Copyright Protection in Generative AI: A Technical Perspective
Abstract.
Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
1. Introduction
Recently, generative AI models have been extensively developed to produce a wide range of synthesized content, including text, images, audio, and code, among others. For example, advanced image generative models, such as Diffusion Models (DMs) (Ho et al., 2020), can produce highly realistic and detailed photographs and paintings. Similarly, large language models (LLMs) like ChatGPT (Achiam et al., 2023) can be leveraged to compose coherent and creative text articles with arbitrary genres and storylines. We refer to these advanced models as “Deep Generative Models” (DGMs). However, because of the remarkable fidelity and authenticity of the generated contents from DGMs, concerns have been raised regarding the associated copyright issues. For example, the New York Times sued OpenAI and Microsoft for using copyrighted work for training chatGPT 111https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html, https://www.nytimes.com/2024/01/08/technology/openai-new-york-times-lawsuit.html. Midjourney was accused to output images copied from commercial films222https://spectrum.ieee.org/midjourney-copyright. These copyright issues may pertain to various parties involved in the generation process. In specifics:
-
(1)
Source Data Owners. To generate high-quality contents, DGMs require training on a large amount of data, collected from various resources such as the Internet, even without the permission of the original data owner. As demonstrated in recent studies (Carlini et al., 2022, 2023), it is likely that both DMs and LLMs can produce contents with a high coincidence to parts of the training data samples. Besides, DGMs can also be utilized to directly edit the contents or imitate the artistic styles from source images and texts. These facts raise concerns for the data owners, as DGMs can generate data that closely resembles or replicates their original data without authorization.
-
(2)
DGM Users. DGMs are also frequently utilized by DGM users and assist DGM users for creative composing. However, whether the DGMs users should receive copyright for their generated contents is still a complex and evolving legal and ethical issue. For example, in 2023333Registration of “Zarya of the Dawn”, US Copyright Office refused to register a graphic novel for an artist facilitated by Midjourney444https://www.midjourney.com/ (a popular AI image generation model). However, another giant generative-AI company, OpenAI, claims that the model users own the created data via the models from OpenAI, including the right to reprint, sell, and merchandise555https://openai.com/policies/terms-of-use.
-
(3)
DGM Providers. The DGM providers contribute great efforts on the training of a DGM. It includes collecting and processing the large amount of data, engineering on the training and tuning for optimized model performance. Therefore, the DGM providers also have reasons to demand the copyright of the generative contents.
It has been under active discussion among government officials, lawmakers, and the general public, about who should claim the copyright and how to protect it. For instance, in early 2023, the U.S. Copyright Office initiated a process to gather feedback on copyright-related concerns related to generative AI. This included the discussions on the scope of copyright for works created via using AI tools and the use of copyrighted materials in AI training. Additionally, legal perspectives on these matters have also been explored in various opinions (Zirpoli, 2023; Franceschelli et al., 2022; Samuelson, 2023). However, in this article, we approach the topic from a different angle, where we provide an overview on existing computational methodologies, which have been proposed for copyright protection from a technical perspective. These are potential viable solutions for either AI model creator or model users, for copyright protection. In general, these computational techniques can be categorized according to the receiver of the copyright:
-
•
For source data owners, the protection on their original works could be achieved by: (a) “Crafting unrecognizeable examples”, which refers to the process that the data owners manipulate their data to hinder DGMs from extracting information; (b) “Watermark techniques” can be used by the data owner to trace and distinguish whether a generated work is produced based on their original creation; (c) “Machine Unlearning” means that the data owner can request a deletion of their data from the model or its output, once they identify the copyright infringement; (d) “Dataset De-duplication” removes duplicated data to mitigate the memorization effect to prevent the training data from being generated; (e) “Alignment” which uses a reward signal to reduce the memorization in LLMs; and (f) others including improved training and generation algorithms for better behaviors of LLMs.
-
•
For DGM users who create new works assisted by DGMs, the protected object is the generated contents from DGMs. Thus, the techniques for this type of copyright is barely related to the generation process of DGMs, as traditional copyright protection strategies can be also applied for protection of the DGM generated contents.
-
•
For DGM providers, there are representative “watermarking strategies” to inject the watermarks into the generated content or model parameters, such that we can track the ownership of the model.
Given the diversity in protection objectives, as well as DGM applications, we are motivated to have an overview on existing computational methods in this direction. Essentially, in Section 2, we will majorly discuss the copyright protection techniques for DGMs in the image domain. In Section 3, we discuss the strategies for text generation. Finally, we discuss the related problems in other domains, such as graphs, codes and audio generation in Section 4. In each section, we will introduce the background knowledge of existing DGMs, as well as the existing methodologies for data protection under different scenarios.
2. Copyright in Image Generation
In this section, we first introduce background knowledge on existing popular image generation models. Then, we define the problems related to the copyright issues for these image generation models, and introduce different strategies which can be utilized for data and model copyright protection.
2.1. Background: DGMs for Image Generation
In the era of deep learning, there are various types of image generation models that have been extensively studied. Most of them follow a pipeline to first collect a set of training images , whose samples’ distribution can be denoted as , and a model is trained to explicitly or implicitly estimate this data distribution. We denote the learned distribution as . During the image generation stage, the new images are generated by sampling from the learned distribution . For example, some popular models (Goodfellow et al., 2014a; Ho et al., 2020) can be written as the form of , which takes random noise (following distributions such as Gaussian Distribution) as input and generates samples . Besides, there are more advanced generative models, which can generate new samples based on user’s particular demands. For example, there are conditional generative models (Mirza et al., 2014) to generate samples which belong to a specific sub-distribution of , where can denote the given condition. In text-to-image models (Rombach et al., 2022), the condition can also be formatted as a language prompt for the desired generated samples. Furthermore, there are also advanced models which can directly take inputs from a few source samples , and then edit or modify them to obtain new samples . In the following, we provide a brief overview on the mechanisms of several popular image generative models.
-
•
Autoencoders (Vincent et al., 2010; Kingma et al., 2013) refer to the generative models, which consist of an encoder module and a decoder module for image reconstruction. In detail, the encoder projects a real image into a latent vector in the latent space. Then, the decoder takes the input of the latent vectors to generate new samples . The decoder is trained to reconstruct the original sample from the its latent produced by the encoder. In the work (Kingma et al., 2013), the latent vectors are further regulated to follow a standard Gaussian distribution. During the generation process, new latent vectors are sampled from the regulated distribution directly without the encoder and then decoded to obtain the generated images.
-
•
Generative Adversarial Networks (GAN) (Goodfellow et al., 2014a) are proposed to synthesize images via solving a min-max game. In GANs, there are two adversarial players, a generator and a discriminator . The generator aims to generate images that are highly realistic, while the discriminator aims to determining whether a sample is real or synthesized by . By solving the min-max problem, and will eventually converge to a point at which is well trained to distinguish the real and fake images, but can generate convincing images that are still possible to confuse . The adversarial min-max problem can be formulated as:
(1) where is the generated images, given the latent vector ( is the predefined distribution like an isotropic Gaussian noise). In Eq. (1) the goal of is to be trained to generate more authentic and realistic samples to mislead .
-
•
Diffusion Models, like DDPM (Ho et al., 2020), are a type of generative models which generate images via two -step Markov processes: a forward process and a reverse process. The forward process gradually adds noise to transform an input image into an isotropic Gaussian sample . In the reverse process, a denoising neural network is trained to transform a sample from the Gaussian distribution into the image distribution. The forward process can be formulated as:
where and controls the variance of injected noise. Then, the reverse process learns to denoise from noisy variable to less-noisy variable . The denoising step is approximately equivalent to estimating the injected noise with a parametric neural network in practice. The network is trained to minimize distance between estimated noise and true noise:
(2) Once the training of denoising network is complete, a new image can be generated starting from a random noise by solely employing the reverse process.
Based on DDPM, Latent Diffusion Model (LDM) (Rombach et al., 2022) is a specific class of diffusion models, which apply the forward process in the latent space instead of the pixel (image) space. In detail, to train an LDM, an input image is first mapped to its latent representation , where is a given image encoder. Then the forward process continues by repeatedly adding noise to the latent representation for steps, while the reverse process generates data by the denoising network . Once the latent representation is generated by the reverse process, it is then decoded by a decoder model to get the final generated image .
-
•
Text-to-image Diffusion Models, such as Stable Diffusion (SD) (Rombach et al., 2022), MidJourney, and DALLE2, allow the model users to generate images based on language descriptions. Stable Diffusion is achieved by combining LDMs with CLIP (Radford et al., 2021), a powerful model that learns the connection between the concepts of human language and images. Briefly speaking, given one of a few sentences as a prompt, a new image is produced following the basic pipeline of LDM, but conditioning on the (embedding of) language information of the given prompt. As a result, the generated contents can contain the desired semantic features and patterns by the prompt.
Recently there are more advanced techniques such as Textual Inversion (Gal et al., 2022) and DreamBooth (Ruiz et al., 2023) which further upgrade text-to-image diffusion models for customized image editing and modifying. For example, one can fine-tune SD on a few “input images” via the algorithm of DreamBooth, to make the model learn new objects from the input images, and then generate new images for the targeted object in different scenes.
2.2. Copyright Issues in Image Generation
The development of Deep Generative Models (DGMs) marks a noteworthy advancement in image generation. Nevertheless, the impressive quality and authenticity of the generated images, as well as the efficiency in producing new ones, give rise to legitimate concerns regarding copyright matters within the realm of DGMs.
Data copyright protection. For the source data owner, which refers to the party or individual who owns the originality of image works, their data can be intentionally or unintentionally collected by model trainers as training samples to construct DGMs as introduced above. For example, recent studies (Carlini et al., 2023; Vyas et al., 2023) have demonstrated that popular DGMs are highly possible to completely replicate their training data samples, which is called memorization. The possibility of data replication may severely offend the ownership of the original data samples. Moreover, the development of fine-tuning strategies such as DreamBooth can greatly improve the efficiency for unauthorized parties to directly edit or modify the source data to obtain new samples, which also severely infringes the copyright of the original works.
Model copyright protection. To obtain DGMs with advanced generation performance, it is always necessary for the model trainers to invest a significant amount of funds and labor. It grants them intellectual property rights over the trained model. However, recent works also identify the possibility to steal others models (Tramèr et al., 2016).
2.3. Data Copyright Protection
In this subsection, we review the techniques for the source data owners to protect their data copyrights. In general, we can categorize these techniques into four major types.
-
•
Unrecognizable Examples, which aim to prevent models from learning important features of protected images. This often results in the generation of either low-quality images or completely incorrect ones;
-
•
Watermark, which involves inserting unnoticeable watermarks into protected images. Data owners can detect these watermarks if their data is used for training;
-
•
Machine Unlearning, which aims to ablate the contribution of copyrighted data on the DGM to prevent the model from generating based on the information of the protected images;
-
•
Dataset De-duplication, which mitigates the memorization by removing the duplicated data from training set.
In the four categories, unrecognizable examples and watermarks are employed from the side of source data owners. They modify their data before releasing to the public to protect the copyright. As for machine unlearning and dataset de-duplication, they are proposed for the model builders who aim to provide DGM services legally without infringement on the copyrighted data. Next, we will introduce these strategies in detail.
2.3.1. Unrecognizable Examples
From the perspective of the source data owner, one major strategy for data protection is to make their data “unrecognizable” to potential DGMs. In general, a data owner can consider injecting imperceptible perturbations into the protected images, such that the DGMs cannot effectively exploit useful features from them, and hence hardly generate qualified new samples. These works of “unrecognizable examples” can be categorized based on how the DGM is utilized to extract information from the source image: (1) “inference-stage protection” counteracts DGMs which operate without the need for fine-tuning on the source image . These models are capable of extracting image features directly from the source image in an inference mode; (2) “training-stage protection” is against DGMs that is fine-tuned on the source images to extract the desired information and generate new samples based on the extracted information. Targeting on these two types of image editing manners, a variety of data copyright protection strategies are devised.
1) Inference stage protection. Well-trained DGMs, such as GAN models and diffusion models, can be directly used for various image generation tasks, including image-to-image synthesis and image editing. Thus, it is crucial to address inference-stage protection which aims at preventing models from extracting important information.
GAN-based methods. UnGANable (Li et al., 2022b) is the first defense system against a method commonly used for altering photographs or artistic creations, called GAN Inversion (Zhu et al., 2016, 2020; Abdal et al., 2019). It uses adversarial examples (Goodfellow et al., 2014b) to mislead GAN in latent space. Ruiz et al. (2020) aimed at data protection against Image-Translation GAN (Liu et al., 2017), which is a variant of conditional GAN that directly generates new images by inputting a source image instead of a random latent vector. It can generate an image which is manipulated from the source image . They use adversarial examples to maximize the distortion in the generated image. Yeh et al. (2020) aimed to protect users’ images from DeepNude (Sigal Samuel, 2019), a deep generative software based on the image-to-image translation algorithm. This method also borrows the idea of adversarial examples. It defines adversarial loss for Nullifying Attack which maximizes the distance of features extracted by the generator between perturbed images and the original image, as well as adversarial loss for Distorting Attack. Besides, Huang et al. (2021) expanded adversarial examples to more practical “grey-box” and “black-box” settings, which refer to the case that the data owner is unaware of the specific model that might be used for potential copyright infringement. This method adopts a surrogate model to approximate the manipulation model and update surrogate parameters and adversarial examples in an alternative manner. These examples demonstrate that the framework to generate adversarial examples can be adapted to different image manipulation models by properly designing the loss function for different specific tasks.
