Continual Pre-Training for Cross-Lingual LLM Adaptation:
Enhancing Japanese Language Capabilities
Abstract
Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
1 Introduction

Large language models (LLMs) such as ChatGPT have attracted significant attention by demonstrating human-level language understanding and generation capabilities, as well as generalizability to various fields.
However, many LLMs, including Llama 2 (Touvron et al., 2023), are primarily trained on English corpora, and their performance in other languages, especially in those with syntactic structures and writing systems greatly different from English, is decreased (OpenAI et al., 2023).
Motivated by this performance gap, establishing methods to build LLMs that excel in Japanese (hereafter referred to as Japanese LLMs) is an important research issue in Japan. In particular, since English language resources are outstanding in terms of quality and quantity, insights on effectively utilizing both Japanese and English language resources are in high demand.
For example, it is estimated that there are approximately nine times more English web pages than Japanese web pages111Statistics of Common Crawl Monthly Archives:
https://commoncrawl.github.io/cc-crawl-statistics.
However, pre-training from scratch using both Japanese and English language data requires enormous computational resources, making it difficult to acquire insights in a timely manner.
Therefore, we choose to conduct Japanese continual pre-training from English LLMs, aiming to save computational resources, and obtain insights on how to transfer the knowledge and abilities learned by English LLMs to Japanese. Recently, there has been an increasing number of attempts to adapt LLMs to other languages using continual pre-training (Gupta et al., 2023; Cui et al., 2023; Pires et al., 2023; Zhu et al., 2023; Zhao et al., 2024), but a comprehensive investigation on the effectiveness of continual pre-training has not been conducted. For example, the relationship between the amount of Japanese data used for continual pre-training and model performance, and the impact of the model size on this relationship, are unclear. We construct Swallow, an LLM with enhanced Japanese capabilities, by performing continual pre-training on Llama 2’s 7b, 13b, and 70b models using a Japanese corpus. We then evaluate the performance on six types of tasks including question answering and machine translation in both Japanese and English to analyze changes in knowledge and abilities in both languages. As a result, we demonstrated performance improvements in almost all Japanese tasks for all model sizes (Figure 1).
Furthermore, to identify efficient methodologies for cross-lingual continual pre-training, we also investigate the impact of vocabulary expansion and the effectiveness of Japanese-English parallel corpora. Vocabulary expansion has the effect of shortening token sequence lengths and improving the learning and generation efficiency of Japanese text by adding Japanese characters and words. However, previous studies have not sufficiently analyzed the extra cost of optimizing parameters for the added vocabulary or the impact on performance due to the increase in the amount of learnable text. Therefore, in this study, we conducted a comprehensive evaluation of the impact of vocabulary expansion on the performance of both Japanese and English. Vocabulary expansion improved Japanese text generation efficiency up to 78%, due to a 56.2% token reduction in the Swallow Corpus, without compromising downstream task accuracy, except summarization.
Parallel corpora are known to have the effect of promoting cross-lingual transfer in multilingual models (Chi et al., 2022; Hu et al., 2020; Feng et al., 2022). However, the effectiveness of parallel corpora in continual pre-training settings of the target language has not been studied in detail. Our experimental results reveal that simply mixing parallel corpora with plain text corpora improves the accuracy of machine translation tasks.
The contributions of this study are as follows:
-
•
Swallow achieved the highest performance in Japanese among all models developed in Japan (as of December 2023). We demonstrate that cross-lingual continual pre-training can achieve higher performance with fewer computational resources compared to Japanese LLMs trained from scratch.
-
•
We show that continual pre-training is effective for improving Japanese abilities, especially question answering tasks that require Japanese knowledge.
-
•
We provide evidence that the Japanese performance of language models improves monotonically as the amount of Japanese training data increases.
-
•
We show that vocabulary expansion does not affect performance in most tasks, and only degrades performance in automatic summarization.
-
•
We reveal that using parallel corpora together enhances translation ability without affecting the performance of other tasks.
2 Related work
2.1 Continual pre-training
Continual pre-training is a form of domain adaptation where additional pre-training tasks are performed on a pre-trained language model using text from the target downstream task before fine-tuning the model on that task (Lee et al., 2019; Beltagy et al., 2019; Sung et al., 2019). Since the emergence of open and high-performance English LLMs, there have been an increasing number of attempts to perform continual pre-training to adapt LLMs to other tasks and languages (Gupta et al., 2023; Cui et al., 2023; Pires et al., 2023; Zhu et al., 2023; Zhao et al., 2024). However, a comprehensive investigation of the effects of continual pre-training for various model sizes and training data sizes has not been conducted.
2.2 Vocabulary expansion
Vocabulary expansion is a method to increase the vocabulary of a trained LLM. The Japanese writing system differs from English, where kanji characters tend to be converted into UTF-8 byte sequences. For example, a Japanese single-character noun 猫 (cat) is represented by three byte-level tokens <0xE7> <0x8C> <0xAB>, which do not provide any semantic meaning. This treatment not only looks unreasonable as Japanese representation but also increases the sequence length of Japanese text as well as the cost of text generation (Ahia et al., 2023). Adding Japanese characters and words to the vocabulary can reduce the number of tokens required to represent Japanese text and alleviate this problem.
In domain adaptation of text embedding models, it is known that adding vocabulary from the target domain can improve performance (Sachidananda et al., 2021; Yao et al., 2021).
In contrast, the main motivation for vocabulary expansion in continual pre-training of LLMs is to improve training and generation efficiency in the target language, and there is little knowledge about its impact on performance.
Examples of vocabulary expansion in building Japanese LLMs 222Japanese Stable LM Beta: https://ja.stability.ai/blog/japanese-stable-lm-beta are limited to evaluating Japanese language ability, and do not evaluate the English language ability. Examples of vocabulary expansion in Chinese LLMs (Cui et al., 2023) only report the performance with vocabulary expansion, and do not compare with a base model. In multilingual LLMs (Ahuja et al., 2023), it was shown that the vocabulary size for each language correlates with performance, but these studies train longer as the vocabulary is expanded, so the isolated impact of vocabulary size remains unclear.
2.3 Parallel corpus
In multilingual text embedding models, it has been reported that pre-training with the language modeling objective using parallel corpora mitigates language-specific hidden state vectors and promotes cross-lingual transfer (Chi et al., 2022; Hu et al., 2020; Feng et al., 2022). In applications to LLMs, it has been reported that using parallel sentences for instruction tuning can improve translation ability more efficiently than using the same amount of multilingual corpora (Zhu et al., 2023; Ranaldi et al., 2023). However, the effectiveness of combining continual pre-training with parallel corpora remains unclear.
3 Continual pre-training
The continual pre-training of Swallow involves expanding the vocabulary of a pre-trained model and then performing continual pre-training using corpora primarily consisting of Japanese. The models are evaluated on six types of tasks in Japanese and English. The evaluation results are compared with LLMs developed in English-speaking regions and in Japan, to demonstrate the comparative effectiveness of our continual pre-training approach. In this section, we describe the training settings, training corpus, vocabulary expansion method, and evaluation method.
