Continuous Profit Maximization: A Study of Unconstrained Dr-submodular Maximization
Abstract
Profit maximization (PM) is to select a subset of users as seeds for viral marketing in online social networks, which balances between the cost and the profit from influence spread. We extend PM to that under the general marketing strategy, and form continuous profit maximization (CPM-MS) problem, whose domain is on integer lattices. The objective function of our CPM-MS is dr-submodular, but non-monotone. It is a typical case of unconstrained dr-submodular maximization (UDSM) problem, and take it as a starting point, we study UDSM systematically in this paper, which is very different from those existing researcher. First, we introduce the lattice-based double greedy algorithm, which can obtain a constant approximation guarantee. However, there is a strict and unrealistic condition that requiring the objective value is non-negative on the whole domain, or else no theoretical bounds. Thus, we propose a technique, called lattice-based iterative pruning. It can shrink the search space effectively, thereby greatly increasing the possibility of satisfying the non-negative objective function on this smaller domain without losing approximation ratio. Then, to overcome the difficulty to estimate the objective value of CPM-MS, we adopt reverse sampling strategies, and combine it with lattice-based double greedy, including pruning, without losing its performance but reducing its running time. The entire process can be considered as a general framework to solve the UDSM problem, especially for applying to social networks. Finally, we conduct experiments on several real datasets to evaluate the effectiveness and efficiency of our proposed algorithms.
Index Terms:
Continuous profit maximization, Social networks, Integer lattice, dr-submodular maximization, Sampling strategies, Approximation algorithmI Introduction
Online social networks (OSNs) were becoming more and more popular to exchange ideas and make friends gradually in recent years, and accompanied by the rise of a series of social giants, such as Twitter, Facebook, Wechat, and LinkedIn. People tended to share what one sees and hears, and discuss some hot issues on these social platforms instead of traditional ways. Many companies or advertisers exploited to spread their products, opinions or innovations. By offering those influential users free or discounted samples, information can be spread across the whole network through word-of-mouth effect [1] [2]. Inspired from that, the influence maximization (IM) problem [3] was formulated, which selects a subset of users (seed set) to maximizing the expected follow-up adoptions (influence spread) for a given information cascade. In this Kempe et al.’s seminal work [3], IM was defined on the two basic discrete diffusion models, independent cascade model (IC-model) and linear threshold model (LT-model), and these two models can be generalized to the triggering model. Then, they proved the IM problem is NP-hard, and obtain a -approximation under the IC/LT-model by use of a simple hill-climbing in the framework of monotonicity and submodularity.
Since this seminal work, plenty of related problems based on IM that used for different scenarios emerged [4] [5]. Among them, profit maximization (PM) [6] [7] [8] [9] [10] is the most representative and widely used one. Consider viral marketing for a given product, the gain is the influence spread generated from our selected seed set in a social network. However, it is not free to activate those users in this seed set. For instance, in a real advertisement scenario, discounts and rewards are usually adopted to improve users’ desire to purchase and stimulate consumption. Thus, the net profit is equal to influence spread minus the expense of seed set, where more incentives do not imply more benefit. Tang et al. [8] proved the objective function of PM is submodular, but not monotone, and double greedy algorithm has a -approximation if the objective value is non-negative. Before this, Kempe et al. [11] proposed the generalized marketing instead of the seed set. A marketing strategy is denoted by where a user will be activated as a seed with probability . Thus, the seed set is not deterministic, but activated probabilistically according to a marketing strategy. In this paper, we propose a continuous profit maximization under the general marketing strategies (CPM-MS) problem, which aims to choose the optimal marketing vector such that the net profit can be maximized. Each component stand for the investment to marketing action . Actually, in order to promote their products, a company often adopts multiple marketing techniques, such as advertisements, discounts, cashback, and propagandas, whose effects are different to customers at different levels. Therefore, CPM-MS is much more generalized than traditional PM.
In this paper, after formulating our CPM-MS problem, we discuss its properties first. We show that its objective function is NP-hard, and given a marketing vector , it is #P-hard to compute the expected profit exactly. Because of the difficulty to compute the expected profit, we give an equivalent method that needs to run Monte-Carlo simulations on a constructed graph. Then, we prove that the objective function of CPM-MS problem is dr-submodular, but not monotone. Extended from set function to vector function on integer lattice, the dr-submodularity has a diminishing return property. For the unconstrained submodular maximization (USM), Buchbinder et al. [12] proposed a randomized double greedy algorithm that can achieve a tight -approximation ratio. To our CPM-MS problem, we are able to consider it as a case of unconstrained dr-submodular maximization (UDSM) inspired by USM. Here, we introduce a lattice-based double greedy algorithm for the UDSM, and a -approximation can be obtained as well if objective value is non-negative. The marketing vector is defined on , thus this approximation can be guaranteed only when the sum of objective values on and is not less than zero, which is hard to be satisfied in the real applications. Imagine to offer all marketing actions full investments, is it still profitable? The answer is no. To overcome this defect, we design a lattice-based iterative pruning technique. It shrinks the searching space gradually in an iterative manner, and then we initialize our lattice-based double greedy with this smaller searching space. According to this revised process, the objective values on this smaller space are very likely to be non-negative, thereby increasing greatly the applicability of our algorithm’s approximation. As mentioned earlier, even if we can use Monte-Carlo simulations to estimate the expected profit, its time complexity is too high, and thus restrict its scalability. Here, based on the reverse influence sampling (RIS) [13] [14] [15] [16], we design an unbiased estimator for the profit function, which can estimate the objective value of a given marketing vector accurately if the number of samplings is large enough. Next, we take this estimator as our new objective function, combine with lattice-based pruning and double greedy algorithm, and propose DG-IP-RIS algorithm eventually. It guarantees to obtain a -approximation under a weak condition, whose time complexity is improved significantly. Finaly, we conduct several experiments to evaluate the superiority of our proposed DG-IP-RIS algorithm to other heuristic algorithms and compare their running times respectively, especially with the help of reverse sampling, which support the effectiveness and efficiency of our approaches strongly.
