medical image segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11632–11640, 2019.
- [6] Yi-Hsin Chen, Wei-Yu Chen, Yu-Ting Chen, Bo-Cheng Tsai, Yu-Chiang Frank Wang, and Min Sun. No more discrimination: Cross city adaptation of road scene segmenters. In Int. Conf. Comput. Vis., pages 1992–2001, 2017.
- [7] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In IEEE Conf. Comput. Vis. Pattern Recog., pages 3213–3223, 2016.
- [8] Dengxin Dai and Luc Van Gool. Dark model adaptation: Semantic image segmentation from daytime to nighttime. In 2018 21st International Conference on Intelligent Transportation Systems (ITSC), pages 3819–3824. IEEE, 2018.
- [9] Shuai Di, Qi Feng, Chun-Guang Li, Mei Zhang, Honggang Zhang, Semir Elezovikj, Chiu C Tan, and Haibin Ling. Rainy night scene understanding with near scene semantic adaptation. IEEE Transactions on Intelligent Transportation Systems, 2020.
- [10] Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, and Hanqing Lu. Dual attention network for scene segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 3146–3154, 2019.
- [11] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving. In IEEE Conf. Comput. Vis. Pattern Recog., pages 3354–3361.
- [12] Clément Godard, Oisin Mac Aodha, and Gabriel J Brostow. Unsupervised monocular depth estimation with left-right consistency. In IEEE Conf. Comput. Vis. Pattern Recog., pages 270–279, 2017.
- [13] Chunle Guo Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. Zero-reference deep curve estimation for low-light image enhancement. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1780–1789, June 2020.
- [14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conf. Comput. Vis. Pattern Recog., pages 770–778, 2016.
- [15] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. Cycada: -consistent adversarial domain adaptation. pages 1989–1998. PMLR, 2018.
- [16] Judy Hoffman, Dequan Wang, Fisher Yu, and Trevor Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016.
- [17] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. In Int. Conf. Comput. Vis., pages 603–612, 2019.
- [18] Tomas Jenicek and Ondrej Chum. No fear of the dark: Image retrieval under varying illumination conditions. In Int. Conf. Comput. Vis., pages 9696–9704, 2019.
- [19] Myeongjin Kim and Hyeran Byun. Learning texture invariant representation for domain adaptation of semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 12975–12984, 2020.
- [20] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. Int. Conf. Learn. Represent., 2014.
- [21] Yunsheng Li, Lu Yuan, and Nuno Vasconcelos. Bidirectional learning for domain adaptation of semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 6936–6945, 2019.
- [22] Qing Lian, Fengmao Lv, Lixin Duan, and Boqing Gong. Constructing self-motivated pyramid curriculums for cross-domain semantic segmentation: A non-adversarial approach. In Int. Conf. Comput. Vis., pages 6758–6767, 2019.
- [23] G. Lin, A. Milan, C. Shen, and I. Reid. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., July 2017.
- [24] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Int. Conf. Comput. Vis., pages 2980–2988, 2017.
- [25] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In IEEE Conf. Comput. Vis. Pattern Recog., pages 2794–2802, 2017.
- [26] Sauradip Nag, Saptakatha Adak, and Sukhendu Das. What’s there in the dark. In IEEE Int. Conf. Image Process., pages 2996–3000. IEEE, 2019.
- [27] Deepak Pathak, Philipp Krahenbuhl, and Trevor Darrell. Constrained convolutional neural networks for weakly supervised segmentation. In Int. Conf. Comput. Vis., pages 1796–1804, 2015.
- [28] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. Int. Conf. Learn. Represent., 2015.
- [29] Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In Eur. Conf. Comput. Vis., pages 102–118. Springer, 2016.
- [30] Eduardo Romera, Luis M Bergasa, Kailun Yang, Jose M Alvarez, and Rafael Barea. Bridging the day and night domain gap for semantic segmentation. In 2019 IEEE Intelligent Vehicles Symposium (IV), pages 1312–1318. IEEE, 2019.
- [31] German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In IEEE Conf. Comput. Vis. Pattern Recog., pages 3234–3243, 2016.
- [32] Leonid I Rudin, Stanley Osher, and Emad Fatemi. Nonlinear total variation based noise removal algorithms. Physica D: nonlinear phenomena, 60(1-4):259–268, 1992.
- [33] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. In Int. Conf. Comput. Vis., pages 7374–7383, 2019.
- [34] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis., 126(9):973–992, 2018.
- [35] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. arXiv preprint arXiv:2005.14553, 2020.
- [36] Swami Sankaranarayanan, Yogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 3752–3761, 2018.
- [37] Lei Sun, Kaiwei Wang, Kailun Yang, and Kaite Xiang. See clearer at night: towards robust nighttime semantic segmentation through day-night image conversion. In Artificial Intelligence and Machine Learning in Defense Applications, volume 11169, page 111690A. International Society for Optics and Photonics, 2019.
- [38] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. Learning to adapt structured output space for semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 7472–7481, 2018.
- [39] Johan Vertens, Jannik Zürn, and Wolfram Burgard. Heatnet: Bridging the day-night domain gap in semantic segmentation with thermal images. arXiv preprint arXiv:2003.04645, 2020.
- [40] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Pérez. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 2517–2526, 2019.
- [41] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In IEEE Conf. Comput. Vis. Pattern Recog., pages 8798–8807, 2018.
- [42] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process., 13(4):600–612, 2004.
- [43] Zhonghao Wang, Mo Yu, Yunchao Wei, Rogerio Feris, Jinjun Xiong, Wen-mei Hwu, Thomas S Huang, and Honghui Shi. Differential treatment for stuff and things: A simple unsupervised domain adaptation method for semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 12635–12644, 2020.
- [44] Zuxuan Wu, Xintong Han, Yen-Liang Lin, Mustafa Gokhan Uzunbas, Tom Goldstein, Ser Nam Lim, and Larry S Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. In Eur. Conf. Comput. Vis., pages 518–534, 2018.
- [45] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, and Nong Sang. Learning a discriminative feature network for semantic segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1857–1866, 2018.
- [46] Yuhui Yuan and Jingdong Wang. Ocnet: Object context network for scene parsing. 2018.
- [47] Oliver Zendel, Markus Murschitz, Martin Humenberger, and Wolfgang Herzner. How good is my test data? introducing safety analysis for computer vision. Int. J. Comput. Vis., 125(1-3):95–109, 2017.
- [48] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process., 26(7):3142–3155, 2017.
- [49] Xiaomei Zhang, Yingying Chen, Bingke Zhu, Jinqiao Wang, and Ming Tang. Part-aware context network for human parsing. In IEEE Conf. Comput. Vis. Pattern Recog., pages 8971–8980, 2020.
- [50] Yang Zhang, Philip David, and Boqing Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In Int. Conf. Comput. Vis., pages 2020–2030, 2017.
- [51] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In IEEE Conf. Comput. Vis. Pattern Recog., pages 2881–2890, 2017.
- [52] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Int. Conf. Comput. Vis., pages 2223–2232, 2017.
- [53] Xinge Zhu, Hui Zhou, Ceyuan Yang, Jianping Shi, and Dahua Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In Eur. Conf. Comput. Vis., pages 568–583, 2018.