Cross-Layer Distillation with Semantic Calibration
Abstract
Knowledge distillation is a technique to enhance the generalization ability of a student model by exploiting outputs from a teacher model. Recently, feature-map based variants explore knowledge transfer between manually assigned teacher-student pairs in intermediate layers for further improvement. However, layer semantics may vary in different neural networks and semantic mismatch in manual layer associations will lead to performance degeneration due to negative regularization. To address this issue, we propose Semantic Calibration for cross-layer Knowledge Distillation (SemCKD), which automatically assigns proper target layers of the teacher model for each student layer with an attention mechanism. With a learned attention distribution, each student layer distills knowledge contained in multiple teacher layers rather than a specific intermediate layer for appropriate cross-layer supervision. We further provide theoretical analysis of the association weights and conduct extensive experiments to demonstrate the effectiveness of our approach. Code is avaliable at https://github.com/DefangChen/SemCKD.
Index Terms:
Knowledge Distillation, Semantic Calibration, Cross-Layer Distillation, Attention Mechanism.1 Introduction
How to improve the generalization ability and compactness of deep neural networks keeps attracting widespread attention among a large number of researchers [1, 2, 3]. In the past few years, a lot of techniques have sprung up to deal with these two issues, making the deep models become more powerful [4, 5, 6, 7] or more portable [8, 9, 10, 11]. Among these techniques, knowledge distillation (KD) provides a promising solution to simultaneously achieve better model performance as well as maintain simplicity [9].
The insightful observation that the generalization ability of a lightweight model can be improved by training to match the prediction of a powerful model stems from some pioneering works on model compression [12, 13]. Recently this idea is popularized by knowledge distillation in which the powerful model named as teacher is pre-trained and its outputs are exploited to improve the performance of the lightweight model named as student [9]. Instead of using discrete labels, the student model employs class predictions from the teacher model as an effective regularization to avoid trapping in over-confident solutions [14, 15]. A major drawback in the vanilla KD is that the knowledge learned by a classification model is represented only by the prediction of its final layer [9]. Although the relative probabilities assigned to different classes provide an intuitive understanding about model generalization, knowledge transfer in such a highly abstract form overlooks a wealth of information contained in intermediate layers. To further boost the effectiveness of distillation, recent works explore various representations of feature maps to capture the enriched knowledge [16, 17, 18, 19, 20, 21]. An interpretation for the success of feature-map based knowledge distillation is that the multi-layer feature representations respect hierarchical concept learning process and will entail reasonable inductive bias [1, 22].
However, intermediate layers in teacher and student models tend to have different levels of abstraction [18, 23, 20]. A particular challenge in feature-map distillation is thus to ensure appropriate layer associations for maximum performance. But existing efforts still enable knowledge transfer based on hand-crafted layer assignments [16, 18, 17, 19, 20, 21]. Such strategies may cause semantic mismatch in certain teacher-student layer pairs, leading to negative regularization in the student model training and deterioration of its performance. As we have no prior knowledge of intermediate layer semantics, layer association becomes a non-trivial problem. Systematic approaches need to be developed for more effective and flexible knowledge transfer using feature maps.
In this paper, we propose Semantic Calibration for cross-layer Knowledge Distillation (SemCKD) to exploit intermediate knowledge by keeping the transfer in a matched semantic level. An attention mechanism is applied to automatically learn soft layer association, which effectively binds a student layer with multiple semantic-related target layers rather than a fixed one in the teacher model. To align the spatial dimensions of feature maps in each layer pair for calculating the total loss, feature maps of the student layers are projected to the same dimensions as those in the associated target layers. By taking advantage of semantic calibration and feature-map transfer across multiple layers, the student model can be effectively optimized with more appropriate guidance. The overall contributions of this paper are summarized as follows:
-
•
We propose a novel technique to significantly improve the effectiveness of feature-map based knowledge distillation. Our approach is readily applicable to heterogeneous settings where different architectures are used for teacher and student models.
-
•
Learning soft layer association by our proposed attention mechanism can effectively alleviate semantic mismatch in cross-layer knowledge distillation, which is verified in Section 4.3.
- •
-
•
Extensive experiments on standard benchmarks with a large variety of settings based on popular network architectures demonstrate that SemCKD consistently generalizes better than state-of-the-art approaches.
2 Related Work
2.1 Knowledge Distillation
Nowadays complex deep neural networks with millions of parameters or an ensemble of such models has achieved great success in various settings [27, 28, 29, 30, 31], but it is still a huge challenge to efficiently deploy them in applications with limited computational and storage resources [8, 2]. There are some pioneering efforts, collectively known as model compression, proposing a series of feasible solutions to this problem, such as knowledge distillation [13, 9], low-rank approximation [8, 32], quantization [33, 11] and pruning [10, 34]. Among these techniques, knowledge distillation is perhaps the easiest and the most hardware-friendly one for implementation due to its minimal modification to the regular training procedure.
Given a lightweight student model, the aim of vanilla KD is to improve its generalization ability by training to match the predictions, or soft targets, from a pre-trained cumbersome teacher model [9]. The intuitive explanation for the success of KD is that compared to discrete labels, fine-grained information among different categories in soft targets may provide extra supervision to improve the student model performance [9, 14]. A new interpretation for this improvement is that soft targets act as a learned label smoothing regularization to keep the student model from producing over-confident predictions [15]. To save the expense of pre-training, some online variants have been proposed to explore cost-effective collaborative learning [35, 36, 37]. By training a group of student models and encouraging each one to distill the knowledge in group-derived soft targets as well as ground-truth labels, these approaches could even surpass the vanilla KD in some teacher-student combinations [36, 37].
2.2 Feature-Map Distillation
Rather than only formalizing knowledge in a highly abstract form like predictions, recent methods attempted to leverage information contained in intermediate layers by designing elaborate knowledge representations. A bunch of techniques have been developed for this purpose, such as aligning hidden layer responses called hints [16], encouraging the similar patterns to be elicited in the spatial attention maps [17] and maximizing the mutual information through variational inference [19]. Since the spatial dimensions of feature maps or their transformations from teacher and student models usually vary, a straightforward step before the subsequent loss calculation is to match them by adding convolutional layers or pooling layers [16, 17, 19]. Some other parameter-free alternatives capture the transferred knowledge by crude pairwise similarity matrices [18] or hybrid kernel formulations built on them to avoid mismatch, such as cosine-based and t-student transformations [20]. With these pre-defined representations, all above approaches perform knowledge transfer with certain hand-crafted layer associations [16, 18, 17, 19, 20, 21]. Unfortunately, as pointed in the previous work [20], these hard associations would make the student model suffer from negative regularization, limiting the effectiveness of feature-map distillation. We will discuss this negative regularization in more depth in Section 4.3.1.
Although a large number of approaches explored various knowledge representations over the past few years [16, 18, 17, 19, 20, 21], very few have considered to leverage these representations in a better fashion. The most related approach to ours, which is proposed recently, works on channel or group-wise association within given teacher-student layer pairs [21, 38]. The main difference is that we exploit feature maps from a more general cross-layer level rather than channel or group level.
