Contrastive Language-Image Pretrained Models are Zero-Shot Human Scanpath Predictors
Abstract
Understanding the mechanisms underlying human attention is a fundamental challenge for both vision science and artificial intelligence. While numerous computational models of free-viewing have been proposed, less is known about the mechanisms underlying task-driven image exploration. To address this gap, we present CapMIT1003, a database of captions and click-contingent image explorations collected during captioning tasks. CapMIT1003 is based on the same stimuli from the well-known MIT1003 benchmark, for which eye-tracking data under free-viewing conditions is available, which offers a promising opportunity to concurrently study human attention under both tasks. We make this dataset publicly available to facilitate future research in this field. In addition, we introduce NevaClip, a novel zero-shot method for predicting visual scanpaths that combines contrastive language-image pretrained (CLIP) models with biologically-inspired neural visual attention (NeVA) algorithms. NevaClip simulates human scanpaths by aligning the representation of the foveated visual stimulus and the representation of the associated caption, employing gradient-driven visual exploration to generate scanpaths. Our experimental results demonstrate that NevaClip outperforms existing unsupervised computational models of human visual attention in terms of scanpath plausibility, for both captioning and free-viewing tasks. Furthermore, we show that conditioning NevaClip with incorrect or misleading captions leads to random behavior, highlighting the significant impact of caption guidance in the decision-making process. These findings contribute to a better understanding of mechanisms that guide human attention and pave the way for more sophisticated computational approaches to scanpath prediction that can integrate direct top-down guidance of downstream tasks.
1 Introduction
Visual attention is an essential cognitive process in human beings, enabling selective processing of relevant portions of visual input while disregarding irrelevant information. This function not only facilitates efficient information processing but also plays a crucial role in shaping perception and awareness [12, 16]. By directing attention toward specific content within a scene, individuals are able to construct a coherent and meaningful representation of their visual environment. Seminal works by Buswell, [5] and Tatler et al., [25] investigated the relationship between eye-movement patterns and high-level cognitive factors to demonstrate the influential role of task demands on eye movements and visual attention. According to Tatler et al., [24], human eye movements follow a distinctive temporal pattern. Individuals’ initial fixations are primarily influenced by bottom-up visual features, displaying a notable consistency across different subjects. However, these fixations rapidly diverge as individuals’ unique goals and motivations, i.e. their tasks, come into play. This relationship between attention and task becomes particularly relevant when attention interplays with language: Altmann and Kamide, [1] suggested a link between language processing and visual attention based on object affordances, while Mishra, [17] demonstrated the influence of visual attention on language behavior.

Despite great interest in understanding mechanisms underlying task-driven visual exploration, most current computational models of visual attention focus on free viewing [4], which primarily involves bottom-up saliency, and overlooks the influence of different tasks. In Itti et al., [9], conspicuity maps are combined to create a saliency map, which expresses for each location in the visual field the probability of being attended by humans. Recently, deep learning approaches demonstrated state-of-the-art performance in saliency prediction tasks [19, 7, 26]. Saliency methods can be combined with the Winner-Take-All algorithm [13], to progressively generate fixation sequences. Gaze shifts are described in [3] as a stochastic process with non-local transition probabilities in a saliency field. A constrained random walk is performed in this field to simulate attention as a search mechanism. Zanca and Gori, [27] describe attention as a dynamic process, where eye movements are governed by three fundamental principles: boundedness of the retina, attractiveness of gradients, and brightness invariance. Zanca et al., [28] propose a mechanism of attention that emerges from the movement of a unitary mass in a gravitational field. In this approach, specific visual features, such as intensity, optical flow, and a face detector, are extracted for each location and compete to attract the focus of attention. Recently, Schwinn et al., [22] proposed the Neural Visual Attention (NeVA) algorithm to generate visual scanpaths in a top-down manner. This method imposes a biologically-inspired foveated vision constraint to generate human-like scanpaths without directly training for this objective but exploiting the top-down guidance of the loss of a pretrained vision model in an iterative optimization scheme.
