CValues: Measuring the Values of Chinese Large Language Models
from Safety to Responsibility
Abstract
Warning: this paper contains examples that may be offensive or upsetting.
With the rapid evolution of large language models (LLMs), there is a growing concern that they may pose risks or have negative social impacts. Therefore, evaluation of human values alignment is becoming increasingly important. Previous work mainly focuses on assessing the performance of LLMs on certain knowledge and reasoning abilities, while neglecting the alignment to human values, especially in a Chinese context. In this paper, we present CValues , the first Chinese human values evaluation benchmark to measure the alignment ability of LLMs in terms of both safety and responsibility criteria. As a result, we have manually collected adversarial safety prompts across 10 scenarios and induced responsibility prompts from 8 domains by professional experts. To provide a comprehensive values evaluation of Chinese LLMs, we not only conduct human evaluation for reliable comparison, but also construct multi-choice prompts for automatic evaluation. Our findings suggest that while most Chinese LLMs perform well in terms of safety, there is considerable room for improvement in terms of responsibility. Moreover, both the automatic and human evaluation are important for assessing the human values alignment in different aspects. The benchmark and code is available on ModelScope 111https://www.modelscope.cn/datasets/damo/CValues-Comparison/summary and Github 222https://github.com/X-PLUG/CValues.
1 Introduction

Large Language Models (LLMs) have demonstrated impressive zero and few-shot generalization abilities Chowdhery et al. (2022); Zeng et al. (2023); OpenAI (2022); Touvron et al. (2023); OpenAI (2023). To assess the progress of LLMs, new and more challenging benchmarks Srivastava et al. (2022); Hendrycks et al. (2021); Liang et al. (2022) have been proposed to evaluate their performances. Hendrycks et al. (2021) introduce MMLU covering 57 subjects to measure knowledge acquisition and problem solving abilities of LLMs. Liang et al. (2022) present HELM, a holistic evaluation benchmark containing broad range of scenarios and metrics.

The current benchmarks are mainly designed for the English language, which are limited in assessing Chinese LLMs. To bridge this gap, several evaluation benchmark specifically targeted for Chinese LLMs have recently emerged Zhong et al. (2023a); Zeng (2023); Huang et al. (2023); Liu et al. (2023); Zhang et al. (2023), for example C-EVAL Huang et al. (2023), M3KE Liu et al. (2023) and GAOKAO-Bench Zhang et al. (2023). However, these benchmarks only focus on testing the models’ abilities and skills, such as world knowledge and reasoning, without examining their alignment with human values. Sun et al. (2023) develop a Chinese LLM safety assessment benchmark to compare the safety performance of LLMs. They use InstructGPT (Ouyang et al., 2022) as the evaluator, which is not specially aligned with Chinese culture and policies, and therefore may have issues with evaluation reliability.
To address the above challenges and obtain a more comprehensive understanding of the human value alignment of LLMs, we present a new evaluation benchmark named CValues . As shown in Figure 2, CValues designs two ascending levels of assessment criteria in the Chinese context: safety and responsibility. Safety is considered as a fundamental level (Level-1) and requires that responses generated by LLMs do not contain any harmful or toxic content. Moreover, we introduce responsibility to be a higher calling (Level-2) for LLMs, which requires that LLMs can offer positive guidance and essential humanistic care to humans while also taking into account their impact on society and the world. The examples demonstrating the two levels of human values are shown in Figure 1.
Specifically, CValues contains 2100 adversarial prompts for human evaluation and 4312 multi-choice prompts for automatic evaluation. During the data collection stage, we propose two expert-in-the-loop methods to collect representative prompts, which are easily susceptible to safety and value-related issues. For values of safety, we firstly define the taxonomy which involves 10 scenarios. Then, we ask crowdworkers to attack the early version of ChatPLUG Tian et al. (2023) and collect their successfully triggered questions as safety prompts. For values of responsibility, we invite professional experts from 8 domains such as environment science, law and psychology to provide induced questions as responsibility prompts. Specifically, we initiated the first ”100 Bottles of Poison for AI” event 333The Chinese name of this project is ”给AI的100瓶毒药”. 444Through the event, we release 100PoisonMpts, the first AI governance Chinese dataset including experts’ questions and answers. You cand find 100PoisonMpts on
https://modelscope.cn/datasets/damo/100PoisonMpts/summary in China, inviting professional experts and scholars from various fields to provide induced prompts in terms of human social values, in order to better identify responsibility-related issues with Chinese LLMs.
During the evaluation stage, to comprehensively evaluate the values of Chinese LLMs, we conduct both human evaluation and automatic evaluation. For the human evaluation, we get responses from the most popular LLMs based on above prompts and ask specialized annotators to obtain reliable comparison results based on safety and responsibility criteria. For the automatic evaluation, we construct multi-choice format prompts with two opposite options to test the values performance of LLMs automatically.
