Convergence of Gaussian-smoothed optimal transport distance with sub-gamma distributions and dependent samples
Abstract
The Gaussian-smoothed optimal transport (GOT) framework, recently proposed by Goldfeld et al., scales to high dimensions in estimation and provides an alternative to entropy regularization. This paper provides convergence guarantees for estimating the GOT distance under more general settings. For the Gaussian-smoothed -Wasserstein distance in dimensions, our results require only the existence of a moment greater than . For the special case of sub-gamma distributions, we quantify the dependence on the dimension and establish a phase transition with respect to the scale parameter. We also prove convergence for dependent samples, only requiring a condition on the pairwise dependence of the samples measured by the covariance of the feature map of a kernel space.
A key step in our analysis is to show that the GOT distance is dominated by a family of kernel maximum mean discrepancy (MMD) distances with a kernel that depends on the cost function as well as the amount of Gaussian smoothing. This insight provides further interpretability for the GOT framework and also introduces a class of kernel MMD distances with desirable properties. The theoretical results are supported by numerical experiments.
1 Introduction
There has been significant interest in optimal transport (OT) distances for data analysis, motivated by applications in statistics and machine learning ranging from computer graphics and imaging processing Solomon et al. (2014); Ryu et al. (2018); Li et al. (2018) to deep learning Courty et al. (2016); Shen et al. (2017); Bhushan Damodaran et al. (2018); see Peyré and Cuturi (2019). The OT cost between probability measures and with cost function is defined as
| (1) |
where is the set of all probability measures whose marginals are and . Of central importance to applications in statistics and machine learning is the rate at which the empirical measure of and iid sample approximates the true underlying distribution . In this regard, one of the main challenges for OT distances is that rate convergence suffers from the curse of dimensionality: the number of samples needs to grow exponentially with the dimension of the data Fournier and Guillin (2015).
On a closely related note, OT also suffers from computational issues, particularly in the high-dimensional settings. To address both statistical and computation limitations, recent work has focused on regularized versions of OT including entropy regularization Cuturi (2013) and Gaussian-smoothed optimal transport (GOT) Goldfeld et al. (2020b). The entropy-regularized OT has attracted intensive theoretical interest Feydy et al. (2019); Klatt et al. (2020); Bigot et al. (2019), as well as an abundance of algorithm developments Gerber and Maggioni (2017); Abid and Gower (2018); Chakrabarty and Khanna (2020). In comparison, GOT is less understood both in theory and in computation. The goal of the current paper is thus to deepen the theoretical analysis of GOT under more general settings, so as to lay a theoretical foundation for computational study and potential applications.
In particular, we consider distributions that satisfy only a bounded moment condition and general settings involving dependent samples. For the special case of sub-gamma distributions, we show a phase transition depending on the dimension and with respect to the scale parameter of the sub-gamma distribution. Going beyond the case of iid samples, our convergence rate covers dependent samples as long as a condition on the pair-wise dependence quantified by the covariance of the kernel-space feature map is satisfied. A key step in our analysis is to establish a novel connection between the GOT distance and a family of kernel MMD distances, which can be of independent interest. In the kernel MMD upper bound, the kernel is neither bounded nor translation invariant, and is determined by both the cost function of OT and the amount of Gaussian smoothing. The theoretical findings are supported by numerical experiments.
To summarize our contribution, we provide an overview of the main theoretical results in the next subsection, and then close the introduction with a detailed review of related work. After introducing notations and needed preliminaries in Section 2, we derive upper bounds of GOT using kernel MMD of a new two-moment kernel in Section 3, which leads to the convergence rate results in Section 4 and numerical results in Section 5. All proofs are in the appendix.
1.1 Overview of Main Results
In this paper, we focus on the OT cost associated with the cost function for and . The total variation distance is given by and the -Wasserstein distance is given by if and if Villani (2003).
The minimax convergence rate of was established by (Fournier and Guillin, 2015, Theorem 1) who showed that if has a moment strictly greater than , then
| (2) |
Unfortunately, this means that the sample complexity increases exponentially with the dimension for .
Recently, Goldfeld et al. (2020b) showed that one way to overcome the curse of dimensionality is to consider the Gaussian-smoothed OT distance, defined as
where denotes the iid Gaussian measure with mean zero and variance . Under the assumption that is sub-Gaussian with constant , they proved an upper bound on the converge rate that is independent of the dimension:
The precise the form of the constant is provided for but not for the case unless is also assumed to have bounded support. Ensuing work by Goldfeld et al. (2020a) established the same convergence rate for under the relaxed assumption that has finite moment grater than .
Metric properties of GOT were studied by Goldfeld and Greenewald (2020) who showed that is a metric on the space of probability measures with finite first moment and that the sequence of optimal couplings converges in the limit to the optimal coupling for the unsmoothed Wasserstein distance. Their arguments depend only on the pointwise convergence of the characteristic functions under Gaussian smoothing, and thus also apply to the case of general considered in this paper.
One of the main contributions of this paper is to prove an upper bound on the convergence rate for all orders of and under more general assumptions on . Specifically, we prove the following result:
Theorem 1.
Let be the empirical measure of iid samples from a probability measure on that satisfies for some . There exists a positive constant such that for all ,
| (3) |
This result brings the GOT framework in line with the general setting studied by (Fournier and Guillin, 2015, Theorem 1), and shows that the benefits obtained by smoothing extend beyond the special cases of small and well-controlled tails. To help interpret this result it is important to keep in mind that for , the Wasserstein distance is given by the -th root of the GOT. As for the tightness of the bound, there are two regimes worth considering, namely when as and when is fixed. In the former case, the dependence on seems to be nearly tight. In Section 4.1, we show that if then Theorem 1 implies an upper bound on the unsmoothed convergence rate
| (4) |
Notice that for and this recovers the minimax convergence rate given in (2).