To investigate task-driven human attention and its interplays with language, in this paper we contribute computational models that simulate human attention during the captioning process, while additionally providing a dataset specifically designed for this task. Generating accurate and relevant descriptions of images [14, 23] is an essential task that requires a deep understanding of both the human visual attention mechanism and its connection to language processing. Numerous studies have explored the characteristics of soft attention mechanisms in captioning models, focusing on their correlation with objects present in the scene and their consistency with human annotations [15, 18]. Other works demonstrated the effectiveness of incorporating computational models of visual attention into captioning models [6]. However, to date, there is a lack of computational models that accurately capture the complexities of human attention during captioning tasks and flexibly adapt to multimodal language-image sources.
First, we collect behavioral data from human subjects using a web application. With this procedure, we create CapMIT1003, a database of captions and click-contingent image explorations collected under captioning tasks. CapMIT1003 is based on the well-known MIT1003 dataset [11], which comprises 1003 images along with corresponding eye-tracking data of subjects engaged in free-viewing. We developed a click-contingent paradigm, drawing inspiration from prior studies on free viewing [10], which is designed to emulate the natural viewing behavior of humans. By exploiting a computer mouse as a substitute for an eye tracker, this approach enabled a large-scale data collection, without the need for specialized equipment. This integrated dataset holds significant importance as it enables the study of both tasks simultaneously. We make this dataset publicly available as a valuable resource for investigating the relationship between human attention, language, and visual perception, fostering a deeper understanding of the cognitive processes involved in captioning.
To study the relationships between the collected visual explorations and captions, we combine the previously illustrated Neural Visual Attention [22] algorithms with Contrastive Language-Image Pretrained (CLIP) [21] models, that effectively map images and associated captions onto the same feature representation. The basic idea is that, by selectively attending to and revealing portions of the image that are semantically related to the concepts expressed in the caption, we increase the cosine similarity between the visual embedding of the foveated image and its corresponding caption. An overview of the approach is illustrated in Figure 1. By setting this as a target for the NeVA algorithm, subsequent fixations are chosen to maximize the cosine similarity between the visual and text embeddings through an iterative optimization process. It is worth noticing that this method is entirely unsupervised, as no human data is utilized for training.
Our findings demonstrate that generating scanpaths conditioned on the correctly associated captions results in highly plausible scanpath trajectories, as evidenced by the similarity to corresponding human attention patterns. When conditioning the scanpath generation on captions provided by other users for the same image, scanpath plausibility slightly decreases. However, generating scanpaths conditioned on random captions, given by other subjects on different images, leads to systematically unplausible visual behaviors, with performance equivalent to that of a random baseline. Furthermore, we observe that, by employing visual embedding of the clean image as a target caption representation, we achieve the best results in terms of scanpath plausibility, setting a state-of-the-art result for the newly collected dataset. These findings together highlight the effectiveness of our approach in leveraging captions to guide visual attention during scanpath generation and demonstrate the utility of contrastive language-image pretrained models as zero-shot scanpath predictors. All data and code will be released on GitHub after publication.
2 Data collection
In this section, we introduce CapMIT1003, an integrated dataset combining captions, and click-contingent image explorations. This dataset is crucial as it offers a valuable resource to explore the interplay between human attention, language, and visual perception, contributing to a deeper understanding of cognitive processes in captioning. It builds over the well-known benchmark MIT1003 [11], which contains eye-tracking data collected under free-viewing conditions.
2.1 Web-based crowdsourcing of visual explorations and captions
We developed a web application that presents images to participants and prompts them to provide textual descriptions while performing click-contingent image explorations. Users were asked to visually explore and provide a caption for up to fifty distinct images from the MIT1003 dataset [11]. Images were presented sequentially, one after another. We used the protocol defined in Jiang et al., [10] for which crowdsourcers are presented with a completely blurred version of the image, and can unveil details on specific locations by clicking. A click will reveal information in an area corresponding to two degrees of visual angle, calculated with respect to the original dataset experimental setup described in [11]. This process is aimed at simulating a human’s foveated vision. Subjects can click up to ten times, before providing a caption. We instructed users to describe the content of the image with "one or two sentences", in English. All clicks and captions are stored in a database, while no personal information has been collected.
