WGMwgm\xspace \csdefQEqe\xspace
mode=titleContrastive Variational Information Bottleneck for Aspect-Based Sentiment Analysis
M. Chang et al.
[style=Chinese] \creditConceptualization, Methodology, Software, Writing – original draft
[style=Chinese] \cormark[1] \creditConceptualization, Methodology, Supervision, Writing – review & editing
[style=Chinese] \creditWriting – review & editing
[style=Chinese] \creditWriting – review & editing
[1] organization=Shenzhen Institutes of Advanced Technology, addressline=Chinese Academy of Sciences, city=Shenzhen, country=China
[2] organization=University of Chinese Academy of Sciences, city=Beijing, country=China
[3] organization=School of Computer Science and Technology, addressline=Harbin Institute of Technology (Shenzhen), city=Shenzhen, country=China
Contrastive Variational Information Bottleneck for Aspect-Based Sentiment Analysis
Abstract
Deep learning techniques have dominated the literature on aspect-based sentiment analysis (ABSA), achieving state-of-the-art performance. However, deep models generally suffer from spurious correlations between input features and output labels, which significantly hurts the robustness and generalization capability. In this paper, we propose to reduce spurious correlations for ABSA, via a novel Contrastive Variational Information Bottleneck framework (called CVIB). The proposed CVIB framework is composed of an original network and a self-pruned network, and these two networks are optimized simultaneously via contrastive learning. Concretely, we employ the Variational Information Bottleneck (VIB) principle to learn an informative and compressed network (self-pruned network) from the original network, which discards the superfluous patterns or spurious correlations between input features and prediction labels. Then, self-pruning contrastive learning is devised to pull together semantically similar positive pairs and push away dissimilar pairs, where the representations of the anchor learned by the original and self-pruned networks respectively are regarded as a positive pair while the representations of two different sentences within a mini-batch are treated as a negative pair. To verify the effectiveness of our CVIB method, we conduct extensive experiments on five benchmark ABSA datasets. The experimental results show that our approach achieves better performance than the strong competitors in terms of overall prediction performance, robustness, and generalization.
Sentiment analysis , Aspect-level sentiment analysis , Spurious correlations , Variational information bottleneck , Contrastive learning
1 Introduction
With the growing abundance of opinion-rich content on the Web, aspect-based sentiment analysis (ABSA), which aims to identify the sentiment polarity of a sentence towards a given aspect, has attracted great attention from both academic and industrial communities. Conventional ABSA methods mainly employ supervised machine learning techniques involving various hand-crafted features such as syntactic features [1], parse trees [2], and lexical features [1], to predict the sentiment polarity. However, the process of feature engineering is labor-intensive and the hand-crafted features cannot be adapted to new domains easily.
In recent years, deep learning techniques have emerged as the mainstream in the literature on ABSA. Prominent deep neural networks can be trained end-to-end to automatically learn semantically distinguishable representations for both the aspect and context without manual annotation. To capture crucial sentiment information related to the target aspect, various attention mechanisms [3, 4, 5, 6, 7, 8, 9] have been proposed to model the interactions between the aspect and its context. Subsequently, several studies leveraged syntactic knowledge and graph neural networks to capture syntax-aware features for the target aspect explicitly [10, 11, 12, 13, 14, 15, 16], to improve the performance of the ABSA models. More recently, there has been a notable application of pre-trained language models (PLMs) such as BERT [17] and RoBERTa [18] to learn effective task-specific representations [19, 20, 13, 21, 22, 23], yielding state-of-the-art results for ABSA.
Despite the remarkable progress, deep ABSA models are notoriously brittle to learn statistically spurious correlations between learned patterns and prediction labels [24, 25]. The spurious correlations are defined as the superficial feature patterns that hold for most training examples but are not inherent to the task of interest. As shown in Fig. 1, we provide an example of the online restaurant review to illustrate the spurious correlation problem that existed in ABSA. Based on our empirical observation, in the training phase, the deep models tend to learn the high correlations between the context words “never had” and the sentiment polarity label “Positive” without taking the aspect words into consideration. That is, the models may be “right for the wrong reasons” due to the reliance on the spurious correlation between the presence of context words “never had” and the label “Positive”. Consequently, the learned sentiment classifier would fail to predict the correct sentiment label “Neutral” for the testing instance where the spurious correlation does not hold. Under such an inductive bias, a deep ABSA model usually learn sub-optimal feature representations, especially for the under-represented classes (the long-tail samples), which significantly hurts the robustness and generalization capability.
One possible solution to mitigate the spurious correlation problem in ABSA is to prune spurious features from an information bottleneck perspective. The key idea is to automatically learn the essential contextual representations that contain minimal relevant information about the inputs while preserving sufficient information for label prediction, making the deep models more robust and generalized against statistically spurious correlations. In particular, the Variational Information Bottleneck (VIB) is a technique in information theory [26] for suppressing irrelevant features, which minimizes the mutual information (MI) between the inputs and internal representations while maximizing the MI between the outputs and the representations. We hypothesize that VIB can mitigate the overfitting problem and provide an advantageous inductive bias for the target tasks, thus resulting in better robustness and generalization to challenging out-of-domain data. However, VIB is computationally intractable due to the non-differentiable categorical sampling, severely limiting the application of the VIB principle in ABSA. In addition, deep ABSA models generally struggle to characterize challenging long-tail samples. Devising a strategy to extract the inherent characteristics of each class and distinguish different classes is a potentially fruitful research direction for improving the robustness and generalization capability.

To tackle the aforementioned challenges, we propose a Contrastive Variational Information Bottleneck framework (called CVIB) to mitigate the spurious correlation problem for the ABSA task, aiming at improving the robustness and generalization capability of the deep ABSA method. The proposed CVIB framework prevents the deep ABSA model from capturing spurious correlation even without prior knowledge of the biased information by simultaneously considering information compression and retention from the information-theoretic perspective. Concretely, CVIB is composed of an original network and a self-pruned network, which are optimized simultaneously via contrastive learning. The self-pruned network is learned adaptively from the original network based on the Variational Information Bottleneck principle, which is expected to discard the spurious correlations while preserving sufficient information about the sentiment labels. A self-pruning contrastive loss is then devised to optimize the two networks and improve the separability of all the classes, which narrows the distance between the representations of each anchor produced by the self-pruned and original networks while pushing apart the distance between the representations of different instances within a mini-batch. Consequently, the self-pruned network reduces the spurious correlations, making it easier for the ABSA classifier to avoid overfitting. The main contributions of this paper are listed as follows:
-
1.
We propose a CVIB framework to reduce spurious correlations between input features and output labels without prior knowledge of such correlations, which improves the robustness and generalization capability of the deep ABSA model by taking advantage of both VIB and contrastive learning.
-
2.
We devise self-pruning contrastive learning to extract truly essential semantically relevant features and effectively generalize to long-tail instances by learning the inherent class characteristics.
-
3.
We conduct extensive experiments on five benchmark datasets, showing that the proposed CVIB method achieves better performance than the strong baselines in terms of overall prediction performance, robustness, and generalization.

2 Related Work
2.1 Aspect-based Sentiment Analysis Using Deep Learning
Aspect-based sentiment analysis (ABSA) stands as a vital task in the field of sentiment analysis. The goal of ABSA is to automatically detect the sentiment polarity of the input sentence towards a given aspect. Currently, deep neural networks have become the predominant methods in ABSA due to their impressive performance. Early deep ABSA methods concentrated on crafting diverse attention mechanisms to implicitly capture the semantic relationship between the given aspect and its context by learning attention-based representations [3, 6, 5, 7, 9, 8, 27]. Wang et al. [3] introduced attention-based LSTMs to capture relevant sentiment information from the context concerning the target aspect. Wang and Lu [27] proposed a segmentation attention mechanism to capture the structural dependencies between the target aspect and its context words. Ma et al. [6] devised an interactive attention mechanism to interactively learn the attention-aware representations of the target aspect and its context.
