Critical Window Variable Selection for Mixtures: Estimating the Impact of Multiple Air Pollutants on Stillbirth
Abstract
Understanding the role of time-varying pollution mixtures on human health is critical as people are simultaneously exposed to multiple pollutants during their lives. For vulnerable sub-populations who have well-defined exposure periods (e.g., pregnant women), questions regarding critical windows of exposure to these mixtures are important for mitigating harm. We extend Critical Window Variable Selection (CWVS) to the multipollutant setting by introducing CWVS for Mixtures (CWVSmix), a hierarchical Bayesian method that combines smoothed variable selection and temporally correlated weight parameters to (i) identify critical windows of exposure to mixtures of time-varying pollutants, (ii) estimate the time-varying relative importance of each individual pollutant and their first order interactions within the mixture, and (iii) quantify the impact of the mixtures on health. Through simulation, we show that CWVSmix offers the best balance of performance in each of these categories in comparison to competing methods. Using these approaches, we investigate the impact of exposure to multiple ambient air pollutants on the risk of stillbirth in New Jersey, 2005-2014. We find consistent elevated risk in gestational weeks 2, 16-17, and 20 for non-Hispanic Black mothers, with pollution mixtures dominated by ammonium (weeks 2, 17, 20), nitrate (weeks 2, 17), nitrogen oxides (weeks 2, 16), PM2.5 (week 2), and sulfate (week 20). The method is available in the R package CWVSmix.
keywords:
, , , , , and
1 Introduction
Throughout their lives, humans are simultaneously exposed to multiple contaminants that may adversely impact their health. Ambient air pollutants represent a major source of potentially hazardous exposures. Numerous past studies have estimated associations between ambient exposures and multiple adverse health outcomes, with some findings consistent enough to suggest a causal relationship (Brunekreef and Holgate, 2002; Kampa and Castanas, 2008; Stieb et al., 2012). However, the majority of these studies relied on statistical models that examined the role of a single pollutant on a health outcome. Therefore, the findings may represent an incomplete understanding of the impact that pollution mixtures have on health. New statistical methods are needed to address this issue, though a number of challenges in their development have been previously identified, particularly high correlation between exposures due to shared emission sources and meteorological drivers (Dominici et al., 2010).
Recently, there has been a shift away from single pollutant approaches towards the development of multipollutant methods (e.g., Davalos et al. (2017); Ferrari and Dunson (2019, 2020); Antonelli et al. (2020); Reich et al. (2020)). However, the majority of these methods were not designed for the analysis of time-varying mixtures, a feature that introduces additional modeling complications such as strong temporal correlation between exposures. Methods that examine the role of time-varying pollutants on health are particularly important for identifying critical periods of exposure as is often of interest when analyzing pregnancy outcomes, though other health outcomes have also been explored in this context (Warren et al., 2012a, b, 2016, 2020a, 2020b; Chang et al., 2015; Wilson et al., 2017).
Methods that seek to identify critical windows of exposure most often rely on distributed lag models (DLMs) in some form to quantify the relationship between exposure over time and health, with the majority of methods developed for a single or small number of pollutants. Using a Gaussian process, Warren et al. (2012b) introduced a model which allowed for two pollutants to be analyzed jointly while accounting for their cross-covariance. Warren et al. (2012a) extended this model using a semiparametric Bayesian approach which more generally considered four pollutants. However, both frameworks became computationally demanding as the number of pollutants increased. Chen, Mukherjee and Berrocal (2019) proposed a method to explore the impact of two time-varying exposures, including interactions, within a DLM framework. Liu et al. (2018a) extended Bayesian kernel machine regression (BKMR) to accommodate time-varying mixtures and further introduced a computationally feasible framework using mean field variational Bayesian inference (Liu et al., 2018b). However, the authors noted that this method is better suited for a smaller number of shared exposure time periods. More recently, Wilson et al. (2019) introduced BKMR-DLM, a method designed to more flexibly and generally handle multiple exposure time periods while exploring nonlinear and interaction associations between pollutants and the outcome.
Weighted quantile sum (WQS) regression (Carrico et al., 2015) was developed to investigate the impact of multiple non-time-varying exposures on an outcome. It introduces regularization via a set of pollutant-specific weights that are forced to sum to one to stabilize model fitting when considering a large number of contaminants. Extending WQS to the setting of multiple exposure periods, Bello et al. (2017) proposed an algorithm that relied on a DLM, though Gennings et al. (2020) later suggested that it may be more appropriate for a smaller number of pollutants. As a result, Gennings et al. (2020) introduced lagged WQS (LWQS) regression which proposed to fit WQS regression separately at each exposure period to estimate the time-varying weight parameters and obtain the weighted average exposures across time. It then used a DLM to estimate the association between the estimated weighted average exposures and the outcome. However, this two-stage algorithm may be ignoring sources of uncertainty during model fitting (e.g., weight parameters are assumed known in the second stage DLM), may be inefficient since weights are estimated separately at each exposure period (i.e., ignoring potential correlation between weights in nearby exposure periods), and ignores the impact of interactions between exposures.
In this work, we extend the recently developed method for more accurately identifying critical exposure windows in a single pollutant setting (Critical Window Variable Selection (CWVS)) (Warren et al., 2020a) to the multipollutant setting by introducing CWVS for Mixtures (CWVSmix). Similar to LWQS, CWVSmix introduces sum-to-one constraints on time-varying mixture weights in order to introduce regularization and accommodate a large number of pollutants. However, unlike LWQS, CWVSmix is designed to jointly estimate these weights and the estimated mixtures’ impacts on health while employing hierarchical Bayesian variable selection techniques to more formally identify critical windows of exposure and the important pollutants involved in the time-varying mixtures. Additionally, first order interactions between pollutants on a given exposure period are also considered within the framework.
We design a simulation study to compare the performances of CWVSmix and other competing options (including LWQS) with respect to (i) accuracy of the identified critical exposure periods, (ii) estimation of the time-varying pollutant-specific weights, and (iii) risk parameter estimation. We then apply the methodology to investigate the impact that multiple gas and particulate matter ambient air pollutants, estimated using a novel data fusion model (Senthilkumar et al., 2019), have on stillbirth risk in New Jersey (NJ), 2005-2014, with a focus on investigating differences between various race/ethnicity groups.
2 Data
We analyze live birth and fetal death records from the Division of Family Health Services in the NJ Department of Health in 2005-2014. All births/deaths included in our study are singletons with a clinically estimated gestational age of at least 20 weeks, no birth defects, and a conception date in 2005-2013 (based on gestational age and date of birth/death) to avoid the fixed-cohort bias (Strand, Barnett and Tong, 2011). A stillbirth was defined as a fetal death occurring on or after 20 weeks of gestation (e.g., Faiz et al. (2012); Green et al. (2015)). From these records, we extracted information on maternal educational attainment ( high school, high school, high school), maternal age category (, , , ), maternal race/ethnicity (non-Hispanic Black, Hispanic, non-Hispanic White), maternal tobacco use during pregnancy (yes, no), maternal residence at delivery (latitude, longitude), sex of the fetus (male, female), and the season and year of conception.
Due to the large number of live births in each year of analysis and the low prevalence of stillbirth, we opt for a case-control study design similar to Warren et al. (2020a) who investigated the impact of air pollution on very preterm birth. Additionally, we analyze each maternal race/ethnicity group separately to better understand the unique associations corresponding to each group instead of assuming common patterns of risk. Therefore, for each eligible stillbirth in the dataset, we select five controls (i.e., live births) while matching only on race/ethnicity. In Tables S1-S3 of the Supplement, we display summary information for each of the three race/ethnicity groups by stillbirth status.