3.1 Training details
| Params | # Heads | # Layers | Context length | GQA | # Tokens | LR | |
| 7B | 4096 | 32 | 32 | 4096 | 100B | ||
| 13B | 5120 | 40 | 40 | 4096 | 100B | ||
| 70B | 8192 | 64 | 80 | 4096 | ✓ | 100B |
Table 1 shows the hyperparameters of the Swallow models. Preliminary experiments were conducted with reference to Llemma (Azerbayev et al., 2024) and Code Llama (Rozière et al., 2023) to determine the parameters. Since continual pre-training is bound by the model architecture of the base model, Swallow adopts the same Transformer decoder as . The hidden size, number of attention heads, number of layers, and context length are the same as . To maintain consistency with the pre-training phase, a batch size of 1024 was used for all model sizes in Swallow, matching the global batch size of 4M tokens in Llama 2.
The AdamW optimizer (Loshchilov & Hutter, 2019) was employed for training the models, with hyperparameters , , . A cosine learning rate scheduler was used, and the learning rate was set to reach its maximum value at 1,000 warmup steps and finally decays to 1/30 of that value. Additionally, a weight decay of 0.1 and gradient clipping of 1.0 were used. Furthermore, Flash Attention 2 (Dao, 2023) was adopted for improved computational efficiency and memory footprints. Refer to Figure 8 in the appendix for the training loss curve.
3.2 Training corpora
When continually pre-training with full parameters, forgetting previously learned knowledge is a concern (Jin et al., 2022). One method to prevent forgetting is the Experience Replay technique (Chaudhry et al., 2019). This method involves reusing a portion of the data previously used for training the language model during continual pre-training (Scialom et al., 2022). Following this approach, our study incorporates a portion of the English corpus in addition to the target Japanese corpus for continual pre-training.
The corpus used for continual pre-training includes the Swallow Corpus, which is explained in Appendix A, Japanese Wikipedia333https://dumps.wikimedia.org/other/cirrussearch/20230320: Dump dated March 20, 2023., and for English, the RefinedWeb (Penedo et al., 2023) and The Pile (Gao et al., 2020). From these corpora, approximately 100B tokens were sampled for the training data of continual pre-training. The sampling was configured so that 5% of the English text comes from RefinedWeb, another 5% from English arXiv paper texts within The Pile, and the remaining 90% from Japanese texts. The Japanese text comprises about 1.6B tokens from Japanese Wikipedia, with the rest from the Swallow Corpus. The ratio of Japanese to English data in the training set was decided based on preliminary experiments (see Appendix B for details).
3.3 Vocabulary expansion
In this study, we aim to adapt LLMs to languages with different writing systems from the Latin alphabet. For this purpose, we performed vocabulary expansion. Vocabulary expansion refers to the post-hoc addition of vocabulary to an existing LLM. This increases the amount of text that can be trained and generated within the same computational budget, thereby improving computational efficiency. In the vocabulary expansion adopted in Swallow , we constructed Japanese vocabulary, initialized vectors, and added string preprocessing. Below, we provide an overview of each item. For details, see Appendix E.1.
The construction of Japanese vocabulary involved creating a vocabulary (up to 16k) using the BPE algorithm on the Swallow Corpus segmented by MeCab444https://taku910.github.io/mecab/ and the UniDic dictionary555https://clrd.ninjal.ac.jp/unidic/, and adding 11,176 subwords to the LLaMA tokenizer. The resulting vocabulary size was 43,176. The vectors for the embedding and output layers of the added subwords were initialized with the average of the vectors of the subwords segmented by the LLaMA tokenizer, i.e., the subwords trained by Llama 2, following previous research (Yao et al., 2021). String preprocessing was enhanced by adding NFKC normalization to utilize the pre-trained knowledge of alphanumeric characters and symbols in the ASCII code range.
3.4 Evaluation method
The evaluation methods for Japanese and English are shown in Tables 2 and 3, respectively. The dataset consists of five types of Japanese and four types of English tasks, with few-shot settings for question answering (QA), reading comprehension (RC), automatic summarization (AS), arithmetic reasoning (AR), commonsense reasoning (CR) and machine translation (MT). For details, see Appendix G. The selection of tasks was based on discussions in LLM-jp (Han et al., 2024) and the methodology of the paper (Touvron et al., 2023), with an active adoption of tasks related to inference and text generation. The natural language inference task in llm-jp-eval was excluded from evaluation due to unstable scores in the 7b and 13b models (see Appendix F).
| Benchmark | llm-jp-eval (Han et al., 2024) (v1.0.0) | JP LM Evaluation Harness666https://github.com/Stability-AI/lm-evaluation-harness (commit #9b42d41) | ||||||
| Eval. task | Question Answering | RC | AS | AR | Machine Translation | |||
| Dataset | JCQA | JEMHQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT’20En-Ja | WMT’20Ja-En |
| Instances | 1,119 | 120 | 198 | 4,442 | 766 | 250 | 1,000 | 993 |
| Few-shots | 4 | 4 | 4 | 4 | 1 | 4 | 4 | 4 |
| Eval. metric | EM acc. | Char-F1 | Char-F1 | Char-F1 | ROUGE-2 | EM acc. | BLEU | |
| Benchmark | LM Evaluation Harness (Gao et al., 2022) (v0.3.0) | |||||
| Eval. task | QA | RC | CR | AR | ||
| Dataset | OBQA | TrQA | SQuAD2 | HS | XW | GSM8K |
| Instances | 500 | 17,944 | 11,873 | 10,042 | 2,325 | 1,319 |
| Few-shots | 8 | 8 | 8 | 8 | 8 | 8 |
| Eval. metric | acc. | EM acc. | EM acc. | acc. | acc. | EM acc. |
4 Results
4.1 Effects of continual pre-training
| Evaluation in Japanese | |||||||||
| Model | JCQA | JEMHQA | NIILC | JSQuAD | XL-Sum | MGSM | En-Ja | Ja-En | Avg |
| Llama 2-7b | 38.5 | 42.4 | 34.1 | 79.2 | 19.1 | 7.6 | 17.8 | 17.4 | 32.0 |
| Swallow-7b | 48.1 | 50.8 | 59.7 | 85.7 | 18.3 | 12.4 | 25.1 | 15.1 | 39.4 |
| Llama 2-13b | 70.0 | 44.2 | 41.7 | 85.3 | 21.4 | 13.2 | 21.5 | 19.8 | 39.6 |
| Swallow-13b | 78.4 | 50.6 | 64.0 | 90.1 | 21.7 | 20.4 | 27.2 | 17.7 | 46.3 |
| Llama 2-70b | 86.9 | 46.6 | 52.6 | 90.8 | 23.6 | 35.6 | 26.4 | 24.0 | 48.3 |
| Swallow-70b | 93.5 | 62.9 | 69.6 | 91.8 | 22.7 | 48.4 | 30.4 | 23.0 | 55.3 |
| Evaluation in English | |||||||
| Model | OBQA | TrQA | HS | SQuAD2 | XW | GSM8K | Avg |
| Llama 2-7b | 35.8 | 62.7 | 58.6 | 32.1 | 90.5 | 14.1 | 49.0 |
| Swallow-7b | 31.8 | 48.4 | 53.1 | 31.3 | 88.2 | 11.3 | 44.0 |
| Llama 2-13b | 37.6 | 72.6 | 61.5 | 36.8 | 91.4 | 24.0 | 54.0 |
| Swallow-13b | 35.0 | 58.5 | 56.6 | 34.1 | 90.8 | 20.4 | 49.2 |
| Llama 2-70b | 42.8 | 82.4 | 67.4 | 37.7 | 92.9 | 52.8 | 62.7 |
| Swallow-70b | 42.2 | 77.6 | 64.6 | 37.5 | 92.0 | 48.7 | 60.4 |
Table 4 shows the evaluation results of Swallow and its base model on Japanese and English tasks. Figure 1 displays the increase or decrease rate of Swallow ’s scores compared to . The average score of Swallow on Japanese tasks surpasses by approximately 7 points. On the other hand, the English scores are 2–5 points lower, but the performance drop tends to be smaller as the model size increases. When looking at individual tasks777We assess performance changes on a relative scale, considering the differences in task score levels., Japanese question answering (JCQA, JEMHQA, NIILC) shows a significant improvement of up to 75%, and arithmetic reasoning (MGSM) improves by 36–63%. In contrast, English question answering (TrQA) and arithmetic reasoning (GSM8K) degrade by 6–23%. The change in automatic summarization (XL-Sum) is less than 5%. Machine translation shows contrasting results depending on the direction, with a 15–41% improvement in English-to-Japanese (En-Ja) and a 4–13% degradation in Japanese-to-English (Ja-En). Japanese reading comprehension (JSQuAD) has limited room for improvement as ’s score is above 0.8, resulting in less than 10% improvement.