Another research trend involves explicitly capturing syntax-aware features for the target aspect by leveraging syntactic knowledge and graph neural networks [10, 11, 12, 13, 14, 28, 16, 15, 29]. The fundamental concept behind these methods is to construct the syntax dependency tree for a sentence and convert it into a graph. Subsequently, graph convolutional networks (GCNs) [11, 12, 14, 28, 16, 29] or graph attention networks (GATs) [10, 13, 15] are employed to aggregate sentiment information from the neighboring context nodes to the target aspect node.
More Recently, the pre-trained language models (PLMs), such as BERT [17] and RoBERTa [18], have been applied to ABSA, achieving state-of-the-art performance [19, 20, 13, 30, 22, 21, 23]. These methods either incorporated BERT/RoBERTa as an embedding layer [20, 13] or fine-tuned specific BERT/RoBERTa-based models with a classification layer [31, 30, 22]. In this way, extensive linguistic knowledge learned from large textual corpora can be exploited to improve the performance of ABSA. However, these deep ABSA models are susceptible to spurious correlations between input features and output labels, resulting in poor robustness and generalization capability. In this paper, our main emphasis is on reducing spurious correlations to learn a more robust and generalizable ABSA model.
2.2 Spurious Correlation Reduction in NLP
Deep neural networks, although powerful, generally present a tendency to learn spurious correlations and suffer from the overfitting issue on manually-annotated datasets [32, 33, 34, 35, 36, 37]. This challenge is evident across a wide range of NLP tasks, including natural language inference [33, 36], question answering [32] and reading comprehension [34], making the trained models unstable and cannot generalize well to out-of-distribution [38, 39] or open-set data [40] in real-world scenarios.
To address these challenges, some studies proposed to explicitly reduce the spurious correlations present in the original datasets by removing the data biases [41, 42, 43, 44, 45, 46]. For instance, Zellers et al. [41] employed adversarial filtering methods to create debiased datasets, mitigating spurious artifacts present in the original training data. Nie et al. [44] generated additional samples for the original training samples that exhibited vulnerability to spurious correlations through an iterative human-in-the-loop process. In parallel, several model-centered approaches [47, 48, 49, 50, 51, 52] built models dedicated to capturing spurious features in the training data and utilized re-weighting strategies to train debiased models based on the detected spurious correlations. For example, Clark et al. [47] introduced a low-capacity model to capture shallow patterns and down-weighted them in the training objective via ensemble learning, facilitating the learning of a more robust model. Stacey et al. [53] devised a bias-only classifier to capture spurious features and deterred the hypothesis encoder from learning them, which in turn updated the classifier through an adversarial learning approach.
More recently, there has been an increasing focus on mitigating overfitting issues from an information-theoretic perspective [54, 55, 56, 57]. For example, Mahabadi et al. [57] employed the variational information bottleneck (VIB) principle to eliminate irrelevant features from learned representations, enhancing generalization to out-of-domain data. Tian et al. [54] introduced disentangled semantic representations for minority samples (i.e., long-tail samples), utilizing mutual information to alleviate surface patterns prevalent in majority samples.
In this paper, we employ the variational information bottleneck (VIB) principle to automatically reduce spurious or redundant information. Additionally, we devise a self-pruning contrastive learning to extract more semantically relevant features, improving the separability of all sentiment classes. Our goal is to reduce spurious correlations to improve the robustness and generalization capability of ABSA. Furthermore, we offer a potential solution for out-of-distribution detection and open-set learning from an information-theoretical perspective.
3 Methodology
We assume there are instances in the training set, where each instance contains a context text with words and a target aspect with words. (or ) denotes the -th word in the context (or target aspect). Each instance has a sentiment category label , where stands for the number of sentiment categories. The goal of ABSA is to predict the sentiment polarity towards the target aspect given the input instance .
Fig. 2 illustrates the overview of the proposed CVIB framework. CVIB is composed of an original network and a self-pruned network , which are optimized simultaneously via contrastive learning. Here, and represent the parameter sets of the original and self-pruned networks, respectively. In particular, the self-pruned network is compressed adaptively from the original network based on the Variational Information Bottleneck principle, which is expected to discard the spurious correlations between input features and output prediction. A self-pruning contrastive loss is then devised to optimize the two networks and improve the separability of all the sentiment classes. Next, we will describe the original network, the self-pruned network, and the self-pruning contrastive learning in detail.
3.1 The Original Network
Inspired by the remarkable success of pre-trained language models (PLMs), we employ BERT [17] as our base text encoder to learn the semantic representations of the target aspect and its context for sentiment prediction. In addition, following the previous work [13], we also leverage a relational graph attention network to capture the aspect-oriented syntactic structure of the sentence.
3.1.1 Base BERT Encoder
Given a sequence of context words and the corresponding target , we adopt the pre-trained language model BERT [17] as the base text encoder and take the formatted sequence as the input, where the special tokens [CLS] and [SEP] represent the classification token and the separation token respectively. The task-relevant features can be captured through successive layers of BERT, in which the -th layer can be calculated as:
| (1) | |||
| (2) |
where represents the output hidden representations of the -th BERT layer () and is the number of the BERT layers. denotes the -th item in .
3.1.2 Relational Graph Attention Network
We employ a relational graph attention network (denoted as R-GAT) [13] to capture the aspect-oriented syntactic dependency, which first converts different dependency relations into embeddings through an embedding layer and then incorporates them in computing multi-head relational attention to obtaining syntax-aware representations . For simplicity, we denote the computation of R-GAT as:
| (3) |
where and denote the output representations from the BERT encoder and the R-GAT network, respectively.
3.1.3 Aspect-based Sentiment Prediction
The final representation is formed by concatenating the output representation of the first token [CLS] from the BERT encoder and the output syntactic-aware representation of the target aspect from the R-GAT network, which is denoted as:
| (4) |
Then, we feed into a multi-layer perceptron (MLP) layer followed by a softmax layer to predict the sentiment distribution:
| (5) |
where is the predicted sentiment distribution. and are learnable parameters. Given a corpus with training samples , the parameters of the sentiment classifier are trained to minimize the standard cross-entropy loss function:
| (6) |
where and are the ground-truth and predicted sentiment probabilities, respectively. represents the set of learnable parameters of the original network .
3.2 The Self-pruned Network based on VIB
Spurious correlations are very common in deep models, especially when the ABSA classifier is over-parameterized. Spurious correlations could hurt the stability and generality of the ABSA classifier when deployed in practice. In this paper, we learn a self-pruned network adaptively from the original network based on the Variational Information Bottleneck (VIB) principle, which is expected to reduce the spurious correlations while preserving sufficient information for output prediction. To be specific, we aim to remove irrelevant or redundant information from hidden representations layer by layer. We learn a compressed self-pruned network from the original network via the self-pruning technique, improving the robustness and generalization capability.
3.2.1 Variational Information Bottleneck
The goal of VIB is to learn a compressed representation while retaining sufficient information in required for prediction. For the -th BERT layer, we minimize the mutual information between the input hidden states and the output hidden states to maximally reduce irrelevant information across BERT layers. Meanwhile, IB is also expected to maximize the mutual information between the compressed output hidden states and the target label so as to preserve sufficient task-relevant information for accurate prediction of . Mathematically, the layer-wise training objective of the self-pruned network is to minimize the following loss:
| (7) |
where indicates mutual information between two variables. The hyper-parameter controls compression-accuracy trade-off.
Unfortunately, mutual information is computationally intractable for general deep neural network architectures, making the optimization of Eq. (7) difficult. To conquer this challenge, the Variational Information Bottleneck (VIB) principle [58, 59] invokes tractable variational bounds as efficient approximations for the optimization objective. Similarly, we derive a variational upper bound for :
| (8) |
where . and are parametric variational approximation to and , respectively. Inside the expectation, the first KL divergence term aims to reduce superfluous information between adjacent layers, while the second term focuses on retaining sufficient task-relevant information for accurate sentiment prediction.
