bl[gobble]
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ef6ab6e1-814c-4efa-8d37-9b0c91eebea5/x1.png)
Left: Given an input shape collection, our method constructs a graph where each shape is represented as a node and edges indicate shape pairs that are deemed compatible for cross-shape feature propagation. Middle: Our network is designed to compute point-wise feature representations for a given shape (grey shape) by enabling interactions between its own point-wise features and those of other shapes using our cross-shape attention mechanism. Right: As a result, the point-wise features of the shape become more synchronized with ones of other relevant shapes leading to more accurate fine-grained segmentation.
Cross-Shape Attention for Part Segmentation of 3D Point Clouds
Abstract
We present a deep learning method that propagates point-wise feature representations across shapes within a collection for the purpose of 3D shape segmentation. We propose a cross-shape attention mechanism to enable interactions between a shape’s point-wise features and those of other shapes. The mechanism assesses both the degree of interaction between points and also mediates feature propagation across shapes, improving the accuracy and consistency of the resulting point-wise feature representations for shape segmentation. Our method also proposes a shape retrieval measure to select suitable shapes for cross-shape attention operations for each test shape. Our experiments demonstrate that our approach yields state-of-the-art results in the popular PartNet dataset.
{CCSXML}<ccs2012> <concept> <concept_id>10010147.10010178.10010224.10010240.10010242</concept_id> <concept_desc>Computing methodologies Shape representations</concept_desc> <concept_significance>500</concept_significance> </concept> <concept> <concept_id>10010520.10010521.10010542.10010294</concept_id> <concept_desc>Computer systems organization Neural networks</concept_desc> <concept_significance>500</concept_significance> </concept> </ccs2012>
\ccsdesc[500]Computing methodologies Shape representations \ccsdesc[500]Computer systems organization Neural networks
\printccsdescThis is the author’s version of the work. It is posted here for your personal use. The definitive version of the article will be published at Computer Graphics Forum, vol.42, no.5, 2023, https://doi.org/10.1111/cgf.14909.
1 Introduction
Learning effective point-based representations is fundamental to shape understanding and processing. In recent years, there has been significant research in developing deep neural architectures to learn point-wise representations of shapes through convolution and attention layers, useful for performing high-level tasks, such as shape segmentation. The common denominator of these networks is that they output a representation for each shape point by weighting and aggregating representations and relations with other points within the same shape.
In this work, we propose a cross-shape attention mechanism that enables interaction and propagation of point-wise feature representations across shapes of an input collection. In our architecture, the representation of a point in a shape is learned by combining representations originating from points in the same shape as well as other shapes. The rationale for such an approach is that if a point on one shape is related to a point on another shape e.g., they lie on geometrically or semantically similar patches or parts, then cross-shape attention can promote consistency in their resulting representations and part label assignments. We leverage neural attention to determine and weigh pairs of points on different shapes. We integrate these weights in our cross-shape attention scheme to learn more consistent point representations for the purpose of semantic shape segmentation.
Developing such a cross-shape attention mechanism is challenging. Performing cross-attention across all pairs of shapes becomes prohibitively expensive for large input collections of shapes. Our method learns a measure that allows us to select a small set of other shapes useful for such cross-attention operations with a given input shape. For example, given an input office chair, it is more useful to allow interactions of its points with points of another structurally similar office chair rather than a stool. During training, we maintain a sparse graph (Figure Cross-Shape Attention for Part Segmentation of 3D Point Clouds), whose nodes represent training shapes and edges specify which pairs of shapes should interact for training our cross-shape attention mechanism. At test time, the shape collection graph is augmented with additional nodes representing test shapes. New edges are added connecting them to training shapes for propagating representations from relevant training shapes.
We tested our cross-shape attention mechanism on two different backbones to extract the initial point-wise features per shape for the task of part segmentation: a sparse tensor network based on MinkowskiNet [CGS19] and the octree-based network MID-FC [WYZ*21]. For both backbones, we observed that our mechanism significantly improves the point-wise features for segmentation. Compared to the MinkowskiNet baseline, we found an improvement of in mean part IoU in the PartNet benchmark [MZC*19]. Compared to MID-FC, we found an improvement of in mean part IoU, achieving a new state-of-the-art result in PartNet (MID-FC: Ours: ).
In summary, our main technical contribution is an attention-based mechanism that enables point-wise feature interaction and propagation within and across shapes for more consistent segmentation. Our experiments show state-of-the-art performance on the recent PartNet dataset.
2 Related work
We briefly overview related work on 3D deep learning for point clouds. We also discuss cross-attention networks developed in other domains.
2.1 3D deep learning for processing point clouds
Several different types of neural networks have been proposed for processing point sets over the recent years. After the pioneering work of PointNet [QSMG17, QYSG17], several works further investigated more sophisticated point aggregation mechanisms to better model the spatial distribution of points [LCL18, SGS19, LKM19, LHC*20, DLD*21, ZCW*20, LLG*22, ZYX*22, QLP*22]. Alternatively, point clouds can be projected onto local views [SMKL15, QSN*16, KAMC17, HKC*17] and processed as regular grids through image-based convolutional networks. Another line of work converts point representations into volumetric grids [WSK*15, MS15, DCS*17, RWS*18, SWL19, LTLH19] and processes them through 3D convolutions. Instead of uniform grids, hierarchical space partitioning structures (e.g., kd-trees, octrees, lattices) can be used to define regular convolutions [RUG17, KL17, WLG*17, WSLT18, SJS*18, WYZ*21]. Another type of networks incorporate point-wise convolution operators to directly process point clouds [LBS*18, HTY18, XLCT18, LFM*19, GWL18, AML18, HRV*18, WSM*18, XFX*18, WQF19, KZH19, TQD*19]. Alternatively, shapes can be treated as graphs by connecting each point to other points within neighborhoods in a feature space. Then graph convolution and pooling operations can be performed either in the spatial domain [WSL*19, SFYT18, LYYD19, WSS18, ZHW*19, LFXP19, LB19, LMQ*23, JZL*19, XSW*19, WHH*19, HWW*19, LKM19, LAK20], or spectral domain [YSGG17, BMM*15, BMRB16, MBM*17]. Attention mechanisms have also been investigated to modulate the importance of graph edges and point-wise convolutions [XLCT18, XSW*19, WHH*19, YHJY19]. Graph neural network approaches have been shown to model non-local interactions between points within the same shape [WSL*19, LMQ*23, XSW*19, HWW*19]. Finally, several recent works [ZJJ*21, GCL*21, EBD21, ML21, YTR*22, XWL*21, PWT*22, LLJ*22, YGX*23, SEH*23] introduced a variety of transformer-inspired models for point cloud processing tasks. None of the above approaches have investigated the possibility of extending attention across shapes. A notable exception are the methods by Wang et al. [WS19] and Cao et al. [CPBM21] that propose cross-attention mechanisms across given pairs of point cloud instances representing different transformations of the same underlying shape for the specific task of rigid registration. Our method instead introduces cross-attention across shapes within a large collection without assuming any pre-specified shape pairs. Our method aims to discover useful pairs for cross-shape attention and learns representations by propagating them within the shape collection. Our method shows that the resulting features yield more consistent 3D shape segmentation than several other existing point-based networks.
