Creating Language-driven Spatial Variations of Icon Images
Abstract
Editing 2D icon images can require significant manual effort from designers. It involves manipulating multiple geometries while maintaining the logical/physical coherence of the objects depicted in the image. Previous language-driven image editing methods can change the texture and geometry of objects in the image but fail at producing spatial variations, i.e. modifying spatial relations between objects while maintaining their identities. We present a language-driven editing method that can produce spatial variations of icon images. Our method takes in an icon image along with a user’s editing request text prompt and outputs an edited icon image reflecting the user’s editing request. Our method is designed based on two key observations: (1) A user’s editing requests can be translated by a large language model (LLM), with help from a domain specific language (DSL) library, into to a set of geometrical constraints defining the relationships between segments in an icon image. (2) Optimizing the affine transformations of the segments with respect to these geometrical constraints can produce icon images that fulfill the editing request and preserve overall physical and logical coherence. Quantitative and qualitative results show that our system outperforms multiple baselines, enabling natural editing of icon images.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x1.png)
1 Introduction
2D icon images are widely used in advertising, logos, street signs, and more to convey important information in a simplified and understandable way. 2D icons are typically created as vector graphics by manually creating and editing vector curves. Creating icons in this manner can be a time-consuming process requiring designers with specialized skills. To reduce this effort, new icon images can be created by producing spatial variations of existing icons; that is, modifying the spatial relations between and within objects in the image (e.g. re-sizing or re-arranging).
Natural language provides a useful interface for specifying many such variations; in recent years, many methods have been developed for editing images given a text-based editing request [11, 4, 13]. Although these methods are effective at modifying the texture and geometry of objects in an image (e.g. “change the apple to an orange”), they fail at producing spatial variations (e.g. “raise the cup to be above the head” in Fig. 1c). In addition, since these methods are based on models that have been trained on detailed natural images, they perform poorly when applied to icon images.
Despite the simplicity of icon images, producing spatial variations of them can be challenging — involving transforming multiple geometries while maintaining logical and physical coherence of the objects depicted in the image. For example, to “move the lamp shade to touch the base” in Fig. 1a, the regions in the image corresponding to “shade” and “base” need to be recognized; when bringing the shade down to the base, the chain of arm connectors should also be adjusted to keep the physical structure of the lamp intact.
We approach this non-trivial icon image modification problem by dividing it into two sub-problems: (1) How to associate the concepts referred to in the editing request to segments of the image, and (2) How to realize the editing request by modifying the segments in the image. Although our main contribution focuses on the second problem, for the first problem we assume a labelled segmentation is manually created, or a semi-automatic segmentation pipeline using existing open-vocabulary concept grounding models [23] is used. For the second and main problem we address in this work, we frame it as finding affine transformations for each segment such that the editing request is satisfied. One obvious approach to solving this problem is to use a pretrained large language model (LLM) to translate the editing request into affine transformation parameters. However, we observed that LLMs perform quite poorly at this task, struggling to produce appropriate continuous parameter values. We observed that they are much better at describing, in words, the key constraints that the transformed scene must satisfy. We speculate that this is due to the fact that humans also use descriptive words to specify the desired constraints when specifying an edit [1]. Based on these observations, we design a domain specific language (DSL) for describing these constraints (position, pose, size, distance, angle, interaction, etc.) and task an LLM with translating the input edit request into a program in this language.
We further find that LLMs struggle to accurately reason about all the constraints that must be satisfied for every object in the image (e.g. “secondary” effects that must happen in response to the input editing request, such as the lamp arms need to remain connected in Fig. 1a). Thus, our system only relies on the LLM to specify the primary constraints that relate directly to the user’s input editing request. We then rely on a graph based search method that progressively searches for and optimizes additional constraints that preserve the physical and logical coherence of all the objects in the image. We present the following contributions:
-
•
A novel system for converting natural language editing requests into spatial variations of icon images.
-
•
An extensible DSL of differentiable operators that can be used to specify geometrical constraints for visual elements.
-
•
A graph-based constraint search method that progressively identifies appropriate additional constraints for achieving an editing request while preserving the logic and physical coherence of the image scene.
Additionally, we will open source our code along with the evaluation benchmark dataset we crafted upon publication.
2 Related Work
In this section we review related work on language driven diffusion models and icon generation and manipulation.
2.1 Language Driven Image Editing Models
Language driven image editing were widely explored, [3], [8], [16], [26], [19], [27], etc. Diffusion models in particular have been widely utilized for language driven natural image editing tasks, showcasing remarkable results. [24] enable text guided generation via a general cross-attention module. [11] inject text control into a diffusion generation process by manipulating the attention layers. [22] utilizes the clip latent space for text conditioned image generation. [2] allow users to specify a region in the image and replace the masked content with a diffusion process. [25] enables text guided generation by fine-tuning a diffusion model with a handful of examples and special tokens. [13] approaches the task by optimizing a latent code towards a target latent code generated by a diffusion model conditioned on the editing text. [4] train an edit diffusion model on editing paired data. More related work in this line of research include but not limited to [14], [28]. However, a shortcoming of these methods is they can typically only change the texture and geometry of objects in the image. They typically fail at fine-grained manipulation, such as editing the geometry or spatial relationships between objects whilst maintaining the identity of the elements in the image.
2.2 Icon Generation and Manipulation
Related to the modification of icon images is the adjacent problem of conditioned generation of icons images [21, 30, 10, 5, 29]. These works utilize neural networks and learn to generate a sequence of Scalable Vector Graphics (SVG) operations (e.g. points, lines, circles) that can be executed to produce an image. Recent work [7, 12, 31] removes the need for direct SVG supervision by learning to generate icon images directly. The important problem of modifying existing icons to produce spatial variations is not addressed by these methods, as their foremost focus is on generation rather than editing. What’s more, these methods suffer the same problem as natural image editing methods: during generation the identity preservation of the original visual elements in the image is not guaranteed. More closely aligned with our work is Lillicon [9], that tries to solve the icon image editing problem. Lillicon uses transient widgets to select and manipulate features of icons to create their scale variations. However, their method does not take language as input, their system requires considerable user interaction, and the only variations created are limited to scale variations. In contrast, our method doesn’t require much user interaction and can create a wide range of different icon variations driven by language input.
