11email: [email protected]
22institutetext: Graduate School of Science and Engineering, Hosei University, Tokyo33institutetext: JST, PRESTO, Japan
CS-MCNet:A Video Compressive Sensing Reconstruction Network with Interpretable Motion Compensation
Abstract
In this paper, a deep neural network with interpretable motion compensation called CS-MCNet is proposed to realize high-quality and real-time decoding of video compressive sensing. Firstly, explicit multi-hypothesis motion compensation is applied in our network to extract correlation information of adjacent frames(as shown in Fig. 1), which improves the recover performance. And then, a residual module further narrows down the gap between reconstruction result and original signal. The overall architecture is interpretable by using algorithm unrolling, which brings the benefits of being able to transfer prior knowledge about the conventional algorithms. As a result, a PSNR of 22dB can be achieved at 64x compression ratio, which is about to better than state-of-the-art methods. In addition, due to the feed-forward architecture, the reconstruction can be processed by our network in real time and up to three orders of magnitude faster than traditional iterative methods.

1 Introduction
Traditional image or video compression methods, such as JPEG and H.265, compress the data after the measurement. However, compressive sensing, firstly introduced by Candes, Tao and Donoho[1][2] in 2006, allows compression in the sensing process, i.e. sampling part of the signal instead of the entirety. It has been shown that if the target signal has transform sparse properties, i.e.being sparse in a transform domain, then it can be recovered from sample less than the Shannon-Nyquist sampling criterion requires[3]. Suppose the target signal is , CS incorporates the compression into acquisition with a measurement matrix , where :
| (1) |
Here y is the measurements.
Even though traditional compression methods provides higher compression ratio and more mature system in some cases, the characteristic of simultaneous sensing and compression of compressive sensing requires very different encoder and decoder, which is of great importance to some specific areas, such as medical imaging systems, high frame rate video systems, and multimedia data compression.
The compression ratio CR can be defined as . CS reconstruction should be ’sparse’, i.e. the original signal can be represented as , where is called the sparsity basis and the sparse representation of x. While natural images and video are difficult to achieve true sparsity, compressive sensing allows for approximate sparsity as well. Besides, CS reconstruction should also obey restricted isometry property, or RIP[4][5]. It has been proved that RIP rule is equal to measurement basis and sparsity basis being mutually incoherent[6]. Thus, random matrix is commonly chosen in CS measurement. In addition, structured random matrix(SRM) can also meet the requirements and provide additional benefits, such as preserving information or reducing computation and memory consumption.(e.g., [7]).
1.1 Related Works
In the recent decades, many methods have been proposed to solve the CS reconstruction problem[8],[9],[10],[11]. For image reconstruction of compressive sensing, the algorithm of traditional transformation(e.g., wavelets domain[10],[12])runs fast but with low accuracy. Methods that rely on complex sparsity, such as dictionary learning methods[13]generally have better reconstruction performance but lower computational speed. Furthermore, while most research efforts for image CS problems can be directly applied to video CS tasks, they fail to take advantage of the correlation between adjacent frames in a video sequence.
For video CS recovery, in[8], the authors use Gaussian mixture model(GMM) to recover high-frame-rate videos, and the reconstruction can be efficiently computed as an analytical solution. In[14], the authors propose a motion-compensation and block-based method MC-BCS-SPL, which estimate a motion vector from a reference frame and the under-reconstruction frame can then get prediction to improve recover performance. In general, these traditional methods focus on the design of different priors, transformations and sparsity constraints. However, these methods are usually difficult to determine the hyperparameters, such as thresholds or number of iterations, and due to their computational complexity, they can not perform real-time rebuild.
Driven by the powerful learning capabilities of neural networks, a number of DNN-based approaches have been applied[15],[16],[17],[18],[19]. In[19], the authors cast ISTA into deep network form and develope an effective strategy to solve the proximal mapping associated with the sparsity-inducing regularizer using nonlinear transforms. In[17], the authors propose a fully-connected neural network to reconstruct video temporal CS measurement, and a repetitive pattern measurement mask is proposed to make such a task practical. In[15], the authors propose a network named ”CSVideoNet”. The network combines a multi-rate CNN and a synthesizing RNN to improve the trade-off between compression ratio and spatial-temporal resolution of the reconstructed videos. Compared with iterative algorithms, these feed-forward methods significantly reduce time consumption. However, the structure of these networks is often empirically determined and is ambiguous as a black box, which brings difficulty in making targeted improvements.
To resolve the conflict between interpretability and speed of reconstruction, a technique called algorithm unrolling has been applied recently. The technique was proposed by Gregor et al.[20], and builds neural network by unfolding an iterative optimization algorithm to be a hierarchical architecture, which provides a principled framework by expressing traditional iterative algorithms as neural networks, and offers promise in developing interpretable network. There are several networks using algorithm unrolling to solve CS reconstruction[19],[21], but they are developed for image CS tasks rather than specifically for video CS tasks.
In this work, we develop a network, called CS-MCNet, that attempts to use inter-frame information to improve the reconstruction quality of video CS measurements. By mapping the iterative algorithm MC-BCS-SPL into non-iterative neural network, all of CS-MCNet’s block is designed to correspond to an iteration in MC-BCS-SPL. By end-to-end training, our network can learn all parameters efficiently.
1.2 Contribution
Our main contributions are summarized as follows.1)We use neural network modules to replace the optimization steps in traditional model-based approaches and implement them in a simple form that is easy to realize quickly. 2)We propose a multi-hypothesis motion compensation structure. The module exploits the similarity between neighboring frames to improve the reconstruction quality. To the best of our knowledge, it is the first work that explicitly uses motion compensation for video CS reconstruction in deep neural network. 3)We employ a residual module in the network to further improve performance, and this structure also facilitates the training of deeper neural networks. With these improvements, our work outperforms previous work in terms of both reconstruction quality and computational cost.
2 Methodology
By taking advantage of the merits of model based and DNN-based CS methods, CS-MCNet maps the optimization steps into a deep network architecture consisting of a fixed number of stages, each of which is designed to correspond to one iteration in the MC-BCS-SPL algorithm. The overall architecture of CS-MCNet is shown in Fig. 2. The proposed CS-MCNet consists of an encoder (sensing matrix) and a decoder. The encoder performs simultaneous sampling and compression. The decoder consists of several stages, each of which is divided into three parts. Firstly, the decoder roughly recovers input measurements to get a preliminary result. Secondly, it get prediction from a single reference frame. Then the prediction is measured and subtracted from original measurements to get the residual. Thirdly, the residual measurements are recovered and the result is added to the prediction. The output is derived from combining the preliminary result and residual reconstruction linearly. We will introduce each module in the following subsections.