2.2 Cross-attention in other domains
Our method is inspired by recent cross-attention models proposed for video classification, image classification, keypoint recognition, and image-text matching. Wang et al. [WGGH18] introduced non-local networks that allow any image query position to perceive features of all the other positions within the same image or across frames in a video. To avoid huge attention maps, Huang et al. proposes a “criss-cross” attention module [HWH*19] to maintain sparse connections for each position in image feature maps. Cao et al. [CXL*19] simplifies non-local blocks with query-independent attention maps [CXL*19]. Lee et al. [LCH*18] propose cross-attention between text and images to discover latent alignments between image regions and words in a sentence. Hou et al. [HCB*19] models the semantic relevance between class and query feature maps in images through cross-attention to localize more relevant image regions for classification and generate more discriminative features. Sarlin et al. [SDMR19] learns keypoint matching between two indoor images from different viewpoints by leveraging self-attention and cross-attention to boost the receptive field of local descriptors and allow cross-image communication. Chen et al. [CFP21] propose cross-attention between multiscape representations for image classification. Finally, Doersch et al. [DGZ20] introduced a CrossTransformer model for few-shot learning on images. Give an unlabeled query image, their model computes local cross-attention similarities with a number of labeled images and then infers class membership.
Our method instead introduces attention mechanisms across 3D shapes. In contrast to cross-attention approaches in the above domains, we do not assume any pre-existing paired data. The usefulness of shape pairs is determined based on a learned shape compatibility measure.
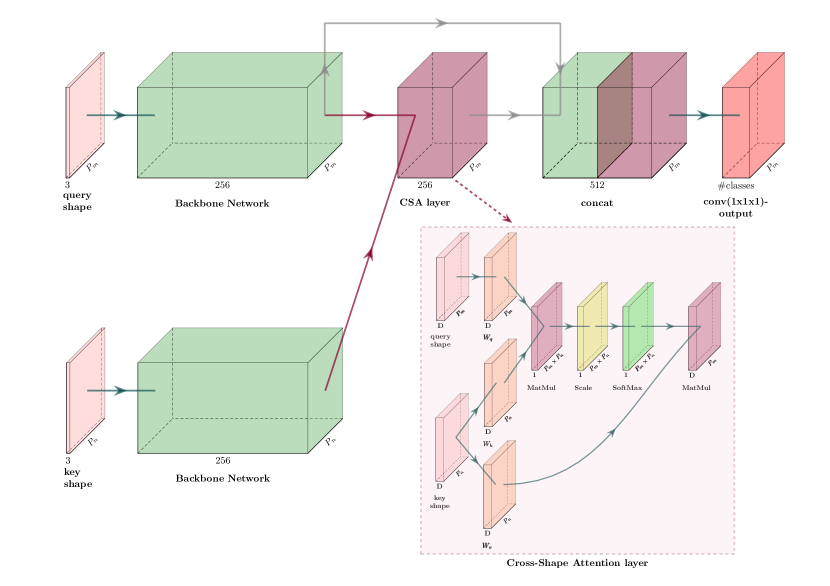
3 Method
Given an input collection of 3D shapes represented as point clouds, the goal of our method is to extract and propagate point-based feature representations from one shape to another, and use the resulting representations for 3D semantic segmentation. To perform the feature propagation, we propose a Cross-Shape Attention (CSA) mechanism. The mechanism first assesses the degree of interaction between pairs of points on different shapes. Then it allows point-wise features on one shape to influence the point-wise features of the other shape based on their assessed degree of interaction. In addition, we provide a mechanism that automatically selects shapes (“key shapes”) to pair with an input test shape (“query shape”) to execute these cross-shape attention operations. In the following sections, we first discuss the CSA layer at test time (Section 3.1). Then we discuss our retrieval mechanism to find key shapes given a test shape (Section 3.2), our training (Section 3.3), test stage (Section 3.4), and finally our network architecture details (Section 3.5).
3.1 Cross-shape attention for a shape pair
The input to our CSA layer is a pair of shapes represented as point clouds: and where represent 3D point positions and are the number of points for each shape respectively. Our first step is to extract point-wise features for each shape.
In our implementation, we experimented with two backbones for point-wise feature extraction: a sparse tensor network based on a modified version of MinkowskiNet [CGS19], and an octree-based network, called MID-FC [WYZ*21] (architecture details for the two backbones are provided in Section 3.5 and supplementary material). The output from the backbone is a per-point -dimensional representation stacked into a matrix for each of the two shapes respectively: and . The CSA layer produces new -dimensional point-wise representations for both shapes:
| (1) |
where is the cross-shape attention function with learned parameters described in the next paragraphs.
Key and query intermediate representations.
Inspired by Transformers [VSP*17], we first transform the input point representations of the first shape in the pair to intermediate representations, called “query” representations. The input point representations of the second shape are transformed to intermediate “key” representations. The keys will be compared to queries to determine the degree of influence of one point on another. Specifically, these transformations are expressed as follows:
| (2) |
where and are point representations for the query shape and key shape , and are learned transformation matrices shared across all points of the query and key shape respectively, and is an index denoting each different transformation (“head”). The dimensionality of the key and query representations is set to , where is the number of heads. These intermediate representations are stacked into the matrices and . Furthermore, the point representations of the key shape are transformed to value representations as:
| (3) |
where is a learned transformation shared across the points of the key shape. These are also stacked to a matrix .
Pairwise point attention.
The similarity of key and query representations is determined through scaled dot product [VSP*17]. This provides a measure of how much one shape point influences the point on the other shape. The similarity of key and query representations is determined for each head as:
| (4) |
where is a cross-attention matrix between the two shapes for each head.
Feature representation updates.
The cross-attention matrix is used to update the point representations for the query shape :
| (5) |
The point-wise features are concatenated across all heads, then a linear transformation layer projects them back to -dimensional space and they are added back to the original point-wise features of the query shape:
| (6) |
where is the number of heads and is another linear transformation. The features are stacked into a matrix , followed by layer normalization [BKH16].
Self-shape attention.
Cross-shape attention for multiple shapes.
We can further generalize the cross-shape operation in order to handle multiple shapes and also combine it with self-shape attention. Given a selected set of key shapes, our CSA layer outputs point representations for the query shape as follows:
| (7) |
where is a set of key shapes deemed compatible for cross-shape attention with shape and is a learned pairwise compatibility function between the query shape and each key shape . The key idea of the above operation is to update point representations of the query shape as a weighted average of attention-modulated representations computed by using other key shapes as well as the shape itself. The compatibility function assesses these weights that different shapes should have for cross-shape attention. It also implicitly provides the weight of self-shape attention when .
Compatibility function.
