Correlation Clustering Algorithm for Dynamic Complete Signed Graphs: An Index-based Approach
[email protected];[email protected])
Abstract
In this paper, we reduce the complexity of approximating the correlation clustering problem from to for any given value of for a complete signed graph with vertices and positive edges where is the arboricity of the graph. Our approach gives the same output as the original algorithm and makes it possible to implement the algorithm in a full dynamic setting where edge sign flipping and vertex addition/removal are allowed. Constructing this index costs memory and time. We also studied the structural properties of the non-agreement measure used in the approximation algorithm. The theoretical results are accompanied by a full set of experiments concerning seven real-world graphs. These results shows superiority of our index-based algorithm to the non-index one by a decrease of %34 in time on average.
Keywords: Correlation clustering Dynamic graphs Online Algorithms
1 Introduction
Clustering is one of the most studied problems in machine learning with various applications in analyzing and visualizing large datasets. There are various models and technique to obtain a partition of elements, such that elements belonging to different partitions are dissimilar to each other and the elements in the same partition are very similar to each other.
The problem of correlation clustering, introduced in [1], is known to be an NP-hard problem for the disagree minimization. Therefore, several different approximation solutions based on its IP formulation exist in the literature. Recently, the idea of a 2-approximation algorithm in [1] is extended in [4] for constructing a -approximation algorithm. The experiments in [4] show acceptable performance for this algorithm in practice, although its theoretical guarantee can be too high, e.g. for . In [3], this algorithm is extended to an online setting where just vertex additions are allowed, and whenever a new vertex is added, it reveals all its positively signed edges. Shakiba in [12] studied the effect of vertex addition/removal and edge sign flipping in the underlying graph to the final clustering result, in order to make the algorithm suitable for dynamic graphs. However, one bottleneck in this way is computing the values of NonAgreement among the edges and identifying the -lightness of vertices. The current paper proposes a novel indexing scheme to remedy this and make the algorithm efficient, not just in terms of dynamic graphs, but for even dynamic hyper-parameter . Our proposed method, in comparison with the online method of [3] is that we allow a full dynamic setting, i.e. vertex addition/removal and edge’s sign flipping. It is known that any online algorithm for the correlation clustering problem has at least -approximation ratio [10]. Note that the underlying algorithm used in the current paper is consistent, as is shown via experimental results [3].
The rest of the paper is organized as follows: In Section 1.1, we highlight our contributions. This is followed by a reminding some basic algorithms and results in Section 2. Then, we introduce the novel indexing structure in Section 3.1 and show how it can be employed to enhance the running-time of the approximate correlation clustering algorithm. Then, we show how to maintain the proposed indices in a full dynamic settings in Section 3.2. In Section 4, we give an extensive experiments which accompanies the theoretical results and show the effectiveness of the proposed indexing structure. Finally, a conclusion is drawn.
1.1 Our Contribution
In this paper, we simply ask
“How can one reduce the time to approximate a correlation clustering of the input graph [4] for varying values of ?”
We also ask
“How can we make the solution to the first question an online solution for dynamic graphs?”
Our answer to the first question is devising a novel indexing-structure which is constructed based on the structural properties of the approximation algorithm and its NonAgreement measure. As our experiments in Section 4 show, the proposed method enhanced the total running-time of querying the clustering for about on average for seven real-world datasets. Then, we make this structure online to work with dynamic graphs based on theoretical results in [12]. The construction of the index itself is highly parallelizable, up to the number of the vertices in the input graph. The idea for parallelization is simple: construct each in the with a separate parallel thread. We also study the intrinsic structures in the NonAgreement measure, to bake more efficient algorithms for index-maintenance due to updates to the underlying graph. More precisely, we show that using the proposed index structure, we can find a correlation clustering for a graph for any given value of in time , compared to the time for the CC. The pre-processing time of the ICC would be with space complexity.
2 Preliminaries
Let be a complete undirected signed graph with vertices. The set of edges is naturally partitioned into positive and negative signed edges, and , respectively. Then, we use to denote . The correlation clustering problem is defined as
| (1) |
where is a clustering. Note that this is the min-disagree variant of the problem.
The constant factor approximation algorithm of [4] is based on two main quantities: (1) -agreement of a positively signed edge , i.e. and are in -agreement if and only if , and (2) -lightness, where a vertex is said to be -light if where . Note that a vertex which is not -light is called -heavy. This is a -approximation algorithm, as is shown in [3]. This algorithm is described in Algorithm 1, which we will refer to the CC algorithm, for short.
