CUP: Critic-Guided Policy Reuse
Abstract
The ability to reuse previous policies is an important aspect of human intelligence. To achieve efficient policy reuse, a Deep Reinforcement Learning (DRL) agent needs to decide when to reuse and which source policies to reuse. Previous methods solve this problem by introducing extra components to the underlying algorithm, such as hierarchical high-level policies over source policies, or estimations of source policies’ value functions on the target task. However, training these components induces either optimization non-stationarity or heavy sampling cost, significantly impairing the effectiveness of transfer. To tackle this problem, we propose a novel policy reuse algorithm called Critic-gUided Policy reuse (CUP), which avoids training any extra components and efficiently reuses source policies. CUP utilizes the critic, a common component in actor-critic methods, to evaluate and choose source policies. At each state, CUP chooses the source policy that has the largest one-step improvement over the current target policy, and forms a guidance policy. The guidance policy is theoretically guaranteed to be a monotonic improvement over the current target policy. Then the target policy is regularized to imitate the guidance policy to perform efficient policy search. Empirical results demonstrate that CUP achieves efficient transfer and significantly outperforms baseline algorithms.
1 Introduction
Human intelligence can solve new tasks quickly by reusing previous policies (Guberman & Greenfield, 1991). Despite remarkable success, current Deep Reinforcement Learning (DRL) agents lack this knowledge transfer ability (Silver et al., 2017; Vinyals et al., 2019; Ceron & Castro, 2021), leading to enormous computation and sampling cost. As a consequence, a large number of works have been studying the problem of policy reuse in DRL, i.e., how to efficiently reuse source policies to speed up target policy learning (Fernández & Veloso, 2006; Barreto et al., 2018; Li et al., 2019; Yang et al., 2020b).
A fundamental challenge towards policy reuse is: how does an agent with access to multiple source policies decide when and where to use them (Fernández & Veloso, 2006; Kurenkov et al., 2020; Cheng et al., 2020)? Previous methods solve this problem by introducing additional components to the underlying DRL algorithm, such as hierarchical high-level policies over source policies (Li et al., 2018, 2019; Yang et al., 2020b), or estimations of source policies’ value functions on the target task (Barreto et al., 2017, 2018; Cheng et al., 2020). However, training these components significantly impairs the effectiveness of transfer, as hierarchical structures induce optimization non-stationarity (Pateria et al., 2021), and estimating the value functions for every source policy is computationally expensive and with high sampling cost. Thus, the objective of this study is to address the question:
Can we achieve efficient transfer without training additional components?
Notice that actor-critic methods (Lillicrap et al., 2016; Fujimoto et al., 2018; Haarnoja et al., 2018) learn a critic that approximates the actor’s Q function and serves as a natural way to evaluate policies. Based on this observation, we propose a novel policy reuse algorithm that utilizes the critic to choose source policies. The proposed algorithm, called Critic-gUided Policy reuse (CUP), avoids training any additional components and achieves efficient transfer. At each state, CUP chooses the source policy that has the largest one-step improvement over the current target policy, thus forming a guidance policy. Then CUP guides learning by regularizing the target policy to imitate the guidance policy. This approach has the following advantages. First, the one-step improvement can be estimated simply by querying the critic, and no additional components are needed to be trained. Secondly, the guidance policy is theoretically guaranteed to be a monotonic improvement over the current target policy, which ensures that CUP can reuse the source policies to improve the current target policy. Finally, CUP is conceptually simple and easy to implement, introducing very few hyper-parameters to the underlying algorithm.
We evaluate CUP on Meta-World (Yu et al., 2020), a popular reinforcement learning benchmark composed of multiple robot arm manipulation tasks. Empirical results demonstrate that CUP achieves efficient transfer and significantly outperforms baseline algorithms.
2 Preliminaries
Reinforcement learning (RL) deals with Markov Decision Processes (MDPs). A MDP can be modelled by a tuple , with state space , action space , reward function , transition function , and discount factor (Sutton & Barto, 2018). In this study, we focus on MDPs with continuous action spaces. RL’s objective is to find a policy that maximizes the cumulative discounted return .
While CUP is generally applicable to a wide range of actor-critic algorithms, in this work we use SAC (Haarnoja et al., 2018) as the underlying algorithm. The soft Q function and soft V function (Haarnoja et al., 2017) of a policy are defined as:
| (1) |
| (2) |
where is the entropy weight. SAC’s loss functions are defined as:
| (3) |
where is the replay buffer, is a hyper-parameter representing the target entropy, and are network parameters, is target network’s parameters, and is the target soft value function.
We define the soft expected advantage of action probability distribution over policy at state as:
| (4) |
measures the one-step performance improvement brought by following instead of at state , and following afterwards.
The field of policy reuse focuses on solving a target MDP efficiently by transferring knowledge from a set of source policies . We denote the target policy learned on at iteration as , and its corresponding soft Q function as . In this work, we assume that the source policies and the target policy share the same state and action spaces.
3 Critic-Guided Policy Reuse
This section presents CUP, an efficient policy reuse algorithm that does not require training any additional components. CUP is built upon actor-critic methods. In each iteration, CUP uses the critic to form a guidance policy from the source policies and the current target policy. Then CUP guides policy search by regularizing the target policy to imitate the guidance policy. Section 3.1 presents how to form a guidance policy by aggregating source policies through the critic, and proves that the guidance policy is guaranteed to be a monotonic improvement over the current target policy. We also prove that the target policy is theoretically guaranteed to improve by imitating the guidance policy. Section 3.2 presents the overall framework of CUP.
3.1 Critic-Guided Source Policy Aggregation
CUP utilizes action probabilities proposed by source policies to improve the current target policy, and forms a guidance policy. At iteration of target policy learning, for each state , the agent has access to a set of candidate action probability distributions proposed by the source policies and the current target policy: . The guidance policy can be formed by combining the action probability distributions that have the largest soft expected advantage over at each state :
| (5) |
The second equation holds as adding to all soft expected advantages does not affect the result of the operator. Eq. 5 implies that at each state, we can choose which source policy to follow simply by querying its expected soft Q value under . Noticing that with function approximation, the exact soft Q value cannot be acquired. The following theorem enables us to form the guidance policy with an approximated soft Q function, and guarantees that the guidance policy is a monotonic improvement over the current target policy.