2.1 Priliminary reconstruction module
The first hidden layer is a fully-connected layer that would provide 3D signal from 2D compressed measurements. Several papers have shown that CNNs can achieve superior performance on CS reconstruction problems compared with simple optimization-based algorithms.[18],[17],[16], thus we use CNN to get the preliminary reconstruction result. Typical CNN architectures used to do recognition, classification, and segmentation are not suitable to the reconstruction problem here. The goal of CNNs in our network is to retain as much detail as possible and need to recover pixels that do not exist based on known information. Therefore, we eliminated the pooling layer, which causes information loss.
To reduce the size of parameters and simplify the network architecture, we use video blocks as input and set the block size to . The convolutional layers, each of which is followed by a ReLU layer except for the final layer, are carefully designed to get amenable recovery performance. All feature maps are the same size as the reconstructed video block, and the number of feature maps is monotonically reduced. The detailed structure of the CNN is shown in Fig. 3. This process resembles the sparse coding stage in CS, where a subset of dictionary atoms are combined to form an estimation of the original input. To improve final reconstruction performance, we pre-train the CNN before training the whole CS-MCNet, since the path is long from the input to the output of the whole net and pre-training can help prevent the vanishing gradient problem[22].

2.2 Multi-hypothesis motion compensation module
Traditional video compression algorithms have long exploited motion compensation to improve video-coding quality[23],[24]; In consideration of bit rate at the encoder side, these techniques use single hypothesis in order to limit the amount of motion vector. However, this limitation doesn’t exist since the motion compensation is all calculated at the decoder side of the system. Thus, multi-hypothesis motion compensation can be considered to combine all available best assumptions in the reference frame. A MH CS reconstruction can be represented as an optimal linear combination of all possible reference blocks:
| (2) |
| (3) |
Here, the subscript ”t” and ”i” represents the index of frame in the video and the index of block in the frame, and is a matrix of dimensionality consisted of rasterizations of the possible blocks within the search window in the reference frame, and . In this context, represents the linear combination of the columns of ; The solution of this optimization can be calculated as a least-squares(LSQ) problem[25].
The proposed network in this paper uses MH motion compensation to improve the recovery performance. Unlike traditional optimization-based solutions to the LSQ problem, we use fully-connected layers to learn the optimal parameters. Due to the similarity of adjacent frames, this MH motion compensation module can be trained appropriately to produce accurate predictions of motion and the recovery quality can be improved by the aggregation of motion and spatial visual features.
To get the reference frame, we design a buffer to store the reconstructed video blocks, as shown in Fig. 2. For the sake of simplicity, we choose to do reconstruction after the reference frame is completely reconstructed. However, the search window actually only involves part of the reference frame, and therefore we can reduce the size of the buffer by carefully designing the rebuilding order. In[15], the authors use LSTM network to do temporal reference, which is similar to motion compensation. However with the experiment, we prove that the utilization of explicit motion compensation module outperforms the RNN based methods and decrease the model size simutaneously.
2.3 Residual reconstruction module
With the prediction of MH motion compensation, we introduce the residual reconstruction module to further narrow down the gap between and . The output of residual learning is fused with the output of preliminary reconstruction module as the final result.

We get the residual signal by measuring the result of MH motion compensation and subtracting it from the original measurements ,
| (4) |
According to[26], the convolutional layers in residual module could be easily trained to approximate the residual, most of which is zero. As shown in Fig. 4, the residual reconstruction module contains one fully-connected layer and five convolution layers. The fully-connected layer has the same function of recover 3D volume signal from 2D measurements as in preliminary reconstruction module. The rest has decreasing number of feature maps and holds the size of . All convolutional layers is followed by a ReLU layer except the last one.
