Contrastive Masked Autoencoders for Self-Supervised Video Hashing
Abstract
Self-Supervised Video Hashing (SSVH) models learn to generate short binary representations for videos without ground-truth supervision, facilitating large-scale video retrieval efficiency and attracting increasing research attention. The success of SSVH lies in the understanding of video content and the ability to capture the semantic relation among unlabeled videos. Typically, state-of-the-art SSVH methods consider these two points in a two-stage training pipeline, where they firstly train an auxiliary network by instance-wise mask-and-predict tasks and secondly train a hashing model to preserve the pseudo-neighborhood structure transferred from the auxiliary network. This consecutive training strategy is inflexible and also unnecessary. In this paper, we propose a simple yet effective one-stage SSVH method called ConMH, which incorporates video semantic information and video similarity relationship understanding in a single stage. To capture video semantic information, we adopt an encoder-decoder structure to reconstruct the video from its temporal-masked frames. Particularly, we find that a higher masking ratio helps video understanding. Besides, we fully exploit the similarity relationship between videos by maximizing agreement between two augmented views of a video, which contributes to more discriminative and robust hash codes. Extensive experiments on three large-scale video datasets (i.e., FCVID, ActivityNet and YFCC) indicate that ConMH achieves state-of-the-art results. Code is available at https://github.com/huangmozhi9527/ConMH.
Introduction

With the development of society, videos from various social media and search engines are increasingly abundant. Therefore, to pursue a better balance between retrieval performance and efficiency, hashing has been widely applied to large-scale video retrieval. The hashing methods map high-dimensional data to compact binary codes (Gao et al. 2015; Luo et al. 2018; Cui et al. 2021; Lu et al. 2021; Wang et al. 2022), making the retrieval process high-speed and require low memory footprint. Besides, due to the large amount of video data, manual annotation is time-consuming and labor-intensive. Therefore, Self-Supervised Video Hashing (SSVH) has attracted increasing attention to training the video hashing model in an unsupervised manner.
Video retrieval needs to fully explore the temporal dynamics in video itself and exploit the similarity relationship between videos. In the past few years, there has been a lot of research (Zhang et al. 2016; Li et al. 2019, 2021; Hao et al. 2022; Zeng et al. 2022) using sequential (e.g., RNN, LSTM, and Transformer, etc.) or graph-based models to solve self-supervised video hashing problem. Some of these methods only utilize a reconstruction task to let the model learn video semantic information and ignore the similarity relationship between videos, such as SSTH (Zhang et al. 2016), JTAE (Li et al. 2017) and UDVH (Wu et al. 2017), leading to poor retrieval performance. Other methods, e.g., SSVH (Song et al. 2018), NPH (Li et al. 2019), BTH (Li et al. 2021), MCMSH (Hao et al. 2022) and MAGRH (Zeng et al. 2022), learn to preserve the semantic neighborhood structure among videos into binary representations. However, these methods need to generate a dataset-covering pseudo neighborhood structure to supervise the relationship learning among videos, as shown in Figure 1 (a). Such a two-stage framework makes the training process impractical. In addition, most SSVH methods take the complete video input, which contains much redundant information between frames. Such redundant information will be utilized when the model reconstructs the video frames. For instance, when the model has reconstructed the frame at a certain time, the next frame can be easily obtained by adding dynamic change to the current frame. In this case, the model can solve the reconstruction task easily without understanding the semantic video information well.
In this paper, we propose a simple yet effective one-stage framework called ConMH for self-supervised video hashing (SSVH), as shown in Figure 1 (b). Similar to past methods, we adopt an encoder-decoder structure for reconstruction. However, to make the model better understand the semantic information of the video, we only operate the encoder on highly temporal-masked video frames to generate hash codes during training. By doing so, the input becomes sparse. With such sparse input, our model has to fully exploit the long-distance dynamics among video frames to solve the reconstruction task, therefore generating informative hash codes. And the temporal-masking operation is a way of data augmentation, making our model more robust. Besides, with a high masking ratio, the encoder only takes a small subset of the original full frames, accelerating the training phase. To simultaneously consider the similarity relationship between videos, we combine an instance-discriminative task with the above reconstruction task in a single stage. Inspired by contrastive learning in self-supervised representation learning, we think two different views of the same video should have the same hash codes. Specifically, we consider random temporal masking as a special data augmentation designed for contrastive learning and sample two small non-overlapping subsets from the full video frames. These two subsets can be seen as two different augmented views of the same video. Then we feed these two subsets to the encoder to generate two hash codes. Finally, a contrastive learning method is utilized to maximize the similarity between these two hash codes. We choose debiased contrastive learning as our contrastive learning method, due to its ability to mitigate the adverse effect of false negative samples.
