Covariance Decomposition as a Universal Limit on Correlations in Networks
Abstract
Parties connected to independent sources through a network can generate correlations among themselves. Notably, the space of feasible correlations for a given network, depends on the physical nature of the sources and the measurements performed by the parties. In particular, quantum sources give access to nonlocal correlations that cannot be generated classically. In this paper, we derive a universal limit on correlations in networks in terms of their covariance matrix. We show that in a network satisfying a certain condition, the covariance matrix of any feasible correlation can be decomposed as a summation of positive semidefinite matrices each of whose terms corresponds to a source in the network. Our result is universal in the sense that it holds in any physical theory of correlation in networks, including the classical, quantum and all generalized probabilistic theories.
1 Introduction
The causal inference problem, i.e., determining the causes of observed phenomena, is a fundamental problem in many disciplines. Given two categories of observed and latent variables, it asks to deduce the causation patterns between the two sets of variables, where the former ones can be measured while the latter ones are hidden. More specifically, the problem is whether the statistics of the observed variables can be modeled with a given causal pattern [29, 18].
In this paper, we restrict ourselves to network causation patterns, which are determined by a bipartite graph with one part for observed variables and one part for latent variables [10, 6]. We can think of the vertices associated to latent variables as sources that produce signals that are independent of each other. We can also think of vertices associated to observed variables as parties who receive signals from their adjacent sources. After receiving these signals, each party performs a measurement whose output determines the value of the corresponding observed variable. For instance, if the signals are classical random variables, the measurement is a function of these variables. Here, we emphasize that the distribution of signals (latent variables) are mutually independent, and an observed variable equals the measurement outcome applied on the adjacent sources. See Figure 1 for an example of a network. Now given such a network with parties, and a joint probability distribution on their observed variables, the question is, can be modeled as the output distribution of the measurement of sources distributed in the network?
Quantum physics introduces seminal aspects to the causal inference problem [13, 11, 2]. The point is that the sources may produce quantum signals, i.e., multipartite entangled states, and parties may perform quantum measurements on the received signals. In this case the answer to the causal inference problem may differ from its answer in the completely classical (local) setting. Indeed, already in the primary example of Bell’s scenario we observe nonlocal correlations in the quantum setting that cannot be modeled classically [5]; this is Bell’s nonlocality. It is the elementary manifestation of a broader phenomenon, called network nonlocality, in which quantum nonlocal correlations admitting a model in some network cannot be modeled classically in the same network.
The existence of quantum models, which give access to more correlations than classical ones, raises the question of the ultimate limits on correlations in networks. In the case of Bell’s scenario, this ultimate limit is given by the no-signaling principle [21]. We imagine that any correlation satisfying this principle can be obtained through ‘measurements’ of ‘states’ in some hypothetical Generalised Probabilistic Theory (GPT) [4, 26, 14, 28]. Such theories generalize quantum physics and formalize the Popescu-Rohrlich box [20, 25]. However, the no-signaling principle alone is insufficient to define the ultimate limits of correlation in networks [12, 3]. In the following, we define these limits through the causality principle (see Figure 1). This resolusion, combined with the inflation technique [32], allow us to derive a universal limit on correlations in networks.
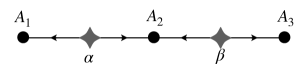
First causality law: Imaging that this network is a part of a larger network, yet the structure of the network in the neighborhood of is the same. Then the marginal distribution in the larger network remains the same.
Second causality law: Since in this network and do not have a common source, we have that .
Recently, Kale et al [15] proved a limit on the set of distributions that can be modeled in a network in the classical setting. They showed that the covariance matrix of functions of output variables associated to such a distribution can be decomposed as a summation of positive semidefinite matrices whose terms somehow correspond to sources in the network. Later, the same result is proven by Åberg et al [1] in the quantum setting, and discussed in Kraft et al [16]. The main contribution of our paper is that this decomposition holds to exist in a large class of networks in any underlying physical theory satisfying the aforementioned causality principle. More precisely, we prove that in any such physical theory, for local scalar functions of outputs of parties, their covariance matrix can be decomposed into a summation of positive semidefinite terms that are associated to sources in the network.
In the rest of this section, after giving some preliminary definitions, we present the statement of our main result and explain its proof techniques.
1.1 Main result
In this paper, we adopt Dirac’s ket-bra notation. We let and denote the computational basis of the -dimensional complex vector space by . The complex conjugate of is . Capital letters represent matrices and the -th entry of matrix is denoted by . For two matrices of the same size, is the Schur or Hadamard product of and , that is a matrix with entries
indicates that is positive semidefinite. We represent the Kronecker delta function by .
Networks.