Diffusion models. Beyond GAN-based models, recently diffusion models have also been exploited for various types of modifying or editing tasks, which exposes a significant risk for copyright infringement. For example, Textual Inversion (Gal et al., 2022) is an image modifying technique by Stable Diffusion, without any training or fine-tuning process. Refer to the illustration in Figure 1, given a few source samples , Textual Inversion aims to extract the knowledge from by linking the sample to a specific text string such as . This process is achieved by adjusting the text embedding of in Stable Diffusion to embed the information of into it. The model user can utilize to compose new prompts,

and generate new images with the information embedded in , such as the original object or style from the source image, which might infringe the copyright of the source images. Targeted on Textual Inversion, the work (Liang et al., 2023a) aims to find an adversarial example to protect the source images . lies out of the distribution of the generated data samples of the diffusion models. Thus, the inversion process cannot find proper language tokens corresponding to the adversarial image. In detail, following the general definition of the diffusion loss in Eq. (2), we define the loss function on a specific sample : , the work (Liang et al., 2023a) aims to find a perturbation to maximize the loss value of the diffusion model on :
Because the diffusion model has a maximized loss on the perturbed image , the sample can be seen as a natural outlier from the distribution of the generated samples of the model. As a result, the Textual Inversion process cannot effectively find reasonable token , and thus protect the original information.
Similar to the idea of (Liang et al., 2023a), the work (Salman et al., 2023) directly leverages the adversarial examples for data protection against a image editing model based on LDM. In the work of (Salman et al., 2023), two attack strategies are proposed: (a) Encoder Attack: Considering a Latent Diffusion Model is employed for image editing, given the encoder model which maps a source image to the representation , the encoder attack searches for an perturbation satisfying where is a target latent representation. In this way, the latent representation of is close to the target representation which is pre-specified to be distinct from the original latent representation , which severely disrupts the LDM process. (b) Diffusion Attack: The full image editing process can be simply denoted as a model , and the generated image can fulfill the generation goal of the model user, the diffusion attack directly finds a perturbation to maximize the discrepancy of the generated sample and :
As a result, the newly generated sample is close to the target image thus very different from , which breaks the original image editing goal. However, addressing this optimization problem is computationally costly due to the extensive number of parameters involved and the multiple steps during the diffusion process. Consequently, they suggested calculating the loss based on only a limited number of steps instead of the entire diffusion process.
According to the discussion in (Salman et al., 2023), currently existing data protection strategies based on adversarial examples still face major drawbacks that can hinder their feasibility and reliability in practice:
-
•
Lack of robustness to transformations. The protected images may also be subject to image transformations and noise purification techniques, such as cropping the image, adding filters to it, or applying a rotation. However, the authors also mention that this problem can be addressed by leveraging “robust” adversarial perturbations, as discussed in (Athalye et al., 2018; Kurakin et al., 2018).
-
•
Generalization on different models. The protection techniques that are designed for one generative model may not be guaranteed to be effective against future versions of these models or other types of generative models. The authors mentioned that one could hope to improve on the “transferability’ of adversarial perturbations (Ren et al., 2022; He et al., 2023; Li et al., 2024). However, these “transferable” perturbations will not always be transferable for all circumstances.
2) Training stage protection Different from directly employing DGMs to generate new images, DGMs are also usually trained or fine-tuned on some source images to effectively learn useful information from for future generations. Therefore, “training-stage protection” aims to add imperceptible noise to the copyrighted images, to break the training process of potential DGMs for data copyright protection.

This type of method is first explored on GAN-based models. For example, GAN-based Deepfake models (Lu., 2018) are representative tools that can be leveraged to swap the faces from the source images to the faces of a target person, which severely abuses the copyrights of both source image holders and target people. Similar tools like EditGAN (Ling et al., 2021) and Introspective Adversarial Network (Brock et al., 2016) are developed to edit images that pose more threats to the copyrights of creative and artistic works. To handle this problem, Yang et al. (2021) proposed to utilize the idea of adversarial examples (Goodfellow et al., 2014b), to break the balance in the min-max game in GAN-based DeepFake models. Specifically, they focus on Deepfake models which are trained on the target person’s face images to generate other face images belonging to the target person. To protect the targeted face being exploited by Deepfake, they directly adopt the fast gradient sign method (FGSM) method to generate adversarial examples for GAN-based models,
| (3) |
where refers to the loss of the discriminator in GAN. During the generation process, the discriminator will have a large loss value on the target samples , which consequently breaks the balance of the min-max game during the training of GAN. As a result, the generated images based on the protected target images will have a degraded quality (see Figure. 2). Notably, in Eq.(3), a transformation operator is introduced to improve the robustness of the perturbation under various image transformations, including resizing, affine transformation and image remapping.
Wang et al. (2022) pointed out that previous adversarial perturbations via gradient-based strategies (e.g, FGSM) could be easily removed or destroyed by image reconstructions such as MagDR (Chen et al., 2021b) and proposed Anti-Forgery targeted on GAN-based Deepfake attacks. Anti-Forgery generates perturbations that are robust to input transformation, natural to human eyes, and applicable to black-box settings. They observed that adversarial perturbations on the LAB color space are robust to input reconstruction. Therefore, they converted the input from RGB space to the LAB color space and added perceptual-aware adversarial perturbations to the color channel to maintain robustness against input transformations including image reconstruction (Chen et al., 2021b) and image compression (Dziugaite et al., 2016).
Regarding diffusion models (Rombach et al., 2022; Ruiz et al., 2023), which can be easily deployed to mimic the style of specific artists, via advanced fine-tuning techniques, the special structure of diffusion models (see Section 2.1) poses unique challenges, especially the denoising procedure during the reverse process can eliminate noises added to the original image (Nie et al., 2022). GLAZE (Shan et al., 2023) is a representative copyright protection method focusing on text-to-image LDM and aiming at protecting artists from style mimicry. As shown in Figure 3, the core idea of GLAZE is to guide the diffusion model to learn an alternative target style that is totally different from the style of protected images. In detail, the method consists of three steps: target style choosing, style transfer, and cloak perturbation computation. GLAZE first chooses a target style which is sufficiently different from the protected style. A pre-trained style-transfer model is utilized to transfer the protected artworks into the target style for optimization. Then, GLAZE computes the cloak perturbation by:
| (4) |
where is the feature extractor of the LDM. This objective minimizes the distance between features of perturbed

images and target-style transferred images, and LPIPS (Zhang et al., 2018) constraints the perturbation to be imperceptible. When fine-tuned on protected arts, the generated images will mimic the target style rather than the arts’ true style.
MIST (Liang et al., 2023b) emphasizes that existing methods generate perturbations relying on some strong assumptions on a specific model which are hard to generalize to other scenarios. For example, perturbations generated for image-to-image DGMs usually fail for Textual Inversion (Salman et al., 2023). Therefore, they propose to generate perturbations that can work for various DGMs simultaneously, including DreamBooth (training-stage) (Ruiz et al., 2023), Textual Inversion (inference-stage) (Gal et al., 2022) and image-to-image generation (Rombach et al., 2022). To achieve this goal, they combine semantic loss from (Liang et al., 2023a) and textual loss from (Salman et al., 2023). They empirically show that the maximization of semantic loss leads to chaotic contents in the generated image, and the maximization of textual loss leads to a mimic of the pre-specified target image. Their empirical results reveal that perturbations from the combination of two losses can protect images under different scenarios.
Anti-DreamBooth (Van Le et al., 2023) specifically targets a powerful finetuning technique, DreamBooth (Ruiz et al., 2023), which is proposed to personalize text-to-image diffusion models onto given source images. DreamBooth has a similar target as Textual Inversion but requires fine-tuning of diffusion models. To avoid malicious usage of DreamBooth on users’ owned images, Anti-DreamBooth aims to attack the training process of DreamBooth, following the idea of data poisoning attacks. In detail, it formulates the protection problem as a bi-level optimization problem, to find perturbation satisfying:
where denotes the training loss for DreamBooth, and refers to the conditional loss of sample in prompt-guided diffusion models. By solving this problem, it searches for the perturbation, such that the fine-tuned diffusion models will disconnect the image with its corresponding language concept because of the high conditional loss. In this way, during the fine-tuning process, DreamBooth will overfit the adversarial images and experience worse performance in synthesizing images with high quality. Later, the work ADAF (Wu et al., 2023) also focuses on text-to-image models but pays more attention to the text part. It points out two drawbacks of existing methods: existing methods ignore the combination of the text encoder and the image encoder; existing methods are not robust to the perturbation of prompts. Consequently, ADAF implements multi-level text-related augmentations to enhance defense stability.
2.3.2. Watermarks
Another approach for protection on source data copyright is to track or detect whether a suspect piece of artwork is generated by a model trained on the copyrighted data. Various AI-generated image detection methods (Epstein et al., 2023; Dogoulis et al., 2023) can be applied to distinguish whether a sample is generated by certain models, which partially fulfill the objective. However, these methods are still not applicable to identify the source of the generated contents. Therefore, the “watermarking” strategy is alternatively studied. This technique involves encoding sophisticated “identifiable information” into the copyrighted source data, such that this information also exists in the generated samples which are trained on the watermarked images. Subsequently, a detector is leveraged to assess whether a suspect image contains this encoded information, to trace and verify the ownership of copyright.
Before DGMs, there exist various watermarking methods(Baluja, 2017; Hayes et al., 2017; Vukotić et al., 2018; Zhu et al., 2018; Zhang et al., 2019; Tancik et al., 2020; Luo et al., 2020) hiding data like a message or even an image behind imperceptible perturbations. These techniques primarily concentrate on hiding information in specific images, without being specifically applied to DGMs. But the objective of protection copyright against malicious DGMs is to identify hidden messages within generated images. Focusing on DDPM (Nichol et al., 2021), Cui et al. (2023a) evaluated whether the injected watermarks via previous methods for traditional image watermarks (Navas et al., 2008; Zhu et al., 2018; Yu et al., 2021) can still be preserved in the generated samples. The empirical results show that these methods are either partially preserved in generated images or requires large perturbation budgets. Therefore, they proposed DiffusionShield (Cui et al., 2023a), a watermarking method designed for diffusion models. To elaborate, blockwise watermarks, are engineered to convey a greater amount of information, allowing distinct copyright information to be more readily decoded. Then, a joint optimization strategy is leveraged to optimize both the pixel values of watermark patches, as well as a decoding model, which is utilized to detect and decode the encoded information from the generated images.
Fine-tuning text-to-image diffusion models, like Stable Diffusion, demonstrates significant potential in personalizing image synthesis and editing. Consequently, watermarking techniques are increasingly applied as a means of copyright protection during the fine-tuning phase. GenWatermark (Ma et al., 2023b) is the first to propose a novel watermark system that is based on the joint learning of a watermark generator and a detector. In particular, it adopts a GAN-like structure, where a GAN generator serves as the watermark generator and a detector is trained to distinguish between clean and watermarked images. Wang et al. (2023) aimed at a method that is independent of the choice of text-to-image diffusion models so that the perturbation can effectively protect the images from various models. In detail, they add specific stealthy transformations on the protected images as well as injecting a corresponding trigger into the caption of those images. Since they use the image warping function as the watermark generator, this method can work without a surrogate model and thus can work on different diffusion models. Cui et al. (2023b) considered a practical scenario where protectors can not control the fine-tuning process and emphasize that previous methods require many fine-tuning steps to learn the embedded watermarks. In order to make the watermark easily recognized by the model, they proposed FT-Shield which adds imperceptible perturbations that can be learned prior to the original image features, like styles and objects, by the text-to-image diffusion model. In the detection stage, a binary classifier is trained to distinguish the watermarked images and clean images. In particular, the perturbations minimize the loss of a diffusion model trained on these perturbed samples as shown in the training objective:
| (5) |
where denotes the parameters of the UNet (Ronneberger et al., 2015) which is the denoise network within the text-to-image model structure, while denotes parameters of the other parts; and denote the protected image and the corresponding caption, respectively. In other words, perturbation in Eq. (5) leads to a rapid decrease in the training loss and thus serves as a ’shortcut’ feature that can be quickly learned and emphasized by the diffusion model.
2.3.3. Machine Unlearning
In addition to the data owners, the protection of the data copyright is also considered by model builders to ensure the legal provision of DGM services. Companies try to filter out the copyrighted data from the training data. For example, Stability AI cooperated with an AI startup Spawning to build tools for data owners to claim their copyright and remove the data from the training set of Stable Diffusion, which has removed 80 million images from the training data of Stable Diffusion 3 666https://the-decoder.com/artists-remove-80-million-images-from-stable-diffusion-3-training-data/. OpenAI also provides solution to the data owners to report the violation of data copyright 777https://adguard.com/en/blog/ai-personal-data-privacy.html. Besides the data filtering, the model builder also takes other strategies like machine unlearning and dataset de-duplication (Section 2.3.4). Depending on whether the intent behind their implementation is motivated by the model builders’ need to legitimize the generation process or the source data owners’ requirements for the model builders, we attribute to machine unlearning (Bourtoule et al., 2021; Nguyen et al., 2022; Zhang et al., 2023a; Kumari et al., 2023) as the passive method and dataset de-duplication (Webster et al., 2023; Somepalli et al., 2023b) as the active method. For the passive method, after the DGM is trained, the model builder provides an interface for data owners to claim their copyright and ablate the influence of copyrighted data from the DGM. The passive method is executed when the source data owners request. In contrast, for the active method, the model builder considers the copyright in the stage of model training. The active method is usually implemented by the model builder without the request of source data owners. In this subsection, we focus on the discussion of machine unlearning in data copyright protection.
Especially, “Machine Unlearning” (Bourtoule et al., 2021) refers to the protocol to make a trained model forget a specific subset of training data, by editing the model parameter to follow the distribution identical to that of a model trained without the forgotten subset. With different subsets of undesirable concepts, machine unlearning can achieve not only copyright protection, but also preserving privacy against membership inference attack and the removal of biased, NSFW and harmful concepts.
Refer to Definition III.1 in (Bourtoule et al., 2021) and Section 3.1 in (Nguyen et al., 2022), assuming that the collected training dataset is , we notate the model obtained by training with the vanilla learning algorithm as . Assuming the undesirable (copyrighted) subset is , and the unlearning mechanism is , the model obtained by with unlearning of can be represented as . The perfect unlearning should have the distribution of parameters of unlearned model, , to be identical to the distribution of model parameter trained on the dataset stripped of the undesirable , i.e.,
| (6) |
where denotes the distribution of a random variable. For the problem of DGM where we consider the distribution of generated samples, and adapt Eq. (6) into:
| (7) |
where is the generated samples from model . By choosing different sub-dataset as , machine unlearning can fulfill various objectives. When is set as the data owned and copyrighted by individuals, the DGM builder utilizes machine unlearning to safeguard the copyright of this data. Zhang et al. (2023a) pointed out four goals of unlearning for DGM: performance (successfully remove target data from the model), integrity (at best keep other data of the model), generality (can be applied to a wide range of data that covers all aspects of human perceptions) and flexibility (can be applied to various models of different tasks and domains). In the following, we discuss different unlearning methods for GANs and Diffusion Models in the image domain.
