DAME: Domain Adaptation for Matching Entities
Abstract.
Entity matching (EM) identifies data records that refer to the same real-world entity. Despite the effort in the past years to improve the performance in EM, the existing methods still require a huge amount of labeled data in each domain during the training phase. These methods treat each domain individually, and capture the specific signals for each dataset in EM, and this leads to overfitting on just one dataset. The knowledge that is learned from one dataset is not utilized to better understand the EM task in order to make predictions on the unseen datasets with fewer labeled samples. In this paper, we propose a new domain adaptation-based method that transfers the task knowledge from multiple source domains to a target domain. Our method presents a new setting for EM where the objective is to capture the task-specific knowledge from pretraining our model using multiple source domains, then testing our model on a target domain. We study the zero-shot learning case on the target domain, and demonstrate that our method learns the EM task and transfers knowledge to the target domain. We extensively study fine-tuning our model on the target dataset from multiple domains, and demonstrate that our model generalizes better than state-of-the-art methods in EM.
1. Introduction
Entity matching (EM) identifies data records that refer to the same real-world entity. EM is an important step in data cleaning and integration (Christen, 2008), knowledge base enrichment (Nickel et al., 2016), and entity linking (Shen et al., 2015). Researchers have studied EM for many years in the context of data mining and integration. In Figure 1, we show examples of pairs of records for EM from Amazon-Google dataset where in both subfigures the above record is from Amazon and the below record is from Google. In Figure 1(a), both records refer to the same real-world entity adobe photoshop 4.0 although in one record the manufacturer value is missing, and the prices are different. In Figure 1(b), the difference in the value of the title attribute in both records clearly indicates that records refer to different entities.


In the past few years, deep learning (DL) has led to a significant improvement in multiple tasks, where DL-based methods achieved state-of-the-art (SOTA) results for text, image, and speech data. In many cases, DL models are trained end-to-end to automatically extract features and build predictive models. This significantly reduces the human effort that is needed in traditional methods for feature engineering, and gives the model the ability to capture specific features that are better than the hand-crafted ones for multiple tasks. Following the success of DL models, researchers have focused on exploring DL in data cleaning and integration. In particular, multiple DL methods have been proposed to solve the EM task (Ebraheem et al., 2018; Fu et al., 2019; Kasai et al., 2019; Mudgal et al., 2018; Zhao and He, 2019). Based on the DL architecture, we can distinguish two groups of models: attribute-level models where a schema matching step is necessary to compare values of corresponding attributes between two records, and record-level models where the records are compared in their entirety. In addition, traditional pretrained embedding, such as Glove (Pennington et al., 2014) and FastText (Bojanowski et al., 2017), is used as word embedding in these DL models. Deep contextualized language models (DCLM), like BERT (Devlin et al., 2019), RoBERTa (Liu et al., 2019), and DistilBERT (Sanh et al., 2019) have been recently proposed to solve multiple tasks (Wang et al., 2018; Sakata et al., 2019; Chen et al., 2020; Trabelsi et al., 2020, 2021b, 2021a; Trabelsi et al., 2022). Different from traditional word embeddings, the pre-trained neural language models are contextual where the representation of a token is a function of the entire sentence. This is mainly achieved by the use of a self-attention structure called a Transformer (Vaswani et al., 2017). Building on DCLM, Ditto (Li et al., 2020) achieved SOTA results in EM.
Although DL methods have led to a significant improvement in the EM task, these models need a huge amount of labeled data for each domain. DL-based models are trained in a supervised setting for each dataset in EM, where a different model is obtained and is fully fine-tuned on a specific dataset. This means that existing models capture the specific signals for each dataset in EM which leads to overfitting on just one dataset. In addition, the knowledge that is learned from one dataset is not explored to better understand the EM task so that the predictions in other datasets can be made with fewer labeled samples.
In order to overcome the limitations of prior methods, we propose a new method, called Domain Adaptation for Matching Entities (DAME), that transfers the task knowledge from multiple source domains to a target domain. Our method presents a new setting for EM where the objective is to capture task-specific knowledge from pretraining our model using multiple source domains, then testing our model on a target domain. In our study, we are interested in two aspects of our model. First, we study the zero-shot learning (ZSL) case of DAME on the target domain. Second, we study the effect of fine-tuning our proposed model on the target domain using different percentages of training data, and we compare our fine-tuned model to SOTA methods. We formulate EM as a mixture of experts with a global shared model (Guo et al., 2018; Kim et al., 2017; Wright and Augenstein, 2020) where each expert is trained on an individual source domain, and the global model is trained on all domains. Then, we aggregate the features from the experts using a global model-guided attention mechanism. We train DAME with unsupervised domain adaptation (DA) loss functions (Guo et al., 2018; Wright and Augenstein, 2020) to reduce the domain shift between the source and target domains.
In summary, we make the following contributions: (1) We propose a new DA-based method for EM. Our new formulation of EM is based on the mixture of experts where we transfer learning from multiple source domains to a target domain. (2) We study the ZSL case on the target domain and demonstrate that our method learns the EM task and transfers the task knowledge to the target domain. (3) We extensively study fine-tuning our model on the target dataset from multiple domains, and demonstrate that our model generalizes better than SOTA methods for most of the datasets.
2. Related work
2.1. Entity matching
EM (Mudgal et al., 2018; Li et al., 2020; Kasai et al., 2019; Ebraheem et al., 2018; Barlaug and Gulla, 2021) is the field of research that solves the problem of finding records that refer to the same real-world entity. EM, also known as data matching, record linkage, entity resolution, etc, has been intensively studied in recent years because EM is an important step in data cleaning and integration. Given two collections of records and , EM classifies a pair of entities into match or non-match. The records from and can have the same or different set of attributes. The value of each attribute is composed of a sequence of tokens.
Comparing all record pairs from and grows quadratically and it becomes very time-consuming to predict the matching records for the input datasets. Therefore, a set of candidate pairs , where is selected in a separate step, called blocking, before running a computationally expensive algorithm for EM. Multiple blocking methods have been proposed in the literature (Christen, 2012b; Fisher et al., 2015; Papadakis et al., 2020). After the blocking step, each record pair is compared to predict a binary label indicating a match or non-match. Prior works have proposed string similarity-based methods to compare records (Christen, 2012a; Elmagarmid et al., 2007; Lu et al., 2019). Traditional supervised classifiers , such as decision trees, support vector machines, and naive Bayes, have been proposed to map the string similarities-based feature vector to a binary class label (Christen, 2008; Bilenko and Mooney, 2003). In addition, rule-based methods have been proposed to solve EM (Dalvi et al., 2013; Elmagarmid et al., 2014; Singh et al., 2017). Recently, DL-based methods have been proposed to solve EM (Ebraheem et al., 2018; Fu et al., 2019; Kasai et al., 2019; Mudgal et al., 2018; Zhao and He, 2019; Li et al., 2020). The DL methods of EM can be categorized into attribute- and record-level comparison methods. Attribute comparators predict the label of a pair of records based on the signals collected from matching values of the same attribute. DeepMatcher (Mudgal et al., 2018), which is the SOTA attribute-level comparator, explores multiple techniques to compute the attribute representation from word embedding, where combining both bidirectional GRU and decomposable attention (Parikh et al., 2016) leads to the best results. FastText (Bojanowski et al., 2017) is used for word embedding in DeepMatcher. The SOTA method in EM is a record-based comparator known as Ditto (Li et al., 2020) which is based on DCLM. Ditto models each record by alternating between attributes and data values with two additional special tokens [COL] and [VAL]. Incorporating attribute names in the record representation provides the Transformer (Vaswani et al., 2017) layers with more information to match attributes of two records. Then, Ditto adapts the sentence pair classification setting to EM in order to compare record pairs using the special tokens [SEP] and [CLS] that are added into the input. In addition, Ditto explores domain-specific optimizations by injecting domain knowledge into the input in the form of span typing and normalization. Ditto uses data augmentation techniques during the training phase with span-, attribute-, and record-level operators consisting of deletion, shuffling, and swapping.
