Contaminated Online Convex Optimization
Abstract
In online convex optimization, some efficient algorithms have been designed for each of the individual classes of objective functions, e.g., convex, strongly convex, and exp-concave. However, existing regret analyses, including those of universal algorithms, are limited to cases in which the objective functions in all rounds belong to the same class and cannot be applied to cases in which the property of objective functions may change in each time step. This paper introduces a novel approach to address such cases, proposing a new regime we term as contaminated online convex optimization. For the contaminated case, we demonstrate that the regret is lower bounded by . Here, signifies the level of contamination in the objective functions. We also demonstrate that the regret is bounded by when universal algorithms are used. When our proposed algorithms with additional information are employed, the regret is bounded by , which matches the lower bound. These are intermediate bounds between a convex case and a strongly convex or exp-concave case.
1 Introduction
Online convex optimization (OCO) is an optimization framework in which convex objective function changes for each time step . OCO has a lot of applications such as prediction from expert advice (Littlestone and Warmuth 1994, Arora et al. 2012), spam filtering (Hazan 2016), shortest paths (Awerbuch and Kleinberg 2004), portfolio selection (Cover 1991, Hazan et al. 2006), and recommendation systems (Hazan and Kale 2012). The performance of the OCO algorithm is compared by regret (defined in Section 3). As shown in Table 1, it is already known that sublinear regret can be achieved for each function class, such as convex, strongly convex, and exp-concave, and the bound depends on the function class. In addition, these upper bounds coincide with lower bounds, so these are optimal. However, these optimal algorithms are applicable to one specific function class. Therefore, we need prior knowledge about the function class to which the objective functions belong.
To solve this problem, many universal algorithms that work well for multiple function classes by one algorithm have been proposed (Hazan et al. 2007, Van Erven and Koolen 2016, Wang et al. 2020, Zhang et al. 2022, Yan et al. 2024). For example, the MetaGrad algorithm proposed by Van Erven and Koolen (2016) achieves an -regret for any sequence of convex objective functions and an -regret if all the objective functions are exp-concave. Universal algorithms are useful in that they can be used without prior knowledge about the objective functions. Some universal algorithms are introduced in Appendix A.3.
A notable limitation of the previous regret analyses about universal algorithms is that they apply only to cases where all the objective functions belong to the same function class. Therefore, for example, if some objective functions in a limited number of rounds are not strongly convex and if the other objective functions are strongly convex, regret bounds for strongly convex functions in previous studies are not always valid. This study aims to remove this limitation.
| FUNCTION CLASS | UPPER BOUNDS | LOWER BOUNDS |
|---|---|---|
| Convex | ||
| (Zinkevich 2003) | (Abernethy et al. 2008) | |
| -exp-concave | ||
| (Hazan et al. 2006) | (Ordentlich and Cover 1998) | |
| -contaminated -exp-concave | ||
| (This work, Corollary 5.5) | (This work, Corollary 4.8) | |
| -contaminated -exp-concave | ||
| (with additional information) | (This work, Theorem 6.2) | (This work, Corollary 4.8) |
| -strongly convex | ||
| (Hazan et al. 2006) | (Abernethy et al. 2008) | |
| -contaminated -strongly convex | ||
| (This work, Corollary 5.7) | (This work, Corollary 4.9) | |
| -contaminated -strongly convex | ||
| (with additional information) | (This work, Theorem 6.2) | (This work, Corollary 4.9) |
1.1 Our Contribution
In this study, we consider the situation in which the function class of the objective may change in each time step . We call this situation contaminated OCO. More specifically, in -contaminated OCO with a function class , we suppose that the objective function does not necessarily belong to the desired function class (e.g., exp-concave or strongly convex functions) in rounds out of the total rounds. Section 3 introduces its formal definition and examples. This class of OCO problems can be interpreted as an intermediate setting between general OCO problems and restricted OCO problems with (-OCOs). Intuitively, the parameter represents the magnitude of the impurity in the sequence of the objective functions, and measures how close the problems are to -OCOs; and respectively correspond to -OCO and general OCO.
The contribution of this study can be summarized as follows: (i) We introduce contaminated OCO, which captures the situations in which the class of the objective functions may change over different rounds. (ii) We find that the Online Newton Step, one of the optimal algorithms for exp-concave functions, does not always work well in contaminated OCO, as discussed in Section 4.1. (iii) We present regret lower bounds for contaminated OCO in Section 4.2. (iv) We show that some existing universal algorithms achieve better regret bounds than ONS for contaminated OCO, which details are given in Section 5. (v) We propose an algorithm that attains the optimal regret bounds under the additional assumption that information of the class of the previous objective function is accessible in Section 6.
Regret bounds of contaminated cases compared to existing bounds are shown in Table 1. The new upper bounds contain bounds in existing studies for exp-concave functions and strongly convex functions as a particular case (). Additionally, the new lower bounds generalize bounds in existing studies for convex functions, exp-concave functions, and strongly convex functions. In cases where only gradient information is available, there is a multiplicative gap of between the second terms of the upper bounds and the lower bounds. This gap is eliminated when the information of the class of the previous objective function is available.