Learning layer association has also been studied in transfer learning. A previous work learns the association weights between source and target networks by additional meta-networks with bi-level optimization [39]. Our approach differs from this one since feature maps of teacher-student layer pairs are both incorporated to derive the association weights while only those of the source network are used in [39]. Another advantage is that our association weights are trained end-to-end with the original student network, i.e. no need for carefully tuned bi-level optimization.
2.3 Feature-Embedding Distillation
Feature embeddings are good substitutes for feature maps to distill knowledge in intermediate layers. Compared to high dimensional feature maps, these vectorized embeddings obtained at the penultimate layer are generally more tractable. Meanwhile, feature embeddings preserve more structural information than the final predictions used in the vanilla KD. Therefore, a variety of feature-embedding distillation approaches have been proposed recently [40, 41, 42, 43, 44, 45]. In these approaches, a commonly used procedure is to organize all instances by a relational graph for knowledge transfer [40, 43, 41, 42]. The main difference among them lies on how the edge weights are calculated. Typical choices include cosine kernel [40], truncated Gaussian RBF kernel [43], or combination of distance-wise and angle-wise potential functions [41]. In contrast to pairwise transfer, some approaches formulate knowledge distillation from the perspective of contrastive learning to capture higher-order dependencies in the representation space [44, 45].
Although our approach mainly focuses on feature-map distillation, it is also compatible with the state-of-the-art feature embedding distillation approach for further performance improvement.

3 Semantic Calibration for Distillation
3.1 Notations and Vanilla Knowledge Distillation
In this section, we briefly recap the basic concepts of vanilla knowledge distillation as well as provide necessary notations for the following illustration.
Given a training dataset consisting of instances from categories and a powerful teacher model pre-trained on the dataset , the goal of vanilla KD is reusing the same dataset to train another simple student model with cheaper computational and storage demand.
For a mini-batch of instances with size , we denote the outputs of each target layer and student layer as and , respectively, where is the channel dimension, and are the spatial dimensions, superscript and reflect the corresponding teacher and student models. These outputs are also named as feature maps. ranges from to the total number of intermediate layers . Note that and may be different especially when the teacher and student models adopt different architectures. The representations at the penultimate layer from teacher and student models are denoted as and , which are mainly used in feature-embedding distillation. Take the student model as an example, outputs of the last fully connected layer are known as logits and the predicted probabilities are calculated with a softmax layer built on the logits, i.e., with the temperature usually equals to . The notation denotes the output of student layer for the -th instance and is a shorthand for .
For classification tasks, in addition to regular cross entropy loss () between the predicted probabilities and the one-hot label of each training sample, classic KD [9] incorporates another alignment loss to encourage the minimization of Kullback-Leibler (KL) divergence [46] between and soft targets predicted by the teacher model
| (1) |
where is a hyper-parameter and a higher leads to more considerable softening effect. The coefficient in the loss function is used to ensure that the gradient magnitude of the part keeps roughly unchanged when the temperature is larger than one [9].
3.2 Feature-Map Distillation
As mentioned earlier, feature maps of a teacher model are valuable for helping a student model achieve better performance. Recently proposed feature-map distillation approaches can be summarized as adding the following loss to Equation (1) for each mini-batch with size
| (2) |
leading to the overall loss as
| (3) |
The functions and in Equation (2) are used to transform feature maps into particular representations. The layer association set of existing approaches are designed as one-pair selection [16, 18] or one-to-one match [17, 19, 20, 21]. As for one-pair selection, the candidate set includes only one pair of a manually specified student layer and a teacher layer , while for one-to-one match, the candidate set includes elements. With these associated layer pairs, the loss in Equation (2) is calculated by a certain distance function . A common practice is to use Mean-Square-Error (MSE) [16] sometimes with a normalization pre-processing [17, 18, 21]. The hyper-parameter in Equation (3) is used to balance the two individual loss terms. The detailed comparison of several representative approaches is provided in Table I.
As shown in Table I, FitNet [16] adds a convolutional transformation, i.e., on top of a certain intermediate layer of the student model, while keeping feature maps from the teacher model unchanged by identity transformation . AT [17] encourages the student to mimic spatial attention maps of the teacher by channel attention. VID [19] formulates knowledge transfer as Mutual Information (MI) maximization between feature maps and expresses the distance function as Negative Log-Likelihood (NLL). The transferred knowledge can also be captured by crude similarity matrices or hybrid kernel transformations build on them [18, 20]. MGD [21] makes the channel dimensions of feature maps in candidate layer pairs become matched by an assignment module . Note that almost twice as much computational and storage resources are needed for HKD [20]. Since it first transfers feature embeddings from the teacher to an auxiliary model, which follows the same architecture as the student but with twice parameters per layer, then performs feature-map distillation from the auxiliary to the student model.
All of the above approaches perform knowledge transfer based on fixed associations between assigned teacher-student layer pairs, which may cause the loss of useful information. Take one-to-one match as an example, extra layers are discarded when and differ. Moreover, forcing feature maps from the same layer depths to be aligned may result in suboptimal associations, since a better choice for the student layer could from different or multiple target teacher layers.
To solve these problems, we propose a new cross-layer knowledge distillation to promote the exploitation of feature-map representations. Based on our learned layer association weights, simple convolutional , and distance are enough to achieve state-of-the-art results.
3.3 Semantic Calibration Formulation
In our approach, each student layer is automatically associated with those semantic-related target layers by attention allocation, as illustrated in Figure 1. Training with soft association weights encourages the student model to collect and integrate multi-layer information to obtain a more suitable regularization. Moreover, SemCKD is readily applicable to situations where the numbers of candidate layers in teacher and student models are different.
The learned association set in SemCKD is denoted as
| (4) |
with the corresponding weight satisfies . The weights for a mini-batch of instances represent the extent to which the target layer is attended in deriving the semantic-aware guidance for the student layer . Each instance will hold its own association weight for the layer pair , which is calculated by function of given feature maps
| (5) |
The detailed design of will be elaborated later. Given these association weights, feature maps of each student layer are projected into individual tensors to align with the spatial dimensions of those from each target layer:
| (6) |
with . Each function includes a stack of three layers with , and convolutions to meet the demand of capability for effective transformation111In practice, a pooling operation is first used to reconcile the height and weight dimensions of and before projections to reduce computational consumption..
Loss function. For a mini-batch of instances with size , the trainable student model and fixed teacher model will produce several feature maps across multiple layers, i.e., and , respectively. After attention allocation and dimensional projections, the feature-map distillation loss () of SemCKD is obtained by simply using for distance function
| (7) | ||||
where feature maps from each student layer are transformed by a projection function as Equation (6) while those from the target layers remain unchanged by identity transformation . Equipped with the learned layer association weights, the total loss is aggregated by a weighted summation of each individual distance among the feature maps from candidate teacher-student layer pairs. Note that FitNet [16] is a special case of SemCKD by fixing to for certain layer pair and for the rest.
