Cross-Impact of Order Flow Imbalance
in Equity Markets
Abstract
We investigate the impact of order flow imbalance (OFI) on price movements in equity markets in a multi-asset setting. First, we propose a systematic approach for combining OFIs at the top levels of the limit order book into an integrated OFI variable which better explains price impact, compared to the best-level OFI. We show that once the information from multiple levels is integrated into OFI, multi-asset models with cross-impact do not provide additional explanatory power for contemporaneous impact compared to a sparse model without cross-impact terms. On the other hand, we show that lagged cross-asset OFIs do improve the forecasting of future returns. We also establish that this lagged cross-impact mainly manifests at short-term horizons and decays rapidly in time.
Keywords: Market impact, Cross-impact, Order flow imbalance, Return prediction.
JEL Codes: C31, C53, G14
1 Introduction
Accurately estimating and forecasting the impact of trading behavior of market participants on the price movements of assets carries practical implications for both practitioners and academics, such as trading cost analysis (Frazzini et al. [23]) and optimal execution of trades. The impact of trades on asset prices, known as price impact, has been the focus of many studies and modeling efforts (Cont et al. [17], Lillo et al. [39]). In a multi-asset setting, several studied have focused on the concept of cross-impact, which attempts to describe the impact of trading a given asset on the price of other assets (see Benzaquen et al. [5], Capponi and Cont [8], Pasquariello and Vega [41]).
Several studies have investigated contemporaneous cross-impact of order flow on returns by examining their cross-correlation structure. For example, Hasbrouck and Seppi [28] revealed that commonality in returns among Dow 30 stocks is mostly attributed to order flow commonality. Tomas et al. [47] built a principled approach to choosing a cross-impact model for various markets. Capponi and Cont [8] showed that the positive covariance between returns of a specific stock and order flow imbalances of other stocks does not necessarily constitute evidence of cross-impact. They further demonstrated that, as long as the common factor in order flow imbalances is taken into account, adding cross-impact terms only marginally improves model performance, and thus may be disregarded. Our study complements Capponi and Cont [8] in several ways: unlike [8] which focuses on in-sample performance, we also consider the forecasting power of cross-order flow using both single and multi-level OFIs. To the best of our knowledge, there have been no studies that examine the influence of order flows on price movements in a multi-asset setting, while also taking into account the deeper levels in the limit order book (LOB).111Xu et al. [53] studied the contemporaneous price impact (not cross-impact) model by extending the model of Cont et al. [17] to multi-level order flow imbalance.
A more challenging problem than explaining contemporaneous returns is to examine the impact of trade orders on prices over future horizons, which has received a lot less attention in the literature, despite its important economic implications. Some studies have examined the relationship between order imbalances and future daily returns.222Several studies, such as Hou [31], Menzly and Ozbas [40], Chinco et al. [12], Buccheri et al. [6], investigated the lead-lag effect in equity returns across various assets, but did not take into account order flows. Chordia et al. [15] revealed that daily stock market returns are strongly related to contemporaneous and lagged order imbalances. Chordia and Subrahmanyam [14] further found that there exists a positive relation between lagged order imbalances and daily individual stock returns. The authors also showed that imbalance-based trading strategies, i.e. buy if the previous day’s imbalance is positive, and sell if the previous day’s imbalance is negative, are able to yield statistically significant profits.Pasquariello and Vega [41] provided empirical evidence of cross-asset informational effects in NYSE and NASDAQ stocks between 1993 and 2004, and demonstrated that the daily order flow imbalance in one stock, or across one industry, has a significant and persistent impact on daily returns of other stocks or industries. Rosenbaum and Tomas [43] provided a characterization of the class of cross-impact kernels for a market that employs Hawkes processes to model trades and applied their method to two instruments from E-Mini Futures.
Given the recent progress in high-frequency trading (HFT), it is increasingly crucial to obtain accurate estimations of the cross-impact on future intraday returns. Benzaquen et al. [5] introduced a multivariate linear model (see Kyle [37]) to describe the structure of cross-impact and found that a significant fraction of the covariance of stock returns can be accounted for by this model. Wang et al. [49, 51] empirically analyzed and discussed the impact of trading a specific stock on the average price change of the whole market or of individual sectors. Schneider and Lillo [44] derived theoretical limits for the size and form of cross-impact and verified them on sovereign bonds data. However, when modeling cross-impact, these methods do not consider the possibility of high correlations between cross-asset order flows, which may result in overfitting issues. This is also evidenced by studies such as Benzaquen et al. [5] and Tomas et al. [47]. Moreover, these studies mainly investigated the cross-impact coefficients for a fixed time period (i.e., in a static setting), ignoring the temporal dynamics of cross-impact.
In recent years, machine learning models including deep neural networks, have achieved substantial developments, leading to their applications in financial markets, especially for the task of modeling stock returns. For example, Huck [32] utilized state-of-the-art techniques, such as random forests, to construct a portfolio over a period of 22 years, and the results demonstrated the power of machine learning models to produce profitable trading signals. Krauss et al. [36] applied a series of machine learning methods to forecast the probability of a stock outperforming the market index, and then constructed long-short portfolios from the predicted one-day-ahead trading signals. Gu et al. [25] employed a set of machine learning methods to make one-month-ahead return forecasts, and demonstrated the potential of machine learning approaches in empirical asset pricing, due to their ability to handle nonlinear interactions. Ait-Sahalia et al. [2] investigated the predictability of high-frequency stock returns and durations using LASSO and tree methods via many relevant predictors derived from returns and order flows. Tashiro et al. [46] and Kolm et al. [35] applied deep neural networks with LOB-based features to predict high-frequency returns. Nonetheless, to the best of our knowledge, cross-asset order flow imbalances have not been considered as predictors for forecasting future high-frequency returns in the literature, which is one of the main directions we explore in the second half of this paper.
1.1 Main contributions
The present study makes two main contributions to the literature regarding the contemporaneous and predictive cross-impact of order flow imbalances on price returns.
First, we revisit the significance of contemporaneous cross-impact by considering various definitions of order flow imbalance (OFI). Instead of only looking at the best-level orders, we systematically examine the impact of multi-level order flows in a cross-asset setting. Our results show that, once information from multi-level order flow is incorporated in the definition of order flow imbalance, cross-impact terms do not provide additional explanatory power for contemporaneous impact, compared to a parsimonious model without cross-impact. To the best of our knowledge, this is the first study to comprehensively analyze the relations between contemporaneous individual returns and multi-level orders in both single-asset and multi-asset settings.
Furthermore, we consider the associated forecasting problem and investigate the predictive power of the cross-asset order flows on future price returns. Our results suggest that cross-impact terms do provide significant information content for intraday forecasting of future returns over a short horizon of up to several minutes, but their predictability decays quickly through time.
1.2 Outline
Section 2 describes our dataset and defines the variables of interest. Section 3 discusses modeling of contemporaneous cross-impact. In Section 4, we first discuss the out-of-sample forecasting performance of cross-impact models over one-minute-ahead horizon from two perspectives: values and economic gains, and then examine the predictability over longer horizons. Finally, we conclude the analysis in Section 5 and highlight potential future research directions.
2 Data and variables
2.1 Data
We use the Nasdaq ITCH data from LOBSTER to compute the independent and dependent variables. Our data includes the top 100 components of S&P 500 index, existing from 2017-01-01 to 2019-12-31.333We select the top 100 components based on their market capitalization as of the most recent market close at the time of our analysis, i.e. 2019-12-31.
Cont et al. [17] found that over short time intervals, price changes are mainly driven by the Order Flow Imbalance (henceforth denoted as OFI). Kolm et al. [35] also demonstrated that forecasting deep learning models trained on OFIs significantly outperform most models trained directly on order books or returns. Therefore, we adopt the OFIs as features in our below analysis.
During the interval , we enumerate the observations of all order book updates by . Given two consecutive order book states for a given stock at and , we compute the bid order flows () and ask order flows () of stock at level at time as
where, and denote the bid price and size (in number of shares) of stock at level , respectively. Similarly, and denote the ask price and ask size at level , respectively. Note that the variable is positive when (i) the bid price increase; (ii) the bid price remains the same and the bid size increases. is negative when (i) the bid price decreases; (ii) the bid price remains the same and the bid size decreases. One can perform an analogous analysis and interpretation for the ask order flows .
Best-level OFI.
It calculates the accumulative OFIs at the best bid/ask side during a given time interval (see Cont et al. [17], Kolm et al. [35]), and is defined as444In Cont et al. [17], OFI was mathematically defined as , where denotes the total size of buy orders that arrived to the current best bid during the time interval ; denotes the total size of buy orders that canceled from the current best bid during the time interval ; denotes the total size of marketable buy orders that arrived to current best ask during the time interval . The quantities for sell orders are defined analogously. However, in the empirical study of Cont et al. [17], the OFI was computed from fluctuations in best bid/ask prices and their sizes according to Eqn (1). The reason is that information about individual orders is not available in the data set. For better comparison, we employ the same formula, i.e. Eqn (1), to compute OFI.
| (1) |
where and are the indexes of the first and the last order book event in the interval .
Deeper-level OFI.
A natural extension of the best-level OFI defined in Eqn (1) is deeper-level OFI (see Xu et al. [53], Kolm et al. [35]). We define OFI at level () as follows
| (2) |
Due to the intraday pattern in limit order depth, we use the average size to scale OFIs at the corresponding levels (consistent with Ahn et al. [1], Harris and Panchapagesan [26]), and consider
| (3) |
where is the average order book depth across the first levels and is the number of events during . In this paper, we consider the top levels of LOB and denote the multi-level OFI vector as .