To prove regret lower bounds in Table 1, we construct distributions of problem instances of contaminated OCO for which any algorithm suffers a certain amount of regret in expected values. Such distributions are constructed by combining suitably designed problem instances of -OCO and general OCO.
To derive novel regret upper bounds without additional information in Table 1, we exploit regret upper bounds expressed using some problem-dependent values such as a measure of variance (Van Erven and Koolen 2016). By combining such regret upper bounds and inequalities derived from the definition of -contaminated OCO, we obtain regret upper bounds, including the regret itself, which can be interpreted as quadratic inequalities in regret. Solving these inequalities leads to regret upper bounds in Table 1.
We develop algorithms that can achieve optimal regret upper bounds, taking into account the function class information of the previous function. To accomplish this, we modified two existing OCO algorithms: the Online Newton Step (ONS), as introduced by Hazan et al. (2006), and the Online Gradient Descent (OGD), presented by Zinkevich (2003). The modification is changing the update process depending on the function class of the last revealed objective function.
2 Related Work
In the context of online learning, adaptive algorithms (Orabona 2019) have been extensively studied due to their practical usefulness. These algorithms work well by automatically exploiting the intrinsic properties of the sequence of objective functions and do not require parameter tuning based on prior knowledge of the objective function. For example, AdaGrad (McMahan and Streeter 2010, Duchi et al. 2011) is probably one of the best-known adaptive algorithms, which automatically adapts to the magnitude of the gradients. Studies on universal algorithms (Hazan et al. 2007, Van Erven and Koolen 2016, Wang et al. 2020, Zhang et al. 2022, Yan et al. 2024), which work well for several different function classes, can also be positioned within these research trends. Our study shows that some of these universal algorithms have further adaptability, i.e., nearly tight regret bounds for contaminated settings.
van Erven et al. (2021) has explored a similar setting to ours, focusing on robustness to outliers. They regard rounds with larger gradient norms than some threshold as outliers and denote the number of outliers as , whose definition differs from ours. They have defined regret only for rounds that are not outliers, terming it robust regret, and have shown that the additional term is inevitable in bounds on robust regret.
Studies on best-of-both-worlds (BOBW) bandit algorithms (Bubeck and Slivkins 2012) and on stochastic bandits with adversarial corruptions (Lykouris et al. 2018, Gupta et al. 2019) are also related to our study. BOBW algorithms are designed to achieve (nearly) optimal performance both for stochastic and adversarial environments, e.g., -regret for stochastic and -regret for adversarial environments, respectively. Stochastic bandits with adversarial corruptions are problems for intermediate environments between stochastic and adversarial ones, in which the magnitude of adversarial components is measured by means of the corruption level parameter . A BOBW algorithm by Bubeck and Slivkins (2012) has shown to have a regret bound of as well for stochastic environments with adversarial corruptions, which is also nearly tight (Ito 2021). In the proof of such an upper bound, an approach referred to as the self-bounding technique (Gaillard et al. 2014, Wei and Luo 2018) is used, which leads to improved guarantees via some regret upper bounds that include the regret itself. Similar proof techniques are used in our study as well.
3 Problem Setting
In this section, we explain the problem setting we consider. Throughout this paper, we assume functions are differentiable and convex.
3.1 OCO Framework and Assumptions
First of all, the mathematical formulation of OCO is as follows. At each time step , a convex nonempty set and convex objective functions are known and is not known. A learner chooses an action and incurs a loss after the choice. Since is unknown when choosing , it is impossible to minimize the cumulative loss for all sequences of . Instead, the goal of OCO is to minimize regret:
Regret is the difference between the cumulative loss of the learner and that of the best choice in hindsight. The regret can be logarithmic if the objective functions are -strongly convex, i.e., for all , or -exp-concave, i.e., is concave on .
Remark 3.1.
The type of information about that needs to be accessed varies depending on the algorithm. Universal algorithms only utilize gradient information, while the algorithm presented in Section 6 requires additional information besides the gradient, such as strong convexity and exp-concavity. The lower bounds discussed in Section 4.2 are applicable to arbitrary algorithms with complete access to full information about the objective functions.
Next, we introduce the following two assumptions. These assumptions are very standard in OCO and frequently used in regret analysis. We assume them throughout this paper without mentioning them.
Assumption 3.2.
There exists a constant such that holds for all .
Assumption 3.3.
There exists a constant such that holds for all and .
These assumptions are important, not only because we can bound and , but also because we can use the following two lemmas:
Lemma 3.4.
(Hazan 2016) Let be an -exp-concave function. Assume that there exist constants such that and hold for all . The following holds for all and all :
Lemma 3.5.
(Hazan 2016) If is a twice differentiable -strongly convex function satisfying for all , then it is -exp-concave.
Lemma 3.5 means that exp-concavity is a milder condition than strong convexity, combining with the fact that is not strongly convex but 1-exp-concave.