3 Overview

In the following sections, several components of our editing system will be introduced, followed by the introduction of our segmentation tool. Our editing system, shown in Fig. 2, takes in an icon image and its associated segmentation map , an edit request text prompt . And it outputs an edited image that reflects the user’s editing request. The input image is a (512*512*3) rgb image, the associated segmentation map is an integer value (512*512) mask where each different integer value corresponds to a different segment. Each segment is also assigned a semantic label expressed as (ObjectName: PartName), e.g. (Table:Leg). This segmentation map can be created manually by the designer, optionally assisted by our semi-auto segmentation tool introduced in 7. The output edited image is a (512*512*3) rgb image. Our editing system first convert the image into a set of labelled segments , where each segment corresponds to a set of pixels in the input image . Then the editing request , which is originally expressed in natural language, is converted into a set of primary constraints by a pre-trained Large Language Model(LLM) assisted by our design DSL constraint library . Next, a hybrid search and optimize algorithm is used to progressively add secondary constraints while optimizing the affine transformation variables such as translation , rotation and scaling for every relevant segment with respect to the full constraints to generate the edited segments. Affine transformation is chosen because our goal is to re-arrange the visual elements present in the image while still maintaining their identity; non-affine editing or deformation will not provide such a guarantee. Finally the edited segments are re-rendered into an image as the output.
4 Image as segments
In order to manipulate the image at object/part level, we choose to discretize the input image as a set of labelled segments using the associated segmentation map . For each segment, it is originally represented as a set of pixels in the image, however, this representation is not convenient for affine manipulation, we thus represent each segment by its boundary geometry defined by a set of 2D paths. A boundary path is represented as a closed loop of connected line segments, each line segment is defined by its two end vertices and . In our boundary formulation, we ignore the inner holes of each segment, this is a choice compatible with our geometrical DSL design which we introduce in 5. With this representation, the affine transformation of the segments can be easily achieved by manipulating the 2D positions of the vertices in the boundary loop. We provide further details in the supplement materials for how the occlusion between segments are handled .
5 Constraint Formulation
With the input image discretized into a set of editable segments , the next step is to establish some desired geometrical constraints for these segments to achieve the goal expressed in the edit request. In this section, we first introduce the design of a DSL constraint specifier library, then describe how it interacts with a pretrained LLM to bridge the gap between natural language editing requests and primary geometrical constraints for segments. Followed by the introduction of a search procedure to add additional secondary constraints from the DSL library to preserve the logical/physical coherence of the scene.
5.1 Design of Domain Specific Language
In order to express editing requests as constraints on segments our DSL library is designed to contain two types of functions: (1) Constraint Specifiers for specifying constraints and (2) Compute Operators for accessing segments. The constraint specifiers are functions that directly specify either a motion type constraint or a geometry violation value, they are formatted as:
| (1) |
with represents motion constraint specifier and represents value constraint specifiers, and represents segment as input parameters, and represents scalar/vector as input parameters. The output scalar value indicating how much the constraint is violated.
The compute operators are functions that can get attributes of the segments, or get the spatial relations between segments, they are formatted as:
| (2) | |||
with represents the compute operators, and represents value constraint specifiers, and represents segment as input parameters, and represents scalar/vector as input parameters. In order to make the DSL general enough to handle segments with different geometry, attributes of segments can only be accessed by using the compute operators, so that all the segment specific geometry computations are handled inside compute operators. These computations are implemented to be fully differentiable with respect to the segment transformation variables to enable gradient based optimization. What’s more, the functions are designed in a way so that they can be combined recursively to express constraints with complex structures. Please see table 1 for a partial overview of the functions in the library.
| Constraint Specifier: |
| Motion constraint specifier(Segment to None): |
| | | | |
| Value constraint specifier(Values to Value): |
| | | |
| Derived value constraint specifier(Segments to Value): |
| | | | | | | | | |
| Compute Operator: |
| Arithmetic operator(Values to Value): |
| — | | | | |
| Attribute operator(Segment to Value): |
| | | | | | | | | | | | |
| Attribute operator(Segment to Segment): |
| | | | | |
| Relation Attribute operator(Segments to Value): |
| | | | |
| Boolean Operator(Segments to Segment): |
| | |
5.2 Large Language Model for Primary Constraints
Given user’s edit request prompt and our DSL library , A pretrained LLM such as GPT-4 or GPT-4V is asked to convert the editing request using functions from the DSL library into a set of the most critical primary constraints which must be satisfied. To make LLM understand better the context of user’s request, we found that providing the image scene information can be crucial for many editing tasks. We represent the image scene as a list of segments, with each segment represented as (1) the semantic label (2) the four vertex positions of the segment’s axis-aligned bounding box. (3) Connection relations between segments. This information provides the LLM with the location, size, semantics, and interaction information of the segments in the image scene. We hide low-level geometry details from the LLM, such as each segments boundary path vertices, as we found empirically that it did not help with our task. We found that including several manually crafted question and answer examples as part of the prompt provided to the LLM can greatly improve the quality of LLM’s output and bias the LLM to output answers that are similar to the provided examples.
