Convolutional neural network based reduced order modeling for multiscale problems
Abstract
In this paper, we combine convolutional neural networks (CNNs) with reduced order modeling (ROM) for efficient simulations of multiscale problems. These problems are modeled by partial differential equations with high-dimensional random inputs. The proposed method involves two separate CNNs: Basis CNNs and Coefficient CNNs (Coef CNNs), which correspond to two main parts of ROM. The method is called CNN-based ROM. The former one learns input-specific basis functions from the snapshots of fine-scale solutions. An activation function, inspired by Galerkin projection, is utilized at the output layer to reconstruct fine-scale solutions from the basis functions. Numerical results show that the basis functions learned by the Basis CNNs resemble data, which help to significantly reduce the number of the basis functions. Moreover, CNN-based ROM is less sensitive to data fluctuation caused by numerical errors than traditional ROM. Since the tests of Basis CNNs still need fine-scale stiffness matrix and load vector, it can not be directly applied to nonlinear problems. The Coef CNNs can be applied to nonlinear problems and designed to determine the coefficients for linear combination of basis functions. In addition, two applications of CNN-based ROM are presented, including predicting MsFEM basis functions within oversampling regions and building accurate surrogates for inverse problems.
keywords: reduced-basis methods; convolutional neural network; random multiscale problems
1 Introduction
Multiscale problems, which encompass phenomenons characterized by significant variations across multiple scales, are widely applied in fields such as materials science, environmental science, biomechanics and many others. Examples include the behavior of composite materials, fluid flow in porous media, biological processes and turbulent fluid dynamics. Many of the problems are often modeled by partial differential equations (PDEs) with random inputs. The randomness is caused by heterogeneity of physical properties. For groundwater, the dispersed phases (e.g., pores or fractures), which may be randomly distributed in the spatial space, lead to fluctuation of hydraulic conductivity [1]. Moreover, the conductivity difference between phases is typically high-contrast. To capture the fine-scale features of systems, the direct numerical simulations using finite element methods are not feasible due to large scale of computation. Therefore, it is necessary to design efficient multiscale simulation methods, especially for real-time applications (e.g., inverse problems and stochastic control [2, 3]) and many-query contexts (e.g., design or optimization [4]).
During last decades, the idea of reduced-order modeling has been proposed for multiscale problems. The construction of reduced-order basis functions is the core of ROM. By fully exploring the local properties of differential operators, a class of multiscale reduction methods use a set of multiscale basis functions, which can effectively capture some fine-scale effects. These multiscale methods include multiscale finite element method (MsFEM) [5, 6], generalized multiscale finite element method (GMsFEM) [7, 8], constraint energy minimizing generalized multiscale finite element method (CEM-GMsFEM) [9, 10] and so on. Based on finite element methods and homogenization theory, the convergence of these methods can be rigorously analyzed. In addition, the same basis functions can be used for different source terms since the construction of multiscale basis functions only involves the differential operators. However, many local problems should be solved for each sample of random inputs to obtain the basis functions, which prevents efficient online computation. Unlike multiscale reduction methods, the reduced-basis methods (RB methods) obtain a universal collection of basis functions by data-driven methods such as greedy algorithm [11] and proper orthogonal decomposition (POD) [12]. However, most existing works have difficulty scaling to high-dimensional problems, such as random inputs based on Gaussian processes [13].
To obtain the approximated solutions, ROM usually implements Galerkin projection on a low-dimensional space spanned by the constructed basis functions. Furthermore, techniques, such as Discrete Empirical Interpolation Methods (DEIM) [14, 15], are used to obtain affine decompositions for nonlinear problems and achieve fast online computation. Although DEIM can significantly reduce online computation costs, there are still a couple of limitations. Firstly, a large number of basis functions are required for high-dimensional and highly nonlinear problems. This will impact on the efficiency of DEIM. Secondly, ROM with DEIM is still nonlinear, and need to recall nonlinear solvers such as Newton methods [16].
The ROM for multiscale problems has two stages: the construction of reduced-order basis functions and the computation of coarsen models. To improve the online efficiency, it is desirable to learn a quick response from samples of random inputs to basis functions. The ROM for multiscale problems assisted by deep learning techniques, which have powerful representation and generalization abilities, gains more and more attentions. For multiscale reduction methods, M. Wang et al. [17] learn the mapping from permeability to GMsFEM basis functions and coarse-scale stiffness matrices on local coarse grids using fully connected neural networks (FNNs). A. Choubineh et al. [18] reconstruct the basis functions of mixed GMsFEM from permeability matrix using Convolutional Neural Networks (CNNs). For reduced-basis methods, S. Cheung et al. [19] firstly use proper orthogonal decomposition (POD) to construct a set of global nodal basis functions. Then an FNN is used to approximate evolution of the coefficients and, therefore, the porous media flow. In addition, learning the mapping from parameters to coefficients using deep learning techniques is not a new idea in the field of non-intrusive reduced-order modeling [20, 21, 22, 23, 24].
In this paper, we consider the case that the multiscale problems are represented by steady partial differential equations with random inputs. Our goal is to develop a data-driven method to model multiscale problems and make fast online predictions. Similar to RB methods, we assume that there are snapshots of fine-scale solutions. Two distinct CNNs are designed through following two main stages of ROM, thus introducing the proposed method as CNN-based ROM. The first ones are called Basis CNNs, which learn the mapping from samples of random inputs to basis functions. Activation functions, inspired by Galerkin projection methods, are utilized at the output layers to reconstruct fine-scale solutions from the basis functions. Besides, condition number under Frobenius norm are included in loss functions to ensure the stability of training. Note that Basis CNNs can provide input-specific basis functions like multiscale reduction methods, which can break the limitation of RB methods for high-dimensional problems. However, the predictions of Basis CNNs are still dependent on fine-scale stiffness matrix and load vector of FEM, which are not available for nonlinear equations at the online stage. To overcome these issues, we design the second CNN, called Coefficient CNNs (Coef CNNs), to learn the final linear combinations of the approximated solutions using the same dataset as the Basis CNNs.
This article is structured as follows. In Section 2, we give the definitions and examples of multiscale problems, which is followed by a brief introduction to the reduced basis methods and convolutional neural networks in Section 3. Section 4 focuses on the proposed method, CNN-based ROM. In this section, we also explore the connections between the proposed method with MsFEM. In Section 5, a few numerical results are presented to illustrate the efficacy of the proposed method and compare it with POD-based RB methods. Two applications of CNN-based ROM are also available in this section, including learning MsFEM basis functions with oversampling techniques and being used as surrogates in inverse problems. Finally, some conclusions are given.
2 Problem setup
In this paper, we consider the following multiscale problems defined in a bounded domain with boundary :
| (2.1) |
where denotes a nonlinear differential operator encoded with random input . More specifically, is a random variable defined on a probability space for any fixed point . Besides, is the nonlinear source term with sufficient regularity. The equations (2.1) thus have unique solutions with the boundary conditions . Next, we give an example for (2.1).
-
•
Diffusion equations. In this case, we introduce a linear elliptic equation with Dirichlet boundary conditions as follows,
(2.2) where is a permeability field with multiscale features, and is Dirichlet boundary condition.