2.2 CapMIT1003 statistics


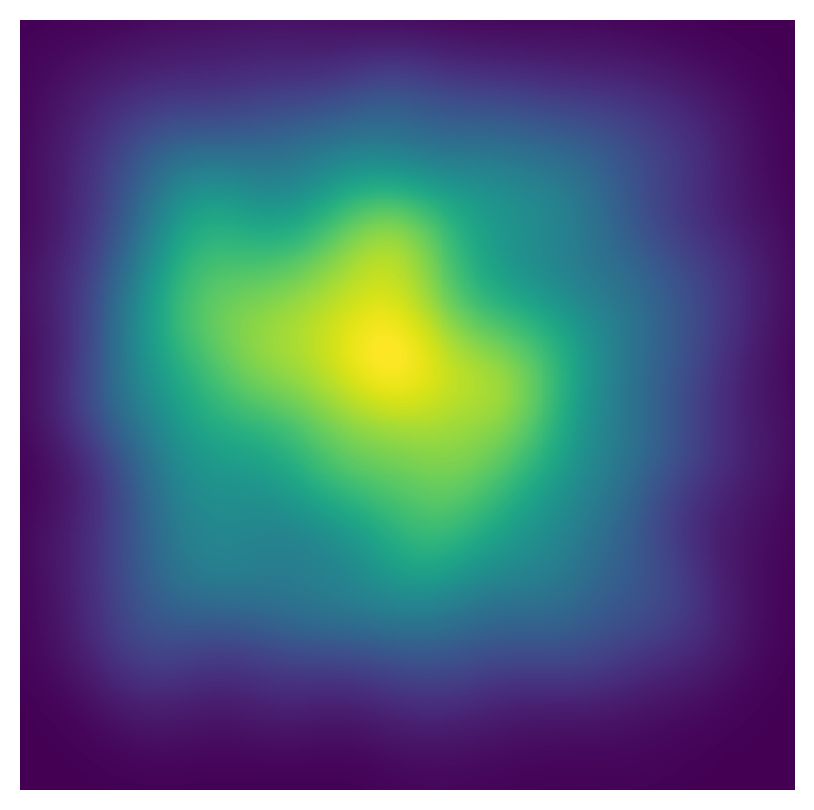
In total, we collected 27865 clicks on 4573 observations over 153 sessions. We excluded 654 observations that were skipped, 33 with no recorded clicks, and 38 captions with less than 3 characters. After these exclusions, we analyzed the data for 1002 of the 1003 images in the pool. The average number of characters per caption was 50.89, with a standard deviation of 33.88. The average number of words per caption was 9.78, with a standard deviation of 6.47. The maximum caption lengths were 259 characters and 51 words, respectively. Figure 2 shows the click density based on all collected clicks. The figure was generated by scaling the position of each click with the size of the corresponding image. Afterward, we used a Gaussian kernel density estimation to calculate the click density. Figure 3 shows the number of observations with each click count from 1 to 10. Using all 10 available clicks was the most favored option.
3 Method
3.1 CLIP
Contrastive Language-Image Pretraining (CLIP) [21], is a method of learning semantic concepts efficiently from natural language supervision, which is trained on a large dataset of (image, text) pairs. CLIP uses a shared embedding space for both modalities. Let be the image encoder and be the text encoder, where represents the trainable parameters of the models. Given an image and a corresponding text , the image embedding is defined as , and the text embedding is defined as .
CLIP models are trained by maximizing the cosine similarity of the embeddings of the correct pairs in the batch while minimizing the cosine similarity of the embeddings of the incorrect pairings. The cosine similarity between two embeddings and is computed as .