5.3 Relation Detection for Secondary Constraints
We observed that relying only on the primary constraints from the LLM can frequently result in either an over-constrained or under-constrained problem. We believe this is due to the lack of geometry understanding with current LLMs. To address this issue, we use the LLM to output the most crucial primary constraints (typically under-constraining), and use a geometry constraint detection method to automatically generate additional candidate secondary constraints . These candidate secondary constraints are crucial to preserve the logical and physical coherence of the scene. Given the initial arrangement of the segments, many potential relations can be detected. We choose to detect the most dominant spatial relations, namely: Inside, Contain, Overlap(Connect). Each has a weak and strong version. The weak version of each relation constraint is constrained by the function , and respectively, the strong version of each relation additionally includes the constraint to indicate they are joined at a fixed point. Based on the two level hierarchy structure (ObjectName:PartName) of labels provided along with the segmentation map, the above mentioned relations can be naturally categorized into intra-object relations and inter-object relations . The preservation of intra-object relations ensures the integrity of the structure of objects, the preservation of inter-object relations ensures the perception consistency between input scene and edited scene. The intra-object relation can be further categorized into crucial intra-object relations and non-crucial intra-object relations , for example, consider the basket example shown in fig 3, the relations between each handle and the basket body are crucial intra-object relations, the relations between the two handles are non-crucial intra-object relations as they are not real connections but due to the initial spatial arrangements. We use the LLM(GPT-4 Vision) to assign types to these intra-object relations. Note that not all secondary constraints need to be satisfied, as some initial relation constraints will prevent us from satisfying the primary constraints. We therefore design a search method to find a subset of secondary constraints to satisfy.
6 Optimization
Given the segments and their constraints generated. The next step is to find the affine transformation(motion) variables translation vector , rotation and scaling for segments with respect to the constraints, thus, with with respect to the editing request. As discussed before, the constraints are categorized as a set of primary constraints given by LLM and a set of candidate secondary constraints generated by geometrical relation detection. The primary constraints will always be included in the transformation finding process as they are the most crucial constraints directly associated with the editing request. For the candidate secondary constraints, the challenge is how to identify a maximum subset of them without violating any primary constraint.
We designed a search method aiming to tackle this challenge problem. Our search method contains two major operations: and . The operation takes in the set of segments along with a set of constraints, and optimize the motion parameters of the segments to satisfy the constraints. In order to run , the state of segments’ transformation(motion) and the state of constraints need to be determined. This is handled by the operation, a operation toggles a segment’s motion state from : Static(N), Translate(T), Translate+Rotate(TR), Translate+Scale(TS), Translate+Rotate+Scale(TRS), and it toggles a relation constraint state from: Strong(ST), Weak(WK), Not exist(N). Once the states are specified, the jointly optimize all the specified motion variables for all segments with respect to (1) all primary constraints and (2) the secondary constraints set to the specified level. Motion variables are optimized using a gradient based optimizer with the Loss as the average of all specified constraints. The output of are a set of optimized motion parameters to edit the segments and a score indicating how much the constraints are violated.
Our method then enforces a search order to apply and across all necessary segments. It is helpful to construct a graph structure , with each node of this graph represents a segment, and each edge represents a relation constraint between two adjacent segments. The general strategy is to gradually propagate from an initial set of nodes and edges to the entire graph, and for each flip, run to evaluate the flipped state. We found that it would greatly reduce the search computation complexity if we perform the search in two sequential passes. In the first pass, we fix the node states and just flip and evaluate the edge states. In the second pass, we fix the edge states from the first stage and just flip and evaluate the node states. In the edge flip pass, we choose the edges that are incident to nodes involved in primary constraints as front edge set, for each subset of the front edge set, the follows a particular order: firstly, the inter-object edges are flipped in the order , then the non-crucial intra-object edges are flipped in the order , finally the crucial intra-object edges are flipped in the order . The intuition is that if the strongest interaction relation does not prevent us from satisfying the primary constraints, then it should be kept to preserve the interaction relation between segments as much as possible. Once all combinations of the front edge sets are flipped and evaluated, the neighbor edges are set to be the new front edge set to continue the search. In the node flipping pass, we again choose the nodes that are directly involved in the primary constraints as the initial front nodes, within the front node set, the motion state of each node is flipped in the following order: , the intuition is that if one type of motion is not necessary for satisfying the constraints, then it is not needed, so that the original characteristics of objects are preserved as much as possible. Once all nodes in the front node set are flipped and evaluated, the neighbor nodes are set to be the new front nodes to continue the search. Please see Fig. 3, Algo. 2, and the supplementary material for more details.
After the two search passes, the final optimized motion parameters will be applied to the segments to produce the final edited segments and then re-rendered into the output image, please see the supplementary material for more discussion of re-rendering.


7 Segmentation Tool
In this section we introduce a pipeline that aims to automatically generate the segmentation map given the input icon image and editing request . We do not claim this tool as part of our main contribution, but rather a tool to speed up the segmentation process and reduce manual effort required by users. Label generation and grounding for icon images is a very hard task as no existing grounding models are trained for icon images, and even for the natural images, current state-of-the-art models are the subject of ongoing research. Our tool is built on top of existing open-vocabulary concept grounding models [23, 20], we expect that as the performance of these models advance in the future, the performance of our tool will improve along with them.
Our segmentation pipeline starts with label generation, given the input icon image , we first use GPT-4V to output the names of objects in the image, we denote this concept set as . Then given the editing request , we use GPT-4 to output the name of the entities present in the request, we denote this concept set as . The final label/concept set is a combination these two sets. As the majority of label grounding models are trained on natural images and can perform poorly on icon images, we take the edge map of the input icon image , together with an image description derived from the concept set , and pass them to a pretrained ControlNet [32] to generate realistic natural images. Then for every generated image, a pretrained concept grounding model such as GroundedSam [23] is used to produce predicted segment region masks for every label , and combined to form a set of labelled region masks . These region masks are then clustered according to their intersection over Union(IOU) ratio . Within each cluster, a representative region mask is picked by choosing the region mask that is closet to the average region shape across all the regions in the cluster. Given the set of all representative region masks , a final resolve process iterate over all pair of representative regions and apply an intersection subtraction operation to ensure no two regions overlap. After the resolve process, a set of labelled segments are produced. Please see Fig. 4 and the supplementary material for more discussion and evaluation of our segmentation tool.
8 Experiments
In order to evaluate our method, we created an evaluation benchmark dataset by selecting 63 images from FIGR-8-SVG [6] dataset, and 65 different editing requests are designed around these images, we manually segment the images and create one possible solution for each editing request as ground truth.
