DAG-based Task Orchestration for Edge Computing
Abstract
As we increase the number of personal computing devices that we carry (mobile devices, tablets, e-readers, and laptops) and these come equipped with increasing resources, there is a vast potential computation power that can be utilized from those devices. Edge computing promises to exploit these underlying computation resources closer to users to help run latency-sensitive applications such as augmented reality and video analytics. However, one key missing piece has been how to incorporate personally owned unmanaged devices into a usable edge computing system. The primary challenges arise due to the heterogeneity, lack of interference management, and unpredictable availability of such devices. In this paper we propose an orchestration framework IBDASH, which orchestrates application tasks on an edge system that comprises a mix of commercial and personal edge devices. IBDASH targets reducing both end-to-end latency of execution and probability of failure for applications that have dependency among tasks, captured by directed acyclic graphs (DAGs). IBDASH takes memory constraints of each edge device and network bandwidth into consideration. To assess the effectiveness of IBDASH, we run real application tasks on real edge devices with widely varying capabilities. We feed these measurements into a simulator that runs IBDASH at scale. Compared to three state-of-the-art edge orchestration schemes, LAVEA, Petrel, and LaTS, and two intuitive baselines, IBDASH reduces the end-to-end latency and probability of failure, by 14% and 41% on average respectively. The main takeaway from our work is that it is feasible to combine personal and commercial devices into a usable edge computing platform, one that delivers low latency and predictable and high availability.
Index Terms:
Edge Computing, Directed Acyclic Graphs, Task Orchestration, Service Time.I Introduction
There has been a surge of latency-sensitive applications running on user-generated streaming data, such as augmented reality and video analytics. Such a surge has driven the wide popularity of edge computing since it offers low latency by performing the computation near the source of the data and offers scalability by distributing the workload among multiple edge devices. After some notable innovations in academic publications over the last few years, we have started seeing the growth of small, edge-located data centers managed by infrastructure providers such as Amazon [1], Microsoft [2] and Google [3]. We refer to such devices as ``Commercial Edge Devices (CEDs)". Being commercially managed, CEDs are expected to be available over extended periods and achieve reasonably low latencies. However, they have the drawbacks of incurring $ cost and still not being widely available. Almost all existing literature on edge computing systems implicitly deals with CEDs as they assume the above desirable properties.
Edge computing systems could also comprise personal devices such as laptops, tablets, and mobile phones. This trend is increasing as such devices are becoming more ubiquitous and are increasing in their compute power. By the end of 2020, it is estimated 6.06B smartphones were in use globally, which is three times the number of PCs, and it is expected to keep growing at a 4% rate and hit 7.69B by 2026 [4]. Moreover, smart devices now have unseen storage and processing power and this trend is continuing. For example, a 2010 Samsung Galaxy S only had just 512MB of RAM and 8GB storage with a single core at 1 GHz, but the 2021 Galaxy Z Fold3 comes with 12GB of RAM and 256GB storage with 8 cores clocking at a maximum of 2.84 GHz. We call such devices that may be pulled into an edge computing system as ``Personal Edge Devices (PEDs)". Running latency-sensitive applications on PEDs is appealing as they are often closer to the user than CEDs, with the same user often carrying multiple PEDs. Furthermore, with the right kind of incentive schemes, the usage of PEDs can be at zero cost. On the other hand, such devices are expected to have sporadic availability and have little to no management of contention that can arise due to multiple co-located applications. Therefore, one has to carefully manage such PEDs in an edge computing system to achieve reliable and low latency executions.
In this paper, we present the design of an edge computing task scheduling scheme that we call IBDASH111IBDASH stands for Interference Based DAG Application ScHeduler and is pronounced as [”īb-dash]. that combines PEDs and CEDs into one system to leverage the benefits of both types of devices. In particular, IBDASH introduces a method to schedule complex latency-sensitive applications, whose tasks (stages) have dependencies and can be represented by directed acyclic graphs (DAGs). The scheduling happens among available PEDs and CEDs to reduce the end-to-end execution latency of each application and the probability of application failure, while accounting for the dependencies among different stages of the application. For example, a video analytic application may do scene change detection and pass onto a second task that does object detection only if there is a scene change. IBDASH also takes into account the interference on a particular device from multiple co-located applications. This is particularly important because in our target class of devices, there do not exist good hardware mechanisms for avoiding contention, as compared to server-class devices [5].
Table I compares the features of our proposed solution IBDASH with prior related works. In particular, prior works such as LAVEA [6] and Petrel [7] propose their orchestration schemes that target client-edge offloading to provide low-latency video analytic and randomized load balancing by leveraging the ``power of two" choice [8] to randomly choose two edge devices and allocate the task to the one which gives better performance. Moreover, LaTS [9] allocates the task to the device that has the shortest estimated latency based on a pre-profiled latency-CPU usage model. On the other hand, JCAB [10] effectively balances the accuracy and energy consumption while keeping low system latency by jointly optimizing configuration adaption and bandwidth allocation. [11] proposes a system that employs low latency offloading techniques jointly with pipeline decoupling methods and fast object tracking methods to enable accurate object detection. However, among these frameworks, some do not consider the heterogeneity of edge devices at all [10, 11] and among those that consider the heterogeneity of edge devices, [6] considers the heterogeneity of CPU architectures, [9] considers the heterogeneity of CPU and GPU mix, and [7] considers the mix of devices as a cloudlet entity. None of these works considers the mix of PEDs and CEDS. Moreover, most of them (except LaTS [9]) do not address the interference of co-located tasks on the same edge device. The previous work IBOT [12] proposed an orchestration scheme that takes the interference among tasks on each edge device into account and orchestrates an optimal execution strategy that jointly optimizes both execution latency and probability of failure. However, IBOT treats each task separately and does not take into account dependencies among tasks within an application and it also fails to address the memory constraints of each edge device since some tasks may require loading models into memory to successfully carry out the task execution.