To compute the compatibility function, we first extract a global, -dimensional vector representation and for the query shape and each key shape respectively through mean-pooling on their self-shape attention representations:
| (8) |
| (9) |
In this manner, the self-attention representations of both shapes provide cues for the compatibility between them expressed using their scaled dot product similarity [VSP*17]:
| (10) |
where and are learned transformations for the query and key shape respectively, and . The final compatibility function is computed as a normalized measure using a softmax transformation of compatibilities of the shape with all other shapes in the set , including the self-compatibility:
| (11) |
3.2 Key shape retrieval
To perform cross-shape attention, we need to retrieve one or more key shapes for each query shape. One possibility is to use the measure of Eq. 10 to evaluate the compatibility of the query shape with each candidate key shape from an input collection. However, we found that this compatibility is more appropriate for the particular task of weighting the contribution of each selected key shape for cross-shape attention, rather than retrieving key shapes themselves (see supplementary for additional discussion). We instead found that it is better to retrieve key shapes whose point-wise representations are on average more similar to the ones of the query shape. To achieve this, we perform the following steps:
(i) We compute the similarity between points of the query shape and the points of candidate key shapes in terms of cosine similarity of their SSA representations:
| (12) |
where .
(ii) Then for each query point, we find its best matching candidate key shape point yielding the highest cosine similarity:
| (13) |
(iii) Finally, we compute the average of these highest similarities across all query points:
| (14) |
The retrieval measure is used to compare the query shape with candidate key shapes from a collection.
3.3 Training
The input to our training procedure is a collection of point clouds with part annotations along with a smaller annotated collection used for hold-out validation. We first train our backbone including a layer that implements self-shape attention alone according to Eq. 3-6 (i.e., in this case). The resulting output features are passed to a softmax layer for semantic segmentation. The network is trained according to softmax loss. Based on the resulting SSA features, we construct a graph (Figure Cross-Shape Attention for Part Segmentation of 3D Point Clouds), where each training shape is connected with shapes, deemed as “key” shapes, according to our retrieval measure of Eq. 14. One such graph is constructed for the training split, and another for the validation split. We then fine-tune our backbone and train a layer that implements our full cross-shape attention involving all key shapes per training shape using the same loss. During training, we measure the performance of the network on the validation split, in terms of part IoU [MZC*19a], and if it reaches a plateau state, we recalculate the -neighborhood of each shape based on the updated features. We further fine-tune our backbone and CSA layer. This iteration of graph update and fine-tuning of our network is performed two times in our implementation.
3.4 Inference
During inference, we create a graph connecting each test shape with training shapes retrieved by the measure of Eq. 14. We then perform a feed-forward pass through our backbone, CSA layer, and classification layer to assess the label probabilities for each test shape.
Variant avg part IoU MinkResUNet 46.8 MinkHRNet 48.0 MinkHRNetCSN-SSA 48.7 MinkHRNetCSN-K1 49.9 MinkHRNetCSN-K2 49.7 MinkHRNetCSN-K3 47.2 MID-FC 60.8 MID-FC-SSA 61.8 MID-FC-CSN-K1 61.9 MID-FC-CSN-K2 61.9 MID-FC-CSN-K3 62.0 MID-FC-CSN-K4 62.1 MID-FC-CSN-K5 62.0
3.5 Architecture
Here we describe the two backbones (MinkNetHRNet, MID-FC) we used to provide point-wise features to our CSA layer.
MinkNetHRNet.
The first backbone is a variant of the sparse tensor network based on MinkowskiNet [CGS19]. We note that our variant performed better than the original MinkowskiNet for 3D segmentation [CGS19], as discussed in our experiments. In a pre-processing step, we normalize the point clouds to a unit sphere and convert them to a sparse voxel grid (voxel size ). After two convolutional layers, the network branches into three stages inspired by the HRNet [WSC*21], a network that processes 2D images in a multi-resolution manner. In our case, the first stage consists of three residual blocks processing the sparse voxel grid in its original resolution. The second stage downsamples the voxel grid by a factor of and processes it through two other residual blocks. The third stage further downsamples the voxel grid by a factor of and processes it through another residual block. The multi-resolution features from the three stages are combined into one feature map through upsampling following [WSC*21]. The resulting feature map is further processed by a convolutional block. The sparse voxel features are then mapped back to points as done in the original MinkowskiNet [CGS19]. Details about the architecture of this backbone are provided in the supplementary.
MID-FC.
The second variant utilizes an octree-based architecture based on the MID-FC network [WYZ*21]. This network also incorporates a three-stage HRNet [WSC*21] to effectively maintain and merge multi-scale resolution feature maps. To implement this architecture, each point cloud is first converted into an octree representation with a resolution of . To train this network, a self-supervised learning approach is employed using a multi-resolution instance discrimination pretext task with ShapeNetCore55 [WYZ*21]. The training process involves two losses: a shape instance discrimination loss to classify augmented copies of each shape instance and a point instance discrimination loss to classify the same points on the augmented copies of a shape instance. This joint learning approach enables the network to acquire generic shape and point encodings that can be used for shape analysis tasks. Finally, the pre-trained network is combined with two fully-connected layers and our CSA layer. During training for our segmentation task, the HRNet is frozen, while we train only the two fully-connected layers and CSA layer for efficiency reasons. Details about the architecture of this backbone are provided in the supplementary.
3.6 Implementation details
We train our Cross Shape Network for each object category of PartNet [MZC*19a] separately, using the standard cross entropy loss, for epochs. We set the batch size equal to 8 for all variants (SSA, K=1,2,3). For optimization we use the SGD optimizer [Rud16] with a learning rate of 0.5 and momentum . We scale learning rate by a factor of , whenever the loss of the hold-out validation split saturates (patience epochs, cooldown epochs). For updating the shape graph for the training and validation split, we measure the performance of the validation split in terms of Part IoU. If it reaches a saturation point (patience epochs, cooldown epochs), we load the best model up to that moment, based on Part IoU performance, and update the graph for both splits. The graph is updated twice throughout our training procedure. For all layers we use batch normalization [IS15] with momentum , except for the CSA module, where the layer normalization [BKH16] is adopted. We also refer readers to our project page with source code for more details.111Our project page marios2019.github.io/CSN includes our code and trained models.
