Contrast, Imitate, Adapt: Learning Robotic Skills from Raw Human Videos
Abstract
Learning robotic skills from raw human videos remains a non-trivial challenge. Previous works tackled this problem by leveraging behavior cloning or learning reward functions from videos. Despite their remarkable performances, they may introduce several issues, such as the necessity for robot actions, requirements for consistent viewpoints and similar layouts between human and robot videos, as well as low sample efficiency. To this end, our key insight is to learn task priors by contrasting videos and to learn action priors through imitating trajectories from videos, and to utilize the task priors to guide trajectories to adapt to novel scenarios. We propose a three-stage skill learning framework denoted as Contrast-Imitate-Adapt (CIA). An interaction-aware alignment transformer is proposed to learn task priors by temporally aligning video pairs. Then a trajectory generation model is used to learn action priors. To adapt to novel scenarios different from human videos, the Inversion-Interaction method is designed to initialize coarse trajectories and refine them by limited interaction. In addition, CIA introduces an optimization method based on semantic directions of trajectories for interaction security and sample efficiency. The alignment distances computed by IAAformer are used as the rewards. We evaluate CIA in six real-world everyday tasks, and empirically demonstrate that CIA significantly outperforms previous state-of-the-art works in terms of task success rate and generalization to diverse novel scenarios layouts and object instances.
Note to Practitioners
This work aims to study robot skill learning from raw human videos. Compared with teleoperation or kinesthetic teaching in the laboratory, such learning method can flexibly utilize large-scale human videos available on the Internet, thereby improving the robot’s ability to generalize to various complex scenarios. Previous works on learning from videos usually have some issues, including requirements for robot actions, consistent viewpoints, similar layouts and low sample efficiency. To alleviate these issues, we propose a three-stage skill learning framework CIA. Temporal alignment is utilized to learn task priors through our proposed transformer-based model and self-supervised loss functions. A trajectory generation model is trained to learn the action priors. To further adapt to diverse scenarios, we propose a two-stage policy improvement method by initialization and interaction. An optimization method is introduced to ensure safe interaction and sample efficiency, where the optimization objective is guided by the learned task priors. The experimental results show that our CIA outperforms other state-of-the-art methods in task success rate and generalization to novel scenarios.
Index Terms:
Robot Learning from Human Videos, Self-supervised Temporal alignment, Sample-Efficient Reinforcement LearningI Introduction
Intelligent agents are expected to master various general-purpose manipulation skills in an open environment. Towards this goal, Reinforcement Learning (RL) and Imitation Learning (IL) have recently made advanced progress in many tasks such as grasping [1], pouring [2], and completing assembly tasks [3]. Despite these remarkable advancements, they cannot scale to various real-world scenarios outside the laboratory. Specifically, RL methods [1] are usually restricted in simple simulations, which leads to insufficient generalization ability to diverse real-world scenarios. IL methods [4] perform supervised learning on demonstration trajectories collected by teleoperation or kinesthetic teaching. However, such data collection is time-consuming and labor-intensive, which is limited to laboratory settings. In contrast, human videos can be easily captured by different people in various scenarios, and fortunately, there are already a large number of videos on the Internet, which contain rich viewpoints, operating embodiments, diverse objects, etc. Therefore, we delve into the question of how to learn robotic skills from underutilized raw human videos (e.g. YouTube videos) and improve generalization.
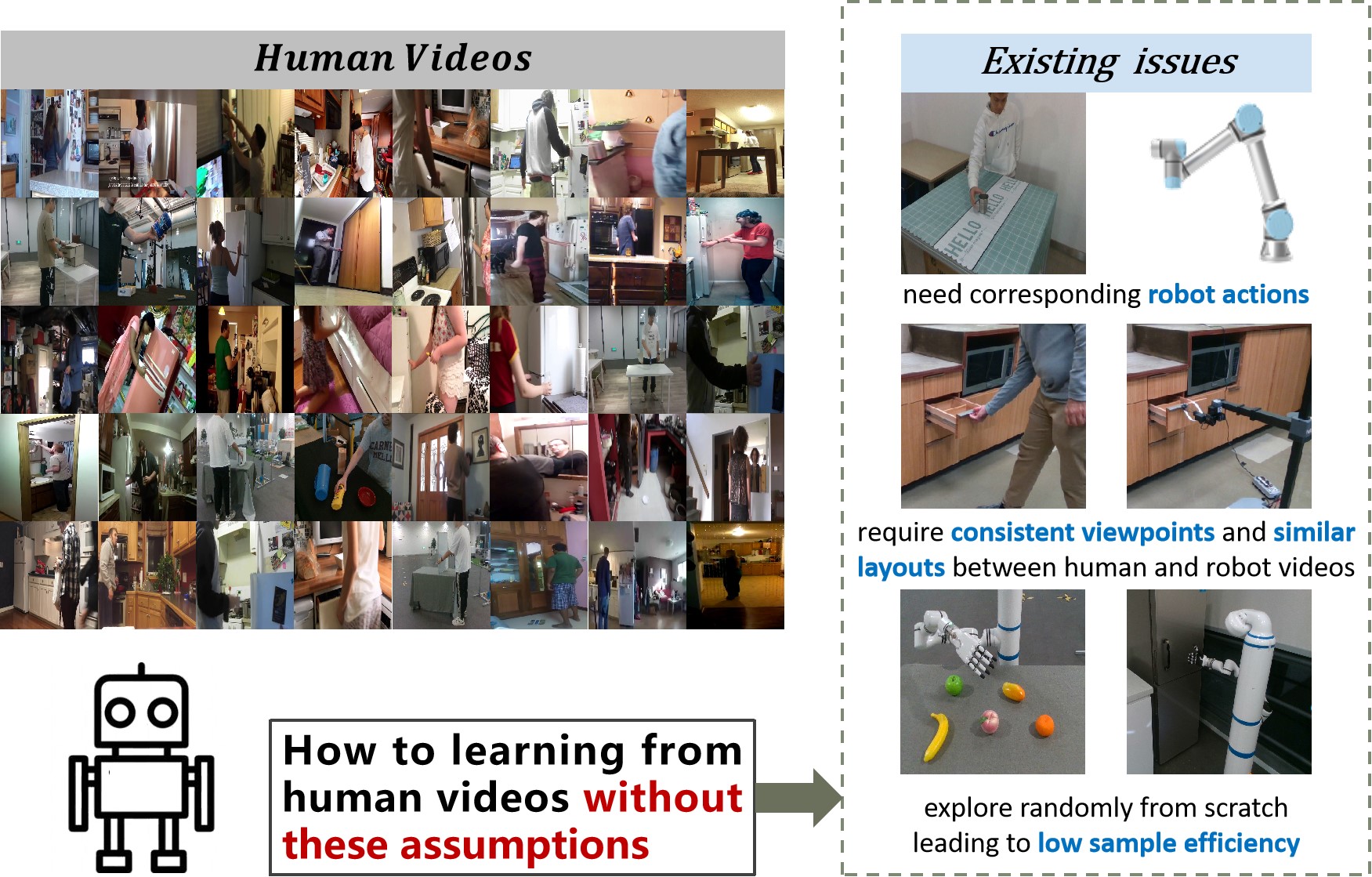
Many works attempt to learn from videos, but have some issues, including introducing unreasonable assumptions about videos or low sample efficiency, which are described in Fig. 1. To be specific, some IL methods utilize Behavior Cloning algorithms [5] to learn pixel-to-action mapping. For instance, Zhang et al. [2] efficiently learn to pour drinks from videos while our previous work [6] proposes viewpoint transformation to deal with inconsistent context issues of human demonstrations. However, these methods require the corresponding action labels, which is impractical for raw human videos and may limit the scalability of IL beyond laboratory settings.