Shakiba in [12] studied theoretical foundation of the CC algorithm in a full dynamic setting. The following result is a summary of Table 1, Corollary 1, and Theorem 4 in [12].
Theorem 1.
Suppose the sign of an edge is flipped. Then, the non-agreement and -lightness of vertices other than the ones whose distance to either and is more than two would not change.
The arboricity of the graph is the minimum number of edge-disjoint spanning forests into which can be decomposed. The following lemma for arboricity is useful in bounding the number of operations.
Lemma 1.
Lemma 2 in [2] Suppose the graph has vertices with edges. Then,
| (2) |
3 Proposed Method
In this section, we describe our novel indexing structure. This structure allows dynamic queries of the correlation clustering with varying values of for dynamic graphs. The proposed algorithm which uses the indexing structure would be called ICC, or indexed-based correlation clustering.
3.1 Indexing structure
For an edge with positive sign, we define its -agreement distance as . Intuitively, this is the infimum of the values which the nodes and are not in -agreement. Let define the set . Without loss of generality, let with the ordering . For a fixed value of , let where .
Observation 1.
For all , is the null graph, i.e. a graph on all nodes without any edges. Moreover, for all , .
Next, we introduce the key ingredient to our indexing structure, called .
Definition 1 (NonAgreement Node Ordering).
The -agreement ordering for each node , denoted by , is defined as an ordered subset of vertices in where:
-
1.
node appears in the ordering if and only if is a positive edge in .
-
2.
for each two distinct vertices which appear in ,
(3) implies appears before .
-
3.
for each node , its -agreement distance is also stored with that node.
The NonAgreement node ordering of the graph is defined as .
In other words, the is a sorted array of neighboring nodes of in in their -agreement distance value. An example NonAgreement node ordering for all vertices in a sample graph is illustrated in Figure 1.

The space and construction time complexities of the are investigated in the next two lemmas.
Lemma 2.
The NonAgreement node ordering for a graph , , can be represented in memory.
Proof.
The number of nodes inside equals to the , for all vertices in as well as the vertex itself. Note that it is not required to explicitly store the vertex itself in the ordering. Cumulatively, the total size required for representing is entries. ∎
Lemma 3.
The time complexity to construct the for all vertices is where is the arboricity of the graph .
Proof.
To compute the value of for all edges , one needs to compute . This requires operations to compute the symmetric difference, given the adjacency lists of and are sorted. However, we can compute their intersection and use it to compute the NonAgreement as follows
| (4) |
Hence, the total time required to compute the values of NonAgreement is equal to
which is known to be bounded by (Lemma 1). Moreover, each is of length which requires sorting by the value of their NonAgreement in , which accumulates to . ∎
The correlation clustering corresponding to a given value of and a graph is the set of connected components of the graph . Given access to , one can respond to the following queries: (1) Is the vertex an -heavy vertex or an -light? (2) Are the endpoints of an edge in -agreement? As we will show in this section, both of these questions can be answered in time using the structure. For a vertex , its -light threshold is defined as .
Lemma 4.
For an and a vertex , is -heavy if and only if the -agreement distance of the -th smallest vertex in is less than . Otherwise, it is -light.
Proof.
The vertices and would be in -agreement if and only if . Whenever the -agreement distance of the -th smallest vertex in is less than , it means that there are at least vertices, including the itself, in -agreement with . This is equivalent the -heavyness of the vertex . On the other hand, if the -agreement distance of the -th smallest vertex in is greater than or equal to , this is equivalent to that the number of vertices in -agreement with is less than , i.e. is -light. ∎
Lemma 5.
Given access to , for all values of and any vertex , identifying the -lightness of can be accomplished in .
Proof.
This is implied by Lemma 4, assuming that the is implemented as an array. ∎
Given access to the index for a graph , a query simply asks for a clustering of the graph for a given value of .
Theorem 2.
Given access to the index , computing a clustering for a given parameter can be accomplished in amortized time, where is the slowly growing inverse of the single-valued Ackermann’s function.
Proof.
Intuitively, we are going to use to construct the graph and compute its connected components incrementally. More formally, we start by putting each vertex to its isolated set in a disjoin-union structure. Then, we identify -heavy vertices , which takes . Next, consider for . For each vertex whose key is smaller than and , we call , which merges the cluster which and belong. These operations takes amortized time [5] using a Disjoint-Set data structure. The correctness of the query algorithm is implied by the Definition 1 and the Lemmas 4 and 5. ∎
Before going any further, we need to state the following results, which intuitively investigate the behavior of the -agreement and -light of edges and vertices through the .Let
| (5) |
where for . Moreover, assume that .