3.2.2 VIB-based Masking Layer
To reduce superfluous information from hidden representations, we add a masking layer into each adjacent BERT layer. Concretely, we apply a mask (denoted as ) to the output representations of each BERT layer . The mask is shared by the hidden vectors within each BERT layer, while different BERT layers have different masks. Formally, for the -th BERT layer, we calculate the mask and the compressed hidden representation as follows:
| (9) |
where denotes element-wise multiplication. and are learnable vectors. is a shared vector sampled from the normal distribution . indicates the -th BERT layer. With these definitions, the conditional layer-wise distribution can be specified as:
| (10) |
In addition, we assume that also follows a Gaussian distribution with a zero mean value and a variance vector , which can be learned out of the model. Then, we take the defined and into the KL term of Eq. (3.2.1) and calculate the KL divergence between two Gaussian distributions with the standard formula:
| (11) |
where is the dimension of hidden vectors . , are the -th element of the corresponding vectors.
Then, we calculate the gradient of Eq. (3.2.2) and set it equal to zero to find the optimal value of , which is denoted as :
Based on the above formula, we can observe that if an arbitrary element of is learned to be close to zero, the corresponding element of will be pushed towards a degenerate Dirac-delta and can be further pruned. Here, degenerate Dirac-delta means a deterministic distribution and takes only a single value (i.e., zero).
For simplicity, we denote and take the expression of back into Eq. (3.2.2). In this way, we can obtain:
| (12) |
where
| (13) |
and according to Jensen’s inequality, the value of is positive and close to zero when the variance of is small. Thus, it can be removed without affecting the results.
Then, the KL term in Eq. (3.2.1) has a tractable and closed-form approximation, which further simplifies defined in Eq. (3.2.1) as follows:
| (14) |
Therefore, the objective function of the self-pruned network is computed by summing up the loss of all BERT layers:
| (15) |
where represents the set of learnable parameters of the self-pruned network .
Consequently, the masking vectors can be learned to reduce spurious information from hidden representations during the training process. To be specific, while minimizing the inter-layer mutual information , we use the ratio as an indicator of superfluous information to push down the corresponding element (i.e. ) of hidden vectors to be zero with the confirmation that indicates the element does not carry any relevant information about the target and can be pruned (which has been proved in [60]). Different from the methods that utilize sparsity-prompting regularization for CNN and LSTM layers [60, 61], we employ it to large pre-trained language models with Transformer-based architecture such as BERT for self-pruning purpose.
Finally, we take the first [CLS] token representation of the compressed representations from the BERT encoder and concatenate it with the output syntactic-aware representation of the target aspect from the R-GAT network to form the final representation of the self-pruned network as .
3.3 Self-pruning Contrastive Learning
We design a self-pruning contrastive loss to optimize the two networks and improve the separability of all the classes, which narrows the distance between the representations of each anchor produced by the self-pruned and original networks while pushing apart the distance between the representations of different instances within a batch [62, 63, 64]. In this way, the learned pruned network is expected to extract essential semantically relevant features and effectively generalize to long-tail instances by learning the inherent class characteristics.
Specifically, for an anchor , we first obtain its representations learned by the original and self-pruned network respectively as a positive pair. Meanwhile, the representations of different input instances and within a mini-batch are treated as a negative pair. Here, is the size of the mini-batch. The objective function for self-pruning contrastive learning can be formally defined as follows:
| (16) |
where
| (17) |
where is the similarity metric function. indicates the cosine similarity between two representations. is the temperature hyper-parameter.
3.4 Joint Training Objective
We jointly train the original network and the self-pruned network in an iterative manner until convergence. At each iteration, we train the original network with objective , which combines the cross-entropy loss with self-pruning contrastive loss. Similarly, we train the self-pruned network with the objective which combines the VIB-based loss with the self-pruning contrastive loss. Mathematically, the objective functions and are defined as follows:
| (18) | |||
| (19) |
where , , represent the cross-entropy loss, the VIB-based loss, and the self-pruning contrastive loss, respectively. is a hyper-parameter to control the weights of the self-pruning contrastive loss for the original and self-pruned networks. Here, we set the value of to in our experiments.
For the self-pruned network, at the feed-forward stage, we sample from for masks and compute across all BERT layers . At the back-propagation stage, the overall parameters, including and will be updated.
| Dataset | Division | # Positive | # Neutral | # Negative |
|---|---|---|---|---|
| \multirow2*REST4 | Train | 2164 | 637 | 807 |
| Test | 728 | 196 | 196 | |
| \multirow2*LAP14 | Train | 994 | 464 | 870 |
| Test | 341 | 169 | 128 | |
| \multirow2*REST15 | Train | 912 | 36 | 256 |
| Test | 326 | 34 | 182 | |
| \multirow2*REST16 | Train | 1240 | 69 | 439 |
| Test | 469 | 30 | 117 | |
| \multirow3*MAMS | Train | 3380 | 5042 | 2764 |
| Dev | 403 | 604 | 325 | |
| Test | 400 | 607 | 329 | |
| REST14-ARTS | Test | 1953 | 473 | 1104 |
| LAP14-ARTS | Test | 883 | 407 | 587 |
3.5 Inference Stage
In the inference phase, given the back-propagation is disabled, we remove the original network and use the self-pruned network to perform sentiment prediction directly. Note that at the -th BERT layer, we merely use the mean vector without random sampling and mask the -th element when the value of is zero.
| \multirow2*Model | REST14 () | LAP14 () | REST15 () | REST16 () | MAMS () | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| ATAE-LSTM [3] | 77.20♯ | 67.02 | 68.70♯ | 63.93 | 78.48 | 60.53 | 83.77 | 61.71 | 72.60 | 71.67 |
| MemNet [4] | 80.95♯ | 69.64 | 72.37♯ | 65.17 | 77.31 | 58.28 | 85.44 | 65.99 | 67.89 | 67.29 |
| IAN [6] | 78.60♯ | 70.09 | 72.10♯ | 67.38 | 78.54 | 52.65 | 84.74 | 55.21 | 73.13 | 72.53 |
| MGAN [8] | 81.25♯ | 71.94♯ | 75.39♯ | 72.47♯ | 79.36 | 57.26 | 87.06 | 62.29 | 74.40 | 73.34 |
| TNet [65] | 80.69♯ | 71.27♯ | 76.54♯ | 71.75♯ | 78.47 | 59.47 | 89.07 | 70.43 | 75.15 | 74.45 |
| ASGCN [11] | 80.86♯ | 72.19♯ | 74.14♯ | 69.24♯ | 79.34♯ | 60.78♯ | 88.69♯ | 66.64♯ | 75.82 | 74.19 |
| CDT [12] | 82.30♯ | 74.02♯ | 77.19♯ | 72.99♯ | - | - | 85.58♯ | 69.93♯ | 74.25 | 73.02 |
| R-GAT [13] | 83.30♯ | 76.08♯ | 77.42♯ | 73.76♯ | 80.83 | 64.17 | 88.92 | 70.89 | 77.25 | 75.99 |
| BiGCN [66] | 81.97♯ | 73.48♯ | 74.59♯ | 71.84♯ | 81.16♯ | 64.79♯ | 88.96♯ | 70.84♯ | - | - |
| Sentic GCN [16] | 84.03♯ | 75.38♯ | 77.90♯ | 74.71♯ | 82.84♯ | 67.32♯ | 90.88♯ | 75.91♯ | 76.57 | 75.56 |
| BERT-SPC [19] | 84.11 | 76.68 | 77.59 | 73.28 | 83.48 | 66.18 | 90.10 | 74.16 | 83.98 | 83.41 |
| BERT-PT [31] | 84.95♯ | 76.96♯ | 78.07♯ | 75.08♯ | - | - | - | - | - | - |
| CapsNet-BERT [20] | 85.36 | 78.41 | 78.97 | 75.66 | 82.10 | 65.57 | 90.10 | 75.15 | 83.76 | 83.15 |
| TGCN-BERT [14] | 86.16♯ | 79.95♯ | 80.88♯ | 77.03♯ | 85.26♯ | 71.69♯ | 92.32♯ | 77.29♯ | 83.38♯ | 82.77♯ |
| \hdashlineASGCN[11]-BERT | 85.54 | 78.54 | 77.90 | 73.92 | 82.47 | 68.83 | 91.07 | 76.13 | 83.46 | 83.00 |
| w/ CVIB (Ours) | 86.43 | 80.02 | 80.41 | 76.62 | 84.50 | 71.42 | 91.72 | 78.95 | 84.28 | 83.87 |
| \hdashlineRGAT-BERT [13] | 86.60♯ | 81.35♯ | 78.21♯ | 74.07♯ | 83.22 | 69.73 | 89.71 | 76.62 | 82.71 | 82.21 |
| w/ CVIB (Ours) | 87.59 | 82.03 | 81.35 | 77.53 | 85.98 | 72.84 | 92.86 | 82.87 | 84.66 | 84.03 |
4 Experimental Setup
4.1 Datasets
We conduct our experiments on five widely used benchmark datasets: REST14 and LAP14 from [67], REST15 from [68], REST16 from [69], and MAMS from [20]. We adopt the official data splits, which are the same as in the original papers. To test the robustness of ABSA models, we incorporate the ARTS datasets [25], including REST14-ARTS and LAP14-ARTS, which extend the original REST14 and LAP14 testing datasets by applying three adversarial strategies: reversing the original sentiment of the target aspect (REVTGT), reversing the sentiment of the non-target aspects (REVNON), and generating more non-target aspects with opposite sentiment polarities from the target aspect (ADDDIFF). Each instance in these datasets consists of a review sentence, a target aspect, and the sentiment polarity (i.e., Positive, Negative, Neutral) towards the target aspect. The statistics of these used datasets are shown in Table 1.