Other RL methods learn a reward function, e.g. a video classifier [7], an embodiment-agnostic representation [8, 9] or disentangled representations of objects [10, 11], which can measure the similarity between robot execution videos and human videos. The rewards are used to make robots perform visually the same actions as humans. However, they require consistent viewpoints and similar layouts between human videos and robot execution videos, which imposes great restrictions on human videos and testing scenarios. In addition, instead of leveraging action priors in human videos to speed up exploration, most RL methods randomly explore from scratch in a vast action space, which leads to low sample efficiency and limits the flexibility of their methods.
The pursuit of efficiently learning robotic skills from human videos and generalizing them to novel scenarios without the above issues remains a non-trivial challenge. To this end, we propose a three-stage skill learning framework denoted as Contrast-Imitate-Adapt (CIA). Our key insight is to learn task priors by contrasting videos and action priors through imitating trajectories from videos, and then use task priors to guide actions to adapt to novel scenario layouts and object instances. To be specific, we propose an interaction-aware alignment transformer (IAAformer) to temporally align video pairs to understand the hand-object interaction process. Attention mechanisms and a hindsight interaction contrastive loss are designed to improve the alignment effect. Then CIA distills the action priors from videos into a trajectory generation model as our policy. To adapt to novel scenarios, we utilize RL to improve the policy. However, it is dangerous and inefficient to interact with the real environment. Therefore, we propose an Inversion-Interaction method to initialize coarse trajectories by GAN inversion and refine them with limited interactions. In particular, we introduce an optimization method based on semantic directions sampling of trajectories for safe interaction and high sampling efficiency. Moreover, the alignment distance computed by IAAformer can serve as the reward function for the proposed optimization method.
We perform extensive experiments on six different real-world manipulation tasks on a robotic arm-hand system. We analyze CIA in terms of success rate, effectiveness, and generalization compared to state-of-the-art baselines. The main contributions of this paper are as follows:
-
•
We introduce a three-stage imitation learning framework CIA that enables agents to learn skills from raw human videos and adapt to novel scenarios.
-
•
We propose IAAformer with self- and cross-attention mechanisms and a hindsight interaction contrastive loss, which can temporally align two videos and compute alignment distance as a subsequent reward function.
-
•
We design a two-stage Inversion-Interaction Method to obtain appropriate trajectories from coarse initialization to refined interaction improvement. Based on trajectory semantic directions in the latent space, we introduce an optimization method to safely and efficiently improve the policy.
-
•
We empirically demonstrate that our CIA can learn robotic skills from Internet human videos and outperform other state-of-the-art methods in six real-world tasks.
II RELATED WORK
II-A Imitation and Reinforcement Learning from Videos
Imitation Learning from Videos Imitation learning (IL) is a promising method to learn robotic skills from demonstrations. To learn from videos, many works propose Behavior Cloning methods to learn the mapping from visual inputs to robot actions. Zitkovich et al. [5] finetune a pre-trained Vision-Language Model on large-scale robot data, enabling strong generalization for many robot tasks. Our previous work [6] learns skills from human demonstrations with inconsistent contexts while Wang et al. [12] learn latent plans from videos to perform long-horizon imitation learning. Zhang et al. [2] propose an one-shot domain-adaptive imitation learning framework to adapt to new scenarios. However, these methods assume access to the corresponding robot actions, which is challenging to achieve in practical settings.
Learning Rewards from Videos To alleviate the issue of lacking robot actions, many works learn various reward functions from offline datasets (e.g. videos) to provide Reinforcement Learning (RL) algorithms. Our previous work [11] learns a disentangled representation in which different parts correspond to different object attributes (position, shape, color) while some works [8, 9] learn an embodiment-agnostic representation. These learned representations can be used to compute the rewards of RL to reproduce the behavior in the videos. Many other works [7, 13] train video classifiers to determine if the task performed by robots is the same as in the expert videos as the reward. However, these methods necessitate consistent viewpoints or similar layouts between human videos and robot execution videos, potentially imposing constraints on the flexibility of IL. In contrast, we aim to learn skills from human videos without these assumptions.
Integrating Reinforcement Learning with Imitation Learning Many works propose to integrate IL with RL to improve the learning efficiency. Dey et al. [14] propose a control criterion to enable the RL policy from imitating the baseline policy to gradually learning an optimal policy. However, it is inflexible to assume that there is a baseline policy. Hafez et al. [15, 16] learn behavior embeddings as task representations from self-organization demonstrations, which are used to perform more efficient RL. Kalashnikov et al. [17] propose a robotic learning system to efficiently learn a wide range of skills by sharing experiences and representations across tasks. Eysenbach et al. [18] use contrastive learning to make the representations correspond to a value function, leading to a much simpler but efficient goal-conditioned RL method. Although these methods use task or state representations to improve the efficiency, a large part of the inefficiencies are caused by huge action spaces, as mentioned in [19]. In contrast, we extract human trajectories for action prior learning, which improves the efficiency of RL learning more directly and efficiently.
Learning from Large-Scale Human Datasets There are many large-scale datasets of human activities with crowd-sourced annotation, e.g. 100 Days of Hands [20] for hand-object interactions, Dex-YCB [21] for grasping of diverse objects. VLOG [22] is collected from YouTube videos uploaded by various people documenting their daily lives. Charades [23] is collected with hundreds of people recording everyday activities in their homes. In our work, we utilize videos in Dex-YCB [21], VLOG [22] and Charades [23] to train our framework.

II-B Temporal Alignment in Self-supervised Representation Learning
Self-supervised temporal alignment has been recently proposed to find per-frame correspondences between two videos, which can effectively capture human activity phases and be used for downstream action learning. Sermanet et al. [24] employ a time-contrastive network (TCN) on time-synchronized videos, despite different viewpoints. Dwibedi et al. [25] propose a temporal cycle consistency (TCC) loss to maximize the embedding distance between matched pairs of two videos. Sanjay et al. [26] and Weizhe et al. [27] adopt Dynamic Time Warping (DTW) as a differential alignment loss. However, the above methods only focus on learning image representations. Relying on the advances in computer vision, Kwon et al. [28] extract 3D human keypoints from the human activity images and learn the temporal alignment on these skeletons. However, this method can only learn skeletal representations, which ignore the information of objects interacting with humans and cannot understand more complex hand-object interaction processes.
II-C Sample-Efficient Reinforcement Learning
The issue of low sampling efficiency is a key limitation of Reinforcement Learning (RL) algorithms. To mitigate this issue, our previous work [10] proposes a reachability discrimination module, which is utilized to search for the most reachable sequence of subgoals to improve the sample efficiency of RL for solving temporally extended tasks. Curiosity-motivated exploration [29] for RL is utilized to encourage agents to visit various states. For quick optimization and convergence, gradient-free Cross-Entropy Method (CEM) and variants [30, 8] are utilized to improve the sample efficiency. In our work, we modify CEM with our trajectory semantic directions in Section III-C3 to interact securely with the real world and converge quickly.