The main technical step in our approach is to establish a novel connection between GOT and a family of kernel MMD distances (Theorem 2). We then show how a particular member of this family, which we call the ‘two-moment’ kernel, defines a metric on the space of probability measures with finite moments strictly greater than (Theorem 3).
In addition to Theorem 1, we also provide further results that elucidate the role of the dimension as well the tail behavior of the underlying distribution (Theorem 6). Furthermore, we address the setting of dependent samples and provide an example illustrating how the connection with MMD can be used to go beyond the usual assumptions involving mixing conditions for stationary processes. Finally, we provide some numerical experiments that support our theory.
1.2 Comparison with Previous Work
The convergence of OT distances continues to be an active area of research Singh and Póczos (2018); Niles-Weed and Berthet (2019); Lei et al. (2020). Building upon the the work of work of Cuturi (2013), a recent line of work has focused on entropy regularized OT defined by
where is the relative entropy between probability measures and . The addition of the regularization term facilitates the numerical approximation using the Sinkhorn algorithm. The amount of regularization interpolates between OT in the limit and the kernel MMD in limit; see Feydy et al. (2019). In contrast to the Gaussian-smoothed Wasserstein distance, entropy regularized OT is not a metric since it does not satisfy the triangle inequality. Convergence rates for entropy regularized OT were obtained by Genevay et al. (2019) under the assumption of bounded support and more recently by Mena and Niles-Weed (2019) under the assumption of sub-Gaussian tails. Further properties have been studied by Luise et al. (2018) and Klatt et al. (2020).
There has also been work focusing on the sliced Wasserstein distance, which is obtained by averaging the one-dimensional Wasserstein distance over the unit sphere Rabin et al. (2011); Bonneel et al. (2015). While the sliced Wasserstein distance is equivalent to the Wasserstein distance in the sense that convergence in one metric implies convergence in another, the rates of convergence need not be the same. See Section 1.2 of Goldfeld et al. (2020a) for further discussion.
Going beyond convergence rates for empirical measures, properties of smoothed empirical measures have been studied in a variety of contexts, including the high noise limit Chen and Niles-Weed (2020) and applications to the estimation of mutual information in deep networks Goldfeld et al. (2018). Finally, we note that there has also been some work on convergence with dependent samples by Fournier and Guillin (2015), who focus on OT distance, and also by Young and Dunson (2019), who consider a closely related entropy estimation problem.
2 Preliminaries
Let be the space of Borel probability measures on and let be the space of probability measures with finite -th moment, i.e, . The Gaussian measure on with mean-zero and covariance is denoted by . The convolution of probability measures and is denoted by . The Gamma function is given by for . We use to denote a generic positive real number, and the value of may change from place to place.
Kernel MMD.
A symmetric function is said to be a positive-definite kernel on if and only if for every , the symmetrix matrix is positive semidefinite. A positive definite kernel can be used to define a distance on probability measure known as RKHS MMD Anderson et al. (1994); Gretton et al. (2005); Smola et al. (2007); Gretton et al. (2012). Let be the space of probability measures such that . For the kernel MMD distance is defined as
The distance is a pseudo-metric in general. A kernel is said to be characteristic to a set of probability measures if and only if is a metric on Gretton et al. (2012); Sriperumbudur et al. (2010). An alternative representation is given by
| (5) |
where iid, and iid. The kernel MMD distance was shown to be equivalent to energy distance in Sejdinovic et al. (2013), and a variant form used in practice is the kernel mean embedding statistics Muandet et al. (2017); Chwialkowski et al. (2015); Jitkrittum et al. (2016). Another appealing theoretical property of the kernel MMD distance is its representation via the spectral decomposition of the kernel Epps and Singleton (1986); Fernández et al. (2008), which gives rise to estimation consistency as well as practical algorithms of computing Zhao and Meng (2015). Kernel MMD has been widely applied in data analysis and machine learning, including independence testing Fukumizu et al. (2008); Zhang et al. (2012) and generative modeling Li et al. (2015, 2017).
Magnitude of multivariate Gaussian.
Our results also depend on some properties of the noncentral chi distribution. Let be a Gaussian vector with mean and identity covariance. The random variable has chi-distribution with parameter . The density is given by
| (6) |
The -th moment of this distribution is denoted by . This function is an even polynomial of degree whenever is an even integer (see Appendix C.1). The special case corresponds to the (central) chi distribution and is given by
3 Upper Bounds on GOT
In this section, we show that GOT is bounded from above by a family of kernel MMD distances. It is assumed throughout that is a positive integer, , and .
3.1 General Bound via Kernel MMD
Consider the feature map defined by
| (7) |
where is the volume of the unit sphere in , is the standard Gaussian density on , and is a probability density function on that satisfies
| (8) |
for some and . This feature map defines a positive semidefinite kernel according to
After some straightforward manipulations (see Appendix A), one finds that is finite on and can be expressed as the product of a Gaussian kernel and a term that depends only on . Specifically,
| (9) |
where
| (10) |
and is the density of the non-central chi-distribution given in (6). Note that this kernel is not shift invariant because of the term .
The next result shows that the MMD defined by this kernel provides an upper bound on the GOT.
Theorem 2.