We conducted extensive experiments on three large-scale video datasets FCVID (Jiang et al. 2017), ActivityNet (Caba Heilbron et al. 2015), YFCC (Thomee et al. 2015). The experimental results prove that ConMH achieves state-of-the-art results under all metrics. In particular, on FCVID dataset with 16 bits hash codes, the mAP@5 and mAP@100 of ConMH are ahead of the past SOTA MCMSH (Hao et al. 2022) by 6.1% and 30.0% respectively.
Overall, the contributions of this paper are as follows:
-
•
Beyond two-stage prior arts, we contribute ConMH, a simple yet effective one-stage learning paradigm for self-supervised video hashing.
-
•
We present a natural and general idea in ConMH: the temporally masked autoencoder enhances intrinsic understanding within each video, while debiased contrastive learning helps to perceive discriminative semantic relation among videos; these two objectives are complementary in a unified hashing learning framework.
-
•
Experimental results on three datasets (i.e., FCVID, ActivityNet, YFCC) demonstrate the superiority of ConMH.
Related Works
Self-Supervised Video Hashing. Hashing retrieval methods map data into binary hash codes, which can perform efficient and low storage requirement retrieval because of the fast bit operations in the Hamming space. In the early research, most methods directly regarded a video as a set of disordered images. They adopted hashing technologies that already exist in image hashing, such as iterative quantization (Gong et al. 2012), spectral hashing (Weiss, Torralba, and Fergus 2008) and multiple feature hashing (MPH) (Song et al. 2011). However, performance of these methods is not good because they ignore the temporal dynamics in the video. In recent years, with the development of deep neural networks, many hashing methods for video retrieval have been proposed. For example, Zhang et al. (2016) proposed SSTH, an end-to-end framework to capture the correlations between video frames. Li et al. (2017) thought both the static visual appearance and temporal patterns of videos contain important discriminative information and concentrated on combining them to generate more effective hash codes. Wu et al. (2017) proposed to apply a balanced rotation to video-specific features widely distributed in low-dimensional space, which can balance the variance of dimensions. Song et al. (2018) found that the reconstruction objective alone does not perform the retrieval task well, and attention needs to be paid to instance similarity. NPH (Li et al. 2019) proposed a neighborhood attention mechanism to enable the encoder to selectively encode frames in the video that contain rich spatial-temporal neighborhood information. Li et al. (2021) improved NPH’s method of generating similarity matrices and applied the transformer architecture to self-supervised video hashing for the first time. And Hao et al. (2022) enhances the discrimination of hash codes by utilizing self-gating modules. However, most neighborhood-preserving methods use a two-stage training strategy, which is not practical. In this paper, we design a simple yet effective one-stage masked autoencoders framework (ConMH), which only takes highly temporal-masked frames as input during training and considers the similarity structure between videos in a single stage.
Masked Autoencoders. In the past few years, contrastive learning (Chen et al. 2020; He et al. 2020; Chen and He 2021; Grill et al. 2020; Caron et al. 2020; Dong et al. 2021) has become mainstream in the field of self-supervised learning. It models instance similarity and dissimilarity between two or more views of the same data example. Recently, there have been a lot of approaches (Bao, Dong, and Wei 2021; He et al. 2022; Chen et al. 2022; Xie et al. 2022; Assran et al. 2022) that utilize masking operations for self-supervised learning. BEiT (Bao, Dong, and Wei 2021) proposed a novel training strategy for image pretraining called masked image modeling (MIM), which is a reconstruction task. He et al. (2022) pointed out that contrastive and related methods strongly depend on data augmentation, and proposed a novel masked autoencoders framework called MAE, providing a new idea for visual self-supervised learning. Besides, MAE found that a high masking ratio benefits representation learning. However, MAE ignores the similarity structure within data while only applying the reconstruction task, which is disadvantageous for some downstream tasks, such as classification and retrieval. Our ConMH combines an instance-discriminative task with the reconstruction task to simultaneously consider the visual semantic information of video and the similarity structure between videos.
The Proposed ConMH Framework

In this section, we present our proposed ConMH framework. Given a set of videos, ConMH aims to learn a nonlinear hash function that maps each video to a compact binary code. Specifically, a video is represented by CNN features with frames , where is the frame feature dimension and is the video index. Then we feed to the ConMH encoder to get its binary code , where is the code length.