III Learning Skills by Contrast-Imitate-Adapt
We propose a novel three-stage robot learning framework comprising Contrast, Imitation and Adaptation (CIA), which can learn robotic skills from raw human videos and generalize to diverse scenarios. The overall framework CIA is shown in Fig. 2. First, we utilize recent advancements in computer vision to predict 3D human keypoints and object bounding boxes as human priors and convert to the learnable priors, which is introduced in Section III-A. Then the proposed interaction-aware alignment transformer (IAAformer) learns temporal alignment as task priors through attention mechanisms and a hindsight interaction contrastive loss, which is presented in Section III-B. And TrajGan is used as the policy to learn action priors. Finally, to adapt to diverse novel scenarios, we propose an Inversion-Interaction method to initialize coarse trajectories by GAN inversion and refine them with limited interactions, which is shown in Section III-C.
III-A Priors Extraction and Transformation
Extracting Human Priors We leverage off-the-shelf advances in computer vision to extract human priors from videos. The process is shown in Fig. 3a. Given each frame of the human video , we use an open-set object detector Grounding DINO [31] to detect the bounding box of the task-relevant objects . Then, a 3D human mesh recovery model OSX [32] is utilized to estimate the joint rotation of 3D human model SMPL-X [33], which can further compute 3D keypoints and 2D keypoints . We use the first wrist rotation to describe the hand rotation . In addition, we employ a contact detection model [20] built on top of Faster-RCNN [34] to predict the binary hand-object contact state . Since single frame detection may be noisy, we use Savitzky-Golay filtering [35] to smooth across timesteps.


Transforming to Learnable Action Priors Although we extract human priors, we lack a fixed anchor to retarget trajectories in videos from different viewpoints into the same coordinate system, e.g. the robot coordinate system. Therefore, such trajectories cannot be directly learned by robots. Previous methods imposed strict consistency constraints on viewpoints [8] or involved complex estimation of wrist-to-world coordinate mappings [19], which leads to cumulative errors.
To this end, we use the Pelvis joint of the SMPL-X model [33] as the human anchor point, and select the fixed vertical offset point of the robotic arm base as the robot origin. We believe that the relative movement between the human wrist and its own anchor point is similar to the relative movement between the end effector of a robotic arm and the robot origin. The specific process is shown in Fig. 3a. First, to mitigate the influence of diverse viewpoints, we set the root body rotation to zero. Then, we obtain the relative position and rotation from the Right Wrist joint to the Pelvis joint through the forward calculation of the human kinematic chain. The relative trajectories, named action priors, can be directly deployed to robots and utilized to train TrajGAN in Section III-C. Some examples of action priors are shown in Fig. 3b. Overall, we obtain priors containing 3D keypoints , the wrist rotation , 2D keypoints , the contact state , the object bounding box and corresponding cropped images .
III-B Learning Task Priors through Temporal Alignment
The goal of IAAformer is to learn task priors by performing temporal alignment to identify frame-by-frame consistency between two videos of the same task. Then, IAAformer can contrast robot execution sequences and human videos to measure the robot’s execution quality. IAAformer explicitly models the hand-object interaction through self- and cross-attention mechanisms. Through our hindsight interaction contrastive loss, we can improve the representation awareness of the interaction process. In addition, a proposed temporal monotonic loss ensures the alignment monotonicity.
III-B1 Architecture of IAAformer
IAAformer is composed of three modules, which are shown in Fig. 4. Interaction-Aware Transformer Encoder is used to model the hand-object interaction with self- and cross-attention mechanisms while Temporal Transformer Encoder focuses on modeling global dependencies across the frames, yielding effective spatiotemporal and contextual cues within the input sequence. A Projection Head is used to merge frame-level features and output the 128-dimensional embedding .
Given a frame and its adjacent frames in the receptive field, the action priors of each frame (including 2D keypoints , 3D keypoints of the human wrist, rotation and the contact state ) are extracted as well as object information () as described in Section III-A. Unlike previous works that only model image features [36, 25] or 3D human skeletons [28], IAAformer takes both action priors and object information as inputs.

Action Encoder (AEnc) is used to extract internal features of the action. A nonlinear projection layer encodes the 2D and 3D action priors extracted in the preprocessing phase to -dimensional features. Then learnable positional embedding is utilized to retrain the position information across the sequence. After adding the two, is obtained and fed to the self-attention module like Transformer Encoder [37, 38], which models the relations between different action priors. Detailed, is first transformed linearly and split into the query matrix , the key matrix and the value matrix . Then the self-attention mechanism is computed by the dot-product operation as denoted in Equ. 1. Finally, the features are encoded by multilayer perceptron (MLP) as .
| (1) |
Object Encoder (OEnc) is proposed to capture changes in objects over time. OEnc takes as input the cropped object images and extracts features by the pre-trained Resnet50 [39]. Then the features are concatenated with the features transformed from the object bounding box . OEnc finally outputs the object features through MLP.
| (2) | ||||
Cross-Attention mechanisms are designed to explicitly model the interaction process between hands and objects. The object features serve as object queries to calculate multi-head attention with action keys and values. The multi-head attention is computed by Equ. 2 and outputs . With such an interaction mechanism, we introduce the object changes into the action representations, which is crucial for subsequent temporal alignment.
Temporal Transformer Encoder is designed to model global temporal dependencies of the input sequence rather than the hand-object spatial interactions. After employing the 1D convolutional layer on the above features , we apply the standard multi-head self-attention blocks and MLP blocks following [37]. The output of Temporal Transformer Encoder is . Since IAAformer is expected to extract features of an intermediate frame based on the input sequence, a projection head with a layer normalization is applied to merge multiple frame features and output 128-dimensional .
III-B2 Matching Loss
We use self-supervised losses to learn the interaction-aware representations. The training process is shown in Fig. 5. Given two videos of the same task, where the length is and , respectively. Each frame is sent to AEnc and OEnc and encoded respectively as and , which forms by the subsequent modules of IAAformer.
Since the frame-level temporal correspondences between two videos are unknown, we utilize temporal cycle-consistency (TCC) loss [25] to mitigate this issue. First, for any frame feature in , we find the nearest neighbor in , denoted as . Then, we determine the nearest neighbor of in , i.e. . The matching is cycle-consistent only if . Therefore, the matching problem is transformed into the classification problem.
| (3) |
| (4) |
To enable gradient backpropagation, the softmax function is used to calculate the soft nearest neighbor for , denoted as Equ. 3. in Equ. 4 is the probability that the -th frame of video matches the -th frame of video . Let denote the cosine similarity between and . We add a temperature parameter to increase the similarity of similar features. The classification logits are . And the ground truth is a one-hot vector while the -th dimension is set to 1. Finally, the TCC loss is optimized by Equ. 5.
| (5) |

However, when trained only on successful interaction videos, TCC loss cannot enable IAAformer to effectively capture the task-relevant structural information in the images. During task execution, minor trajectory deviations may lead to completely different execution results. For instance, for Open drawer task, even if the end effector of the robot is only one centimeter away from the drawer handle, the drawer may not be successfully opened. Therefore, the learned representations should also be sensitive to interactions in diverse failure cases.
To this end, we propose a hindsight interaction contrastive loss to improve interaction awareness by hindsight augmentation. Inspired by advances in Hindsight Experience Replay [40] and our variant works [11, 1] which find successful experiences from unsuccessful interactive data, the insight of our hindsight interaction contrastive loss is to obtain failure experiences from successful human demonstrations.