Let be defined as in (9). For any such that and are finite, the MMD defined by provides and upper bound on the GOT:
The significance of Theorem 2 is twofold. From the perspective of GOT, it provides a natural connection between the role of Gaussian smoothing and normalization of the kernel. From the perspective of MMD, Theorem 2 describes a family of kernels that metrize convergence in distribution as well as convergence in -th moments.
Similar to the analysis of convergence rates in previous work Goldfeld and Greenewald (2020); Goldfeld et al. (2020b), the proof of Theorem 2 builds upon the fact that can be upper bounded by a weighted total variation distance (Villani, 2008, Theorem 6.13). The novelty of Theorem 2 is that it establishes an explicit relationship with the kernel MMD and also provides a much broader class of upper bounds parameterized by the density .
3.2 A ‘Two-moment’ Kernel
One potential limitation of Theorem 2 is that for a particular choice of density , the requirement that is integrable might not be satisfied for probability measures of interest. For example, the convergence rates in Goldfeld and Greenewald (2020) and Goldfeld et al. (2020b) can be obtained as a corollary of Theorem 2 by choosing to be the density of the generalized gamma distribution. However, the inverse of this density grows faster than exponentially, and as a consequence, the resulting bound can be applied only to the case of sub-Gaussian distributions.
The main idea underlying the approach in this section is that choosing a density with heavier tails leads to an upper bound that holds for a larger class of probability measures. Motivated by the functional inequalities appearing in Reeves (2020), we consider the following density function, which belongs to the family of generalized beta-prime distributions:
For this special choice, the function can be expressed as the weighted sum of two moments of the non-central chi distribution. Starting with (9) and simplifying terms leads to the following:
Definition 1.
The two-moment kernel is defined as
| (11) |
for all and , where
In this expression, denotes the -th moment of the non-central chi distribution with degrees of freedom and parameter .
A useful property of the two-moment kernel is that it satisfies the upper bound
where the constant depends only on (see Appendix A for details). As a consequence:
Theorem 3.
Fix any . For all and the MMD defined by the two-moment kernel is a metric on the space of probability measures with finite -th moment. Furthermore, for all ,
Remark 1.
If are even integers then is an even polynomial of degree with non-negative coefficients. For example, if , , and , then
| (12) |
Methods for efficient numerical approximation of are provided in Appendix C.1.
4 Convergence Rate
We now turn our attention to the fundamental question of how well the empirical measure of iid samples approximates the true underlying distribution. Let be a sequence of independent samples with common distribution . The empirical measure is the (random) probability measure on that places probability mass at each sample point:
| (13) |
where denotes the pointmass distribution at .
Distributional properties of the kernel MMD between and have been studied extensively Gretton et al. (2012). For the purposes of this paper, we will focus on the expected difference between these distributions. As a straightforward consequence of (5) one obtains an exact expression for the expectation of the squared MMD:
| (14) |
where are independent draws from . Note that the numerator can also be expressed as , i.e., the squared MMD under samples. By Jensen’s inequality, the first moment satisfies
| (15) |
In the following, we focus on the two-moment kernel given in (11) and study how depends on and the parameters .
We note that because satisfies the triangle inequality, all of the results provided here extend naturally to the two-sample settings where one the goal is to approximate the distance based on the empirical measures and .
4.1 Finite Moment Condition
We begin with an upper bound on that holds whenever has a moment greater than .
Theorem 4.
Let be a random vector that satisfies for some . If is the two-moment kernel given in (11) with parameters and , then
Small noise limit and unsmoothed OT.
It is instructive to consider the implications of Theorem 1 in the limit as converges to zero. By two applications of the triangle inequality and the fact that for every , one finds that, for any , the (unsmoothed) OT distance can be upper bounded according to
| (16) |
Combining (16) with Theorem 1 and then evaluating at leads to the (unsmoothed) convergence rate given in (4).
4.2 Sub-gamma Condition
Next, we provide a refined bound for distributions satisfying a sub-gamma tail condition.
Definition 2.
A random vector is said to be sub-gamma with variance parameter and scale parameter if
| (17) |
for all such that . If this condition holds with then is said to be sub-Gaussian with variance parameter .
Properties of sub-Gaussian and sub-gamma distributions have been studied extensively; see e.g, Boucheron et al. (2013). In particular, if and are independent sub-gamma random vectors with parameters and , respectively, then is sub-gamma with parameters .
The next result provides an upper bound on the moments of the magnitude of a sub-gamma vector. Although there is a rich literature this topic, we were unable to find a previous statement of this result and so it may be of independent interest.
Theorem 5.
Let be a sub-gamma random vector with parameters . For all
| (18) |
where is the -th moment of the chi distribution with degrees of freedom. Furthermore, where
| (19) |
Theorem 6.
In view of (15), Theorem 6 gives an upper bound on the convergence rate of with an explicit dependence on the sub-gamma parameters . For the special case of a sub-Gaussian distribution () and , this bound recovers the results in Goldfeld and Greenewald (2020). Going beyond the setting of sub-Gaussian distributions (i.e., ) this bound quantifies the dependence on the dimension and the scale parameter .
Phase transition in scale parameter.
In the high-dimensional setting where increases with , Theorem 6 exhibits two distinct regimes depending on the behavior of the scale parameter. Suppose that are fixed while scales with . If for some then grows at most exponentially with the dimension:
| (21) |
Conversely if for then the upper bound increases faster than exponentially:
The following example provides a specific example of a sub-gamma distribution which shows that the upper bound in Theorem 6 is tight with respect to the scaling of the dimension and the scale parameter . Full details of this example are provided in Appendix C.2.