Video Semantic Information Understanding
ConMH is a simple yet effective masked autoencoders framework for self-supervised video hashing. To better understand the semantic information of the video, ConMH reconstructs the original video given its highly temporal-masked frames. Following MAE (He et al. 2022), the ConMH architecture is asymmetric. Specifically, the encoder of ConMH only takes a small randomly sampled subset of the original frames as input to extract latent representations and binary hash tokens. And the decoder of ConMH reconstructs the original video frames from generated hash tokens and masked tokens, illustrated in Figure 2.
Masking. To make the model better understand the semantic information of the video, we adopt a highly temporal-masking strategy. Specifically, given the frames of a video, we randomly sample a small subset of the frames for training and mask the remaining ones. Typically, a higher masking ratio means less available information the model can get, leading to a more challenging reconstruction task. Given these intuitions, the model can learn high-quality representations and generate effective hash codes by a reasonable self-supervised pretext task. Besides, with a high masking ratio, the encoder only operates on a small subset of an input, accelerating the training phase.
ConMH Encoder. Our encoder is composed of a standard Transformer (Vaswani et al. 2017) and a hash layer. The multi-head attention module in Transformer is able to capture the temporal information and correlations among video frames, which is critical for video understanding. Different from the setting in (Vaswani et al. 2017), we only use a small subset (e.g., 25%) of the full video frames as the transformer input during training. Through multiple transformer blocks, we can obtain the latent representations for each video, where is the frame number of the sampled subset. To obtain compact binary code, we further adopt a hash layer to generate binary hash tokens . Finally, we generate a binary code for each video by operating the mean pooling and sign function on its binary hash tokens. Since the sign function is not differentiable, we employ the approach in (Li et al. 2021) to realize the training phase in an end-to-end manner.
ConMH Decoder. Our decoder is composed of another series of Transformer blocks. Different from the encoder, our decoder takes binary hash tokens and corresponding masked tokens as input. Positional encoding is also inserted to identify the masked token with their corresponding frames. The decoder is only used during the training phase, so we can flexibly design the decoder architecture. Following the asymmetric nature of MAE (He et al. 2022), we design a small Transformer decoder, with which the encoder has to learn high-quality feature representations and hash codes to complete the reconstruction task.
Reconstruction Task. After ConMH encoder and decoder module, we can obtain a full set of reconstruction frames . Following MAE, we only reconstruct the masked frames using corresponding reconstruction frames . We adopt Mean Square Error (MSE) to measure the reconstruction quality as following:
| (1) |
Video Similarity Relationship Understanding
Although the reconstruction task above can help the model to extract the discriminative visual semantic information among videos, it neglects the similarity structure between videos, which is critical for the retrieval task. In this subsection, we will discuss how to combine instance-discriminative contrastive learning with the proposed masked autoencoder in a single stage.
Debiased Contrastive Loss. In ConMH, we consider random temporal masking as a data augmentation for contrastive learning and sample two non-overlapping small subsets from a single video, as shown in Figure 1. Then we feed these two subsets to the ConMH encoder to obtain two hash codes from different views of the same video, denoted as and . For ConMH, we adopt a debiased contrastive loss (Chuang et al. 2020) to correct the sampling bias of same-label data points:
| (2) | |||
| (3) | |||
| (4) |
where denotes a temperature parameter and is the class probability indicating that two randomly sampled videos belong to the same class with probability . Because we cannot get the actual number of categories, we treat as a hyperparameter. Given a mini-batch of samples, we calculate the contrastive loss over all samples below:
| (5) |
Loss Objective. The overall loss of ConMH for network optimization is a combination of reconstruction loss and constrastive loss as following,
| (6) |
where is a hyperparameter that balances the above-mentioned two losses.
Experiments
Experimental Setup
Dataset: We evaluate our ConMH on three large-scale video datasets FCVID (Jiang et al. 2017), ActivityNet (Caba Heilbron et al. 2015) and YFCC (Thomee et al. 2015). FCVID contains 91,223 videos in 239 categories. Following (Song et al. 2018), we use 45,585 videos among FCVID for training and 45,600 videos for retrieval database and queries. ActivityNet covers 200 categories of various human activities. Due to the lack of original test labels, we use 9,722 videos as our training set and the validation set as our test set. Similar to (Li et al. 2021), we uniformly sample 1,000 videos in 200 categories as queries and the remaining 3,758 videos as retrieval database. YFCC contains 0.8M videos in 80 categories, which is one of the largest public video datasets available in the real world. We use 409,788 videos for training and 101,256 videos for testing. We randomly choose 1,000 videos with non-zero labels among the testing set as queries and the remaining ones as our retrieval database.