As is shown in Fig. 5, hindsight augmentation consists of action augmentation and object augmentation. For each frame of one video , action augmentation adds appropriate Gaussian noise to 3D body joint rotation obtained in Section III-A, thereby obtaining the augmented 2D and 3D body keypoints after passing through the SMPL-X layer [33]. Therefore, is obtained by inputting and to IAAformer. In addition, we use a simpler operation based on a certain probability, which uses action features extracted from other videos as . Similarly, object Augmentation replaces of with of to obtain . To obtain the object features with timesteps, we only use the first frame of and repeat times.
After hindsight augmentation, our hindsight interaction contrastive loss is used to learn representations by minimizing the distance between positive pairs and maximizing the distance between negative samples. Specifically, we formulate our contrastive loss for the positive pair as follows:
| (6) |
| (7) |
| (8) |
| (9) |
where indicates the features in two sequences except the positive pair as negative samples, and and indicate the hindsight augmented features as negative samples.
In addition, we propose a temporal monotonic loss to ensure the monotonicity of the matching. To allow gradient backpropagation, we define a differentiable matching index for the nearest neighbor of in another feature sequence as follows:
| (10) |
where is defined in Equ. 4. Then we formulate as follows:
| (11) |
where is ReLU activation [41]. Therefore, the total loss of IAAformer is the weighted sum of the three above losses, denoted as follows:
| (12) |
where , and , which are determined through the experiments described in Section IV-C.
III-C Policy Learning by Inversion-Interaction
To imitate actions in human videos, we utilize a transformer-based Generative Adversarial Network [42] to generate complex trajectories, denoted as TrajGAN. The network architecture is similar to [43], where four fully connected layers are added at the beginning. We denote the trajectory extracted from one human video as , which contains 3-dimensional 3D keypoints , 3-dimensional rotation of the human wrist and one-dimensional gripper state (the contact state ). The generator of TrajGAN samples an 8-dimensional Gaussian noise as input and output a trajectory , which is fed into the discriminator to predict the probability of whether it comes from the true distribution. In addition, we add a contact discriminator to predict the true probability of the contact points of the generated trajectories.
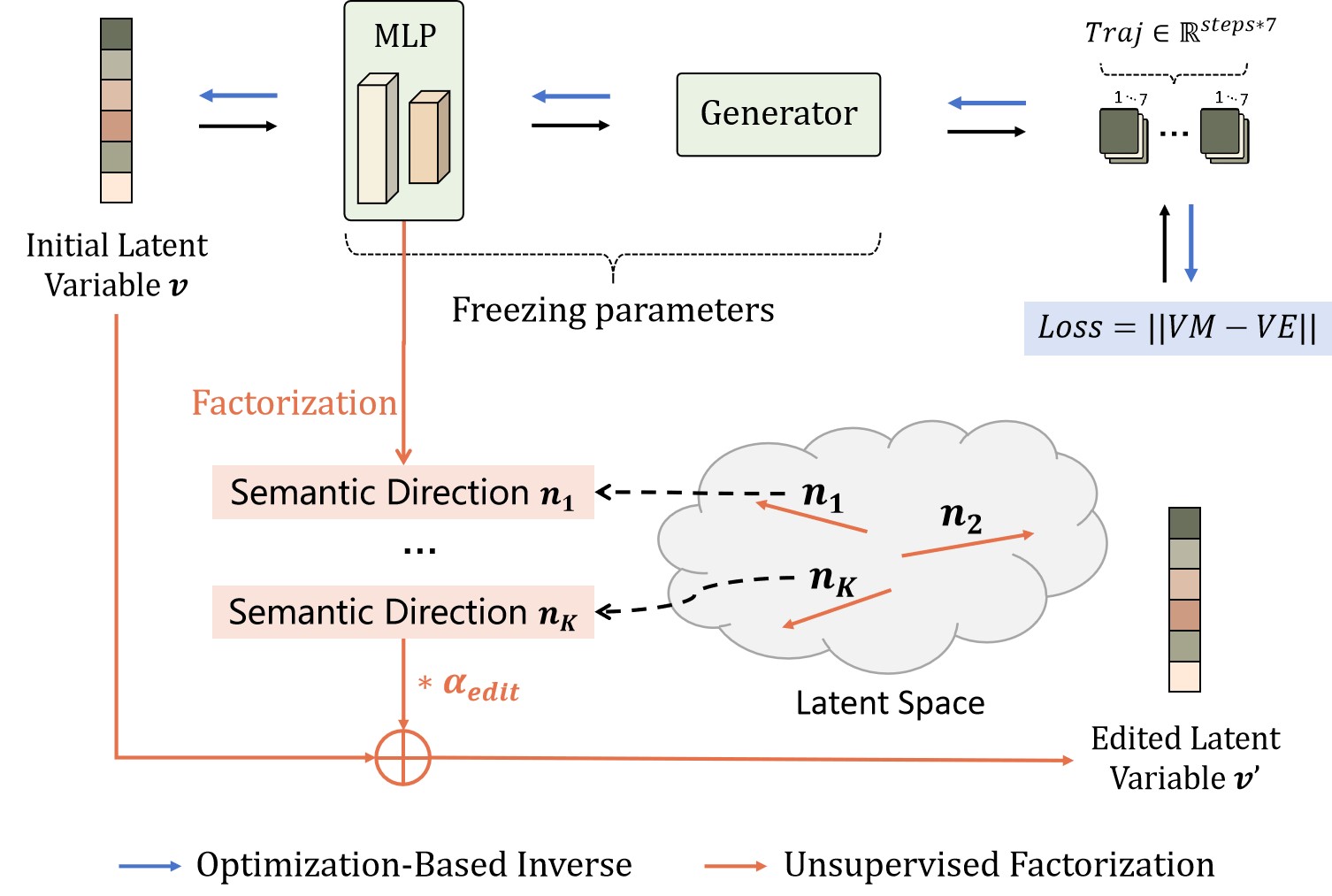
While TrajGAN has the potentials to generalize beyond the training data, the GAN-based architecture does not take environmental information as input. Therefore, TrajGAN needs to edit the generated trajectories to adapt to diverse scenario layouts. We propose a two-stage Inversion-Interaction method, which utilizes GAN inversion to optimize for coarse trajectories and further refine them through limited interaction. In addition, we propose an efficient sampling-based optimization method based on trajectory semantics (TS-CEM) to encourage safe exploration and improve sample efficiency. We summarize the whole algorithm of CIA in Algorithm 1.
III-C1 GAN Inversion for Fast Trajectory Initialization
GAN inversion technique [44] is utilized to find the latent variable in the latent space of the pre-trained GAN with a generation instance. We use optimization-based GAN inversion to obtain the latent variable by gradient backpropagation. While such methods in computer vision take an amount of iterative time to optimize from high-dimensional images, our TrajGAN spend much less time in GAN inversion since the low dimensions of the output trajectories.
The schematic diagram of our GAN inversion is shown in Fig. 6 through blue lines. Taken as input the latent variable , a generator of the pre-trained TrajGAN outputs the trajectory , as . Since the optimal trajectory cannot be available, we utilize the position of the target object to constrain the contact points in the generated trajectory. We obtain the object position in test scenarios through RGBD camera calibration, which we denoted as the environmental variable . Therefore, we compute the optimization objective as follows:
| (13) |
We set the completion of the GAN inversion when () and optimization epochs . Due to optimization on low-dimensional trajectories, the GAN inversion only requires about 20 seconds, and the convergence speed may not be affected by different initial latent variables.
Another use of GAN inversion is to measure the success confidence of tasks in testing scenarios, which can be used to reject the execution of tasks with particularly low confidence in advance. The confidence is computed as follows:
| (14) |
When , it indicates that TrajGAN cannot generate appropriate trajectories. The reason here is that the position of the current environment variable is too far from the distribution of the training data.