We obtained daily estimates of ambient air pollution concentrations from 12 pollutants that covered a 12 by 12 kilometer grid across NJ from 2005-2014 with no spatial or temporal missingness. The pollutants include 24-hour average particulate matter with an aerodynamic diameter less than or equal to 2.5 and 10 microns (PM2.5 and PM10, respectively) and PM2.5 constituents nitrate (NO), ammonium (NH), sulfate (SO), elemental carbon (EC), and organic carbon (OC); 1-hour maximum carbon monoxide (CO), nitrogen dioxide (NO2), nitrogen oxides (NO), and sulfur dioxide (SO2); and 8-hour maximum ozone (O3). These estimates come from a recently introduced spatiotemporal data fusion model that combines measured ambient concentrations with deterministic output from the Community Multiscale Air Quality model (Senthilkumar et al., 2019). The latitude/longitude of the residence at delivery for each birth in the study was linked with the closest 12 by 12 kilometer grid cell centroid and weekly exposures for each pollutant (through gestational week 20) were calculated based on the date of birth and gestational age. This study was approved by the institutional review boards at Rowan and Yale Universities.
3 Critical Window Variable Selection for Mixtures
We introduce CWVSmix, a model for (i) identifying critical windows of exposure to mixtures of time-varying pollutants, (ii) estimating the time-varying relative importance of each individual pollutant and their first order interactions within the mixture, and (iii) quantifying the impact that the identified mixtures have on a health outcome. CWVSmix incorporates hierarchical Bayesian variable selection techniques for defining critical windows and identifying important pollutants within a time-varying mixture, and uses Gaussian processes to allow for smoothness/regularization when estimating a potentially high-dimensional set of parameters that vary across time.
Specifically, we extend CWVS (Warren et al., 2020a) from the single pollutant setting to accommodate multiple exposures and their interactions such that
| (3.1) | ||||
where is the binary adverse health outcome of interest observed for study participant ; is the total number of people in the study; is the probability of experiencing the adverse health outcome; is a vector of person-specific covariates/confounders with accompanying regression parameters ; represents exposure to the pollutant (), corresponding to person ’s spatial location, averaged over exposure period () corresponding to the relevant calendar date range specific to person ’s timing of exposure (e.g., calendar dates that align with the selected gestational week); are time-varying weight parameters that describe the main effect of pollutant in the mixture corresponding to exposure period ; describes the interaction effect between pollutants and on exposure period ; and describes the impact that the mixture of pollutants defined by
| (3.2) |
has on the probability of developing the adverse health outcome.
3.1 Time-Varying Weights
The weight parameters,
| (3.3) |
define the mixture on exposure period and vary across pollutant, interaction, and exposure period, allowing for the possibility that potentially important mixtures are shifting over time. These weights are defined to sum to one during each exposure period such that
for all , allowing the user to determine the relative importance of each term within the mixture. In order to enforce this constraint while simultaneously accounting for the possibility of temporal correlation between these parameters across time (e.g., similar mixture profiles may adversely impact health during nearby periods of pregnancy) and carrying out variable selection for the individual components, we model the weights using multivariate latent variables as
| (3.4) | ||||
where the denominator is defined as the sum of all individual numerator terms corresponding to exposure period such as
| (3.5) | ||||
and represents the indicator function which is equal to one when the input statement is true and is equal to zero otherwise.
The weight parameters in (3.3-3.5) are defined by latent variables where has the same form as in (3.3), and are modeled jointly as
| (3.6) | ||||
where is a length column vector of zeros; is an by identity matrix; represents the total number of main and interaction effect parameters at a single exposure period; represents the Kronecker product; and describes the correlation between the parameter vectors from different exposure periods with defining the level of temporal correlation. Large values of suggest that the mixtures are largely independent across time while small values indicate smoothness in the estimated mixtures. The latent variables are assumed to have a marginal variance equal to one due to identifiability issues caused by the truncation and summation of individual parameters shown in (3.4) and (3.5).
As a result of this specification, the entries of each vector individually sum to one, we allow for the possibility that the mixture weights are similar across exposure time, and variable selection for these parameters is performed simultaneously. Specifically, when a latent variable is , the corresponding weight parameter will be exactly zero based on the truncation seen in (3.4). This formulation also allows for the scenario that only a single pollutant is impacting the risk, as a main effect weight can exactly equal one when its latent variable is and all others are . Additionally an interaction weight can only be non-zero when its corresponding latent parameters is and the associated main effects are both larger than zero; satisfying the strong hierarchy interaction condition (Lim and Hastie, 2015).
3.2 Quantifying Mixture Risk
Because the weight parameters sum to one at each exposure period, the expression in (3.2) can be interpreted as a weighted average of exposures and interactions whose total impact on the outcome is described by . These parameters represent the global variable selection process which describes whether any of the pollutants or interactions have an impact on risk at a specific exposure period. The model for these risk magnitude parameters are specified using the original CWVS framework such that
These parameters are decomposed into continuous, , and binary, , time-varying components for the purposes of conducting temporally smoothed variable selection, where is controlled by the latent time-varying parameters through a probit regression (i.e., is the inverse cumulative distribution function of the standard normal distribution). In order to account for temporal correlation and cross-covariance between these parameters, and are jointly modeled using the linear model of coregionalization (Wackernagel, 2013) where
defines the smoothness of both processes over time. Finally, the variability and cross-covariance of the parameters are defined by for and . More information regarding the induced covariance between these parameters can be found in Warren et al. (2020a).
3.3 Interpreting Parameters
The impact on the log-odds of developing the adverse outcome for a one unit increase in each pollutant (i.e, moving from to for all ) during exposure period is given as
where the baseline pollution levels are involved in the expression due to the inclusion of interaction terms. Note that the main effect parameters are not involved in this expression because all of the weights on a given exposure period sum to one. Similarly, for individual pollutant ,
represents the increase in the log-odds for a one unit increase in pollutant during exposure period (i.e., moving from to for pollutant , with remaining the same for all ). Therefore, and represent the expected change in the log-odds when all exposures start at zero and the relevant exposure(s) are increased by one unit.
3.4 Prior Specifications
We finalize the model by selecting prior distributions for the remaining parameters. When possible, we favor weakly informative priors such that , , where is fixed at a large value and is the length of the vector (including an intercept); , where and are fixed at small values; , and , where is fixed at a large value.
4 Simulation Study
We design a simulation study to determine how CWVSmix performs in comparison to competing approaches with respect to (i) identification of the true critical window set, (ii) estimation of the important pollutants and interactions that comprise the time-varying mixtures, and (iii) estimation of time-varying mixture risk parameters.
For the study, we simulate data from the model in (3.1) where for all since estimation of the covariates/confounders is not the primary interest. The intercept is also set to zero so that approximately half of the simulated outcomes result in the adverse event, similar to the case-control design of our stillbirth application in NJ (Section 5). To investigate realistic settings, we simulate data that closely resemble data from the stillbirth analysis. Specifically, from (3.1) we set the number of exposure periods to 20 () and the number of pollutants to 5 (). The vector of exposures specific to person across all exposure periods and pollutants,
is randomly selected from the complete NJ dataset (i.e., including all race/ ethnicities). An entire exposure profile is selected from a real individual and assigned to a simulated individual in order to maintain the temporal correlation in exposures across time and the cross-covariance among pollutants; both of which would be difficult to mimic otherwise. For each simulated dataset, we use this process to create full exposure profiles for individuals, where around half of these people () develop the adverse outcome in each dataset. This matches the number of stillbirths seen in the non-Hispanic Black stillbirth analysis from the real data application.
From (3.1), we modify , , and to simulate data from different scenarios, with an interest in determining how the competing methods perform as the complexity of the time-varying mixtures increases. In Settings 1, 2, 3, 4, and 5, we assume that 1, 2, 3, 4, and 5 pollutants, respectively, are important drivers of the risk due to mixtures (i.e., those pollutants where ). We include Setting 1 (a single important pollutant) to determine how the methods perform if mixtures are not important features of the analysis and a single pollutant approach is optimal. Within each of these settings, we include sub-settings that determine the exact composition of the time-varying mixture (i.e., choice of and ) and control the level of smoothness of these parameters across exposure period.