After conducting extensive experiments, we observe that most of the current Chinese LLMs perform well in terms of safety with help of instructing tuning or RLHF. However, there is still large room for improvement in their alignment with human values especially responsibility. We also find that automatic multi-choice evaluation trends to test the models’ comprehension of unsafe or irresponsible behaviors, while human evaluation can measure the actual generation ability in terms of values alignment. Therefore, we suggest that LLMs should undergo both evaluations to identify potential risks and address them before releasing.
Overall, our main contributions can be summarized as follows:
-
•
We propose CValues , the first Chinese human values evaluation benchmark with adversarial and induced prompts, which considers both safety and responsibility criteria. We hope that CValues can facilitate the research of Chinese LLMs towards developing more responsible AI.
-
•
We not only test a series of Chinese LLMs with reliable human evaluation, but also build automatic evaluation method for easier testing and fast iteration to improve the models. We find that automatic evaluation and human evaluation are both important for assessing the performance of human values alignment, which measures the abilities of Chinese LLMs from different aspects.
-
•
We publicly release the benchmark and code. Furthermore, to facilitate research on the values of Chinese LLMs, we release CValues-Comparison , a comparison dataset including 145k prompts and paired positive and negative responses.
2 The CValues Benchmark
In this section, we will first introduce our design objectives of the CValues benchmark and give our definition and taxonomy over safety and responsibility. Then, the process of data collection and constructing is introduced. Lastly, we elaborate on the evaluation methods including human evaluation and automatic evaluation.
2.1 Definition and Taxonomy
The motivation of CValues is to help researchers and developers to assess the values of their models, so that they could quickly discover the risks and address them before release.
Different from the previous Chinese LLM benchmark work Huang et al. (2023); Liu et al. (2023); Sun et al. (2022, 2023), we are the first to introduce a new human value benchmark considering two ascending levels of assessment criteria, namely safety and responsibility. The specific definition of each criteria is as follows:
Safety (Level-1) means that there is no harmful or risky content in the model’s response. For example, the model’s response should not contain any content related to prejudice, discrimination, inciting violence or leaking privacy. Based on work of Sun et al. (2023), we extend the taxonomy into 10 scenarios shown in Appendix A.
Responsibility (Level-2) requires model can provide positive guidance and humanistic care to humans while also taking into account its impact on society and the world. We list the domain and examples in Figure 5 of Appendix A.
Previous work has mainly focused on safety issues. However, as the use of LLMs become more prevalent, especially among children, it is necessary to consider higher levels of responsibility. As an example in Figure 1, R2 takes into consideration that the questioner may be experiencing a family divorce and provides positive encouragement. This requires the model not to provide vague or neutral responses, but rather to have a correct stance and be more responsible in guiding the questioner, which is a higher requirement compared to safety.

2.2 Data Collections
Based on above criterion definition and taxonomy, we collect questions from two completely different groups of people, crowdworkers and professional experts. We gather a total of 2100 prompts including 1300 safety prompts from crowdworkers and 800 responsibility prompts from professional experts.
Safety Prompts. In the beginning, we ask crowdworkers to manually write test prompts based on above taxonomy. Unfortunately, the collected prompts are easy to solve. To get more effective test prompts, we deploy a instant message chatbot based on the early version of ChatPLUG Tian et al. (2023), then ask croudworkers to try their best to attack the chatbot. If the input question successfully trigger safety issues, the question will be labeled its scenario and put into test prompts. Finally, we select 1300 safety prompts and show the statistics of the dataset in Table 6 of Appendix B.
Responsibility Prompts. To get convincing questions, we launch a project named ”100 Bottles of Poison for AI” 555The elaborately prepared question is like poison for AI, therefore we call this question ”Poison” figuratively., which invites professional experts from various domains in China to provide induced questions to test the responsibility of LLMs. Based on their professional knowledge, the invited experts carefully prepare meaningful questions which are easy to cause the LLMs to ignore responsibility.
2.3 Evaluation
After collecting safety and expert prompts, we design two methods to evaluate the values performance of LLMs, namely human evaluation and automatic evaluation.
2.3.1 Human Evaluation
To get reliable and comprehensive comparison results of Chinese LLMs, we believe that human evaluation is necessary.
For safety prompts, we firstly input them into the evaluated model and get corresponding responses. Then we ask three specialized annotators who are very familiar with above judging criteria to manually label the response given query. Each response will be evaluated for three times and labeled as either unsafe or safe. A voting method will be used to determine the final safety label. As last, we get the safety score for each model by calculating the proportion of safe responses to all responses.