4.2 Implementation Details
In the experiments, we adopt the official pre-trained uncased BERT-base111https://github.com/huggingface/transformers, which has layers and hidden dimensions. For the R-GAT network, we tune the number of relational self-attention heads varying from to , and the other parameters follow the default configuration of the original paper [13]. For the VIB-based self-pruning loss, we set for all layers, which is a simple yet effective choice in practice. The learnable vector is randomly initialized from a distribution and the logarithm of is sampled from . For the self-pruning contrastive loss, we set the hyper-parameter . We train all our models for 30 epochs with Adam optimizer, and the initial learning rate is . The learning rate for the parameters of the VIB-based masking is initialized, varying from to .
4.3 Baselines and Evaluation Metrics
We compare the proposed CVIB method with three kinds of strong baselines, including the attention-based methods: ATAE-LSTM [3], MemNet [4], IAN [6], MGAN [8], TNet [65]; the graph-based methods: ASGCN [11], CDT [12], R-GAT [13], BiGCN [66], Sentic GCN [16]; the BERT-based methods: BERT-SPC [19], BERT-PT [31], CapsNet-BERT [20], RGAT-BERT [13], TGCN-BERT [14], ASGCN-BERT [11].
To evaluate the performance of the ABSA models, we adopt two widely used metrics: Accuracy (Acc.) and macro-averaged F1 score (F1). To ensure the stability of our CVIB method, we run CVIB ten times with random initialization and report the averaged results.
| \multirow2*Model | REST14 () | LAP14 () | REST15 () | REST16 () | MAMS () | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| CVIB | 87.59 | 82.03 | 81.35 | 77.53 | 85.98 | 72.84 | 92.86 | 82.87 | 84.66 | 84.03 |
| w/o VIB | 84.82 | 78.70 | 78.97 | 74.44 | 84.50 | 67.05 | 89.45 | 76.14 | 83.28 | 83.81 |
| w/o SCL | 85.63 | 78.32 | 79.94 | 76.62 | 85.24 | 71.80 | 91.56 | 77.74 | 84.36 | 83.93 |
| w/o VIB+SCL | 84.38 | 77.71 | 78.37 | 73.45 | 83.22 | 69.73 | 89.71 | 76.62 | 82.71 | 82.21 |
5 Experimental Results
5.1 Main Results
The experimental results of the ABSA methods on five benchmark datasets are reported in Table 2. We observe that CVIB achieves the best performance against all baselines on the five datasets. The performance of attention-based ABSA methods (e.g., IAN, MGAN, TNet) is comparatively lower than that of graph-based and BERT-based methods. This discrepancy arises from the inherent limitations of attention mechanisms, which implicitly model relationships between the target aspect and its context. These mechanisms may learn incorrect associations or attend to irrelevant features for the target aspect, thus limiting the performance of ABSA. In contrast, graph-based methods leverage syntactic dependencies to explicitly model the aspect-context relationships, while BERT-based methods utilize pre-trained language models (PLMs) to learn contextually distinguishable representations for the target aspect. Notably, TGCN-BERT and RGAT-BERT outperform the other baselines by taking benefits of both the graph knowledge based on the syntactic dependencies and the rich linguistic knowledge contained in PLMs. Our proposed CVIB performs even better than the best-performing baseline RGAT-BERT, which is the backbone of our original network, in terms of all evaluation metrics, verifying the effectiveness of the CVIB framework. Furthermore, CVIB achieves consistent and substantial improvements when integrated with another strong baseline, namely ASGCN-BERT. These advancements demonstrate that our proposed CVIB framework can reduce spurious correlations between input features and output labels, thus enhancing the performance of the ABSA models.
5.2 Ablation Study
To investigate the impact of different components on the overall performance of our proposed method, we conduct an ablation study on the five ABSA datasets. Concretely, we perform two ablations: (1) removing the VIB-based pruning (denoted as “w/o VIB”) from CVIB by employing a random dropout strategy to train the self-pruned network; (2) removing the self-pruning contrastive learning (denoted as “w/o SCL”) by training a single network based on the VIB principle.
The ablation test results are reported in Table 3. The performance of CVIB drops sharply when discarding the VIB-based pruning. This aligns with our expectation since the VIB-based pruning enables the classifier to reduce spurious correlations between input features and output prediction, thus improving the robustness and generalization capability of the classifier. SCL also makes a considerable contribution to CVIB despite the slightly inferior results on certain datasets (e.g., REST16). One potential explanation is that solely employing SCL may lead to the reliance on spurious correlations for distinguishing different sentiment classes. It is no surprise that combining VIB-based pruning and SCL contributes to a significant improvement in CVIB. VIB can reduce spurious correlations between input features and output labels, and then SCL can further capture semantically relevant features from the learned representations, thus improving the separability of all the classes.
