D3Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement
Abstract
Scene representation is a crucial design choice in robotic manipulation systems. An ideal representation is expected to be 3D, dynamic, and semantic to meet the demands of diverse manipulation tasks. However, previous works often lack all three properties simultaneously. In this work, we introduce D3Fields—dynamic 3D descriptor fields. These fields are implicit 3D representations that take in 3D points and output semantic features and instance masks. They can also capture the dynamics of the underlying 3D environments. Specifically, we project arbitrary 3D points in the workspace onto multi-view 2D visual observations and interpolate features derived from visual foundational models. The resulting fused descriptor fields allow for flexible goal specifications using 2D images with varied contexts, styles, and instances. To evaluate the effectiveness of these descriptor fields, we apply our representation to rearrangement tasks in a zero-shot manner. Through extensive evaluation in real worlds and simulations, we demonstrate that D3Fields are effective for zero-shot generalizable rearrangement tasks. We also compare D3Fields with state-of-the-art implicit 3D representations and show significant improvements in effectiveness and efficiency. Project Page
Keywords: Implicit 3D Representation, Visual Foundational Model, Zero-Shot Generalization, Robotic Manipulation

1 Introduction
The choice of scene representation is essential in robotic systems. An ideal representation is expected to be simultaneously 3D, dynamic, and semantic to meet the needs of various robotic manipulation tasks in our daily lives. However, previous research on scene representations in robotics often does not encompass all three properties. Some representations exist in 3D space [1, 2, 3, 4], yet they overlook semantic information. Others focus on dynamic modeling [5, 6, 7, 8], but only consider 2D data, neglecting the role of 3D space. Some other works are limited by only considering semantic information such as object instance and category [9, 10, 11, 12, 13].
In this work, we aim to satisfy all three criteria by introducing D3Fields, unified descriptor fields that are 3D, dynamic, and semantic. Notably, D3Fields are implicit 3D representations rather than explicit 3D representations like point clouds. D3Fields take arbitrary 3D coordinates as inputs and output both geometric and semantic information corresponding to these positions. This includes the instance mask, dense semantic features, and the signed distance to the object surface. Notably, deriving these descriptor fields requires no training and is conducted in a zero-shot manner, utilizing large visual foundation models and vision-language models (VLMs). In our approach, we employ a set of advanced models. We first use Grounding-DINO [14], Segment Anything (SAM) [15], XMem [16], and DINOv2 [17] to extract information from multi-view 2D RGB images. We then project arbitrary 3D coordinates back to each camera, interpolate to compute representations from each view, and fuse these data to derive the descriptors associated with these 3D positions, as shown in Figure 1 (left). Leveraging the dense semantic features and instance mask of our representation, we achieve robust tracking 3D points of the target object instances and train the dynamics models. These learned dynamics models can be incorporated into a Model-Predictive Control (MPC) framework to plan for zero-shot generalizable rearrangement tasks.
Notably, the derived representations allow for zero-shot generalizable rearrangement tasks, where the goal is specified by 2D images sourced from the Internet, smartphones, or even generated by AI models. Such goal images have been challenging to manage with previous methods, because they contain varied styles, contexts, and object instances different from the robot’s workspace. Our proposed D3Fields can establish dense correspondences between the robot workspace and the target configurations. Given correspondences, we can define our planning cost and use the MPC framework with the learned dynamics model to derive actions for accomplishing tasks. Remarkably, this task execution process does not require any further training, offering a highly flexible and convenient interface for humans to specify tasks for the robots.
We evaluate our method across a wide range of robotic rearrangement tasks in a zero-shot manner. These tasks include organizing shoes, collecting debris, and organizing office desks, as shown in Figure 1 (right). Furthermore, we provide both quantitative and qualitative comparisons with state-of-the-art implicit 3D representations to demonstrate the effectiveness and efficiency of our approach [18, 19]. Through a detailed analysis of our D3Fields, we offer insights into the category-level generalization capabilities and zero-shot rearrangement capabilities of our approach.
We make three major contributions. First, we introduce a novel representation, D3Fields, that is 3D, semantic, and dynamic. Second, we present a novel and flexible goal specification method using 2D images that incorporate a wide range of styles, contexts, and instances. Third, our proposed robotic manipulation framework supports a broad spectrum of zero-shot rearrangement tasks.