A numerical approximation of the solution of the problem (2.1) can be obtained by finite element methods. Denote by the appropriate solution space, the variational form of the problem (2.1) with homogenous Dirichlet boundary reads: find the approximated solution such that
where
If we partition the spatial domain by the grid size (the corresponding mesh grid is denoted as ), we can obtain a finite-dimensional approximation of by solving the following nonlinear algebra equation,
| (2.3) |
The random input is discretized over the mesh grid , thus is equivalent to a high-dimensional random matrix . The notation represents the -th sample of .
To obtain a high-fidelity approximation of the problems (2.1) that have multiscale features, the number of degrees of freedom is usually required to be large. Given the dataset , our goal is to find a low-dimensional approximation of to solve the variational problems (2.3) efficiently, yet retaining the essential features of the maps .
3 Preliminary knowledge
In this section, we will introduce the preliminary knowledge for the proposed method. The problem outlined in Section 2 will be considered in ROM. In Subsection 3.1, we give a short review of RB methods, accompanied by an analysis of their limitations. Following this, Subsection 3.2 will provide a brief introduction to CNNs and compare them with fully connected neural networks.
3.1 The reduced basis method
The problem (2.3) is a parametrized PDE with high-dimensional parameter space. In the field of model reduction of parametrized PDEs, the RB method has been one of most widely used method. In the following, we briefly review the main ideas of the RB method, which is the foundation of our work. Additional details are referred to [25, 26].
The RB method assume that the high-fidelity approximation has low-dimensional features, i.e., can be well represented by the linear combination of basis functions, . The basis functions construct a space called reduced space (the RB space), which is algebraically denoted by the matrix . Then we can obtain the following RB problem
| (3.1) |
where , and is the reduced vector of degrees of freedom that is called RB solution. A common criterion to obtain the RB problem (3.1) from (2.3) is Galerkin projection [27], that is
| (3.2) |
The computational procedure of RB methods is commonly decomposed into offline and online phases: during offline phase, reduced basis functions are generated, and auxiliary quantities are precomputed. Then, in the online phase, for different instances of the parameters, the RB solutions can be efficiently computed.
3.1.1 The construction of RB space
The goal of RB methods is to find linear approximation spaces for which the worst best-approximation error for elements of ,
is near the Kolmogorov N-width of
The existence of the optimal subspace is guaranteed by the Theorem II.2.3 in [28].
In practical, the reduced basis functions of can be generated by either greedy algorithms or proper orthogonal decomposition (POD). We briefly recall the latter as we will use it in the numerical results for comparision. Given a snapshot matrix of data
the main idea of POD is to find a finite subspace with orthogonal basis to minimize the projection error,
By taking advantage of the singular value decomposition (SVD) of
we can obtain the matrix whose columns are the orthogonal basis of : that is the columns of corresponding to the largest diagonal elements in .
We note that POD is a powerful tool to exploit the low-rank features of data. However, there are still two bottlenecks:
-
•
POD only provide the optimal linear representations of data in sense, and it is not guaranteed that they are the best basis functions in a broader sense.
-
•
RB methods, including POD-based RB methods, try to represent the solutions for different parameters in the same subspace of , which means that a larger number of basis functions are needed to obtain accurate approximation of parametrized PDEs with high-dimensional parameter space. This will affect the efficiency and accuracy of RB methods.
3.1.2 Online stage of RB methods
Efficient implementation of RB-methods relies on the affine decompositions of stiffness matrix and load vectors, that is and can be written in parameter-seperable form, as follows
According to (3.2), we can obtain that
where . Precomputing and in the offline phase, we can avoid operations with a complexity dependent on .
However, affine decompositions of bilinear forms (or linear forms) is a strong assumption, which is not satisfied in many cases. DEIM are used to provide an approximated parameter-seperable representations. During offline phase, POD is used to obtain parameter-independent functions and . Then, during online phase, an interpolation problem is solved to obtain the coefficients and for each new parameters .
DEIM techniques are powerful tool to deal with nonlinear and non-affine RB problems, however there are two main limitations:
-
•
For complex problems (i.e., high-dimensional and nonlinear problems), a large number of basis functions must be employed to obtain an accurate approximation, which prevents efficiency of online computation.
-
•
For nonlinear problems, DEIM can help to reduce the computation costs but can not avoid iteration (such as newton iteration methods) since it is an interpolation method.
3.2 Convolutional Neural Network
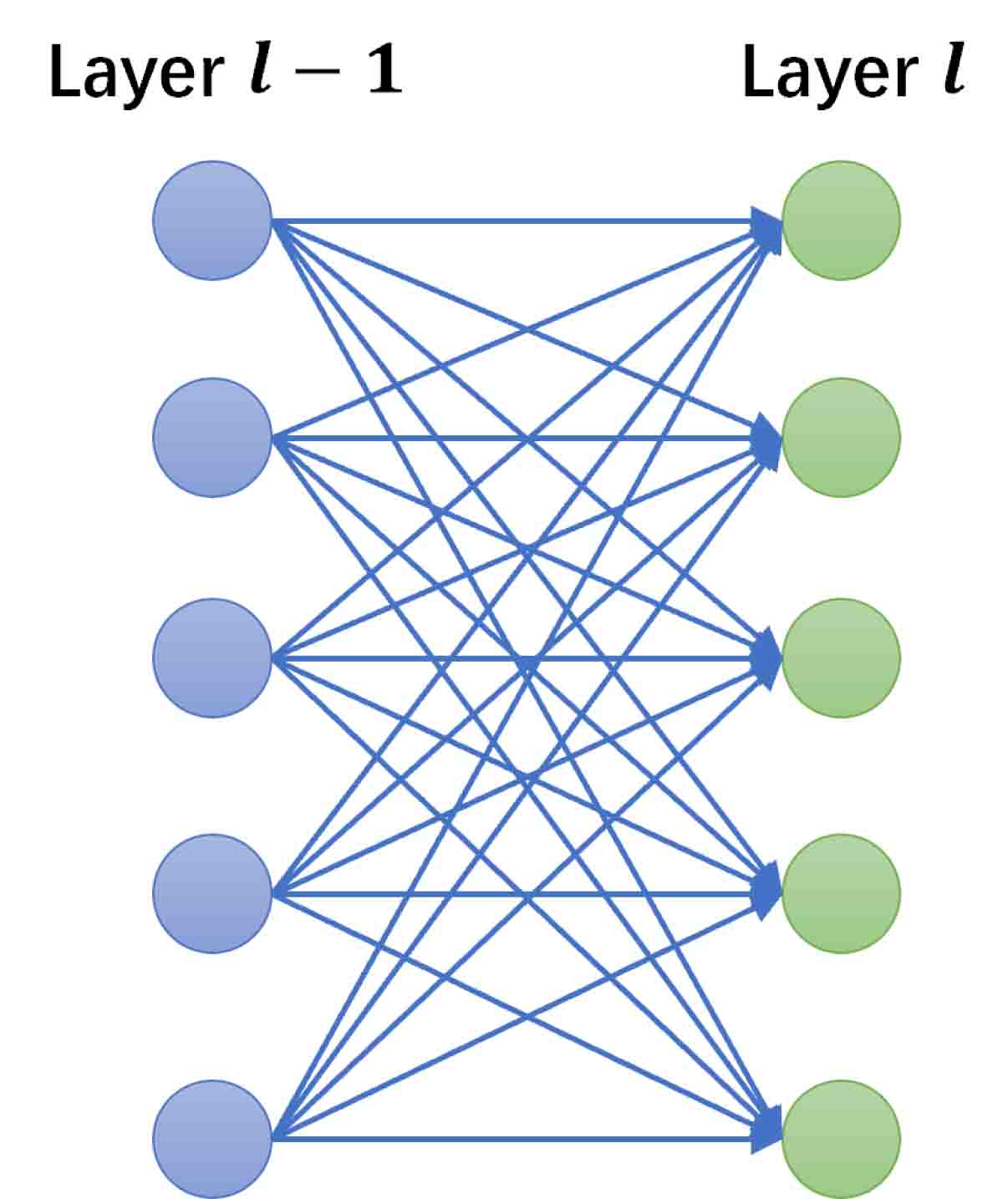
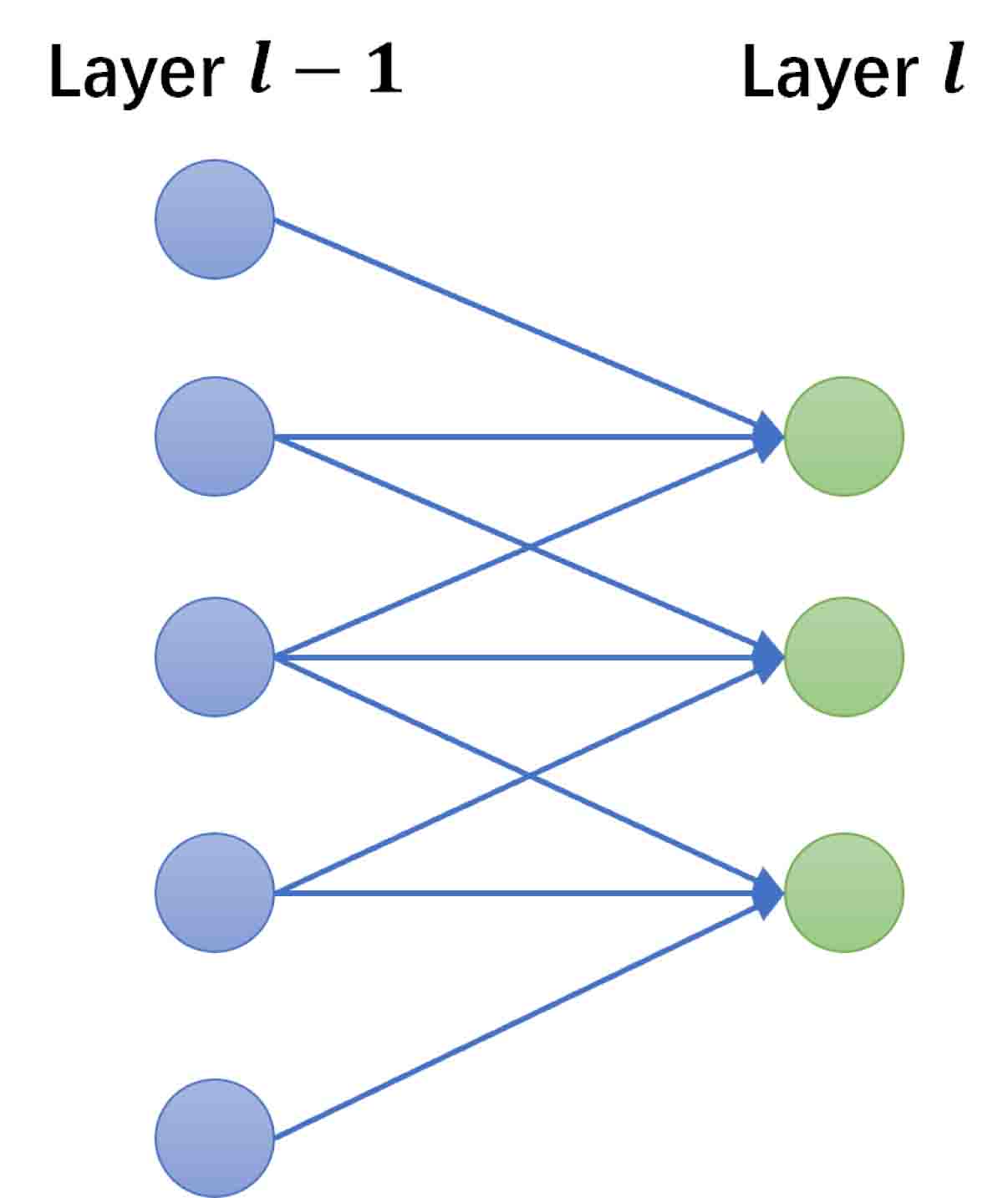
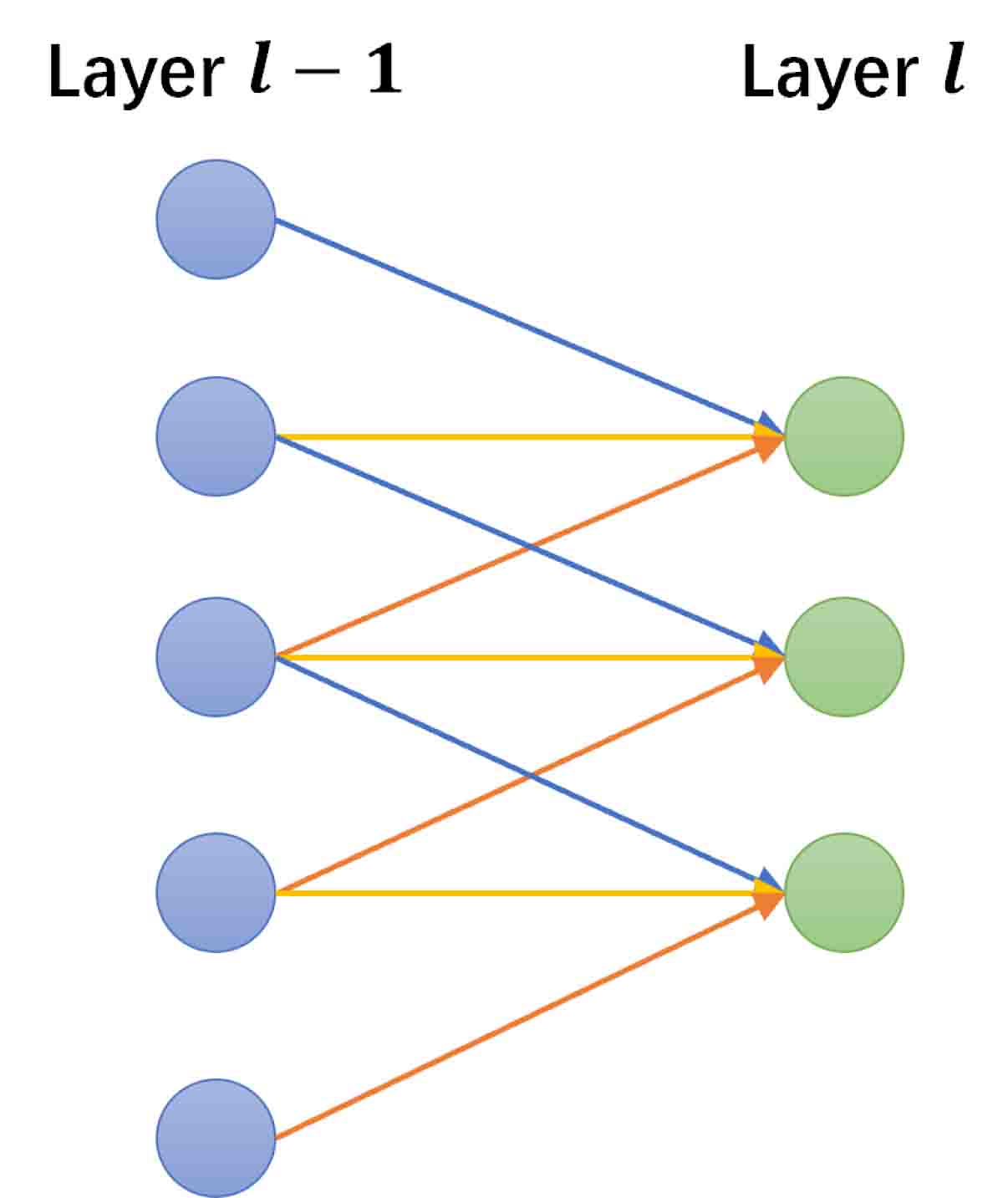
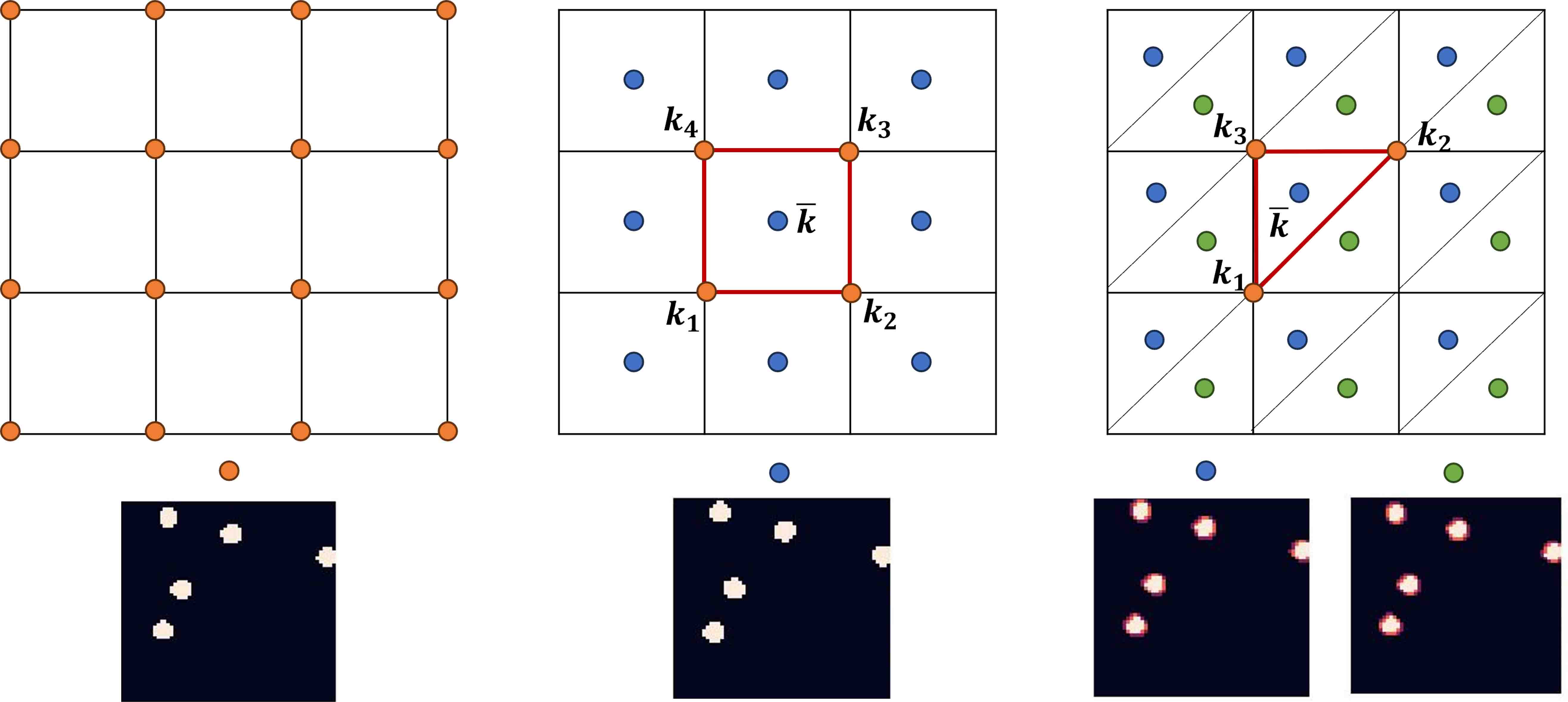
In the field of machine learning, the problem (2.1) can be regarded as an image-to-image regression task [13]. Both the discrete solution and the sample of the random input are matrix with respect to FE mesh , which are usually high-dimensional. Using feed-forward neural networks (FNN) for such tasks usually leads to large training parameters and is prone to overfitting, because they are usually fully-connected, that is, each neuron in one layer is connected to all neurons in the next layer (see Figure 3.1(a)). Convolutional neural networks is a special type of deep neural network that is inspired by human visual system [29] and have been widely used in many fields such as image recognition, natural language processing and so on. There are two special aspects in the architecture of CNN, i.e., local connections (see Figure 3.1(b)) and shared weights (see Figure 3.1(c)), which can well deal with image-to-image regression tasks.
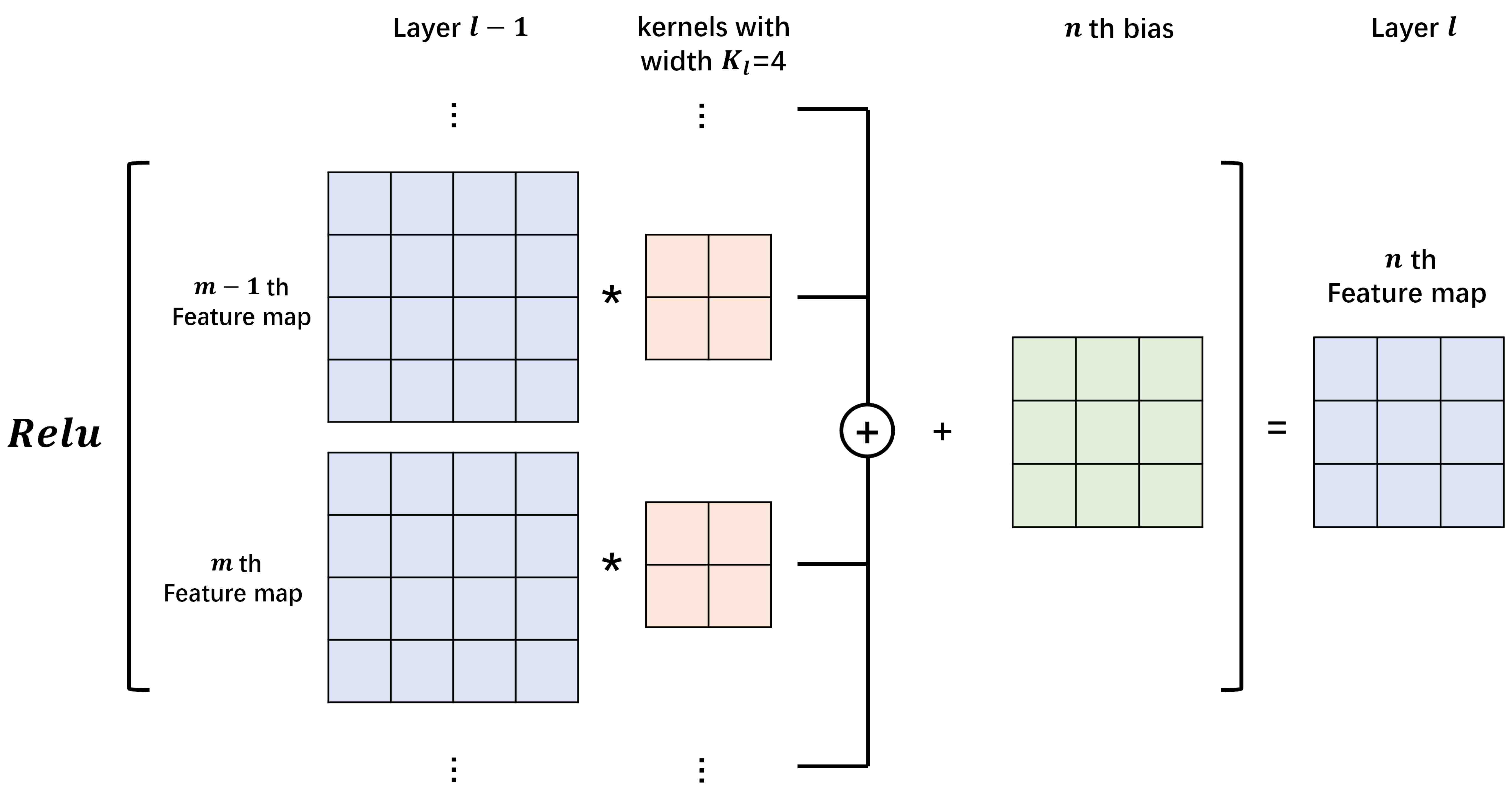
A complete CNN contains convolution layers and pooling layers. We briefly introduce the former as we will use it in the proposed methods. The value of a neuron at position x of the th feature map in the th layer is defined as (see Figure 3.2)
where indexes the feature map in the previous layer (th layer), is the weight of position connected to the th feature map, is the width of the kernel, is the bias of the th feature map in current layer, and is the activation function.
4 Convolutional neural network based reduced-order modeling (CNN-based ROM)
In this section, we will introduce a novel framework for approximating PDEs with random inputs by coupling CNNs with the ideas of the reduced-order modeling, which is called CNN-based ROM. There are two main components of the proposed architecture, that is Basis CNNs and Coefficient CNNs (Coef CNNs). We first learn the input-specific basis functions by Basis CNNs. Besides dataset , FEM bilinear forms (or linear forms) , as parts of activation functions at the output layer, are involved to obtain the reduced-order solution . However, such Basis CNNs alone can only be used to linear problems since unknowns still exists in the FEM bilinear forms (or linear forms). In terms of the results of Basis CNNs, Coef CNNs are thus designed to solve these issues through learning the mapping from to coefficients, which can also improve the online efficiency.
Remark 4.1.
To simplify the notations, we will describe CNN-based ROM for linear problems, i.e.,
| (4.1) |
However, the proposed framework includes the nonlinear cases (2.3), since we can linearize the discrete equations by replacing in and with data .
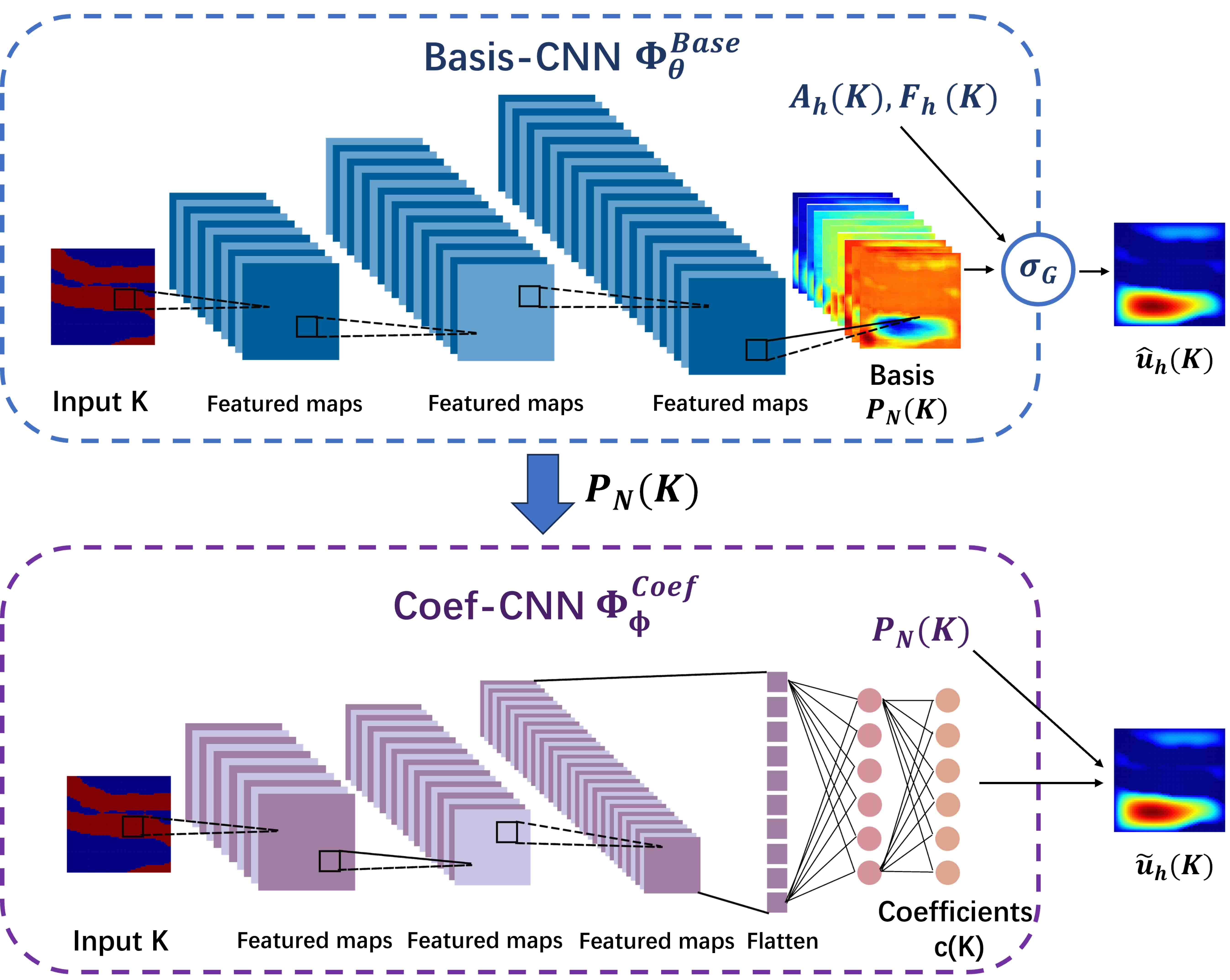
4.1 The Basis CNNs (Basis CNNs)
PDEs with random inputs theoretically have infinite dimensional parameter space. In practical, to capture the multiscale features in the random inputs, we usually sample from random inputs at a very fine FEM mesh . Thus, the problems we considered here have higher dimensional parameter space than ones in traditional RB methods. The success of RB methods significantly depends on the quality of RB basis functions, which can remain the features of the mapping while realizing model reduction. This requires the RB methods capture the common features of PDEs in the same parameter space, therefore it is crucial to choose representative points in parameters space to form the reduced basis functions, which is intractable in high-dimensional parameter space. A large number of reduced basis functions are often used for high-dimensional and nonlinear problems.