3.2 Contaminated Case
In this subsection, we define contaminated OCO and introduce examples that belong to this problem class. The definition is below.
Definition 3.6.
For some function class , a sequence of convex functions belongs to -contaminated if there exists a set of indices such that and holds for all .
For example, if functions other than functions of them are -exp-concave, we call the functions -contaminated -exp-concave. And especially for OCO problems, if the objective functions are contaminated, we call them contaminated OCO.
The following two examples are functions whose function class varies with time step. These examples motivate this study.
Example 3.7.
(Online least mean square regressions) Consider the situation where a batch of input-output data is given in each round and we want to estimate which enable to predict . This can be regarded as an OCO problem whose objective functions are . These functions are -strongly convex, where is the minimum eigenvalue of the matrix . Let for any . Then is -contaminated -strongly convex.
Example 3.8.
(Online classification by using logistic regression) Consider the online classification problem. A batch of input-output data is given in each round and we want to estimate which enable to predict . Suppose that the objective functions are given by . Exp-concavity of on changes with time step. Especially, in the case , is -exp-concave, as proved in Appendix B.1. Let for any , where is defined so that is -exp-concave. Then is -contaminated -exp-concave.
Remark 3.9.
In the two examples above, constants and in the definition of -strong convexity and -exp-concavity can be strictly positive for all time steps. However, since the regret bounds are and for -strongly convex functions and -exp-concave functions respectively, if and are , then the regret bounds become trivial. Analyses in this paper give a nontrivial regret bound to such a case.
4 Regret Lower Bounds
4.1 Vulnerability of ONS
This subsection explains how Online Newton Step (ONS) works for contaminated exp-concave functions. ONS is an algorithm for online exp-concave learning. Details of ONS are in Appendix A.2. The upper bound is as follows.
Proposition 4.1.
If a sequence of objective functions is -contaminated -exp-concave, the regret upper bound of ONS with and is .
This proposition is proved by using the proof for noncontaminated cases by Hazan (2016). A detailed proof is in Appendix B.2. This upper bound seems trivial, but the bound is tight because of the lower bound stated in Corollary 4.6.
Before stating the lower bound, we introduce the following theorem, which is essential in deriving some lower bounds of contaminated cases.
Theorem 4.2.
Let be an arbitrary function class. Suppose that functions are the functions such that and are lower bounds for function class and convex functions, respectively, for some OCO algorithm. If a sequence of objective functions belongs to -contaminated , then regret in the worst case is for the OCO algorithms.
Remark 4.3.
In Theorem 4.2, if the lower bounds and are for all OCO algorithms, then the lower bound is also for all OCO algorithms.
To derive this lower bound, we use the following two instances; one is the instance used to prove lower bound for function class , and the other is the instance used to prove for convex objective functions. By considering the instance that these instances realize with probability , we can construct an instance that satisfies
for all OCO algorithms. A detailed proof of this proposition is postponed to Appendix B.3.
Theorem 4.2 implies that, in contaminated cases, we can derive interpolating lower bounds of regret. The lower bound obtained from this theorem is if , and if . Since the contaminated case can be interpreted as an intermediate regime between restricted -OCO and general OCO, this result would seen as reasonable. This lower bound applies not only to ONS but also to arbitrary algorithms.
To apply Theorem 4.2 to ONS, we show the following lower bound in the case of convex functions. This lower bound shows that ONS is not suitable for convex objective functions.
Proposition 4.4.
For any positive parameters and , ONS incurs regret in the worst case.
To prove this proposition, consider the instance as follows:
where
and is a minimum natural number which satisfies . Then, we can get
A detailed proof of this proposition is postponed to Appendix B.4.
Remark 4.5.
Corollary 4.4 states the lower bound that holds only for ONS. However, if some better algorithms are used, the lower bound can be improved. Therefore, it is not a contradiction that the general lower bound in Table 1 is better than that of ONS. This is also true for Corollary 4.6, which is about the contaminated case.
The lower bound of -exp-concave functions can be derived as follows. The lower bound of -exp-concave functions is (Ordentlich and Cover 1998). Here, when divided by , -exp-concave functions turn into -exp-concave functions, and regret is also divided by . Hence, the lower bound of -exp-concave functions is .
We get the following from this lower bound for exp-concave functions, Proposition 4.4, and Theorem 4.2.
Corollary 4.6.
If a sequence of objective functions is -contaminated -exp-concave, regret in worst case is , for ONS.
This proposition shows that the regret analysis in Proposition 4.1 is strict. While ONS does not work well for contaminated OCO, universal algorithms exhibit more robust performance. In Section 5, we analyze some universal algorithms on this point.
Remark 4.7.
For the 1-dimension instance above, ONS can also be regarded as OGD (Algorithm 2 in Appendix A.1) with stepsize. This implies that we can show that OGD with stepsize can incur regret in the worst case. Therefore, for -contaminated strongly convex functions, regret in worst case is , for OGD with stepsize.
4.2 General Lower Bounds
In this subsection, we present regret lower bounds for arbitrary algorithms.