| Framework | Failure reduction | Supporting DAG | Heterogeneous edge devices | Memory Consideration | Low latency | Orchestration overhead reduction |
|---|---|---|---|---|---|---|
| LaTS [9] | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| Petrel [7] | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| LAVEA [6] | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| Edge Object Detection [11] | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| JCAB [10] | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| IBOT [12] | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| IBDASH (This work) | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |

Figure 1 shows an overview of our proposed solution IBDASH. Each application instance from the end-user consists of one or more tasks, which may have dependencies among them. For example, in Figure 1, we show a DAG example of a video analytics application that shows control and data dependencies among stages. The application is explained in detail in SectionV-C.
In our evaluation, we compare IBDASH with two intuitive baselines, Random allocation and Round Robin, and three state-of-the-art solutions, LAVEA [6], Petrel [7], and LaTS [9]. To test our framework, we use four applications that span various DAG structures from different application domains. Some tasks require models for their execution and some do not. For example, if the task performs object recognition, a pre-trained model is needed on the designated edge device before the task can start running. Compared with existing schemes, IBDASH reduces the average service time of applications by 14% compared to the best baseline scheme. Concurrently with reducing service time, IBDASH reduces the average probability of failure for the application by 41% compared to the best baseline scheme.
In summary, this paper makes the following contributions:
-
1.
We propose an orchestration framework IBDASH, an interference-based dynamic task orchestration scheme that executes DAG-based user applications in a heterogeneous edge computing environment with low latency and low probability of failure.
-
2.
To increase the reliability of edge computing, our solution proposes adding redundancy into the platform by replicating the tasks allocated to devices with a high probability of failure to multiple edge devices.
-
3.
We propose a device availability prediction model and validate it through the data collected by [13].
-
4.
We validate our model via extensive simulation of application instances that arrive randomly within a time period and shows its superiority in reducing average application service time and probability of failure.
II Problem Statement
The combination of CEDs and PEDs, task dependencies within applications, and sporadic availability of PEDs pose unique challenges that have not been addressed in the edge computing literature. We discuss the four primary challenges, whose solutions bring out the novelty in IBDASH.
Substantial heterogeneity in computational capacity: PEDs such as laptops, tablets and mobile devices can have a substantial variation in their compute power, memory, etc. For example, in the current smartphone market, Samsung, Apple, and Xiaomi contribute 20%, 14%, and 13% respectively to the market share and others contribute the remaining 53%. Within each brand, there is a wide range of devices with different capabilities that target different customers. The penetration of different brands in different markets and economies varies widely leading to a natural heterogeneity in the PEDs.
Heterogeneity in task interference pattern: Different tasks, when running on the same edge device, interfere with each other affecting their execution time. There is heterogeneity in the interference experienced by different tasks on an edge device. For example, suppose that we have three tasks where the first task () loads a set of images, the second task () performs convolution on the pre-loaded images, and the third task () rotates the processed images. For such a scenario, Figure 2 shows the different interference patterns for different task types and the different CPU usages for different task types. In Figure 2a, we see that the interference pattern for is different from the interference pattern for . Figure 2b shows that the CPU usage for each task under three different scenarios also varies. The interference patterns and CPU usage differences can be due to multiple reasons, such as resource contention [14], priority scheduling [15], etc. The main insight to note is that the different interference patterns among tasks result in different service times.

Sporadic availability of PEDs: Due to the unmanaged nature of the PEDs, their availability in the network can be hard to predict. For example, in a more predictable scenario such as a classroom setting, when students leave the classroom, their laptops and mobile devices will not be available anymore so any tasks that are scheduled close to the end of class will experience a high probability of failure. However, in other scenarios where people come and go less predictably (e.g., a university library), it would be hard to predict the availability. For instance, in [13] we did an experiment to track the availability of the mobile devices of students on university campus. The results show that the probability of failure for mobile devices (mobile devices disconnect from the crowdsensing framework) increases with the length of time that elapses since they connected to the framework.
DAG-based application orchestrations: The dependency among tasks within the same application adds one more layer of complexity into the orchestration problem as the execution of tasks need to follow a certain order. Some can be executed in parallel and some cannot. Prior work [16] shows that several partition algorithms [17, 18] are developed to achieve different optimization goals such as saving energy [19, 20], reducing execution latency [20]. Our proposed framework IBDASH utilizes the structure within DAG-based application where it explicitly characterizes the task flow and data flow. Then, we orchestrate the task allocation to reduce the overall end-to-end latency and probability of failure. The significant prior work on DAG scheduling in the cloud is less relevant in our context as our EDs are more heterogeneous and less predictable in their availability.
