Cross-domain Cross-architecture Black-box Attacks on Fine-tuned Models with Transferred Evolutionary Strategies
Abstract
Fine-tuning can be vulnerable to adversarial attacks. Existing works about black-box attacks on fine-tuned models (BAFT) are limited by strong assumptions. To fill the gap, we propose two novel BAFT settings, cross-domain and cross-domain cross-architecture BAFT, which only assume that (1) the target model for attacking is a fine-tuned model, and (2) the source domain data is known and accessible. To successfully attack fine-tuned models under both settings, we propose to first train an adversarial generator against the source model, which adopts an encoder-decoder architecture and maps a clean input to an adversarial example. Then we search in the low-dimensional latent space produced by the encoder of the adversarial generator. The search is conducted under the guidance of the surrogate gradient obtained from the source model. Experimental results on different domains and different network architectures demonstrate that the proposed attack method can effectively and efficiently attack the fine-tuned models.
1 Introduction
Fine-tuning is one of the most popular transfer learning methods for training deep learning models with limited labeled data. Many deep learning frameworks, including TensorFlow, PyTorch, MxNet, release pre-trained models to the public, and users can reduce the data labeling burden and save computational costs by fine-tuning from the pre-trained models. However, fine-tuned models are vulnerable to adversarial attacks [34, 37]. An adversarial example is an imperceptible perturbation to the original input so that a target model will make an erroneous prediction [30]. Based on the availability of the knowledge about the target model, adversarial attacks can be categorized into two types, namely white-box and black-box attacks. Black-box attacks do not require the knowledge about the training data and model parameters, and they can only make a few or no queries to the target model, which is a more practical setting. Pioneering works [34, 37] demonstrate that fine-tuned models can be attacked in a black-box manner.


Existing works about Black-box Attacks on Fine-Tuned models (BAFT) are limited by strong assumptions, where their settings assume that the target model is fine-tuned from a source model, associated with some additional knowledge. In [34], it is assumed that the parameters of the low-level layers in the target model are copied from the source model and remain unchanged during the fine-tuning process. But in practice, all the parameters in the target model might be adapted during fine-tuning. The assumption about the training process is relaxed in [37] by allowing fine-tuning the whole network, but it is assumed that the network architecture of the source model is known, and they introduce an auxiliary domain that shares the same input and output spaces as those of the target domain to craft adversarial examples. The knowledge about the network architecture might be unavailable to the attacker, and the introduction of the auxiliary domain requires additional data labeling costs, which limit the feasibility of the proposed attack method.
Thus, we study two novel but more difficult BAFT settings: cross-domain (CD) and cross-domain cross-architecture (CDCA) BAFT, which assume that (1) the target model is a fine-tuned model, and (2) the source domain data is known and accessible. The CD-BAFT setting assumes that the network architecture of the source model and that of the target model are the same while the CDCA-BAFT setting further relaxes the assumption by allowing different architectures. For example, the target model for attacking is a VGG-16-based product image classifier, and it is fine-tuned from a VGG-16 model that is pre-trained on ImageNet. If the attacker coincidentally chooses the exact source model that the target model is fine-tuned from, it corresponds to the CD-BAFT setting. In the CDCA-BAFT setting, the attacker might use a ResNet-50-based ImageNet classifier to attack the target model. The differences between the proposed BAFT settings and the vanilla black-box adversarial attack setting are illustrated in Fig. 1. A schematic view of the two BAFT settings is provided in Fig. 2.


The goal of the CD- and CDCA-BAFT settings is to generate adversarial examples that successfully fool the target model using limited queries with the knowledge about the source domain. Existing black-box attack methods, which can be categorized into two approaches, namely surrogate-based and query-based methods, cannot be trivially applied to our new BAFT settings. Surrogate-based methods use a substitute model as a white-box model, generate adversarial examples using gradient-based white-box attack methods, and finally attack the target model with the generated examples [24]. In our cross-domain settings, it is difficult to obtain the surrogate gradient from the substitute model if the source and target domains have different label spaces. Thus, we cannot compute the gradient via back-propagation using the substitute model. Query-based methods estimate the gradient with zeroth-order optimization methods [6, 15]. Though they estimate gradients without accessing the internal parameters of the target model, large amounts of queries are needed to obtain an accurate gradient estimate, particularly for high-dimensional inputs like images, which makes the attack inefficient. Hence, existing methods cannot meet the requirements of effectiveness and efficiency and the BAFT task remains an open challenge.
