Coordinated Defense Allocation in Reach-Avoid Scenarios with Efficient Online Optimization
Abstract
In this paper, we present a dual-layer online optimization strategy for defender robots operating in multiplayer reach-avoid games within general convex environments. Our goal is to intercept as many attacker robots as possible without prior knowledge of their strategies. To balance optimality and efficiency, our approach alternates between coordinating defender coalitions against individual attackers and allocating coalitions to attackers based on predicted single-attack coordination outcomes. We develop an online convex programming technique for single-attack defense coordination, which not only allows adaptability to joint states but also identifies the maximal region of initial joint states that guarantees successful attack interception. Our defense allocation algorithm utilizes a hierarchical iterative method to approximate integer linear programs with a monotonicity constraint, reducing computational burden while ensuring enhanced defense performance over time. Extensive simulations conducted in 2D and 3D environments validate the efficacy of our approach in comparison to state-of-the-art approaches, and show its applicability in wheeled mobile robots and quadcopters.
Index Terms:
Multirobot systems, coordination, task allocation, optimization and optimal control.I Introduction
Effective task execution in many multirobot systems necessitates both cooperation among team members and competition against adversarial agents. Multiplayer adversarial games, characterized by conflicting objectives, serve as an ideal platform to investigate the delicate interplay between cooperation and competition. Techniques derived from multiplayer adversarial games have been applied to a wide range of real-world applications, including search and rescue [1], autonomous vehicles [2], security [3], among others. Nevertheless, solving multiplayer adversarial games optimally and efficiently remains a formidable challenge due to the high dimensionality of the solution space, the need for fast decision-making, and the uncertainty induced by unknown opposing strategies. Although deep multi-agent reinforcement learning [4, 5, 6] offers powerful tools, these approaches currently encounter difficulties in managing non-stationarity during training, restricting their applicability in real-world adversarial scenarios.
This paper delves into a class of multiplayer adversarial games, known as multiplayer reach-avoid games, wherein two teams strive to attack or defend a target set without awareness of their opponent’s strategies. The reach-avoid game exhibits close connections with other types of adversarial games, such as pursuit-evasion [7, 8, 9, 10, 11], capture-the-flag [12, 13, 14], and perimeter defense [15, 16, 17], among others. In a typical multiplayer reach-avoid game, the attacker team tries to reach the target set with as many robots as possible while avoiding capture, whereas the defender team seeks to prevent such incursions by capturing attackers outside the target set. In this work, we focus on the defensive perspective of multiplayer reach-avoid games within convex environments, proposing an effective strategy for the defender team to minimize the number of successful attackers entering the target set, irrespective of the attacker team’s decisions.
A conventional approach to devising defense strategies for multirobot systems employs the reach-avoid differential game framework. This framework casts the problem as a zero-sum game with two opposing players, aiming to determine whether the joint state can be guided to a target set without entering an avoid set [18], [19]. Unlike the traditional Hamilton-Jacobi reachability problem [20], reach-avoid differential games introduce additional challenges due to the state constraints imposed by the avoid set. Within the reach-avoid differential game framework, defense strategies can be generated by solving the Hamilton-Jacobi-Isaacs (HJI) equation or a related variant offline [21]. However, the HJI method and its numerical approximation [22], [23] struggle to decouple the inherent computational complexities, leading to poor scalability in large-scale multirobot systems.
To overcome these limitations, our work focuses on the decomposition method, which partitions the problem into two distinct yet interrelated subproblems: single-attack defense coordination and defense allocation. The former involves developing a coordination strategy for a coalition of defenders to prevent an individual attacker from reaching the target set. If successful, we say the defender coalition wins against the attacker. The latter, on the other hand, seeks to optimally assign defender coalitions to attackers by evaluating the predicted outcomes of selected single-attack coordination scenarios. A defense strategy can be obtained by solving these subproblems in an alternating manner. In contrast to the HJI method, the decomposition method offers a more tractable solution by leveraging problem structure and improving computational efficiency. We introduce online optimization techniques for both subproblems, ensuring the real-time adaptability and scalability of our approach for dynamic interactions.
As the foundation of our framework, we present an online convex programming-based defense coordination algorithm for any defender coalition against a single attacker. Our algorithm adapts to every joint state of the defender coalition and attacker, and identifies the maximum defense-winning region of initial joint states, regardless of any admissible strategy employed by the attacker. The underlying principle behind our approach leverages the concept of the safe-reachable set to devise objective functions. The safe-reachable set represents the collection of positions an attacker can reach without being captured by any defender given the current joint state. We then translate the single-attack defense coordination problem into an online robust maximization problem, where the robustness accounts for the worst-case scenario the attacker could employ. Solving this online robust maximization problem yields the corresponding defense coordination strategy.
Building upon the single-attack defense coordination results, we develop an allocation algorithm that ensures a monotonic improvement in defense performance. This algorithm incorporates predicted outcomes from single-attack defense coordination scenarios to formulate the problem as integer linear programs (ILPs) that rely on the joint state. We employ a heuristic method to tackle the ILPs and incorporate a monotonicity constraint. This constraint guarantees that the expected number of attackers unable to reach the target set is monotonically non-decreasing over time, facilitating a sustained improvement in defense performance as the game progresses. At the core of our algorithm is a hierarchical iterative method that approximately solves the ILPs, with each hierarchy defined by the concepts of active defense set and irreducibility to balance optimality and efficiency. By aggregating the suboptimal solutions obtained across all hierarchies, we derive a solution that substantially diminishes the number of selected pairs of defender coalitions and attackers within the ILPs, while preserving a certain degree of optimality.
I-A Related Work
In this subsection, we provide an overview of the current state-of-the-art in single-attack defense coordination and defense allocation, highlighting the prevailing issues and unresolved challenges within each domain.
One approach to single-attack defense coordination involves constructing the HJI solution analytically [24], [25]. Garcia et al. [24] present the derivation of the optimal defense strategy for two defenders against a single attacker in a 3D scenario with a point target set and zero capture radii. Another approach employs mixed pursuit-defense strategies, where some defenders are designated as pursuers focusing on directly capturing the attacker [26], [27]. In [27], it is shown that the attacker is guaranteed capture outside a circular target set within a bounded 2D convex domain for a set of initial joint states. This is achieved by assigning one defender to perform defense, while the remaining defenders implement the area-minimization strategy based on the attacker’s Voronoi cell, as developed in [28, 29].
Recently, a series of geometric-based works by Yan et al. has been proposed for deriving defense coordination strategies [30, 31, 32, 33]. Central to these approaches is the set that characterizes the attacker’s locations which can be safely reached through admissible strategies. This concept was first introduced in [34] as the “safe region” and later reformulated for cooperative pursuit in [35] as the “safe-reachable set”. We adopt the term safe-reachable set to emphasize the combination of safety and reachability. In cases where the capture radii are zero and the maximum speeds of defenders are all greater than that of the attacker, the safe-reachable set reduces to the Apollonius circle/sphere. Building on the Apollonius circle (resp. sphere), an analytical defense strategy is given for a set of initial joint states involving two defenders in a 2D (or 3D) convex domain with a line segment (resp. plane) shaped target set [30] (resp. [32]), ensuring the attacker cannot enter the target set. This defense coordination technique has been extended to accommodate an arbitrary number of defenders in both specific 2D and 3D scenarios [31], [33]. Notably, the approach presented in [33] is capable of handling cases involving non-zero capture radii.
Despite the progress made in single-attack defense coordination strategies, the existing approaches have mainly concentrated on specific cases with particular target sets or scenarios with zero capture radii. As a result, a comprehensive solution for general convex target sets in convex environments and non-zero capture radii remains an open challenge. Moreover, the defense strategies developed thus far are applicable only to a portion of the joint space, which may not adequately address real-world situations in which the attacker deviates from the optimal strategy. These limitations underscore the need for more adaptable defense coordination methods that can be applied to a broader range of scenarios.
In the context of defense allocation, the problem can be reformulated into joint state-dependent ILPs. Distinct from classical multirobot allocation problems [36, 37], the objective function here hinges on the estimated outcomes involving all defenders against a single attacker, which generally suffers from computational burdens when attempting a direct solution. In [38], the authors rely on the HJI method to exclusively examine pairwise interactions between defenders and attackers. While this approach enables polynomial-time solutions through the Ford-Fulkerson algorithm [39] or its improvement, the Hopcroft-Karp algorithm [40], it oversimplifies the problem by reducing the level of cooperation among defenders. The study presented in [41] concentrates on the assignment of performance improvement under the assumption that all attackers can be captured, which restricts the applicability of their approach. By the results of the geometric-based approach to single-attack defense coordination, the ILP in [31] is resolved exclusively at the initial time, with the resulting assignment maintained throughout the entire process. This approach can guarantee the capture of a certain number of attackers, whereas it lacks robustness in response to the dynamic interactions among agents. To overcome this limitation, the approach introduced in [31] is further refined in [33] by approximately solving the ILPs with a polynomial-time method. Nevertheless, this solution entails employing all possible combinations of single-attack defense coordination, which can be time-consuming in practical applications.
From the preceding discussion, it is evident that existing defense allocation methods fail to tackle the time-consuming issue associated with identifying the estimated outcomes of selected pairs of defender coalitions and individual attackers, particularly when the estimated outcomes cannot be readily provided offline. Moreover, when the optimal solution of the ILP remains unattainable due to efficiency constraints, current approaches fall short in offering guidance to enhance cooperative defense performance. Consequently, there is a demand for innovative solutions on defense allocation that balance optimality and computational efficiency.
I-B Contributions
Our contributions are summarized as fourfold:
-
1.
Our defense strategy extends the applicability over previous methods to convex domains that contain a general convex target set in both 2D and 3D spaces, and it accommodates scenarios involving defenders with nonzero capture radii.
-
2.
Our single-attack defense coordination algorithm, which is implemented through online convex programming, is designed to yield the maximum defense-winning region. The algorithm is applicable to all joint states, rather than being confined to a limited portion of the joint space as seen in existing strategies. This allows for a higher chance of winning when facing non-optimal attack strategies.
-
3.
We propose a defense allocation algorithm that effectively reduces the computational load associated with determining the predicted outcomes of selected defender coalition-attacker pairs. This efficiency is a major advancement, as existing methods often struggle with time-consuming computations that hinder their practical use. Moreover, our algorithm is designed to incrementally improve defense performance, ensuring continual enhancement over time. This is particularly valuable in situations where the optimal allocation is unattainable due to efficiency constraints.
-
4.
We provide a comprehensive evaluation of our algorithm through both simulations and real-world physics engine validations in 2D and 3D scenarios. This rigorous testing showcases the superiority of our algorithm in comparison to existing state-of-the-art approaches, demonstrating improvements in both optimality and efficiency.
I-C Organization and Notation
The remainder of this paper is organized as follows. In Section II, we formulate the problem of cooperative defense in multiplayer reach-avoid games and decompose it into two subproblems: single-attack defense coordination and defense allocation. In Section III, we present a defense strategy for a coalition against a single attacker. Section IV reformulates the defense allocation problem as an ILP and presents a heuristic method to approximate the solution. Finally, Section V presents the simulation results that benchmark the effectiveness of our approach.
We use the following notation throughout the paper. Let be the -dimensional Euclidean space, and be the Euclidean norm. Given a vector , the normalizer is defined as if and otherwise. In the scalar case, is equivalent to the sign function. The indicator function of a set is denoted by and defined as if and otherwise. The cardinality of a set is denoted by . Given a set of vectors , is used to denote the column vector consisting of the entries of for in sequence. The Cartesian product of copies of a set is denoted by .
II Problem Formulation
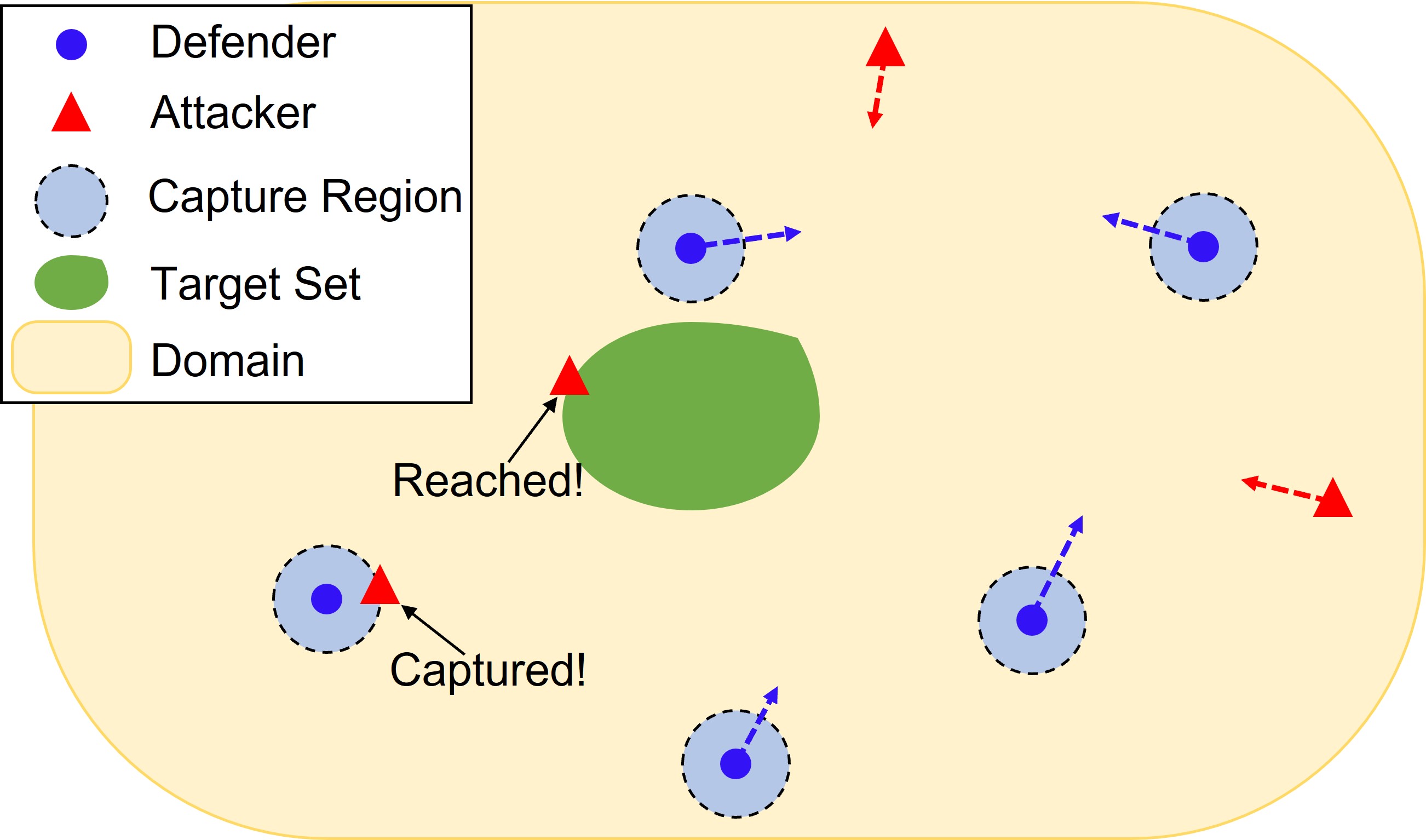
Consider a multiplayer reach-avoid game involving a team of defender robots (called defenders) competing against a team of attacker robots (called attackers) within a confined domain containing a designated target set. The primary objective of the attacker team is to deploy as many robots as possible to reach the target set while avoiding capture by any defender, whereas the defender team strives to prevent the attackers from entering the target set. An illustrative depiction of this game is provided in Fig. 1. This paper primarily focuses on the defense perspective, wherein we aim to develop a strategy for the defending team to minimize the total number of attackers that successfully reach the target set, without prior knowledge of the attackers’ strategy.