We analyze the impact of continual pre-training on Japanese abilities and knowledge. In the case of arithmetic reasoning (Ja: MGSM, En: GSM8K), while shows superiority in English (GSM8K MGSM), Swallow improves MGSM, but GSM8K degrades to a similar level, suggesting that the reasoning ability in English has not been fully transferred to Japanese. Considering the reports of reasoning ability transfer in instruction tuning (Ye et al., 2023), combining instruction datasets could be a promising strategy to bring Japanese arithmetic reasoning to the same level observed in English.

Regarding knowledge, the significant improvement in question answering suggests that the acquisition of Japanese knowledge has progressed. Figure 3 illustrates the impact of continual pre-training on the scoring of each question in the NIILC QA dataset. The dense color in the upper left corner indicates that many questions have shifted from incorrect to correct answers, while the opposite is uncommon. This trend suggests that continual pre-training successfully incorporated new knowledge and corrected inaccurate responses.
4.2 Comparison with full-scratch models
| Evaluation in Japanese | |||||||||
| Model | JCQA | JEMHQA | NIILC | JSQuAD | XL-Sum | MGSM | En-Ja | Ja-En | Avg |
| calm2-7b | 22.0 | 50.5 | 50.7 | 78.0 | 2.3 | 6.0 | 23.5 | 15.0 | 31.0 |
| Swallow -7b | 48.1 | 50.8 | 59.7 | 85.7 | 18.3 | 12.4 | 25.1 | 15.1 | 39.4 |
| llm-jp-13b-v1.0 | 22.6 | 47.9 | 38.6 | 77.4 | 10.8 | 2.4 | 19.6 | 11.9 | 28.9 |
| PLaMo-13b | 22.7 | 51.9 | 41.4 | 76.2 | 10.3 | 3.6 | 15.8 | 12.0 | 29.2 |
| Swallow -13b | 78.4 | 50.6 | 64.0 | 90.1 | 21.7 | 20.4 | 27.2 | 17.7 | 46.3 |
Table 5 shows the evaluation results of the Swallow and major Japanese LLMs trained from scratch (see Table 10 in the appendix for model references). Note that these models are all general-purpose language models without instruction tuning. Compared to the LLMs trained from scratch in Japan (calm-7b, llm-jp-13b-v1.0, PLaMo-13b) (see Appendix H.1 for details of each model), the average score of Swallow is 8.4 to 17.4 points higher, demonstrating the usefulness of continual pre-training.
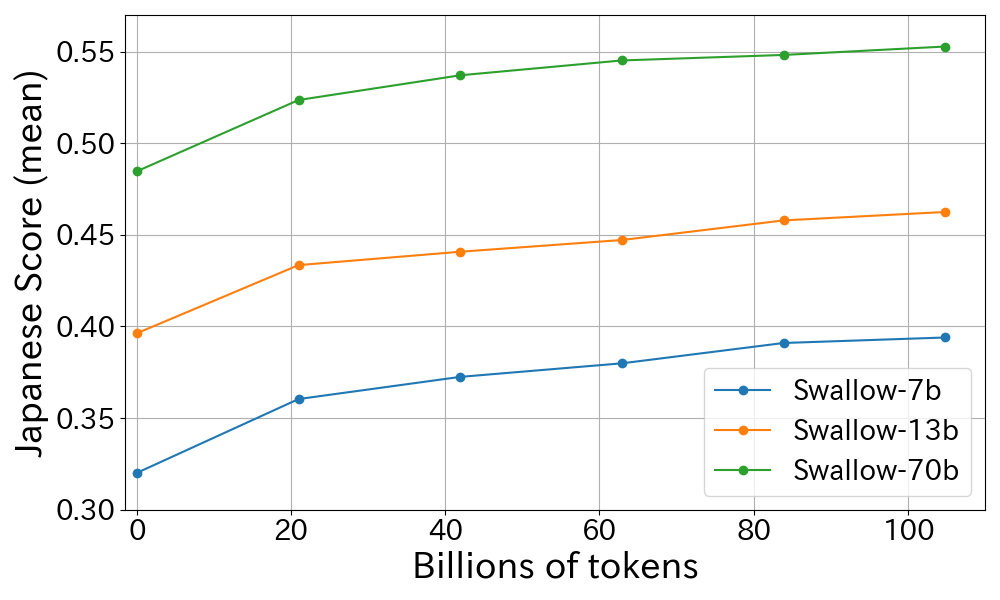
4.3 Scalability to training tokens
Figure 3 depicts the relationship between the volume of training data (number of tokens) used for continual pre-training and the average performance score on the Japanese benchmark. We evaluated the performance of Swallow 7b, 13b, and 70b at each interval of approximately 20B tokens of the training data. The figure reveals a monotonic upward trend in average scores in correlation with the augmentation of Japanese training data for continual pre-training. Notably, the largest performance increase occurs in the initial training stage with 20B tokens, with subsequent gains diminishing. However, performance consistently improves as the amount of training data increases, suggesting that the performance improvement has not saturated even with approximately 100B tokens of continual pre-training.
5 Analysis
5.1 Vocabulary expansion
5.1.1 Experimental setup and motivation for vocabulary expansion
To investigate the impact of vocabulary expansion (VE) — specifically, the addition of Japanese words and characters — we compare models pre-trained with and without VE. The model pre-trained without VE is denoted as hereafter. Incorporating VE can shorten token sequences, thereby enhancing the efficiency of both training and generating Japanese text. However, the impact of vocabulary expansion on performance is unclear. Intuitively, if the added vocabulary is poorly optimized, it may degrade performance. Yet, studies on domain adaptation scenarios report that VE enhances performance (Sachidananda et al., 2021; Yao et al., 2021). Additionally, being able to train with more text within the same computational budgets could positively influence performance.