Using Theorem 4.2, we can get a lower bound of -contaminated exp-concave functions. As mentioned in Section 4.1, regret lower bound of -exp-concave functions is . From this lower bound and that of convex functions is (Abernethy et al. 2008), we can derive the following lower bound. This corollary shows that -contamination of exp-concave functions worsens regret lower bound at least .
Corollary 4.8.
If is -contaminated -exp-concave, regret in worst case is , for all OCO algorithms.
According to Abernethy et al. (2008), the regret lower bound in the case of -strongly convex functions is . Therefore, following a similar corollary is derived in the same way.
Corollary 4.9.
If a sequence of objective functions is -contaminated -strongly convex, regret in worst case is , for all OCO algorithms.
5 Regret Upper Bounds by Universal Algorithms
In this section, we explain the regret upper bounds of some universal algorithms when the objective functions are contaminated. The algorithms we analyze in this paper are multiple eta gradient algorithm (MetaGrad) (Van Erven and Koolen 2016), multiple sub-algorithms and learning rates (Maler) (Wang et al. 2020), and universal strategy for online convex optimization (USC) (Zhang et al. 2022). Though there are two variations of MetaGrad; full MetaGrad and diag MetaGrad, in this paper, MetaGrad means full MetaGrad. We denote , , and .
Concerning MetaGrad and Maler, following regret bounds hold without assuming exp-concavity or strong convexity:
Theorem 5.1.
Theorem 5.2.
Though Theorem 5.2 is derived only for in the original paper by Wang et al. (2020), the proof is also valid even when is any vector in , so we rewrite the statement in this form. The proof of this generalization is provided in Appendix B.5. Further explanations of universal algorithms are in Appendix A.3.
Concerning the regret bound of contaminated exp-concavity, the following theorem holds. This theorem’s assumption is satisfied when using MetaGrad or Maler, and the result for them is described after the proof of this theorem.
Theorem 5.3.
Let be a constant such that is -exp-concave (if is not exp-concave, then is ) for each . Suppose that
| (1) |
holds for some functions , , and point . Then, it holds for any that
where , .
Before proving this theorem, we prepare a lemma. The proof of this lemma is given in Appendix B.6.
Lemma 5.4.
For all , if , then .
Proof of Theorem 5.3.
The core of this proof is inequality (3), which can be regarded as a quadratic inequality. Solving this inequality enables us to obtain a regret upper bound for contaminated cases from a regret upper bound for non-contaminated cases.
Theorem 5.3 combined with Theorem 5.1, Theorem 5.2, and Theorem A.1 in the appendix gives upper bounds for universal algorithms; MetaGrad, Maler, and USC. The following corollary shows that, even if exp-concave objective functions are -contaminated, regret can be bounded by an additional term of . This regret bound is better than ONS’s in the parameter .
Corollary 5.5.
If a sequence of objective functions is -contaminated -exp-concave, the regret bound of MetaGrad, Maler, and USC with MetaGrad or Maler as an expert algorithm is
| (4) |
where .
We only give proof for MetaGrad and Maler here, and the proof for USC will be provided in Appendix B.7.
Proof.
As for strongly convex functions, we can get a similar result as Theorem 5.3.
Theorem 5.6.
Let be a constant such that is -strongly convex (if is not strongly convex, then is ) for each . Suppose that
holds for some functions , , and point . Then, it holds for any that
where .
This theorem can be derived in almost the same manner as the proof of Theorem 5.3, other than using the definition of strong convexity and . A more detailed proof is in Appendix B.8.
Theorem 5.6 combined with Theorem 5.1, Theorem 5.2, and Theorem A.1 in the appendix gives upper bounds for universal algorithms; MetaGrad, Maler, and USC. This corollary shows that, even if strongly convex objective functions are -contaminated, regret can be bounded by an additional term of if Maler or USC with Maler as an expert algorithm is used.
Corollary 5.7.
If a sequence of objective functions is -contaminated -strongly convex, the regret bound of MetaGrad, Maler, and USC with Maler as an expert algorithm is
where is in the case of MetaGrad and 1 in the case of the other two algorithms.
This corollary can be derived from Theorem 5.6 in almost the same manner as the proof of Corollary 5.5. A more detailed proof is in Appendix B.9 and Appendix B.10.
Remark 5.8.
Remark 5.9.
Note that the universal algorithms analyzed in this section do not require additional information other than the gradient, which is a valuable property in practical use. However, comparing lower bounds in Corollary 4.8 and Corollary 4.9 with upper bounds in Corollary 5.5 and Corollary 5.7 respectively, there are gaps between them. This implies that our upper bounds in this section or lower bounds in Section 4.2 might not be tight. As we will discuss in the next section, this gap can be removed if additional information on function classes are available while it is not always the case in real-world applications.
6 Regret Upper Bounds Given Additional Information
In this section, we propose a method that achieves better bounds than those of universal algorithms discussed in the previous section under the condition that the information of the class of the last objective function is revealed. The experimental performance of this method is shown in Appendix C.
