∎
2 Instituto Politécnico Nacional (IPN), Centro de Inovación y Desarrollo Tecnológico en Cómputo (CIDETEC), Ciudad de México, México
3Consejo Nacional de Ciencia y Tecnología (CONACYT) Ciudad de México, México
Custom Distribution for Sampling-Based Motion Planning
Abstract
Sampling-based motion planning algorithms are widely used in robotics because they are very effective in high-dimensional spaces. However, the success rate and quality of the solutions are determined by an adequate selection of their parameters such as the distance between states, the local planner, and the sampling distribution. For robots with large configuration spaces or dynamic restrictions, selecting these parameters is a challenging task. This paper proposes a method for improving the performance to a set of the most popular sampling-based algorithms, the Rapidly-exploring Random Trees (RRTs) by adjusting the sampling method. The idea is to replace the uniform probability density function (U-PDF) with a custom distribution (C-PDF) learned from previously successful queries in similar tasks. With a few samples, our method builds a custom distribution that allows the RRT to grow to promising states that will lead to a solution. We tested our method in several autonomous driving tasks such as parking maneuvers, obstacle clearance and under narrow passages scenarios. The results show that the proposed method outperforms the original RRT and several improved versions in terms of success rate, tree density and computation time. In addition, the proposed method requires a relatively small set of examples, unlike current deep learning techniques that require a vast amount of examples.
Keywords:
sampling-based motion planning RRT bias sampling autonomous driving autonomous parking1 Introduction

The motion planning problem can be defined as the task of determining the set of inputs for an open-loop control that drives the robot from an initial state to a goal state in a collision-free state space while the kinematic and differential constraints are satisfied b1 . Motion planning has been investigated from different perspectives b14 using techniques such as potential fields, neural networks b29 or genetic algorithms b30 to name a few. In particular, we are interested in motion planning for autonomous vehicles where the problem has been addressed from formal approaches like control theory b27 to machine learning. For a complete review, the reader is referred to b26 .
In the last decades, the attention has been focused on sampling-based motion planners (SBMP) due to their simplicity and good performance even in high dimensional spaces b24 . For sampling-based methods, there are two main approaches: the single-query models and multi-query models. For example, the rapidly exploring random tree (RRT)b5 and the probabilistic roadmap (PRM)b4 respectively. Based on them, a large variety of ideas have emerged to cover the weak aspects in order to improve the quality of the solutions or to reduce the computational time. A good example is the RRT*b12 variation where the solution converges to the optimum and more recently the Stable Sparse RRT (SST)b10 method that produces sparse trees or the Fast Marching Tree (FMT*)b28 for complex motion planning problems. Other works have been focused on tuning the algorithm parameters; for example, recent methods use reinforcement learning to establish the distance metric b6 , the local planner strategy b13 or the probability distribution b7 . Unfortunately, these approaches require a very large number of examples to infer knowledge, because they are based on deep learning. Nevertheless, we share the enthusiasm of exploring the cross-field between motion planning and machine learning. Some examples in this field are: in b29 , the method uses a neural planner, in b25 the planning is carried out in a learned representation that reduces the state space and in b32 , a convolutional neuronal network (CNN) is used to generate a non-uniform sampling.
This paper studies the way by which the planner samples the state space. In this sense, typically a uniform sampling distribution (U-PDF) is the first option because it produces a graph or roadmap that spans evenly over the free state space. However, in some cases it is not the best choice. For example, in planners such as the PRM; a uniform distribution has poor performance in environments where there are narrow passages because these regions are poorly sampled. To solve the aforementioned problem, some techniques oversample such passages, e.g. the bridge test b9 or the medial axis methodb34 , which allows refining the connectivity in narrow passages or the Gaussian sampling strategy b15 , b8 , whose objective is to obtain a model of the free state spaces, including these difficult passages; other approaches focus on extracting local characteristics from the workspace for biasing the sampling b17 , b18 , b19 . These hybrid sampling strategies are appropriate for planners with a multi-query model like PRM because they maintain a connected roadmap, and this offers the possibility of reusing the roadmap for different queries. But for a single-query model it may be impractical because each query needs to create a new graph hence covering the complete work-space might be unnecessary, while it is more important to achieve a high convergence rate and low computational cost. For this reasons, it is very important to explore new ways to efficiently sample the state space, specially when a small dataset of examples is available. Some works combine techniques from different areas, e.g. b22 , where the authors combine the advantages of SBMP with graph-based sampling techniques.