4 Results
Category Bed Bott Chai Cloc Dish Disp Door Ear Fauc Knif Lamp Micr Frid Stor Tabl Tras Vase avg. #cat. SpiderCNN [XFX*18] 36.2 32.2 30.0 24.8 50.0 80.1 30.5 37.2 44.1 22.2 19.6 43.9 39.1 44.6 20.1 42.4 32.4 37.0 0 PointNet++ [QYSG17] 30.3 41.4 39.2 41.6 50.1 80.7 32.6 38.4 52.4 34.1 25.3 48.5 36.4 40.5 33.9 46.7 49.8 42.5 0 ResGCN-28 [LMQ*23] 35.9 49.3 41.1 33.8 56.2 81.0 31.1 45.8 52.8 44.5 23.1 51.8 34.9 47.2 33.6 50.8 54.2 45.1 0 PointCNN [LBS*18] 41.9 41.8 43.9 36.3 58.7 82.5 37.8 48.9 60.5 34.1 20.1 58.2 42.9 49.4 21.3 53.1 58.9 46.5 0 CloserLook3D [LHC*20] 49.5 49.4 48.3 49.0 65.6 84.2 56.8 53.8 62.4 39.3 24.7 61.3 55.5 54.6 44.8 56.9 58.2 53.8 0 MinkResUNet [CGS19] 39.4 44.2 42.3 35.4 57.8 82.4 33.9 45.8 57.8 46.7 25.0 53.7 40.5 45.0 35.7 50.6 58.8 46.8 0 MinkHRNetCSN-K1 (ours) 42.1 54.0 42.5 42.9 58.2 83.2 43.5 51.5 59.4 47.8 27.9 57.4 43.7 46.2 36.8 51.5 60.0 49.9 0 MID-FC [WYZ*21] 51.6 56.5 55.7 55.3 75.6 91.3 56.6 53.8 64.6 55.4 31.2 78.7 63.1 62.8 45.7 65.8 69.3 60.8 1 MID-FC-CSN-K4 (ours) 52.2 58.6 55.7 57.7 76.4 91.4 58.9 54.5 65.2 62.2 33.1 79.2 64.0 62.9 46.0 67.2 69.9 62.1 16
We evaluated our method for fine-grained shape segmentation qualitatively and quantitatively. In the next paragraphs, we discuss the used dataset, evaluation metrics, comparisons, and an analysis considering the computation time and size of our CSA layer.
Dataset.
We use the PartNet dataset [MZC*19a] for training and evaluating our method according to its provided training, validation, and testing splits. Our evaluation focuses on the fine-grained level of semantic segmentation, which includes 17 out of the 24 object categories present in the PartNet dataset. We trained our network and competing variants separately for each object category.
Evaluation Metrics.
For evaluating the performance of our method and variants, we used the standard Part IoU metric, as also proposed in the PartNet benchmark [MZC*19a]. The goal of our evaluation is to verify the hypothesis that our self-attention and cross-shape attention mechanisms yield better features for segmentation than the ones produced by any of the two original backbones on the task of semantic shape segmentation.
Ablation.
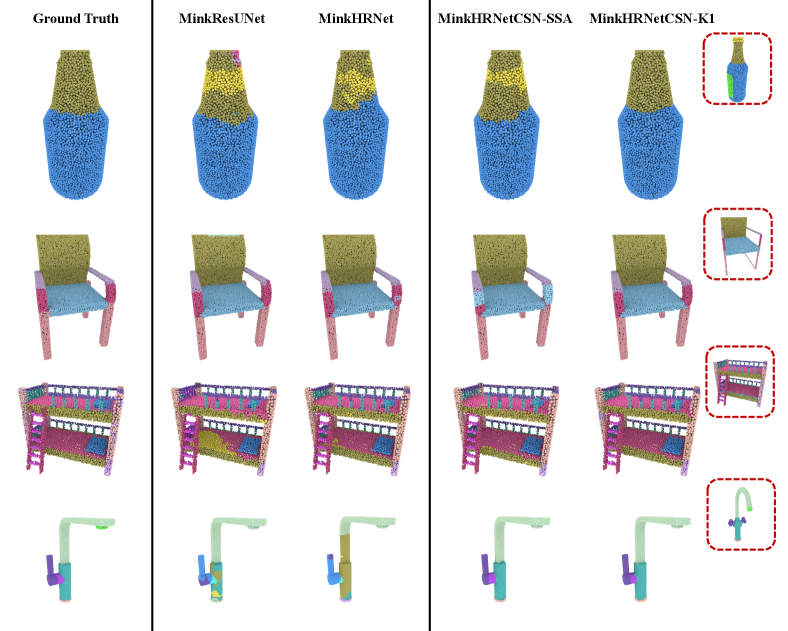
Table 1 reports the mean part IoU performance averaged the PartNet’s part categories for the original backbones (“MinkHRNet”) and (”MID-FC”). We first observe that our backbone variant “MinkHRNet” improves over the original “MinkResUNet” proposed in [CGS19], yielding an improvement of in mean Part IoU. Our variant based on self-shape attention alone (“MinkHRNetCSN-SSA”) further improves our backbone by in Part IoU. We further examined the performance of our cross-shape attention (CSA layer) tested in the variants “MinkHRNetCSN-K1”, “MinkHRNetCSN-K2”, and “MinkHRNetCSN-K3”, where we use key shapes per query shape. Our CrossShapeNet with (“MinkHRNetCSN-K1”) offers the best performance on average by improving Part IoU by another with respect to using self-shape attention alone. When using key shapes in cross-shape attention, the performance drops slightly ( in Part IoU on average) compared to using , and drops even more when using . Thus, for the MinkowskiNet variants, it appears that the optimal number of key shapes is ; we suspect that the performance drop for higher is due to the issue that the chance of retrieving shapes that are incompatible to the query shape is increased with larger numbers of retrieved key shapes.
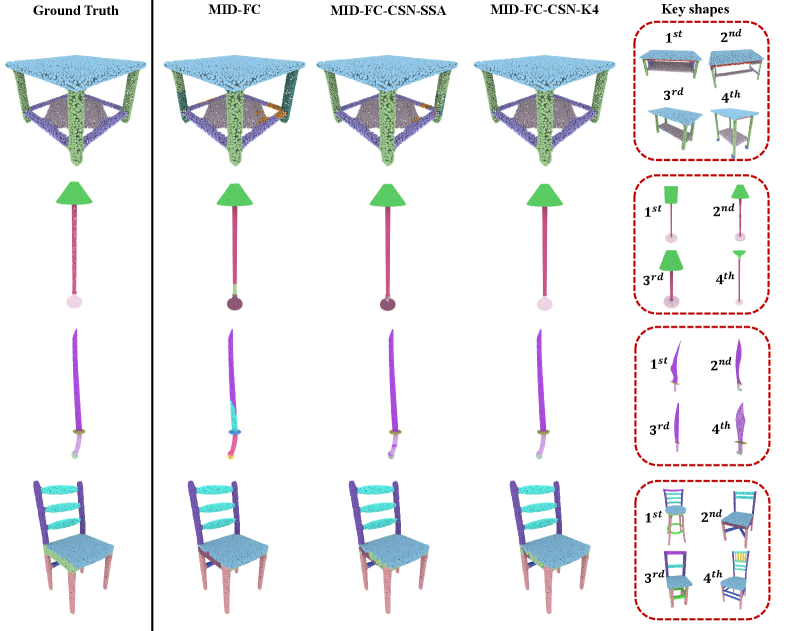
We also observe improvements using the MID-FC backbone. Note that this backbone has higher performance than the MinkowskiNet variants due to its pretraining and fine-tuning strategies [WYZ*21]. Our variant based on self-shape attention alone (“MID-FC-SSA”) further improves the original MID-FC backbone by in mean Part IoU. When using cross-shape attention, the optimal performance is achieved when using key shapes (“MID-FC-CSN-K4”), which improves Part IoU by another with respect to using self-shape attention alone. We note that the above improvements are quite stable – by repeating all experiments times, the standard deviation of mean Part IoU is . This means that the above differences are significant – even the improvement of of “MID-FC-CSN-K4” over “MID-FC-SSA” is of scale .