To address the above challenges, we propose Transferred Evolutionary Strategies (TES). Our method is composed of two stages. In the first stage, we train an adversarial generator in the source domain. The adversarial generator adopts an encoder-decoder architecture. It first maps the clean input to a low-dimensional latent space and then decodes the latent representation into an adversarial example. The low-dimensional latent space encodes semantic adversarial patterns that are rather transferable [1, 23, 14]. Furthermore, it limits the search in the second stage in a low-dimensional space and improves the query efficiency. In the second stage, the latent representation is used as a starting point. We obtain the surrogate gradient from the source model using a soft labeling mechanism, which represents a target domain label in the source domain label space as the probability score predicted by the source model. Then the search in the latent space is guided with the surrogate gradient using evolutionary strategies [21]. The soft labeling mechanism bridges the heterogeneous label spaces and allows obtaining surrogate gradients, which circumvents the limitation of existing surrogate-based methods. Though the surrogate gradient does not perfectly align with the true gradient, they might be correlated and hence using the surrogate gradient improves the efficiency of the search. Experimental results on multiple domains and various backbone network architectures demonstrate the effectiveness and efficiency of the proposed attack method.
2 Related Works
We review related literature on adversarial attacks and defenses and training deep neural networks with soft labels in the following.
Adversarial Attacks and Defenses. Adversarial attacks and defenses have drawn attention from the machine learning research community in recent years [35, 18]. Based on the knowledge that the attacker can access, adversarial attacks are categorized into two types, namely white-box and black-box attacks. White-box attacks assume that the attacker has full knowledge of the target model, and the adversarial examples can be found by gradient computation [30, 10, 22, 25, 16, 4, 20]. On the other hand, black-box attacks can only query the output of the target model. The model output can be either probability scores [6, 15, 17, 9, 14] or a single hard label (top-1 prediction) [3, 7, 8, 5]. The two black-box attack settings are referred to as score-based and decision-based attacks. In this paper, we focus on the score-based attacks and leave decision-based attacks for future exploration.
Score-based black-box attack methods can be categorized into two approaches, namely surrogate-based [24, 19] and query-based [6, 15, 2, 17, 32] methods. Surrogate-based methods train a substitute model, attack the substitute model with white-box attack methods, and finally attacks the target model using the generated adversarial examples. Query-based methods use gradient-free optimization methods, for example, zeroth-order-optimization [6] and evolutionary strategies [15, 17]. Surrogate-based methods cannot be readily applied to the proposed BAFT settings because it is hard to obtain surrogate gradients from the substitute model due to the different label spaces of the two domains. Query-based methods need large amounts of queries, which makes the attack inefficient.
Recently, there are a few attempts to combine surrogate-based and query-based methods [9, 11, 14], and they achieve state-of-the-art attack results on vanilla black-box attacks. The Prior-RGF method proposed in [9] searches adversarial examples in the original input space under the guidance of surrogate gradients. The subspace attack [11] is conducted in low-dimensional subspaces spanned by surrogate gradients. But these methods cannot be directly applied to the BAFT settings due to the mismatched label spaces. The TREMBA method proposed in [14] optimizes in a transferable low-dimensional latent space, but they do not utilize surrogate gradients, which makes their attack less efficient. Hence, existing black-box attack methods cannot address the unique challenges in the proposed BAFT settings.
Most adversarial attacks assume that the target model of attack is trained in an individual domain, while attacks on fine-tuned models are less studied. The black-box attack method towards fine-tuned models proposed in [34] assumes that the target model copies and freezes the first few layers from a pre-trained model, which might not hold in practice. Zhang et al. systematically evaluate the robustness of transfer learning models under both white-box and black-box FGSM attacks in [37]. They introduce an auxiliary domain to bridge the label space discrepancy. Their method suffers from two limitations. Firstly, the introduction of the auxiliary domain requires additional data labeling costs. Secondly, they assume that the network architecture of the pre-trained model is known. Compared to these two works, our proposed BAFT settings are more practical by allowing cross-architecture attacks. In addition, our proposed attack method does not require auxiliary domain annotation.
To defend against adversarial attacks, one natural and effective approach is to augment the training data with adversarial examples, which is known as adversarial training [20, 31, 36]. The attack and defense methods compete against each other and formulate an arms race. The initial move to conduct successful attacks in the BAFT settings is crucial for advancing the research in developing robust fine-tuned models.