8.1 Our method greatly outperforms other LLM based parametric editing baselines
In this experiment, we compare our editing method against several LLM based editing methods that we implemented. gpt4/gpt4v-dm: Direct Motion parameters prediction , this method takes in the geometry information(boundary vertex positions) of segments, and ask GPT-4 or GPT-4V to output the affine transformation parameters for every segment. gpt4/gpt4v-dc: Direct Constraints prediction, this method takes in the geometry information(boundary vertex positions) of segments, and ask GPT-4 or GPT4Vision to output the all potential constraints expressed in our DSL. The GPT-4V version of these baselines additionally take in the colored segmented image as input to have more visual information. For all the experiments, the GT segmentation map is given. The relative 2D Chamfer Distance is computed as the Chamfer Distance between the boundary points of predicted edited segment and corresponding GT edited segment then divided by the size of the GT edited segment. Please see Table 2, Fig. 5 and Fig. 7 for the comparisons. The results demonstrate our method clearly outperforms all baselines by a large margin.
| gpt4-dm | gpt4v-dm | gpt4-dc | gpt4v-dc | Ours | |
| CD | 4.03 | 2.37 | 1.58 | 1.40 | 0.41 |
| Original | gpt4-dm | gpt4v-dm | gpt4-dc | gpt4v-dc | Ours | Human |
| ”Rotate the handles apart so that the distance between their top regions is equal to half of the basket’s horizontal length” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Scale the fish body to reduce its horizontal length by 50%” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Move the lamp shade to touch the base” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Move and rotate the hand so that its bottom region is aligned with the top region of the 2nd cube from the left” | ||||||
 |
 |
 |
 |
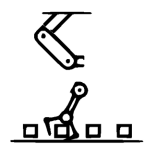 |
 |
 |
| ”Raise the cup to be above the head” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Reduce the horizontal length of the table by 40%” | ||||||
 |
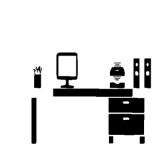 |
 |
 |
 |
 |
 |
8.2 Our method outperforms diffusion based image editing methods by a large margin
In this experiment, we compare our editing method against several state-of-the-art diffusion based image editing methods: sdi2i: Stable Diffusion Image2Image [24] , ip2p: InstrauctPix2Pix [4], imagic: Imagic [13], for each of these methods, we first apply the methods (as implemented by Hugging Face) directly on the input icon image to produce results. Additionally, we perform comparisons on variations of these methods. Considered that these methods are mostly trained on natural images and do not take semantic segmentation as input (which our methods have access to), we try to partially address this for a fairer comparison. We designed a lift-and-project variation of these methods, this process uses the labels from the segmentation along with the edge map of the input image to generate a more realistic image using ControlNet [32], then we apply these editing methods to edit the generated images, we then use GroundedSam [23] to detect the shape of the labels and rasterize them back to an icon image for error computation, please see the supplementary material for more details. Method names with an ”L” appended (sdi2iL, ip2pL and imagicL) indicates the lift-and-project version is used. We compute the image space mean-squared-error between the edited image and the GT image. The Chamfer Distance used in the previous experiment cannot be used here because we do not have the paired segments between the original image and the edited image. Please see Table 3 and Fig. 6 for comparisons. The results show that our method outperforms all baselines by a large margin.
| sdi2i | sdi2iL | ip2p | ip2pL | imagic | imagicL | Ours | |
|---|---|---|---|---|---|---|---|
| Image MSE | 5056 | 7222 | 8808 | 6979 | 16707 | 5540 | 3148 |
| Original | sdi2i | ip2p | imagic | sdi2iL | ip2pL | imagicL | Ours | Human |
| ”Reduce the vertical length of the fuselage by 50%” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Put one bubble on the left of the straw and the other bubble on the right of the straw” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Raise the cup to be above the head” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Move and rotate the right leaf of the plant to touch the sofa” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Rotate the umbrella by 45 degrees” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Reduce the vertical length of the vase by 50%, move down the flowers to keep touching the vase” | ||||||||
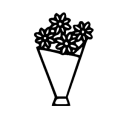 |
 |
 |
 |
 |
 |
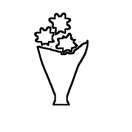 |
 |
 |
8.3 Ablation Study
We study the effectiveness of our state search components described in Section 6 and report these results in Table 4 and Fig. 4. We find that without relation constraint search, where all the candidate relation constraints exist, the optimization can become over-constrained and prevent us from achieving the editing goal. Without motion search, some segments are unnecessary modified which leads to less preservation of object features.
| Ours | -MS | -RS | -MS, -RS | |
| CD | 0.475 | 0.509 | 0.997 | 1.040 |
8.4 Full Automatic Pipeline
Please see the Fig. 12 for the editing results of our full automatic pipeline. In this experiment, the only input is the icon image and the editing request, without any GT segmentation or label provided. The segmentation is first automatically predicted by our segmentation tool and then used with the editing pipeline. As you can see, our full automatic pipeline can produce reasonable editing results for some images and its performance can be further improved when segmentation tool pipeline it rely on gets improved. Please see the supplementary material for the discussion of how to evaluate our segmentation tool and how much it can reduce the manual effort required from users.
8.5 Limitations and Failure Cases
The main failure modes are associated with some fundamental challenges of the 2D icon editing task: One failure mode occurs when the editing request is too abstract resulting in the LLM failing to output the correct constraints. Another failure mode occurs when the icon image depicts a perspective rendered 3D scene where the spatial relations become too complex. Refer to the supplementary material for extended discussion of limitations.
8.6 Additional Results
Please see Fig, 11 for multiple editing strategies(given by LLM) of the same editing request and Fig. 10 for results with segment completion enabled. Please see the supplementary material for more results, such as re-use of the same segmentation for multiple requests, examples of LLM constraint formation, and more qualitative comparison results.
