Covariance Steering with Optimal Risk Allocation
Abstract
This paper extends the optimal covariance steering problem for linear stochastic systems subject to chance constraints so as to account for an optimal allocation of the risk. Previous works have assumed a uniform risk allocation in order to cast the optimal control problem as a semi-definite program (SDP), which can be solved efficiently using standard SDP solvers. An Iterative Risk Allocation (IRA) formalism is used to solve the optimal risk allocation problem for covariance steering using a two-stage approach. The upper-stage of IRA optimizes the risk, which is a convex problem, while the lower-stage optimizes the controller with the new constraints. The process is applied iteratively until the optimal risk allocation that achieves the lowest total cost is obtained. The proposed framework results in solutions that tend to maximize the terminal covariance, while still satisfying the chance constraints, thus leading to less conservative solutions than previous methodologies. In this work, we consider both polyhedral and cone state chance constraints. Finally, we demonstrate the approach to a spacecraft rendezvous problem and compare the results with other competing approaches.
I Introduction
In this paper we address the problem of finite-horizon stochastic optimal control of a discrete linear time-varying (LTV) system with white-noise Gaussian diffusion. The control task is to steer the state from an initial Gaussian distribution to a final Gaussian distribution with known statistics. In addition to the boundary conditions, we consider chance constraints that restrict the probability of violating state constraints to be less than a certain threshold. In general, hard state constraints are difficult to impose in stochastic systems because the noise can be unbounded, so chance constraints are typically used to deal with this problem by imposing a small, but finite, probability of violating the constraints. In the literature, one encounters two kinds of chance constraints; individual chance constraints and joint chance constraints [1]. Individual chance constraints limit the probability of violating each constraint, while joint chance constraints limit the probability of violating any constraint over the whole time horizon. In this paper, we consider the case of joint chance constraints, because they are a more natural choice for most applications of interest.
Control of stochastic systems can be best formulated as a problem of controlling the distribution of trajectories over time. Moreover, Gaussian distributions are completely characterized by their first and second moments, so the control problem can be thought of as one of steering the mean and the covariance to the desired terminal values. The problem of covariance control has a history dating back to the ’80s, with the works of Hotz and Skelton [2, 3]. Much of the early work focused on the infinite horizon problem, where the state covariance asymptotically approaches its terminal value. Only recently has the finite-horizon problem drawn attention, with much of the early work focusing on the so-called covariance steering (CS) problem, namely, the problem of steering an initial distribution to a final distribution at a specific final time step subject to linear time-varying (LTV) dynamics. The problem can be thought of as a linear-quadratic Gaussian (LQG) problem with a condition on the terminal covariance [4]. Moreover, it has been shown that the finite-horizon covariance steering controller can be constructed as a state-feedback controller, and the problem can be formulated either as a convex program [4, 5], or as the solution of a pair of Lyapunov differential equations coupled through their boundary conditions [6, 7]. Alternatively, for certain special cases one can solve the CS problem directly by solving an LQ stochastic problem with a particular choice of cost weights [8]. Other approaches [9, 10] use an affine-disturbance feedback controller having two components, one that steers the mean state and the other that steers the covariance.
Steering the covariance is related to the theory of steering marginal distributions, which has a long history, stemming from the problem of Schrödinger bridges and optimal mass transport [7, 11, 12, 13]. Most recent work on covariance steering has focused on incorporating physical constraints on the system, such as state chance constraints [14], obstacles in path-planning environments [10], input hard constraints [15], incomplete state information [16], and extensions in the context of stochastic model predictive control [17] and nonlinear systems [18, 19, 20].
In this work, we first review the formalism for the Covariance Steering Chance Constraint (CSCC) problem, to account for optimal risk allocation. By risk allocation we mean allocating the probability of violating each individual chance constraint at each time step. For example, if there are chance constraints and time steps, there would be total allocations for the whole problem. Previous works [8, 14, 10, 15, 17] have assumed a constant risk allocation, so that the resulting problem can be turned into a semi-definite program (SDP). Here, however, we adopt an iterative two-stage algorithm that optimizes the risk distribution over all time steps, and subsequently optimizes the controller by solving a SDP. Other works have tried to optimize the risk using techniques such as ellipsoidal relaxation[21] and particle control[22]. However, ellipsoidal relaxation techniques are overly conservative and lead to highly suboptimal solutions. Particle control methods are computationally too demanding, since the number of decision variables grows with the number of particles. The two-stage risk allocation scheme proposed in this work is computed iteratively until the cost is within a given tolerance of the minimum, from which we get the optimal risk allocation for the problem, as well as the optimal controller.
The contributions of this work are as follows: First, we propose the first work that solves the covariance steering problem while optimally allocating the risk of violating chance constraints. Second, we extend previous similar results in the literature that only deal with polyhedral constraints to the case of cone constraints. Third, we provide a result of independent interest for convexifying the chance constraints for the case of conical regions. Finally, and in order to illustrate the proposed risk allocation algorithm, we use as an example a rendezvous problem between two spacecraft, in which the approaching spacecraft’s control inputs are constrained to be within some bounds, while its position should remain within a predetermined LOS region during the whole maneuver. Both polyhedral and cone LOS constraints are investigated and compared.
This work extends the preliminary results of [23] along several directions. First, while in [23] only polyhedral chance constraints were handled, in this work we also treat the important – and much more difficult – case of cone constraints. Indeed, in many applications the constraints are given in the form of a conical region (e.g., line-of-sight (LOS) constraints). Approximating such cone constraints with many intersecting hyperplanes would make the problem computationally expensive and quite challenging in terms of achieving high accuracy approximations. Second, we also present a way to approximate such cone chance constraints as special cases of general quadratic constraints in terms of two-sided polyhedral constraints. Third, we apply this formulation to the case of LOS cone chance constraints, and compare with a polyhedral approximation. Fourth, we present a geometric relaxation of the cone chance constraints, which is more natural in real-life applications. Finally, we compare our results with stochastic MPC-type approaches.
The paper is structured as follows: In Section II we define the general stochastic optimal control problem for steering a distribution from an initial Gaussian to a terminal Gaussian with joint state chance constraints. In Section III we review the two-stage risk allocation formalism, and formulate the SDP for the optimal controller as well as the proposed iterative risk allocation algorithm. In Section IV we present two different convex relaxations of quadratic chance constraints, one in terms of a two-sided linear constraint relaxation, and the other based on a geometrical construction. Finally, in Section V we implement the theory to the spacecraft rendezvous and docking problem with both polyhedral and cone chance constraints, and compare with stochastic MPC methods.
II Problem Statement
We consider the following discrete-time stochastic time-varying system subject to noise
| (1) |
where , with time steps , where representing the finite horizon. The uncertainty is a zero-mean white Gaussian noise with unit covariance, i.e., and . Additionally, we assume that , for . The initial state is a random vector drawn from the normal distribution
| (2) |
where is the initial state mean and is the initial state covariance. The objective is to steer the trajectories of (1) from the initial distribution (2) to the terminal distribution
| (3) |
where and are the state mean and covariance at time , respectively. The cost function to be minimized is
| (4) |
where and for all . Additionally, and over the whole horizon, we impose the following joint chance constraint that limits the probability of state violation to be less than a pre-specified threshold, i.e.,
| (5) |
where denotes the probability of an event, is the state constraint set, and .