Soft Labels. For multi-class classification tasks, data instances usually adopt a ‘‘hard’’ labeling mechanism. Each instance is assigned to a class, and the membership is binary, i.e., the instance is either a member of a class or not. Soft labels are defined as a weighted mixture of hard labels and the uniform distribution or probability scores, and they have been used to improve network performance [29] and knowledge distillation [13]. In this paper, we use soft labels to bridge the gap between the mismatched label spaces of the two domains. We represent target domain labels as the probability scores predicted by the source model and then obtain the surrogate gradient. To the best of our knowledge, this is the first attempt that applies soft labels to cross-domain black-box adversarial attacks.

3 Transferred Evolutionary Strategies
We first introduce the problem setup and then present the proposed black-box attack method. Our source code is available at https://github.com/HKUST-KnowComp/TES.


3.1 Problem Setup
We focus on the black-box attacks on the image classification models in this paper. The target model for attacking is a fine-tuned model. To avoid confusion with the target model for attacking, the source domain and the target domain are denoted by and , respectively. Without the loss of generality, we omit the subscript that indicates the domain. Let denote the number of labeled samples in a domain, and there is . The input and output spaces are denoted by and , respectively. A neural network, denoted by , learns the mapping from the input space to the output space, and there is . The image classifier is usually a Convolutional Neural Network (CNN). The output of the network, denoted by , predicts the probability over the whole label space.
To attack a neural network , an adversarial example, denoted by , can be found by solving the following optimization problem:
where denotes the -norm distance, denotes the perturbation budget, denotes a classification loss, and denotes a label that is different from the ground truth label (). The objective of the above optimization problem is to find an adversarial example within the -norm -ball of the clean input that makes the network output an incorrect prediction . We assume that the classification loss is the cross-entropy loss, and the distance measure is the distance in the following. There are two types of adversarial attacks, namely untargeted and targeted attacks. For untargeted attacks, an arbitrary label that is different from the ground truth label is considered a successful attack. For targeted attacks, should equal to a pre-defined label, denoted by , where there is .
The BAFT settings assume that the target model is fine-tuned from a source model. Hence is fine-tuned from a model trained in . The CD-BAFT setting assumes that is directly fine-tuned from , while and can have different architectures in the CDCA-BAFT setting. The two settings are illustrated in Figs. 2a and 2b, respectively.
3.2 Transferred Evolutionary Strategies
We propose a two-stage black-box attack method that leverages the prior knowledge from the source domain. In the first stage, we train an adversarial generator that maps a clean image to an adversarial one. In the second stage, we obtain a surrogate gradient from the source model with the soft label mechanism that handles the heterogeneous label spaces of the two domains. Then the surrogate gradient is exploited to guide the search in the latent feature space parameterized by the adversarial generator. The details of the adversarial generator training, the soft labeling mechanism, and the guided evolutionary search are given in subsequent sections. The illustrations of the two stages are shown in Figs. 3 and 4a.
3.2.1 Adversarial Generator Training
Let denote the adversarial generator. It maps a clean example to an adversarial one: . The adversarial generator is composed of an encoder and a decoder which are denoted by and , respectively. There is . We denote the latent representation produced by the encoder by and there is . The decoder then projects the latent representation into an unnormalized perturbation. To ensure that the adversarial example falls within the -ball of the clean input, the unnormalized perturbation is firstly transformed with a function and then scaled by a factor : . Hence the condition is satisfied.
To train the adversarial generator, we adopt the C&W attack loss [4]. The loss function for untargeted and targeted attacks are defined in Eqs. (1) and (2), respectively.
| (1) |
where denotes the -th dimension of the output of the classifier before the Softmax transformation, and denotes a threshold. By optimizing the loss function, the logit value at the -th dimension is expected to be larger than the logit value at the ground truth label by the margin so that the network will make an incorrect prediction other than the ground truth label .
Similarly, the loss function for targeted attacks is:
| (2) |
where is the pre-defined target class. By optimizing , the classifier tends to output the prediction with the generated adversarial example as the input.
3.2.2 Soft Labeling
In the second stage, we need to search in the low-dimensional latent space parameterized by the encoder under the guidance of the surrogate gradient from the source model .