Integrated OFI.
Our following analysis in Section 2.2 will show that there exist strong correlations between multi-level OFIs, and that the first principal component can explain over 89% of the total variance among multi-level OFIs. In order to make use of the information embedded in multiple LOB levels and avoid overfitting, we propose an integrated version of OFIs via Principal Components Analysis (PCA) as shown in Eqn (4), which only preserves the first principal component.555We would like to thank an anonymous reviewer for suggesting an analysis of various aggregations of multi-level OFIs, as detailed in Appendix A. We further normalize the first principal component by dividing by its norm so that the weights of multi-level OFIs in constructing integrated OFIs sum to 1, leading to
| (4) |
where is the first principal vector computed from historical data. To the best of our knowledge, this is the first work to aggregate multi-level OFIs into a single variable.
Logarithmic returns.
Our dependent variable is the logarithmic asset return. Specifically, we define the returns over the interval as follows:
| (5) |
where is the mid-price at time , i.e. .
2.2 Summary statistics
Table 1 presents the summary statistics of multi-level OFIs, integrated OFIs, and returns for the top 100 components of S&P 500 index. These descriptive statistics (e.g. mean, std, etc) are computed at the minute level and aggregated across trading days and stocks.
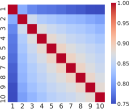
Figure 1 reveals that even though the correlation structure of multi-level OFIs may vary across stocks, they all show strong relationships (above 75%). It is worth pointing out that the best-level OFI exhibits the smallest correlation with any of the remaining nine levels, a pattern that persists across different stocks. Table 2 further reveals that the first principal component explains more than 89% of the total variance.
| Mean (bp) | Std (bp) | Skewness | Kurtosis | 10% (bp) | 25% (bp) | 50% (bp) | 75% (bp) | 90% (bp) | |
|---|---|---|---|---|---|---|---|---|---|
| -0.01 | 6.26 | -0.04 | 1.89 | -7.97 | -3.45 | 0.03 | 3.47 | 7.90 | |
| 0.01 | 6.86 | -0.04 | 1.04 | -8.86 | -3.88 | 0.02 | 3.95 | 8.85 | |
| -0.01 | 7.05 | -0.04 | 0.71 | -9.26 | -4.08 | 0.01 | 4.11 | 9.19 | |
| -0.02 | 7.22 | -0.05 | 0.68 | -9.50 | -4.21 | 0.01 | 4.24 | 9.40 | |
| -0.03 | 7.14 | -0.05 | 0.79 | -9.38 | -4.14 | 0.01 | 4.15 | 9.25 | |
| -0.03 | 6.87 | -0.04 | 0.96 | -8.98 | -3.94 | 0.01 | 3.95 | 8.85 | |
| -0.03 | 6.39 | -0.05 | 1.29 | -8.31 | -3.59 | 0.01 | 3.59 | 8.16 | |
| -0.03 | 6.03 | -0.05 | 1.59 | -7.80 | -3.37 | 0.01 | 3.36 | 7.66 | |
| -0.05 | 5.71 | -0.05 | 1.96 | -7.38 | -3.18 | 0.01 | 3.14 | 7.19 | |
| -0.05 | 5.38 | -0.05 | 2.52 | -6.92 | -2.97 | 0.01 | 2.91 | 6.74 | |
| 0.01 | 6.53 | -0.05 | 0.76 | -8.52 | -3.81 | 0.05 | 3.89 | 8.47 | |
| 0.02 | 4.81 | -0.04 | 1.85 | -6.22 | -2.71 | 0.00 | 2.79 | 6.23 |
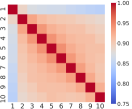
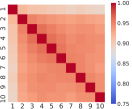
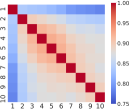
| Principal Component | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Explained Variance Ratio | 89.06 | 4.99 | 2.28 | 1.28 | 0.80 | 0.54 | 0.39 | 0.29 | 0.21 | 0.15 |
| (6.12) | (3.52) | (1.26) | (0.74) | (0.48) | (0.34) | (0.25) | (0.19) | (0.15) | (0.11) |
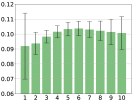
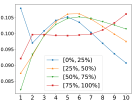
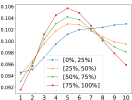
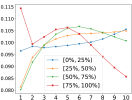
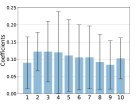
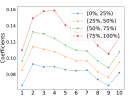
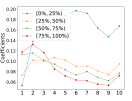
In Figure 2, we show statistics pertaining to the weights attributed to the top 10 levels in the first principal component. Plot 2(a) shows the average weights, and the one standard deviation bars, across all stocks in the universe. Plot 2(a) reveals that the best-level OFI has the smallest weight in the first principal component, but the highest standard deviation, hinting that it fluctuates significantly across stocks. Plots (b-d) show various patterns for the first principal component of multi-level OFIs, for each quantile bucket of various stock characteristics, in particular, for volume, volatility and spread. For instance, in Figure 2(b), the red curve shows the average weights in the first principal component for each of the 10 levels, where the average is taken over all the top 25% largest volume stocks. A striking pattern that emerges from this figure is that for high-volume (red line in 2(b)), and low-volatility stocks (blue line in 2(c)), OFIs deeper in the LOB receive more weights in the first component. However, for low-volume (blue line in 2(b)), and large-spread stocks (red line in 2(d)), the best-level OFIs account more than the deeper-level OFIs.
3 Contemporaneous cross-impact
In this section, we study the existence of contemporaneous cross-impact by comparing it with the price impact model studied in Cont et al. [17].
3.1 Models
Price impact of best-level OFIs.
We first pay attention to the price impact of best-level OFI () on contemporaneous returns () that materialize over the same time bucket as the OFI, via the model
| (6) |
Here, and are the intercept and slope coefficients, respectively. is a noise term summarizing the influences of other factors, such as the OFIs at even deeper levels, and potentially the trading behaviors of other stocks. For the sake of simplicity, we refer to the above regression model as and use ordinary least squares (OLS) to estimate it.
Price impact of integrated OFIs.
The second model specification takes into account the impact of multi-level OFIs by leveraging the integrated OFIs, which we set up as follows and use OLS for estimation.
| (7) |
Cross-impact of best-level OFIs.
Assuming there are stocks in the studied universe, we incorporate the multi-asset best-level OFIs, , as candidate features to help fit the returns of the -th stock . For simplicity, we denote the impact from itself (stock ) as Self and that from other stocks as Cross, as shown below,
| (8) |
Therefore, represents the influence of the -th stock’s best-level OFIs on the returns of stock .
Cross-impact of integrated OFIs.
Finally, we incorporate the cross-asset integrated OFIs to explore the impact of multi-level OFIs from other assets, resulting in the following model,
| (9) |
Sparsity of cross-impact.
As we are aware, OLS regression becomes ill-posed when there are fewer observations than parameters. Recall that we are now considering independent variables in Eqns (8) and (9). Assuming the time interval is one minute and we are interested in estimating the intraday cross-impact models, e.g. relying on the 30-min estimation window and 1-min returns (as in Cont et al. [17]), then it seems inappropriate to estimate and for intraday scenarios using the OLS regression with more variables than observations. Moreover, the multicollinearity issue of features contradicts the necessary condition for a well-posed OLS. As displayed in Figure 3, a significant portion of the cross-asset correlations based on the best-level OFIs cannot be ignored. For example, approximately 10% of correlations are larger than 0.30. Last, Capponi and Cont [8] found that a certain number of cross-impact coefficients from their OLS regressions are not statistically significant at the 1% significance level.
With all the above considerations in mind, we assume that there is a small number of assets having a significant impact on a specific stock , as opposed to the entire universe, in and . To this end, we apply the Least Absolute Shrinkage and Selection Operator (LASSO)666LASSO is a regression method that performs both variable selection and regularization, in order to enhance the prediction accuracy and interpretability of regression models (see more in Hastie et al. [29]). It can be formulated as a linear regression model and the objective function consists of two parts, i.e. the sum of squared residuals, and the constraint on the regression coefficients. In this work, we employ the cross-validation to choose the penalty weight for each regression. to solve Eqns (8) and (9). The sparsity of cross-impact terms also facilitates the explanation of coefficients. Note that even though the sparsity of the cross-impact terms is not theoretically guaranteed, our empirical evidence confirms this modeling assumption.
3.2 Empirical results
For a more representative and fair comparison with previous studies, we apply a similar procedure described in Cont et al. [17] to our experiments. We exclude the first and last 30 minutes of the trading day due to the increased volatility near the opening and closing sessions, in line with Hasbrouck and Saar [27], Chordia et al. [15], Chordia and Subrahmanyam [14], Cont et al. [17], Capponi and Cont [8]. In particular, we use each non-overlapping 30-minute estimation window during the intraday time interval 10:00 am - 3:30 pm to estimate the regressions, namely Eqns (6), (7), (8), and (9). Within each window, returns and OFIs are computed for every minute.