Remark 1: We assume that the system (1) is controllable, that is, for any , and no noise (), there exists a sequence of control inputs that steer the system from to .
First, we provide an alternative description of the system (1) in order to solve the problem at hand. Using [8, 14, 10, 15, 17], we can reformulate (1) as
| (6) |
where , and are the state, input, and disturbance sequences, respectively. The matrices , and are defined accordingly [8]. Using this notation, we can write the cost function compactly as
| (7) |
where and are defined accordingly. Note that since and for all , it follows that and . The initial and terminal conditions (2) and (3) can be written as
| (8) |
and
| (9) |
where , and picks out the th component of a vector. Consequently, the state chance constraints (5) can be written as
| (10) |
In summary, we wish to solve the following stochastic optimal control problem.
Problem 1 : Given the system (6), find the optimal control sequence that minimizes the objective function (7), subject to the initial state (8), terminal state (9), and the state chance constraints (10).
III Chance Constrained Covariance Steering with Risk Allocation
III-A Lower-Stage Covariance Steering
Borrowing from the work in [10], we adopt the control policy
| (11) |
where , and is given by
| (12a) | ||||
| (12b) | ||||
Remark 2: The proposed control scheme (11)-(12) leads to a convex programming formulation of Problem 1 as follows.
Using (11)-(12), we can write the control sequence as
| (13) |
where and a matrix containing the gains . It follows that the dynamics can be decoupled into a mean and error state as follows
| (14) | ||||
| (15) |
Additionally, by noting that the cost function (7) can be decoupled into a mean cost and a covariance cost , the cost function takes the form [10]
| (16) |
where . The terminal constraints can be reformulated as
| (17a) | ||||
| (17b) | ||||
Qualitatively speaking, steers the mean of the system to , while steers the covariance to . In order to make the problem convex, we relax the terminal covariance constraint (17b) to , which can be written as the linear matrix inequality (LMI)
| (18) |
III-B Polyhedral Chance Constraints
When dealing with the risk allocation problem, it is customary to assume that the state constraint set is a convex polytope , so that
| (19) |
where and . Under this assumption, the probability of violating the state constraints (10) can be written as
| (20) |
Equation (20) represents the objective that the joint probability of violating any of the state constraints over the horizon is less than or equal to . Using Boole’s Inequality [24, 25], one can decompose a joint chance constraint into individual chance constraints as follows
| (21) |
with
| (22) |
where each represents the probability of violating the th constraint at time step . Notice that the probability in (21) is of a random variable with mean and covariance . Thus, (21) can be equivalently written as
| (23) |
where denotes the cumulative distribution function of the standard normal distribution. Simplifying (23) and noting that yields
| (24) |
Remark 3: Since , it follows that , and in (III-B) can be computed from its Cholesky decomposition.
The expression in (III-B) gives inequality constraints for the optimization problem. In summary, Problem 1 is converted into a convex programming problem.
Problem 2 : Given the system (14) and (15), find the optimal control sequences and that minimize the cost function (III-A)
subject to the terminal state constraints (17a) and (18), and the individual chance constraints (III-B).
Remark 4: Note that it is not possible to decouple the mean and covariance controllers in the presence of chance constraints, because of (III-B).
III-C Risk Allocation Optimization
Since are decision variables in (III-B), the constraints are bilinear, which makes it difficult to solve this problem. As mentioned previously, in order to transform Problem 2 to a more tractable form, the allocation of the risk levels may be assumed to be fixed to some pre-specified values, usually uniformly. In this case, are no longer decision variables and the problem can be efficiently solved as an SDP. However, a better approach is to allocate concurrently when solving the optimization Problem 2, so as to minimize the total cost. This gives rise to a natural two-stage optimization framework [26].
Following the approach in [26], the upper stage optimization finds the optimal risk allocation , and the lower stage solves the CS problem for the optimal controller given the risk allocation from the upper-stage.
Let the value of the objective function after the lower-stage optimization for a given risk allocation be , that is,
| (25) |
where is given in (III-A). The upper-stage optimization problem can then be formulated as follows.
Problem 3 (Risk Allocation):
| (26) | ||||
| such that | (27) | |||
| (28) |
As shown in [26], Problem 3 is a convex optimization problem, given that the objective function is convex, and .
III-D Iterative Risk Allocation Motivation
Even though we have formulated the solution of Problem 2 as a two-stage optimization problem, it is not clear yet how to solve Problem 3 efficiently in order to determine the optimal risk allocation. To gain insight into the solution, we first state a theorem from [26] about the monotonicity of .
Theorem 1.
The optimal cost from solving Problem 2 is a monotonically decreasing function in , that is,
| (29) |
Proof.
See [26]. ∎
In the following section, we use this theorem to create an iterative algorithm that solves Problem 3 by lowering the cost at each iteration. The main idea is that, by carefully increasing the risk allocations , Theorem 1 guarantees that the optimal cost will be reduced with each successive iteration. As such, the algorithm lowers the risk, equivalently tightens the constraints, for the constraints that are too conservative, and increases the risk, equivalently loosens the constraints, for the constraints that are already active. The following remark introduces this idea and defines active and inactive constraints in the context of risk allocation.
Remark 5: The chance constraints can be written in yet another form that will prove useful below. Starting from (III-B), notice that we can write the chance constraints as
| (30) |
The quantity represents the true risk experienced by the optimal trajectories, i.e, when using . Clearly, the risk we have selected does not need to be equal to the actual risk once the optimization is completed. When these values are equal we will say that the constraint (30) is active, and is inactive otherwise. Good solutions correspond to cases when the true risk is within a small margin of the allocated risk. Many having values smaller than their true counterparts would imply an overly conservative solution.
III-E Iterative Risk Allocation Algorithm
We can exploit Theorem 1 in the context of CS to create an iterative risk allocation algorithm that simultaneously finds the optimal risk allocation and the optimal control pair . To this end, suppose we start with some feasible risk allocation , for all , where denotes the iteration number. Using this risk allocation, we then solve Problem 2 to get the optimal controller , which corresponds to the optimal mean trajectory at iteration . Next, we construct a new risk allocation as follows: for all such that is active, we keep the corresponding allocation the same, i.e, . However, for all such that is inactive we let . This corresponds to tightening the constraints. Since this new risk allocation is smaller, and since is a monotonically increasing function, it follows that . Furthermore, this implies that
| (31) |
Constraint (III-E) ensures that the optimal solution for is feasible for . Furthermore, since , it follows that , so the optimal solution for is also the optimal solution for as well, hence .
Next, we construct a new risk allocation from as follows. For all such that is inactive, leave the new risk allocation the same. For all such that is active, let , which corresponds to relaxing the constraints. Following the same logic, Theorem 1 implies that . Thus, we have laid out an iterative scheme for a sequence of risk allocations that continually lowers the optimal cost.
This leads to Algorithm 1 that solves the optimal risk allocation for the CS problem subject to chance constraints. Note that the algorithm is initialized with a constant risk allocation. To tighten the inactive constraints in Line 9, the corresponding risk is scaled by a parameter that weighs the current risk with the true risk from that solution. Additionally, to loosen the active constraints in Line 13, the corresponding risk is increased proportionally to the residual risk remaining.