For multiscale reduction methods, a set of local problems require to be solved at the online stage to obtain the basis functions, which may be time-consuming for large-scale problems. In addition, basis functions constructed by multiscale reduction methods also lack global information due to localization.
To solve these issues, we learn the basis functions from data for each instance of random inputs, i.e.,
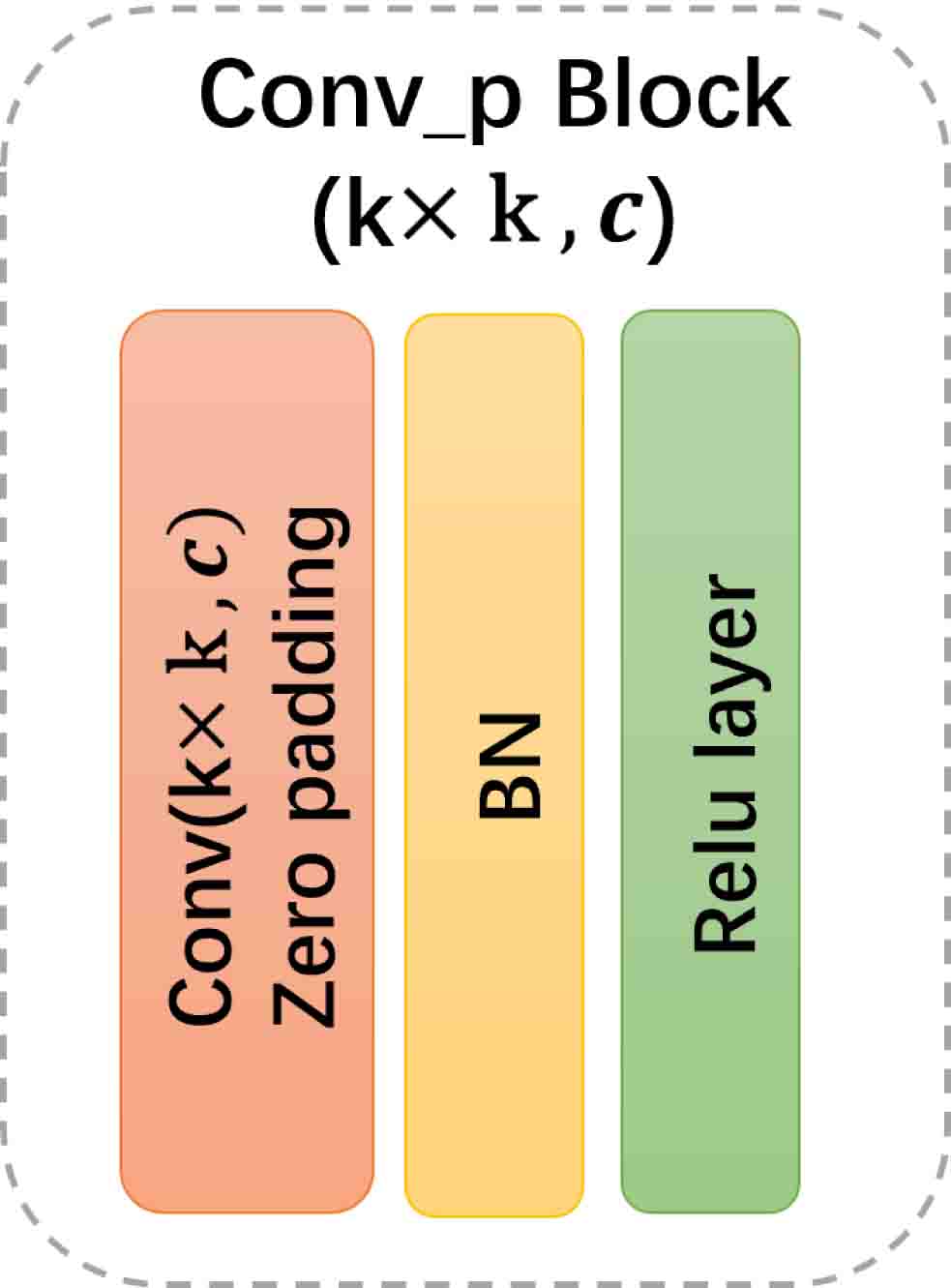
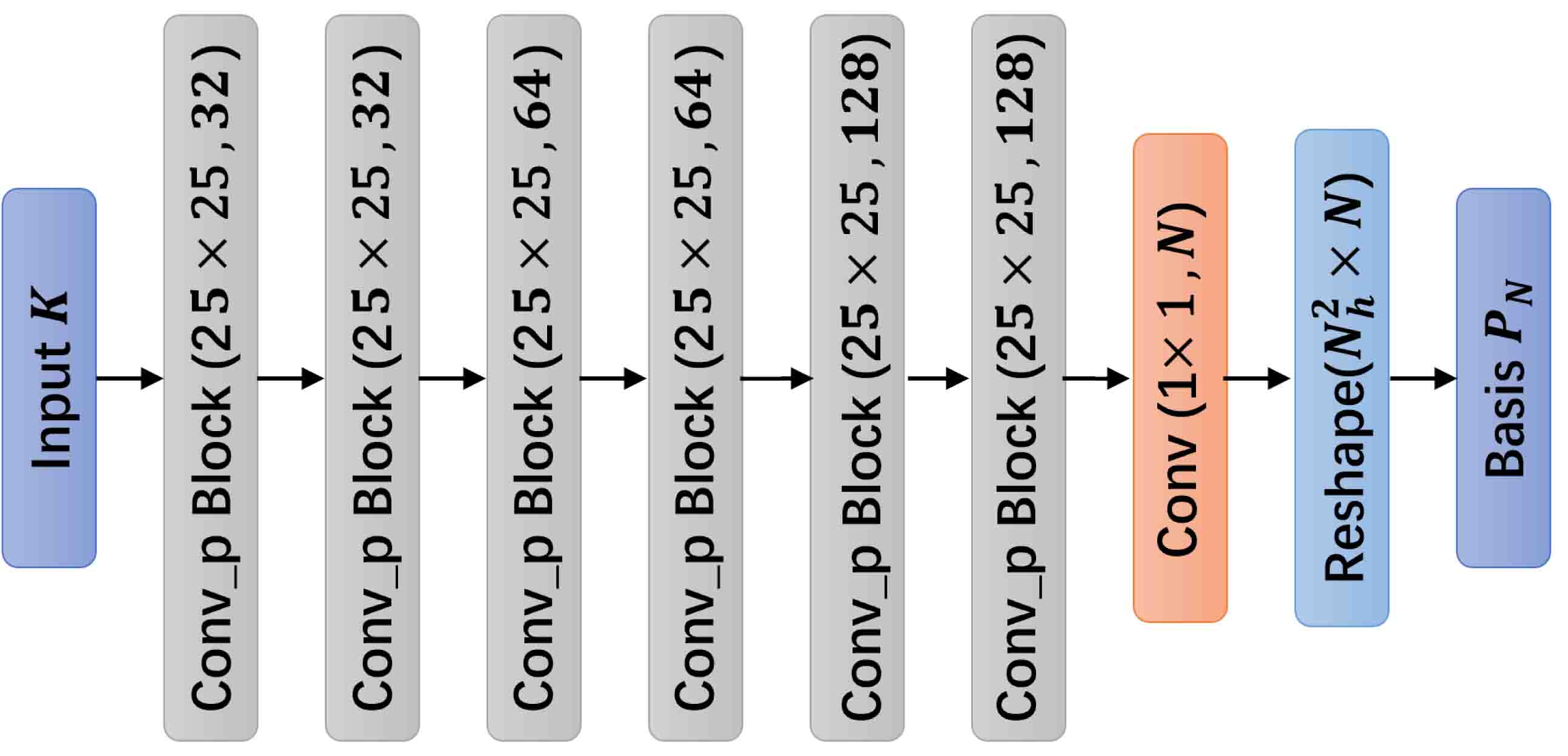
To capture the multiscale features from image-like inputs , CNN is a good choice. Compared with FNN, local connections and shared weights in the CNN can help better extract significant local features and significantly reduce the trainable parameters. To maintain the integrity of spatial information, pooling layers are not included in Basis CNNs and padding techniques are used to keep the size of feature maps after convolution operations. In addition, we apply Batch Normalization layers (BN) after the convolutional layers (Conv) and before the activation functions (see Figure 4.2(a)) to accelerate model convergence and avoid overfitting [31]. In the last layer, convolutional layer are used to adjust the number of basis functions and fuse features of different channels. The specific architecture of Basis CNNs refer to Figure 4.2(b).
4.1.1 Galerkin-projection activation function
In this subsection, we will introduce an activation function at the output layer to reconstruct the high-fidelity solution from basis functions, that is, using to approximate the high-fidelity solutions . Given by Basis CNNs, we use Galerkin projection to obtain by solving the algebra equation (3.1). Define the residual by
Forcing the residual of orthogonal to , satisfied
We can then obtain the approximated solution by solving above algebra equation, i.e.,
where . We call it Galerkin-projection activation functions and define it as a function of , that is
where .
Above all, We can write the forward propagation of Basis CNNs as
| (4.2) |
Remark 4.2.
For elliptic equations, such as the diffusion equations (2.2), lemma [32] gaurantees that defined in (4.2) best approximate the truth in the linear space spanned by . More formally, we denote the bounded and -elliptic bilinear form by , which leads to the definition of the norm . Then there is a constant , such that
Remark 4.3.
When training the networks, back-propagation algorithms require the derivatives of the loss function with respect to trainable parameters. Therefore, a well-defined activation function must be differentiable with respect to input variables, i.e., reduced basis functions . The -th column of is represented as . Denote the reduced-order solution by and the elements of matrix by , we can compute them as follows
where is the -th unit vector. Besides, the element of matrix are
4.1.2 Loss function
Given the dataset and FEM bilinear forms (or linear forms) , we define the loss function as follows
| (4.3) | ||||
where the is the norm. In practical, we approximate the norm in the loss function at the discrete points on the FEM mesh , and is the condition number under Frobenious norm, i.e.,
The first term of loss function (4.3) trains the neural networks to approximate the data. As shown in Remark 4.3, the training depends on the inverse of . However, learned by neural networks may be ill-conditioned because it does not have good properties, such as orthogonality [33]. To guarantee the stability of training and the reduced-order model (3.1), we impose the second term in the loss function. In theoretical analysis, condition number under 2-norm are widely used, but it is intractable to compute during training. Therefore, we choose the condition number under Frobenious norm here. The stability parameter is a hyperparameter.
4.2 The Coefficient CNNs (Coef CNNs)
The Basis CNNs can generate a reduced-order basis function of the problem (4.1) for given input , and the corresponding reduced-order model can be written as follows
| (4.4) |
where and . Here, the computation of and still depend on , which prevents the efficiency of online stage. Besides, we should note that Basis CNNs alone is not applicable for nonlinear equations because and not only depend on input but also unknown solution . To overcome these issues and extend the idea to nonlinear problems, Coef CNNs are designed to learn the coefficients of linear combination to approximate high fidelity solution , i.e.,
where is a -dimensional vector with elements . Combined with the result of Basis CNNs, we can obtain the following surrogates of the equations (2),
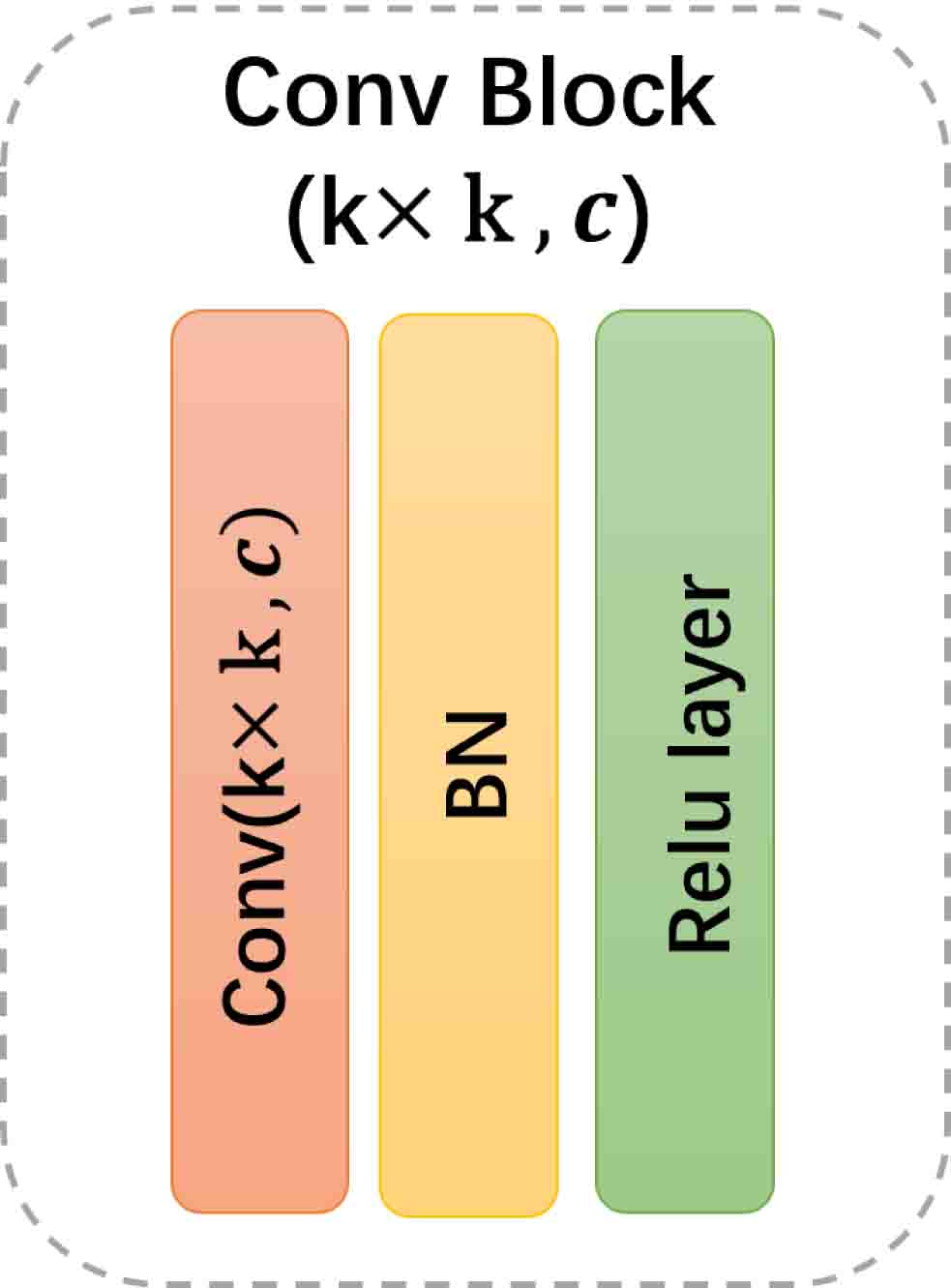
The architecture of Coef CNNs is similar to encoders and bottlenecks of Convolutional Autoencoder[34]. Convolutional blocks (see Figure 4.3(a)) are first connected to capture local features from input . Fully connected layers (FC) at last few layers help to compress the extracted feature into a smaller vector representation. (see Figure 4.3(b)).
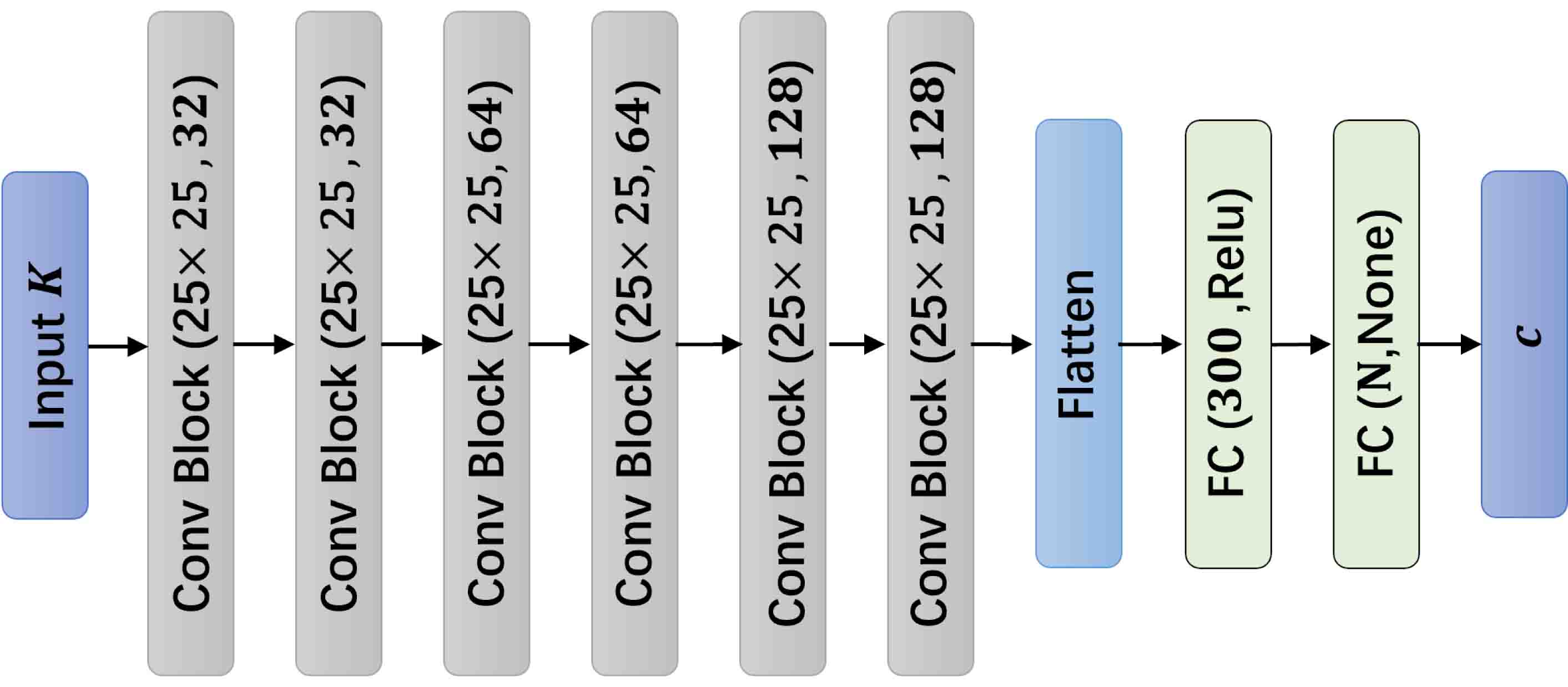
Finally, We use following loss function to train the coefficient CNNs,
4.3 Connections with multiscale finite element methods
CNN-based ROM tries to obtain the reduced basis functions by extracting multiscale features from data. Therefore, the Basis CNNs need to be retrained for different source terms. Rather than directly solving above issues, we attempt to find connections between the proposed methods and another class of multiscale model reduction methods, called multiscale finite element methods (MsFEM)[5]. For convenience, we use the diffusion problems as an example (2.2).