3.2 Neural Visual Attention (NeVA)
Let be a sequence of fixation points, also called scanpath in what follows. Given a visual stimulus and its coarse version , Schwinn et al., [22] define a foveated stimulus as
where is the current fixation point at time , and is a Gaussian blob centered on with standard deviation . A scanpath is generated iteratively, by an optimization procedure. Let be any task model, and its associated loss. The next fixation location is determined by a local search in order to minimize the loss
where is a target output for the specific downstream task. This approach can be applied to any pretrained vision model.
3.3 Generating scanpaths with CLIP embeddings (NevaClip)
To use NeVA in combination with CLIP, we need to modify the optimization procedure to incorporate the cosine similarity between (foveated) stimuli and caption embeddings in the loss function.
Let be a visual stimulus and be its associated caption. We use CLIP’s visual encoder as the task model, where the downstream task is, at each step, to maximize the cosine similarity between the foveated image embedding and caption embeddings, i.e.,
| (1) |
where , and . Then, the NeVA optimization procedure described in the previous subsection can be extended to generate a complete visual scanpath for a given stimulus and its associated caption embedding . To simplify the notation, we denote this procedure as
| (2) |
where is the sequence of fixation points that constitute the scanpath. This approach provides an efficient method for generating scanpaths that are optimized to minimize the distance between the foveated versions of the stimulus, highlighting specific portions of the image, and the semantic concepts included in the captions. The pseudo-code in algorithm 1 illustrates the overall procedure.
We observe that, as a consequence of its training, the CLIP visual embedding of the clean image (i.e., not foveated), can be considered as the ideal caption’s embedding. By employing the CLIP visual embedding of the clean image as a target in the NeVA optimization procedure, we can generate a scanpath without an explicit caption, i.e.,
| (3) |
We refer to this approach as the NevaClip (visually-guided). Although it violates the biological constraint of partial information by having access to the whole stimulus (we in fact need the entire clean image in advance to compute ), this serves us as a gold standard as it potentially minimizes the distribution shift between captions provided by our users in our study and captions that CLIP would assign the same image. Furthermore, this configuration of the NevaClip model is relevant for practical applications in which processing the entire stimulus is feasible, while we do not have real-time access to the subject’s caption.



4 Experiments
4.1 Experimental setup
We adhere to the original implementation of the Neva algorithm with 20 optimization steps111https://github.com/SchwinnL/NeVA. Random restarts during the local search were not allowed, as we found out this induces a favorable proximity preference [13] to the next fixation. In [22] past explorations are incorporated into the agent’s state, modulated by a forgetting factor. In our experiments, we found that optimal results were achieved for NevaClip with a forgetting factor of . This indicates that the system operates under a Markovian assumption, where only information from the last fixation is used in order to determine the next location to be attended. We use the implementation of the CLIP model provided by the original authors222https://github.com/openai/CLIP. When not stated otherwise, all NevaClip results are presented for the Resnet50 backbone. For all competitor models, the original code provided by the authors is used.
4.2 Baselines and models
In order to investigate the relationship between captions and their corresponding visual explorations, we evaluate four distinct variations of our NevaClip algorithm. These versions differ only on the target embedding used as a guide for visual exploration, as described in equations 1, 2, and 3.
NevaClip (correct caption). Scanpaths are generated maximizing the alignment between visual embeddings of the foveated stimuli, and text embeddings of the corresponding captions, as described in equation 2.
NevaClip (different caption, same image). Scanpath are generated to maximize the alignment between visual embeddings of the foveated stimuli, and text embeddings of the captions provided by a different subject on the same image.
NevaClip (different caption, different image). Scanpath are generated to maximize the alignment between visual embeddings of the foveated stimuli, and text embeddings of the random captions provided by a different subject on a different image.
NevaClip (visually-guided). Scanpath are generated to maximize the alignment between visual embeddings of the foveated stimuli, and the visual embedding of the clean version of the same image, as described in equation 3.
We define three baselines, to better position the quality of the results.
Random. Scanpaths are generated by subsequently sampling fixation points from a uniform probability distribution defined over the entire stimulus area.