If the label is available, the surrogate gradient with respect to the latent representation, denoted by , can be obtained by a simple backward propagation. However, this cannot be trivially applied in the BAFT settings because the label spaces of the source domain and the target domain do not agree, and it is unknown how to represent a target domain label in the source domain label space . For example, suppose the source domain is ImageNet, and there are two classes, ‘‘batteries’’ and ‘‘alarm clock’’, in the target domain. For the ‘‘batteries’’ class, it does not appear in the ImageNet label space. While for the ‘‘alarm clock’’ class, there are multiple ‘‘clock’’ related classes in the ImageNet label space, including ‘‘analog clock’’, ‘‘digital clock’’, and ‘‘wall clock’’. There is no correspondence between the two label spaces, and it is also difficult to build one manually.
To circumvent the heterogeneity of the label spaces, we utilize a soft labeling mechanism in this paper. Let denote the representation of the -th class of the target domain () in the source domain label space, and denote the number of samples in the target domain whose label is . Since high-level layers of a CNN contain visual semantic information, the soft label is defined as the mean of the probability predictions produced by the source domain network:
| (3) |
Hence we build a mapping between the two label spaces. Consequently, the surrogate gradient can be obtained by where denotes the Kullback-Leibler divergence.
3.2.3 Guided Evolutionary Strategies
With the latent representation produced by the encoder and the surrogate gradient obtained from the pre-trained model, we then search in the low-dimensional latent space under the guidance of the surrogate gradient. To incorporate the prior knowledge from the surrogate gradient, we adopt the guided evolutionary strategies (guided ES) [21].
The search is conducted in an iterative manner. We start from the latent representation produced by the encoder, and there is . The dimension of the latent representation is denoted by . Let denote the maximum number of queries that is allowed by the target model. At the -th step (), an adversarial example can be obtained by feed-forwarding the latent representation through the decoder. A surrogate gradient, denoted by , can be obtained by back-propagation after querying Model A. Then an orthonormal basis for the subspace, denoted by , can be generated with the surrogate gradient by QR decomposition:
| (4) |
where is an orthogonal matrix and denotes the QR decomposition operation.
A noise vector, denoted by , is sampled from with:
| (5) |
where denotes a identity matrix and is a hyperparameter that balances the search in the full parameter space and the guiding subspace.
The gradient can then be estimated by antithetic sampling:
| (6) |
where denotes the number of noise samples, denotes the overall scale of the estimate, and there are and .
To summarize, the proposed black-box attack method is outlined in Algorithm 1. The guided ES process is illustrated in Fig. 4b.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ba12367e-3422-434c-bac9-0c87f30b40fd/x3.png)
| Dataset | # classes | # train set | # test set | |
|---|---|---|---|---|
| ImageNet | 1,000 | 1.28M | 50K | |
| Office-Home | Art | 65 | 1,941 | 486 |
| Clipart | 3,492 | 873 | ||
| Product | 3,551 | 888 | ||
| Real World | 3,485 | 872 | ||
4 Experimental Results
We present our experimental results in the following.
| Domain | Upper | Fool rate | Mean queries | |||||
|---|---|---|---|---|---|---|---|---|
| FGSM | PGD | AG | TREMBA | TES | TREMBA | TES | ||
| Art | 72.02 | 25.72 | 50.41 | 65.43 | 70.78 | 71.60 | 78.08 | 67.83 |
| Clipart | 76.17 | 8.71 | 11.34 | 16.04 | 48.11 | 48.80 | 1,021.01 | 1,018.15 |
| Product | 90.65 | 36.26 | 72.75 | 85.59 | 88.63 | 89.30 | 65.93 | 51.33 |
| Real World | 83.03 | 27.06 | 62.16 | 77.64 | 81.31 | 81.77 | 76.02 | 73.32 |
| Domain | Upper | Fool rate | Mean queries | |||||
|---|---|---|---|---|---|---|---|---|
| FGSM | PGD | AG | TREMBA | TES | TREMBA | TES | ||
| Art | 71.55 | 1.46 | 26.57 | 39.54 | 60.88 | 64.02 | 473.90 | 373.25 |
| Clipart | 76.79 | 0.23 | 0.00 | 4.69 | 28.37 | 29.07 | 1,509.10 | 1,498.62 |
| Product | 90.72 | 0.11 | 5.15 | 0.92 | 48.11 | 59.79 | 1,409.73 | 1,261.27 |
| Real World | 83.04 | 0.81 | 19.16 | 41.11 | 66.67 | 72.47 | 591.77 | 450.01 |
Datasets. ImageNet [27], which is a large-scale image database, is used as the source domain. The source domain network is pre-trained on its train set, and the adversarial generator is trained on its validation set. Four transfer tasks are constructed from the Office-Home dataset [33] which is a popular transfer learning benchmark dataset. The dataset statistics are listed in Table 1. There are only a few thousand labeled samples in the training sets of the target domains, and consequently, it is impossible to train deep learning models in the target domains without transferring the knowledge from the source domain. Some sample images from the Office-Home dataset are shown in Fig. 5. The distributions of the four domains are different, and the distribution of an arbitrary target domain is different from that of the ImageNet dataset as well.