2.2. Domain adaptation
DA studies the transfer of task knowledge from a single or multiple labeled source domains to an unlabeled target domain. In this paper, we are interested in the case of multiple source domains known as Multi-Source DA (MSDA). Using only unlabeled data from the target domain is known as Unsupervised DA (UDA).
Existing approaches in UDA focus on reducing the domain shift between the source and target domains by aligning feature vectors (Ben-David et al., 2006; Pan et al., 2010). Representation learning methods have been proposed for UDA such as domain adversarial networks (Zhang et al., 2017; Shen et al., [n.d.]). and denoising autoencoders (Chen et al., 2012). Other representation learning methods include comparing the marginal distribution between the source and target domains in an adversarial way (Guo et al., 2018) and minimizing the covariance between the source and target representations (Sun et al., 2016). An effective strategy in the case of MSDA is known as a mixture of experts (Guo et al., 2018; Kim et al., 2017; Wright and Augenstein, 2020). Kim et al. (Kim et al., 2017) proposed to incorporate an attention mechanism to combine the predictions from multiple models trained on the source domains. Guo et al. (Guo et al., 2018) proposed a method that is based on a mixture of experts where the posteriors of the models are combined using a point-to-set Mahalanobis distance metric between an input sample and source domains. Wright and Augenstein (Wright and Augenstein, 2020) improved the performance of the mixture of experts using DCLM as experts in source domains. This work follows a line of research that investigates the use of Transformers (Vaswani et al., 2017) in DA (Gururangan et al., 2020; Han and Eisenstein, 2019; Ma et al., 2019; Rietzler et al., 2020). Ma et al. (Ma et al., 2019) improved the performance of BERT in the target domain for natural language inference by incorporating a similarity of a given target domain to source domains with curriculum learning (Bengio et al., 2009). AdaptaBERT (Han and Eisenstein, 2019) is a BERT-based model that is proposed in the case of UDA for the sequence labeling by adding a masked language modeling in the target domain. Fine-tuning of BERT on the target domain was also shown to be effective in the sentiment analysis task (Rietzler et al., 2020). Gururangan et al. (Gururangan et al., 2020) combines both domain and task adaptive pretraining to improve the performance of RoBERTa on multiple NLP tasks. The task-adaptive pretraining represents pretraining on unlabeled datasets that are relevant to the task by continuing pretraining RoBERTa on these datasets.
3. Problem statement
Our formulation of DA in EM task is based on the unsupervised multi-source DA setting which consists of labeled source domains , where ( is the -th instance of with a label ), and unlabeled target domain ( is the -th instance of ). The objective is to learn a classifier using labeled data from source domains and unlabeled data from the target domain so that (1) produces accurate predictions on the target domain without fine-tuning (ZSL case), and (2) generalizes better than SOTA methods on the target domain after partially or fully fine-tuning.
4. Domain adaptation for matching entities
In this section, we introduce our proposed method DAME which is a DA-based method for matching entities. We first describe the architecture of DAME, and then present the DA-based training strategy to update the parameters of our proposed model. Finally, we present our fine-tuning strategy in the case of using labeled samples from the target domain to update DAME.
4.1. DAME architecture
There are multiple datasets that are available for the EM task. Therefore, our model is based on formulating the EM as a mixture of domain experts in the case of DA. Each expert model is trained on one source domain. We denote by , the expert model that is trained on . Training a mixture of experts and shared models improves the performance when multiple source domains are available as shown in prior works (Guo et al., 2018; Kim et al., 2017; Wright and Augenstein, 2020). Therefore, we also add a global model that is trained using all the source domains .
DCLM have been proposed in the DA setting to solve multiple tasks (Wright and Augenstein, 2020; Gururangan et al., 2020; Han and Eisenstein, 2019; Ma et al., 2019; Rietzler et al., 2020). We propose to incorporate DCLM in our DA-based model to solve the EM task. Each and are initialized using DistillBERT (Sanh et al., 2019) which is a distilled version of BERT with fewer parameters. We choose to use DistilBERT as the main component for the expert and global models for two reasons. First, by incorporating DCLM, we compare records in their entirety which has been shown to be more effective than attribute-based comparisons. Second, DistilBERT has a reduced size and comparable performance to BERT, and our objective is to include many source domains while keeping the time and memory complexity reasonable. In general, our proposed model has four modules:
| (1) |
is a representation module that produces the sequence input from a pair of records , is a feature extractor that produces multiple embeddings for the sequence input of the record pair using expert models and the global model , is an attention module that aggregates the embeddings of the expert models to produce the final multi-source embedding, and is a classification layer that maps the final embedding to a confidence score to make a matching/non-matching decision on a record pair.
4.1.1. Representation module
Each record pair is composed of two data entries and that correspond to candidate rows from two collections of data entries and . Both and are from the same source domain. Each data entry is a set of attribute-value pairs denoted by , where is the number of attributes in each record. We follow the encoding of Ditto (Li et al., 2020) for serializing data entries to produce a sequence for each record from the attribute-value pairs:
| (2) |
where and are special tokens that denote the start of attributes and values, respectively. The input of EM is a pair of records . So, takes as input a pair of records, and produces a sequence pair of serialized entries that is given by:
| (3) |
where [SEP] and [CLS] are BERT special tokens that are added into the sequence similar to the sentence pair classification setting.
4.1.2. Feature extractor
We have DistilBERT models: expert models and a global shared model . We use as input to the models to extract source domain-based embeddings denoted by , and a global model-based embedding denoted by . The embeddings from the source domain models and the global model are extracted using the hidden state of the [CLS] token from the last Transformer block in each DistilBERT model. In conclusion, the output of is given by:
| (4) |
4.1.3. Attention module
When aggregating the embeddings that are extracted using , the embeddings from the source domains and the global model should not be treated equally as there are domains that are more relevant to a given record pair than others. We use a parameterized attention model that attends to all domains using a dot product-based attention where three parametric matrices are introduced: a query matrix , a key matrix , and a value matrix , where is the dimension of the embedding. We first concatenate all the expert embeddings from to form an embedding matrix denoted by . The attention operations are defined by:
| (5) |
An important design choice in our attention module is the use of the global representation to map the query matrix to a query vector . Given that the global model is trained on all the source domains, we expect the global model’s embedding to transfer to the target domain, and by consequence we obtain more accurate attention weights in the target domain to aggregate the source domains, mainly in the zero-shot learning case. The output of the attention module is used as input to the classification layer to predict the matching score of the input record pair .