Example 1.
Suppose that where is a standard Gaussian vector and is an independent Gamma random variable with shape parameter and scale parameter . Then, satisfies the sub-gamma condition with parameters and so the upper bound in Theorem 6 applies. Moreover, for every pair the expectation of the two-moment kernel satisfies the following lower bound
| (22) |
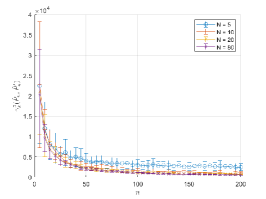
The bounds on given in (20) and (22) are shown in Figure 1 as a function of for various values of . The plot demonstrates a phase transition at the critical value of . Further computational results on this example are given in Section 5.1.

4.3 Dependent Samples
Motivated by applications involving Markov chain Monte Carlo there is significant interest in understanding the rate of convergence when there is dependence in the samples. Within the literature, this question is often address by focusing on stationary sequences satisfying certain mixing conditions Peligrad (1986). The basic idea is that the dependence between and decays rapidly as increases, then the effect of the dependence is negligible.
To go beyond the usual mixing conditions, a particularly useful property of the kernel MMD distance is that the second moment of depends only on the pairwise correlation in the samples. This perspective is useful for settings where there may not be a natural notion of time.
To make things precise, suppose that is a collection of (possibly dependent) samples with identical distribution . For each let denote the law of . Starting with (5), the expectation of the squared MMD can now be decomposed as
| (23) |
where . Notice that the first term in this decomposition is the second moment under independent samples. The second term is non-negative and depends only on the pairwise dependence, i.e., the difference between and the probability measure obtained by the product of its marginals.
In some cases, it is natural to argue that only a small number of the terms are nonzero. More generally it is desirable to provide guarantees in terms of measures of dependence that do not rely on the particular choice of kernel. The next result provides such a bound in terms of the Hellinger distance.
Lemma 7.
If , then
where denotes the Hellinger distance.
The following example is inspired by random feature kernel interpretation of neural networks Rahimi and Recht (2008).



Example 2.
Let be a -valued Gaussian processes with mean zero and covariance function . Suppose that samples from are generated according to where are points on the unit sphere and is a function that maps a standard Gaussian vector into a vector with distribution . Because Hellinger distance is non-increasing under the mapping given by , it can be verified that
Thus, by (23) and Lemma 7, there exists a constant depending only on such that
| (24) |
This inequality holds for any set of points . To gain insight into the typical scaling behavior when the samples are nearly orthogonal on average, let us suppose that the are drawn independently from the uniform distribution on the sphere. Then, and by, standard concentration arguments, one finds that the following upper bound holds with high probability when is large:
| (25) |
5 Numerical Results
In this section, we compute the upper bounds of GOT distance provided by the the empirical kernel MMD distance.



5.1 Bounds under Sub-gamma Condition
The sub-gamma condition allow us to address distributions that do not satisfy the sub-Gaussian condition. Upper bounds on the convergence rate for this class of distributions follow from Theorem 3 combined with Theorem 6.
For sub-gamma as in Example 1, has upper bound (UB) and lower bound (LB) as in (20) and (22) respectively. Here, in addition to the theoretical UB and LB as shown in Figure 1, we also compute the estimate of approximated by the two-sample estimator. Let and be the empirical measure defined as in (13) for independent iid copies of the sub-gamma random vector as in Example 1, and , respectively. Define , and then . Because the empirical kernel MMD (squared) distance can be computed numerically from the two samples of sub-gamma random vectors, we can estimate the expectation of by empirical average over Monte-Carlo replicas. Detailed numerical techniques to compute the two-moment kernel and experimental setup are provided in the appendix.
The results are shown in Figure 2, where we set the parameter controlling the shape and scale of as , . The data dimension takes multiple values, and the kernel bandwidth takes values 1 and 4. In both cases, the left plot shows the same information as Figure 1 in view of increasing , so as to be compared to the right plot. The right plot focuses on the case of small , where the empirical estimates of observe the UB. Notably, these values also lie between the UB and LB (recall that the LB applies to but not ) for both cases of , and approach the LB when . This shows that our theoretical UB captures an important component of the kernel MMD distances for this example of .
5.2 Dependent Samples via Gaussian Process
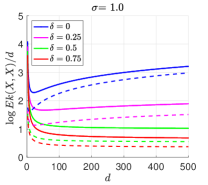
We generate dependent samples following a Gaussian process as in Example 2 in Section 4.3, and numerically compute the values of by its two-sample version , using the same kernel as in the first experiment. Theoretically, when is large, is expected to concentrate at its mean value as in (24), and then since are uniformly sampled on the -sphere, we also expect concentration at the value of (25).
We set , and vary from 5 to 100. The data are in dimension , the kernel parameters are , , , and for each value of and , are computed for 100 realizations of the dependent random variables , conditioned on one realization of the vectors ’s. The results are shown in Figure 3, where for the small values of , the computed approximate values of are decreasing because they are dominated by the contribution from the dependence in the samples, namely the part that is upper-bounded by the second term depending on in (24). As increases, these values converge to certain positive value which decrease as increases.
Specifically, we take the average over the mean values of for as an estimate of the limiting values, and Figure 3 (right) shows that these values decay as , as they correspond to the first term in (24). These numerical results show the competing two factors as predicted by the analysis in Section 4.3.