The idea that learning input-specific basis functions by Basis CNNs comes from MsFEM. MsFEM is also a model reduction method, which is realized by constructing multiscale finite element basis functions that are adaptive to the local property of differential operators. Therefore, the basis functions of MsFEM is -specific for the given differential operators. Unlike traditional FEM, which need fine meshes to capture small-scale features accurately, MsFEM enriches the basis functions by solving local problems on a coarse grid . For each element , four nodal basis functions satisfy
| (4.5) |
Let be the four nodal points of . We pose the constraints and assume that the basis functions vary linearly along the boundary . Here, is Kronecker Delta fuction.
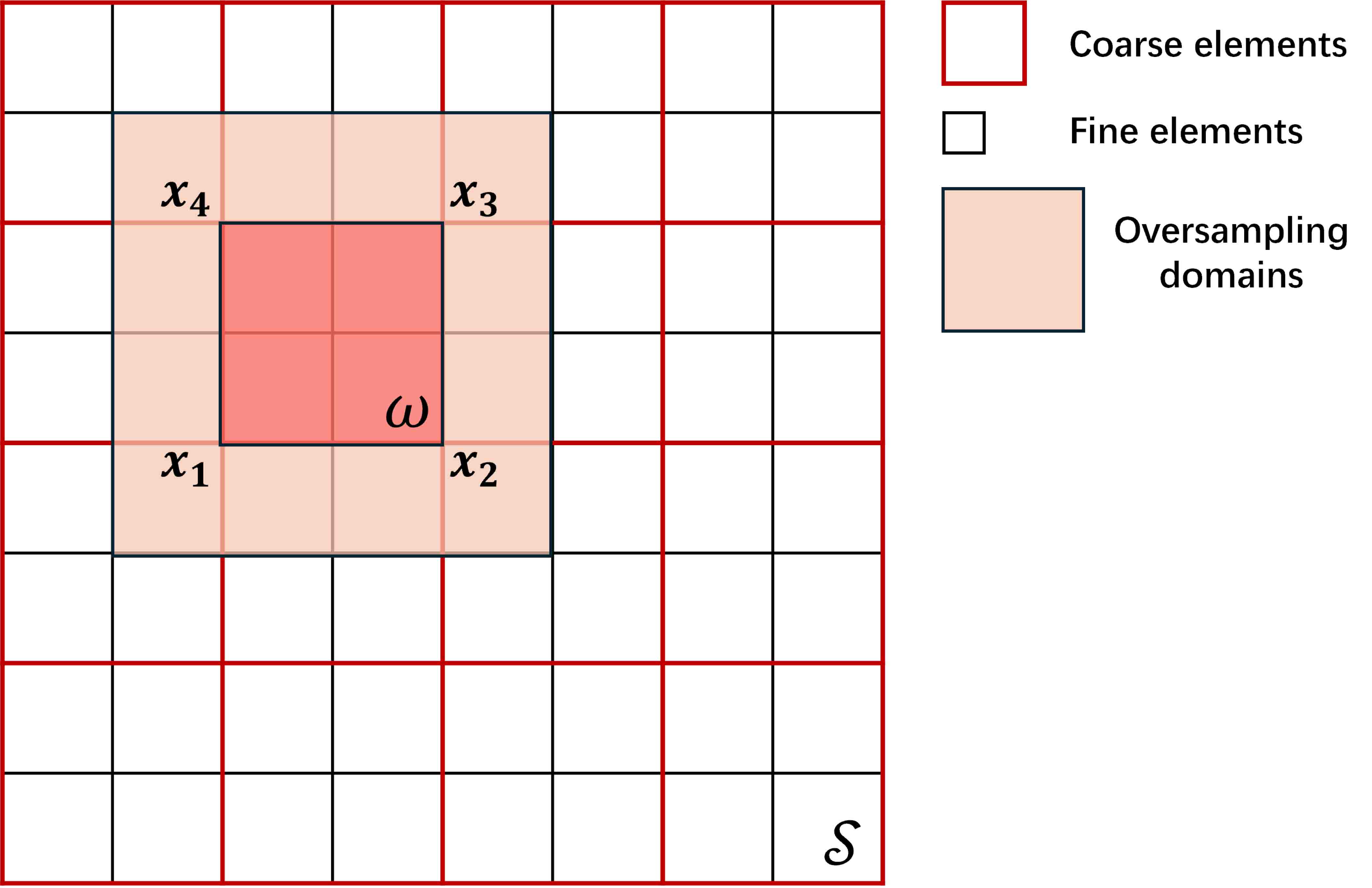
Using CNN-based ROM to learn multiscale finite element basis functions in the oversampling domains. Similar to other numerical upscaling methods, MsFEM also suffers ”resonance” effects. Oversampling is a common strategy to overcome this difficulty. In practical, to avoid repeated computations, the spatial space is usually decomposed into a number of large sampling regions. Each of these sampling regions contains many coarse elements. The choice of sampling regions size is a balance between accuracy and efficiency. Large size usually leads to faster convergence rate, but it is not practical on the online stage. Here, we use CNN-based ROM to learn the basis functions in a relative large Oversampling domains, which can even be the same as computational domain . Such application can not only help to reduce online time of MsFEM with oversampling techniques but also breaks some limitations of the proposed method. The implementation details and numerical results can be found in Section 5.1.2.
5 Numerical results
In this section, the numerical results for various multiscale problems with random inputs are presented to show the accuracy and efficiency of CNN-based ROM method.
To illustrate numerical results quantitatively, we define the relative test mean error as follows,
| (5.1) |
where have different meanings for different cases, specifically, for Basis CNNs and for Coef CNNs. The reference solutions are obtained by FEM methods on mesh with either square or triangle elements. The inputs of both neural networks are the samples of defined in Section 2. It should be noted that FEM methods require the value of on the integral points while we now only have the values on the nodes. To deal with this contradiction, we use element means for the integral points (see Figure 5.1).
5.1 Applications to Darcy flow
The Darcy flow, which models how flow moves in a porous medium, has been widely studied in civil, geotechnical, and petroleum engineering [35]. In this subsection, we consider the single-phase Darcy flow for pressure , i.e.,
| (5.2) |
The weak form of above equation is the following:
In this section, we use finite-dimensional space with bilinear basis functions defined on rectangular elements to obtain the high-fidelity approximation of , then the stiffness matrix belongs to and has entries
| (5.3) |
and the load vector belongs to and has entries
| (5.4) |
The approximated solution can thus be obtained by
| (5.5) |
Next, we will show that the proposed methods works for different types of random inputs . In addition, since Darcy flow (5.2) is a linear equation, we only use Basis CNNs to learn the mapping from to for convenience. The efficacy of Coef CNNs will be demonstrated in Section 5.2.
5.1.1 Darcy flow with binomial point process
In the fist test case, we consider the binomial point process defined on for any given . Let any subset of be and be n points with the distribution and the density . Then the number of points in can be defined as the following random variable
where is the indicator function and takes value as
The probability of each random variables in is the same and can be defined as follows,
Then is distributed to a binomial distribution with and . We introduce the set
where is the sample of and is the radius of points. Then we can define the two-scale random permeability , where points of permeability are randomly distributed in the background media of conductivity . Specifically,
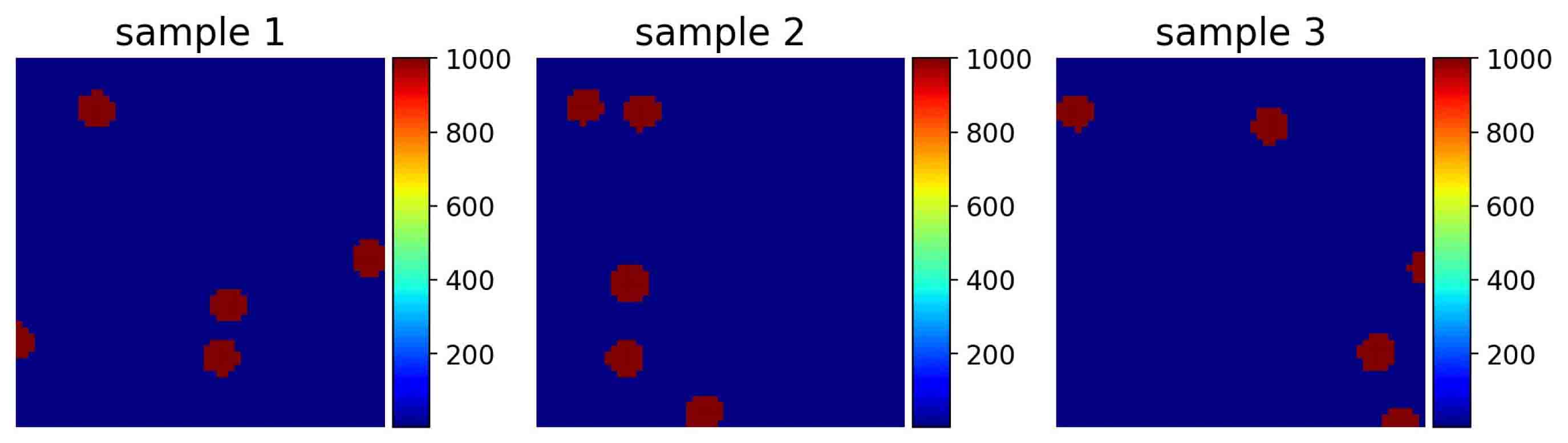
Here, we consider the special case that , is the uniform distribution on and takes . In the following experiments, we discretize over the uniform FEM mesh with rectangular elements and nodes, denoted by . Several instances of are given in Figure 5.2.
In this paper, we only approximate the solutions on the free nodes, i.e., the spatial resolution of inputs is . The configuration of Basis CNNs are shown in Figure 4.2(b) with more details in Table 1. The 2nd-3th columns of Table 1 show the spatial resolution of feature maps and the number of parameters of each layer. This configuration will be used in all experiments except that the spatial resolution of feature maps varies with different cases.
| Layers | Resolution H W | The number of parameters |
| Input | 59 59 | - |
| Convp block (25 25,32,1) | 59 59 | 20000 |
| Convp block (25 25,32,1) | 59 59 | 20000 |
| Convp block (25 25,64,1) | 59 59 | 40000 |
| Convp block (25 25,64,1) | 59 59 | 40000 |
| Convp block (25 25,128,1) | 59 59 | 80000 |
| Convp block (25 25,128,1) | 59 59 | 80000 |
| Conv(25 25,1,1) | 59 59 | 625 |
| Reshape | 3481 10 | - |
The Basis CNNs are trained with Adam optimizer with loss (4.3). The initial learning rate is 0.0001 and cosine decay, which is a built-in function of TensorFlow, is used. The batch size is set as 32 and the model is trained for 100 epochs. Each sample in the dataset is composed of four variables, they are permeability , high-fidelity solution , stiffness matrix and load vector , respectively (see equation (5.3)-(5.5)). We collect the data pairs for 12740 different samples of , 10240 of which are selected as training data and the rest are used to test the generalization ability of CNN-based ROM.
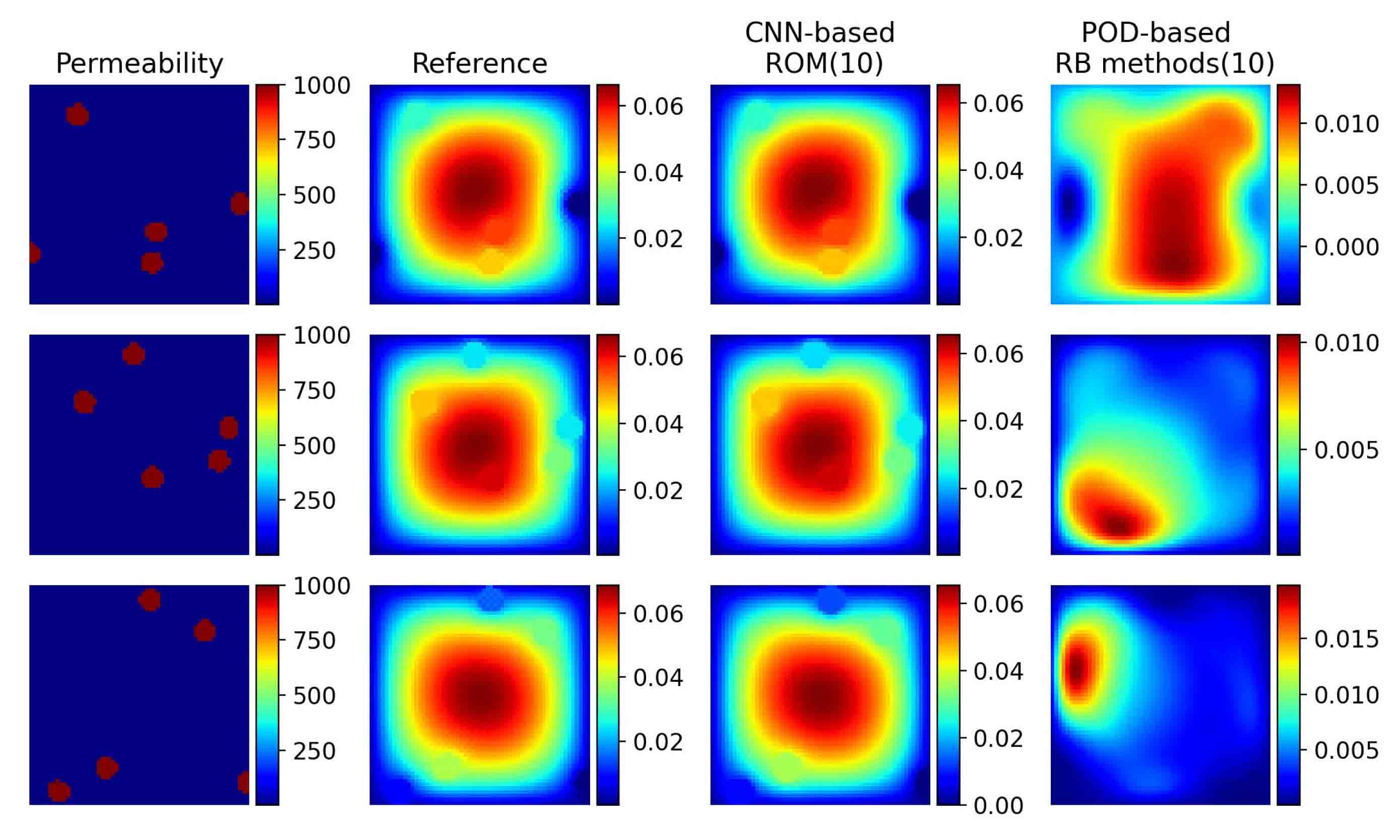
Compared with POD-based RB methods. In the following context, we compare the predictive performance of CNN-based ROM with POD-based RB methods introduced in Section 3. Figure 5.3 illustrates that CNN-based ROM can approximate the high-fidelity solution accurately using few number of RB basis functions (), which can not be achieved by POD-based RB methods. Since the accuracy of POD-based RB methods is highly dependent on the number of RB basis functions , we let equal 10, 20, 30, 40, 50, 800, 900, 1000, respectively and record the relative test mean errors in Table 2. As shown in table, POD-based RB methods requires 900-1000 RB basis functions to achieve the same accuracy as the proposed method, which directly affects the efficiency of the online computation.
| The number of basis | 10 | 20 | 30 | 40 | 50 | 800 | 900 | 1000 |
| POD-based RB methods | 81.42% | 65.56% | 54.50% | 47.96% | 43.47% | 4.46% | 3.68% | 3.08% |
| CNN-based ROM | 3.52% | 3.39% | 3.29% | 3.23% | 3.43% | - | - | - |
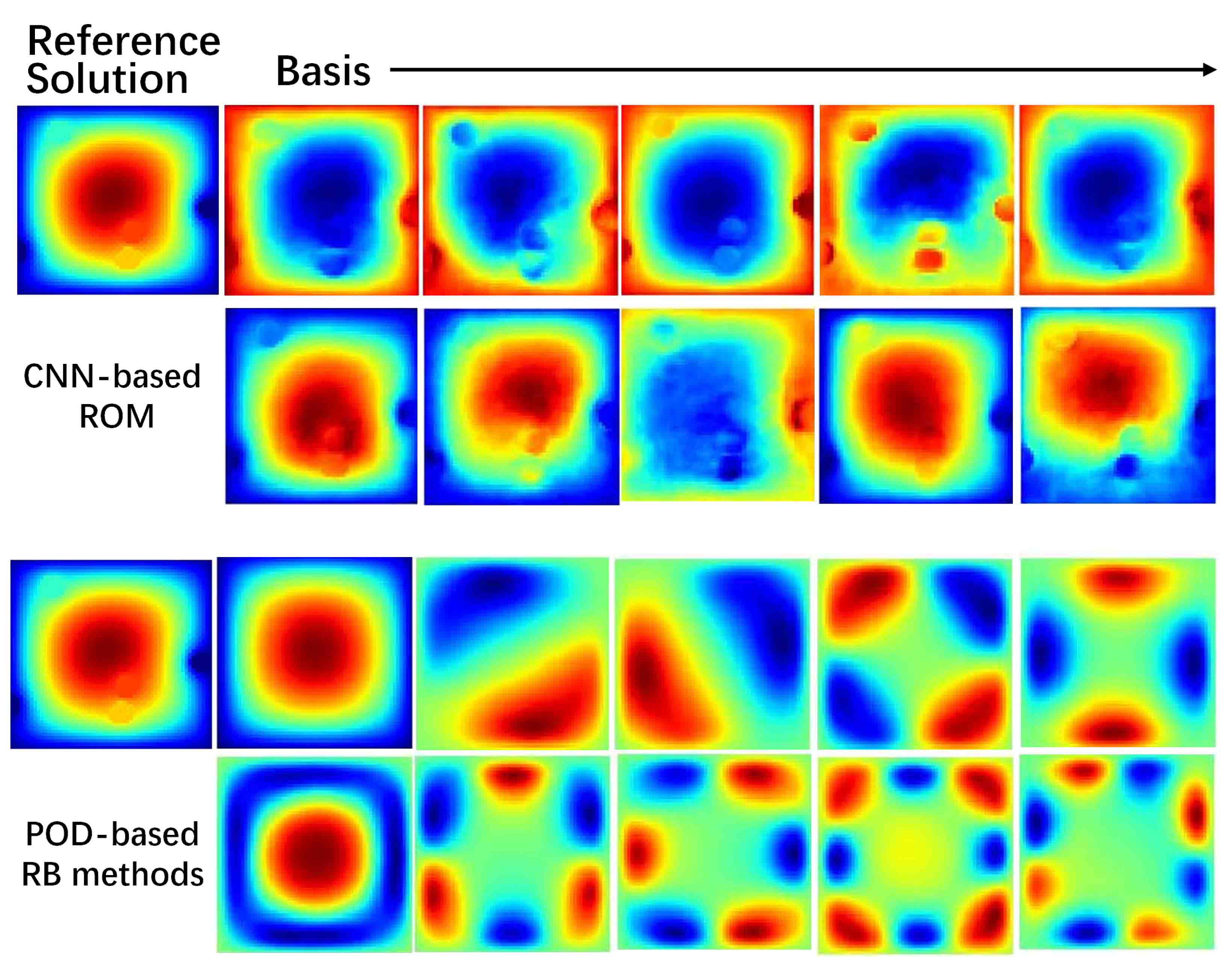
The RB methods exploit low-rank features of the data, which is usually called modes, that characterize physical processes. Therefore, we show the RB basis functions learned by CNN-based ROM and POD-based RB methods in Figure 5.4. Note that for POD-based RB basis functions, the modes are distributed around the center and dominant modes alternate arrangement. In contrast, the shape of the CNN-based RB basis functions are very much like the data. Such input-different basis functions can help reduce the number of basis functions needed for approximation. However, they lack interpretability, which is the common problem of deep learning techniques.