Baselines. As a novel black-box attack setting, there are no readily available baselines. We adapt the attack method proposed in [37], consider the state-of-the-art attack method on attacking ImageNet classifiers, and compare the proposed attack method with them.
-
•
Surrogate-based methods: Adversarial examples are produced using Model A and directly attack the target model with the generated adversarial examples. Two gradient-based methods, FGSM and PGD, are used. These two methods adapt the method proposed in [37] to the BAFT settings by using the soft labeling mechanism presented in Section 3.2.2. We also include attacking with the adversarial generator, denoted by AG, as a baseline. These three methods do not query the target model.
-
•
Query-based method: Some state-of-the-art black-box attack methods [9, 11] on attacking ImageNet classifiers do not apply to the BAFT settings because surrogate gradients cannot be obtained under the mismatched label spaces. We consider TREMBA [14] that does not rely on surrogate gradients and achieves competing results on attacking ImageNet.
Evaluation Metrics. The efficacy of the attack method is measured by fool rate, which is the proportion of the test set images that successfully attack the target model. The higher the fool rate is, the more effective the attack is. For query-based methods, we also report mean queries to evaluate the efficiency of the attack. Smaller mean queries indicate a more efficient attack. Only the samples that are correctly classified by the target model are used for attacking, and hence the classification accuracy on the clean test set is the upper bound of the fool rate. The best result of each task is highlighted in boldface.
| Domain | Upper | Fool rate | Mean queries | |||||
|---|---|---|---|---|---|---|---|---|
| FGSM | PGD | AG | TREMBA | TES | TREMBA | TES | ||
| Art | 72.02 | 9.67 | 9.05 | 20.58 | 66.67 | 69.34 | 420.39 | 301.44 |
| Clipart | 76.17 | 6.87 | 4.70 | 8.25 | 44.10 | 45.36 | 1,182.17 | 1,157.17 |
| Product | 90.65 | 26.46 | 17.00 | 43.02 | 84.57 | 87.05 | 371.45 | 227.24 |
| Real World | 83.03 | 16.40 | 13.76 | 36.58 | 75.46 | 79.01 | 443.10 | 285.99 |
| Domain | Upper | Fool rate | Mean queries | |||||
|---|---|---|---|---|---|---|---|---|
| FGSM | PGD | AG | TREMBA | TES | TREMBA | TES | ||
| Art | 71.55 | 0.21 | 0.42 | 0.00 | 25.31 | 36.40 | 1,687.60 | 1,511.83 |
| Clipart | 76.79 | 0.00 | 0.00 | 0.23 | 12.43 | 12.90 | 1,910.46 | 1,894.30 |
| Product | 90.72 | 0.11 | 0.11 | 0.00 | 23.60 | 32.99 | 1,841.39 | 1,724.56 |
| Real World | 83.04 | 0.46 | 0.23 | 0.35 | 27.76 | 39.49 | 1,736.76 | 1,509.51 |
4.1 Implementation Details
All the experiments are implemented with the PyTorch [26] deep learning framework.
The target models use VGG16 [28] as backbone networks. The source models are also VGG16 networks in the CD-BAFT setting, and they adopt the Resnet-50 [12] architecture in the CDCA-BAFT attacks. The backbone networks are pre-trained on ImageNet, and they are provided by the torchvision package.
The perturbation budget equals . For the PGD attack, it runs iterations with a step size of . For the query-based attack methods, the maximum number of queries allowed is , the number of noise samples is and the hyper-parameters , , and are selected from , , and , respectively. For the targeted attacks, we set the target class as the ‘‘TV’’ class. The images whose labels are ‘‘TV’’ are excluded from the test set. For the other images, the objective of the targeted attack is to make the target model output ‘‘TV’’ as predictions.
4.2 Results
For untargeted attacks, the adversarial examples produced by the surrogate-based methods are rather transferable. For example, AG achieves a fool rate at on the Product task, which is close to the upper bound of , and it is achieved without any access to the target domain data or model. FGSM performs the worst among the three surrogate-based methods since it takes only one step along the gradient direction to generate the adversarial example. PGD improves over FGSM by taking iterative steps. AG achieves the highest fool rate among the three surrogate-based methods, and it provides a good starting point for searching. The query-based methods, both TREMBA and TES, outperform the surrogate-based methods by a large margin. Compared to TREMBA, TES further raises the fool rate since it utilizes the surrogate gradient from the source model while TREMBA ignores such prior knowledge. Moreover, the improvement of the fool rate is achieved with reduced mean queries.