Comparisons with other methods.
Table 2 includes comparisons with other methods reporting their performance on PartNet per category [XFX*18, QYSG17, LMQ*23, LBS*18, LHC*20, WYZ*21] along with our best performing variants (“MinkHRNetCSN-K1” and “MID-FC-CSN-K4”). Compared to the original MinkowskiNet (“MinkResUNet”), our “MinkHRNetCSN-K1” variant achieves an improvement of in terms of mean Part IoU in PartNet. Compared to “MID-FC”, our best variant (“MID-FC-CSN-K4”) also offers a noticeable improvement of in mean Part IoU. To the best of our knowledge, the result of our best variant represents the highest mean Part IoU performance achieved in the PartNet benchmark so far. As it can been in the last column of Table 2, our method improves performance for out of categories.
Qualitative Results.
Figures 2 shows qualitative comparisons for MinkowskiNet-based variants – specifically our best variant in this case using cross-shape attention with , self-shape attention, our MinkNetHR backbone, and the original MinkowskiNet. Our backbone often improves the labeling relative to the original MinkowskiNet (e.g., see bed mattress, or monitor base). Our cross-shape attention tends to further improve upon fine-grained details in the segmentation e.g., see the top of the bottle, the armrests in the chair, and the bottom of the blade, pushing the segmentation to be more consistent with the retrieved key shape shown in the inlet images. Figure 3 shows comparisons for the MID-FC-based variants, including using cross-shape attention with , self-shape attention, and the original MID-FC. We can drive similar conclusions – our method improves the consistency of segmentation especially for fine-grained details e.g., the lower bars of the table, the bottom of the lamp, the handle of the sword, and the sides of the seat.
Number of parameters.
Our CSA layer adds a relatively small overhead in terms of number of parameters. The MID-FC backbone has parameters, the MinkHRNet has parameters, while the CSA layer adds parameters.
Computation.
The cross-shape operation (Eq. 7) has linear time complexity wrt the number of used key shapes () and quadratic time complexity wrt the number of points per shape during both training and testing. To accelerate computation, subsets of points could be used as key points, as done in sparsified formulations of attention [ZGD*20, LSH*22]. The construction of the shape graph during training has quadratic time complexity wrt the number of the training shapes in the input collection. This is because the retrieval measure (Eq. 14) must be evaluated for all pairs of training shapes in our current implementation. For example, our CSA layer for requires approximately hours on a NVidia to train for the largest PartNet category ( more compared to training either backbone alone) due to the iterative graph construction and fine-tuning discussed in Section 3.3. A more efficient implementation could involve a more hierarchical approach e.g., perform clustering to select only a subset of training shapes as candidate key shapes for the retrieval measure. During inference, the time required per test shape exhibits linear complexity wrt the number of training shapes used for retrieval. In our experiments, testing time ranges from sec (“Dish” class with the smallest number of shapes) to sec (“Table” class with the largest number of shapes).
5 Conclusion
We presented a method that enables interaction of point-wise features across different shapes in a collection. The interaction is mediated through a new cross-shape attention mechanism. Our experiments show improvements of this interaction in the case of fine-grained shape segmentation.
Limitations.
The performance increase comes with a higher computational cost at training and test time. It would be interesting to explore if further performance gains can be achieved through self-supervised pre-training [XGG*20, WYZ*21, SDR*22] that could in turn guide our attention mechanism. Sparsifying the attention and accelerating the key shape retrieval mechanism would also be important to decrease the time complexity. Another future research direction is to explore how to generalize the cross-shape attention mechanism from single shapes to entire scenes.
Acknowledgments.
This project has received funding from Adobe Research and the EU H2020 Research and Innovation Programme and the Republic of Cyprus through the Deputy Ministry of Research, Innovation and Digital Policy (GA 739578).
References
- [AML18] Matan Atzmon, Haggai Maron and Yaron Lipman “Point Convolutional Neural Networks by Extension Operators” In TOG 37.4, 2018
- [BKH16] Jimmy Ba, Jamie Ryan Kiros and Geoffrey E. Hinton “Layer Normalization” In arXiv:1607.06450, 2016
- [BMM*15] Davide Boscaini et al. “Learning class-specific descriptors for deformable shapes using localized spectral convolutional networks” In CGF 34.5, 2015
- [BMRB16] Davide Boscaini, Jonathan Masci, Emanuele Rodolà and Michael Bronstein “Learning shape correspondence with anisotropic convolutional neural networks” In Proc. NIPS, 2016
- [CFP21] Chun-Fu (Richard) Chen, Quanfu Fan and Rameswar Panda “CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification” In Proc. ICCV, 2021
- [CGS19] Christopher Choy, JunYoung Gwak and Silvio Savarese “4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks” In Proc. CVPR, 2019
- [CPBM21] Anh-Quan Cao, Gilles Puy, Alexandre Boulch and Renaud Marlet “PCAM: Product of Cross-Attention Matrices for Rigid Registration of Point Clouds” In Proc. ICCV, 2021
- [CXL*19] Yue Cao et al. “GCNet: Non-local networks meet squeeze-excitation networks and beyond” In Proc. CVPR Workshops, 2019
- [DCS*17] Angela Dai et al. “ScanNet: Richly-annotated 3d reconstructions of indoor scenes” In Proc. CVPR, 2017
- [DGZ20] Carl Doersch, Ankush Gupta and Andrew Zisserman “Crosstransformers: spatially-aware few-shot transfer” In Proc. NIPS, 2020
- [DLD*21] Congyue Deng et al. “Vector Neurons: a general framework for SO(3)-equivariant networks” In Proc. ICCV, 2021
- [EBD21] Nico Engel, Vasileios Belagiannis and Klaus Dietmayer “Point transformer” In IEEE Access 9, 2021
- [GCL*21] Meng-Hao Guo et al. “Pct: Point cloud transformer” In CVM 7.2, 2021
- [GWL18] Fabian Groh, Patrick Wieschollek and Hendrik P.. Lensch “Flex-Convolution (Million-Scale Point-Cloud Learning Beyond Grid-Worlds)” In Proc. ACCV, 2018