In Sub-Setting A, we assume that the same pollutants and interactions are impacting the outcome at each exposure period and at the same magnitude during each period (i.e., is the same for each included in the critical window set). This represents complete smoothness of the weights across time. In Sub-Setting B, we allow for an intermediate level of smoothness by once again assuming that the same set of pollutants and interactions are important at each exposure period but allowing their relative contributions to the mixtures to change across time (i.e., only the non-zero entries of change for each in the critical window set). In Sub-Setting C, we assume that the set of important pollutants/interactions and their relative contributions to the mixtures, can entirely vary across exposure periods, with only the total number of important main effects consistent across time (i.e., the zero and non-zero entries of can change for each in the critical set, with only the total number of non-zero parameters consistent across time). This results in a complete lack of smoothness in these parameters across time.
The interaction pattern changes with each simulated dataset and is determined by the specific simulation setting. For example, in Setting 2 where only two main effect pollutants are non-zero, only the interaction between those two pollutants is eligible to be non-zero (i.e., strict hierarchy for interactions). Additionally, each eligible interaction term has a 50% chance of being active in a given simulated dataset. This allows there to be variability in the interaction pattern across the simulated datasets, resulting in a more realistic setup where only a subset of potential interactions are active. In Sub-Setting C, this selection process happens separately at each critical week so that the important interactions are varying across time. Across all settings, we simulate the non-zero weight parameters using a distribution to ensure that they sum to one.
One simulated realization of the weight parameters across all simulation study settings is shown in Figure 1 where the true critical window set includes five exposure periods that we arbitrarily define as the first five weeks of exposure for plotting purposes. We note that simulating data from Setting 1B is not possible with only one important pollutant at each critical week since we can not vary the weights among this single pollutant (i.e., the non-zero weight must always be equal to one). From Figure 1, it is clear how the complexity of the mixtures increase as we move from Settings 1 to 5 and how the weights become less smooth as we move from Sub-Settings A to C.














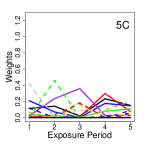
For each simulated dataset, we randomly select how many exposure periods will be part of the critical window set (i.e., between one and seven; e.g., ), the first exposure period where the risk becomes elevated (i.e., between one and when possible; e.g., ), and define the critical window set as the consecutive exposure periods beginning on . For the exposure periods selected in the critical window set, the corresponding parameters are fixed at , which is the sum of the posterior means of for all exposure periods identified in the critical window set from the non-Hispanic Black stillbirth NJ CWVSmix data analysis; providing realistic effect sizes for simulation. The remaining parameters are set to zero. The result is simulated datasets where the true critical window sets differ by length and location during the exposure period, with consecutively defined non-zero effect sizes during this period. A similar simulation framework was used in Warren et al. (2020a).
In addition to fitting CWVSmix to each simulated dataset, we also explore two comparable alternative approaches for identifying critical exposure windows when multiple time-varying exposures are available. Both methods represent modifications of (3.1) and are given as:
-
•
Equal Weight CWVS (EW): All pollutants and interactions are given the same weight at each exposure period (i.e., for all , , and ) and the original CWVS method is used to analyze the averaged time-varying exposures. Therefore, (3.1) becomes
-
•
LWQS CWVS: At each individual exposure period, WQS regression is used to estimate as and the original CWVS method is used to analyze the resulting weighted time-varying exposures. Therefore, (3.1) becomes
EW serves as a baseline method to determine the impact that ignoring the time-varying weighting has on various aspects of analysis. In our version of LWQS, we opt for CWVS instead of a traditional DLM that does not include a variable selection component in order to more fairly compare findings across methods. Comparing CWVSmix with LWQS in this study allows us to determine the benefits of jointly estimating the weights and risk parameters within a single framework that accounts for temporal correlation between parameters and variable selection of the weights (CWVSmix) as opposed to a more ad hoc two-stage model fitting approach (LWQS).
4.1 Simulation Study Results
For the CWVSmix prior distributions from Section 3.4, we select , , and . CWVSmix is fit using the CWVSmix R package (https://github.com/warrenjl/CWVSmix) with model fitting details provided in Section S1 of the Supplement. For CWVS, we select prior distributions as described in Warren et al. (2020a) and use the CWVS R package for model fitting (https://github.com/warrenjl/CWVS). For LWQS, we use the gWQS R package (Renzetti et al., 2020) for fitting the WQS regressions based on 100 bootstrap samples where we modify the original algorithm so that all samples are used in the final estimation instead of choosing a risk direction a priori. This adjustment was made based on the failure of the original algorithm across several simulated datasets to produce effects in the prespecified direction and is in line more recent WQS work which also avoids this directionality assumption (Colicino et al., 2020).
From each simulation setting, we generate 100 datasets, resulting in a total of 1,400 for analysis. For each dataset, we fit each competing method and collect 1,000 samples from the joint posterior distribution after removing the first 10,000 iterations during a burn-in period and thinning the next 10,000 samples by a factor of 10 to reduce posterior autocorrelation.
For each method and setting, we estimate the accuracy of a method to identify the true critical weeks as CW Accuracy =
where is the true global risk parameter at exposure period in simulated dataset and is the set of estimated critical window exposure periods. We define an exposure period as being in the critical window set if the posterior inclusion probability is larger than 0.50 and its exponentiated quantile-based 90% credible interval, excluding exact ones (i.e., conditional on ), is entirely above or below one. This critical window definition was shown to outperform competing options with respect to accuracy in Warren et al. (2020a).
We also calculate the average mean squared error (AMSE) of the estimators of and , averaged over all exposure time periods in the critical window set and pollutants/interactions, such as
where is the true set of exposure periods in the critical window set for simulated dataset ; represents the number of exposure periods in the critical window set; is the vector of simulated outcomes for dataset ; is the posterior mean of the main effect weight parameters when the corresponding risk magnitude parameter is non-zero (similar definition holds for the interaction parameters); and is the true main effect weight parameter (similar definition holds for the interaction parameters). When calculating AMSE for EW and LWQS, and are both replaced by for EW, and by and , respectively, for LWQS.
Next, we estimate the AMSE of the estimators of (odds ratio scale), averaged over all exposure time periods, such as
where is the posterior mean of the non-zero component of the risk parameter.
We also estimate the accuracy of CWVSmix to identify the important weight parameters across the critical window time periods. A main effect weight parameter is “selected” in the model if its posterior inclusion probability is larger than 0.50 while an interaction weight parameter is selected if this probability is larger than 0.125 and the corresponding main effect parameters are both selected. The threshold of 0.125 is based on the weight definition in (3.4), where , , and must each be greater than zero for to be non-zero; and the prior probability of each of these events is 0.50. For each analyzed dataset, we use this procedure to classify each weight parameter during the true critical weeks as selected or not and then compare these estimates with the true classifications to calculate accuracy. EW and LWQS do not include a variable selection component for the weights, so their performances can not be compared.