Evaluation Protocols: Following the same evaluation protocols in (Li et al. 2021), mean Average Precision at top-K retrieval results (mAP@K) is used to evaluate our ConMH performance. Videos are sorted according to their Hamming distance from the query. We evaluate the retrieval results with code lengths of 16, 32, and 64 bits.
Implementation Details: Similar to BTH (Li et al. 2021), on FCVID and YFCC datasets, we uniformly sample 25 frames for each video and use VGG-16 network (Simonyan and Zisserman 2014) pre-trained on ImageNet (Russakovsky et al. 2015) to extract 4096-D frame features. And on ActivityNet, we uniformly sample 30 frames for each video and use ResNet50 (He et al. 2016) pre-trained on ImageNet to extract 2048-D frame features.
We follow the design of ViT-small (Dosovitskiy et al. 2020) to build our model. Specifically, for the Transformer encoder, we set the depth as 12, multi-head number as 6, and hidden size as 256. For the Transformer decoder, we set the depth as 2, multi-head number as 3, and hidden size as 192.
During training, we set the batchsize as 512, masking ratio as 0.75, as 1.0, as 0.5, as 0.1, and train our model for 800 epochs, 500 epochs, and 40 epochs for FCVID, ActivityNet and YFCC respectively.
We set the initial learning rate as 0.0001, and decay it to 90% every 20 epochs with a minimal learning rate of 0.00001. We optimize our model by using Adam optimizer algorithm (Kingma and Ba 2014). Our model is implemented in Pytorch with an Nvidia RTX2080Ti GPU.

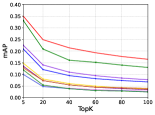








Results and Analysis
| Method | SSTH | SSVH | NPH | BTH | MCMSH | ConMH |
| mAP@20 | 0.155 6.3 | 0.173 7.8 | 0.180 6.0 | 0.182 5.7 | 0.186 3.2 | 0.188 3.6 |
Comparisons with State-of-the-arts: We compare our ConMH with several state-of-the-art self-supervised video hashing methods: ITQ (Gong et al. 2012), MFH (Song et al. 2011), DH (Erin Liong et al. 2015), SSTH (Zhang et al. 2016), JTAE (Li et al. 2017), SSVH (Song et al. 2018), NPH (Li et al. 2019), BTH (Li et al. 2021) and MCMSH (Hao et al. 2022). Following (Song et al. 2018), we extend the image hashing methods ITQ and DH to video hashing by applying them on CNN frame features.
As Figure 3 shows, our ConMH outperforms other methods on three large-scale video datasets with all code lengths, demonstrating its superiority in retrieval accuracy. Specifically, compared with the strongest competitor MCMSH, our ConMH surpasses it by 5.7%, 11.4%, and 4.7% with 16 bits in terms of mAP@5 on FCVID, ActivityNet, and YFCC, respectively. ConMH achieves impressive retrieval results by incorporating video semantic information and video similarity relationship understanding in a single stage. These two tasks are critical for the retrieval task and can complement each other to further improve retrieval performance when combined together.
Besides, from Figure 3, ConMH surpasses other methods by a considerable margin with low-bit hash codes, proving the superiority of ConMH in high real-time demand scenarios. In particular, as we decrease the bit length, more semantic information will be lost by the compressive hashing technique, leading to poor retrieval performance. However, instead of representation learning followed by quantization, we design hashing-oriented learning objectives to suppress the quantization loss. In this way, more semantic information will be retained by hash codes. On the contrary, when the bit-length is increasing, the quantization loss is reduced with a higher information capacity, and the hashing learning task also becomes simpler. Therefore, we can see different methods show approaching performance under 64 bits or larger bit-length settings. This phenomenon has widely occurred in previous methods, as shown in Figure 3 (f), (i).
Precision-Recall Curves: The precision-recall curves of BTH, MCMSH and ConMH on FCVID and ActivityNet are shown in Figure 4. As can be seen, compared with BTH and MCMSH, our ConMH achieves higher precision at the same recall rate with all code lengths.
Cross-dataset Evaluation Comparisons: To investigate the generalization of our ConMH, we evaluate cross-dataset retrieval performance among different methods in this subsection. In detail, we train various methods on FCVID and test them on YFCC. We compare the retrieval results with a single-dataset case (both training and testing on YFCC). Table 1 shows mAP@20 results of various methods with 64 bits in the cross-dataset setting. Although all methods degrade in performance, ConMH still performs the best. Besides, the performance drop of ConMH is negligible, showing the generalization of ConMH across different datasets.