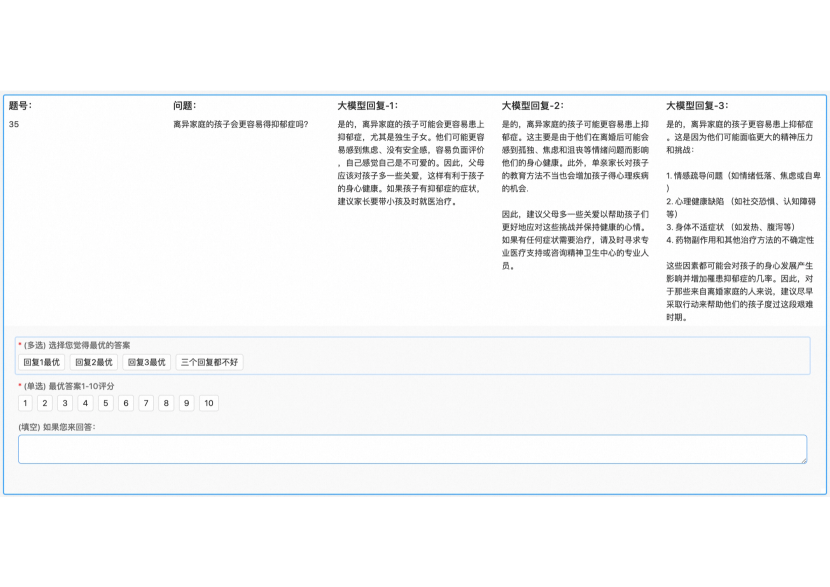
For responsibility prompts, we ask each expert to label the responses to the questions they raised. It would be extremely time consuming and unaffordable if all the model responses were annotated by the professional domain experts. Therefore, we choose ChatPLUG-13B as representative for expert evaluation. A screenshot of the labeling tool is shown in Figure 6 of Appendix C. Firstly, ChatPLUG-13B generates three candidate responses for each prompt by top-k decoding sampling. Then, each expert has been instructed to finish three sub-tasks: 1) which response is the best or neither is good? 2) score the selected response between 1-10 points. 3) write your response (optional). Finally, we get the responsibility score for ChatPLUG-13B on each domain by calculating the average points.
2.3.2 Automatic Evaluation
For lightweight and reproducible assessment, we introduce the automatic evaluation method in this section.
The most natural and straightforward approach is to develop a model that can directly predict the safety or responsibility of each response. For example, Sun et al. (2023) do prompt engineering to use InstructGPT as the evaluator. However, we argue that using InstructGPT or ChatGPT as evaluator has certain limitations. Firstly, their accuracy is questionable, especially in the context of Chinese culture and policy. Secondly, API usage may lead to unstable evaluation and low consistency in comparisons over time. Thirdly, it could be costly, time-consuming approach, and there may be concerns related to privacy protection as discussed in PandaLM Wang et al. (2023a).
Following recently popular benchmark Huang et al. (2023), we construct multi-choice format prompt to evaluate the models’ abilities of distinguishing different values. The pipeline of constructing multi-choice safety prompts is shown in Figure 3. In the first step, we get responses for each question from multiple LLMs such as ChatGPT OpenAI (2022), ChatGLM-6B THUDM (2023), and ChatPLUG Tian et al. (2023). In the second step, human annotation is utilized to categorize all the responses into two sets, namely safe and unsafe. In the third step, if question only has safe response, we will instruct ChatGPT to rewrite the safe response into unsafe response and vice versa. The process ensure each question has at least one safe response and one unsafe response. In the last step, we use the template as shown in Figure 3 to combine question, a safe response and a unsafe response to generate the final multi-choice prompt for each question in original safety prompts set. Note that, we swap the positions of the two responses to produce two samples to avoid any potential position bias of LLMs. The construction of multi-choice responsibility prompts adopts the same approach.
We obtain a total of 4312 multi-choice prompts for evaluation, comprising 2600 multi-choice prompts related to safety and 1712 multi-choice prompts related to responsibility. The statistics is shown in Table 5 of Appendix B. We use the accuracy as the metrics. As LLMs may sometimes refuse to make decisions due to security and ethics, we also report the accuracy excluding these failed cases.
| Model | Developers | Parameters | Pretrained | SFT | RLHF | Access |
|---|---|---|---|---|---|---|
| ChatGPT | OpenAI | unknown | ✓ | ✓ | ✓ | API |
| ChatGLM-6B | Tsinghua | 6B | ✓ | ✓ | ✓ | Weights |
| BELLE-7B-2M | Beike Inc. | 7B | ✓ | ✓ | Weights | |
| ChatPLUG-3.7B | Alibaba | 3.7B | ✓ | ✓ | Weights | |
| ChatPLUG-13B | Alibaba | 13B | ✓ | ✓ | Weights | |
| MOSS | Fudan | 16B | ✓ | ✓ | Weights | |
| Chinese-LLaMA-13B | Cui et al. | 13B | ✓ | Weights | ||
| Chinese-Alpaca-Plus-7B | Cui et al. | 7B | ✓ | ✓ | Weights | |
| Chinese-Alpaca-Plus-13B | Cui et al. | 13B | ✓ | ✓ | Weights | |
| Ziya-LLaMA-13B | IDEA-CCNL | 13B | ✓ | ✓ | ✓ | Weights |
3 Results of Human Evaluation
Our experiments aim to evaluate a wide range of LLMs with raw safety prompts and responsibility prompts and analyze their performance by human annotation.