2 Related Works
Foundation Models for Robotics. Large Language Models (LLMs) have demonstrated promising reasoning capabilities for language. Robotics researchers have used LLMs to generate plans for manipulation [20, 21, 22, 23]. Yet, their perception modules fall short in simultaneously modeling the 3D geometry, semantics, and dynamics of objects. Meanwhile, visual foundation models, such as SAM [15] and DINOv2 [17], have demonstrated impressive zero-shot generalization capabilities across various vision tasks. While prior visual models, like Dense Object Nets [24], can encode similar semantic information on a small-scale dataset, these foundational models show better generalization capabilities on various object categories and scenarios. However, their focus is primarily on 2D vision tasks. Grounding these models in a dynamic 3D environment remains a challenge. Recent works showcase how to ground these foundational models in the 3D world and help imitation learning to generalize [25, 26, 27, 28]. Still, these works do not emphasize dynamics learning or achieve zero-shot generalization ability.
Neural Fields for Robotic Manipulation. There are various approaches leveraging neural fields as a representation for robotic manipulation [29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42]. Among them, a series of works distilling neural feature fields from visual foundation models are closely related to us [43, 44, 45, 46, 19]. However, they often require dense camera views for a quality field, which is expensive and impractical for real-world scenarios. Also, distilled neural fields need retraining for new scenes, which is time-consuming and inefficient. In contrast, our D3Fields require no training for new scenes and can work with sparse views and dynamic settings. GNFactor and FeatureNeRF train neural feature fields that can be conditioned on sparse views [47, 18]. However, such fields are often trained on a small dataset, making them hard to generalize to novel instances and scenes, whereas our D3Fields offer better generalization capability to new instances.
3 Method

3.1 Problem Formulation
We formulate our problem as a zero-shot rearrangement problem given a 2D goal image and RGBD images from multiple fixed viewpoints. We denote the workspace scene representation as . Our goal is to find an optimal action sequence to minimize the task objective:
| (1) | |||||
| s.t. | |||||
where is the cost function measuring the distance between the terminal representation and the goal representation . Representation extraction function takes in the current multi-view RGBD observations and outputs the current representation . is the dynamics function that predicts the future representation , conditioned on the current representation and action . The optimization aims to find the action sequence that minimizes the cost function .
3.2 D3Fields Representation
We assume that we can access multiple RGBD cameras with fixed viewpoints to construct D3Fields. Multi-view RGBD observations are first fed into visual foundational models. Then we obtain 2D feature volumes . D3Fields are implicit functions defined as follows:
| (2) |
where can be an arbitrary 3D coordinate in the world frame, and corresponds to the signed distance , the semantic descriptor , and the instance probability distribution of instances. could be different across scenarios.
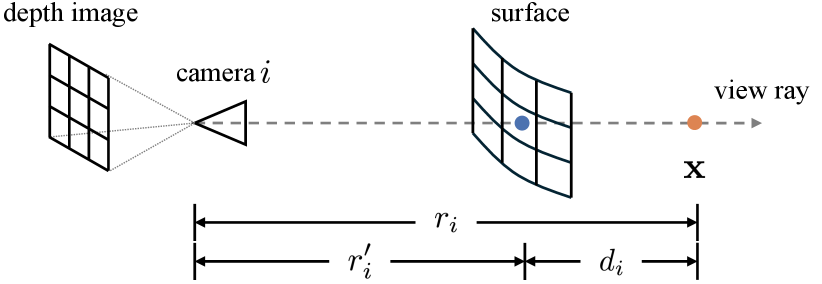
As an overview, our pipeline first projects into the image space of each camera. Then, we can obtain the truncated depth difference between projected depth and real depth reading using Equation 3. Afterwards, we assign weights to each viewpoint using Equation 4 and interpolate the semantic features and instance masks for each camera using Equation 5. Finally, we fuse features from all viewpoints to obtain the final descriptor using Equation 6.