Fine-tuning with a modified objective is usually used to achieve Eq. (7) for DGMs efficiently. Compared with data filtering and re-training from scratch (Nichol et al., 2022; Ramesh et al., 2022), it is more efficient in time and energy. For example, a representative method (Kong et al., 2023b) modifies the min-max adversarial objective of GAN by mixing the undesirable data with generated data as negative (fake) samples of the discriminator. Thus, the fine-tuned discriminator will not consider the undesirable data as true samples and the generator will be fine-tuned to avoid generating it. Another unlearning method considers how to change the guidance of conditions in conditional DGMs, like text-to-image models. The copyrighted images can be transformed as concepts like styles, branches, person names, and so on. By re-directing the conditional representations of these concepts to conditions unrelated to the copyrights, the generated images can avoid infringement on the copyrighted images. Kong et al. (2023a) represent the undesirable concepts as . They fine-tune the DGM to push the condition representation of concepts belonging to towards a concept which is not in the undesirable set. Meanwhile, to keep the other benign concepts unchanged, the fine-tuning objective also includes a term maintaining the representation of them as follows
| (8) |
where is the fine-tuned condition representation function, while is the original condition function. The condition representation of undesired is re-directed towards the benign concept and can avoid to guide the model to produce the samples of concepts from . Kong et al. (2023a) applied this general framework on different DGMs like class-conditional GAN (Mirza et al., 2014), and GAN-based text-to-image models (Zhu et al., 2019). Besides, Kong et al. (2021) also extended this method to diffusion-based text-to-speech models.
More unlearning methods by fine-tuning are tailored for Generative Diffusion Models, especially the text-to-image Stable Diffusion (SD) (Rombach et al., 2022) (refer to Section 2.1). Specifically, Kumari et al. (2023) proposed to unlearn SD by matching the conditional distribution of undesirable concepts to anchor concepts in every diffusion step, which means the output of the denoising network is flipped to anchor concepts that is unrelated to the undesirable ones. The anchor concepts can be random noise, , or the conditional distribution of benign concepts . With the anchor concept of random noise, the fine-tuning objective is
| (9) |
This objective tries to induce the new diffusion network to generate random noise if the input condition is from the undesirable concepts from . If the model is unlearned by benign concepts, the fine-tuning objective is
| (10) |
is the output under benign conditions. By optimizing this objective, the output under undesirable concepts will be re-directed towards the benign concepts. This method has a similar intuition to the second term in Eq. (8), but Eq. (8) fine-tunes the component for conditional representation, while Eq. (9) and Eq. (10) fine-tune the whole diffusion network of SD. In addition, a similar regularization term to keep the other desirable concepts unchanged is also combined with Eq. (9) and Eq. (10).
Zhang et al. (2023a) proposed the method called Forget-Me-Not to resteer the cross-attention layers in SD by minimizing the values of attention maps, which disrupts the guidance of text condition in diffusion process. In Stable Diffusion (Rombach et al., 2022; Zhang et al., 2023a), the cross-attention of UNet transfers information from conditional text to hidden features through dot product and softmax. The attention maps are calculated based on hidden features and embeddings of condition texts. The attention maps will show the information of the undesirable concepts. Thus, distrupting the attention map will lead to a broken diffusion process. The fine-tuning objective of Forget-Me-Not minimizes the values in the attention map to disrupt the guidance of condition texts. In this way, Forget-Me-Not can mislead and remove the undesirable concepts from the final generated data.
Different from the above two unlearning methods for diffusion models, Gandikota et al. (2023) targeted on the classifier-free diffusion generation (Ho et al., 2022). The classifier-free diffusion guidance does not reply on a classifier for conditional generation, which is opposite to the classifier-based diffusion guidance. The classifier-based diffusion guidance modifies the denoising step to follow the feature captured by an auxiliary classifier :
where provides the information of what features should have if wants to be classified as . This guidance can shape into step by step, and is the parameter to control the strength of the classifier guidance (Dhariwal et al., 2021). In contrast, the classifier-free diffusion guidance uses the difference between the outputs of conditional denoising diffusion model and unconditional denoising diffusion model as the guidance to boost the influence of conditions:
where is different between conditional and unconditional model, i.e. the influence of condition. It can also provide the information of the features that should possess to likely generate it into class . The classifier-free diffusion model makes use of this information to guide the generation process. Gandikota et al. (2023) proposed ESD which uses the opposite of the guidance as the unlearning objective to fine-tune SD:
The formulation uses several instances of diffusion models, and . is fixed for quantifying the opposite of guidance, while the is the unlearned network to solve. ESD has two variants, ESD-x and ESD-u. They have the same fine-tuning objective, but choose different subsets of parameters to fine-tune. ESD-x fine-tunes the cross-attention layers, while ESD-u fine-tunes non-cross-attention modules. Gandikota et al. (2023) found that the ESD-x can control the unlearned data according to the specific prompt, such as a named artistic style, and has little influence on other concepts. ESD-u can unlearn concepts from SD no matter whether a specific prompt is used, which is more suitable for global unlearning like NSFW.
2.3.4. Dataset De-duplication
Memorization is another problem that threatens the copyright of source data. It refers to the problem that the generation model might produce images that are the same as the training data (van den Burg et al., 2021). It is found by many works that duplicated examples in the training data are more possible to be generated (Webster, 2023; Somepalli et al., 2023a; Carlini et al., 2023). Somepalli et al. (2023a) also argued that memorization is associated with the frequency at which data is replicated. Carlini et al. (2023) pointed out that the samples that are easy to be memorized usually duplicated for many times.
Therefore, dataset de-duplication is necessary to mitigate the memorization and prevent the model from generating the training data. It is attributed to an active method because de-duplication is conducted by the model builder for the purpose of providing legal services. Webster et al. (2023) proposed a method to search the duplicate training images by CLIP (Radford et al., 2021). First, it trains the auto-encoders to compress the images and texts into latent space. It proposes Subset Nearest Neighbor CLIP (SNIP) to fine-tune the encoder for compression and keep the distance between neighbors at the same time. After compression, it uses the inverted file system (IVF) to approximately search the duplicated images. The whole huge dataset is divided into small groups by -means, and the duplication is searched within the closest centroids. Then the found data is de-duplicated to reduce the memorization. OpenAI used a similar strategy to train DALL·E 2 (OpenAI, [n. d.]). It first divides the training data into clusters, and then search the similar data within the union set of a small number of clusters.
Somepalli et al. (2023b) pointed out that the conditions of diffusion model, i.e. the text caption, will also influence memorization. Their experiments demonstrated that during the fine-tuning of Stable Diffusion, the memorization is more likely to happen if the captions (or text prompts) of different images are more diverse. But it does not mean the totally random captions can exacerbate memorization. Actually, the captions that are correlated with image content but have more diversity can lead to more severe memorization. However, diverse captions of the duplicated images can reduce the memorization. They also found that more training epochs have similar influence to duplication which increases the memorization. This means more epochs may mimic the duplication. Based on these findings, they concluded that for a single image and duplicated images, the diverse captions can help slow down the memorization. They proposed a few methods to process the captions during fine-tuning to avoid memorization, including multiple captions (which randomly samples from 20 captions generated by BLIP (Li et al., 2022a) for each image when training), random token replacement & addition (which randomly replaces tokens/words in the caption with a random word, or add a random word to the caption at a random location) and so on.
2.4. Model Copyright Protection
This subsection summarizes the strategies for protecting the copyright of DGMs for image generation. This protection is important for two major reasons. First, a powerful DGM, which necessitates extensive computational resources and well-annotated data for its creation, needs to be safeguarded from copyright infringements (such as being stolen by malicious users to offer unauthorized paid services). Second, the unregulated distribution of those models may lead to ethical concerns, including their potential misuse for generating misinformation, which necessitates techniques to identify the origin of an image.
Deep Generative Model Watermarking is a common solution for model copyright protection. It involves incorporating distinct information, known as a watermark, into the models before their deployment. The embedded watermark can be retrieved from a potentially infringing model or its generated data to confirm any suspected copyright violations. To achieve good performance in protecting the model while preserving the original generation performance, the watermarking technique should incorporate the following key properties: (a) Fidelity: the ability of the watermarking method to not significantly impact the general performance of the model (the diversity and visual quality of the generated images); (b) Integrity: the accuracy with which the watermark can be extracted; (c) Capacity: the length of message that can be effectively encoded to and extracted from the watermark; (d) Robustness: the ability of the watermark to withstand alterations to the model or perturbation on the watermarked generated images; and (e) Efficiency: the computational cost of the watermark embedding and extraction process.
The proposed DGM watermarking methods can be summarized into three categories according to the specific way they embed the watermark:
-
•
Parameter-based watermarking encodes the watermark message into the model’s parameters or structural configurations;
-
•
Image-based watermarking embeds the watermark message into every image generated by the model;
-
•
Triggered-based watermarking secretly incorporates a trigger to the protected model such that an image with copyright information will be generated once the trigger is activated.
2.4.1. Parameter-based watermarking
This type of watermarking techniques aims to subtly incorporate watermark information into the network’s internal weights or structural configurations. It is known as a “white-box” method because full access to these elements is required to implement and extract the watermark. Parameter-based watermarking has been widely applied for verifying the ownership of classification models (Uchida et al., 2017; Darvish Rouhani et al., 2019; Zhao et al., 2021) and has also been extended to protect DGMs in recent years.
Ong et al. (2021) proposed to embed the signature of a GAN model to the scaling factors, , of the normalization layer of the generators. The loss for watermark embedding is:
| (11) |
where refers to the predefined binary watermark message and denotes the number of channels. This objective stipulates that the scaling factor of the -th channel, denoted as , adopts either a positive or negative polarity (+/-) as determined by . The term is a constant employed to regulate the minimum value of . The sign loss is added to the original training loss of the GAN model (e.g., a DCGAN (Radford et al., 2015), SRGAN (Ledig et al., 2017) or CycleGAN (Zhu et al., 2017)) to form the overall training objective of the generators. With this embedding strategy, the capacity of the watermark is determined by the total number of channels in the normalization layers. In the verification stage, the embedded message can be easily extracted by looking at the signs of the specific scaling factors of the model.
2.4.2. Image-based watermarking
This group of watermarking approaches embeds watermark messages into all the images generated by the model to be protected. To achieve this goal, various studies suggested using an additional deep-learning-based network for embedding watermarks after the image generation process. In detail, once the DGMs create the images, these extra watermark embedding networks apply watermarks to the images before they are released to public. For example, Zhang et al. (2022a) proposed two frameworks for watermark embedding based on the Human Visual System (HVS) to reduce the impact of the watermark on the visual quality of the generated images. Leveraging the fact that humans are more sensitive to changes in green color and brightness, they recommended embedding watermarks into the Red (R) and Blue (B) channels in the RGB color system or the U/V channels in the Discrete Cosine Transform (DCT) domain. In either framework, each channel carries a unique watermark, allowing for the extraction of two distinct watermarks from a single image.

As a following-up work, Zhang et al. (2023b) noted that images marked using prior watermark embedding networks display significant high-frequency artifacts in the frequency domain. As shown in Figure 4, slight spatial artifacts are detectable in the generated image marked by the method described in Wu et al. (2020). And obvious grid-like high-frequency artifacts can be found in the DCT heat map of the marked image. These artifacts, mainly due to the up-sampling and down-sampling convolution operations of the GAN-like embedding network, could compromise the watermark’s imperceptibility. To tackle the problem, they designed a new watermark embedding network which is capable of suppressing high-frequency artifacts through anti-aliasing. The anti-aliasing is primarily implemented by introducing a low-pass filter before the down-sampling process and appending a convolutional layer after the nearest-neighbor up-sampling process, adopting strategies demonstrated to be effective in previous research. In addition to using a separate watermark embedder, some other strategies consider directly modifying the host generative network so that the host network itself can embed the watermark while achieving the original generation task. At the same time, an external watermark decoder should be trained to correctly extract the watermark information from the generated images. To achieve this goal in GANs, Fei et al. (2022) proposed to update the training objective of the generator by:
where and refer to the discriminator and generator of GAN respectively, refers to the watermark decoder, means the prior distribution of the latent space, is the ground truth watermark message, is a regularization parameter and represents the binary cross entropy. The first term in the equation is the standard generator loss, while the second term is for ensuring the correctness of the decoded binary watermark message. It is noted that the watermark decoder they applied here is retrieved from a well-developed standard image-watermarking framework and its parameters are fixed in the training process of . With the above training objective, the model can be either trained from scratch or fine-tuned from a non-watermarked pre-trained GAN model.
Yu et al. (2020) also proposed a fingerprinting technique to trace the outputs of GANs back to their source, which can help identify misuse. The core difference between it and the work of Fei et al. (2022) is that the trained generator takes both the latent code and the embedding of the fingerprint (a sequence of bits) as its input, which increases the efficiency and scalability of the fingerprinting mechanism. Once the model is trained, multiple instances of fingerprinted generators which focus on embedding different fingerprint messages can be directly obtained. In their algorithm, the watermark encoder, , which maps fingerprint to its embedding, the decoder, , which obtains the latent code and fingerprint from a watermarked image, the discriminator and the generator of GAN are optimized together with the following loss:
In this objective, the first term refers to the original training loss of a GAN model and the second term is the regularization term firstly proposed by Srivastava et al. (2017) for mitigating the mode collapse issue of GANs. The term is the cross entropy loss of the fingerprint decoding to ensure the correctness of the reconstruction of the fingerprint. The here refers to the sigmod function. The formulation of the last term is designed to ensure the perceptual similarity between images generated with the same latent code but different fingerprints, which guarantees that the latent code exclusively controls the content of the generated images, irrespective of the fingerprint variations.