3.2.1 In-sample performance
We first measure the model performance via in-sample adjusted-, denoted as the in-sample or IS . From Table 3, we first observe that can explain 71.16% of the in-sample variation of a stock’s contemporaneous returns, consistent with the findings of Cont et al. [17]. Meanwhile, displays higher and more consistent explanation power, with an average adjusted value of 87.14% and a standard deviation of 9.16%, indicating the effectiveness of our integrated OFIs.777We also investigate price impact with multi-level OFIs in Appendix B. The results demonstrate that the price impact model using integrated OFIs outperforms those using multi-level OFIs in out-of-sample tests.
Table 3 also shows that the in-sample values increase as cross-asset OFIs are included as additional features, which is not surprising given that (respectively, ) is a nested model of (respectively, ). However, the increments of the in-sample are smaller when using integrated OFIs (87.85%-87.14%=0.71%), compared to the counterpart using best-level OFIs (73.87%-71.16%=2.71%). This indicates that cross-asset multi-level OFIs may not provide additional information on the variance in returns compared to the price impact model with integrated OFIs.
| Best-level OFIs | Integrated OFIs | |||
|---|---|---|---|---|
| IS | 71.16 | 73.87 | 87.14 | 87.85 |
| (13.80) | (12.23) | (9.16) | (8.58) | |
Next, we take a closer look at the cross-impact coefficients based on either the best-level or integrated OFIs, i.e. and . Table 4 reveals the frequency of self-impact and cross-impact variables selected by LASSO, i.e. the frequency of (respectively, ). We observe that self-impact variables are consistently chosen in both and , as found in Cont et al. [17]. However, another interesting observation is that the frequency of a cross-asset integrated OFI variable selected by is around 1/2 of its counterpart in . When we turn to the size of the average regression coefficients as shown in Table 4, we obtain reasonably consistent results. The self-impact is much higher than the cross-impact in both the and models, while the cross-impact coefficients in are about 1/3 in scale of their counterparts in . This difference in scale may suggest that the cross-impact terms are less important in the model, however, it is worth noting that even small cross-term coefficients can have a non-negligeable effect when aggregated at portfolio level.
| Frequency (%) | Magnitude | |||
|---|---|---|---|---|
| Self | 99.85 | 99.96 | 1.02 | 1.24 |
| (0.34) | (0.18) | (0.31) | (0.34) | |
| Cross | 17.34 | 8.29 | ||
| (2.78) | (2.56) | () | () | |
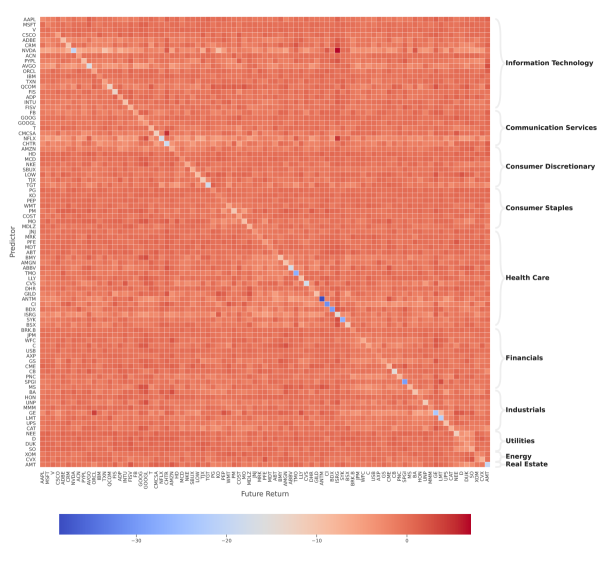
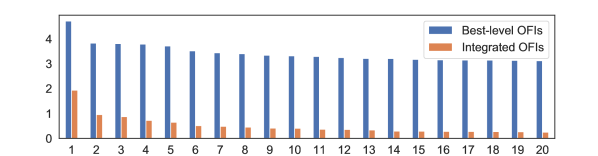
In addition, cross-impact being large/small is a statement about a matrix, more related with its singular values and relative magnitudes, rather than the individual value of the coefficients. Figure 4 shows a comparison of the top 20 singular values of the coefficient matrices given by the best-level and integrated OFIs.888Here we only use the off-diagonal elements, i.e. and . The relatively large singular values of the best-level OFI matrix are a consequence of the higher edge density, and thus average degree, of the network. Note that both networks exhibit a large top singular value of the adjacency matrix (akin to the usual market mode in Laloux et al. [38]), and the integrated OFI network has a faster decay of the spectrum, thus revealing its low-rank structure.
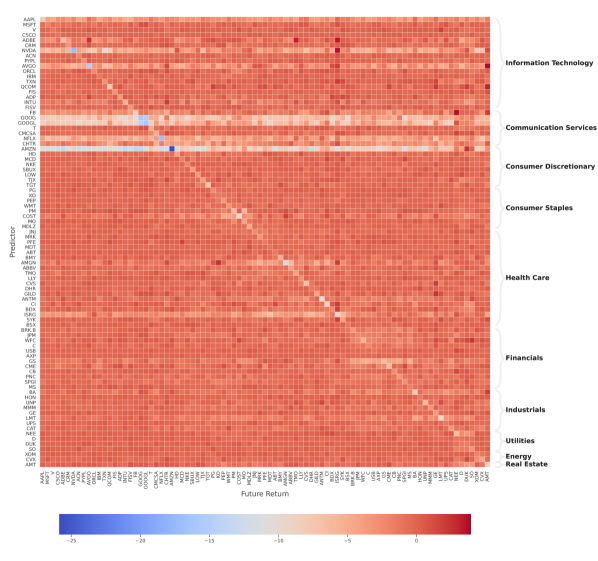
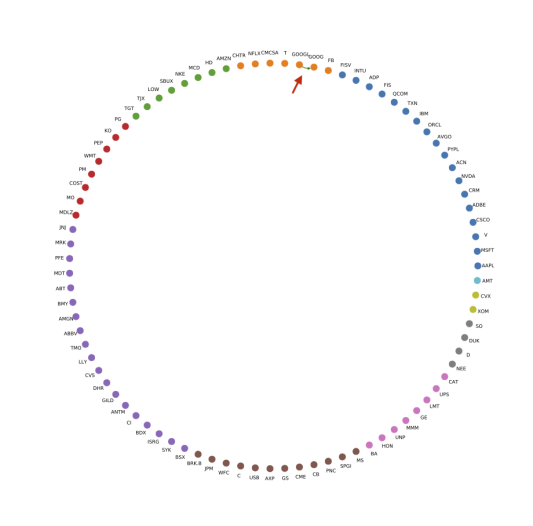
We visualize a network for each coefficient matrix, which only preserves the edges larger than a given threshold (following Kenett et al. [34], Curme et al. [20]), as shown in Figure 5. We color stocks according to the GICS sector division, and sort them by their market capitalization within each sector.999The Global Industry Classification Standard (GICS) is an industry taxonomy developed in 1999 by MSCI and Standard & Poor’s (S&P) for use by the global financial community. As one can see from Figure 5(a), the cross-impact coefficient matrix displays a sectorial structure, in accordance with previous studies (e.g. Benzaquen et al. [5]). This behavior could be fueled by index arbitrage strategies, where traders may, for example, trade an entire basket of stocks coming from the same sector against an index.
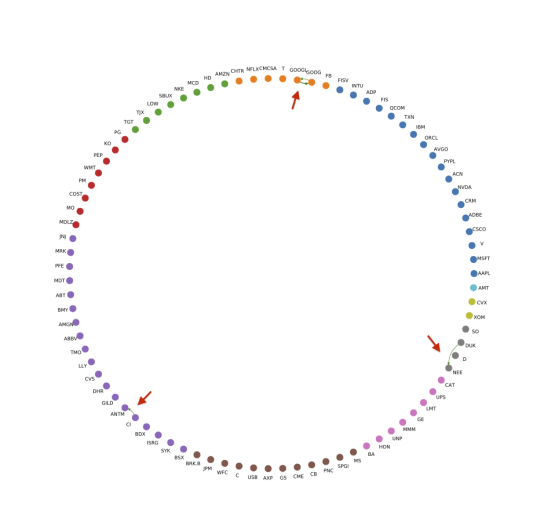
Figure 5(b) presents the network of cross-impact coefficients based on integrated OFIs, i.e. . Compared with Figure 5(a), the connections in Figure 5(b) are much weaker, implying that the cross-impact from stocks can be potentially explained by a stock’s own multi-level OFIs, to a large extent. Note that there is only one connection from GOOGL to GOOG, as pointed out at the top of Figure 5(b). This stems from the fact that both stock ticker symbols pertain to Alphabet (Google). Our study also reveals that OFIs of GOOGL have more influence on the returns of GOOG, not the other way around. The main reason might be that GOOGL shares have voting rights, while GOOG shares do not.
In Figures 5(c) and 5(d), we set lower threshold values (75-th, respectively, 25-th percentile of coefficients) in order to promote more edges in the networks based on integrated OFIs. Interestingly, we observe only four connections in Figure 5(c). Except from bidirectional links between GOOGL and GOOG, there exists a one-way link from Cigna (CI) to Anthem (ANTM), and another one-way link from Duke Energy (DUK) to NextEra Energy (NEE). Anthem announced to acquire Cigna in 2015. After a prolonged breakup, this merger finally failed in 2020. Therefore, it is unsurprising that the OFIs of Cigna can affect the price movements of Anthem. Conversely, Anthem’s OFIs also have an impact on the price movements of Cigna, but to a lesser extent. Further research should be undertaken to investigate this phenomenon. In terms of the second pair, Duke Energy rebuffed NextEra’s acquisition interest in 2020. Note that 2020 is not in our sample period. This finding hints that certain market participants may have noticed the special relationship between Duke Energy and NextEra Energy before this mega-merger was proposed.