For a single-query model like the RRT or any tree-based algorithm, the traditional approach consists of sampling the space randomly with a U-PDF and growing the tree iteratively until the goal state is reached. One way to improve the performance is to find a method for guiding the tree growth. For example, in b16 and b20 , the tree is guided by selecting the option of expansion with maximal expected utility but, this type of method modifies the structure of the algorithm, which can be hard to implement. Other works, such as b21 , reuse the found paths by developing a framework to improve the performance with respect to the computing time.
In this way, recent works use the knowledge from previous experience to improve performance. This emerging field, denominated experience based-planning b31 , takes vantage on the suppose that the workspace is similar in multiples tasks. Therefore, previous paths can be useful for futures tasks. For example, in b23 and b33 the previous knowledge is used to reduce the query resolution time.
The proposed method uses the knowledge from previous queries to improve the sampling function. Our hypothesis is that for each environment there is a more appropriate sampling function different from the uniform distribution. It focuses on tuning the probability density function used in the sampling method so that it builds sparser trees and at the same time it increases the success rate with relatively few samples. See Figure 1 as example. In other words, we are interested in guiding the tree by only replacing the sampling function without making further modifications to the algorithm. We have compared our method versus the classic version of RRT with a uniform distribution and versus an RRT version with the distribution skewed by the target state (RRT-goal-bias) in five tasks, task 1 is a low speed obstacle avoidance, tasks 2 and 3 are parking manoeuvres, task 4 is a more complex environment with narrow passages and task 5 is a high speed obstacle avoidance. The experiments show that our method generates directed trees that are especially useful in environments where the robot has a similar goal but its initial state varies. Direct trees imply a lower computing time; for robotic tasks where we need a solution path almost immediately, reducing the planning time while maintaining or improving the success rate for the algorithm is a critical problem for autonomous navigation. For this reason, the proposed experiments are useful tasks for autonomous driving cars, like autonomous parking and evasive maneuvers at low and high speeds. Our method minimizes the effects of a not well-adapted sampling domain and has significant improvement over classic RRT. In addition, our results provide evidence that the method can be applicable across other planners or robotic platforms.
The rest of the paper is organized as follows. In section 2, we present the generality of RRT algorithm and its parameters for the three proposed environments. In section 3, we make the description of the proposed method. In section 4, we present the numerical results about our custom distribution compared against the classic RRT and goal-bias version. Finally, in section 5, we present the conclusions and future work.
2 Theoretical background
This section briefly describes the RRT algorithm and its parameters such as the robot model, the distance metric and the environment for the proposed tasks.
2.1 Robot model
For the presented experiments, we define the robot’s State Transition Equation (STE) with a kinematic model (in sub-section 2.1.1) for tasks with low-speed profile and as a dynamic model (in sub-section 2.1.2) for tasks that involve a high-speed profile.
2.1.1 Kinematic model
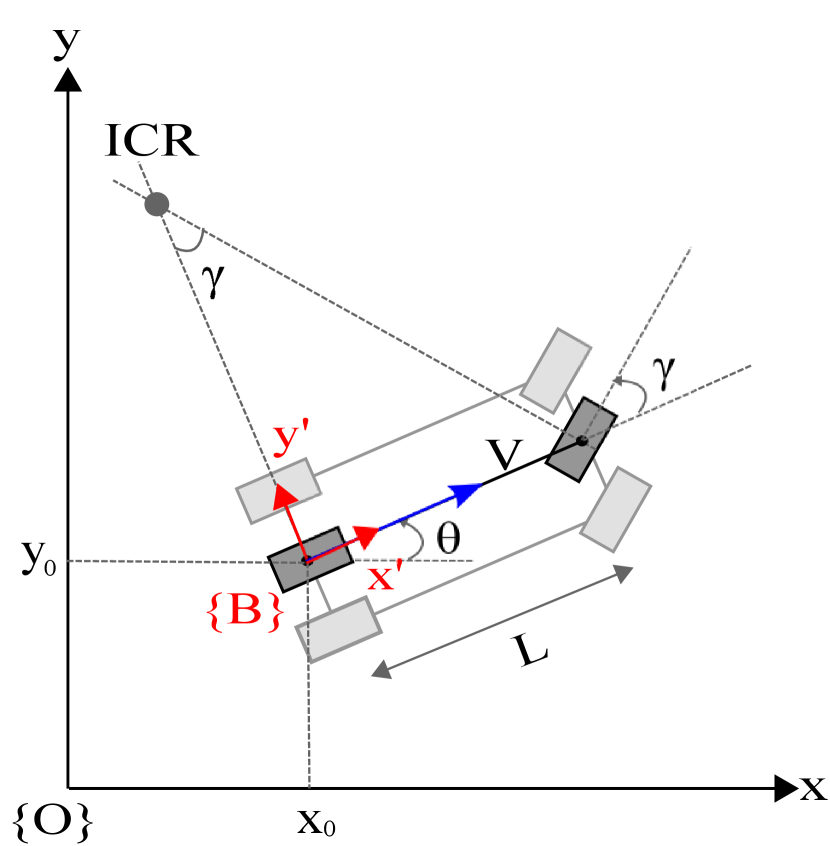
For the kinematic model, the STE is defined by a non-linear ordinary differential equation presented in column vector form in equation (1). The reader can be deduced this equation from the diagram in Figure 2.