5.1.2 Impact of vocabulary expansion




Figure 5 shows the performance of Swallow relative to Swallow, where the vocabulary expansion was not applied to the latter. Regarding Japanese language capabilities, the overall impact of vocabulary expansion on performance is minor. When examining specific tasks, we observe the performance change in question answering approximately 10%, yet there is no consistent trend of either improvement or degradation across different model sizes. Therefore, the increase in the amount of training text brought from the vocabulary expansion does not directly affect performance. There was also no significant difference in convergence characteristics in the performance curve. Automatic summarization (XL-Sum) degraded by about 5–15% with vocabulary expansion for all model sizes888This trend remained unchanged after instruction tuning, so it does not seem to be a problem with instruction following ability.. This suggests that the impact of vocabulary expansion may be more apparent in tasks that involve processing longer contexts.
5.2 Parallel corpus
5.2.1 Experimental setup for parallel corpus
In the experiments to investigate the effectiveness of parallel corpora, we use Swallow as the baseline to separate the impact of vocabulary expansion, and examine the performance when incorporating parallel corpora in the continual pre-training. We used JParaCrawl 3.0 (Morishita et al., 2022) corpus, which contains approximately 22 million Japanese-English parallel sentences extracted from the web.
We investigate three different settings to utilize a parallel corpus, as shown in Table 8 and further explained in Appendix E.2. These methods vary by training sequence and task format. The training sequence can be “two-staged”, where the parallel corpus is used first and followed by the multilingual corpus, or ”mixed”, where it is combined with the multilingual corpora from the start. For task formats, we have “next token prediction” (NTP), which involves concatenating parallel sentences, and “translation instruction” (TI), where the target sentence is predicted based on the source sentence and a translation instruction. Both formats are applied in two directions, JaEn and EnJa, for each pair of parallel sentences.
5.2.2 Effectiveness of parallel corpus
Figure 5 shows the rate of increase or decrease in scores when using a parallel corpus in conjunction with continual pre-training, with Swallow without vocabulary expansion as the baseline. Translation performance improved by 9–24% for En-Ja and 14–51% for Ja-En. The improvement in Ja-En is particular to the parallel corpus. Regarding the usage of the corpus, we found that the next token prediction format with a “mixed” setting or the translation instruction format in a “two-staged” setting was effective. In other words, we proved that simply mixing parallel sentences into the multilingual corpus and conducting continual pre-training can effectively improve translation performance. This finding is consistent with the claim that the translation capabilities of LLMs stem from parallel sentences incidentally present in plain text corpora (Briakou et al., 2023).
The relative change in scores for tasks other than translation was within 15%, without showing consistent improvement or decline across different model sizes. Therefore, no evidence was obtained that the parallel corpus promotes cross-lingual transfer and improves abilities other than translation.
6 Conclusions
In this study, we developed Swallow, leveraging Llama 2 models for enhanced Japanese language performance through continual pre-training on Japanese datasets, and analyzed their performance to address the lack of comprehensiveness in model size, training data size, and evaluation methods in previous studies. Through our evaluation, we found that continual pre-training significantly boosts Japanese abilities, particularly in knowledge-intensive question answering task. Consequently, we demonstrated that continual pre-training is an efficient approach for achieving high performance, as the continual pre-trained models outperform Japanese LLMs that are trained from scratch. We also observed that performance improves in line with increases in training data. Furthermore, in our quest for a more efficient methodology, we investigated how expanding the vocabulary and incorporating parallel corpora into continual pre-training affect performance. We revealed that while the vocabulary expansion improves computational efficiency, it has little impact on performance except for summarization. Additionally, we found that simply integrating parallel sentences into plain text corpora improves translation performance, particularly for Japanese-English, but it does not hurt the performance of other tasks. The experimental results and analyses in this study provide important insights into the effectiveness of continual pre-training, the impact of vocabulary expansion, and the effects of using parallel corpora in the development of LLMs for non-English languages.
7 Ethical considerations
Swallow is subject to the same well-recognized limitations of other LLMs, including the inability to update information after the pretraining phase, the potential for non-factual generation such as unqualified advice, and a propensity towards hallucinations.
Similar to other large language models, Swallow may produce content that is harmful, offensive, or biased due to being trained on datasets derived from publicly available online sources. We commit to ongoing fine-tuning and plan to release updated versions of Swallow as we make further advancements in resolving these issues.
8 Reproducibility statement
Acknowledgments
This work was supported by the ABCI Large-scale Language Model Building Support Program of the AI Bridging Cloud Infrastructure (ABCI), built and operated by the National Institute of Advanced Industrial Science and Technology (AIST). We would like to thank Mr. Takuya Akiba of Sakana AI for providing valuable advice on training. We also received advice on vocabulary expansion methods from Mr. Tatsuya Hiraoka of Fujitsu Ltd.
In the evaluation experiments of the trained LLMs, we utilized data and insights developed and made publicly available by LLM-jp. This research was supported by JST, CREST, JPMJCR2112.
References
- Ahia et al. (2023) Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David Mortensen, Noah Smith, and Yulia Tsvetkov. Do all languages cost the same? Tokenization in the era of commercial language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9904–9923, 2023. URL https://aclanthology.org/2023.emnlp-main.614.
- Ahuja et al. (2023) Kabir Ahuja, Harshita Diddee, Rishav Hada, Millicent Ochieng, Krithika Ramesh, Prachi Jain, Akshay Nambi, Tanuja Ganu, Sameer Segal, Mohamed Ahmed, Kalika Bali, and Sunayana Sitaram. MEGA: Multilingual evaluation of generative AI. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4232–4267, 2023. URL https://aclanthology.org/2023.emnlp-main.258.
- Azerbayev et al. (2024) Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen Marcus McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics. In the Twelfth International Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/forum?id=4WnqRR915j.
- Barrault et al. (2020) Loïc Barrault, Magdalena Biesialska, Ondřej Bojar, Marta R. Costa-jussà, Christian Federmann, Yvette Graham, Roman Grundkiewicz, Barry Haddow, Matthias Huck, Eric Joanis, Tom Kocmi, Philipp Koehn, Chi-kiu Lo, Nikola Ljubešić, Christof Monz, Makoto Morishita, Masaaki Nagata, Toshiaki Nakazawa, Santanu Pal, Matt Post, and Marcos Zampieri. Findings of the 2020 conference on machine translation (WMT20). In Proceedings of WMT, pp. 1–55, 2020. URL https://aclanthology.org/2020.wmt-1.1.
- Beltagy et al. (2019) Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3615–3620, 2019. URL https://aclanthology.org/D19-1371.
- Briakou et al. (2023) Eleftheria Briakou, Colin Cherry, and George Foster. Searching for needles in a haystack: On the role of incidental bilingualism in PaLM’s translation capability. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), pp. 9432–9452, 2023. URL https://aclanthology.org/2023.acl-long.524.
- Chaudhry et al. (2019) Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K. Dokania, Philip H. S. Torr, and Marc’Aurelio Ranzato. On tiny episodic memories in continual learning. arXiv:1902.10486, 2019.
- Chi et al. (2022) Zewen Chi, Shaohan Huang, Li Dong, Shuming Ma, Bo Zheng, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, Heyan Huang, and Furu Wei. XLM-E: Cross-lingual language model pre-training via ELECTRA. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6170–6182, 2022. URL https://aclanthology.org/2022.acl-long.427.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv:2110.14168, 2021.
- Cui et al. (2023) Yiming Cui, Ziqing Yang, and Xin Yao. Efficient and effective text encoding for Chinese LLaMA and Alpaca. arXiv:2304.08177, 2023.