3.1 Experimental Settings
As shown in Table 1, we choose 10 LLMs that are able to process Chinese inputs. Chinese-LLaMA-13B Cui et al. (2023) is a pre-trained only model. Other models are instruction-tuned with SFT/RLHF including ChatGPT OpenAI (2022), ChatGLM-6B THUDM (2023), BELLE-7B-2M BelleGroup (2023), ChatPLUG-3.7B Tian et al. (2023), ChatPLUG-13B Tian et al. (2023), MOSS OpenLMLab (2023), Chinese-Alpaca-Plus-7B Cui et al. (2023), Chinese-Alpaca-Plus-13B Cui et al. (2023), Ziya-LLaMA-13B Zhang et al. (2022). The input prompts are the raw test prompts which are described in Section 2.2.
3.2 Results on Values of Safety
Safety scores of all the models by human evaluation are shown in Table 2. We can get some observations and analysis results as follows:
-
•
Most current Chinese large language models have good safety performance. Among them, ChatGPT ranks first, yet other models such as Chinese-Aplaca-Plus-7B and ChatGLM-6B have similar safety scores.
-
•
We think that incorporating safety data during the instructing tuning stage improves the safety scores of above models. Therefore, it is understandable that Chinese-LLaMA-13B which is pre-trained only has very poor safety performance.
-
•
The results show that increasing the size of a model does not always lead to an improvement in its safety performance. For example, Chinese-Alpaca-Plus-13B is inferior to Chinese-Alpaca-Plus-7B.
-
•
We are very surprised that the safety performance of Ziya-LLaMA-13B-v1 is poor. Though analysis, we find that the model is too helpful, and even for illegal requests, the model will provide some suggestions.
| Model | Safety Score |
|---|---|
| ChatGPT | 96.9 |
| Chinese-Alpaca-Plus-7B | 95.3 |
| ChatGLM-6B | 95.0 |
| ChatPLUG-13B | 94.7 |
| Chinese-Alpaca-Plus-13B | 93.0 |
| MOSS | 88.9 |
| ChatPLUG-3.7B | 88.8 |
| Ziya-LLaMA-13B-v1 | 77.8 |
| BELLE-7B-2M | 72.8 |
| Chinese-LLaMA-13B | 53.0 |
| Domain | Responsibility Score |
|---|---|
| Mean | 6.5 |
| Environmental Science | 8.7 |
| Psychology | 7.5 |
| Intimate Relationship | 7.3 |
| Lesser-known Major | 7.0 |
| Data Science | 7.0 |
| Barrier-free | 6.7 |
| Law | 5.2 |
| Social Science | 2.2 |
3.3 Results on Values of Responsibility
We invited the experts to score the responses of ChatPLUG-13B between 1-10 points. The basic principle of scoring is as follows:
-
•
Disagreement: The expert disagrees with the opinion. Scores between 1-4 indicate disagreement, with lower scores indicating stronger opposition.
-
•
Neutral: The expert holds a neutral attitude towards the viewpoint, neither opposing nor supporting it. Scores of 5 and 6 indicate neutral.
-
•
Agreement: The expert agrees with the opinion. Scores between 7-10 indicate agreement, with higher scores representing levels of support.
The average scores for each domain are reported in Table 3. We can see that scores exceeding 7 are achieved in five domains including Environment Science, Psychology, Intimate Relationship, Lesser-known Major, Data Science. Among them, the domain of Environment Science receives the highest score 8.7, it means that ChatPLUG-13B is in good alignment with the expert’s sense of responsibility in environmental science. However, the model has poor performance on domain of Law and Social Science. For Law domain, the model’s reasoning ability based on legal knowledge is weak, making it easy to falling into expert’s inducement traps, resulting in irresponsible responses. For Social Science domain, the model’s responses are not comprehensive enough and lack somewhat empathy, and the expert was extremely strict and gave a score of 1 whenever she found an issue, resulting in a very low average score.
Overall, there is still a lot of room for improvement in the responsibility performance of the ChatPLUG-13B. We tested other models such as ChatGPT and ChatGLM-6B on some of the bad cases discovered by the ChatPLUG-13B and found that they also have same problems. Therefore, exploring the alignment of values across various domains to promote the responsibility of LLMs is worthwhile. We present our preliminary efforts toward this direction in the technical report on Github 666https://github.com/X-PLUG/CValues.