More concretely, we map an arbitrary 3D point to the th viewpoint’s image space. We denote the projected pixel as and the distance from to the th viewpoint as (Figure 3). By interpolating the th viewpoint’s depth image , we compute the corresponding depth reading from the depth image as . Then we can compute the truncated depth difference as
| (3) |
where specifies the truncation threshold for the Truncated Signed Distance Function (TSDF). Given the truncated depth difference, we compute weights and for each viewpoint as
| (4) |
Here is the explanation and design justification for each term.
-
:
It represents the visibility of in camera . is the indicator function, which equals to 1 when and equals to 0 otherwise. When , is behind the surface, which means is not visible in camera and .
-
:
It is the weight for the th viewpoint. Since we only have a confident estimation when is close to the surface, will decay as increases. For that is far away, degrades to .
Then we extract the semantic feature and instance mask in each viewpoint using
| (5) |
where DINOv2 [17] extracts the semantic feature volume from RGB image. is the instance mask volume using Grounded-SAM [14, 15]. Note that is a one-hot vector and already associated to ensure consistent instance indexing across different views. Finally, we fuse the semantic features and instance masks from all viewpoints using
| (6) |
where is a small number to avoid numeric issues. Since the process of projection, interpolation, and fusion is differentiable, is differentiable when is within the truncation threshold.
3.3 Keypoints Tracking and Dynamics Learning
This section will present how to use the dynamic implicit 3D descriptor field to track keypoints and train dynamics. Without loss of generality, consider the tracking of a single object instance . For clarity, we denote and from as and . We initialize the tracked keypoints by sampling points close to the surface of the desired instance. To track keypoints , we formulate the tracking problem as an optimization problem:
| (7) |
As is differentiable, we could use a gradient-based optimizer. This method could be naturally extended to multiple-instance scenarios. We found that relying solely on features for tracking can be unstable. Therefore, if we know that the tracked object is rigid, we can apply additional rigid constraints and distance regularization for more stable tracking.
Keypoint tracking enables dynamics model training on real data. We instantiate the dynamics model as graph neural networks (GNNs). We follow [48] to predict object dynamics. Please refer to [49, 48] for more details on how to train the graph-based neural dynamics model. The trained dynamics model will be used for trajectory optimization in Section 3.4.
3.4 Zero-Shot Generalizable Robotic Rearrangement
In this section, we will describe how to define the planning cost for our zero-shot rearrangement framework. As shown in Figure 2 (c), we first find the correspondence between the descriptor fields and goal image using Equation 8. Then we define the cost function in Equation 9 to measure the distance between the current state and the goal state. Finally, we optimize the action sequence to minimize the cost function as described in Section 3.1.
As described in Section 3.2, we initially sample points and obtain the associated features from the descriptor fields. We correspond to the goal image to define 2D goal points . Firstly, we compute the feature distance between th pixel of and th sampled point of . Then we normalize using the softmax over the whole image and obtain the weight . Lastly, we find the 2D point corresponding to the th 3D point using weighted sum. The computation process is summarized in the following:
| (8) |
where is the feature volume extracted from using DINOv2, and is the hyperparameter to determine whether the heatmap is more smooth or concentrating. Although Equation. 8 only shows a single instance case, it could be naturally extended to multiple instances by using instance mask information.

Note that is in the image space, and the current state representation, is in 3D space. To reconcile this discrepancy, we introduce a virtual reference camera. We project into the reference image and obtain its 2D positions . Consequently, we define the task cost function as follows:
| (9) |
Given the planning cost, we could use an MPC framework to derive the action sequence to minimize the cost function. Specifically, we use MPPI to optimize the action sequence [50]. At each time step, we sample a set of action sequences and evaluate the cost function. Then we update the action sequence using the cost function and repeat the process until convergence. This process will be repeated for each time step until the task is completed. More details regarding the method are included in the supplementary material.
4 Experiments
We design and organize our experiments to answer three key questions about our method: (1) How efficient and effective our D3Fields is compared to existing neural representations? (2) What kind of manipulation tasks can be enabled by our framework, and what type of generalization can it achieve? (3) Why can our D3Fields enable these tasks and be generalizable?
4.1 Experiment Setup
In the real world, we use four RGBD cameras positioned at the corners of the workspace and employ the Kinova® Gen3 arm for action execution. In the simulation, we use OmniGibson and the Fetch robot for mobile manipulation tasks [51]. Our evaluations span various tasks, including organizing shoes, collecting debris, tidying the table, and so on. More details are in the supplementary material.