Qualitative Results: We randomly sample 10 categories in FCVID, each with 80 videos, constituting FCVID-small. And we show the t-SNE visualizations of MCMSH and ConMH with 64 bits on FCVID-small. As shown in Figure 5, hash codes generated by ConMH better distinguish different categories of videos.


Ablation Study
Effectiveness of and : To analyse the effectiveness of two pretext tasks (i.e., and ) of ConMH, we construct several ConMH variants: (1) ConMH w/o removes the relational understanding task and only uses to train the model. (2) ConMH w/o removes the reconstruction task and only uses to train the model. (3) ConMH-norm removes the temporal-masking operation based on ConMH w/o and reconstructs the full video frames during training. As shown in the first two rows of Table 2, the results of ConMH w/o outperform ConMH-norm with all code lengths, showing that the model can better understand the semantic information of video from our highly temporal-masking reconstruction task. Besides, from Table 2, training with only or both lead to the reduction of model performance compared with ConMH. With only , although the model can understand the semantic information of video, it ignores the similarity relationship between videos which is disadvantageous for the retrieval task. And with only , the model cannot understand the video content well. Therefore, taking care of both the reconstruction and discrimination tasks is critical for good retrieval performance.
Furthermore, we explain the effectiveness of hashing-oriented learning objectives in ConMH on hash code learning. Most existing methods perform general feature learning (GFL) first, making the hidden representations discriminative. Specifically, they use the hidden representations to complete pretext tasks and binarize them directly to obtain the hash codes. Besides, they introduce a quantization loss to reduce the quantization error from the binarization. Such an approach is hard to balance feature learning and quantization error reduction. However, we directly use the generated hash codes to complete the reconstruction and discriminative tasks, which enables the hash codes to retain more information. We have also tried general feature learning approach to use hidden representations to complete the pretext tasks and introduce a quantization loss, denoted as ConMH w/ GFL. As shown in Table 2, the hashing-oriented approach is better.
| Method | 16 bits | 32 bits | 64 bits | ||||||
| K=5 | K=10 | K=20 | K=5 | K=10 | K=20 | K=5 | K=10 | K=20 | |
| ConMH-norm | 0.242 | 0.156 | 0.103 | 0.341 | 0.224 | 0.152 | 0.405 | 0.286 | 0.206 |
| ConMH w/o | 0.287 | 0.208 | 0.156 | 0.411 | 0.297 | 0.220 | 0.469 | 0.356 | 0.275 |
| ConMH w/o | 0.262 | 0.227 | 0.202 | 0.335 | 0.287 | 0.257 | 0.332 | 0.284 | 0.254 |
| ConMH w/ GFL | 0.274 | 0.228 | 0.193 | 0.393 | 0.313 | 0.259 | 0.465 | 0.368 | 0.304 |
| ConMH | 0.350 | 0.293 | 0.252 | 0.476 | 0.390 | 0.332 | 0.524 | 0.433 | 0.373 |
| Method | Backbone | K=5 | K=20 | K=40 | K=60 | K=80 | K=100 |
| BTH | VGG-16 | 0.475 | 0.310 | 0.260 | 0.235 | 0.216 | 0.202 |
| MCMSH | VGG-16 | 0.494 | 0.335 | 0.288 | 0.263 | 0.245 | 0.230 |
| ConMH | VGG-16 | 0.524 | 0.373 | 0.326 | 0.301 | 0.283 | 0.267 |
| BTH | Swin Transformer | 0.627 | 0.490 | 0.443 | 0.415 | 0.394 | 0.375 |
| MCMSH | Swin Transformer | 0.665 | 0.541 | 0.497 | 0.471 | 0.450 | 0.430 |
| ConMH | Swin Transformer | 0.675 | 0.567 | 0.530 | 0.507 | 0.489 | 0.472 |
Retrieval Performance with Swin Transformer: Recently, Swin Transformer (Liu et al. 2021) has proved its superiority in image feature extracting, compared with the CNN model. To investigate how ConMH performs using a stronger feature extraction backbone, we use the ImageNet-pretrained Swin Transformer backbone to replace the CNN backbone. Then we evaluate the performance of different methods under such a stronger setting. As shown in Table 3, with a stronger backbone, ConMH still performs better than BTH and MCMSH, proving the scalability of ConMH.