Theorem 1
Let be an approximation of such that
| (6) |
Define
| (7) |
Then,
| (8) |
Theorem 8 provides a way to choose source policies using an approximation of the current target policy’s soft Q value. As SAC learns such an approximation, the guidance policy can be formed without training any additional components.
The next question is, how to incorporate the guidance policy into target policy learning? The following theorem demonstrates that policy improvement can be guaranteed if the target policy is optimized to stay close to the guidance policy.
Theorem 2
If
| (9) |
then
| (10) |
where is the largest possible absolute value of the reward, is the largest entropy of , and is the largest possible absolute difference of the policy entropy.
According to Theorem 2, the target policy can be improved by minimizing the KL divergence between the target policy and the guidance policy. Thus we can use the KL divergence as an auxiliary loss to guide target policy learning. Proofs of this section are deferred to Appendix B.1 and Appendix B.2. Theorem 8 and Theorem 2 can be extended to common “hard” value functions (deferred to Appendix B.3), so CUP is also applicable to actor-critic algorithms that uses “hard” Bellman updates, such as A3C (Mnih et al., 2016).
3.2 CUP Framework

In this subsection we propose the overall framework of CUP. As shown in Fig. 1, at each iteration , CUP first forms a guidance policy according to Eq. 7, then provides additional guidance to policy search by regularizing the target policy to imitate (Wu et al., 2019; Fujimoto & Gu, 2021). Specifically, CUP minimizes the following loss to optimize :
| (11) |
where is the original actor loss defined in Eq. (3), and is a hyper-parameter controlling the weight of regularization. In practice, we find that using a fixed weight for regularization has two problems. First, it is difficult to balance the scale between and the regularization term, because grows as the Q value gets larger. Secondly, a fixed weight cannot reflect the agent’s confidence on . For example, when no source policies have positive soft expected advantages, . Then the agent should not imitate anymore, as cannot provide any guidance to further improve performance. Noticing that the soft expected advantage serves as a natural confidence measure, we weight the KL divergence with corresponding soft expected advantage at that state:
| (12) |