Center. Scanpaths are randomly sampled from a -dimensional Gaussian distribution centered in the image. We used the center matrix provided in Judd et al., [11], associated with the MIT1003 dataset.
Clicks Density. Scanpaths are randomly sampled from a -dimensional density distribution obtained by cumulating all clicks in the dataset.
We compare our approach to four state-of-the-art unsupervised models of human visual attention. It is worth mentioning that none of these models is designed to exploit information from the caption.
NeVA (original) [22]. We employ the guidance of a classification downstream task, which was demonstrated to produce the highest similarity to humans in the original paper. We use the optimized version of the algorithm, provided by the authors.
Constrained Levy Exploration (CLE) [3]. Scanpath is described as a realization of a stochastic process. We used saliency maps by [9] to define non-local transition probabilities. Python implementation provided by the authors in [2].
Gravitational Eye Movements Laws (G-EYMOL) [28]. Scanpath is obtained as the motion of a unitary mass within gravitational fields generated by salient visual features.
Winner-take-all (WTA) [13]. Based on the saliency maps by Itti et al., [9], the next fixation is selected at the location of maximum saliency. Inhibition-of-return allows switching to new locations.
| CapMIT1003 | MIT1003 | |
| Model | Captioning | Free-viewing |
| Random baseline | 0.26 (0.13) | 0.30 (0.11) |
| Center baseline | 0.27 (0.13) | 0.33 (0.12) |
| ClickDensity baseline | 0.27 (0.13) | 0.32 (0.11) |
| G-Eymol | 0.34 (0.17) | 0.46 (0.16) |
| Neva (original) | 0.34 (0.17) | 0.47 (0.16) |
| CLE | 0.30 (0.19) | 0.47 (0.18) |
| WTA+Itti | 0.31 (0.16) | 0.37 (0.14) |
| NevaClip (correct caption) | 0.35 (0.18) | 0.50 (0.17) |
| NevaClip (different caption, same image) | 0.34 (0.17) | 0.50 (0.17) |
| NevaClip (different caption, different image) | 0.26 (0.14) | 0.37 (0.15) |
| NevaClip (visually-guided) | 0.38 (0.19) | 0.57 (0.18) |
4.3 Metrics and evaluation
To measure the similarity between simulated and human scanpaths, we compute ScanPath Plausibility (SPP) [8], using the string-based time-delay embeddings (SBTDE) [22] as a basic metric. The SBTDE accounts for stochastic components which are typical of the process of human visual attention [20], by searching for similar subsequences at different times. This metric can be computed for each subsequence length, expressively indicating the predictive power of models at each stage of the exploration. The SBTDE at subsequence length is computed as
where are the two scanpaths to be compared, and are the sets of all possible contiguous sublengths of size in and , respectively. We use the string-edit distance to compute the distance between subsequences. The SPP accounts for large variability between human subjects, by considering only the human scanpath with the minimum distance for each stimulus. To obtain a similarity measure, ranging from (minimum similarity) and (maximum similarity), we consider the SBTDE complement to one. Let be a simulated scanpath, and a set of human reference scanpaths, for each sublength , scanpath plausibility is defined as
Since human explorations, both for clicks and eye-tracking, can be of different lengths, for each subject we compute the metric up to , where is the length of the human scanpath.


4.4 Results on CapMIT1003 (captioning task)
Table 1 summarises results on the CapMIT1003 dataset. The NevaClip (visually-guided), which exploits the guidance of the clean image embedding, significantly outperforms all other approaches by a substantial margin. As expected, NevaClip (different subject, different image), which generates a scanpath using a label from a different image and a different subject, performs similarly to the Random Baseline. We observed that this configuration systematically explores non-relevant objects that align with the misleading caption or, in their absence, emphasizes the background, which typically possesses an average feature representation (see Figure 4). The NevaClip (correct caption) performs slightly better than the NevaClip (different subject, same image), demonstrating that the caption provided by the subject brings useful information about their own visual exploration behavior. Among competitors, G-Eymol and Neva (original) compete well, despite not incorporating any caption information. It is worth noting that all approaches are unsupervised, and the scanpath prediction is performed zero-shot. Supervised approaches could benefit from exploiting more information contained in the caption for personalized scanpath prediction.