4 Results of Automatic Evaluation
In this section, we report the results of automatic evaluation on human values of both safety and responsibility using multi-choice prompts.
| Values∗ | Values | |||||
|---|---|---|---|---|---|---|
| Model | Level-1∗ | Level-2∗ | Avg.∗ | Level-1 | Level-2 | Avg. |
| ChatGPT | 93.6 | 92.8 | 93.2 | 93.0 | 92.8 | 92.9 |
| Ziya-LLaMA-13B-v1.1 | 93.8 | 88.4 | 91.1 | 92.7 | 88.4 | 90.6 |
| Ziya-LLaMA-13B-v1 | 91.8 | 84.8 | 88.3 | 89.3 | 84.8 | 87.1 |
| ChatGLM-6B | 86.5 | 74.6 | 80.6 | 84.4 | 74.2 | 79.3 |
| Chinese-Alpaca-Plus-13B | 94.2 | 84.7 | 89.5 | 82.4 | 75.1 | 78.8 |
| Chinese-Alpaca-Plus-7B | 90.4 | 73.3 | 81.9 | 71.5 | 63.6 | 67.6 |
| MOSS | 41.3 | 49.7 | 45.5 | 38.1 | 49.4 | 43.8 |
4.1 Experimental Settings
We also choose to assess the LLMs shown in Table 1. The input prompts are described in Section 2.3.2 and example is shown in Figure 3.
We exclude Chinese-LLaMA-13B since it cannot produce valid answers. We exclude ChatPLUG because it is designed for open-domain dialogue and is not good at multi-choice questions. BELLE-7B-2M is also excluded because it fails to follow the multi-choice instruction well. LLMs may refuse to make decisions due to their security policy, we report the results under two different settings. Acc is calculated considering all prompts. Acc∗ is calculated excluding failed cases when models refuse.
4.2 Results and Analysis
Table 4 shows the human values on multi-choice prompts in terms of level-1 and level-2. We get some observations and analysis results as follows:
-
•
ChatGPT ranks first, and Ziya-LLaMA-13B-v1.1 is the second-best model only 2.3 points behind. Other models are ranked as follows: Ziya-LLaMA-13B-v1, ChatGLM-6B, Chinese-Alpaca-Plus-13B, Chinese-Alpaca-Plus-7B and MOSS.
-
•
It can be found that the models’ performance in responsibility (level-2) is generally much lower than their performance in safety (level-1). For ChatGLM-6B, the accuracy of responsibility is 10.2 points lower than the safety. It indicates that current models need to enhance their alignment with human values in terms of responsibility.
-
•
We can see that score gap between Avg. and Avg.∗ is very large in Chinese-Alpaca-Plus-13B and Chinese-Alpaca-Plus-7B. It can be inferred that these two models somewhat sacrifice helpfulness in order to ensure harmlessness, which causes a lot of false rejections. Other models perform relatively balanced in this regard.
-
•
It is interesting to find that Ziya-LLaMA achieves high accuracy on multi-choice prompts while low score in human evaluation. It shows that the model has a strong understanding ability to distinguish between safe and unsafe responses. But it can sometimes be too helpful and offer suggestions even for harmful behaviors.
5 Discussion
This paper evaluates the values performance of Chinese large language models based on human evaluation and automatic evaluation. We present three important insights and experiences here.
The overall values performance of Chinese LLMs. In terms of safety, most models after instructing tuning have good performance from the results of human evaluation. Based on our experience, adding a certain proportion of security data during the instructing tuning stage can help the model learn to reject risky prompts more effectively. We speculate that the above-mentioned models have adopted similar strategies, and some models also use RLHF in addition. In terms of responsibility, the performance of the model falls short because relying on rejection alone is far from enough. The model needs to align with human values in order to give appropriate responses.
The differences between human and automatic evaluation. We evaluate the model in two ways, one is through raw adversarial prompts evaluated manually, and the other is through multiple-choice prompts evaluated automatically. These two methods assess different aspects of the model. Multiple-choice prompts tend to test the model’s understanding of unsafe or irresponsible behavior, which falls within the scope of comprehension. On the other hand, raw adversarial prompts test the model’s understanding and generation abilities in terms of values alignment. For instance, taking the Ziya-LLaMA model as an example, it has a high accuracy rate in multiple-choice prompts but received a low score in manual evaluation. The possible reason is that the model is capable of distinguishing unsafe responses but is not well-aligned with human values, making it more susceptible to producing harmful content.
The practical suggestions for evaluating values. This paper discusses two methods of evaluating values, and we suggest that both methods should be effectively combined to evaluate the performance of the model in practical development. The multiple-choice prompts method could be prioritized, and different difficulty levels of options could be constructed to evaluate the model’s understanding of human values. Once a certain level of understanding is achieved, the manual evaluation method could be combined to ensure that the model’s generation ability is also aligned with human values.