4.2. Training strategy
In the multi-source DA setting, we have labeled source domains , where , and an unlabeled target domain . Our training phase is based on the multi-task learning setting. In each batch for the training phase, we sample pairs of records from a given source . Our loss function is composed of four parts and is given by:
| (6) |
where , , , and are hyperparameters that control the contribution of each loss to the final loss function ; each of , , , and represents a task-specific loss.
4.2.1. Expert domain loss
represents the expert model of , for all . To optimize each expert model , we add a classification layer that predicts the probabilities of matches and non-matches for each domain . So, in total we add classification layers. Given that is sampled from the -th domain, the domain expert loss is given by:
| (7) |
where denotes the cross entropy loss function.
4.2.2. Global model loss
The global model is trained on all the source domains in order to learn a universal embedding for the EM task that supports transfer to the target domain while maintaining important matching signals for each source domain. In addition, the embedding of the global model is multiplied with the query matrix in the attention module to compute the contribution of each source domain to the final representation. After learning how to aggregate features in the training phase on source domains, the global model guides the attention module to pick the most important source domains for the target domain during the testing phase. To optimize the global model , we add a classification layer that predicts the probabilities of matches and non-matches for all source domains. The global model loss is given by:
| (8) |
4.2.3. Meta-target loss
In DA, the objective is to incorporate multiple source domains to predict labels for samples from the target domain during the testing phase. In order to simulate the process of DA during the training phase, we use the meta-target and meta-sources similar to Guo et al. (Guo et al., 2018). Given that is sampled from the -th domain, the meta-target is the -th source domain and the meta-sources are . The meta-model differs only on the feature extractor part compared to . is given by:
| (9) |
where:
| (10) |
The same attention module is applicable to the output of the meta-feature extractor where the query matrix based on the global model attends to all the expert embeddings in the key matrix regardless of the number of expert models. Finally, the meta-target loss for the batch is given by:
| (11) |
4.2.4. Adversarial loss
The global model plays an important role in the attention module . Learning a domain invariant embedding from the global model makes the transfer to the target domain smoother as the attention weights should be more accurate. To obtain a domain invariant representation from , we adapt the domain adversarial training for EM. Similar to the generative adversarial network (GAN), a min-max objective function is introduced to optimize the parameters of the generator which is the global model and the discriminator denoted by . The parameters of are optimized to predict the domain of a sample using , and the parameters of are optimized to produce a confusing representation for . We alternate between updating and . Given that is sampled from the -th domain, in order to update , we minimize which is given by:
| (12) |
is minimized with respect to only the parameters of . Then, we set to update the parameters of when minimizing ( parameters are fixed). Unlabeled samples from the target domain can also be considered as an additional domain when updating the parameters of and by alternating between minimizing and , respectively. In this case, the total number of labels that are used in is equal to .
4.3. Fine-tuning DAME on the target domain
During fine-tuning DAME on the target domain, we only update the weights of the global model , attention weights , and the classification layer , and we keep the weights of the expert models frozen. The objective of the fine-tuning step is to slightly update the parameters of DAME to incorporate dataset-specific signals related to the target domain without changing the parameters of expert models. There are multiple fine-tuning scenarios on the target domain. First, we can use all the samples from the target domain or only a limited budget of samples for fine-tuning. Second, in the case of having access to only a limited budget of samples, we can randomly choose samples, or adapt active learning (AL) selection strategies to select the most promising samples. We experiment with all the scenarios and produce AL results using methods from (Wang and Shang, 2014; Gal et al., 2017; Sener and Savarese, 2018).
5. Evaluation
5.1. Data collections
Table 1 represents all the 12 datasets that we use in our experiments. Datasets are collected from the entity resolution Benchmark datasets (Köpcke et al., 2010) and the Magellan data repository (Konda et al., 2016). These datasets cover multiple domains including clothing, electronics, citation, restaurant, products, music, and software. Each dataset is composed of candidate pairs of records from two structured tables that have the same set of attributes. The datasets vary in the size and this simulates real-world scenarios where there are some domains that are more frequent than others. The total number of attributes in all datasets ranges from 1 to 8. The rate of matches in all datasets ranges from 9.39% to 24.48%. Clearly, there is a class imbalance in all datasets where the non-matching class is significantly larger than the matching class. Each dataset is split into training, validation, and testing, and we use the same pre-splited datasets in Ditto (Li et al., 2020).
| Dataset | Domain | Size | % matches | nb attributes |
|---|---|---|---|---|
| Shoes | clothing | 5,805 | 21.95 | 1 |
| Cameras | electronics | 5,255 | 22.03 | 1 |
| Computers | electronics | 8,094 | 22.42 | 1 |
| Watches | electronics | 6,413 | 22.85 | 1 |
| DBLP-GoogleScholar | citation | 28,707 | 18.62 | 4 |
| DBLP-ACM | citation | 12,363 | 17.95 | 4 |
| Fodors-Zagats | restaurant | 946 | 11.62 | 6 |
| Beer | product | 450 | 15.11 | 4 |
| iTunes-Amazon | music | 539 | 24.48 | 8 |
| Abt-Buy | product | 9,575 | 10.73 | 3 |
| Amazon-Google | software | 11,460 | 10.18 | 3 |
| Walmart-Amazon | electronics | 10,242 | 9.39 | 5 |



5.2. Baselines
We compare the performance of our proposed model against the best performing method in the category of attribute-level comparators which is DeepMatcher (Mudgal et al., 2018) (the previous SOTA), and the SOTA in EM which is Ditto (Li et al., 2020). We are interested in two aspects of our proposed model DAME. First, we evaluate the ZSL case for DAME by comparing the performance to baselines that are trained on different percentages of training data. Second, we compare the results of fine-tuning DAME on the target domain against training the baselines on the target domain.
5.3. Experimental Setup
We evaluate the performance of DAME and baselines on the EM task using precision, recall, F1-score, and accuracy of predictions on the testing set. We use , and to denote that the difference in a given evaluation metric between Ditto trained on of data and DAME (ZSL) is less than 0.15, and less than 0.1, respectively. We use to denote that either the difference between Ditto trained on of data and DAME (ZSL) is less than 0.05 or DAME (ZSL) is better than Ditto trained on of data. DAME is trained for 3 epochs on the source domains. We compare fine-tuning results for DAME and baselines after training for 10 epochs on the same percentage of training data from the target domain. The hyperparameters , , , and are fine-tuned for one dataset and then kept the same for all the experiments. We distinguish 3 sets of experiments based on the structure of datasets. The first set of experiments studies DA for Shoes, Cameras, Computers, and Watches. These datasets have a unique attribute which is title. The second set of experiments also studies DA for datasets that have similar structures which are DBLP-GoogleScholar and DBLP-ACM. The set of attributes for these two datasets are title, authors, venue, and year. The third set of experiments is related to DA in the wild where we study DA using all 12 datasets regardless of the structures and domains. DAME code is available on Github111https://github.com/medtray/DAME.