We denote , , , and . The algorithm using additional information is shown in Algorithm 1 ( is dimensional identity matrix, and means ). This algorithm is a generalization of OGD and ONS. Indeed, gives normal OGD and gives normal ONS.
Before stating the regret upper bounds of Algorithm 1, we prepare the following lemma:
Lemma 6.1.
Let be the sequence generated by Algorithm 1 and , , , and be as defined above. Then, the following inequalities hold:
| (5) | ||||
| (6) | ||||
| (7) |
Proof.
Inequality (5) can be obtained as follows:
where is the minimum eigenvalue of the matrix , which at least increases by when .
Using this lemma, we can bound the regret of Algorithm 1 as follows:
Theorem 6.2.
Let be defined at the beginning of this section. Algorithm 1 guarantees
Proof.
When , from the definition of strong convexity,
| (8) |
holds. When , from Lemma 3.4,
| (9) |
holds. When , since is convex,
| (10) |
holds. From the update rule of , inequalities (8), (9), and (10) can be combined into one inequality
where is the indicator function, i.e., if , and otherwise. The first and second terms in the right-hand side can be bounded as follows:
The first equality is from the algorithm, the second equality is from the law of cosines, and the last inequality is from the nonexpansiveness of projection. Therefore, we have
By summing up from to , we can bound regret as follows:
The key point of Theorem 6.2 is that the second term of the regret upper bound is proportional to . Compared with Corollary 5.5, we can see that additional information improves the regret upper bound.
Remark 6.3.
Remark 6.4.
As mentioned in Remark 5.9, the algorithms analyzed in this section need information that is not always available in the real world. Therefore, the improved regret bound in Theorem 6.2 is theoretical, and regret bounds for universal algorithms explained in Section 5 are more important in real applications. However, the algorithm in this section has the notable advantage that its regret upper bounds match the lower bounds.
7 Conclusion
In this paper, we proposed a problem class for OCO, namely contaminated OCO, the property whose objective functions change in time steps. On this regime, we derived some upper bounds for existing and proposed algorithms and some lower bounds of regret. While we successfully obtained optimal upper bounds with additional information of the function class of the last revealed objective function, there are still gaps of or between the upper bound and the lower bound without additional information. One natural future research direction is to fill these gaps. We believe there is room for improvement in the upper bounds and the lower bounds seem tight. Indeed, lower bounds in this study interpolate well between tight bounds for general OCO and for (restricted) -OCO.
Acknowledgments
Portions of this research were conducted during visits by the first author, Kamijima, to NEC Corporation.
References
- Abernethy et al. (2008) J. D. Abernethy, P. L. Bartlett, A. Rakhlin, and A. Tewari. Optimal strategies and minimax lower bounds for online convex games. In Conference on Learning Theory, pages 414–424, 2008.
- Arora et al. (2012) S. Arora, E. Hazan, and S. Kale. The multiplicative weights update method: a meta-algorithm and applications. Theory of Computing, 8(1):121–164, 2012.
- Awerbuch and Kleinberg (2004) B. Awerbuch and R. D. Kleinberg. Adaptive routing with end-to-end feedback: Distributed learning and geometric approaches. In Proceedings of the thirty-sixth annual ACM symposium on Theory of Computing, pages 45–53, 2004.
- Bubeck and Slivkins (2012) S. Bubeck and A. Slivkins. The best of both worlds: Stochastic and adversarial bandits. In Conference on Learning Theory, pages 42.1–42.23, 2012.
- Cover (1991) T. M. Cover. Universal portfolios. Mathematical Finance, 1(1):1–29, 1991.
- Duchi et al. (2011) J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(7), 2011.
- Gaillard et al. (2014) P. Gaillard, G. Stoltz, and T. Van Erven. A second-order bound with excess losses. In Conference on Learning Theory, pages 176–196. PMLR, 2014.
- Gupta et al. (2019) A. Gupta, T. Koren, and K. Talwar. Better algorithms for stochastic bandits with adversarial corruptions. In Conference on Learning Theory, pages 1562–1578. PMLR, 2019.
- Hazan (2016) E. Hazan. Introduction to online convex optimization. Found. Trends Optim., 2:157–325, 2016.
- Hazan and Kale (2012) E. Hazan and S. Kale. Projection-free online learning. In 29th International Conference on Machine Learning, ICML 2012, pages 521–528, 2012.
- Hazan et al. (2006) E. Hazan, A. Agarwal, and S. Kale. Logarithmic regret algorithms for online convex optimization. Machine Learning, 69:169–192, 2006.
- Hazan et al. (2007) E. Hazan, A. Rakhlin, and P. Bartlett. Adaptive online gradient descent. Advances in Neural Information Processing Systems, 20, 2007.
- Ito (2021) S. Ito. On optimal robustness to adversarial corruption in online decision problems. Advances in Neural Information Processing Systems, 34:7409–7420, 2021.
- Littlestone and Warmuth (1994) N. Littlestone and M. K. Warmuth. The weighted majority algorithm. Information and Computation, 108(2):212–261, 1994.