| (1) |
Let denoted the state space such that , where is the set of coordinates in the inertial frame. Then, and define position on the plane and defines the car orientation. This model is suitable for tasks that involve low velocity of translation where it is not necessary considerate a tire model. From equation (1) the variable represents the robot input such that . See equation (2).
| (2) |
where is the translational velocity and, is the steering angle of the front wheels. It is important to point out that a car-like vehicle has the non-holonomic constraint , which limits its ability to move in arbitrary directions b3 , making difficult some tasks like parking manoeuvres.
2.1.2 Dynamic model
For the task with a high-speed profile, we defined the STE according to equation (3). This model is obtained from the analysis of the diagram of forces shown in Figure 3 where we presented a bicycle model of a car-like robot with traction in front an rear tires.
| (3) |
Where and symbolizes the components for translation velocity and the rotational velocity about the z-axis. The physical parameters of the model are the mass (), the momentum of inertia about z-axis () and the distance to center of mass from the rear () and front () wheels. This values are taking from Table 2. The control input is defined according to 4
| (4) |
From the equation 4 the forces and denotes the traction in the front and rear tires, indicates the steering angle and the transverse stiffness coefficient that we estimate for the model car as () with this coefficient we can calculated the lateral forces in the tires and agree with and where the slip angles and are approximated as for the front tire and for the rear tire.

2.2 Rapidly-exploring random trees
Sampling-based motion planning is a set of incremental sampling and searching algorithms. Their target is to avoid the explicit construction of the obstacle space, , and to explore the state space, , with a sampling scheme b1 . The RRT is a special case of the family referred to as rapidly exploring Dense Trees (RDTs); these algorithms have a dense covering of the , and this feature allows them to be probabilistically complete. The goal is to build a topological graph or tree denoted by where each vertex is a state, and each edge is a path that connects two vertices inside the free space \ b1 . Unlike PRM b1 , the RRT follows a single-query model, for each query defined by a initial and goal state , the planner returns a tree and whether the query was successful, a branch of the tree is a path to the goal state. In short, the RRT algorithm b1 follows the steps shown in Algorithm 1.
The Vertex Selection Method (VSM) consist of generating a random vertex between the proposed lower and upper state limits and finding the nearest existing vertex, according to a metric function then, if this vertex is an element of the free state space, , and it satisfies the conditions of Local Planning Method (LPM), this vertex is added to the tree as a new vertex, . If the method reaches a solution it returns true and the algorithm finish, in other case, it returns to the VSM, this process is repeated for iterations.
2.3 Metric functions
To determine the similarity between two states, we propose the functions described in sub-section 2.3.1 for the kinematic model and a function for dynamic model in sub-section 2.3.2.
2.3.1 Metric for kinematic model
For the kinematic model the similarity between two states and is a weighted and normalized sum defined by the equation (5).
| (5) |
where and determine the similarity between position and orientation, equations (6) and (7) respectively. In equation (6) the pairs () and () are the maximum and minimums values for the position states. The variables and weigh the metrics for each of the proposed tasks and, they are statistically determined in every environment. In the cases presented with a kinematic model, task 1 and 4 , and for task 2 and 3 , . The weight’s value change according to the relevance of being well-oriented or shortening distances to the objective for the current task.
| (6) |
| (7) |
2.3.2 Metric function for dynamic model
For the dynamic model the similarity between two states
and
is calculated in equation (8) formed with the contribution of equation (9) for the position and orientation states and equation (10) for the dynamic variables.
| (8) |
| (9) |
| (10) |
Let that denoted a value to weighted the sum according to a specific characteristic of the problem.