4.2 D3Fields Efficiency and Effectiveness

In this section, we compare our D3Fields with two baselines, Distilled Feature Fields (F3RM) [19] and FeatureNeRF [18]. For F3RM, we use four camera views as inputs and the DINOv2 features as the supervision and stop the distillation process at 2,000 steps, which is defaulted by the authors [19]. We first compare our D3Fields with F3RM and FeatureNeRF in terms of the correspondence accuracy, as shown in Figure 5. We reconstruct the mesh from our 3D implicit representation using marching cubes. We then select DINOv2 features from the source image and visualize the corresponding heatmap on the reconstructed feature mesh. We could see that our D3Fields could reconstruct the mesh with high quality and highlight semantically similar areas across different instances and contexts, while F3RM fails to reconstruct the mesh accurately, which leads to an inaccurate correspondence heatmap. Since FeatureNeRF is only pre-trained on a small dataset, it fails to construct an accurate mesh of the scene and find accurate correspondence in novel scenes, demonstrating our representation’s effectiveness in reconstructing meshes and encoding semantic features. Quantitative comparisons are included in the supplementary material.
We also evaluate the time efficiency of constructing the implicit representation given four RGBD views across four scenes on the machine with A6000 GPU. Our method takes seconds, which is significantly more efficient than F3RM, which takes seconds.
4.3 Zero-Shot Generalizable Rearrangement

We conduct a qualitative evaluation of D3Fields in common robotic rearrangement tasks in a zero-shot manner, with partial results displayed in Figure 1 and Figure 6. We observed several key capabilities of our framework, which are as follows:
Generalization to AI-Generated Goal Images. In Figure 1, the goal image is rendered in a Van Gogh style, which is distinctly different from those in the workspace. Since D3Fields encode semantic information, capturing shoes with varied appearances under similar descriptors, our framework can manipulate shoes based on AI-generated goal images.
Compositional Goal Images. In the office desk organization task in Figure 1, the robot first arranges the mouse and pen to match the goal image. Then, the robot repositions the mug from the top of a box to the mug pad, guided by a separate goal image of the upright mug. This example illustrates that our system can accomplish tasks using compositional goal images.
Generalization across Instances and Materials. Figure 4 and Figure 1 also show our framework’s ability to generalize across various instances and materials. For example, the debris collection in Figure 1 shows our framework’s ability to handle granular objects. Figure 6 further shows our framework’s instance-level generalization, where the goal instances distinct from ones in the workspace.
Generalization across Simulation and Real World. We evaluated our framework in the simulator, as shown in the utensil organization and mug organization examples in Figure 6. Given goal images from the real world, our framework can also manipulate objects to the goal configurations. This underscores our framework’s generalization capabilities between simulation and the real world.
4.4 D3Fields Analysis

To obtain a more thorough understanding of our D3Fields, we first extract the mesh using the marching cube algorithm. We evaluate vertices from the extracted mesh using our D3Fields and obtain the associated segmentation information and semantic features, as visualized in Figure 7. Mask fields in Figure 7 show a distinct 3D instance segmentation in different scenarios, even clustering scenes like cans and toothpaste. The 3D instance segmentation enables the downstream planning module to distinguish and manipulate multiple instances, as shown in the mug organization tasks.
Additionally, we visualize the semantic features by mapping them to RGB space using PCA. We observe that our semantic fields show consistent color patterns across different instances. In the provided shoe example, even though various shoes have distinct appearances and poses, they exhibit similar color patterns: shoe heels are represented in green, and shoe toes in red. We observed similar patterns for other object categories such as mugs and forks. The consistent semantic features across various instances help our manipulation framework to achieve category-level generalization. When encountering novel instances, our D3Fields can still establish the correspondence between the workspace and the goal image using semantic features. In addition, we analyze in the supplementary to show that D3Fields have better 3D consistency compared to simple point cloud stitching.