- Lykouris et al. (2018) T. Lykouris, V. Mirrokni, and R. Paes Leme. Stochastic bandits robust to adversarial corruptions. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, pages 114–122, 2018.
- McMahan and Streeter (2010) H. B. McMahan and M. Streeter. Adaptive bound optimization for online convex optimization. Conference on Learning Theory, page 244, 2010.
- Orabona (2019) F. Orabona. A modern introduction to online learning. arXiv preprint arXiv:1912.13213, 2019.
- Ordentlich and Cover (1998) E. Ordentlich and T. M. Cover. The cost of achieving the best portfolio in hindsight. Math. Oper. Res., 23:960–982, 1998.
- Van Erven and Koolen (2016) T. Van Erven and W. M. Koolen. Metagrad: Multiple learning rates in online learning. Advances in Neural Information Processing Systems, 29, 2016.
- van Erven et al. (2021) T. van Erven, S. Sachs, W. M. Koolen, and W. Kotlowski. Robust online convex optimization in the presence of outliers. In Conference on Learning Theory, pages 4174–4194. PMLR, 2021.
- Wang et al. (2020) G. Wang, S. Lu, and L. Zhang. Adaptivity and optimality: A universal algorithm for online convex optimization. In Uncertainty in Artificial Intelligence, pages 659–668. PMLR, 2020.
- Wei and Luo (2018) C.-Y. Wei and H. Luo. More adaptive algorithms for adversarial bandits. In Conference on Learning Theory, pages 1263–1291. PMLR, 2018.
- Yan et al. (2024) Y.-H. Yan, P. Zhao, and Z.-H. Zhou. Universal online learning with gradient variations: A multi-layer online ensemble approach. Advances in Neural Information Processing Systems, 36, 2024.
- Zhang et al. (2022) L. Zhang, G. Wang, J. Yi, and T. Yang. A simple yet universal strategy for online convex optimization. In International Conference on Machine Learning, pages 26605–26623. PMLR, 2022.
- Zinkevich (2003) M. A. Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. In International Conference on Machine Learning, 2003.
Appendix A Existing Algorithms and Known Regret Bounds
This section introduces existing algorithms for OCO and their regret bounds.
A.1 OGD Algorithm
In OCO, one of the most fundamental algorithms is online gradient descent (OGD), which is shown in Algorithm 2. An action is updated by using the gradient of the point and projected onto the feasible region in each step. If all the objective functions are convex and learning rates are set , the regret is bounded by (Zinkevich 2003), and if all the objective functions are -strongly convex and learning rates are set , the regret is bounded by (Hazan et al. 2006).
A.2 ONS Algorithm
If all the objective functions are -exp-concave, ONS, shown in Algorithm 3, works well. This is an algorithm proposed by Hazan et al. (2006) as an online version of the offline Newton method. This algorithm needs parameters , and if and , then the regret is bounded by .
A.3 Universal Algorithms
In real-world applications, it may be unknown which function class the objective functions belong to. To cope with such cases, many universal algorithms have been developed. Most universal algorithms are constructed with two types of algorithms: a meta-algorithm and expert algorithms. Each expert algorithm is an online learning algorithm and not always universal. In each time step, expert algorithms update , and a meta-algorithm integrates these outputs in some way, such as a convex combination. In the following, we explain three universal algorithms: multiple eta gradient algorithm (MetaGrad) (Van Erven and Koolen 2016), multiple sub-algorithms and learning rates (Maler) (Wang et al. 2020), and universal strategy for online convex optimization (USC) (Zhang et al. 2022).
First, MetaGrad is an algorithm with multiple experts, each with a different parameter as shown in Algorithm 4 and 5. In contrast to nonuniversal algorithms that need to set parameters beforehand depending on the property of objective functions, MetaGrad sets multiple so that users do not need prior knowledge. It is known that MetaGrad achieves and regret bounds for convex, -strongly convex and -exp-concave objective functions respectively.
Second, Maler is an algorithm with three types of expert algorithms: a convex expert algorithm, strongly convex expert algorithms, and exp-concave expert algorithms, as shown in Algorithm 6 to 9. They are similar to OGD with stepsize, OGD with stepsize, and ONS, respectively. Expert algorithms contain multiple strongly convex expert algorithms and multiple exp-concave expert algorithms with multiple parameters like MetaGrad. It is known that Maler achieves and regret bounds for convex, -strongly convex and -exp-concave objective functions respectively.
Finally, USC is an algorithm with many expert algorithms, as shown in Algorithm 10. In contrast to Maler, which contains OGD and ONS as expert algorithms, USC contains more expert algorithms. To integrate many experts, USC utilizes Adapt-ML-Prod (Gaillard et al. 2014) as a meta-algorithm, which realizes universal regret bound. Concerning the regret bound of USC, there is a theorem as follows.
Theorem A.1.
(Zhang et al. 2022) Let be a set of expert algorithms and be an output of th algorithm in time step. Then,
where .