- Dao (2023) Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. arXiv:2307.08691, 2023.
- Feng et al. (2022) Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. Language-agnostic BERT sentence embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 878–891, 2022. URL https://aclanthology.org/2022.acl-long.62.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile: an 800GB dataset of diverse text for language modeling. arXiv:2101.00027, 2020.
- Gao et al. (2022) Leo Gao, Jonathan Tow, Stella Biderman, Charles Lovering, Jason Phang, Anish Thite, Fazz, Niklas Muennighoff, Thomas Wang, sdtblck, tttyuntian, researcher2, Zdeněk Kasner, Khalid Almubarak, Jeffrey Hsu, Pawan Sasanka Ammanamanchi, Dirk Groeneveld, Eric Tang, Charles Foster, kkawamu1, xagi dev, uyhcire, Andy Zou, Ben Wang, Jordan Clive, igor0, Kevin Wang, Nicholas Kross, Fabrizio Milo, and silentv0x. EleutherAI/lm-evaluation-harness: v0.3.0, 2022. URL https://doi.org/10.5281/zenodo.7413426.
- Gupta et al. (2023) Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats Leon Richter, Quentin Gregory Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort. Continual pre-training of large language models: How to re-warm your model? In Workshop on Efficient Systems for Foundation Models @ ICML2023, 2023. URL https://openreview.net/forum?id=pg7PUJe0Tl.
- Han et al. (2024) Namgi Han, Nobuhiro Ueda, Masatoshi Otake, Satoru Katsumata, Keisuke Kamata, Hirokazu Kiyomaru, Takashi Kodama, Saku Sugawara, Bowen Chen, Hiroshi Matsuda, Yusuke Miyao, Yugo Miyawaki, and Koki Ryu. llm-jp-eval: Automatic evaluation tool for Japanese large language models [llm-jp-eval: 日 本語大規模言語モデルの自動評価ツール] (in Japanese). In the 30th Annual Meeting of Japanese Association for Natural Language Processing (NLP2024), 2024. URL https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/A8-2.pdf.
- Hasan et al. (2021) Tahmid Hasan, Abhik Bhattacharjee, Md. Saiful Islam, Kazi Mubasshir, Yuan-Fang Li, …, and Rifat Shahriyar. XL-sum: Large-scale multilingual abstractive summarization for 44 languages. In Findings of the Association for Computational Linguistics (ACL), pp. 4693–4703, 2021. URL https://aclanthology.org/2021.findings-acl.413.
- Hu et al. (2020) Junjie Hu, Sebastian Ruder, Aditya Siddhant, Graham Neubig, Orhan Firat, and Melvin Johnson. XTREME: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation. In Proceedings of the 37th International Conference on Machine Learning, pp. 4411–4421, 2020. URL https://proceedings.mlr.press/v119/hu20b.html.
- Huang et al. (2019) Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and zhifeng Chen. GPipe: Efficient training of giant neural networks using pipeline parallelism. In Advances in Neural Information Processing Systems, volume 32, 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf.
- Ishii et al. (2023) Ai Ishii, Naoya Inoue, and Satoshi Sekine. Construction of a Japanese multi-hop QA dataset for QA systems capable of explaining the rationale [根拠を説明可能な質問応答システムのための日本語マルチホップqaデータセット構築] (in Japanese). In the 29th Annual Meeting of Japanese Association for Natural Language Processing (NLP2023), pp. 2088–2093, 2023. URL https://www.anlp.jp/proceedings/annual_meeting/2023/pdf_dir/Q8-14.pdf.
- Jin et al. (2022) Xisen Jin, Dejiao Zhang, Henghui Zhu, Wei Xiao, Shang-Wen Li, Xiaokai Wei, Andrew Arnold, and Xiang Ren. Lifelong pretraining: Continually adapting language models to emerging corpora. In Proceedings of BigScience Episode #5 – Workshop on Challenges & Perspectives in Creating Large Language Models, pp. 1–16, 2022.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 1601–1611, 2017. URL https://aclanthology.org/P17-1147.
- Kawazoe et al. (2015) Ai Kawazoe, Ribeka Tanaka, Koji Mineshima, and Daisuke Bekki. An inference problem set for evaluating semantic theories and semantic processing systems for Japanese [日本語意味論テストセットの構築] (in Japanese). In the 21st Annual Meeting of Japanese Association for Natural Language Processing (NLP2015), pp. 704–707, 2015. URL https://www.anlp.jp/proceedings/annual_meeting/2015/pdf_dir/E4-1.pdf.
- Korthikanti et al. (2023) Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large Transformer models. Proceedings of the 6th Machine Learning and Systems Conference, 2023.
- Kudo & Richardson (2018) Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 66–71, 2018. URL https://aclanthology.org/D18-2012.
- Kurihara et al. (2022) Kentaro Kurihara, Daisuke Kawahara, and Tomohide Shibata. JGLUE: Japanese general language understanding evaluation. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pp. 2957–2966, 2022. URL https://aclanthology.org/2022.lrec-1.317.
- Lee et al. (2019) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, 2019. URL https://doi.org/10.1093/bioinformatics/btz682.
- Loshchilov & Hutter (2019) Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? A new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2381–2391, 2018. URL https://aclanthology.org/D18-1260.
- Morishita et al. (2022) Makoto Morishita, Katsuki Chousa, Jun Suzuki, and Masaaki Nagata. JParaCrawl v3.0: A large-scale English-Japanese parallel corpus. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pp. 6704–6710, 2022. URL https://aclanthology.org/2022.lrec-1.721.
- Narayanan et al. (2021) Deepak Narayanan, Amar Phanishayee, Kaiyu Shi, Xie Chen, and Matei Zaharia. Memory-efficient pipeline-parallel DNN training. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 7937–7947, 2021. URL https://proceedings.mlr.press/v139/narayanan21a.html.
- OpenAI et al. (2023) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. GPT-4 technical report, 2023.
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The RefinedWeb dataset for Falcon LLM: Outperforming curated corpora with web data, and web data only. arXiv:2306.01116, 2023.
- Pires et al. (2023) Ramon Pires, Hugo Abonizio, Thales Sales Almeida, and Rodrigo Nogueira. Sabiá: Portuguese large language models. arXiv:2304.07880, 2023.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, 2016. URL https://aclanthology.org/D16-1264.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 784–789, 2018. URL https://aclanthology.org/P18-2124/.
- Ranaldi et al. (2023) Leonardo Ranaldi, Giulia Pucci, and Andre Freitas. Empowering Cross-lingual Abilities of Instruction-tuned Large Language Models by Translation-following demonstrations. arXiv:2308.14186, 2023.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. Code Llama: Open foundation models for code. arXiv:2308.12950, 2023.
- Sachidananda et al. (2021) Vin Sachidananda, Jason Kessler, and Yi-An Lai. Efficient domain adaptation of language models via adaptive tokenization. In Proceedings of the Second Workshop on Simple and Efficient Natural Language Processing, pp. 155–165, 2021. URL https://aclanthology.org/2021.sustainlp-1.16.
- Scialom et al. (2022) Thomas Scialom, Tuhin Chakrabarty, and Smaranda Muresan. Fine-tuned language models are continual learners. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 6107–6122, 2022. URL https://aclanthology.org/2022.emnlp-main.410.