Similar idea of weights modulation has also been applied for the protection of LDMs. Kim et al. (2023) proposed to incorporate the watermark message to generated images by modulating the parameters of each layer of the decoder of LDM. Specifically, after the watermark message is obtained, a mapping network is applied to derive the feature representation of the message. Then an affine transformation layer is developed for each layer of the decoder . The affine transformation layer is applied to match the dimension of the message representation to the dimension of the model’s weights. Then the weight modulation is conducted following the formulation:
| (12) |
where and refers to the pre-trained and fingerprinted parameters of the decoder , , , denote the dimensions of the input, output, and kernel of each layer, and denotes the scale of the modulation to the th output channel. When the watermark message is encoded, a watermark decoder is also required to retrieve the watermark from the generated images. The watermark decoder as well as the mapping network are jointly trained with the following loss:
where denotes the binary cross entropy of watermark decoding:
in which refers to the latent feature of an image , denotes the output of the decoder whose weights being modulated by Eq.(12), and refers to the sigmoid activation function. refers to a Bernoulli distribution. is the regularization term inhibiting the influence of the watermark to the quality to the generated image.
Another work (Xiong et al., 2023), which also aims to protect the copyright of LDMs, has a similar pipeline to Kim et al. (2023). The major difference is that the feature representation of the watermark message is not used to modulate the weight of the decoder , but is combined with the intermediate outputs of the fine-tuned decoder such that the image generated by is watermarked. Under the pipeline, a watermark decoder is also required to extract the watermark from the generated image.
Additionally, the work of Fernandez et al. (2023), which also focus on the protection of Latent Diffusion Models (LDMs), suggested to directly apply a classical neural network-based watermarking method, HiddeN (Zhu et al., 2018), to jointly optimize the parameters of a watermark encoder and extractor. Then the decoder of the LDM is fine-tuned such that all images it generates contain a given watermark that can be extracted by the pre-trained watermark extractor.
Unlike the previously mentioned methods that require modifying the generative networks to include watermarks in their generated images, Yu et al. (2021) achieved this by solely watermarking the training images of the generative models. To ensure that the watermark can be successfully transferred from the training images to the generated images of GANs, they developed a deep-learning-based structure for watermark (or “fingerprints” in their paper) embedding and extraction. Similar to the other watermark embedding-extraction framework, the training objective of the watermark embedder and decoder also consists of a loss which guides the decoder to decode the fingerprint correctly and an loss which penalizes any deviation of the watermarked image from the original image. Although the framework proposed by Yu et al. (2021) was originally designed for DeepFake detection and misinformation prevention, its functionality can be extended to verifying the copyright of GANs, as the watermark on the generated images can indicate their source. Additionally, Zhao et al. (2023b) experimentally verified that this technique can be extended to safeguard the copyright of unconditional and class-conditional diffusion models.
While the previous methods consider incorporating the watermarking embedding procedure in the training process of the generative models, Wen et al. (2023) proposed Tree-Ring Watermarks, a watermarking framework specified for diffusion models which conducts the watermark encoding in the sampling process. As shown in Figure 5, the watermark is embedded into the initial noise vector used for sampling. In order to ensure that the watermark can achieve a better robustness against multiple image modification such as cropping, dilation, flipping, and rotation, they suggest to encode the watermark patterns to the Fourier space of the image. After the image is generated, watermark detection is done by inverting the diffusion process to reconstruct the noise vector. This is done using the DDIM (Song et al., 2020) inversion process. In detail, the initial noise vector is described in Fourier space as:
where refers to a binary mask, is the key chosen for the watermark. The key is designed to be ring-shaped in the Fourier space to ensure that the watermark is invariant to certain common image transformations. In the detection stage, the watermark is detected if the difference between the inverted noise vector and the pre-defined key in the Fourier domain of the watermarked area is below a tuned threshold .

Another work which considers adding the watermark in the images’ sampling process is Nie et al. (2023). This approach, which target to protect the copyright of LDM or StyleGAN2 (Karras et al., 2020), does not require a network to conduct the watermark embedding and decoding but suggest to directly modify the latent features (either generated by the multi-layer perception network of the StyleGAN2 or sampled by the diffusion process of LDM) by matrix operation. In detail, let denotes an orthonormal subspace of the space of the latent feature and denotes its complementary subspace, the watermarked latent feature is
The notation refers to the watermark message, represents the pseudo-inverse of , denotes the projection of to , and denotes a hyperparameter to control the strength of the watermark. In the detection stage, in order to retrieve the watermark from the image, an optimization problem is solved:
where refers to the LPIPS metric (Zhang et al., 2018) which evaluates the visual similarity of two images. The lower and upper bound of , and , are chosen based on empirical observation.
2.4.3. Trigger-based watermarking
The trigger-based watermarking follows the basic technical scheme of backdoor attack (Wang et al., 2019; Saha et al., 2020; Chen et al., 2017), which embeds a trigger into a neural network to cause a failed classification by activating the trigger. In the protection of DGM copyright, once the trigger is integrated into the protected model, the activation of this trigger in the input will cause the model to generate a watermarked output. By examining the presence or absence of the watermark in this output, the model owner can determine whether a suspect model has been illicitly derived from the protected, watermarked model. Consequently, if the watermark is detected in the example of triggered generation, it substantiates the claim of copyright infringement regarding the model.
Ong et al. (2021) also proposed a trigger-based watermark framework to protect the copyright of GANs. It first adds the trigger onto which is the input of the generator to get the triggered input . The protected GAN is trained towards the goal that once the trigger is input to , the output will be generated with a watermark. The model owner can input a trigger into the suspect model and verify whether the model is stolen from the copyrighted model by checking the existence of watermark in the output. For different types of GAN, the triggered input is obtained by different manually defined rules. For example, in DCGAN, the trigger is encoded with a binary representation :
where is the elementwise production, and is the dimension of . The triggered input means each dimension of is encoded with one dimension in . The triggered input is expected to cause to generate a watermarked target . During the training of GAN, the trigger pair is included in a regularization term for this. The term is formulated as
where SSIM refers to the structural similarity. The regularization term is combined with the training loss of by a coefficient :
However, the trigger-based method is not implemented in isolation. Instead, it is integrated with the parameter-based watermarking approach, as detailed in Equation (11), following the practice outlined in (Ong et al., 2021).
Besides the protection of GANs, Liu et al. (2023c) proposed to watermark Stable Diffusion by injecting triggers into the prompt. According to the method, when specific triggers are present in the prompt, Stable Diffusion will produce an image with a watermark. If the resulting image closely resembles the watermarked prototype, it confirms that the model is safeguarded by the designated watermark. Liu et al. (2023c) developed two different approaches for integrating triggers, NaiveWM and FixedWM. NaiveWM embeds a specific word at a random location within the prompt, while FixedWM places a specific word at a predetermined position in the prompt. The chosen trigger word should be nonsensical to avoid accidental activation. For embedding the trigger-based watermark into Stable Diffusion, a triggered dataset is employed to fine-tune the model. Additionally, a clean dataset is also used in the fine-tuning process to preserve the quality of generation when the trigger is not activated. Zhao et al. (2023b) proposed a similar idea, but did not consider the stealthiness of the trigger. Their method directly uses “[V]” as the whole triggered prompt.
Different from Liu et al. (2023c) and Zhao et al. (2023b) that embedded the watermark into the guidance of prompt, Peng et al. (2023a) watermarked by injecting triggers into the diffusion process. In the reverse process of generative diffusion models, when the trigger is added onto the current step, the subsequent will be generated towards the watermarked image. By repeating injecting the trigger into the reverse process, the final generated image will be a watermarked image that can be used to verify the copyright of the model. For embedding the watermark, the model is trained with both triggered dataset and clean dataset. During training, when the data comes from triggered dataset, the triggered noise is input into the denoising network of diffusion model and the network is optimized to denoise towards the watermarked image. During the both forward and reverse process, the trigger is added into step by
where is the trigger, and is the state of step . For reverse process, is the image denoised from the last step, while for forward process, it is the diffused image accumulated by the Gaussian noise in the forward steps. This protection method can be used for both training from scratch and fine-tuning. Although this method can also protect the copyright by verifying whether the final output is watermarked or not, the extraction of watermark requires the modification on each diffusion step which is more strict than the previous methods that only need to trigger in the prompt.
3. Copyright in Text Generation
In this section, we first define the problem of copyright protection in text and unique properties in text domain. Then we introduce data copyright and model copyright protection by providing the taxonomy of existing methods.
3.1. Background: DGMs for text generation
In the realm of text generation, our focus is primarily on Large Language Models (LLMs), due to their outstanding capabilities and the potential risks they entail. As key components of DGMs, LLMs have notably propelled advancements in the field of text generation. They exhibit remarkable emergent abilities, significantly boosting performance in a range of NLP tasks. However, alongside their exceptional efficacy, LLMs also present substantial concerns, particularly in the realms of copyright. The considerable commercial value and the high costs associated with their training further underscores the importance of addressing these issues. In Section 3, which focuses on the text domain, we explore LLMs in detail, acknowledging their unparalleled efficiency and effectiveness in text generation, while also considering the associated concerns in copyright protection.
Training and Inference of LLMs. Generally, Large Language Models (LLMs) are constructed to comprehend human language and produce coherent, contextually relevant text. To achieve this objective, most existing LLMs can be categorized into “pre-trained LLMs” and “fine-tuned LLMs”. For the pre-trained LLMs, they are trained on a massive amount of internet text data, aiming to grant them the ability to predict the probable subsequent token based on its preceding tokens. Through this process, the models can obtain an understanding of the patterns and structures inherent in human language. Many early LLMs, such as GPT-2 (Radford et al., 2019), GPT-3 (Brown et al., 2020), OPT (Zhang et al., 2022b), GPT-Neo (Black et al., 2021), and others, have been developed in this procedure, to be equipped with the ability to complete sentences by generating the possible subsequent tokens.
Through various fine-tuning technologies, LLMs have been made increasingly flexible and adept at various downstream tasks. Specifically, the Instruction Tuning (Zhang et al., 2023c) strategy is employed to enable LLMs to handle diverse language tasks based on users’ requests. This versatility allows LLMs to be applied as general assistants for tasks such as question answering (Lu et al., 2022). Furthermore, Reinforcement Learning with Human Feedback (RLHF) is utilized to help LLMs better align with human values, enhance the reliability of generated outputs, and improve ethical decision-making (Ouyang et al., 2022). Based on these advancements, advanced LLMs like ChatGPT 888https://chat.openai.com/, Claude999https://www.anthropic.com/index/claude-2, Bard (Manyika et al., 2023), and LLaMA 2 (Touvron et al., 2023), have been developed.
Notations. Next, we introduce key notations we will use in this paper. We denote an arbitrary text which is composed of a sequence of tokens with length . Many popular LLMs follow an “auto-regressive” manner: given a sequence of prior tokens , a language model calculates the probability of the next token conditioning on the preceding tokens. We denote the probability that model predict the -th word as by , where and is the vocabulary. Based on this design, the likelihood of each token in the original sentence given by the model can be defined as:
| (13) |
which is the probability of the model to give an output token to be the same as in the text. Similarly, we can also define the likelihood of the whole sentence given by the model , which is the overall likelihood of all tokens in the sentence:
| (14) |
For most existing LLMs, during the (pre-)training process, the model is trained to maximize this likelihood, so that the model can learn to generate the texts following the distributions of training texts. During the LLM’s inference process, the model will generate the texts, by making sampling from the tokens with high likelihood.
3.2. Copyright Issues in Text Generation
Data copyright protection. The data copyright problem regarding the use of LLMs has attracted extensive focus and debates. The definition of copyright violation varies across countries and laws. Generally, it means the use of works protected by copyright without permission for a usage where such permission is required, thereby infringing certain exclusive rights granted to the copyright holder, such as the right to reproduce, distribute, display or perform the protected work, or to make derivative works101010https://en.wikipedia.org/wiki/Copyright_infringement. Similarly, Lee et al. (2023a) also note that “plagiarism occurs when any content including text, source code, or audio-visual content is reused without permission or citation from an author of the original work.” However, as evident from the following laboratory and court cases, current LLMs demonstrate various plagiarism behaviors, which can be divided into three types: verbatim plagiarism, paraphrase plagiarism, and idea plagiarism:
-
•
Verbatim Plagiarism, which refers to directly copying the origin data completely or partially.
-
•
Paraphrase Plagiarism, which refers to composing new works including consent word replacement, statement rearrangement, or even translate sentences back and forth, from copyrighted works.
-
•
Idea Plagiarism, which refers to copying the core idea of the copyrighted material.
Cases in Laboratory. There are existing lines of work showing that Large Language Models (LLMs) tend to memorize and emit parts of its training data (which may include copyrighted materials), referred to as the “memorization effect of LLMs”. Although such effect is widely believed to be essential for language model’s performance and generalization, it also raises serious risks on data copyright protection. Carlini et al. (2021) first found that LLMs can memorize and leak specific training examples, by devising a data extraction attack, which can effectively examine the training data verbatim from GPT-2. Then, Carlini et al. (2022) further quantified such phenomena in detail and found that the memorization effect grows with the model scales, number of replicates, as well as the prompt length. Similarly, Tirumala et al. (2022) suggested that lager LMs generally memorize faster and less likely to forget information. Besides, they found that nouns and numbers are more likely to be memorized.
Zhang et al. (2021) defined ”counterfactual memory” which quantifies the performance difference between models trained on the specific data and models not trained on that. Biderman et al. (2023) investigated correlations of memory phenomena between large and small models and between partially-trained and fully-trained models. They suggested that we can use partially trained-model to efficiently predict whether the data is memorized by a fully-trained model. Furthermore, Zeng et al. (2023) explored the memorization behavior of fine-tuned LLMs and identified some feature dense tasks such as dialog and summarization present high memorization effects, and demonstrated the correlation between attention scores and task-specific memorization.
