Leonard Jung \Email[email protected]
\NameAlexander Estornell \Email[email protected]
\NameMichael Everett \Email[email protected]
\addrNortheastern University, Boston, MA 02215, USA
\LinesNumbered
Contingency Constrained Planning with MPPI within MPPI
Abstract
For safety, autonomous systems must be able to consider sudden changes and enact contingency plans appropriately. State-of-the-art methods currently find trajectories that balance between nominal and contingency behavior, or plan for a singular contingency plan; however, this does not guarantee that the resulting plan is safe for all time. To address this research gap, this paper presents Contingency-MPPI, a data-driven optimization-based strategy that embeds contingency planning inside a nominal planner.
By learning to approximate the optimal contingency-constrained control sequence with adaptive importance sampling, the proposed method’s sampling efficiency is further improved with initializations from a lightweight path planner and trajectory optimizer.
Finally, we present simulated and hardware experiments demonstrating our algorithm generating nominal and contingency plans in real time on a mobile robot.
Experiment Video Video will be added soon
keywords:
Contingency planning, model-predictive control, data-driven optimization, robotics1 Introduction
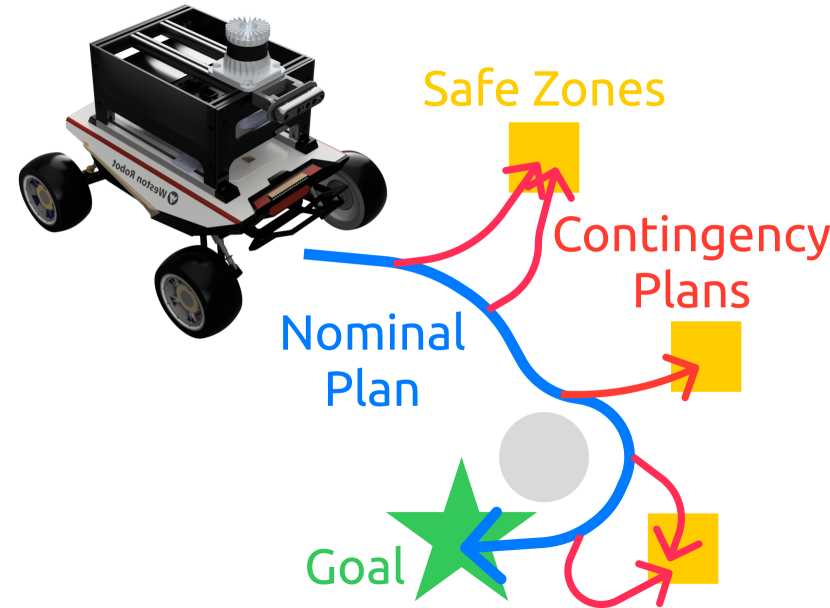
Autonomous systems in real environments need to be able to handle sudden major changes in the operating conditions. For example, a car driving on the highway may need to swerve to safety if a collision occurs ahead, or a humanoid robot may need to grab hold of a railing if its foot slips on the stairs. Since there may be only a fraction of a second to recognize and respond to such events, this paper aims to develop an approach for always ensuring a contingency plan is available and can be immediately executed, if necessary.
A key challenge in this problem is to ensure a contingency plan always exists, without impacting the nominal plan too much. In standard approaches, where the nominal planner does not account for contingencies, the system could enter states from which no contingency plan exists; this may be tolerable if the failure event never occurs while the system is in one of those states but could lead to major safety failures in the worst case. [9683388] considered these backup plans by adding weighted terms to the cost function, which encourage staying out of these contingency-free areas, but does not have any guarantee. Alternatively, the methods of [alsterda2021contingency] and [9729171] explicitly plan alternative trajectories through a branching scheme and optimize both a nominal and set of contingency trajectories simultaneously. However, again, these methods must balance between the nominal trajectory cost and the tree of backup plans. [9729171, li2023marc, 10400882] all addressed risk-aware contingency planning with stochastic interactions with other agents; thus, these algorithms aim to minimize risk and cost over a tree of possible future scenarios, again only providing a balance between aggressive and safe behavior. [tordesillas2019faster] solved a contingency constrained problem by planning both an optimistic plan and a contingency plan that branches off to stay in known-free space. However, for more complicated safety requirements (e.g., a collection of safe regions that must remain reachable within a given time limit), the mixed integer programming problem proposed in that work becomes too expensive to solve in real time.