- Sekine (2003) Satoshi Sekine. Development of a question answering system focused on an encyclopedia [百科事典を対象とした質問応答システムの開発] (in Japanese). In the 9th Annual Meeting of Japanese Association for Natural Language Processing (NLP2003), pp. 637–640, 2003. URL https://www.anlp.jp/proceedings/annual_meeting/2003/pdf_dir/C7-6.pdf.
- Shi et al. (2023) Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. Language models are multilingual chain-of-thought reasoners. In the Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=fR3wGCk-IXp.
- Sugimoto et al. (2023) Tomoki Sugimoto, Yasumasa Onoe, and Hitomi Yanaka. Jamp: Controlled Japanese temporal inference dataset for evaluating generalization capacity of language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), pp. 57–68, 2023. URL https://aclanthology.org/2023.acl-srw.8.
- Sung et al. (2019) Chul Sung, Tejas Dhamecha, Swarnadeep Saha, Tengfei Ma, Vinay Reddy, and Rishi Arora. Pre-training BERT on domain resources for short answer grading. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 6071–6075, 2019. URL https://aclanthology.org/D19-1628.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158, 2019. URL https://aclanthology.org/N19-1421.
- Tikhonov & Ryabinin (2021) Alexey Tikhonov and Max Ryabinin. It’s all in the heads: Using attention heads as a baseline for cross-lingual transfer in commonsense reasoning. In Findings of the Association for Computational Linguistics (ACL), pp. 3534–3546, 2021. URL https://doi.org/10.18653/v1/2021.findings-acl.310.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023.
- Yanaka & Mineshima (2021) Hitomi Yanaka and Koji Mineshima. Assessing the generalization capacity of pre-trained language models through Japanese adversarial natural language inference. In Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pp. 337–349, 2021. URL https://aclanthology.org/2021.blackboxnlp-1.26.
- Yanaka & Mineshima (2022) Hitomi Yanaka and Koji Mineshima. Compositional evaluation on Japanese textual entailment and similarity. Transactions of the Association for Computational Linguistics, 10:1266–1284, 2022. URL https://aclanthology.org/2022.tacl-1.73.
- Yao et al. (2021) Yunzhi Yao, Shaohan Huang, Wenhui Wang, Li Dong, and Furu Wei. Adapt-and-distill: Developing small, fast and effective pretrained language models for domains. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 460–470, 2021. URL https://aclanthology.org/2021.findings-acl.40.
- Ye et al. (2023) Jiacheng Ye, Xijia Tao, and Lingpeng Kong. Language versatilists vs. specialists: An empirical revisiting on multilingual transfer ability. arXiv:2306.06688, 2023.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4791–4800, 2019. URL https://aclanthology.org/P19-1472.
- Zhao et al. (2024) Jun Zhao, Zhihao Zhang, Luhui Gao, Qi Zhang, Tao Gui, and Xuanjing Huang. Llama beyond English: An empirical study on language capability transfer. arXiv:2401.01055, 2024.
- Zhu et al. (2023) Wenhao Zhu, Yunzhe Lv, Qingxiu Dong, Fei Yuan, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. Extrapolating large language models to non-english by aligning languages. arXiv:2308.04948, 2023.
Appendix A Swalllow Corpus
Swallow Corpus was constructed by extracting and refining Japanese text from the Common Crawl archives, which consist of 21 snapshots collected between 2020 and 2023, comprising approximately 63.4 billion pages. The resulting corpus contains about 312.1 billion characters (approximately 173 million pages).
Appendix B Ratio of training data
The ratio of mixing Japanese and English texts was determined through preliminary experiments. We tested two experimental settings with a JA:EN ratio of 5:5 and 9:1, and compared the average performance on Japanese tasks after training on approximately 20B tokens. In the preliminary experiments, the 9:1 setting slightly outperformed the 5:5 setting in terms of the average score on Japanese tasks, hence we adopted the 9:1 JA:EN ratio. While the goal was to construct a powerful LLM specialized for the target language, transferring knowledge from English was also one of the objectives. It has been shown that including 1% of the pre-trained data in training can prevent catastrophic forgetting (Scialom et al., 2022), but due to the unavailability of Llama 2’s training data and budgetary constraints, the preliminary experiments were conducted only with the 5:5 and 9:1 ratios.
Appendix C Training loss curves

Appendix D Distributed parallel training of models
Training large language models on a single GPU is challenging due to both GPU memory constraints and the time required for training. In terms of GPU memory, even using the latest H100 80GB, it is difficult to train the 7B model used in this study. Moreover, even if the model parameters, gradients, and optimizer states could fit on a single GPU, training on a single GPU would require an unrealistic amount of time to complete. Therefore, in this study, we adopted distributed parallel training, combining data parallelism and model parallelism.
D.1 Training environment
We utilized the AI Bridging Cloud Infrastructure (ABCI) of the National Institute of Advanced Industrial Science and Technology, Japan for training. We employed mixed precision (bfloat16) and used multiple NVIDIA A100 nodes for distributed parallel training. Each node is equipped with eight NVIDIA A100 40GB GPUs, and the nodes are interconnected via InfiniBand HDR.
D.2 Distributed training
| Number of Parameters | DP | TP | PP | SP | Distributed Optimizer |
| 7B | 16 | 2 | 2 | ✓ | ✓ |
| 13B | 8 | 2 | 4 | ✓ | ✓ |
| 70B | 4 | 8 | 8 | ✓ | ✓ |
To efficiently perform the training process, we adopted 3D parallelism, which integrates data parallelism, tensor parallelism, and pipeline parallelism, aiming for high computational efficiency and efficient memory utilization. We used the Megatron-LM999https://github.com/NVIDIA/Megatron-LM library for training. Table 6 shows the distributed training settings for each model size. In addition, we incorporated the following techniques:
- Efficient Memory Consumption
-
By using the Distributed Optimizer in Megatron-LM, we distributed the optimizer states across data-parallel processes and eliminated redundancy, reducing the required memory usage. The Distributed Optimizer efficiently communicates using Reduce Scatter and All Gather, enabling memory reduction with the same communication cost as regular data parallelism.
- Topology-aware 3D Mapping
-
In 3D parallelism, Transformer blocks are distributed across multiple GPUs using pipeline parallelism, and the parameters within each layer are distributed using tensor parallelism. As proposed in Megatron-LM (Narayanan et al., 2021), we placed the workers requiring more communication (tensor parallel workers) within the same node. This is because intra-node communication using NVLink is faster than inter-node communication. Additionally, considering the communication for gradient averaging in data parallelism, we placed data-parallel workers within the same node as much as possible. Pipeline parallelism requires less communication compared to other parallelization methods, using P2P (Point-to-Point) communication. Therefore, we placed pipeline stages across nodes.
- Adoption of 1F1B for Memory Efficiency
-
By using PipeDream-Flush (Narayanan et al., 2021), a 1F1B (one forward pass followed by one backward pass) pipeline parallelism, we ensured that only a number of micro-batches less than or equal to the number of pipeline stages require activation, improving memory efficiency compared to GPipe (Huang et al., 2019).
- Parallelization using Sequence Parallelism
-
Tensor parallelism parallelizes Self-Attention and MLP blocks, but not Layer-Norms and Dropouts, resulting in redundant memory usage of these components across tensor-parallel processes. To improve efficiency, we utilized Sequence Parallelism (Korthikanti et al., 2023). By using Sequence Parallelism in conjunction with tensor parallelism, memory efficiency can be achieved without the overhead of communication costs.