III Preliminaries and Notations
III-A Feasibility of PEDs: A survey
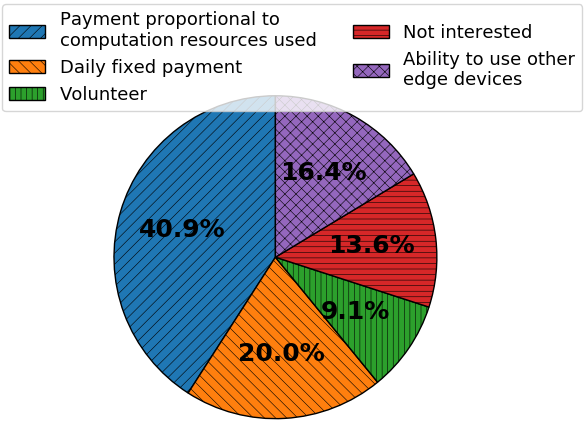
We conducted a user study with 110 participants from USA and India that are engaged in diverse fields such as educators, software professionals, students, engineering professionals, etc. to understand their willingness to share their computing devices (e.g., laptops, desktops, tablets, etc.) as edge devices. Figure 3(a) shows that 86.4% of the participants are willing to share their devices under one of four proposed incentive schemes. Only 13.6% of the participants were not interested in sharing their devices at all, primarily due to privacy and security concerns. Moreover, Figure 3(b) indicates that the majority of the participants are willing to share 0-40% of their CPU resources. The amount of CPU resources people are willing to share varies as well depending on the device type. As shown in Figure 3(c), we obtained a double Gaussian device usage pattern with peaks at 90% and 30% of usage indicating that most people either use their devices very heavily (video editing, running sophisticated software, etc.) or use them only for computationally light applications such as browsing, reading, etc. The average usage across all users was 50.9%, thereby supporting our claim that a lot of devices are not utilized to their capacity.
Now, we introduce the notations and terms used in our framework IBDASH and show them in Table II. In particular, we explain the DAG, edge computing, task orchestration, and main system metrics.
| Symbol | Definition |
|---|---|
| Types of tasks for a given application | |
| Total number of edge devices | |
| Number of stages in DAG | |
| DAG representation of the application | |
| Execution latency of on ED j | |
| Model upload latency for to ED j | |
| Memory available on edge device j | |
| Memory required for | |
| Data transfer latency for Task i input | |
| End-to-end latency for task | |
| End to end latency for the application | |
| Input data for task | |
| End-to-end latency of stage | |
| Placement of task | |
| Dependency of task | |
| in terms of other tasks | |
| Placement of each task in graph G | |
| Probability of failure of application, | |
| given by graph G | |
| Tracker for the number of replications | |
| Probability of failure threshold | |
| Threshold on the Replication degree | |
| Probability that fail | |
| Network bandwidth | |
| Model required for | |
| Total and free space on each ED | |
| Available models on each edge device | |
| # executing tasks and types on each ED | |
| Weight score of joint optimization | |
| Weighted score after PF reduction |


III-B Directed Acyclic Graphs
Each application is represented as a directed acyclic graph (DAG) . The set of nodes represents the individual tasks in an application instance, while the set of edges characterizes the dependency among those tasks. The dependency can mean both execution order dependency or data dependency. In particular, an edge from task to task indicates that needs to be finished before the start of .
III-C End-to-end Latency and Probability of Failure
Throughout the paper, we used the terms end-to-end latency and probability of failure to describe the goal of joint optimization. End-to-end latency is defined as the time from when the first task in the DAG-based application starts executing till the last task finishes its execution. For this purpose, we assume that the clocks on all devices are synchronized, which can be achieved through means such as [21]. In this paper, we use the average end-to-end latency of hundreds of application instances to evaluate the performance of our orchestration strategy. The term probability of failure is defined as the probability that the application instance did not successfully finish its execution. An application instance may not complete its execution because one of the edge devices becomes unavailable in the middle of task execution, or the owner of the edge device decided to perform some heavy-duty task, which results in the edge device being less responsive.
Having explained the problem statement and the main notations used in our work, we now turn our attention to the design of IBDASH.
IV Our Proposed Solution: IBDASH
To target the problems we listed in Section II, we propose the framework IBDASH, which is an interference-based orchestration scheme for DAG-based applications that aims at jointly optimizing the end-to-end latency and probability of failure for application instances. The rest of this section covers the task interference in our framework, the components of the framework, and our proposed orchestration algorithm.
IV-A Interference service time plots
We define interference as a linear service time plot that characterizes the execution time of a new task of type on , given that tasks of type are already running on that edge device. For example, on a given edge device, for a new task , we can plot interference plots for every other type of task including itself. Therefore, there are overall such plots and pairs of m and c values to characterize all interference plots for that edge device. The expected service time of the new incoming task on , which has , , , running tasks is given by:
| (1) |
The above equation assumes that the interference patterns are independent and additive, which we verify experimentally (Section V Figure 4). Lower interference coefficient (, values) of an application for a device means the shorter estimated execution latency for running that application on the device. A pairwise interference coefficient matrix has been defined as , in which each row contains pairs of m, c values for that particular edge device. The element means that if we want to schedule a new task of type while k instances of are already running on edge device p, the estimated service time for can be calculated as . We use the matrix to record the allocation of each task and the estimated time it will be on that edge device, then we can calculate the number of running tasks on each device at a certain time by a simple summation.
IV-B Design Components
The proposed framework contains three main functions, DAG transformation, minimum service time scheduling, and failure likelihood reduction. When a new application instance arrives, the framework first transforms the application's DAG and divides the execution into stages. The advantage of dividing the DAG into stages is that the dependency of the tasks is embedded within the stages and all tasks within the same stage can be executed in parallel. Figure 1 shows an example of staged DAG for video analytics applications. Such staging process is performed through modified Breadth-First Search where the stage of a node is the length of the longest path from the start node.
After staging the DAG, the orchestrator uses the profiling data (saved in matrix ) to retrieve the interference coefficients ((m, c) value pairs) and using matrix to retrieve the number of running tasks of each task type on the edge device of interest. The execution latency of the task is estimated using Equation 1 and denoted as . Besides the execution latency, some tasks may require models to successfully execute the task. Therefore, we introduce the term to denote the models required for task (this may be null in cases) and to express the corresponding model uploading latency, which depends on both the model size and the network bandwidth . Another important latency factor is the data transfer latency of the input data for task if it is from other edge devices, and this is expressed as . The device that gives minimum latency of the task , which is the summation of the minimum execution latency, model uploading latency and data transmission latency for . The choice of the edge device is one that minimizes this combined latency and is given by
Here, is the current network bandwidth, is the maximum available network bandwidth, is the memory required for 's execution, including memory to store data and model, and is the available memory on .