In USC, expert algorithms are chosen so that holds. This theorem holds without assuming exp-concavity or strong convexity. In addition, it is known that USC achieves , and regret bounds for convex, -strongly convex and -exp-concave objective functions respectively, where , .
Appendix B MISSING PROOFS
In this section, we explain missing proofs.
B.1 Proof of the Exp-Concavity of the Function in Example 3.8
In this subsection, we present the proof of the exp-concavity of the function in Example 3.8 in the case . Before the proof, we introduce the following lemma.
Lemma B.1.
(Hazan 2016) A twice-differentiable function is -exp-concave at if and only if
Using this lemma, we can check the exp-concavity of the function .
Proof.
B.2 Proof of Proposition 4.1
This subsection presents the proof of Proposition 4.1.
Proof.
Let . We can bound regret as follows:
where is defined in the same way as defined in Theorem 5.3. The first inequality is from Lemma 3.4. In the last inequality, the first term is bounded by because of the proof of ONS’s regret bound by Hazan (2016). The second term is bounded by from by definition of . ∎
B.3 Proof of Theorem 4.2
This subsection presents the proof of Theorem 4.2.
Proof.
Let and be instances used to prove lower bound for function class and for convex objective functions, respectively, and be objective functions of at time step , and be sets which decision variables of belong to. Here, take a set so that there exist surjections . For this , let be an instance whose objective function at time step is and be an instance whose objective function at time step is if , and some function in whose minimizer is the same as the minimizer of otherwise. For these instances, consider the case that instances and realize with probability . In this case, the expectation of regret satisfies
for all OCO algorithms. Therefore, Theorem 4.2 follows. ∎
B.4 Proof of Proposition 4.4
This subsection presents the proof of Proposition 4.4.
Proof.
Consider the instance as follows:
where
and is a minimum natural number which satisfies . Then,
| (11) |
The second inequality is from . If ,
| (12) |
For the first term, since
for all , and if , we have
Now, is defined as
and therefore, we get
where is a minimum time step which satisfies , i.e., . From this, for sufficiently large so that , we have
| (13) |
Next, for the second term of equation (12), if and , we then have
and since holds from , we have
Therefore, from
we have
| (14) |
We can derive the same bound similarly in the case of .
B.5 Proof of Theorem 5.2
This subsection proves that Theorem 5.2 holds for any . Before stating the proof of Theorem 5.2, we introduce two following lemmas. Here, , , , , , and are introduced in Algorithm 6.
Lemma B.2.
Remark B.3.
According to Wang et al. (2020),
holds instead of inequality (15). However, the above inequality needs to be corrected. In the last part of the proof of this lemma in their paper, they derived
From the definition of and , we have
though they treated this term as . Combining these relationships, we get inequality (15). This mistake seems to be a mere typo since the regret bound in their paper coincides with the result derived from the inequality (15).
Lemma B.4.
B.6 Proof of Lemma 5.4
Proof.
Since holds when , it is sufficient to consider the case . If , then we have
By solving this, we have
The second inequality holds from the inequality for , and the last inequality holds from the inequality of arithmetic and geometric means. ∎
B.7 Proof of Corollary 5.5 for USC
This subsection presents the proof of Corollary 5.5 for USC.
Proof.
Similar to equation (2), if , inequality
holds. By combining these inequalities, we have
From Lemma 5.4 with and , we have
Since in USC, we obtain the following loose upper bound:
On the other hand, by thinking of the case that th expert is MetaGrad or Maler, from Corollary 5.5 for MetaGrad and Maler,
Combining these bounds, we get
∎
B.8 Proof of Theorem 5.6
This subsection presents the proof of Theorem 5.6.
Proof.
From the definition of strong convexity, we have
If , 0 is the upper bound, so it is sufficient to think of the case . In this case, we have
From the assumption of Theorem 5.6, there exists a positive constant such that
Last inequality holds from the inequality for . Here, we use Lemma 5.4 with and ,
From this inequality and , Theorem 5.6 follows. ∎
B.9 Proof of Corollary 5.7 for MetaGrad and Maler
This subsection presents the proof of Corollary 5.7 for MetaGrad and Maler.
B.10 Proof of Corollary 5.7 for USC
This subsection presents the proof of Corollary 5.7 for USC.
Proof.
From the definition of strong convexity, we have
If , 0 is the upper bound, so it is sufficient to think of the case . In this case, we have
By combining these inequalities, we have
From Lemma 5.4 with and , we have
Since in USC, we obtain the following loose upper bound:
On the other hand, by thinking of the case that th expert is Maler, from Corollary 5.7 for Maler, we have
Combining these bounds, we get
∎
B.11 The Lemma in the Proof of Theorem 6.2
In this subsection, we introduce the following lemma used in the proof of Theorem 6.2.
Lemma B.5.