9 Conclusion
We presented a language-driven editing system to create spatial variations of icon images, our method greatly outperforms several alternative editing baselines and proven to be the only method (among all demonstrated methods) that is capable of natural editing of icon images. For future work we are interested to generalize our editing method to support more editing operations (such as local deformation, split and merge of objects) that are beyond affine transformations.
| Original | gpt4-dm | gpt4v-dm | gpt4-dc | gpt4v-dc | Ours | Human |
| ”Move the leftmost candle(with flame) and rightmost candle(with flame) to touch the 2nd layer of the cake” | ||||||
 |
 |
 |
 |
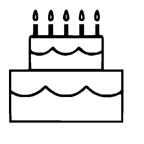 |
 |
 |
| ”Move the shade down to touch the sofa by shortening the lamp support” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Halve the horizontal length of the umbrella head, halve the vertical length of the umbrella support” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Rotate the direction of the claws by 90%” | ||||||
 |
 |
 |
 |
 |
 |
 |
| ”Move the right arrow to the left side of the bow” | ||||||
 |
 |
 |
 |
 |
 |
 |
| Original | sdi2i | ip2p | imagic | sdi2iL | ip2pL | imagicL | Ours | Human |
| ”Move the person to the left inner region of the bus” | ||||||||
 |
 |
 |
 |
 |
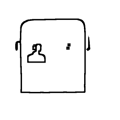 |
 |
 |
 |
| ”Make the two ice cubes at the same vertical position” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Swap the position of the lollipop and the upper candy” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Move the lamp to touch and to be on top of the sofa” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Make all trees the same vertical length” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ”Rotate the fan blade by 60 degrees” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Original | -MS, -RS | -RS | -MS | Ours |
| ”Rotate the handles apart so that the distance between their top regions is equal to half of the basket’s horizontal length” | ||||
 |
 |
 |
 |
 |
| ”Swap the positions of the door and the leftmost window” | ||||
 |
 |
 |
 |
 |
| ”Put one bubble on the left of the straw and the other bubble on the right of the straw” | ||||
 |
 |
 |
 |
 |
| ”Reduce the vertical length of the fuselage by 50%” | ||||
 |
 |
 |
 |
 |
| ”Reduce the horizontal length of the table by 40%” | ||||
 |
 |
 |
 |
 |
| ”Scale the fish body to reduce its horizontal length by 50%” | ||||
 |
 |
 |
 |
 |
| ”Move the lamp shade to touch the base” | ||||
 |
 |
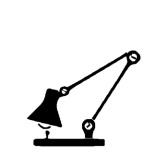 |
 |
 |
| ”Put the book to touch and on top of the cup” | ||||
 |
 |
 |
 |
 |
| ”Raise the cup to be above the head” | ||||
 |
 |
 |
 |
 |
| ”Move and rotate the right leaf of the plant to touch the sofa” | ||||
 |
 |
 |
 |
 |
| Original | Without Occlusion Guess | With Occlusion Guess |
| ”Move the leftmost candle(with flame) and rightmost candle(with flame) to touch the 2nd layer of the cake” | ||
 |
 |
 |
| ”Move and rotate the paddle to the right region of the boat” | ||
 |
 |
 |
| ”Pull the carrot out of the bowl” | ||
 |
 |
 |
| Original | Interpretation 1 | Interpretation 2 |
| ”Raise the cup to be above the head” | ||
 |
 |
 |
| ”Halve the vertical length of the right building while keep it connected to the ground” | ||
 |
 |
 |
| ”Reduce the horizontal length of the table by 40%” | ||
 |
 |
 |
| ”Scale the fish body to make its horizontal length shorter” | ||
 |
 |
 |
| Original | Ours Seg | Ours Edit | Original | Ours Seg | Ours Edit |
|---|---|---|---|---|---|
| ”Move the lamp shade to touch the base” | ”Reduce the vertical length of the fuselage by 50%” | ||||
 |
 |
 |
 |
 |
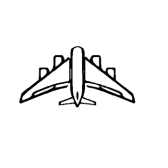 |
| ”Move the right arrow to the left side of the bow” | ”Move the smallest star to the left of all other stars” | ||||
 |
 |
 |
 |
 |
 |
| ”Halve the vertical length of the right building…” | ”Rotate the umbrella by 45 degrees” | ||||
 |
 |
 |
 |
 |
 |
| ”Put the book to touch and on top of the cup” | ”… grass vertical length is equal to the vertical length of the box support column” | ||||
 |
 |
 |
 |
 |
 |
| ”Move and scale the moon to touch the bed” | ”Reduce the vertical length of bread by 50%” | ||||
 |
 |
 |
 |
 |
 |
| Original | Seg-Tool | GT | Original | Seg-Tool | GT |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
10 Supplementary Materials for Creating language-driven spatial variations of icon images
10.1 Occlusion Completion
Given the initial arrange of the segments in the scene, some segments may be occluded by other segment , as the consequence of this occlusion, the geometry information of the occluded region in segment is lost. During the editing, if the front segment is moved to a different location, the occluded region in segment will become visible. In such case, user may want the missing geometry to be filled for the naturalness of the scene. In order to do so, we designed a segment completion method and allow user to choose if some guessed geometry should be generated and appended to the occluded segments. The method start by extracting the boundary edge map of the occluded segment and feed it into a pretrained ControlNet [32] together with its semantic label to generate multiple images of the guessed complete version of segment . Then a pre-trained label detection model such as GroundedSam or others [23, 15, 20, 18, 17] is used to extract the shape of the complete version of , a voting procedure is then applied to choose the shape that is closet to the mean geometry of all guessed shapes as the final complete shape of . Please see fig 14 for the illustration of the method.

10.2 More details for optimization
Please see algo 2 for more details of the optimization process. Two state matrices for motion states and for relation states are initialized according to the LLM’s primary constraint specification. In the relation search stage, the front edges are firstly identified, then the combinations of the front edges are iterated, for each combination, the FlipRelation() flip the relations states as : The inter-object relations are set from Strong(ST) to Weak(WK). : The inter-object relations are set from Weak to Not Exist. : The non-crucial intra-object relations are set from Strong(ST) to Not Exist(N). : The crucial intra-object relations are set from Strong(ST) to Weak(WK). The Solve() is then applied to evaluate the flipped states in order, the score outputs from is the violation value of all primary constraints and secondary constraints set to the flipped state. Each flipped state inherit the value from the previous state. Optional Early stop can be performed if the score is low enough. If not stopped, the front edges are updated to non-visited neighbor edges and repeat the process. In the motion search stage, the front nodes are firstly identified, then for each segment in the front nodes, the FlipMotion() flips the motion states as : : the motion type is set to Translate+Rotate+Scale(TRS), : the motion type is set to Translate+Rotate(TR), : the motion type is set to Translate+Scale(TS), : the motion type is set to Translate(T), : the motion type is set to Not Exist(N). If not stopped, the front nodes are updated to non-visited neighbor nodes and repeat the process. Once both search stages end, the output optimized segments are the final edited segments.