We study scenarios where the domain and target set, denoted as and respectively, are bounded, closed, and convex. Concretely, we assume that and are defined by the zero sublevel sets of smooth convex functions and , where and belong to the index sets and , respectively. Thus, these sets can be expressed as follows:
| (1) | ||||
| (2) |
In this context, we model the robots as particles, with defenders indexed by and attackers indexed by . Besides, the robots are assumed to move within the domain with single-integrator dynamics:
| (3) | ||||
| (4) |
where and (resp. and ) represent the position and velocity of defender (resp. attacker ).
We define as the joint state of the system (3)-(4). Thus, the joint state satisfies the constraint:
| (5) |
Additionally, we define the control inputs of defender and attacker as and , respectively. These control inputs are subject to the following constraints:
| (6) | ||||
| (7) |
Here, and are the maximum speeds of defender and attacker , respectively. To prevent attackers from easily outrunning defenders, we impose a constraint on the maximum speed ratio, requiring that defenders possess equal or greater speed capabilities than attackers:
| (8) |
where denotes the ratio of defender ’s maximum speed relative to that of attacker .
In the multiplayer reach-avoid game, interactions between defenders and attackers are determined by their relative positions. Specifically, attacker is said to be captured by defender if the distance between their positions is less than a positive constant :
| (9) |
where represents the th capture radius. This leads to the capture region of defender defined as .
To simplify our analysis, we assume that attackers that have been captured or have reached the target set become stationary, while defenders can proceed with their tasks after capturing an attacker. This assumption allows us to focus on active attackers, which are defined as those attackers who have neither been captured nor reached the target set. The active attackers at the joint state are indexed by , where and is defined as:
| (10) |
Keeping this in mind, we can modify the input constraint for attacker as follows:
| (11) |
In this game, we adopt a state feedback information pattern wherein each team makes decisions according to the current joint state without accessing the control inputs of the opposing team. Under this information pattern, an admissible strategy for defender (resp. attacker ) is defined as a mapping from the joint state to the input constraint set (resp. ) such that (resp. ). We define an admissible defense strategy as the collection of all defenders’ admissible strategies, denoted by . Likewise, an admissible attack strategy, denoted by , is defined as the collection of all attackers’ admissible strategies.
The outcome of the multiplayer reach-avoid game is evaluated in terms of a payoff function, which quantifies the total number of attackers reaching the target set up to the terminal time . We consider the terminal time to be free, meaning that the game continues until all attackers have been captured or have reached the target set. Given an initial joint state and a pair of admissible defense and attack strategies and , the payoff function is formally defined as:
| (12) |
The goal of the defender team is to minimize the value of the payoff function by choosing appropriate defense strategies, regardless of any admissible attack strategy.
Problem 1 (Cooperative Defense in Multiplayer Reach-Avoid Games)
Given a domain and a target set as defined by (1) and (2), along with an initial joint state of the system (3)-(4), we seek to find an admissible defense strategy that minimizes the payoff function against any admissible attack strategy . This corresponds to solving the following minimax optimal control problem:
Solving Problem 1 poses significant challenges due to several factors, such as the high dimensionality of the joint state, the discreteness of the payoff function, and the presence of both cooperative and competitive interactions among agents. A widely used approach to tackling these challenges is to employ the differential game formulation, which involves solving the HJI equation or its invariant. However, as the dimension of the joint state increases, the computational complexity of this method becomes intractable, particularly in multi-agent scenarios.
To tackle the aforementioned challenges, we decompose Problem 1 into two interconnected subproblems:
-
•
Single-Attack Defense Coordination Problem: Given a coalition of defenders and a single attacker, design an admissible strategy for the coalition to prevent the attacker from reaching the target set, irrespective of any admissible strategy employed by the attacker. In this context, a coalition refers to a group of defenders collaboratively working to protect against a specific attacker.
-
•
Multi-Attack Defense Allocation Problem: Building upon the solution to the Single-Attack Defense Coordination Problem, design an allocation algorithm that assigns coalitions to active attackers, with the objective of minimizing the payoff function (12). Recall that, active attackers are those that have not been captured or have not yet reached the target set.
The Single-Attack Defense Coordination Problem is solved in a continuous-time manner, wherein the outcome of the multiplayer reach-avoid game is binary: the attacker either succeeds in reaching the target set or is captured outside the target set. We say that the coalition wins if the attacker can never enter the target set; otherwise, the coalition is considered defeated. Consequently, the problem of single-attack defense coordination is to find a winning strategy for the coalition against the attacker. Conversely, the Multi-Attack Defense Allocation Problem is handled in a discrete-time framework, where each time instant corresponds to an implementation of the allocation. We refer to these time instants as allocation times. At each allocation time, the allocation algorithm reevaluates the assignment of active attackers to coalitions based on the current joint state.
Integrating the solutions of these two subproblems results in a holistic solution to Problem 1. Given the current joint state, we initially identify the set of active attackers by checking their relative distances to the defenders up to the last time instant. Subsequently, the solution to the Multi-Attack Defense Allocation Problem dictates the assignment of active attackers to coalitions. For each specified coalition-attacker pair, we then apply the solution to the Single-Attack Defense Coordination Problem to compute the control input for each defender in the corresponding coalition. This dual-layer scheme continues to update in real-time, effectively decomposing the high-dimensional, complex minimax optimal control problem into smaller, more tractable problems.
III Defense Coordination Against A Single Attacker
In this section, we present a defense strategy for a coalition in multiplayer reach-avoid games involving a single attacker. Our approach begins with a formal definition of the safe-reachable set and a derivation of its sublevel set representation. Leveraging the minimum squared distance between the safe-reachable set and the target set, we construct an objective function that transcribes the single-attack defense coordination problem into its online robust maximization. The solution to this robust maximization leads to an online convex programming-based defense strategy, which guarantees the coalition’s victory for a specific region of initial joint states. To increase the chances of winning against non-optimal attack strategies, we further propose a dual-mode switching defense strategy to fit with all initial joint states.
III-A Safe-Reachable Set
In the multiplayer reach-avoid game with a single attacker, the binary outcome of an initial joint state is determined by the reach-avoid set [18]. This set comprises joint states from which the attacker can reach the target set without being captured by any of the defenders. By solving an HJI equation numerically, the reach-avoid set can be represented as a sublevel set of the HJI solution [42]. However, the backward computation associated with this method suffers from the curse of dimensionality, hindering its application to multi-agent systems [23]. In contrast, the safe-reachable set seeks to collect the attacker’s reachable locations that remain capture-free given the current joint state [35]. This set can be computed using forward computation, which only concerns the attacker’s position state and does not involve solving for the target set reachability, making it more computationally efficient. We will demonstrate that under our problem settings, the binary outcome of an initial joint state can also be characterized by the safe-reachable set.
A formal definition of the safe-reachable set for a coalition-attacker pair is given below. Consider a coalition and an attacker with dynamics described by (3) and (4), respectively, and denote their joint state as . In light of (9), the capture-free condition for attacker can be expressed as follows:
| (13) |
where . To account for the dependence of agent trajectories on their initial states and strategies, we introduce the notations and , which respectively denote the trajectory of attacker over time starting from using the attack strategy , and the trajectory of defender over time starting from using the defense strategy .
Definition 1 (Safe-Reachable Set)
Given a joint state of , the safe-reachable set (SRS) for attacker induced by the coalition consists of all positions satisfying the following properties:
-
1.
(Reachability) There exists a time instant and an admissible attack strategy over the interval such that the attacker can reach position at time :
-
2.
(Safety) For any admissible defense strategy used by the defenders , the capture-free condition (13) holds for all :
The SRS offers a predictive way to evaluate the capture-free condition (13) by incorporating the dynamic and input constraints of both opponents. When the SRS is nonempty, it implies that the attacker is currently situated within the SRS, and the capture-free condition is satisfied for the current joint state, as per Definition 1. Moreover, the size of the SRS can be used to anticipate the attacker’s ability to move freely without compromising safety. A larger SRS indicates that the attacker has more options for safe movement, regardless of any defense strategies that may be employed.
Similar to the reach-avoid set, the SRS admits a sublevel set representation. Consider a point inside the SRS that attacker can reach at time . Simultaneously, defender can arrive at point using the constant strategy . According to Definition 1, adheres to the capture-free condition . On the other hand, since attacker can safely reach , the time must fulfill , with representing the minimum time for attacker to reach . This leads to , which can be rewritten as with
| (14) |
and . Moreover, satisfying inequality (14) for every is sufficient to ensure that lies within the SRS.
Proposition 1 (Sublevel Set Representation)
Proof: We have shown that for each , and the remaining is detailed in Appendix -A.
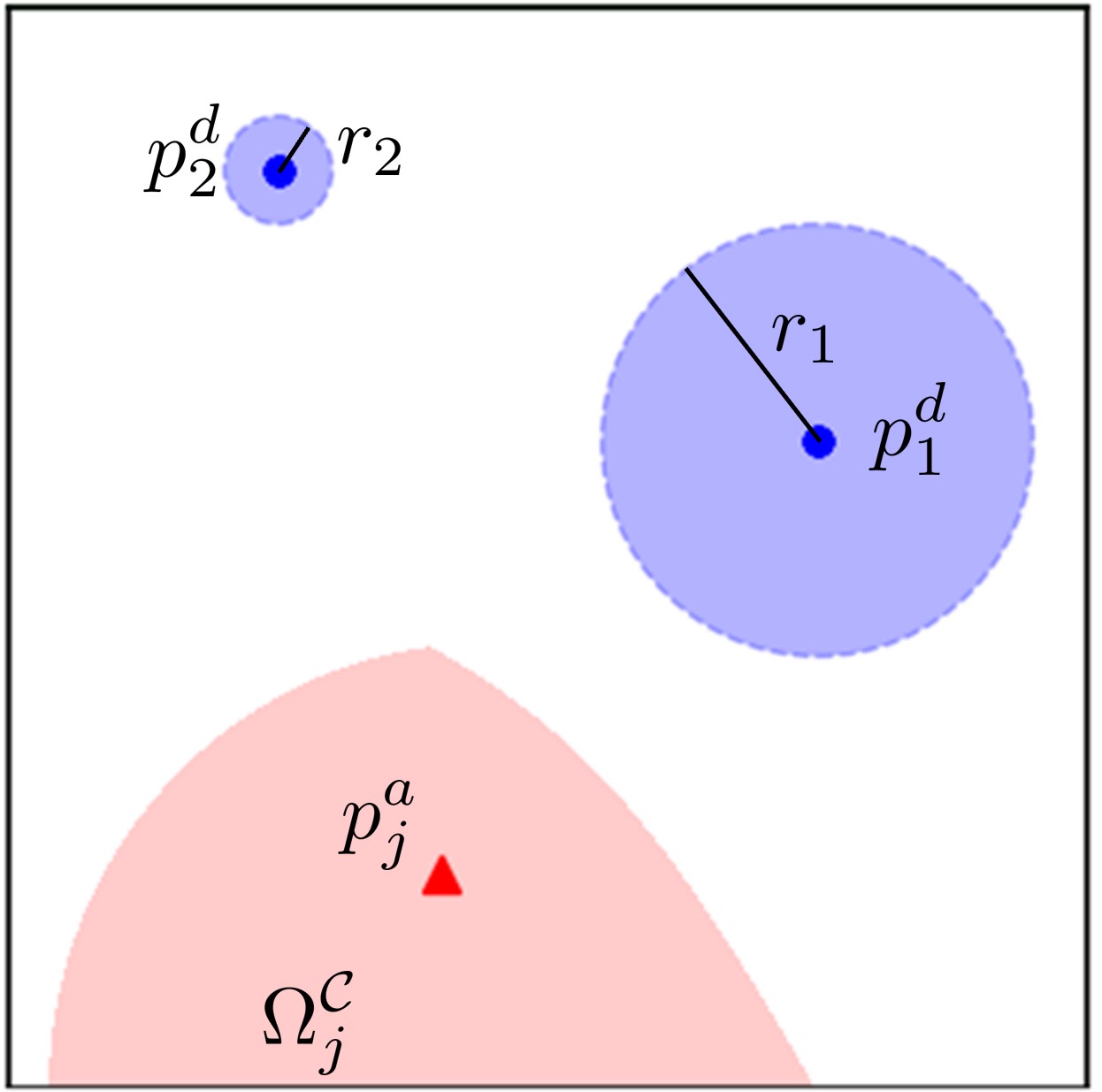
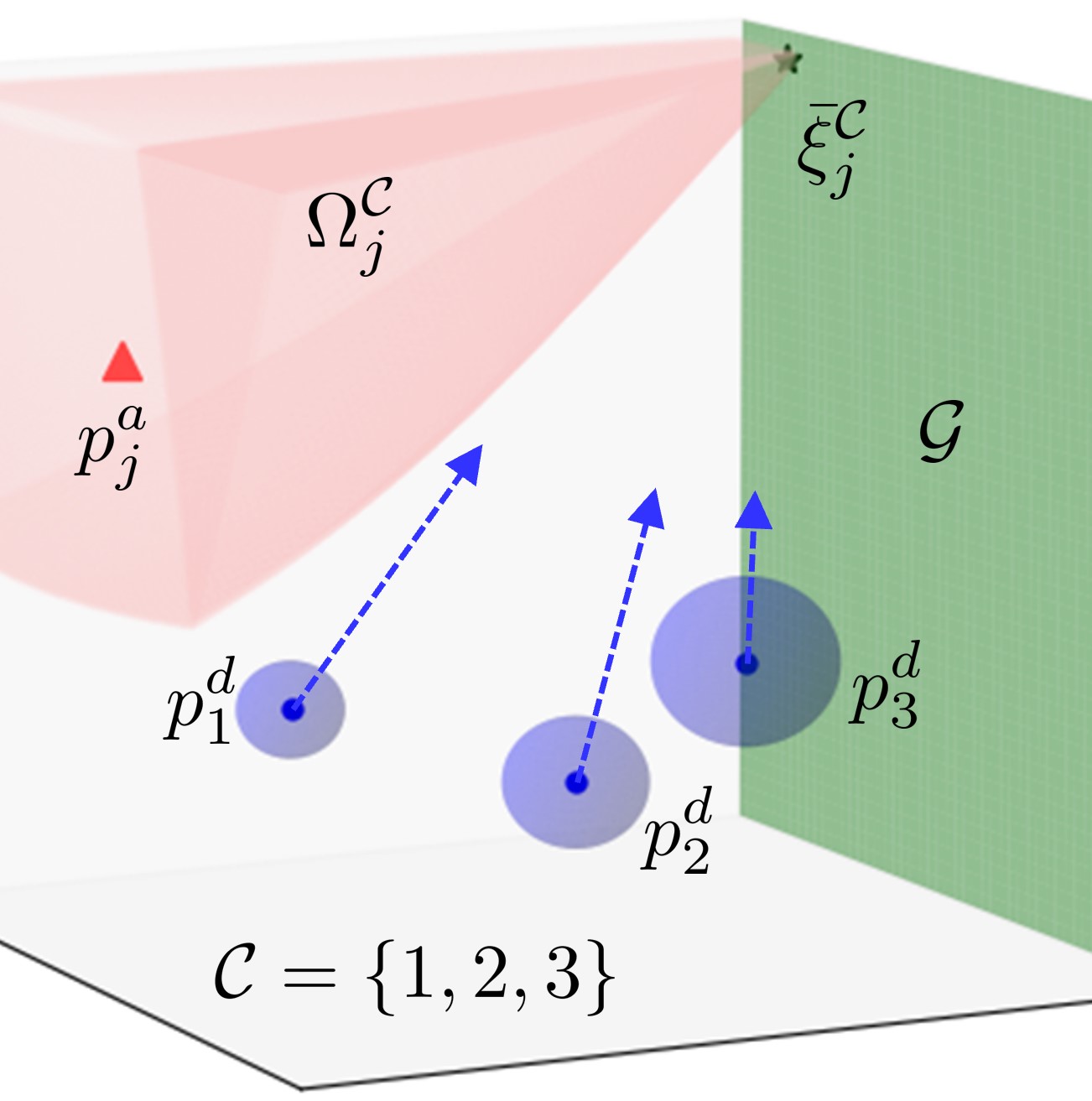
The SRS serves as a generalization of both the Voronoi diagram and Apollonius diagram by accommodating nonzero capture radii. As evident from equation (15), when all the capture radii equal zero, the SRS simplifies to the Voronoi cell if and to the Apollonius circle/sphere if . Unlike the Voronoi diagram and Apollonius diagram, the SRS partitions the space based on the attacker’s capacity to move freely without being captured, factoring in the defenders’ capture radii, as depicted in Fig. 2. This distinctive characteristic of the SRS enables a more realistic representation of the interaction between the attacker and defenders, enhancing defense coordination with unpredictable attacker movements.