IV Cone Chance Constraints
In many engineering applications polytopic constraints such as (19) are not realistic. Most often, the constraints have the form of a convex cone, namely, the feasible region is characterized by
| (32) |
Cone constraints such as (32) are more realistic, as they better describe the feasible space. As with the case of a polyhedral feasible state space , we want the state to be inside throughout the whole time horizon. However, since the dynamics are stochastic, this assumption is relaxed to the condition that the probability that the state is not inside this set is less than or equal to . In the context of convex cone state constraints, this condition becomes
| (33a) | ||||
| (33b) | ||||
Remark 6: Although the set is convex, the chance constraint may not be convex. Specifically, for large , it is possible that the chance constraint (33a) is non-convex [27].
Since there is no guarantee that (33) will be a convex constraint, we need to make a convex approximation so that (33) holds for all .
IV-A Two-Sided Approximation of Cone Constraints
In order to approximate the cone chance constraint (33a), we first replace the cone constraint in (33a) with the quadratic chance constraint
| (34) |
Remark 7: The chance constraint (34) is a relaxation of the original chance constraint (33a). The proof of this result is given in Appendix A.
Note that (34) can be equivalently written as
| (35) |
where and denotes the th row of . Squaring both sides of (35) and letting yields
| (36) |
The following proposition enables the conversion of a quadratic constraint of the form (36) to a collection of two-sided (absolute value) constraints. To simplify the notation, below we drop the subscript from the corresponding expressions.
Proposition 1.
The quadratic constraint
| (37) |
is satisfied if the following constraints are satisfied
| (38a) | |||
| (38b) | |||
| (38c) | |||
for some non-negative and .
Proof.
We now present two methods for approximating the two-sided chance constraints (38a), one that utilizes a result from [27], and one that utilizes the reverse union bound.
IV-A1 Three-cut Outer Approximation
We state, without proof, the following lemma from [27].
Lemma 1.
Let be a jointly distributed Gaussian random vector with mean and positive definite covariance matrix , and let . Let be the Cholesky decomposition of . Let and be decision variables. Then,
| (41a) | ||||
| (41b) | ||||
| (41c) | ||||
| (41d) | ||||
is a second order cone (SOC) outer approximation of the constraint
| (42) |
which, in fact, guarantees
| (43) |
IV-A2 Reverse Union Bound Approximation
The following proposition gives an alternate approximation of the two-sided chance constraint (38a) using the cumulative distribution function of the normal distribution.
Proposition 2.
Let for all and . Assume that the convex SOC constraints
| (45a) | |||
| (45b) | |||
are satisfied for some , and . Then, the chance constraints (38a) are satisfied as well.
Proof.
Equation (38a) can equivalently be written as
| (46) |
or, equivalently, as
| (47) |
Applying the reverse union bound on (47) yields
| (48) |
Thus, if the constraint
| (49) |
is satisfied, then inequality (47) holds and the original chance constraints (38a) will be satisfied as well. The constraint in (49) is equivalent to the following decoupled constraints
| (50a) | |||
| (50b) | |||
| (50c) | |||
Since is a Gaussian random variable with mean and covariance , it follows that the probabilities in (50a)-(50b) can be written in terms of the standard normal cumulative distribution function as follows
| (51a) | |||
| (51b) | |||
Finally, substituting the mean dynamics (14) and the corresponding covariance in to (51) yields the desired result. ∎
Remark 8: In the three-cut approximation, the parameters need to be fixed so that the resulting constraints in (44) are not bilinear in the decision variables.
Similarly, in the reverse union bound approximation, the parameters and need to be fixed so that the resulting constraints in (45) are not bilinear in the decision variables.
Remark 9: In (38b), the constraints can be equivalently written as
| (52) |
Plugging in the mean dynamics (14) into the definition of yields the SOC constraints
| (53) |
In summary, the relaxed cone chance constraints (34) can be approximated using two-sided chance constraints as in (44) with (53) through the three-cut approximation, or alternatively as in (45) with (53) through the reverse union bound inequality. Since these constraints are convex, the resulting problem is convex and can be solved using standard SDP solvers, similarly to the polyhedral chance constraint case. In the three-cut approximation, there will a total of constraints per time step, or total SOC constraints. In the reverse union bound approximation, there will be a total of constraints per time step, or total SOC constraints. Although the RUB relaxation is computationally more efficient, the three-cut relaxation is, in general, less conservative. This was confirmed from our numerical examples in Section V.
IV-B Geometric Approximation
We limit the following discussion to the three-dimensional case, which is often the case in practice when enforcing position constraints. However, the results can be generalized to -dimensional convex cones by using a concentration inequality for random variables [28]. For simplicity, let in (32), which corresponds to a cone centered at the origin. Letting the state be , where denotes the position, the chance constraints (33) become
| (54) |
or equivalently,
| (55) |
where parametrize the cone. In most three-dimensional applications, the matrix has two nonzero diagonal elements, and one zero diagonal element. As such, the vector will have one zero element. Let be defined such that it extracts the nonzero elements of . This is needed so as to reduce the dimensionality of the random vector inside the norm, from which we can more easily approximate the chance constraint. It follows that the chance constraints (55) become
| (56) |
where . From a geometric point of view, one can think of the constraints (56) as imposing, at each time step , that the random vector lies inside the disk of radius with probability greater than , However, since is a stochastic process, it follows that the radius of the disk is uncertain, therefore, and similar to Section IV-A, we relax the chance constraint such that the Gaussian vector lies within the mean radius of the disk .
Using this approximation, the chance constraints (33a) become
| (57) |
Note that the random variable is Gaussian such that , with mean and covariance . So far, we have turned the convex cone chance constraint (33a) into the chance constraint (57) that requires the probability of a Gaussian random vector being inside a circle of a given radius be greater than . Similar to the methodology in [28], this problem can be analytically solved as follows.
Proposition 3.
Let be a two-dimensional random vector. Then, for ,
| (58) |
Proof.
The probability density function (PDF) of is given by
| (59) |
Then, the probability in (58) is given explicitly by
| (60) |
where . Changing coordinates such that so that , note that the sets and are equivalent. Thus, the integral in (60) becomes
| (61) |
where . The last integral is straightforward to evaluate in two dimensions, namely,
| (62) |
which yields the desired result. ∎
Lemma 2.
Let be a two-dimensional random vector, let , and let . Then,
| (63) |
Proof.
Since the covariance matrix is positive definite, we can decompose it as where is a diagonal matrix containing the eigenvalues of and is an orthogonal matrix. Since , it follows that
| (64) |
From the previous expression, it follows that
| (65) |
Rearranging the previous inequality gives , and using (58), it follows that
| (66) |
Setting achieves the desired result. Geometrically, the level sets define the contours of ellipses having probability and the level sets are the smallest circles that contain these ellipses. ∎
Theorem 2.
Let be a two-dimensional random vector, let , and let . Then,
| (67) |
Proof.