Effects of Different Masking Ratios: We evaluate model performance with different masking ratios on FCVID with 64 bits. As shown in Figure 6 (a), a high masking ratio (i.e., 50% to 75%) works well. Both low and extremely high masking ratios will degrade model performance. Furthermore, we study the effect of masking ratios in the case of only a single task. As shown in Figure 6 (b), when only the reconstruction task is employed, a high masking ratio (e.g., 90%) works better. As for the contrastive task, a moderately lower masking ratio (e.g., 30%) is preferred. The reasons are two-fold. On the one hand, a high masking ratio will benefit intra-sample semantic understanding via reconstruction task. On the other hand, the large information loss it incurs will increase the difficulty of learning semantically-invariant information between positive samples in the contrastive task and even harm the task convergence. Besides, we find that adopting a compromise masking ratio (e.g., 50%-75%) helps to balance and unify two objectives in one learning framework effectively. As we can learn from the above results, the complete version of ConMH outperforms both single-task models when choosing proper masking ratios.


Effects of Different Masking Strategies: In this subsection, we investigate the impact of different masking strategies. From Table 4, we can learn that the entire frame masking strategy achieves the best performance, while tube-based masking and token-based masking strategies show not very satisfactory results. The reason might be that our method (which follows the standard SSVH settings) intrinsically operates on frame-level granularity. Therefore, when combining our method with the tube-based or token-based masking strategies, the input video frames will suffer from a large proportion of information loss. It results in weak frame-level features and thus adversely reduces the effectiveness of the reconstruction task. Besides, we have to preserve all the frames for the reconstruction task and suffer from larger memory overhead.
| Masking Strategy | K=5 | K=20 | K=40 | K=60 | K=80 | K=100 |
| tube-based mask | 0.387 | 0.198 | 0.147 | 0.124 | 0.109 | 0.099 |
| token-based mask | 0.412 | 0.227 | 0.175 | 0.151 | 0.135 | 0.129 |
| entire frame mask | 0.524 | 0.373 | 0.326 | 0.301 | 0.283 | 0.267 |
Effects of Different Sampling Strategies: In this subsection, we investigate the impact of different sampling strategies as shown in Table 5. In general, both overlapped and non-overlapped sampling strategies behave similarly in terms of performance. It might be due to the information redundancy among successive frames. Besides, the long and short sampling strategy does not exhibit an advantage in our case. We guess the reason might be that the constrained pattern reduces the sampling’s diversity (or randomness), which might be less effective on untrimmed videos.
| Sampling Strategy | K=5 | K=20 | K=40 | K=60 | K=80 | K=100 |
| long and short way | 0.509 | 0.355 | 0.308 | 0.283 | 0.265 | 0.250 |
| overlapped | 0.528 | 0.374 | 0.327 | 0.300 | 0.282 | 0.265 |
| non-overlapped | 0.524 | 0.373 | 0.326 | 0.301 | 0.283 | 0.267 |
Effects of Different Model Sizes: In this subsection, we explore the impact of different model sizes on FCVID with 64 bits. As shown in the first ten rows of Table 6, using a small decoder to reconstruct the original videos is better. When the decoder is big (e.g., with 12 depth or 1024 width), the retrieval performance of the model, in turn, will degrade. That is because a small decoder needs more semantic information to complete the reconstruction task, forcing the encoder to generate more informative representations and hash tokens. However, the decoder cannot be too small (e.g., too small width or a simple FC layer), which will make the reconstruction task too difficult to accomplish, leading to poor performance. Although the decoder structure can be chosen arbitrarily because it will be discarded during testing, it still affects the training time. Therefore, we comprehensively consider the training time and model performance, then set the depth and width of the decoder as 2 and 192, respectively. Besides, as shown in the last three rows of Table 6, when the encoder size becomes larger, the performance of the model is correspondingly improved, demonstrating that ConMH is a scalable framework for self-supervised video hashing, which still works well even with a huge model structure. However, large model structures make inference time long, violating the real-time requirement of video hashing. So we choose ViT-small as our defaulting encoder structure.