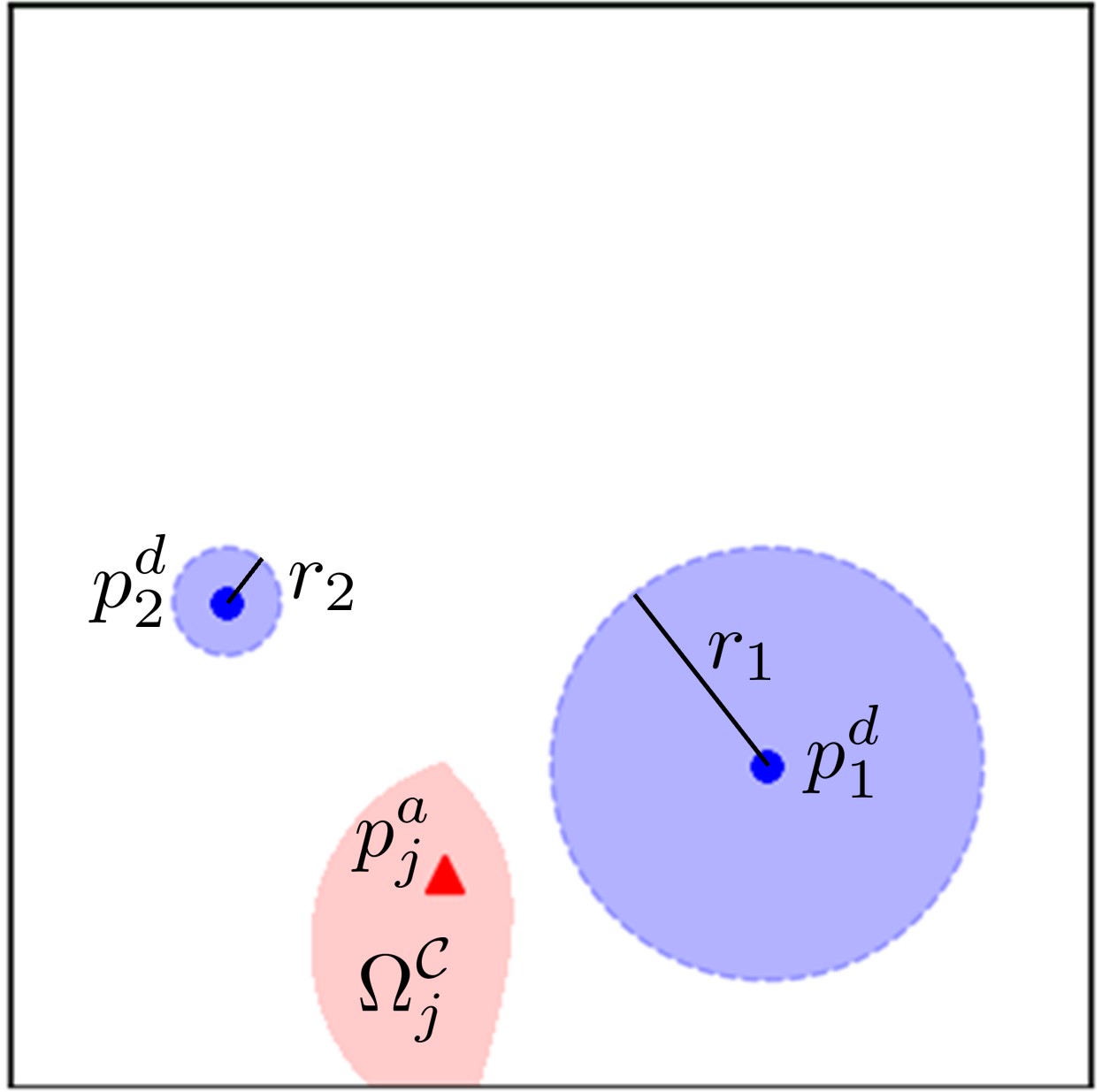
III-B Single-Attack Objective Function
Having the SRS concept, we next develop an objective function for the single-attack defense coordination problem. Given that the SRS pertains to the attacker’s forward reachability, it is natural to define an objective function that connects the SRS and the target set in terms of their minimum distance. With this in mind, we propose the minimum squared distance between the SRS and the target set as the objective function, which we refer to as the single-attack objective function:
| (16) |
Since both the SRS and the target set are convex and admit sublevel set representations, according to Proposition 1 and the assumption on the target set, the value of can be determined by solving the following parametric convex program:
| (17) |
where the joint state serves as the parametric vector.
The single-attack objective function provides a quantitative measure for the binary outcome of the single-attacker multi-defender reach-avoid game. It is essential to note that the value of is always nonnegative for a nonempty SRS, and positive if the intersection between the SRS and the target set is empty. This suggests that retaining the positivity of is critical in preventing the attacker from reaching the target set. Consequently, a winning guarantee condition for the coalition can be derived in terms of the single-attack objective function.
Lemma 1 (Defense-Winning Condition)
For a given coalition-attacker pair at the initial joint state, the coalition is guaranteed to win against attacker if and only if there exists an admissible defense strategy such that, for any admissible attack strategy, the single-attack objective function remains positive throughout the duration:
Proof: For sufficiency, if remains positive for all , then the SRS cannot intersect the target set during this time interval. Since the attacker’s position is always contained within the non-empty SRS, the attacker can never enter the target set. This implies that the coalition is guaranteed to win the game. For necessity, assume for the sake of contradiction that the coalition wins while for some . According to Definition 1, there is an admissible attack strategy starting from time that drives attacker to the target set within a finite time. This, however, contradicts the assumption that the coalition wins.
Remark 1 (Online Robust Maximization)
Lemma 1 confirms that if the strict zero superlevel set of is robustly positively invariant [43] under an admissible defense strategy, then the coalition can guarantee victory against any admissible attack strategy. The notion of robustness means that the coalition must maximize the single-attack objective function for the worst-case attack strategy. As a consequence, the optimal defense coordination problem can be converted into an online robust maximization of the single-attack objective function for the coalition at each joint state.
III-C Defense-Winning Strategy
We proceed to derive a defense-winning strategy for the coalition by performing online robust maximization of the single-attack objective function when it has a positive value. In light of Pontryagin’s Maximum Principle for differential games (cf. Theorem 8.2 in [44]), robustly maximizing for the coalition amounts to robustly maximizing its time derivative with respect to the inputs , . Note that, the time derivative of along the joint state trajectory is given by
| (18) |
To measure the effect of each agent’s input on , we need to determine the gradients of concerning the positions of all agents. Fortunately, by invoking the Karush–Kuhn–Tucker (KKT) conditions (cf. Theorem 12.1 in [44]), a linear correspondence can be made almost everywhere between the gradients of and those of , given in (14).
Proposition 2 (Gradient Correspondence)
Proof: See Appendix -B.
Proposition 2 provides a tractable procedure for generating a defense strategy that approximately robustly maximizes , assuming that (20) holds almost everywhere. This procedure entails deriving the gradient of the functions , for each and as follows:
| (20) |
where . By substituting (20) with into (19) and noting that the parameter is nonnegative, we can obtain an almost robust optimal defense strategy for defender in coalition given by:
| (21) |
for such that the convex program (17) has a unique solution. Moreover, it can be shown that the uniqueness of the solution to (17) is guaranteed as long as remains positive.
Proposition 3 (Solution Uniqueness)
Proof: See Appendix -C.
We are now ready to present the main result of this section, which asserts that the almost robust optimal defense strategy given by (21) guarantees a win for the coalition once the joint state lies within the region .
Theorem 1 (Defense-Winning Strategy)
For any initial joint state within the region , the coalition is ensured to win against attacker under the defense strategy (21), irrespective of any admissible attack strategies.
Proof: In light of Proposition 2, inserting (19) along with (20) and (21) into (18) reveals that for almost every ,
where the first and second inequalities hold due to and , respectively. As such, is non-decreasing over the time interval . This implies that for all , which in turn completes the proof, as established by Lemma 1.
Remark 2 (Maximum Defense-Winning Region)
The defense-winning region is maximum in the sense that contains all initial joint states for which the coalition can assuredly win against attacker . This is because if an initial joint state is not in , then it will lead to according to the definition of . This implies that attacker can safely reach the target set as stated by Lemma 1. Therefore, the outcome of a single-attack multi-defender reach-avoid game can be fully determined by checking whether the current joint state lies within the defense-winning region .
III-D Dual-Mode Switching Defense Coordination
We have identified a region of joint states within which the almost robust optimal defense strategy (21) ensures victory for the coalition. This defense strategy relies on the solution of the convex program (17), which typically does not guarantee solution uniqueness for joint states outside . In real-world scenarios, as the attack strategy is unknown, it would be advantageous for the defense strategy to handle any joint state, not just those within the region . By doing so, the chances of winning for the coalition against non-optimal attack strategies are increased. In the remainder of this section, we focus on utilizing the concept of SRS to extend the defense strategy to cover the entire joint state space.
We start by proposing a novel objective function specifically designed for joint states outside the region . The single-attack objective function is not suitable for this purpose, as it cannot distinguish between joint states that are not in , resulting in zero values for all such joint states. Given that an intelligent attacker tends to reach the target set safely and rapidly, and the intersection between the SRS and the target set is nonempty for , the objective function is defined as the minimum squared distance between the attacker’s position and the intersection between the SRS and the target set:
| (22) |
The convexity of the SRS enables the determination of through the solution of the parametric convex program:
| (23) |
The uniqueness of the solution to (23) is guaranteed since the projection of onto the convex and closed set is unique [45].
The objective function is then employed to derive a defense strategy for which . Based on the definition of , the goal of the coalition is to robustly maximize over time, which can be accomplished by robustly maximizing the time derivative of . To achieve this, we need to determine the gradient of with respect to the position of each defender in the coalition. Analogous to Proposition 2, it can be shown that for almost every , there is a set of nonnegative constants , , such that
| (24) |
where is the unique solution to the convex program (23). The proof of (24), owing to its similarity to that of Proposition 2, can be found in Appendix -B. Considering the almost everywhere holding of (24), substituting (20) with into (24) yields an almost robust optimal defense strategy for :
| (25) |
This defense strategy, together with the defense strategy (21) for , constitutes a dual-mode switching defense strategy applicable to the entire joint state space. The proposed algorithm for coordinating the defense against a single attacker is outlined in Algorithm 1.
Remark 3 (Almost-Optimal Waypoint for Defense Coordination)
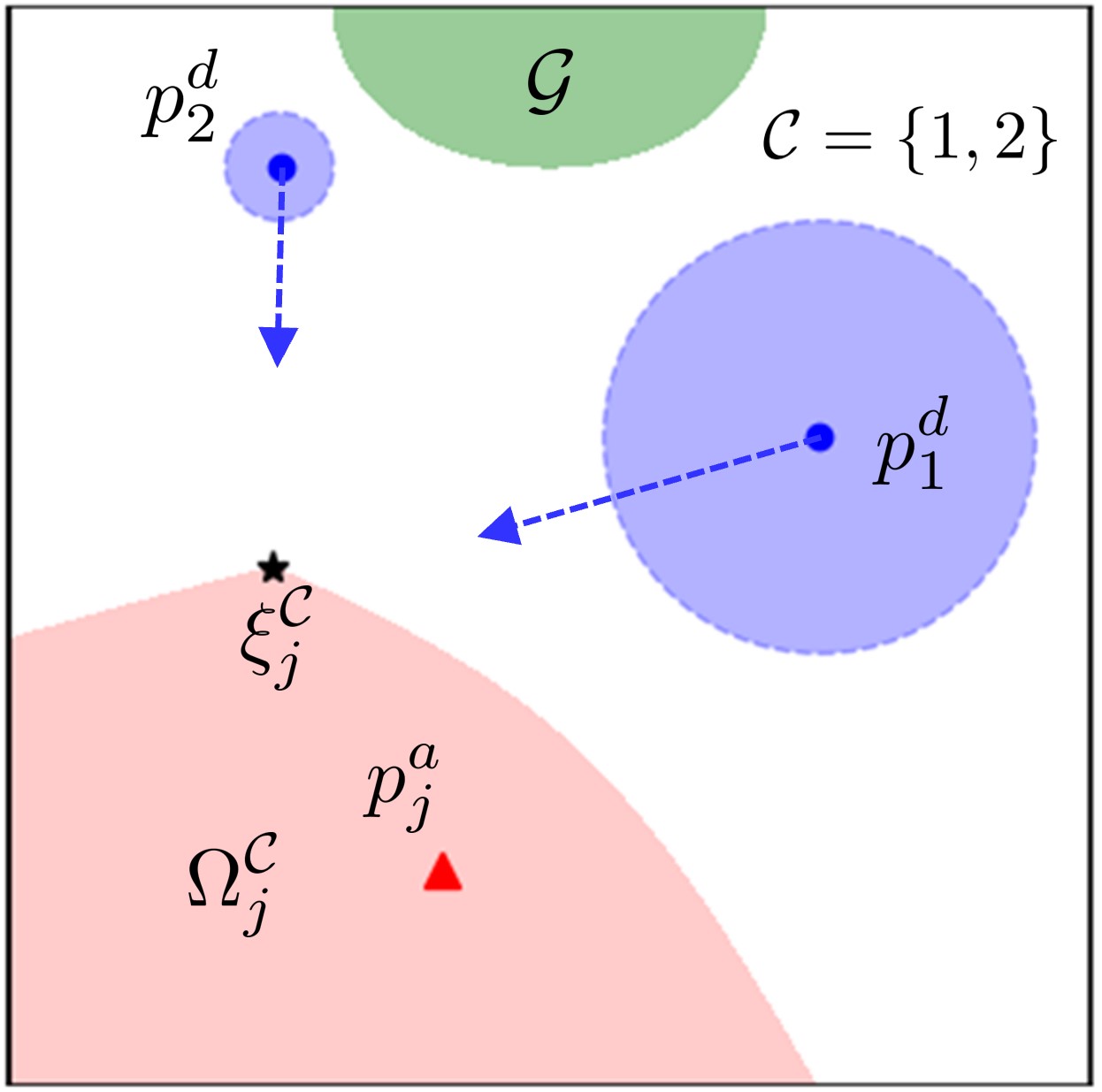
Algorithm 1 suggests that the -dimensional vector defined by
| (26) |
which is obtained by solving the convex program (17) or (23), serves as an almost-optimal waypoint for the coalition. This waypoint provides a reference point for the defenders in the coalition to coordinate their movements, depending on whether the joint state lies within the region or not, as illustrated in Fig. 3. By following the almost-optimal waypoint, the coalition can effectively adapt their defense strategy to defend against a single attacker.