- [HCB*19] Ruibing Hou et al. “Cross Attention Network for Few-shot Classification” In Proc. NIPS, 2019
- [HKC*17] Haibin Huang et al. “Learning Local Shape Descriptors from Part Correspondences with Multiview Convolutional Networks” In TOG 37.1, 2017
- [HRV*18] Pedro Hermosilla et al. “Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds” In TOG 37.6, 2018
- [HTY18] Binh-Son Hua, Minh-Khoi Tran and Sai-Kit Yeung “Pointwise convolutional neural networks” In Proc. CVPR, 2018
- [HWH*19] Zilong Huang et al. “CCNet: Criss-cross attention for semantic segmentation” In Proc. CVPR, 2019
- [HWW*19] Wenkai Han et al. “Point2Node: Correlation Learning of Dynamic-Node for Point Cloud Feature Modeling” In arXiv:1912.10775, 2019
- [HZRS16] Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun “Deep Residual Learning for Image Recognition” In Proc. CVPR, 2016
- [IS15] Sergey Ioffe and Christian Szegedy “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” In Proc. ICML, 2015
- [JZL*19] Li Jiang et al. “Hierarchical point-edge interaction network for point cloud semantic segmentation” In Proc. CVPR, 2019
- [KAMC17] Evangelos Kalogerakis, Melinos Averkiou, Subhransu Maji and Siddhartha Chaudhuri “3D shape segmentation with projective convolutional networks” In Proc. CVPR, 2017
- [KL17] Roman Klokov and Victor Lempitsky “Escape from cells: Deep KD-networks for the recognition of 3d point cloud models” In Proc. CVPR, 2017
- [KZH19] Artem Komarichev, Zichun Zhong and Jing Hua “A-CNN: Annularly convolutional neural networks on point clouds” In Proc. CVPR, 2019
- [LAK20] Marios Loizou, Melinos Averkiou and Evangelos Kalogerakis “Learning Part Boundaries from 3D Point Clouds” In CGF 39.5, 2020
- [LB19] Loic Landrieu and Mohamed Boussaha “Point cloud oversegmentation with graph-structured deep metric learning” In Proc. CVPR, 2019
- [LBS*18] Yangyan Li et al. “PointCNN: Convolution On X-Transformed Points” In Proc. NIPS, 2018
- [LCH*18] Kuang-Huei Lee et al. “Stacked cross attention for image-text matching” In Proc. ECCV, 2018
- [LCL18] Jiaxin Li, Ben Chen and Gim Lee “SO-Net: Self-Organizing Network for Point Cloud Analysis” In Proc. CVPR, 2018
- [LFM*19] Yongcheng Liu et al. “DensePoint: Learning Densely Contextual Representation for Efficient Point Cloud Processing” In Proc. ICCV, 2019
- [LFXP19] Yongcheng Liu, Bin Fan, Shiming Xiang and Chunhong Pan “Relation-shape convolutional neural network for point cloud analysis” In Proc. CVPR, 2019
- [LHC*20] Ze Liu et al. “A Closer Look at Local Aggregation Operators in Point Cloud Analysis” In Proc. ECCV, 2020
- [LKM19] Eric-Tuan Le, Iasonas Kokkinos and Niloy J Mitra “Going Deeper with Point Networks” In arXiv:1907.00960, 2019
- [LLG*22] Shitong Luo et al. “Equivariant Point Cloud Analysis via Learning Orientations for Message Passing” In Proc. CVPR, 2022
- [LLJ*22] Xin Lai et al. “Stratified Transformer for 3D Point Cloud Segmentation” In Proc. CVPR, 2022
- [LMQ*23] Guohao Li et al. “DeepGCNs: Making GCNS Go as Deep as CNNs” In TPAMI 45.6, 2023
- [LSH*22] Difan Liu et al. “ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions” In TOG 41.4, 2022
- [LTLH19] Zhijian Liu, Haotian Tang, Yujun Lin and Song Han “Point-Voxel CNN for efficient 3D deep learning” In Proc. NIPS, 2019
- [LYYD19] Shiyi Lan, Ruichi Yu, Gang Yu and Larry S Davis “Modeling local geometric structure of 3D point clouds using Geo-CNN” In Proc. CVPR, 2019
- [MBM*17] Federico Monti et al. “Geometric deep learning on graphs and manifolds using mixture model cnns” In Proc. CVPR, 2017
- [ML21] Kirill Mazur and Victor Lempitsky “Cloud Transformers: A Universal Approach to Point Cloud Processing Tasks” In Proc. ICCV, 2021
- [MS15] Daniel Maturana and Sebastian Scherer “Voxnet: A 3D convolutional neural network for real-time object recognition” In Proc. IROS, 2015
- [MZC*19] Kaichun Mo et al. “PartNet: A Large-scale Benchmark for Fine-grained and Hierarchical Part-level 3D Object Understanding” In Proc. CVPR, 2019
- [MZC*19a] Kaichun Mo et al. “PartNet: A Large-Scale Benchmark for Fine-Grained and Hierarchical Part-Level 3D Object Understanding” In Proc. CVPR, 2019
- [PWT*22] Yatian Pang et al. “Masked Autoencoders for Point Cloud Self-supervised Learning” In arXiv:2203.06604, 2022
- [QLP*22] Guocheng Qian et al. “PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies” In Proc. NIPS, 2022
- [QSMG17] Charles R. Qi, Hao Su, Kaichun Mo and Leonidas Guibas “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation” In Proc. CVPR, 2017
- [QSN*16] Charles R Qi et al. “Volumetric and multi-view cnns for object classification on 3d data” In Proc. CVPR, 2016
- [QYSG17] Charles R. Qi, Li Yi, Hao Su and Leonidas J. Guibas “PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space” In Proc. NIPS, 2017
- [Rud16] Sebastian Ruder “An overview of gradient descent optimization algorithms” In arXiv:1609.04747, 2016
- [RUG17] Gernot Riegler, Ali Osman Ulusoy and Andreas Geiger “OctNet: Learning Deep 3D Representations at High Resolutions” In Proc. CVPR, 2017
- [RWS*18] Dario Rethage et al. “Fully-convolutional point networks for large-scale point clouds” In Proc. ECCV, 2018
- [SDMR19] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich “SuperGlue: Learning Feature Matching with Graph Neural Networks” In arXiv:1911.11763, 2019
- [SDR*22] G. Sharma et al. “PRIFIT: Learning to Fit Primitives Improves Few Shot Point Cloud Segmentation” In Proc. SGP, 2022
- [SEH*23] Jonas Schult et al. “Mask3D: Mask Transformer for 3D Semantic Instance Segmentation” In Proc. ICRA, 2023
- [SFYT18] Yiru Shen, Chen Feng, Yaoqing Yang and Dong Tian “Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling” In Proc. CVPR, 2018
- [SGS19] Nitish Srivastava, Hanlin Goh and Ruslan Salakhutdinov “Geometric Capsule Autoencoders for 3D Point Clouds” In arXiv:1912.03310, 2019
- [SJS*18] Hang Su et al. “SPLATNet: Sparse Lattice Networks for Point Cloud Processing” In Proc. CVPR, 2018
- [SMKL15] Hang Su, Subhransu Maji, Evangelos Kalogerakis and Erik Learned-Miller “Multi-view convolutional neural networks for 3d shape recognition” In Proc. ICCV, 2015
- [SWL19] Shaoshuai Shi, Xiaogang Wang and Hongsheng Li “PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud” In Proc. CVPR, 2019
- [TQD*19] Hugues Thomas et al. “KPConv: Flexible and deformable convolution for point clouds” In Proc. CVPR, 2019