4.5 Results on MIT1003 (free-viewing task)
The NevaClip (visually-guided) approach again significantly outperforms all competitors by a substantial margin. NevaClip (correct caption) and NevaClip (different subject, same image) also performs better than state-of-the-art models NeVA (original) and G-Eymol. These results demonstrate a substantial overlap between the two tasks, as discussed later in section 4.7.
4.6 The influence of CLIP’s vision backbone.
We compare the performance of NevaClip (correct caption) for different backbones. Results are presented in table 2. ResNet50 obtains a SPP SBTDE of 0.35 ( 0.18), while ResNet101 and ViT-B/32 obtain 0.33 ( 0.17) and 0.33 ( 0.18), respectively. While the performance of different backbones is comparable, simpler models such as ResNet50 might benefit from simpler representations, which lead to less over-specific visual explorations. A similar observation was made by Schwinn et al., [22], where a combination of a simpler model and task exhibited the best performance in terms of similarity to humans.
4.7 Critical comparison: free-viewing vs. captioning
As expected, capturing attention in captioning tasks proves to be more challenging compared to free-viewing, as it involves the simultaneous consideration of multiple factors such as image content, language, and semantic coherence. This is reflected in the results, where all approaches achieve lower performance in terms of scanpath plausibility (see table 1) for the captioning task. The ranking of models remains consistent across both tasks, with free-viewing models performing reasonably well on both datasets. This observation suggests a substantial overlap between free viewing and captioning, possibly due to the initial phases of exploration being predominantly driven by bottom-up factors rather than task-specific demands.
Simulating realistic scanpaths becomes increasingly challenging after just a few fixations, and this difficulty is particularly pronounced in the context of captioning, as illustrated in Figure 5. This result is in line with existing literature [24] demonstrating how human visual attention diverges quickly due to individual goals.
Upon analyzing the click density map depicted in Figure 2, we observe that captioning elicits significantly more diverse exploratory patterns compared to free viewing, which exhibits a more pronounced center bias [11]. The same figure also reveals that a portion of the clicks is distributed in a grid-like fashion, indicating a tendency of users to perform a systematic strategy for spread out visual exploration. This finding makes sense considering the nature of captioning, which assumes a holistic understanding of the scene, unlike free viewing which does not impose such requirements.
| CapMIT1003 | ||
|---|---|---|
| Backbone | Num. parameters | Captioning |
| RN50 [21] | 26M | 0.35 (0.18) |
| RN101 [21] | 44.6M | 0.33 (0.17) |
| ViT-B/32 [21] | 86M | 0.33 (0.18) |
5 Conclusions
In this paper, we first introduced the CapMIT1003 database, which consists of captions and click-contingent image explorations collected under captioning tasks. This dataset extends the well-known MIT1003 benchmark, collected under free-viewing conditions. We make this dataset publicly available to facilitate future research in this area. To model the relationship between scanpaths and captions, we introduced NevaClip, a novel zero-shot method for predicting visual scanpaths. This approach generates gradient-driven visual explorations under the biological constraint of foveated vision that demonstrate superior plausibility compared to existing unsupervised computational models of human visual attention, for both captioning and free-viewing tasks.
Our experimental results emphasized the significant impact of caption guidance in the decision-making process of NevaClip. Conditioning NevaClip with incorrect or misleading captions led to random behavior, highlighting the role of accurate caption information in guiding attention. This finding underlines the importance of future work in considering top-down guidance from downstream tasks in scanpath prediction and motivates the development of more sophisticated computational approaches.
References
- Altmann and Kamide, [2007] Altmann, G. T. and Kamide, Y. (2007). The real-time mediation of visual attention by language and world knowledge: Linking anticipatory (and other) eye movements to linguistic processing. Journal of memory and language, 57(4):502–518.