Attention Allocation. Now we provide concrete steps to obtain the association weights. As pointed in previous works, feature representations contained in a trained neural network are progressively more abstract as the layer depth increases [1, 47, 48]. Thus, layer semantics in teacher and student models usually varies. Existing hand-crafted strategies, which did not take this factor into consideration, may not suffice due to negative effects caused by semantic mismatched layers [20]. To further improve the performance of feature-map distillation, each student layer had better associate with the most semantic-related target layers to derive its own regularization.
Layer association based on attention mechanism provides a potentially feasible solution for this goal. Based on the observation that feature maps produced by similar instances probably become clustered at separate granularity in different intermediate layers [18], we regard the proximity of pairwise similarity matrices as a good measurement of the inherent semantic similarity. These matrices are calculated as
| (8) |
where is a reshaping operation, and therefore and are matrices.
Inspired by the self-attention framework [49], we separately project the pairwise similarity matrices of each student layer and associated target layers into two subspaces by a Multi-Layer Perceptron () to alleviate the effect of noise and sparseness. For the -th instance
| (9) |
The parameters of and are learned during training to generate query and key vectors and shared by all instances. Then, is calculated as follows
| (10) |
where for calculating the attention weights is named as Embeded Gaussian operation in the non-local block [50]. Attention-based allocation provides a possible way to suppress negative effects caused by layer mismatch and integrate positive guidance from multiple target layers, which is supported by the theoretical discussion in Section 3.4 and empirical evidence in Section 4.3. Although our proposed SemCKD distills only the knowledge contained in intermediate layers, its performance can be further boosted by incorporating additional regularization, e.g., feature-embedding distillation. The full training procedure with the proposed semantic calibration formulation is summarized in Algorithm 1.
3.4 Theoretical Insights
In this section, we present a theoretical connection between our proposed attention allocation and the famous Orthogonal Procrustes problem [25, 26, 51].
The key design of attention allocation is function , which measures the strength of association weights and should satisfy non-negative constrain. In our approach, this constrain is naturally ensured since each used feature maps have passed a ReLU activation function (). Thus, we can safely replace the Embedded Gaussian with a computation-efficient Dot Production operation in Equation (10), which has achieved empirical success in the previous work [50]. Additional, we omit the constant normalization term suggested by [50] in the following discussion for simplicity.
Suppose that the in Equation (9) equals to identity transformation222A similar result will be obtained for the case with the original ., and the attention weight for candidate layer pair is calculated by averaging the weights of all instances
| (11) | ||||
where 333We suppose the vectorized feature maps from teacher and student models sharing the same dimension in what follows.. From the last Equation of (11), we can see that actually measures the extent to which the extracted feature maps from teacher and student models are shared or similar. We then establish a connection between this weight and the optimal value of the Orthogonal Procrustes problem.
Lemma 1.
Given a matrix with the -th largest singular value denoted as , and , . The Frobenius norm and nuclear norm will bound each other
| (12) |
Proof. Since , the inequality always holds, which implies that . Based on the Cauchy-Schwarz inequality and let , we can obtain that . ∎
The Orthogonal Procrustes problem. This optimization problem seeks an orthogonal transformation to make the matrix align with the matrix such that Frobenius norm of the residual error matrix is minimized [25, 26]. The mathematical expression is presented as follows
| (13) |
Since and , are constants, the objective of Equation (13) can be rewritten as an equivalent one
| (14) |
By applying the method of Lagrange multipliers [52], we can convert this constrained problem into an unconstrained one to find the solution , where and are obtained by singular value decomposition [51]. Thus, the maximum objective of Equation (14) is
| (15) |
Our crucial observation is that if we interpret as a measurement of inherent semantic similarity for feature maps, our designed layer association weights will naturally achieve semantic calibration.
Given vectorized feature maps from the teacher and student models and , the irreducible error of orthogonal transformation from to , as discussed in the above, is related to , or . The larger means that these two representations are more similar from the perspective of orthogonal transformation. Since the lemma 1 implies that increasing tends to increase and vice versa, will tend to be larger if becomes larger. That is to say, attention allocation achieve semantic calibration by assigning larger weight for a certain teacher-student layer pair once the generated feature maps of student layer can be orthogonally transformed into those of the associated target layer with relatively lower error.
3.5 Softening Attention
A simple yet effective variant to further improve the performance of SemCKD is presented in this section. Similar to softening predicted probabilities in the vanilla KD as Equation (1), we find that softening attention in Equation (10) is also helpful. But the reason behind these two seemingly similar steps are completely different. The former is to capture more structural information among different classes while the latter is to smooth the gradient direction guided by different target layers for each student layer in training.
In this variant SemCKDτ, we replace Equation (10) as
| (16) |
4 Experiments
We conduct extensive experiments in this section to demonstrate the effectiveness of our proposed approach. In addition to comparing with some representative feature-map distillation approaches, we provide results to support and explain the success of our semantic calibration strategy in helping student models obtain a proper regularization through several carefully designed experiments (Section 4.3) and ablation studies (Section 4.4). Moreover, we provide a variant SemCKDτ for further performance improvement and show that SemCKD generalizes well in different scenarios such as transfer learning, few-shot learning as well as noisy-label learning. SemCKD is also compatible with the state-of-the-art feature-embedding distillation technique to achieve better results. Finally, sensitivity analysis to the hyper-parameter is reported.
| Student | VGG-8 | VGG-13 | ShuffleNetV2 | ShuffleNetV2 | MobileNetV2 | ShuffleNetV1 |
|---|---|---|---|---|---|---|
| 70.46 0.29 | 74.82 0.22 | 72.60 0.12 | 72.60 0.12 | 65.43 0.29 | 71.36 0.25 | |
| KD [9] | 72.73 0.15 | 77.17 0.11 | 75.60 0.21 | 75.49 0.24 | 68.70 0.22 | 74.30 0.16 |
| FitNet [16] | 72.91 0.18 | 77.06 0.14 | 75.44 0.11 | 75.82 0.22 | 68.64 0.12 | 74.52 0.03 |
| AT [17] | 71.90 0.13 | 77.23 0.19 | 75.41 0.10 | 75.91 0.14 | 68.79 0.13 | 75.55 0.19 |
| SP [18] | 73.12 0.10 | 77.72 0.33 | 75.54 0.18 | 75.77 0.08 | 68.48 0.36 | 74.69 0.32 |
| VID [19] | 73.19 0.23 | 77.45 0.13 | 75.22 0.07 | 75.55 0.18 | 68.37 0.24 | 74.76 0.22 |
| HKD [20] | 72.63 0.12 | 76.76 0.13 | 76.24 0.09 | 76.64 0.05 | 69.23 0.16 | 75.89 0.09 |
| MGD [21] | 72.39 0.16 | 77.17 0.22 | 75.74 0.21 | 75.78 0.29 | 68.55 0.14 | — |
| SemCKD | 75.27 0.13 | 79.43 0.02 | 76.39 0.12 | 77.62 0.32 | 69.61 0.05 | 76.31 0.20 |
| Teacher | ResNet-32x4 | ResNet-32x4 | VGG-13 | ResNet-32x4 | WRN-40-2 | ResNet-32x4 |
| 79.42 | 79.42 | 74.64 | 79.42 | 75.61 | 79.42 |
4.1 Experimental Setup
4.1.1 Dataset
In this paper, four popular datasets including CIFAR-100 [53], STL-10 [54], Tiny-ImageNet [55] and ImageNet [56] are used to conduct a series of tasks on image classification, transfer learning, few-shot learning and noisy-label learning. A standard preprocessing procedure is adopted as previous works [27, 44], that is, all images are normalized by channel means and standard deviations.