Now, let us define as the stage latency. Therefore, the end-to-end latency of the entire application is the sum of the longest latency task in each stage.
| (3) |
In the end, due to the sporadic availability of PEDs, IBDASH adds redundancy to replicate tasks that are assigned to edge devices with a high probability of failure to other edges devices. The goal of this redundant replication is to reduce the average probability of failure of the application instance below a certain threshold or to the minimum probability of failure within the replication degree constraints. For each edge device that was chosen to execute task , we predict the probability of failure of that edge device during the estimated service time of task and this is the probability of failure of task , which is denoted by . If is above a certain threshold , IBDASH replicates on another edge device which gives the next optimal minimum service time. We keep repeating the replication until is reduced below the probability of failure threshold or the number of replications for reaches the replication degree . Every task within the application instance needs to be successfully executed so that the entire application can be counted as successful. Therefore, our framework seeks to minimize the probability of failure of every single task. We use to denote the probability of success for , then uses the intersection of the probability of success for all tasks to denote the probability of success for the entire application instance. Such intersection notation captures the dependence among tasks (which is captured by conditional probabilities). In our setup, we used the data to estimate such conditional probabilities of task successes.
| (4) |
The final optimization problem is given by
| (5) |
where is the joint optimization parameter that is controlled by the user to give proper weight for end-to-end latency and probability of failure.
IV-C Orchestration algorithm description
The orchestration algorithm is shown in Algorithm 1. It greedily examines each task on available edge devices, while concurrently considering the allocation of its prerequisite tasks to minimize application latency and likelihood of failure globally. The algorithm outputs the placement choice for each task in the application on an edge device, PED or CED.
Line 4-17 checks each task in each stage against all available edge devices for estimated latency and consider the extra data transmission and modeling uploading latency globally when tasks with dependency are assigned to different devices. Line 6 calculates the expected execution latency of task on . Line 7-10 estimates the model uploading latency based on network bandwidth and whether the task requires models for its execution and the model's availability on the targeted edge device. Line 11-14 estimates the input data transmission latency for task based on the dependency of task , which is denoted as . Line 15-16 sums up execution latency, model uploading latency, and data transmission latency then save the end-to-end latency for task and the corresponding edge device identifier to a priority queue. By the end of the execution of the for loop from lines 5-17, we will end up with the expected latency of on each edge device. Line 18 dequeues from the priority queue and the dequeued item contains the most optimized end-to-end latency placement for task . Line 19-27 removes not frequently used model to free space and uploads the required models to the targeted edge device and updates the structure which is used to keep track of the model availability on each device and structure, which is used to keep track of the memory available on each device. Line 28 calculates the probability of failure of the task on the device based on its dependency then a weighted optimization score is calculated in line 29.
Now, the algorithm checks the probability of failure against the preset threshold . If the probability of failure is greater than the threshold and the number of replications for the task is less than replication degree , line 31 dequeues the next item and lines 32-40 recalculate the weighted optimization score with the new probability of failure and the execution latency. If the new weighted optimization score is less than the previous weighted score, we replicate the task. Then repeating this process until the probability of failure is below the threshold , or replication degree reached, or the queue is exhausted. Line 42 records the task allocation and line 44 records the longest latency in the current stage and makes sure that tasks from the next stage will not start until the previous stage is finished due to dependency. Finally, line 46 keeps track of the end-to-end latency of the entire application instance.
V Experiments
We seek to answer the following evaluation questions:
-
•
RQ1: What is the interference pattern among tasks?
-
•
RQ2: How does IBDASH's performance compare to other baseline schemes with respect to end-to-end latency and failure likelihood?
-
•
RQ3: How to predict the availability of edge devices?
-
•
RQ4: How do the parameters affect the latency and failure likelihood achieved by IBDASH?
V-A Interference pattern verification
In Section IV-A, we assume that the interference patterns among tasks are independent and additive. We validate this assumption through an experiment whose result is shown in Figure 4. Two computationally intensive tasks have been used to verify our assumption on two different platforms. In particular, task represents matrix multiplication of randomly generated floating point entries 100 times and task denotes inversion of matrices with the above randomly generated floating entries. The two platforms used in this experiment are a Macbook Pro (3.1GHz dual-core Intel core i5 and 8GB 2133 MHz LPDDR3 memory) and a Huawei Nexus 6P (Qualcomm Snapdragon 810 with 3GB RAM), as these reflect two possible PEDs with widely varying capabilities. The matrix size used in tasks and are 10001000 and 100100 for MacBook Pro and Nexus 6P, respectively. From Figure 4a and 4b, we see that the average execution latency has a linear relationship with the number of (same type) tasks running on the edge device for both platforms by looking at and . Moreover, we also see that the lines representing and have almost complete overlap. The same pattern is also observed for and , which verifies our assumption that the interference pattern is additive.