5 Conclusion
In this work, we introduce D3Fields, which implicitly encode 3D semantic features and 3D instance masks, and model the underlying dynamics. Our emphasis is on zero-shot generalizable rearrangement tasks specified by 2D goal images of varying styles, contexts, and instances. Our framework excels in executing a diverse array of robotic rearrangement tasks in both simulated and real-world scenarios. Its performance greatly surpasses baseline methods such as FeatureNeRF and F3RM in terms of efficiency and effectiveness.
Limitation.
Our method lifts 2D visual foundation models to the 3D world, enabling a range of zero-shot rearrangement manipulation tasks. However, we both benefit from and are limited by their capabilities. For example, the semantic feature field is not fine-grained enough to distinguish between the right and left sides of shoes. Visual foundation models with more fine-grained semantic features are needed. In addition, rearrangement tasks could fail when they need to follow a specific manipulation order to avoid collision with other objects, e.g. a crowded scene. In the future, incorporating a task planner to handle clustered scenes could be a valuable direction.
Acknowledgments
This work is partially supported by Sony Group Corporation, the Stanford Institute for Human-Centered AI (HAI), and Google. The opinions and conclusions expressed in this article are solely those of the authors and do not reflect those of the sponsoring agencies.
References
- Manuelli et al. [2020] L. Manuelli, Y. Li, P. Florence, and R. Tedrake. Keypoints into the future: Self-supervised correspondence in model-based reinforcement learning. In Conference on Robot Learning (CoRL), 2020.
- Li et al. [2021] Y. Li, S. Li, V. Sitzmann, P. Agrawal, and A. Torralba. 3d neural scene representations for visuomotor control. arXiv preprint arXiv:2107.04004, 2021.
- Shi et al. [2022] H. Shi, H. Xu, Z. Huang, Y. Li, and J. Wu. Robocraft: Learning to see, simulate, and shape elasto-plastic objects with graph networks. arXiv preprint arXiv:2205.02909, 2022.
- Ze et al. [2023] Y. Ze, N. Hansen, Y. Chen, M. Jain, and X. Wang. Visual reinforcement learning with self-supervised 3d representations. IEEE Robotics and Automation Letters (RA-L), 2023.
- Hafner et al. [2019] D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels. In International conference on machine learning, pages 2555–2565. PMLR, 2019.
- Yan et al. [2021] W. Yan, A. Vangipuram, P. Abbeel, and L. Pinto. Learning predictive representations for deformable objects using contrastive estimation. In J. Kober, F. Ramos, and C. Tomlin, editors, Proceedings of the 2020 Conference on Robot Learning, volume 155 of Proceedings of Machine Learning Research, pages 564–574. PMLR, 16–18 Nov 2021.
- Wang et al. [2023] Y. Wang, Y. Li, K. Driggs-Campbell, L. Fei-Fei, and J. Wu. Dynamic-Resolution Model Learning for Object Pile Manipulation. In Proceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.047.
- Minderer et al. [2019] M. Minderer, C. Sun, R. Villegas, F. Cole, K. P. Murphy, and H. Lee. Unsupervised learning of object structure and dynamics from videos. Advances in Neural Information Processing Systems, 32, 2019.
- Tremblay et al. [2018] J. Tremblay, T. To, B. Sundaralingam, Y. Xiang, D. Fox, and S. Birchfield. Deep object pose estimation for semantic robotic grasping of household objects. In Conference on Robot Learning, pages 306–316. PMLR, 2018.
- Tyree et al. [2022] S. Tyree, J. Tremblay, T. To, J. Cheng, T. Mosier, J. Smith, and S. Birchfield. 6-dof pose estimation of household objects for robotic manipulation: An accessible dataset and benchmark. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13081–13088. IEEE, 2022.
- Jatavallabhula et al. [2023] K. M. Jatavallabhula, A. Kuwajerwala, Q. Gu, M. Omama, G. Iyer, S. Saryazdi, T. Chen, A. Maalouf, S. Li, N. V. Keetha, A. Tewari, J. Tenenbaum, C. de Melo, M. Krishna, L. Paull, F. Shkurti, and A. Torralba. ConceptFusion: Open-set multimodal 3D mapping. In Proceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.066.
- Mazur et al. [2023] K. Mazur, E. Sucar, and A. J. Davison. Feature-realistic neural fusion for real-time, open set scene understanding. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8201–8207. IEEE, 2023.