6 Conclusion and Discussion
The paper proves new convergence rates of GOT under general settings. Our results require only a finite moment condition and in the special case of sub-gamma distributions, we quantify the dependence on the dimension and show a phase transition with respect to the scale parameter. Furthermore, our results cover the setting of dependent samples where convergence is proved only requiring a condition on pairwise sample dependence expressed by the kernel. Throughout our analysis, the main theoretical technique is to establish an upper bound using a kernel MMD where the kernel is called a “two-moment” kernel due to its special properties. The kernel depends on the cost function of the OT as well as the Gaussian smoothing used in GOT.
For the tightness of the kernel MMD upper bound, as has been pointed out in the comment beneath Theorem 1, our result shows that the convergence rate of is tight in some regimes where with and the result matches the minimax rate in the unsmoothed OT setting. Alternatively, if is bounded away from zero then it may be possible to obtain a better rate of convergence. For example, Proposition 6 in Goldfeld et al. (2020b) shows that if the pair satisfies an additional chi-square divergence condition, then converges at rate , which is faster than the general upper bound of appearing in our paper. In this direction, pinning down the exact convergence rate in terms of regularity conditions on remains an interesting open question for future work. In addition, it would be interesting to investigate the relationship between the Gaussian smoothing used in this paper and the multiscale representation of in terms of partitions of the support of , which was used in the analysis in Fournier and Guillin (2015) as well as the related work Weed et al. (2019).
In practice, the tightness of the kernel MMD upper bound also depends on the choice of kernel, which can be optimized for the data distribution and the level of smoothing in GOT. The question of whether the kennel MMD provides a useful alternative to OT distance in applications can be worthwhile of further investigation. Finally, another important direction of future work is to study computational methods and applications of the GOT approach, particularly in the high dimensional space. Currently, no specialized algorithm for GOP from finite samples has been developed, except for the direct method of applying any OT algorithm, e.g., entropy OT (Sinkhorn), to data with additive Gaussian noise Goldfeld and Greenewald (2020). Progress on the computational side will also enable various applications of GOT, e.g., the evaluation of generative models in machine learning.
References
- Abid and Gower (2018) Brahim Khalil Abid and Robert M Gower. Greedy stochastic algorithms for entropy-regularized optimal transport problems. arXiv preprint arXiv:1803.01347, 2018.
- Anderson et al. (1994) Niall H Anderson, Peter Hall, and D Michael Titterington. Two-sample test statistics for measuring discrepancies between two multivariate probability density functions using kernel-based density estimates. Journal of Multivariate Analysis, 50(1):41–54, 1994.
- Bhushan Damodaran et al. (2018) Bharath Bhushan Damodaran, Benjamin Kellenberger, Rémi Flamary, Devis Tuia, and Nicolas Courty. Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 447–463, 2018.
- Bigot et al. (2019) Jérémie Bigot, Elsa Cazelles, Nicolas Papadakis, et al. Central limit theorems for entropy-regularized optimal transport on finite spaces and statistical applications. Electronic Journal of Statistics, 13(2):5120–5150, 2019.
- Bonneel et al. (2015) Nicolas Bonneel, Julien Rabin, Gabriel Peyré, and Hanspeter Pfister. Sliced and radon wasserstein barycenters of measures. Journal of Mathematical Imaging and Vision, 51(1):22–45, 2015.
- Boucheron et al. (2013) Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. Concentration inequalities: A nonasymptotic theory of independence. Oxford university press, 2013.
- Chakrabarty and Khanna (2020) Deeparnab Chakrabarty and Sanjeev Khanna. Better and simpler error analysis of the sinkhorn–knopp algorithm for matrix scaling. Mathematical Programming, pages 1–13, 2020.
- Chen and Niles-Weed (2020) Hong-Bin Chen and Jonathan Niles-Weed. Asymptotics of smoothed wasserstein distances. arXiv preprint arXiv:2005.00738, 2020.
- Chwialkowski et al. (2015) Kacper P Chwialkowski, Aaditya Ramdas, Dino Sejdinovic, and Arthur Gretton. Fast two-sample testing with analytic representations of probability measures. In Advances in Neural Information Processing Systems, pages 1981–1989, 2015.
- Courty et al. (2016) Nicolas Courty, Rémi Flamary, Devis Tuia, and Alain Rakotomamonjy. Optimal transport for domain adaptation. IEEE transactions on pattern analysis and machine intelligence, 39(9):1853–1865, 2016.
- Cuturi (2013) Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In Advances in neural information processing systems, pages 2292–2300, 2013.
- Epps and Singleton (1986) TW Epps and Kenneth J Singleton. An omnibus test for the two-sample problem using the empirical characteristic function. Journal of Statistical Computation and Simulation, 26(3-4):177–203, 1986.
- Fernández et al. (2008) V Alba Fernández, MD Jiménez Gamero, and J Muñoz García. A test for the two-sample problem based on empirical characteristic functions. Computational statistics & data analysis, 52(7):3730–3748, 2008.
- Feydy et al. (2019) Jean Feydy, Thibault Séjourné, François-Xavier Vialard, Shun-ichi Amari, Alain Trouvé, and Gabriel Peyré. Interpolating between optimal transport and mmd using sinkhorn divergences. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 2681–2690, 2019.
- Fournier and Guillin (2015) Nicolas Fournier and Arnaud Guillin. On the rate of convergence in Wasserstein distance of the empirical measure. Probability Theory and Related Fields, 162(3):707–738, 2015. doi: 10.1007/s00440-014-0583-7.