III-C2 Safe and Efficient Trajectory Refinement via Interaction
The initialized trajectory still may not result in a high success rate in task execution, due to deviations between the contact position of the generated trajectory and the object, the inappropriate posture of the end effector, camera calibration errors, etc. Therefore, it is necessary to learn a policy to further refine the trajectory by interacting with the environment.
The key issue in interacting with real environments is the trade-off between interaction safety and exploration efficiency. We assume that the initialized rough trajectory is reasonable, and therefore the interaction trajectory should not be too far from it to cause danger, nor too close to it to cause inefficient exploration. To this end, we propose to discover semantic directions of trajectories in an unsupervised manner, which are utilized for reasonable and controllable editing of trajectories. Many works prove that GANs spontaneously have some directions in the latent space that represent semantic attributes of generations, such as the color, position and shape of objects [11]. In our case, the semantic direction may be the translation or rotation of the trajectory in a certain direction. By correctly finding these semantic directions, we can use them to make meaningful edits to the generated trajectory and control the intensity of the edits.
In TrajGAN, each layer learns a transformation from input to output. Focusing on the first four fully connected layers , the affine transformation on the latent variables can be expressed as follows:
| (15) |
where is the -dimensional feature. and denote the weight and bias of respectively. Like prior works [11, 45], the editing model on the latent variables is formulated as follows:
| (16) |
where denotes the editing scale. We can see that given any latent variable , we can utilize to adjust the intensity of editing. Therefore, the weight parameter should contain rich knowledge about the semantic attributes of the trajectory. The problem of discovering semantic directions can be factorized by solving the following optimization problem:
| (17) |
where denotes the top- important semantics. Lagrange multipliers are introduced to solve this problem as follows:
| (18) | ||||
By taking the partial derivative of in Equ. 18, we obtain
| (19) |
Therefore, we can calculate the eigenvectors of the matrix and select the eigenvectors with the largest eigenvalues as the semantic directions . With several proper semantic directions, agents can edit trajectories in a controllable and reasonable manner to explore in the environment.
III-C3 Optimization Procedure Based on Trajectory Semantics
Reinforcement learning algorithms suffer from low sampling efficiency in vast action spaces and complex environments. To this end, we introduce Cross Entropy Method [30] based on Trajectory Semantic sampling (TS-CEM) as an efficient gradient-free optimization method.
Given the task and the initial latent variable , we sample a semantic direction from and an editing scale from . And we obtain the corresponding trajectory . Therefore, we execute R=20 trajectories in the real world and record the corresponding videos . To iteratively improve the policy without human supervision, we utilize IAAformer to compute the alignment distances of randomly sampled human demonstrations and robot execution sequences as reward functions. The reward is computed as follows:
| (20) |
where denotes the frame feature in the robot’s execution video and denotes the corresponding nearest neighbor frame in a randomly selected human demonstration video. Based on such rewards, we rank these trajectories and consider the trajectories of the top five highest rewards as elite trajectories, which can be used to compute the distribution parameters of the semantic direction and the editing scale in the next iteration.
IV Experimental result and analysis
Various experiments are conducted to validate the effectiveness of the framework CIA and each component. We first introduce our experimental setup in Section IV-A. In the following sections, our experiments tend to address these questions:
-
1.
How does our CIA compare with prior state-of-the-art works in imitation learning from videos?
-
2.
Does IAAformer match two videos well over time and understand the interaction process?
-
3.
What is the effect of the initialization based on GAN inversion and the editing based on trajectory semantics in the TrajGAN?
-
4.
Is each component of CIA really effective for learning from human videos?
-
5.
How well can CIA adapt to novel scenario layouts, and novel object instances?
IV-A Experimental Setup
IV-A1 Hardware Platform
To perform experiments in various scenarios, we use a Realman RM65 robotic arm mounted horizontally on a mobile chassis with an Inspire five-finger dexterous hand as our humanoid agent, as is shown in Fig. 7. We use a Cartesian position controller to translate the end effector of the robotic arm and an in-built orientation controller to control the rotation. We simplify the degree of freedom of the hand into a 1-dimensional binary on-off state. An Intel Realsense D435 camera is utilized, which is mounted either on the robot head or externally fixed, depending on the task. In addition, we use 6 NVIDIA V100 GPUs to train all the networks. The full training takes about 5 hours.


IV-A2 Manipulation Tasks and Training Data
To validate our framework CIA, we select six tasks that can be abundantly found in existing human daily behavior video datasets. The tasks include Grasping, Opening refrigerator, Closing refrigerator, Opening drawer, Closing drawer, and Wiping shown in Fig. 7a. Note that the human videos of these tasks lack corresponding robot actions, and they vary in terms of viewpoints, execution embodiments, and scenario layouts. The objects used in the testing scenarios are shown in Fig. 7b.
We choose 2853 videos in Dex-YCB [21] for Grasping of diverse objects in diverse viewpoints. Each other task has 365-950 videos from VLOG [22] and Charades [23], where various people record these everyday tasks with diverse objects in various environments. To select appropriate videos, we compute the temporal alignment distance between each video of the same task and the other 50 videos, and eliminate videos whose average temporal alignment distance is more than the threshold 0.5.
IV-A3 Evaluation Metric
| Method | Success Rate (%) | |||||
| Grasp | Open | Open | Wipe | Close | Close | |
| Drawer | Refrig. | Drawer | Refrig. | |||
| BC | 0.40 | 0.33 | 0.23 | 0.53 | 0.47 | 0.40 |
| CQL-CLS | 0.37 | 0.20 | 0.17 | 0.47 | 0.33 | 0.37 |
| CQL-CASA | 0.47 | 0.27 | 0.20 | 0.47 | 0.50 | 0.43 |
| CQL-ours | 0.57 | 0.40 | 0.27 | 0.57 | 0.57 | 0.53 |
| CIA-w/o-Iter | 0.43 | 0.37 | 0.33 | 0.50 | 0.67 | 0.63 |
| CIA-w/-1Iter | 0.77 | 0.63 | 0.57 | 0.73 | 0.83 | 0.87 |
| CIA-w/-2Iter | 0.90 | 0.87 | 0.73 | 0.93 | 0.97 | 0.93 |
| Trial number | 30 | 30 | 30 | 30 | 30 | 30 |
We use the success rate to measure the performance of the methods. Following the temporal alignment literature [25, 26, 28], we utilize three metrics for the evaluation of our IAAformer. After training the IAAformer, we freeze the parameters and evaluate in the trained representation space.
Success Rate is utilized to measure the performance of CIA and other baselines. Success is determined when the robot’s execution video matches with the human demonstration.
Phase Classification evaluates the representation quality based on the per-frame fine-grained classification accuracy. We train an SVM classifier on an annotated subset of the training dataset to predict phase categories.
Phase Progression measures the ability of representations to capture the progress of an action over time. A linear regressor is used to predict the phase progression values. It is computed as the average -squared measure between the predictions and the ground truth progress values.
Kendall’s Tau is a statistical measure to measure the monotonicity of matching order over time. Compared to the above two metrics, it does not require additional labels. It is in the range of , where 1 denotes perfect alignments and -1 denotes alignments in reverse order.