The CIFAR-100 dataset contains 50,000 training samples and 10,000 testing samples, which are drawn from 100 fine-grained classes. Each training image is padded by 4 pixels on each size and extracted as a randomly sampled 32x32 crop or its horizontal filp for data augmentation. The ImageNet dataset coming from ILSVRC-2012 is a more challenging for large-scale classification. It consists of about 1.3 million training images and 50,000 validation images from 1,000 classes. Each training image is extracted as a randomly sampled 224x224 crop or its horizontal filp without any padding operation. The following two datasets are used for transfer learning task where all images are downsampled to 32x32. The STL-10 dataset contains 5,000 training images and 8,000 testing images from 10 classes. The Tiny-ImageNet contains 100,000 training images and 10,000 validation images from 200 classes.
4.1.2 Network Architectures
A large variety of teacher-student combinations based on popular networks are used for evaluation [57, 27, 58, 59, 60, 61]. The number behind “VGG-” or “ResNet-” represents the depth of networks. “WRN-d-w” represents wide-ResNet with depth and width factor . The number behind “x” in “ResNet-8x4”, “ResNet-32x4”, “ResNet-34x4” or “ShuffleNetV2x0.5” indicates that the number of filters in each layer is expanded or contracted with the certain factor.
4.1.3 Compared Approaches
Three kinds of knowledge distillation approaches based on transferring knowledge from different positions are compared through our paper, which are listed as follows
-
•
Logits distillation includes the vanilla KD [9].
- •
- •
| Student | WRN-16-2 | ShuffleNetV1 | MobileNetV2 | MobileNetV2 | VGG-8 | ResNet-8x4 |
|---|---|---|---|---|---|---|
| 73.41 0.27 | 71.36 0.25 | 65.43 0.29 | 65.43 0.29 | 70.46 0.29 | 73.09 0.30 | |
| KD [9] | 74.87 0.09 | 75.13 0.19 | 68.39 0.32 | 69.70 0.15 | 73.38 0.05 | 74.42 0.05 |
| FitNet [16] | 74.87 0.14 | 75.28 0.21 | 68.28 0.21 | 69.33 0.23 | 73.63 0.11 | 74.32 0.08 |
| AT [17] | 75.34 0.08 | 76.39 0.05 | 67.15 0.16 | 69.37 0.26 | 73.51 0.08 | 75.07 0.03 |
| SP [18] | 74.79 0.05 | 75.92 0.29 | 67.20 0.71 | 70.04 0.27 | 73.53 0.23 | 74.29 0.07 |
| VID [19] | 75.27 0.08 | 75.97 0.25 | 67.94 0.24 | 69.92 0.30 | 73.63 0.07 | 74.55 0.10 |
| HKD [20] | 74.99 0.08 | 75.98 0.09 | 68.88 0.08 | 69.97 0.21 | 73.06 0.24 | 74.86 0.21 |
| MGD [21] | 74.79 0.18 | — | 67.34 0.41 | 69.68 0.24 | 73.47 0.24 | 74.36 0.16 |
| SemCKD | 76.24 0.21 | 76.83 0.27 | 69.00 0.19 | 70.24 0.12 | 74.43 0.25 | 76.23 0.04 |
| Teacher | ResNet-32x4 | WRN-40-2 | ResNet-32x4 | ShuffleNetV2 | VGG-13 | ResNet-32x4 |
| 79.42 | 75.61 | 79.42 | 72.60 | 74.64 | 79.42 |
4.1.4 Training Details
We use stochastic gradient descent with Nesterov momentum and set the momentum to 0.9 in all experiments. For CIFAR-100, we follow the setting of CRD [44], that is, the initial learning rate is set as 0.01 for MobileNetV2, ShuffleNetV1/V2 and 0.05 for other architectures. All models are trained for 240 epochs and the learning rate is divided by 10 at 150, 180 and 210 epochs. We set the mini-batch size to 64 and the weight decay to . All results are reported in means (standard deviations) over 4 trials. For ImageNet, the initial learning rate is 0.1 and divided by 10 at 30 and 60 of the total 90 training epochs. We set the mini-batch size to 256 and the weight decay to . All results are reported in a single trial. We set the hyper-parameter of SemCKD to 400 and the temperature for the vanilla KD loss in Equation (1) to throughout this paper. The detailed implementation could be found in our open-source code. We regard the building blocks of teacher and student networks as target layer and student layer in practice, which are significantly less than the total number of neural networks.
4.1.5 Evaluation Metrics
Besides the widely used Top-1 test accuracy (%) for performance evaluation, we adopt another metric named as Relative Improvement () and its variant Average Relative Improvement () to obtain an intuitive sense about the quantitative improvement [44, 24].
| (17) |
where is the number of combinations and , , refer to the accuracies of SemCKD, a certain feature-map distillation and a regularly trained student model in the -th setting, respectively. This evaluation metric reflects the extent to which SemCKD further improves on the basis of existing approaches compared to the improvement made by these approaches upon baseline student models.
A computation-friendly metric called Semantic Mismatch score (SM-score) is proposed as an alternative to the intractable nuclear norm calculation for in Equation (15). SM-score is calculated by the average Euclidean distance between the generated similarity matrices of each associated teacher-student layer pair
| (18) |
where denotes the number of candidate layer pairs, and are similarity matrices of student layer and target layer , respectively. always equal to for compared approaches.
4.1.6 Computing Infrastructure
All of the experiments are implemented by PyTorch [62] and conducted on a server containing one NVIDIA TITAN X-Pascal GPU as well as a server containing eight NVIDIA RTX 2080Ti GPUs.
| Student | ResNet-18 | ShuffleV2x0.5 | ResNet-18 |
| 69.67 | 53.78 | 69.67 | |
| KD [9] | 70.62 | 53.73 | 70.54 |
| FitNet [16] | 70.31 | 51.46 | 70.42 |
| AT [17] | 70.30 | 52.83 | 70.30 |
| SP [18] | 69.99 | 51.73 | 70.12 |
| VID [19] | 70.30 | 53.97 | 70.26 |
| HKD [20] | 68.86 | 51.60 | 68.44 |
| MGD [21] | 70.37 | 52.96 | 70.18 |
| SemCKD | 70.87 | 53.99 | 70.66 |
| Teacher | ResNet-34 | ResNet-34∗ | ResNet-34∗ |
| 73.26 | 73.54 | 73.54 |
4.2 Comparison of Different Feature-Map Distillation
Table II and III give the Top-1 test accuracy (%) on CIFAR-100 based on twelve network combinations, which consists of two homogeneous settings, i.e., the teacher and student share similar architectures (VGG-8/13, ResNet-8x4/32x4), and ten heterogeneous settings. Each column apart from the first and last rows includes the results of a certain student model trained by various approaches under the supervision of the same teacher model. The results of the vanilla KD are also included for comparison. There are two combinations where the MGD [21] is not applicable and denoted as ’—’.