3 Custom sampling distribution
In this section, we propose a methodology for constructing a custom probability density function (C-PDF) that will be used by the planner in order to improve its performance in similar tasks. The methodology consists of executing the RRT planner for an initial query that we denominated the construction query. If the construction query produces a successful path, then we collect specific data from the generated samples; otherwise, we discard the samples. We repeat this process until reaching samples to approximate a C-PDF. Finally, we use this function together with the rejection sampling method b2 as sampling source in a new set of queries improving the planner performance. In section 3.1, we explain the details of this process taking the environment of task 1 as example and in section 3.2, we explain the details of the sampling method.
3.1 Collecting data
Let us suppose that a uniform distribution, , draws the samples during the tree construction. In ideal conditions, each random sample () should generate a new vertex () for the tree, . But for different reasons, e.g., falls in the obstacle space or the new vertex is worst than the nearest vertex in terms of the metric function, only a reduced percentage of samples produces a vertex. We call to the set of samples from that generates a new vertex in the tree as . Note that are random states and in the majority of the cases they do not correspond to the vertices in the tree; therefore, they do not contain the solution path. However, these random samples contain information for directing the tree growth. So, for several queries, if one of them is successful then there is a branch in that solves the query. This branch is the solution path and it is written as . has elements and each one was drawn from a corresponding element in . So, we call to the sub-set of that generated as . See Figure 4.


By analyzing , we can notice that these samples follow a different distribution compared with the original and this trend continues for each new test for the same query. An example of this process can be seen in Figure 5. So, our hypothesis is that a solution path can be directly drawn from a distribution , which is different from . Since is unknown, our objective is inferring its shape by collecting a significant number of samples. To do this, we make several queries to the planner and we store the samples until elements are collected.
The collection process is summarized in Algorithm 2. Where the output is the set that denotes the set of samples that approximates . Note that is the set of samples, obtained from , accumulated after repeating the construction query and, is the set of samples after a single query. Please note that the sets , , and are obtained from a sampling process to guide the growth of the graph, and hence they might not be part of the graph, unlike the sets and which belong to .
Let denote the RRT path planning described in Algorithm 3 and the method for finding a path within . Please note that Algorithm 2 is proposed in b24 , we only add a simple modifications highlighted in gray to save and return the tree together with the sets and . The line in uses the tree along with the initial and goal state as inputs for the function to find the path . Finally in lines to , if is not an empty set, then we retrieve the samples that build the path in this case the function receives the element together with the sets and to seeks the correspondent sample, otherwise we do not add samples. The process continues until samples are reached.
An open question is about how many samples, , we need to approximate ; for now is the number of collected samples after a fixed number of tests for a single o multiples construction queries. The complete information about the collecting process for each task is available in Table 1. The reader can see in Figure 6 the collecting process for one test in task 1.
| Task |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | single(1) | 20 | 0.4 | 541 | ||||||||
| 2 | single(1) | 20 | 0.6 | 1464 | ||||||||
| 3 | single(1) | 20 | 0.45 | 583 | ||||||||
| 4 | multiple(10) | 10 | 0.18 | 2110 | ||||||||
| 5 | single(1) | 10 | 0.7 | 134 |


3.2 Sampling data from the custom distribution
Once we have several samples, then we use the rejection sampling method to generate new samples. Since is unknown and it is only approximated, we call to the actual distribution C-PDF (custom PDF), where C-PDF is composed by the set . In order to find the C-PDF, we need express the states variables in a normalized sampling space. For this purpose, we use the equation (11).
| (11) |
The sub-script iterates for each state variable, the sub-script iterates for each element of the set ; and are the lower and upper limits in the . Applying the equation (11) to each element, we obtain the sampling space for the state variables in each environment.