3.2.2 Out-of-sample performance
Although the in-sample estimation yields interesting findings, practitioners are eventually concerned about the out-of-sample estimation. Therefore, we propose to perform the following out-of-sample tests. We use the above fitted models to estimate returns on the following 30-minute data and compute the corresponding , denoted as out-of-sample or OS .101010Previous studies either investigated the in-sample (including Cont et al. [17], Capponi and Cont [8]), or adopted a cross-validation method (e.g. Xu et al. [53]). However, these works failed to consider the generalization error of their models or damaged the chronological order of the time-series data. In contrast, we obey the temporal ordering in our study. These matters are vital to practitioners, as only the historical data are accessible for the model fit in practice.
Table 5 reports the average values and their standard deviations of out-of-sample of , , , and . We first focus on the models using best-level OFIs. It appears has a slight advantage compared with for out-of-sample tests with an improvement of 1.39% (=66.03%-64.64%). However, when involving multi-level or integrated OFIs, the performance of is slightly worse than , indicating that the cross-impact model with integrated OFIs cannot provide extra explanatory power to the price impact model with integrated OFIs. Overall, we observe that the models using integrated OFIs unveil significant and consistent improvements over those using only best-level OFIs.
| Best-level OFIs | Integrated OFIs | |||
|---|---|---|---|---|
| OS | 64.64 | 66.03 | 83.83 | 83.62 |
| (21.82) | (19.51) | (16.90) | (14.53) | |
In general, we observe strong evidence implying provides a better out-of-sample estimate than , while for and , the evidence is opposite. However, it is important to note that these conclusions are based on a point estimate and do not necessarily indicate statistical significance. Therefore, we perform the following hypothesis test for each stock on the out-of-sample data to assess statistical significance,
We employ the approach from Giacomini and White [24] and Chinco et al. [12] to assess statistical significance through a Wald-type test (see Ward and Ahlquist [52]). Theorem 1 in Giacomini and White [24] implies that we can use a standard -test to evaluate the statistical significance of changes in . A -value less than a given significance level rejects the null hypothesis in favor of the alternative at the confidence level, implying has significantly better estimation than . We also implement this test for the comparison between and .
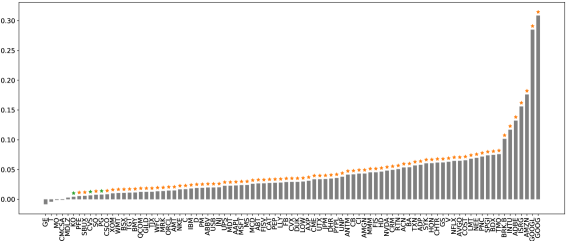
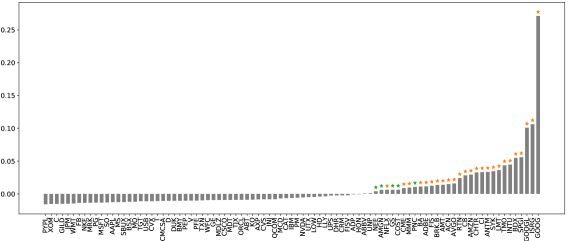
Figure 6 illustrates the main results from the above hypothesis tests. When using only the best-level OFIs, the cross-impact model is superior to the price impact model for 91.0% (94.4%) of stocks, at the 1% (5%) confidence level. However, when examining the models using integrated OFIs, we reject the null hypothesis (i.e., in favor of the cross-impact model) only for 28.1% (33.7%) of stocks at the 1% (5%) confidence level. As expected, cross-impact terms can significantly improve the explanatory power of the price impact model for GOOG and GOOGL.
Dynamics of limit order book may depend on the tick-to-price ratio, or alternatively, the fraction of time that the bid-ask spread is equal to one tick for a given stock (Curato and Lillo [19]). We examine whether this dependence also extends to cross-asset OFIs.111111We would like to thank an anonymous reviewer for suggesting this analysis. Our findings, presented in Table 6, suggest that cross-asset OFIs can better explain the price dynamics of stocks with a larger tick-to-price ratio.
| 44.38 | 62.51 | 77.55 | 70.70 | |
| 53.01 | 66.32 | 72.50 | 78.34 | |
| 68.14 | 84.58 | 88.14 | 89.86 | |
| 72.01 | 84.80 | 88.51 | 91.01 |
3.3 Discussion about contemporaneous cross-impact
3.3.1 Impact on stocks
In summary, our previous results mainly show that when considering only the best-level OFI of a single stock, the addition of the best-level OFI from other stocks slightly increases the explanatory power. On the other hand, when the information from multiple levels is integrated into the OFI, the improvement is negligible. In the meantime, it is unsurprising that taking into account more levels in the LOB () could better explain price changes, compared to only considering best-level orders ().
After observing these results, several natural questions may arise: How can the above facts be reconciled?121212One possible explanation for those facts is that the duration of the cross-impact terms might be shorter than the current time interval (30 minutes) used in our experiments, rendering the cross-impact terms vanish in out-of-sample tests. To verify this assertion, we implement additional experiments where models are updated more frequently. The results (deferred to Appendix D) reveal that even under higher-frequency updates (1-min) of the models, there is no benefit from introducing cross-impact terms to the price impact model with integrated OFIs. How do the cross-asset best-level OFIs interact with the multi-level OFIs, when modeling contemporaneous returns?
To address these questions, we consider the following scenario, also depicted in Figure 7. For simplicity, we denote the order from trading strategy on stock (respectively, ) as (respectively, ). Analogously, we define orders from strategy and . Let us next consider the orders of stock . There are three orders from different portfolios, given by , and . is at the third bid level of stock and linked to an order at the best ask level of stock , i.e. . Also, is at the best ask level of stock and linked to an order at the best bid level of stock , i.e. . Finally, is an individual bid order at the best level of stock .
We observe that the best-level limit orders from stock may be linked to price movements of stock through paths and . Thus the price impact model for stock which only utilizes its own best-level orders will ignore the information of , while the cross-impact model can partially collect it along the path . This might illustrate why the best-level OFIs of multiple assets can provide slightly additional explanatory power to the price impact model using only the best-level OFIs.
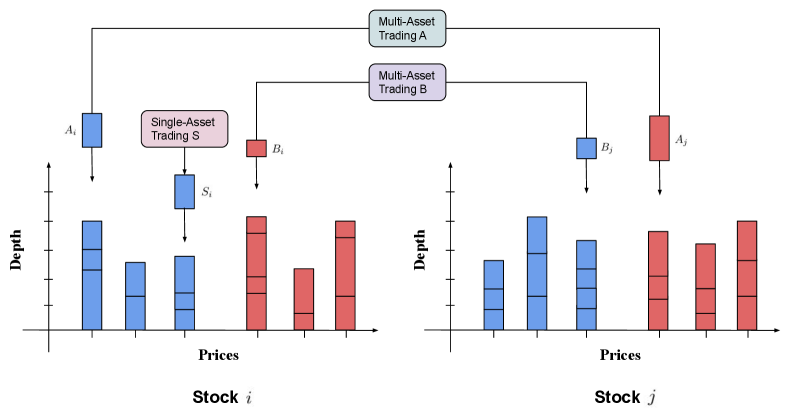
Nonetheless, if we can integrate multi-level OFIs in an efficient way (in our example, aggregate order imbalances caused by orders , and ), then there is no need to consider OFIs from other stocks for modeling price dynamics. For example, information hidden in the path can be leveraged as long as is well absorbed into new integrated OFIs. In this sense, for stock , cross-asset best-level OFIs (including ) are surrogates of its own OFIs at different levels (here ), to a certain extent. The likelihood of this relationship is attributed to massive portfolio trades that submit or cancel limit orders across a variety of assets at different levels.131313Cao et al. [7], Hautsch and Huang [30], Sirignano [45], Chakrabarty et al. [11] showed that the depth of some deeper levels (such 2-3) is higher than the best level depth. We put forward this mechanism which potentially explains why the cross-impact model with integrated OFIs cannot provide additional explanatory power compared to the price impact model with integrated OFIs.141414It would be a very interesting research direction to derive testable predictions for this mechanism in future work. However, so far it hinges on the availability of client-ID based LOB data, i.e. knowing that the same market participant is behind the orders for two related instruments, released at approximately the same time, such as , .
3.3.2 Impact on portfolios
A related question is about the aggregation of cross-impact at portfolio level. Let us consider the OFI of portfolio as , where is the weight of asset in a portfolio. Then the price impact for portfolio is
| (10) | ||||
where is the intercept and is the noise term.
On the other hand, the cross-impact for portfolio is
| (11) | ||||
where is the intercept.
Comparing (10) and (11) shows that cross-impact at portfolio level depends on the angles of and . On one hand, if individual assets exhibit a universal pattern of price dynamics, i.e. , we may conclude that the portfolio return is driven by its own order flows, to a large extent. On the other hand, if the portfolio places most of the weight on a specific stock or a set of stocks with similar patterns of price dynamics, then the portfolio returns are also driven by its own order flows, rather than by cross-impact. In other scenarios, it is necessary to consider the cross-impact. One can perform an analogous analysis for models with integrated OFIs.