V Spacecraft Rendezvous Example
V-A IRA-CS with Polytopic Chance Constraints
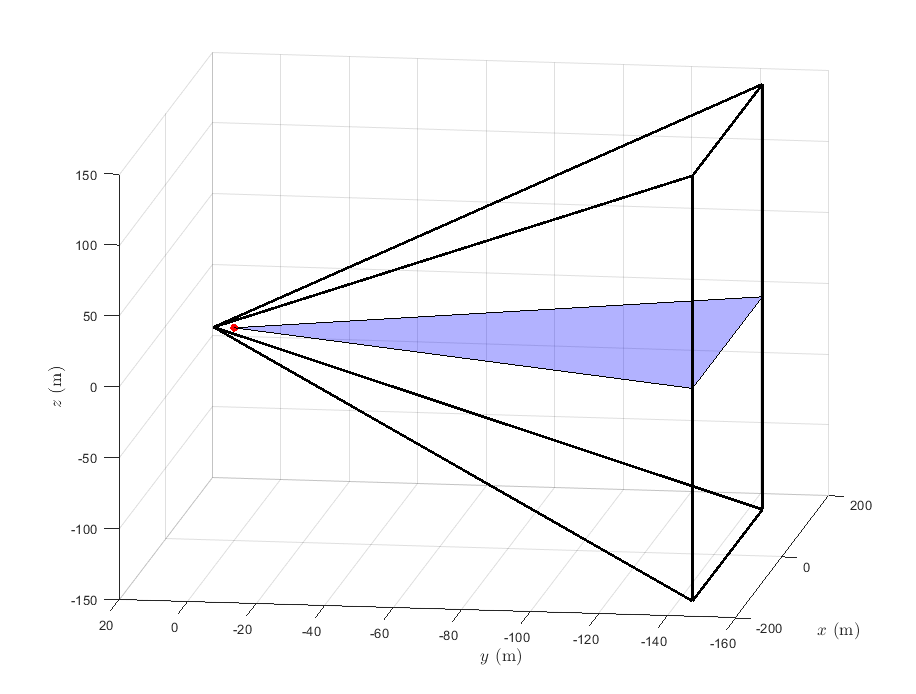
In this section, we implement the previous theory of CS with optimal risk allocation to the problem of spacecraft proximity operations in orbit. We consider the problem where one of the spacecraft, called the Deputy, approaches and docks with the second spacecraft, called the Chief, such that in the process, the Deputy remains within the line-of-sight (LOS) of the Chief, defined initially to be the polytopic region shown in Figure 1.
It is assumed that the two spacecraft are in the LVLH frame, that is, a rotating reference frame where the axis is oriented in the direction of the center of the Earth, the axis negative to the orbit normal, and the axis to complete the right hand rule. Moreover, assuming that the Chief is in a circular orbit (at an altitude km), the relative dynamics of the motion between the two spacecraft are given by the Clohessy-Wiltshire-Hill Equations [29],
| (74a) | ||||
| (74b) | ||||
| (74c) | ||||
where kg is the mass of the Deputy, is the orbital frequency, and represents the thrust input components to the spacecraft. It is assumed that the thrust is generated by a chemical propulsion system with PWM (pulse-width-modulation) able to implement continuous thrust profiles from impulsive forces.
The equations of motion (74) are written in a relative coordinate system, where the Chief is located at the origin, and represent the position of the Deputy with respect to the Chief. Note that the dynamics are decoupled from the dynamics; furthermore, the dynamics are globally asymptotically stable, so in theory we only need to control the planar dynamics. In Figure 1 the blue area represents the planar region. To write the system in state space form, let to obtain the LTI system , where
| (75) |
and . To discretize the system, we divide the time interval into steps, with a time interval sec. Assuming a zero-order hold (ZOH) on the control and adding noise that captures any modeling and discretization errors, as well as other environmental disturbances, yields the discrete system
| (76) |
where , . We choose the associated noise characteristics as [30]. We assume that the initial state mean and covariance are and , respectively. We wish to steer the distribution from the above initial state to the final mean with final covariance , while minimizing the cost function (4) with weight matrices and . We impose the joint probability of failure over the whole horizon to be , which implies that the probability of violating any state constraint over the whole horizon is less than 3%. The control inputs are bounded as N, which corresponds to a maximum acceleration of 10 cm/s2. Note that these bounds are hard constraints as opposed to (soft) chance constraints. To implement this input hard constraint within the CS framework, the algorithm in [15] was used (see also Appendix C). It should be noted here that since saturation of the input may lead to non-Gaussian state evolution, the chance constraint inequality (23) may not hold anymore. For our purposes though, the formulated SOC constraints work well even for the non-Gaussian case. This may lead to somewhat more conservative results, but for our problem, the difference turned out to be negligible.
Lastly, in the iterative risk allocation algorithm, we use a scaling parameter in Line 10 of the algorithm, where represents the current iteration. The SDP in Problem 2 was implemented in MATLAB using YALMIP[31] along with MOSEK[32] to solve the relevant optimization problems.
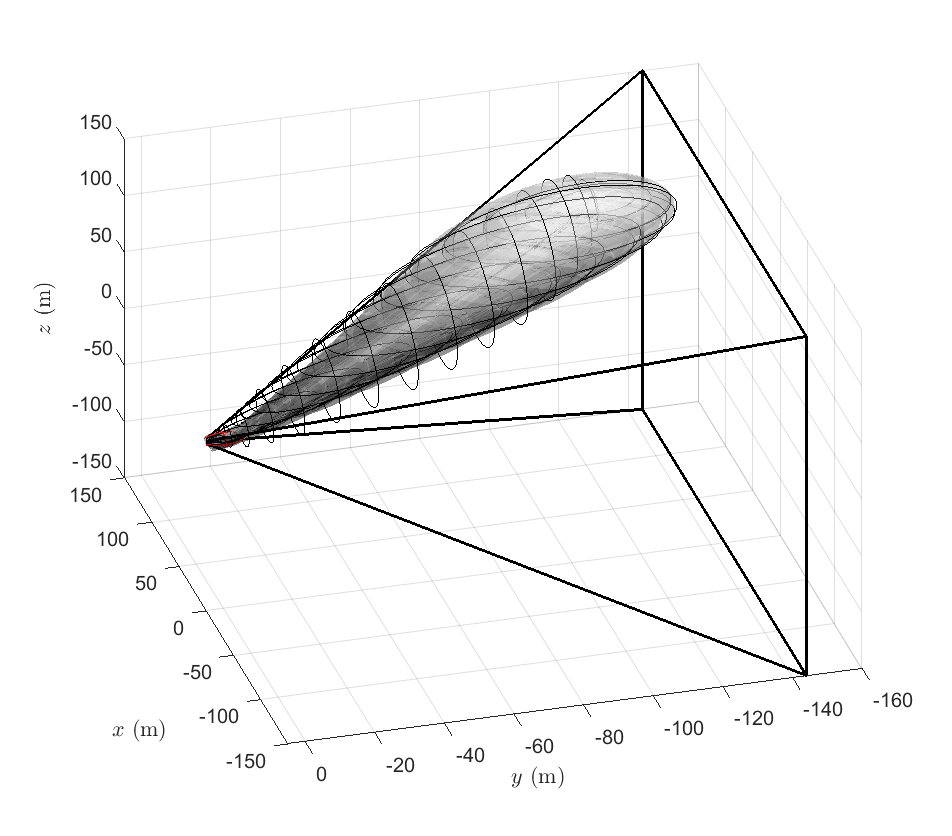
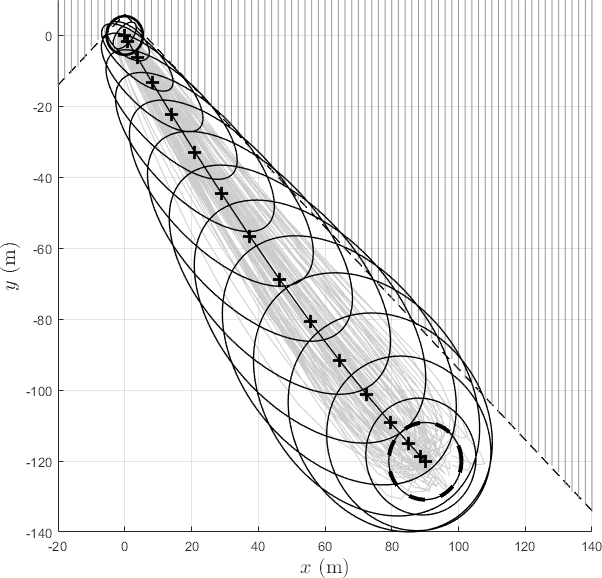
Figures 2 and 3 show the trajectories with optimal risk allocation, and Figure 3 shows the two-dimensional planar motion. Figure 4 compares the terminal trajectories of CS with a uniform risk allocation with the proposed method. The two solutions look similar and both satisfy the terminal constraints on the mean and the covariance. However, due to the relaxation , the uniform risk allocation scheme leads to more conservative solutions, as shown in Figure 4. The volume of the final covariance ellipsoid, is smaller for the uniform allocation solution compared to the optimal allocation solution (see Table I). In fact, we see that a consequence of optimal risk allocation is that it maximizes the final covariance given all the constraints, while still being bounded by .