V-B Edge device profiling
To test IBDASH's joint optimization of end-to-end latency and probability of failure under edge devices with various capabilities, we profiled 7 different AWS EC2 instances and a Macbook Pro for the 4 applications used in our simulation. The detailed configurations are shown in Table III. Note that different configurations emulate different compute power, memory and number of CPUs, which result in different interference patterns for each device.
| ED id | Instance type | (v)CPUs | Memory(GB) | Frequency(GHz) |
|---|---|---|---|---|
| ED0 | Macbook Pro 2017 | 2 | 8 | 3.1 |
| ED1 | t2.xlarge | 4 | 16 | 2.3 |
| ED2 | t2.2xlarge | 8 | 32 | 2.3 |
| ED3 | t3.xlarge | 4 | 16 | 2.5 |
| ED4 | t3a.xlarge | 4 | 16 | 2.2 |
| ED5 | c5.2xlarge | 8 | 16 | 3.4 |
| ED6 | c5.4xlarge | 16 | 32 | 3.4 |
| ED7 | t3.2xlarge | 8 | 32 | 2.5 |

Every pair of values (task interference parameter) between every two tasks are profiled on each of the eight edge devices. In addition, LaTS [9] makes an assumption that there is a parametric model that captures the relationship between latency and CPU usage. For our baseline experiments with LaTS, we have to determine this parametric relationship in our experimental setting. Therefore, we also profiled the relationship between the CPU usage and task execution latency and fitted a linear regression model to capture such a relationship. Figure 5 shows the profiling data collected on the t2.xlarge EC2 instance at 5 different CPU usage levels for different task types. From this result, we conclude that there is a linear relationship between the log(latency) and the CPU usage. We use this linear relationship for latency estimation for our experiments with the baseline LaTS.
V-C Testing Applications
The simulator for our proposed framework IBDASH is built in Python and four applications (Figure 6) from different application domains such as machine learning (LightGBM), data analytics (Mapreduce sort), mathematics (Matrix computation) and video analytics, that span a variety of dependency levels among tasks (DAGs) have been used for testing the generality of IBDASH.
We now describe our four applications and corresponding DAGs representing dependency among tasks.




(1) LightGBM: Figure 6(a) shows a DAG representation of the application which trains decision trees and combines them to form a random forest predictor. Such application first reads the training examples and performs dimension reduction (PCA). Then, a user-specified number of functions train the decision trees in parallel (every function randomly selects 90% for training, 10% for validation). In the end, all trained models are collected and combined to get tested on held-out test data. The inputs of such application are the handwritten images databases: NIST(800K images) and MNIST (60K images).
(2) MapReduce Sort: Figure 6(b) shows a DAG representation of the MapReduce sort. At the first stage, the parallel mappers (MAPs) fetch input data and generate intermediate files. In the next stage, the reducers sort the intermediate file and write the result back to the storage.
(3) Video Analytics: Figure 6(c) shows a DAG representation of the video analytics application. At the first stage, the input video is split into multiple chunks, then a significant frame is extracted from each chunk. Eventually, the significant frame will be used for classification.
(4) Matrix Computation: Figure 6(d) is a matrix computation application, where all tasks are heavy matrix computations. Such setup can be mapped into various mathematics applications. In particular, the tasks used in this application are matrix inversion, matrix-matrix multiplication and matrix-vector multiplication.
V-D Baseline Systems
We compare our orchestration scheme with the following baselines:
LAVEA [6]: LAVEA is a system built to offload computation between clients and edge nodes to provide low-latency video analytics. We compare our scheme with their best performing scheme, Shortest Queue Length First (SQLF), which tries to balance the number of tasks running on each edge device.
Petrel [7]: Petrel is a randomized load balancing framework that utilizes the strategy of 'the power of two choices' [8]. The framework randomly selects two edge devices and offloads the task to the one that has the lowest expected service time.
LaTS [9]: LaTS is a latency-aware task scheduling heuristic that distributes tasks to edge devices based on the predicted execution latency of each task through a model which characterizes the relationship between execution latency and CPU usage of the edge device node.
Round Robin: In this scheme, the tasks in each application instance are distributed to edge devices present in network in round-robin manner.
Random: In this scheme, the task will be distributed to edge devices present in network randomly.
V-E Performance Metrics
Service Time: We define the service time for an application instance scheduled by the orchestrator as the end-to-end latency, starting from the execution of the first task until the last task finishes its execution. In our simulation, application instances may arrive in a clustered manner, which can cause tasks to accumulate on edge devices and result in longer end-to-end latency for some instances. Therefore, the average service time for a single application instance across all application instances of all applications throughout the entire simulation period is used in our measurement and is measured in seconds.
Probability of Failure (PF): The probability of failure for an application instance is defined as , where denotes the probability that all tasks composing the application instance (not counting the replicas) are executed successfully. Tasks can fail due to sporadic availability of edge devices or tasks taking abnormally long to execute (e.g., a person leaves the room with his laptop during the middle of the task execution).
V-F Evaluation of Heterogeneity
Recall that heterogeneity across edge devices is captured in our work through various computing powers (Section V-B) of different edge devices and a mix of PEDs and CEDs.

To show the impact of heterogeneity, we used the exponential function to simulate the sporadic availability of different edge devices with different failing rates (i.e., different s) for different devices. The exponential form makes sense as the average probability of failure increases as simulation time passes.
This experiment is meant to validate that the exponential model can be used as a good prediction of the probability of availability of edge devices and the set of values used in our simulation are realistic. We used the mobility trace from [13] to validate our assumption. The mobility data is collected over one month (Feb 7th - Mar 7th, 2018) with 50 users on a university campus. Each user was performing their daily routine while their smartphones were running tasks for collecting sensor data, such as geolocation. The missing data points in the data sets indicate students turned off their devices, have no network access or quit the data collection program for their own reasons. By analyzing the mobility data, we show the corresponding results in Figure 7a, which shows the change of probability of availability since it first becomes available.
| ED devices | ED0 | ED1 | ED2 | ED3 | ED4 | ED5 | ED6 | ED7 |
|---|---|---|---|---|---|---|---|---|
Table IV shows different sets of values that have been used in our simulations. simulates the scenario of a mixture of PEDs and CEDs. represents the scenario when there are only CEDs present and represents when there are only PEDs available. We specifically plot the set of (mix of CEDS and PEDs) and the real-world data collected from the real-world participants in Figure 7b, and we see that the model for fits the real-world data well which verifies our assumption that exponential function can be used as a good prediction for device availability with careful selection of failure rates .