(Hazan 2016) Let be positive definite matrices. We then have
Appendix C Numerical Experiments
In this section, we explain experimental results. We compare the performances of 5 OCO algorithms; OGD with stepsizes , ONS, MetaGrad, Algorithm 1 with (Con-ONS), and Algorithm 1 with (Con-OGD). We include OGD, ONS, and MetaGrad because OGD and ONS are famous OCO algorithms, and MetaGrad is one of the universal algorithms. All the experiments are implemented in Python 3.9.2 on a MacBook Air whose processor is 1.8 GHz dual-core Intel Core i5 and memory is 8GB.
C.1 Experiment 1: Contaminated Exp-Concave
In this experiment, we set , and the objective function is as follows:
where is chosen uniformly at random under the condition that . is -contaminated 1-exp-concave and the minimum value of is if . We repeat this numerical experiment in 100 different random seeds and calculate their mean and standard deviation. Other parameters are shown in Table 2.
We compare the performances of 4 OCO algorithms: OGD, ONS, MetaGrad, and Con-ONS. The parameters of ONS are set as and .
| 1000 | 250 | 100 | 1 |
The time variation of regret and is shown in Figure 1. In the graphs presented in this paper, the error bars represent the magnitude of the standard deviation. Standard deviations in the graphs are large because contamination causes fluctuation in the sequence of solutions. Only points where t is a multiple of 25 are plotted to view the graph easily. The left graph shows that the regrets of all methods are sublinear. MetaGrad and ONS perform particularly well, followed by Con-ONS. From the right graph, we can confirm that of all methods converge to the optimal solution quickly. OGD seems influenced by contamination a little stronger than other methods.

|
|
C.2 Experiment 2: Contaminated Strongly Convex
In this experiment, , and the objective function is as follows:
where is chosen uniformly at random under the condition that . is -contaminated 1-strongly convex and the minimum value of is if . We repeat this numerical experiment in 100 different random seeds and calculate their mean and standard deviation. Other parameters are shown in Table 3.
We compare the performances of 3 OCO algorithms: OGD, MetaGrad, and Con-OGD.
| 1000 | 250 | 1 | 1 |
The time variation of regret and is shown in Figure 2. Only points where is a multiple of 25 are plotted to view the graph easily. The left graph shows that the regrets of all methods are sublinear. The performance of Con-OGD is the best, followed by MetaGrad and OGD, showing correspondence with the theoretical results. From the right graph, we can confirm that of all methods converge to the optimal solution quickly.

|

|
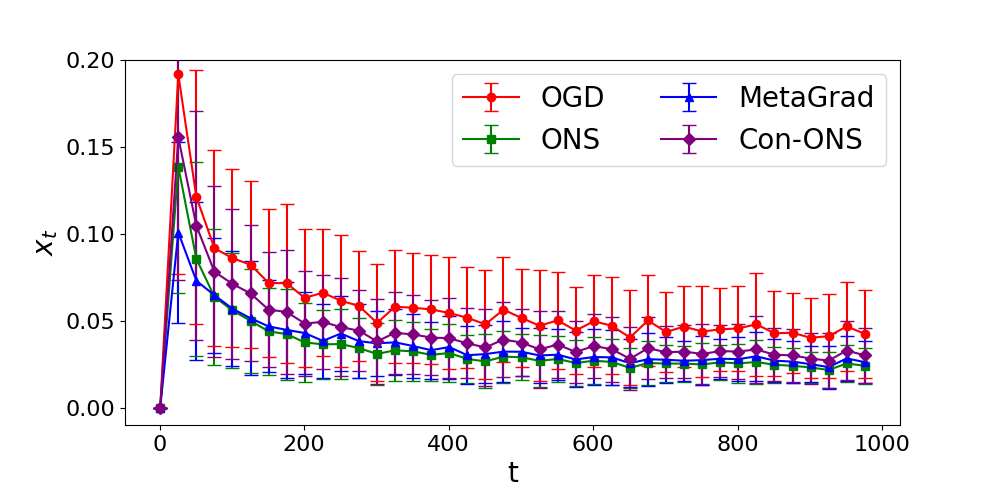
C.3 Experiment 3: Mini-Batch Least Mean Square Regressions
Experimental settings are as follows. We use the squared loss as the objective function:
which is exemplified in Example 3.7. In this experiment, each component of the vector is taken from a uniform distribution on independently. We set and assume there exists an optimal solution which is taken from a uniform distribution on , i.e., we take . We set firstly and compute thresholds and based on , though this is impossible in real applications. Parameters , , are calculated for each and , e.g., , , and for some sequence. The parameters of ONS are set as described in Section A.2. Other parameters are shown in Table 4.
| 10 | 5 | 1000 | 250 |

|

|
The time variation of regret and is shown in Figure 3. The performances of OGD, Con-OGD, and Con-ONS are almost the same in this experiment. The left graph shows that OGD’s, MetaGrad’s, and our proposed method’s regrets are sublinear and consistent with the theoretical results. Though this is out of the graph, ONS’s regret is almost linear even if we take . From the right graph, we can confirm that of OGD, MetaGrad, and proposed methods converge to some point quickly, and that of ONS does not change so much. The poor performance of ONS is because is too small to take large enough stepsizes. This result shows the vulnerability of ONS.