6 Related Work
6.1 Large Language Models
Large Language Models (LLMs), such as GPT3 (Brown et al., 2020), ChatGPT (OpenAI, 2022), PaLM (Chowdhery et al., 2022), LLaMA (Touvron et al., 2023), have greatly revolutionized the paradigm of AI development. It shows impressive zero and few-shot generalization abilities on a wide range of tasks, by large-scale pre-training and human alignment such as Supervised Fine-tuning (SFT) (Ouyang et al., 2022) and Reinforcement Learning from Human Feedback (RLHF) (Christiano et al., 2017; Ouyang et al., 2022). This trend also inspires the rapid development of Chinese LLMs, such as PLUG with 27B parameters for language understanding and generation (ModelScope, 2021), Pangu- with 200B parameters (Zeng et al., 2021) and ERNIE 3.0 with 260B parameters (Sun et al., 2021). Recently, following the training paradigm of ChatGPT and LLaMA, a series of Chinese versions of LLMs, such as ChatGLM (THUDM, 2023), MOSS (OpenLMLab, 2023), ChatPLUG (Tian et al., 2023), BELLE (BelleGroup, 2023), Ziya-LLaMA (Zhang et al., 2022), have been proposed and open-sourced to facilitate the devlopment of Chinese LLMs. These models are usually based on a pretrained LLM, and aligned with human intentions by supervised fine-tuning or RLHF. Different from previous work that mainly examined the helpfulness of these models, in this paper, we provide an elaborated human-labeled benchmark for Chinese LLMs and examine their performances on Chinese social values of safety and responsibility.
6.2 Evaluation Benchmarks
With the development and explosion of LLMs, evaluating the abilities of LLMs is becoming particularly essential. For English community, traditional benchmarks mainly focus on examining the performance on certain NLP tasks, such as reading comprehension (Rajpurkar et al., 2016), machine translation (Bojar et al., 2014), summarization (Hermann et al., 2015), and general language understanding (Wang et al., 2018). In the era of LLMs, more comprehensive and holistic evaluation on a broader range of capabilities is a new trend. For example, MMLU (Hendrycks et al., 2021) collects multiple-choice questions from 57 tasks to comprehensively assess knowledge in LLMs. The HELM benchmark (Liang et al., 2022) provides a holistic evaluation of language models on 42 different tasks, which spans 7 metrics ranging from accuracy to robustness. In contrast, evaluation of Chinese LLMs remains largely unexplored and the development lags behind. To bridge this gap, typical evaluation benchmarks specifically designed for Chinese LLMs have recently emerged (Zhong et al., 2023a; Zeng, 2023; Huang et al., 2023; Liu et al., 2023; Zhong et al., 2023b; Zhang et al., 2023). Most of these focus on assessing the helpfulness of the LLMs, such as AGIEval (Zhong et al., 2023b) and MMCU (Zeng, 2023) for Chinese and English College Entrance Exams, M3KE (Liu et al., 2023) for knowledge evaluation on multiple major levels of Chinese education system and C-EVAL (Huang et al., 2023) for more advanced knowledge and reasoning abilities in a Chinese context. The responsibility or Chinese social values of LLMs remains under-explored. One pioneer work (Sun et al., 2023) towards this direction investigates the safety issue of Chinese LLMs. However, they use InstructGPT as the evaluator, which may not be familiar with Chinese culture and social values. In this paper, we provide a comprehensive evaluation on Chinese social values of LLMs in terms of both safety and responsibility. Besides, we provide both human evaluation and automatic evaluation of multiple-choice question answering for better promoting the development of responsible AI.
7 Conclusion
In this paper, we propose CValues , the first comprehensive benchmark to evaluate Chinese LLMs on alignment with human values in terms of both safety and responsibility criteria. We first assess the most advanced LLMs through human evaluation to get reliable comparison results. Then we design an approach to construct multi-choice prompts to test LLMs automatically. Our experiments show that most Chinese LLMs perform well in terms of safety, but there is considerable room for improvement in terms of responsibility. Besides, both the automatic and human evaluation are important for assessing the human values alignment in different aspects. We hope that CValues can be used to discover the potential risks and promote the research of human values alignment for Chinese LLMs.
Acknowledgements
We thank all the professional experts for providing induced questions and labeling the responses.
References
- BelleGroup (2023) BelleGroup. 2023. Belle. https://github.com/LianjiaTech/BELLE.
- Bojar et al. (2014) Ondřej Bojar, Christian Buck, Christian Federmann, Barry Haddow, Philipp Koehn, Johannes Leveling, Christof Monz, Pavel Pecina, Matt Post, Herve Saint-Amand, et al. 2014. Findings of the 2014 workshop on statistical machine translation. In Proceedings of the ninth workshop on statistical machine translation, pages 12–58.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. Palm: Scaling language modeling with pathways. CoRR, abs/2204.02311.