5.4. Experimental results
5.4.1. DA for Shoes, Computers, Watches, Cameras
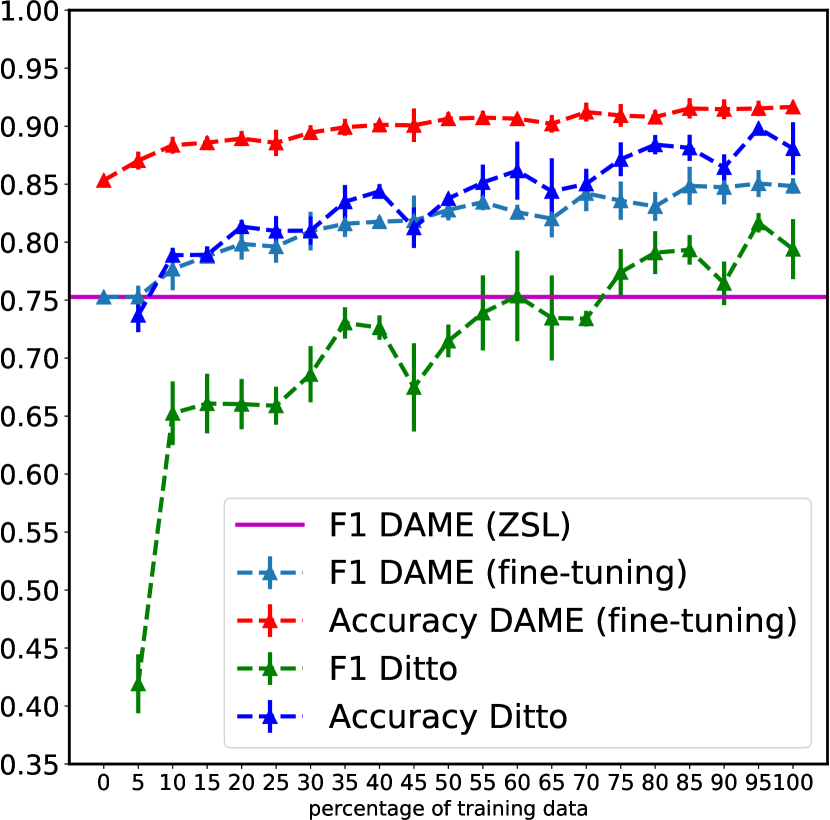
Figure 2 shows the comparison of DAME results against Ditto for Shoes, Computers, Watches, and Cameras. The caption of each subfigure represents the target domain, and the remaining 3 domains represent the source domains. Each data point represents the mean of 5 trials, and the vertical line in each data point represents the standard deviation (std). The plots report two evaluation metrics: F1 score and accuracy. In all figures, the light blue plot represents the F1 score of DAME, and is compared against the green plot that represents the F1 score of Ditto; the red plot represents the accuracy of DAME, and is compared against the blue plot that represents the accuracy of Ditto. DAME and Ditto outperform DeepMatcher for all evaluation metrics by a large margin, so that we only include DAME and Ditto results to avoid clutter in the figures. The magenta color represents the F1 score of the DAME (ZSL) for the target domain, which is equivalent to 0% of supervised training data from the target domain. We achieve high F1 scores for DAME (ZSL) for both Shoes and Cameras datasets, where the F1 score for DAME (ZSL) is equivalent to training Ditto on 72% and 85% of training data for the Shoes and Cameras, respectively. The results are lower for Computers and Watches where the F1 score of DAME (ZSL) is equivalent to Ditto trained on around 25% of training data. Figure 2 shows the results of fine-tuning DAME using different percentages of training data. Fine-tuning DAME leads to a better and more stable (smaller std in most fractions of the training data) performance than Ditto for all datasets which means that DAME generalizes better than existing methods in EM for datasets with similar structures. This can be explained by the important role of DA in learning the task so that the weights are better warmed up for EM.
5.4.2. DA for DBLP-GoogleScholar, DBLP-ACM
Table 2 summarizes the performance of different approaches on the second set of datasets with the same structure which is composed of DBLP-GoogleScholar and DBLP-ACM. In this case, we have one target dataset and one source dataset. We achieve high results for DAME (ZSL) for both datasets. In addition, fine-tuning DAME slightly increases the F1 and accuracy for both datasets. So, consistent with the first set of experiments, we conclude that DAME transfers the task knowledge from the source domains to a target domain in the case of datasets with similar structures.
5.4.3. DA in the wild
We study the case of transferring knowledge between datasets with different domains and structures. We call this setting DA in the wild which simulates real-world scenarios. Table 4 (end of the paper) shows extensive experiments on 12 datasets reporting evaluation metrics for multiple methods. DAME (ZSL) achieves a better F1 score than DeepMatcher trained with 50% of training data from the target domain for 7 out of 12 datasets. The difference between the F1 score of Ditto trained on of data and DAME (ZSL) is less than 0.1, and 0.05 for 83% and 41% of datasets, respectively. By comparing the F1 score of fine-tuning all methods using 50% of training data from the target domain, we achieve SOTA results for 10 out of 12 datasets. By comparing the F1 score of fine-tuning all methods using all training data from the target domain, we achieve SOTA results for 10 out of 12 datasets. This means that DAME generalizes better than existing methods for datasets in the wild.







5.4.4. Expert models vs Global model
Figure 3 shows the comparison of F1 score results with different numbers of expert domains against using the global model representation during the testing phase on the target domain in the case of ZSL. The x-axis represents the number of experts that we use for predictions. For example, if the number of experts is equal to 6, it means that we randomly choose 6 experts and we drop the remaining 5 experts. Each data point in Figure 3 represents an average of 5 trials. The dashed line represents the F1 score for the global model. For 10 out of 12 datasets, combining multiple experts using the attention network leads to better results than the global model. Figure 3 shows that the fewest number of experts needed to outperform the global model was 5 (DBLP-ACM); the most required was 11 (Cameras). Overall, we obtain better F1 scores for the mixture of experts when we increase the number of experts. This means that the experts help to better understand the EM task, and therefore transfer the learned task knowledge to the unseen target domain.