Under the hood of , the constraints input to the solver will be firstly converted into a constraint tree, with leaf nodes as segments or constant values, with the non-leaf nodes as operations that act on one or multiple segments or values (its children nodes). The root node always corresponds to one of the constraint specifier, this is to ensure the final output value of every constraint indicates how much this constraint is violated. During the optimization, the solver will perform a post-order traversal of the tree to compute the final constraint violation value as a loss value. We use Adam optimizer with a gradually decreasing(starting from lr=10) learning rate for optimizing the affine transformation variables. Each optimization run takes maximum 150 iterations. Additionally, we can choose to create a proxy segment for each segment to run the optimization, the proxy segment is constructed by a ray-shooting process, for each pixel, we shoot K 2D rays(uniformly spaced around the circle centered on the pixel) outward from the pixel, if a majority of these rays(ratio¿=0.9) hit the original segment, the pixel is marked as part of the proxy segment. With this process, we obtained a set of pixels used to create the proxy segment. One benefit of doing so is to make the inside check of segments be consistent with our DSL (so that anything inside the inner holes of an segment is still considered as inside of the element).
10.3 Re-render
As described in the main paper, once the transformation for segments are updated. The final step is to re-render them back to an image. The depth ordering of the segments will be crucial for the re-rendering of the edited segments. We developed an algorithm to decide the ordering relation between two segments given their initial spatial configurations. Given two segments and , Our method starts by extracting the boundary region around the intersection region between and , then for each segment, we compute the farthest path length between any two points in the boundary region . The path must be formed inside the segment, for each point pair , we run a breath-first-search(BFS) from to , the number of search steps will be saved as the path length for . the longest path length for segment is indicated as and the longest path length for segment is indicated as . The shorter path indicates that this object is convex and extruding into the other object, that we usually perceive as this object occluded the other object. This rule is summarized as the following, If : segment i is occluded by segment j, If : segment j is occluded by segment i, If : The depth order is not determined. Once the depth ordering of segments are determined, we can raster the segments into a color image buffer with the help of a depth image buffer. Please see fig 15 for illustration.

10.4 Evaluation for Segmentation Tool
The output labelled segments of the segmentation tool pipeline described in the main paper may not always be well aligned with user’s understanding of the image scene. This is caused by multiple sources: (1) The label generated by GPT4Vision may not be accurate, (2) The ControlNet generated image may not be an accurate reflection of the input image scene, (3) The performance of label grounding models such as GroundedSam or GLIP is still far from ideal. As a result, some regions are over-split while others are under-split, and the assigned labels may also need to be adjusted. Based on these observations, we designed some metrics to measure how much our segmentation tool can close the gap between raw input and GT segmentation, in other words, how much our tool can help the user to spend less manual effort on labeling and segmentation. We designed two metrics for evaluating the amount of effort that user may need to manually spent based on the auto-generated labelled segments from our tool. We assume that a simple segmentation and label fixing tool would allow users to do two operations: (1) Drawing a path in the image indicating the boundary path of a segment, (2) Changing an incorrect label assigned to one segment into a different label. As you can see, in the case of under-split, user can draw additional paths on a segment to reach the desired split. In the case of over-split, user can changing the labels of adjacent segments so that they are merged as one segment. In the case of incorrect label, only changing the label is enough. As the consequences of these two fixing operations, two evaluation metrics are naturally emerged: (1) The length of the additional boundary paths drawn on top of the predicted boundary paths. (2) The number of label correcting operation. Please see fig 16 for the illustration of these metrics. For metric (1), we compute it by measuring how many GT segment boundary pixels are not covered by predicted segment boundary pixels, for each GT segment boundary pixel, we search if there is a predicted boundary pixel within a radius(r = 20) of this GT pixel. For metric (2), we count the number of mismatched labels assigned to predicted segments and GT segments. We also include the numbers of these two metrics computed on the original input (indicates the total manual effort a user need to spent given the original unsegmented image) for comparison. Please see table 5 for this comparison. As you can see, the path need to be drawn(fix) become much shorter after using our segmentation tool, the label correcting numbers are slightly higher but it is a relative cheap operation. In summary, our segmentation tool can greatly reduce the user’s manual effort for creating the labelled segmentation that is required by the editing process.
Another thing to notice is that an edit can be achieved with different segmentation results, please see fig 17 for illustration of the editing results generated by our editing system with different segmentation configuration.
| Manual | Ours | |
|---|---|---|
| Missing path length | 612 | 366 |
| Mismatched label count | 6.6 | 8.1 |




10.5 Additional Results
Please see fig 21 for additional comparison results against different GPT based editing methods. Please see fig 22 for additional comparison results against different diffusion based editing methods. Please see fig 23 for additional ablation comparison results with different components removed from our editing system. Please see fig 24 for the editing results of how the same segmentation map can be re-used multiple times for different editing text prompt. Please see fig 25 and 26 for additional results for our segmentation tool. Please see table 6 for examples of what it looks like for the GPT to output constraints using our designed DSL.
10.6 Failure Cases
We observed several failure modes of our method. The first failure case occur when the editing request is too abstract so that the spatial relation is only implicitly specified. For example in the first editing task in fig 20, the LLM had a hard time associating the ”dig” action with our DSL operators which then leads to inaccurate constraints. The second relative rare failure case is caused by sub-optimal hyper-parameters in the optimization method, and can lead to less desired result (the second task in fig 20). The third case is caused by inaccurate primary constraints generated by LLM, in the third task in fig 20, the LLM thinks the ”length” in the editing request meant to be the vertical length of the handle rather than the principal length of the handle. We expect that as the performance of LLMs advanced in the future, some of these failure modes will be mitigated. Another type of failure modes is that when the input icon image contains many perspective rendered 3D objects so that the spatial relations of the objects can become quite complex and goes beyond the capability of our DSL and scene representation.