A network is a bipartite graph whose vertex set consists of sources and parties. The sources are denoted by for , and parties are denoted by for . (and sometimes ) indicates that the source is connected to the party . We assume throughout this paper that the networks do not have isolated vertices meaning that each source is adjacent to at least one party, and each party is adjacent to at least one source. Moreover, we assume that there are no two sources in the network whose adjacent sets of parties are comparable under inclusion since otherwise one of them is redundant and can be merged with the other one.
Output distribution.
In the network , each source sends some signals to its adjacent parties, and each party after receiving signals from its adjacent sources, performs a measurement and outputs the result . The joint distribution of these outputs is denoted by .
Underlying physical theory.
In this paper, we do not make any assumption about the nature of signals and measurements. Hence, we consider any correlation which can be obtained in any Generalized Probabilistic Theory (GPT), i.e., from any hypothetical model for correlations in networks beyond classical and quantum physics.
The causal structure of the Bell scenario can be derived from the no-signaling principle alone. This approach fails in general networks. Hence, we need to accept the network causal structure. Here, we assume the causality principle from which two laws are followed. By the first causality law, the marginal distribution of the outputs of a group of parties depends only on the sources adjacent to them, and not on the structure of the network beyond those sources. By the second causality law, two groups of parties who do not share a common source are uncorrelated, and their marginal distribution factorizes. We think of these two causality laws as the only generic restrictions on GPTs in networks.111Our first causality law follows from the the no-signaling principle, and our second causality law is called the independence principle in [12, 3]. Thus, as an alternative solution we can also take the No-Signaling and the Independence principles (called NSI [12, 3]) instead of the causality principle. See [19] for a discussion on these different approaches. See Figure 1.
We also assume that we can make independent and identical copies of the sources and parties of a network . That is, we assume that we can repeat the process (experiment) under which the sources produce their signals and the parties perform their measurements. For instance, for a source of that emits some signal, we can make an independent copy of it that emits the same signal. We emphasize that we do not clone this signal; we only repeat the process under which it is produced. We give more details on these assumptions and their consequences in Subsection 2.1.
Covariance matrix.
Suppose that each party applies a real or complex function on her output. Associated to the distribution and these functions we consider the covariance matrix . This is an matrix whose -th entry equals
where the expectations are with respect to the output distribution . It is well-known and can easily be verified that the covariance matrix is always positive semidefinite.
In this paper, we are interested in certain decompositions of covariance matrices.
Definition 1 (-compatible matrix decomposition).
Let be a network with sources , , and parties , . For any source let be the set of matrices such that
-
–
is positive semidefinite,
-
–
The -th entry of is non-zero only if and .
Then we say that a positive semidefinite matrix admits an -compatible matrix decomposition if there are , , such that .
For an example of a network-compatible matrix decomposition, consider the network of Figure 1. As mentioned in the caption of this figure, by the independence principle . This means that . Then an -compatible matrix decomposition for the covariance matrix takes the form
where the two matrices on the right hand side are positive semidefinite and belong to and , respectively.
In this paper, we prove that the covariance matrix defined above admits an -compatible matrix decomposition with the minimal aforementioned assumptions on the underlying physical theory. To prove our result we need to restrict to a subclass of networks first introduced in [22].
Definition 2 (No double common-source network).
A network is called a No Double Common-Source (NDCS) network if for any two parties , there are at most one source adjacent to both of them.
Observe that a network in which all sources are bipartite (i.e., each source is adjacent to exactly two parties) are automatically NDCS.222Recall that we assume there is no redundant source in the network. We can now formally state the main result of this paper.
Theorem 3 (Main result).
Let be an NDCS network with sources , , and parties , . Consider signals emitted by sources and measurements performed by the parties in an arbitrary underlying physical theory that satisfies the no-signaling and independence principles. Suppose that this results in an output joint distribution . Let be a function of the output of party . Then the covariance matrix admits an -compatible matrix decomposition.
In [15] and [1] the above theorem is proven for the classical and quantum theories without the NDCS assumption and for vector-valued functions beyond the scalar ones. Nevertheless, Theorem 3 states the validity of covariance decomposition in the box world [28, 26] as well as any GPT [4, 14].
Remark that this theorem is tight, in the sense that given an NDCS network and a positive semidefinite matrix that admits an -compatible matrix decomposition, there exists an output distribution of the network whose covariance matrix is . Indeed, letting be an -compatible matrix decomposition of , assume that source sends a multivariate Gaussian distribution with covariance matrix to its adjacent parties (each coordinate to its associated party). Then, if each party outputs the summation of all received (one-dimensional) Gaussian signals, the joint output distribution would be a Gaussian distribution whose covariance matrix is .
Proof ideas.
Our main conceptual idea in proving Theorem 3 is the so called inflation technique [32] (see Subsection 2.1). Using non-fanout inflations, we consider certain expansions of the network by adding copies of the sources and parties and connecting them based on similar rules as in . Then we consider the covariance matrix associated to the inflated network. As a covariance matrix, it is again positive semidefinite. This fact imposes some conditions on the original covariance matrix. Then we show that these conditions imply that the covariance matrix admits an -compatible matrix decomposition.