Remark 4 (Individual Attack Strategy)
As a byproduct of our analysis, we can also derive a strategy for the single attacker. Contrary to the defenders’ goal, the attacker seeks to minimize robustly for , and robustly for . Employing a similar approach to that used in the derivation of the defense strategy, we arrive at the following attack strategy:
| (27) |
where , defined as (26), also serves as an almost-optimal waypoint for the attacker. The detailed derivation is omitted in this paper, as our primary focus lies on the defense perspective.
IV Defense Allocation for Multiple Attackers
In this section, we delve into the dynamic problem of allocating coalitions to multiple attackers. Building upon our previous results on defense coordination for single-attack scenarios, we reformulate the defense allocation problem as a joint state-dependent integer linear program (ILP), but solving this ILP in real-time may become computationally infeasible as the agent size grows. To address this issue, we propose an alternative solution that integrates two key components: the Hierarchical Integer Linear Programming (HILP) method and the Monotonic Defense Enhancement Allocation (MDEA) algorithm. The HILP method iteratively constructs a hierarchy based on the concepts of active defense sets and irreducibility, leading to a computationally efficient suboptimal solution. The MDEA algorithm then incorporates this suboptimal solution while enforcing a monotonicity constraint, ensuring that the expected number of attackers that fail to reach the target set remains non-decreasing over time.
IV-A Integer Linear Program Formulation
Following the classical taxonomy of multirobot task allocation proposed by Gerkey et al. [36], the defense allocation problem can be categorized as a single-task robot, multirobot task, and instantaneous assignment problem. Under the current joint state, each defender can defend against at most one attacker at a time, each attacker can be simultaneously guarded by multiple defenders, and the assignment only concerns the present moment. To represent the assignment, a binary matrix called the assignment matrix is used, where the entry if attacker is assigned to defender , and 0 otherwise. In addition, since all defenders are single-task, the assignment matrix must respect the conflict-free constraint, i.e., the row sum of the assignment matrix should not exceed 1.
To better model the effect of each coalition-attacker pair on the defense performance, we introduce an alternative matrix representation. Let , be the list of all different coalitions in which . We define the coalition assignment matrix to be such that
| (28) |
and if attacker is allocated to coalition . The coalition assignment matrix inherently induces an assignment matrix through the linear transformation:
| (29) |
where denotes the incidence matrix representing the binary relationship between defenders and coalitions. Specifically, if and 0 otherwise. To maintain the single-task property, the conflict-free constraint is defined through the induced assignment matrix as
| (30) |
Additionally, the redundancy-free constraint is imposed on :
| (31) |
ensuring that each attacker is assigned to at most one coalition.
We now present an objective function incorporating decision variables as elements of the coalition assignment matrix. Recalling Theorem 1, if at the joint state , an admissible defense strategy for exists that prevents attacker from reaching the target set. In light of this, we designate as a feasible coalition-attacker pair at if . In line with the payoff function given in (12), the reward for assigning attacker to coalition , denoted by , is set as 1 if is feasible and attacker is active, and 0 otherwise, i.e.,
with given in (10). Subsequently, the objective function, depending on the choice of a coalition assignment matrix at a given joint state , is defined as the total sum of the rewards of all assigned coalition-attacker pairs:
| (32) |
We refer to as the multi-attack objective function, which signifies the expected number of attackers that will be unable to access the target set from the current joint state. The reason behind this objective function is that it enables the assessment of defense performance in multi-attack scenarios.
Lemma 2 (Defense Performance Assessment)
Let be an admissible defense strategy associated with time-dependent coalition assignment matrices that consistently satisfy constraints (28), (30), and (31). Suppose there exists a time instant , such that for all admissible attack strategies,
| (33) |
holds over the time interval , where is the number of captured attackers up to time , and is a positive integer. Then, the payoff function under the defense strategy is bounded by , i.e.,
for any admissible attack strategy .
Proof: Let denote the number of attackers that have entered the target set up to time . At time , each attacker must be either captured, active, or have entered the target set. Hence, we have . Since the multi-attack objective function only concerns active attackers, it follows that . Combining this with inequality (33) yields for all , implying that for all . Consequently, based on the definition of the payoff function, we obtain .
Remark 5 (Online Maximization and Monotonicity Constraint)
Lemma 2 implies that one way to minimize the payoff function , against any admissible attack strategies, is to maximize the multi-attack objective function with respect to the coalition assignment matrix at each joint state . This leads to the following integer linear program (ILP) for the multi-attack defense allocation problem along the joint state trajectory:
| (34) |
Furthermore, to ensure overall defense performance, Lemma 2 highlights the significance of maintaining a robustly positively invariant superlevel set for the function with a level . Here, the value represents the expected number of attackers that fail to reach the target set at time . A sufficient condition for preserving the superlevel set property is to impose the monotonicity constraint, given by:
| (35) |
where , are the allocation times with . It should be noted that the optimal solution to the ILP (34) automatically satisfies the monotonicity constraint (35).
Although solving the ILP (34) provides an optimal solution to the defense allocation problem, it entails a substantial computational burden, particularly as the number of agents increases. This is mainly due to the vast amount of possible coalition-attack pairs, which not only leads to a large-scale ILP but more importantly, requires considerable computational effort to determine the multi-attack objective function. In the case of defenders and active attackers, there are possible coalition-attacker pairs, implying that the same amount of convex programs of the form (17) need to be calculated to specify the corresponding rewards. To alleviate the computational burden, we propose a heuristic algorithm for the ILP (34) in Section IV-C to generate a suboptimal solution, which will then be fed into an allocation algorithm to ensure the monotonicity constraint (35) in Section IV-D. In particular, prior to detailing the heuristic algorithm, we will derive two critical components in the next section, which together construct a hierarchy that facilitates the generation of a suboptimal solution for the ILP (34).
IV-B Active-Defense Set and Irreducibility
The optimal solution to the ILP (34) tends to favor feasible coalition-attacker pairs comprising smaller coalitions. On one hand, the multi-attack objective function is influenced only by feasible coalition-attacker pairs, as the reward for an infeasible pair is zero. On the other hand, smaller coalitions are less likely to violate the conflict-free constraint (30), and thus more likely to contribute positively to the multi-attack objective function. As a result, the key to striking a balance between optimality and efficiency in solving the ILP (34) is to identify as many feasible sub-pairs of coalition-attacker pairs with small amounts of defenders as possible while keeping the computational cost low. Here, a sub-pair of a coalition-attacker pair refers to a subset of the coalition that is also paired with the same attacker. To this end, we will focus on seeking feasible sub-pairs of a coalition-attacker pair from the aspects of optimality and efficiency in the subsequent analysis.
As a point of departure, we revisit the convex program (17) subject to a feasible coalition-attacker pair . As shown in Theorem 1, the vector extracted from the solution to (17) establishes an almost-optimal waypoint for the coalition , which must lie on the boundary of the SRS . Moreover, owing to the convexity of the SRS, some of the inequality constraints , must be active at . As such, we can define an index set of defenders through an active set in the convex program (17) that incorporates the almost-optimal waypoint .
Definition 2 (Active-Defense Set)
Suppose the coalition-attacker pair is feasible at the joint state . The active-defense set (ADS) for is the active set of the inequality constraints , in (17) at the almost-optimal waypoint , i.e.,
| (36) |
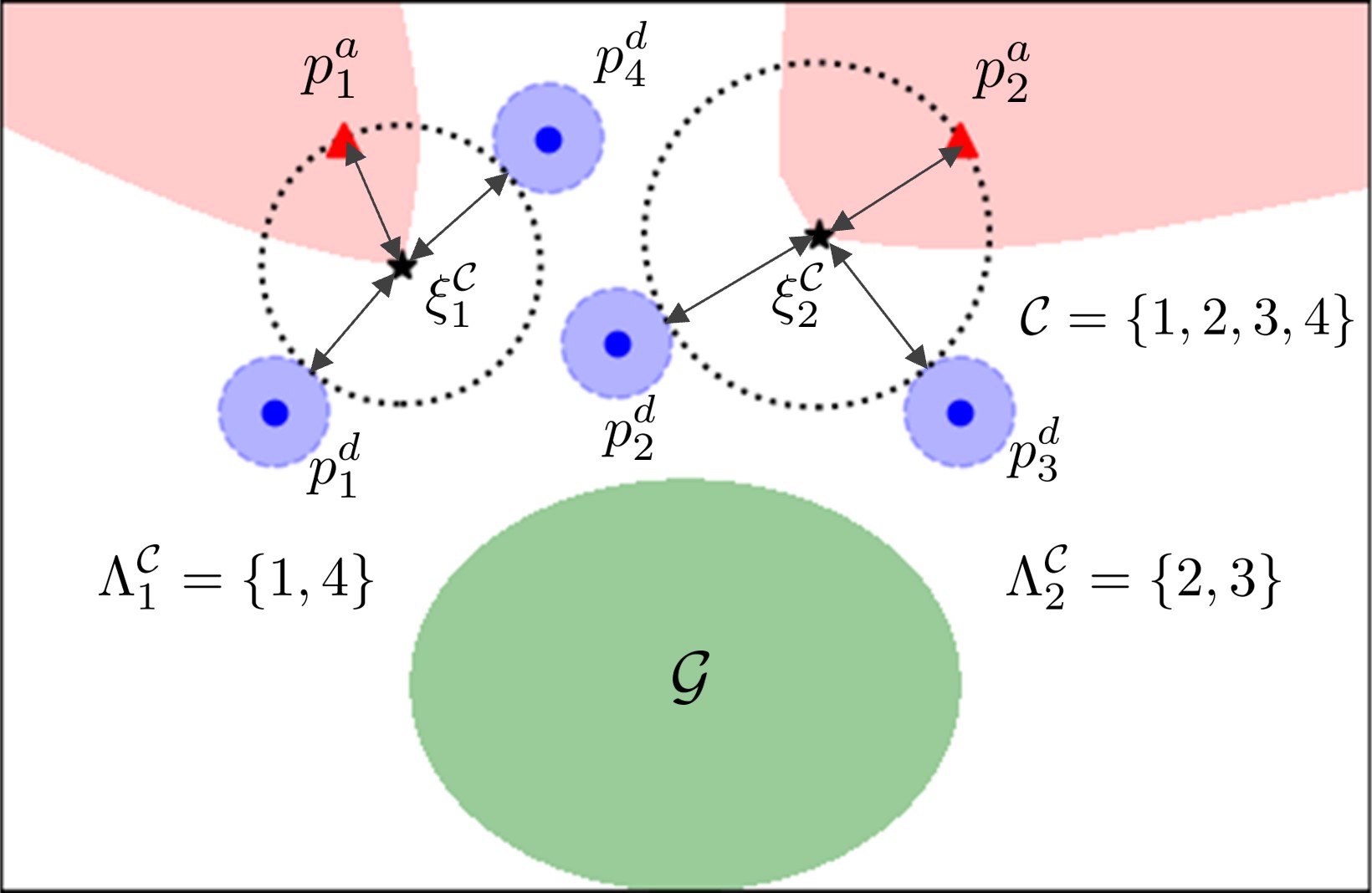
The construction of the ADS does not necessitate the computation of any additional convex programs. This is because the feasibility of the coalition-attacker pair has already been verified using a convex program of the form (17), and the almost-optimal waypoint can be determined as a byproduct of this computation. It is worth noting that the ADS concept indeed provides a proximity-based method for obtaining a specific sub-pair, which is associated with both locations of the attacker and the target set, as illustrated in Fig. 4. Furthermore, it can be shown that such a sub-pair inherits the feasibility of the original coalition-attacker pair.
Proposition 4 (Feasibility)
If the coalition-attacker pair is feasible at the joint state , then the sub-pair is also feasible at the corresponding joint state.
Proof: See Appendix -D.
We turn to look at how to generate feasible sub-pairs of a sufficiently small scale. While the ADS allows for feasible sub-pair generation without incurring additional computational effort, the resulting sub-pair size may not be minimum with respect to feasibility. In other words, the sub-pair may include redundant defenders that could be removed without affecting the feasibility of the sub-pair. To precisely quantify the redundancy, we introduce the following definition.
Definition 3 (Irreducibility)
A feasible coalition-attacker pair is said to be irreducible at a joint state if there is no proper subset of such that is feasible.
Given a feasible coalition-attacker pair , we can develop an iterative procedure to generate all irreducible sub-pairs. The process commences by evaluating size-1 subsets of . If , is inherently deemed irreducible and the process terminates. Otherwise, we check each size-1 subset for irreducibility by confirming whether . Then, we remove the element of from for which is irreducible, forming a new set . If , all irreducible sub-pairs have been identified, and the process ends. In case further iterations are required, we repeat with all size- subsets of for , where is analogously defined by removing elements from . The procedure continues until either or at the iteration . Moreover, the number of iterations can be reduced by noting that the cardinality of the coalition for any irreducible sub-pair is upper bounded by the dimension of the domain.