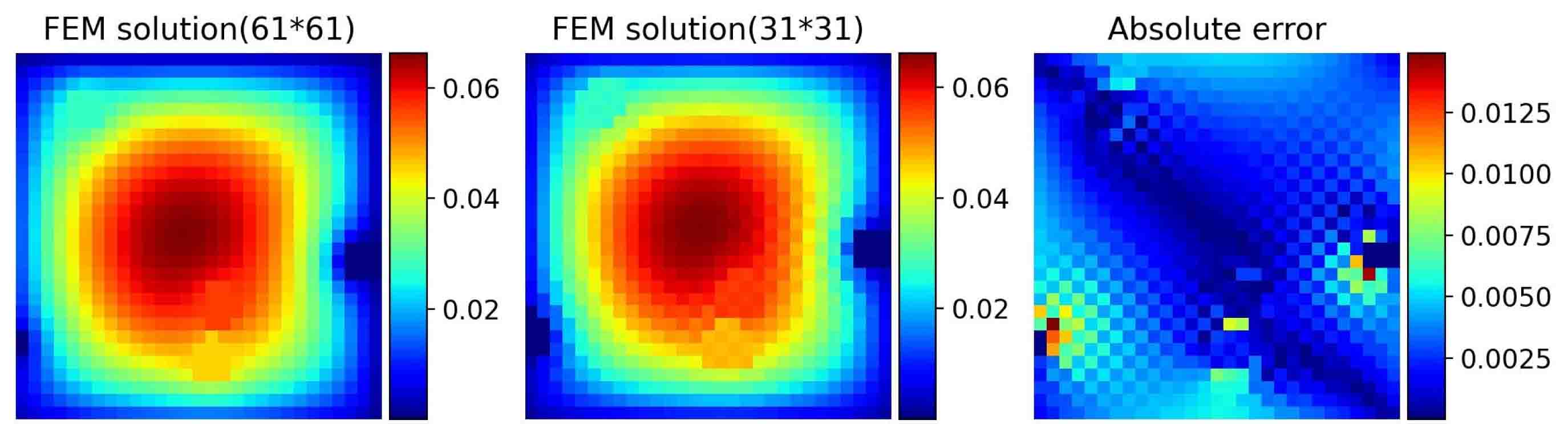
Our training data are generated by FEM, which has approximation error. For instance, FEM solutions on a mesh with nodes are less accurate than those on a mesh with (see Figure 5.5). We use a Gaussian distribution with means of zero and standard deviations of 0.001 to simulate the errors caused by numerical methods, which is shown in the second column of Figure 5.6.
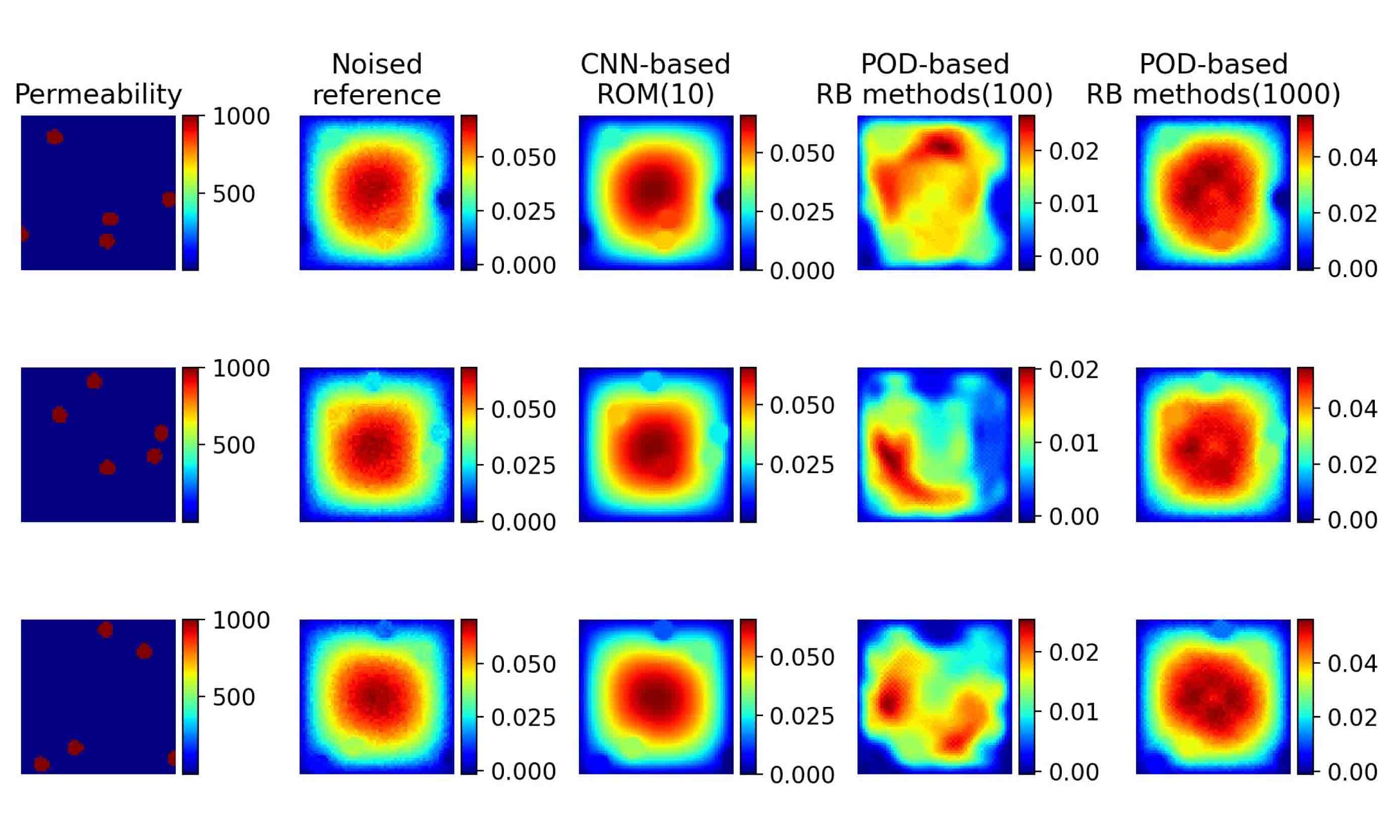
Using the noisy data, we train the Basis CNNs with and implement POD-based RB methods with again. The numerical results are presented in Figure 5.6. CNN-based ROM shows a clear advantage and a de-noising effect.
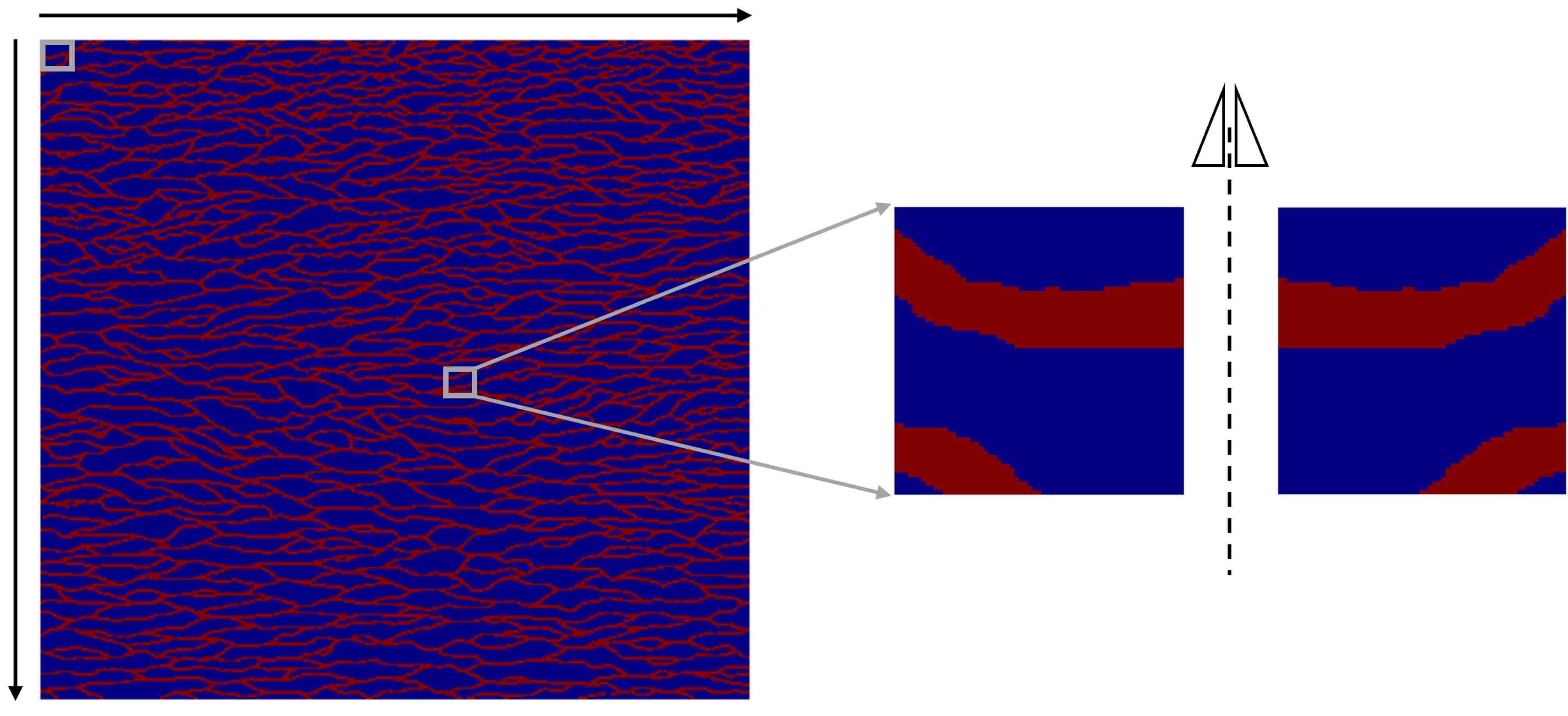
5.1.2 Darcy flow in a channelized aquifer
In this subsection, we consider the random input in Figure 5.7, which simulates the hydraulic conductivity field of a channelized aquifer [36]. The total number of pixels is . Channel and matrix materials are assigned hydraulic conductivity values of 1000 and 1, respectively. To introduce randomness, we extract 23104 small images of resolution from the large image by moving along both the horizontal and vertical directions with an interval of 16 pixels for each movement. To obtain enough training data, we flip the generated images horizontally (see Figure 5.7). We finally get 46208 images, among which 40960 images are collected as training dataset and the rest are used for test. Then Basis CNNs with architecture (Table 1) are trained using Adam optimizer for 50 epochs. The relative tests mean error is and the generalization ability of the proposed method is intuitively presented in Figure 5.8.
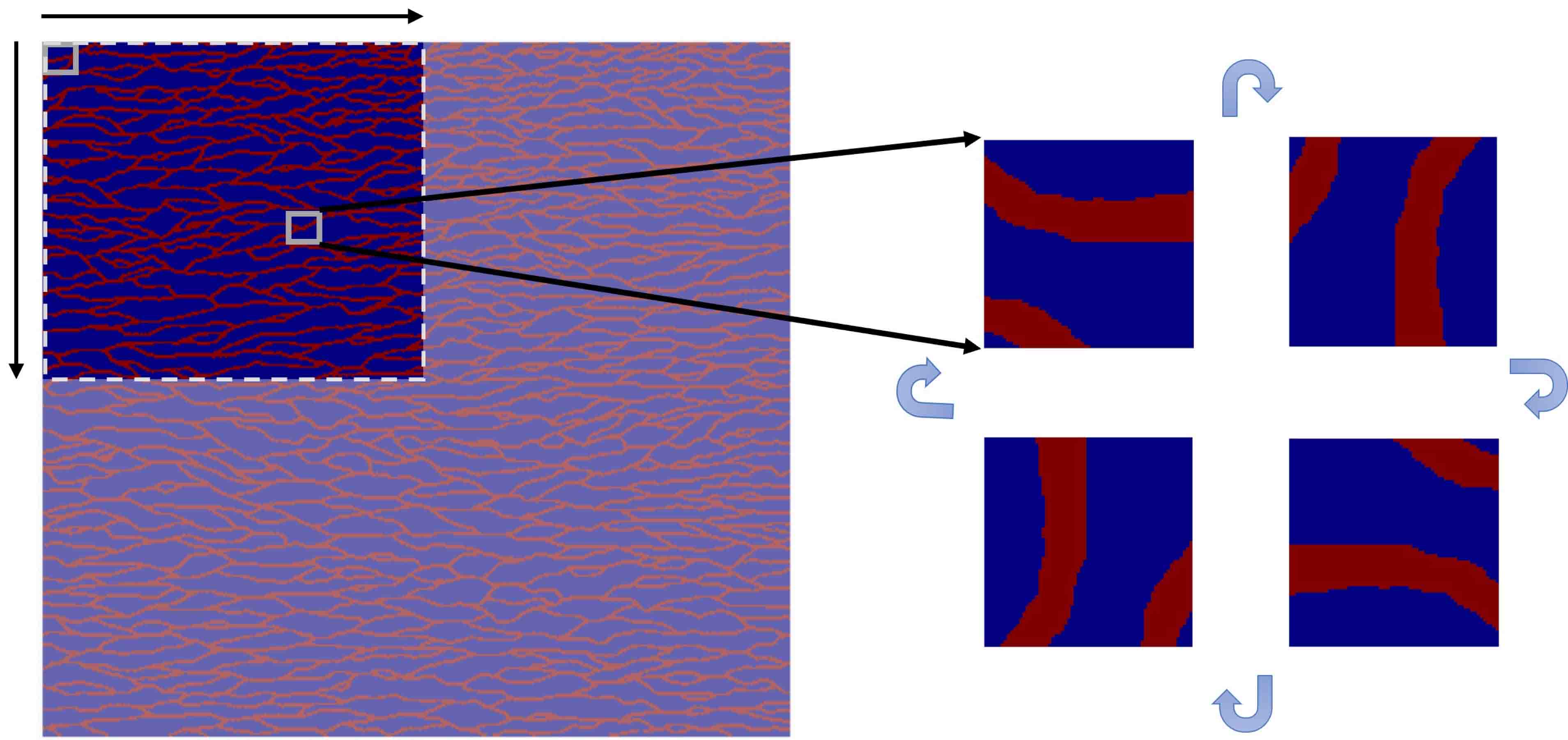
Next, we use the upper-left quarter of this background field to validate the ideas in Section 4.3, i.e., the total number of pixels is . Here, we consider an extreme case that the oversampling domain covers the whole computational region. Linear boundary conditions defined in equation (4.5) are used for the oversampling domain. Four nodal basis functions are obtained with different boundary conditions. Rather than training four different CNNs, we fully utilize the rotational symmetry of the boundary conditions, i.e., each boundary condition can be rotated clockwise by 90 degrees to overlap with another boundary condition. This can be accomplished by rotating background field. More specifically, we use Basis CNNs to learn the following equation,
To generate training and test dataset, we first obtain 5625 sub-image of resolution by moving along both the horizontal and vertical directions with an interval of 16 pixels for each movement. Then each sample are rotated clockwise by 90 degrees three times to acquire three additional samples (see Figure 5.9).