IV-B Evaluation of CIA and Comparison to Baselines
To answer the first question, we compare CIA to several state-of-the-art baselines. Since performing general RL in the real world is time-consuming, we compare with a SOTA offline RL, Conservative Q-learning (CQL) [46], which is trained on offline datasets without interaction. We follow [7, 13] to train a classifier to determine whether human videos and robot videos belong to the same task category as the sparse reward. We call this baseline CQL-CLS. And we compare against a competing SOTA method for learning representations by temporal alignment. We refer to CQL-CASA to compute the distance in the CASA representation space as the reward. We also train CQL using rewards computed by our IAAformer, denoted as CQL-ours. In addition, we compare to behavior cloning (BC), which predicts the actions from the input, reflecting prior works [6, 2]. We found that these baselines hardly predict correct actions from raw pixel input, due to the significant visual differences between human videos and test scenarios. Therefore, we use the three-dimensional contact points as the object’s coordinates, along with the robotic end-effector position, which are fed into 3 fully connected layers to predict seven-dimensional actions described in Section IV-A2.
The comparison results on six real-world everyday tasks are shown in Table. I. Success rates are computed out of 30 trials and each task contains different object categories and locations. We also show the success rates of our CIA without and with 1 or 2 iterations. Note that in each iteration, the robot executes 20 trajectories, and each trajectory takes approximately 40 seconds. So each iteration takes about 15 minutes. As is shown, our CIA significantly outperforms all the baselines. In particular, offline RL methods are difficult to complete tasks and have poor generalization performances. Interestingly, CQL-ours outperforms CQL-CLS and CQL-CASA, which indicates that our objective function can identify good interaction trajectories and task progress. The Behavior Cloning method performs similarly to CQL-CASA in that optimization is performed by averaging the error at each step, which results in inaccuracies at critical contact points with the object.

As is shown, our CIA can improve the performance iteratively, and CIA with two iterations can achieve a success rate of 90% on most tasks. Some examples of successful execution trajectories on six tasks are shown in Fig. 8. However, we note that the success rates of Closing drawer and Closing refrigerator tasks are lower than other tasks since these tasks require high-precision movements. In particular, the robot is also limited by its arm span when opening a large refrigerator.
IV-C Comparison With Prior Temporal Alignment Methods
To answer the second question, we compare IAAformer against previous state-of-the-art temporal alignment methods. TCC [25] proposes a cycle-consistency loss to learn the visual features. LAV [26] proposes a Soft-DTW loss and a temporal regularization terms to learn frame-level features. CASA [28] utilizes a contrastive loss to temporally align the pair of 3D skelatal sequences. For a fair comparison, we modify the output feature dimensions of these feature extractors to be the same as our IAAformer.

| Input | Phase | Phase | Kendall’s | |||||||
| Task | Method | Type | Class(%) | Progression | Tau | |||||
| Refrig | TCC[25] | Image | 36.61 | 0.4358 | 0.4813 | |||||
| LAV[26] | Image | 41.89 | 0.5833 | 0.6348 | ||||||
| CASA[28] | 3D Pose | 63.07 | 0.6808 | 0.7606 | ||||||
| IAA(ours) | 3D Pose+Obj | 78.94 | 0.8351 | 0.8502 | ||||||
| Grasp | TCC[25] | Image | 76.79 | 0.5513 | 0.3859 | |||||
| LAV[26] | Image | 81.71 | 0.4955 | 0.5177 | ||||||
| CASA[28] | 3D Pose | 85.10 | 0.6125 | 0.6909 | ||||||
| IAA(ours) | 3D Pose+Obj | 93.65 | 0.9027 | 0.9341 | ||||||
| Phase | Phase | Kendall’s | ||||||||||
| Model | Class(%) | Progression | Tau | |||||||||
| 1 | 0.6 | 0.3 | 0.01 | 77.61 | 0.8266 | 0.8451 | ||||||
| 2 | 0.5 | 0.5 | 0.01 | 77.92 | 0.8309 | 0.8447 | ||||||
| 3 | 0.3 | 0.6 | 0.01 | 78.94 | 0.8351 | 0.8502 | ||||||
The comparison experiment results of Opening refrigerators and Grasping tasks are presented in Table. II. IAAformer significantly outperforms other methods in three evaluation metrics for two task datasets. For TCC [25] and LAV [26], the entire image input resulted in lower performance due to the lack of explicit structured information (e.g. hand trajectories, object coordinates of interest). CASA [28] shows some improvements, but the improvements are limited due to the lack of object coordinates which provide interactive cues. In contrast, our IAAformer explicitly accounts for hand and object information through self- and cross-attention mechanisms, thereby improving the understanding of interactive processes. Some fine-grained retrieval results of different tasks are visualized in Fig. 9. It shows that IAAformer can successfully retrieve temporal similar frames from other videos based on one query frame.
To study the impact of different loss coefficients on alignment performance, we present the results of comparative experiments on Open refrigerator task in Table. III. As is shown, model 3 with , and has slightly better performance on the three evaluation metrics, which demonstrates the effectiveness of our hindsight interaction contrastive loss.

Interaction awareness of IAAformer. To demonstrate IAAformer’s understanding of the interaction process, we visualize the alignment results between two sequences without and with the hindsight augmentation, which are shown in Fig. 10. The left subfigure shows that two original videos with different time lengths match well. For each frame in sequence 2, we find the frame with the highest similarity in sequence 1. For clarity, we set the value of the most similar frame to 1 and the others, which are below the threshold of 0.3, to 0. In the right subfigure, we perform minor action augmentations to sequence 1, resulting in an unsuccessful interaction. It can be seen that IAAformer can distinguish the mismatch between two interaction processes after the first few frames. This indicates that using IAAformer can be used to compute the reward function for subsequent policy improvement.
IV-D Trajectory Initialization and Controllably Editing

To answer the third question, we demonstrate the results of task-specific TrajGANs for three tasks: Grasp, Open refrigerator and Open drawer in Fig. 11. A small number of extracted trajectories and generated trajectory examples are shown in the left two columns while the third column shows the trajectories initialized by GAN inversion. We let the red, green, and blue points represent the starting point, the contact point, and the endpoint, respectively. In addition, the orange point represents the environmental variable, which is the expected contact point. As is shown, GAN inversion can be utilized to initial trajectories well by minimizing the distance between the environmental variable and the contact point.
Controllable editing capabilities based on the semantic directions are crucial for agents to safely explore the environment. To demonstrate the semantic directions by unsupervised discovery, we edit the latent codes in the TrajGAN latent space of the Grasp task, which are visualized in Fig. 12. Three main semantic directions are discovered by the factorization of parameters described in Method III-C2. Specifically, taking the first line as an example, we randomly sample a latent variable and gradually add a weighted direction . Then, TrajGAN takes as input the edited latent variable and generates the trajectory corresponding to the semantic changes. From left to right, as the editing scale increases, the contact points of the generated trajectories move towards the z-axis. Therefore, by controlling the editing scale and semantic directions, small adjustments can be made near the initialization trajectory, which can be used for safe exploration in real environments.
IV-E Ablation Analysis of Each Component of CIA
To answer the fourth question about the effectiveness of each component, we first perform several ablation experiments to analyze each module of our IAAformer on Open refrigerator and Grasp tasks, which is shown in Table. IV. For simplicity, we use IAA to represent IAAformer. These modules include hindsight interaction contrastive loss, temporal monotonic loss and attention mechanisms, referred to as HA, ML and Atten respectively. As is shown, IAA with 3D pose as input can perform poorly like CASA, which indicates the importance of object information as input for understanding task processes. We found that IAA w/o HA performs well in Kendall’s Tau while IAA w/o ML performs well in the first two metrics. It demonstrates that the temporal monotonic loss can help improve the alignment monotonicity and the hindsight interaction contrastive loss can help improve the ability of representation to understand the task process. In addition, self- and cross-attention mechanisms can further improve the temporal alignment performance of IAAformer.