| Method | Shoes | Computers | Watches | Cameras |
|---|---|---|---|---|
| DAME (ZSL) | 0.7527 | 0.7946 | 0.7936 | 0.8507 |
| DAME (full training data) | 0.8483 | 0.8947 | 0.9371 | 0.8941 |
| Random Sampling (5%) | 0.7527 | 0.8181 | 0.8004 | 0.8664 |
| Least Confidence (Wang and Shang, 2014) (5%) | 0.7818 | 0.8402 | 0.8209 | 0.8745 |
| Entropy Sampling (Wang and Shang, 2014) (5%) | 0.7859 | 0.8464 | 0.8166 | 0.8748 |
| USDE (Gal et al., 2017) (5%) | 0.7877 | 0.8437 | 0.8151 | 0.8775 |
| BALD (Gal et al., 2017) (5%) | 0.7852 | 0.8472 | 0.8313 | 0.8705 |
| K-Centers Greedy (Sener and Savarese, 2018) (5%) | 0.7674 | 0.8271 | 0.8206 | 0.8687 |
| K-Means (Sener and Savarese, 2018) (5%) | 0.7527 | 0.8042 | 0.8097 | 0.8596 |
| Core-Set (Sener and Savarese, 2018) (5%) | 0.7621 | 0.8304 | 0.8168 | 0.8734 |
| Random Sampling (25%) | 0.8120 | 0.8418 | 0.8528 | 0.8741 |
| Least Confidence (Wang and Shang, 2014) (25%) | 0.8228 | 0.8804 | 0.8677 | 0.8888 |
| Entropy Sampling (Wang and Shang, 2014) (25%) | 0.8207 | 0.8770 | 0.8740 | 0.8925 |
| USDE (25%) (Gal et al., 2017) | 0.8286 | 0.8741 | 0.8688 | 0.8842 |
| BALD (25%) (Gal et al., 2017) | 0.8247 | 0.8835 | 0.8872 | 0.8941 |
| K-Centers Greedy (Sener and Savarese, 2018) (25%) | 0.8155 | 0.8771 | 0.8869 | 0.8780 |
| K-Means (Sener and Savarese, 2018) (25%) | 0.8057 | 0.8658 | 0.8694 | 0.8737 |
| Core-Set (Sener and Savarese, 2018) (25%) | 0.8161 | 0.8696 | 0.8812 | 0.8776 |
5.4.5. DAME with Active learning
So far, we have discussed the performance of fine-tuning DAME using randomly selected samples from the target domain. To improve the results of fine-tuning our model, we investigate multiple AL selection techniques given a limited budget of labeled instances. Table 3 shows the results of multiple AL selection methods applied to the DAME (ZSL) model. The starting point is our DA-based model which is not fine-tuned on the target domain, and the best performance corresponds to DAME fine-tuned on all training data from the target domain. We report results using two budget levels: 5% and 25% of the training data from the target domain. The simplest baseline is Random Sampling. The remaining baselines can be categorized into two groups: the confidence-based baselines which are: Least Confidence (Wang and Shang, 2014), Entropy Sampling (Wang and Shang, 2014), Uncertainty Sampling with Dropout Estimation (USDE) (Gal et al., 2017), and Bayesian Active Learning Disagreement (BALD) (Gal et al., 2017); and the embedding-based baselines which are K-Centers Greedy (Sener and Savarese, 2018), K-Means (Sener and Savarese, 2018), and Core-Set (Sener and Savarese, 2018). The selection of samples in the first group is based on the confidence scores of the training data from the target domain that are computed using the DAME (ZSL) model. For example, for a budget of samples, Least Confidence corresponds to the top samples with the lowest confidence level. Multiple predictions for a given sample are needed for USDE and BALD to compute the uncertainty functions, and we obtain these different predictions by activating the dropout layers during the inference phase on the target domain. The second group is based on the embeddings of samples from the target domain that are obtained using the DAME (ZSL) model. Clustering of the input space is then applied to determine centers of clusters or core sets. Table 3 shows that the confidence-based methods lead to better results than the embedding-based methods. In particular, when we select 25% of samples using the BALD method for the Cameras dataset, we achieve the same F1 score of a fully fine-tuned DAME model using all training data from the target domain. This indicates that the predictions from the classification layer of our model accurately reflect the data points where DA was unsuccessful. Therefore, by fine-tuning on these samples from the training data, our model generalizes better on the testing set of the target domain.
5.4.6. Visualization
We show the embedding of DAME in the case of ZSL. Figure 4 shows the t-SNE visualization of the final embeddings for the target and source domains after DA in the wild (ZSL case). We only show the embeddings of four domains due to the space limitation in the paper, but we notice similar patterns for all the datasets. The gray and blue colors represent randomly selected data points from the source domains with a label 0 and label 1, respectively; the green and red colors represent randomly selected data points from the testing set of the target domain with a label 0 and label 1, respectively. 12 domains are used in each experiment, where the caption of each subfigure in Figure 4 represents the target domain, and the 11 remaining datasets represent the source domains. The best case is to have a mixture of blue and red dots which represent the matching class for the source and target domains, respectively, and a mixture of gray and green dots which represent the non-matching class for the source and target domains, respectively. This means that we transfer the task knowledge from sources to the target domain for both labels. For example, for Computers and DBLP-ACM, we obtain embeddings that respect the matching and non-matching classes as shown in Figure 4 (a) and (b), respectively. On the other hand, for Amazon-Google and Walmart-Amazon, there are green dots that are closer to the blue dots than the gray dots as shown in Figure 4 (c) and (d), respectively, and this leads to incorrect predictions for DAME (ZSL).
6. Conclusions
We have shown that our proposed model transfers learning from multiple source domains to an unseen target domain in the EM task. We formulate the EM task as a mixture of experts that capture task-specific knowledge from pretraining on multiple source domains and testing on a target domain. We evaluate DAME in two aspects. First, we study the ZSL case on the target domain and demonstrate that DAME learns the EM task and transfers knowledge to the target domain. Second, we study fine-tuning DAME on the target domain and demonstrate that DAME generalizes better than SOTA methods for most of the datasets. We showed that our results hold in two scenarios which are EM for datasets with similar structures and EM in the wild. Our experimental section contains extensive experiments over 12 datasets with different domains, sizes and structures. In addition, we showed the importance of selecting a specific set of samples in the fine-tuning of the target domain by studying AL methods with limited budget.
Future work includes extending our model to pairs of records with different sets of attributes, and enriching our DA-based model with external knowledge, such as knowledge graphs, to better understand the EM task and therefore transfer more knowledge to the target domain.
