22email: {ys92, vashok, guha}@rice.edu, {TNetherton, LECourt}@mdanderson.org
CT reconstruction from few planar X-rays with application towards low-resource radiotherapy
Abstract
CT scans are the standard-of-care for many clinical ailments, and are needed for treatments like external beam radiotherapy. Unfortunately, CT scanners are rare in low and mid-resource settings due to their costs. Planar X-ray radiography units, in comparison, are far more prevalent, but can only provide limited 2D observations of the 3D anatomy. In this work, we propose a method to generate CT volumes from few () planar X-ray observations using a prior data distribution, and perform the first evaluation of such a reconstruction algorithm for a clinical application: radiotherapy planning. We propose a deep generative model, building on advances in neural implicit representations to synthesize volumetric CT scans from few input planar X-ray images at different angles. To focus the generation task on clinically-relevant features, our model can also leverage anatomical guidance during training (via segmentation masks). We generated 2-field opposed, palliative radiotherapy plans on thoracic CTs reconstructed by our method, and found that isocenter radiation dose on reconstructed scans have error with respect to the dose calculated on clinically acquired CTs using X-ray views. In addition, our method is better than recent sparse CT reconstruction baselines in terms of standard pixel and structure-level metrics (PSNR, SSIM, Dice score) on the public LIDC lung CT dataset. Code is available at: https://github.com/wanderinrain/Xray2CT.
Keywords:
CT Reconstruction Radiation Planning Sparse Reconstruction Deep Learning Implicit Neural Representations1 Introduction
CT scans are the standard-of-care for diagnosis and treatment of many diseases. However, due to their costs and infrastructure requirements, global inequities in access to CT scanners exist in many low-to-middle income countries (LMICs) [7]. This lack of CT access impacts many facets of healthcare such as external beam radiotherapy, in which a treatment planning system calculates the ionizing dose to a patient’s tumor and surrounding tissues by utilizing the electron density information from the CT voxels. In comparison, planar X-ray units are far more prevalent in LMICs than CT units, and recent studies [16, 22] demonstrate that significant information in CT scans may be estimated from sparse observations using deep generative networks trained over large datasets. With this motivation, we propose a learning-based algorithm for synthesizing CT volumes from few () planar X-ray images, and demonstrate basic feasibility for radiotherapy planning for post-mastectomy chest walls (extremely prevalent for women in low-resource settings).
State-of-the-art CT reconstruction methods from sparse views are based on learning complex priors with neural networks and operate in both the sinogram [18, 15], and voxel [22, 6, 9, 16] spaces. Several voxel-based methods use convolutional neural networks (CNNs) optimized on (CT, X-ray) supervised pairs with views [22, 16, 9]. Others use implicit neural representations (INRs), networks that map voxel coordinates to intensity values and can better reconstruct high-frequency details than CNNs [21]. However, INRs are typically fit using only the input views (i.e., self-supervised), and so require at least 20 views to attain reasonable results [24]. If such an approach were used with planar radiography, the large number of planar image acquisitions becomes practically infeasible, as technologists would need to reposition the patient and detector per orientation. In addition, previous studies provide limited evaluation, using only pixel-level reconstruction metrics like PSNR and SSIM [20].
To the best of our knowledge, we propose the first supervised CT reconstruction algorithm from few ( 5) planar X-ray views using INRs. We build on the pixelNeRF [23] model design for sparse view synthesis problems. Our model first extracts 2D feature images from each input planar X-ray using a CNN U-Net[12]. For each 3D coordinate, it then uses an INR to predict the output CT’s intensity given the coordinate, and a set of 2D features obtained by projecting the coordinate onto each feature image based on the known geometry of the X-ray imaging system. Our training loss function includes both a typical reconstruction term, and a segmentation term (captured by a pretrained segmentation network) which we hypothesize will be useful because radiotherapy plans rely on accurate anatomical boundaries.
We evaluated our method on reconstructing CT scans from 1 to 4 input planar X-rays. First, our method outperforms neural network baselines on the public LIDC-IDRI [1] lung CT dataset in terms of pixel-level (PSNR, SSIM) and structural (Dice Similarity Coefficient (DSC)[5]) metrics. Next, we evaluated our method using an in-house thoracic CT dataset for post-mastectomy chest wall radiotherapy, in which the tumor has been removed prior to the acquisition of the CT scan and the target of the radiotherapy would need only consider organs within the CT (e.g., chest wall, lungs, heart, spinal cord). 2-field opposed radiotherapy plans generated from our model’s reconstructions obtain error with respect to isocenter dose compared to clinical scans, well below the criterion for dose verification accuracy [25]. We conclude by discussing limitations and steps to move towards clinical application.