| Task | Method | Input | Phase | Phase | Kendall’s | |||||
| Type | Class(%) | Progression | Tau | |||||||
| Refrig. | IAA | 3D Pose | 69.72 | 0.7194 | 0.7463 | |||||
| IAA w/o HA | 3D Pose+Obj | 73.14 | 0.7633 | 0.8107 | ||||||
| IAA w/o ML | 3D Pose+Obj | 74.95 | 0.7879 | 0.7562 | ||||||
| IAA w/o Atten | 3D Pose+Obj | 78.16 | 0.8292 | 0.8385 | ||||||
| IAA(ours) | 3D Pose+Obj | 78.94 | 0.8351 | 0.8502 | ||||||
| Grasp | IAA | 3D Pose | 85.82 | 0.7583 | 0.7794 | |||||
| IAA w/o HA | 3D Pose+Obj | 86.62 | 0.8319 | 0.8785 | ||||||
| IAA w/o ML | 3D Pose+Obj | 87.03 | 0.8458 | 0.8062 | ||||||
| IAA w/o Atten | 3D Pose+Obj | 89.38 | 0.8904 | 0.9168 | ||||||
| IAA(ours) | 3D Pose+Obj | 93.65 | 0.9027 | 0.9341 | ||||||
We also compare the impact of various modules in the proposed Inversion-Interaction method on the success rate of Grasp and Open drawer tasks, which is shown in Table V. CIA-w/o-inversion represents that CIA randomly samples and generates trajectories from the latent space of the trained TrajGAN without initialization by GAN inversion. CIA-w/o-interactions only relies on the trajectory initialization without the subsequent policy improvement through interaction. CIA-w/o-IAAformer replaces the IAAformer with a video classifier to determine whether human videos and robot videos belong to the same task category as the reward. As is shown in Table V, CIA-w/o-inversion has difficulty in completing two tasks, since it’s inefficient to optimize reasonable trajectories through a small amount of sampling in the vast latent space using two iterations. CIA-w/o-interactions performs better, which shows the necessity of using initialization to efficiently find the vicinity of the optimal trajectory. CIA-w/o-IAAformer is also limited by the inappropriate objective function. With all the components, CIA can achieve the success rate of 90% in Grasp and 87% in Open drawer.
| Methods | Grasp | Open drawer |
| CIA-w/o-inversion | 0.27 | 0.17 |
| CIA-w/o-interactions | 0.43 | 0.37 |
| CIA-w/o-IAAformer | 0.37 | 0.43 |
| CIA | 0.90 | 0.87 |
IV-F Adaptation of CIA
Adaptation to Novel Scenarios. We have verified that our proposed CIA can achieve a success rate of 90% in Grasp task (Table I). Note that the object positions in our experiments are different from those in human videos. Some test trajectories with various scenario layouts are shown in Fig. 13. As is shown, CIA can adapt to various scenario layouts successfully. Specifically, CIA can grasp different object instances at different positions and heights. In addition, CIA takes advantage of the generalization of the visual foundational model [31] to adapt to different backgrounds and contexts, as shown in the different rows of the figure.
Adaptation to Novel Object Instances. To verify the CIA’s adaptability to diverse object instances, we randomly change the position of objects in experiments of different tasks. For the Grasp task, CIA can successfully grasp various fruits, milk cartons, coffee bottles and other beverage bottles, which is shown in Fig. 7b and 13. We used two different sizes of refrigerators and drawers for testing Open/Close refrigerator and Open/Close drawer tasks. In Wipe task, we change the position of the words to be erased on the whiteboard. As is shown in Table I, CIA can adapt to different object instances with a high success rate.

IV-G Failure Analysis
Some failure examples of Open drawer and Grasp tasks are shown in Fig. 14. In the above example, the robot fails to grasp the drawer handle due to the inaccuracy between the contact points in the generated trajectory and environmental variables, i.e. the handle. In the example below, the apple slides out of the hand, which can be prevented by improving the accuracy of robot hand positions or postures.
V Conclusion
We propose a three-stage real-world robot learning framework, denoted as Contrast-Imitate-Adapt (CIA), which can learn robotic skills from raw human videos. Leveraging advances in computer vision, task priors and action priors are extracted. Subsequently, an Interaction-Aware Alignment transformer (IAAformer) with attention mechanisms and a hindsight interaction contrastive loss is designed to learn task priors by temporally aligning two videos. Moreover, Editable Movement Primitive (TrajGAN) is trained to generate trajectories to imitate action priors. To adapt to novel scenarios different from the human videos, the Inversion-Interaction method is proposed to utilize GAN inversion in the latent space to initialize coarse trajectories and refine them through limited interaction. Notably, we introduce Cross Entropy Method based on Trajectory Semantic sampling (TS-CEM) for safe and efficient interaction, where the contrast results produced by IAAformer as rewards. We empirically demonstrate that CIA can significantly outperform previous state-of-the-art methods in six everyday tasks.

Our work suggests several potential directions for future research. In terms of learning task priors, while CIA utilizes a contrast between robot and human videos as an evaluation for robot execution, other methods, e.g. vision-language foundational models, can also be explored to achieve this functionality. In terms of learning action priors, accomplishing more complex tasks, e.g. dealing with occluded objects, remains a challenge. In addition, while CIA employs trajectory generation models for open-loop robot control, designing more robust models to generate real-time and reasonable trajectories for closed-loop control is another open issue.
References
- [1] Z. Qian, M. You, H. Zhou, X. Xu, and B. He, “Goal-conditioned reinforcement learning with disentanglement-based reachability planning,” IEEE Robotics and Automation Letters, vol. 8, no. 8, pp. 4721–4728, 2023.
- [2] D. Zhang, W. Fan, J. Lloyd, C. Yang, and N. F. Lepora, “One-shot domain-adaptive imitation learning via progressive learning applied to robotic pouring,” IEEE Transactions on Automation Science and Engineering, 2022.
- [3] J. Li, H. Shi, and K.-S. Hwang, “Using goal-conditioned reinforcement learning with deep imitation to control robot arm in flexible flat cable assembly task,” IEEE Transactions on Automation Science and Engineering, 2023.
- [4] D. Zhang, Q. Li, Y. Zheng, L. Wei, D. Zhang, and Z. Zhang, “Explainable hierarchical imitation learning for robotic drink pouring,” IEEE Transactions on Automation Science and Engineering, vol. 19, no. 4, pp. 3871–3887, 2021.
- [5] B. Zitkovich, T. Yu, and et. al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” in 7th Annual Conference on Robot Learning, 2023.
- [6] Z. Qian, M. You, H. Zhou, X. Xu, and B. He, “Robot learning from human demonstrations with inconsistent contexts,” Robotics and Autonomous Systems, vol. 166, p. 104466, 2023.
- [7] L. Shao, T. Migimatsu, Q. Zhang, K. Yang, and J. Bohg, “Concept2robot: Learning manipulation concepts from instructions and human demonstrations,” The International Journal of Robotics Research, vol. 40, no. 12-14, pp. 1419–1434, 2021.
- [8] S. Bahl, A. Gupta, and D. Pathak, “Human-to-robot imitation in the wild,” 2022.