| CW Accuracy | AMSE() | AMSE() | |||||||||
| Setting | EW | LWQS | CWVSMix | EW | LWQS | CWVSMix | EW | LWQS | CWVSmix | ||
| 1A | 90.45 | 94.65 | 96.70 | 6.22 | 0.76 | 0.71 | 3.84 | 2.85 | 2.59 | ||
| 1C | 94.45 | 94.05 | 95.90 | 6.22 | 3.64 | 2.58 | 3.02 | 3.03 | 2.69 | ||
| 2A | 92.65 | 94.50 | 96.45 | 3.42 | 1.21 | 0.95 | 3.19 | 3.00 | 2.68 | ||
| 2B | 92.25 | 92.65 | 95.45 | 3.49 | 1.85 | 1.42 | 3.07 | 3.19 | 2.77 | ||
| 2C | 94.60 | 95.05 | 96.00 | 3.30 | 2.43 | 1.83 | 2.65 | 2.88 | 2.58 | ||
| 3A | 94.25 | 94.50 | 96.25 | 2.19 | 1.39 | 1.12 | 2.61 | 3.10 | 2.70 | ||
| 3B | 94.20 | 94.25 | 95.85 | 2.07 | 1.73 | 1.27 | 2.71 | 3.33 | 2.81 | ||
| 3C | 95.80 | 94.95 | 96.20 | 2.05 | 1.99 | 1.40 | 2.51 | 2.96 | 2.65 | ||
| 4A | 95.00 | 95.00 | 96.10 | 1.23 | 1.37 | 1.01 | 2.33 | 3.02 | 2.70 | ||
| 4B | 95.70 | 94.20 | 96.45 | 1.20 | 1.54 | 1.09 | 2.42 | 3.25 | 2.75 | ||
| 4C | 95.75 | 95.55 | 96.45 | 1.29 | 1.69 | 1.16 | 2.29 | 3.08 | 2.58 | ||
| 5A | 95.45 | 95.50 | 96.05 | 0.77 | 1.35 | 0.85 | 2.34 | 3.08 | 2.78 | ||
| 5B | 96.60 | 94.95 | 96.85 | 0.77 | 1.60 | 0.97 | 2.13 | 2.94 | 2.50 | ||
| 5C | 95.45 | 94.60 | 95.80 | 0.79 | 1.51 | 0.93 | 2.18 | 3.09 | 2.65 | ||
| Max. SE | 1.13 | 0.70 | 0.54 | 0.11 | 0.15 | 0.12 | 0.22 | 0.20 | 0.16 | ||
In Table 1 we display the results from the study across all methods and simulation settings. CWVSmix outperforms both competing methods in terms of accuracy of the identified critical windows across all settings. In terms of estimating the mixture weight parameters, use of CWVSmix results in reduced AMSE in Settings 1-4 (across all sub-settings). In Setting 5, where the proportion of all pollutants/interactions that are important becomes large, EW results in improved performance. This finding is sensible because as this proportion grows, it means that most of the weight parameters will be non-zero as shown in Figure 1. Because so many weights are non-zero, it becomes less likely that one or two pollutants will dominate the mixture. Therefore, a model that assumes all pollutants are contributing equally is likely a reasonable option. LWQS more often outperforms EW in terms of estimating the weight parameters while the accuracy results between the two methods are similar. CWVSmix results in improved estimation of the global risk parameters in Settings 1 and 2, and is outperformed in Settings 3-5 by EW. As the proportion of important pollutants/interactions grows, EW becomes a more efficient option for understanding the global impact of all pollutants. However, EW does not provide insights on the important drivers of this global risk like CWVSmix and LWQS.
| Effects | ||
| Setting | Main | Interaction |
| 1A | 94.26 (1.14) | 96.12 (1.00) |
| 1C | 78.20 (1.47) | 86.19 (1.22) |
| 2A | 86.45 (1.27) | 91.22 (0.98) |
| 2B | 80.52 (1.68) | 85.09 (1.57) |
| 2C | 69.91 (1.35) | 78.92 (1.34) |
| 3A | 75.03 (1.56) | 78.56 (1.85) |
| 3B | 78.71 (1.61) | 75.52 (2.00) |
| 3C | 69.15 (1.11) | 70.99 (1.45) |
| 4A | 72.64 (1.76) | 65.29 (1.51) |
| 4B | 73.94 (1.40) | 64.65 (1.57) |
| 4C | 67.35 (1.45) | 58.60 (1.43) |
| 5A | 67.55 (1.40) | 57.49 (1.30) |
| 5B | 70.01 (1.53) | 55.13 (1.09) |
| 5C | 72.59 (1.61) | 55.05 (1.02) |
In Table 2, the accuracy of the variable selection procedure for the critical week weight parameters is displayed across each simulation setting. Generally, the performance improves when the proportion of important pollutants/interactions is small. However, across all settings the accuracy is above 0.50, suggesting that the method is differentiating important and unimportant features with some success. Overall, the simulation study results suggest that CWVSmix offers an improved balance between critical window accuracy, mixture estimation, and risk estimation than the other methods and is relatively robust to the data simulation setting. Additionally, it consistently outperforms LWQS across all considered settings.
5 Stillbirth in New Jersey, 2005-2014
We analyze the impact that exposure to multiple ambient air pollutants has on the risk of stillbirth using the data from NJ, 2005-2014, previously described in Section 2. Stillbirth is defined as the death of a baby before or during a delivery occurring after 20 completed weeks of gestation and impacts around 1 in 160 births in the United States (Hoyert and Gregory, 2016). Some known maternal risk factors include Black race, 35 years of age and older, low socioeconomic status, and smoking. Past studies have investigated the link between stillbirth and exposure to various indoor and ambient air pollution with somewhat mixed findings, though the evidence suggests further studies are warranted; see Pope et al. (2010), Siddika et al. (2016), and Bekkar et al. (2020) for recent reviews.
First, we conduct single pollutant analyses using CWVS, where each of the 12 pollutants in the study are analyzed individually and critical windows of exposure are identified. These analyses are conducted for each pollutant and race/ethnicity (i.e., non-Hispanic Black, Hispanic, and non-Hispanic White) separately. Important individual pollutants identified by the single pollutant analyses are then used in the multipollutant/mixture approaches for critical window identification by applying CWVSmix and the competing methods from Section 4 to the data.
We also include an additional competing method which uses principal component analyses (PCAs) to reduce the dimensionality of the exposures prior to analysis. Specifically, at a selected gestational week, we apply PCA to the standardized exposures from all pollutants and interactions (across all individuals in the study) and extract factor loadings from the first principal component (i.e., pollutant/interaction- and gestational week-specific weights). Using these factor loadings, we construct the factor score (i.e., weighted exposure) for each individual. This process is repeated separately at each gestational week, resulting in 20 weighted exposures for each individual. We then use CWVS to analyze the impact that these standardized PCA weighted exposures have on stillbirth risk. This method differs from CWVSmix and LWQS because the weights are not forced to sum to one, and the weight values are determined by correlation between pollutants and do not consider associations with the stillbirth outcome.
For all models, the outcome is an indicator of a stillbirth for pregnancy and we select the first exposure weeks since each included pregnancy had a gestational age of at least 20 weeks. In total, we consider average weekly exposures to the pollutants described in Section 2 (i.e., CO, EC, NH, NO2, NO, NO, O3, OC, PM10, PM2.5, SO2, and SO). The covariates included in include categorical variables for the year and season of conception, an indicator of maternal tobacco use during pregnancy (yes vs. no), maternal age category ([25, 30) vs. 25, [30, 35) vs. 25, 35 vs. 25), maternal educational attainment (high school vs. high school, high school vs. high school), sex of the fetus (male vs. female), and the latitude/longitude of the maternal residence at delivery to account for unexplained spatial variation in stillbirth risk.
Average weekly air pollution exposures were scaled by subtracting off the median value and dividing by the interquartile range (IQR) on a specific gestational week of pregnancy, resulting in an IQR interpretation for the risk parameters. Specifically, an IQR increase from the median exposure level of each pollutant during gestational week corresponds to an odds ratio of with respect to stillbirth risk for EW, LWQS, and CWVSmix (see Section 3.3 for more information). For PCA, because the weight parameters do not sum to one, the corresponding effect is given as
where are the PCA main effect weights (similar definition holds for the interaction parameters). In Figures S1-S3 of the Supplement, we display the IQRs for each pollutant and race/ethnicity across every gestational week for the purposes of interpretation.
For CWVSmix and each application of CWVS, we collect 10,000 posterior samples from the joint posterior distribution after discarding the first 10,000 during a burn-in period and thinning the next 100,000 by a factor of 10 to reduce posterior autocorrelation. Trace plots of individual parameters and the Geweke diagnostic (Geweke et al., 1991) were used to assess convergence of each model, with no obvious signs of non-convergence observed. Prior distributions and model fitting details match those from Section 4.1.