There are two ways for drawing new samples: i) to consider the elements of the state as independent variables or ii) to include the correlation between them. In the experiment section, we test both cases. For the tasks with a low dimension state space, task 1, 2, 3, we express all the random variables as independent random variables. Where they are divided in ten bins to generate the histograms shown in Figure 6. To improve the results in tasks with a more complex environment and with a larger search space. For the task 4 and 5, we consider the correlation between random variables, see Figure 11 and 7. In both cases, we use the rejection sampling method b2 to generate the C-PDF into the parameters of the planner. The idea of this method is sampling a target distribution usually normalized from a more simple distribution denominated proposal distribution. To apply the method we need to propose a scaling constant such that i.e. the scaling proposal distribution covers the target distribution over the range of . The next step is to generate a random number from the scaled proposal distribution and to propose a candidate sample in the interval if the then the sample is accepted in other case is rejected. For a detailed explication the reader is refereed to b2 . We implemented a discrete version of this method using a uniform distribution as proposal distribution and each one of the distributions formed by the variables as target distribution. To differentiate the cases when we reconstruct the C-PDF with correlation we call it C*-PDF
4 Experiments
To evaluate the proposed methodology, we select environments that represent common tasks in the autonomous driving scene. First, we proposed three scenarios with equal dimensions but with different obstacle space distribution, tasks 1 to 3. In task 4, we proposed an environment with a larger search space and narrow passages. Finally, for task 5, we used a high-dimensional state space for a dynamic model. The proposed environments were designed for a test robot of scale 1:10 with the characteristics described in Table 2. For all the experiments, the test queries are a set of random queries with the same for which the C distribution was built, but a random
| Car-like robot | |
|---|---|
| Height | m |
| Length | m |
| Width | m |
| Distance between axis() | m |
| Rear distance to center of gravity | m |
| Front distance to center of gravity | m |
| Mass() | kg |
| Moment of inertia () | |
We describe in sub-section 4.1 the generality of proposed environments. In sub-section 4.2, we describe the performance metrics. In the section 4.3, we expose the comparative results for tasks 1 to 3 between the U-PDF and the C-PDF and the RRT goal bias version (GB-PDF) for a group of ten random queries. For task 4 and task 5, we expose the comparative for U-PDF, GB-PDF, C-PDF and C*-PDF for a group of three and five random queries respectively.

4.1 Proposed tasks

All the tasks are defined in a , such that it contains an obstacle region described as . For the first three tasks, see Figure 8, the lower and upper world coordinates for the are defined as for Lower State () and for Upper State (). For the fourth task, see Figure 9, for and for . For the fifth task, see Figure 10, with a dynamic model for and , for .
Based on the previous scenarios the proposed tasks are:
-
•
Task 1: Avoiding a static obstacle. The goal in this task is to avoid a static obstacle that obstructs the route of the car.
-
•
Task 2: Parallel parking: Parking in a lot with dimensions and between two rectangles.
-
•
Task 3: Line parking. Parking in a lot with dimensions and between two rectangular obstacles placed longitudinally.
-
•
Task 4: Narrow passages. Find a route in map with narrow passages.
-
•
Task 5: High speed obstacle avoidance. To avoid static obstacles while the robot advances with a high-speed profile. In this task, the dynamic model is applied.


Each experiment with the kinematic model used a set of discrete control inputs formed by three sub-set inputs denoted as low-speed, high-speed and reverse-speed formed a total of discrete inputs by each sub-set, see table 3. For example, the input number 2 is the pair , the input and in the same way by the consecutive inputs.
| Stop | ||
|---|---|---|
| Hight velocity | ||
| Low velocity | ||
| Reverse |
In task 5, we used in addition to the stop input three input sets conformed by 19 inputs each one; low traction forces to move forward and backward and high traction forces to move only forward as shown in Table 4.
| Stop | ||||
|---|---|---|---|---|
| High velocity | ||||
| Low velocity | ||||
| Reverse |
4.2 Performance metrics
To evaluate the performance of our method we utilized the next four metrics:
-
1.
Tree density. The number of vertices of the tree.
-
2.
Connectivity percentage. The percentage of iterations that produces and connects a new vertex.
-
3.
Vertices in the path. The amount of vertices in the solution path.
-
4.
Success rate. The percentage of queries that find a solution within a limit of iterations.


4.3 Experiments analysis
In Table 5, we present the results for tasks 1 to 3 using a U-PDF, GB-PDF, C-PDF and C*-PDF. In Table 7, we present the results for task 5 for using U-PDF, GB-PDF, C-PDF and C*-PDF.