- [9] Y. Zhou, Y. Aytar, and K. Bousmalis, “Manipulator-Independent Representations for Visual Imitation,” in Proceedings of Robotics: Science and Systems, Virtual, July 2021.
- [10] Z. Qian, M. You, H. Zhou, X. Xu, and B. He, “Goal-conditioned reinforcement learning with disentanglement-based reachability planning,” IEEE Robotics and Automation Letters, 2023.
- [11] Z. Qian, M. You, H. Zhou, and B. He, “Weakly supervised disentangled representation for goal-conditioned reinforcement learning,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2202–2209, 2022.
- [12] C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y. Zhu, and A. Anandkumar, “Mimicplay: Long-horizon imitation learning by watching human play,” in 7th Annual Conference on Robot Learning, 2023.
- [13] S. Nair, E. Mitchell, K. Chen, S. Savarese, C. Finn et al., “Learning language-conditioned robot behavior from offline data and crowd-sourced annotation,” in Conference on Robot Learning. PMLR, 2022, pp. 1303–1315.
- [14] S. Dey, S. Pendurkar, G. Sharon, and J. P. Hanna, “A joint imitation-reinforcement learning framework for reduced baseline regret,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 3485–3491.
- [15] M. B. Hafez and S. Wermter, “Continual robot learning using self-supervised task inference,” IEEE Transactions on Cognitive and Developmental Systems, 2023.
- [16] M. B. Hafez and S. Wermter, “Behavior self-organization supports task inference for continual robot learning,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 6739–6746.
- [17] D. Kalashnikov, J. Varley, Y. Chebotar, B. Swanson, R. Jonschkowski, C. Finn, S. Levine, and K. Hausman, “Mt-opt: Continuous multi-task robotic reinforcement learning at scale,” arXiv preprint arXiv:2104.08212, 2021.
- [18] B. Eysenbach, T. Zhang, S. Levine, and R. R. Salakhutdinov, “Contrastive learning as goal-conditioned reinforcement learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 35 603–35 620, 2022.
- [19] K. Shaw, S. Bahl, and D. Pathak, “Videodex: Learning dexterity from internet videos,” in Conference on Robot Learning. PMLR, 2023, pp. 654–665.
- [20] D. Shan, J. Geng, M. Shu, and D. F. Fouhey, “Understanding human hands in contact at internet scale,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9869–9878.
- [21] Y.-W. Chao, W. Yang, Y. Xiang, P. Molchanov, A. Handa, J. Tremblay, Y. S. Narang, K. Van Wyk, U. Iqbal, S. Birchfield et al., “Dexycb: A benchmark for capturing hand grasping of objects,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9044–9053.
- [22] D. F. Fouhey, W.-c. Kuo, A. A. Efros, and J. Malik, “From lifestyle vlogs to everyday interactions,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4991–5000.
- [23] G. A. Sigurdsson, G. Varol, X. Wang, A. Farhadi, I. Laptev, and A. Gupta, “Hollywood in homes: Crowdsourcing data collection for activity understanding,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer, 2016, pp. 510–526.
- [24] P. Sermanet, C. Lynch, J. Hsu, and S. Levine, “Time-contrastive networks: Self-supervised learning from multi-view observation,” 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 486–487, 2017.
- [25] D. Dwibedi, Y. Aytar, J. Tompson, P. Sermanet, and A. Zisserman, “Temporal cycle-consistency learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1801–1810.
- [26] S. Haresh, S. Kumar, H. Coskun, S. N. Syed, A. Konin, Z. Zia, and Q.-H. Tran, “Learning by aligning videos in time,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 5548–5558.
- [27] W. Liu, B. Tekin, H. Coskun, V. Vineet, P. Fua, and M. Pollefeys, “Learning to align sequential actions in the wild,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2181–2191.
- [28] T. Kwon, B. Tekin, S. Tang, and M. Pollefeys, “Context-aware sequence alignment using 4d skeletal augmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8172–8182.
- [29] N. Savinov, A. Raichuk, R. Marinier, D. Vincent, M. Pollefeys, T. Lillicrap, and S. Gelly, “Episodic curiosity through reachability,” in International Conference on Learning Representations (ICLR), 2019, pp. 1–20.
- [30] P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y. Rubinstein, “A tutorial on the cross-entropy method,” Annals of operations research, vol. 134, no. 1, pp. 19–67, 2005.
- [31] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” arXiv preprint arXiv:2303.05499, 2023.
- [32] J. Lin, A. Zeng, H. Wang, L. Zhang, and Y. Li, “One-stage 3d whole-body mesh recovery with component aware transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21 159–21 168.
- [33] G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 975–10 985.
- [34] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” Advances in neural information processing systems, vol. 28, 2015.
- [35] A. Savitzky and M. J. Golay, “Smoothing and differentiation of data by simplified least squares procedures.” Analytical chemistry, vol. 36, no. 8, pp. 1627–1639, 1964.
- [36] P. Sermanet, C. Lynch, Y. Chebotar, J. Hsu, E. Jang, S. Schaal, S. Levine, and G. Brain, “Time-contrastive networks: Self-supervised learning from video,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 1134–1141.
- [37] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [38] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [39] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [40] M. Andrychowicz, D. Crow, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, and W. Zaremba, “Hindsight experience replay,” in NIPS, 2017.
- [41] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, pp. 436–444, 2015.
- [42] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” 2014.
- [43] X. Xu, M. You, H. Zhou, Z. Qian, W. Xu, and B. He, “Gan-based editable movement primitive from high-variance demonstrations,” IEEE Robotics and Automation Letters, vol. 8, no. 8, pp. 4593–4600, 2023.
- [44] W. Xia, Y. Zhang, Y. Yang, J.-H. Xue, B. Zhou, and M.-H. Yang, “Gan inversion: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3121–3138, 2022.
- [45] Y. Shen and B. Zhou, “Closed-form factorization of latent semantics in gans,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1532–1540.
- [46] A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 1179–1191, 2020.
Zhifeng Qian received the B.S. degree from Soochow University, China in 2018. He is currently working toward the Ph.D. degree in Tongji University, China. His research interests include imitation learning, deep reinforcement learning.
Mingyu You (Member, IEEE) received the B.S. and Ph.D. degrees from Zhejiang University, China, in 2002 and 2007. She is currently a Professor in Tongji University. Her research interests include artificial intelligence and robotic learning.
Hongjun Zhou (Member, IEEE) received the B.S. degree from Dalian University of Technology, China, in 1994, and the M.S. and Ph.D. degrees from Chuo University, Japan, in 2001 and 2004. He is currently an Associate Professor in Tongji University. His research interests include robot SLAM and robot imitation learning.
Xuanhui Xu received the B.S. degree from Donghua University, China in 2018. He is currently working toward the Ph.D. degree in Tongji University. His research interests include multimedia understanding and imitation learning.
Hao Fu received the Master’s degree from Tongji University, China in 2021. He is currently working toward the Ph.D. degree in Tongji University. His research interests include multi-agent system and deep reinforcement learning.
Jinzhe Xue received the B.S. degree from Tongji University, China in 2022. He is currently working toward the M.S. degree with the College of Electronics and Information Engineering, Tongji University.
Bin He (Member, IEEE) received the B.S. degree from Jilin University, Changchun, China, in 1996, and the Ph.D. degree from Zhejiang University, China, in 2001. He is currently a Professor in Tongji University, Shanghai, China. His current research interests include intelligent robot control and biomimetic microrobots.