Cases in Court. Recently, The New York Times initiated a lawsuit against OpenAI and Microsoft, alleging copyright infringement111111https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html. The lawsuit asserts that OpenAI and Microsoft used millions of articles from The Times to train their automated chatbots. These chatbots, the suit contends, now rival The Times in providing reliable information. The complaint seeks restitution for what The Times describes as “billions of dollars in statutory and actual damages” arising from the “unauthorized replication and exploitation of The Times’s distinct and valuable works.” A specific allegation made in the lawsuit is that ChatGPT, when queried about current events, occasionally generates responses containing “verbatim excerpts” from articles published by The New York Times. These articles are typically behind a paywall, accessible only to subscribers. Moreover, the lawsuit highlights instances where the Bing search engine, incorporated with ChatGPT, reportedly displayed content sourced from a New York Times-owned website. This usage was done without providing direct links to the articles or including the referral links that The Times employs for revenue generation.
Model copyright protection. For LLMs, the infringement on model copyright is in line with the model copyright protection in the image domain. The model builder invests a significant amount of funds and labor into the construction of LLMs, which naturally grants them intellectual property rights over the trained model.
3.3. Data Copyright Protection
According to the previous discussed cases, a majority of research works study how to improve the training scheme of LLMs to avoid replicating its training data samples. These methods are generally proposed from the perspective of model builders to prevent copyright infringement and provide legal services. In text domain, they can be categorized according to the major reasons which cause the memorization / plagiarism behaviors of LLMs:
- •
-
•
Improved training & generation algorithms: the model builder can also modify the training objective and text generation procedure to avoid potential reproduction behavior of LLMs.
-
•
Alignment strategies: the model builder devises new alignment strategies to reduce memorization in LLMs.
-
•
Machine unlearning, which services to delete the copyrighted materials from LLMs, once the owners of the copyrighted materials identify the infringement.
Similar to image domain, machine unlearning can be seen as the passive method requested by the data owner, while the others are active approaches directly conducted by the model builder during the model construction stage.
3.3.1. Data De-duplication
In the training of Large Language Models (LLMs), a key issue is the memorization of training data , particularly when it involves copyrighted data . To improve copyright security, one major method is to de-duplicate to reduce memorization. It refers to the process that the model builder removes the duplicated data samples from the training set of LLMs. Lee et al. (2021) found that existing NLP datasets contain many duplicated and near-duplicated substrings, leading to over 1% of language model outputs being exact copies from training data. To address this, they developed ExactSubstr and NearDup for dataset de-duplication. ExactSubstr removes long shared substrings between two samples by concatenating the entire dataset into a single sequence and using a suffix array for easy deletion of adjacent repetitive sequences. NearDup utilizes MinHash (Broder, 1997) to identify potential document matches, followed by rigorous similarity checks or direct deletion of duplicates. This process, which includes sorting -grams of each document and applying the Jaccard Index for similarity, significantly reduces model memorization, decreases training time, and improves evaluation accuracy by reducing train-test overlap. Kandpal et al. (2022) found that language models’ likelihood of regenerating training sequences superlinearly correlates with their frequency in the dataset. They also noted significant improvements in privacy protection following de-duplication in these models.
3.3.2. Improved Training & Generation algorithms
Chu et al. (2023) define copyright protection for LLMs as ensuring the model’s output for any input does not significantly resemble any copyrighted content in , as measured by a metric . The training goal for a dataset with copyrighted and non-copyrighted data is to fine-tune the model to achieve:
| (15) |
where , measures the possibility to generate and higher means less possibility of generating . Thus, Eq. (15) means the output of should maintain less possibility to come from copyrighted data or be similar to data. To attain this goal, Chu et al. (2023) introduce a method known as copyright regression. In a simplified regression case, denote training data, where is the input and is the target output. The model is trained to get . denote copyrighted data. An additional term is added to the training objective to discourage the model from generating outputs matching the copyrighted data, with a scalar coefficient . Consequently, the training objective is modified to , integrating an inverse term that strikes a crucial balance between performance and copyright protection, and helps mitigate the model’s tendency to generate copyrighted outputs. However, the method in (Chu et al., 2023) requires the model builder to know which training samples are copyrighted, which are not executable for most existing LLMs.
In the text generation stage, there are also ways to protect copyright, even if the model has memorized a part of copyrighted data. These methods manipulate the generation process of LLMs to avoid the occurrence of copyrighted information. Ippolito et al. (2022) developed a memorization-free (MEMFREE) decoding strategy using bloom filters to effectively eliminate all direct memorization of text. Unlike traditional retroactive censoring, which repetitively runs the language model with varied seeds but identical prompts until non-resembling training set outputs are generated, MEMFREE efficiently targets memorization at the -gram level during the decoding phase, rather than examining the entire sentence. Specifically, it assesses whether any -gram in the generated sequence matches those in the training set, suppressing any such occurrences and prompting re-sampling from the model. This approach, however, fails in the case that the generated text is similar but not exactly the same as the memorized content. The authors highlight that strict definitions of verbatim memorization are insufficient, as they do not address subtler forms of memorization. They note that even models adept at avoiding exact memorization are vulnerable to approximated memorization, which can be subtly bypassed through creatively altered ”style-transfer” prompts.
3.3.3. LLM Alignment Protection
Refer to the discussion in Section 3.1, LLM alignment strategies, such as RLHF, have been widely applied for constructing better LLMs aligned with human values, such as enhancing the reliability of generated outputs, and improving ethical decision-making. Therefore, the similar pipeline of model alignment can also be investigated from the perspective of copyright protection. The study by Kassem et al. (2023) introduces a model alignment strategy designed to prevent memorization in LLMs. Namely, they proposed a reward-based DeMemorization (DeMem) framework to reduce memorization in language models (LMs) by employing a paraphrasing strategy. The framework uses negative similarity, specifically a BERTScore metric, as a reward signal. By inputting prefixes from the original pre-training dataset into the LM to generate suffixes, the dissimilarity between the true and generated suffixes is calculated. This score is then maximized during training to ensure that the LM’s tendency to replicate verbatim memorization is diminished. Besides, they found that when model size increases, both the convergence rate and dissimilarity score increase, suggesting that larger models may tend to “forget” the memorized data faster.
3.3.4. Machine Unlearning
Even if the LLM has memorized some copyrighted data, the model builder can thereafter use “machine unlearning” techniques to delete the copyrighted information for copyright protection. For example, Eldan et al. (2023) first used a reinforced model to identify key tokens by comparing logits with a baseline model. Then, unique expressions in the data are replaced with generic ones, and new labels are generated to mimic a model not trained on the data. Finally, they show that fine-tuning the model with these labels can effectively remove the original text from the model’s memory upon contextual prompting. Chen et al. (2023b) proposed an efficient method EUL for updating Large Language Models (LLMs) without full retraining by integrating “lightweight unlearning layers”. The
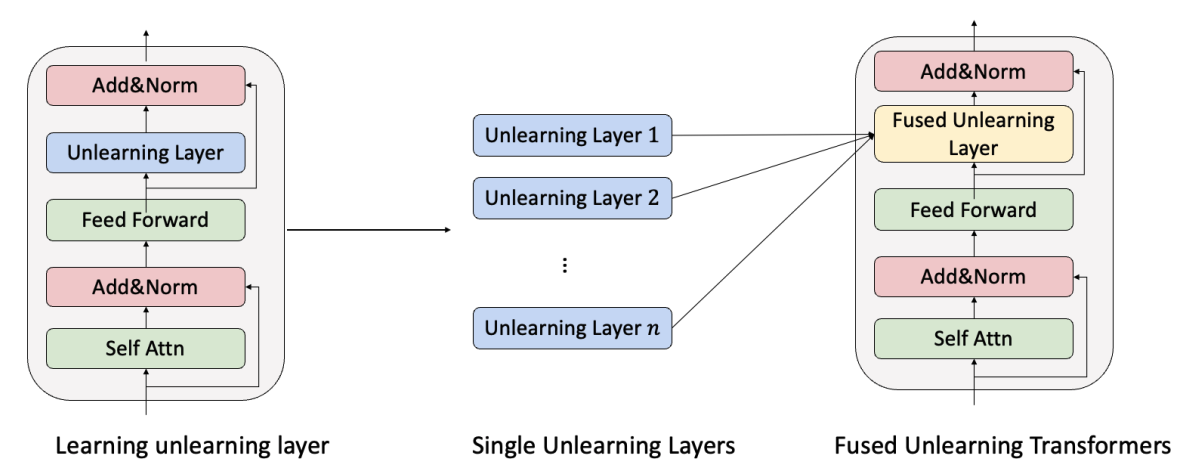
pipeline of EUL is shown in Figure 6. These layers are trained using a selective teacher-student objective within the transformer architecture. Additionally, to handle a sequence of forgetting operations, a fusion mechanism is employed to merge various unlearning layers efficiently where each learns to forget different sets of data. Yao et al. (2023) proposed a resource-efficient unlearning method that only requires negative examples that we want the LLM to forget, without the need for access to the original training set. Their method mainly utilizes gradient ascent to make the model forget the undesired information, like user-reported or red-teaming failed cases. Besides, they also added additional loss terms to enforce the model generated similar outputs with the unlearned model on some normal inputs to maintain their utility. Pawelczyk et al. (2023) explored a new class of unlearning methods for LLMs called “In-Context Unlearning”(ICUL) without access to the model parameters. ICUL first inverts the label of the data to be forgotten and then incorporates a set of correctly labeled data points to mitigate over-correction, finally, it integrates the query input into the altered training template and prompts the model to predict with no temperature adjustment to erase the specified data from the model’s knowledge. Their empirical results suggest that ICUL reliably removes the influence of training points and show that label flipping for in-context examples can impact the model’s output.
3.4. Model Copyright Protection
The development of LLMs such as ChatGPT/GPT-4 has significantly enhanced their ability to generate human-like texts. Many companies have integrated LLMs into interactive user interfaces like New Bing, yielding numerous benefits. However, the emergence of LLMs also brings forth new challenges. On one hand, LLM increased the difficulty in distinguishing between genuine content and fake news, propaganda, or misinformation generated by LLMs like GPT-4. On the other hand, LLMs are susceptible to theft. For example, Taori et al. (2023) demonstrated the possibility of distilling LLMs solely through API access. This underscores the importance of safeguarding the copyright of LLMs, which often require significant resources for training. In light of these concerns, the protection methods can be classified into two categories based on their objectives:
-
•
Watermark, which ascertains whether given texts are generated by the LLMs owned by the respective company.
-
•
Model parameter protection, which detects unauthorized model stealing the proprietary model parameters.
In the following of this section, we discuss the protection on text generation model from the two perspectives.
3.4.1. Watermark
This type of protection aims to detect whether a text is generated by a particular LLM. Watermarking-based methods are majorly explored to detect LLM-generated texts. In general, this type of method attaches a watermark generator with LLMs which modify the generated texts to include pre-designed watermarks and a detector is used to determine whether suspicious texts contain watermarks. In this subsection, we conduct a comprehensive analysis of various watermarking methods, with a focus on discussing their robustness and the trade-offs between detection accuracy and text quality.
In Kirchenbauer et al. (2023b), LLM-generated texts with watermarks are generated by forcing the model to sample words from a partition of vocabulary with a higher probability. In detail, a “green list” is a random partition of the vocabulary decided by a random function with the hash of the previous token as the random seed. During the text generation process of an LLM, the probability of green list is increased in the sampling step. Thus, tokens from green list has a high probability of being sampled. Since the green list is decided by the previous tokens, this operation forms the matching between green lists and the consequent tokens. A higher proportion of token from green list indicate the text is more possible to generated by a watermarked model. A -test is conducted to detect this matching between tokens and determine whether the test texts is generated with or without knowledge of the green list. The texts that have a significant -score will be detected as LLM-generated texts. Based on the work (Kirchenbauer et al., 2023b), Yoo et al. (2023) improved it by partitioning the vocabulary into lists of more colors instead of just green list. This method can encode a message like the ownership information into the text, and enrich the application of watermarks. Takezawa et al. (2023) highlighted that longer generated texts typically exhibit higher -scores. To accommodate this, it may be reasonable to relax the strict proportion requirements of the green list for lengthier texts.
However, due to the fact that the watermark in the texts is easy to be perturbed by attack methods like paraphrasing, synonym replacement and so on, more works focusing on the robustness of watermarks are proposed. For example, in the watermarking method of Kirchenbauer et al. (2023a), once the previous token is reworded by paraphrase, the seed of the random function will also change which causes a different green list and disturb the matching between the green list and the consequent token. Kirchenbauer et al. (2023a) leveraged an improved hashing scheme to enhance the reliability and robustness of this watermarking in real scenarios. This method uses more previous tokens to compute the random seed to increase the tolerance of paraphrase if part of the tokens are reworded, and a windowed test called WinMax is leveraged in the detection process. Zhao et al. (2023a) proposed Unigram-Watermark against paraphrasing attacks. It changes the method of Kirchenbauer et al. (2023b) with a fixed “green list” which does not change no matter what the hash of the previous token is. They proved that the fixed list can also be secure and robust. However, this robustness requires a constraint that only a limited amount of words can be changed, which is strict in practical scenarios.
Ren et al. (2023) proposed the method called SemaMark to use the semantics as the seed of the hash function. Because the hash of the token is easy to change by paraphrase, but the semantics are usually stable. SemaMark uses the embeddings of the previous tokens, which represent the semantic information, as the seed of the random function to decide the green list. The embeddings can be obtained from the LLM itself. Even though the malicious user wants to use paraphrase to remove the watermark for copyright infringement, the semantics are likely to remain unchanged and will not influence the partition of the green list for the consequent token. Thus, the watermark is robust and will not be easily removed by paraphrase. Liu et al. (2023b) proposed a similar method which uses an additional text embedding model to extract the embeddings.
Fu et al. (2023) found that the random selection of green list might be conflicted with the original semantics. For example, the tokens in the generated output for a summarization task will have a overlap with the input text to summarize. Thus, Fu et al. (2023) proposed to incorporate the semantically related tokens into green list and randomly partition the rest vocabulary. The semantically related tokens are selected by the similarity with the previous inputs. This can further increase the fraction of green list matching in watermarked text and thus improve the detection performance.