2 Method
Let represent input planar X-rays acquired from different orientations , where , and represents the associated ground truth CT volume111We assume a uniform dimension here for simplicity, but our method can handle arbitrary dimensions.. Our goal is to learn a model that maps X to . The main challenge of this reconstruction task is to combine the information from the different X-ray views into one shared 3D space. The overview of key components in our approach is illustrated in Fig. 1.

Building on pixelNeRF[23], we propose a model with three components: a 2D feature extraction network that extracts planar X-ray image features, a projection operation that maps 3D coordinates and a viewing angle to 2D coordinates, and an INR (implemented with functions and ) that maps 3D coordinates and 2D feature vectors to voxel intensities. We supervise the entire model with a loss function consisting of a reconstruction error, and an (optional) segmentation error penalizing incorrect anatomical boundaries.
X-ray CNN: We implement function with a 2D CNN U-Net [12], which outputs an image encoding multiscale features per pixel for .
Projection: maps a 3D coordinate and angle to the corresponding 2D location on image based on the known X-ray imager geometry. For example, if the X-rays were generated via parallel beam radiation, each point will be orthogonally projected onto along angle . For fan-beam radiation, each point will be projected based on rays emanating from a 3D source point. The output of this operator is a feature vector .
Conditional INR: Next, we use features to estimate the voxel intensity at location p. We use two multilayer perceptrons (MLPs) to do this: and . operates on each view independently, and is responsible for combining a Fourier feature transform [19] of p and feature vector from view into an embedding . Fourier feature coordinate transforms empirically result in better high-frequency reconstructions compared to the coordinates on their own. Next, we compute the average embedding over all views , and feed it into MLP , which outputs , an estimate of the intensity value (a scalar) at p. We use three residual blocks for both MLPs, containing fully-connected linear layers with 128 neurons and sinusoidal periodic activation functions [17].
Loss Function: We train our model using the loss: , consisting of a typical mean squared error (MSE) term, and an (optional) term evaluating Dice score [5] between the segmentation masks of the two scans, estimated by pretrained segmentation network .
3 Experiments
We evaluated our model using the public Lung Image Database Consortium (LIDC-IDRI) [1] lung CT dataset, and an in-house Thoracic CT dataset from patients who received radiotherapy (gathered under an IRB approved protocol). LIDC includes 1018 patients, which we randomly split into 868/50/100 train/validation/test groups, and Thoracic includes 997 patients which we randomly split into 850/47/100 train/validation/test scans. We clipped all voxel values to Hounsfield Units (HU). We resampled each scan to mm3 resolution, cropped it to a cube, and then resized it to voxels. We generated four planar X-ray views per CT at angles of: (Lateral), , (Frontal), and using the Digitally Reconstructed Radiograph (DRR) generator Plastimatch[14], with energy level 50keV. For our segmentation loss, we trained one segmentation network per dataset using a UNet [2, 12]. For LIDC, we trained the segmentation network on 3 structures (left & right lung, nodule) using the LUNA16[13] dataset. For Thoracic, we trained on 9 structures (see Fig. 3 for names) predicted by nnUNet network [8] used for contouring in the clinic. In the following results, we call our models trained without the segmentation loss Ours, and those trained with the segmentation loss Ours-Seg.
Metrics: We evaluated performance using three types of metrics: voxel level (PSNR, SSIM [20]), structural level (Dice Similarity Coefficient [5], or DSC), and radiation dose (Isocenter dose). Isocenter dose is defined as the calculated dose (in centigray or cGy) deposited to a point in the patient’s body at a distance of 100 cm away from a megavoltage X-ray source.
Baselines: We experimented with two neural network baselines: X2CT-CNN [22] and Neural Attenuation Fields (NAF) [24]. X2CT-CNN is a CNN for reconstructing CT scans from 1 or 2 (orthogonal) views. NAF is a recently proposed implicit neural representation (INR) that handles arbitrary viewing angles in CT reconstruction (like our model), but uses no prior training data. We trained both baselines from scratch on each dataset separately.
Implementation: We implemented our models in PyTorch [11] and ran all experiments on NVIDIA A100 GPUs with 40/80 GB of memory. We set the batch size to 1 and trained for 100 epochs per model.We used the ADAM [10] optimizer with an initial learning rate of 3e-5, and decreased the learning rate to 3e-6 after 50 epochs.
Radiotherapy planning: Using 10 randomly selected patients from the Thoracic dataset, we generated radiotherapy plans with 2-field opposed beam arrangements using the RayStation commercial treatment planning system [3]. We set the isocenter within the thoracic spine of each clinical CT, fractional dose to 200 cGy, beam energy to 15 MV, and the radiation field size to 10 10 cm2 at isocenter. We performed rigid image registration so that radiation plans may be directly compared between the clinical and reconstructed CTs. Isocenter dose was compared between clinical plans and plans made on reconstructed CTs.

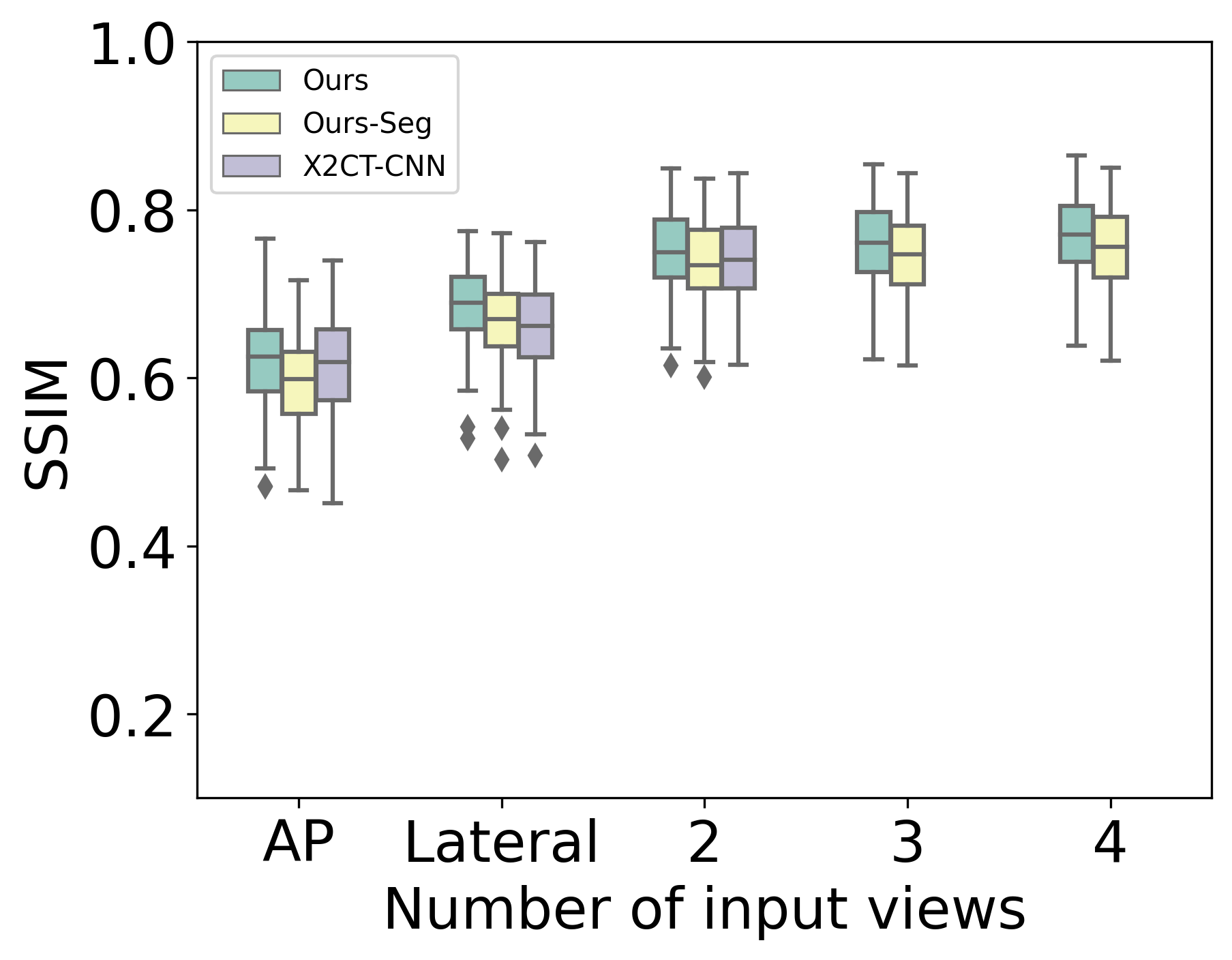



3.1 Results
First, we compare our models to baselines on LIDC using PSNR, SSIM, and DSC. NAF [24] performs poorly with a few number of views. For example, with 4 input views, 95% confidence intervals of PSNR, SSIM, and DSC are , , and , respectively. Fig. 2 shows the performance of our models and X2CT-CNN. Our models outperform X2CT-CNN for all views, with a particularly striking difference in DSC.
Moving from 1 to 2 views yields the largest marginal gains. Ours-Seg has higher DSC than Ours, but has slightly lower PSNR/SSIM. See Supplementary for a table with detailed results.

Next, Fig. 3 presents DSC boxplots of Ours-Seg with segmentation training on Thoracic. Again, the largest improvement occurs moving from 1 to 2 views, and the most difficult structures to contour are BrachialPlexus and Esophagus, likely because these structures are small in size. We also show sample reconstruction results with overlaid contours for two patients in Fig. 4 visually confirming the performance improvement near boundaries with more viewing angles.
| 2 Views | 4 Views | |
|---|---|---|
| Ours | 0.30 (0.35) | 0.25 (0.26) |
| Ours-Seg | 0.25 (0.26) | 0.50 (0.57) |
Finally, Fig. 5 shows dose distribution results from treatment plans generated on reconstructed CTs using 2 and 4 input views. The shapes of the isodose lines closely resemble that of the ground truth, and in particular, for the high dose region (pointed to by white arrow). Additionally, average isocenter dose errors are under 1% (see Table 1), below the criterion for dose verification accuracy [25].
4 Discussion and Conclusion
Results demonstrate the feasibility of reconstructing CTs from few planar X-ray images. Segmentation guidance during training improves DSC (see Fig. 2), but did not have a consistent effect on isocenter dose error. The simple planning technique used in this work is used to treat regions in the spine and provide robustness against small uncertainties in patient position. Thus, the radiotherapy dose for this technique is not sensitive to small changes in CT voxel information, which may explain why segmentation-guided training had minimal effects. Further studies using complex, segmentation-driven treatment planning for multiple regions in the body would elucidate the relationship between subtle feature changes in the CT and its impact upon dose. Structural and dose level metrics presented here indicate that our approach also has potential for use with more complex treatments.
Results also show that our model combining a 2D CNN and INR is better for this task (in terms of voxel level metrics) than an INR only (NAF) that does not leverage prior training data, or a traditional CNN (X2CT-CNN) which suffers in modeling high-frequency details. Maximum performance gain occurs moving from 1 to 2 views, which makes sense since two orthogonal views are generally needed to confirm an object’s location within the body [4].
Virtually all existing sparse CT reconstruction studies evaluate results using voxel-level metrics like PSNR and SSIM. This work makes the contribution of additionally evaluating in terms of radiotherapy plans. This is important, because all details need not be recovered for an algorithm to be clinically useful, a fact overlooked by PSNR and SSIM.
There are several exciting next steps to push this work forwards. First, CT reconstruction from few planar X-ray images is a highly ill-posed task and so there are infinitely many possible solutions per planar X-ray image input(s). By returning only one solution, our model is forced to produce scans that are the perceptual “average” of possible solutions. Incorporating a probabilistic formulation will help produce sharper results and quantify reconstruction uncertainties. Second, while the inference power of neural networks are remarkable, they are also known to “hallucinate” details. We will need further analysis into when and why such models make errors, with a particular focus on atypical subject cases. A focus of our next work will be 3-dimensional conformal radiotherapy planning for chest wall (post-mastectomy). For this specific use case, the tumor and diseased breast tissue is removed before the patient receives a CT and the target of the radiotherapy is the chest wall. Thus, tumor hallucination can be avoided and the development of such a technique will be extremely beneficial for women in low-resource settings, since post-masectomy radiotherapy is extremely prevalent. Finally, in practice we cannot assume that planar X-ray images are acquired at precise angles and depths. Development (and evaluation) of a model that can handle variable acquisition settings would therefore be a valuable contribution.
Acknowledgment
This work was supported by NSF CAREER: IIS-1652633.