- Liu et al. [2023a] W. Liu, Y. Du, T. Hermans, S. Chernova, and C. Paxton. Structdiffusion: Language-guided creation of physically-valid structures using unseen objects. In RSS 2023, 2023a.
- Liu et al. [2023b] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023b.
- Kirillov et al. [2023] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, and R. Girshick. Segment anything. arXiv:2304.02643, 2023.
- Cheng and Schwing [2022] H. K. Cheng and A. G. Schwing. XMem: Long-term video object segmentation with an atkinson-shiffrin memory model. In ECCV, 2022.
- Oquab et al. [2023] M. Oquab, T. Darcet, T. Moutakanni, H. V. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y. Huang, H. Xu, V. Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without supervision, 2023.
- Ye et al. [2023] J. Ye, N. Wang, and X. Wang. Featurenerf: Learning generalizable nerfs by distilling foundation models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8962–8973, 2023.
- Shen et al. [2023] W. Shen, G. Yang, A. Yu, J. Wong, L. P. Kaelbling, and P. Isola. Distilled feature fields enable few-shot manipulation. In 7th Annual Conference on Robot Learning, 2023.
- Brohan et al. [2023] A. Brohan, Y. Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, et al. Do as i can, not as i say: Grounding language in robotic affordances. In Conference on Robot Learning, pages 287–318. PMLR, 2023.
- Huang et al. [2023] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models. In Conference on Robot Learning, pages 1769–1782. PMLR, 2023.
- Liang et al. [2023] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500. IEEE, 2023.
- Huang et al. [2023] W. Huang, C. Wang, R. Zhang, Y. Li, J. Wu, and L. Fei-Fei. Voxposer: Composable 3d value maps for robotic manipulation with language models. In 7th Annual Conference on Robot Learning, 2023.
- Florence et al. [2018] P. R. Florence, L. Manuelli, and R. Tedrake. Dense object nets: Learning dense visual object descriptors by and for robotic manipulation. In A. Billard, A. Dragan, J. Peters, and J. Morimoto, editors, Proceedings of The 2nd Conference on Robot Learning, volume 87 of Proceedings of Machine Learning Research, pages 373–385. PMLR, 29–31 Oct 2018.
- Zhu et al. [2023] Y. Zhu, Z. Jiang, P. Stone, and Y. Zhu. Learning generalizable manipulation policies with object-centric 3d representations. In 7th Annual Conference on Robot Learning, 2023.
- Gervet et al. [2023] T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki. Act3d: 3d feature field transformers for multi-task robotic manipulation. In Conference on Robot Learning, pages 3949–3965. PMLR, 2023.
- Xian et al. [2023] Z. Xian, N. Gkanatsios, T. Gervet, T.-W. Ke, and K. Fragkiadaki. Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation. In 7th Annual Conference on Robot Learning, 2023.
- Ke et al. [2024] T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations. Arxiv, 2024.
- Zhu et al. [2021] L. Zhu, A. Mousavian, Y. Xiang, H. Mazhar, J. van Eenbergen, S. Debnath, and D. Fox. Rgb-d local implicit function for depth completion of transparent objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4649–4658, 2021.
- Ichnowski et al. [2021] J. Ichnowski, Y. Avigal, J. Kerr, and K. Goldberg. Dex-nerf: Using a neural radiance field to grasp transparent objects. In 5th Annual Conference on Robot Learning, 2021.
- Simeonov et al. [2022] A. Simeonov, Y. Du, A. Tagliasacchi, J. B. Tenenbaum, A. Rodriguez, P. Agrawal, and V. Sitzmann. Neural descriptor fields: Se (3)-equivariant object representations for manipulation. In 2022 International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2022.
- Driess et al. [2022] D. Driess, J.-S. Ha, M. Toussaint, and R. Tedrake. Learning models as functionals of signed-distance fields for manipulation planning. In Conference on Robot Learning, pages 245–255. PMLR, 2022.
- Jiang et al. [2021] Z. Jiang, Y. Zhu, M. Svetlik, K. Fang, and Y. Zhu. Synergies Between Affordance and Geometry: 6-DoF Grasp Detection via Implicit Representations. In Proceedings of Robotics: Science and Systems, Virtual, July 2021. doi:10.15607/RSS.2021.XVII.024.