From Table II and III, we can see that SemCKD consistently achieves higher accuracy than state-of-the-art feature-map distillation approaches. The distributions of relative improvement are plotted in Figure 2. On average, SemCKD shows significantly relative improvement (60.03%) over all these approaches. Specifically, the best case happens in the “VGG-8 & ResNet-32x4” setting where the over AT [17] is 242%. When compared to the most competitive one named as HKD [20], which relies on a costly teacher-auxiliary-student paradigm as discussed in Section 3.2, the becomes rather small on two settings (3.93% for “ShuffleNetV2 & ResNet-32x4”, 9.98% for “MobileNetV2 & WRN-40-2”). But in general, SemCKD still relatively outperforms HKD for 45.82%, showing that our approach indeed make better use of intermediate information for effective distillation.
We also find that none of the compared approaches can consistently beats the vanilla KD on CIFAR-100, which probably due to semantic mismatch among associated layer pairs. This problem becomes especially severe for one-pair selection (FitNet method fails in 7/12 cases and MGD method fails in 8/12 cases), the situation where the number of candidate layer is larger than (4/6 of methods fail in the “ShuffleNetV2 & VGG-13” setting) and MobileNetV2 is used as the student model (5/6 or 4/6 of methods fail in the “MobileNetV2 & ResNet-32x4/WRN-40-2” settings). Nevertheless, our semantic calibration formulation helps alleviate semantic mismatch to a great extent, leading to satisfied performance of SemCKD. Similar observations are obtained in Table IV for the results on a large-scale image classification dataset.


4.3 Semantic Calibration Analysis
In this section, we experimentally study the negative regularization caused by manually specified layer associations and provide some explanations for the success of SemCKD by the proposed criterion and visual evidence.
4.3.1 Negative regularization
This effect occurs when feature-map distillation with a certain layer association performs poorer than the vanilla KD. To reveal its existence, we train the student model with only one specified teacher-student layer pair in various settings. The involved network architectures consist of “VGG-8 & ResNet-32x4”, “MobileNetV2 & WRN-40-2”, “ShuffleNetV2 & VGG-13” and “ResNet-8x4 & ResNet-32x4”. The numbers of candidate target layers and student layers for each case are (3, 4), (3, 4), (4, 3) and (3, 3), respectively.
Figure 3 shows the results of student models with these 12 or 9 teacher-student layer combinations. For better comparison, results of the vanilla KD and SemCKD are plotted as dash horizontal lines with different colors. We can see that the performance of a student model becomes extremely poor for some layer associations, which is probably caused by large semantic gaps. Typical results include “Student Layer-4 & Target Layer-3” in Figure 3 (a), “Student Layer-1, 2 & Target Layer-3” in Figure 3 (b), “Student Layer-1 & Target Layer-4” in Figure 3 (c) and “Student Layer-1, 3 & Target Layer-3” in Figure 3 (d).
Another finding is that one-to-one layer association is suboptimal since better results can be achieved by exploiting information in a target layer with different depth, such as “Student Layer-1 & Target Layer-2” in Figure 3 (b), “Student Layer-3 & Target Layer-4” in Figure 3 (c) and “Student Layer-1 & Target Layer-2” in Figure 3 (d). Although training with certain hand-craft layer associations could outperform SemCKD in a few cases, such as “Student Layer-3,4 & Target Layer-3” in Figure 3 (b), SemCKD still performs reasonably well against a large selection of associations, especially knowledge of the best layer association for any of network combinations is not available in advance. Nevertheless, those cases in which SemCKD is inferior to the best one indicate that there is extra room for refinement of our association strategy.
4.3.2 Semantic Mismatch Score
We then evaluate whether SemCKD actually leads to less semantic mismatch solutions compared with other approaches. A new metric called SM-score is proposed as Equation (18), which hopefully represents the degree of difference between the captured pairwise similarity among instances in certain semantic level. Additionally, we adopt CKA [23] to evaluate the similarity between extracted feature maps as the previous work [45]. We calculate the SM-scores (log-scale) and CKA values of each approach across training epochs and average them in the last 10 epochs, which already keep almost unchanged, as the final ones reported in Table V. in the Table V indicates the larger (smaller) the better. Thanks to our soft layer association, the lowest semantic mismatch score and nearly the largest CKA through the training process is achieved by SemCKD.
4.3.3 Visualization
To further provide visual explanations for the advantage of SemCKD, we randomly select several images from ImageNet labeled by “Bow tie”, “Rain barrel”, “Racer”, “Bathhub”, “Goose”, “Band aid”, “Sweatshirt”, “Saltshaker”, “Rock crab” and “Woollen”, and use Grad-CAM [63] to highlight the regions which are considered to be important for a model to predict the corresponding labels.
From Figure 4, we can see that the class-discriminative regions are centralized by SemCKD, which is similar to the teacher model in most cases, while being scatted around the surroundings by compared approaches. As visualized in the fifth column, where the images are labeled with “Bathtub”, another failure mode of the compared approaches is that they sometimes regard the right regions as background while putting their attention on the spatial adjacency object. As for the images in the eighth column labeled with “Sweatshirt”, the teacher model puts its attention on a wrong region corresponding to the label “sliding door”, which leads the student model trained with vanilla KD to make the same mistake and leads other compared approaches to focus on the wrong region corresponding to the label “jean”. Moreover, SemCKD can capture more semantic-related information like highlighting the head and neck to identify a “Goose” in the image.

| Equal Allocation | w/o Projection | w/o | w/o Similarity Matrices | Shared Allocation | SemCKD |
|---|---|---|---|---|---|
| 72.94 0.87 | 72.51 0.16 | 72.78 0.29 | 74.75 0.14 | 74.87 0.21 | 75.27 0.13 |

4.4 Ablation Study
In Table VI, we present the evaluation results of five kinds of ablation studies based on the “VGG-8 & ResNet-32x4” combination. Specifically, the first kind confirms the benefit of adaptively learning attention allocation for cross-layer knowledge distillation, the second to the fourth ones confirm the benefit of each individual component for obtaining attention weights, and the last one confirms the benefit of assigning each instance with independent weights.
(1) Equal Allocation. In order to validate the effectiveness of allocating the personalized attention of each student layer to multiple target layers, equal weights assignment is applied instead. This causes a lower accuracy by 2.33% (from 75.27% to 72.94%) and a considerably larger variance by 0.74% (from 0.13% to 0.87%).
(2) w/o Projection. Rather than projecting the feature maps of each student layer to the same dimension as those in the target layers by Equation (6), we add a new to project the pairwise similarity matrices of teacher-student layer pairs into another subspace to generate value vectors. Thus the Mean-Square-Error among feature maps in Equation (7) is replaced by these value vectors to calculate the overall loss, which reduces the performance by 2.76%.