where is the approximated soft expected advantage, are two hyper-parameters, and is the approximated soft value function. This adaptive regularization weight automatically balances between the two losses, and ignores the regularization term at states where cannot improve over anymore. We further upper clip the expected advantage with the absolute value of to avoid the agent being overly confident about due to function approximation error .
CUP’s pseudo-code is presented in Alg. 1. The modifications CUP made to SAC are marked in red. Additional implementation details are deferred to Appendix D.1.
4 Experiments
We evaluate on Meta-World (Yu et al., 2020), a popular reinforcement learning benchmark composed of multiple robot manipulation tasks. These tasks are both correlated (performed by the same Sawyer robot arm) and distinct (interacting with different objects and having different reward functions), and serve as a proper evaluation benchmark for policy reuse. The source policies are achieved by training on three representative tasks: Reach, Push, and Pick-Place. We choose several complex tasks as target tasks, including Hammer, Peg-Insert-Side, Push-Wall, Pick-Place-Wall, Push-Back, and Shelf-Place. Among these target tasks, Hammer and Peg-Insert-Side require interacting with objects unseen in the source tasks. In Push-Wall and Pick-Place-Wall, there is a wall between the object and the goal. In Push-Back, the goal distribution is different from Push. In Shelf-Place, the robot is required to put a block on a shelf, and the shelf is unseen in the source tasks. Video demonstrations of these tasks are available at https://meta-world.github.io/. Similar to the settings in Yang et al. (2020a), in our experiments the goal position is randomly reset at the start of every episode. Codes are available at https://github.com/NagisaZj/CUP.
4.1 Transfer Performance on Meta-World
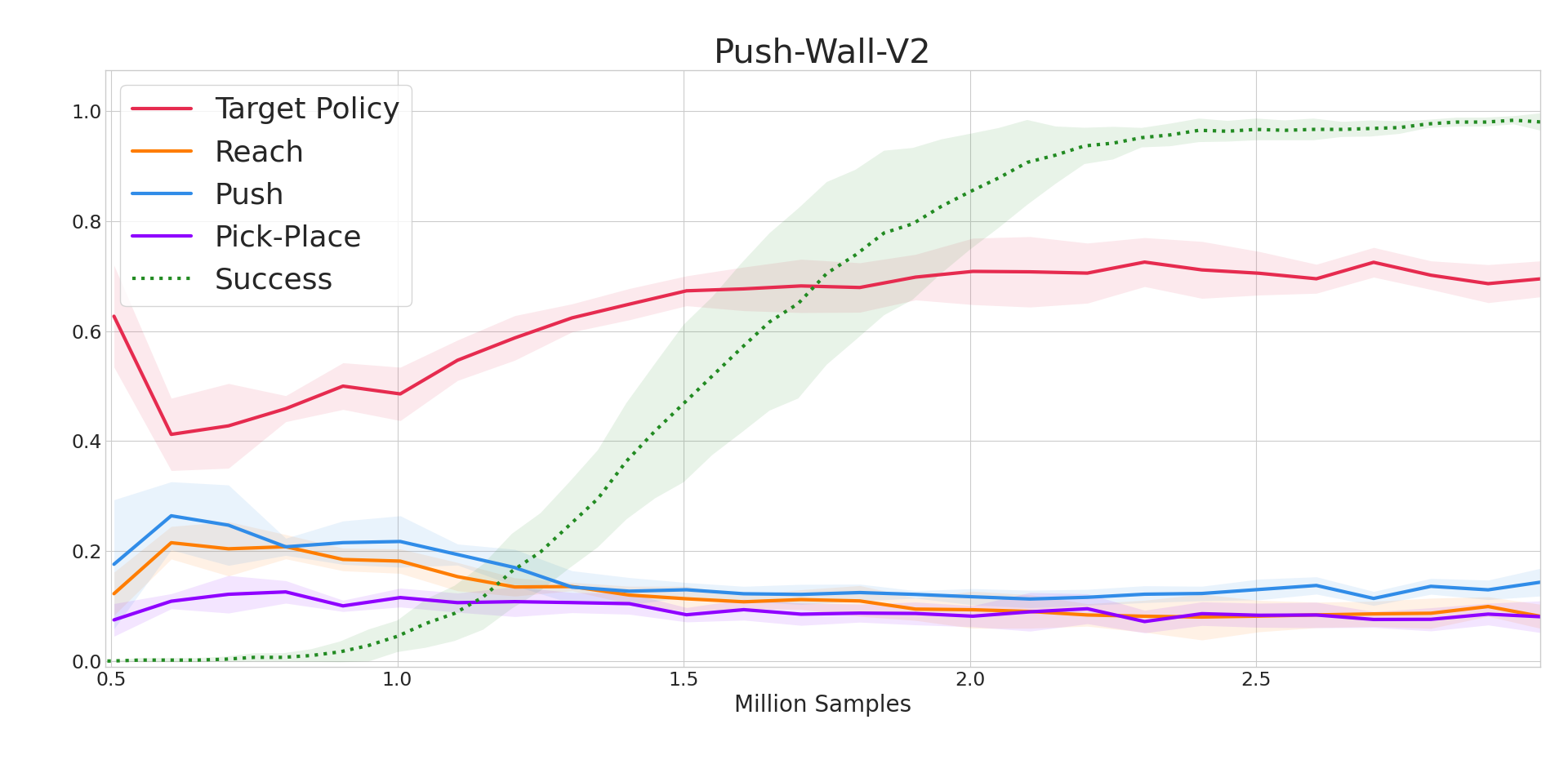
We compare against several representative baseline algorithms, including HAAR (Li et al., 2019), PTF (Yang et al., 2020b), MULTIPOLAR (Barekatain et al., 2021), and MAMBA (Cheng et al., 2020). Among these algorithms, HAAR and PTF learn hierarchical high-level policies over source policies. MAMBA aggregates source policies’ V functions to form a baseline function, and performs policy improvement over the baseline function. MULTIPOLAR learns a weighted sum of source policies’ action probabilities, and learns an additional network to predict residuals. We also compare against the original SAC algorithm. All the results are averaged over six random seeds. As shown in Figure 2, CUP is the only algorithm that achieves efficient transfer on all six tasks, significantly outperforming the original SAC algorithm. HAAR has a jump-start performance on Push-Wall and Pick-Pick-Wall, but fails to further