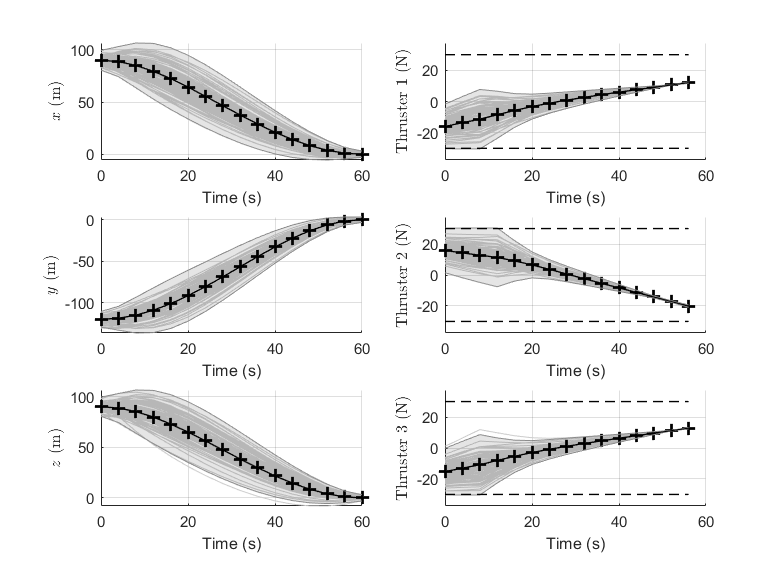
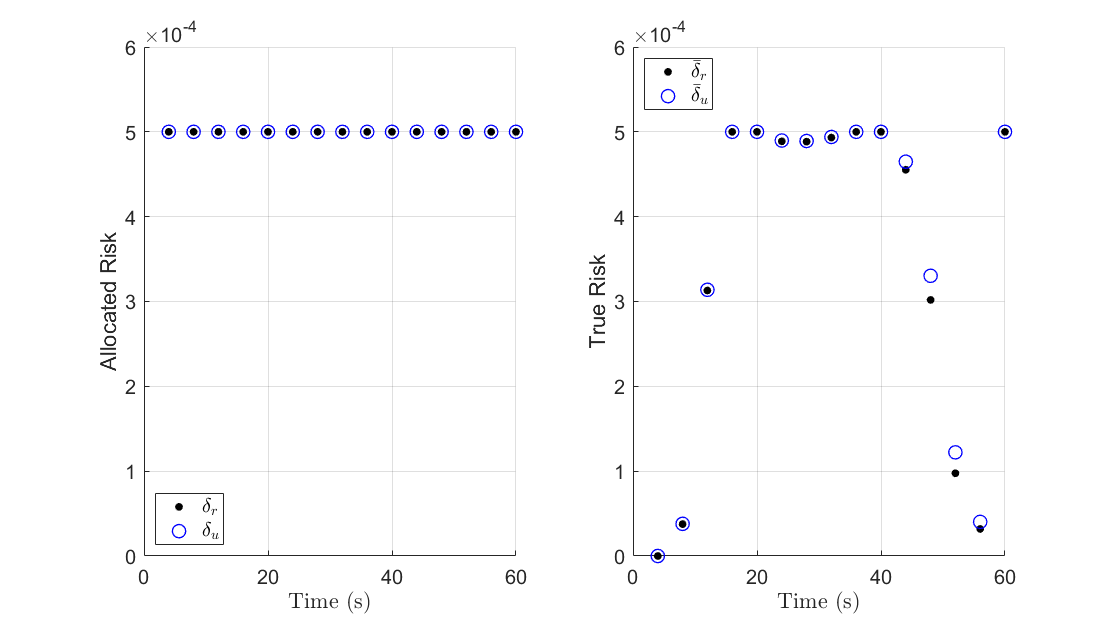
Figure 5 shows the state trajectories and the optimal controls for the polyhedral chance constraints. The control is almost linear but has a large variance in the first 10 time steps, where it may saturate due to the disturbances. Figure 8 shows the a priori allocation of risk, as well as the true risk once the optimization is completed, where corresponds to the risk allocated for the right boundary and for the risk allocated for the top boundary. Notice that in Figure 8(a) the true risk exposure is much lower than the allocated risk, which confirms the conclusion that the solutions for the uniform allocation case can be overly conservative. Comparing to Figure 8(b), we see a close correspondence between the allocated risk and the true risk exposure over the whole horizon for the optimal risk allocation case. It should be noted that although the true risk is still slightly less than the allocated risk, the error between the two is much smaller when compared to that of the uniform risk allocation strategy.