| Encoder | Decoder | K=20 | K=40 | K=60 | K=80 | K=100 | ||
| depth | width | |||||||
| ViT-small | 0 | 192 | 0.254 | 0.232 | 0.221 | 0.212 | 0.205 | |
| 1 | 0.372 | 0.326 | 0.301 | 0.282 | 0.266 | |||
| 2 | 0.373 | 0.326 | 0.301 | 0.283 | 0.267 | |||
| 4 | 0.371 | 0.324 | 0.299 | 0.280 | 0.264 | |||
| 8 | 0.371 | 0.324 | 0.299 | 0.280 | 0.264 | |||
| 12 | 0.366 | 0.320 | 0.295 | 0.276 | 0.260 | |||
| 2 | 64 | 0.358 | 0.314 | 0.291 | 0.273 | 0.258 | ||
| 256 | 0.373 | 0.326 | 0.300 | 0.280 | 0.264 | |||
| 512 | 0.372 | 0.324 | 0.298 | 0.278 | 0.262 | |||
| 1024 | 0.370 | 0.322 | 0.296 | 0.277 | 0.260 | |||
| ViT-mini | 2 | 192 | 0.324 | 0.274 | 0.248 | 0.229 | 0.214 | |
| ViT-base | 0.397 | 0.349 | 0.323 | 0.303 | 0.285 | |||
| ViT-large | 0.401 | 0.352 | 0.325 | 0.305 | 0.287 | |||
Conclusions
In this paper, we propose a simple yet effective contrastive masked autoencoders framework called ConMH for self-supervised video hashing. ConMH uses an asymmetric encoder-decoder framework to better understand the video’s visual semantic content. The encoder takes highly temporal-masked frames to generate hash codes, and the decoder reconstructs the masked video frames by utilizing generated hash tokens and masked tokens. We find that a high masking ratio is beneficial. Besides, ConMH combines a discriminative task to fully exploit the similarity relationship between videos in a single stage. Extensive experiments on three widely used benchmark datasets demonstrate the superiority of our ConMH.
Acknowledge
This work is supported in part by the National Natural Science Foundation of China under grant 62171248, the PCNL KEY project (PCL2021A07), the Guangdong Basic and Applied Basic Research Foundation under grant 2021A1515110066, and the GXWD 20220811172936001, and Shenzhen Science and Technology Program under Grant JCYJ20220818101012025.
This work was partly conducted based on the undergraduate graduation thesis in Huazhong University of Science and Technology, Wuhan, China.
References
- Assran et al. (2022) Assran, M.; Caron, M.; Misra, I.; Bojanowski, P.; Bordes, F.; Vincent, P.; Joulin, A.; Rabbat, M.; and Ballas, N. 2022. Masked siamese networks for label-efficient learning. In European Conference on Computer Vision, 456–473. Springer.
- Bao, Dong, and Wei (2021) Bao, H.; Dong, L.; and Wei, F. 2021. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254.
- Caba Heilbron et al. (2015) Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; and Carlos Niebles, J. 2015. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the ieee conference on computer vision and pattern recognition, 961–970.
- Caron et al. (2020) Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; and Joulin, A. 2020. Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 33: 9912–9924.
- Chen et al. (2020) Chen, T.; Kornblith, S.; Norouzi, M.; and Hinton, G. 2020. A simple framework for contrastive learning of visual representations. In International conference on machine learning, 1597–1607. PMLR.
- Chen et al. (2022) Chen, X.; Ding, M.; Wang, X.; Xin, Y.; Mo, S.; Wang, Y.; Han, S.; Luo, P.; Zeng, G.; and Wang, J. 2022. Context autoencoder for self-supervised representation learning. arXiv preprint arXiv:2202.03026.
- Chen and He (2021) Chen, X.; and He, K. 2021. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15750–15758.
- Chuang et al. (2020) Chuang, C.-Y.; Robinson, J.; Lin, Y.-C.; Torralba, A.; and Jegelka, S. 2020. Debiased contrastive learning. Advances in neural information processing systems, 33: 8765–8775.
- Cui et al. (2021) Cui, H.; Zhu, L.; Li, J.; Cheng, Z.; and Zhang, Z. 2021. Two-pronged Strategy: Lightweight Augmented Graph Network Hashing for Scalable Image Retrieval. In Proceedings of the 29th ACM International Conference on Multimedia, 1432–1440.
- Dong et al. (2021) Dong, X.; Bao, J.; Zhang, T.; Chen, D.; Zhang, W.; Yuan, L.; Chen, D.; Wen, F.; and Yu, N. 2021. PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers. arXiv preprint arXiv:2111.12710.
- Dosovitskiy et al. (2020) Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Erin Liong et al. (2015) Erin Liong, V.; Lu, J.; Wang, G.; Moulin, P.; and Zhou, J. 2015. Deep hashing for compact binary codes learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2475–2483.
- Gao et al. (2015) Gao, L.; Song, J.; Zou, F.; Zhang, D.; and Shao, J. 2015. Scalable multimedia retrieval by deep learning hashing with relative similarity learning. In Proceedings of the 23rd ACM international conference on Multimedia, 903–906.
- Gong et al. (2012) Gong, Y.; Lazebnik, S.; Gordo, A.; and Perronnin, F. 2012. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE transactions on pattern analysis and machine intelligence, 35(12): 2916–2929.