improve due to optimization non-stationarity induced by jointly training high-level and low-level policies. MULTIPOLAR achieves comparable performance on Push-Wall and Peg-Insert-Side, because the Push source policy is useful on Push-Wall (implied by HAAR’s good jump-start performance), and learning residuals on Peg-Insert-Side is easier (implied by SAC’s fast learning). In Pick-Place-Wall, the Pick-Place source policy is useful, but the residual is difficult to learn, so MULTIPOLAR does not work. For the remaining three tasks, the source policies are less useful, and MULTIPOLAR fails on these tasks. PTF fails as its hierarchical policy only gets updated when the agent chooses similar actions to one of the source policies, which is quite rare when the source and target tasks are distinct. MAMBA fails as estimating all source policies’ V functions accurately is sampling inefficient. Algorithm performance evaluated by success rate is deferred to Appendix E.1.







4.2 Analyzing the Guidance Policy
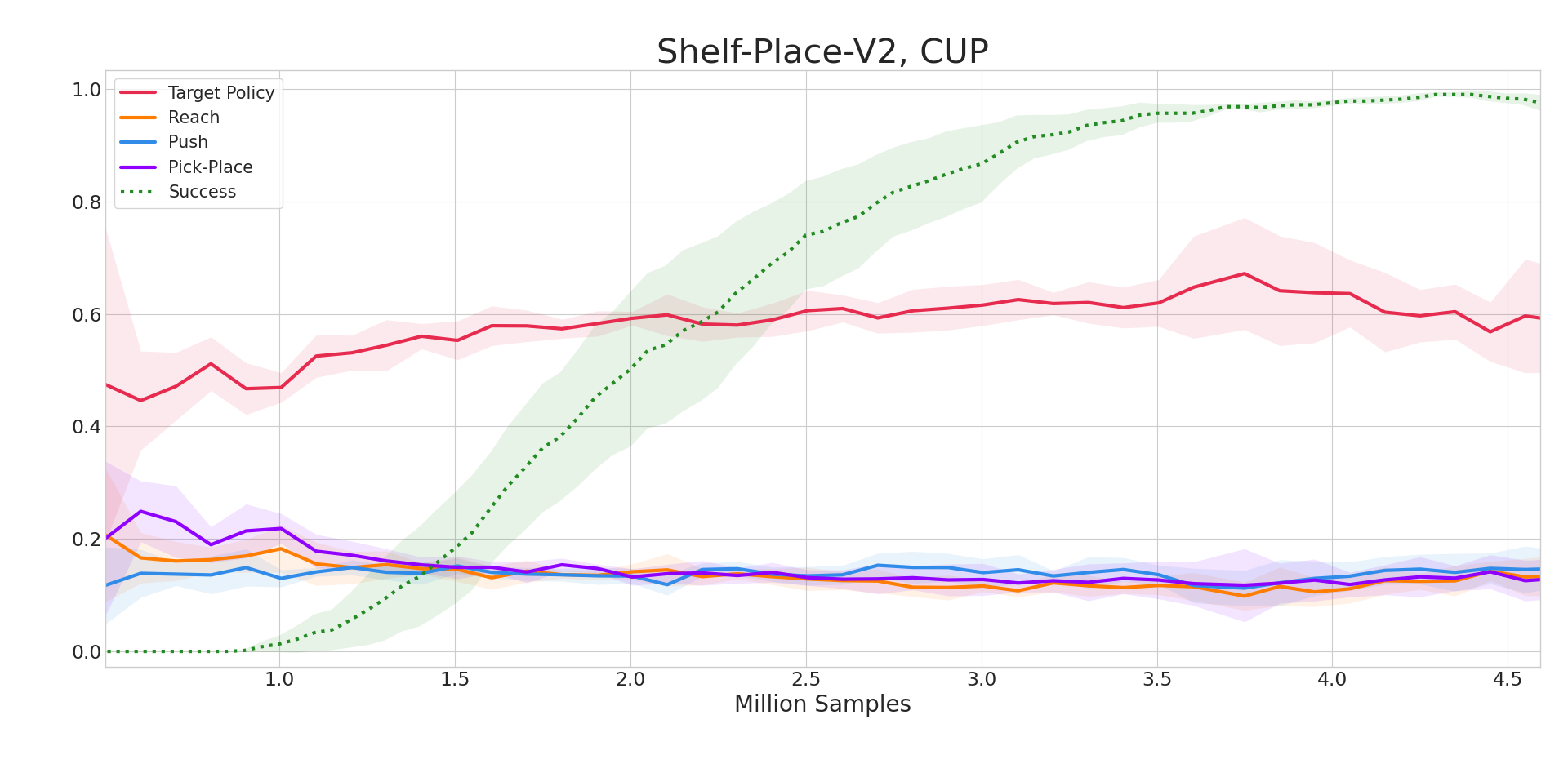
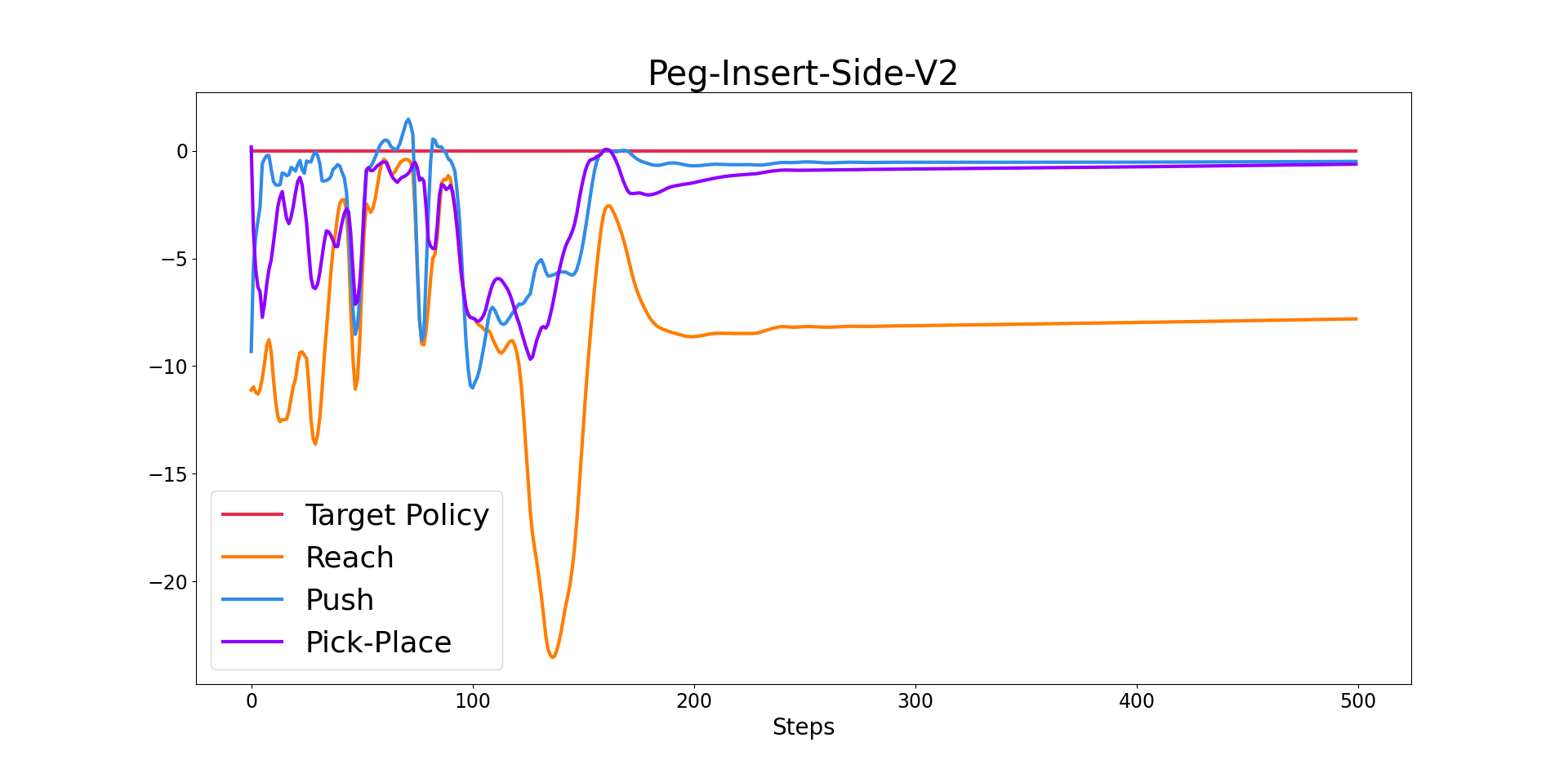
This subsection provides visualizations of CUP’s source policy selection. Fig. 3 shows the percentages of each source policy being selected throughout training on Push-Wall. At early stages of training, the source policies are selected more frequently as they have positive expected advantages, which means that they can be used to improve the current target policy. As training proceeds and the target policy becomes better, the source policies are selected less frequently. Among these three source policies, Push is chosen more frequently than the other two source policies, as it is more related to the target task. Figure 4 presents the source policies’ expected advantages over an episode at convergence in Pick-Place-Wall. The Push source policy and Reach source policy almost always have negative expected advantages, which implies that these two source policies can hardly improve the current target policy anymore. Meanwhile, the Pick-Place source policy has expected advantages close to zero after 100 environment steps, which implies that the Pick-Place source policy is close to the target policy at these steps. Analyses on all six tasks as well as analyses on HAAR’s source policy selection are deferred to Appendix E.2 and Appendix E.6, respectively.

4.3 Ablation Study
This subsection evaluates CUP’s sensitivity to hyper-parameter settings and the number of source policies. We also evaluate CUP’s robustness against random source policies, which do not provide meaningful candidate actions for solving target tasks.