Proposition 5 (Upper Bounded Cardinality)
In an -dimensional domain, if the coalition-attacker pair is irreducible, then has cardinality no greater than .
Proof: See Appendix -E.
We summarize our findings of identifying irreducible sub-pairs of a feasible coalition-attacker pair in Algorithm 2. It should be emphasized that when solving the ILP (34), we can focus on irreducible coalition-attacker pairs rather than all possible pairs. This is because replacing a coalition-attacker pair with one of its irreducible sub-pairs will not affect the optimal value of the multi-attack objective function. In general, Algorithm 2 can lower the number of convex programs needed to determine the multi-attack objective function. However, directly using the concept of irreducibility could lead to heavy computational loads. For instance, computing all irreducible sub-pairs in the worst-case scenario requires up to compute convex programs for a coalition-attacker pair . To improve computational efficiency, a more effective approach would be to combine the concept of irreducibility with that of the ADS.
IV-C Hierarchical Integer Linear Programming
We now exhibit the integration of the ADS and irreducibility concepts to establish the first level of the hierarchy for the ILP (34). Our approach initiates by checking coalition-attack pairs of the form and only focusing on feasible ones. The proximity-based sub-pair is then taken into account, where is the ADS for the feasible pair . Finally, irreducible sub-pairs of are selected to refine the multi-attack objective function . As a result, we assign the highest priority to coalition-attacker pairs that are irreducible and have as a subset of . Compared to directly prioritizing all irreducible sub-pairs of , this method reduces the potential computational challenges while offering a considerable amount of feasible sub-pairs.
After specifying the first hierarchy level, we can derive a suboptimal solution to the ILP (34). Let denote the first priority set that contains all coalition-attacker pairs with the highest priority. In the case where is empty, no feasible coalition-attacker pairs exist, and the ILP solution simply corresponds to a zero coalition assignment matrix. To confine the selection of coalition-attacker pairs solely to those within , we impose the following constraint on the decision variables:
| (37) |
By resolving the ILP (34) with the additional constraint (37), we attain a suboptimal solution denoted as , which provides a lower bound on the optimal value of the multi-attack objective function. In order to evaluate , we define two index sets and in which contains the indices of defenders that remain unassigned to any attacker based on , and if omits attacker and is feasible. If either or is empty, there are no more available coalition-attacker pairs and further steps are not needed.
The above procedure can be iteratively applied, if possible, to improve the suboptimal solution. At iteration , the -th priority set is formed by identifying all irreducible coalition-attacker pairs for which is contained in the ADS for a feasible and . The decision variables are then restricted to through the binary constraint:
| (38) |
resulting in a subproblem of the original ILP (34):
| (39) |
Having a solution to the subproblem (39), represented by , the suboptimal solution to the ILP (34) is updated by adding to the previous suboptimal solution, leading to
The procedure terminates at the th iteration when is empty or one of the index sets and is empty, where and are obtained by excluding the indices related to from and , respectively.
In summary, our approach to solving the ILP (34) is outlined in Algorithm 3, which strikes a balance between optimality and efficiency, as demonstrated by the subsequent proposition.
Proposition 6 (Optimality-Efficiency Tradeoff)
Algorithm 3 possesses two key properties:
1) (Optimality) If is empty after the first iteration, then the suboptimal solution is an optimal solution to the ILP (34).
2) (Efficiency) If the cardinality of the ADS for each in each iteration is at most , then the total number of calculations for the convex program of the form (17) is less than .
Proof: See Appendix -F.
The assumptions made in Proposition 6 for Algorithm 3 are satisfied in many practical scenarios. For instance, if the ADSs for the coalition-attacker pair , are mutually disjoint, then the set becomes empty after the first iteration and the suboptimal solution is optimal for the ILP (34). Such a scenario commonly arises when the attackers are sparsely distributed relative to the defenders. Furthermore, empirical results indicate that the cardinality of the ADSs typically does not exceed the number of defenders. Compared to directly solving the ILP, where the number of calculations for the convex program of the form (17) grows exponentially with the number of defenders, the calculation times for our algorithm do not empirically depend on the number of defenders and are only quadratically dependent on the number of active attackers. Consequently, Algorithm 3 offers a viable alternative for tackling the ILP in large-scale scenarios with many defenders, especially when conventional approaches become computationally infeasible.
IV-D Monotonic Defense Enhancement Allocation
Once acquiring the suboptimal solution produced by Algorithm 3, we adjust it by incorporating the monotonicity constraint (35). Specifically, we update the coalition assignment matrix at each time step by equating it to the solution derived from Algorithm 3 if the monotonicity constraint (35) is met; otherwise, we retain the updated coalition assignment matrix from the previous step. Note that the number of active attackers may change between two consecutive time steps. As such, we need to set the columns of the previous coalition assignment matrix to zero for those corresponding to attackers captured at the current time step before executing the update. This approach offers the advantage of maintaining the validity of all inequalities in (34) without requiring additional computation of the ILP, thereby reducing the computational effort.
While the above approach effectively integrates the monotonicity constraint (35), it may give rise to undesired oscillatory behaviors in defense allocation. Such oscillations occur when a defender’s assignment repeatedly switches between two distinct attackers, potentially impairing the system’s performance. These oscillations stem from the fact that Algorithm 3 might produce non-unique solutions, leading to the equality in (35) holding. To tackle this issue, we implement a stricter version of the monotonicity constraint (35), updating the coalition assignment matrix only when the inequality constraint (35) is strictly fulfilled. This ensures that we stick to the previous coalition assignment matrix when the equality in (35) holds, thus avoiding oscillations while still enforcing the monotonicity constraint (35).
Our approach to the multi-attack defense allocation problem is summarized in Algorithm 4, which consists of two components. The first component imposes the monotonicity constraint (35) on the solution obtained from Algorithm 3. For the initial step, and are respectively set to and . The second part uses a greedy algorithm that allocates each unassigned defender to the nearest unassigned active attacker. This is inspired by the observation that a closer the defender-attacker pair results in a reduced SRS. To achieve this, we first convert the coalition assignment matrix into the corresponding assignment matrix in terms of the linear equation (29). We then update the assignment matrix using the greedy algorithm and revert it to the coalition assignment matrix through the pseudoinverse of the incidence matrix. The greedy algorithm is computationally efficient and provides a valuable supplement to the first component of Algorithm 4.
We are now able to encode the solution to the multi-attack defense allocation problem into an admissible defense strategy for the multiplayer reach-avoid game. Given the output of Algorithm 4, , we define the assignment rule as follows:
| (40) |
where denotes the case of an unassigned defender. For each active attacker , the coalition against attacker induced by is given by:
Combining Algorithm 1 with the assignment rule as described in (40), we obtain an admissible defense strategy of the form:
| (41) |
where is the almost-optimal waypoint defined in (26). If a defender is unassigned, its control input is set to zero for the sake of energy saving.
Theorem 2 (Performance-Guaranteed Defense Strategy)
For any initial joint state , the payoff function under the defense strategy given by (41), and any admissible attack strategy satisfies the following inequality:
| (42) |
where is the multi-attack objective function defined in (32), is the initial solution of Algorithm 4, and is the number of attackers captured at the initial joint state. Moreover, the function is monotonically non-decreasing along the system trajectory.
Proof: The enforcement of the monotonicity constraint (35) in Algorithm 4 ensures that the sequence is monotonically non-decreasing. Further, it is noted that remains constant within each time interval , as the assignment of defenders to active attackers is updated only at the time instants . As a result, is non-decreasing. This indicates that the inequality (33) holds with , which in turn, according to Lemma 2, leads to the satisfaction of the inequality (42) for the payoff function.
Theorem 2 provides a solid assurance that our defense strategy (41) is capable of achieving a performance level no worse than the bound of the payoff function specified in (42) for any initial joint state. Theorem 2 also establishes that the function , representing the expected number of attackers that fail to reach the target set, is monotonically non-decreasing over time. This property suggests that the upper bound of the payoff function in (42) becomes progressively tighter as the game progresses, leading to a continuous improvement in the performance of the proposed strategy. In the next section, we will present empirical results to demonstrate performance enhancement in practical scenarios.
V Simulations
In this section, we evaluate the performance and efficiency of our proposed single-attack defense coordination and allocation algorithms through a series of simulated experiments. All algorithms are written in Python, with convex programs and ILP implemented using the CVXPY solver [46]. We conduct the experiments on an Ubuntu 20.04 operating system equipped with an i9-10900 5.2 GHz CPU and 32 GB RAM, featuring 10 physical cores and 20 threads. To demonstrate the effectiveness of our approach, we benchmark our algorithms against current state-of-the-art algorithms in both 2D and 3D scenarios. Initially, we examine the Dual-Mode Switching Defense Coordination (DMSDC) algorithm (Algorithm 1), which serves as the basis for subsequent experiments with the monotonic defense enhancement allocation (MDEA) algorithm (Algorithm 4). Furthermore, to demonstrate the applicability of our algorithms in practical settings, we extend our evaluation to a more realistic simulation environment utilizing Gazebo with the robot operating system (ROS) [47].
V-A Single-Attack Defense Coordination
We start with the DMSDC for the problem of single-attack defense coordination. Our approach is compared with two existing methods: the multi-agent pursuit-defense strategy presented in [27] for a 2D scene and the analytical HJI-based strategy introduced in [24] for a 3D scene. We conduct simulations in a 2D rectangular domain of with a unit circle as the target set, and a 3D box domain of with the origin as the target set. To examine the effectiveness of our approach in guaranteeing the coalition’s win under various initial joint states, we perform 2000 randomized simulations with different numbers of defenders and capture radii for both the 2D and 3D scenarios. To ensure a fair comparison, we adopt the attack strategy given in (27) across all methods and set the maximum speed ratios to 1. The simulation outcomes are classified into four categories based on whether the coalition wins the game:
-
•
True Positive: The percentage of cases where both methods successfully capture the attacker.
-
•
False Negative: The percentage of cases where our method succeeds while the comparison method fails to capture the attacker.
-
•
False Positive: The percentage of cases where our method fails while the comparison method succeeds in capturing the attacker.
-
•
True Negative: The percentage of cases where both methods fail in capturing the attacker.
Table I showcases the 2D simulation results, which highlight the superior performance of our proposed algorithm over the multi-agent pursuit-defense strategy. Notably, our algorithm captures the attacker in 7.1% to 22.4% more instances than the multi-agent pursuit-defense strategy, without any occurrences where our algorithm fails while the multi-agent pursuit-defense strategy prevails. Interestingly, as the capture radius increases, our algorithm records a higher percentage of false negatives. This observation can be attributed to the fact that the Voronoi diagram employed in the multi-agent strategy does not inherently account for nonzero capture radii, whereas our algorithm exploits the safe-reachable set of the attacker to devise a more effective defense coordination strategy. Moreover, we note that when the number of defenders increases from 2 to 3, both capture radius scenarios exhibit a higher percentage of false negatives. This result arises from the multi-agent pursuit-defense strategy utilizing only one defender for defense, with the remaining defenders acting as pursuers. In contrast, our algorithm capitalizes on the collective strength of multiple defenders to achieve overall coordination.
| Defender | Capture | True | False | False | True |
|---|---|---|---|---|---|
| Number | Radius | Positive | Negative | Positive | Negative |
| 2 | 0.5 | 25.6% | 7.1% | 0% | 67.3% |
| 3 | 0.5 | 33.0% | 10.0% | 0% | 57.0% |
| 2 | 3.0 | 33.9% | 18.8% | 0% | 47.3% |
| 3 | 3.0 | 41.6% | 22.4% | 0% | 36.0% |
On the other hand, the 3D simulation results displayed in Table II indicate that our proposed algorithm outperforms the analytical HJI-based strategy. Specifically, our algorithm captures the attacker in up to 13.6% more instances than the analytical HJI-based strategy when the capture radius is 2, and there are no cases in which our algorithm fails while the analytical HJI-based strategy succeeds. It should be emphasized that the analytical HJI-based strategy is designed for cases with zero capture radii; consequently, the performance of our algorithm closely aligns with the analytical HJI-based strategy when the capture radius is near zero, which in turn demonstrates the optimality of our approach. Additionally, our algorithm exhibits better performance as the number of defenders increases, similar to our 2D comparison. This improvement is due to the analytical HJI-based strategy focusing solely on scenarios with one or two defenders, whereas our approach accommodates multiple defenders.
| Defender | Capture | True | False | False | True |
|---|---|---|---|---|---|
| Number | Radius | Positive | Negative | Positive | Negative |
| 2 | 0.1 | 66.5% | 0.9% | 0% | 32.6% |
| 3 | 0.1 | 72.2% | 1.6% | 0% | 26.2% |
| 2 | 2.0 | 84.3% | 7.3% | 0% | 8.4% |
| 3 | 2.0 | 81.6% | 13.6% | 0% | 5.2% |
V-B Multiple-Attack Defense Allocation
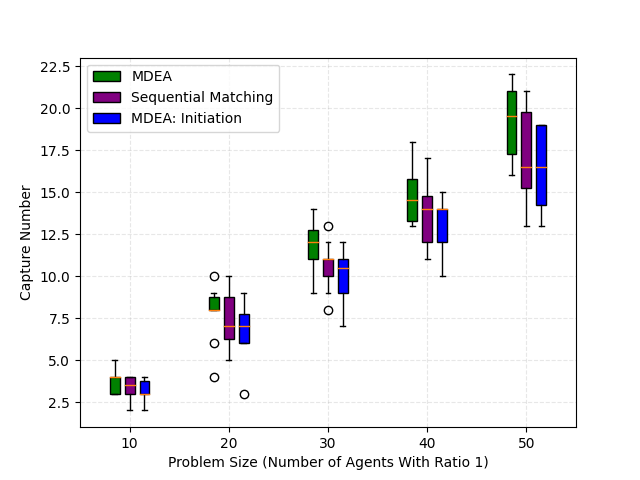
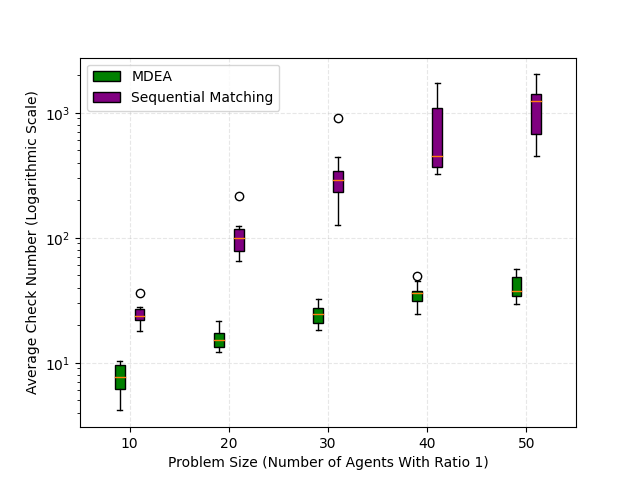
We next examine the MDEA algorithm for the multi-attack defense allocation problem. We compare our approach to two existing algorithms: the analytical barrier introduced in [31] for a 2D scenario and the sequential matching presented in [33] for a 3D scenario. To conduct our experiments, we use five groups of agents, maintaining a 1:1 ratio between defenders and attackers. The number of agents in each group ranges from 10 to 50, and we perform simulations with 10 different initial joint states for each group. We employ the same domain as described in Section V-A, with variations in the target sets for the different scenarios. Specifically, the 2D scenario has a rectangular domain of with the line segment as the target set, while the 3D scenario has a box domain of with the flat face as the target set.