In fact, the mechanism depicted in Figure 7 aligns with this analysis. For example, orders placed on stock represented by and have the potential to affect the price movements of that stock, which subsequently affect the returns of portfolio , even if and have no direct association with . Additionally, may have a different influence on the performance of because of the (potentially) different price dynamics of stock . Therefore, it may be necessary to take into account cross-asset OFIs when developing models for portfolio returns.
To examine the potential of cross-asset OFIs in explaining portfolio returns, we choose two widely-used portfolio construction methods: the equal-weighted portfolio (EW), and the eigenportfolio151515See Avellaneda and Lee [3]. using the 1st principal component (Eig1). Table 7 summarizes the out-of-sample of various models on these two portfolios. As Table 7 shows, there is a significant difference between and , and , indicating that cross-impact is a crucial factor when modeling portfolio returns. Again, the models using the integrated OFIs outperform their counterparts using the best-level OFIs.
| Best-level OFIs | Integrated OFIs | |||
|---|---|---|---|---|
| EW | 79.29 | 81.03 | 85.26 | 87.97 |
| (6.24) | (6.16) | (3.54) | (2.78) | |
| Eig1 | 80.73 | 81.95 | 84.69 | 87.70 |
| (6.75) | (6.36) | (3.70) | (2.84) | |
4 Forecasting future returns
In the previous section, the definitions of price impact and cross-impact are based on contemporaneous OFIs and returns, meaning that both quantities pertain to the same bucket of time. In this section, we extend the above studies to future returns, and probe into the forward-looking price impact and cross-impact models.
4.1 Predictive models
We first propose the following forward-looking price impact and cross-impact models, denoted as , , , and , respectively. () uses the lagged best-level (integrated) OFIs of stock to predict its own future return during , while () involves the lagged multi-asset best-level (integrated) OFIs. We employ OLS to fit the forward-looking price impact models and LASSO to fit the cross-impact models.
| (12) | ||||
| (13) | ||||
| (14) | ||||
| (15) |
where is the forecasting horizon of future returns and represents the set of lags.
Furthermore, we compare OFI-based models with return-based models studied in previous works, where lagged returns are involved as predictors. AR (Eqn (16)) is an autoregressive (AR) model using various returns over different time horizons, inspired by Corsi [18], Ait-Sahalia et al. [2]. CAR (Chinco et al. [12]) uses the entire cross-section lagged returns as candidate predictors, as detailed in Eqn (17). We employ OLS to fit the ARs and LASSO to fit the CARs.
| (16) | ||||
| (17) |
4.2 Empirical results
In this experiment, observations associated with returns and OFIs are computed minutely, i.e. minute.161616Note that we choose to use the physical time as opposed to the trading time. This is because each stock has its own specific trading time, which is asynchronous with that of others. Thus it is difficult to work out the cross–impact between stocks on a trading time scale, also see Wang et al. [49, 50]. The choice of a 1-minute bin size allows us to abstract away from microstructure effects which are not the focus of the present mesoscopic study, as is the case in Benzaquen et al. [5], Chinco et al. [12]. Following Chinco et al. [12], we use data from the previous 30 minutes to estimate the model parameters and apply the fitted model to forecast future -minute returns. We then move one minute forward and repeat this procedure to compute the rolling -minute-ahead return forecasts. For all models, we initially focus on the 1-minute forecasting horizon. In Section 4.3, we consider return forecasts over longer horizons, including minutes, to assess the strength and duration of price impact and cross-impact.
Following the analysis of Cartea et al. [9], Chinco et al. [12], we demonstrate the effectiveness of the forward-looking price impact and cross-impact models from two perspectives: (1) statistical performance, and (2) economic gain.
4.2.1 Statistical performance
Table 8 summarizes the out-of-sample values of the aforementioned predictive models when predicting the subsequent 1-minute returns, i.e. . It appears the cross-impact models (respectively, , CAR) achieve higher out-of-sample statistics compared to the price impact models (respectively, , AR). We also implement the same hypothesis test described in Section 3 to investigate the statistical significance (unreported) of these results. We observe that the cross-impact models exhibit significantly superior performance than the price impact models across all stocks, at the 1% confidence level.
| Best-level OFIs | Integrated OFIs | Returns | ||||
|---|---|---|---|---|---|---|
| AR | CAR | |||||
| OS | -0.37 | -0.10 | -0.36 | -0.10 | -0.36 | -0.10 |
| (0.10) | (0.05) | (0.08) | (0.05) | (0.11) | (0.05) | |
Most of the empirical literature in return prediction focuses its evaluations on out-of-sample . However, we remark that negative values do not imply that the forecasts are economically meaningless (see more discussions in Kelly et al. [33], Choi et al. [13]).171717A simple example can be framed as follows. Consider a model with one predictor and suppose that the estimated predictive coefficient is a significantly large multiple of the actual value. In this case, the will become negative. However, the predictions will be perfectly correlated with the true expected return, resulting in a positive expected return for our strategy. Proposition 4 in Kelly et al. [33] further proposed that we can worry less about the positivity of out-of-sample from a prediction model and focus more on the out-of-sample performance of specific trading strategies based on predicted returns. To emphasize this point, we will incorporate these return forecasts into a forecast-based trading strategy, and showcase their profitability in the following subsection.
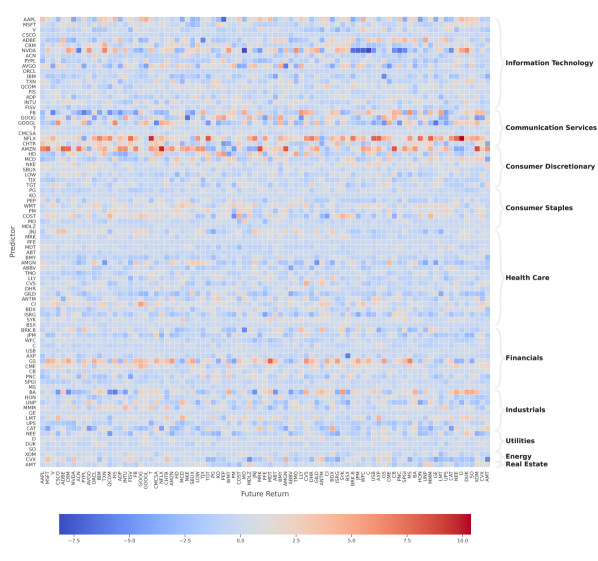
Considering the different magnitudes of the OFIs and returns, we first normalize the coefficient matrix of each model by dividing by the average of the absolute coefficients. Figure E.1 (deferred to Appendix E) shows the average coefficient matrices of , , and CAR. For example, as revealed in Figure E.1(a) (), for a specific stock, the main influence comes from its own OFI, i.e. the absolute values of diagonal elements are significantly larger than the off-diagonal ones. We observe that cross-impact is often negative, consistent with Pasquariello and Vega [41]. Except for the self-impact, most stocks are also influenced by stocks in Communication Services, Consumer Discretionary and Information Technology.
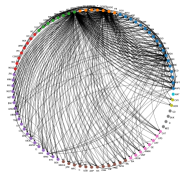
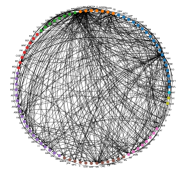
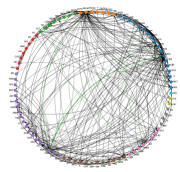
To better illustrate the interactions between different stocks, we construct a network for each normalized coefficient matrix and only preserve the cross-asset edges (i.e. off-diagonal elements) larger than the 95-th percentile of coefficients. Figure 8 illustrates some of the main characteristics of the coefficient networks for , , and CAR. For example, we again observe that there are more edges from Communication Services, Consumer Discretionary and Information Technology, indicating they may contain more predictive power for others.
| Group In-degree Centrality | Group Out-degree Centrality | |||||
|---|---|---|---|---|---|---|
| Best-level OFIs | Integrated OFIs | Returns | Best-level OFIs | Integrated OFIs | Returns | |
| Information Technology | 0.12 | 0.36 | 0.26 | 0.46 | 0.62 | 0.59 |
| Communication Services | 0.06 | 0.24 | 0.20 | 0.85 | 0.74 | 0.60 |
| Consumer Discretionary | 0.09 | 0.20 | 0.15 | 0.86 | 0.51 | 0.17 |
| Consumer Staples | 0.03 | 0.15 | 0.09 | 0.00 | 0.11 | 0.01 |
| Health Care | 0.10 | 0.37 | 0.19 | 0.12 | 0.22 | 0.59 |
| Financials | 0.12 | 0.21 | 0.17 | 0.03 | 0.41 | 0.08 |
| Industrials | 0.10 | 0.19 | 0.20 | 0.00 | 0.39 | 0.27 |
| Utilities | 0.00 | 0.07 | 0.04 | 0.00 | 0.06 | 0.00 |
| Energy | 0.06 | 0.07 | 0.04 | 0.00 | 0.14 | 0.00 |
| Real Estate | 0.00 | 0.05 | 0.02 | 0.00 | 0.00 | 0.01 |
To gain a better understanding of the structural properties of the resulting network, we aggregate node centrality measures (see Everett and Borgatti [22]) at the sector level, and also perform a spectral analysis of the adjacency matrix. From Table 9, we observe that the out-degree centrality of Communication Services, Consumer Discretionary and Information Technology is significantly larger than that of others, consistent with previous findings. Figure 8(c) also shows that the network based on returns contains more inner-sector connections than the other two counterparts, thus implying a sectorial structure. Table 10 presents the top five most significant stocks in terms of out-degree centrality in each network, which exhibit more impact on the prices of other stocks.
| Best-level OFIs | Integrated OFIs | Returns |
|---|---|---|
| AMZN | NFLX | NVDA |
| GOOG | AMZN | NFLX |
| GOOGL | NVDA | ISRG |
| NVDA | GS | AVGO |
| NFLX | FB | GE |
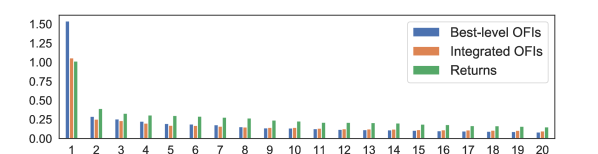
Figure 9 shows a barplot with the average value for the top 20 largest singular values of the network adjacency matrix, for best-level OFIs, integrated OFIs, and returns, where the average is performed over all constructed networks. For ease of visualization and comparison, we first normalize the adjacency matrix before computing the top singular values, which exhibit a fast decay. In addition to the significantly large top singular value revealing that the networks have a strong rank-1 structure, the next 6-8 singular values are likely to correspond to the more prominent industry sectors.