V-G Evaluation of End-to-End Latency
In our experiment, we repeated a 15s simulation cycle 20 times giving a total simulation time of 5 minutes. In each cycle, 1000 application instances arrive randomly clustered within the initial 1.5s and there are 100 edge devices uniformly distributed among the 8 device classes listed in Table III. Their corresponding interference coefficients are collected from real-world experiments. It can be observed from Figure 8 that the average service time of IBDASH outperforms other orchestration schemes except for LaTS under all three scenarios (CEDs, PEDs, the mix of CEDs and PEDs (50%:50%)) for all applications due to its awareness of the co-located task interference. The reason that LaTS outperforms IBDASH in execution latency comparison is that LaTS allocates the majority of tasks to a single powerful device. However, if that device were to become unavailable, then the performance of LaTS will suffer drastically.




V-H Evaluation of Probability of Failure

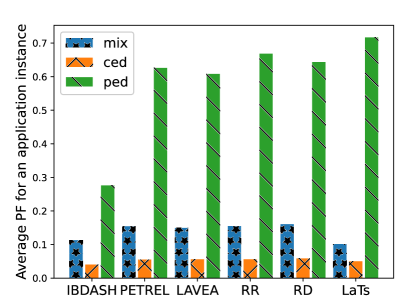


Figure 9 demonstrates the average probability of failure of application instances under six different orchestration schemes for three different scenarios. We see that IBDASH outperforms other baselines under all three scenarios, especially in the scenario where edge devices are a combination of PEDS and CEDs or all are PEDs as IBDASH offers the redundant replication to reduce the probability of failure. IBDASH is better than LaTS by 29.7% for mix, 58.5% for PEDs, and 34% CEDs on average across four applications. We emphasize that LaTS outperforms IBDASH in rare cases since the majority of tasks are allocated to a single device. If that single device being allocated had a low probability of failure, the overall probability of failure value is low. However, as discussed earlier, this can lead to a catastrophic failure of all application instances.
V-I Microscopic View
To show the advantage of using IBDASH in detail, we performed separate experiments (shown in Figure 10 and Figure 11) with 8 edge devices (one from each class) so that we can plot the loads, which is the number of tasks on each device and examine the load distribution. We zoom into one of the 15s simulation cycles for this experiment. We see that IBDASH tends to allocate more tasks on edge devices with low interference coefficients to reduce the overall service time, in this case, devices ED5 and ED6. On the other hand, LAVEA [6] chooses to allocate the task to the edge device with the least number of running tasks, which results in the load being fairly balanced on each edge device. Petrel [7] chooses two edge devices randomly and allocates the task to the one which has a lower expected service time. It results in a fairly balanced load distribution as well except for those edge devices with significantly larger interference coefficients compared to others. LaTS [9] allocates the majority of the tasks to ED5 due to its significant superiority of performance compared to others. Even though it does produce low execution latency, it results in a highly imbalanced allocation, which has negative consequences. Both Round Robin and Random allocation result in task accumulation on edge devices with high interference coefficients due to their fixed task distribution scheme, which leads to a long service time.
From Figure 11, we see that when the probability of failure of edge devices increases toward the end of the simulation, our orchestrator IBDASH starts to replicate the tasks to reduce the probability of failure, which results in increasing the overall number of tasks on some edge devices (Figure 10) and correspondingly the average service time for the application instance goes up due to the redundant tasks. For Petrel [7], LAVEA [6], the average probability of failure is higher as they do not have the extra redundancy to reduce the probability of failure. As for LaTS [9], it assigned most tasks to a single device, which happens to have a low probability of failure, so it shows a fairly low probability of failure.


V-J Evaluation of Joint Optimization of End-to-end Latency and Probability of Failure
To evaluate the joint optimization of our orchestration scheme, we performed a sweep of the replication threshold and (separately) of the joint optimization parameter . The result is shown in Figure 12.


In Figure 12(a), initially, when the probability of failure is assigned much more weight than the service time, the algorithm tends to optimize the probability of failure as much as it can until it meets the probability of failure threshold or replication degree . At around , IBDASH starts to prioritize optimizing service time as more weight is given to it and shorter service time gives a better joint optimization score. Throughout the sweep, we see the general trend is that as the normalized service time decreases, the average probability of failure increases. However, there are some fluctuations in the sweep. For example, at , we see that there is a temporary drop in the probability of failure and an increase in the average service time. The reason for this is that as the value changes in each sweep, the task allocation changes as well. Therefore, this change in task allocation can result in fluctuations for both probability of failure and service time, but the general trend is not affected as shown in Figure 12(a).
From Figure 12(b), we see that as we increase the replication degree, the average service time increases while the average probability of failure decreases, then it stays fairly stable after around 6 replications as IBDASH is able to determine that further replications will not result in better joint optimization, therefore it stops replicating.
VI Related Work
Scheduling on the edge: One of the most important goals in edge computing is reducing the end-to-end latency to enable latency-sensitive applications for users. Several prior works such as LaTS [9], LAVEA [6], and Petrel [7] propose scheduling strategies that aim at minimizing the service time in a multi-edge collaborative environment. We have shown that IBDASH outperforms these schemes in terms of average service time and probability of failure in a heterogeneous edge computing setting. Other works consider joint optimization of low latency and other goals under some constraints [20, 22]. In particular, [20] focuses on the latency and accuracy optimization for video analytics under battery, network, and cost constraints. There is a growing body of work on low-latency scheduling on the edge [23, 24] and a subset considers DAG-based applications [25]. However, none of these works considers the interference among co-located tasks or intermittent availability of a subset of devices.