Organization: Sec. II discusses the related work. Sec. III is dedicated to introduce diffusion model, and formulate the problem based on that. The properties and computability of our CPM-MS problem are presented in Sec. IV. Sec. V is the main contributions, including lattice-based double greedy and pruning algorithms. Sec. VI analyzes the time complexity and designs speedup algorithms based on sampling strategies. Experiments and discussions are presented in Sec. VII and VIII is the conclusion for this paper.
II Related Work
Influence Maximization: Kempe et al. [3] formulated IM to a combinatorial optimization problem, generalized the triggering model, including IC-model and LT-model, and proposed a greedy algorithm with -approximation by adopting Monte-Carlo simulations. Given a seed set, Chen et al. proved that computing its exact influence spread under the IC-model [17] and LT-model [18] are #P-hard, and they designed two heuristic algorithms that can solve IM problem under the IC-model [17] and LT-model [18], which reduce the computation overhead effectively. Brogs et al. [13] took RIS to estimate the influence spread first, subsequently, a lot of researchers utilized RIS to design efficient algorithms with -approximation. Tang et al. [14] proposed TIM/TIM+ algorithms, which were better than Brogs et al.’s IM method regardless of accuracy and time complexity. Then, they developed a more efficient algorithm, IMM [15], based on martingale analysis. Nguyen et al. [19] designed SSA/D-SSA and claimed it reduces the running time significantly without losing approximation ratio, but still be doubted by other researchers. Recently, Tang et al. [16] created an online process of IM, and it can be terminated at any time and get a solution with its approximation guarantee.
Profit Maximization: Domingos et al. [1] [2] studied viral marketing systematically first, and they proposed customers’ value and utilized markov random fields to model the process of viral marketing. Lu et al. [6] distinguished between influence and actual adoption, and designed a decision-making process to explain how to adopt a product. Zhang et al. [7] studied the problem of distributing a limited budget across multiple products such that maximizing total profit. Tang et al. [8] analyzed and solved USM problem by double greedy algorithm thoroughly with PM as background, and proposed iterative pruning technique, which is different from our pruning process, because our objective function is defined on integer lattice. Tong et al. [9] considered the coupon allocation in the PM problem, and designed efficient randomized algorithms to achieve -approximation with high probability. Guo et al. [10] proposed a budgeted coupon problem whose domain is constrained, and provided a continuous double greedy algorithm with a valid approximation.
(Dr-)submodular maximization: Nemhauser et al. [20] [21] began to study monotone submodular maximization problem, and laid the theoretical foundation, where IM problem was the most relevant work. However, PM is submodular, but not monotone, which is a case of USM [22] [12]. Feige et al. [22] pointed out no approximation algorithm exists for general USM unless giving an additional assumption, and they developed a deterministic local search wich -approximation and a randomized local search with -approximation for maximizing non-negative submodular function. Assume non-negativity satisfied as well, Buchbinder et al. [12] optimized it to -approximation further with much lower computational complexity. Soma et al. [23] generalized the diminishing return property to the integer lattice first, and solved submodular cover problem with a bicriteria approximation algorithm. Then, they [24] studied monotone dr-submodular maximization problem exhaustively, where they designed algorithms with -approximation under the cardinality, polymatroid, and knapsack constraint. Even if the UDSM problem was discussed in [25], their techniques and backgrounds were very different from ours. Therefore, how to solve UDSM, especially when non-negativity cannot be satisfied, is still an open problem, which is the main contribution of this paper.
III Problem Formulation
In this section, we provides some preliminaries to the rest of this paper, and fomulate our continuous profit maximization problem under the general marketing strategies.
III-A Influence model
An OSN can be abstracted as a directed graph where is the set of nodes (users) and is the set of edges (relationship between users). We default and when given . For each directed edge , we say is an outgoing neighbor of , and is an incoming neighbor of . For any node , let denote its set of incoming neighbors, and denote its set of outgoing neighbors. In the process of influence diffusion, we consider a user is active if she accepts (is activated by) the information cascade from her neighbors or she is selected as a seed successfully. To model the influence diffusion, Kempe et al. [3] proposed two classical models, IC-model and LT-model.
Let be a seed set and be the set of all active nodes at time step . The influence diffusion initiated by can be represented by a discrete-time stochastic process. At time step , all nodes in are activated, so we have . Under the IC-model, there is a diffusion probabiltiy associated with each edge . We set at time step first; then, for each node , activated first at time step , it have one chance to activate each of its inactive outgoing neighbor with probability . We add into if activates successfully at . Under the LT-model, each edge has a weight , and each node has a threshold sampled uniformly in and . We set at time step first; then, for each inactive node , it can be activated if . We add into if is activated successfully at . The influence diffusion terminates when no more inactive nodes can be activated. In this paper, we consider the triggering mode, where IC-model and LT-model are its special cases.
Definition 1 (Triggering Model [3]).
Each node selects a triggering set randomly and independently according to a distribution over the subsets of . We set at time step first; then, for each inactive node , it can be activated if there is at least one node in activated in . We add into if is activated successfully at . The influence diffusion terminates when no more inactive nodes can be activated.
From above, a triggering model can be defined as , where is a set of distribution over the subsets of each .
III-B Realization
For each node , under the IC-model, each node appears in ’s random triggering set with probability independently. Under the LT-model, at most one node can appear in , thus, for each node , with probability exclusively and with probability . Now, we can define the realization (possible world) of graph under the triggering model , that is
Definition 2 (Realization).
Given a directed graph and triggering model , a realization of is a set of triggering set sampled from distribution , denoted by . For each node , we have respectively.
If a node appears in ’s triggering set, , we say edge is live, or else edge is blocked. Thus, realization can be regarded as a subgraph of , which is the remaining graph by removing these blocked edges. Let be the probability of realization of sampled from distribution , that is,
| (1) |
where is the probability of sampled from . Under the IC-model, , and under the LT-model, for each and deterministically.
Given a seed set , we consider as a random variable that denotes the number of active nodes (influence spread) when the influence diffusion of terminates under the triggering model . Then, the number of nodes that are reachable from at least one node in under a realization , , is denoted by . Thus, the expected influence spread , that is
| (2) |
where it is the weighted average of influence spread under all possible graph realizations. The IM problem aims to find a seed set , such that , to maximize the expected influence spread .
Theorem 1 ([3]).