- [VSP*17] Ashish Vaswani et al. “Attention is All you Need” In Proc. NIPS, 2017
- [WGGH18] Xiaolong Wang, Ross Girshick, Abhinav Gupta and Kaiming He “Non-local neural networks” In Proc. CVPR, 2018
- [WHH*19] L. Wang et al. “Graph Attention Convolution for Point Cloud Semantic Segmentation” In Proc. CVPR, 2019
- [WLG*17] Peng-Shuai Wang et al. “O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis” In TOG 36.4, 2017
- [WQF19] Wenxuan Wu, Zhongang Qi and Li Fuxin “Pointconv: Deep convolutional networks on 3d point clouds” In Proc. CVPR, 2019
- [WS19] Yue Wang and Justin M. Solomon “Deep Closest Point: Learning Representations for Point Cloud Registration” In Proc. ICCV, 2019
- [WSC*21] Jingdong Wang et al. “Deep High-Resolution Representation Learning for Visual Recognition” In TPAMI 43.10, 2021
- [WSK*15] Zhirong Wu et al. “3D shapenets: A deep representation for volumetric shapes” In Proc. CVPR, 2015
- [WSL*19] Yue Wang et al. “Dynamic Graph CNN for Learning on Point Clouds” In TOG 38.5, 2019
- [WSLT18] Peng-Shuai Wang, Chun-Yu Sun, Yang Liu and Xin Tong “Adaptive O-CNN: A Patch-based Deep Representation of 3D Shapes” In TOG 37.6, 2018
- [WSM*18] Shenlong Wang et al. “Deep parametric continuous convolutional neural networks” In Proc. CVPR, 2018
- [WSS18] Chu Wang, Babak Samari and Kaleem Siddiqi “Local Spectral Graph Convolution for Point Set Feature Learning” In arXiv:1803.05827, 2018
- [WYZ*21] Peng-Shuai Wang et al. “Unsupervised 3D Learning for Shape Analysis via Multiresolution Instance Discrimination” In Proc. AAAI, 2021
- [XFX*18] Yifan Xu et al. “SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters” In arXiv:1803.11527, 2018
- [XGG*20] Saining Xie et al. “PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding” In Proc. ECCV, 2020
- [XLCT18] Saining Xie, Sainan Liu, Zeyu Chen and Zhuowen Tu “Attentional shapecontextnet for point cloud recognition” In Proc. CVPR, 2018
- [XSW*19] Qiangeng Xu et al. “Grid-GCN for Fast and Scalable Point Cloud Learning” In arXiv:1912.02984, 2019
- [XWL*21] Peng Xiang et al. “SnowflakeNet: Point Cloud Completion by Snowflake Point Deconvolution With Skip-Transformer” In Proc. ICCV, 2021
- [YGX*23] Yu-Qi Yang et al. “Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding” In arXiv:2304.06906, 2023
- [YHJY19] Shi Yunxiao, Fang Haoyu, Zhu Jing and Fang Yi “Pairwise Attention Encoding for Point Cloud Feature Learning” In Proc. 3DV, 2019
- [YSGG17] Li Yi, Hao Su, Xingwen Guo and Leonidas J Guibas “SyncSpecCNN: Synchronized spectral cnn for 3d shape segmentation” In Proc. CVPR, 2017
- [YTR*22] Xumin Yu et al. “Point-BERT: Pre-Training 3D Point Cloud Transformers with Masked Point Modeling” In Proc. CVPR, 2022
- [ZCW*20] Junming Zhang et al. “Point Set Voting for Partial Point Cloud Analysis” In IEEE Robotics and Automation Letters 6, 2020
- [ZGD*20] Manzil Zaheer et al. “Big Bird: Transformers for Longer Sequences.” In Proc. NIPS, 2020
- [ZHW*19] Kuangen Zhang et al. “Linked Dynamic Graph CNN: Learning on point cloud via linking hierarchical features” In arXiv:1904.10014, 2019
- [ZJJ*21] Hengshuang Zhao et al. “Point transformer” In Proc. ICCV, 2021
- [ZYX*22] Chen Zhao et al. “Rotation invariant point cloud analysis: Where local geometry meets global topology” In Pattern Recognition 127.C, 2022
– Supplementary Material –
| Cross-shape network architecture | CSN(query , key , #classes ) | |
|---|---|---|
| Index | Layer | Out |
| 1 | Input: | |
| 2 | Mink-HRNet(, , ) | - query point repr. |
| 3 | Mink-HRNet(, , ) | - key point repr. |
| 4 | CSA(Out(2), Out(2), 256, 4) | - query SSA repr. |
| 5 | CSA(Out(3), Out(3), 256, 4) | - key SSA repr. |
| 6 | Linear-Q(avg-pool(Out(4)), ) | - query global repr. |
| 7 | Linear-K(avg-pool(Out(4)), ) | - query global repr. |
| 8 | Linear-K(avg-pool(Out(5)), ) | - key global repr. |
| 9 | ScaledDotProduct(Out(6), Out(7)) | - query-query similarity |
| 10 | ScaledDotProduct(Out(6), Out(8)) | - query-key similarity |
| 11 | Softmax(Out(9), Out(10)) | - compatibility |
| 12 | CSA(Out(2), Out(3), 256, 4) | - query CSA repr. |
| 13 | Out(4) compatbility[0] + Out(12) compatbility[1] | - cross-shape attention |
| 14 | Softmax(Conv(ConCat(Out(2), Out(13)), 512, )) | - per-point part label probabilities |
Category Bed Bott Chai Cloc Dish Disp Door Ear Fauc Knif Lamp Micr Frid Stor Tabl Tras Vase avg. #cat. Part IoU MinkHRNetCSN-K1 (Eq. 14) 42.1 54.0 42.5 42.9 58.2 83.2 43.5 51.5 59.4 47.8 27.9 57.4 43.7 46.2 36.8 51.5 60.0 49.9 16 MinkHRNetCSN-K1 (Eq. 10) 38.7 47.0 41.9 40.8 55.7 82.3 41.3 50.5 57.9 37.3 24.7 56.2 44.1 45.9 32.3 51.4 58.8 47.4 1
Appendix A: Backbone architecture details
MinkHRNetCSN architecture details.
In Table 3 we describe the overall Cross-Shape Network architecture for key shapes per query shape, based on the HRNet [WSC*21] backbone (“MinkHRNetCSN-K1”). For and SSA variants, we use the same architecture. First, for an input query-key pair of shapes and , point-wise features and are extracted using the “Mink-HRNet” backbone (Layers 2 and 3). For each set of point features their self-shape attention representations are calculated via the Cross-Shape Attention layer (Layers 4 and 5). The query shape point self-shape attention representations are then aggregated into a global feature using mean-pooling and undergo two separate linear transformations (Linear-Q and Linear-K in Layers 6 and 7, respectively). Leveraging these, the self-shape similarity is computed, using the scaled dot product (Layer 9). For the key shape point self-shape attention representations, we use only the Linear-K transformation on the key shape’s global feature (Layer 8), and calculate the query-key similarity (Layer 10). The compatibility for the cross-shape attention is computed as the softmax transformation of these two similarity measures (Layer 11). The cross-shape point representations of the query shape, propagating point features from the key shape, are extracted by our CSA module in Layer 12. The self-shape (Layer 4) and cross-shape (Layer 12) point representations are combined together, weighted by the pairwise compatibility, resulting in the cross-shape attention representations (Layer 13). Finally, part label probabilities are extracted per point, through a convolution and a softmax transformation (Layer 14), based on the concatenation of the query shape’s backbone representations and cross-shape attention representations .