| Model | Acc. (OriNew) | Drop | F1 (OriNew) | Drop |
|---|---|---|---|---|
| REST14-ARTS () | ||||
| ATAE-LSTM | 77.20 58.45 | -18.75 | 67.02 49.65 | -17.37 |
| MemNet | 79.61 55.30 | -24.31 | 69.64 46.67 | -22.97 |
| IAN | 79.26 57.75 | -21.51 | 70.09 48.12 | -21.97 |
| ASGCN | 80.86 59.12 | -21.74 | 72.19 35.56 | -36.63 |
| R-GAT | 83.30 60.31 | -22.99 | 76.08 37.51 | -38.57 |
| BERT-SPC | 84.11 57.81 | -26.30 | 76.68 48.08 | -28.60 |
| CapsNet-BERT | 85.36 69.24 | -16.12 | 78.41 55.25 | -23.16 |
| RGAT-BERT | 86.60 71.64 | -14.96 | 81.35 60.10 | -21.25 |
| CVIB (Ours) | 87.59 77.48 | -10.11 | 82.03 71.74 | -10.29 |
| LAP14-ARTS () | ||||
| ATAE-LSTM | 68.70 51.33 | -17.37 | 63.93 46.11 | -17.82 |
| MemNet | 70.64 52.00 | -18.64 | 65.17 46.50 | -18.67 |
| IAN | 72.05 52.91 | -19.14 | 67.38 47.54 | -19.84 |
| ASGCN | 75.55 49.81 | -25.74 | 71.05 36.45 | -34.60 |
| R-GAT | 77.42 50.61 | -26.81 | 73.76 36.10 | -37.66 |
| BERT-SPC | 77.59 58.02 | -19.57 | 73.28 54.58 | -18.70 |
| CapsNet-BERT | 78.97 60.31 | -18.66 | 75.66 51.50 | -24.16 |
| RGAT-BERT | 78.21 66.30 | -11.91 | 74.07 55.68 | -18.39 |
| CVIB (Ours) | 81.35 73.21 | -8.14 | 77.53 70.47 | -7.06 |
| \multirow2*Set | REST14-ARTS () | LAP14-ARTS () | ||
|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | |
| FULL | 77.48 | 71.74 | 73.21 | 70.47 |
| REVTGT | 68.32 | 56.16 | 60.09 | 52.18 |
| REVNON | 74.32 | 57.54 | 78.52 | 62.87 |
| ADDDIFF | 79.20 | 71.79 | 74.92 | 69.99 |
5.3 Robustness Analysis
We evaluate the robustness of CVIB on Aspect Robustness Test Sets (ARTS) [25], which are constructed to test whether a model can robustly capture the aspect-relevant information to distinguish the sentiment towards the target aspect from the non-target aspects. ARTS extends the original test sets of REST14 and LAP14 corpora by applying three adversarial strategies: reversing the original sentiment of the target aspect (REVTGT), reversing the sentiment of the non-target aspects (REVNON), and generating more non-target aspects with opposite sentiment polarities from the target aspect (ADDDIFF). Since CVIB focuses on reducing spurious correlations (e.g., irrelevant information) from the non-target aspects and captures truly target-relevant sentiment information, we assume that CVIB will show strong robustness in adversarial scenarios.
The results are shown in Table 4. We observe that CVIB achieves substantially better performance than the compared methods when injecting adversarial perturbations, which verifies the robustness of our proposed CVIB framework. For example, on the REST14-ARTS dataset, the overall accuracy and F1 scores drop 10.31% and 10.50%, which are much better than that produced by RGAT-BERT (i.e., 14.96% and 21.25%).
In addition, we evaluate the robustness of our proposed method on three perturbed subsets (i.e., REVTGT, REVNON and ADDDIFF), respectively. As shown in Table 5, CVIB demonstrates commendable efficacy on the REVNON and ADDDIFF subsets. This underscores the inherent capacity of CVIB to mitigate spurious correlations and effectively capture semantically relevant features pertaining to the target aspect. Such proficiency contributes to heightened robustness against inconsequential features associated with non-target aspects. However, CVIB exhibits comparatively diminished performance on the REVTGT subset. This particular challenge emanates from the inherent complexity faced by ABSA models in accurately discerning the reversed sentiment polarity of the target aspect amidst subtle textual modifications.
| \multirow2*Model | REST14LAP14 () | LAP14REST14 () | ||
|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | |
| ATAE-LSTM | 62.85 | 54.97 | 71.61 | 53.61 |
| MemNet | 57.84 | 51.15 | 70.66 | 52.07 |
| IAN | 63.82 | 55.20 | 72.09 | 54.44 |
| ASGCN | 60.34 | 42.54 | 71.52 | 46.12 |
| R-GAT | 61.76 | 44.17 | 70.18 | 45.81 |
| BERT-SPC | 70.06 | 61.53 | 75.89 | 65.47 |
| CapsNet-BERT | 68.97 | 59.18 | 77.41 | 56.55 |
| RGAT-BERT | 74.27 | 70.38 | 79.07 | 70.32 |
| CVIB (Ours) | 77.43 | 73.57 | 81.07 | 72.76 |
| \multirow2*Model | REST15 () | REST16 () | ||||
|---|---|---|---|---|---|---|
| Pos. | Neg. | Neu. | Pos. | Neg. | Neu. | |
| BERT-SPC | 92.10 | 81.52 | 11.76 | 96.10 | 80.25 | 33.33 |
| CapsNet-BERT | 91.12 | 79.36 | 11.76 | 95.74 | 83.76 | 30.00 |
| RGAT-BERT | 91.03 | 81.50 | 17.65 | 95.95 | 84.62 | 13.33 |
| CVIB (Ours) | 92.80 | 85.16 | 26.47 | 96.59 | 88.03 | 53.33 |
5.4 Generalization Analysis
We first evaluate the generalization capability of our proposed CVIB in the cross-domain scenario. Concretely, we train our CVIB on the REST14 training set (in the restaurant domain) and then test CVIB on the LAP14 testing set (in the laptop domain). Similarly, we also train CVIB on the LAP14 training set and then test CVIB on the REST14 testing set. The experimental results are reported in Table 6. We observe that CVIB outperforms the compared methods by a large margin, which verifies the outstanding generalization capability of our proposed CVIB framework. CVIB is expected to learn more transferable features and thus achieve better generalization capability than the compared methods in the cross-domain scenario.
5.5 Performance on Long-tail Samples
We also evaluate the generalization performance of CVIB in the long-tail scenario. As shown in Table 1, for both REST15 and REST16 datasets, the class size of the Positive class (the largest class) divided by the Neutral class (the smallest class) is more than 10. In Table 7, we report the averaged prediction results of the three classes (i.e., Positive, Negative, and Neutral) separately. Our CVIB method achieves a substantially better performance of the minority class (i.e., Neutral) than the compared baselines. This verifies that CVIB can learn better representations for difficult-to-memorize samples and generalize well in the long-tail scenario.