4.2.2 Economic gains
On the basis of return forecasts, we employ a portfolio construction method, proposed by Chinco et al. [12], to evaluate the economic gains of the aforementioned predictive models.
Forecast-implied portfolio.
For a specific forecasting model , the motivations of portfolio construction can be summarized as follows.
-
•
It only executes an order when the one-minute-ahead return forecast exceeds the bid-ask spread.
-
•
It buys/sells more shares of the -th stock when the absolute value of one-minute-ahead return forecast for -th stock is higher.
-
•
It buys/sells more shares of the -th stock when the one-minute-ahead return forecasts for the -th stock tend to be less volatile throughout the trading day.
This strategy allocates a fraction of its capital to the -th stock
| (18) |
where represents the one-minute-ahead return forecast according to model for minute , represents the relative bid-ask spread at time , represents the standard deviation of the model’s one-minute-ahead return forecasts for the -th stock during the previous 30 minutes of trading, i.e. the standard deviation of in-sample fits. The denominator is the total investment so that the strategy is self-financed. If there are no stocks with forecasts that exceed the spread in a given minute, then we set .
Finally, we compute the profit and loss (PnL) of the resulting portfolios on each trading day by summing the strategy’s minutely returns as in Chinco et al. [12].
| Best-level OFIs | Integrated OFIs | Returns | ||||
|---|---|---|---|---|---|---|
| AR | CAR | |||||
| PnL | 0.21 | 0.43 | 0.23 | 0.39 | 0.23 | 0.40 |
| (0.12) | (0.17) | (0.13) | (0.19) | (0.13) | (0.18) | |
Table 11 compares the performance (annualized PnL) of the forecast-implied strategies, based on forecast returns from various predictive models. It is worth noting that in the following analysis, the strategy ignores trading costs, as this is not the focus of our paper. Table 11 shows that portfolios based on forecasts of the forward-looking cross-impact model outperform those based on forecasts of the forward-looking price impact model.
4.3 Longer forecasting horizons
One-minute-ahead return forecasts are not the only time horizon of interest to practitioners and academics. Additionally, we evaluate the performance of the above models and examine the forecasting ability of cross-impact terms over longer prediction horizons.
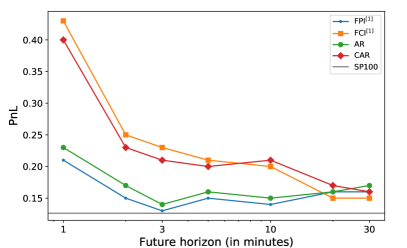
Figure 10 illustrates the model predictability from the perspective of raw annualized PnL across multiple horizons.181818To plot this figure, we only accumulate the PnLs between [10:31, 15:30], which is the shared trading period for the studied forecasting horizons. Due to the similar performance of and (respectively, and ) over longer horizons, we only show the curves of , , AR, CAR, and a benchmark (S&P100 ETF). It appears that superior forecasting ability arises from cross-asset terms at short horizons. However, the PnL of cross-asset models declines more quickly over longer horizons. A further study with more focus on the reasons for the predictability of cross-asset OFIs over multiple horizons is therefore suggested. Finally, the models in which each stock only relies on its own returns/OFIs marginally outperform their counterparts which use the entire cross-sectional predictors.
4.4 Discussion about predictive cross-impact
Tables 8 and 11 reveal that, in contrast to the price impact model, multi-asset OFIs can provide considerably more additional explanatory power for future returns compared to contemporaneous returns. A possible explanation for this asymmetric phenomenon is that there exists a time lag between when the OFIs of a given stock are formed (a so-called flow formation period) and the actual time when traders notice this change of flow and incorporate it into their trading model (see Buccheri et al. [6]).191919A closely-related phenomenon is the Epps effect documented by Epps [21], which showed that the empirical correlation estimates tend to decrease when the sampling is done at high frequencies. Previous research (including Renò [42], Tóth and Kertész [48], Zhang [54]) demonstrated that the Epps effect might be explained by the non-synchronicity, the possible lead-lag relationship between stock returns, etc. Tóth and Kertész [48] also described that the Epps effect might be caused by the reaction time of traders to news and events, which is usually spread out over a time interval of a few minutes. For example, assume a trader submitted an unexpectedly large amount of buy limit orders of Apple (AAPL) at 10:00 am, at either the first level or potentially deeper in the book. Other traders may notice this anomaly and adjust their portfolios (including Apple) at a later time, for example, 10:01 am. In this case, the OFIs of Apple may indicate future price changes of other stocks.
Consistent with our explanation, Hou [31] argued that the gradual diffusion of industry information is a leading cause of the lead-lag effect in stock returns. Cohen and Frazzini [16] found that certain stock prices do not promptly incorporate news pertaining to economically related firms, due to the presence of investors subject to attention constraints. Further research should be undertaken to investigate the origins of the success of multi-asset OFIs in predicting future returns.
It is also interesting to note that forward-looking models using integrated OFIs cannot significantly outperform models using the best-level OFIs. This phenomenon might stem from the fact that the integrated OFIs do not explicitly take into account the level information (distance of a given level to the best bid/ask) of multi-level OFIs, and are agnostic to different sizes resting at different levels on the bid and ask sides of the book. Previous studies (such as Hasbrouck and Saar [27], Cao et al. [7], Cenesizoglu et al. [10]) demonstrated that traders might strategically choose to place their orders in different levels of the book depending on various factors, therefore limit orders at different price levels may contain different information content with respect to predicting future returns. A further study with more focus on the impact of multi-level OFIs over different time horizons is suggested.
5 Conclusion
We have systematically examined the impact of OFIs from multiple perspectives. The main contributions can be summarized as follows.
First, we verify the effects of multi-level and cross-asset OFIs on contemporaneous price dynamics. We introduce a new procedure to examine the cross-impact on contemporaneous returns. Under the sparsity assumption of cross-impact coefficients, we use LASSO to describe such a structure and compare the performances with the price impact model which only utilizes a stock’s own OFIs. We implement models with the best-level OFIs and integrated OFIs, respectively. The results first demonstrate that our integrated OFIs provide a higher explanatory power for price movements than the widely-used best-level OFIs. More interestingly, in comparison with the price impact model using best-level OFIs, the cross-impact model exhibits additional explanatory power. However, the cross-impact model with integrated OFIs cannot provide extra explanatory power to the price impact model with integrated OFIs, indicating the effectiveness of our integrated OFIs.
In addition, we apply the price impact and cross-impact models to the challenging task of predicting future returns. The results reveal that involving cross-asset OFIs can increase out-of-sample . We subsequently demonstrate that this increase in out-of-sample leads to additional economic profits, when incorporated in common trading strategies, thus providing evidence of cross-impact over short future horizons. We also find that predictability of cross-impact terms vanishes quickly over longer horizons.
Future research directions.
There are a number of interesting avenues to explore in future research. One such direction pertains to the assessment of whether cross-asset multi-level OFIs can improve the forecast of future returns (in the present work, we only considered the best-level OFI and integrated OFI due to limited computing power). Another interesting direction pertains to performing a similar analysis as in the present paper, but for the last 15-30 minutes of the trading day, where a significant fraction of the total daily trading volume occurs. For example, for the first few months of 2020 in the US equity market, about 23% of trading volume in the 3,000 largest stocks by market value has taken place after 3:30 pm, compared with about 4% from 12:30 pm to 1 pm (Banerji [4]). It would be an interesting study to explore the interplay between the OFI dynamics and this surge of trading activity at the end of U.S. market hours.
References
- Ahn et al. [2001] Hee-Joon Ahn, Kee-Hong Bae, and Kalok Chan. Limit orders, depth, and volatility: Evidence from the stock exchange of Hong Kong. Journal of Finance, 56(2):767–788, 2001.
- Ait-Sahalia et al. [2022] Yacine Ait-Sahalia, Jianqing Fan, Lirong Xue, and Yifeng Zhou. How and when are high-frequency stock returns predictable? Available at SSRN 4095405, 2022.