This leads to another important challenge: ensuring computational efficiency despite needing to generate both a nominal and a contingency plan from each state along the way. One approach would be to use exact reachability algorithms (e.g., 8263977; 9341499) to keep the planner out of contingency-free areas. However, computing the reachable sets is expensive, not strictly necessary, and would still require subsequently finding the contingency trajectories. Instead, this paper proposes to use an inexpensive contingency planner embedded inside the nominal planner. If the contingency planner finds a valid contingency plan, the nominal planner knows that state is acceptable, and the corresponding contingency plan is already available. Meanwhile, if the contingency planner fails to find a trajectory within a computation budget, the nominal planner can quickly (albeit conservatively) update its plans to avoid that state. To handle these discrete contingency events on top of generic nominal planning problems, our method, Contingency-MPPI, builds on model-predictive path integral (MPPI) control.
To summarize, this paper’s contributions include: (i) a planning algorithm that embeds contingency planning inside a nominal planner to ensure that a contingency plan exists from every state along the nominal plan, (ii) extensions of this planner using lightweight optimization problems to improve the sample-efficiency via better initial guesses, and (iii) demonstrations of the proposed method in simulated environments and on a mobile robot hardware platform to highlight the real-time implementation.
2 Problem Formulation
Denote a general nonlinear discrete-time system with state, , and control, at time . To indicate a trajectory, we use colon notation (e.g., ) and -step dynamics . Additionally and indicate the state and control trajectory reshaped into a vector, and represents the covariance matrix of the reshaped control trajectory.
The contingency-constrained planning problem is to find a nominal trajectory, , to minimize cost , along with contingency trajectories that drive the system into a safe set, , within steps, from each state along the nominal trajectory:
| (1a) | |||||
| s.t. | (1b) | ||||
| (1c) | |||||
Other common costs/constraints (e.g., obstacle avoidance, control limits), can be added as desired.
3 Contingency-MPPI
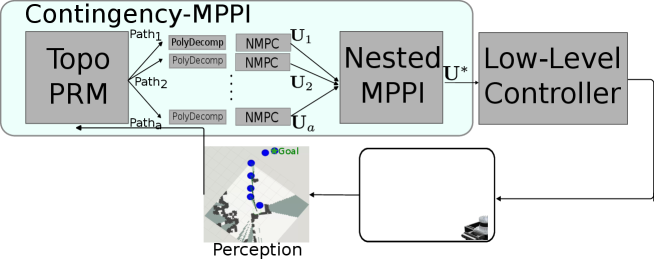
Ignoring the contingency constraint Eq. 1c, MPPI is a powerful method for solving Eq. 1 when the dynamics or costs are non-convex. This section shows how to extend MPPI to handle Eq. 1c as well, by nesting another sampling process into MPPI. First, we review the vanilla MPPI algorithm in Section 3.1, then describe our Nested-MPPI in Section 3.2. To increase sampling efficiency, a path-finding and trajectory optimization step (Section 3.3) is used to seed Nested-MPPI (LABEL:sec:backend) with ancillary controllers. This approach is summarized in Fig. 2.
3.1 Background: Model Predictive Path Integral Control
To summarize MPPI following asmar2023model, consider the entire control trajectory as a single input , sampled from distribution with density
| (2) |
where are the mean and covariance of . The objective of MPPI is to minimize the KL-divergence between this proposed distribution, , and an (unknown) optimal control distribution , defined with respect to a cost function of the form
| (3) |
The optimal control distribution has density , based on a state-dependent cost, and a nominal control distribution, , with density
| (4) |
Here, is a normalizing constant, is the inverse temperature, and is the base control, which is usually either zero or a nominal distribution from iterations of adaptive importance sampling. Then, to find the optimal control trajectory we can minimize the KL-divergence between and ,
| (5) |
Using adaptive importance sampling, the optimal control can be approximated by drawing samples from a distribution with proposed input ,
| (6) | |||
| (7) | |||
| (8) |
(6) finds an (information-theoretic) optimal open-loop control sequence that can be implemented in a receding horizon by shifting one timestep ahead and re-running the algorithm. As in asmar2023model, we weigh the control cost by a factor and shift all sampled trajectory costs by the minimum sampled cost, for numerical stability.