2.4 Learning Algorithm
Given the training data pairs , CS-MCNet firstly gets measurements with sensing matrix. Then serves as input of the decoder and generates the reconstruction result. We wanted to reduce the discrepancy between the raw measurements and the MH motion compensation measurements, i.e.the residual signal. Therefore, the loss function for CS-MCNet is designed as follows:
| (5) |
| (6) |
where is the scale factor to control the influence of motion compensation on the total loss. Determined by experiment, we set to be 0.5 during training to get the best performance.
We choose MSE to calculate the loss, which is a commonly used metric to quantitatively evaluate recovery quality. The proposed framework can also be adapted to other loss functions. Adam optimizer with default parameters is chosen to optimize the proposed network.
3 Experiment
We compare our methods with state-of-the-art approaches, including iterative optimization based methods and DNN based methods. For fairness, we set the block size of and retrained the reference networks with our self-built dataset. It should be emphasized that we rewrote CSVideoNet with Pytorch, whose original code was implemented by Torch. We took parameters from the original model files provided by the authors, however we cannot guarantee that it will achieve the same performance as the original code. Furthermore, to prove the advantage of exploiting motion compensation, image specific methods are also included. Both noiseless and noise measurements are tested and we also discuss the performance of our proposed network under different network parameters(i.e. number of stages). Two metrics, peak signal-to-noise ration(PSNR) and structural similarity(SSIM) are used to evaluate the performance, and visualization of the results are provided.
3.1 Implementation Details
As there is no standard dataset designed for video CS, we use UCF-101 dataset[27] to build our own training dataset. UCF-101 dataset includes 13k clips and about 27 hours of video, which is collected from YouTube and is divided into 101 action classes. We extract only the luminance component of the extracted frames and crop the central patch from each frame. All of the patches are segmented into non-overlapping blocks. We randomly choose video sequences from UCF-101 dataset and finally get around 300,000 pairs of data for training and validation in total.
Our model is implemented with PyTorch and all the experiments are performed on a workstation with an Intel Xeon CPU and a Nvidia GeForce RTX2080 GPU. Our networks are trained for 200 epochs with batch size of 400. We normalize the input pre-feature to zero mean and standard deviation one. We set the starting learning rate to 0.01 and divide the learning rate by 10 if the loss of the current epoch is greater than that of the previous epoch. Except for the last subsection, we use 4 cascaded stages in the following experiments.
3.2 Comparison with the State-of-the-art
We compare the reconstruction performance of our proposed method with several reference work of CS reconstruction[14],[11],[8],[15],[19],[17]. The summarized information about all baseline approaches is listed in Table 1. All the methods reconstruct video blocks from its CS measurements independently, and the result of average PSNR, SSIM and time consumption for each method on the test dataset is reported in Fig. 5. To save training time, all methods are tested under CR of 16. From the results we can observe that CS-MCNet outperforms the reference method in terms of metrics and time consumption. Compared with conventional image CS algorithm BCS-SPL, D-AMP, and video CS algorithm MC-BCS-SPL, GMM, our DNN-based CS-MCNet benefits from learnable parameters and feed-forward architecture, and thus gets better reconstruction quality and uses less time. The similar DNN based methods DeepVideoCS, CSVideoCS and ISTANet either uses barely CNN or combines CNN and RNN to extract inexplicit motion features. In contrast to them, our work exploits explicit MH motion compensation, further improving the quality of the reconstruction and compressing the size of the model, which makes it easier and faster to train and deploy.
| Image CS | Model Based | BCS-SPL[14] | block based CS with smooth projected Landweber |
| D-AMP[11] | Denoising-based approximate message passing | ||
| DNN Based | ISTANet[19] | CNN inspired by ISTA algorithm | |
| Video CS | Model Based | MC-BCS-SPL[14] | motion compensation block based CS |
| GMM[8] | Gaussian mixture model | ||
| DNN Based | DeepVideoCS[17] | deep neural network with fully-connected layers | |
| CSVideoNet[15] | a multi-rate CNN and a synthesizing RNN | ||
| CS-MCNet | proposed approach |

To further validate the advantages of using MH motion compensation, we do comparison with MC-BCS-SPL and ISTA under different CRs of 4,16 and 64. As shown in Table 2, CS-MCNet achieves relatively better performance, especially under high compression ratio. CS-MCNet outperforms MC-BCS-SPL both on reconstruction quality and time consumption, since its learnable parameters can be better optimized through end-to-end training, and GPU acceleration makes it three orders of magnitude faster than iterative methods. As for ISTANet, which also uses algorithm unrolling and has a similar residual block structure, the utilization of inter-frame information helps our network achieve better reconstruction quality, though the storage of reference frame requires extra storage space and time consumption.
| CR | Metric | ISTANet[19] | MC-BCS-SPL[14] | CS-MCNet:proposed |
|---|---|---|---|---|
| 4 | PSNR | 33.851 | 31.067 | 33.35 |
| SSIM | 0.953 | 0.834 | 0.918 | |
| 16 | PSNR | 26.618 | 26.141 | 29.707 |
| SSIM | 0.583 | 0.436 | 0.789 | |
| 64 | PSNR | 19.93 | 19.79 | 21.45 |
| SSIM | 0.382 | 0.288 | 0.528 |
Visual examples of some reference methods are shown in Fig. 6. The ground truth is also shown in Fig. 6. As we can see, CS-MCNet provides the best detail of selected methods and suffers minimal block effect. CS-MCNet produces sharper edges in the highlight areas and a more uniform image overall. This comparison demonstrates that inter-frame information is significant for video CS reconstruction, and the image CS approaches are not suitable for video tasks. Through further optimization, we believe that CS-MCNet has the potential to be applied on real-time reconstruction of high-frame-rate video CS.

-/-

30.375/0.871

-/-

26.621/0.806

-/-

28.592/0.865












3.3 Reconstruction Under Noise
In this subsection, we investigate the performance of our proposed network in the presence of measurement noise. The measurement of CS usually involves noise in practice caused by devices, and the measurement model should now be modified as
| (7) |
where n is the additive measurement noise.
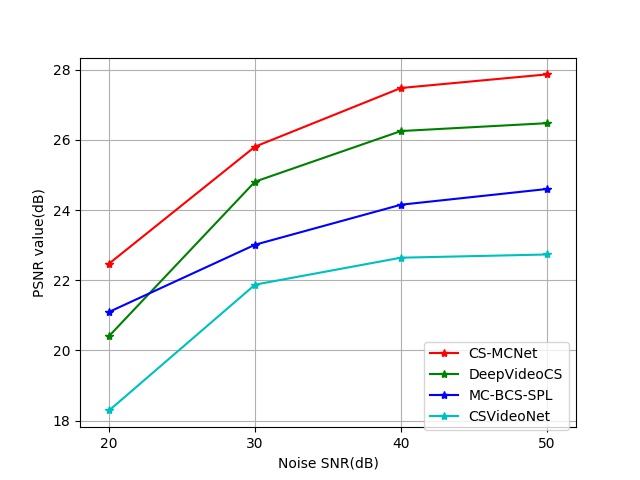
We conduct experiment with input measurements contaminated by random Gaussian noise, and all other parameters remain the same as in the noiseless case. We test the performance at four level of SNR from 20dB to 50dB under CR of 16. The result is shown in Fig. 7. It can be observed that at different noise level, CS-MCNet can achieve stable reconstruction performance and outperform the reference methods consistently. It is worth emphasizing that we did not retrain the network with noise measurement and all the experiments in this subsection are implemented with noiseless model, which shows the robustness of our model under different measurement conditions. Besides, it is easy to combat with performance degradation under noise by cascading our network with a deep denoising architecture or other denoising algorithm.
3.4 Discussion
As described earlier, the number of stages of CS-MCNet corresponds to the number of iterations of the original algorithm. In this subsection, we mainly focuses on the structure parameter of CS-MCNet, i.e. the nubmer of stages. From Table 3, we can find that as the number of stages increases from 2 to 4, the performance improves under different CRs. This can be explained by the fact that the deeper the neural network, the better its learning capacity. However, as the number of stages increases to 5, the performance deteriorates. We speculate that the reason is that while a deeper structure may help to fit the training data more accurately, it also makes it more difficult to train, resulting in an undertrained model. The training time increased slightly when the number of stages is less than 4 and increases rapidly when the number of stages is further increased. For CS-MCNet with no more than 4 stages, the time used to train an epoch varies from 30 to 40 minutes with GPU acceleration, but for networks with 5 or more stages, it can take more than an hour. To strike a balance between the effectiveness of the reconstruction and the cost of training, we empirically decides to use CS-MCNet with 4 stages.
| CR | Metric | 2 stages | 3 stages | 4 stages | 5 stages |
|---|---|---|---|---|---|
| 4 | PSNR | 32.776 | 32.892 | 32.936 | 32.656 |
| SSIM | 0.904 | 0.905 | 0.909 | 0.910 | |
| 16 | PSNR | 26.268 | 26.399 | 26.834 | 26.097 |
| SSIM | 0.691 | 0.697 | 0.698 | 0.684 | |
| 64 | PSNR | 21.312 | 21.412 | 21.447 | 21.359 |
| SSIM | 0.379 | 0.391 | 0.382 | 0.386 | |
| Average | PSNR | 26.864 | 26.862 | 26.979 | 26.797 |
| SSIM | 0.658 | 0.664 | 0.663 | 0.659 |
4 Conclusion
Inspired by the MC-BCS-SPL algorithm, we use algorithmic unrolling to build a novel deep neural network to perform video compressive sensing reconstruction. Our proposed CS-MCNet has an interpretable multi-hypothesis motion compensation module that can exploit the correlation of neighboring frames in the video, which is important for improving reconstruction quality. The feedforward structure allows for fast CS reconstruction using GPU acceleration. CS-MCNet has been shown to outperform the reference method in terms of reconstruction quality and time consumption, and has the potential to be developed as a common framework for video CS applications. One direction of our future work is to integrate this network with video codec systems in general, and specifically on the task of bit rate control.
References
- [1] Candes, E.J., Tao, T.: Near-optimal signal recovery from random projections: Universal encoding strategies? IEEE Transactions on Information Theory 52 (2006) 5406–5425
- [2] Donoho, D.L.: Compressed sensing. IEEE Transactions on Information Theory 52 (2006) 1289–1306