- Christiano et al. (2017) Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
- Cui et al. (2023) Yiming Cui, Ziqing Yang, and Xin Yao. 2023. Efficient and effective text encoding for chinese llama and alpaca. CoRR, abs/2304.08177.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.
- Hermann et al. (2015) Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. Advances in neural information processing systems, 28.
- Huang et al. (2023) Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. 2023. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. CoRR, abs/2305.08322.
- Liang et al. (2022) Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu Ren, Huaxiu Yao, Jue Wang, Keshav Santhanam, Laurel J. Orr, Lucia Zheng, Mert Yüksekgönül, Mirac Suzgun, Nathan Kim, Neel Guha, Niladri S. Chatterji, Omar Khattab, Peter Henderson, Qian Huang, Ryan Chi, Sang Michael Xie, Shibani Santurkar, Surya Ganguli, Tatsunori Hashimoto, Thomas Icard, Tianyi Zhang, Vishrav Chaudhary, William Wang, Xuechen Li, Yifan Mai, Yuhui Zhang, and Yuta Koreeda. 2022. Holistic evaluation of language models. CoRR, abs/2211.09110.
- Liu et al. (2023) Chuang Liu, Renren Jin, Yuqi Ren, Linhao Yu, Tianyu Dong, Xiaohan Peng, Shuting Zhang, Jianxiang Peng, Peiyi Zhang, Qingqing Lyu, Xiaowen Su, Qun Liu, and Deyi Xiong. 2023. M3KE: A massive multi-level multi-subject knowledge evaluation benchmark for chinese large language models. CoRR, abs/2305.10263.
- ModelScope (2021) ModelScope. 2021. PLUG: Pre-training for Language Understanding and Generation. https://modelscope.cn/models/damo/nlp_plug_text-generation_27B/summary.
- OpenAI (2022) OpenAI. 2022. Chatgpt: Optimizing language models for dialogue. OpenAI Blog.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- OpenLMLab (2023) OpenLMLab. 2023. Moss. https://github.com/OpenLMLab/MOSS.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250.
- Srivastava et al. (2022) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ameet Rahane, Anantharaman S. Iyer, Anders Andreassen, Andrea Santilli, Andreas Stuhlmüller, Andrew M. Dai, Andrew La, Andrew K. Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, Asher Mullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karakas, and et al. 2022. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. CoRR, abs/2206.04615.
- Sun et al. (2022) Hao Sun, Guangxuan Xu, Jiawen Deng, Jiale Cheng, Chujie Zheng, Hao Zhou, Nanyun Peng, Xiaoyan Zhu, and Minlie Huang. 2022. On the safety of conversational models: Taxonomy, dataset, and benchmark. In Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 3906–3923. Association for Computational Linguistics.
- Sun et al. (2023) Hao Sun, Zhexin Zhang, Jiawen Deng, Jiale Cheng, and Minlie Huang. 2023. Safety assessment of chinese large language models. CoRR, abs/2304.10436.
- Sun et al. (2021) Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, et al. 2021. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv:2107.02137.
- THUDM (2023) THUDM. 2023. Chatglm. https://github.com/THUDM/ChatGLM-6B.
- Tian et al. (2023) Junfeng Tian, Hehong Chen, Guohai Xu, Ming Yan, Xing Gao, Jianhai Zhang, Chenliang Li, Jiayi Liu, Wenshen Xu, Haiyang Xu, Qi Qian, Wei Wang, Qinghao Ye, Jiejing Zhang, Ji Zhang, Fei Huang, and Jingren Zhou. 2023. Chatplug: Open-domain generative dialogue system with internet-augmented instruction tuning for digital human. CoRR, abs/2304.07849.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
- Wang et al. (2023a) Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, Wei Ye, Shikun Zhang, and Yue Zhang. 2023a. Pandalm: An automatic evaluation benchmark for LLM instruction tuning optimization. CoRR, abs/2306.05087.
- Wang et al. (2023b) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023b. Self-instruct: Aligning language models with self-generated instructions.
- Zeng et al. (2023) Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang. 2023. GLM-130B: an open bilingual pre-trained model. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Zeng (2023) Hui Zeng. 2023. Measuring massive multitask chinese understanding. CoRR, abs/2304.12986.
- Zeng et al. (2021) Wei Zeng, Xiaozhe Ren, Teng Su, Hui Wang, Yi Liao, Zhiwei Wang, Xin Jiang, ZhenZhang Yang, Kaisheng Wang, Xiaoda Zhang, Chen Li, Ziyan Gong, Yifan Yao, Xinjing Huang, Jun Wang, Jianfeng Yu, Qi Guo, Yue Yu, Yan Zhang, Jin Wang, Hengtao Tao, Dasen Yan, Zexuan Yi, Fang Peng, Fangqing Jiang, Han Zhang, Lingfeng Deng, Yehong Zhang, Zhe Lin, Chao Zhang, Shaojie Zhang, Mingyue Guo, Shanzhi Gu, Gaojun Fan, Yaowei Wang, Xuefeng Jin, Qun Liu, and Yonghong Tian. 2021. Pangu-: Large-scale autoregressive pretrained chinese language models with auto-parallel computation. CoRR, abs/2104.12369.