D.3 Computational efficiency
Table 7 shows the computational performance in TFLOPS per GPU during the actual training process.
In terms of execution efficiency, the 70B model achieved over 50%, indicating that the training was conducted efficiently101010The theoretical values (312 TFLOPS) are extracted from the specifications of the NVIDIA A100 BFLOAT16 Tensor Core (without sparsity):
https://www.nvidia.com/en-us/data-center/a100/..
| # Params | # Nodes | TFLOPS/GPU | Execution efficiency |
| 7B | 4 | 134 | 43.0 % |
| 13B | 8 | 143 | 45.8 % |
| 70B | 32 | 158 | 50.6 % |
D.4 Computation required for training
The training of Swallow 7b, 13b, and 70b required approximately FLOPS, FLOPS, FLOPS of computation, respectively. 111111The calculation of FLOPs is based on the formula presented in APPENDIX: FLOATING-POINT OPERATIONS of (Narayanan et al., 2021), with modifications made to adapt to the Llama architecture.
Appendix E Details of experimental setup
E.1 Vocabulary expansion method
The Japanese vocabulary was constructed using a randomly sampled subset (1.5B tokens) of the word-segmented Swallow Corpus. However, to treat symbols as independent subwords, words containing symbols were split at both ends of the symbols. Following , we used the BPE algorithm implemented in SentencePiece (Kudo & Richardson, 2018). The vocabulary size was set to 16k, the smallest among the three sizes (16k, 32k, 48k) tested in preliminary experiments, as there was no performance difference in Japanese tasks. Two post-processing steps were applied to the subword vocabulary constructed by SentencePiece. Firstly, the whitespace escape characters added by SentencePiece were removed. This is because, unlike during the vocabulary construction phase, word segmentation using MeCab is not performed in tokenization during training and inference. Secondly, the size of the additional vocabulary was intentionally adjusted to be a multiple of 8. This is a measure to facilitate distributed parallel training of the model.
The scores of the added subwords were used as-is from the BPE results output by SentencePiece. This decision was made based on the judgment that conflicts between the merge rules of the original vocabulary and the added vocabulary are extremely rare. In fact, the original vocabulary of the tokenizer does not contain Japanese subwords of two or more characters.
E.2 Usage of parallel corpora
The following templates show how Japanese-English parallel sentences are converted into next token prediction format (top) and translation instruction format (bottom). Note that for the translation instruction format, only the target language sentence is the target for training (next token prediction).
[Japanese sentence] [English sentence] [English sentence] [Japanese sentence]
Please translate the following Japanese text into English. [Japanese sentence] [English sentence] Please translate the following English text into Japanese. [English sentence] [Japanese sentence]
The intention behind the “two-staged” setting, which switches to the plain text corpus after exhausting the parallel corpus was based on the assumption that parallel sentences could facilitate the switch from English-centric to Japanese-centric training. Note that the we didn’t experiment with the translation instruction format with the “mixed” setting due to the constraints of the LLM training library.
| Task format | Training seq. | Number of training tokens [] |
| Next Token Prediction | Two-staged | 5.6 |
| Next Token Prediction | Mixed | 5.6 |
| Translation Instruction | Two-staged | 2.8 |
Appendix F Issues in evaluating natural language inference tasks



For the natural language inference datasets included in llm-jp-eval, more specifically, Jamp (Sugimoto et al., 2023), JaNLI (Yanaka & Mineshima, 2021), JNLI (Kurihara et al., 2022), JSeM (Kawazoe et al., 2015), and JSICK (Yanaka & Mineshima, 2022), we confirmed score fluctuations due to the class imbalance in multiple models. First, Figure 9 shows the class distributions of both the ground truth and the predictions made by Swallow-7b. Both the ground truth and predictions are greatly imbalanced, with the most frequent class accounting for over 95% of all predictions in three datasets. As a result, scores significantly fluctuate depending on whether the most frequent classes in predictions and ground truth align by chance. Figure 10 shows the learning curve of Swallow-7b on these datasets. While fluctuations of about 40 points occurred in two datasets, this was due to transitions in the most frequent class of predictions. The imbalance in prediction was not unique to Swallow but was also observed in other 7b and 13b models (Figure 11). From these observations, we concluded that it is misleading to discuss natural language inference abilities based solely on scores, leading to the exclusion from our evaluation. For a fair and stable evaluation of this task, addressing the imbalance in ground truth classes is recommended.
Appendix G Evaluation methods for Japanese and English
The Japanese benchmarks include llm-jp-eval (Han et al., 2024) for a comprehensive evaluation of language models in Japanese, and the JP Language Model Evaluation Harness, which is designed for a more focused assessment of language model capabilities. The datasets cover a range of tasks including multiple-choice and open-ended question answering (JCQA (Kurihara et al., 2022), JEMHQA (Ishii et al., 2023), NIILC (Sekine, 2003)), machine reading comprehension (JSQuAD (Kurihara et al., 2022)), automatic summarization (XL-Sum (Hasan et al., 2021)), arithmetic reasoning (MGSM (Shi et al., 2023)), and machine translation (WMT’20 En-Ja and Ja-En (Barrault et al., 2020)). Below, we describe six notable task datasets included in these benchmarks.
JCQA
JCommonsenseQA (JCQA) is a Japanese question-answering dataset in a five-choice format that assesses common sense knowledge. It is the Japanese version of CommonsenseQA (Talmor et al., 2019), which was created to evaluate common sense reasoning ability, and consists of pairs of question sentence and answer choices. The knowledge covered by JCQA has a good balance of Japanese linguistic knowledge and common sense knowledge. Moreover, since the incorrect answers are generated by language models, the dataset contains questions that cannot be solved just by avoiding semantically unrelated choices.
JEMHQA
JEMHopQA (JEMHQA) is a Japanese open-ended question answering dataset that was originally designed as a multi-hop QA task. In our task setting, the dataset is used to evaluate a model’s ability to generate answers directly from the given questions. The questions in JEMHQA are created using information from the Japanese version of Wikipedia, ensuring a diverse range of topics and entities. JEMHQA serves as an important benchmark for evaluating the extent of knowledge and ability to answer questions through reasoning with that knowledge.
JSQuAD
JSQuAD is a Japanese machine reading comprehension dataset, which is the Japanese version of SQuAD (Rajpurkar et al., 2016). It focuses on question-answering style, which involves reading a document and a question, and then extracting a segment of text in the document as the answer. JSQuAD utilizes article paragraphs from the Japanese version of Wikipedia as its source documents.
NIILC
NIILC is a dataset created for the purpose of developing question-answering systems in Japanese, featuring relatively straightforward questions that can be answered by referencing an encyclopedia. This makes it valuable for evaluating the encyclopedic knowledge of LLMs. We use only the question and answer pairs from the dataset, although the original dataset includes additional metadata like question types and evidence sentences.
XL-Sum
XL-Sum Japanese version is a dataset created by extracting the Japanese portion from XL-Sum, a large-scale summarization dataset collected from BBC News articles, and further filtering it into a subset suitable for abstractive summarization. The dataset was filtered by calculating the 15-gram overlap rate between articles and summaries, selecting pairs with low overlap rates. Consequently, this dataset necessitates the ability to paraphrase and abstract information, rather than simply extracting sentences.