- Weng et al. [2023] T. Weng, D. Held, F. Meier, and M. Mukadam. Neural grasp distance fields for robot manipulation. In IEEE International Conference on Robotics and Automation (ICRA), 2023.
- Driess et al. [2022] D. Driess, I. Schubert, P. Florence, Y. Li, and M. Toussaint. Reinforcement learning with neural radiance fields. In Advances in Neural Information Processing Systems (NeurIPS), 2022.
- Shim et al. [2023] D. Shim, S. Lee, and H. J. Kim. SNeRL: Semantic-aware neural radiance fields for reinforcement learning. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 31489–31503. PMLR, 23–29 Jul 2023.
- Yen-Chen et al. [2022] L. Yen-Chen, P. Florence, J. T. Barron, T.-Y. Lin, A. Rodriguez, and P. Isola. NeRF-Supervision: Learning dense object descriptors from neural radiance fields. In IEEE Conference on Robotics and Automation (ICRA), 2022.
- Tang et al. [2023] Z. Tang, B. Sundaralingam, J. Tremblay, B. Wen, Y. Yuan, S. Tyree, C. Loop, A. Schwing, and S. Birchfield. RGB-only reconstruction of tabletop scenes for collision-free manipulator control. In ICRA, 2023.
- Zhou et al. [2023] A. Zhou, M. J. Kim, L. Wang, P. Florence, and C. Finn. Nerf in the palm of your hand: Corrective augmentation for robotics via novel-view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17907–17917, 2023.
- [40] N. M. (Mahi)Shafiullah, C. Paxton, L. Pinto, S. Chintala, and A. Szlam. CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory. In Proceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.074.
- Wi et al. [2022a] Y. Wi, A. Zeng, P. Florence, and N. Fazeli. Virdo++: Real-world, visuo-tactile dynamics and perception of deformable objects. arXiv preprint arXiv:2210.03701, 2022a.
- Wi et al. [2022b] Y. Wi, P. Florence, A. Zeng, and N. Fazeli. Virdo: Visio-tactile implicit representations of deformable objects. In 2022 International Conference on Robotics and Automation (ICRA), pages 3583–3590. IEEE, 2022b.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. In M. Meila and T. Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR, 18–24 Jul 2021.
- Caron et al. [2021] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- Kerr et al. [2023] J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik. Lerf: Language embedded radiance fields. In International Conference on Computer Vision (ICCV), 2023.
- Sharma et al. [2023] S. Sharma, A. Rashid, C. M. Kim, J. Kerr, L. Y. Chen, A. Kanazawa, and K. Goldberg. Language embedded radiance fields for zero-shot task-oriented grasping. In 7th Annual Conference on Robot Learning, 2023.
- Ze et al. [2023] Y. Ze, G. Yan, Y.-H. Wu, A. Macaluso, Y. Ge, J. Ye, N. Hansen, L. E. Li, and X. Wang. Multi-task real robot learning with generalizable neural feature fields. In 7th Annual Conference on Robot Learning, 2023.
- Li et al. [2020] Y. Li, T. Lin, K. Yi, D. Bear, D. L. Yamins, J. Wu, J. B. Tenenbaum, and A. Torralba. Visual grounding of learned physical models. In International Conference on Machine Learning, 2020.
- Li et al. [2019] Y. Li, J. Wu, R. Tedrake, J. B. Tenenbaum, and A. Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. In ICLR, 2019.
- Williams et al. [2017] G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou. Information theoretic mpc for model-based reinforcement learning. In 2017 IEEE international conference on robotics and automation (ICRA), pages 1714–1721. IEEE, 2017.
- Li et al. [2022] C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Martín-Martín, C. Wang, G. Levine, M. Lingelbach, J. Sun, M. Anvari, M. Hwang, M. Sharma, A. Aydin, D. Bansal, S. Hunter, K.-Y. Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, S. Savarese, H. Gweon, K. Liu, J. Wu, and L. Fei-Fei. BEHAVIOR-1k: A benchmark for embodied AI with 1,000 everyday activities and realistic simulation. In 6th Annual Conference on Robot Learning, 2022.