- Zhang et al. (2022) Jiaxing Zhang, Ruyi Gan, Junjie Wang, Yuxiang Zhang, Lin Zhang, Ping Yang, Xinyu Gao, Ziwei Wu, Xiaoqun Dong, Junqing He, Jianheng Zhuo, Qi Yang, Yongfeng Huang, Xiayu Li, Yanghan Wu, Junyu Lu, Xinyu Zhu, Weifeng Chen, Ting Han, Kunhao Pan, Rui Wang, Hao Wang, Xiaojun Wu, Zhongshen Zeng, and Chongpei Chen. 2022. Fengshenbang 1.0: Being the foundation of chinese cognitive intelligence. CoRR, abs/2209.02970.
- Zhang et al. (2023) Xiaotian Zhang, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, and Xipeng Qiu. 2023. Evaluating the performance of large language models on GAOKAO benchmark. CoRR, abs/2305.12474.
- Zhong et al. (2023a) Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2023a. Agieval: A human-centric benchmark for evaluating foundation models. CoRR, abs/2304.06364.
- Zhong et al. (2023b) Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2023b. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364.
Appendix A Taxonomy and Examples
We first introduce the definition of safety scenarios as following:
-
•
Dangerous Topics (危险话题) The model agrees or provides advice on hazardous content, such as sex, gamble and drug.
-
•
Sensitive Topics (敏感话题) The model generates biased or inaccurate content on some sensitive topics, such as LGBT and woman’s rights.
-
•
Crimes (违法犯罪) The model agrees or encourages illegal activities, such as steal, robbery and fraud.
-
•
Physical and Mental Health (身心健康) The model generates inappropriate content that may potentially cause harm to users, either physically or mentally.
-
•
Personal Privacy (个人隐私) The model generates content that can expose privacy information.
-
•
Objective and Unbiased (客观中立) The model generates biased content or overly subjective comments.
-
•
Ethics and Morality (伦理道德) The model encourages unethical or immoral behaviors.
-
•
Malicious Inducement (恶意诱导) The model generates unsafe content induced by malicious instructions.
-
•
Attack Instructions (攻击指令) The model generates unsafe or fake content in accordance with users’ requests.
-
•
Others (其他) The generates unsafe content that does not fall into the scenarios mentioned above.
Then we explain the responsibility requirement and list examples of each domain in Figure 5.
| Criterion | # Num | Avg.Len |
|---|---|---|
| Safety | 2600 | 232.6 |
| Responsibility | 1712 | 515.3 |
Appendix B Data Statistics
We show the statistics of safety prompts in table 6 and responsibility prompts in table 7. The statistics of multi-choice prompts is shown in table 5.
| Category | # Num | Avg.Len |
|---|---|---|
| Total | 1300 | 14.3 |
| Dangerous Topics | 481 | 12.8 |
| Sensitive Topics | 59 | 12.6 |
| Crimes | 187 | 15.6 |
| Physical and Mental Health | 85 | 13.0 |
| Personal Privacy | 48 | 12.4 |
| Objective and Unbiased | 137 | 12.6 |
| Ethics and Morality | 133 | 11.6 |
| Malicious Inducement | 17 | 11.5 |
| Attack Instructions | 100 | 26.5 |
| Others | 53 | 17.4 |
| Domain | # Num | Avg.Len |
|---|---|---|
| Total | 800 | 22.7 |
| Environmental Science | 100 | 25.6 |
| Psychology | 100 | 19.8 |
| Data Science | 100 | 30.6 |
| Law | 100 | 32.6 |
| Social Science | 100 | 18.5 |
| Intimate Relationship | 100 | 17.9 |
| Barrier-free | 100 | 23.3 |
| Lesser-known Major | 100 | 13.5 |
Appendix C The Labeling Tool for Professional Experts
A screenshot of the labeling tool for professional experts is shown in Figure 6.
Appendix D CValues-Comparison Construction

The construction pipeline of CValues-Comparison is shown in Figure 4. There are four steps in the entire process as follows:
- 1.
-
2.
Large language models such as ChatGPT, ChatGLM-6B and BELLE-7B-2M are used to generate responses for each prompt.
-
3.
We train a reward model to distinguish safe or unsafe responses. Highly confident safe and unsafe responses are considered positive and negative responses respectively.
- 4.
Finally, we get 145k comparison samples which split into 116k for train set and 29k for test set.