- Avellaneda and Lee [2010] Marco Avellaneda and Jeong-Hyun Lee. Statistical arbitrage in the US equities market. Quantitative Finance, 10(7):761–782, 2010.
- Banerji [2020] Gunjan Banerji. The 30 Minutes that Can Make or Break the Trading Day, 2020. URL https://www.wsj.com/articles/the-30-minutes-that-can-make-or-break-the-trading-day-11583886131?reflink=desktopwebshare_permalink.
- Benzaquen et al. [2017] Michael Benzaquen, Iacopo Mastromatteo, Zoltan Eisler, and Jean-Philippe Bouchaud. Dissecting cross-impact on stock markets: An empirical analysis. Journal of Statistical Mechanics: Theory and Experiment, 2017(2):023406, 2017.
- Buccheri et al. [2021] Giuseppe Buccheri, Fulvio Corsi, and Stefano Peluso. High-frequency lead-lag effects and cross-asset linkages: a multi-asset lagged adjustment model. Journal of Business & Economic Statistics, 39(3):605–621, 2021.
- Cao et al. [2009] Charles Cao, Oliver Hansch, and Xiaoxin Wang. The information content of an open limit-order book. Journal of Futures Markets: Futures, Options, and Other Derivative Products, 29(1):16–41, 2009.
- Capponi and Cont [2020] Francesco Capponi and Rama Cont. Multi-asset market impact and order flow commonality. SSRN, 2020. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3706390.
- Cartea et al. [2018] Álvaro Cartea, Ryan Donnelly, and Sebastian Jaimungal. Enhancing trading strategies with order book signals. Applied Mathematical Finance, 25(1):1–35, 2018.
- Cenesizoglu et al. [2022] Tolga Cenesizoglu, Georges Dionne, and Xiaozhou Zhou. Asymmetric effects of the limit order book on price dynamics. Journal of Empirical Finance, 65:77–98, 2022.
- Chakrabarty et al. [2022] Bidisha Chakrabarty, Terrence Hendershott, Samarpan Nawn, and Roberto Pascual. Order exposure in high frequency markets. Available at SSRN 3074049, 2022.
- Chinco et al. [2019] Alex Chinco, Adam D Clark-Joseph, and Mao Ye. Sparse signals in the cross-section of returns. Journal of Finance, 74(1):449–492, 2019.
- Choi et al. [2022] Darwin Choi, Wenxi Jiang, and Chao Zhang. Alpha go everywhere: Machine learning and international stock returns. Available at SSRN 3489679, 2022.
- Chordia and Subrahmanyam [2004] Tarun Chordia and Avanidhar Subrahmanyam. Order imbalance and individual stock returns: Theory and evidence. Journal of Financial Economics, 72(3):485–518, 2004.
- Chordia et al. [2002] Tarun Chordia, Richard Roll, and Avanidhar Subrahmanyam. Order imbalance, liquidity, and market returns. Journal of Financial Economics, 65(1):111–130, 2002.
- Cohen and Frazzini [2008] Lauren Cohen and Andrea Frazzini. Economic links and predictable returns. Journal of Finance, 63(4):1977–2011, 2008.
- Cont et al. [2014] Rama Cont, Arseniy Kukanov, and Sasha Stoikov. The price impact of order book events. Journal of Financial Econometrics, 12(1):47–88, 2014.
- Corsi [2009] Fulvio Corsi. A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics, 7(2):174–196, 2009.
- Curato and Lillo [2015] Gianbiagio Curato and Fabrizio Lillo. How tick size affects the high frequency scaling of stock return distributions. Financial Econometrics and Empirical Market Microstructure, pages 55–76, 2015.
- Curme et al. [2015] Chester Curme, Michele Tumminello, Rosario N Mantegna, H Eugene Stanley, and Dror Y Kenett. Emergence of statistically validated financial intraday lead-lag relationships. Quantitative Finance, 15(8):1375–1386, 2015.
- Epps [1979] Thomas W Epps. Comovements in stock prices in the very short run. Journal of the American Statistical Association, 74(366a):291–298, 1979.
- Everett and Borgatti [1999] Martin G Everett and Stephen P Borgatti. The centrality of groups and classes. The Journal of Mathematical Sociology, 23(3):181–201, 1999.
- Frazzini et al. [2012] Andrea Frazzini, Ronen Israel, and Tobias J Moskowitz. Trading costs of asset pricing anomalies. Fama-Miller Working Paper, Chicago Booth Research Paper, (14-05), 2012.
- Giacomini and White [2006] Raffaella Giacomini and Halbert White. Tests of conditional predictive ability. Econometrica, 74(6):1545–1578, 2006.
- Gu et al. [2020] Shihao Gu, Bryan Kelly, and Dacheng Xiu. Empirical asset pricing via machine learning. Review of Financial Studies, 33(5):2223–2273, 2020.
- Harris and Panchapagesan [2005] Lawrence E Harris and Venkatesh Panchapagesan. The information content of the limit order book: evidence from NYSE specialist trading decisions. Journal of Financial Markets, 8(1):25–67, 2005.
- Hasbrouck and Saar [2002] Joel Hasbrouck and Gideon Saar. Limit orders and volatility in a hybrid market: The Island ECN. Stern School of Business Dept. of Finance Working Paper FIN-01-025, 2002.
- Hasbrouck and Seppi [2001] Joel Hasbrouck and Duane J Seppi. Common factors in prices, order flows, and liquidity. Journal of Financial Economics, 59(3):383–411, 2001.
- Hastie et al. [2009] Trevor Hastie, Robert Tibshirani, and Jerome Friedman. The elements of statistical learning: data mining, inference, and prediction. Springer Science & Business Media, 2009.
- Hautsch and Huang [2012] Nikolaus Hautsch and Ruihong Huang. The market impact of a limit order. Journal of Economic Dynamics and Control, 36(4):501–522, 2012.
- Hou [2007] Kewei Hou. Industry information diffusion and the lead-lag effect in stock returns. Review of Financial Studies, 20(4):1113–1138, 2007.
- Huck [2019] Nicolas Huck. Large data sets and machine learning: Applications to statistical arbitrage. European Journal of Operational Research, 278(1):330–342, 2019.
- Kelly et al. [2022] Bryan T Kelly, Semyon Malamud, and Kangying Zhou. The virtue of complexity in return prediction. Journal of Finance, forthcoming, 2022.
- Kenett et al. [2010] Dror Y Kenett, Michele Tumminello, Asaf Madi, Gitit Gur-Gershgoren, Rosario N Mantegna, and Eshel Ben-Jacob. Dominating clasp of the financial sector revealed by partial correlation analysis of the stock market. PloS One, 5(12):e15032, 2010.
- Kolm et al. [2023] Petter N Kolm, Jeremy Turiel, and Nicholas Westray. Deep order flow imbalance: Extracting alpha at multiple horizons from the limit order book. Mathematical Finance, to appear, 2023.
- Krauss et al. [2017] Christopher Krauss, Xuan Anh Do, and Nicolas Huck. Deep neural networks, gradient-boosted trees, random forests: Statistical arbitrage on the S&P 500. European Journal of Operational Research, 259(2):689–702, 2017.
- Kyle [1985] Albert S Kyle. Continuous auctions and insider trading. Econometrica: Journal of the Econometric Society, pages 1315–1335, 1985.
- Laloux et al. [2000] Laurent Laloux, Pierre Cizeau, Marc Potters, and Jean-Philippe Bouchaud. Random matrix theory and financial correlations. International Journal of Theoretical and Applied Finance, 3(03):391–397, 2000.
- Lillo et al. [2003] Fabrizio Lillo, J Doyne Farmer, and Rosario N Mantegna. Master curve for price-impact function. Nature, 421(6919):129–130, 2003.
- Menzly and Ozbas [2010] Lior Menzly and Oguzhan Ozbas. Market segmentation and cross-predictability of returns. Journal of Finance, 65(4):1555–1580, 2010.
- Pasquariello and Vega [2015] Paolo Pasquariello and Clara Vega. Strategic cross-trading in the US stock market. Review of Finance, 19(1):229–282, 2015.
- Renò [2003] Roberto Renò. A closer look at the epps effect. International Journal of Theoretical and Applied Finance, 6(01):87–102, 2003.
- Rosenbaum and Tomas [2021] Mathieu Rosenbaum and Mehdi Tomas. A characterisation of cross-impact kernels. arXiv preprint arXiv:2107.08684, 2021.
- Schneider and Lillo [2019] Michael Schneider and Fabrizio Lillo. Cross-impact and no-dynamic-arbitrage. Quantitative Finance, 19(1):137–154, 2019.
- Sirignano [2019] Justin A Sirignano. Deep learning for limit order books. Quantitative Finance, 19(4):549–570, 2019.
- Tashiro et al. [2019] Daigo Tashiro, Hiroyasu Matsushima, Kiyoshi Izumi, and Hiroki Sakaji. Encoding of high-frequency order information and prediction of short-term stock price by deep learning. Quantitative Finance, 19(9):1499–1506, 2019.
- Tomas et al. [2022] Mehdi Tomas, Iacopo Mastromatteo, and Michael Benzaquen. How to build a cross-impact model from first principles: Theoretical requirements and empirical results. Quantitative Finance, 22(6):1017–1036, 2022.
- Tóth and Kertész [2009] Bence Tóth and János Kertész. The epps effect revisited. Quantitative Finance, 9(7):793–802, 2009.