The architecture of our backbone network, “Mink-HRNet”, is described in Table 6. Based on an input shape, our backbone first extracts point representations through two consecutive convolutions (Layers 2-5). Then, three multi-resolution branches are deployed. The first branch, called High-ResNetBlock (Layers 6, 8 and 15), operates on the input shape’s resolution, while the other two, Mid-ResNetBlock (Layers 9 and 16) and Low-ResNetBlock (Layer 17), downsample the shape’s resolution by a factor of 2 and 4, respectively. In addition, feature representations are exchanged between these branches, through downsampling and upsampling modules (Layers 7, 10-14). The point representations of the two low-resolution branches are upsampled to the original resolution (Layers 18-20) and by concatenating them with point features of the high-resolution branch, point representations are extracted for the input shape, through a full-connected layer (Layers 21 and 22).
The Cross-Shape Attention (CSA), Downsampling and Upsampling layers, along with Residual Basic Block are described in more detail in Table 7.
| MID-FC-Cross-shape network architecture | MID-FC-CSN(query , key , #classes ) | |
|---|---|---|
| Index | Layer | Out |
| 1 | Input: | |
| 2 | MID-Net(, , ) | - query point repr. |
| 3 | MID-Net(, , ) | - key point repr. |
| 4 | CSA(Out(2), Out(2), 256, 8) | - query SSA repr. |
| 5 | CSA(Out(3), Out(3), 256, 8) | - key SSA repr. |
| 6 | Linear-Q(avg-pool(Out(4)), ) | - query global repr. |
| 7 | Linear-K(avg-pool(Out(4)), ) | - query global repr. |
| 8 | Linear-K(avg-pool(Out(5)), ) | - key global repr. |
| 9 | ScaledDotProduct(Out(6), Out(7)) | - query-query similarity |
| 10 | ScaledDotProduct(Out(6), Out(8)) | - query-key similarity |
| 11 | Softmax(Out(9), Out(10)) | - compatibility |
| 12 | CSA(Out(2), Out(3), 256, 8) | - query CSA repr. |
| 13 | Out(4) compatbility[0] + Out(12) compatbility[1] | - cross-shape attention |
| 14 | Softmax(FC(Out(13), 256, )) | - per-point part label probabilities |
Mink-HRNet backbone Mink-HRNet(shape repr. , in_feat , out_feat ) Index Layer Out 1 Input: 2 Conv(, , ) 3 ReLU(BatchNorm(Out(2))) 4 Conv(Out(3), , ) 5 ReLU(BatchNorm(Out(4))) 6 High-ResNetBlock( BasicBlock(Out(5), )) 7 Downsampling(Out(6), 64, 128) 8 High-ResNetBlock( BasicBlock(Out(6), )) 9 Mid-ResNetBlock( BasicBlock(ReLU(Out(7)), )) 10 Downsampling(Out(8), 64, 128) 11 ReLU(Downsampling(Out(8), 64, 128)) 12 Downsampling(Out(11), 128, 256) 13 Upsampling(Out(9), 128, 64) 14 Downsampling(Out(9), 128, 256)) 15 High-ResNetBlock( BasicBlock(ReLU(Out(8)+Out(13)), )) 16 Mid-ResNetBlock( BasicBlock(ReLU(Out(9) + Out(10)), )) 17 Low-ResNetBlock( BasicBlock(ReLU(Out(12) + Out(14)), )) 18 ReLU(Upsampling(Out(16), 128, 128)) 19 ReLU(Upsampling(Out(17), 256, 256)) 20 ReLU(Upsampling(Out(19), 256, 256)) 21 Conv(ConCat(Out(3), Out(15), Out(18), Out(20)), 480, ) 22 ReLU(BatchNorm(Out(21)))
Cross-Shape Attention Layer CSA(query , key , #feats , #heads ) Index Layer Out 1 Input: 2 Linear-Q() 3 Linear-K() 4 Linear-V() 5 Attention(Out(2), Out(3)) 6 MatMul(Out(5), Out(4)) 7 Linear(ConCat(Out(6)), , ) 8 LayerNorm( Out(7)) Downsampling Layer Downsampling(shape repr. , in_feat , out_feat ) 1 Input: 2 Conv(, , , stride ) 3 BatchNorm(Out(2)) Upsampling Layer Upsampling(shape repr. , in_feat , out_feat ) 1 Input: 2 TrConv(, , , stride ) 3 BatchNorm(Out(2)) Residual Basic Block BasicBlock(shape repr. , #feats ) 1 Input: 2 Conv(, , ) 3 ReLU(BatchNorm(Out(2))) 4 Conv(Out(3), , ) 5 ReLU( + BatchNorm(Out(4)))
MID-FC-CSN architecture details.
Similar to the MinkHRNetCSN, the MID-FC-CSN variant also follows a comparable architecture (see Table 5). To extract point features and for the input query-key pair of shapes, the “MID-Net” backbone is utilized (Layers 2 and 3). This backbone also adopts a three-stage HRNet architecture, which is built on an octree-based CNN framework [WLG*17]. ResNet blocks with a bottleneck structure [HZRS16] are used in all multi-resolution branches, and feature sharing is achieved using downsample and upsample exchange blocks, implemented by max-pooling and tri-linear up-sampling, respectively. The CSA module (Layers 4 and 12) is employed to construct the self-shape and cross-shape attention features for the query shape. These are then weighted by the learned pairwise compatibility (Layers 4-11) and aggregated to generate the final cross-shape attention representations (Layer 13). Part label probabilities are extracted per point using a fully-connected layer and a softmax transformation based on the cross-shape attention representations (Layer 14).
Appendix B: Key shape retrieval measure comparison
As an additional ablation, we evaluated the performance of our “MinkHRNetCSN-K1” variant for two key shape retrieval measures (see Section 3.2 in the main text). The first relies on the point-wise representations between a query and a key shape and retrieves key shapes that are on average more similar to their query counterparts (Eq. 14). The second measure, takes into account only the global representations of a query-key pair of shapes (Eq. 10). In Table 4 we report the performance for both measures, in terms of Part IoU and Shape IoU. Our default variant, “MinkHRNetCSN-K1 (Eq. 14)”, achieves better performance according to Part IoU (), and it outperforms the other variant (“MinkHRNetCSN-K1, Eq. 10)” in 16 out 17 object categories. This is a strong indication that the key shape retrieval measure based in Eq. 14 is more effective in retrieving key shapes for cross-shape attention.