Under a triggering model , the expected influence spread is monotone and submodular with respect to seed set .
III-C Problem Definition
Under the general marketing strategies, the definition of IM problem will be different from above [3]. Let be the collection of non-negative integer vector. A marketing strategy can be denoted by a -dimensional vector , and we call it “marketing vector”. Each component , means the number of investment units assigned to marketing action . For example, tells us that marketing strategy assigns investment units to marketing action . Given a marketing vector , the probability that node is activated as a seed is denoted by strategy function , where . Thus, unlike the standard IM problem, the selection of seed set is not deterministic, but stochastic. Given a marketing vector , the probability of seed set sampled from , that is
| (3) |
where is the probability that exactly nodes in are selected as seeds, but not in S are not selected as seeds under the marketing strategy , because each node is select as a seed independently. Thus, the expected influence spread of marketing vector under the triggering model can be formulated, that is
| (4) | ||||
| (5) |
As we know, benefit is the gain obtained from influence spread and cost is the price required to pay for marketing strategy. Here, we assume each unit of marketing action , , is associated with a cost . Then, the total cost function can be defined as . For simplicity, we consider the expected influence spread as our benefit. Thus, the expected profit we can obtain from marketing strategy is the expected influence spread of minus the cost of , that is
| (6) |
where . Therefore, the continuous profit maximization under the general marketing strategies (CPM-MS) problem is formulated as follows:
Problem 1 (CPM-MS).
Given a triggering model , a constraint vector and a cost function , the CPM-MS problem aims to find an optimal marketing vector that maximizes its expected profit . That is, .
IV Properties of CPM-MS
In this section, we introduce the submodularity on integer lattice, and then analyze the submodularity and computability of our CPM-MS problem.
IV-A Submodularity on Integer Lattice
Generally, defined on set, a set function is monotone if for any , and submodular if . The submodularity of set function implies a diminishing return property, thus for any and . These two definitions of submodularity on set function are equivalent. Defined on integer lattice, a vector function is monotone if for any , and submodular if for any , where and . Here, implies for each component . Besides, we consider a vector function is diminishing return submodular (dr-submodular) if for any and , where is the -th unit vector with the -th component being and others being . Different from the submodularity for a set function, for a vector function, is submodular does not mean it is dr-submodular, but the oppposite is true. Thus, dr-submodularity is stronger than submodularity generally.
Lemma 1.
Given a set function and a vector function , they sastisfy
| (7) |
If is monotone and submodular and is monotone and dr-submodular for each , then is monotone and dr-submodular.
Proof.
Theorem 2.
Given a triggering model , the profit function is dr-submodular, but not monotone.
Proof.
From Lemma 1, Theorem 1, and Equation (5), we have known that the expected influence spread is monotone and dr-submodular because is monotone and submodular. Thus, we have iff . Thus, is dr-submodular. ∎
IV-B Computability
Given a seed set , it is #P-hard to compute the expected influence spread under the IC-model [17] and the LT-model [18]. Assume that a marketing vector and for where user is a seed if and only if . According to the Equation (4), the expected influence spread is equivalent to in which . Thereby, given a marketing vector , computing the expected influence spread is #P-hard as well under the IC-model and LT-model. Subsequently, a natural question how to estimate the value of given effectively. To estimate , we usually adopt Monte-Carlo simulations. However, it is inconvenient for us to use such a method here because the randomness comes from two parts, one is from the seed selection, and the other is from the process of influence diffusion. Therefore, we require to design a more simple and efficient method.
First, we are able to establish an equivalent relationship between and . Given a social network and a marketing vector , we create a constructed graph by adding a new node and a new directed edge for each node to . Take IC-model for instance, the diffusion probability for this new edge can be set as . Then, we have
| (8) |
where and imply that we compute them under the graph and the constructed graph .
Theorem 3.
Given a social network and a marketing vector , the expected influence spread can be estimated with -approximation by Monte-Carlo simulations in running time.
Proof.
Mentioned above, we can compute on the constructed graph instead of on the original graph. Let , the value of can be estimated by Monte-Carlo simulations according to (2). Based on Hoeffding’s inequality, we can note that
where is the number of Monte-Carlo simulations and . We have , and to achieve a -estimation, the number of Monte-Carlo simulations . For each iteration of simulations in the constructed graph, it takes running time. Thus, we can obtain a -approximation of in running time. ∎
Based on the Theorem 3, we can get an accurate estimation for the objective function , shown as (6), of CPM-MS problem by adjusting the parameter and definitely.
V Algorithms Design
From the last section, we have known that the objective function of CPM-MS is dr-submodular, but not monotone. In this section, we develop our new methods based on the double greedy algorithm [12] for our CPM-MS, and obtain an optimal approximation ratio.
V-A Lattice-based Double Greedy
For non-negative submodular functions, Buchbinder et al. [12] designed a double greedy algorithm to get a solution for the USM problem with a tight theoretical guarantee. Under the deterministic setting, the double greedy algorithm has a -approximation, while it has a -approximation under the randomized setting. Extending from set to integer lattice, we derive a revised double greedy algorithm that is suitable for dr-submodular functions, namely UDSM problem. We adopt the randomized setting, and the lattice-based double greedy algorithm is shown in Algorithm 1. We omit the subscript of , denote it by from now on.
Here, we denote by , the marginal gain of adding component by . Generally, this algorithm is initialized by , and for each component , we increase by or decrease by until they are equal in each inner (while) iteration. The result returned by Algorithm 1 has . Then, we have the following conclusion which can be inferred directly from double greedy algorithm in [12], that is
Theorem 4.
Here, for any is equivalent to say , namely because of , which is a natural inference from the dr-submodularity.
V-B Lattice-based Iterative Pruning
According to Theorem 4, -approximation is based on an assumption that , and this is almost impossible in may real application scenarios. It means that we are able to gain profit if giving all marketing action full investments, which is ridiculous for viral marketing. However, a valid approximation ratio cannot be obtained by using Algorithm 1 when exists. To address this problem, Tang et al. [8] proposed a groundbreaking techniques, called iterative pruning, to reduce the search space such that the objective is non-negative in this space and without losing approximation guarantee. But their techniques are designed for submodular function based on set domain, it cannot be applied to dr-submodular function directly. Inspired by [8], we develop an iterative pruning technique suitable for dr-submodular functions in this section, which is a non-trival transformation from set to integer lattice.