The iterative risk allocation algorithm is robust in the sense that the algorithm will assign risk proportionately to how close the solution trajectories are to the boundaries of the state space. Since solutions are close to the right and top boundaries of the allowable LOS region for most of the horizon, the optimal allocation weighs the respective risks more than those of the left and bottom boundaries. Thus, IRA purposefully steers the trajectories away from the boundaries proportionally to the amount of risk that is allocated to violating those respective boundaries. Table I shows the true joint probability of failure, defined as
| (77) |
It is clear that the uniform risk allocation does not even come close to the desired design of , while the IRA gives a true probability of failure very close to the desired one.
| - | Uniform | IRA Poly | IRA TC | IRA RUB |
|---|---|---|---|---|
| 0.0123 | 0.02998 | 0.029990 | 0.029994 | |
| 0.5546 | 0.6279 | 3.6818 | 3.7038 | |
| - | IRA GEO | CS-SMPC [17] | SMPC [33] | |
| 0.029979 | 0.01128 | 0.00105 | ||
| 4.0909 | - | - |
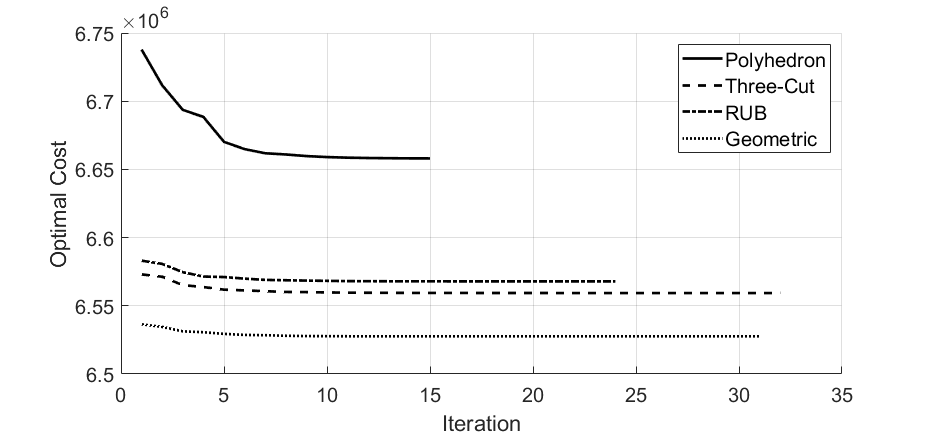
Finally, we looked at the optimal cost function over each IRA iteration, as in Figure 9. The convergence criterion set in this example is , or when all of the constraints are active or inactive, which can be proved in [26] to be a sufficient condition for optimality for Problem 3. We see that indeed (29) holds, and the optimization resulted even in a slight decrease of the objective function. Thus, the iterative risk allocation algorithm optimizes the risk allocation at each time step without increasing the cost.
V-B IRA-CS with Cone Chance Constraints
For this example, the following representation of a cone was used
| (78) |
where and is the standard 3D rotation matrix. The angle of rotation is , which corresponds to a body-mounted sensor on the Chief that is angled to the relative position vector of the Deputy. Additionally, , and , where is the cone half-angle. Lastly, , which corresponds to an offset of 10 meters from the origin. For the geometric approximation, we set , and . The constant choice of parameters for all was used across all constraints in the three-cut approximation and was used for the reverse union bound approximation. Lastly, the initial state was changed to for this simulation.
It should be noted that a rotated cone about the th axis can be put in the form of a standard cone as in (32) via the transformation
| (79) |
Thus, it is possible to make successive rotations of a cone by adjusting the cone parameters and . In the context of the given parametrization, the cone becomes the set
| (80) |
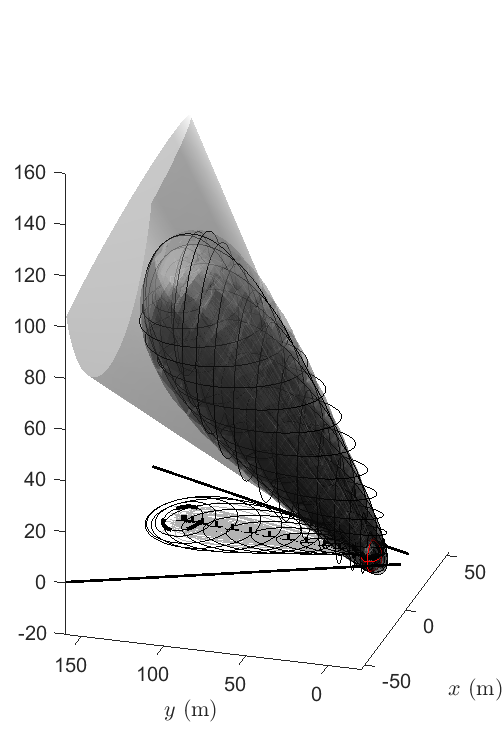
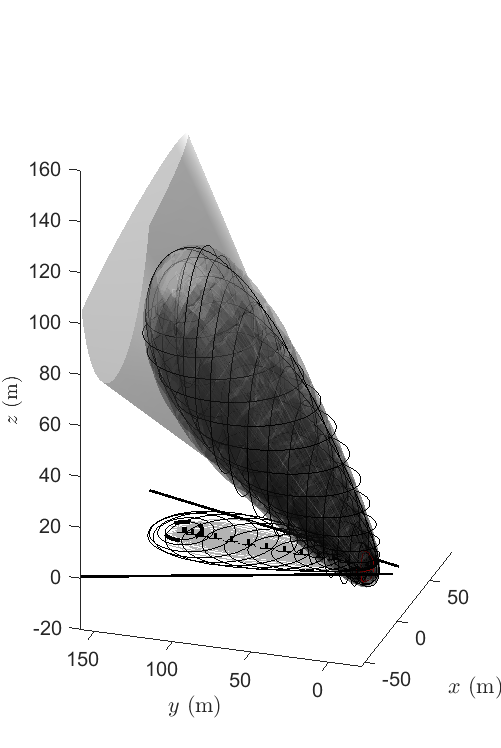
Figure 9 compares the results of the three approximations, with the geometric one being the best and the three-cut approximation being less conservative than the RUB approximation, as expected. Figure 12 shows the optimal trajectories in the three-dimensional space and in the projection on the - plane, respectively. It should be noted that for both the three-cut and RUB approximations of the cone constraint, and since we approximated the quadratic constraints as SOC constraints at each time step, the IRA algorithm needs to be adjusted as follows. In Line 5 of Algorithm 1, a constraint is active at time step if any of the constraints in (38a) are active. Similarly, when tightening the constraints in Line 10, the maximum true risk is used. This is not needed for the geometric approximation because it approximates each cone chance constraint as a single convex constraint for each , so the standard IRA algorithm is applicable.
From Table I, the geometric approximation actually has the highest terminal covariance of all four IRA methods discussed. Other than that, the two optimal inputs and trajectories are very similar from Figure 8, and both successfully steer the distribution of states to the terminal distribution, while satisfying the cone constraints.
V-C Comparison with MPC-based Controllers
In addition to comparing the presented methods with each other, it is also worthwhile to compare these methods to MPC-based methods in the context of the spacecraft rendezvous problem. Although there exists a significant literature on the use of MPC-based approaches for satellite rendezvous and proximity operations in space [34, 35, 36, 37, 38], most of these results assume deterministic dynamics and do not handle directly chance constraints. To this end, we applied two recent stochastic MPC (SMPC) formulations, outlined in [17] and [33], and compared them to the present formulation. Note that, with the exception of [17] and [33], most SMPC methods [39, 40, 34] assume bounded disturbances and/or chance constraints on the input, while in the present case, we assume more general, unbounded disturbances with hard constraints on the input, making the problem much harder to solve as a result.