- Boccignone et al., [2019] Boccignone, G., Cuculo, V., and D’Amelio, A. (2019). How to look next? a data-driven approach for scanpath prediction. In International Symposium on Formal Methods, pages 131–145. Springer.
- Boccignone and Ferraro, [2004] Boccignone, G. and Ferraro, M. (2004). Modelling gaze shift as a constrained random walk. Physica A: Statistical Mechanics and its Applications, 331(1-2):207–218.
- Borji and Itti, [2012] Borji, A. and Itti, L. (2012). State-of-the-art in visual attention modeling. IEEE transactions on pattern analysis and machine intelligence, 35(1):185–207.
- Buswell, [1935] Buswell, G. T. (1935). How people look at pictures: a study of the psychology and perception in art.
- Chen and Zhao, [2018] Chen, S. and Zhao, Q. (2018). Boosted attention: Leveraging human attention for image captioning. In Proceedings of the European conference on computer vision (ECCV), pages 68–84.
- Cornia et al., [2018] Cornia, M., Baraldi, L., Serra, G., and Cucchiara, R. (2018). Sam: Pushing the limits of saliency prediction models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1890–1892.
- Fahimi and Bruce, [2021] Fahimi, R. and Bruce, N. D. (2021). On metrics for measuring scanpath similarity. Behavior Research Methods, 53(2):609–628.
- Itti et al., [1998] Itti, L., Koch, C., and Niebur, E. (1998). A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on pattern analysis and machine intelligence, 20(11):1254–1259.
- Jiang et al., [2015] Jiang, M., Huang, S., Duan, J., and Zhao, Q. (2015). Salicon: Saliency in context. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1072–1080.
- Judd et al., [2009] Judd, T., Ehinger, K., Durand, F., and Torralba, A. (2009). Learning to predict where humans look. In 2009 IEEE 12th international conference on computer vision, pages 2106–2113. IEEE.
- Kietzmann et al., [2011] Kietzmann, T. C., Geuter, S., and König, P. (2011). Overt visual attention as a causal factor of perceptual awareness. PloS one, 6(7):e22614.
- Koch and Ullman, [1987] Koch, C. and Ullman, S. (1987). Shifts in selective visual attention: towards the underlying neural circuitry. In Matters of intelligence, pages 115–141. Springer.
- Li et al., [2019] Li, S., Tao, Z., Li, K., and Fu, Y. (2019). Visual to text: Survey of image and video captioning. IEEE Transactions on Emerging Topics in Computational Intelligence, 3(4):297–312.
- Liu et al., [2017] Liu, C., Mao, J., Sha, F., and Yuille, A. (2017). Attention correctness in neural image captioning. In Proceedings of the AAAI conference on artificial intelligence, volume 31.
- Macknik and Martinez-Conde, [2009] Macknik, S. L. and Martinez-Conde, S. (2009). The role of feedback in visual attention and awareness. Cognitive Neurosciences, 1.
- Mishra, [2009] Mishra, R. K. (2009). Interaction of language and visual attention: evidence from production and comprehension. Progress in Brain Research, 176:277–292.
- Mun et al., [2017] Mun, J., Cho, M., and Han, B. (2017). Text-guided attention model for image captioning. In Proceedings of the AAAI conference on artificial intelligence, volume 31.
- Pan et al., [2017] Pan, J., Ferrer, C. C., McGuinness, K., O’Connor, N. E., Torres, J., Sayrol, E., and Giro-i Nieto, X. (2017). Salgan: Visual saliency prediction with generative adversarial networks. arXiv preprint arXiv:1701.01081.
- Pang et al., [2010] Pang, D., Takeuchi, T., Miyazato, K., Yamato, J., Kashino, K., et al. (2010). A stochastic model of human visual attention with a dynamic bayesian network. arXiv preprint arXiv:1004.0085.
- Radford et al., [2021] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Schwinn et al., [2022] Schwinn, L., Precup, D., Eskofier, B., and Zanca, D. (2022). Behind the machine’s gaze: Neural networks with biologically-inspired constraints exhibit human-like visual attention. Transactions on Machine Learning Research.