- Fukumizu et al. (2008) Kenji Fukumizu, Arthur Gretton, Xiaohai Sun, and Bernhard Schölkopf. Kernel measures of conditional dependence. In Advances in neural information processing systems, pages 489–496, 2008.
- Genevay et al. (2019) Aude Genevay, Lénaic Chizat, Francis Bach, Marco Cuturi, and Gabriel Peyré. Sample complexity of sinkhorn divergences. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 1574–1583. PMLR, 2019.
- Gerber and Maggioni (2017) Samuel Gerber and Mauro Maggioni. Multiscale strategies for computing optimal transport. The Journal of Machine Learning Research, 18(1):2440–2471, 2017.
- Goldfeld and Greenewald (2020) Ziv Goldfeld and Kristjan Greenewald. Gaussian-smoothed optimal transport: Metric structure and statistical efficiency. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Palermo, Italy, 2020.
- Goldfeld et al. (2018) Ziv Goldfeld, Ewout van den Berg, Kristjan Greenewald, Igor Melnyk, Nam Nguyen, Brian Kingsbury, and Yury Polyanskiy. Estimating information flow in deep neural networks. arXiv preprint arXiv:1810.05728, 2018.
- Goldfeld et al. (2020a) Ziv Goldfeld, Kristjan Greenewald, and Kengo Kato. Asymptotic guarantees for generative modeling based on the smooth wasserstein distance. Advances in Neural Information Processing Systems, 33, 2020a.
- Goldfeld et al. (2020b) Ziv Goldfeld, Kristjan Greenewald, Jonathan Niles-Weed, and Yury Polyanskiy. Convergence of smoothed empirical measures with applications to entropy estimation. IEEE Transactions on Information Theory, 66(7):4368–4391, July 2020b.
- Gretton et al. (2005) Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. Measuring statistical dependence with hilbert-schmidt norms. In International conference on algorithmic learning theory, pages 63–77. Springer, 2005.
- Gretton et al. (2012) Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test. Journal of Machine Learning Research, 13(Mar):723–773, 2012.
- Jitkrittum et al. (2016) Wittawat Jitkrittum, Zoltán Szabó, Kacper P Chwialkowski, and Arthur Gretton. Interpretable distribution features with maximum testing power. In Advances in Neural Information Processing Systems, pages 181–189, 2016.
- Johnson et al. (1995) Norman L Johnson, Samuel Kotz, and Narayanaswamy Balakrishnan. Continuous univariate distributions. John Wiley & Sons, Ltd, 1995.
- Klatt et al. (2020) Marcel Klatt, Carla Tameling, and Axel Munk. Empirical regularized optimal transport: Statistical theory and applications. SIAM Journal on Mathematics of Data Science, 2(2):419–443, 2020.
- Lei et al. (2020) Jing Lei et al. Convergence and concentration of empirical measures under wasserstein distance in unbounded functional spaces. Bernoulli, 26(1):767–798, 2020.
- Li et al. (2017) Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos. Mmd gan: Towards deeper understanding of moment matching network. In Advances in Neural Information Processing Systems, pages 2203–2213, 2017.
- Li et al. (2018) Wuchen Li, Ernest K Ryu, Stanley Osher, Wotao Yin, and Wilfrid Gangbo. A parallel method for earth mover’s distance. Journal of Scientific Computing, 75(1):182–197, 2018.
- Li et al. (2015) Yujia Li, Kevin Swersky, and Rich Zemel. Generative moment matching networks. In International Conference on Machine Learning, pages 1718–1727, 2015.
- Luise et al. (2018) Giulia Luise, Alessandro Rudi, Massimiliano Pontil, and Carlo Ciliberto. Differential properties of sinkhorn approximation for learning with wasserstein distance. In Advances in Neural Information Processing Systems, pages 5859–5870, 2018.
- Mena and Niles-Weed (2019) Gonzalo Mena and Jonathan Niles-Weed. Statistical bounds for entropic optimal transport: sample complexity and the central limit theorem. In 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), 2019.
- Muandet et al. (2017) K. Muandet, K. Fukumizu, B. Sriperumbudur, and B. Schölkopf. Kernel Mean Embedding of Distributions: A Review and Beyond. 2017.
- Niles-Weed and Berthet (2019) Jonathan Niles-Weed and Quentin Berthet. Minimax estimation of smooth densities in wasserstein distance, 2019.
- Peligrad (1986) Magda Peligrad. Recent advances in the central limit theorem and its weak invariance principle for mixing sequences of random variables (a survey). In Dependence in probability and statistics, pages 193–223. Springer, 1986.
- Peyré and Cuturi (2019) Gabriel Peyré and Marco Cuturi. Computational Optimal Transport, volume 11 of 355-607. Foundations and Trends in Machine Learning, 2019.
- Rabin et al. (2011) Julien Rabin, Gabriel Peyré, Julie Delon, and Marc Bernot. Wasserstein barycenter and its application to texture mixing. In International Conference on Scale Space and Variational Methods in Computer Vision, pages 435–446. Springer, 2011.
- Rahimi and Recht (2008) Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Advances in neural information processing systems, pages 1177–1184, 2008.
- Reeves (2020) Galen Reeves. A two-moment inequality with applications to rényi entropy and mutual information. Entropy, 22(11), 2020.
- Ryu et al. (2018) Ernest K Ryu, Yongxin Chen, Wuchen Li, and Stanley Osher. Vector and matrix optimal mass transport: theory, algorithm, and applications. SIAM Journal on Scientific Computing, 40(5):A3675–A3698, 2018.