To safeguard against the deciphering of the green list’s watermark rule, Liu et al. (2023a) introduced an unfalsifiable approach. This technique employs a fully connected layer to ascertain the green list for each token position, taking into account preceding tokens. The input for this layer comprises a pre-established window of prior tokens. Liu et al. (2023a) claimed that their method resists cracking owing to the substantial size of the window and the difficulty in extracting the network for the green list by external parties, primarily because of the absence of clear ground truth labels.
The previous watermarking methods rely on the “green list”, which is shown to harm the quality of generated texts (Sato et al., 2023; Takezawa et al., 2023; Hu et al., 2023; Kuditipudi et al., 2023; Christ et al., 2023). Kuditipudi et al. (2023) proposed a distortion-free watermarking scheme and took the randomness of watermark key into consideration. They assume the watermarked generation given a random watermark key is where is defined in Eq. (13). Then the watermark is claimed as distortion-free if
| (16) |
In particular, they implement the with a decoder that maps a sequence of uniform random variables and permutations to tokens using inverse transform sampling as follows:
In this equation, the watermark key , is a random permutation and is a pre-specified threshold. With this formulation, is designed to select the token possessing the smallest index within the permutation ensuring that CDF of related to reaches a minimum threshold of . For identifying watermarked text, the detection process involves correlating the token indices within the text against . On the contrary, the indices of tokens in the non-watermarked text will be i.i.d uniform irrespective of the text itself and thus not correlated to the watermark key . This scheme is shown to be distortion-free with respective to the definition in Eq. (16).
Hu et al. (2023) also proposed a watermark called Unbiased Watermark aiming to guarantee the non-degradation of the text quality. This method leverages distribution reweighting to modify the original generation distribution into the watermarked distribution. In detail, given a watermark code , they define a reweighting function mapping the distribution to the watermarked version . When taking the randomness of into consideration, the watermark is claimed as unbiased if and only if
| (17) |
This equation indicates that although the generation distribution for each individual token is distorted, the mean output token probabilities remain the original distribution when considering the randomness of . In practice, they first select a 1024-bit random bitstring as a key , then the watermark code is generated via a hash function whose inputs are and the token sequence , i.e. . Finally, a delta function is used as the reweighting function to create the watermarked distribution. They showed that this procedure satisfies Eq. (17), thus unbiased. During the detection stage, they leverage the likelihood ratio test and compute a log likelihood ratio (LLR) score to detect the watermarks.
The above watermark methods require the access to generation process and cannot be used to the scenarios of black-box models or when there is only API for the LLM available. Yang et al. (2023) developed a binary-encoding-based watermarking framework for black-box language models. To be more specific, original words in generated texts are encoded as bit-0, and part of their synonym candidates are encoded as bit-1. Then a hash function is leveraged to randomly substitute bit-0 words with bit-1 synonyms, and a -test is conducted to infer the change of distribution for bit-1 and bit-0.
From a different perspective, a family of watermarks named Easymark is proposed in (Sato et al., 2023) to add watermarks directly to the generated texts rather than the generation distribution. Whitemark, the most representative method in this family, exploits the fact that Unicode has many codepoints for whitespace and it replaces a whitespace from the original codepoint U+0020 to another codepoint such as U+2004. Then during the detection process, the number of U+2004 is counted to determine if the text is watermarked. Therefore, this method does not distort the distribution during generation and does not change the original meaning of the text.
3.4.2. Model Parameter Protection

This type of protection aims to detect unauthorized models stealing the proprietary model parameters. Birch et al. (2023) proposed the Model Leeching attack method, which can distill characteristics by questioning an LLM. This method can extract task capability from ChatGPT-3.5-Turbo, achieving 73% Exact Match (EM) similarity and SQuAD EM and F1 accuracy scores of 75% and 87% with only $50 cost Birch et al. (2023). After getting an extracted model, attackers can then inverse the model, inference membership, leak privacy data, and theft model intellectual property. Peng et al. (2023b) proposed an Embedding Watermark method called EmbMarker which can defend against model extraction attacks from Embedding as a Service (EaaS). As shown in Figure 7, EmbMarker selects a set of moderately frequent words from a general text corpus to create a trigger set. It then chooses a target embedding to serve as the watermark. This watermark is inserted into the embeddings of texts that contain trigger words, functioning as a backdoor. The intensity of the watermark insertion is proportional to the quantity of trigger words present in the text. This method ensures the efficient transfer of the watermark backdoor to the EaaS-stealer’s model for copyright verification purposes, while simultaneously minimizing any negative effects on the original utility of the embeddings. Fan et al. (2023) proposed FateLLM, an industrial-grade federated learning framework for LLMs, which can protect the intellectual property of LLMs by using a federated intellectual property protection approach. Every client autonomously confirms the presence of watermarks in the model, asserting their individual ownership of the federated model. This verification is achieved without revealing any private training data or confidential watermark details. Additionally, the approach ensures the preservation of data privacy throughout both the training and inference phases by employing privacy-protective mechanisms. He et al. (2022) uncovered that prevailing watermarking techniques often disrupt the word distribution. This distortion can be exploited to deduce the watermarked words by analyzing the frequency changes in potential watermark candidates through sufficient statistical methods. Consequently, this makes the watermarks relatively easy to identify and remove. Therefore, they proposed CATER for protecting text generation APIs via more stealthy watermarks. In detail, CATER injects the watermarks in a word distribution conditional on linguistic features (condition ) such as part-of-speech and dependency tree (Nadkarni et al., 2011), while maintaining the original word distribution.
4. Other domains
In this section, we will discuss copyright protection in various domains, including code and audio. It is important to acknowledge that, in contrast to areas like LLMs and image generation, the fields of code and audio generation have relatively fewer studies focused on copyright protection against DGMs. We will outline and discuss the existing methods employed in the generation of code and audio in this segment.
4.1. Code Generation
Code copyright is a critical aspect of the text domain with distinctive characteristics. As opposed to other forms of textual content, codes are often accompanied by explicit copyright licenses, and code owners are able to take more proactive strategies to protect their data. In this survey, code copyright protection majorly refers to preventing the usage of copyrighted code as a part of the training data for machine learning models without the explicit permission of the copyright holder. For example, Copilot (https://copilot.github.com/), a closed-source deep learning code generation model, is trained using a wide range of open-source code repositories sourced from GitHub, without consideration for their licenses. It has been observed that Copilot occasionally reproduces identical code snippets with copyleft licenses from its training dataset while generating code (Lee et al., 2023b). As these models learn from the data they are trained on, they can generate new code that is strikingly similar to the copyrighted code, potentially leading to copyright infringement, which poses a significant threat to code copyright protection.
There are different aspects to protect code copyright. From the model builder’s perspective, they can carefully curate their training data and train the model to provide reference during generation, so that the data sources are legal and can be tracked. For example, Li et al. (2023) took several important steps to ensure safe release of their code-LLMs StarCoder and StarCoderBase, including an improved Personally Identifiable Information (PII) redaction pipeline and a novel attribution tracing tool, making the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license. To remove PII from the training data, the authors trained an encoder-only model called StarEncoder and then fine-tuned it for the Named Entity Recognition (NER) task to detect PII. Yan et al. (2022) introduced a tool named WhyGen that explains the generated code by referring to training examples. The method extracts an inference fingerprint from the neural network when generating the code and using the inference fingerprint to get the most similar examples from training data. The inference fingerprint is produced by the activation values of a set of intermediate neurons in the network during the inference pass. The authors claimed that if Whygen with the auto-completion feature is used in an IDE, it can help reduce the concern about using source code from copyrighted project without permission.
From the perspective of code owners, they have the solutions to proactively protect their codes via poisoning or watermarking. Lee et al. (2023b) designed and implemented a prototype, CoProtector, which uses data poisoning techniques to defend source code repositories against such exploits. Specifically, given a repository to protect, CoProtector generates two distinct types of poison instances from its original code artifact. One type aims to reduce the performance of Copilot-like DGMs, and the other can reliably embed backdoors for later detection. In addition, CoProtector proposes a collaborative protection framework that manages protected poison repositories and amount of poison instances in the network. Ji et al. (2022) designed a set of lightweight transformations that can be applied to codes before they are open-source released. They also leveraged a pre-trained code embedding model (e.g., CodeBERT (Feng et al., 2020)) to guide the selection of transformations. The transformed codes are called “unlearnable examples” so that code generation models trained on these codes can only obtain faulty knowledge.
Besides, code owners can also check the safety of their source codes via membership inference. Ma et al. (2023a) proposed CodeForensic, which uses membership inference to audit whether codes are misused for training a code generator. Particularly, it leverages a reference-model-based likelihood ratio test (LRT) to ascertain if a specific code snippet is present in a model’s training dataset. The experimental outcomes indicate that the LRT-based membership inference can deliver satisfactory results. However, the method is limited in practical application due to its reliance on the access to logits of the generative model.
4.2. Audio Generation
Utilizing zero-shot voice synthesis technology, it is now possible to generate realistic audio from just a few seconds of a speaker’s recording. Consequently, the implementation of watermarking in the audio domain is essential to prevent model misuse and data infringement. Among existing methods, the primary focus is on protection of model copyright.
Chen et al. (2023a) introduced a post-watermarking method called WavMark to accelerate the detection synthesized audio and prevent the unauthorized usage of audio generation models. The post-watermarking process, as applied in WavMark, modifies the audio after its generation. It incorporates a watermark by encoding a message into the frequency domain of the generated audio. The model owner can detect the watermark by extracting the message from suspect audios. The whole framework of WavMark is a invertible neural network that is composed of cascaded invertible blocks. Each block can be applied in both a encoding way and a decoding way. WavMark first transforms the audio to watermark into frequency domain by a short-time Fourier, which is denoted as . Then the network encodes a 32-bit message into the audio by the encoding operation in each block:
where , , and is a dense block introduced by Wang et al. (2018), and and is the message and audio data in -th block. The decoding operation is starting from and a random sampled starting point of message :
The invertible neural network is trained to minimized the distance of encoded and decoded messages. In this way, WavMark can encode and decode a message from the frequency domain of an generated audio.
Cao et al. (2023) proposed a watermarking method to protect the copyright of audio-generative diffusion models. This method follows the main idea of trigger-based watermarking in Section 2.4.3. It incorporates a trigger mechanism into the diffusion model. Once the trigger is activated by a pre-defined input, the model will generate a watermarked audio to verify the ownership of the audio-generative diffusion model. To make the trigger invisible, this method uses environmental natural sounds and Infrasounds around 10Hz, which are typically ignored in daily life. From an acoustic standpoint, environmental sounds blend with ambient noise encountered by machines, while Infrasounds are inaudible to humans and indiscernible in mel-spectrograms. Additionally, it’s important that these watermarking triggers do not significantly impact the performance of the original diffusion model, so that the generated samples remain true to the training data if there is no trigger in the input of the diffusion model.
5. Discussion
While a range of technical approaches have been suggested, numerous challenges remain unresolved in this field. In this section we will explore the existing issues and consider potential future directions for copyright protection within deep generative models.
First, we discuss the data copyright protection from the following three perspectives:
Comprehensiveness. In image generation, most of the protection for data copyright conducted by the source data owner is tailored for a specific model or learning algorithm. However, they cannot prevent the model builder from learning the data with a different generative model, which means they cannot provide a comprehensive protection against different DGMs. For example, the unrecognizable examples by Shan et al. (2023); Liang et al. (2023b) focus on Stable Diffusion, and Van Le et al. (2023) prevent the fine-tuning scheme of DreamBooth. The watermark like methods proposed by Ma et al. (2023b); Wang et al. (2023) is also designed for one type of DGMs. A dive to the effectiveness of these methods in safeguarding data against a range of generative models, rather than just tailored ones, is essential. A thorough protection encompassing a wide array of DGMs is significantly more meaningful. Its challenge stems from the distinct architectures and unique properties of various generative models, making it challenging to devise protections for specific vulnerabilities. Despite these obstacles, pursuing comprehensive research in this field is essential and may lead to a deeper understanding of DGM characteristics.
Data protection by owners besides image domain. Although several methods to protect the data copyright are developed to the source data owners in image domain (Shan et al., 2023; Liang et al., 2023b; Cui et al., 2023a; Webster et al., 2023), there are fewer works for text and other domains. On the one hand, the DGMs in other domains like the code, audio, graph and video do not have the same level of development as image. On the other hand, the protection in some domains like text is much harder than image, because the modification on image can be designed as invisible to human eyes but effective on DGMs, while text is discrete and is hard to be designed as imperceptible. Despite the difficulty, it is necessary to propose the protection from the side of source data owner for other domains, especially in text domain which is fast developing and causes increasing concerns in the data copyright. Also, the copyright protection for multi-modality generation (Ma et al., 2023c; Zhan et al., 2023; Ruan et al., 2023; Pichler et al., 2010) in both data copyright and model copyright is also crucial.
Infringement detection. Injecting watermark into images to accelerate the infringement detection has been introduced in Section 2.3.2, which aims to help source data owners protect their data copyright. Infringement detection can also benefit the model builder. Before releasing the generated output to the users, the builder can first check whether the output is infringing the copyright of training data (like a memorized training sample). If the output to be released is detected as infringement, the model builder can use some following-up strategies like adding references to the source of the content or removing the suspicious part to avoid the infringement. However, detecting infringement on the training data is not trivial, especially that current DGMs usually require a large amount of training data to ensure the generated quality and diversity. The dataset de-duplication in Section 2.3.4 and Section 3.3.1 provides potential solutions. It is an offline strategy that can be achieved before training. However, for infringement detection, a faster real-time searching is necessary to mitigate negative impact on the generation speed. Another issue is that, compared with memorization problem, the infringement on the copyright of abstract concepts, such as the style of an artwork or a product, and the original storylines and characters created by authors, is hard to confirm. The memorized samples often bear a high resemblance to the copyrighted material121212https://spectrum.ieee.org/midjourney-copyright, https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html, making infringement easy to confirm. In contrast, if a generated sample replicates the style of a picture but diverges significantly in content from the original, it becomes much harder to detect and confirm whether the generated sample stems from copyrighted data or not.