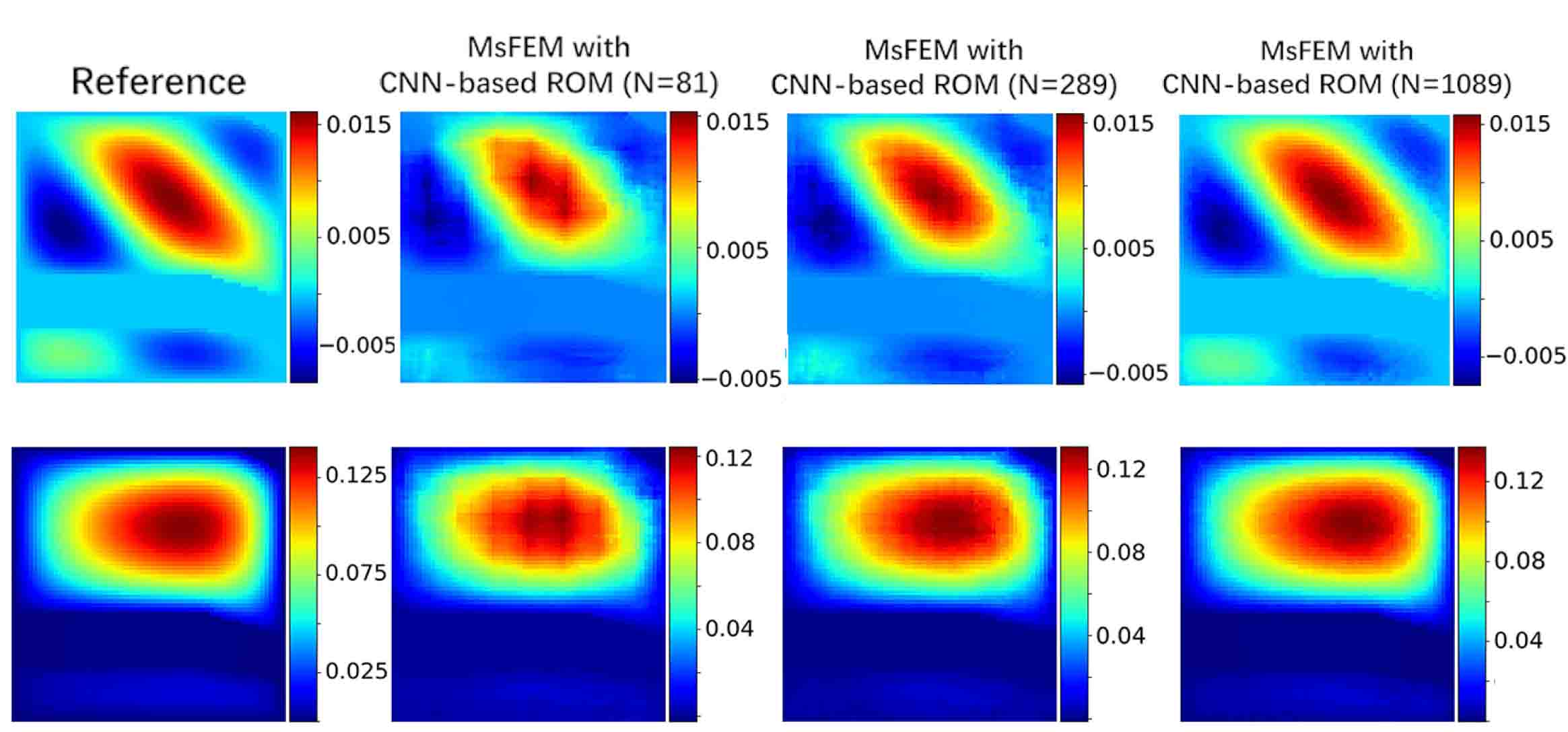
The relative test mean error is and several test instances are shown in Figure 5.10. Note that the basis functions learned by Basis CNNs are temporary, we construct the true multiscale finite element basis functions in each coarse elements from the linear combination of , i.e.,
where the coefficients is determined by conditions . This leads to non-conforming basis functions which is dealt with by simply taking averages on the boundary because there only exists an jump across [5]. The numerical results depicted in Figure 5.10 demonstrate that the same basis functions can be used for different types of source terms and the numerical solution is convergent to the reference as the number of basis functions is large enough.
5.2 Applications to nonlinear flows
In this subsection, we consider more complex cases, namely nonlinear flows. The logarithm of the random input is restricted to be a Gaussian random field, i.e.,
| (5.6) |
where is the constant mean function with value . The covariance function is a finite positive semi-definite function, which is also call reproducing kernel on [13]. In this test case, we take and the covariance function is specified in the following form using vector 2-norm,
| (5.7) |
where is a hyperparameter called bandwidth. Decreasing the bandwidth leads to the covariance between points and decreasing at a faster rate with respect to Euclidean distance , which makes the discretized field realizations vary highly even across adjacent grid points (see Figure 5.11). In the following two subsections, we will take and KLE are used to sample from , i.e.,
| (5.8) |
where and are the eigenvalues and eigenfunctions of the covariance function , are i.i.d standard norm, and is the number of expansion terms that is used to control the intrinsic dimensionality.
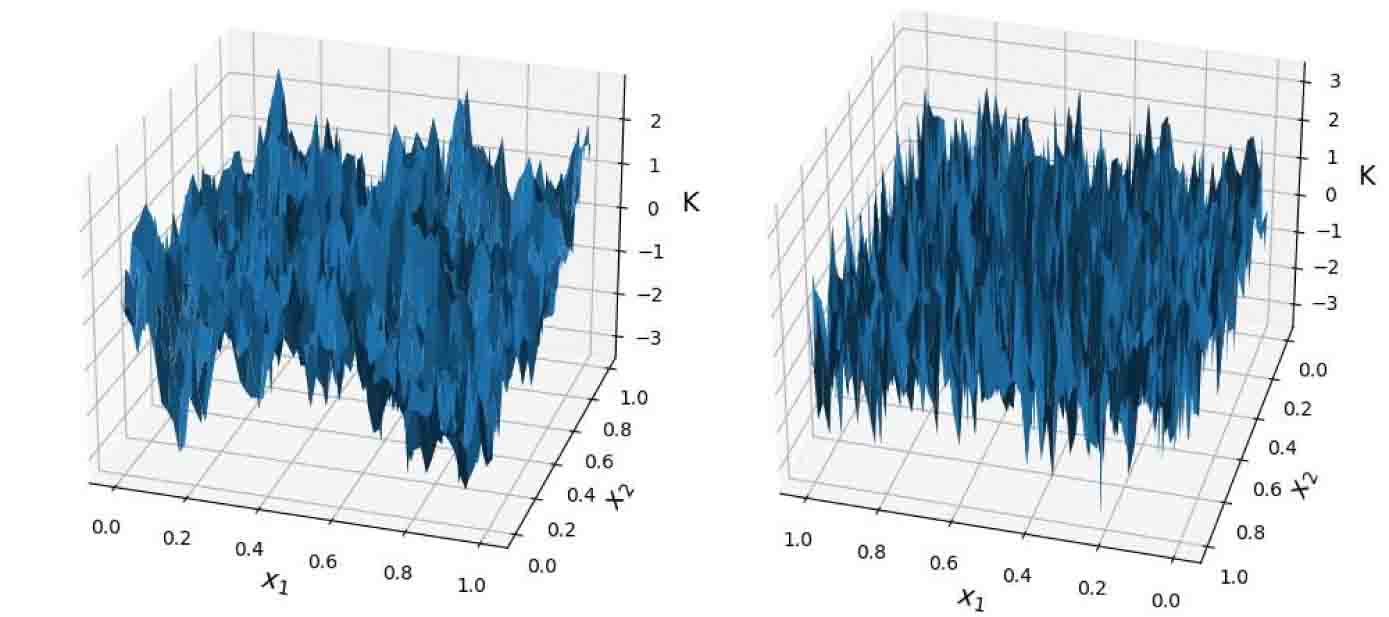
5.2.1 Nonlinear source terms
We first consider the case that the source term is nonlinear as follows,
| (5.9) |
The weak form of above equation is that find , such that
| (5.10) |
We solve above variational problems by Newton’s iteration methods on a fixed mesh with rectangular elements and nodes. Once we get the high-fidelity solution , we can obtain entries of stiffness matrix and the load vector are
where is the bilinear basis functions of . Here, we use element means to approximate the value of at the integral points (the same as Figure 5.1). The Basis CNNs with architecture (Table 1) are first trained using 5120 data pairs. Since is unknown for test instances, Basis CNNs themselves can not realize online computation. We further use Coef CNNs to learn the mapping from to the coefficients . The specific architecture of Coef CNNs is presented in Table 3
| Layers | Resolution H W | The number of parameters |
| Input | 63 63 | - |
| Conv block (25 25,32,1) | 63 63 | 20000 |
| Conv block (25 25,32,2) | 32 32 | 20000 |
| Conv block (25 25,64,1) | 32 32 | 40000 |
| Conv block (25 25,64,2) | 16 16 | 40000 |
| Conv block (25 25,128,1) | 16 16 | 80000 |
| Conv block (25 25,128,2) | 8 8 | 80000 |
| FC(300) | 300 1 | 2457600 |
| FC(300) | 300 1 | 90000 |
| FC(10) | 10 1 | 3000 |
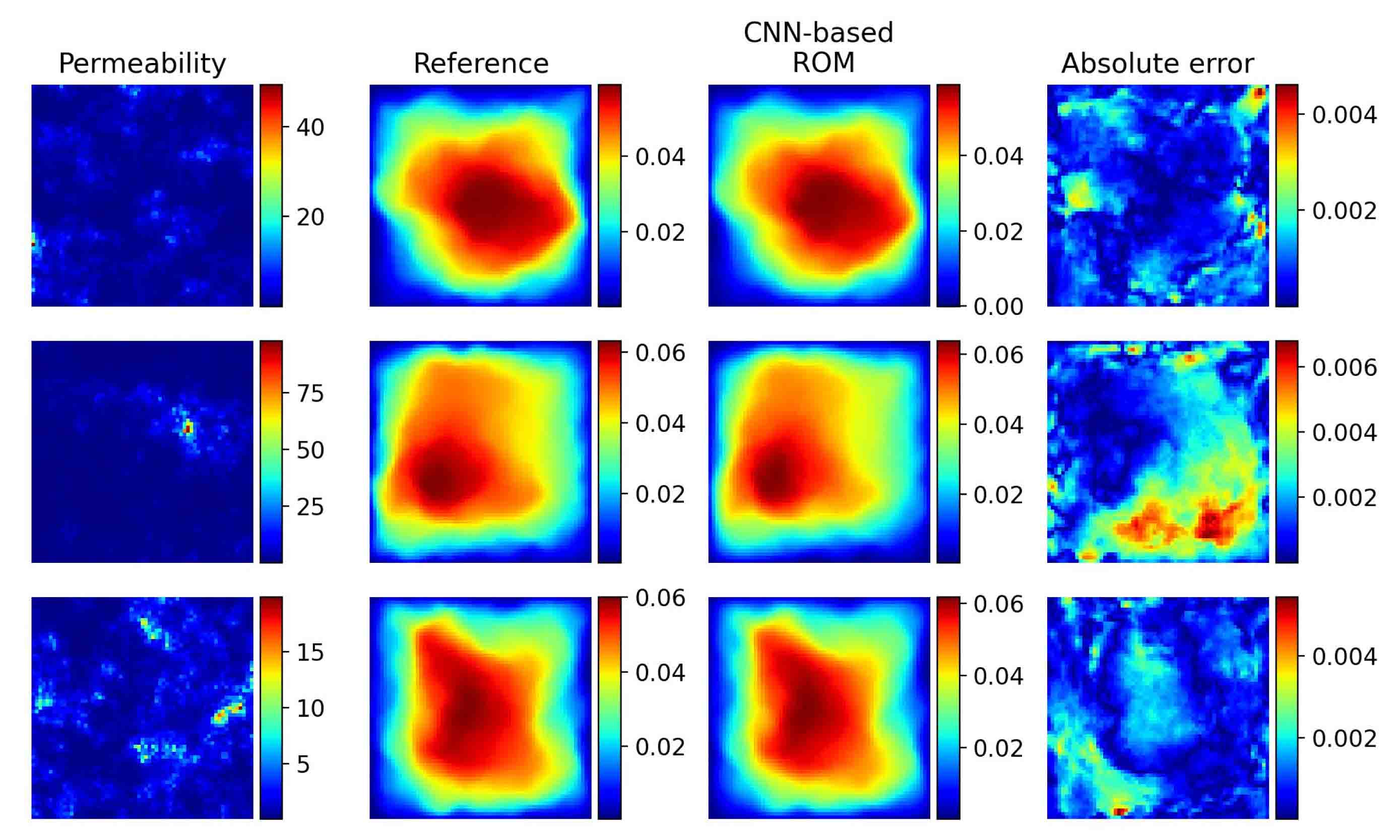
The same dataset is used to train Coef RNN. The relative test mean error is , which is estimated by 2500 test instances. Besides, several results are shown in Figure 5.12. Compared to traditional ROM, which need iterative methods on the online stage, we can directly obtain the prediction of solutions using CNN-based ROM.
5.2.2 Nonlinear differential operators
In this section, we consider the p-Laplacian equations as follows,
| (5.11) |
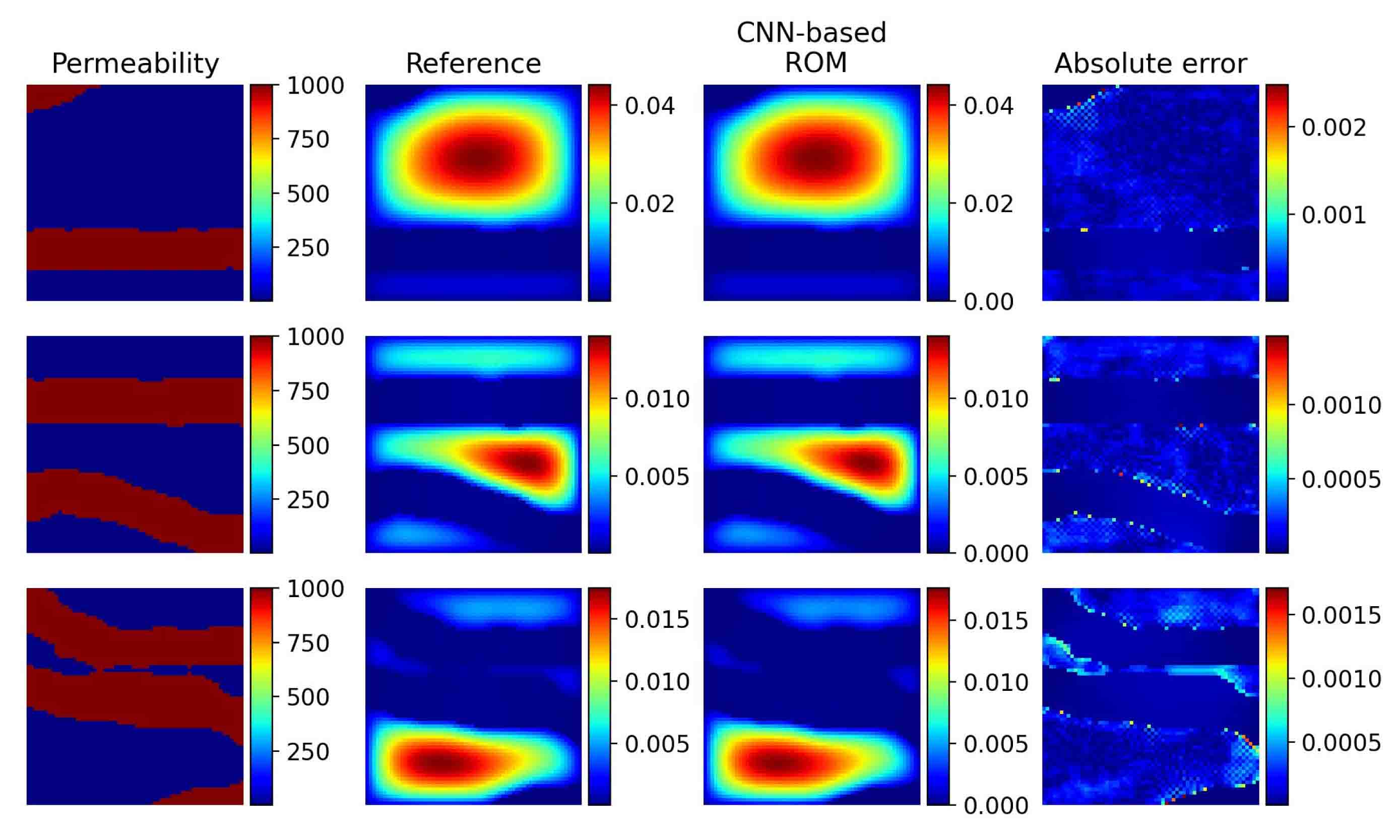
The p-Laplacian operator in the left hand of equation (5.11) is derived from a nonlinear Darcy law and continuity equation. For p=2, equation (5.11) is equivalent to the equation in Section 5.1, which is linear. Here, we take , and minimize the total potential energy of the flow, i.e.,
We approximate on the mesh with triangular elements and nodes. The above optimization problems are solved for 12740 samples of the log-Gaussian random field with bandwidth 0.1 by an efficient algorithm [37], among which 10240 instances are split to training dataset and the rest are used for test. The stiffness matrix is computed by assuming that is accurately approximated by , which has entries
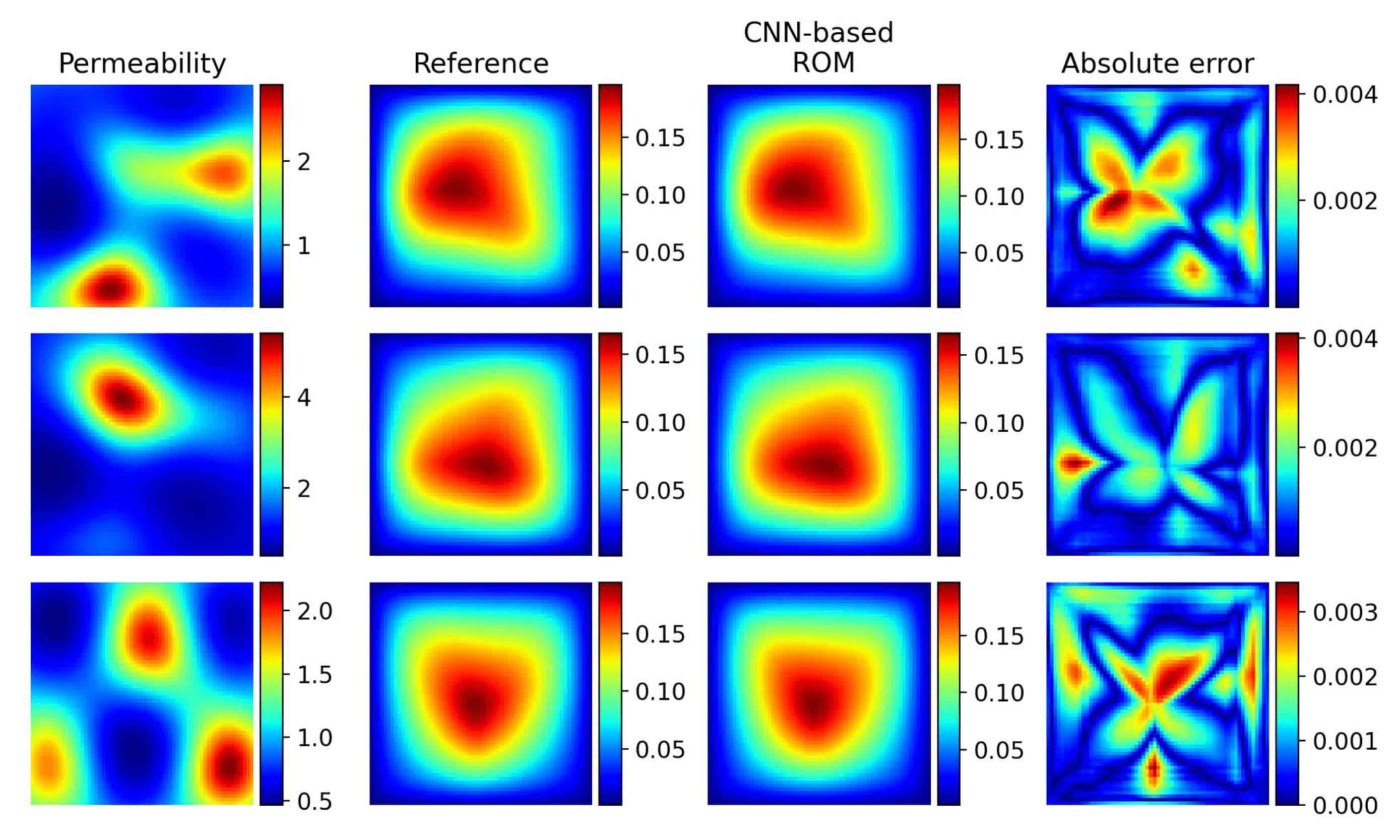
where is the piecewise linear basis functions of . The definition of load vector is the same as equation (5.4). We train both Basis CNNs and Coef CNNs by Adam for 50 epochs. The relative test mean error is and several test instances are shown in Figure 5.13.