- Sejdinovic et al. (2013) Dino Sejdinovic, Bharath Sriperumbudur, Arthur Gretton, and Kenji Fukumizu. Equivalence of distance-based and rkhs-based statistics in hypothesis testing. The Annals of Statistics, pages 2263–2291, 2013.
- Shen et al. (2017) Jian Shen, Yanru Qu, Weinan Zhang, and Yong Yu. Wasserstein distance guided representation learning for domain adaptation. arXiv preprint arXiv:1707.01217, 2017.
- Singh and Póczos (2018) Shashank Singh and Barnabás Póczos. Minimax distribution estimation in Wasserstein distance, 2018. [Online]. Available https://arxiv.org/abs/1802.08855.
- Smola et al. (2007) Alex Smola, Arthur Gretton, Le Song, and Bernhard Schölkopf. A hilbert space embedding for distributions. In International Conference on Algorithmic Learning Theory, pages 13–31. Springer, 2007.
- Solomon et al. (2014) Justin Solomon, Raif Rustamov, Leonidas Guibas, and Adrian Butscher. Earth mover’s distances on discrete surfaces. ACM Transactions on Graphics (TOG), 33(4):67, 2014.
- Sriperumbudur et al. (2010) Bharath K Sriperumbudur, Arthur Gretton, Kenji Fukumizu, Bernhard Schölkopf, and Gert RG Lanckriet. Hilbert space embeddings and metrics on probability measures. The Journal of Machine Learning Research, 11:1517–1561, 2010.
- Villani (2003) Cédric Villani. Topics in optimal transportation. Number 58. American Mathematical Soc., 2003.
- Villani (2008) Cédric Villani. Optimal transport: old and new, volume 338. Springer Science & Business Media, 2008.
- Weed et al. (2019) Jonathan Weed, Francis Bach, et al. Sharp asymptotic and finite-sample rates of convergence of empirical measures in wasserstein distance. Bernoulli, 25(4A):2620–2648, 2019.
- Young and Dunson (2019) Alexander L Young and David B Dunson. Consistent entropy estimation for stationary time series. arXiv preprint arXiv:1904.05850, 2019.
- Zhang et al. (2012) Kun Zhang, Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Kernel-based conditional independence test and application in causal discovery. arXiv preprint arXiv:1202.3775, 2012.
- Zhao and Meng (2015) Ji Zhao and Deyu Meng. Fastmmd: Ensemble of circular discrepancy for efficient two-sample test. Neural computation, 2015.
Appendix A Upper Bounds on GOT
This section provides proofs of the upper bounds on the GOT provided in Section 3. For the convenience of the reader we repeat some of the necessary definitions. Recall that the feature map is defined by
| (A.1) |
where is the volume of the unit sphere in , is the standard Gaussian density on , and is a probability density function on that satisfies
| (A.2) |
for some and .
Lemma A.1.
The feature map in (A.1) defines a positive semidefinite kernel according to
| (A.3) |
Furthermore, this kernel can also be expressed as
| (A.4) |
where
| (A.5) |
and is the density of when with .
Proof.
First we establish that is square integrable. By the assumed lower bound in (A.2) and the fact that , we can write
| (A.6) |
This integral is the moment generating function of the non-central chi-square distribution with degrees of freedom and non-centrality parameter evaluated at . Under the assumption , this integral is finite.
To establish the form given in (A.4) we can expand the squares to obtain:
Since the first factor does not depend on , it follows that
In this case, we recognize the integral as the expectation of under the chi-distribution with degrees of freedom and parameter . ∎
A.1 Proof of Theorem 2
The following result is an immediate consequence of (Villani, 2008, Theorem 6.13) adapted to the notation of this paper.
Lemma A.2 ((Villani, 2008, Theorem 6.13)).
For any ,
| (A.7) |
where denotes the absolute variation the signed measure .
To proceed, let and denote the probability density functions of and , respectively. By Lemma A.2, the OT distance between and is bounded from above by the weighted total variation distance:
| (A.8) |
In the following we will show that provides an upper bound on the right-hand side of (A.8). To proceed, recall that the kernel MMD can be expressed as
| (A.9) |
where are iid and are iid . The assumptions and ensure that these expectations are finite, and so, by Fubini’s theorem, we can interchange the order of integration:
For each , it follows that
and this leads to
where . Combining this expression with (A.9) leads to
Finally, we note that is a probability density function on (it is non-negative and integrates to one) and so by Jensen’s inequality and the convexity of the square,
In view of (A.8), this establishes the desired result.
A.2 Proof of Theorem 3
The fact that the kernel MMD provides an upper bound on follows directly from Theorem 2. All the remains to be shown is that is integrable for any probability measure with finite -th moment, where . To this end, we note that by the triangle inequality,
for all . Under the assumptions on , we have and so there exists a constant such that
Thus, the existence of finite -th moment is sufficient to ensure that is integrable.
Appendix B Convergence Rate
This section provides proofs for the results in Section 4 of the main text as well as Theorem 1. To simplify the notation, we define and let where .
Let us first consider some properties of . Since the two moment kernel satisfies , it follows from the definition of that
| (A.10) |
Suppose that there exists numbers and such that
| (A.11) |
Choosing
| (A.12) |
leads to
| (A.13) |
In other words, optimizing the choice of results in an upper bound on that depends on only the geometric mean of the upper bounds on .
Lemma A.3.
Let be a random vector satisfying
| (A.14) |
for some function for . Then, if , (A.11) holds with
| (A.15) |
where .
Proof.
This result follows from Minkowski’s inequality, which gives
for all and the upper bound on in Theorem 5. ∎
B.1 Proof of Theorem 1
The result follows immediately by combining Theorem 4 and Equation (11) in the main text.