5.1 Data Application Results
In Figures S4-S9 of the Supplement, we display the single pollutant results for all race/ethnicity analyses and individual pollutants. Similar to Warren et al. (2020a), we present posterior means and quantile-based 95% credible intervals for , along with posterior inclusion probabilities at each gestational week (i.e., ). For non-Hispanic Black mothers, increased exposure during weeks 2 (PM2.5), 16 (NO), 17 (NH, NO), and 20 (NH, SO), is associated with elevated risk of stillbirth. The results for Hispanic and non-Hispanic White mothers are null across all pollutants and gestational weeks. Based on this initial screening, we use these five pollutants in the subsequent multipollutant modeling.















In Tables S4-S6 of the Supplement, we display posterior inference for the regression parameters across each race/ethnicity analysis using CWVSmix. Consistent findings across the groups suggest that older mothers with less educational attainment are more likely to have a stillbirth; male babies are also more likely to result in a stillbirth. While tobacco use during pregnancy had an odds ratio greater than one in each analysis, only for non-Hispanic White mothers did its credible interval exclude one.
| Pregnancy Week | ||||
| Effect | 2 | 16 | 17 | 20 |
| NH | 61.24 | 48.24 | 69.09 | 64.81 |
| NO | 57.37 | 47.90 | 58.01 | 32.66 |
| NO | 52.79 | 69.46 | 40.38 | 39.19 |
| PM2.5 | 62.17 | 40.79 | 42.15 | 42.70 |
| SO | 44.36 | 34.51 | 46.79 | 61.45 |
| NH NO | 14.30 | 10.18 | 18.79 | 9.61 |
| NH NO | 15.00 | 16.12 | 14.89 | 13.76 |
| NH PM2.5 | 24.39 | 10.65 | 13.41 | 15.20 |
| NH SO | 13.30 | 6.91 | 11.90 | 15.79 |
| NO NO | 16.88 | 13.45 | 10.46 | 7.53 |
| NO PM2.5 | 21.23 | 10.56 | 14.12 | 8.69 |
| NO SO | 15.55 | 10.18 | 17.57 | 10.80 |
| NO PM2.5 | 16.38 | 16.95 | 9.50 | 11.29 |
| NO SO | 14.29 | 9.62 | 9.65 | 15.27 |
| PM2.5 SO | 13.22 | 6.62 | 8.94 | 12.41 |
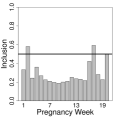
In Figures 2 and 3, and Figure S10 in the Supplement, we display the results by race/ethnicity for each of the different multipollutant approaches (i.e., estimated risk parameters, posterior inclusion probabilities, and estimated weight parameters where applicable). As in the simulation study and Warren et al. (2020a), we present inference for the risk and weight parameters on a specific exposure period given that it was included in the model (i.e., ). For non-Hispanic Black mothers, all methods indicate that elevated exposures during gestational weeks 2 and 17 are associated with increased risk of stillbirth. All methods other than PCA include week 20 in the critical set, while CWVSmix and LWQS additionally include week 16.
To better understand the important drivers of this risk, we present the posterior inclusion probabilities (see Section 4.1) for the weights during each of the estimated critical weeks from CWVSmix in Table 3. Recall that no other method performs variable selection at this level of the model. During gestational week 2, the estimated mixture profile is mainly driven by NH, NO, NO, PM2.5, and many of the first order interactions. In week 16, the risk is driven by NO, while in 17 it is due to NH, NO, and their interaction. NH, SO, and their interaction dominate the risk on week 20. The estimated weights from LWQS often align with those from CWVSmix, though without the ability to carry out variable selection it becomes more difficult to interpret the findings. The PCA method gives similar weights to all pollutants and is consistent across all race/ethnicity groups as it does not consider the outcome when defining the weights.





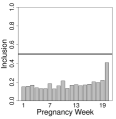










For Hispanic mothers (Figure 2), EW, PCA, and CWVSmix all suggest no significant associations, while LWQS indicates a protective association on gestational week 13, and an adverse association during weeks 9, 10, 19, and 20. No weeks are identified as part of a critical window set for non-Hispanic White mothers using any of the methods (Figure S10 of the Supplement).
6 Discussion
In this work, we introduced CWVSmix, a method to simultaneously identify critical windows of exposure to multiple time-varying exposures, determine the time-varying relative importance of individual pollutants/interactions within the mixture, and estimate risk associations for exposure mixtures. Through a simulation study, we showed that CWVSmix offers the best balance of performance across each of these areas with respect to the competing methods. In particular, LWQS, which attempts to estimate these mixture weights and associations at each exposure time period separately, is shown to produce critical window identification accuracy, estimates of mixture weights, and estimates of risk that are always less optimal than CWVSmix. This suggests that jointly estimating the weights and risk parameters and accounting for temporal correlation in exposures while identifying critical windows may be important features of an analysis. Additionally, the variable selection procedure introduced for the weight parameters allows for a more intuitive explanation of the drivers of risk during a specific exposure period.
By introducing weights that sum to one and are between zero and one, we assume that (i) pollutants impact the risk in the same direction on a given exposure period and (ii) main and interaction effects are in the same direction. For (i), we do not enforce that the global risk parameter must be positive or negative, which avoids bias in these estimates when that assumption is violated. For (ii), we anticipate that if two main effects have adverse (or protective) impacts on risk, then their interaction will either intensify this relationship or be negligible. The benefit of this formulation is the interpretability of the findings when describing the composition of a harmful mixture, similar to source apportionment methods, and that it can effectively collapse to a single pollutant model given that a main effect weight can be exactly equal to one.
In our application to stillbirth risk due to multiple ambient air pollution exposures, we found elevated risk of stillbirth for non-Hispanic Black mothers who experience higher concentrations of NH, NO, NO, PM2.5, and SO. Previous work in this area has led to mixed findings regarding the harmful pollutants and exposure periods, with several works relying on single pollutant approaches fit across multiple exposure periods. Using CWVSmix, we can now more accurately identify the critical exposure periods while accounting for exposure mixtures. Additionally, use of the fused air pollution estimates gives us the opportunity to investigate less commonly studied pollutants.
The differences observed between the competing methods in the data application must be interpreted in the context of the simulation study conclusions when determining which results are likely most reliable. Findings in Table 1 from the simulation study, which was designed to resemble the NJ stillbirth data application, indicate that CWVSmix is more likely to accurately identify the true critical window set, yield improved estimates of the weight parameters, and yield improved estimates of the risk parameters when the proportion of important pollutants/interactions is relatively small. The variable selection findings from the NJ stillbirth analysis in Table 3 suggest that the data application most closely resembles Settings 1 and 2 from the simulation study, where CWVSmix outperformed the competing methods across all metrics (Table 1). Additionally, the protective association estimated using LWQS in the Hispanic data application (but not CWVSmix) is likely due to the lack of smoothness in the estimated weights, and provides some additional support to suggest that CWVSmix may yield more reliable results in this case. Because WQS is fit separately at each exposure period in the LWQS algorithm, the model remains unadjusted for the other time-varying exposures when the weight parameters are estimated. This may also contribute to the findings observed in the simulation study and NJ data applications.
The ambient air pollution estimates from the data fusion model represent a major strength of this work. Typically, only a handful of regularly monitored pollutants are able to be included in a particular analysis, depending on the timeframe and spatial location of the study. In our case, we had excellent space-time coverage of our estimates, allowing us to investigate associations that are less common, with increased sample sizes. However, for some of the pollutants (e.g., PM2.5 constituents) the measurements in space-time are limited and the model-derived estimates further away from the measurements may be more biased than those near the measurements. In addition, the SO2 estimates have substantial uncertainty due to the plume nature of these pollutant fields that is difficult to capture with either monitoring or modeling.