4.3.1 Hyper-Parameter Sensitivity

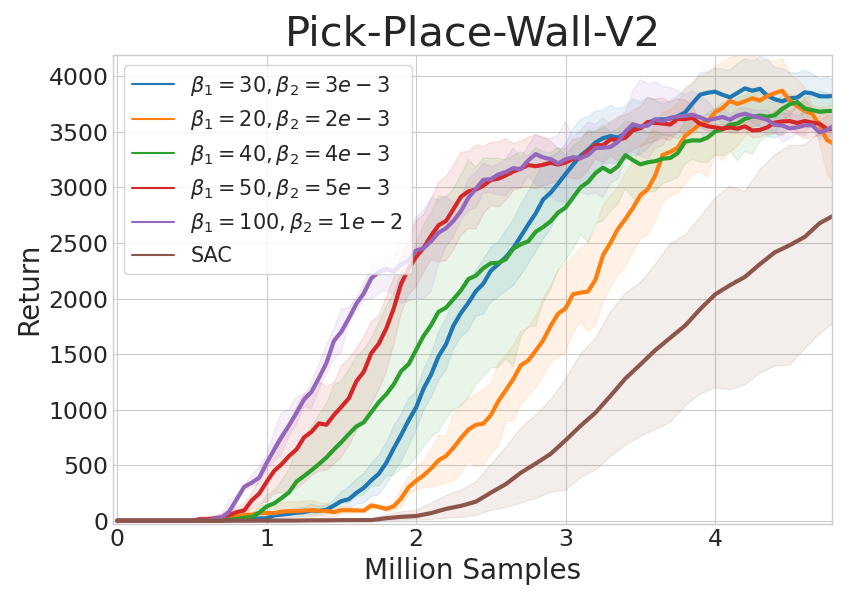
For all the experiments in Section 4.1, we use the same set of hyper-parameters, which indicates that CUP is generally applicable to a wide range of tasks without particular fine-tuning. CUP introduces only two additional hyper-parameters to the underlying SAC algorithm, and we further test CUP’s sensitivity to these additional hyper-parameters. As shown in Fig. 5, CUP is generally robust to the choice of hyper-parameters and achieves stable performance.
4.3.2 Number of Source Policies
We evaluate CUP as well as baseline algorithms on a larger source policy set. We add three policies to the original source policy set, which solve three simple tasks including Drawer-Close, Push-Wall, and Coffee-Button. This forms a source policy set composed of six policies. As shown in Fig. 6, CUP is still the only algorithm that solves all the six target tasks efficiently. MULTIPOLAR suffers from a decrease in performance, which indicates that learning the weighted sum of source policies’ actions becomes more difficult as the number of source policies grows. The rest of the baseline algorithms have similar performance to those using three source policies. Fig. 7 provides a more direct comparison of CUP’s performance with different number of source policies. CUP is able to utilize the additional source policies to further improve its performance, especially on Pick-Place-Wall and Peg-Insert-Side. Further detailed analysis is deferred to Appendix E.3.












4.3.3 Interference of Random Source Policies
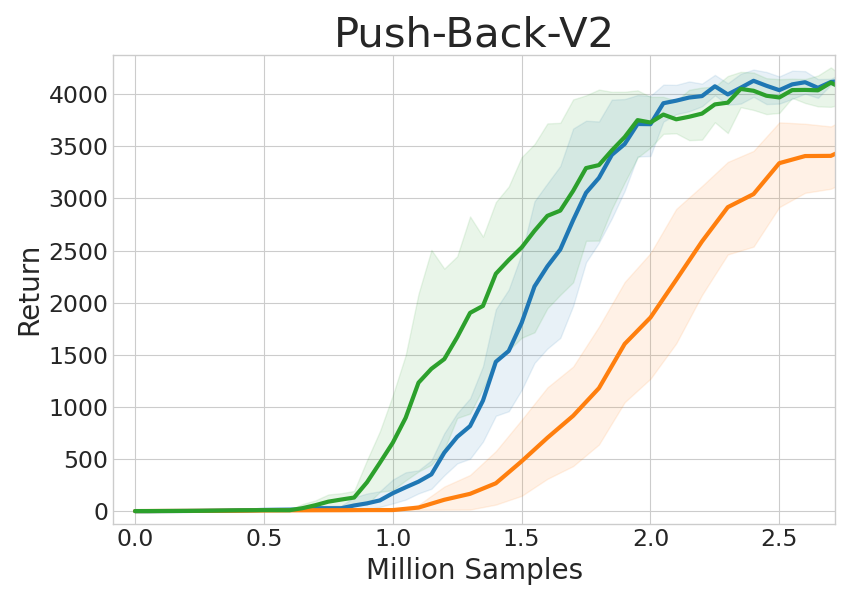
In order to evaluate the efficiency of CUP’s critic-guided source policy aggregation, we add random policies to the set of source policies. As shown in Fig. 8, adding up to 3 random source policies does not affect CUP’s performance. This indicates that CUP can efficiently choose which source policy to follow even if there exist many source policies that are not meaningful. Adding 4 and 5 random source policies leads to a slight drop in performance. This drop is because that as the number of random policies grows, more random actions are sampled, and taking argmax over these actions’ expected advantages is more likely to be affected by errors in value estimation.
To further investigate CUP’s ability to ignore unsuitable source policies, we design another transfer setting that consists of another two source policy sets. The first set consists of three random policies that are useless for the target task, and the second set adds the Reach policy to the first set. As demonstrated in Fig. 8, when none of the source policies are useful, CUP performs similarly to the original SAC, and its sample efficiency is almost unaffected by the useless source policies. When there exists a useful source policy, CUP can efficiently utilize it to improve performance, even if there are many useless source policies.


5 Related Work
Policy reuse.
A series of works on policy reuse utilize source policies for exploration in value-based algorithms (Fernández & Veloso, 2006; Li & Zhang, 2018; Gimelfarb et al., 2021), but they are not applicable to policy gradient methods due to the off-policyness problem (Fujimoto et al., 2019). AC-Teach (Kurenkov et al., 2020) mitigates this problem by improving the actor over behavior policy’s value estimation, but still fails in more complex tasks. One branch of methods train hierarchical high-level policies over source policies. CAPS (Li et al., 2018) guarantees the optimality of the hierarchical policies by adding primitive skills to the low-level policy set, but is inapplicable to MDPs with continuous action spaces. HAAR (Li et al., 2019) fine-tunes low-level policies to ensure optimality, but joint training of high-level and low-level policies induce optimization non-stationarity (Pateria et al., 2021). PTF (Yang et al., 2020b) trains a hierarchical policy, which is imitated by the target policy. However, the hierarchical policy only gets updated when the target policy chooses similar actions to one of the source policies, so PTF fails in complex tasks with large action spaces. Another branch of works aggregate source policies via their Q functions or V functions on the target task. Barreto et al. (2017) and Barreto et al. (2018) focus on the situation where source tasks and target tasks share the same dynamics, and aggregate source policies by choosing the policy that has the largest Q at each state. They use successor features to mitigate the heavy computation cost brought by estimating Q functions for all source policies. MAMBA (Cheng et al., 2020) forms a baseline function by aggregating source policies’ V functions, and guides policy search by improving the policy over the baseline function. Finally, MULTIPOLAR (Barekatain et al., 2021) learns a weighted sum over source policies’ actions, and learns an auxiliary network to predict residuals around the aggregated actions. MULTIPOLAR is computationally expensive, as it requires querying all the source policies at every sampling step. Our proposed method, CUP, focuses on the setting of learning continuous-action MDPs with actor-critic methods. CUP is both computationally and sampling efficient, as it does not require training any additional components.