(3) w/o . A simple linear transformation is used to obtain query and key vectors in Equation (9) instead of the two-layer non-linear transformation , which includes “Linear-ReLU-Linear-Normalization”. The 2.49% performance drop indicates that the usefulness of to alleviate the effect of noise and sparseness.
(4) w/o Similarity Matrices. We skip the similarity matrices calculation in Equation (8) and directly employ feature maps of candidate layer pairs to obtain the query and key vectors. Specifically, we replace Equation (9) with , The 0.52% performance decline indicates the benefit of similarity matrices for the subsequent attention calculation. Another reason for not using feature maps is that this will cause a considerable memory cost to generate query and key vectors due to the larger spatial dimensions ().
(5) Shared Allocation. Instead of learning an independent attention allocation across teacher-student layer pairs for each training instance, we make all instances share the same association weights during the whole training process. This will incur 0.40% accuracy drop.
4.5 Softening Attention
In this section, we conduct experiments on a large number of teacher-student combinations to verify the effectiveness of softening attention in SemCKD.
| Percentage | 25% | 50% | 75% | 100% |
|---|---|---|---|---|
| Student | 55.26 0.33 | 64.28 0.20 | 68.21 0.16 | 70.46 0.29 |
| KD [9] | 59.23 0.23 | 67.16 0.14 | 70.32 0.16 | 72.73 0.15 |
| FitNet [16] | 60.29 0.32 | 67.58 0.25 | 70.84 0.33 | 72.91 0.18 |
| AT [17] | 59.72 0.21 | 66.94 0.13 | 70.18 0.36 | 71.90 0.13 |
| SP [18] | 60.93 0.22 | 67.92 0.22 | 71.22 0.28 | 73.12 0.10 |
| VID [19] | 60.15 0.15 | 67.91 0.19 | 70.86 0.15 | 73.19 0.23 |
| HKD [20] | 58.96 0.24 | 67.25 0.31 | 70.38 0.26 | 72.63 0.12 |
| MGD [21] | 60.03 0.17 | 67.31 0.14 | 70.59 0.29 | 72.39 0.16 |
| SemCKD | 64.82 0.20 | 70.76 0.23 | 73.06 0.25 | 75.27 0.13 |
| Percentage | 0% | 10% | 20% | 30% | 40% | 50% |
|---|---|---|---|---|---|---|
| Student | 70.46 0.29 | 66.48 0.27 | 60.08 0.16 | 49.57 0.11 | 39.93 0.15 | 32.81 0.11 |
| KD [9] | 72.73 0.15 | 71.39 0.33 | 67.99 0.20 | 62.53 0.29 | 58.70 0.21 | 54.54 0.13 |
| FitNet [16] | 72.91 0.18 | 71.59 0.23 | 68.25 0.20 | 62.68 0.17 | 58.94 0.39 | 54.93 0.19 |
| AT [17] | 71.90 0.13 | 70.81 0.19 | 67.75 0.29 | 61.81 0.15 | 57.94 0.27 | 54.08 0.30 |
| SP [18] | 73.12 0.10 | 71.73 0.27 | 68.49 0.18 | 62.94 0.38 | 59.21 0.29 | 54.81 0.39 |
| VID [19] | 73.19 0.23 | 72.02 0.08 | 68.72 0.14 | 63.22 0.27 | 59.26 0.40 | 55.26 0.29 |
| HKD [20] | 72.63 0.12 | 68.87 0.31 | 62.71 0.14 | 52.41 0.14 | 43.84 0.06 | 36.94 0.18 |
| MGD [21] | 72.39 0.16 | 71.34 0.08 | 68.09 0.19 | 62.56 0.27 | 58.65 0.31 | 54.57 0.39 |
| SemCKD | 75.27 0.13 | 73.81 0.19 | 70.62 0.15 | 65.16 0.10 | 60.93 0.06 | 57.19 0.19 |
As shown in Figure 5, we test the performance of each student model with different softness and draw an orange curve for the results of SemCKDτ. To preserve as much information as possible in the teacher model during knowledge transfer, previous works attempt to adjust the distillation position to the front of the ReLU operation [64, 21], which is called pre-activation distillation. We also combine this operation into SemCKDτ and name this variant as SemCKDτ+Pre. Additionally, the results of original SemCKD are plotted as the horizontal lines for comparison.
In most cases, we can see that softening attention indeed improves the performance of SemCKD by a considerable margin. For example, when , the absolute accuracy boost is 0.47% and 0.86% in the “VGG-8 & ResNet-32x4” and “MobileNetV2 & WRN-40-2” settings, respectively. Another evidence to support the necessity of softness is that there will be a significant performance degeneration when is less than 1. The reason is that the attention weights will be sharpened in this situation and make the overall target direction become largely influenced by a certain component. Generally, or is a satisfying initial choice in practice for a given teacher-student combination. We also find that SemCKDτ+Pre could only outperform SemCKDτ slightly but will be inferior to SemCKD distinctly when “MobileNetV2” is used for the student model.
4.6 Generalization to Different Scenarios
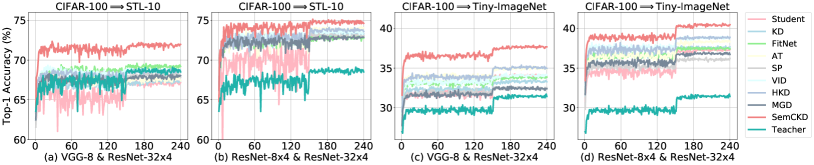
4.6.1 Transfer Learning
We conduct a series of experiments on two dataset pairs with two network combinations to evaluate the transferability of learned representations. Each model trained with the corresponding approach on CIFAR-100 is adopted to extract representations for the images from STL-10 or Tiny-ImageNet. Then, we train another linear classifier on these representations for evaluation.
As shown in Figure 6, SemCKD beats all compared approaches by a considerable margin. Specifically, SemCKD outperforms the second best one (FitNet) by 2.76% absolute accuracy in Figure 6 (a). Although representations learned by the teacher model transfer worst in the most settings (3/4) as discussed in [44], SemCKD still absolutely improves the performance of student models by 3.25% on average.
4.6.2 Few-Shot Learning and Noisy-Label Learning
We further evaluate the performance of SemCKD in few-shot learning and noisy-label learning scenarios. All these experiments indicate that SemCKD can make better use of training data and is relatively robust to noisy perturbation.