As is typically the case when linking environmental exposures to birth records data, we used residence at delivery to define the spatial location of data linkage. This may introduce measurement error for some participants in the study, though Warren et al. (2017) showed that critical window identification is relatively robust to this type of error. In (3.6), we assume independence a priori between the weight parameters within an exposure time period due to the potentially large dimension of this matrix (i.e., by ) as the number of pollutants increases. Future methods work that could reduce this dimensionality, possibly through incorporation of auxiliary information about the chemicals in a mixture, may be able to accommodate this correlation (Reich et al., 2020). Future work may also want to consider interactions between pollutants on different exposure periods, which will require further methodological extensions.
When determining which method to use in future multipollutant applications, we recommend designing a simulation study based on important features of the analysis dataset and comparing the competing approaches. Additionally, computing times may be important to consider based on the size of the dataset. In Table S7 of the Supporting Information, we show the average computing times in minutes for each of the methods in the simulation study. EW, which relies on CWVS, is clearly the fastest algorithm, followed by CWVSmix and LWQS. The LWQS run times are impacted by the number of bootstrap samples requested and the number of exposure periods where the WQS algorithm must be applied. Overall, CWVSmix offers an intuitive and interpretable method for analyzing the impact of multiple time-varying exposures on an adverse health outcome.
References
- Antonelli et al. (2020) {barticle}[author] \bauthor\bsnmAntonelli, \bfnmJoseph\binitsJ., \bauthor\bsnmMazumdar, \bfnmMaitreyi\binitsM., \bauthor\bsnmBellinger, \bfnmDavid\binitsD., \bauthor\bsnmChristiani, \bfnmDavid\binitsD., \bauthor\bsnmWright, \bfnmRobert\binitsR., \bauthor\bsnmCoull, \bfnmBrent\binitsB. \betalet al. (\byear2020). \btitleEstimating the health effects of environmental mixtures using Bayesian semiparametric regression and sparsity inducing priors. \bjournalAnnals of Applied Statistics \bvolume14 \bpages257–275. \endbibitem
- Bekkar et al. (2020) {barticle}[author] \bauthor\bsnmBekkar, \bfnmBruce\binitsB., \bauthor\bsnmPacheco, \bfnmSusan\binitsS., \bauthor\bsnmBasu, \bfnmRupa\binitsR. and \bauthor\bsnmDeNicola, \bfnmNathaniel\binitsN. (\byear2020). \btitleAssociation of air pollution and heat exposure with preterm birth, low birth weight, and stillbirth in the US: a systematic review. \bjournalJAMA Network Open \bvolume3 \bpagese208243–e208243. \endbibitem
- Bello et al. (2017) {barticle}[author] \bauthor\bsnmBello, \bfnmGhalib A\binitsG. A., \bauthor\bsnmArora, \bfnmManish\binitsM., \bauthor\bsnmAustin, \bfnmChristine\binitsC., \bauthor\bsnmHorton, \bfnmMegan K\binitsM. K., \bauthor\bsnmWright, \bfnmRobert O\binitsR. O. and \bauthor\bsnmGennings, \bfnmChris\binitsC. (\byear2017). \btitleExtending the Distributed Lag Model framework to handle chemical mixtures. \bjournalEnvironmental Research \bvolume156 \bpages253–264. \endbibitem
- Brunekreef and Holgate (2002) {barticle}[author] \bauthor\bsnmBrunekreef, \bfnmBert\binitsB. and \bauthor\bsnmHolgate, \bfnmStephen T\binitsS. T. (\byear2002). \btitleAir pollution and health. \bjournalThe Lancet \bvolume360 \bpages1233–1242. \endbibitem
- Carrico et al. (2015) {barticle}[author] \bauthor\bsnmCarrico, \bfnmCaroline\binitsC., \bauthor\bsnmGennings, \bfnmChris\binitsC., \bauthor\bsnmWheeler, \bfnmDavid C\binitsD. C. and \bauthor\bsnmFactor-Litvak, \bfnmPam\binitsP. (\byear2015). \btitleCharacterization of weighted quantile sum regression for highly correlated data in a risk analysis setting. \bjournalJournal of Agricultural, Biological, and Environmental Statistics \bvolume20 \bpages100–120. \endbibitem
- Chang et al. (2015) {barticle}[author] \bauthor\bsnmChang, \bfnmHoward H\binitsH. H., \bauthor\bsnmWarren, \bfnmJoshua L\binitsJ. L., \bauthor\bsnmDarrow, \bfnmLnydsey A\binitsL. A., \bauthor\bsnmReich, \bfnmBrian J\binitsB. J. and \bauthor\bsnmWaller, \bfnmLance A\binitsL. A. (\byear2015). \btitleAssessment of critical exposure and outcome windows in time-to-event analysis with application to air pollution and preterm birth study. \bjournalBiostatistics \bvolume16 \bpages509–521. \endbibitem
- Chen, Mukherjee and Berrocal (2019) {barticle}[author] \bauthor\bsnmChen, \bfnmYin-Hsiu\binitsY.-H., \bauthor\bsnmMukherjee, \bfnmBhramar\binitsB. and \bauthor\bsnmBerrocal, \bfnmVeronica J\binitsV. J. (\byear2019). \btitleDistributed lag interaction models with two pollutants. \bjournalJournal of the Royal Statistical Society: Series C (Applied Statistics) \bvolume68 \bpages79–97. \endbibitem
- Colicino et al. (2020) {barticle}[author] \bauthor\bsnmColicino, \bfnmElena\binitsE., \bauthor\bsnmPedretti, \bfnmNicolo Foppa\binitsN. F., \bauthor\bsnmBusgang, \bfnmStefanie A\binitsS. A. and \bauthor\bsnmGennings, \bfnmChris\binitsC. (\byear2020). \btitlePer-and poly-fluoroalkyl substances and bone mineral density: Results from the Bayesian weighted quantile sum regression. \bjournalEnvironmental Epidemiology (Philadelphia, Pa.) \bvolume4. \endbibitem
- Davalos et al. (2017) {barticle}[author] \bauthor\bsnmDavalos, \bfnmAngel D\binitsA. D., \bauthor\bsnmLuben, \bfnmThomas J\binitsT. J., \bauthor\bsnmHerring, \bfnmAmy H\binitsA. H. and \bauthor\bsnmSacks, \bfnmJason D\binitsJ. D. (\byear2017). \btitleCurrent approaches used in epidemiologic studies to examine short-term multipollutant air pollution exposures. \bjournalAnnals of Epidemiology \bvolume27 \bpages145–153. \endbibitem
- Dominici et al. (2010) {barticle}[author] \bauthor\bsnmDominici, \bfnmFrancesca\binitsF., \bauthor\bsnmPeng, \bfnmRoger D\binitsR. D., \bauthor\bsnmBarr, \bfnmChristopher D\binitsC. D. and \bauthor\bsnmBell, \bfnmMichelle L\binitsM. L. (\byear2010). \btitleProtecting human health from air pollution: shifting from a single-pollutant to a multi-pollutant approach. \bjournalEpidemiology (Cambridge, Mass.) \bvolume21 \bpages187. \endbibitem