Given a dr-submodular function defined on , we have two vectors and , such that: (1) if , or else for ; (2) if , or else for .
Lemma 2.
We have .
Proof.
For any component , we have but ; and but . Because of dr-submodularity, it satisfies . Thus, and . Subsequently, . ∎
Then, we define a collection denoted by that contains all the marketing vectors that satisfies . Apparently, is a subcollection of .
Lemma 3.
All optimal solutions that satisfy are contained in the collection , i.e., for all .
Proof.
For any component , we consider any vector with , we have because of dr-submodularity. Thereby, has a larger profit than for sure, so the -th component of the optimal marketing vector at least eqauls to , which indicates . On the other have, consider , we have . Thereby, has a less profit than for sure, so the -th component of the optimal marketing vector at most equals to , which indicates . Thus, . ∎
From above, Lemma 3 determines a range for the optimal vector, thus reducing the search space. Then, the collection can be pruned further in an iterative manner. Now, the upper bound of the optimal vector is , i.e., , hereafter, we are able to increase to , where if , or else for . The lower bound of the optimal vector is , i.e., , and similarly we are able to decrease to , where if , or else for . In this process, it generates a more compressed collection than . We repeat this process iteratively until and cannot be increased and decreased further. The Lattice-basedPruning algorithm is shown in Algorithm 2. The collection returned by Algorithm 2 is denoted by .
Lemma 4.
All optimal solutions that satisfy are contained in the collection , and holds for all and any .
Proof.
First, we show that the collection generated in current iteration is a subcollection of that generated in previous iteration, namely . We prove it by induction. In Lemma 2, we have shown that . For any , we assume that is satisfied. Given a component , for any , we have . Because of the dr-submodularity, we have , which indicates . Similarly, for any , we have . Because of the dr-submodularity, we have , which indicates . Moreover, for any , we have . Due to and dr-submodularity, we have , which indicates . Thus, we conclude that holds for any .
Then, we show that any optimal solutions are contained in the collection returned by Algorithm 2, namely . We prove it by induction. In Lemma 3, we have shown that . For any , we assume that is satisfied. Given a component , for any , we have . Because of the dr-submodularity, we have , which implies . Otherwise, if , we have , which contradicts the optimality of , thus . Similarly, for any , we have . Because of the dr-submodularity, we have , which implies . Otherwise, if , we have , which contradicts the optimality of , thus . Thus, we conclude that holds for any , and . The proof of Lemma is completed. ∎
Lemma 5.
For any two vectors with and a dr-submodular function , we have
| (10) |
where we define .
To understand Lemma 5, we give a simple example here. Let vector be , subsequently we can see and . From the definition of (10), we have , which reflects the essence and correctness of Lemma 5 definitely.
Lemma 6.
The and are monotone non-decreasing with the increase of .
Proof.
We prove that and respectively. Given a component , for any , we have . Because of the dr-submodularity, we have , where . According to the Lemma 5, that is
| (11) |
where . The inequality (11) is established since its dr-submodularity, that is definitely. Besides, since , we have . Similarly, for any , we have . Because of the dr-submodularity, we have , where . According to the Lemma 5, that is
| (12) |
where . The inequality (12) is established since its dr-submodularity, that is definitely. Besides, since , we have . ∎
At this time, we can initialize with instead of starting with in Algorithm 1, where the search space required to be checked is reduced to . Then, we are able to build the approximation ratio for our revised lattice-based double greedy algorithm.
Proof.
It can be extended from the proof of Lemma 3.1 in [12]. This procedure is complicated, so we omit here because of space limitation. ∎
Theorem 5.
Proof.
Based on Lemma 4, we have , hence . If , we can get that . ∎
From Theorem 5, it enables us to obtain the same approximation ratio by applying the lattice-based double greedy algorithm initialized by using iterative pruning if we have . According to the Lemma 6, that is . To achieve this condition is much easier than . Therefore, the applications of Algorithm 1 with a theoretical bound are extended greatly by the technique of lattice-based iterative prunning.
VI Speedup by Sampling Techniques
In this section, we analyze the time complexity of Algorithm 1 and Algorithm 2, and then discuss how to reduce their running time by sampling techniques.
VI-A Time Complexity
First, we assume there is a value oracle for computing the marginal gain of increasing or decreasing component by . If we initialize and at the beginning of lattice-based double greedy algorithm (Algorithm 1), we have to take times together for checking each component whether to increase or decrease it by . Consider shrinking collection to by applying lattice-based iterative pruning (Algorithm 2) first, we use it to initialize and at the beginning of Algorithm 1, and then running the Algorithm 1. For each component , we check its marginal gain times in the iterative pruning, thus totally times. Then, we are required to check times in subsequent double greedy initialized by . Combine together, we have to check times. Hence, the time complexity is . However, to compute the marginal gain of profit is a time consuming process, and the running time is given by Theorem 3, which is not acceptable in a large-scale social graph as well as a large searching space.
VI-B Sampling Techniques
To overcome the #P-hardness of computing the objective , we borrow from the idea of reverse influence sampling (RIS) [13]. In the beginning, consider traditional IM problem, we need to introduce the concept of reverse reachable set (RR-set) first. Given a triggering model , a random RR-set can be generated by selecting a node uniformly and sampling a graph realization from , then collecting those nodes can reach in . RR-sets rooted at is the collected nodes that are likely to influence . A larger expected influence spread a seed set has, the higher the probability that intersects with a random RR-set is. Given a seed set and a random RR-set , we have .
Extended to the lattice domain, given a marketing vector , its expected influence spread under the triggering model can be denoted by [27]. Let be a collection of random RR-sets generated independently, we have
| (14) |
that is an unbiased estimator of . From here, the vector that maximizes will be close to the optimal solution intuitively, and more and more close with the increase of . Similar to , fix the collection , the is dr-submodular, but not monotone as well. By Theorem 5, Algorithm 1 offers a -approximation if is satisfied after the process of pruning.