5.2.3 Application to inverse problems
As shown in above numerical results, the proposed method provides an efficient and precise surrogate model for the random multiscale equation (2.1). In this section, we will apply CNN-based ROM to inverse problems. Given dataset observed by sensors on the spatial points , we want to estimate the coefficient vector of KLE expansion of the Gaussian random fields defined in equation (5.8).
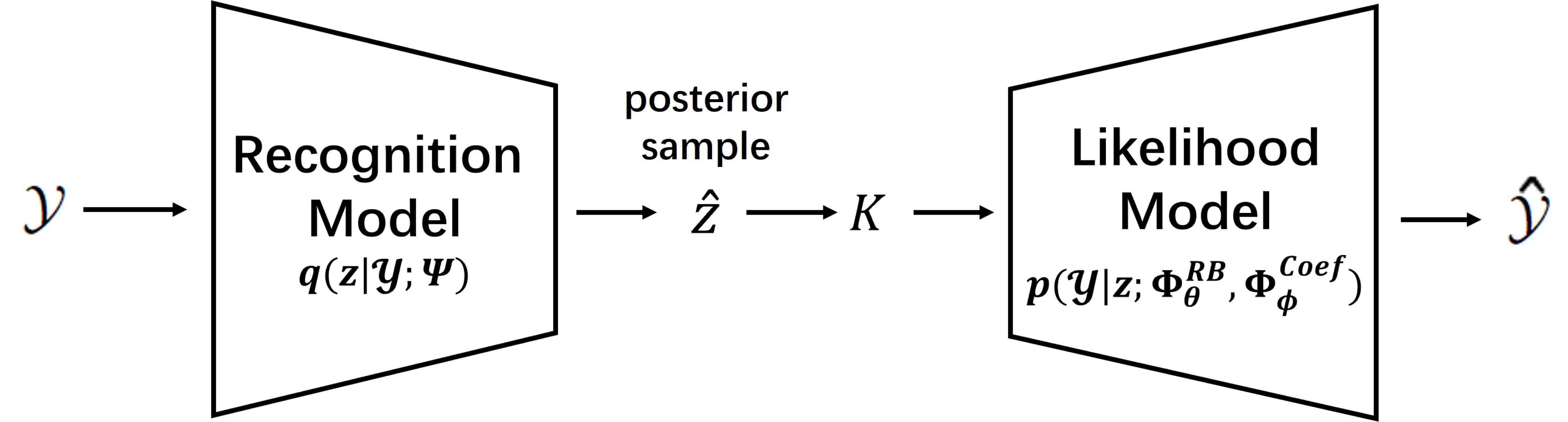
A method that combines Variational Autoencoder (VAE) [39] with CNN-based ROM is introduced to solve this problem. The schema of this method is presented in Figure 5.14. VAE is a type of generative model that belongs to the family of Autoencoders, specifically designed for learning latent representation of the input data and generate new data samples. It is composed of the recognition model, which learn the mapping from input data to parameters of posteriors for latent variables, and the likelihood model, which reconstructs data from latent space. In standard VAE, both recognition model and likelihood model are represented by neural networks. As an unsupervised method, VAE learn the latent variables purely by data, which is not suitable for inverse problems. Hence, we use the trained CNN-based ROM as parts of likelihood model to constrain the learning of latent variables, which is inspired by PDE-constrained Bayesian inversion methods [38]. Therefore, we call the method Surrogate-constrained VAE and the unknown parameters are only contained in the recognition model, that is
where are the local variational parameters that define the posterior distributions that approximate the true posterior . The mapping is a fully-connected neural networks. The problem thus becomes solving for the global variational parameters . Using such a neural network, we can obtain the posterior estimation of coefficients by passing the observation data through , which can not be achieved by PDE-constrained Bayesian inversion methods.
Next, we will use variational inference to learn the parameters . Because the likelihood of data is hard to computed, we instead minimize the lower bound of it that is known as evidence lower bound (ELBO),
| (5.12) |
where is the likelihood model with i.i.d Gaussian observation noise , i.e.,
And is the prior, we take it the standard Gaussian distribution because the coefficients of KLE of Gaussian random field is distributed to i.i.d Gaussian distribution. The approximation posterior distribution are also Gaussian with mean vector and covariance matrix , i.e.,
Furthermore, we can understand the equation (5.12) from the perspective of inverse problems. The first term aims at maximizing the likelihood of the reconstructed data. The second term is the Kullback-Leibler divergence of two probability density, which is defined as
It works as the regularization term such that posterior is as similar as possible to prior, which can help to alleviate the ill-posedness of the inverse problem. In terms of reparametrization tricks [39], we can use gradient descent algorithms, such as Adam, to optimize neural network parameters . Once the recognition model is trained, we can also estimate the expectations of by Monte Carlo method, i.e.,
| (5.13) |
where is the discrete vector of eigenfunctions in KLE (5.8). Similarly, we can also obtain the variance of based on estimations (5.13)
| (5.14) |
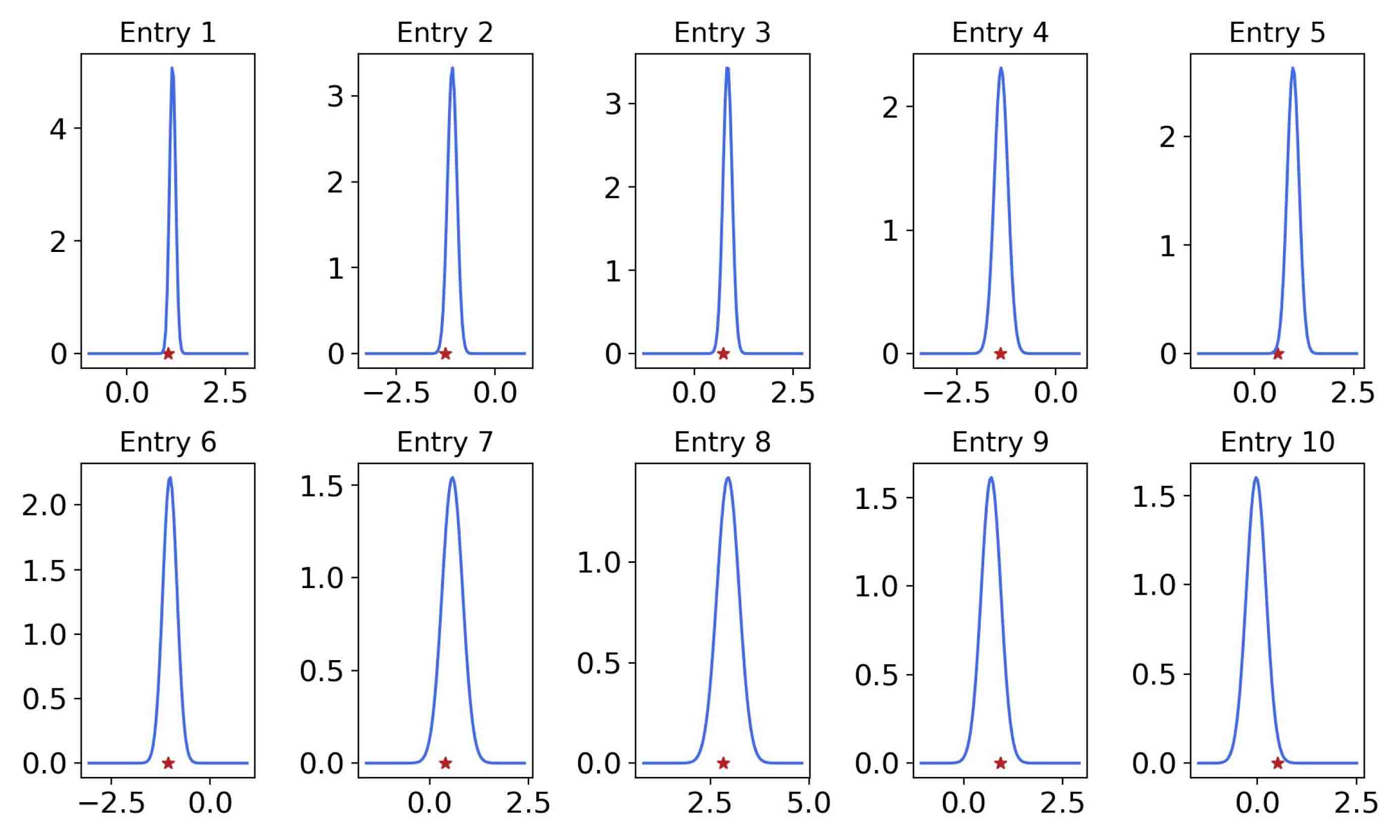
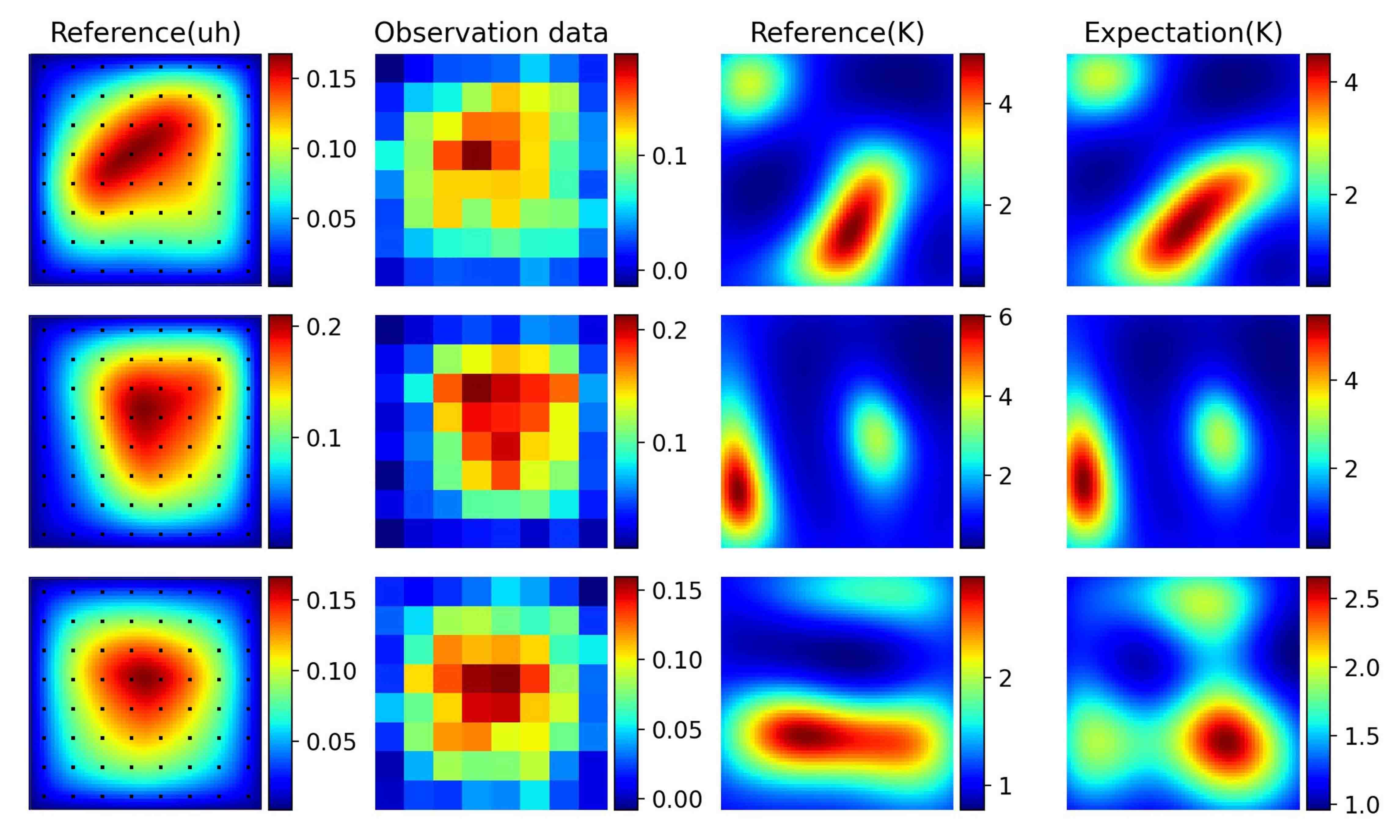
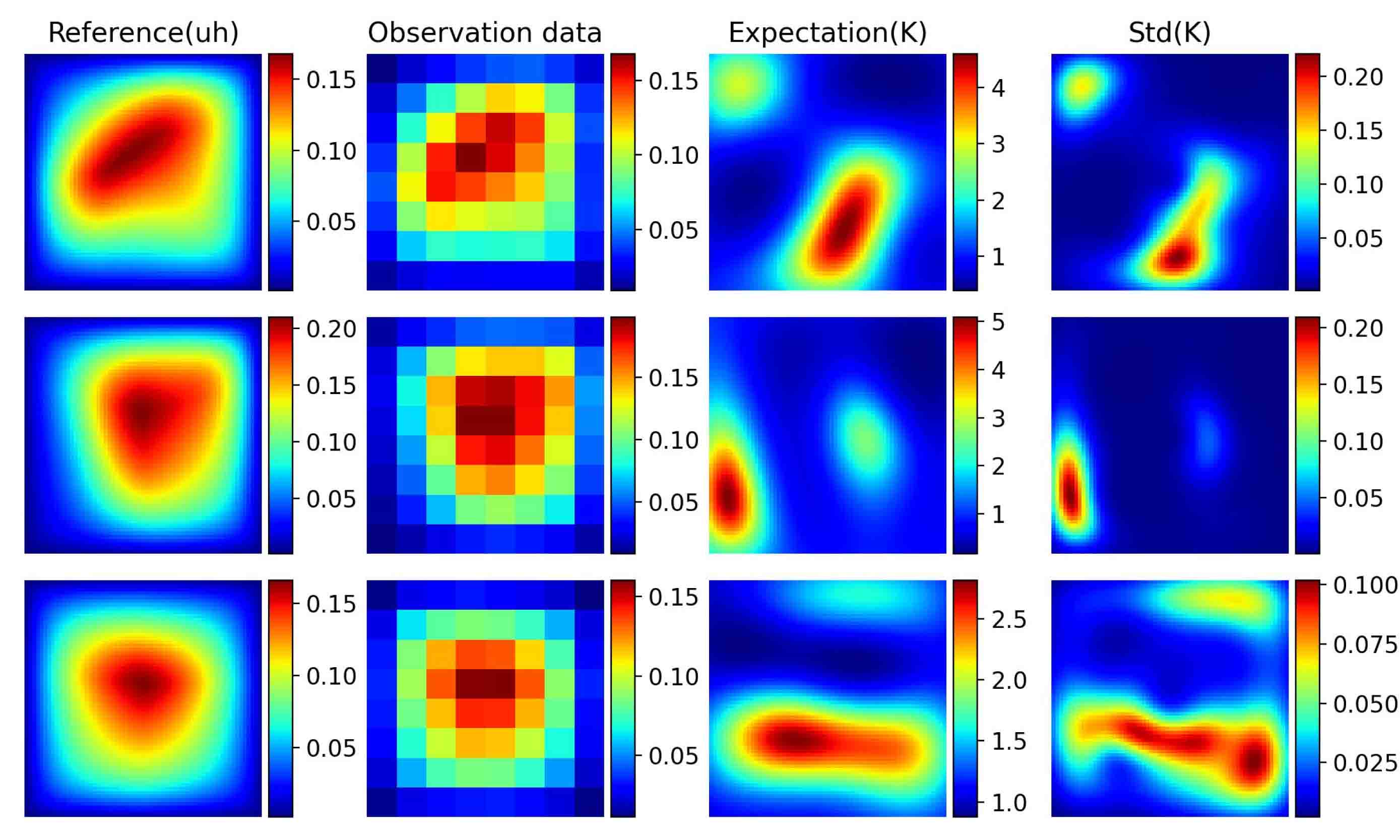
Finally, we will demonstrate the performance of Surrogate-constrained VAE for p-Laplacian equation in Section 5.2.2. We first place sensors uniformly in the spatial space as shown in the first column of Figure 5.15 and assume that the observation noise is 0.01. We can see from Figure 5.15 that Surrogate-constrained VAE can accurately estimate the expectation of permeability . The posterior density of coefficients of the test instance in the first row of Figure 5.15 are further drawn in Figure 5.16. We also change the noise level, we can see from Figure 5.17 that the standard deviations decrease as the noise level decrease.