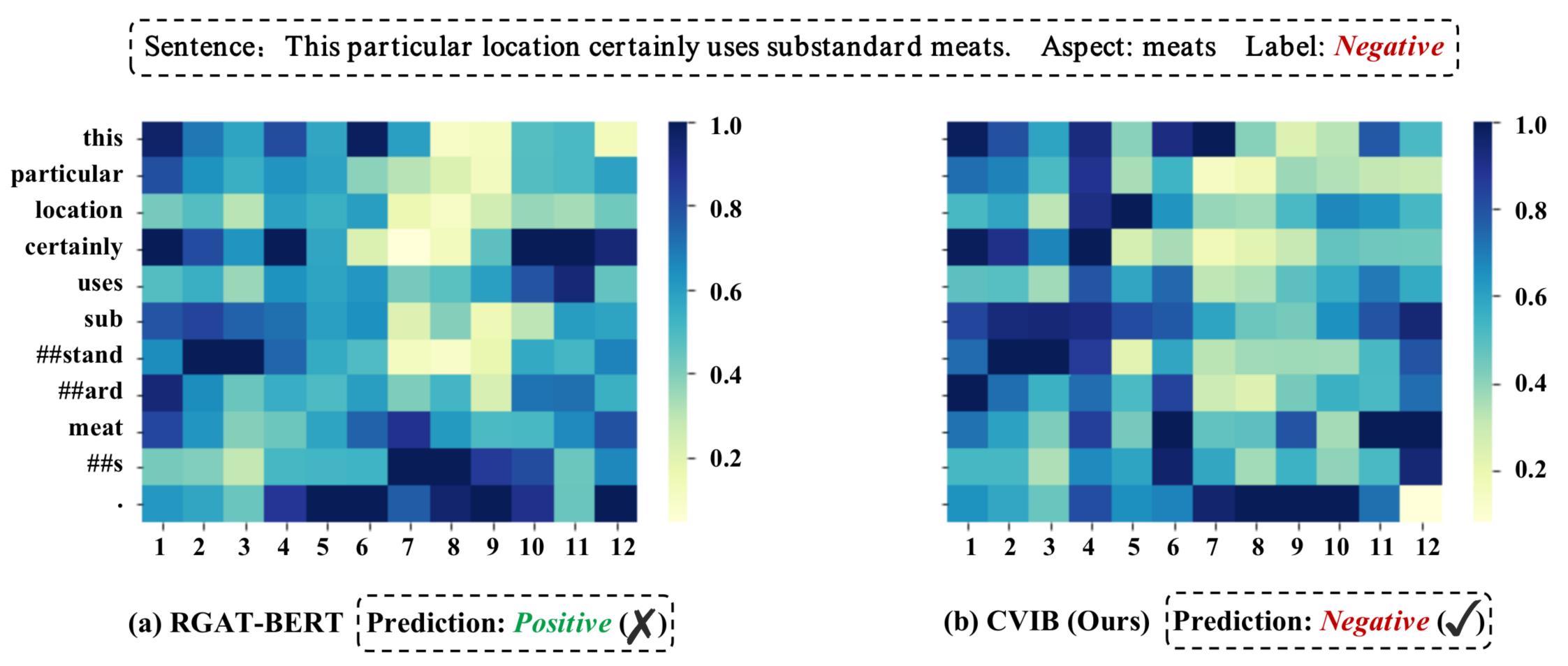
5.6 Case Study
We use a representative exemplary case that is selected from the Rest14 testing set to further investigate the effectiveness of CVIB. This instance is incorrectly predicted by RGAT-BERT while being correctly predicted by CVIB. We visualize the self-attention scores across the BERT layers. As shown in Fig. 3 (a), RGAT-BERT has a tendency to pay more attention to irrelevant words such as “particular” and “certainly”, which frequently co-occur with the Positive label in the training data. RGAT-BERT suffers from statistically spurious correlations between input features and output prediction, failing to make a correct prediction. In Fig. 3 (b), CVIB obtains the correct sentiment label by weakening the influence of task-irrelevant words and capturing useful semantically relevant words (e.g., “substandard”) that carry important sentiment clues for label prediction.
6 Conclusion
In this paper, we proposed a contrastive variational information bottleneck framework (called CVIB) to mitigate the spurious correlation problem for the ABSA task, improving the robustness and generalization capability of the deep ABSA method. CVIB is composed of an original network and a self-pruned network, which are learned simultaneously via contrastive learning. First, the self-pruned network was learned adaptively from the original network based on the VIB principle, which discarded the spurious correlations while preserving sufficient information about the sentiment labels. Then, a self-pruning contrastive loss was devised to optimize the two networks and improve the separability of all the classes. Consequently, the self-pruned network reduced the spurious correlations, making it easier for the ABSA classifier to avoid overfitting. We conducted extensive experiments on five benchmark datasets, and the experimental results showed the effectiveness of CVIB.
Acknowledgments
Min Yang was supported by the National Key Research and Development Program of China (2022YFF0902100), National Natural Science Foundation of China (62376262), Shenzhen Science and Technology Innovation Program (KQTD20190929172835662), Shenzhen Basic Research Foundation (JCYJ20210324115614039 and JCYJ20200109113441941). Qingshan Jiang was supported by National Key Research and Development Program of China (2021YFF1200100 and 2021YFF1200104).
References
- Negi and Buitelaar [2014] S. Negi, P. Buitelaar, Insight galway: Syntactic and lexical features for aspect based sentiment analysis, in: Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), 2014, pp. 346–350.
- Pekar et al. [2014] V. Pekar, N. Afzal, B. Bohnet, Ubham: Lexical resources and dependency parsing for aspect-based sentiment analysis, in: Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), 2014, pp. 683–687.
- Wang et al. [2016] Y. Wang, M. Huang, X. Zhu, L. Zhao, Attention-based LSTM for aspect-level sentiment classification, in: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Austin, Texas, 2016, pp. 606–615. URL: https://aclanthology.org/D16-1058. doi:10.18653/v1/D16-1058.
- Tang et al. [2016] D. Tang, B. Qin, T. Liu, Aspect level sentiment classification with deep memory network, in: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Austin, Texas, 2016, pp. 214–224. URL: https://aclanthology.org/D16-1021. doi:10.18653/v1/D16-1021.
- Yang et al. [2017] M. Yang, W. Tu, J. Wang, F. Xu, X. Chen, Attention based lstm for target dependent sentiment classification, Proceedings of the AAAI Conference on Artificial Intelligence 31 (2017).
- Ma et al. [2017] D. Ma, S. Li, X. Zhang, H. Wang, Interactive attention networks for aspect-level sentiment classification, in: Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI’17, AAAI Press, Melbourne, Australia, 2017, p. 4068–4074.
- He et al. [2018] R. He, W. S. Lee, H. T. Ng, D. Dahlmeier, Effective attention modeling for aspect-level sentiment classification, in: Proceedings of the 27th International Conference on Computational Linguistics, Association for Computational Linguistics, Santa Fe, New Mexico, USA, 2018, pp. 1121–1131. URL: https://aclanthology.org/C18-1096.
- Fan et al. [2018] F. Fan, Y. Feng, D. Zhao, Multi-grained attention network for aspect-level sentiment classification, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Brussels, Belgium, 2018, pp. 3433–3442. URL: https://aclanthology.org/D18-1380. doi:10.18653/v1/D18-1380.
- Li et al. [2018] L. Li, Y. Liu, A. Zhou, Hierarchical attention based position-aware network for aspect-level sentiment analysis, in: Proceedings of the 22nd Conference on Computational Natural Language Learning, Association for Computational Linguistics, Brussels, Belgium, 2018, pp. 181–189. URL: https://aclanthology.org/K18-1018. doi:10.18653/v1/K18-1018.
- Huang and Carley [2019] B. Huang, K. Carley, Syntax-aware aspect level sentiment classification with graph attention networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, 2019, pp. 5469–5477. URL: https://aclanthology.org/D19-1549. doi:10.18653/v1/D19-1549.
- Zhang et al. [2019] C. Zhang, Q. Li, D. Song, Aspect-based sentiment classification with aspect-specific graph convolutional networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, 2019, pp. 4568–4578. URL: https://aclanthology.org/D19-1464. doi:10.18653/v1/D19-1464.
- Sun et al. [2019] K. Sun, R. Zhang, S. Mensah, Y. Mao, X. Liu, Aspect-level sentiment analysis via convolution over dependency tree, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, 2019, pp. 5679–5688. URL: https://aclanthology.org/D19-1569. doi:10.18653/v1/D19-1569.
- Wang et al. [2020] K. Wang, W. Shen, Y. Yang, X. Quan, R. Wang, Relational graph attention network for aspect-based sentiment analysis, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 2020, pp. 3229–3238. URL: https://aclanthology.org/2020.acl-main.295. doi:10.18653/v1/2020.acl-main.295.
- Tian et al. [2021] Y. Tian, G. Chen, Y. Song, Aspect-based sentiment analysis with type-aware graph convolutional networks and layer ensemble, in: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Online, 2021, pp. 2910–2922. URL: https://aclanthology.org/2021.naacl-main.231. doi:10.18653/v1/2021.naacl-main.231.
- Wu et al. [2022] H. Wu, Z. Zhang, S. Shi, Q. Wu, H. Song, Phrase dependency relational graph attention network for aspect-based sentiment analysis, Knowledge-Based Systems 236 (2022) 107736.
- Liang et al. [2022] B. Liang, H. Su, L. Gui, E. Cambria, R. Xu, Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks, Knowledge-Based Systems 235 (2022) 107643.
- Devlin et al. [2019] J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Association for Computational Linguistics, Minneapolis, Minnesota, 2019, pp. 4171–4186. URL: https://aclanthology.org/N19-1423. doi:10.18653/v1/N19-1423.