Second, for the model copyright protection, we present the following aspects:
Robustness. The purification techniques for watermark and adversarial perturbations have challenged the robustness of watermark protection on model copyright in both image generation (Nie et al., 2022; Yoon et al., 2021; Chen et al., 2021a) and text generation (Krishna et al., 2023; Ren et al., 2023). In image generation models, the imperceptibility of watermarks is a key reason why the watermark is easy to remove by methods like denoising. In text generation models, the watermark is vulnerable because the watermark is encoded based on the tokens, and thus operations such as paraphrasing can easily change the tokens by rewording and reordering. In fact, the robustness issue also exists in the protection on data copyright like unrecognisable examples and watermarks for source data owners.
Trade-off between protection and performance. The introduction of watermarks can potentially reduce the generation quality. Wen et al. (2023) and Cui et al. (2023b) found that the watermarks will cause influence on the generated contents by Stable Diffusion. The trajectory of reverse process in diffusion model is sensitive to the change since the change might be accumulated in the long generation steps. Ajith et al. (2023) also pointed out that the watermark method on LLMs will reduce the generated quality on the long-term generation task like summarization. Thus, developing protection methods that can maintain the performance of the model is necessary.
Flexibility. The protection is usually designed for one specific type of models and lack of flexibility. For example, in Section 2.4, the methods proposed by (Ong et al., 2021), (Zhang et al., 2023b), (Fei et al., 2022), (Yu et al., 2020) and (Yu et al., 2021) are all tailored for GANs. The effectiveness of the protection on other model architectures are not guaranteed. If one protection method is adaptable to a variety of DGMs, it eliminates the need for redundant efforts in redesigning for different models, thereby enhancing the efficiency of the protection process. This opens up opportunities for third-party providers to offer such protective services. They could utilize a versatile method to secure different DGMs without the requirement for constant redesigning. This strategy not only streamlines the process but also represents a vital direction in the realm of model copyright protection.
For the epilogue, we recognize that the issue of copyright protection in deep generative models remains a work in progress, encompassing both data and model security. The rapid evolution of DGMs is catalyzing the establishment of effective regulatory oversight, fostering healthy market dynamics, and facilitating the empowerment of various industries. This progression demands not only improvements in model performance but also a critical evaluation of how these technologies are utilized, ensuring their use is reasonable and standardized. Copyright protection stands as a pivotal concern, and it is anticipated that in the foreseeable future, it will garner increased attention and resources from both industrial and academic spheres. Our hope is that this work can serve as a guiding framework and a source of inspiration for possible forthcoming directions in the realm of copyright protection for future researchers who wants to develop tools in this field from the perspective of techniques.
References
- (1)
- Abdal et al. (2019) Rameen Abdal et al. 2019. Image2stylegan: How to embed images into the stylegan latent space?. In Proceedings of the IEEE/CVF international conference on computer vision. 4432–4441.
- Achiam et al. (2023) OpenAI Josh Achiam et al. 2023. GPT-4 Technical Report. https://api.semanticscholar.org/CorpusID:257532815
- Ajith et al. (2023) Anirudh Ajith et al. 2023. Performance Trade-offs of Watermarking Large Language Models. arXiv:2311.09816 (2023).
- Athalye et al. (2018) Anish Athalye et al. 2018. Synthesizing robust adversarial examples. In International conference on machine learning. PMLR, 284–293.
- Baluja (2017) Shumeet Baluja. 2017. Hiding images in plain sight: Deep steganography. Advances in neural information processing systems 30 (2017).
- Biderman et al. (2023) Stella Biderman et al. 2023. Emergent and predictable memorization in large language models. arXiv:2304.11158 (2023).
- Birch et al. (2023) Lewis Birch et al. 2023. Model Leeching: An Extraction Attack Targeting LLMs. arXiv:2309.10544 (2023).
- Black et al. (2021) Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. 2021. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow. https://doi.org/10.5281/zenodo.5297715 If you use this software, please cite it using these metadata..
- Bourtoule et al. (2021) Lucas Bourtoule et al. 2021. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 141–159.
- Brock et al. (2016) Andrew Brock et al. 2016. Neural photo editing with introspective adversarial networks. arXiv:1609.07093 (2016).
- Broder (1997) Andrei Z Broder. 1997. On the resemblance and containment of documents. In Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171). IEEE, 21–29.
- Brown et al. (2020) Tom Brown et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Cao et al. (2023) Xirong Cao et al. 2023. Invisible Watermarking for Audio Generation Diffusion Models. arXiv:2309.13166 (2023).
- Carlini et al. (2021) Nicholas Carlini et al. 2021. Extracting Training Data from Large Language Models.. In USENIX Security Symposium, Vol. 6.
- Carlini et al. (2022) Nicholas Carlini et al. 2022. Quantifying memorization across neural language models. arXiv:2202.07646 (2022).
- Carlini et al. (2023) Nicholas Carlini et al. 2023. Extracting training data from diffusion models. arXiv:2301.13188 (2023).
- Chen et al. (2023a) Guangyu Chen et al. 2023a. WavMark: Watermarking for Audio Generation. arXiv:2308.12770 (2023).
- Chen et al. (2023b) Jiaao Chen et al. 2023b. Unlearn What You Want to Forget: Efficient Unlearning for LLMs. arXiv:2310.20150 (2023).
- Chen et al. (2017) Xinyun Chen et al. 2017. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv:1712.05526 (2017).
- Chen et al. (2021a) Xinyun Chen et al. 2021a. Refit: a unified watermark removal framework for deep learning systems with limited data. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security. 321–335.
- Chen et al. (2021b) Zhikai Chen et al. 2021b. Magdr: Mask-guided detection and reconstruction for defending deepfakes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9014–9023.
- Christ et al. (2023) Miranda Christ et al. 2023. Undetectable Watermarks for Language Models. arXiv:2306.09194 (2023).
- Chu et al. (2023) Timothy Chu et al. 2023. How to Protect Copyright Data in Optimization of Large Language Models? arXiv:2308.12247 (2023).
- Cui et al. (2023a) Yingqian Cui et al. 2023a. DiffusionShield: A Watermark for Copyright Protection against Generative Diffusion Models. arXiv:2306.04642 (2023).
- Cui et al. (2023b) Yingqian Cui et al. 2023b. FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models. arXiv:2310.02401 (2023).
- Darvish Rouhani et al. (2019) Bita Darvish Rouhani et al. 2019. Deepsigns: An end-to-end watermarking framework for ownership protection of deep neural networks. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 485–497.
- Dhariwal et al. (2021) Prafulla Dhariwal et al. 2021. Diffusion models beat gans on image synthesis. Advances in neural information processing systems 34 (2021), 8780–8794.
- Dogoulis et al. (2023) Pantelis Dogoulis et al. 2023. Improving Synthetically Generated Image Detection in Cross-Concept Settings. In Proceedings of the 2nd ACM International Workshop on Multimedia AI against Disinformation. 28–35.
- Dziugaite et al. (2016) Gintare Karolina Dziugaite et al. 2016. A study of the effect of jpg compression on adversarial images. arXiv:1608.00853 (2016).
- Eldan et al. (2023) Ronen Eldan et al. 2023. Who’s Harry Potter? Approximate Unlearning in LLMs. arXiv:2310.02238 (2023).
- Epstein et al. (2023) David C Epstein et al. 2023. Online detection of ai-generated images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 382–392.
- Fan et al. (2023) Tao Fan et al. 2023. FATE-LLM: A Industrial Grade Federated Learning Framework for Large Language Models. arXiv:2310.10049 (2023).
- Fei et al. (2022) Jianwei Fei et al. 2022. Supervised gan watermarking for intellectual property protection. In 2022 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 1–6.
- Feng et al. (2020) Zhangyin Feng et al. 2020. Codebert: A pre-trained model for programming and natural languages. arXiv:2002.08155 (2020).
- Fernandez et al. (2023) Pierre Fernandez et al. 2023. The stable signature: Rooting watermarks in latent diffusion models. arXiv:2303.15435 (2023).
- Franceschelli et al. (2022) Giorgio Franceschelli et al. 2022. Copyright in generative deep learning. Data & Policy 4 (2022), e17.
- Fu et al. (2023) Yu Fu et al. 2023. Watermarking conditional text generation for ai detection: Unveiling challenges and a semantic-aware watermark remedy. arXiv:2307.13808 (2023).
- Gal et al. (2022) Rinon Gal et al. 2022. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv:2208.01618 (2022).
- Gandikota et al. (2023) Rohit Gandikota et al. 2023. Erasing concepts from diffusion models. arXiv:2303.07345 (2023).
- Goodfellow et al. (2014a) Ian Goodfellow et al. 2014a. Generative adversarial nets. Advances in neural information processing systems 27 (2014).
- Goodfellow et al. (2014b) Ian J Goodfellow et al. 2014b. Explaining and harnessing adversarial examples. arXiv:1412.6572 (2014).
- Hayes et al. (2017) Jamie Hayes et al. 2017. Generating steganographic images via adversarial training. Advances in neural information processing systems 30 (2017).
- He et al. (2023) Pengfei He et al. 2023. Sharpness-Aware Data Poisoning Attack. arXiv:2305.14851 (2023).
- He et al. (2022) Xuanli He et al. 2022. Cater: Intellectual property protection on text generation apis via conditional watermarks. Advances in Neural Information Processing Systems 35 (2022), 5431–5445.
- Ho et al. (2020) Jonathan Ho et al. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840–6851.
- Ho et al. (2022) Jonathan Ho et al. 2022. Classifier-free diffusion guidance. arXiv:2207.12598 (2022).
- Hu et al. (2023) Zhengmian Hu et al. 2023. Unbiased watermark for large language models. arXiv:2310.10669 (2023).
- Huang et al. (2021) Qidong Huang et al. 2021. Initiative defense against facial manipulation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 1619–1627.
- Ippolito et al. (2022) Daphne Ippolito et al. 2022. Preventing Verbatim Memorization in Language Models Gives a False Sense of Privacy. arXiv:2210.17546 (2022).
- Ji et al. (2022) Zhenlan Ji et al. 2022. Unlearnable Examples: Protecting Open-Source Software from Unauthorized Neural Code Learning.. In SEKE. 525–530.
- Kandpal et al. (2022) Nikhil Kandpal et al. 2022. Deduplicating training data mitigates privacy risks in language models. In International Conference on Machine Learning. PMLR, 10697–10707.
- Karras et al. (2020) Tero Karras et al. 2020. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8110–8119.
- Kassem et al. (2023) Aly Kassem et al. 2023. Preserving Privacy Through Dememorization: An Unlearning Technique For Mitigating Memorization Risks In Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 4360–4379.
- Kim et al. (2023) Changhoon Kim et al. 2023. WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models. arXiv:2306.04744 (2023).
- Kingma et al. (2013) Diederik P Kingma et al. 2013. Auto-encoding variational bayes. arXiv:1312.6114 (2013).
- Kirchenbauer et al. (2023a) John Kirchenbauer et al. 2023a. On the Reliability of Watermarks for Large Language Models. arXiv:2306.04634 (2023).
- Kirchenbauer et al. (2023b) John Kirchenbauer et al. 2023b. A watermark for large language models. arXiv:2301.10226 (2023).
- Kong et al. (2021) Zhifeng Kong et al. 2021. DiffWave: A Versatile Diffusion Model for Audio Synthesis. In International Conference on Learning Representations.
- Kong et al. (2023a) Zhifeng Kong et al. 2023a. Data Redaction from Conditional Generative Models. arXiv:2305.11351 (2023).
- Kong et al. (2023b) Zhifeng Kong et al. 2023b. Data redaction from pre-trained gans. In 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 638–677.
- Krishna et al. (2023) Kalpesh Krishna et al. 2023. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. arXiv:2303.13408 (2023).
- Kuditipudi et al. (2023) Rohith Kuditipudi et al. 2023. Robust distortion-free watermarks for language models. arXiv:2307.15593 (2023).
- Kumari et al. (2023) Nupur Kumari et al. 2023. Ablating concepts in text-to-image diffusion models. arXiv:2303.13516 (2023).
- Kurakin et al. (2018) Alexey Kurakin et al. 2018. Adversarial examples in the physical world. In Artificial intelligence safety and security. Chapman and Hall/CRC, 99–112.
- Ledig et al. (2017) Christian Ledig et al. 2017. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4681–4690.
- Lee et al. (2023a) Jooyoung Lee et al. 2023a. Do language models plagiarize?. In Proceedings of the ACM Web Conference 2023. 3637–3647.
- Lee et al. (2021) Katherine Lee et al. 2021. Deduplicating training data makes language models better. arXiv:2107.06499 (2021).
- Lee et al. (2023b) Taehyun Lee et al. 2023b. Who Wrote this Code? Watermarking for Code Generation. arXiv:2305.15060 (2023).
- Li et al. (2022a) Junnan Li et al. 2022a. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning. PMLR, 12888–12900.
- Li et al. (2023) Raymond Li et al. 2023. StarCoder: may the source be with you! arXiv:2305.06161 (2023).
- Li et al. (2024) Yaxin Li et al. 2024. Neural Style Protection: Counteracting Unauthorized Neural Style Transfer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3966–3975.
- Li et al. (2022b) Zheng Li et al. 2022b. UnGANable: Defending Against GAN-based Face Manipulation. arXiv:2210.00957 (2022).
- Liang et al. (2023a) Chumeng Liang et al. 2023a. Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples. arXiv:2302.04578 (2023).
- Liang et al. (2023b) Chumeng Liang et al. 2023b. Mist: Towards Improved Adversarial Examples for Diffusion Models. arXiv:2305.12683 (2023).
- Ling et al. (2021) Huan Ling et al. 2021. Editgan: High-precision semantic image editing. Advances in Neural Information Processing Systems 34 (2021), 16331–16345.
- Liu et al. (2023a) Aiwei Liu et al. 2023a. A Private Watermark for Large Language Models. arXiv:2307.16230 (2023).
- Liu et al. (2023b) Aiwei Liu et al. 2023b. A semantic invariant robust watermark for large language models. arXiv:2310.06356 (2023).