Figure 15 shows the result from the MPC-based methods in [17] and [33]. In [17], the authors iteratively solve a covariance steering problem over a receding horizon. There are two terminal constraints at every time step; the first is on the mean state to be inside a maximally positive invariant (MPI) set defined by , where is the associated gain that satisfies , and is an assignable state covariance [41]. The second, and similar to this work, is a constraint on the terminal covariance to be less than or equal to , where is the aforementioned assignable covariance. Similarly, in [33] there are again two terminal constraints on the mean and the covariance, but in this case, the MPI set is defined as , where is the gain computed as the solution of an LQ problem for the nominal system, and is chosen to solve the Lyapunov equation .
In [33], the algorithm was not able to solve the rendezvous problem with the given parameters for a control bound of N, as this was not enough control authority to reach the MPI set at the end of the horizon (). The MPC problems became feasible only when the bounds were relaxed to more than five times that of the current work. Additionally, in both SMPC formulations, the designer is not allowed to freely choose the terminal covariance, since in order for the problem to be feasible, the terminal covariance must satisfy certain constraints. Lastly, although both MPC controllers successfully steer the system to the origin, there are no guarantees of recursive feasibility for the closed loop system and the solutions are more sub-optimal compared to that of the current work, as there is no optimization over the risks since they are uniformly allocated. As a result, the true risk in these MPC methods is much lower than the design goal, as shown in Table I. Further, there is no current work to date that can incorporate MPC-based methods for conical state spaces as was proposed here. As such, one potential future application of the proposed CS-IRA algorithm is in the context of SMPC, which would lead to less conservative and more optimal trajectory designs, without having to uniformly allocate risk or use a polyhedral approximation of the LOS cone.
VI Conclusion
In this paper, we have incorporated an iterative risk allocation (IRA) strategy to optimize the probability of violating the state constraints at every time step within the covariance steering problem of a linear stochastic system subject to chance constraints. For the covariance steering problem, we showed that employing IRA not only leads to less conservative solutions that are more practical, but also tends to maximize the final covariance. Additionally, the use of IRA in the context of CS with chance constraints results in optimal solutions that have a true risk much closer to the intended design requirements, compared to the use of a uniform risk allocation. We also implemented quadratic chance constraints in the form of convex cones, which are more accurate and natural for many engineering applications. Using two different relaxation methods these quadratic chance constraints can be made convex and the IRA algorithm can be used to optimize the risk. Lastly, we also propose a geometric approximation of the cone chance constraints, which is valid when the constraint space is three dimensional, as is often the case when constraining the position of a vehicle, and which is less conservative than either of the two two-sided approximations. All proposed relaxations result in convex programs, where the two-stage IRA algorithm is applicable.
VII Acknowledgment
This work has been supported by NASA University Leadership Initiative award 80NSSC20M0163 and ONR award N00014-18-1-2828. The first author also acknowledges support from the Georgia Tech School of Aerospace Engineering Graduate Fellows Program. The article solely reflects the opinions and conclusions of its authors and not any NASA entity.
References
- [1] P. Li, M. Wendt, and G. Wozny, “A probabilistically constrained model predictive controller,” Automatica, vol. 38, pp. 1171–1176, 2002.
- [2] A. F. Hotz and R. E. Skelton, “A covariance control theory,” in 24th IEEE Conference on Decision and Control, Fort Lauderdale, FL, Dec 11–13, 1985, pp. 552–557.
- [3] A. Hotz and R. E. Skelton, “Covariance control theory,” International Journal of Control, vol. 46, no. 1, pp. 13–32, 1987.
- [4] E. Bakolas, “Optimal covariance control for discrete-time stochastic linear systems subject to constraints,” in 55th IEEE Conference on Decision and Control, Las Vegas, NV, Dec 12–14, 2016, pp. 1153–1158.
- [5] ——, “Finite-horizon covariance control for discrete-time stochastic linear systems subject to input constraints,” Automatica, vol. 91, pp. 61–68, 2018.
- [6] A. Halder and E. D. B. Wendel, “Finite horizon linear quadratic gaussian density regulator with wasserstein terminal cost,” in American Control Conference, Boston, MA, July 6–8, 2016, pp. 7249–7254.
- [7] Y. Chen, T. T. Georgiou, and M. Pavon, “Optimal steering of a linear stochastic system to a final probability distribution – Part I,” IEEE Transactions on Automatic Control, vol. 61, no. 5, pp. 1158–1169, 2016.
- [8] M. Goldshtein and P. Tsiotras, “Finite-horizon covariance control of linear time-varying systems,” in 56th IEEE Conference on Decision and Control, Melbourne, Australia, Dec 12–15 2017, pp. 3606–3611.
- [9] E. Bakolas, “Finite-horizon separation-based covariance control for discrete-time stochastic linear systems,” in 57th IEEE Conference on Decision and Control, Miami Beach, FL, Dec 17–19, 2018, pp. 3299–3304.
- [10] K. Okamoto and P. Tsiotras, “Optimal stochastic vehicle path planning using covariance steering,” IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 2276–2281, 2019.
- [11] Y. Chen, T. T. Georgiou, and M. Pavon, “Optimal steering of a linear stochastic system to a final probability distribution – Part II,” IEEE Transactions on Automatic Control, vol. 61, no. 5, pp. 1170–1180, 2016.
- [12] ——, “Optimal steering of a linear stochastic system to a final probability distribution – Part III,” IEEE Transactions on Automatic Control, vol. 63, no. 9, pp. 3112–3118, 2018.
- [13] Y. Chen, T. T. Georgiou, and A. Tannenbaum, “Vector-valued optimal mass transport,” 2017, arXiv:1611.09946.
- [14] K. Okamoto, M. Goldshtein, and P. Tsiotras, “Optimal covariance control for stochastic systems under chance constraints,” IEEE Control System Letters, vol. 2, pp. 266–271, 2018.
- [15] K. Okamoto and P. Tsiotras, “Input hard constrained optimal covariance steering,” in 58th IEEE Conference on Decision and Control, Nice, France, Dec 11–13, 2019, pp. 3497–3502.
- [16] E. Bakolas, “Covariance control for discrete-time stochastic linear systems with incomplete state information,” in American Control Conference, Seattle, WA, 2017, pp. 432–437.
- [17] K. Okamoto and P. Tsiotras, “Stochastic model predictive control for constrained linear systems using optimal covariance steering,” 2019, arXiv:1905.13296.
- [18] J. Ridderhof, K. Okamoto, and P. Tsiotras, “Nonlinear uncertainty control with iterative covariance steering,” in 58th IEEE Conference on Decision and Control, Nice, France, Dec 11–13 2019, pp. 3484–3490.
- [19] E. Bakolas and A. Tsolovikos, “Greedy finite-horizon covariance steering for discrete-time stochastic nonlinear systems based on the unscented transform,” 2020, arXiv:2003.03679.
- [20] Z. Yi, Z. Cao, E. Theodorou, and Y. Chen, “Nonlinear covariance control via differential dynamic programming,” 2019, arXiv:1911.09283.