- Wang et al. [2016a] Shanshan Wang, Rudi Schäfer, and Thomas Guhr. Average cross-responses in correlated financial markets. European Physical Journal B, 89(9):207, 2016a.
- Wang et al. [2016b] Shanshan Wang, Rudi Schäfer, and Thomas Guhr. Cross-response in correlated financial markets: individual stocks. European Physical Journal B, 89(4):105, 2016b.
- Wang et al. [2018] Shanshan Wang, Sebastian Neusüß, and Thomas Guhr. Statistical properties of market collective responses. European Physical Journal B, 91:1–11, 2018.
- Ward and Ahlquist [2018] Michael D Ward and John S Ahlquist. Maximum likelihood for social science: strategies for analysis. Cambridge University Press, 2018.
- Xu et al. [2018] Ke Xu, Martin D Gould, and Sam D Howison. Multi-level order-flow imbalance in a limit order book. Market Microstructure and Liquidity, 4(3-4):1950011, 2018.
- Zhang [2011] Lan Zhang. Estimating covariation: Epps effect, microstructure noise. Journal of Econometrics, 160(1):33–47, 2011.
Appendix A Aggregation of multi-level OFIs
Table 2 presents evidence of the effectiveness of PCA in selecting weights for combining multi-level OFIs. However, Figure 2 shows that the weights derived from PCA are not extremely different. This prompts us to consider a simpler method, namely the simple average (SA), to achieve similar performance. Table A.1 reveals that the explained variance of the SA increases as more levels are included. Nonetheless, the SA across 10 levels is inferior to the first principal component (PC) in terms of EVR, i.e. 85.07% of SA vs 89.06% of PC in Table 2. Additionally, Table A.2 provides further evidence that PC consistently performs better than SA across different subsets grouped by stock-specific characteristics.
| Average across | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Explained Variance Ratio | 13.82 | 22.81 | 32.53 | 42.73 | 52.58 | 61.45 | 68.82 | 75.10 | 80.49 | 85.07 |
| (9.04) | (10.09) | (10.35) | (10.17) | (9.58) | (8.69) | (7.71) | (7.10) | (7.23) | (8.14) |
| Volume | Volatility | Spread | ||
|---|---|---|---|---|
| SA | 83.02 | 85.09 | 81.84 | |
| PC | 85.79 | 89.64 | 89.90 | |
| SA | 87.33 | 84.75 | 87.97 | |
| PC | 89.93 | 89.12 | 91.17 | |
| SA | 86.93 | 85.23 | 87.57 | |
| PC | 90.76 | 89.03 | 89.81 | |
| SA | 83.55 | 85.23 | 83.03 | |
| PC | 90.23 | 88.48 | 85.53 |
We then perform the price impact and cross-impact analysis with simple average multi-level OFIs, denoted as and , respectively. As shown in Table A.3, has a similar performance with , consistent with our main analysis. This again confirms that as long as multi-level orders are taken into account, adding cross-impact terms cannot significantly improve model performance. On the other hand, is slightly better than . A future research direction might be to devise various weighting schemes that average the OFI information across the multiple levels, where the weights could be given, for example, by an inverse function of the distance of each price level to the mid-price or applying tensor-SVD/PCA on this data.
| OS | 82.34 | 82.51 | 83.83 | 83.62 |
|---|---|---|---|---|
| (18.02) | (14.27) | (16.90) | (14.53) |
Appendix B Contemporaneous price impact of multi-level OFIs
To explicitly identify the impact of deeper-level OFIs, we also consider an extended version of by incorporating multi-level OFIs as features in the model
| (19) |
Recall that is the OFI at level . We refer to this model as , and use OLS to estimate it.
The top panel of Table B.1 shows that the in-sample values increase as more multi-level OFIs are included as features, which is not surprising given that is a nested model of . However the increments of the in-sample are descending, indicating that much deeper LOB data might be unable to provide additional information. This argument is confirmed by the models’ performance on out-of-sample data, as shown at the bottom panel of Table B.1. Out-of-sample reaches a peak at .
| IS | 71.16 | 81.61 | 85.07 | 86.69 | 87.66 | 88.30 | 88.74 | 89.04 | 89.24 | 89.38 |
|---|---|---|---|---|---|---|---|---|---|---|
| (13.80) | (11.80) | (10.76) | (10.30) | (10.05) | (9.86) | (9.71) | (9.57) | (9.45) | (9.34) | |
| OS | 64.64 | 75.81 | 79.47 | 81.13 | 82.05 | 82.65 | 83.01 | 83.16 | 83.15 | 83.11 |
| (21.82) | (19.83) | (18.87) | (18.61) | (18.58) | (18.65) | (18.78) | (18.93) | (19.49) | (20.93) |
Impact comparison between multi-level OFIs.
An interesting question is whether the OFIs at different price levels contribute evenly in terms of price impact. Based on Figure 1(a), we conclude that multi-level OFIs have different contributions to price movements. Generally, OFIs at the second-best level manifest greater influence than OFIs at the best level in model , which is perhaps counter-intuitive, at first sight.
We further investigate how the coefficients vary across stocks with different characteristics, such as volume, volatility, and bid-ask spread. Figure B.1 (b)-(d) reveals that for stocks with high-volume and small-spread, order flow posted deeper in the LOB has more influence on price movements. The results regarding spread are in line with Xu et al. [53], where it is observed that for large-spread stocks (AMZN, TSLA, and NFLX), the coefficients of (OFIs at the -th level) tend to get smaller as the LOB level increases, while for small-spread stocks (ORCL, CSCO, and MU), the coefficients of may become larger as increases.
Cont et al. [17] concluded that the effect of on price changes is only second-order or null. There are two likely causes for the differences between their findings and ours. First, the data used in Cont et al. [17] includes 50 stocks (randomly picked from S&P500 constituents) for a single month in 2010, while we use the top 100 large-cap stocks for 36 months during 2017-2019. Second, Cont et al. [17] considered the average of the coefficients across 50 stocks. In our work, we first group 100 stocks by firm characteristics, and then study the average coefficients of each subset. Therefore, our results are based on a more granular analysis, across a significantly longer period of time.

Appendix C Comparison with Capponi & Cont (2020)
One closely related work is Capponi and Cont [8] (CC hereafter), where the authors propose a two-step procedure to justify the significance of cross-impact terms and render a different conclusion about cross-impact.
In the first step, the authors use OLS to decompose each stock’s OFIs () into the common factor of OFIs (), that is the first principal component of the multi-asset order flow imbalances, and obtain the idiosyncratic components () of the OFIs, for each individual stock.
| (20) |
In the second step, they regress returns () of stock against (i) the common factor of OFIs (), (ii) the idiosyncratic components of its own OFIs (), and (iii) the idiosyncratic components of the OFIs of other stocks (). Finally, we arrive at the cross-impact model proposed by Capponi and Cont [8] in Eqn (21), denoted as .
| (21) |
is compared with a parsimonious model (Eqn (22)), in which only the common order flow factor and a stock’s own idiosyncratic OFI are utilized.
| (22) |
We estimate the and models on historical data, under the same setting as in Section 3.2. Given that there are more features than observations, we employ LASSO in the second step to testify the intraday cross-impact of the idiosyncratic OFIs.
Similarly, we present the both in-sample and out-of-sample values of and in Table C.1. We observe small improvements (1.37% in in-sample tests, 0.58% in out-of-sample tests) from to . From considering Tables 3, 5, and C.1, we also observe that introducing the common factor leads to quite small changes in the model’s explanatory power of price dynamics in the in-sample and out-of-sample tests. Moreover, the models employing integrated OFIs continually outperform others.
| IS | 72.58 | 73.95 |
|---|---|---|
| (13.22) | (12.56) | |
| OS | 64.78 | 65.36 |
| (19.95) | (18.68) |
Capponi and Cont [8] claim that the main determinants of impact is from idiosyncratic order flow imbalance as well as a market order flow factor common across stocks; we conclude that as long as the multi-level OFIs are included, additional cross-impact terms are not necessary. The results also reveal that the sparse price impact model with integrated (or multi-level) OFIs can explain the price dynamics better than the models proposed by Capponi and Cont [8].
Appendix D High-frequency updates of contemporaneous models
In this experiment, we use a 30-minute window to estimate contemporaneous models. We then apply the estimated coefficients to fit data in the next one minute, and repeat this procedure every minute. The results summarized in Table D.1 reveal similar conclusions as in Section 3, illustrating the robustness of our findings.
| Best-level OFIs | Integrated OFIs | |||
|---|---|---|---|---|
| IS | 70.80 | 73.55 | 86.10 | 86.84 |
| (13.10) | (12.73) | (9.64) | (8.79) | |
| OS | 59.67 | 61.46 | 78.88 | 78.91 |
| (23.15) | (18.96) | (16.78) | (15.02) | |
Appendix E Additional results of Section 4
One interesting question to consider when examining the predictability of cross-impact is whether the lead-lag effect is linked to the frequency of LOB updates. As shown in Table E.1, the results indicate that assets with a higher frequency of book updates tend to lead “slower” assets, which aligns with the findings reported by Kolm et al. [35].
| -0.38 | -0.37 | -0.36 | -0.34 | |
| -0.12 | -0.11 | -0.10 | -0.09 | |
| -0.37 | -0.35 | -0.35 | -0.33 | |
| -0.12 | -0.11 | -0.10 | -0.09 |