Targeted CD-BAFT attacks are more challenging since the fool rates of all methods decrease. Surrogate-based methods perform poorly on targeted attacks. For example, the fool rates of FGSM are below in all four domains. Query-based methods are again more advantageous than surrogate-based methods. For example, AG almost fails to attack the target model in the Product domain while the fool rate of the TREMBA raises to , and TES further achieves an improvement of compared to TREMBA.
| Attack type | Upper | Fool rate | Mean queries | ||
|---|---|---|---|---|---|
| w/o AG | TES | w/o AG | TES | ||
| Untargeted | 72.02 | 51.85 | 71.60 | 989.16 | 67.83 |
| Targeted | 71.55 | 8.79 | 64.02 | 1,967.25 | 373.25 |
The results of the untargeted and targeted CDCA-BAFT attack results are listed in Tables 4 and 5, respectively. Similar to the results of the CD-BAFT attacks, TES achieves the highest fool rates among all attack methods on all the tasks, and it requires fewer mean queries than TREMBA does.
For untargeted attacks, the fool rates of the CDCA-BAFT attacks decrease compared to their counterparts of the CD-BAFT attacks. For example, the fool rate of AG on the Art domain is , which lags behind the fool rate of the untargeted CD-BAFT attack by . This indicates that the latent representations produced by the adversarial generator are less transferable if the source model and the target model adopt different network architectures.
Targeted CDCA-BAFT attacks are the most challenging setting since the fool rates of surrogate-based methods are close to , and the mean queries of both query-based methods exceed . The improvement of TES over TREMBA in terms of the fool rate on the four tasks is , , , and , respectively. The advantage of TES on the Clipart dataset is not very significant. We hypothesize that this is because the Clipart dataset is the most dissimilar to the source domain ImageNet, as shown in Fig. 5, and the prior knowledge from the source domain is not informative.
In summary, the results under different BAFT settings demonstrate that TES is not only effective but efficient as well.
| Attack type | Upper | Fool rate | Mean queries | |||||
|---|---|---|---|---|---|---|---|---|
| FGSM | PGD | AG | TREMBA | TES | TREMBA | TES | ||
| Untargeted | 80.04 | 22.02 | 33.13 | 49.38 | 76.34 | 78.40 | 259.76 | 164.39 |
| Targeted | 79.71 | 1.26 | 3.35 | 17.78 | 52.93 | 58.58 | 1,064.77 | 896.51 |
| Model A architecture | Upper | Fool rate | Mean queries | |||||
|---|---|---|---|---|---|---|---|---|
| FGSM | PGD | AG | TREMBA | TES | TREMBA | TES | ||
| VGG16 | 80.04 | 13.37 | 12.96 | 12.14 | 60.08 | 61.11 | 827.31 | 818.95 |
| Densenet161 | 15.02 | 13.79 | 22.63 | 70.37 | 72.22 | 592.93 | 527.90 | |
5 Ablation Experiments
Several factors may influence the effectiveness and efficiency of adversarial attacks. We conduct ablation experiments to investigate four factors: (1) the necessity of the adversarial generator, (2) the effectiveness of the soft labels, (3) network architectures, (4) parameter sensitivity. The ablation experiments are conducted on the Art domain if not specified.
5.1 The Necessity of the Adversarial Generator
In the proposed TES method, we conduct the guided ES in the latent space parameterized by the encoder of the adversarial generator. The guided ES can also be conducted in the original input space, which can be viewed as extending the method in [9] to the BAFT setting. We compare the results obtained with and without the adversarial generator in Table 6. The results demonstrate that searching in the low-dimensional latent space noticeably improves the effectiveness and efficiency of the attacks, and the introduction of the adversarial generator is necessary.