- [21] D. H. van Hessem, “Stochastic inequality constrained closed loop model predictive control with application to chemical process operation,” Ph.D. dissertation, Delft University of Technology, 2004.
- [22] L. Blackmore, “A probabilistic particle control approach to optimal, robust predictive control,” in AIAA Guidance, Navigation, Control Conference, Keystone, CO, Aug 21–24, 2006, pp. 1–15.
- [23] J. Pilipovsky and P. Tsiotras, “Chance-constrained optimal covariance with iterative risk allocation,” in American Control Conference, New Orleans, LA, May 26–28, 2021, submitted.
- [24] A. Prékopa, “Boole-Bonferroni inequalities and linear programming,” Operations Research, vol. 36, no. 1, pp. 145–162, 1988.
- [25] L. Blackmore, H. X. Li, and B. C. Williams, “A probabilistic approach to optimal robust path planning with obstacles,” in American Control Conference, Minneapolis, MN, June 14–16, 2006, pp. 1–7.
- [26] M. Ono and B. C. Williams, “Iterative risk allocation: A new approach to robust model predictive control with a joint chance constraint,” in 47th IEEE Conference on Decision and Control, Cancun, Mexico, Dec 8–11, 2008, pp. 3427–3432.
- [27] M. Lubin, D. Bienstock, and J. Vielma, “Two-sided linear chance constraints and extensions,” 2016, arXiv:1507.01995.
- [28] J. Ridderhof, J. Pilipovsky, and P. Tsiotras, “Chance-constrained covariance control for low-thrust minimum-fuel trajectory optimization,” in AAS/AIAA Astrodynamics Specialist Conference, Lake Tahoe, CA, Aug 9–13 2020.
- [29] W. Weisel, Spaceflight Dynamics. McGraw-Hill Book Co, 1989.
- [30] A. Vinod and M. Oishi, “Affine controller synthesis for stochastic reachability via difference of convex programming,” in 58th IEEE Conference on Decision and Control, Nice, France, 2019, pp. 7273–7280.
- [31] J. Lofberg, “YALMIP: A toolbox for modeling and optimization in matlab,” in IEEE International Symposium on Computer Aided Control Systems Design, Taipei, Taiwan, 2004, pp. 284–289.
- [32] MOSEK ApS, The MOSEK Optimization Toolbox for MATLAB Manual. Version 8.1., 2017. [Online]. Available: http://docs.mosek.com.
- [33] M. Farina, L. Giulioni, L. Magni, and R. Scattolini, “A probabilistic approach to model predictive control,” in 52nd IEEE Conference on Decision and Control, Florence, Italy, Dec 10–13 2013, pp. 7734–7739.
- [34] M. Mammarella, E. Capello, M. Lorenzen, F. Dabbene, and F. Allgöower, “A general sampling-based SMPC approach to spacecraft proximity operations,” in 56th IEEE Conference on Decision and Control, Melbourne, Australia, 2017, pp. 4521–4526.
- [35] A. Weiss, M. Baldwin, R. S. Erwin, and I. Kolmanovsky, “Model predictive control for spacecraft rendezvous and docking: Strategies for handling constraints and case studies,” IEEE Transactions on Control Systems Technology, vol. 23, no. 4, pp. 1638–1647, 2015.
- [36] D. C. S., H. Park, and I. Kolmanovsky, “Model predictive control approach for guidance of spacecraft rendezvous and proximity maneuvering,” International Journal of Robust and Nonlinear Control, vol. 22, no. 12, pp. 1398–1427, 2012.
- [37] M. Leomanni, E. Rogers, and S. B. Gabriel, “Explicit model predictive control approach for low-thrust spacecraft proximity operations,” Journal of Guidance, Control, and Dynamics, vol. 37, no. 6, pp. 1780–1790, 2014.
- [38] H. Park, C. Zagaris, J. Vigili-Llop, R. Zappulla, I. Kolmanovsky, and M. Romano, “Analysis and experimentation of model predictive control for spacecraft rendezvous and proximity operations with multiple obstacle avoidance,” in AIAA/AAS Astrodynamics Specialist Conference, Long Beach, CA, 2016, pp. 4521–4526.
- [39] D. Q. Mayne, M. M. Seron, and S. V. Raković, “Robust model predictive control of constrained linear systems with bounded disturbances,” Automatica, vol. 41, no. 2, pp. 219–224, 2005.
- [40] M. Mammarella, E. Capello, H. Park, G. Guglieri, and M. Romano, “Tube-based robust model predictive control for spacecraft proximity operations in the presence of persistent disturbance,” Aerospace Science and Technology, vol. 77, pp. 585–594, 2018.
- [41] E. Collins and R. Skelton, “A theory of state covariance assignment for discrete systems,” IEEE Transactions on Automatic Control, vol. 32, no. 1, pp. 35–41, 1987.
- [42] M. J. Wainwright, High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge University Press, 2019.
- [43] A. W. Marshall and I. Olkin, “Multivariate chebyshev inequalities,” The Annals of Mathematical Statistics, pp. 1001–1014, 1960.
A. Cone Chance Constraint Relaxation
Lemma 3.
The quadratic chance constraint
| (A.1) |
where is a relaxation of the cone chance constraint
| (A.2) |
Proof.
Since it follows that follows a non-central distribution with probability density function [42]. Let and notice that . The chance constraint (A.2) then takes the form . The probability that one random variable is less than or equal another random variable is given by
| (A.3) |
where is the joint probability distribution function of the random variables and . Next, write , where with probability density and let . The inner integral in (A.3) then becomes
It follows that
| (A.4) |
Noticing that
the last expression in (Proof.) implies that
which achieves the desired result. In order words, if the relaxed chance constraint is satisfied, then the original chance constraint is satisfied as well. ∎
B. Reverse Union Bound
Lemma 4.
Let the events , such that , for some , for all . Then,
| (B.1) |
C. Input Hard Constrained Covariance Controller
We assume that the hard input constraints on the control are affine, i.e., they are of the form
| (C.1) |
Theorem 3 ([15]).
The control law
| (C.2) |
where is governed by the dynamics
| (C.3) | ||||
| (C.4) |
where is an element-wise symmetric saturation function with pre-specified saturation value of the th entry of the input as
| (C.5) |
converts Problem 1 to the following convex programming problem that constrains the control to a maximum saturation value
| subject to | |||
| (C.6) | |||
| (C.7) | |||
| (C.8) | |||
| (C.9) | |||
| (C.10) | |||
| (C.11) | |||
| (C.12) |
where is a decision (slack) variable,
| (C.13) |
| (C.14) |
Further,
| (C.15) | ||||
| (C.16) |
In addition, and are constant, given by
| (C.17) | ||||
| (C.18) |
where denotes the th row of , and is a unit vector with th element 1.
Note that the saturation of the input will result, in general, in a non-Gaussian distribution of the state. As a result, the chance constraint inequalities (III-B) must be replaced by another set of inequalities, for example, of the Chebyshev-Cantelli type [43]. More details can be found in [15]. For the spacecraft rendezvous problem in Section V, it turned out, however, that the original chance constraint formulation worked well, which means that the Chebyshev-Cantelli inequality formulation of the chance constraints may be overly conservative for this problem.