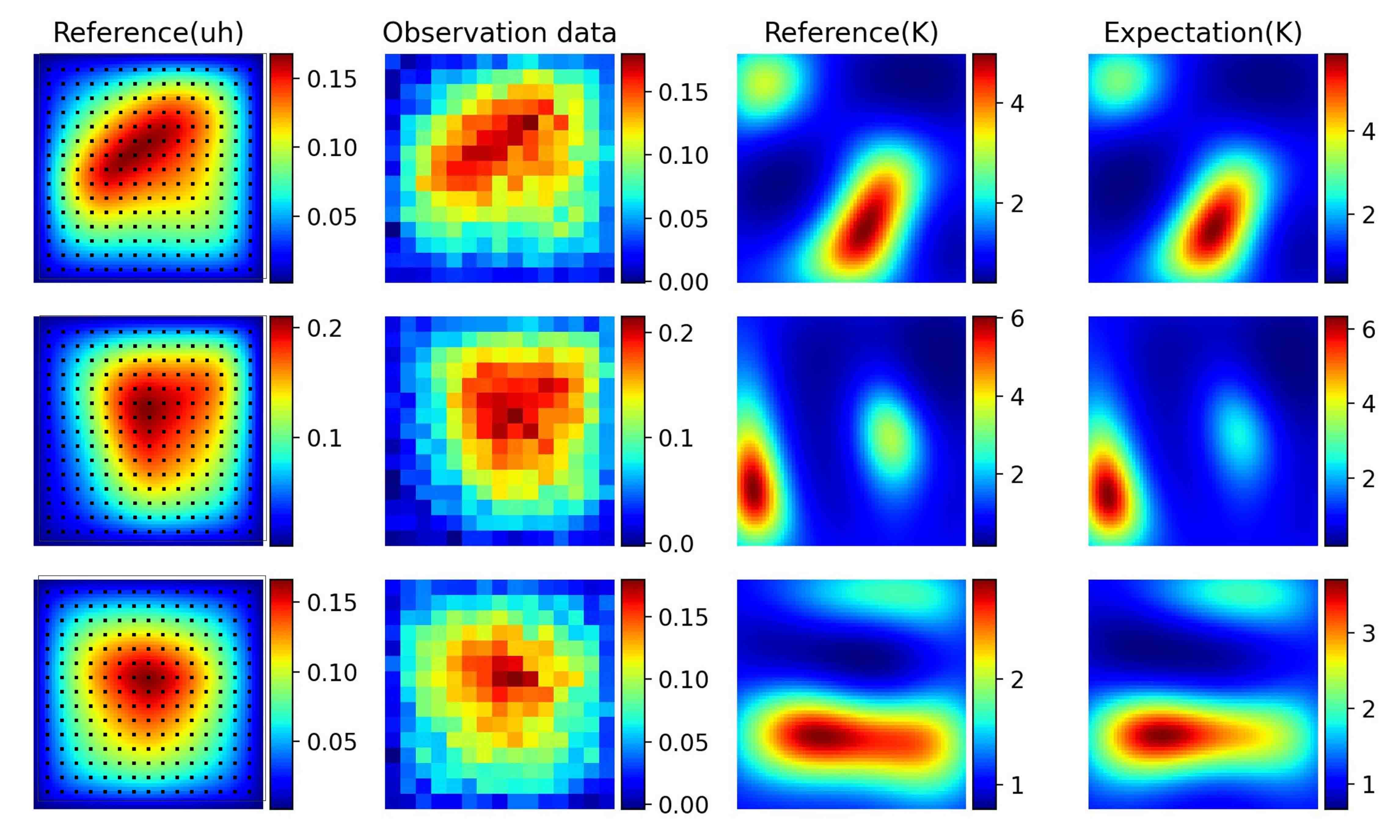
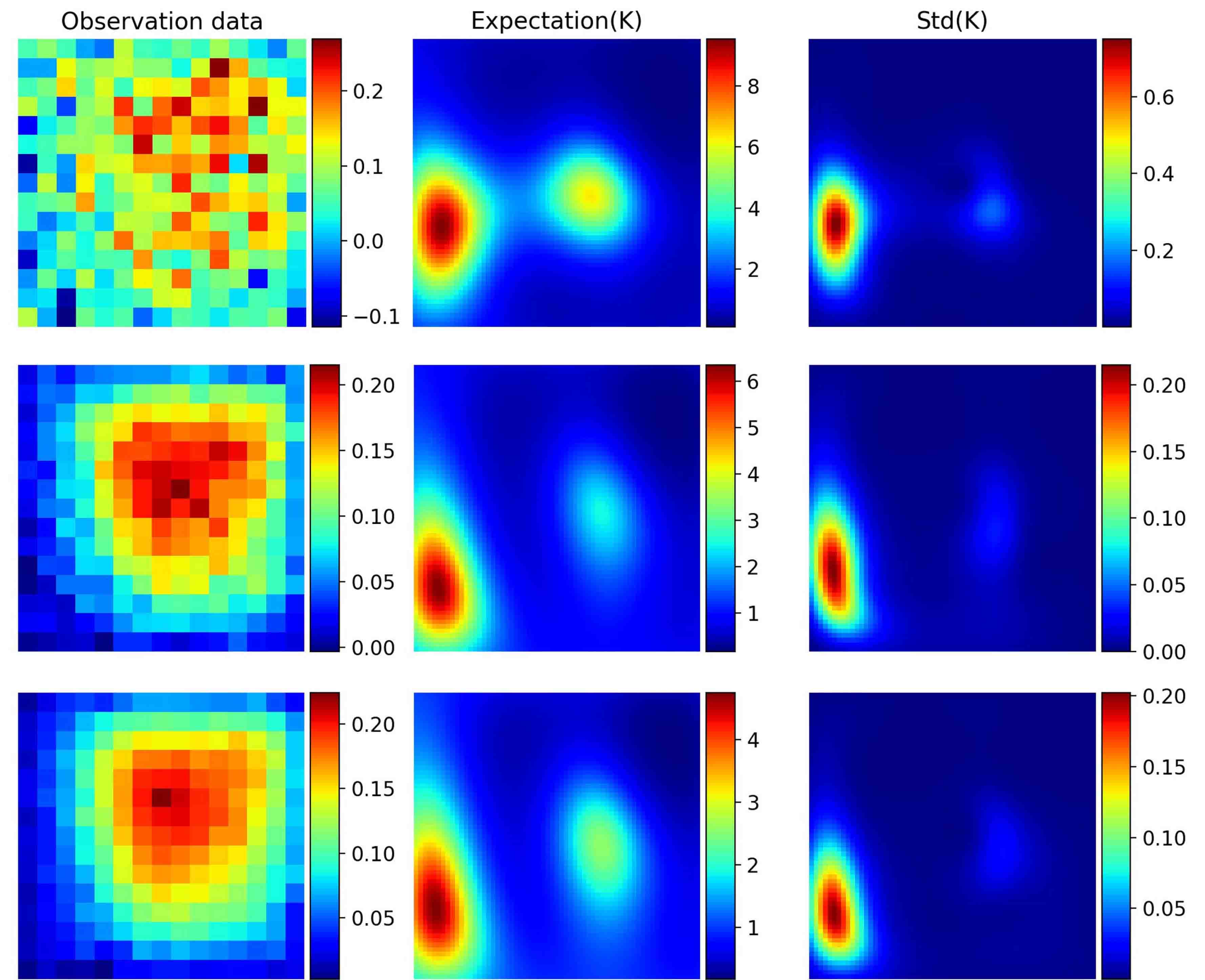
To further illustrates performance of the proposed method, we fix the noise level and use more sparse observation data with sensors. The estimation in Figure 5.18 only captures the basic shapes of permeability due to the high noise level. We thus decrease the noise level to 0.001, the performance, shown in Figure 5.19, is improved as expected. It is observed that the standard deviations will be higher for less accurate estimation.
6 Conclusion
In this paper, we have provided a data-driven ROM methods for multiscale problems with high-dimensional random inputs, which was called CNN-based ROM. After reviewing the multiscale reduction methods and reduced basis methods, we first summarized the ROM as two main parts: the construction of reduced-order basis functions and the computation of coarse-grid, which inspired the designs of two distinct CNNs in the proposed method.
The first CNN was called Basis CNNs, which was used to learn input-specific basis functions for linear model reduction. At the output layer, activation function defined by Galerkin projection were utilized to reconstruct fine-scale solutions and constrained the learning of basis functions. On the one hand, such settings could break the limitations of the RB methods for high-dimensional problems. On the other hand, compared to multiscale reduction methods, there is no need for computing a lot of local problems online to obtain the basis functions. Because the reduced-order model learned by CNNs might be ill-conditioned, we used condition number under Frobenious norm to guarantee the stability of training. In addition, Numerical results showed that the basis functions learned by Basis CNNs were similar to fine-scale solutions, thus the number of reduced-order basis could be less than POD-based RB methods. Moreover, ROM assisted by deep learning techniques was less sensitive to data fluctuation caused by numerical methods than traditonal ROM. Fine-scale stiffness matrix and load vector were needed in Basis CNNs, which was computationally expensive and not available for nonlinear problems at the online stage. To overcome these limitations, we designed the second CNN called Coefficient CNN (Coef) to learn the coefficients of linear combination.
We also provided two applications of CNN-based ROM. We first explored the connections between the proposed method and MsFEM. It was shown that CNN-based ROM could be used for learning MsFEM basis functions within large oversampling regions. Thus, the learned basis functions could be used for different source terms. In the last subsection of numerical results, it was demonstrated that CNN-based ROM could be used as surrogates for solving inverse problems of the p-Laplacian equation with Gaussian random field.
At the end, we would like to remark some limitations of our methods, which can be further investigated in the future. Firstly, basis functions learned by CNN-based ROM itself can not be used for different boundaries and different source terms. Secondly, the dataset consists of fine-scale solutions is not easy to obtain, ROM based on mixed data of coarse-scale and fine-scale simulations can be considered. Finally, we will extend our methods to the dynamical systems.
References
- [1] M. Alotaibi, H. Chen, S. Sun, Generalized multiscale finite element methods for the reduced model of Darcy flow in fractured porous media, Journal of Computational and Applied Mathematics. 413 (2022) 114305.
- [2] Y. Xia, N. Zabaras, Bayesian multiscale deep generative model for the solution of high-dimensional inverse problems, Journal of Computational Physics. 455 (2022) 111008.
- [3] L. Jiang, L. Ma, A hybrid model reduction method for stochastic parabolic optimal control problems, Computer Methods in Applied Mechanics and Engineering. 370 (2020) 113244.
- [4] J. Capers, L. Stanfield, J. Sambles, S. Bayes, A. Powell, A. Hibbins, S. Horsley, Physical review applied. 21 (2024) 014005.
- [5] T. Hou, X. Wu, A multiscale finite element method for elliptic problems in composite materials and porous media. Journal of Computational Physics. 134 (1997) 169-189.
- [6] L. Jiang, Y. Efendiev, G. Victor, Multiscale methods for parabolic equations with continuum spatial scales, Discrete and Continuous Dynamical Systems. 8 (2012) 833-859.
- [7] Y. Efendiev, J. Galvis, T. Hou, Generalized multiscale finite element methods (GMsFEM), Journal of Computational Physics. 251 (2013) 116-135.
- [8] E. Chung, Yalchin Efendiev, T. Hou, Adaptive multiscale model reduction with generalized multiscale finite element methods, Journal of Computational Physics. 320 (2016) 69-95.
- [9] E. Chung, Y. Efendiev, W. Leung, Constraint energy minimizing generalized multiscale finite element method, Computer Methods in Applied Mechanics and Engineering. 339 (2018) 298-319.
- [10] M. Li, E. Chung, L., Jiang, A constraint energy minimizing generalized multiscale finite element method for parabolic equations, Multiscale Modeling and Simulation. 17 (2019) 996-1018.
- [11] M. Yano, Discontinuous Galerkin reduced basis empirical quadrature procedure for model reduction of parametrized nonlinear conservation laws, Advances in Computational Mathematics. 45 (2019) 2287-2320.
- [12] R. Zimmermann, S. Görtz, Improved extrapolation of steady turbulent aerodynamics using a non-linear POD-based reduced order model, The Aeronautical Journal. 116 (2012) 1079-1100.
- [13] Y. Zhu, N. Zabaras, Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification, Journal of Computational Physics. 366 (2018) 415-447.
- [14] S. Chaturantabut, D. Sorensen, Discrete Empirical Interpolation for Nonlinear Model Reduction, in: Proceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference, 2009, pp. 4316-4321.
- [15] F. Negri, Andrea Manzoni, David Amsallem, Efficient model reduction of parametrized systems by matrix discrete empirical interpolation, Journal of Computational Physics. 303 (2015) 431-454.
- [16] S. Brunton, J. Kutz, Data-driven science and engineering: machine learning, dynamical systems and control, Cambridge university press, 2022, pp. 500-504.
- [17] M. Wang, S. Cheung, E. Chung, Y. Efendiev, W. Leung, Y. Wang, Prediction of discretization of GMsFEM Using Deep Learning, Mathematics. 7 (2019) 412.
- [18] A. Choubineh, J. Chen, F. Coenen, F. Ma, an innovative application of deep learning in multiscale modeling of subsurface fluid flow: Reconstructing the basis functions of the mixed GMsFEM, Journal of Petroleum Science and Engineering. 216 (2022) 110751.
- [19] S. Cheung, E. Chung, Y. Efendiev, E. Gildin, Y. Wang, J. Zhang, Deep global model reduction learning in porous media flow simulation, Computational Geosciences. 24 (2020) 261-274.
- [20] J. Hesthaven, S. Ubbiali, Non-intrusive reduced order modeling of nonlinear problems using neural networks, Journal of Computational Physics. 363 (2018) 55-78.
- [21] S. Fresca, L. Dede, A. Manzoni, A comprehensive deep learning-based approach to reduced order modeling of nonlinear time-dependent parametrized PDEs, Journal of Scientific Computing. 87 (2021) 1-36.
- [22] M. Mignolet, A. Przekop, S. Rizzi, S. Spottswood, A review of indirect/non-intrusive reduced order modeling of nonlinear geometric structures, Journal of Sound and Vibration. 332 (2013) 2437-2460.
- [23] Q. Wang, J. Hesthaven, D. Ray, Non-intrusive reduced order modeling of unsteady flows using artificial neural networks with application to a combustion problem, Journal of Computational Physics. 384 (2019) 289-307.
- [24] X. Zhang, L. Jiang, Conditional variational autoencoder with Gaussian process regression recognition for parametric models, Journal of Computational and Applied Mathematics. 438 (2024) 115532.
- [25] A. Quarteroni, A. Mabzoni, F. Negri, Reduced basis methods for partial differential equations, Springer, 2016.
- [26] M. Ohlberger, S. Rave, Reduced basis methods: success, limitations and future challenges, Proceedings of ALGORITMY, 2016, pp. 1-12.
- [27] N. Santo, S. Deparis, L. Pegolotti, Data-driven approximation of parametrized PDEs by reduced basis and neural networks, Journal of Computational Physics. 416 (2020) 109550.
- [28] A. Pinkus, n-widths in approximation theory, volume 7 of Ergebnisse der Mathematik und ihrer Grenzgebiete, Springer-Verlag, 1985.
- [29] N. Kruger, P. Janssen, S. Kalkan, M. Lappe, A. Leonarid, L. Piater, A. Rodriguez-Sanchez, L. Wiskott, Deep hierarchies in the primate visual cortex: what can we learn for computer vision?, IEEE Trans Pattern Anal Mach Intell. 35 (2013) 1847-1871.
- [30] R. Yamashita, M. Nishio, R. DO, K. Togashi, Convolutional neural networks: an overview and application in radiology, Insights into Imaging. 9 (2018) 611-629.
- [31] S. Loffe, C. Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Proceedings of the 32nd International Conference on Machine Learning. 37 (2015) 448-456.
- [32] M. Gockenbach, Understanding and Implementing the Finite Element Method, Society for Industrial and Applied Mathematics, 2006, pp. 59-62.
- [33] P. Benner, A. Cohen, M. Ohlberger, K. Willcox, Model Reduction and Approximation: Theory and Algorithms, Society for Industrial and Applied Mathematics, 2016, pp. 65-136.
- [34] J. Masci, U. Meier, D. Ciresan, J. Schmidhuber, Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction, Springer-Verlag. 6791 (2011) 52-59.
- [35] A. Masud, T. Hughes, A stabilized mixed finite element method for Darcy flow, Computer methods in applied mechanics and engineering. 191 (2002) 4341-4370.
- [36] E. Laloy, R. Herault, D. Jacques, N. Linde, Training-Image Based Geostatistical Inversion Using a Spatial Generative Adversarial Neural Network. Water Resources Research. 54 (2018) 381-406.
- [37] S. Loisel, Efficient algorithms for solving the p-Laplacian in polynomial time, Numerische Mathematik. 146 (2020) 369-400.
- [38] J. Cockayne, C. Oates, T. Sullivan, M. Girolami, Probabilistic numerical methods for PDE-constrained Bayesian inverse problems, AIP Conference Proceedings, 1853 (2017) 060001.
- [39] L. Cinelli, M. Marins, E. Silva, S. Netto, Variational Methods for Machine Learning with Applications to Deep Networks, Springer, 2021, pp. 151-152.