From a more technical point of view, we first note that, fixing a network , the space of covariance matrices associated to forms a convex cone (see Definition 4). On the other hand, the space of matrices that admit an -compatible matrix decomposition is also a convex cone. To prove Theorem 3 we need to show that these two convex cones coincide. To this end, based on the theory of dual cones (see Subsection 2.2), it suffices to show that the associated dual cones are equal. Next, to prove equality in the dual picture, we use the inflation technique as discussed above. Putting these together, the theorem is proven when contains only bipartite sources (see Theorem 8). For general NDCS networks we also need to use the theory of embezzlement, first introduced in [30] in the context of entanglement theory (see Subsection 2.3).
2 Main tools
In this section we explain the main three tools we use in the proof of Theorem 3, namely, non-fanout inflations, the theory of dual cones and the theory of embezzlement.
2.1 Non-fanout inflation

The inflation technique [32] is a method to obtain constraints over the output correlations produced in a network . Here, we give a formal definition of a restricted class of inflations called non-fanout inflations.
Consider a network with sources , , and parties , outputting with joint distribution . In the inflated network of order , which we denote by , we consider copies of each source which we denote by , and copies of each party which we denote by . Let and be an adjacent source and party in . We assume that their associated copies are connected in as follows. Fix some permutation on . Then we assume that is adjacent to for any . Observe that in , any party is adjacent to the same number of sources and of the same types as in . Similarly, any source in is adjacent to the same number of parties and of the same types as in . Therefore, sources and parties in can behave similarly to the sources and parties in the original network by producing the same signals and performing the same measurements. The output of is denoted by , and the joint distribution of the outputs is denoted by
| (1) |
For an example of a non-fanout inflation see Figure 2.
In this paper, we assume that the underlying physical theory satisfies causality in the network, which is defined through the following two laws:
First causality law.
The marginal distribution of the outputs of a group of parties depends only on the structure of the network near those parties. For instance, suppose that share a source in and that is the unique such source. This means that in . Then the first principle states that the marginal distribution of outputs of in coincides with that of in , i.e., . The point is that the correlation between parties in are created in the very same way as the one between parties in .
As a consequence of this principle, if compute functions on their outputs, and similarly compute identical functions , respectively, then we have .
Second causality law.
If two groups of parties do not share any common source, then their marginal distribution factorizes. For instance, if do not share any source in (which may be the case even if share a source in ), then the marginal distribution factorizes as , where the second equality follows from the first principle. This, in particular, means that if and are functions of the outputs of , then we have .
Importantly, these two laws and inflation are more than a method to find limitations on correlations. They provide the definition of the ultimate limits of correlations in networks, hence should be satisfied by any GPT in network (see [7, 19]). We emphasize that we only consider non-fanout inflations meaning that we do not clone signals. In the classical theory signals can be cloned, so, e.g., a bipartite source in may become tripartite in . Indeed, the inflation technique with unbounded fanout exactly characterizes distributions in classical networks [17]. Here, as we consider arbitrary theories, we restrict only to non-fanout inflations. Such inflations has also been considered in [12].
2.2 Cones and duality
One of the main tools that we use to prove our main theorem is the theory of dual cones [8]. Here, restricting to cones of real or complex self-adjoint (Hermitian) matrices, we review the basic definitions and properties. Let us first introduce the Hilbert-Schmidt inner product on the space of matrices given by where is the adjoint of . Cones and dual cones are defined as follows:
Definition 4.
A subset of self-adjoint matrices is called a convex cone if
-
•
For and we have ,
-
•
For any we have .
Moreover, the dual cone of is defined by
An important example of a convex cone is the set of positive semidefinite matrices, that is self-dual.
In the proof of Theorem 3 we will use the following basic properties of dual cones, whose proofs are left for Appendix A.
Lemma 5.
[8] The followings hold for both the real and complex scalar fields:
-
(i)
For any cone , we have where is the closure of . Moreover, the dual cone is convex and closed.
-
(ii)
For any two cones we have .
-
(iii)
For any closed convex cone we have .
-
(iv)
For any closed convex cones , we have that is a closed convex cone.
-
(v)
For any closed convex cones , their sum is a convex cone (but not necessarily closed).
-
(vi)
For any closed convex cones we have .
-
(vii)
For any closed convex cones we have .
2.3 Embezzlement
Embezzlement is another pivotal idea in our proof of Theorem 3. Entanglement embezzlement is a compelling notion in quantum information theory first introduced in [30]. In the following we present the construction of the universal embezzling family of this paper, but without referring to entanglement. For any integer define
| (2) |
where is the Harmonic number and a normalization factor.
Lemma 6.