- Liu et al. (2017) Ming-Yu Liu et al. 2017. Unsupervised image-to-image translation networks. Advances in neural information processing systems 30 (2017).
- Liu et al. (2023c) Yugeng Liu et al. 2023c. Watermarking Diffusion Model. arXiv:2305.12502 (2023).
- Lu et al. (2022) Pan Lu et al. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems 35 (2022), 2507–2521.
- Lu. (2018) S.-A. Lu. 2018. faceswap-gan. https://github.com/shaoanlu/faceswap-GAN
- Luo et al. (2020) Xiyang Luo et al. 2020. Distortion agnostic deep watermarking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 13548–13557.
- Ma et al. (2023a) Wanlun Ma et al. 2023a. The” code”of Ethics: A Holistic Audit of AI Code Generators. arXiv:2305.12747 (2023).
- Ma et al. (2023b) Yihan Ma et al. 2023b. Generative Watermarking Against Unauthorized Subject-Driven Image Synthesis. arXiv:2306.07754 (2023).
- Ma et al. (2023c) Yiyang Ma et al. 2023c. Unified multi-modal latent diffusion for joint subject and text conditional image generation. arXiv:2303.09319 (2023).
- Manyika et al. (2023) James Manyika et al. 2023. An overview of bard: an early experiment with generative ai. AI. Google Static Documents 2 (2023).
- Mirza et al. (2014) Mehdi Mirza et al. 2014. Conditional generative adversarial nets. arXiv:1411.1784 (2014).
- Nadkarni et al. (2011) Prakash M Nadkarni et al. 2011. Natural language processing: an introduction. Journal of the American Medical Informatics Association 18, 5 (2011), 544–551.
- Navas et al. (2008) KA Navas et al. 2008. Dwt-dct-svd based watermarking. In 2008 3rd International Conference on Communication Systems Software and Middleware and Workshops (COMSWARE’08). IEEE, 271–274.
- Nguyen et al. (2022) Thanh Tam Nguyen et al. 2022. A survey of machine unlearning. arXiv:2209.02299 (2022).
- Nichol et al. (2021) Alexander Quinn Nichol et al. 2021. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning. PMLR, 8162–8171.
- Nichol et al. (2022) Alexander Quinn Nichol et al. 2022. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. In International Conference on Machine Learning. PMLR, 16784–16804.
- Nie et al. (2023) Guangyu Nie et al. 2023. Attributing Image Generative Models using Latent Fingerprints. arXiv:2304.09752 (2023).
- Nie et al. (2022) Weili Nie et al. 2022. Diffusion Models for Adversarial Purification. In International Conference on Machine Learning. PMLR, 16805–16827.
- Ong et al. (2021) Ding Sheng Ong et al. 2021. Protecting intellectual property of generative adversarial networks from ambiguity attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3630–3639.
- OpenAI ([n. d.]) OpenAI. [n. d.]. DALL·E 2 pre-training mitigations. https://openai.com/research/dall-e-2-pre-training-mitigations
- Ouyang et al. (2022) Long Ouyang et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Pawelczyk et al. (2023) Martin Pawelczyk et al. 2023. In-context unlearning: Language models as few shot unlearners. arXiv:2310.07579 (2023).
- Peng et al. (2023a) Sen Peng et al. 2023a. Protecting the Intellectual Property of Diffusion Models by the Watermark Diffusion Process. arXiv:2306.03436 (2023).
- Peng et al. (2023b) Wenjun Peng et al. 2023b. Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark. arXiv:2305.10036 (2023).
- Pichler et al. (2010) Bernd J Pichler et al. 2010. PET/MRI: paving the way for the next generation of clinical multimodality imaging applications. Journal of Nuclear Medicine 51, 3 (2010), 333–336.
- Radford et al. (2015) Alec Radford et al. 2015. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434 (2015).
- Radford et al. (2019) Alec Radford et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Radford et al. (2021) Alec Radford et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763.
- Ramesh et al. (2022) Aditya Ramesh et al. 2022. Hierarchical text-conditional image generation with clip latents. arXiv:2204.06125 (2022).
- Ren et al. (2022) Jie Ren et al. 2022. Transferable unlearnable examples. arXiv:2210.10114 (2022).
- Ren et al. (2023) Jie Ren et al. 2023. A Robust Semantics-based Watermark for Large Language Model against Paraphrasing. arXiv:2311.08721 (2023).
- Rombach et al. (2022) Robin Rombach et al. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695.
- Ronneberger et al. (2015) Olaf Ronneberger et al. 2015. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 234–241.
- Ruan et al. (2023) Ludan Ruan et al. 2023. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10219–10228.
- Ruiz et al. (2020) Nataniel Ruiz et al. 2020. Disrupting deepfakes: Adversarial attacks against conditional image translation networks and facial manipulation systems. In Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16. Springer, 236–251.
- Ruiz et al. (2023) Nataniel Ruiz et al. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22500–22510.
- Saha et al. (2020) Aniruddha Saha et al. 2020. Hidden trigger backdoor attacks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 11957–11965.
- Salman et al. (2023) Hadi Salman et al. 2023. Raising the cost of malicious ai-powered image editing. arXiv:2302.06588 (2023).
- Samuelson (2023) Pamela Samuelson. 2023. Generative AI meets copyright. Science 381, 6654 (2023), 158–161.
- Sato et al. (2023) Ryoma Sato et al. 2023. Embarrassingly simple text watermarks. arXiv:2310.08920 (2023).
- Shan et al. (2023) Shawn Shan et al. 2023. Glaze: Protecting artists from style mimicry by text-to-image models. arXiv:2302.04222 (2023).
- Sigal Samuel (2019) Sigal Samuel. 2019. A guy made a deepfake app to turn photos of women into nudes. It didn’t go well. https://www.vox.com/2019/6/27/18761639/ai-deepfake-deepnude-app-nude-women-porn.
- Somepalli et al. (2023a) Gowthami Somepalli et al. 2023a. Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6048–6058.
- Somepalli et al. (2023b) Gowthami Somepalli et al. 2023b. Understanding and Mitigating Copying in Diffusion Models. arXiv:2305.20086 (2023).
- Song et al. (2020) Jiaming Song et al. 2020. Denoising diffusion implicit models. arXiv:2010.02502 (2020).
- Srivastava et al. (2017) Akash Srivastava et al. 2017. Veegan: Reducing mode collapse in gans using implicit variational learning. Advances in neural information processing systems 30 (2017).
- Takezawa et al. (2023) Yuki Takezawa et al. 2023. Necessary and sufficient watermark for large language models. arXiv:2310.00833 (2023).
- Tancik et al. (2020) Matthew Tancik et al. 2020. Stegastamp: Invisible hyperlinks in physical photographs. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2117–2126.
- Taori et al. (2023) Rohan Taori et al. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Tirumala et al. (2022) Kushal Tirumala et al. 2022. Memorization without overfitting: Analyzing the training dynamics of large language models. Advances in Neural Information Processing Systems 35 (2022), 38274–38290.
- Touvron et al. (2023) Hugo Touvron et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288 (2023).
- Tramèr et al. (2016) Florian Tramèr, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. 2016. Stealing machine learning models via prediction APIs. In 25th USENIX security symposium (USENIX Security 16). 601–618.
- Uchida et al. (2017) Yusuke Uchida et al. 2017. Embedding watermarks into deep neural networks. In Proceedings of the 2017 ACM on international conference on multimedia retrieval. 269–277.
- van den Burg et al. (2021) Gerrit van den Burg et al. 2021. On memorization in probabilistic deep generative models. Advances in Neural Information Processing Systems 34 (2021), 27916–27928.
- Van Le et al. (2023) Thanh Van Le et al. 2023. Anti-DreamBooth: Protecting users from personalized text-to-image synthesis. arXiv:2303.15433 (2023).
- Vincent et al. (2010) Pascal Vincent et al. 2010. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of machine learning research 11, 12 (2010).
- Vukotić et al. (2018) Vedran Vukotić, Vivien Chappelier, and Teddy Furon. 2018. Are deep neural networks good for blind image watermarking?. In 2018 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 1–7.
- Vyas et al. (2023) Nikhil Vyas et al. 2023. Provable copyright protection for generative models. arXiv:2302.10870 (2023).
- Wang et al. (2019) Bolun Wang et al. 2019. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 707–723.
- Wang et al. (2022) Run Wang et al. 2022. Anti-Forgery: Towards a Stealthy and Robust DeepFake Disruption Attack via Adversarial Perceptual-aware Perturbations. arXiv:2206.00477 (2022).
- Wang et al. (2018) Xintao Wang et al. 2018. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European conference on computer vision (ECCV) workshops. 0–0.
- Wang et al. (2023) Zhenting Wang et al. 2023. How to detect unauthorized data usages in text-to-image diffusion models. arXiv:2307.03108 (2023).
- Webster (2023) Ryan Webster. 2023. A Reproducible Extraction of Training Images from Diffusion Models. arXiv:2305.08694 (2023).
- Webster et al. (2023) Ryan Webster et al. 2023. On the De-duplication of LAION-2B. arXiv:2303.12733 (2023).
- Wen et al. (2023) Yuxin Wen et al. 2023. Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust. arXiv:2305.20030 (2023). https://arxiv.org/abs/2305.20030v3
- Wu et al. (2020) Hanzhou Wu et al. 2020. Watermarking neural networks with watermarked images. IEEE Transactions on Circuits and Systems for Video Technology 31, 7 (2020), 2591–2601.
- Wu et al. (2023) Ruijia Wu et al. 2023. Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework. arXiv:2305.03980 (2023).
- Xiong et al. (2023) Cheng Xiong et al. 2023. Flexible and Secure Watermarking for Latent Diffusion Model. In Proceedings of the 31st ACM International Conference on Multimedia. 1668–1676.
- Yan et al. (2022) Weixiang Yan et al. 2022. WhyGen: explaining ML-powered code generation by referring to training examples. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 237–241.
- Yang et al. (2021) Chaofei Yang et al. 2021. Defending against gan-based deepfake attacks via transformation-aware adversarial faces. In 2021 international joint conference on neural networks (IJCNN). IEEE, 1–8.
- Yang et al. (2023) Xi Yang et al. 2023. Watermarking Text Generated by Black-Box Language Models. arXiv:2305.08883 (2023).
- Yao et al. (2023) Yuanshun Yao et al. 2023. Large Language Model Unlearning. arXiv:2310.10683 (2023).
- Yeh et al. (2020) Chin-Yuan Yeh et al. 2020. Disrupting image-translation-based deepfake algorithms with adversarial attacks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops. 53–62.
- Yoo et al. (2023) KiYoon Yoo et al. 2023. Advancing beyond identification: Multi-bit watermark for language models. arXiv:2308.00221 (2023).
- Yoon et al. (2021) Jongmin Yoon et al. 2021. Adversarial purification with score-based generative models. In International Conference on Machine Learning. PMLR, 12062–12072.
- Yu et al. (2020) Ning Yu et al. 2020. Responsible disclosure of generative models using scalable fingerprinting. arXiv:2012.08726 (2020).
- Yu et al. (2021) Ning Yu et al. 2021. Artificial fingerprinting for generative models: Rooting deepfake attribution in training data. In Proceedings of the IEEE/CVF International conference on computer vision. 14448–14457.
- Zeng et al. (2023) Shenglai Zeng et al. 2023. Exploring Memorization in Fine-tuned Language Models. arXiv:2310.06714 (2023).
- Zhan et al. (2023) Fangneng Zhan et al. 2023. Multimodal image synthesis and editing: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023).
- Zhang et al. (2021) Chiyuan Zhang et al. 2021. Counterfactual memorization in neural language models. arXiv:2112.12938 (2021).
- Zhang et al. (2023a) Eric Zhang et al. 2023a. Forget-me-not: Learning to forget in text-to-image diffusion models. arXiv:2303.17591 (2023).
- Zhang et al. (2022a) Li Zhang et al. 2022a. Generative Model Watermarking Based on Human Visual System. arXiv:2209.15268 (2022).
- Zhang et al. (2023b) Li Zhang et al. 2023b. Generative Model Watermarking Suppressing High-Frequency Artifacts. arXiv:2305.12391 (2023).
- Zhang et al. (2018) Richard Zhang et al. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition. 586–595.
- Zhang et al. (2019) Ru Zhang et al. 2019. Invisible steganography via generative adversarial networks. Multimedia tools and applications 78 (2019), 8559–8575.
- Zhang et al. (2022b) Susan Zhang et al. 2022b. Opt: Open pre-trained transformer language models. arXiv:2205.01068 (2022).
- Zhang et al. (2023c) Shengyu Zhang et al. 2023c. Instruction tuning for large language models: A survey. arXiv:2308.10792 (2023).
- Zhao et al. (2021) Xiangyu Zhao et al. 2021. Structural watermarking to deep neural networks via network channel pruning. In 2021 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 1–6.
- Zhao et al. (2023a) Xuandong Zhao et al. 2023a. Provable Robust Watermarking for AI-Generated Text. arXiv:2306.17439 (2023).
- Zhao et al. (2023b) Yunqing Zhao et al. 2023b. A recipe for watermarking diffusion models. arXiv:2303.10137 (2023).
- Zhu et al. (2018) Jiren Zhu et al. 2018. Hidden: Hiding data with deep networks. In Proceedings of the European conference on computer vision (ECCV). 657–672.
- Zhu et al. (2020) Jiapeng Zhu et al. 2020. In-domain gan inversion for real image editing. In European conference on computer vision. Springer, 592–608.
- Zhu et al. (2016) Jun-Yan Zhu et al. 2016. Generative visual manipulation on the natural image manifold. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14. Springer, 597–613.
- Zhu et al. (2017) Jun-Yan Zhu et al. 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision. 2223–2232.
- Zhu et al. (2019) Minfeng Zhu et al. 2019. Dm-gan: Dynamic memory generative adversarial networks for text-to-image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5802–5810.
- Zirpoli (2023) Christopher T Zirpoli. 2023. Generative Artificial Intelligence and Copyright Law. (2023).