Policy regularization.
Adding regularization to policy optimization is a common approach to induce prior knowledge into policy learning. Distral (Teh et al., 2017) achieves inter-task transfer by imitating an average policy distilled from policies of related tasks. In offline RL, policy regularization serves as a common technique to keep the policy close to the behavior policy used to collect the dataset (Wu et al., 2019; Nair et al., 2020; Fujimoto & Gu, 2021). CUP uses policy regularization as a means to provide additional guidance to policy search with the guidance policy.
6 Conclusion
In this study, we address the problem of reusing source policies without training any additional components. By utilizing the critic as a natural evaluation of source policies, we propose CUP, an efficient policy reuse algorithm without training any additional components. CUP is conceptually simple, easy to implement, and has theoretical guarantees. Empirical results demonstrate that CUP achieves efficient transfer on a wide range of tasks. As for future work, CUP assumes that all source policies and the target policy share the same state and action spaces, which limits CUP’s application to more general scenarios. One possible future direction is to take inspiration from previous works that map the state and action spaces of an MDP to another MDP with similar high-level structure (Wan et al., 2020; Zhang et al., 2020; Heng et al., 2022; van der Pol et al., 2020b, a). Another interesting direction is to incorporate CUP into the continual learning setting (Rolnick et al., 2019; Khetarpal et al., 2020), in which an agent gradually enriches its source policy set in an online manner.
Acknowledgements
This work is supported in part by Science and Technology Innovation 2030 – “New Generation Artificial Intelligence” Major Project (No. 2018AAA0100904), National Natural Science Foundation of China (62176135), and China Academy of Launch Vehicle Technology (CALT2022-18).
References
- Barekatain et al. (2021) Barekatain, M., Yonetani, R., and Hamaya, M. Multipolar: multi-source policy aggregation for transfer reinforcement learning between diverse environmental dynamics. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pp. 3108–3116, 2021.
- Barreto et al. (2017) Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., van Hasselt, H. P., and Silver, D. Successor features for transfer in reinforcement learning. Advances in neural information processing systems, 30, 2017.
- Barreto et al. (2018) Barreto, A., Borsa, D., Quan, J., Schaul, T., Silver, D., Hessel, M., Mankowitz, D., Zidek, A., and Munos, R. Transfer in deep reinforcement learning using successor features and generalised policy improvement. In International Conference on Machine Learning, pp. 501–510. PMLR, 2018.
- Ceron & Castro (2021) Ceron, J. S. O. and Castro, P. S. Revisiting rainbow: Promoting more insightful and inclusive deep reinforcement learning research. In International Conference on Machine Learning, pp. 1373–1383. PMLR, 2021.
- Cheng et al. (2020) Cheng, C.-A., Kolobov, A., and Agarwal, A. Policy improvement via imitation of multiple oracles. Advances in Neural Information Processing Systems, 33:5587–5598, 2020.
- Fedotov et al. (2003) Fedotov, A. A., Harremoës, P., and Topsoe, F. Refinements of pinsker’s inequality. IEEE Transactions on Information Theory, 49(6):1491–1498, 2003.
- Fernández & Veloso (2006) Fernández, F. and Veloso, M. Probabilistic policy reuse in a reinforcement learning agent. In Proceedings of the fifth international joint conference on Autonomous agents and multiagent systems, pp. 720–727, 2006.
- Fujimoto & Gu (2021) Fujimoto, S. and Gu, S. S. A minimalist approach to offline reinforcement learning. Advances in Neural Information Processing Systems, 34, 2021.
- Fujimoto et al. (2018) Fujimoto, S., Hoof, H., and Meger, D. Addressing function approximation error in actor-critic methods. In International conference on machine learning, pp. 1587–1596. PMLR, 2018.
- Fujimoto et al. (2019) Fujimoto, S., Meger, D., and Precup, D. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning, pp. 2052–2062. PMLR, 2019.
- Gimelfarb et al. (2021) Gimelfarb, M., Sanner, S., and Lee, C.-G. Contextual policy transfer in reinforcement learning domains via deep mixtures-of-experts. In Uncertainty in Artificial Intelligence, pp. 1787–1797. PMLR, 2021.
- Guberman & Greenfield (1991) Guberman, S. R. and Greenfield, P. M. Learning and transfer in everyday cognition. Cognitive Development, 6(3):233–260, 1991.
- Haarnoja et al. (2017) Haarnoja, T., Tang, H., Abbeel, P., and Levine, S. Reinforcement learning with deep energy-based policies. In International Conference on Machine Learning, pp. 1352–1361. PMLR, 2017.
- Haarnoja et al. (2018) Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P., et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905, 2018.
- Heng et al. (2022) Heng, Y., Yang, T., ZHENG, Y., Jianye, H., and Taylor, M. E. Cross-domain adaptive transfer reinforcement learning based on state-action correspondence. In The 38th Conference on Uncertainty in Artificial Intelligence, 2022.
- Kakade & Langford (2002) Kakade, S. and Langford, J. Approximately optimal approximate reinforcement learning. In In Proc. 19th International Conference on Machine Learning. Citeseer, 2002.
- Khetarpal et al. (2020) Khetarpal, K., Riemer, M., Rish, I., and Precup, D. Towards continual reinforcement learning: A review and perspectives. arXiv preprint arXiv:2012.13490, 2020.
- Kurenkov et al. (2020) Kurenkov, A., Mandlekar, A., Martin-Martin, R., Savarese, S., and Garg, A. Ac-teach: A bayesian actor-critic method for policy learning with an ensemble of suboptimal teachers. In Conference on Robot Learning, pp. 717–734. PMLR, 2020.
- Li & Zhang (2018) Li, S. and Zhang, C. An optimal online method of selecting source policies for reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Li et al. (2018) Li, S., Gu, F., Zhu, G., and Zhang, C. Context-aware policy reuse. arXiv preprint arXiv:1806.03793, 2018.