[30] For any , integer and sufficiently large the following holds. Let be a normal -dimensional vector satisfying for all . Then there exists a permutation such that
Here we identified with , e.g., via , and is the permutation matrix associated with given by . Note that by abuse of notation we consider as a vector in both and (by padding it with zero coordinates).
For the sake of completeness, we give the proof of this lemma in Appendix B.
We now generalize the above lemma to the case where the coordinates of are not necessarily non-negative. For this generalization we will use another class of states. For an integer , let be a -th root of unity and define
| (3) |
Lemma 7.
For any , integer and sufficiently large the following holds. Let be an arbitrary normal -dimensional vector. Then there exist a permutation such that
Here as in the previous lemma we identify with via a fixed map, and by abuse of notation we consider as a vector in both and (by padding it with zero coordinates).
Proof.
Let with and . Then for any there exists an integer such that
| (4) |
Let be the permutation matrix acting on that shifts the basis vectors by 1:
Then we have . Next, let
Note that is a permutation matrix acting on . Then we have
Therefore, letting and using (4), for sufficiently large , the vector is arbitrarily close to . On the other hand, by Lemma 6, there is a permutation matrix acting on such that for sufficiently large , the vector is sufficiently close to . Putting these together, we find that for sufficiently large , the vector is sufficiently close to . We are done since is a multiplication of permutation matrices, and is a permutation matrix itself.
∎
3 Bipartite-source networks
In this section, as a warm up and to convey some of our ideas, we prove Theorem 3 for networks all of whose sources are bipartite and the functions are real. Such a network can be visualized as a graph with nodes representing parties and edges representing sources. Thus for such networks, a source adjacent to two parties is denoted by and sometimes by .
In the following we restate Theorem 3 for bipartite-source networks and real functions.
Theorem 8 (Main result, bipartite-source networks).
Let be a network with parties , and with sources , , that are all bipartite. Consider signals emitted by sources and measurements performed by the parties in an arbitrary underlying physical theory that satisfies the no-signaling and independence principles. Suppose that this results in an output joint distribution . Let be a real function of the output of party . Then the covariance matrix admits an -compatible matrix decomposition.
Our proof of this theorem is in two steps. First, based on non-fanout inflations, we show in Lemma 10 that the Schur product of the covariance matrix with any sign matrix (to be defined) is positive semidefinite. Then, using the theory of dual cones, in Lemma 11 we show that any matrix with the aforementioned property admits an -compatible matrix decomposition.
Definition 9 (Sign matrix).
Consider a network all of whose sources are bipartite. A sign function on is a function that assigns to any source of . Then a sign matrix associated to is an symmetric matrix such that
| (5) |
Note that if parties do not have a common source, then the entry is unconstrained and can take any value.
We can now state our first lemma.
Lemma 10.
Let be a network with parties and with bipartite sources. Let be an arbitrary real function of the output of . Then for any sign matrix , the Schur product is positive semidefinite.
Note that although the entries of a sign matrix for which do not have a common source are not uniquely determined in terms of , the Schur product depends only on (by the independence principle, the corresponding entries in vanish, forcing those entries in to be zero).
Proof.
To prove this lemma we use the inflation technique discussed in Subsection 2.1. Consider the following non-fanout inflation of . For any party in consider two parties in the inflated network . Then for any source in consider two sources in . If , we connect one of them to and the other one to . If , then we connect one of them to and the other one to . See Figure 2 for an example of a sign function and its associated inflation.
Now suppose that party computes function of her output, and let be the covariance matrix of these functions, that is a positive semidefinite matrix. Suppose that we index rows and columns of by , and , representing party . Then as mentioned in Subsection 2.1 entries of can be computed as follows:
-
•
,
-
•
if do not have a common source in ,
-
•
if is a source in and ,
-
•
if is a source in and .
Indeed, the covariance matrix can be written as
| (6) |
where
Next, introducing the Hadamard matrix
we find that
| (7) |
Recall that is positive semidefinite. Then the matrix on the right hand side of (7), and any of its principal submatrices, is also positive semidefinite. This means that the submatrix consisting of rows and columns indexed by , , that is equal to
is positive semidefinite. ∎
We now show that any matrix satisfying the condition of Lemma 10 admits an -compatible matrix decomposition.
Lemma 11.
Let be a network with parties and with bipartite sources. Consider an positive semidefinite matrix such that if do not share a source. Then admits an -compatible matrix decomposition if and only if is positive semidefinite where
is the comparison matrix of .
We note that this lemma is first proven in [24] in the context of coherence theory in the special case where the underlying graph is complete (i.e., every two parties share a source). Moreover, the importance of this lemma in the causal inference problem has been notified in [16]. This lemma also has applications in entanglement theory [27]. We will generalise it in Lemma 14. Here we present a proof different from those of [24, 27].
Proof.