| Original | gpt4-dm | gpt4v-dm | gpt4-dc | gpt4v-dc | Ours |
| ”Rotate the left arm to be on the same altitude as the shoulder” | |||||
 |
 |
 |
 |
 |
 |
| ”Reduce the vertical length of the fuselage by 50%” | |||||
 |
 |
 |
 |
 |
 |
| ”Reduce the vertical length of the vase by 50%, move down the flowers to keep touching the vase” | |||||
 |
 |
 |
 |
 |
 |
| ”Swap the position of the lollipop and the upper candy” | |||||
 |
 |
 |
 |
 |
 |
| ”Move the shade down to touch the sofa by shortening the lamp support” | |||||
 |
 |
 |
 |
 |
 |
| ”Reduce the horizontal length of the bus by 50%” | |||||
 |
 |
 |
 |
 |
 |
| ”Increase the horizontal length of the stool table by 50%” | |||||
 |
 |
 |
 |
 |
 |
| ”Halve the horizontal length of the umbrella head, halve the vertical length of the umbrella support” | |||||
 |
 |
 |
 |
 |
 |
| ”Swap the position of the door and the window” | |||||
 |
 |
 |
 |
 |
 |
| ”Move the middle star so that three stars form an equilateral triangle” | |||||
 |
 |
 |
 |
 |
 |
| ”Move the left chair to be on the right side of the right chair” | |||||
 |
 |
 |
 |
 |
 |
| Original | sdi2i | ip2p | imagic | sdi2iL | ip2pL | imagicL | Ours |
| ”Reduce the vertical length of the cup by 50%” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Move the water under the bottle spray” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Reduce the vertical length of the sail column by 50%” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Move the bird, scale the swing, so that the bird is moved down by 25%, keep the cage fixed” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Move the clouds to touch their nearest trees” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Scale all the grass so that their vertical length is equal to the vertical length of the box support column” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Grow the trees to the same vertical length as the house” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Make the ears 50% smaller in horizontal length” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
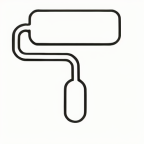
| ”Halve the horizontal length of the roller head” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
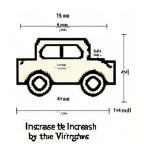
| ”Increase the vertical length of the windows by 200%” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Make the door 50% higher” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
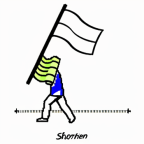
| ”Shorten the flag handle and flag by 50%” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| ”Move and scale the moon to touch the bed” | |||||||
 |
 |
 |
 |
 |
 |
 |
 |
| Original | -MS, -RS | -RS | -MS | Ours |
| ”Reduce the vertical length of the sail column by 50%” | ||||
 |
 |
 |
 |
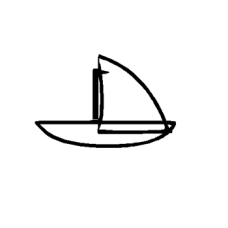 |
| ”Make the ears 50% smaller in horizontal length” | ||||
 |
 |
 |
 |
 |
| ”Make the door 50% higher” | ||||
 |
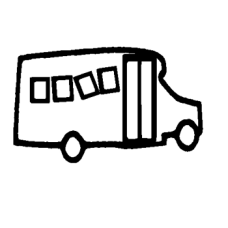 |
 |
 |
 |
| ”Move the water under the bottle spray” | ||||
 |
 |
 |
 |
 |
| ”Halve the horizontal length of the roller head” | ||||
 |
 |
 |
 |
 |
| ”Move the lamp to touch and to be on top of the sofa” | ||||
 |
 |
 |
 |
 |
| ”Reduce the vertical length of the cup by 50%” | ||||
 |
 |
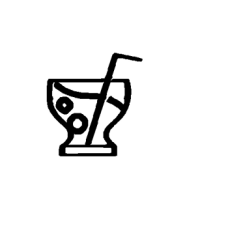 |
 |
 |
| ”Move the leftmost candle(with flame) and rightmost candle(with flame) to touch the 2nd layer of the cake” | ||||
 |
 |
 |
 |
 |
| ”Rotate the bike body so that the right side wheel’s vertical position is raised by 50%” | ||||
 |
 |
 |
 |
 |
| Original | Seg | Request1 | Request2 | Request3 |
| Request1 : Move and rotate the hand so that its bottom region is aligned with the top region of the 2nd cube from the left Request2 : Move and rotate the hand so that its bottom region is aligned with the top region of the 2nd cube from the right Request3 : Move and rotate the hand so that its bottom region is aligned with the top region of the leftmost cube | ||||
 |
 |
 |
 |
 |
| Request1 : Move the shade down to touch the sofa by shortening the lamp support Request2 : Reduce the horizontal length of the sofa by 50% Request3 : Swap the positions of ing and the book together with bookshelf | ||||
 |
 |
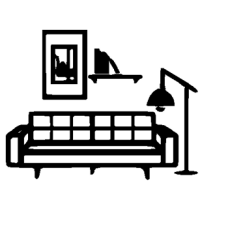 |
 |
 |
| Request1 : Move the lamp shade to touch the base Request2 : Halve both horizontal and vertical length of the shade Request3 : Rotate the shade by 45 degree | ||||
 |
 |
 |
 |
 |
| Request1 : Scale the vertical length of the right building and its windows as a whole by 50% while keep the building on the ground Request2 : Decrease the vertical length of all the windows of the right building by 50% Request3 : Scale the horizontal length of the left building by 50% | ||||
 |
 |
 |
 |
 |
| Request1 : Move the plant to touch and be on top of the sofa Request2 : Move the plant together with the supporting table to touch and be on top of the sofa Request3 : Scale the lamp to be the same height as the sofa | ||||
 |
 |
 |
 |
 |
| Original | Seg-tool | GT |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Original | Seg-tool | GT |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Original | GT-Seg | LLM primary constraints |
|---|---|---|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x631.png)
|
seg0:(basket:handle) seg1:(basket:handle) seg2:(basket:top) seg3:(basket:body) | ”Rotate the handles apart so that the distance between their top regions is equal to half of the basket’s horizontal length” rotate(seg0), rotate(seg1) equal(center_distance(top_inner_region(seg0), top_inner_region(seg1)), 0.5 horizontal_length(union(seg0, seg1, seg2, seg3))) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x632.png)