5.2 The Effectiveness of Soft Labels
| Class names | Art | Clipart |
|---|---|---|
| Alarm clock | Analog clock (0.54), stop watch (0.14), wall clock (0.08) | Analog clock (0.36), wall clock (0.12), stop watch (0.04) |
| Bed | Quilt (0.25), studio couch (0.13), four-poster (0.09) | Envelope (0.10), cradle (0.06), studio couch (0.05) |
| Keyboard | Computer keyboard (0.33), crossword (0.24), space bar (0.18) | Computer keyboard (0.23), space bar (0.19), notebook computer (0.06) |
As a case study, in Table 9, we report the top 3 predictions and their probability scores of three classes in the Art and Clipart domains. The predictions are produced by the ImageNet pre-trained VGG16 network. Despite the mismatched label spaces, for the target domain labels, the top predictions in the source domain are some visually similar classes. The qualitative results suggest that the soft labels retain general visual semantic information and might help obtain surrogate gradients.
5.3 Network Architectures
The experimental results in Section 4.2 are obtained when the target models adopt VGG16 as the backbone network. We repeat the experiments on the target models whose backbone network is ResNet-50.
The results of the CD-BAFT setting are shown in Table 7. Similar to the results obtained when the target network is a VGG16 network, TES remains effective and efficient, which demonstrates that our proposed method is insensitive to different network architectures.
The results of untargeted CDCA-BAFT attacks when Model A adopt various network architectures are shown in Table 8. The target model is fixed to use ResNet-50 as the backbone network, and the source model adopts two different backbones, VGG16 and Densenet161. The attack is more effective when the source model uses a more expressive backbone network as the fool rates of all the methods increase when the source model is a Densenet161 network.



5.4 Parameter Sensitivity
In the guided evolutionary strategies, a hyper-parameter is introduced to balance the search in the full parameter space and the guiding subspace. We report the fool rates and the mean queries obtained with various values in Fig. 6. The lowest fool rate and the maximum mean queries are achieved when there is , and it corresponds to discarding prior knowledge from the source model and searching in the full parameter space. When there is and the prior knowledge from the source model is exploited, the effectiveness and efficiency of the attack are improved.
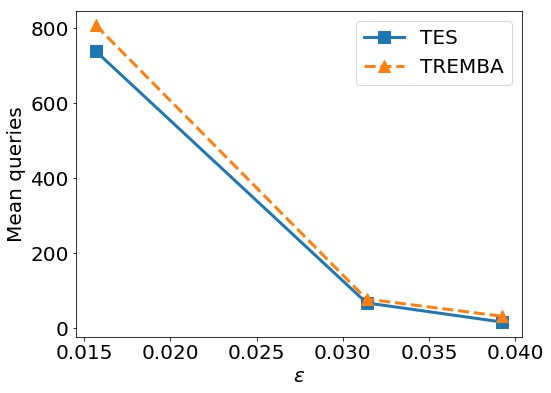
In addition, we analyze the effect of the perturbation size in Fig. 7. The proposed TES method outperforms the TREMBA baseline consistently under various perturbation sizes.
6 Conclusion
The robustness of fine-tuned neural networks has been less studied despite their prevalence. Thus, we propose two novel cross-domain and cross-domain cross-architecture based BAFT settings. With these two settings, we further propose a two-stage black-box attack method that fails fine-tuned models effectively and efficiently. We expect that the proposed setting and method will facilitate future research on building transfer learning models that are both effective and robust. As future works, we will develop defenses against the attacks in the BAFT settings.
Acknowledgments and Disclosure of Funding
The authors of this paper were supported by the NSFC Fund (U20B2053) from the NSFC of China, the RIF (R6020-19 and R6021-20) and the GRF (16211520) from RGC of Hong Kong, the MHKJFS (MHP/001/19) from ITC of Hong Kong and the National Key R&D Program of China (2019YFE0198200) with special thanks to HKMAAC and CUSBLT, and the Jiangsu Province Science and Technology Collaboration Fund (BZ2021065). We also thank the support from the UGC Research Matching Grants (RMGS20EG01-D, RMGS20CR11, RMGS20CR12, RMGS20EG19, RMGS20EG21).
References
- [1] Shumeet Baluja and Ian Fischer. Learning to attack: Adversarial transformation networks. In AAAI, pages 2687--2695. AAAI Press, 2018.
- [2] Arjun Nitin Bhagoji, Warren He, Bo Li, and Dawn Song. Practical black-box attacks on deep neural networks using efficient query mechanisms. In ECCV, pages 154--169. Springer, 2018.
- [3] Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. In ICLR, 2018.
- [4] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy, pages 39--57. IEEE Computer Society, 2017.
- [5] Jinghui Chen and Quanquan Gu. Rays: A ray searching method for hard-label adversarial attack. In KDD, pages 1739--1747. ACM, 2020.