We prove this lemma using the theory of dual cones. We first introduce two sets of positive semidefinite matrices as follows:
-
•
We let be the set of positive semidefinite matrices such that if do not have a common source in , and .
-
•
We let be the set of positive semidefinite matrices that admit an -compatible matrix decomposition. Note that using the notation we introduced in Definition 1 we have .
The statement of the lemma says that . As shown in Appendix C it is not hard to verify that both are closed convex cones. Then using Lemma 5, to establish it suffices to prove that and .
:
For any there is a decomposition with . We note that for any positive semidefinite matrix we have . This means that for any . Therefore, is positive semidefinite and .
:
We need to show that for any and we have . To this end, first remark that by Lemma 5, we have . On the other hand, for , the cone is the set of matrices whose -block, i.e., the principal submatrix consisting of rows and columns indexed by , is positive semidefinite. Therefore, means that for any we have . Then we have
where is the vector with coordinates , . Here the last inequality holds since by assumption and . ∎
We can now give the proof of Theorem 8.
Proof of Theorem 8.
By Lemma 11 we need to show that is positive semidefinite where . On the other hand, since by assumption entries of are real, there is a sign matrix such that . Next, by Lemma 10 we know that is positive semidefinite. We are done.
∎
We remark that in Theorem 8 for simplicity of presentation and conveying some of our ideas we restrict to real functions . In the next section where we prove Theorem 3 in its most general form, we cover complex functions as well. Nevertheless, here we briefly explain the changes we should make in the above proofs in order to include complex functions.
Lemma 11 already works for complex matrices, so we only need to generalize Lemma 10. To this end, let be a function that associates a norm-1 complex number to any source . Then we define the generalised sign matrix to be an matrix with entries
| (8) |
We note that for any positive semidefinite matrix , there is an appropriate such that . Thus for complex functions , we need to generalize Lemma 10 and show that for any function with . To prove such a lemma, observe that for sufficiently large , there are such that is arbitrarily small, where is the -th root of unity. Then by a continuity argument it suffices to show that in the special case where . To prove this, we consider an inflation of with copies per source and party. Letting be copies of , we connect to parties and , the -th and -th copies of and respectively. Next, we consider the covariance matrix associated to this inflated network that is an positive semidefinite matrix. The block of this matrix associated to the source equals times a permutation matrix that is a shift by . Then, conjugating this matrix with the block-diagonal matrix all of whose diagonal blocks are Fourier transform, we can simultaneously diagonalize all blocks of the covariance matrix. Next, putting the second diagonal element of these blocks together we obtain an matrix that is equal to . Thus, this matrix is positive semidefinite since it is a principal submatrix of a positive semidefinite matrix. This gives the proof of Lemma 10 for complex functions.
In the next section, building on the above ideas, we generalize Theorem 8 for arbitrary NDCS networks and for arbitrary complex functions.
4 NDCS networks
In this section we prove Theorem 3 in its most general form. As in the previous section, the proof is in two steps. We first show in Lemma 13 (which generalises Lemma 10) that the Schur product of the covariance matrix with any twisted Gram matrix (to be defined) is positive semidefinite. We prove this using non-fanout inflations. Then in Lemma 14 (which generalises Lemma 11) we show that any matrix with the aforementioned property admits an -compatible matrix decomposition. To prove this result we use the theory of dual cones and the idea of embezzlement discussed in Subsection 2.3.
Let us first generalise the notion of sign matrices. Here, the sign function in Definition 9 is replaced by a collection of permutations and a set of vectors.
Definition 12 (Twisted Gram matrix).
Let be an arbitrary NDCS network with parties . Let be arbitrary -dimensional vectors. Also for any source and parties with , let be an arbitrary permutation on . Let be the associated permutation matrix acting on (i.e., for any ). Then a twisted Gram matrix associated to these vectors and permutations is an matrix such that
| (9) |
Note that, when parties do not share any common source, is unconstrained and can take any value. Also, note that is well-defined since by the NDCS assumption if have a common source, then it is unique.
We can now generalise Lemma 10.
Lemma 13.
Let be an arbitrary NDCS network with parties . Let , , be an arbitrary scalar function of the output of . Then for any twisted Gram matrix , the Schur product is positive semidefinite.
Proof.
Let be a twisted Gram matrix given by (9). Note that the entries of that are not specified by (9) are not important since by the independence principle the corresponding entries in vanish, so is independent of those entries of . We consider a non-fanout inflation of the network as follows. For any party we consider copies , and for any source we consider copies . If source is adjacent to party in , in the inflated network we connect source to the party . This fully describes the inflated network. Next, we assume that party computes that is identical to . Then the covariance matrix
is positive semidefinite. Observe that is an matrix consisting of blocks of size . These blocks labeled by pairs with and denoted by are described as follows:
-
–
The -block is diagonal with on the diagonal, i.e., .