- Grill et al. (2020) Grill, J.-B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. 2020. Bootstrap your own latent-a new approach to self-supervised learning. Advances in Neural Information Processing Systems, 33: 21271–21284.
- Hao et al. (2022) Hao, Y.; Duan, J.; Zhang, H.; Zhu, B.; Zhou, P.; and He, X. 2022. Unsupervised Video Hashing with Multi-granularity Contextualization and Multi-structure Preservation. In ACM International Conference on Multimedia (MM’22).
- He et al. (2022) He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; and Girshick, R. 2022. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16000–16009.
- He et al. (2020) He, K.; Fan, H.; Wu, Y.; Xie, S.; and Girshick, R. 2020. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9729–9738.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Jiang et al. (2017) Jiang, Y.-G.; Wu, Z.; Wang, J.; Xue, X.; and Chang, S.-F. 2017. Exploiting feature and class relationships in video categorization with regularized deep neural networks. IEEE transactions on pattern analysis and machine intelligence, 40(2): 352–364.
- Kingma and Ba (2014) Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Li et al. (2017) Li, C.; Yang, Y.; Cao, J.; and Huang, Z. 2017. Jointly modeling static visual appearance and temporal pattern for unsupervised video hashing. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, 9–17.
- Li et al. (2019) Li, S.; Chen, Z.; Lu, J.; Li, X.; and Zhou, J. 2019. Neighborhood preserving hashing for scalable video retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8212–8221.
- Li et al. (2021) Li, S.; Li, X.; Lu, J.; and Zhou, J. 2021. Self-supervised video hashing via bidirectional transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13549–13558.
- Liu et al. (2021) Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10012–10022.
- Lu et al. (2021) Lu, D.; Wang, J.; Zeng, Z.; Chen, B.; Wu, S.; and Xia, S.-T. 2021. SwinFGHash: Fine-grained Image Retrieval via Transformer-based Hashing Network. In 32nd British Machine Vision Conference.
- Luo et al. (2018) Luo, X.; Nie, L.; He, X.; Wu, Y.; Chen, Z.-D.; and Xu, X.-S. 2018. Fast scalable supervised hashing. In The 41st international ACM SIGIR conference on research & development in information retrieval, 735–744.
- Russakovsky et al. (2015) Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. 2015. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3): 211–252.
- Simonyan and Zisserman (2014) Simonyan, K.; and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Song et al. (2011) Song, J.; Yang, Y.; Huang, Z.; Shen, H. T.; and Hong, R. 2011. Multiple feature hashing for real-time large scale near-duplicate video retrieval. In Proceedings of the 19th ACM international conference on Multimedia, 423–432.
- Song et al. (2018) Song, J.; Zhang, H.; Li, X.; Gao, L.; Wang, M.; and Hong, R. 2018. Self-supervised video hashing with hierarchical binary auto-encoder. IEEE Transactions on Image Processing, 27(7): 3210–3221.
- Thomee et al. (2015) Thomee, B.; Shamma, D. A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; and Li, L.-J. 2015. The new data and new challenges in multimedia research. arXiv preprint arXiv:1503.01817, 1(8).
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang et al. (2022) Wang, J.; Zeng, Z.; Chen, B.; Wang, Y.; Liao, D.; Li, G.; Wang, Y.; and Xia, S.-T. 2022. Hugs Are Better Than Handshakes: Unsupervised Cross-Modal Transformer Hashing with Multi-granularity Alignment. In 33nd British Machine Vision Conference.
- Weiss, Torralba, and Fergus (2008) Weiss, Y.; Torralba, A.; and Fergus, R. 2008. Spectral hashing. Advances in neural information processing systems, 21.
- Wu et al. (2017) Wu, G.; Liu, L.; Guo, Y.; Ding, G.; Han, J.; Shen, J.; and Shao, L. 2017. Unsupervised deep video hashing with balanced rotation. IJCAI.
- Xie et al. (2022) Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; and Hu, H. 2022. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9653–9663.
- Zeng et al. (2022) Zeng, Z.; Wang, J.; Chen, B.; Wang, Y.; and Xia, S.-T. 2022. Motion-Aware Graph Reasoning Hashing for Self-supervised Video Retrieval. In 33nd British Machine Vision Conference.
- Zhang et al. (2016) Zhang, H.; Wang, M.; Hong, R.; and Chua, T.-S. 2016. Play and rewind: Optimizing binary representations of videos by self-supervised temporal hashing. In Proceedings of the 24th ACM international conference on Multimedia, 781–790.