References
- [1] Armato III, S.G., McLennan, G., Bidaut, L., McNitt-Gray, M.F., Meyer, C.R., Reeves, A.P., Zhao, B., Aberle, D.R., Henschke, C.I., Hoffman, E.A., et al.: The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical physics 38(2), 915–931 (2011)
- [2] Balakrishnan, G., Zhao, A., Sabuncu, M.R., Guttag, J., Dalca, A.V.: Voxelmorph: a learning framework for deformable medical image registration. IEEE transactions on medical imaging 38(8), 1788–1800 (2019)
- [3] Bodensteiner, D.: Raystation: External beam treatment planning system. Medical Dosimetry 43(2), 168–176 (2018)
- [4] Broder, J.: Chapter 5 - imaging the chest: The chest radiograph. In: Broder, J. (ed.) Diagnostic Imaging for the Emergency Physician, pp. 185–296. W.B. Saunders, Saint Louis (2011). https://doi.org/https://doi.org/10.1016/B978-1-4160-6113-7.10005-5, https://www.sciencedirect.com/science/article/pii/B9781416061137100055
- [5] Dice, L.R.: Measures of the amount of ecologic association between species. Ecology 26(3), 297–302 (1945)
- [6] Ge, R., He, Y., Xia, C., Xu, C., Sun, W., Yang, G., Li, J., Wang, Z., Yu, H., Zhang, D., et al.: X-ctrsnet: 3d cervical vertebra ct reconstruction and segmentation directly from 2d x-ray images. Knowledge-Based Systems 236, 107680 (2022)
- [7] Hricak, H., Abdel-Wahab, M., Atun, R., Lette, M.M., Paez, D., Brink, J.A., Donoso-Bach, L., Frija, G., Hierath, M., Holmberg, O., et al.: Medical imaging and nuclear medicine: a lancet oncology commission. The Lancet Oncology 22(4), e136–e172 (2021)
- [8] Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods 18(2), 203–211 (2021)
- [9] Jiang, Y., Li, P., Zhang, Y., Pei, Y., Guo, Y., Xu, T., Yuan, X.: 3d volume reconstruction from single lateral x-ray image via cross-modal discrete embedding transition. In: Machine Learning in Medical Imaging: 11th International Workshop, MLMI 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 4, 2020, Proceedings 11. pp. 322–331. Springer (2020)
- [10] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- [11] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019)
- [12] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. pp. 234–241. Springer (2015)
- [13] Setio, A.A.A., Traverso, A., De Bel, T., Berens, M.S., Van Den Bogaard, C., Cerello, P., Chen, H., Dou, Q., Fantacci, M.E., Geurts, B., et al.: Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medical image analysis 42, 1–13 (2017)
- [14] Sharp, G.C., Li, R., Wolfgang, J., Chen, G., Peroni, M., Spadea, M.F., Mori, S., Zhang, J., Shackleford, J., Kandasamy, N.: Plastimatch: an open source software suite for radiotherapy image processing. In: Proceedings of the XVI’th International Conference on the use of Computers in Radiotherapy (ICCR), Amsterdam, Netherlands (2010)
- [15] Shen, L., Pauly, J., Xing, L.: Nerp: implicit neural representation learning with prior embedding for sparsely sampled image reconstruction. IEEE Transactions on Neural Networks and Learning Systems (2022)
- [16] Shen, L., Zhao, W., Xing, L.: Patient-specific reconstruction of volumetric computed tomography images from a single projection view via deep learning. Nature biomedical engineering 3(11), 880–888 (2019)
- [17] Sitzmann, V., Martel, J., Bergman, A., Lindell, D., Wetzstein, G.: Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems 33, 7462–7473 (2020)
- [18] Sun, Y., Liu, J., Xie, M., Wohlberg, B., Kamilov, U.S.: Coil: Coordinate-based internal learning for tomographic imaging. IEEE Transactions on Computational Imaging 7, 1400–1412 (2021)
- [19] Tancik, M., Srinivasan, P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J., Ng, R.: Fourier features let networks learn high frequency functions in low dimensional domains. Advances in Neural Information Processing Systems 33, 7537–7547 (2020)
- [20] Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
- [21] Xie, Y., Takikawa, T., Saito, S., Litany, O., Yan, S., Khan, N., Tombari, F., Tompkin, J., Sitzmann, V., Sridhar, S.: Neural fields in visual computing and beyond. In: Computer Graphics Forum. vol. 41, pp. 641–676. Wiley Online Library (2022)
- [22] Ying, X., Guo, H., Ma, K., Wu, J., Weng, Z., Zheng, Y.: X2ct-gan: reconstructing ct from biplanar x-rays with generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10619–10628 (2019)
- [23] Yu, A., Ye, V., Tancik, M., Kanazawa, A.: pixelnerf: Neural radiance fields from one or few images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4578–4587 (2021)
- [24] Zha, R., Zhang, Y., Li, H.: Naf: Neural attenuation fields for sparse-view cbct reconstruction. In: Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, September 18–22, 2022, Proceedings, Part VI. pp. 442–452. Springer (2022)
- [25] Zhu, T.C., Stathakis, S., Clark, J.R., Feng, W., Georg, D., Holmes, S.M., Kry, S.F., Ma, C.M.C., Miften, M., Mihailidis, D., et al.: Report of aapm task group 219 on independent calculation-based dose/mu verification for imrt. Medical physics 48(10), e808–e829 (2021)