-
–
If and parties do not share any source, then the -block is .
-
–
If and parties share source , then the -block equals . See Figure 3 to verify this.

Let be a matrix such that
Such a matrix can be constructed as follows. If , then let . Otherwise, start with and extend it to an orthonormal basis; put those basis vectors in the columns of a matrix to get a unitary matrix; finally multiply this unitary by to obtain . Next, let be the block diagonal matrix whose -th block on the diagonal is . Then is a positive semidefinite matrix consisting of blocks . Therefore, the principal submatrix of consisting of the -entry of all these blocks is also a positive semidefinite matrix. Denoting this matrix by , the entries of are computed as follows:
-
–
.
-
–
If and parties do not share any source, then the -block is .
-
–
If and parties share source , then .
Therefore,
and it is a positive semidefinite matrix. We are done.
∎
In the following lemma we present a description of the dual cone of positive semidefinite matrices that admit a network-compatible matrix decomposition. This lemma may be of independent interest, notably in coherence and entanglement theory.
Lemma 14.
Let be an arbitrary NDCS network with parties , and sources , . Let be the cone of positive semidefinite matrices that admit an -compatible matrix decomposition. Then
where is the set of twisted Gram matrices of Definition 12, and is its closure.
Note that this lemma is a generalization of Lemma 11, expressed in the dual picture. In the bipartite case, twisted Gram matrices turn to (generalized) sign matrices which have a much simpler description. Then the dual cone , that is the cone of interest, is easily characterized; it contains all matrices whose comparison matrix is positive semidefinite. This provides the explicit characterization of in Lemma 11. In the multipartite case, the set takes a much more complicated structure, so characterizing the dual cone is not easy. To clarify this issue, note that assuming that all sources are bipartite, the permutations that we need to use are either transpositions (in the real case) or shifts (in the complex case). Such permutations can be simultaneously diagonalized using Fourier transform as we did in the proof of Lemma 10 and mentioned at the end of Section 3. However, in the multipartite case, we need to use arbitrary permutations that cannot be simultaneously diagonalized. This makes it difficult to obtain a simple direct description of the cone .
Proof.
For any matrix we let be the principal submatrix of consisting of rows and columns indexed by parties with . We call the -block of . Let be the cone of positive semidefinite matrices whose only non-zero entries are in their -block, i.e., only if . We note that as the dual of the cone of positive semidefinite matrices is itself, is the space of matrices whose -block is positive semidefinite. On the other hand, by definition , so by Lemma 5 we have
That is, consists of matrices whose -block for any source is positive semidefinite.
:
By definition, any -block of any matrix is a Gram matrix and is positive semidefinite. Then by the above discussion, we have . On the other hand , as a dual cone, is closed. Therefore, .
:
Let . In the following we show that can be approximated by elements of with arbitrary precision, which shows that . To this end, we note that if do not share any source, the -entries of matrices in can take any value. So such entries of can be ignored in approximating with elements of . Indeed, it suffices to consider entries of that belong to an -block for some source .
Since by the characterization of , the -block of is positive semidefinite, there are vectors , for any with , such that
By padding these vectors with zero coordinates if necessary, we assume that for all , for some . To prove the lemma we need to show that for any there are vectors and permutations such that
To construct these vectors we use Lemma 7. Let
where and are defined in (2) and (3) respectively. By Lemma 7 there exists a permutation such that
where as . This means that for sufficiently large , the vector is arbitrarily close to . Therefore, for sufficiently large we have
We are done.
∎
Proof of Theorem 3.
Using the notation of Lemma 14 we need to show that
To this end, using , it suffices to show that for any we have
Then using established in Lemma 14 and by a continuity argument, we may assume that and takes the form (9). Now letting , we have
On the other hand, by Lemma 13 the matrix is positive semidefinite. Therefore, .
∎
5 Conclusion
In this paper we showed that the covariance matrix of any output distribution of NDCS networks can be written as a summation of certain positive semidefinite matrices. This result holds in the local classical theory, the quantum theory, the box world [28, 26] and more generally in any GPT [4, 14, 31] compatible with the network structure. To our knowledge, our result provides the first universal limit on correlations in generic networks, beyond constraints derived in specific ones (see [12, 3]). As also mentioned in [15, 1] this covariance decomposition condition can be stated as a semidefinite program and can be verified efficiently.
Our proof technique is valid only for the subclass of NDCS networks, while the covariance decomposition is known to hold for all networks in the case of local and quantum models. Hence, the necessity of this NDCS assumption in the case of generic GPTs is an open question; does the network-compatible matrix decomposition holds in all GPTs for networks that do not satisfy the NDCS assumption? Another open problem is to generalize our results for vector-valued functions beyond scalar ones.