- [3] Duarte, M.F., Davenport, M.A., Takhar, D., Laska, J.N., Sun, T., Kelly, K.F., Baraniuk, R.G.: Single-pixel imaging via compressive sampling. IEEE Signal Processing Magazine 25 (2008) 83–91
- [4] Candes, E.J., Wakin, M.B.: An introduction to compressive sampling. IEEE Signal Processing Magazine 25 (2008) 21–30
- [5] Candès, E.J., Romberg, J.K., Tao, T.: Stable signal recovery from incomplete and inaccurate measurements. Communications on Pure and Applied Mathematics 59 (2006) 1207–1223
- [6] Baraniuk, R., Davenport, M.A., DeVore, R.A., Wakin, M.B.: A simple proof of the restricted isometry property for random matrices. Constructive Approximation 28 (2008) 253–263
- [7] Zhou, J., Zhou, J., Guo, L.: Angular intra prediction based measurement coding algorithm for compressively sensed image. In: 2018 IEEE International Conference on Multimedia Expo Workshops (ICMEW). (2018) 1–6
- [8] Yang, J., Yuan, X., Liao, X., Llull, P., Sapiro, G., Brady, D.J., Carin, L.: Gaussian mixture model for video compressive sensing. In: 2013 IEEE International Conference on Image Processing. (2013) 19–23
- [9] Daubechies, I., Defrise, M., De Mol, C.: An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Communications on Pure and Applied Mathematics 57 (2004) 1413–1457
- [10] He, L., Carin, L.: Exploiting structure in wavelet-based bayesian compressive sensing. IEEE Transactions on Signal Processing 57 (2009) 3488–3497
- [11] Metzler, C.A., Maleki, A., Baraniuk, R.G.: From denoising to compressed sensing. IEEE Transactions on Information Theory 62 (2016) 5117–5144
- [12] Qu, X., Guo, D., Ning, B., Hou, Y., Lin, Y., Cai, S., Chen, Z.: Undersampled mri reconstruction with patch-based directional wavelets. Magnetic Resonance Imaging 30 (2012) 964 – 977
- [13] Zhan, Z., Cai, J., Guo, D., Liu, Y., Chen, Z., Qu, X.: Fast multiclass dictionaries learning with geometrical directions in mri reconstruction. IEEE Transactions on Biomedical Engineering 63 (2016) 1850–1861
- [14] Mun, S., Fowler, J.E.: Residual reconstruction for block-based compressed sensing of video. In: 2011 Data Compression Conference. (2011) 183–192
- [15] Xu, K., Ren, F.: Csvideonet: A real-time end-to-end learning framework for high-frame-rate video compressive sensing. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). (2018) 1680–1688
- [16] Yao, H., Dai, F., Zhang, S., Zhang, Y., Tian, Q., Xu, C.: Dr2-net: Deep residual reconstruction network for image compressive sensing. Neurocomputing 359 (2019) 483 – 493
- [17] Iliadis, M., Spinoulas, L., Katsaggelos, A.K.: Deep fully-connected networks for video compressive sensing. Digital Signal Processing 72 (2018) 9 – 18
- [18] Kulkarni, K., Lohit, S., Turaga, P., Kerviche, R., Ashok, A.: Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2016) 449–458
- [19] Zhang, J., Ghanem, B.: Ista-net: Interpretable optimization-inspired deep network for image compressive sensing. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2018) 1828–1837
- [20] Gregor, K., LeCun, Y.: Learning fast approximations of sparse coding. In: Proceedings of the 27th International Conference on International Conference on Machine Learning. ICML’10, Madison, WI, USA, Omnipress (2010) 399–406
- [21] Yang, Y., Sun, J., Li, H., Xu, Z.: Admm-csnet: A deep learning approach for image compressive sensing. IEEE Transactions on Pattern Analysis and Machine Intelligence 42 (2020) 521–538
- [22] Erhan, D., Bengio, Y., Courville, A., Manzagol, P., Vincent, P., Bengio, S.: Why does unsupervised pre-training help deep learning? Journal of Machine Learning Research 11 (2010) 625–660
- [23] Tekalp, A.M.: Digital Video Processing. 2nd edn. Prentice Hall Press, USA (2015)
- [24] Jain, J., Jain, A.: Displacement measurement and its application in interframe image coding. IEEE Transactions on Communications 29 (1981) 1799–1808
- [25] Tramel, E.W., Fowler, J.E.: Video compressed sensing with multihypothesis. In: 2011 Data Compression Conference. (2011) 193–202
- [26] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2016) 770–778
- [27] Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. ArXiv abs/1212.0402 (2012)