Observation 2.
For any , the endpoints of all positive signed edges are not in -agreement.
Observation 3.
For any , the endpoints of all positive signed edges are in -agreement.
By the Observation 2, the correlation clustering output by the Algorithm 1 for all values of would be the collection of singleton vertices, i.e. . However, we cannot say that for , the output is a single cluster, i.e. the set . Why is that? As increases, the number of edges in -agreement would increase, however, the number of -light vertices would increase, too (By Corollary 1, which follows soon). Hence, there is a trade-off for choosing a suitable value of to get the minimum number of clusters. We would discuss this issue further in Section 4 (Experiments).
Theorem 3.
Let and be two distinct vertices. If and are in -agreement, then they would be in -agreement, too. Also, if and are not in -agreement, then they would not be in -agreement.
Proof.
The proof is a direct implication of the NonAgreement definition. Given that and are in -agreement, we have , i.e. and are in -agreement, too. Similarly, given that and are not in -agreement, we have , i.e. and are not in -agreement, too. ∎
Theorem 4.
Let and . If is -light, then would be -light, too. Also, if is -heavy, then it would be -heavy.
Proof.
This is implied by the definition of -lightness and Theorem 3. ∎
Two other important cases are not considered in Theorem 4, i.e. (1) Is it possible that a vertex be -heavy, but becomes -light for some values ?, and (2) Is it possible that a -light vertex becomes -heavy for some values of ? The answer to both of these questions is affirmative. By Theorems 3 and 4 and the previous discussion, we can state the following corollary.
Corollary 1.
Let .
-
1.
The number of positively signed edges whose endpoints are in -agreement is greater than or equal to the number of positive edges whose endpoints are in -agreement. In other words, the agreement relation is monotone.
-
2.
The number of vertices which are -light can be either greater or less than or even equal to the number of -light vertices. In other words, the lightness relation is not necessarily monotone.
The Baseline idea is to recompute the NonAgreement for each new value of , which takes , as is described in the proof of Lemma 2, deciding on the -heaviness of the vertices in in time and computing the connected components of the graph as the output in time . Totally, the time complexity of the Baseline is .
To conclude, using the index structure we invest space (Lemma 2) and (Lemma 3) time to construct the which make it possible to answer each query with varying values in time (Theorem 2). Comparing this with time for the Baseline reveals that our index-based structure makes query times faster for variable values of .
Given access to NAO, the algorithm 2 constructs the graph . Note that the output of the algorithms 1 and 2 are the same. As answering whether a vertex is -heavy or the endpoints of an edge are in -agreement can be answered in time, the running-time of the algorithm 2 would be for the for loop and to compute the connected components of . Totally, the running-time of the query algorithm in the ICC would be , compared to the time for the CC.
To model queries over a graph for various values of , we use a -Schedule defined as
| (6) |
Note that we consider as a set of strictly increasing real numbers, just for the sake of simplicity in notation. In a real life scenario, any time one can ask for a clustering with any value of .
3.2 Maintaining the index
The index structure introduced in Section 3.1 is used to compute a clustering of a static graph for user-defined dynamic values of . In this section, we revise this structure to make it suitable for computing a clustering of a dynamic graph for dynamic values of .
There are three different operations applicable to the underlying graph of the CorrelationClustering: (1) flipping the sign of an edge , (2) adding a new vertex , and (3) removing an existing vertex . These operations are considered in Lemmas 6, 7, and 8, respectively.
Shakiba in [12] has shown that flipping the sign of an edge , the -agreement of edges whose both endpoints are not in the union of the positive neighborhood of its endpoints does not change (Propositions 2 and 4 in [12]). Therefore, we just need to compute the -agreement for positive edges where .
Lemma 6.
Assuming the sign of an edge is flipped.
-
1.
Assuming the sign of edge was prior to the flipping, then and would be no more in -agreement since their edge is now negatively signed. The vertices and are removed from the arrays and , respectively. Moreover, we need to update the values of the non-agreement for vertices and in for all vertices .
-
2.
Assuming the sign of edge was prior to the flipping, then their is computed and the vertices and are added to proper sorted place in and , respectively. Moreover, we need to recompute the for all and update their -agreement values.