The main conceptual tool in our proof is the inflation technique. It is proven in [17] that inflations with unbounded fanout characterize correlations in the local classical model. On the other hand, non-fanout inflation allows for a characterization of the ultimate limits on correlations in networks [12, 7, 19]. Our results show that even non-fanout inflations induce quite powerful limits on correlations in networks. To our knowledge, our work contains the first proof exploiting inflated networks of arbitrary sizes.
Note that the covariance matrix of a correlation depends only on its bipartite marginals. Yet, even the simple hexagon inflation of the triangle network (see Figure 2) allows for proving restrictions on multipartite marginals [12]. Thus, it would be interesting to find generic limits imposed on multipartite correlation functions by considering well-chosen families of non-fanout inflations, possibly of unbounded size. For instance, it would be interesting to see if the Finner’s inequality [9], as a constraint on multipartite correlations, holds for arbitrary GPTs. This inequality is proven in [23] for the quantum as well as the box world when the underlying network is the triangle.
At last, let us mention that our results may be of interest beyond causal inference in networks, particularly in coherence and entanglement theory. In Lemma 11 and Lemma 14 we characterized the space of matrices that admit a network-compatible matrix decomposition. Lemma 11 has applications in coherence and entanglement theory. Thus, Lemma 14 as a generalization of this lemma may find applications in these theories or elsewhere. Moreover, the proof of this theorem shows that the idea of embezzlement may find other applications in matrix analysis beyond the entanglement theory.
Acknowledgements.
The authors are thankful to Amin Gohari for bringing the example of Gaussian sources to their attention to show the tightness of Theorem 3; and to Elie Wolfe, Stefano Pironio and Nicolas Gisin for clarifying the different ways to define the ultimate limits of correlations in networks. M.-O.R. is supported by the Swiss National Fund Early Mobility Grant P2GEP2_191444 and acknowledges the Government of Spain (FIS2020-TRANQI and Severo Ochoa CEX2019-000910-S), Fundació Cellex, Fundació Mir-Puig, Generalitat de Catalunya (CERCA, AGAUR SGR 1381) and the ERC AdG CERQUTE.
References
- [1] J. Åberg, R. Nery, C. Duarte, and R. Chaves. Semidefinite tests for quantum network topologies. Physical Review Letters, 125(11):110505, 2020.
- [2] J.-M. A. Allen, J. Barrett, D. C. Horsman, C. M. Lee, and R. W. Spekkens. Quantum common causes and quantum causal models. Phys. Rev. X, 7:031021, Jul 2017.
- [3] J.-D. Bancal and N. Gisin. Non-local boxes for networks. arXiv preprint arXiv:2102.03597, 2021.
- [4] J. Barrett. Information processing in generalized probabilistic theories. Phys. Rev. A, 75:032304, Mar 2007.
- [5] J. S. Bell. On the Einstein Podolsky Rosen paradox. Physics Physique Fizika, 1(3):195, 1964.
- [6] C. Branciard, N. Gisin, and S. Pironio. Characterizing the Nonlocal Correlations Created via Entanglement Swapping. Phys. Rev. Lett., 104:170401, Apr 2010.
- [7] X. Coiteux-Roy, E. Wolfe, and M.-O. Renou. In preparation. 2021.
- [8] J. Dattorro. Convex optimization & Euclidean distance geometry. Meboo Publishing, 2010.
- [9] H. Finner. A Generalization of Holder’s Inequality and Some Probability Inequalities. The Annals of probability, 20:1893–1901, 1992.
- [10] T. Fritz. Beyond Bell’s theorem: correlation scenarios. New Journal of Physics, 14(10):103001, oct 2012.
- [11] T. Fritz. Beyond Bell’s theorem ii: Scenarios with arbitrary causal structure. Communications in Mathematical Physics, 341:391–434, 2016.
- [12] N. Gisin, J.-D. Bancal, Y. Cai, P. Remy, A. Tavakoli, E. Z. Cruzeiro, S. Popescu, and N. Brunner. Constraints on nonlocality in networks from no-signaling and independence. Nature Communications, 11(1):1–6, 2020.
- [13] R. L. J. Henson and M. F. Pusey. Theory-independent limits on correlations from generalized bayesian networks. New Journal of Physics, 16:113043, 2014.
- [14] P. Janotta and R. Lal. Generalized probabilistic theories without the no-restriction hypothesis. Phys. Rev. A, 87:052131, May 2013.
- [15] A. Kela, K. Von Prillwitz, J. Åberg, R. Chaves, and D. Gross. Semidefinite tests for latent causal structures. IEEE Transactions on Information Theory, 66(1):339–349, 2019.
- [16] T. Kraft, C. Spee, X.-D. Yu, and O. Gühne. Characterizing quantum networks: Insights from coherence theory. arXiv preprint arXiv:2006.06693, 2020.
- [17] M. Navascués and E. Wolfe. The inflation technique completely solves the causal compatibility problem. Journal of Causal Inference, 8(1):70–91, 2020.