MGSM
MGSM is a dataset created by selecting 250 elementary school arithmetic word problems from GSM8K (Cobbe et al., 2021) and manually translating them. As it deals with Japanese arithmetic word problems, it requires both Japanese linguistic knowledge and mathematical reasoning ability.
Appendix H Comparison of models trained from scratch and other continual pre-training models
Table 9 shows the evaluation results of pre-trained models and continual pre-training models, with the majority developed in Japan (see Table 10 in the appendix for the sources of the models). Some LLMs trained from scratch outside of Japan (Mistral v0.1, Qwen-7B, Qwen-14B) show higher Japanese performance than Llama 2. The models that are continually pre-trained from these LLMs (japanese-stablelm-base-gamma-7b, nekomata-7b, nekomata-14b) show higher average scores than Swallow, suggesting that the performance differences in the base models are reflected.
| Model | Japanese evaluation dataset | ||||||||
| JCQA | JEMHQA | NIILC | JSQuAD | XL-Sum | MGSM | En-Ja | Ja-En | Avg | |
| calm2-7b | 22.0 | 50.5 | 50.7 | 78.0 | 2.3 | 6.0 | 23.5 | 15.0 | 31.0 |
| J Stable LM 7b | 36.1 | 44.8 | 44.3 | 83.2 | 22.0 | 7.2 | 19.5 | 12.3 | 33.7 |
| ELYZA-7b | 57.9 | 47.0 | 40.2 | 82.3 | 13.1 | 6.0 | 18.0 | 12.9 | 34.7 |
| youri-7b | 46.2 | 47.8 | 50.0 | 85.1 | 19.6 | 6.4 | 26.7 | 19.7 | 37.7 |
| Mistral v0.1 7B | 73.0 | 42.5 | 27.2 | 85.6 | 20.1 | 17.6 | 14.1 | 17.3 | 37.2 |
| J Stable LM 7b | 73.6 | 46.4 | 55.7 | 89.1 | 22.9 | 16.8 | 23.9 | 15.6 | 43.0 |
| Qwen-7B | 77.1 | 42.3 | 23.8 | 85.9 | 13.7 | 21.6 | 16.9 | 18.0 | 37.4 |
| nekomata-7b | 74.2 | 49.3 | 50.2 | 87.1 | 16.8 | 12.4 | 26.7 | 18.2 | 41.8 |
| Llama-2-7b | 38.5 | 42.4 | 34.1 | 79.2 | 19.1 | 7.6 | 17.8 | 17.4 | 32.0 |
| Swallow-7b | 48.1 | 50.8 | 59.7 | 85.7 | 18.3 | 12.4 | 25.1 | 15.1 | 39.4 |
| llm-jp-13b-v1.0 | 22.6 | 47.9 | 38.6 | 77.4 | 10.8 | 2.4 | 19.6 | 11.9 | 28.9 |
| PLaMo-13b | 22.7 | 51.9 | 41.4 | 76.2 | 10.3 | 3.6 | 15.8 | 12.0 | 29.2 |
| ELYZA-13b | 74.0 | 42.6 | 46.8 | 87.2 | 14.1 | 3.2 | 22.0 | 14.9 | 38.1 |
| Qwen-14B | 88.3 | 42.4 | 32.2 | 89.8 | 18.5 | 38.8 | 22.2 | 22.2 | 44.3 |
| nekomata-14b | 91.7 | 57.8 | 61.1 | 91.5 | 21.3 | 35.6 | 29.9 | 23.1 | 51.5 |
| Llama-2-13b | 70.0 | 44.2 | 41.7 | 85.3 | 21.4 | 13.2 | 21.5 | 19.8 | 39.6 |
| Swallow-13b | 78.4 | 50.6 | 64.0 | 90.1 | 21.7 | 20.4 | 27.2 | 17.7 | 46.3 |
| J Stable LM 70b | 91.2 | 49.3 | 60.4 | 91.9 | 25.7 | 41.6 | 27.7 | 23.4 | 51.4 |
| Llama-2-70b | 86.9 | 46.6 | 52.6 | 90.8 | 23.6 | 35.6 | 26.4 | 24.0 | 48.3 |
| Swallow-70b | 93.5 | 62.9 | 69.6 | 91.8 | 22.7 | 48.4 | 30.4 | 23.0 | 55.3 |
H.1 Details of models trained from scratch
- calm2-7b
-
A model with the Llama architecture trained on 1.3T tokens of Japanese and English corpora.
- llm-jp-13b-v1.0
-
A model with the GPT-2 architecture trained on 300B tokens of Japanese and English corpora.
- PLaMo-13b
-
A model trained on 180B tokens of Japanese, 1.32T tokens of English, totaling 1.5T tokens.
Appendix I Sources of evaluated models
Table 10 lists the names of the models used in the experiments and their corresponding Hugging Face Model Names. The abbreviations in the “Training detail” column of Table 10 are defined as follows: VE for vocabulary expansion, CT for continual pre-training, and PT for pre-training from scratch.
The models with “Ja & En” in their Training detail were trained on both Japanese and English data, while those with “Zh & En” were trained using Chinese and English data. Models with “Ja” were trained solely on Japanese data, and those with “En” were primarily trained on English data.
Note that the “Training detail” column presents the major data source used for training. However, some models may also use small amounts of other types of data in their training data, for example, source code, mathematical texts, and corpora in other languages.
| Model | Training detail | Model name on Hugging Face |
| calm2-7b | (PT, Ja & En) | cyberagent/calm2-7b |
| J Stable LM 7b | (CT, Ja & En) | stabilityai/japanese-stablelm-base-beta-7b |
| ELYZA-7b | (CT, Ja) | elyza/ELYZA-japanese-Llama-2-7b |
| youri-7b | (CT, Ja & En) | rinna/youri-7b |
| Mistral v0.1 (7B) | (PT, En) | mistralai/Mistral-7B-v0.1 |
| J Stable LM 7b | (CT, Ja & En) | stabilityai/japanese-stablelm-base-gamma-7b |
| Qwen-7B | (PT, Zh & En) | Qwen/Qwen-7B |
| nekomata-7b | (CT, Ja & En) | rinna/nekomata-7b |
| Llama-2-7b | (PT, En) | meta-llama/Llama-2-7b-hf |
| Swallow-7b | (CT, VE, Ja & En) | tokyotech-llm/Swallow-7b-hf |
| llm-jp-13b-v1.0 | (PT, Ja & En) | llm-jp/llm-jp-13b-v1.0 |
| PLaMo-13b | (PT, Ja & En) | pfnet/plamo-13b |
| ELYZA-13b | (CT, Ja) | elyza/ELYZA-japanese-Llama-2-13b |
| Qwen-14B | (PT, Zh & En) | Qwen/Qwen-14B |
| nekomata-14b | (CT, Ja & En) | rinna/nekomata-14b |
| Llama-2-13b | (PT, En) | meta-llama/Llama-2-13b-hf |
| Swallow-13b | (CT, VE, Ja & En) | tokyotech-llm/Swallow-13b-hf |
| J Stable LM 70b | (CT, Ja & En) | stabilityai/japanese-stablelm-base-beta-70b |
| Llama-2-70b | (PT, En) | meta-llama/Llama-2-70b-hf |
| Swallow-70b | (CT, VE, Ja & En) | tokyotech-llm/Swallow-70b-hf |