During the simulation, we track two metrics to evaluate the effectiveness and computational efficiency of our proposed algorithm. The first metric is the capture number, representing the total number of attackers captured throughout the game, which is complementary to the payoff function. The second metric is the check number, denoting the count of convex programs of the form (17) computed within the multi-attack objective function defined in (32). This metric plays a crucial role in computational complexity, particularly when the agent size increases, as witnessed by our empirical results. In these cases, it can be seen that our single-attack defense coordination strategy (21) is the limiting case of that proposed in [31] when the capture radii tend to zero, and it includes the one proposed in [33] as a special case. To ensure a fair comparison with other algorithms, we employ a low capture radius of for the 2D scenario and for the 3D scenario. Similarly, we adopt the attack strategy given in (27) and set the maximum speed ratios to 1, as described in Section V-A.
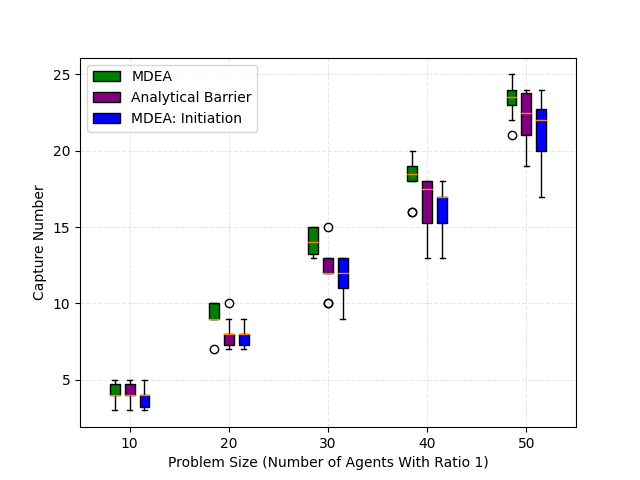
We employ boxplots to display the results of our 2D simulation in Fig. 5, indicating that our MDEA algorithm outperforms the analytical barrier approach. Three colors are used to represent three cases: 1) MDEA applied at each allocation time; 2) analytical barrier, which performs allocation only at the initial joint state; 3) MDEA implemented solely at the initial joint state, akin to the analytical barrier. As illustrated in Fig. 5, MDEA yields a considerable improvement over the analytical barrier, with its median values consistently exceeding those of the analytical barrier. Furthermore, the capture number achieved by MDEA surpasses that attained at the initial joint state, demonstrating the defense performance improvement of our approach as proven in Theorem 2. In Fig. 5, it can be observed that the analytical barrier exhibits a constant check number for each case, equal to the dimension of the decision variables in the ILP (34). Conversely, the check number of MDEA at the initial joint state is significantly lower than that of the analytical barrier, highlighting the superior computational efficiency of our method.
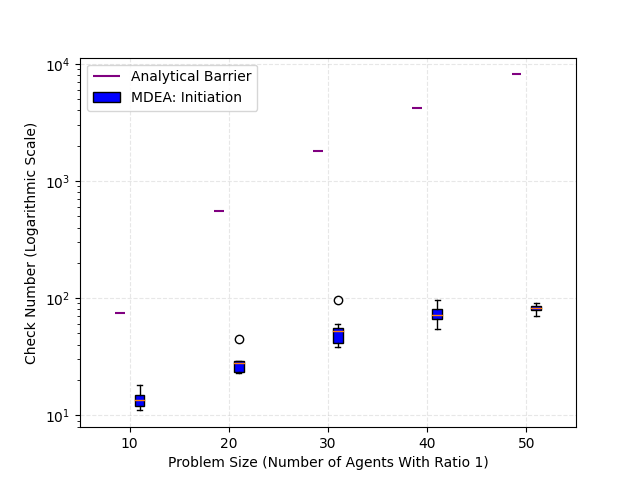
In the 3D simulation, our MDEA algorithm also outperforms the sequential matching method, as depicted in Fig. 6. We employ the same three colors to represent three cases as in the 2D simulation, with the analytical barrier replaced by sequential matching. As illustrated in Fig. 6, MDEA surpasses the sequential matching with higher median values of capture number. Moreover, MDEA attains a final capture number that exceeds the expected capture number initially obtained by the algorithm, thereby demonstrating the effectiveness of our approach in enhancing defense performance. Besides, Fig. 6 reveals that the average check number achieved by MDEA is significantly lower than that of the sequential matching, where the average check number is calculated by averaging the check number of each step. This showcases the computational efficiency of our approach.
V-C Gazebo Simulators with ROS




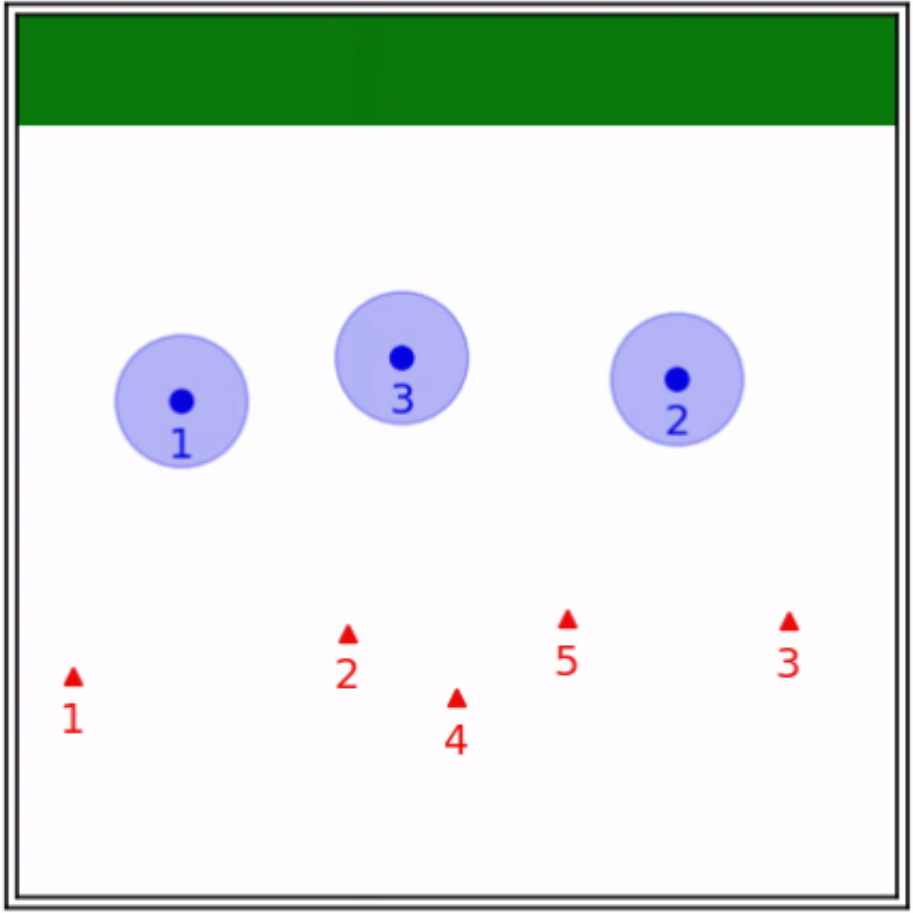
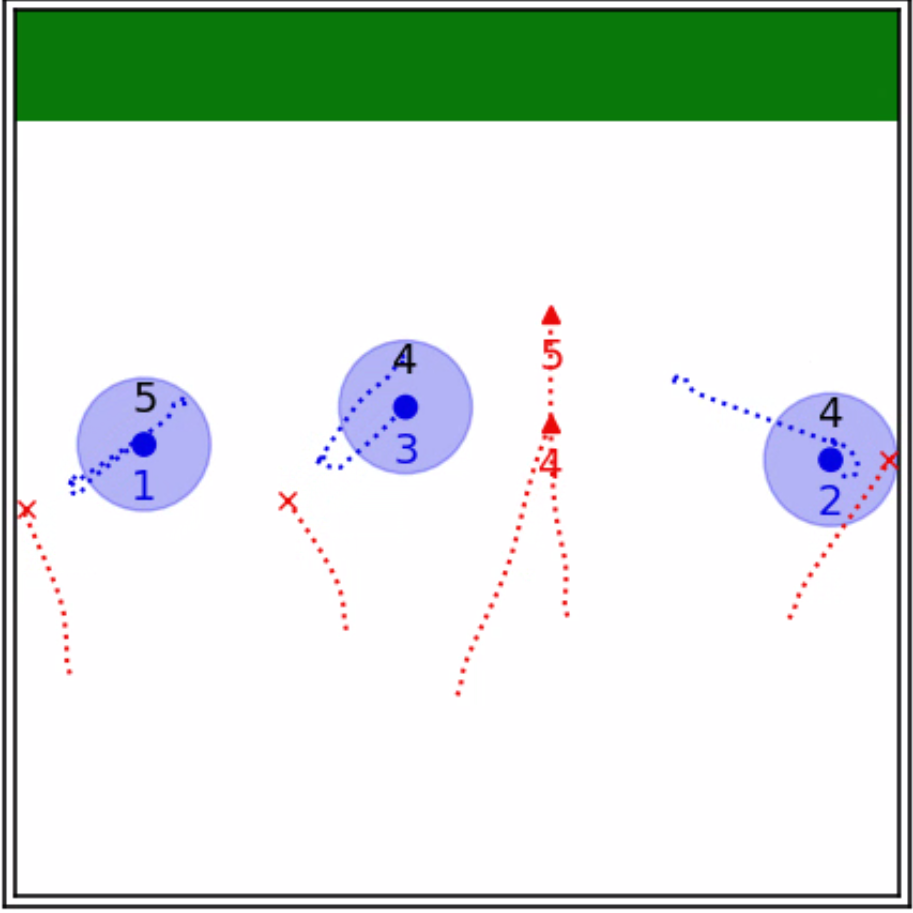
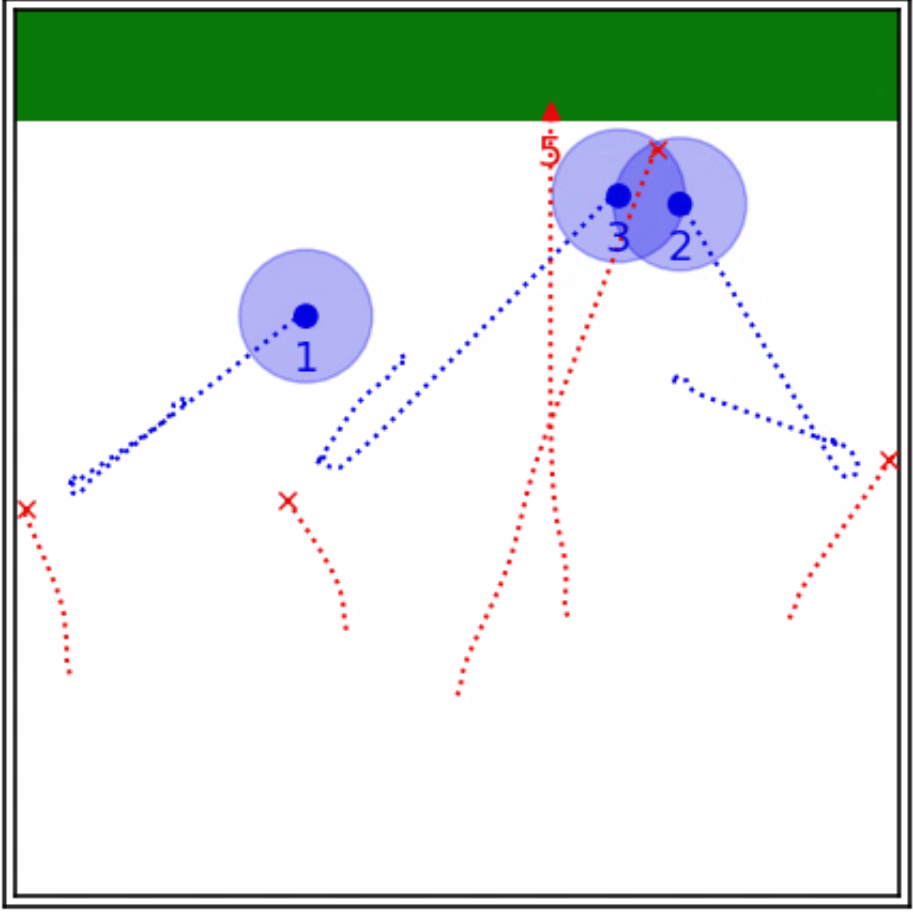
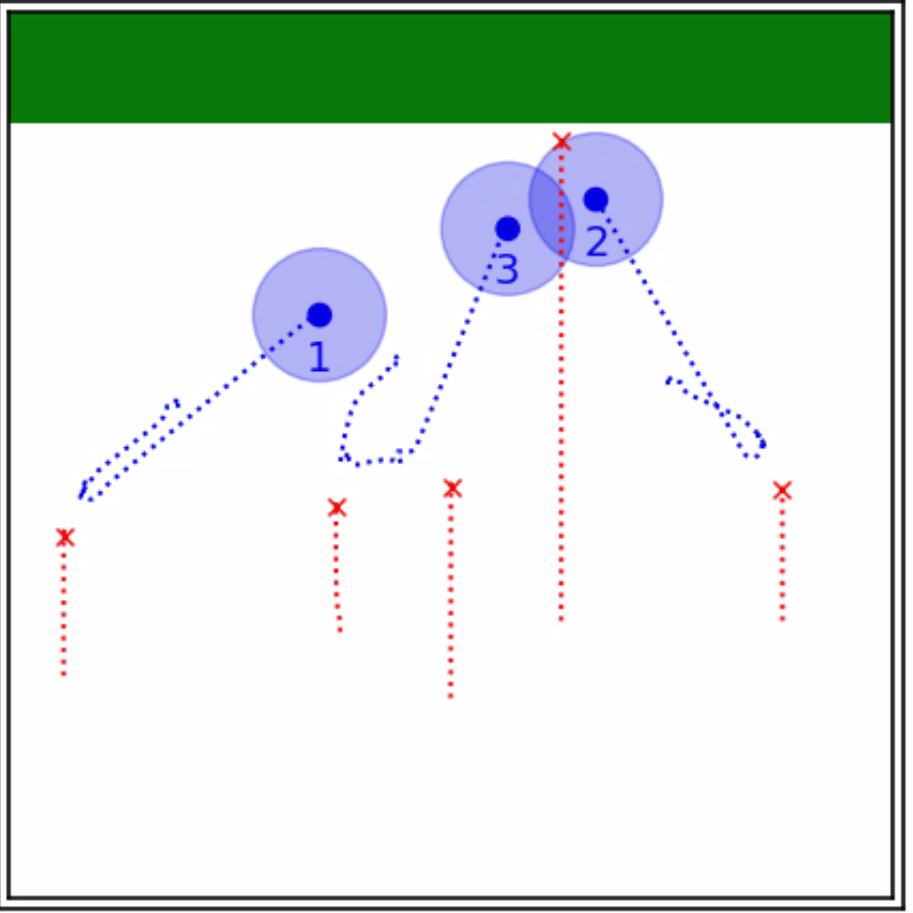




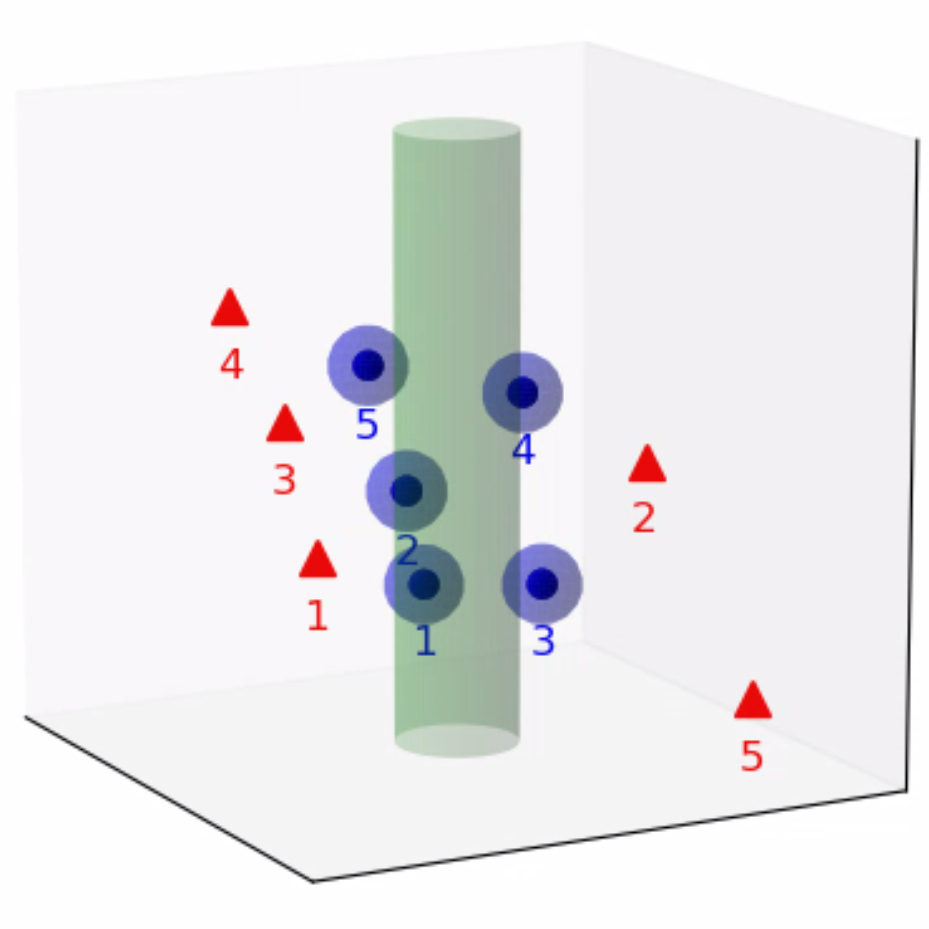
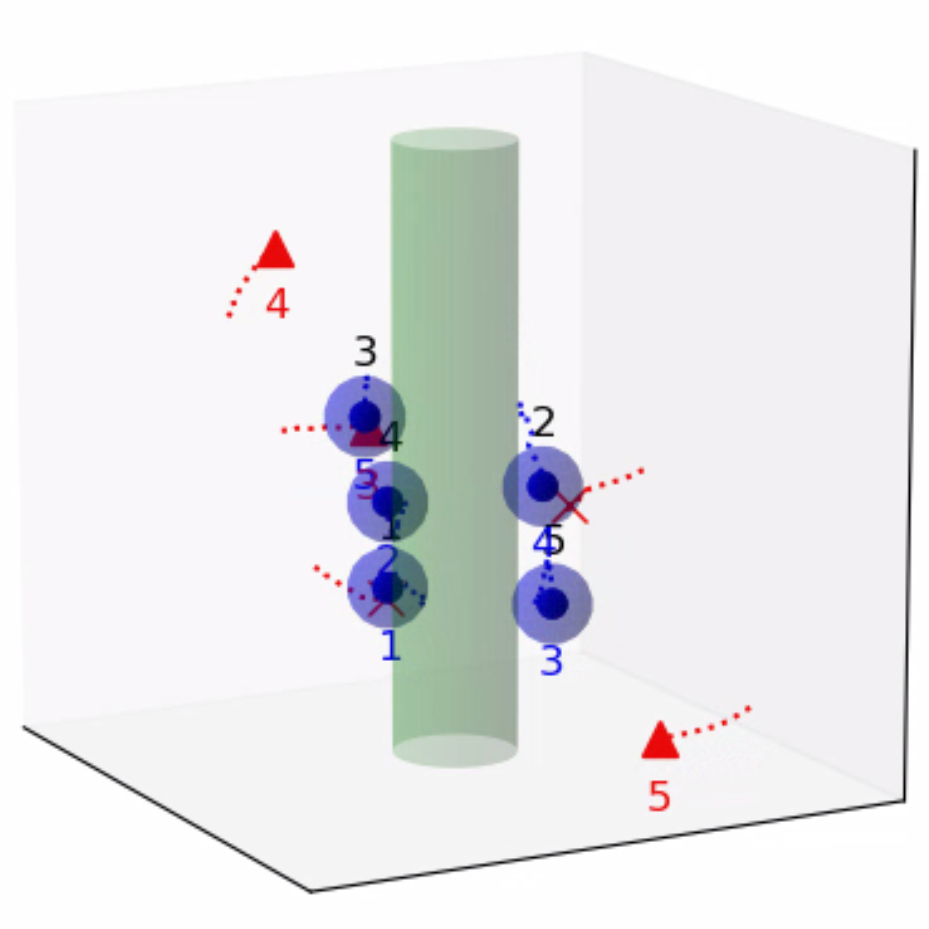
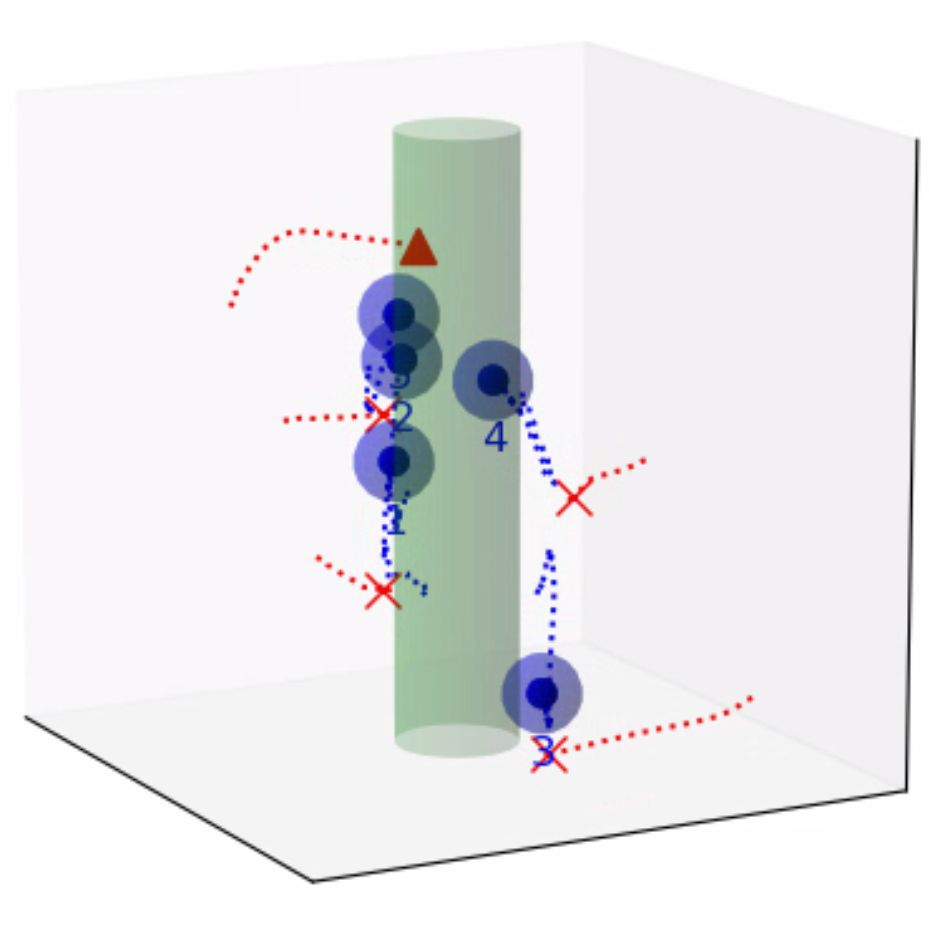
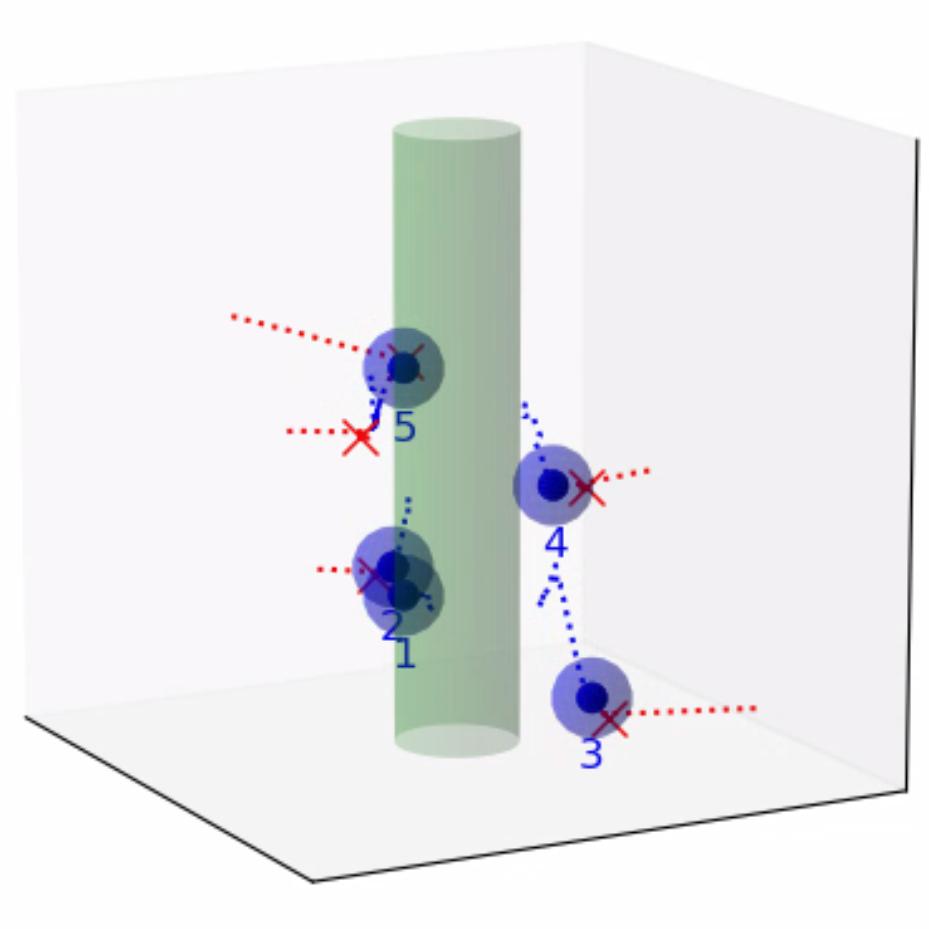