| Random query for task 1 to 3 | |||||||||||||||||
|
|
|
|
|
|
||||||||||||
| Task 1 | |||||||||||||||||
| U-PDF | 0.83 | 73.60 | |||||||||||||||
| GB-PDF | 3718.40 | ||||||||||||||||
| C-PDF | 0.92 | 0.60 | |||||||||||||||
| Task 2 | |||||||||||||||||
| U-PDF | 0.65 | 164.04 | |||||||||||||||
| GB-PDF | 1.15 | ||||||||||||||||
| C-PDF | 570.26 | 0.96 | |||||||||||||||
| Task 3 | |||||||||||||||||
| U-PDF | 0.65 | 114.43 | 1.33 | ||||||||||||||
| GB-PDF | |||||||||||||||||
| C-PDF | 1224.16 | 0.96 | |||||||||||||||
| Random query for task 4 | |||||||||||||||||
|
|
|
|
|
|
||||||||||||
| Task 4 | |||||||||||||||||
| U-PDF | 110.00 | 2.65 | |||||||||||||||
| GB-PDF | 4064.86 | ||||||||||||||||
| C-PDF | 0.73 | 0.26 | |||||||||||||||
| C* -PDF | 0.72 | 0.46 | |||||||||||||||
| Random query for task 5 | |||||||||||||||||
|
|
|
|
|
|
||||||||||||
| Task 5 | |||||||||||||||||
| U-PDF | 359.46 | 7.87 | 21.95 | 0.46 | |||||||||||||
| GB-PDF | 310.59 | 6.45 | 21.66 | 0.33 | |||||||||||||
| C-PDF | 315.13 | 14.88 | 22.23 | 0.60 | |||||||||||||
| C* -PDF | 201.86 | 13.52 | 22.70 | 0.66 | |||||||||||||
4.3.1 Random query results for task 1 to 3
We generated a set of random , while the is fixed. We show the comparative results for the random queries in each scenario using the U-PDF, GB-PDF and C-PDF in the Table 5. We summarized the result below:
-
•
The C-PDF increases the success rate by +% with respect to U-PDF and +% with respect to GB-PDF.
-
•
The density of the tree decreases by % with respect to U-PDF and -% with respect to the goal bias version.
This results imply less dense tree, therefore, less computational time when the nearest node is computed. We also have a considerable increment in the probability of success when making a query. This advantages are important because a robot in real operation need to plan in a short time. On the other hand, we have some negative consequence when using the C-PDF:
-
•
Connectivity is reduced by -% with respect to U-PDF but it is increased +% with respect to GB-PDF.
-
•
The number of the vertex in the path is increased by +% with respect to U-PDF and +% with respect to goal bias RRT version.
The decrease in the percentage of connectivity means that more iterations do not add nodes to the tree. Although the decrease is not significant, more precise modelling of the distribution could reduce this adverse effect. On the other hand, the increase in the number of vertices in the path is the result of having an increase in branches near the goal state, which implies that its impact on the distance in meters does not have a significant increase. Examples of the tree for each distribution can be seen in Figure 12.
4.3.2 Random query results for task 4
For the narrow passage task (task 4), we include two versions of the custom PDF; the version without correlation, C-PDF, and the version with correlation, C*-PDF. The reader can see the complete results in Table 6. Table 6 shows that the bests results are obtained when we use the C*-PDF because it is a better approximation for the custom function C. The loss of connectivity and the increase of the number of vertices in the path are natural consequences of having a skewed distribution due to the loss of variety in the generation of random vertices. However, for the connectivity is important to do not have an excessive loss in order to reduce the computing time. The results show that our method has better connectivity than the goal bias version, although it is worst than the U-PDF but this increase is not significant since we have sparse trees. For the path measurement, we only consider, by obvious reason the successful queries. In Table 5, we present the path in terms of the number of vertices and path distance in meters. In general fewer vertices imply fewer control actions, therefore, energy savings. Our C*-PDF presents a considerable increment with respect to a U-PDF (+%) in terms of vertices but a low increment in terms of meters (+%) which means that the founding path has redundant actions, we consider that an optimization process can reduce the number of vertices.
In Figure 13, we can see the gradual tree growth. Please observe, that when we use a C*-PDF, we can reach the goal region in fewer vertices. We can see how 1000 vertices are enough to have a branch in the goal region. With the uniform and the GB-PDF, the tree has no branches outside the first quadrant of the room. Moreover, for U-PDF, after 10,000 iterations, any vertex could get out of the first quadrant. For the GB-PDF, after 10,000 iterations, the tree has branches in the first and third quadrant, but only a few branches begin to approach to the goal region. While with the C*-PDF, we have a branch in every quadrant and an important vertices density in the goal region, therefore a greater probability of finding a solution. In other words, the C*-PDF explodes the workspace more efficiently than the uniform and goal bias versions. That is an important characteristic in any search method.
4.3.3 Random query results for task 5
In Table 7, we show the results for the dynamic tests. We can observe how the trend to find a path solution in a limited number of iterations increases when we use a C-PDF, about +0.14 concerning a U-PDF and +0.27 concerning a GB-PDF. This increment is more noticeable for C*-PDF. For this task, the tree density remains without major changes for U-PDF, GB-PDF and C-PDF but with a notable reduction for C*-PDF. We can explain this issue due to the path that resolves the query needs to explore the entire workspace, but the C*-PDF reduces the search space. Another outstanding fact is the significant increment in the connectivity percentage for the C-PDF and C*-PDF, about double with respect to the other two distributions. We believe that a custom PDF improves the connectivity in space states, where the metric is difficult to be obtained, due to the lower percentage of connectivity. For this experiment, we can say that a custom PDF provides feasible directions of growth. In the same way that tasks 1 to 3, we can observe that a C-PDF does not create paths that improve or impair the solution in terms of the number of vertices.