|
seg0:(bubble0:bubble) seg1:(fish:body) seg2:(fish:fin) seg3:(bubble2:bubble) seg4:(fish:eye) | ”Scale the fish body to reduce its horizontal length by 50%” scale(seg1), adjust(seg2), adjust(seg4) equal(horizontal_length(seg1), 0.5 horizontal_length(old_copy(seg1))) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x633.png)
|
seg0:(lamp:shade) seg1:(lamp:arm connector) seg2:(lamp:arm connector) seg3:(lamp:base connector) seg4:(lamp:base) | ”Move the lamp shade to touch the base” move(seg0) touch(seg0, seg4) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x634.png)
|
seg0:(cloud:cloud) seg1:(umbrella:umbrella) seg2:(person:head) seg3:(cup:cup) seg4:(person:arm) seg5:(person:body) seg6:(chair:chair) seg7:(person:arm) | ”Raise the cup to be above the head” move(seg3), adjust(seg4), on_top(seg3, seg2) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x635.png)
|
seg0:(painting:painting) seg1:(lamp:connector) seg2:(book:book) seg3:(lamp:support) seg4:(lamp:shade) seg5:(bookshelf:bookshelf) seg6:(sofa:sofa) | ”Move the shade down to touch the sofa by shortening the lamp support” move(seg4), scale(seg3), stay(seg6), touch(seg4, seg6), smaller(vertical_length(seg3), vertical_length(old_copy(seg3))) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c5b7ba6-da11-4753-bbfc-4c379f1e2699/x636.png)
|
seg0:(airplane:fuselage) seg1:(airplane:engine) seg2:(airplane:engine) seg3:(airplane:wing) seg4:(airplane:wing) seg5:(airplane:engine) seg6:(airplane:engine) seg7:(airplane:tail) seg8:(airplane:tail) | ”Reduce the vertical length of the fuselage by 50%” scale(seg0), equal(vertical_length(seg0), 0.5 * vertical_length(old_copy(seg0))) |
References
- [1] Samuel Acquaviva, Yewen Pu, Marta Kryven, Catherine Wong, Gabrielle E Ecanow, Maxwell Nye, Theodoros Sechopoulos, Michael Henry Tessler, and Joshua B Tenenbaum. Communicating natural programs to humans and machines. arXiv preprint arXiv:2106.07824, 2021.
- [2] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18208–18218, June 2022.
- [3] Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten, and Tali Dekel. Text-driven layered image and video editing. In ECCV, 2022.
- [4] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. arXiv preprint arXiv:2211.09800, 2022.
- [5] Alexandre Carlier, Martin Danelljan, Alexandre Alahi, and Radu Timofte. Deepsvg: A hierarchical generative network for vector graphics animation, 2020.
- [6] Louis Clouâtre and Marc Demers. FIGR: few-shot image generation with reptile. CoRR, abs/1901.02199, 2019.
- [7] Kevin Frans, Lisa B. Soros, and Olaf Witkowski. Clipdraw: Exploring text-to-drawing synthesis through language-image encoders. In ArXiv, 2021.
- [8] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion, 2022.
- [9] Wilmot Li Gilbert Louis Bernstein. Lillicon: Using transient widgets to create scale variations of icons. ACM Transactions on Graphics, 2015.
- [10] David Ha and Douglas Eck. A Neural Representation of Sketch Drawings. ArXiv e-prints, Apr. 2017.
- [11] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- [12] Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1911–1920, 2023.
- [13] Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. In Conference on Computer Vision and Pattern Recognition 2023, 2023.
- [14] Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2426–2435, June 2022.
- [15] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023.
- [16] Gihyun Kwon and Jong Chul Ye. Clipstyler: Image style transfer with a single text condition. arXiv preprint arXiv:2112.00374, 2021.
- [17] Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767, 2023.
- [18] Liunian Harold Li*, Pengchuan Zhang*, Haotian Zhang*, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In CVPR, 2022.
- [19] Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Lu Jiang, and Ming-Hsuan Yang. Text-driven image editing via learnable regions. arXiv preprint arXiv:2311.16432, 2023.
- [20] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- [21] Raphael G. Lopes, David Ha, Douglas Eck, and Jonathon Shlens. A learned representation for scalable vector graphics. In ICCV, 2019.
- [22] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents, 2022.
- [23] Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks, 2024.
- [24] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2021.
- [25] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. 2022.
- [26] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022.
- [27] Ming Tao, Bing-Kun Bao, Hao Tang, Fei Wu, Longhui Wei, and Qi Tian. De-net: Dynamic text-guided image editing adversarial networks. In AAAI, 2023.
- [28] Qian Wang, Biao Zhang, Michael Birsak, and Peter Wonka. Mdp: A generalized framework for text-guided image editing by manipulating the diffusion path, 2023.
- [29] Yuqing Wang, Yizhi Wang, Longhui Yu, Yuesheng Zhu, and Zhouhui Lian. Deepvecfont-v2: Exploiting transformers to synthesize vector fonts with higher quality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18320–18328, 2023.
- [30] Ronghuan Wu, Wanchao Su, Kede Ma, and Jing Liao. Iconshop: Text-guided vector icon synthesis with autoregressive transformers. ACM Transactions on Graphics (TOG), 42(6):1–14, 2023.
- [31] XiMing Xing, Chuang Wang, Haitao Zhou, Jing Zhang, Qian Yu, and Dong Xu. Diffsketcher: Text guided vector sketch synthesis through latent diffusion models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [32] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models, 2023.