Applying these changes is applicable in where .
Proof.
The correctness of this lemma follows from the discussion just before it. Therefore, we would just give the time analysis. In the first case, finding the vertices in each is of . The removal would be amortized time.
The second case, i.e. flipping the sign from to , would cost more, as it may require changing all the positive edges with both endpoints the in the set . In the worst case, one may assume that all the -agreement between the edges with both endpoints inside is changed. Therefore, we need to update each of them on their corresponding indices. We need to add vertices and to the and , respectively, based on . Finding their correct position inside sorted s is possible with comparisons. Again, adding them at their corresponding position would take amortized time. For the other positive edges with both endpoints in the set , such as , we might need to update their -agreement. Without loss of generality, assume that . Doing so requires re-computation of , in , querying the NonAgreement inside , in time , and then possible updating its position, in both and requires . In the worst case, all the elements in may need update. Therefore, this case can be accomplished in
in the worst-case. ∎
Using Lemma 6, we can state the algorithm (Algorithm 3) which flips the sign of the edge . The correctness and the running-time of this algorithm follows directly from Lemma 6.
There are cases where a set of positive edges are also given for a newly added vertex . One can first add the vertex with all negative edges, and afterwards, flip all the edges in , so they would become positively signed. However, a batch operation would give us higher performance in practice.
Lemma 7.
Assume that a vertex is added to graph with new positive signed edges . Then,
-
1.
If , then does not need any updates and we just add a new to with as its only element in constant-time.
-
2.
Otherwise, let . We need to compute the for each positive edges with after adding all the new positive edges in , and possibly update and . This would require
(7) operations in the worst case.
Proof.
The correctness would follow immediately from the Lemma 6. Again, the first case can be accomplished in time. For the second case, we need to calculate values of NonAgreement, and add them or update them in their corresponding s. This would require
| (8) |
by exactly the same discussion as in Lemma 6. ∎
Remark 1.
The algorithm (Algorithm 4) adds a new vertex to and all its neighboring positively signed edges , and updates the . The correctness and the running-time of this algorithm follows directly from Lemma 7.
For the last operation, removing an existing vertex with a set of positive adjacent edges , can be accomplished by first flipping the sign of all of its adjacent edges in from to , and afterwards, removing its from . Similar to vertex addition, we can do it also in batch-mode, hoping for better performance in practice. The algorithm for the is similar to the algorithm (Algorithm 4).
Lemma 8.
Assume that an existing vertex is removed from the graph with the set of adjacent positive signed edges . Then,
-
1.
If , then has a single element, itself, and can be easily removed from . Nothing else would require a change, so it is of constant-time complexity.
-
2.
Otherwise, let . We need to compute the for each positive edges with after removing all the edges in , and possibly update and . In the worst-case, this would require
(9) operations.
4 Experiments
To evaluate the proposed method, we used 7 graphs which are formed by user-user interactions. These datasets are described in Table 1 and are accessible through the SNAP [8]. The smallest dataset consists of 22 470 nodes with 171 002 edges and the largest one consists of 317 080 nodes with 1 049 866 edges. In all these graphs, we consider the existing edges as positively signed and non-existing edges as negatively signed.
The distribution of the NonAgreements for each dataset is illustrated in Figures 2(a) to 8(a). The distribution of NonAgreements of the edges in almost all the datasets obeys the normal distribution, except small imperfections in Arxiv ASTRO-PH (Figure 2(a)), Arxiv COND-MAT (Figure 4(a)), and DBLP (Figure 8(a)). Moreover, more detailed statistics on these distributions are given in Tables 2. One single observation is that the most frequent value of the NonAgreement in all the sample datasets is . Why is that? Without loss of generality, assume that . Then, . By the assumption , i.e. the intersection of the neighborhood of vertices and consists of at most half of the neighborhood of . Also, exactly half of the neighborhood of falls at the intersection of the neighborhood of and . Intuitively, the vertex has clustering preference with extra vertices at least the number of vertices which both and have clustering preference. Similarly, the vertex has clustering preference with exactly half extra vertices which both and have clustering preference.
For each dataset, we have used a different set of -Schedules, depending on the distribution of their NonAgreements. More precisely: (1) we have sorted the values of non-agreements in each dataset in a non-decreasing order, with repetitions. (2) Then, we have selected distinct values equally spaces of these values. (3) The -Schedule was set to the selected values in the second step, which appended the value of at the beginning and the value of to the end if either does not exists. Totally, the number of -Schedule for each dataset is either , or .