- [6] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In AISec, pages 15--26. ACM, 2017.
- [7] Minhao Cheng, Thong Le, Pin-Yu Chen, Huan Zhang, Jinfeng Yi, and Cho-Jui Hsieh. Query-efficient hard-label black-box attack: An optimization-based approach. In ICLR, 2019.
- [8] Minhao Cheng, Simranjit Singh, Patrick H. Chen, Pin-Yu Chen, Sijia Liu, and Cho-Jui Hsieh. Sign-opt: A query-efficient hard-label adversarial attack. In ICLR, 2020.
- [9] Shuyu Cheng, Yinpeng Dong, Tianyu Pang, Hang Su, and Jun Zhu. Improving black-box adversarial attacks with a transfer-based prior. In NeurIPS, pages 10932--10942, 2019.
- [10] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In ICLR, 2015.
- [11] Yiwen Guo, Ziang Yan, and Changshui Zhang. Subspace attack: Exploiting promising subspaces for query-efficient black-box attacks. In NeurIPS, pages 3820--3829, 2019.
- [12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770--778. IEEE Computer Society, 2016.
- [13] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [14] Zhichao Huang and Tong Zhang. Black-box adversarial attack with transferable model-based embedding. In ICLR, 2020.
- [15] Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. In ICML, volume 80, pages 2142--2151. PMLR, 2018.
- [16] Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial examples in the physical world. In ICLR Workshop, 2017.
- [17] Yandong Li, Lijun Li, Liqiang Wang, Tong Zhang, and Boqing Gong. Nattack: Learning the distributions of adversarial examples for an improved black-box attack on deep neural networks. In ICML, volume 97, pages 3866--3876. PMLR, 2019.
- [18] Yao Li, Minhao Cheng, Cho-Jui Hsieh, and Thomas CM Lee. A review of adversarial attack and defense for classification methods. The American Statistician, pages 1--44, 2021.
- [19] Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. Delving into transferable adversarial examples and black-box attacks. In ICLR, 2017.
- [20] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In ICLR, 2018.
- [21] Niru Maheswaranathan, Luke Metz, George Tucker, Dami Choi, and Jascha Sohl-Dickstein. Guided evolutionary strategies: augmenting random search with surrogate gradients. In ICML, volume 97, pages 4264--4273. PMLR, 2019.
- [22] Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. Deepfool: a simple and accurate method to fool deep neural networks. In CVPR, pages 2574--2582. IEEE Computer Society, 2016.
- [23] Muhammad Muzammal Naseer, Salman H Khan, Muhammad Haris Khan, Fahad Shahbaz Khan, and Fatih Porikli. Cross-domain transferability of adversarial perturbations. In NeurIPS, pages 12885--12895, 2019.
- [24] Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. Practical black-box attacks against machine learning. In ACM ASIACCS, pages 506--519, 2017.
- [25] Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In EuroS&P, pages 372--387. IEEE, 2016.
- [26] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, pages 8026--8037, 2019.
- [27] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet large scale visual recognition challenge. IJCV, 115(3):211--252, 2015.
- [28] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- [29] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, pages 2818--2826. IEEE Computer Society, 2016.
- [30] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In ICLR, 2014.
- [31] Florian Tramèr, Alexey Kurakin, Nicolas Papernot, Ian J. Goodfellow, Dan Boneh, and Patrick D. McDaniel. Ensemble adversarial training: Attacks and defenses. In ICLR, 2018.
- [32] Chun-Chen Tu, Paishun Ting, Pin-Yu Chen, Sijia Liu, Huan Zhang, Jinfeng Yi, Cho-Jui Hsieh, and Shin-Ming Cheng. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In AAAI, pages 742--749. AAAI Press, 2019.
- [33] Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. In CVPR, pages 5385--5394. IEEE Computer Society, 2017.
- [34] Bolun Wang, Yuanshun Yao, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. With great training comes great vulnerability: Practical attacks against transfer learning. In USENIX Security, pages 1281--1297. USENIX Association, 2018.
- [35] Xiaoyong Yuan, Pan He, Qile Zhu, and Xiaolin Li. Adversarial examples: Attacks and defenses for deep learning. IEEE TNNLS, 2019.
- [36] Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. In ICML, volume 97, pages 7472--7482. PMLR, 2019.
- [37] Yinghua Zhang, Yangqiu Song, Jian Liang, Kun Bai, and Qiang Yang. Two sides of the same coin: White-box and black-box attacks for transfer learning. In KDD, pages 2989--2997. ACM, 2020.