Now, we begin to design our algorithm based on the idea of reverse sampling. First, we need to sample the enough number of random RR-sets so that its estimation to the objective function is accurate. Let , , and be three adjustable parameters, where they satisfy
| (15) |
where . Then, we can set that
| (16) | |||
| (17) | |||
| (18) |
where the is the lower bound of the optimal objective . The algorithm that combining double greedy with reverse sampling and iterative pruning, called DG-IP-RIS algorithm, is shown in Algorithm 3.
In DG-IP-RIS algorithm, we estimate the number of random RR-sets in line 4, and then generate a collection of random RR-sets with the size of . The objective is computed based on this , from which we are able to get a solution by iterative pruning and double greedy algorithm. In the first step, we require to compute a lower bound of optimal value , which is shown in Algorithm 4. Here, we increase the component by with the largest marginal gain at each iteration until there is no component having positive marginal gain. After the while loop, we can obtain a vector and set , because is satisfied with a high probability under the setting of . Like this, we have as well because the largest marginal gain should be greater than due to the dr-submodularity, or else the definition of our problem is not valid and meaningless. For convenience, given a random RR-set , we denote in subsequent proof.
Lemma 8.
The returned by Algorithm 4 satisfies with at least probability.
Proof.
For any marketing vector , we want to obtain . By the additive form of Chernoff-Hoeffding Inequality, it is equivalent to compute, that is
When is defined as (16), we have definitely. By the union bound, the above relationship holds for the generated in line 10 of Algorithm 3 with a probablity less than . ∎
Remark 1.
Given a marketing vector , for each component , the possible values of are , thus the number of possible values for is . Thereby the total number of possible combinations for vector is , which explains why the union bound in the previous lemma happened.
Lemma 9 (Chernoff bounds [28]).
Given a collection , each is an i.i.d. random variable with , we have
| (19) |
| (20) |
where we assume that .
Lemma 10.
Given a collection with , for any marketing vector , it satisfies with at least probability.
Proof.
For any marketing vector , we want to obtain . By the Chernoff bound, defined as (19), it is equivalent to compute, that is
| (21) |
From Lemma 9 and , we have
By the union bound, the above relationship holds for any with at most probability. ∎
Lemma 11.
Given a collection with , for an optimal solution , it satisfies with at least probability.
Proof.
For an optimal solution , we want to obtain . By the Chernoff bound, defined as (20), it is equivalent to compute, that is
| (22) |
From Lemma 9 and , we have
The above relationship holds for the optimal solution with at most probability. ∎
Let be the result returned by Algorithm 3. If and are accurate estimations to the and , we can say this solution has an effective approximation guarantee, which is shown in Theorem 6.
Theorem 6.
For our CPM-MS problem, if it satisfies , for any and , the marketing vector returned by Algorithm 3 is a -approximation, that is
| (23) |
holds with at least probability.
Proof.
Based on Lemma 10, holds with at least probability, and on Theorem 5, we have . Thus, . By Lemma 11, holds with at least probability, thus we have . Combined with that holds with , by the union bound, (23) holds with at least probability. ∎
Finally, we consider the running time of Algorithm 3. Given a collection with , we have . To compute , it takes time, and to generate a random RR-set, it takes times. Thus, the time complexity of Algorithm 3 is . Besides, this running time can be reduced further. Look at the forms of (16) (17) and (18), is apparently less than and . Therefore, we are able to select the remaining two parameters such that .
VII Experiments
In this section, we carry out several experiments on different datasets to validate the performance of our proposed algorithms. It aims to test the efficiency of DG-IP-RIS algorithm (Algorithm 3) and its effectiveness compared to other heuristic algorithms. All of our experiments are programmed by python, and run on Windows machine with a 3.40GHz, 4 core Intel CPU and 16GB RAM. There are four datasets used in our experiments: (1) NetScience [29]: a co-authorship network, co-authorship among scientists to publish papers about network science; (2) Wiki [29]: a who-votes-on-whom network, which come from the collection Wikipedia voting; (3) HetHEPT [30]: an academic collaboration relationship on high energy physics area; (4) Epinions [30]: a who-trust-whom online social network on Epinions.com, a general consumer review site. The statistics information of these four datasets is represented in Table I. For undirected graph, each undirected edge is replaced with two reversed directed edges.
| Dataset | n | m | Type | Avg.Degree |
| NetScience | 0.4K | 1.01K | undirected | 5.00 |
| Wiki | 1.0K | 3.15K | directed | 6.20 |
| HetHEPT | 12.0K | 118.5K | undirected | 19.8 |
| Epinions | 75.9K | 508.8K | directed | 13.4 |














VII-A Experimental Settings
We test different algorithms based on IC/LT-model. For the IC-model, the diffusion probability for each is set to the inverse of ’s in-degree, i.e., , and for the LT-model, the weight for each is set as well, which are adopted by previous studies of IM widely [3] [13] [14] [15] [19]. Then, we need to consider our strategy function, that is
| (24) |
where is an attenuation coefficient, and for and , where a unit of investment to marketing action activates user to be a seed with the probability , and each activation is independent. Here, we define vector .
We assume there are five marketing action totally, namely and , and . Thus, for each . Besides, we set , is sampled from and is sampled from uniformly. Apparently, is monotone and dr-submodular with respect to . For example, consider a marketing vector and a node with , we have definitely. For the cost function , we adopt a uniform cost distribution. The cost for a unit of marketing action , , is set as , where is a cost coefficient. The cost coefficient defined above is used to regulate the effect of cost on objective function. For example, is monotone dr-submodular if ; When we set , it implies if all users in a given social network can be influenced by full marketing vector , or else this profit is negative; If , we have definitely.