- Sharma et al., [2020] Sharma, H., Agrahari, M., Singh, S. K., Firoj, M., and Mishra, R. K. (2020). Image captioning: a comprehensive survey. In 2020 International Conference on Power Electronics & IoT Applications in Renewable Energy and its Control (PARC), pages 325–328. IEEE.
- Tatler et al., [2005] Tatler, B. W., Baddeley, R. J., and Gilchrist, I. D. (2005). Visual correlates of fixation selection: Effects of scale and time. Vision research, 45(5):643–659.
- Tatler et al., [2010] Tatler, B. W., Wade, N. J., Kwan, H., Findlay, J. M., and Velichkovsky, B. M. (2010). Yarbus, eye movements, and vision. i-Perception, 1(1):7–27.
- Wang et al., [2019] Wang, W., Shen, J., Xie, J., Cheng, M.-M., Ling, H., and Borji, A. (2019). Revisiting video saliency prediction in the deep learning era. IEEE transactions on pattern analysis and machine intelligence, 43(1):220–237.
- Zanca and Gori, [2017] Zanca, D. and Gori, M. (2017). Variational laws of visual attention for dynamic scenes. Advances in Neural Information Processing Systems (NeurIPS), 30.
- Zanca et al., [2019] Zanca, D., Melacci, S., and Gori, M. (2019). Gravitational laws of focus of attention. IEEE transactions on pattern analysis and machine intelligence, 42(12):2983–2995.
Appendix A Data Collection Instructions and Web Application Interface
The following instructions were displayed to the subjects right before starting the experiment:
-
•
In this study you are asked to provide a caption for 50 images.
-
•
Images are shown to you sequentially, one after another.
-
•
Each image is initially completely blurry, and you can click on it up to ten times to reveal more details.
-
•
After completing your exploration, describe the content of the image in 1-2 sentences in the text box on the right and click on submit. The caption must be in English.
-
•
If you are very unsure of the content of the image, you can skip it by clicking the “Skip” button.
-
•
Please take your time and try your best to reveal as much of the image as possible before providing a caption.
The web application’s instruction page for data collection is depicted in Figure 7(i). This page serves to acquaint participants with the task requirements by presenting them with examples of captions. Figure 6(b) showcases the appearance of the web application during the captioning task. The image is positioned on the left side, where clicking on it reveals details about the left-most penguin. On the right side, a text box is provided for participants to enter their captions after completing the exploration. Two buttons are available for participants: a "continue" button, which submits the provided caption, and a "skip" button, which can be used when participants are unable to provide a textual description.


Appendix B Estimated Clicks Densities Split by their Order
Figure 7 shows the estimated clicks densities split by their order. The first two klicks show a strong bias towards the center of the image. Following clicks are often used to perform exploration within the image and the final clicks again show a bias towards the center of the image.








Appendix C Scanpath examples
In the subsequent analysis, we present a collection of qualitative examples showcasing scanpaths derived from NevaClip. For each scanpath, both the corresponding captions and a comparison with human reference are provided. This presentation aims to illustrate the effectiveness and reliability of NevaClip in generating scanpaths by examining instances with both accurate and randomly generated captions.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1198772915.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i100856683.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i104267087.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i104880109.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i106389849.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i113941602.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1163341362.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1182505554.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1245116076.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1275003744.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1425519942.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1540552783.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1583042749.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1740677522.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1870142757.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2062358324.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2130135439.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2155084730.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2168982172.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2240166669.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2243931087.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2252150223.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2255800269.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2293362913.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2298125807.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i2300094693.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i113985471.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i443027538.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/i1025132509.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/istatic_outdoor_nature_tanzania_photos_by_fredo_durand_060811_125130__Z9B0580.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e41b88e-bba3-488d-8093-e279069339f9/istatic_street_outdoor_palma_mallorca_spain_IMG_0805.png)