Following the setting of [45], we randomly sample 25%, 50% and 75% training images from each class on CIFAR-100 to make several few-shot learning datasets, and randomly perturb 10%, 20%, 30%, 40% and 50% labels of training images to make noisy-label learning datasets. From Table VII and VIII, we can see that SemCKD consistently outperforms compared approaches as well as the regular training in all settings. The improvement will become larger as the number of available training images reduces or the number of perturbed training images increases. Specifically, as shown in Table VII, SemCKD can surpass the regularly trained student model by training with only 50% original dataset and become comparable to state-of-the-art approaches given additional 25% training images. Similarly, from Table VIII, we can see that SemCKD can surpass state-of-the-art approaches by training with 10% noisy data, and surpass the regularly trained student model even with additional 10% noisy data in training images.
| Student | PKT [40] | RKD [41] | IRG [42] | CC [43] | CRD [44] | SemCKD | SemCKD+CRD | Teacher |
|---|---|---|---|---|---|---|---|---|
| VGG-8 | 73.11 0.21 | 72.49 0.08 | 72.57 0.20 | 72.63 0.30 | 73.54 0.19 | 75.27 0.13 | 75.52 0.09 | ResNet-32x4 |
| 70.46 0.29 | 79.42 | |||||||
| VGG-13 | 77.43 0.11 | 76.93 0.19 | 76.91 0.15 | 77.16 0.19 | 77.48 0.13 | 79.43 0.02 | 79.48 0.07 | ResNet-32x4 |
| 74.82 0.22 | 79.42 | |||||||
| ShuffleNetV2 | 75.82 0.28 | 75.51 0.34 | 75.65 0.39 | 75.40 0.19 | 76.11 0.27 | 76.39 0.12 | 76.58 0.29 | VGG-13 |
| 72.60 0.12 | 74.64 | |||||||
| ShuffleNetV2 | 75.88 0.06 | 75.67 0.25 | 75.45 0.27 | 75.47 0.28 | 77.04 0.61 | 77.62 0.32 | 77.94 0.33 | ResNet-32x4 |
| 72.60 0.12 | 79.42 | |||||||
| MobileNetV2 | 68.68 0.29 | 68.71 0.20 | 68.83 0.18 | 68.68 0.14 | 69.98 0.27 | 69.61 0.05 | 70.55 0.11 | WRN-40-2 |
| 65.43 0.29 | 75.61 | |||||||
| ShuffleNetV1 | 74.48 0.16 | 74.22 0.26 | 74.11 0.12 | 74.26 0.49 | 75.34 0.24 | 76.31 0.20 | 76.60 0.08 | ResNet-32x4 |
| 71.36 0.25 | 79.42 | |||||||
| WRN-16-2 | 75.07 0.12 | 74.93 0.45 | 74.73 0.23 | 74.91 0.15 | 75.89 0.38 | 76.24 0.21 | 76.32 0.14 | ResNet-32x4 |
| 73.41 0.27 | 79.42 | |||||||
| ShuffleNetV1 | 75.42 0.24 | 75.25 0.16 | 75.24 0.23 | 75.23 0.22 | 75.89 0.24 | 76.83 0.27 | 76.92 0.26 | WRN-40-2 |
| 71.36 0.25 | 75.61 | |||||||
| MobileNetV2 | 67.99 0.29 | 67.46 0.55 | 67.89 0.26 | 67.68 0.22 | 69.39 0.11 | 69.00 0.19 | 69.81 0.42 | ResNet-32x4 |
| 65.43 0.29 | 79.42 | |||||||
| MobileNetV2 | 69.57 0.14 | 69.39 0.41 | 69.51 0.31 | 70.00 0.17 | 70.83 0.17 | 70.27 0.12 | 71.07 0.07 | ShuffleNetV2 |
| 65.43 0.09 | 72.60 | |||||||
| VGG-8 | 73.40 0.30 | 73.42 0.14 | 73.31 0.12 | 73.33 0.23 | 74.31 0.17 | 74.43 0.25 | 74.67 0.11 | VGG-13 |
| 70.46 0.29 | 74.64 | |||||||
| ResNet-8x4 | 74.61 0.25 | 74.36 0.23 | 74.67 0.15 | 74.50 0.13 | 75.59 0.07 | 76.23 0.04 | 76.68 0.19 | ResNet-32x4 |
| 73.09 0.30 | 79.42 |
4.7 Extension to Feature-Embedding Distillation
Knowledge transfer based on feature embeddings of the penultimate layer is another alternative to improve the generalization ability of student models. We compare the performance of several newly proposed approaches on the same twelve network combinations as Table II and Table III. Additionally, we report the results of student models trained by simply adding the loss of CRD [44] into the original one of SemCKD without tuning any hyper-parameter.
From Table IX, we can observe that the performance can be further boosted by training with “SemCKD+CRD” in all cases, which confirms that our approach holds a very satisfying property to be highly compatible with the state-of-the-art feature-embedding distillation approach.
4.8 Sensitivity Analysis
Finally, we evaluate the impact of hyper-parameter on the performance. We compare three representative knowledge distillation approaches, including logits distillation (KD [9]), feature-embedding distillation (CRD [44]) and feature-map distillation (SemCKD). The range of hyper-parameter for SemCKD is set as 100 to 1100 at equal interval of 100, while the hyper-parameter for CRD ranges from 0.5 to 1.5 at equal interval of 0.1, adopting the same search space as the original paper [44]. Note that the hyper-parameter always equals to for the vanilla KD, leading to a horizontal line in Figure 7.
It is seen that SemCKD achieves the best results in all cases and outperforms CRD at about 1.73% absolute accuracy for the default hyper-parameter setting. Figure 7 also shows that the performance of SemCKD keeps very stable after the hyper-parameter is greater than 400, which indicates that our proposed method works reasonably well in a wide range of search space for the hyper-parameter .

5 Conclusion
In this paper, we focus on a critical but neglected issue in feature-map based knowledge distillation, i.e., how to alleviate performance degeneration resulted from negative regularization in manually specified layer pairs. Our strategy is to use an attention mechanism for association weight learning, based on which knowledge could be transferred in a matched semantic space. We further provide empirical evidence to support the semantic calibration capability of SemCKD and connect the association weights with the classic Orthogonal Procrustes problem. Extensive experiments show that SemCKD consistently outperforms the compared state-of-the-art approaches and our softening attention variant SemCKDτ further widens the lead. Moreover, our approach is readily applicable to different tasks, network architectures, and highly compatible with the feature-embedding distillation approach.
References
- [1] Y. Bengio, A. C. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013.
- [2] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding,” in International Conference on Learning Representations, 2016.
- [3] C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understanding deep learning requires rethinking generalization,” in International Conference on Learning Representations, 2017.
- [4] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in International Conference on Computer Vision, 2015, pp. 1026–1034.
- [5] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” Journal of Machine Learning Researh, vol. 15, no. 1, pp. 1929–1958, 2014.
- [6] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in International Conference on Machine Learning, 2015, pp. 448–456.
- [7] H. Zhang, M. Cissé, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” in International Conference on Learning Representations, 2018.
- [8] M. Denil, B. Shakibi, L. Dinh, N. De Freitas et al., “Predicting parameters in deep learning,” in Advances in Neural Information Processing Systems, 2013, pp. 2148–2156.
- [9] G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [10] S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural network,” in Advances in Neural Information Processing Systems, 2015, pp. 1135–1143.
- [11] A. Polino, R. Pascanu, and D. Alistarh, “Model compression via distillation and quantization,” in International Conference on Learning Representations, 2018.