Interference-based scheduling: A few efforts study the availability of heterogeneous edge devices and interference among tasks on the same edge device [9, 26, 27]. LaTS [9] proposed to use a Latency-CPU usage model to address the interference among co-located tasks. It constantly monitors the CPU usage on each edge device and combines with the Latency-CPU usage model to schedule tasks to get the minimum predicted latency. Moreover, [27] proposed a score-based edge service scheduling algorithm that evaluates network, compute, and reliability capabilities of edge nodes, but the drawback of such algorithm is that it requires sharing of monitoring information across all devices which is infeasible in edge computing. Compared to those frameworks, IBDASH considers the heterogeneity in edge computing and requires much less information sharing among all edge devices.
Edge device reliability and failure prevention: There is a significant amount of work on investigating the reliability of edge devices and failure prevention [28, 29, 30]. [30] conducted a small scale experiment to show the trade-offs between reliability and latency for edge nodes and server-less computing functions. [28] proposed three different algorithms for offloading that are based on heuristic search to reduce the failure probability and latency, but it fails to address the interference of task co-location on the same edge device and the heterogeneity of edge devices. [29] proposed a fault detection model based on the long short-term memory (LSTM) recurrent neural networks that are used in industrial robot manipulators. None of those frameworks addresses how to predict edge device availability. On the other hand, our work offers a model for edge device availability prediction and consequently guides the extra redundancy needed for application success.
VII Discussion and Future Work
In this section, we present extensions of IBDASH that would need to be implemented to handle some use cases. First, the current algorithm checks each incoming task against all available edge devices. This procedure can result in high orchestration overhead for simple tasks when many edge devices available. This problem can be addressed through edge device clustering based on (static) capabilities and (dynamic) load on each device. Then the computation overhead reduces from number of devices to number of clusters. Any of several existing techniques for edge device clustering can be used, such as [31]. Second, we hope that the execution latencies of tasks within the same stage are fairly balanced. A long latency task in a stage can delay the execution of later stage tasks. The task execution latency balancing can be achieved through further task partitioning. Third, the linearity in the task interference plots may not hold if the number of tasks running on an edge device is large enough to cause a discontinuous change such as cache spillage. In that case, a higher-order characterization (say, quadratic or piece-wise linear) of the interference plots is needed to accurately predict the execution latency. Finally, we use exponential functions to predict the sporadic availability of edge devices. Even though we validated this assumption using real-world mobility data, this may not hold in certain scenarios (say a student class schedule changes from one module to the next). This can be improved by using the history of availability of each edge device and semi-Markov process to predict availability.
VIII Conclusion and Takeaways
In this paper, we proposed a novel orchestration framework, IBDASH, that enables multi-stage applications to be executed on edge computing systems. Crucially IBDASH can incorporate personal edge devices (PEDs) along with commercial edge devices (CEDs) in executing the tasks that constitute the application. To support this, we make three novel contributions. First, IBDASH determines the dependency among different tasks within an application represented using a DAG. Second, IBDASH leverages PEDs while accounting for the possibility of resource contention and low and unpredictable availability of such devices. Third, IBDASH jointly minimizes the average application execution latency (via dynamic scheduling) and application failure likelihood (via task replication). We evaluated IBDASH with four applications that span various DAG structures, with unit measurements of real application tasks on real devices. We compared IBDASH with three state-of-the-art edge scheduling solutions, LAVEA, Petrel, and LaTS. We observe that IBDASH yields an average reduction of 14% on the service time of applications and reduces the average probability of failure for the applications by 41%.
There are three takeaways from our work that are of general applicability to edge computing systems. First, it is possible to leverage highly heterogeneous devices to compose a usable, i.e., low-latency and reliable, edge computing platform. Second, it is feasible to use unmanaged edge devices (called PEDs here) to create the usable edge computing platform, if these are combined with commercially managed devices. Third, a usable edge computing platform, unlike a cloud computing platform, must manage anticipated failures by proactively replicating tasks as these are far more likely than in the cloud computing world.
References
- [1] ``Amazon: Lambda@edge,'' https://aws.amazon.com/lambda/edge/, 2020, accessed: 2021-12-21.
- [2] ``Microsoft: The future of computing: intelligent cloud and intelligent edge,'' https://azure.microsoft.com/en-us/overview/future-of-cloud/, 2020, accessed: 2022-01-11.
- [3] ``Google: Edge network,'' https://peering.google.com/, 2020, accessed: 2021-12-21.
- [4] ``Your phone is now more powerful than your pc,'' https://bit.ly/344UsiR, 2021, accessed: 2022-01-11.
- [5] L. Wang, M. Li, Y. Zhang, T. Ristenpart, and M. Swift, ``Peeking behind the curtains of serverless platforms,'' in USENIX ATC, 2018, pp. 133–146.
- [6] S. Yi, Z. Hao, Q. Zhang, Q. Zhang, W. Shi, and Q. Li, ``Lavea: Latency-aware video analytics on edge computing platform,'' in 2nd ACM/IEEE Symposium on Edge Computing, 2017, pp. 1–13.
- [7] L. Lin, P. Li, J. Xiong, and M. Lin, ``Distributed and application-aware task scheduling in edge-clouds,'' in 2018 14th International Conference on Mobile Ad-Hoc and Sensor Networks (MSN), 2018, pp. 165–170.
- [8] M. Mitzenmacher, ``The power of two choices in randomized load balancing,'' IEEE Transactions on Parallel and Distributed Systems, vol. 12, no. 10, pp. 1094–1104, 2001.