| Target dataset | Method | Precision | Recall | F1 | Accuracy |
| Fodors-Zagats | DAME (ZSL) | 0.9565§ | 1.0000§ | 0.9777§ | 0.9947§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.93600.0559 | 0.83330.0428 | 0.88010.0334 | 0.97350.0074 | |
| Ditto (Li et al., 2020) (50% training data) | 1.0000 | 0.9545 | 0.9767 | 0.9947 | |
| DAME (50% training data) | 0.9565 | 1.0000 | 0.9777 | 0.9947 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.90920.0756 | 0.98480.0214 | 0.94370.0423 | 0.98580.0108 | |
| Ditto (Li et al., 2020) (full training data) | 1.0000 | 0.9545 | 0.9767 | 0.9947 | |
| DAME (full training data) | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Beer | DAME (ZSL) | 0.7368§ | 1.000§ | 0.8484§ | 0.9450§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.80950.0673 | 0.40470.0336 | 0.53960.0448 | 0.89370.0103 | |
| Ditto (Li et al., 2020) (50% training data) | 0.72110.0288 | 0.6428 | 0.67940.0128 | 0.90650.0054 | |
| DAME (50% training data) | 0.7801 0.0433 | 1.000 | 0.87580.0273 | 0.95600.0109 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.81830.0581 | 0.71420.0583 | 0.75880.0193 | 0.93040.0051 | |
| Ditto (Li et al., 2020) (full training data) | 0.81740.0396 | 0.92850.0714 | 0.86600.0089 | 0.9560 | |
| DAME (full training data) | 0.7801 | 1.000 | 0.8758 | 0.9560 | |
| iTunes-Amazon | DAME (ZSL) | 0.6750 | 1.000§ | 0.8059‡ | 0.8807‡ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.90050.0226 | 0.79010.0698 | 0.84060.0464 | 0.92660.0198 | |
| Ditto (Li et al., 2020) (50% training data) | 0.86850.0114 | 0.85180.0370 | 0.85940.0132 | 0.93110.0045 | |
| DAME (50% training data) | 0.93330.0666 | 0.9629 | 0.94670.0344 | 0.97240.0183 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.91390.0149 | 0.91350.0174 | 0.91350.0088 | 0.95710.0043 | |
| Ditto (Li et al., 2020) (full training data) | 0.92820.0317 | 0.92590.0370 | 0.92580.0027 | 0.9633 | |
| DAME (full training data) | 0.98070.0192 | 0.9259 | 0.95240.0090 | 0.97700.0045 | |
| Abt-Buy | DAME (ZSL) | 0.4545 | 0.6796† | 0.5447 | 0.8778‡ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.69780.0416 | 0.53550.0397 | 0.60330.0112 | 0.92440.0021 | |
| Ditto (Li et al., 2020) (50% training data) | 0.79160.0312 | 0.78390.0169 | 0.78700.0069 | 0.95430.0028 | |
| DAME (50% training data) | 0.79600.0078 | 0.78640.0097 | 0.79110.0088 | 0.95530.0018 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.73820.0214 | 0.61810.0127 | 0.67250.0082 | 0.93520.0022 | |
| Ditto (Li et al., 2020) (full training data) | 0.92060.0095 | 0.78640.0097 | 0.84810.0015 | 0.9697 | |
| DAME (full training data) | 0.82430.0252 | 0.85920.0097 | 0.84100.0084 | 0.96500.0026 | |
| Amazon-Google | DAME (ZSL) | 0.5431 | 0.6453§ | 0.5898‡ | 0.9084§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.56230.0395 | 0.53270.0708 | 0.54160.0161 | 0.90850.0063 | |
| Ditto (Li et al., 2020) (50% training data) | 0.70550.0037 | 0.67090.017 | 0.68770.0107 | 0.93780.0015 | |
| DAME (50% training data) | 0.63390.0327 | 0.74350.0683 | 0.68090.0099 | 0.92910.0032 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.70020.0281 | 0.60110.0344 | 0.64540.0082 | 0.93260.0017 | |
| Ditto (Li et al., 2020) (full training data) | 0.67090.0077 | 0.80980.0064 | 0.73380.0020 | 0.94000.0010 | |
| DAME (full training data) | 0.70460.0038 | 0.76920.0213 | 0.73530.0076 | 0.94350.0006 | |
| Shoes | DAME (ZSL) | 0.6798§ | 0.8135§ | 0.7407§ | 0.8450§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.63460.0250 | 0.71630.0303 | 0.67190.0041 | 0.80960.0082 | |
| Ditto (Li et al., 2020) (50% training data) | 0.71370.0240 | 0.75590.0881 | 0.73010.0290 | 0.84960.0046 | |
| DAME (50% training data) | 0.82340.0189 | 0.84230.0084 | 0.83250.0055 | 0.90770.0046 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.69080.0366 | 0.79880.0162 | 0.74000.0179 | 0.84680.0158 | |
| Ditto (Li et al., 2020) (full training data) | 0.75690.0377 | 0.83890.0118 | 0.79500.0155 | 0.88190.0129 | |
| DAME (full training data) | 0.84210.0222 | 0.87960.0152 | 0.86000.0043 | 0.92200.0041 | |
| Computers | DAME (ZSL) | 0.7957§ | 0.8729§ | 0.8325§ | 0.9043§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.57620.0239 | 0.75470.0536 | 0.65290.0315 | 0.78200.0169 | |
| Ditto (Li et al., 2020) (50% training data) | 0.80200.0085 | 0.90800.0083 | 0.85170.0085 | 0.91390.0050 | |
| DAME (50% training data) | 0.83030.0268 | 0.90630.0234 | 0.86590.0039 | 0.92340.0045 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.70020.0258 | 0.83500.0356 | 0.76140.0270 | 0.85760.0157 | |
| Ditto (Li et al., 2020) (full training data) | 0.8682 | 0.91470.0117 | 0.89080.0055 | 0.93890.0027 | |
| DAME (full training data) | 0.86300.0076 | 0.92640.0033 | 0.89350.0025 | 0.93980.0018 | |
| Watches | DAME (ZSL) | 0.7267† | 0.9124§ | 0.8090‡ | 0.8834‡ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.69970.0260 | 0.72740.0478 | 0.71260.0314 | 0.84150.0151 | |
| Ditto (Li et al., 2020) (50% training data) | 0.86640.0037 | 0.89960.0054 | 0.88270.0045 | 0.93520.0024 | |
| DAME (50% training data) | 0.86910.0196 | 0.91600.0109 | 0.89170.0051 | 0.93970.0039 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.77710.0093 | 0.83090.0169 | 0.80300.0087 | 0.88960.0044 | |
| Ditto (Li et al., 2020) (full training data) | 0.91450.0030 | 0.91780.0164 | 0.91610.0097 | 0.95450.0049 | |
| DAME (full training data) | 0.90100.0038 | 0.94700.0091 | 0.92340.0023 | 0.95750.0009 | |
| Cameras | DAME (ZSL) | 0.8376§ | 0.8958§ | 0.8657§ | 0.9243§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.58960.0063 | 0.68630.0630 | 0.63280.0275 | 0.78420.0058 | |
| Ditto (Li et al., 2020) (50% training data) | 0.7585 0.0694 | 0.86280.0607 | 0.80200.0127 | 0.88310.0175 | |
| DAME (50% training data) | 0.8801 0.0312 | 0.88710.0295 | 0.88250.0011 | 0.93560.0028 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.69860.0280 | 0.78470.0075 | 0.73880.0159 | 0.84860.0124 | |
| Ditto (Li et al., 2020) (full training data) | 0.85730.0075 | 0.90620.0173 | 0.88090.0042 | 0.93330.0014 | |
| DAME (full training data) | 0.89170.0013 | 0.90700.0017 | 0.89630.0001 | 0.9432 | |
| Walmart-Amazon | DAME (ZSL) | 0.3558 | 0.9015§ | 0.5102 | 0.8369† |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.69380.0171 | 0.54740.0217 | 0.61180.0167 | 0.93460.0023 | |