- [12] C. Bucilua, R. Caruana, and A. Niculescu-Mizil, “Model compression,” in Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2006, pp. 535–541.
- [13] J. Ba and R. Caruana, “Do deep nets really need to be deep?” in Advances in Neural Information Processing Systems, 2014, pp. 2654–2662.
- [14] R. Müller, S. Kornblith, and G. E. Hinton, “When does label smoothing help?” in Advances in Neural Information Processing Systems, 2019.
- [15] L. Yuan, F. E. Tay, G. Li, T. Wang, and J. Feng, “Revisiting knowledge distillation via label smoothing regularization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 3902–3910.
- [16] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” in International Conference on Learning Representations, 2015.
- [17] S. Zagoruyko and N. Komodakis, “Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer,” in International Conference on Learning Representations, 2017.
- [18] F. Tung and G. Mori, “Similarity-preserving knowledge distillation,” in International Conference on Computer Vision, 2019, pp. 1365–1374.
- [19] S. Ahn, S. X. Hu, A. C. Damianou, N. D. Lawrence, and Z. Dai, “Variational information distillation for knowledge transfer,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 9163–9171.
- [20] N. Passalis, M. Tzelepi, and A. Tefas, “Heterogeneous knowledge distillation using information flow modeling,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 2336–2345.
- [21] K. Yue, J. Deng, and F. Zhou, “Matching guided distillation,” in European Conference on Computer Vision, 2020, pp. 312–328.
- [22] C. Farabet, C. Couprie, L. Najman, and Y. LeCun, “Learning hierarchical features for scene labeling,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1915–1929, 2013.
- [23] S. Kornblith, M. Norouzi, H. Lee, and G. E. Hinton, “Similarity of neural network representations revisited,” in International Conference on Machine Learning, vol. 97, 2019, pp. 3519–3529.
- [24] D. Chen, J.-P. Mei, Y. Zhang, C. Wang, Z. Wang, Y. Feng, and C. Chen, “Cross-layer distillation with semantic calibration,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2021, pp. 7028–7036.
- [25] J. R. Hurley and R. B. Cattell, “The procrustes program: Producing direct rotation to test a hypothesized factor structure,” Behavioral science, vol. 7, no. 2, p. 258, 1962.
- [26] P. H. Schönemann, “A generalized solution of the orthogonal procrustes problem,” Psychometrika, vol. 31, pp. 1–10, 1966.
- [27] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [28] K. He, G. Gkioxari, P. Dollár, and R. B. Girshick, “Mask R-CNN,” in International Conference on Computer Vision, 2017, pp. 2980–2988.
- [29] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton et al., “Mastering the game of go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017.
- [30] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019, pp. 4171–4186.
- [31] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” in Advances in Neural Information Processing Systems, 2019, pp. 5754–5764.
- [32] A. Novikov, D. Podoprikhin, A. Osokin, and D. P. Vetrov, “Tensorizing neural networks,” in Advances in Neural Information Processing Systems, 2015, pp. 442–450.
- [33] Y. Gong, L. Liu, M. Yang, and L. Bourdev, “Compressing deep convolutional networks using vector quantization,” in International Conference on Learning Representations, 2015.
- [34] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,” in International Conference on Learning Representations, 2017.
- [35] R. Anil, G. Pereyra, A. Passos, R. Ormándi, G. E. Dahl, and G. E. Hinton, “Large scale distributed neural network training through online distillation,” in International Conference on Learning Representations, 2018.
- [36] Y. Zhang, T. Xiang, T. M. Hospedales, and H. Lu, “Deep mutual learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4320–4328.
- [37] D. Chen, J.-P. Mei, C. Wang, Y. Feng, and C. Chen, “Online knowledge distillation with diverse peers.” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 3430–3437.
- [38] Y. Guan, P. Zhao, B. Wang, Y. Zhang, C. Yao, K. Bian, and J. Tang, “Differentiable feature aggregation search for knowledge distillation,” in European Conference on Computer Vision, 2020, pp. 469–484.
- [39] Y. Jang, H. Lee, S. J. Hwang, and J. Shin, “Learning what and where to transfer,” in International Conference on Machine Learning, 2019.
- [40] N. Passalis and A. Tefas, “Learning deep representations with probabilistic knowledge transfer,” in European Conference on Computer Vision, 2018, pp. 283–299.
- [41] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 3967–3976.
- [42] Y. Liu, J. Cao, B. Li, C. Yuan, W. Hu, Y. Li, and Y. Duan, “Knowledge distillation via instance relationship graph,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7096–7104.
- [43] B. Peng, X. Jin, D. Li, S. Zhou, Y. Wu, J. Liu, Z. Zhang, and Y. Liu, “Correlation congruence for knowledge distillation,” in International Conference on Computer Vision, 2019, pp. 5006–5015.
- [44] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” in International Conference on Learning Representations, 2020.
- [45] G. Xu, Z. Liu, X. Li, and C. C. Loy, “Knowledge distillation meets self-supervision,” in European Conference on Computer Vision, 2020, pp. 588–604.
- [46] S. Kullback and R. A. Leibler, “On information and sufficiency,” The Annals of Mathematical Statistics, vol. 22, no. 1, pp. 79–86, 1951.
- [47] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in European Conference on Computer Vision, 2014, pp. 818–833.
- [48] I. Goodfellow, Y. Bengio, A. Courville, and Y. Bengio, Deep learning. MIT press Cambridge, 2016, vol. 1, no. 2.
- [49] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998–6008.
- [50] X. Wang, R. B. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7794–7803.
- [51] G. H. Golub and C. F. Van Loan, Matrix computations. JHU press, 2013, vol. 3.
- [52] D. P. Bertsekas, Constrained optimization and Lagrange multiplier methods. Academic press, 2014.
- [53] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Technical Report, 2009.
- [54] A. Coates, A. Y. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” in International Conference on Artificial Intelligence and Statistics, 2011, pp. 215–223.
- [55] A. Torralba, R. Fergus, and W. T. Freeman, “80 million tiny images: A large data set for nonparametric object and scene recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 30, no. 11, pp. 1958–1970, 2008.
- [56] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and F. Li, “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015.
- [57] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations, 2015.
- [58] S. Zagoruyko and N. Komodakis, “Wide residual networks,” in Proceedings of the British Machine Vision Conference, 2016.
- [59] M. Sandler, A. G. Howard, M. Zhu, A. Zhmoginov, and L. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520.
- [60] X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6848–6856.
- [61] N. Ma, X. Zhang, H. Zheng, and J. Sun, “Shufflenet V2: practical guidelines for efficient CNN architecture design,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 122–138.
- [62] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems, 2019, pp. 8024–8035.
- [63] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in International Conference on Computer Vision, 2017, pp. 618–626.
- [64] B. Heo, J. Kim, S. Yun, H. Park, N. Kwak, and J. Y. Choi, “A comprehensive overhaul of feature distillation,” in International Conference on Computer Vision, 2019, pp. 1921–1930.