In addition, the number of Monte-Carlo simulations for each estimation to profit function is . For those algorithms that adopt speedup by sampling techniques, the parameters setting of four datasets is shown in Table II. Next, we denote “XXX” is achieved by Monte-Carlo simulations, but “XXXS” is achieved with speedup by sampling techniques. The algorithms we compare in this experiment are shown as follows: (1) DG(S): lattice-based double greedy feed with ; DGIT(S): lattice-based double greedy feed with the collection returned by lattice-based iterative pruning; (3) Greedy(S): select the component with maximum marginal gain until no one has postive gain; (4) Random: select the component randomly until reaching negative marginal gain.
| Dataset | ||||
|---|---|---|---|---|
| NetScience | 0.10 | 0.10 | 0.10 | 10.00 |
| Wiki | 0.10 | 0.10 | 0.10 | 10.00 |
| HetHEPT | 0.15 | 0.10 | 0.10 | 10.00 |
| Epinions | 1.00 | 0.10 | 0.10 | 10.00 |
VII-B Experimental Results
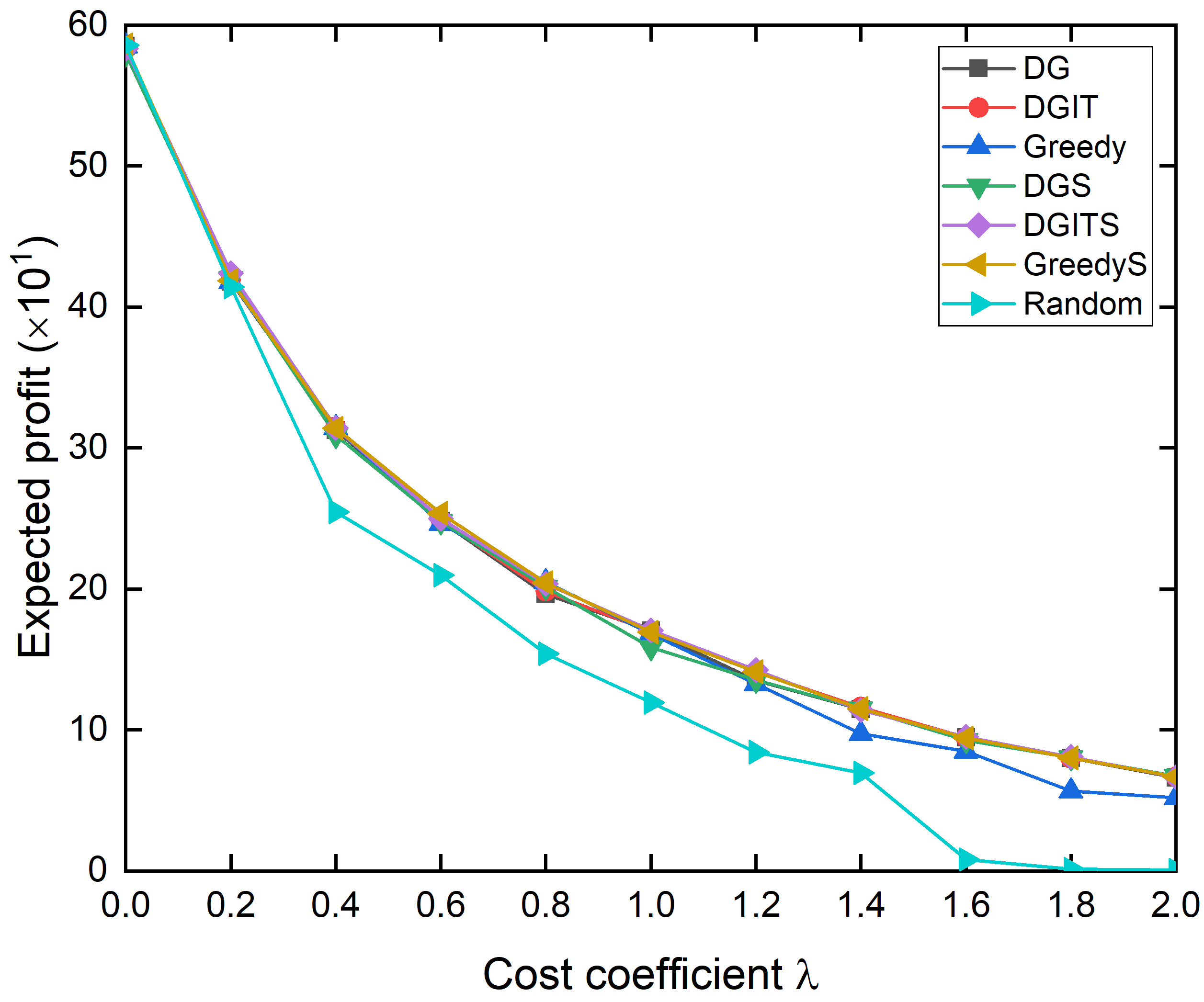
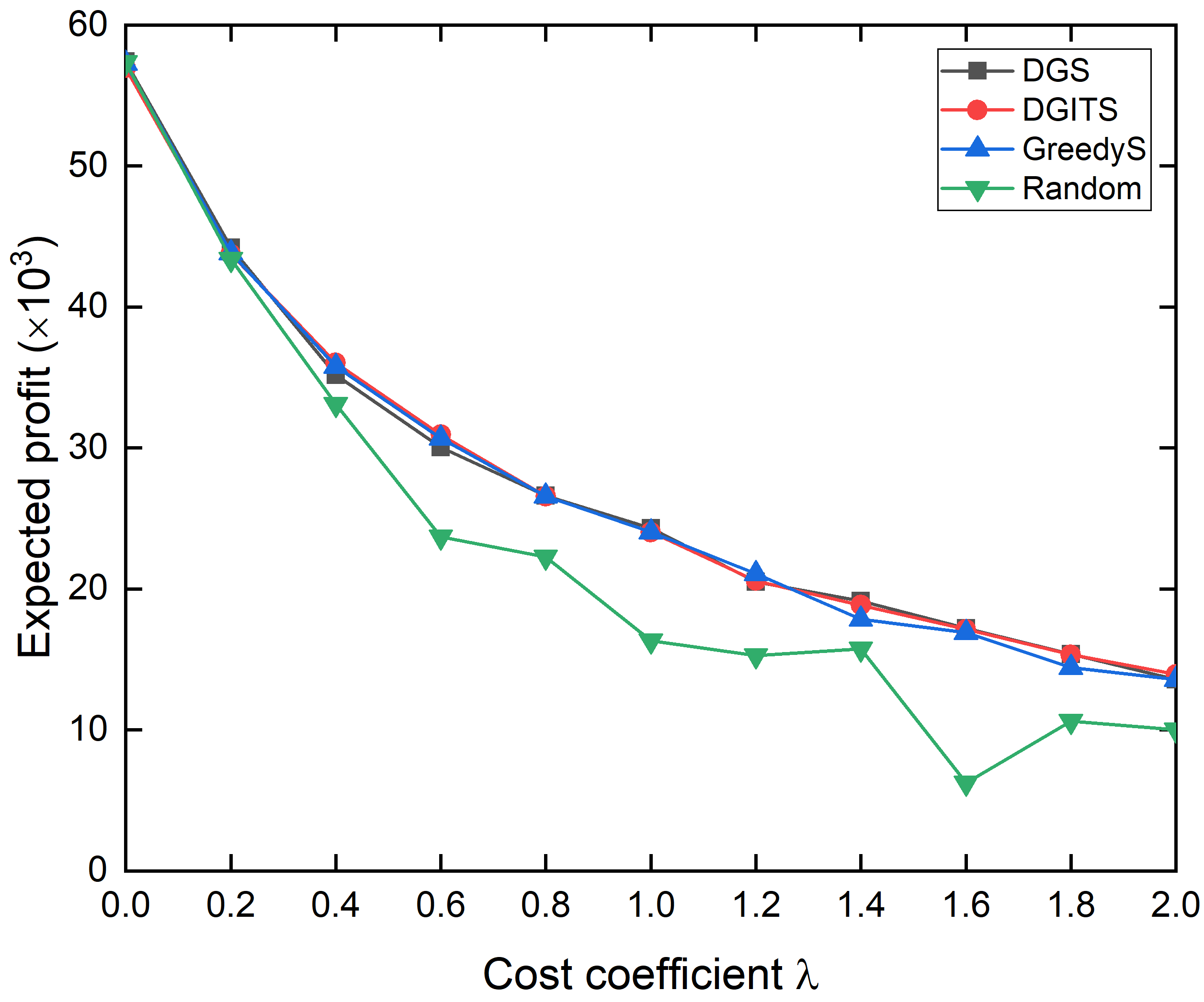
Fig. 1 and Fig. 2 draws the expected profit and running time produced by different algorithms under the IC-model and LT-model. From the left columns of Fig. 1 and Fig. 2, we can see that the expected profits decrease with the increase of cost coefficient, which is obvious because a larger cost coefficient implies larger cost for a unit of investment. Its trend is close to the inverse proportional relationship, namely . Then, the expected profits achieved by DG, DGIT, DGS, and DGITS(DG-IP-RIS) only have very slight even negligible gaps. By comparing the performance between DG and DGS (between DGIT and DGITS), it can show that speedup by sampling techinques is completely effective, which can estimate the objective function accurately. By comparing the performance between DG and DGIT (between DGS and DGITS), it can prove that the optimal solution lies in the shrinked collection returned by itertive pruning, because DGIT does not make the performance of original DG worse. It means that the expected profit will not be reduced at least if we initial double greedy with the shrinked collection returned by iterative pruning. However, do such a thing, it can provide a theoretical bound, so as to avoid some extreme situations. In addition, even if Greedy(S) gives a satisfactory solution in our experiment, there are still some exceptions, for example, (c) in Fig. 1 and (g) in Fig. 2. It often happens in some positions with larger cost coefficients.