Finally, we evaluate the practical applicability of our proposed algorithm using the Gazebo simulators in conjunction with ROS. To address real-world scenarios, we incorporate a multi-agent collision avoidance approach based on the control barrier function, as presented by Wang et al. [48]. Additionally, we utilize the mapping provided in [49] to convert the velocity vectors generated by our algorithm into corresponding linear and angular velocity commands. We conduct experiments in two different environments: a 2D indoor setting and a 3D outdoor setting. The indoor environment is designed as a square space surrounded by walls, with a rectangular region adjacent to one of the walls serving as the target set. In this scenario, TurtleBot3 Burger wheeled mobile robots are deployed as agents, featuring maximum linear and angular velocities of 0.22m/s and 2.84rad/s, respectively. On the other hand, the outdoor environment is characterized by a box-shaped region elevated above the ground, with a cylindrical region designated as the target set to represent a no-fly zone in real-world scenarios. Here, Iris quadcopter robots are employed as agents. The computed velocity vector is utilized as a reference point to regulate the robot’s velocity and heading. The linear and angular velocity references are set to 0.8m/s and 0rad/s, respectively, enabling the Iris quadcopter robots to move swiftly towards the reference point while preserving safety. The safety radii for the TurtleBot3 Burger and Iris robots are 0.1m and 0.5m, respectively, while their capture radii are set to 0.6m and 1.5m, respectively. Both robotics platforms operate at a frequency of 50Hz, with a defense allocation frequency of 10Hz.
To test the effectiveness of our proposed algorithm, we use two different attack strategies and examine the defender team’s adaptability in response to these variations. The first strategy is the optimal attack strategy given in (27), where attacker moves towards the almost-optimal waypoint , as specified in (26). The second strategy termed the straight-line approach, entails each attacker heading toward the nearest point on the target set, with the objective of minimizing the time required to reach the target set while disregarding the risk of potential capture by the defenders. The simulation process can be seen in the attached video, and illustrative snapshots are provided in Fig. 7 and Fig. 8. In the 2D indoor scenario, featuring a configuration of five attackers and three defenders, our proposed algorithm exhibits a high level of effectiveness, achieving a final capture number of four for the optimal attack strategy and five for the straight-line attack strategy. Likewise, in the 3D outdoor scenario, comprising five attackers and five defenders, the algorithm demonstrates its robustness by attaining a final capture number of four for the optimal attack strategy and five for the straight-line attack strategy. These results substantiate the effectiveness of our proposed algorithm in diverse environmental settings.
VI Conclusion
In this article, we presented a dual-layer online optimization strategy for defenders in multiplayer reach-avoid games, with the goal of minimizing the number of successful attackers entering a convex target set within a convex domain while facing unknown attack strategies. We devised a dual-mode switching defense algorithm for defender coalitions to counter individual attackers via online convex programming. This algorithm induces the maximum defense-winning region for initial joint states, sharpening the chances of winning while offering scalability. Additionally, we developed a monotonic defense enhancement allocation algorithm for determining coalition assignment matrices in integer linear programs (ILPs) by incorporating predicted outcomes from single-attack coordination. This algorithm employs a hierarchical iterative method to approximate ILPs and includes a monotonicity constraint, reducing the chosen coalition-attacker pairs while maintaining a non-decreasing expected number of unsuccessful attackers over time. We assessed our approach’s performance across diverse multi-robot systems and environments, demonstrating its superiority in terms of optimality and efficiency. Moreover, Gazebo simulations confirmed the real-world applicability and potential for practical robotics implementation. In future work, extending our approach to encompass non-convex environments and integrating more complex agent models could enhance the performance and applicability of our proposed framework. In addition, accounting for attackers with different priorities may better reflect real-world scenarios and further refine the defense strategies employed in our approach.