- Li et al. (2019) Li, S., Wang, R., Tang, M., and Zhang, C. Hierarchical reinforcement learning with advantage-based auxiliary rewards. Advances in Neural Information Processing Systems, 32, 2019.
- Lillicrap et al. (2016) Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. In ICLR (Poster), 2016.
- Mnih et al. (2016) Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pp. 1928–1937. PMLR, 2016.
- Nair et al. (2020) Nair, A., Gupta, A., Dalal, M., and Levine, S. Awac: Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020.
- Ostrovski et al. (2021) Ostrovski, G., Castro, P. S., and Dabney, W. The difficulty of passive learning in deep reinforcement learning. Advances in Neural Information Processing Systems, 34:23283–23295, 2021.
- Pateria et al. (2021) Pateria, S., Subagdja, B., Tan, A.-h., and Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Computing Surveys (CSUR), 54(5):1–35, 2021.
- Rolnick et al. (2019) Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., and Wayne, G. Experience replay for continual learning. Advances in Neural Information Processing Systems, 32, 2019.
- Silver et al. (2017) Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
- Sodhani et al. (2021) Sodhani, S., Zhang, A., and Pineau, J. Multi-task reinforcement learning with context-based representations. In International Conference on Machine Learning, pp. 9767–9779. PMLR, 2021.
- Sutton & Barto (2018) Sutton, R. S. and Barto, A. G. Reinforcement learning: An introduction. MIT press, 2018.
- Teh et al. (2017) Teh, Y., Bapst, V., Czarnecki, W. M., Quan, J., Kirkpatrick, J., Hadsell, R., Heess, N., and Pascanu, R. Distral: Robust multitask reinforcement learning. Advances in neural information processing systems, 30, 2017.
- van der Pol et al. (2020a) van der Pol, E., Kipf, T., Oliehoek, F. A., and Welling, M. Plannable approximations to mdp homomorphisms: Equivariance under actions. arXiv preprint arXiv:2002.11963, 2020a.
- van der Pol et al. (2020b) van der Pol, E., Worrall, D., van Hoof, H., Oliehoek, F., and Welling, M. Mdp homomorphic networks: Group symmetries in reinforcement learning. Advances in Neural Information Processing Systems, 33:4199–4210, 2020b.
- Vinyals et al. (2019) Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Dudzik, A., Chung, J., Choi, D. H., Powell, R., Ewalds, T., Georgiev, P., et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- Wan et al. (2020) Wan, M., Gangwani, T., and Peng, J. Mutual information based knowledge transfer under state-action dimension mismatch. arXiv preprint arXiv:2006.07041, 2020.
- Wu et al. (2019) Wu, Y., Tucker, G., and Nachum, O. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361, 2019.
- Yang et al. (2020a) Yang, R., Xu, H., Wu, Y., and Wang, X. Multi-task reinforcement learning with soft modularization. Advances in Neural Information Processing Systems, 33:4767–4777, 2020a.
- Yang et al. (2020b) Yang, T., Hao, J., Meng, Z., Zhang, Z., Hu, Y., Chen, Y., Fan, C., Wang, W., Wang, Z., and Peng, J. Efficient deep reinforcement learning through policy transfer. In AAMAS, pp. 2053–2055, 2020b.
- Yu et al. (2020) Yu, T., Quillen, D., He, Z., Julian, R., Hausman, K., Finn, C., and Levine, S. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning, pp. 1094–1100. PMLR, 2020.
- Zhang et al. (2020) Zhang, Q., Xiao, T., Efros, A. A., Pinto, L., and Wang, X. Learning cross-domain correspondence for control with dynamics cycle-consistency. arXiv preprint arXiv:2012.09811, 2020.
Checklist
-
1.
For all authors…
-
(a)
Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes]
-
(b)
Did you describe the limitations of your work? [Yes] See Section 2.
-
(c)
Did you discuss any potential negative societal impacts of your work? [Yes] See Appendix A.
-
(d)
Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes]
-
(a)
- 2.
-
3.
If you ran experiments…
-
(a)
Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [Yes] See the supplemental materials.
-
(b)
Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [Yes] See Appendix D.1.
-
(c)
Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [Yes] See Section 4.
-
(d)
Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [Yes] See Appendix D.1.
-
(a)
-
4.
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
-
(a)
If your work uses existing assets, did you cite the creators? [Yes] See Section 4
-
(b)
Did you mention the license of the assets? [Yes] See the supplemental materials.
-
(c)
Did you include any new assets either in the supplemental material or as a URL? [N/A]
-
(d)
Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [N/A]
-
(e)
Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [N/A]
-
(a)
-
5.
If you used crowdsourcing or conducted research with human subjects…
-
(a)
Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
-
(b)
Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
-
(c)
Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
-
(a)
Appendix A Broader Social Impact
We believe policy reuse serves as a promising way to transfer knowledge among AI agents. This ability will enable AI agents to master new skills efficiently. However, we are also aware of possible negative social impacts, such as plagiarizing other AI products by querying and reusing their policies.
Appendix B Proofs
B.1 Proof for Theorem 8
Proof. As , we have that for all , the difference between the true value function and the approximated value function is bounded:
As is contained in , with defined in Eq. (7), it is obvious that for all , . Then for all ,
B.2 Proof of Theorem 2
Proof. According to Pinsker’s inequality (Fedotov et al., 2003), , where is the L1 norm. So we have that for all , . According to the Performance Difference Lemma (Kakade & Langford, 2002), we have that for all :
where 111We slightly abuse the notation here to indicate that the agent start deterministically from state . is the normalized discounted state occupancy distribution. Note that
| (14) | |||
| (15) |
Eventually, we have .
B.3 Critic-Guided Source Policy Aggregation under “Hard” Value Functions
In this section we override the notation , to represent “hard” value functions, and override the notation to represent the expected advantage, which is defined as . Then Theorem 8 and Theorem 2 can be extended as below.
Theorem 3
Let be an approximation of such that
| (16) |
Define
| (17) |
Then,
| (18) |
Theorem 4
If
| (19) |
then
| (20) |
where is the largest possible absolute value of the reward.
Theorem 18 and Theorem 4 implies that CUP can still guarantee policy improvement under hard Bellman updates. Proofs are given below.
Proof for Theorem 18.
As , we have that for all , the difference between the true value function and the approximated value function is bounded:
As is contained in , with defined in Eq. (17), it is obvious that for all , . Then for all ,
Proof for Theorem 4.