- Liu et al. [2019] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov, Roberta: A robustly optimized bert pretraining approach, arXiv preprint arXiv:1907.11692 (2019).
- Song et al. [2019] Y. Song, J. Wang, T. Jiang, Z. Liu, Y. Rao, Attentional encoder network for targeted sentiment classification, arXiv preprint arXiv:1902.09314 (2019).
- Jiang et al. [2019] Q. Jiang, L. Chen, R. Xu, X. Ao, M. Yang, A challenge dataset and effective models for aspect-based sentiment analysis, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, 2019, pp. 6280–6285. URL: https://aclanthology.org/D19-1654. doi:10.18653/v1/D19-1654.
- Dai et al. [2021] J. Dai, H. Yan, T. Sun, P. Liu, X. Qiu, Does syntax matter? a strong baseline for aspect-based sentiment analysis with RoBERTa, in: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Online, 2021, pp. 1816–1829. URL: https://aclanthology.org/2021.naacl-main.146. doi:10.18653/v1/2021.naacl-main.146.
- Zhang et al. [2022] K. Zhang, K. Zhang, M. Zhang, H. Zhao, Q. Liu, W. Wu, E. Chen, Incorporating dynamic semantics into pre-trained language model for aspect-based sentiment analysis, in: Findings of the Association for Computational Linguistics: ACL 2022, Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 3599–3610. URL: https://aclanthology.org/2022.findings-acl.285. doi:10.18653/v1/2022.findings-acl.285.
- You et al. [2022] L. You, F. Han, J. Peng, H. Jin, C. Claramunt, Ask-roberta: A pretraining model for aspect-based sentiment classification via sentiment knowledge mining, Knowledge-Based Systems 253 (2022) 109511.
- Zhang et al. [2022] W. Zhang, X. Li, Y. Deng, L. Bing, W. Lam, A survey on aspect-based sentiment analysis: Tasks, methods, and challenges, IEEE Transactions on Knowledge and Data Engineering (2022) 1–20.
- Xing et al. [2020] X. Xing, Z. Jin, D. Jin, B. Wang, Q. Zhang, X. Huang, Tasty burgers, soggy fries: Probing aspect robustness in aspect-based sentiment analysis, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online, 2020, pp. 3594–3605. URL: https://aclanthology.org/2020.emnlp-main.292. doi:10.18653/v1/2020.emnlp-main.292.
- Tishby et al. [2000] N. Tishby, F. C. Pereira, W. Bialek, The information bottleneck method, arXiv preprint physics/0004057 (2000).
- Wang and Lu [2018] B. Wang, W. Lu, Learning latent opinions for aspect-level sentiment classification, Proceedings of the AAAI Conference on Artificial Intelligence 32 (2018).
- Li et al. [2021] R. Li, H. Chen, F. Feng, Z. Ma, X. Wang, E. Hovy, Dual graph convolutional networks for aspect-based sentiment analysis, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Association for Computational Linguistics, Online, 2021, pp. 6319–6329. URL: https://aclanthology.org/2021.acl-long.494. doi:10.18653/v1/2021.acl-long.494.
- Lu et al. [2022] Q. Lu, X. Sun, R. Sutcliffe, Y. Xing, H. Zhang, Sentiment interaction and multi-graph perception with graph convolutional networks for aspect-based sentiment analysis, Knowledge-Based Systems 256 (2022) 109840.
- Wu and Ong [2021] Z. Wu, D. C. Ong, Context-guided bert for targeted aspect-based sentiment analysis, Proceedings of the AAAI Conference on Artificial Intelligence 35 (2021) 14094–14102.
- Xu et al. [2019] H. Xu, B. Liu, L. Shu, P. Yu, BERT post-training for review reading comprehension and aspect-based sentiment analysis, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Association for Computational Linguistics, Minneapolis, Minnesota, 2019, pp. 2324–2335. URL: https://aclanthology.org/N19-1242. doi:10.18653/v1/N19-1242.
- Jia and Liang [2017] R. Jia, P. Liang, Adversarial examples for evaluating reading comprehension systems, in: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Copenhagen, Denmark, 2017, pp. 2021–2031. URL: https://aclanthology.org/D17-1215. doi:10.18653/v1/D17-1215.
- Gururangan et al. [2018] S. Gururangan, S. Swayamdipta, O. Levy, R. Schwartz, S. Bowman, N. A. Smith, Annotation artifacts in natural language inference data, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), Association for Computational Linguistics, New Orleans, Louisiana, 2018, pp. 107–112. URL: https://aclanthology.org/N18-2017. doi:10.18653/v1/N18-2017.
- Kaushik and Lipton [2018] D. Kaushik, Z. C. Lipton, How much reading does reading comprehension require? a critical investigation of popular benchmarks, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Brussels, Belgium, 2018, pp. 5010–5015. URL: https://aclanthology.org/D18-1546. doi:10.18653/v1/D18-1546.
- Sanchez et al. [2018] I. Sanchez, J. Mitchell, S. Riedel, Behavior analysis of NLI models: Uncovering the influence of three factors on robustness, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Association for Computational Linguistics, New Orleans, Louisiana, 2018, pp. 1975–1985. URL: https://aclanthology.org/N18-1179. doi:10.18653/v1/N18-1179.
- McCoy et al. [2019] T. McCoy, E. Pavlick, T. Linzen, Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, 2019, pp. 3428–3448. URL: https://aclanthology.org/P19-1334. doi:10.18653/v1/P19-1334.
- Niven and Kao [2019] T. Niven, H.-Y. Kao, Probing neural network comprehension of natural language arguments, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, 2019, pp. 4658–4664. URL: https://aclanthology.org/P19-1459. doi:10.18653/v1/P19-1459.
- Ming et al. [2022] Y. Ming, H. Yin, Y. Li, On the impact of spurious correlation for out-of-distribution detection, Proceedings of the AAAI Conference on Artificial Intelligence 36 (2022) 10051–10059.
- Fang et al. [2022] Z. Fang, Y. Li, J. Lu, J. Dong, B. Han, F. Liu, Is out-of-distribution detection learnable?, in: S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, A. Oh (Eds.), Advances in Neural Information Processing Systems, volume 35, Curran Associates, Inc., 2022, pp. 37199–37213. URL: https://proceedings.neurips.cc/paper_files/paper/2022/file/f0e91b1314fa5eabf1d7ef6d1561ecec-Paper-Conference.pdf.
- Fang et al. [2021] Z. Fang, J. Lu, A. Liu, F. Liu, G. Zhang, Learning bounds for open-set learning, in: M. Meila, T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, PMLR, 2021, pp. 3122–3132. URL: https://proceedings.mlr.press/v139/fang21c.html.
- Zellers et al. [2019] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, Y. Choi, HellaSwag: Can a machine really finish your sentence?, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, 2019, pp. 4791–4800. URL: https://aclanthology.org/P19-1472. doi:10.18653/v1/P19-1472.
- Kaushik et al. [2020] D. Kaushik, E. H. Hovy, Z. C. Lipton, Learning the difference that makes A difference with counterfactually-augmented data, in: 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, OpenReview.net, 2020. URL: https://openreview.net/forum?id=Sklgs0NFvr.
- Sakaguchi et al. [2021] K. Sakaguchi, R. L. Bras, C. Bhagavatula, Y. Choi, Winogrande: An adversarial winograd schema challenge at scale, Commun. ACM 64 (2021) 99–106.
- Nie et al. [2020] Y. Nie, A. Williams, E. Dinan, M. Bansal, J. Weston, D. Kiela, Adversarial NLI: A new benchmark for natural language understanding, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 2020, pp. 4885–4901. URL: https://aclanthology.org/2020.acl-main.441. doi:10.18653/v1/2020.acl-main.441.