-A Proof of Proposition 1
Proof: To show the convexity of the SRS, we first exhibit that for each , is convex with respect to . Note that can be decomposed into a sum of three terms: . Owing to the maximum speed ratio constraint (8) and the positivity of , the coefficients of the first two terms are non-negative. Consequently, these two terms are convex, as the (squared) Euclidean norm is a convex function. The convexity of then follows from the fact that the last term is linear, and the sum of convex functions is itself a convex function.
It remains to establish that if satisfies the inequality , then belongs to the SRS. Given any such , consider the constant attack strategy over the time interval , where . The reachability property of the SRS holds by noting that attacker can reach from along the line segment connecting and using . On the other hand, any point on can be expressed as with parameter , which is reached by attacker at time using . Under the same time, the closest point to that defender can reach from , denoted by , must lie on the straight line that connects and , as defender can move in any direction. This leads to . Besides, the convexity of implies that , which in turn indicates that . As a result, for any admissible defense strategy , for all , yielding the safety property of the SRS.
-B Proofs of Proposition 2 and (24)
Proof: Consider the Lagrangian function of (17):
where and is the Lagrange multiplier. The KKT conditions asserts that for the optimal solution , there is a Lagrange multiplier with nonnegative components such that , i.e.,
| (43) | |||
| (44) |
Additionally, for any interior point and any , one of the following three cases occurs: i) ; ii) and ; iii) and . In particular, since is continuously differentiable, the set of interior points for which the last case holds has measure zero, according to the results from real analysis [50]. Thus, the complementarity condition implies that for almost every , , i.e.,
| (45) |
Similar derivations can be respectively employed to the complementarity conditions , and , , yielding that for almost every ,
| (46) |
and for all , where the latter equation together with (44) leads to
| (47) |
Therefore,
holds for almost every . This completes the proof of Proposition 2 by examining (18).
To verify the equality (24), we consider the Lagrangian function of (23):
with the Lagrange multiplier . Analogous to the proof of Proposition 2, the KKT conditions imply that there is a Lagrange multiplier with nonnegative components such that
| (48) |
and for almost every ,
| (49) |
and
| (50) |
Consequently, the proof is done by noting that
-C Proof of Proposition 3
Proof: The proof is conducted by contradiction. Suppose there are such that , where
| (51) |
is the minimum squared distance from to the target set. We claim that the line segment connecting and , denoted as with parameter , must lie on the zero level set defined by for some . First, note that the line segment must lie within the SRS due to its convexity. Next, by the Definition of , we know that for all , and thus for all . Furthermore, since is convex, we have . Therefore, for all , indicating that the line segment is on the boundary of the SRS. Lastly, we verify the claim by noting that if for some , then the point lies strictly within the SRS, which would contradict the result that lies on the boundary of the SRS. However, the claim violates the fact that the zero level set defined by contains no line segments. This is because can never have infinite solutions, where is the normal vector to the zero level set of .
-D Proof of Proposition 4
Proof: It suffices to show by contradiction that with , or equivalently in which is defined in (51). Assume that . In this case, we have as . To reach a contradiction, we consider the line segment connecting and , which is parameterized by as . Since is the ADS for , it follows that for all . Due to the continuity of with respect to , there exists for each such that for all . Let be the minimum of all . Then for all . Moreover, since the line segment lies within , we have for all . As a result, . However, it is noted that , which contradicts the fact that the minimum value of occurs at .
-E Proof of Proposition 5
Proof: According to Proposition 4, it is sufficient to establish that for any feasible coalition-attacker pair with , there exists a subset of with such that . For each , the almost-optimal waypoint lies on the tangent of the zero level set , and thus satisfies the linear equation , where is the normal vector of at . Since an -dimensional solution can be uniquely determined by at most independent linear equations, there is a subset of with such that is the unique solution to the linear equations for all . Moreover, due to the sublevel set representation of , can be chosen in a way that for some neighborhood of . Consequently, by the convexity of the SRS, we can conclude that .
-F Proof of Proposition 6
Proof: Optimality: Note that the maximum possible value for the multi-attack objective function is equal to the number of active attackers for which the coalition-attacker pair is feasible. In view of Algorithm 3, an index is removed from after the first iteration if and only if is infeasible or attacker is included in the suboptimal solution . Hence, the emptiness of after the first iteration indicates that achieves the maximum possible value of , rendering it an optimal solution to the ILP (34). Efficiency: In each iteration of Algorithm 3, there are two steps that require the computation of the convex program of the form (17): determining the feasibility of the coalition-attacker pair , and identifying all irreducible sub-pairs of . The former step requires only one calculation, while the latter step, performed using Algorithm 2, demands at most computations given that the cardinality of the ADS does not exceed . Thus, the total number of computations at this iteration for one attacker is at most . Moreover, the number of iterations is constrained by the number of active attackers , since at least one attacker is removed from the set after each iteration. The total number of calculations for all iterations is therefore at most , which is less than .
References
- [1] R. Vidal, O. Shakernia, H. J. Kim, D. H. Shim, and S. Sastry, “Probabilistic pursuit-evasion games: theory, implementation, and experimental evaluation,” IEEE transactions on robotics and automation, vol. 18, no. 5, pp. 662–669, 2002.
- [2] S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC), 2017, pp. 2242–2253.
- [3] C. Robin and S. Lacroix, “Multi-robot target detection and tracking: taxonomy and survey,” Autonomous Robots, vol. 40, pp. 729–760, 2016.
- [4] R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” Advances in neural information processing systems, vol. 30, 2017.
- [5] T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 7234–7284, 2020.
- [6] K. Zhang, Z. Yang, and T. Başar, “Multi-agent reinforcement learning: A selective overview of theories and algorithms,” Handbook of reinforcement learning and control, pp. 321–384, 2021.
- [7] T. H. Chung, G. A. Hollinger, and V. Isler, “Search and pursuit-evasion in mobile robotics,” Autonomous robots, vol. 31, no. 4, pp. 299–316, 2011.
- [8] E. Bakolas and P. Tsiotras, “Relay pursuit of a maneuvering target using dynamic voronoi diagrams,” Automatica, vol. 48, no. 9, pp. 2213–2220, 2012.
- [9] A. Alexopoulos, T. Schmidt, and E. Badreddin, “Cooperative pursue in pursuit-evasion games with unmanned aerial vehicles,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2015, pp. 4538–4543.
- [10] C. De Souza, R. Newbury, A. Cosgun, P. Castillo, B. Vidolov, and D. Kulić, “Decentralized multi-agent pursuit using deep reinforcement learning,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4552–4559, 2021.
- [11] R. Zhang, Q. Zong, X. Zhang, L. Dou, and B. Tian, “Game of drones: Multi-uav pursuit-evasion game with online motion planning by deep reinforcement learning,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [12] H. Huang, J. Ding, W. Zhang, and C. J. Tomlin, “A differential game approach to planning in adversarial scenarios: A case study on capture-the-flag,” in 2011 IEEE International Conference on Robotics and Automation. IEEE, 2011, pp. 1451–1456.
- [13] E. Garcia, D. W. Casbeer, and M. Pachter, “The capture-the-flag differential game,” in 2018 IEEE conference on decision and control (CDC). IEEE, 2018, pp. 4167–4172.
- [14] M. Jaderberg, W. M. Czarnecki, I. Dunning, L. Marris, G. Lever, A. G. Castaneda, C. Beattie, N. C. Rabinowitz, A. S. Morcos, A. Ruderman et al., “Human-level performance in 3d multiplayer games with population-based reinforcement learning,” Science, vol. 364, no. 6443, pp. 859–865, 2019.
- [15] D. Shishika and V. Kumar, “Local-game decomposition for multiplayer perimeter-defense problem,” in 2018 IEEE conference on decision and control (CDC). IEEE, 2018, pp. 2093–2100.
- [16] L. Guerrero-Bonilla and D. V. Dimarogonas, “Perimeter surveillance based on set-invariance,” IEEE Robotics and Automation Letters, vol. 6, no. 1, pp. 9–16, 2020.
- [17] S. Velhal, S. Sundaram, and N. Sundararajan, “A decentralized multirobot spatiotemporal multitask assignment approach for perimeter defense,” IEEE Transactions on Robotics, 2022.
- [18] K. Margellos and J. Lygeros, “Hamilton–jacobi formulation for reach–avoid differential games,” IEEE Transactions on automatic control, vol. 56, no. 8, pp. 1849–1861, 2011.
- [19] J. F. Fisac, M. Chen, C. J. Tomlin, and S. S. Sastry, “Reach-avoid problems with time-varying dynamics, targets and constraints,” in Proceedings of the 18th international conference on hybrid systems: computation and control, 2015, pp. 11–20.
- [20] I. M. Mitchell, A. M. Bayen, and C. J. Tomlin, “A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games,” IEEE Transactions on automatic control, vol. 50, no. 7, pp. 947–957, 2005.
- [21] T. Başar and G. J. Olsder, Dynamic noncooperative game theory. SIAM, 1998.
- [22] B. Landry, M. Chen, S. Hemley, and M. Pavone, “Reach-avoid problems via sum-or-squares optimization and dynamic programming,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 4325–4332.
- [23] Z. Zhou, J. Ding, H. Huang, R. Takei, and C. Tomlin, “Efficient path planning algorithms in reach-avoid problems,” Automatica, vol. 89, pp. 28–36, 2018.
- [24] E. Garcia, D. W. Casbeer, and M. Pachter, “Optimal strategies for a class of multi-player reach-avoid differential games in 3d space,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4257–4264, 2020.
- [25] H. Fu and H. H.-T. Liu, “Justification of the geometric solution of a target defense game with faster defenders and a convex target area using the hji equation,” Automatica, vol. 149, p. 110811, 2023.
- [26] S. Pan, H. Huang, J. Ding, W. Zhang, C. J. Tomlin et al., “Pursuit, evasion and defense in the plane,” in 2012 American Control Conference (ACC). IEEE, 2012, pp. 4167–4173.
- [27] Z. Deng and Z. Kong, “Multi-agent cooperative pursuit-defense strategy against one single attacker,” IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 5772–5778, 2020.
- [28] H. Huang, W. Zhang, J. Ding, D. M. Stipanović, and C. J. Tomlin, “Guaranteed decentralized pursuit-evasion in the plane with multiple pursuers,” in 2011 50th IEEE Conference on Decision and Control and European Control Conference. IEEE, 2011, pp. 4835–4840.
- [29] A. Pierson, Z. Wang, and M. Schwager, “Intercepting rogue robots: An algorithm for capturing multiple evaders with multiple pursuers,” IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 530–537, 2016.
- [30] R. Yan, Z. Shi, and Y. Zhong, “Reach-avoid games with two defenders and one attacker: An analytical approach,” IEEE transactions on cybernetics, vol. 49, no. 3, pp. 1035–1046, 2018.
- [31] ——, “Task assignment for multiplayer reach–avoid games in convex domains via analytical barriers,” IEEE Transactions on Robotics, vol. 36, no. 1, pp. 107–124, 2019.
- [32] ——, “Guarding a subspace in high-dimensional space with two defenders and one attacker,” IEEE Transactions on Cybernetics, vol. 52, no. 5, pp. 3998–4011, 2020.
- [33] R. Yan, X. Duan, Z. Shi, Y. Zhong, and F. Bullo, “Matching-based capture strategies for 3d heterogeneous multiplayer reach-avoid differential games,” Automatica, vol. 140, p. 110207, 2022.
- [34] R. Isaacs, Differential games: a mathematical theory with applications to warfare and pursuit, control and optimization. Courier Corporation, 1999.
- [35] Z. Zhou, W. Zhang, J. Ding, H. Huang, D. M. Stipanović, and C. J. Tomlin, “Cooperative pursuit with voronoi partitions,” Automatica, vol. 72, pp. 64–72, 2016.
- [36] B. P. Gerkey and M. J. Matarić, “A formal analysis and taxonomy of task allocation in multi-robot systems,” The International journal of robotics research, vol. 23, no. 9, pp. 939–954, 2004.
- [37] G. A. Korsah, A. Stentz, and M. B. Dias, “A comprehensive taxonomy for multi-robot task allocation,” The International Journal of Robotics Research, vol. 32, no. 12, pp. 1495–1512, 2013.
- [38] M. Chen, Z. Zhou, and C. J. Tomlin, “Multiplayer reach-avoid games via pairwise outcomes,” IEEE Transactions on Automatic Control, vol. 62, no. 3, pp. 1451–1457, 2017.
- [39] L. R. Ford and D. R. Fulkerson, “Maximal flow through a network,” Canadian journal of Mathematics, vol. 8, pp. 399–404, 1956.
- [40] J. E. Hopcroft and R. M. Karp, “An n^5/2 algorithm for maximum matchings in bipartite graphs,” SIAM Journal on computing, vol. 2, no. 4, pp. 225–231, 1973.
- [41] E. Garcia, D. W. Casbeer, A. Von Moll, and M. Pachter, “Multiple pursuer multiple evader differential games,” IEEE Transactions on Automatic Control, vol. 66, no. 5, pp. 2345–2350, 2020.
- [42] I. M. Mitchell et al., “A toolbox of level set methods,” UBC Department of Computer Science Technical Report TR-2007-11, p. 31, 2007.
- [43] F. Blanchini, “Set invariance in control,” Automatica, vol. 35, no. 11, pp. 1747–1767, 1999.
- [44] J. Nocedal and S. Wright, Numerical optimization. Springer Science & Business Media, 2006.
- [45] S. Boyd, S. P. Boyd, and L. Vandenberghe, Convex optimization. Cambridge university press, 2004.
- [46] S. Diamond and S. Boyd, “Cvxpy: A python-embedded modeling language for convex optimization,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2909–2913, 2016.
- [47] N. Koenig and A. Howard, “Design and use paradigms for gazebo, an open-source multi-robot simulator,” in 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)(IEEE Cat. No. 04CH37566), vol. 3. IEEE, 2004, pp. 2149–2154.
- [48] L. Wang, A. D. Ames, and M. Egerstedt, “Safety barrier certificates for collisions-free multirobot systems,” IEEE Transactions on Robotics, vol. 33, no. 3, pp. 661–674, 2017.
- [49] S. G. Lee, Y. Diaz-Mercado, and M. Egerstedt, “Multirobot control using time-varying density functions,” IEEE Transactions on robotics, vol. 31, no. 2, pp. 489–493, 2015.
- [50] H. L. Royden and P. Fitzpatrick, Real analysis. Macmillan New York, 1988, vol. 32.