B.2 Proof of Theorem 4
By Lyapunov’s inequality and Minkowski’s inequality, it follows that for ,
where the last step holds because and the assumption . Thus, for , the bound in (A.13) becomes
Recalling that gives the stated result.
B.3 Proof of Theorem 5
Lemma A.4.
Let be a sub-gamma random vector with parameters . For all and ,
| (A.16) |
where . In particular, if , then
| (A.17) |
Proof.
Let where is independent of and distributed uniformly on the unit sphere in . Since is orthogonally invariant, it may be assumed that and thus is equal in distribution to . Therefore,
The variable has density function
and so the moments are given by
To bound the absolute moments of we use the basic inequality with , which leads to
for all . Noting that is equal in distribution to and then using the sub-gamma assumption along with the fact that is a unit vector yields
Combining the above displays yields (A.16).
Finally, under the specified value of it follows that
and plugging this expression back into the bound gives (A.17). ∎
Theorem 5 now follows as a corollary of Lemma A.4. Starting with (A.17) and using the basic inequality leads to
To simplify the expressions involving the Gamma functions we use the lower bound for , which leads to
Combining this bound with the expression above yields
This completes the proof of Theorem 5.
B.4 Proof of Theorem 6
Since is sub-gamma with parameters it follows that is sub-gamma with parameters . For we can apply Theorem 5 to obtain
Under the specified value of , it then follows from (A.13) that
| (A.18) |
To proceed, let and consider the decomposition
where
Using the basic inequalities and , the term can be bounded from above as follows:
Similarly, one finds that
Combining these bounds with the fact that leads to
Plugging this inequality back into (A.18) yields
| (A.19) |
Finally, by the lower bound and the basic inequality for we can write
Hence,
This bound holds for all . Evaluating with and recalling that gives the stated result.
B.5 Proof of Lemma 7
Note that is absolutely continuous with respect to and let denote the Radon-Nikodym derivative. Then
where the last step is by the Cauchy-Scharz inequality and we have used that fact that .
Next, since for any positive semidefinite kernel, it follows that
and thus the stated result follows from the assumption .
Appendix C Experimental Details and Additional Results
In this section, we provide details of the experiments in Section 5 of the main text and additional numerical results. Our experiments are based on the two-moment kernel given in Definition 1.
C.1 Numerical Computation of the Two-Moment Kernel
To evaluate the two-moment kernel given in Definition 1 we need to numerically compute the function , which is the -th moment of the non-central chi-distribution with degrees of freedom and parameter . For all , this function can be written as a Poisson mixture of the (central) moments according to
| (A.20) |
This series can be approximated efficiently by retaining only the terms with .
Alternatively, if where is an integer, then is the -th moment of the chi-square distribution with degrees of freedom and non-centrality parameter . The integer moments of this distribution can be obtained by differentiating the moment generating function. An explicit formula is given by (Johnson et al., 1995, pg. 448)
| (A.21) |
Here we see that is a degree polynomial in .
Accordingly, for any tuple such that are even integers, the two-moment kernel defined in (11) can be expressed as
| (A.22) |
where and the coefficients are given by
| (A.23) |
with .
C.2 Details for Example 1
We now consider Example 1, a specific example of a sub-gamma distribution which shows that the upper bound in Theorem 6 is tight with respect to the scaling of the dimension and the scale parameter . Specifically, let where is a standard Gaussian vector and is an independent Gamma random variable with shape parameter and scale parameter .
Lemma A.5.
For such that , it holds that
| (A.24) |
In particular, this means that is a sub-gamma random vector with parameters . Furthermore, for ,
| (A.25) |
Proof.
Observe that where . Hence
Recognizing the right-hand side as the moment generating function of the Gamma distribution evaluated at yields (A.24). To see that this distribution satisfies the sub-gamma condition, we use the basic inequality for all .
The expression for the moments follows immediately from the independence of and and the fact that has Gamma distribution with shape parameter and scale parameter , which implies that has a chi distribution with degrees of freedom. ∎
Since satisfies the sub-gamma condition with parameters the upper bound in Theorem 6 applies. Alternatively, for each pair we can consider the exact expression for given in (A.10) where and
Minimizing this expression with respect to yields
| (A.26) |
To get a lower bound on the moments, we use
| (A.27) |
Combining the above displays leads to (22). Using Stirling’s approximation as it can be verified that the minimum of this lower bound with respect to satisfies the same scaling behavior with respect to as the upper bound in Theorem 6. Namely, the bound exponential in if and superexponential in if .
C.3 Experiments in Section 5.1
In this experiment, , the random variable is generated according to the distribution in Example 1, and the kernel bandwidth takes values and . The parameters of the two-moment kernel are specified as in Theorem 6 with parameters , and can be computed as in Appendix C.1.
In the Monte-Carlo computation of the average of (the right column of Figure 2), samples of are partitioned into two independent datasets and , each having samples. The kernel MMD (squared) distance has the empirical estimator Gretton et al. (2012)
and then, by definition,
Recall that
and then
Thus, if we define
the expectation of equals .
C.4 Experiments in Section 5.2
In this experiment, , , and the parameters of the two-moment kernel are specified as in Theorem 6 with parameters . Figure 3 in the main text plots the values of as a function of increasing and for various values of . Figure A.1 plots as a function of increasing and for various values of . Note that in this setting, the typical correlation between samples is of magnitude , and thus the overall dependence is not negligible when is relatively small compared to .