- [18] J. Pearl. Causality. Cambridge University Press, 2009.
- [19] S. Pironio. In preparation. 2021.
- [20] S. Popescu and D. Rohrlich. Quantum Nonlocality as an Axiom. Found. Phys., 24(3):379–385, 1994.
- [21] S. Popescu and D. Rohrlich. Causality and nonlocality as axioms for quantum mechanics. In Causality and Locality in Modern Physics, pages 383–389. Springer, 1998.
- [22] M.-O. Renou and S. Beigi. Network nonlocality via rigidity of token-counting and color-matching. arXiv preprint arXiv:2011.02769, 2020.
- [23] M.-O. Renou, Y. Wang, S. Boreiri, S. Beigi, N. Gisin, and N. Brunner. Limits on correlations in networks for quantum and no-signaling resources. Physical Review Letters, 123(7):070403, 2019.
- [24] M. Ringbauer, T. R. Bromley, M. Cianciaruso, L. Lami, W. S. Lau, G. Adesso, A. G. White, A. Fedrizzi, and M. Piani. Certification and quantification of multilevel quantum coherence. Physical Review X, 8(4):041007, 2018.
- [25] V. Scarani. Feats, Features and Failures of the PR-box. In AIP Conference Proceedings. AIP, 2006.
- [26] A. J. Short and J. Barrett. Strong nonlocality: a trade-off between states and measurements. New J. Phys., 12(3):033034, 2010.
- [27] S. Singh and I. Nechita. The ppt2 conjecture holds for all choi-type maps. arXiv preprint arXiv:2011.03809, 2020.
- [28] P. Skrzypczyk and N. Brunner. Couplers for non-locality swapping. New J. Phys., 11(7):073014, 2009.
- [29] P. Spirtes, C. Glymour, R. Scheines, D. Heckerman, C. Meek, G. Cooper, and T. Richardson. Causation, prediction, and search. MIT Press, 2000.
- [30] W. van Dam and P. Hayden. Universal entanglement transformations without communication. Physical Review A, 67(6):060302, 2003.
- [31] M. Weilenmann and R. Colbeck. Self-testing of physical theories, or, is quantum theory optimal with respect to some information-processing task? Phys. Rev. Lett., 125:060406, Aug 2020.
- [32] E. Wolfe, R. W. Spekkens, and T. Fritz. The inflation technique for causal inference with latent variables. Journal of Causal Inference, 7(2), 2019.
Appendix A Proof of Lemma 5
Items (i), (ii), (iv) and (v) follow from the definition of dual cones.
To prove (iii), note that by definition . To prove the inclusion in the other direction, let . Since is convex, by the Hahn-Banach separation theorem there exists and such that for all and . We note that by the definition of cones, belongs to . Therefore, . On the other hand, suppose that is such that . Then letting , we have . Therefore, which is a contradiction. This means that for any we have . As a result, while we have . This means that does not belong to . Therefore, the complement of is a subset of the complement of which means that .
To prove (vi) note that by (ii) we have for . Then since is a closed convex cone and closed under summation, we have . To prove the other direction, suppose that . Then by the Hahn-Banach separation theorem and following similar steps as in the proof of (iii) we find that there exists such that for all , and . Since , for , by definition . Then by (iii) we have . This means that . On the other hand, , so . We conclude that the complement of is a subset of the complement , which means that .
For (vii) take the dual of both sides of (iv) and use (iii).
Appendix B Proof of Lemma 6
Let be the state obtained from via identification of with , so the coordinates of are for . Let be the permutation that sorts these coordinates in the decreasing order. Therefore,
with the multi-set of ’s being the same as the multi-set of ’s and . In the following we show that is close to when is large.
Let
Then we have . Moreover, by the normalization of we have
This means that
Next, using the fact that we conclude that
Therefore,
Thus, is arbitrarily close to for sufficiently large . We are done since is obtained from by applying a permutation.
Appendix C and are closed convex cones
In this appendix we show that the two sets defined in the proof of Lemma 11 are closed convex cones.
From the definition it is clear that is closed and that for and . Then we need to show that for , we have . Let be an arbitrary vector. We compute
where is the vector whose coordinates are ’s, and in the last line we use . As a result, and . Therefore, is a closed convex cone.
From the definition it is clear that is a convex cone. Thus we need to show that is closed. Indeed, the sum of closed convex cones is not necessarily closed, yet this holds for . To prove this, suppose that the sequence tends to as . Since ’s and are positive semidefinite, for sufficiently large we have . On the other hand, since belongs to , there are such that . Again using the fact that ’s are positive semidefinite, for sufficiently large we have
Then by a compactness argument, there is subsequence such that exists for all . Now since is closed, we have . On the other hand,
This means that . Therefore, is also a closed convex cone.