5 Conclusions and future work
We presented a method for building, with relatively few samples, a custom sampling distribution for random sampling planners. We show evidence that sampling from this custom distribution improves the performance of the RRT planner with respect to a uniform distribution or the RRT goal bias in the proposed tasks. To sample from the custom probabilistic distribution function, we use the rejection sampling method. We also observed that considering the correlation between random variables improves the performance. We tested the method inside five virtual environments using the kinematic and dynamic model for a car-like robot. The selected tasks are common tasks for autonomous vehicles in low-speed and high-speed profiles and even for an environment with narrow passages. The results showed that our method reduced the number of vertices in the tree, especially when the state space is high-dimensional and with obstacles. To be specific, the proposed method decreases the number the vertices in the tree and at the same time increases the likelihood of finding a solution. Based on these experiments, we provide evidence that a custom distribution based on the task improves the performance of sampling-based motion planners. In future work, we will explore techniques that use larger data-sets such as deep-learning to model a custom probability density function in order to deal with changes in the workspace.
Acknowledgements
This article was supported by the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional (SIP-IPN) under the research grants, 20210268. Gabriel O. Flores Aquino thank the support from CONACYT.
References
- (1) LaValle S M (2006) Planning Algorithms. Cambridge University Press
- (2) Latombe J C (1991) Robot motion planning. Kluwer Academic Publisher
- (3) Qureshi A H, Miao Y, Simeonov A, Yip M C (2021) Motion Planning Networks: Bridging the Gap Between Learning-Based and Classical Motion Planners. in IEEE Transactions on Robotics, vol. 37, no. 1, pp. 48-66. doi: 10.1109/TRO.2020.3006716
- (4) Mohanty P K, Dewang H S (2021) A smart path planner for wheeled mobile robots using adaptive particle swarm optimization. J Braz. Soc. Mech. Sci. Eng. 43, 101. https://doi.org/10.1007/s40430-021-02827-7
- (5) Korayem M H, Nazemizadeh M, Nohooji H R (2014) Optimal point-to-point motion planning of non-holonomic mobile robots in the presence of multiple obstacles. J Braz. Soc. Mech. Sci. Eng. 36, 221–232. https://doi.org/10.1007/s40430-013-0063-5
- (6) González , Pérez J, Milanés V, Nashashibi F (2016) A Review of Motion Planning Techniques for Automated Vehicles. in IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 4, pp. 1135-1145. doi: 10.1109/TITS.2015.2498841
- (7) LaValle S M (1998) Rapidly-Exploring Random Trees: A New Tool for Path Planning Computer Science Dept, Iowa State University
- (8) LaValle S M, Kuffner J J (2001) Randomized Kinodynamic Planning. The International Journal of Robotics Research, 20(5), 378-400. doi:10.1177/02783640122067453
- (9) Kavraki L E, Svestka P, Latombe JC, Overmars M H (1996) Probabilistic roadmaps for path planning in high-dimensional configuration spaces. in IEEE Transactions on Robotics and Automation, vol. 12, no. 4, pp. 566-580. doi: 10.1109/70.508439
- (10) Karaman S, Frazzoli E (2011) Sampling-based algorithms for optimal motion planning. The International Journal of Robotics Research, 30(7), 846-894. doi:10.1177/0278364911406761
- (11) Li Y, Littlefield Z, Bekris K E (2016) Asymptotically optimal sampling-based kinodynamic planning. The International Journal of Robotics Research, 35(5), 528-564. doi:10.1177/0278364915614386
- (12) Janson L, Schmerling E, Clark A, Pavone M (2015) Fast marching tree: A fast marching sampling-based method for optimal motion planning in many dimensions. The International Journal of Robotics Research, 34(7), 883-921. doi:10.1177/0278364915577958
- (13) Chiang H-T L, Hsu J, Fiser M, Tapia L, Faust A (2019) RL-RRT: Kinodynamic Motion Planning via Learning Reachability Estimators From RL Policies. in IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4298-4305. doi: 10.1109/LRA.2019.2931199