- Faiz et al. (2012) {barticle}[author] \bauthor\bsnmFaiz, \bfnmAmbarina S\binitsA. S., \bauthor\bsnmRhoads, \bfnmGeorge G\binitsG. G., \bauthor\bsnmDemissie, \bfnmKitaw\binitsK., \bauthor\bsnmKruse, \bfnmLakota\binitsL., \bauthor\bsnmLin, \bfnmYong\binitsY. and \bauthor\bsnmRich, \bfnmDavid Q\binitsD. Q. (\byear2012). \btitleAmbient air pollution and the risk of stillbirth. \bjournalAmerican Journal of Epidemiology \bvolume176 \bpages308–316. \endbibitem
- Ferrari and Dunson (2019) {barticle}[author] \bauthor\bsnmFerrari, \bfnmFederico\binitsF. and \bauthor\bsnmDunson, \bfnmDavid B\binitsD. B. (\byear2019). \btitleIdentifying main effects and interactions among exposures using Gaussian processes. \bjournalarXiv preprint arXiv:1911.01910. \endbibitem
- Ferrari and Dunson (2020) {barticle}[author] \bauthor\bsnmFerrari, \bfnmFederico\binitsF. and \bauthor\bsnmDunson, \bfnmDavid B\binitsD. B. (\byear2020). \btitleBayesian factor analysis for inference on interactions. \bjournalJournal of the American Statistical Association \bpages1–12. \endbibitem
- Gennings et al. (2020) {barticle}[author] \bauthor\bsnmGennings, \bfnmChris\binitsC., \bauthor\bsnmCurtin, \bfnmPaul\binitsP., \bauthor\bsnmBello, \bfnmGhalib\binitsG., \bauthor\bsnmWright, \bfnmRobert\binitsR., \bauthor\bsnmArora, \bfnmManish\binitsM. and \bauthor\bsnmAustin, \bfnmChristine\binitsC. (\byear2020). \btitleLagged WQS regression for mixtures with many components. \bjournalEnvironmental Research \bvolume86 \bpages109529. \endbibitem
- Geweke et al. (1991) {bbook}[author] \bauthor\bsnmGeweke, \bfnmJohn\binitsJ. \betalet al. (\byear1991). \btitleEvaluating the Accuracy of Sampling-based Approaches to the Calculation of Posterior Moments \bvolume196. \bpublisherFederal Reserve Bank of Minneapolis, Research Department Minneapolis, MN, USA. \endbibitem
- Green et al. (2015) {barticle}[author] \bauthor\bsnmGreen, \bfnmRochelle\binitsR., \bauthor\bsnmSarovar, \bfnmVarada\binitsV., \bauthor\bsnmMalig, \bfnmBrian\binitsB. and \bauthor\bsnmBasu, \bfnmRupa\binitsR. (\byear2015). \btitleAssociation of stillbirth with ambient air pollution in a California cohort study. \bjournalAmerican Journal of Epidemiology \bvolume181 \bpages874–882. \endbibitem
- Hoyert and Gregory (2016) {barticle}[author] \bauthor\bsnmHoyert, \bfnmDonna L\binitsD. L. and \bauthor\bsnmGregory, \bfnmElizabeth CW\binitsE. C. (\byear2016). \btitleCause of fetal death: data from the fetal death report, 2014. \endbibitem
- Kampa and Castanas (2008) {barticle}[author] \bauthor\bsnmKampa, \bfnmMarilena\binitsM. and \bauthor\bsnmCastanas, \bfnmElias\binitsE. (\byear2008). \btitleHuman health effects of air pollution. \bjournalEnvironmental Pollution \bvolume151 \bpages362–367. \endbibitem
- Lim and Hastie (2015) {barticle}[author] \bauthor\bsnmLim, \bfnmMichael\binitsM. and \bauthor\bsnmHastie, \bfnmTrevor\binitsT. (\byear2015). \btitleLearning interactions via hierarchical group-lasso regularization. \bjournalJournal of Computational and Graphical Statistics \bvolume24 \bpages627–654. \endbibitem
- Liu et al. (2018a) {barticle}[author] \bauthor\bsnmLiu, \bfnmShelley H\binitsS. H., \bauthor\bsnmBobb, \bfnmJennifer F\binitsJ. F., \bauthor\bsnmLee, \bfnmKyu Ha\binitsK. H., \bauthor\bsnmGennings, \bfnmChris\binitsC., \bauthor\bsnmClaus Henn, \bfnmBirgit\binitsB., \bauthor\bsnmBellinger, \bfnmDavid\binitsD., \bauthor\bsnmAustin, \bfnmChristine\binitsC., \bauthor\bsnmSchnaas, \bfnmLourdes\binitsL., \bauthor\bsnmTellez-Rojo, \bfnmMartha M\binitsM. M., \bauthor\bsnmHu, \bfnmHoward\binitsH. \betalet al. (\byear2018a). \btitleLagged kernel machine regression for identifying time windows of susceptibility to exposures of complex mixtures. \bjournalBiostatistics \bvolume19 \bpages325–341. \endbibitem
- Liu et al. (2018b) {barticle}[author] \bauthor\bsnmLiu, \bfnmShelley H\binitsS. H., \bauthor\bsnmBobb, \bfnmJennifer F\binitsJ. F., \bauthor\bsnmClaus Henn, \bfnmBirgit\binitsB., \bauthor\bsnmSchnaas, \bfnmLourdes\binitsL., \bauthor\bsnmTellez-Rojo, \bfnmMartha M\binitsM. M., \bauthor\bsnmGennings, \bfnmChris\binitsC., \bauthor\bsnmArora, \bfnmManish\binitsM., \bauthor\bsnmWright, \bfnmRobert O\binitsR. O., \bauthor\bsnmCoull, \bfnmBrent A\binitsB. A. and \bauthor\bsnmWand, \bfnmMatt P\binitsM. P. (\byear2018b). \btitleModeling the health effects of time-varying complex environmental mixtures: mean field variational Bayes for lagged kernel machine regression. \bjournalEnvironmetrics \bvolume29 \bpagese2504. \endbibitem
- Pope et al. (2010) {barticle}[author] \bauthor\bsnmPope, \bfnmDaniel P\binitsD. P., \bauthor\bsnmMishra, \bfnmVinod\binitsV., \bauthor\bsnmThompson, \bfnmLisa\binitsL., \bauthor\bsnmSiddiqui, \bfnmAmna Rehana\binitsA. R., \bauthor\bsnmRehfuess, \bfnmEva A\binitsE. A., \bauthor\bsnmWeber, \bfnmMartin\binitsM. and \bauthor\bsnmBruce, \bfnmNigel G\binitsN. G. (\byear2010). \btitleRisk of low birth weight and stillbirth associated with indoor air pollution from solid fuel use in developing countries. \bjournalEpidemiologic Reviews \bvolume32 \bpages70–81. \endbibitem
- Reich et al. (2020) {barticle}[author] \bauthor\bsnmReich, \bfnmBrian J\binitsB. J., \bauthor\bsnmGuan, \bfnmYawen\binitsY., \bauthor\bsnmFourches, \bfnmDenis\binitsD., \bauthor\bsnmWarren, \bfnmJoshua L\binitsJ. L., \bauthor\bsnmSarnat, \bfnmStefanie E\binitsS. E., \bauthor\bsnmChang, \bfnmHoward H\binitsH. H. \betalet al. (\byear2020). \btitleIntegrative statistical methods for exposure mixtures and health. \bjournalAnnals of Applied Statistics \bvolume14 \bpages1945–1963. \endbibitem
- Renzetti et al. (2020) {bmanual}[author] \bauthor\bsnmRenzetti, \bfnmStefano\binitsS., \bauthor\bsnmCurtin, \bfnmPaul\binitsP., \bauthor\bsnmJust, \bfnmAllan C\binitsA. C., \bauthor\bsnmBello, \bfnmGhalib\binitsG. and \bauthor\bsnmGennings, \bfnmChris\binitsC. (\byear2020). \btitlegWQS: Generalized Weighted Quantile Sum Regression \bnoteR package version 3.0.0. \endbibitem