Appendix C Discussion on the Influence of Over-Estimation
As CUP takes an argmax over expected Q values, it may suffer from the value over-estimation issue in DRL (Ostrovski et al., 2021). Although CUP may over-estimate values on rarely selected actions, this over-estimation serves as a kind of exploration mechanism, encouraging the agent to explore actions suggested by the source policies and potentially improving the learning target policy. If the source policies give unsuitable actions, then after exploration this over-estimation is resolved and these unsuitable actions will not be selected again. Results in Figure 8 suggest that even if all source policies are random and do not give useful actions, CUP still performs similarly to the original SAC, and is almost unaffected by the over-estimation issue, as over-estimation is addressed after exploring these actions.
Appendix D Experimental Settings
D.1 Additional Implementation Details
To improve CUP’s computation efficiency, we store the source polices’ output in the replay buffer. As we can query source policies with batches of states, and each state in the buffer only need to be queried for once, CUP is computationally efficient. Empirically, CUP only takes about 30% more wall-clock time than SAC to run the same number of environment steps. All experiments are run on GeForce GTX 2080 GPUs. The policy regularization is added after 0.5M environment environment steps to achieve more stable learning.
SAC utilizes two Q functions to mitigate the overestimation error. When CUP forms the guidance policy, we use the max value of the two target Q functions to estimate the expected advantage, which contributes to bolder exploration. Using target networks contributes to more stable training.
Equation 5 requires estimating expectations over Q values. In practice, to be efficient, we estimate the expectation by sampling a few actions (e.g., 3 actions) from each action probability distribution proposed by the source policies, and find it sufficient to achieve stable performance.
As for HAAR, we fix the source policies, and train a high-level policy as well as an additional low-level policy with HAAR’s auxiliary rewards.
D.2 Hyper-Parameter Details
All hyper-parameters used in our experiments are listed in Table 1. We use the same set of hyper-parameters for all six tasks. We also use the same set of hyper-parameters for both CUP and the SAC baseline. Most hyper-parameters are adopted from Sodhani et al. (2021).
| Hyper-Parameter | Hyper-Parameter Values | ||
|---|---|---|---|
| batch size | 1280 | ||
| non-linearity | ReLU | ||
| actor/critic network structure |
|
||
| policy initialization | standard Gaussian | ||
| exploration parameters | run a uniform exploration policy 50k steps | ||
| learning rates for all networks | 3e-4 | ||
| # of samples / # of train steps per iteration | 10 env steps / 1 training step | ||
| optimizer | adam | ||
| Episode length (horizon) | 500 | ||
| beta for all optimizers | (0.9, 0.999) | ||
| discount | 0.99 | ||
| reward scale | 1.0 | ||
| temperature | learned | ||
|
500k | ||
| 30 | |||
| 3e-3 |
D.3 Discussions on Hyper-Parameter Design
CUP has two additional hyper-parameters compared to SAC, and . We provide some insight on choosing and . Note that the maximum weight for the KL regularization is , and the original actor loss has roughly the same magnitude as . So roughly determines the maximum regularization weight. Following previous works on regularization [1,2], (0.1, 1) is a reasonable range for . As a consequence, we choose (0.04, 1) as the range of for our hyper-parameter ablation studies. What’s more, as upper bounds the maximum confidence on the expected advantage estimation (Section 3.2), should be decreased if a large variance in performance is observed. These two insights efficiently guide the design of and . As shown in Section 4.3, CUP achieves stable performance on a large range of s and s.
Appendix E Additional Experiment Results
E.1 Success Rate Evaluation
Fig. 9 and Fig.10 shows performance evaluated by success rates. The performance is consistent with performance evaluated by cumulative return.












E.2 Guidance Policy Analysis for All Tasks
This subsection provides analyses of guidance policies on all six tasks, as shown in Fig. 11 and Fig. 12. Results demonstrate that the Pick-Place source policy is the most useful in Shelf-Place, Hammer, and Pick-Place-Wall, while the Push source policy is the most useful in Push-Back and Push-Wall. In Peg-Insert-Side, both source policies are of similar usefulness.











E.3 CUP’s Ability to Use Additional Source Policies
In Fig. 6 the improvement brought by additional source policies is mild, because the original three source policies have already provided sufficient support for policy reuse, as demonstrated in Fig. 13. To evaluate CUP’s ability to utilize additional source policies, we design another two sets of source policies. Set 1 consists of three source policies that solve Reach, Peg-Insert-Side, and Hammer, while Set 2 adds source policies trained on Push-Back, Pick-Place-Wall, and Shelf-Place to Set 1. As Set 1 is less related to our target task Push-Wall, CUP must utilize the additional source policies in Set 2 to improve its performance. As demonstrated in Fig. 14, CUP can efficiently take advantage of the additional source policies to achieve efficient learning.


E.4 CUP’s Source Policy Selection on the Source Task
To further investigate CUP’s formation of the guidance policy, we train CUP on one of the source tasks, Push. As shown in Fig. 15, the corresponding source policy Push is selected frequently. After the target policy converges, CUP selects the target policy and the Push policy for roughly the same frequency, as they can both solve the task.

E.5 Experiments on Additional Tasks
We evaluate CUP on Bin-Picking and Stick-Pull, two tasks less related to the source policies. As demonstrated in Fig. 16, in this harder setting, CUP’s performance improvement over SAC is smaller. To investigate this, we provide an analysis on CUP’s source policy selection. As shown in Fig. 17, the smaller improvement is because that source policies are less related to the target tasks, as they are selected less frequently.




E.6 Analyzing Non-Stationarity in HRL Methods
To further analyze the advantages of CUP and demonstrate the non-stationarity problem of HRL methods, we illustrate the percentages of each low-level policy being selected by HAAR’s high-level policy. HAAR’s low-level policy set consists of the three source policies and an additional trainable low-level policy, which is expected to be selected at states where no source policies give useful actions. As demonstrated in Fig. 18 and Fig. 18, HAAR’s low-level policy selection suffers from a large variance over different random seeds, and oscillates over time. This is because that as the low-level policy keeps changing, the high-level transition becomes non-stationary and leads to unstable learning. In comparison, as shown in Fig. 18 and Fig. 18, CUP’s source policy selection is much more stable and achieves superior performance, as it selects source policies according to expected advantages instead of high-level policies, and avoids the non-stationarity problem.