| Ditto (Li et al., 2020) (50% training data) | 0.85010.0206 | 0.70980.0466 | 0.77210.0191 | 0.96070.0017 | |
| DAME (50% training data) | 0.80820.0019 | 0.80830.0103 | 0.80820.0061 | 0.96380.0009 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.69710.0183 | 0.60100.0223 | 0.64480.0067 | 0.93760.0011 | |
| Ditto (Li et al., 2020) (full training data) | 0.88830.0459 | 0.76940.0336 | 0.82270.0004 | 0.96870.0014 | |
| DAME (full training data) | 0.86150.0090 | 0.78750.0207 | 0.82260.0071 | 0.96800.0007 | |
| DBLP-GoogleScholar | DAME (ZSL) | 0.9077§ | 0.8490‡ | 0.8737‡ | 0.9499§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.93470.0034 | 0.94390.0074 | 0.93850.0019 | 0.97700.0006 | |
| Ditto (Li et al., 2020) (50% training data) | 0.93560.0030 | 0.94480.0065 | 0.93850.0016 | 0.97710.0005 | |
| DAME (50% training data) | 0.93670.0019 | 0.94110.0037 | 0.93890.0028 | 0.97710.0010 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.94890.0014 | 0.93730.0018 | 0.94310.0016 | 0.97890.0006 | |
| Ditto (Li et al., 2020) (full training data) | 0.93580.0025 | 0.95420.0009 | 0.94490.0008 | 0.97930.0003 | |
| DAME (full training data) | 0.93920.0023 | 0.95370.0032 | 0.94640.0003 | 0.9798 | |
| DBLP-ACM | DAME (ZSL) | 0.8661† | 0.9854§ | 0.9219‡ | 0.9651§ |
| DeepMatcher(Mudgal et al., 2018) (50% training data) | 0.97870.0098 | 0.97630.0056 | 0.97740.0020 | 0.99190.0008 | |
| Ditto (Li et al., 2020) (50% training data) | 0.98650.0066 | 0.98650.0011 | 0.98650.0027 | 0.99510.0010 | |
| DAME (50% training data) | 0.97870.0055 | 0.98310.0011 | 0.98090.0033 | 0.99310.0012 | |
| DeepMatcher(Mudgal et al., 2018) (full training data) | 0.98550.0056 | 0.98690.0022 | 0.98610.0039 | 0.99450.0014 | |
| Ditto (Li et al., 2020) (full training data) | 0.98650.0011 | 0.98650.0022 | 0.98650.0016 | 0.99510.0006 | |
| DAME (full training data) | 0.98650.0032 | 0.98680.0033 | 0.9866 | 0.9951 |
References
- (1)
- Barlaug and Gulla (2021) Nils Barlaug and Jon Atle Gulla. 2021. Neural Networks for Entity Matching: A Survey. ACM Trans. Knowl. Discov. Data 15, 3 (2021), 52:1–52:37.
- Ben-David et al. (2006) Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. 2006. Analysis of Representations for Domain Adaptation. In Advances in Neural Information Processing Systems 19, Bernhard Schölkopf, John C. Platt, and Thomas Hofmann (Eds.). MIT Press, 137–144.
- Bengio et al. (2009) Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML, Vol. 382. ACM, 41–48.
- Bilenko and Mooney (2003) Mikhail Bilenko and Raymond J. Mooney. 2003. Adaptive duplicate detection using learnable string similarity measures. In Proceedings of the Ninth SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 39–48.
- Bojanowski et al. (2017) Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomás Mikolov. 2017. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguistics 5 (2017), 135–146.
- Chen et al. (2012) Minmin Chen, Zhixiang Eddie Xu, Kilian Q. Weinberger, and Fei Sha. 2012. Marginalized Denoising Autoencoders for Domain Adaptation. In Proceedings of the 29th International Conference on Machine Learning, ICML 2012. icml.cc / Omnipress.
- Chen et al. (2020) Zhiyu Chen, Mohamed Trabelsi, Jeff Heflin, Yinan Xu, and Brian D. Davison. 2020. Table Search Using a Deep Contextualized Language Model. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Association for Computing Machinery, 589–598.
- Christen (2008) Peter Christen. 2008. Febrl -: an open source data cleaning, deduplication and record linkage system with a graphical user interface. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1065–1068.
- Christen (2012a) Peter Christen. 2012a. Data Matching - Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer.
- Christen (2012b) Peter Christen. 2012b. A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication. IEEE Trans. Knowl. Data Eng. 24, 9 (2012), 1537–1555.
- Dalvi et al. (2013) Nilesh N. Dalvi, Vibhor Rastogi, Anirban Dasgupta, Anish Das Sarma, and Tamás Sarlós. 2013. Optimal hashing schemes for entity matching. In 22nd International World Wide Web Conference, WWW. 295–306.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT.
- Ebraheem et al. (2018) Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq R. Joty, Mourad Ouzzani, and Nan Tang. 2018. Distributed Representations of Tuples for Entity Resolution. Proc. VLDB Endow. 11, 11 (2018), 1454–1467.
- Elmagarmid et al. (2014) Ahmed K. Elmagarmid, Ihab F. Ilyas, Mourad Ouzzani, Jorge-Arnulfo Quiané-Ruiz, Nan Tang, and Si Yin. 2014. NADEEF/ER: generic and interactive entity resolution. In International Conference on Management of Data, SIGMOD 2014. ACM, 1071–1074.
- Elmagarmid et al. (2007) Ahmed K. Elmagarmid, Panagiotis G. Ipeirotis, and Vassilios S. Verykios. 2007. Duplicate Record Detection: A Survey. IEEE Trans. Knowl. Data Eng. 19, 1 (2007), 1–16.
- Fisher et al. (2015) Jeffrey Fisher, Peter Christen, Qing Wang, and Erhard Rahm. 2015. A Clustering-Based Framework to Control Block Sizes for Entity Resolution. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, August 10-13, 2015. ACM, 279–288.
- Fu et al. (2019) Cheng Fu, Xianpei Han, Le Sun, Bo Chen, Wei Zhang, Suhui Wu, and Hao Kong. 2019. End-to-End Multi-Perspective Matching for Entity Resolution. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019. ijcai.org, 4961–4967.
- Gal et al. (2017) Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian Active Learning with Image Data. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 (Proceedings of Machine Learning Research, Vol. 70). PMLR, 1183–1192.
- Guo et al. (2018) Jiang Guo, Darsh J. Shah, and Regina Barzilay. 2018. Multi-Source Domain Adaptation with Mixture of Experts. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 4694–4703.
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasovic, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020. Association for Computational Linguistics, 8342–8360.
- Han and Eisenstein (2019) Xiaochuang Han and Jacob Eisenstein. 2019. Unsupervised Domain Adaptation of Contextualized Embeddings for Sequence Labeling. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019. Association for Computational Linguistics, 4237–4247.