- Senthilkumar et al. (2019) {barticle}[author] \bauthor\bsnmSenthilkumar, \bfnmNiru\binitsN., \bauthor\bsnmGilfether, \bfnmMark\binitsM., \bauthor\bsnmMetcalf, \bfnmFrancesca\binitsF., \bauthor\bsnmRussell, \bfnmArmistead G\binitsA. G., \bauthor\bsnmMulholland, \bfnmJames A\binitsJ. A. and \bauthor\bsnmChang, \bfnmHoward H\binitsH. H. (\byear2019). \btitleApplication of a Fusion Method for Gas and Particle Air Pollutants between Observational Data and Chemical Transport Model Simulations Over the Contiguous United States for 2005–2014. \bjournalInternational Journal of Environmental Research and Public Health \bvolume16 \bpages3314. \endbibitem
- Siddika et al. (2016) {barticle}[author] \bauthor\bsnmSiddika, \bfnmNazeeba\binitsN., \bauthor\bsnmBalogun, \bfnmHamudat A\binitsH. A., \bauthor\bsnmAmegah, \bfnmAdeladza K\binitsA. K. and \bauthor\bsnmJaakkola, \bfnmJouni JK\binitsJ. J. (\byear2016). \btitlePrenatal ambient air pollution exposure and the risk of stillbirth: systematic review and meta-analysis of the empirical evidence. \bjournalOccupational and Environmental Medicine \bvolume73 \bpages573–581. \endbibitem
- Stieb et al. (2012) {barticle}[author] \bauthor\bsnmStieb, \bfnmDavid M\binitsD. M., \bauthor\bsnmChen, \bfnmLi\binitsL., \bauthor\bsnmEshoul, \bfnmMaysoon\binitsM. and \bauthor\bsnmJudek, \bfnmStan\binitsS. (\byear2012). \btitleAmbient air pollution, birth weight and preterm birth: a systematic review and meta-analysis. \bjournalEnvironmental Research \bvolume117 \bpages100–111. \endbibitem
- Strand, Barnett and Tong (2011) {barticle}[author] \bauthor\bsnmStrand, \bfnmLinn Beate\binitsL. B., \bauthor\bsnmBarnett, \bfnmAdrian G\binitsA. G. and \bauthor\bsnmTong, \bfnmShilu\binitsS. (\byear2011). \btitleMethodological challenges when estimating the effects of season and seasonal exposures on birth outcomes. \bjournalBMC Medical Research Methodology \bvolume11 \bpages49. \endbibitem
- Wackernagel (2013) {bbook}[author] \bauthor\bsnmWackernagel, \bfnmHans\binitsH. (\byear2013). \btitleMultivariate Geostatistics: An Introduction with Applications. \bpublisherSpringer Science & Business Media. \endbibitem
- Warren et al. (2012a) {barticle}[author] \bauthor\bsnmWarren, \bfnmJoshua\binitsJ., \bauthor\bsnmFuentes, \bfnmMontserrat\binitsM., \bauthor\bsnmHerring, \bfnmAmy\binitsA. and \bauthor\bsnmLanglois, \bfnmPeter\binitsP. (\byear2012a). \btitleBayesian spatial–temporal model for cardiac congenital anomalies and ambient air pollution risk assessment. \bjournalEnvironmetrics \bvolume23 \bpages673–684. \endbibitem
- Warren et al. (2012b) {barticle}[author] \bauthor\bsnmWarren, \bfnmJoshua\binitsJ., \bauthor\bsnmFuentes, \bfnmMontserrat\binitsM., \bauthor\bsnmHerring, \bfnmAmy\binitsA. and \bauthor\bsnmLanglois, \bfnmPeter\binitsP. (\byear2012b). \btitleSpatial-temporal modeling of the association between air pollution exposure and preterm birth: identifying critical windows of exposure. \bjournalBiometrics \bvolume68 \bpages1157–1167. \endbibitem
- Warren et al. (2016) {barticle}[author] \bauthor\bsnmWarren, \bfnmJoshua L\binitsJ. L., \bauthor\bsnmStingone, \bfnmJeanette A\binitsJ. A., \bauthor\bsnmHerring, \bfnmAmy H\binitsA. H., \bauthor\bsnmLuben, \bfnmThomas J\binitsT. J., \bauthor\bsnmFuentes, \bfnmMontserrat\binitsM., \bauthor\bsnmAylsworth, \bfnmArthur S\binitsA. S., \bauthor\bsnmLanglois, \bfnmPeter H\binitsP. H., \bauthor\bsnmBotto, \bfnmLorenzo D\binitsL. D., \bauthor\bsnmCorrea, \bfnmAdolfo\binitsA. and \bauthor\bsnmOlshan, \bfnmAndrew F\binitsA. F. (\byear2016). \btitleBayesian multinomial probit modeling of daily windows of susceptibility for maternal PM2.5 exposure and congenital heart defects. \bjournalStatistics in Medicine \bvolume35 \bpages2786–2801. \endbibitem
- Warren et al. (2017) {barticle}[author] \bauthor\bsnmWarren, \bfnmJoshua L\binitsJ. L., \bauthor\bsnmSon, \bfnmJi-Young\binitsJ.-Y., \bauthor\bsnmPereira, \bfnmGavin\binitsG., \bauthor\bsnmLeaderer, \bfnmBrian P\binitsB. P. and \bauthor\bsnmBell, \bfnmMichelle L\binitsM. L. (\byear2017). \btitleInvestigating the Impact of Maternal Residential Mobility on Identifying Critical Windows of Susceptibility to Ambient Air Pollution During Pregnancy. \bjournalAmerican Journal of Epidemiology \bvolume187 \bpages992–1000. \endbibitem
- Warren et al. (2020a) {barticle}[author] \bauthor\bsnmWarren, \bfnmJoshua L\binitsJ. L., \bauthor\bsnmKong, \bfnmWenjing\binitsW., \bauthor\bsnmLuben, \bfnmThomas J\binitsT. J. and \bauthor\bsnmChang, \bfnmHoward H\binitsH. H. (\byear2020a). \btitleCritical window variable selection: estimating the impact of air pollution on very preterm birth. \bjournalBiostatistics \bvolume21 \bpages790–806. \endbibitem
- Warren et al. (2020b) {barticle}[author] \bauthor\bsnmWarren, \bfnmJoshua L\binitsJ. L., \bauthor\bsnmLuben, \bfnmThomas J\binitsT. J., \bauthor\bsnmChang, \bfnmHoward H\binitsH. H. \betalet al. (\byear2020b). \btitleA spatially varying distributed lag model with application to an air pollution and term low birth weight study. \bjournalJournal of the Royal Statistical Society Series C \bvolume69 \bpages681–696. \endbibitem
- Wilson et al. (2017) {barticle}[author] \bauthor\bsnmWilson, \bfnmAnder\binitsA., \bauthor\bsnmChiu, \bfnmYueh-Hsiu Mathilda\binitsY.-H. M., \bauthor\bsnmHsu, \bfnmHsiao-Hsien Leon\binitsH.-H. L., \bauthor\bsnmWright, \bfnmRobert O\binitsR. O., \bauthor\bsnmWright, \bfnmRosalind J\binitsR. J. and \bauthor\bsnmCoull, \bfnmBrent A\binitsB. A. (\byear2017). \btitleBayesian distributed lag interaction models to identify perinatal windows of vulnerability in children’s health. \bjournalBiostatistics \bvolume18 \bpages537–552. \endbibitem
- Wilson et al. (2019) {barticle}[author] \bauthor\bsnmWilson, \bfnmAnder\binitsA., \bauthor\bsnmHsu, \bfnmHsiao-Hsien Leon\binitsH.-H. L., \bauthor\bsnmChiu, \bfnmYueh-Hsiu Mathilda\binitsY.-H. M., \bauthor\bsnmWright, \bfnmRobert O\binitsR. O., \bauthor\bsnmWright, \bfnmRosalind J\binitsR. J. and \bauthor\bsnmCoull, \bfnmBrent A\binitsB. A. (\byear2019). \btitleKernel Machine and Distributed Lag Models for Assessing Windows of Susceptibility to Mixtures of Time-Varying Environmental Exposures in Children’s Health Studies. \bjournalarXiv preprint arXiv:1904.12417. \endbibitem