An interesting observation is the number of clusters for in Figures 2(b) to 8(b). Note that we use to denote the interval for some non-zero constant . When but less than , the number of clusters is minimum. As it gets closer to , the number of clusters increases with a much greater descent than the decrease in the number of clusters as it gets close to from .
As in Corollary 1, by increasing the , the number of vertices in -agreement is a non-decreasing function, which is confirmed by the plots in Figures 2(a) to 8(a) as the number of vertices in -non-agreement is given by a non-increasing function. By closer visual inspection of these figures, we can see that the shape of the plot for the number of -non-agreement vertices in all these graphs is almost the same, with inflection point around the value of . This is due to the intrinsic nature of the .
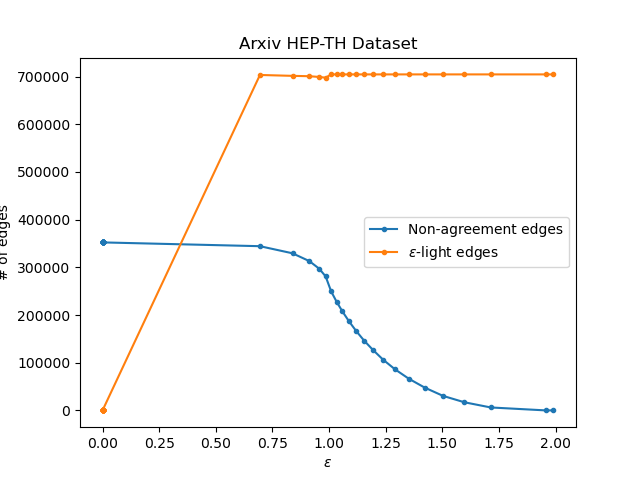
Similarly, the non-monotonicity result stated in Corollary 1 is observed in the same figures for the number of -light vertices. By a visual inspection, the trend of the number of -light vertices for almost all datasets, except for the Arxiv HEP-TH (Figure 5(a)) and the EU-Email (Figure 7(a)), is the same: the number of -light vertices increases as increases up to some point (first interval), then decreases slightly (second interval), and finally increases and would be asymptotically equal to the number of vertices in the graphs (last interval). For Arxiv HEP-TH and EU-Email, we have the same trend, however, the second interval is very small.
| Dataset | Nodes | Edges |
|---|---|---|
| Arxiv ASTRO-PH [7] | 18 772 | 198 110 |
| MUSAE-Facebook [11] | 22 470 | 171 002 |
| Arxiv COND-MAT [7] | 23 133 | 93 497 |
| Arxiv HEP-TH [6] | 27 770 | 352 807 |
| Enron-Email [9] | 36 692 | 183 831 |
| EU-Email [7] | 265 214 | 420 045 |
| DBLP [13] | 317 080 | 1 049 866 |
| Dataset | Distinct | Minimum | Maximum | Top 2 frequent values | |
|---|---|---|---|---|---|
| Arxiv ASTRO-PH | 16 436 | 0.015 873 0 | 1.967 21 | 1 — 9 664 | 0.5 — 2 992 |
| MUSAE-Facebook | 12 988 | 0.031 746 | 1.978 02 | 1 — 18 534 | 1.25 — 2 346 |
| Arxiv COND-MAT | 3 893 | 0.044 444 4 | 1.964 91 | 1 — 12 018 | 0.5 — 4 954 |
| Arxiv HEP-TH | 23 285 | 0.086 956 5 | 1.976 19 | 1 — 24 852 | 1.333 33 — 4 910 |
| Enron-Email | 20 273 | 0.090 909 1 | 1.954 55 | 1 — 31 704 | 0.5 — 6 796 |
| EU-Email | 28 612 | 0.117 647 | 1.990 52 | 1 — 441 520 | 0.997 658 — 682 |
| DBLP | 11 611 | 0.013 793 1 | 1.981 13 | 1 — 167 590 | 0.5 — 67 238 |
All the algorithms for the naive and the proposed index-based correlation clustering algorithms are implemented in C++111https://github.com/alishakiba/Correlation-Clustering-Algorithm-for-Dynamic-Complete-Signed-Graphs-An-Index-based-Approach without any parallelization and the experiments are done using an Ubuntu 22.04.1 TLS with an Intel Core i7-10510U CPU @ 1.80GHz with 12 GB of RAM. The time for running the naive correlation clustering algorithm (Algorithm 1), denoted here as CC, as well as the time for the index-based correlation clustering algorithm denoted as ICC, is given in Figures 2(d) to 8(d)). Note that the time reported for the ICC in these figures does not include the required time for constructing the s, as they are constructed once and used throughout the -Schedule. The running-time to read the graph as well as constructing the s is reported in Table 3 in milliseconds. The CC and ICC algorithms are the same, except that in CC, the non-agreement values of the edges and the -lightness of the vertices are computed for each given value of , however, in ICC these are computed and stored in the proposed s structure once and used for clustering with respect to different values of . As it can be observed in Figures 2(d) to 8(d), the running time for the ICC, excluding the time to construct the s for once, is largely smaller than the one for CC. On average, our approach for the described -Schedule lead to decrease in clustering time. This enhancement comes at the cost of pre-computing the s, which costs on average of the time for a single run of CC, which is quite small and makes the ICC efficient in cases where one requires to have multiple clustering for various values of .