- Kasai et al. (2019) Jungo Kasai, Kun Qian, Sairam Gurajada, Yunyao Li, and Lucian Popa. 2019. Low-resource Deep Entity Resolution with Transfer and Active Learning. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers. Association for Computational Linguistics, 5851–5861.
- Kim et al. (2017) Young-Bum Kim, Karl Stratos, and Dongchan Kim. 2017. Domain Attention with an Ensemble of Experts. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017. 643–653.
- Konda et al. (2016) Pradap Konda, Sanjib Das, Paul Suganthan G. C., AnHai Doan, Adel Ardalan, Jeffrey R. Ballard, Han Li, Fatemah Panahi, Haojun Zhang, Jeffrey F. Naughton, Shishir Prasad, Ganesh Krishnan, Rohit Deep, and Vijay Raghavendra. 2016. Magellan: Toward Building Entity Matching Management Systems. Proc. VLDB Endow. 9, 12 (2016), 1197–1208.
- Köpcke et al. (2010) Hanna Köpcke, Andreas Thor, and Erhard Rahm. 2010. Evaluation of entity resolution approaches on real-world match problems. Proc. VLDB Endow. 3, 1 (2010), 484–493.
- Li et al. (2020) Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan. 2020. Deep Entity Matching with Pre-Trained Language Models. Proc. VLDB Endow. 14, 1 (2020), 50–60. https://doi.org/10.14778/3421424.3421431
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv abs/1907.11692 (2019).
- Lu et al. (2019) Jiaheng Lu, Chunbin Lin, Jin Wang, and Chen Li. 2019. Synergy of Database Techniques and Machine Learning Models for String Similarity Search and Join. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019. ACM, 2975–2976.
- Ma et al. (2019) Xiaofei Ma, Peng Xu, Zhiguo Wang, Ramesh Nallapati, and Bing Xiang. 2019. Domain Adaptation with BERT-based Domain Classification and Data Selection. In Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP. Association for Computational Linguistics, 76–83.
- Mudgal et al. (2018) Sidharth Mudgal, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, Ganesh Krishnan, Rohit Deep, Esteban Arcaute, and Vijay Raghavendra. 2018. Deep Learning for Entity Matching: A Design Space Exploration. In Proceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018. ACM, 19–34.
- Nickel et al. (2016) Maximilian Nickel, Kevin Murphy, Volker Tresp, and Evgeniy Gabrilovich. 2016. A Review of Relational Machine Learning for Knowledge Graphs. Proc. IEEE 104, 1 (2016), 11–33.
- Pan et al. (2010) Sinno Jialin Pan, Xiaochuan Ni, Jian-Tao Sun, Qiang Yang, and Zheng Chen. 2010. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010. ACM, 751–760.
- Papadakis et al. (2020) George Papadakis, Dimitrios Skoutas, Emmanouil Thanos, and Themis Palpanas. 2020. Blocking and Filtering Techniques for Entity Resolution: A Survey. ACM Comput. Surv. 53, 2 (2020), 31:1–31:42.
- Parikh et al. (2016) Ankur P. Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. 2016. A Decomposable Attention Model for Natural Language Inference. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, 1-4, 2016. The Association for Computational Linguistics, 2249–2255.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 1532–1543.
- Rietzler et al. (2020) Alexander Rietzler, Sebastian Stabinger, Paul Opitz, and Stefan Engl. 2020. Adapt or Get Left Behind: Domain Adaptation through BERT Language Model Finetuning for Aspect-Target Sentiment Classification. In Proceedings of The 12th Language Resources and Evaluation Conference, LREC 2020. European Language Resources Association, 4933–4941.
- Sakata et al. (2019) Wataru Sakata, Tomohide Shibata, Ribeka Tanaka, and Sadao Kurohashi. 2019. FAQ Retrieval Using Query-Question Similarity and BERT-Based Query-Answer Relevance. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 1113–1116.
- Sanh et al. (2019) Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. CoRR abs/1910.01108 (2019).
- Sener and Savarese (2018) Ozan Sener and Silvio Savarese. 2018. Active Learning for Convolutional Neural Networks: A Core-Set Approach. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net.
- Shen et al. ([n.d.]) Jian Shen, Yanru Qu, Weinan Zhang, and Yong Yu. [n.d.]. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18). 4058–4065.
- Shen et al. (2015) Wei Shen, Jianyong Wang, and Jiawei Han. 2015. Entity Linking with a Knowledge Base: Issues, Techniques, and Solutions. IEEE Trans. Knowl. Data Eng. 27, 2 (2015), 443–460.
- Singh et al. (2017) Rohit Singh, Venkata Vamsikrishna Meduri, Ahmed K. Elmagarmid, Samuel Madden, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Armando Solar-Lezama, and Nan Tang. 2017. Synthesizing Entity Matching Rules by Examples. Proc. VLDB Endow. 11, 2 (2017), 189–202.
- Sun et al. (2016) Baochen Sun, Jiashi Feng, and Kate Saenko. 2016. Return of Frustratingly Easy Domain Adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 12-17, 2016. AAAI Press, 2058–2065.
- Trabelsi et al. (2020) Mohamed Trabelsi, Jin Cao, and Jeff Heflin. 2020. Semantic Labeling Using a Deep Contextualized Language Model. CoRR abs/2010.16037 (2020).
- Trabelsi et al. (2021a) Mohamed Trabelsi, Jin Cao, and Jeff Heflin. 2021a. SeLaB: Semantic Labeling with BERT. In International Joint Conference on Neural Networks, IJCNN 2021, Shenzhen, China, July 18-22, 2021. IEEE, 1–8.
- Trabelsi et al. (2021b) Mohamed Trabelsi, Zhiyu Chen, Brian D. Davison, and Jeff Heflin. 2021b. Neural ranking models for document retrieval. Inf. Retr. J. 24, 6 (2021), 400–444.
- Trabelsi et al. (2022) Mohamed Trabelsi, Zhiyu Chen, Shuo Zhang, Brian D. Davison, and Jeff Heflin. 2022. StruBERT: Structure-aware BERT for Table Search and Matching. In Proceddings of The ACM Web Conference 2022.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems 30. 5998–6008.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Association for Computational Linguistics, 353–355.
- Wang and Shang (2014) Dan Wang and Yi Shang. 2014. A new active labeling method for deep learning. In 2014 International Joint Conference on Neural Networks, IJCNN 2014, Beijing, China, July 6-11, 2014. IEEE, 112–119.
- Wright and Augenstein (2020) Dustin Wright and Isabelle Augenstein. 2020. Transformer Based Multi-Source Domain Adaptation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020. Association for Computational Linguistics, 7963–7974.
- Zhang et al. (2017) Yuan Zhang, Regina Barzilay, and Tommi S. Jaakkola. 2017. Aspect-augmented Adversarial Networks for Domain Adaptation. Trans. Assoc. Comput. Linguistics 5 (2017), 515–528.
- Zhao and He (2019) Chen Zhao and Yeye He. 2019. Auto-EM: End-to-end Fuzzy Entity-Matching using Pre-trained Deep Models and Transfer Learning. In The World Wide Web Conference, WWW 2019. ACM, 2413–2424.