- (14) Faust A et al (2018) PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-Based Planning. IEEE International Conference on Robotics and Automation (ICRA) pp. 5113-5120. doi: 10.1109/ICRA.2018.8461096
- (15) Ichter B, Harrison J, Pavone M (2018) Learning Sampling Distributions for Robot Motion Planning. IEEE International Conference on Robotics and Automation (ICRA), pp. 7087-7094. doi: 10.1109/ICRA.2018.8460730
- (16) Ichter B and Pavone M (2019) Robot Motion Planning in Learned Latent Spaces. in IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 2407-2414. doi: 10.1109/LRA.2019.2901898
- (17) Wang J, Chi W, Li C, Wang C, Meng M (2020) Neural RRT*: Learning-Based Optimal Path Planning. in IEEE Transactions on Automation Science and Engineering, vol. 17, no. 4, pp. 1748-1758. doi: 10.1109/TASE.2020.2976560
- (18) Hsu D, Tingting Jiang, Reif J, Zheng Sun (2003) The bridge test for sampling narrow passages with probabilistic roadmap planners. IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), pp. 4420-4426 vol.3. doi: 10.1109/ROBOT.2003.1242285
- (19) Lien JM, Thomas S L, Amato N M (2003) A general framework for sampling on the medial axis of the free space. IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), pp. 4439-4444 vol.3. doi: 10.1109/ROBOT.2003.1242288
- (20) Boor V, Overmars M H, van der Stappen A F (1999) The Gaussian sampling strategy for probabilistic roadmap planners. Proceedings IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), 1999, pp. 1018-1023 vol.2, doi: 10.1109/ROBOT.1999.772447
- (21) Lin Y, (2006) The Gaussian PRM Sampling for Dynamic Configuration Spaces 9th International Conference on Control, Automation, Robotics and Vision, pp. 1-5. doi: 10.1109/ICARCV.2006.345422
- (22) van den Berg J P, Overmars M H (2005) Using Workspace Information as a Guide to Non-uniform Sampling in Probabilistic Roadmap Planners. The International Journal of Robotics Research, 24(12), 1055–1071. https://doi.org/10.1177/0278364905060132
- (23) Kurniawati H, Hsu D (2004) Workspace importance sampling for probabilistic roadmap planning. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), pp. 1618-1623 vol.2. doi: 10.1109/IROS.2004.1389627
- (24) Zucker M, Kuffner J, Bagnell J A (2008) Adaptive workspace biasing for sampling-based planners. IEEE International Conference on Robotics and Automation, pp. 3757-3762. doi: 10.1109/ROBOT.2008.4543787
- (25) Gammell J D, Srinivasa S S, Barfoot T D (2015) Batch Informed Trees (BIT*): Sampling-based optimal planning via the heuristically guided search of implicit random geometric graphs. IEEE International Conference on Robotics and Automation (ICRA) pp. 3067-3074. doi: 10.1109/ICRA.2015.7139620
- (26) Burns B, Brock O (2007) Single-Query Motion Planning with Utility-Guided Random Trees. Proceedings IEEE International Conference on Robotics and Automation pp. 3307-3312. doi: 10.1109/ROBOT.2007.363983
- (27) Yershova A, Jaillet L, Simeon T, LaValle S M (2005) Dynamic-Domain RRTs: Efficient Exploration by Controlling the Sampling Domain. Proceedings of the 2005 IEEE International Conference on Robotics and Automation, pp. 3856-3861. doi: 10.1109/ROBOT.2005.1570709
- (28) Berenson D, Abbeel P, Goldberg K (2012) A robot path planning framework that learns from experience. IEEE International Conference on Robotics and Automation pp. 3671-3678. doi: 10.1109/ICRA.2012.6224742
- (29) Chamzas C, Shrivastava A, Kavraki L E (2019) Using Local Experiences for Global Motion Planning. International Conference on Robotics and Automation (ICRA) pp. 8606-8612. doi: 10.1109/ICRA.2019.8794317
- (30) Coleman D, Şucan I A, Moll M, Okada K, Correll N (2015) Experience-based planning with sparse roadmap spanners. IEEE International Conference on Robotics and Automation (ICRA) pp. 900-905. doi: 10.1109/ICRA.2015.7139284
- (31) Kim B, Wang Z, Kaelbling L P, Lozano-Pérez T (2019) Learning to guide task and motion planning using score-space representation. The International Journal of Robotics Research, 38(7), 793–812. https://doi.org/10.1177/0278364919848837
- (32) Corke P (2006) Robotics, Vision and Control , 2da ed. Springer, pp.109–111
- (33) Bishop C (2006) Pattern Recognition and Machine Learning. Springer, pp.528-530
- (34) LaValle S M (2002) Motion Strategy Library. http://msl.cs.uiuc.edu/msl/. Acceded 2019