From the right columns of Fig. 1 and Fig. 2, the trend of running time with cost coefficient is a little complex, but there are two apparent characteristics. First, by comparing between DG and DGS (between DGIT and DGITS, or between Greedy and GreedyS), we can see that their running times are reduced significantly by our sampling techniques. Here, in order to test the running time of different algorithms, we do not use parallel acceleration in our implementations. Generally speaking, the running times of algorithms implemented by sampling do not exceed 10% of the corrsponding algorithms implemented by Monte-Carlo simulations in average. Second, look at DGS and DGITS, their running times increase with the increase of cost coeffient. This is because the lower bound of optimal solution returned by Algorithm 4 will be smaller and smaller as cost efficient grows, resulting in a larger and . Hence, the number of random RR-sets needed to be generated and searched will increases certainly. Third, by comparing between DGS and DGITS, their running times are roughly equal, shown as (f) (h) in Fig. 1 and Fig. 2. It infers that initializing by iterative prunning will not increase the time complexity actually, which is very meaningful.
Table III and Table IV shows the effect of lattice-based iterative prunning on the sum of initialized objective values under the IC-model and LT-model, where we denote and for convenience. When cost coefficient , in all cases, thus there is no approximation guarantee if we run double greedy algorithm feed with directly. However, with the help of iterative prunning, holds for most of cases. Like this, our DGIT(S) algorithm is able to offer a -approximate solution according to Theorem 5 and Theorem 6.
| NetScience | Wiki | HetHEPT | ||||
| 0.8 | -22 | 219 | -127 | 379 | -586 | 7050 |
| 1.0 | -97 | 178 | -303 | 256 | -2860 | 848 |
| 1.2 | -174 | 101 | -481 | 213 | -5065 | 751 |
| 1.4 | -250 | -2 | -658 | 147 | -7329 | -317 |
| 1.6 | -325 | 82 | -836 | -11 | -9523 | -463 |
| 1.8 | -401 | 55 | -1015 | -269 | -11795 | 500 |
| 2.0 | -477 | -17 | -1192 | -792 | -14031 | -137 |
| NetScience | Wiki | HetHEPT | ||||
| 0.8 | 24 | 294 | -64 | 482 | 1406 | 1410 |
| 1.0 | -51 | 229 | -242 | 390 | -869 | 1186 |
| 1.2 | -126 | 33 | -420 | 177 | -3080 | 887 |
| 1.4 | -202 | 159 | -599 | 228 | -5332 | 392 |
| 1.6 | -278 | -6 | -776 | 166 | -7603 | -948 |
| 1.8 | -353 | 11 | -954 | 66 | -9807 | -106 |
| 2.0 | -429 | 93 | -1132 | -778 | -12063 | 229 |
VIII Conclusion
In this paper, we propose the continuous profit maximization problem first, and based on it, we study unconstrained dr-submodular problem further. For UDSM problem, lattice-based double greedy is an effective algorithm, but there is not approximation guarantee unless all objective values are non-negative. To solve it, we propose lattice-based iterative pruning, and derive it step by step. With the help of this technique, the possibility of satisfying non-negative is enhanced greatly. Our approach can be used as a flexible framework to address UDSM problem. Then, back to CPM-MS problem, we design a speedup strategy by using sampling techniques, which reduce its running time significantly without losing approximation guarantee. Eventually, we evaluate our proposed algorithms on four real networks, and the results validate their effectiveness and time efficiency thoroughly.