- [9] W. Zhang, S. Li, L. Liu, Z. Jia, Y. Zhang, and D. Raychaudhuri, ``Hetero-edge: Orchestration of real-time vision applications on heterogeneous edge clouds,'' in IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, 2019, pp. 1270–1278.
- [10] C. Wang, S. Zhang, Y. Chen, Z. Qian, J. Wu, and M. Xiao, ``Joint configuration adaptation and bandwidth allocation for edge-based real-time video analytics,'' in IEEE INFOCOM 2020 - IEEE Conference on Computer Communications, 2020, pp. 257–266.
- [11] L. Liu, H. Li, and M. Gruteser, ``Edge assisted real-time object detection for mobile augmented reality,'' in The 25th Annual International Conference on Mobile Computing and Networking, 2019.
- [12] S. Suryavansh, C. Bothra, K. T. Kim, M. Chiang, C. Peng, and S. Bagchi, ``I-bot: Interference-based orchestration of tasks for dynamic unmanaged edge computing,'' arXiv preprint arXiv:2011.05925, 2020.
- [13] H. Zhang, M. A. Roth, R. K. Panta, H. Wang, and S. Bagchi, ``Crowdbind: Fairness enhanced late binding task scheduling in mobile crowdsensing,'' 2020 International Conference on Embedded Wireless Systems and Networks, p. 61–72, 2020.
- [14] R. Hood, H. Jin, P. Mehrotra, J. Chang, J. Djomehri, S. Gavali, D. Jespersen, K. Taylor, and R. Biswas, ``Performance impact of resource contention in multicore systems,'' in 2010 IEEE International Symposium on Parallel Distributed Processing (IPDPS), 2010, pp. 1–12.
- [15] A. Arunarani, D. Manjula, and V. Sugumaran, ``Task scheduling techniques in cloud computing: A literature survey,'' Future Generation Computer Systems, vol. 91, pp. 407–415, 2019.
- [16] L. Lin, X. Liao, H. Jin, and P. Li, ``Computation offloading toward edge computing,'' Proceedings of IEEE, vol. 107, no. 8, pp. 1584–1607, 2019.
- [17] B.-G. Chun, S. Ihm, P. Maniatis, M. Naik, and A. Patti, ``Clonecloud: Elastic execution between mobile device and cloud,'' in 6th European Conference on Computer Systems (Eurosys), 2011, p. 301–314.
- [18] E. Cuervo, A. Balasubramanian, D.-k. Cho, A. Wolman, S. Saroiu, R. Chandra, and P. Bahl, ``Maui: Making smartphones last longer with code offload,'' in Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, 2010, p. 49–62.
- [19] Z. Li, C. Wang, and R. Xu, ``Computation offloading to save energy on handheld devices: A partition scheme,'' in CASES, 2001, p. 238–246.
- [20] X. Ran, H. Chen, X. Zhu, Z. Liu, and J. Chen, ``Deepdecision: A mobile deep learning framework for edge video analytics,'' IEEE Conference on Computer Communications (INFOCOM), pp. 1421–1429, 2018.
- [21] J. Koo, R. K. Panta, S. Bagchi, and L. Montestruque, ``A tale of two synchronizing clocks,'' in Proceedings of the 7th ACM Conference on Embedded Networked Sensor Systems (Sensys), 2009, pp. 239–252.
- [22] Y. Sahni, J. Cao, and L. Yang, ``Data-aware task allocation for achieving low latency in collaborative edge computing,'' IEEE Internet of Things Journal, vol. 6, no. 2, pp. 3512–3524, 2019.
- [23] D. Zhang, N. Vance, Y. Zhang, M. T. Rashid, and D. Wang, ``Edgebatch: Towards ai-empowered optimal task batching in intelligent edge systems,'' in Real-Time Systems Symposium (RTSS), 2019, pp. 366–379.
- [24] T. He, H. Khamfroush, S. Wang, T. La Porta, and S. Stein, ``It's hard to share: Joint service placement and request scheduling in edge clouds with sharable and non-sharable resources,'' in 38th International Conference on Distributed Computing Systems (ICDCS), 2018, pp. 365–375.
- [25] H. Liao, X. Li, D. Guo, W. Kang, and J. Li, ``Dependency-aware application assigning and scheduling in edge computing,'' IEEE Internet of Things Journal, 2021.
- [26] R. C. Chiang and H. H. Huang, ``Tracon: Interference-aware scheduling for data-intensive applications in virtualized environments,'' in Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, 2011.
- [27] A. Aral, I. Brandic, R. B. Uriarte, R. De Nicola, and V. Scoca, ``Addressing application latency requirements through edge scheduling,'' Journal of Grid Computing, vol. 17, 12 2019.
- [28] J. Liu and Q. Zhang, ``Offloading schemes in mobile edge computing for ultra-reliable low latency communications,'' IEEE Access, vol. 6, pp. 12 825–12 837, 2018.
- [29] D. Park, S. Kim, Y. An, and J.-Y. Jung, ``Lired: A light-weight real-time fault detection system for edge computing using lstm recurrent neural networks,'' Sensors, vol. 18, no. 7, 2018.
- [30] H. Inaltekin, M. Gorlatova, and M. Chiang, ``Virtualized control over fog: Interplay between reliability and latency,'' IEEE Internet of Things Journal, vol. 5, no. 6, pp. 5030–5045, 2018.
- [31] A. Asensio, X. Masip-Bruin, R. Durán, I. de Miguel, G. Ren, S. Daijavad, and A. Jukan, ``Designing an efficient clustering strategy for combined fog-to-cloud scenarios,'' Future Generation Computer Systems, p. 392–406, 2020.