| Dataset | Time to construct (ms) | Time to read graph (ms) |
|---|---|---|
| Arxiv ASTRO-PH | 1 677 | 543 |
| MUSAE-Facebook | 1 391 | 427 |
| Arxiv COND-MAT | 521 | 346 |
| Arxiv HEP-TH | 12 530 | 725 |
| Enron-Email | 2 498 | 525 |
| EU-Email | 4 479 | 958 |
| DBLP | 4 620 | 2 167 |



























5 Conclusion
In this paper, we proposed a novel indexing structure to decrease the overall running-time of an approximation algorithm for the correlation clustering problem. This structure can be constructed in time with memory. Then, we can output a correlation clustering for any value of in , compared with time complexity of the ordinary correlation clustering algorithm. Moreover, the proposed index can be efficiently maintained during updates to the underlying graph, including edge sign flip, vertex addition and vertex deletion. The theoretical results are accompanied with practical results in the experiments using seven real world graphs. The experimental results show about %34 decrease in the running-time of queries.
A future research direction would be studying this algorithm in parallel frameworks such as Map-Reduce and make it scalable to very Big graphs. Another research direction would be enhancing the approximation guarantee of the algorithm, or devising more efficient algorithms in terms of approximation ratio.
References
- [1] Nikhil Bansal, Avrim Blum, and Shuchi Chawla. Correlation clustering. Machine learning, 56(1):89–113, 2004.
- [2] Norishige Chiba and Takao Nishizeki. Arboricity and subgraph listing algorithms. SIAM Journal on computing, 14(1):210–223, 1985.
- [3] Vincent Cohen-Addad, Silvio Lattanzi, Andreas Maggiori, and Nikos Parotsidis. Online and consistent correlation clustering. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors, Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 4157–4179. PMLR, 17–23 Jul 2022.
- [4] Vincent Cohen-Addad, Silvio Lattanzi, Slobodan Mitrović, Ashkan Norouzi-Fard, Nikos Parotsidis, and Jakub Tarnawski. Correlation clustering in constant many parallel rounds. In International Conference on Machine Learning (ICML), pages 2069–2078. PMLR, 2021.
- [5] Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. Introduction to algorithms. MIT Press, 2022.
- [6] Jure Leskovec, Jon Kleinberg, and Christos Faloutsos. Graphs over time: densification laws, shrinking diameters and possible explanations. In Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, pages 177–187, 2005.
- [7] Jure Leskovec, Jon Kleinberg, and Christos Faloutsos. Graph evolution: Densification and shrinking diameters. ACM transactions on Knowledge Discovery from Data (TKDD), 1(1):2–es, 2007.
- [8] Jure Leskovec and Andrej Krevl. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014.
- [9] Jure Leskovec, Kevin J Lang, Anirban Dasgupta, and Michael W Mahoney. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Mathematics, 6(1):29–123, 2009.
- [10] Claire Mathieu, Ocan Sankur, and Warren Schudy. Online correlation clustering. In 27th International Symposium on Theoretical Aspects of Computer Science-STACS 2010, pages 573–584, 2010.
- [11] Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-scale attributed node embedding, 2019.
- [12] Ali Shakiba. Online correlation clustering for dynamic complete signed graphs. arXiv preprint arXiv:2211.07000, 2022.
- [13] Jaewon Yang and Jure Leskovec. Defining and evaluating network communities based on ground-truth. In Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics, pages 1–8, 2012.