Acknowledgment
This work is partly supported by National Science Foundation under grant 1747818.
References
- [1] P. Domingos and M. Richardson, “Mining the network value of customers,” in Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, 2001, pp. 57–66.
- [2] M. Richardson and P. Domingos, “Mining knowledge-sharing sites for viral marketing,” in Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, 2002, pp. 61–70.
- [3] D. Kempe, J. Kleinberg, and É. Tardos, “Maximizing the spread of influence through a social network,” in Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, 2003, pp. 137–146.
- [4] J. Guo and W. Wu, “A novel scene of viral marketing for complementary products,” IEEE Transactions on Computational Social Systems, vol. 6, no. 4, pp. 797–808, 2019.
- [5] J. Guo, T. Chen, and W. Wu, “A multi-feature diffusion model: Rumor blocking in social networks,” arXiv preprint arXiv:1912.03481, 2019.
- [6] W. Lu and L. V. Lakshmanan, “Profit maximization over social networks,” in 2012 IEEE 12th International Conference on Data Mining. IEEE, 2012, pp. 479–488.
- [7] H. Zhang, H. Zhang, A. Kuhnle, and M. T. Thai, “Profit maximization for multiple products in online social networks,” in IEEE INFOCOM 2016-The 35th Annual IEEE International Conference on Computer Communications. IEEE, 2016, pp. 1–9.
- [8] J. Tang, X. Tang, and J. Yuan, “Profit maximization for viral marketing in online social networks,” in 2016 IEEE 24th International Conference on Network Protocols (ICNP). IEEE, 2016, pp. 1–10.
- [9] G. Tong, W. Wu, and D.-Z. Du, “Coupon advertising in online social systems: Algorithms and sampling techniques,” arXiv preprint arXiv:1802.06946, 2018.
- [10] J. Guo, T. Chen, and W. Wu, “Budgeted coupon advertisement problem: Algorithm and robust analysis,” IEEE Transactions on Network Science and Engineering, pp. 1–1, 2020.
- [11] D. Kempe, J. Kleinberg, and É. Tardos, “Maximizing the spread of influence through a social network,” Theory OF Computing, vol. 11, no. 4, pp. 105–147, 2015.
- [12] N. Buchbinder, M. Feldman, J. Seffi, and R. Schwartz, “A tight linear time (1/2)-approximation for unconstrained submodular maximization,” SIAM Journal on Computing, vol. 44, no. 5, pp. 1384–1402, 2015.
- [13] C. Borgs, M. Brautbar, J. Chayes, and B. Lucier, “Maximizing social influence in nearly optimal time,” in Proceedings of the twenty-fifth annual ACM-SIAM symposium on Discrete algorithms. SIAM, 2014, pp. 946–957.
- [14] Y. Tang, X. Xiao, and Y. Shi, “Influence maximization: Near-optimal time complexity meets practical efficiency,” in Proceedings of the 2014 ACM SIGMOD international conference on Management of data, 2014, pp. 75–86.
- [15] Y. Tang, Y. Shi, and X. Xiao, “Influence maximization in near-linear time: A martingale approach,” in Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 2015, pp. 1539–1554.
- [16] J. Tang, X. Tang, X. Xiao, and J. Yuan, “Online processing algorithms for influence maximization,” in Proceedings of the 2018 International Conference on Management of Data, 2018, pp. 991–1005.
- [17] W. Chen, C. Wang, and Y. Wang, “Scalable influence maximization for prevalent viral marketing in large-scale social networks,” in Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, 2010, pp. 1029–1038.
- [18] W. Chen, Y. Yuan, and L. Zhang, “Scalable influence maximization in social networks under the linear threshold model,” in 2010 IEEE international conference on data mining. IEEE, 2010, pp. 88–97.
- [19] H. T. Nguyen, M. T. Thai, and T. N. Dinh, “Stop-and-stare: Optimal sampling algorithms for viral marketing in billion-scale networks,” in Proceedings of the 2016 International Conference on Management of Data, 2016, pp. 695–710.
- [20] G. L. Nemhauser, L. A. Wolsey, and M. L. Fisher, “An analysis of approximations for maximizing submodular set functions—i,” Mathematical programming, vol. 14, no. 1, pp. 265–294, 1978.
- [21] M. L. Fisher, G. L. Nemhauser, and L. A. Wolsey, “An analysis of approximations for maximizing submodular set functions—ii,” in Polyhedral combinatorics. Springer, 1978, pp. 73–87.
- [22] U. Feige, V. S. Mirrokni, and J. Vondrák, “Maximizing non-monotone submodular functions,” SIAM Journal on Computing, vol. 40, no. 4, pp. 1133–1153, 2011.
- [23] T. Soma and Y. Yoshida, “A generalization of submodular cover via the diminishing return property on the integer lattice,” in Advances in Neural Information Processing Systems, 2015, pp. 847–855.
- [24] ——, “Maximizing monotone submodular functions over the integer lattice,” Mathematical Programming, vol. 172, no. 1-2, pp. 539–563, 2018.
- [25] T. Soma, “Non-monotone dr-submodular function maximization,” in Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. AAAI, 2017, pp. 898–904.
- [26] J. Guo, T. Chen, and W. Wu, “Continuous activity maximization in online social networks,” arXiv preprint arXiv:2003.11677, 2020.
- [27] W. Chen, R. Wu, and Z. Yu, “Scalable lattice influence maximization,” arXiv preprint arXiv:1802.04555, 2018.
- [28] R. Motwani and P. Raghavan, Randomized algorithms. Cambridge university press, 1995.
- [29] R. A. Rossi and N. K. Ahmed, “The network data repository with interactive graph analytics and visualization,” in AAAI, 2015. [Online]. Available: http://networkrepository.com
- [30] J. Leskovec and A. Krevl, “SNAP Datasets: Stanford large network dataset collection,” http://snap.stanford.edu/data, Jun. 2014.