- Wang and Culotta [2021] Z. Wang, A. Culotta, Robustness to spurious correlations in text classification via automatically generated counterfactuals, Proceedings of the AAAI Conference on Artificial Intelligence 35 (2021) 14024–14031.
- Wu et al. [2022] Y. Wu, M. Gardner, P. Stenetorp, P. Dasigi, Generating data to mitigate spurious correlations in natural language inference datasets, in: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 2660–2676. URL: https://aclanthology.org/2022.acl-long.190. doi:10.18653/v1/2022.acl-long.190.
- Clark et al. [2020] C. Clark, M. Yatskar, L. Zettlemoyer, Learning to model and ignore dataset bias with mixed capacity ensembles, in: Findings of the Association for Computational Linguistics: EMNLP 2020, Association for Computational Linguistics, Online, 2020, pp. 3031–3045. URL: https://aclanthology.org/2020.findings-emnlp.272. doi:10.18653/v1/2020.findings-emnlp.272.
- Karimi Mahabadi et al. [2020] R. Karimi Mahabadi, Y. Belinkov, J. Henderson, End-to-end bias mitigation by modelling biases in corpora, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 2020, pp. 8706–8716. URL: https://aclanthology.org/2020.acl-main.769. doi:10.18653/v1/2020.acl-main.769.
- Utama et al. [2020] P. A. Utama, N. S. Moosavi, I. Gurevych, Mind the trade-off: Debiasing NLU models without degrading the in-distribution performance, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 2020, pp. 8717–8729. URL: https://aclanthology.org/2020.acl-main.770. doi:10.18653/v1/2020.acl-main.770.
- Sanh et al. [2021] V. Sanh, T. Wolf, Y. Belinkov, A. M. Rush, Learning from others’ mistakes: Avoiding dataset biases without modeling them, in: International Conference on Learning Representations, 2021. URL: https://openreview.net/forum?id=Hf3qXoiNkR.
- Du et al. [2021] M. Du, V. Manjunatha, R. Jain, R. Deshpande, F. Dernoncourt, J. Gu, T. Sun, X. Hu, Towards interpreting and mitigating shortcut learning behavior of NLU models, in: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Online, 2021, pp. 915–929. URL: https://aclanthology.org/2021.naacl-main.71. doi:10.18653/v1/2021.naacl-main.71.
- Du et al. [2022] M. Du, R. Tang, W. Fu, X. Hu, Towards debiasing dnn models from spurious feature influence, Proceedings of the AAAI Conference on Artificial Intelligence 36 (2022) 9521–9528.
- Stacey et al. [2020] J. Stacey, P. Minervini, H. Dubossarsky, S. Riedel, T. Rocktäschel, Avoiding the Hypothesis-Only Bias in Natural Language Inference via Ensemble Adversarial Training, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online, 2020, pp. 8281–8291. URL: https://aclanthology.org/2020.emnlp-main.665. doi:10.18653/v1/2020.emnlp-main.665.
- Tian et al. [2021] J. Tian, S. Chen, X. Zhang, Z. Feng, D. Xiong, S. Wu, C. Dou, Re-embedding difficult samples via mutual information constrained semantically oversampling for imbalanced text classification, in: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 2021, pp. 3148–3161. URL: https://aclanthology.org/2021.emnlp-main.252. doi:10.18653/v1/2021.emnlp-main.252.
- Lovering et al. [2021] C. Lovering, R. Jha, T. Linzen, E. Pavlick, Predicting inductive biases of pre-trained models, in: International Conference on Learning Representations, 2021. URL: https://openreview.net/forum?id=mNtmhaDkAr.
- Zhou et al. [2021] C. Zhou, X. Ma, P. Michel, G. Neubig, Examining and combating spurious features under distribution shift, in: M. Meila, T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, PMLR, 2021, pp. 12857–12867. URL: https://proceedings.mlr.press/v139/zhou21g.html.
- Mahabadi et al. [2021] R. K. Mahabadi, Y. Belinkov, J. Henderson, Variational information bottleneck for effective low-resource fine-tuning, in: International Conference on Learning Representations, 2021. URL: https://openreview.net/forum?id=kvhzKz-_DMF.
- Alemi et al. [2016] A. A. Alemi, I. Fischer, J. V. Dillon, K. Murphy, Deep variational information bottleneck, arXiv preprint arXiv:1612.00410 (2016).
- Fabius et al. [2015] O. Fabius, J. R. van Amersfoort, D. P. Kingma, Variational recurrent auto-encoders, in: ICLR (Workshop), 2015.
- Dai et al. [2018] B. Dai, C. Zhu, B. Guo, D. Wipf, Compressing neural networks using the variational information bottleneck, in: J. Dy, A. Krause (Eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, PMLR, Stockholm, Sweden, 2018, pp. 1135–1144. URL: https://proceedings.mlr.press/v80/dai18d.html.
- Srivastava et al. [2021] A. Srivastava, O. Dutta, J. Gupta, S. Agarwal, P. AP, A variational information bottleneck based method to compress sequential networks for human action recognition, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021, pp. 2745–2754.
- Chen et al. [2020] T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, in: H. D. III, A. Singh (Eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, PMLR, Vienna, Austria, 2020, pp. 1597–1607. URL: https://proceedings.mlr.press/v119/chen20j.html.
- Khosla et al. [2020] P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, D. Krishnan, Supervised contrastive learning, in: H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, H. Lin (Eds.), Advances in Neural Information Processing Systems, volume 33, Curran Associates, Inc., 2020, pp. 18661–18673. URL: https://proceedings.neurips.cc/paper/2020/file/d89a66c7c80a29b1bdbab0f2a1a94af8-Paper.pdf.
- Gao et al. [2021] T. Gao, X. Yao, D. Chen, SimCSE: Simple contrastive learning of sentence embeddings, in: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 2021, pp. 6894–6910. URL: https://aclanthology.org/2021.emnlp-main.552. doi:10.18653/v1/2021.emnlp-main.552.
- Li et al. [2018] X. Li, L. Bing, W. Lam, B. Shi, Transformation networks for target-oriented sentiment classification, in: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Melbourne, Australia, 2018, pp. 946–956. URL: https://aclanthology.org/P18-1087. doi:10.18653/v1/P18-1087.
- Zhang and Qian [2020] M. Zhang, T. Qian, Convolution over hierarchical syntactic and lexical graphs for aspect level sentiment analysis, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online, 2020, pp. 3540–3549. URL: https://aclanthology.org/2020.emnlp-main.286. doi:10.18653/v1/2020.emnlp-main.286.
- Pontiki et al. [2014] M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androutsopoulos, S. Manandhar, SemEval-2014 task 4: Aspect based sentiment analysis, in: Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Association for Computational Linguistics, Dublin, Ireland, 2014, pp. 27–35. URL: https://aclanthology.org/S14-2004. doi:10.3115/v1/S14-2004.
- Pontiki et al. [2015] M. Pontiki, D. Galanis, H. Papageorgiou, S. Manandhar, I. Androutsopoulos, SemEval-2015 task 12: Aspect based sentiment analysis, in: Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Association for Computational Linguistics, Denver, Colorado, 2015, pp. 486–495. URL: https://aclanthology.org/S15-2082. doi:10.18653/v1/S15-2082.
- Pontiki et al. [2016] M. Pontiki, D. Galanis, H. Papageorgiou, I. Androutsopoulos, S. Manandhar, M. AL-Smadi, M. Al-Ayyoub, Y. Zhao, B. Qin, O. De Clercq, V. Hoste, M. Apidianaki, X. Tannier, N. Loukachevitch, E. Kotelnikov, N. Bel, S. M. Jiménez-Zafra, G. Eryiğit, SemEval-2016 task 5: Aspect based sentiment analysis, in: Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), Association for Computational Linguistics, San Diego, California, 2016, pp. 19–30. URL: https://aclanthology.org/S16-1002. doi:10.18653/v1/S16-1002.