3.1.1 Enforcing Hard Constraints in MPPI
While MPPI does not explicitly handle constraints, such as avoiding obstacles or the existence of a contingency plan, one can add terms to the objective with infinite cost when constraints are violated. For example, with a nominal cost and constraints, the augmented cost is , where
| (9) |
When the constraints are satisfied, the trajectory cost (and its weight in importance sampling) depends only on the nominal cost, such as minimum time or distance to the goal. If the constraints are not satisfied, the trajectory has infinite cost and receives zero weight in importance sampling. Thus, only trajectories meeting all constraints are considered, and their weights depend solely on the nominal cost. If no trajectory satisfies all constraints in an iteration, all samples get zero weight, and the mean control trajectory remains unchanged for the next MPPI iteration. However, if any trajectory met the constraints in the previous step, the executed control trajectory will still be safe
3.2 Nested-MPPI
[H] \DontPrintSemicolon
Input:
Output: Nominal & contingency control sequences
Parameters: (nominal); (system); (cost)
\BlankLine; \For(\tcp*[f]AIS loop) \KwTo \For \KwTo
\lIf\tcpAncillary Control \lElse \For \KwTo \lIf \lIf
\BlankLine\For
\KwTo
\ReturnNested-MPPI
[H] \DontPrintSemicolon
Input: : State sequence
Output: Contingency control sequence & score
Parameters: (contingency); (system/sampling); (costs)
\BlankLine \For\KwTo \For \KwTo \For \KwTo \lIf else \For \KwTo \lIf \lIf
\lElseIf\lIf else
\Return
This section introduces Nested-MPPI, which is summarized in Section 3.2. This algorithm is based on the MPPI in alsterda2021contingency and allows for ancillary controllers as proposed in trevisan2024biased. Our key innovation begins on Section 3.2, where a second level of MPPI executes in each state along each rollout of the nominal MPPI. This second level, described in Section 3.2, optimizes for a contingency plan (with a different cost function than the nominal plan) as a way of evaluating the reachability constraint, Eq. 1c.
To both find contingency trajectories and evaluate whether the reachability constraint (1c) is satisfied for any control sequence, we first roll out each control sequence by passing it through the zero-noise nonlinear dynamics model to get the state sequence . Then, at each state for , we run rounds of adaptive importance sampling MPPI with samples and timesteps starting at to generate contingency state and control trajectories (lines 3.2-3.2 in Alg. 3.2). To encourage these contingency trajectories to reach safe states within timesteps, we use state-dependent cost
| (10) |
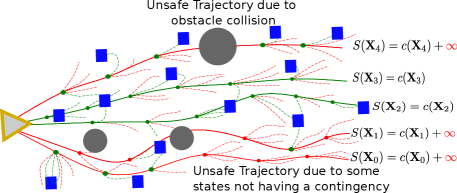
Then, as seen in Figure 3, if any of the contingency trajectories successfully reaches a safe state within timesteps, we mark that state along as safe (green). If all states along are marked as safe, then we mark and its corresponding control as safe; otherwise, we mark the trajectory as unsafe, and add to its corresponding cost. In Section 3.2 Section 3.2, to initialize the proposed distribution for contingencies at each state, a number of sample control trajectories are drawn from a uniform distribution along control bounds , and the cross-entropy method is used on the best trajectories to determine an initial mean and covariance.
3.3 Improving the Sampling Efficiency of Nested-MPPI: Frontend
Although Section 3.2 considers all costs and constraints from Eq. 1, the sampling process can result in many or even all trajectories with infinite costs (if the sampling distribution is far from the optimal distribution), which leads to uninformed updates to the distribution. To remedy this, one may simply sample more sequences; however, each additional sequence requires computing , which requires an additional MPPI computations. Thus, rather than simply increasing the number of samples, we propose to approximate locally optimal and consider them as a new sampling distribution(s) into Section 3.2, as described in LABEL:sec:backend. First, we find several different paths between the start and goal. For each path, we then perform a convex decomposition to find an under approximation of the safe space, and finally perform a nonlinear MPC to solve for a candidate control sequence.
3.3.1 Topo-PRM
To find several alternative paths through the workspace, we leverage Topo-PRM proposed in 9196996. As Topo-PRM finds a collection of topologically distinct paths through the environment, our planner can ”explore” the free-space and return multiple promising guiding paths. However as Topo-PRM does not consider safe zones, it may return paths that are not near safe zones, and thus no contingencies exist. Thus, we modify the algorithm to sample randomly from safe states fraction of the time to bias our roadmap to find paths that include safe states. To further bias the paths towards safe zones, denoting as the maximum speed of our vehicle in the creation of our workspace occupancy grid, we add pseudo-obstacles by marking occupied voxels that are farther than away from any given safe zone.
3.3.2 Nonlinear MPC
To transform each path into an ancillary control trajectory, we first find the point that is along the path, and then perform a convex decomposition using the approach from 7839930 of the free space along the path from our start point to . Next, we find knot points by discretizing points along the path from to . Denoting the polyhedral constraint in which point lies within, we solve the following nonlinear programming problem to recover a candidate ancillary control trajectory: