Construction of Protograph-Based Partially Doped Generalized LDPC Codes
Abstract
In this paper, we propose a new code design technique, called partial doping, for protograph-based generalized low-density parity-check (GLDPC) codes. While the conventional construction method of protograph-based GLDPC codes is to replace some single parity-check (SPC) nodes with generalized constraint (GC) nodes applying to multiple variable nodes (VNs) that are connected in the protograph, the proposed technique can select any VNs in the protograph to be protected by GC nodes. In other words, the partial doping technique facilitates finer tuning of doping, which in turn enables a sophisticated code optimization with higher degree of freedom. We construct the proposed partially doped GLDPC (PD-GLDPC) codes using the partial doping technique and optimize the PD-GLDPC codes by the protograph extrinsic information transfer (PEXIT) analysis. In addition, we propose a condition guaranteeing the linear minimum distance growth of the PD-GLDPC codes and use the condition for the optimization. Experimental results show that the optimized PD-GLDPC codes outperform the conventional GLDPC codes and have competitive performance compared to the state-of-the-art protograph-based LDPC codes without the error floor phenomenon over the binary erasure channel (BEC).
Index Terms:
Generalized low-density parity-check (GLDPC) codes, partial doping, partially doped GLDPC (PD-GLDPC) codes, protograph, protograph extrinsic information transfer (PEXIT), typical minimum distance.I Introduction
Low-density parity-check (LDPC) codes, first introduced in [1], have received much attention due to their low decoding complexity and capacity approaching performance [2].
An LDPC code is defined over a bipartite graph consisting of variable nodes (VNs) and single parity-check (SPC) nodes.
As a generalized class of LDPC codes, generalized LDPC (GLDPC) codes were introduced in [3], which are constructed by replacing some SPC nodes with generalized constraint (GC) nodes.
GC nodes are defined by code constraints of a linear code with a larger minimum distance [4], which makes GLDPC codes have a larger minimum distance [5]. In addition, GLDPC codes have several advantages over LDPC codes such as faster decoding convergence [6] and a better asymptotic threshold at the cost of the additional decoding complexity and redundancy introduced by GC nodes [7].
Many types of linear codes for GC nodes, also called as the component codes, are used in the GLDPC codes such as Hamming codes [8], Hadamard codes [9], Bose–Chaudhuri–Hocquenghem (BCH) codes, and Reed-Solomon (RS) codes [10].
The research on GLDPC codes is extended to spatially coupled LDPC codes [11, 12, 13] and doubly GLDPC codes [14, 15, 16].
Moreover, some capacity approaching GLDPC codes were constructed using irregular random GLDPC codes [7, 17].
LDPC codes can be constructed from a small bipartite graph called protograph. Many researches on the protograph-based LDPC codes were previously carried out under various scenarios [18, 19, 20].
Moreover, the protograph-based GLDPC codes were thoroughly studied in [21]-[24], but they mainly focused on the low-rate codes [21, 22, 23, 24].
Protograph-based GLDPC codes can be constructed from a small protograph [25] using the so called doping technique [26].
Doping a GC node, defined by a linear code of length and dimension , means the replacement of an SPC node by the GC node with constraints, which causes a rate loss.
In the perspective of VNs, VNs are selected to be doped by a GC node, assuming that there are no parallel edges in the protograph.
Thus, the smallest unit of doping, also called the doping granularity, is
for the conventional protograph doping technique.
In other words, the conventional doping technique has two limitations: 1) the degree of the SPC node to be replaced should be , which implies that the doping operation is dependent on the underlying protograph and the parameter of component codes and 2) one cannot choose a finer doping granularity less than and thus the code design cannot be sophisticated.
Due to the limited design flexibility, there has been little works on the well-designed optimization for protograph-based GLDPC codes especially for medium to high code rates.
In this paper, we propose a new doping technique, called partial doping on the VNs, to minimize the doping granularity and enlarge the code design freedom.
In detail, the partial doping involves the following three steps: 1) A VN to be doped is selected in the protograph. 2) The Tanner graph is obtained by the lifting operation [25] from the protograph with a lifting factor . 3) Additional GC nodes are connected to the lifted VNs in the Tanner graph after lifting the protograph.
The main difference from the conventional protograph doping technique is that the partial doping operation is conducted on the Tanner graph instead of the protograph domain.
Thus, it is possible to partially dope on a single VN in the protograph and the doping granularity becomes one, which is also independent of .
In other words, the partial doping enables fine tuning of the code structure regardless of the underlying protograph and the parameter of component codes.
Specifically, the selection of VNs to be protected by GC nodes and the rate loss can be adjusted in a more flexible manner.
We denote the proposed protograph-based GLDPC codes constructed using the partial doping as partially doped GLDPC (PD-GLDPC) codes.
The structural characteristics of the PD-GLDPC codes have several advantages.
First, the PD-GLDPC codes are structurally adequate to adopt the puncturing technique that compensates the rate-loss.
Since the partially doped VNs are highly and locally protected by GC nodes, the performance loss occurred by puncturing the doped VNs is relatively small while attaining the code rate gain.
Second, the asymptotic performance of the PD-GLDPC codes can be analyzed by the low-complexity extrinsic information transfer (EXIT) analysis.
For the conventional protograph doped GLDPC codes [26], the exact EXIT analysis is provided in [27], where the topology for the a priori and extrinsic mutual information of GC nodes is considered.
Since the cases of the topology grow exponentially with the component code length , the computational complexity is too high to design a fast optimization algorithm.
On the contrary, GC nodes in the PD-GLDPC codes can be analyzed by an average manner EXIT analysis in [28] because GC nodes in the PD-GLDPC codes are incident to VNs lifted from a single VN in the protograph.
The a priori and extrinsic mutual information of GC nodes can be evaluated by a single value, which facilitates a fast optimization algorithm.
Using this advantage, we propose an efficient optimization algorithm for the PD-GLDPC codes.
In addition, we propose the condition guaranteeing the linear minimum distance growth of the PD-GLDPC codes.
We analytically prove that the PD-GLDPC code ensembles satisfying the condition have the typical minimum distance and use this condition for the construction of the PD-GLDPC codes in this paper.
Also, we propose novel methods to optimize the asymptotic performance, i.e., the threshold of the code ensemble, by using the protograph EXIT (PEXIT) analysis [29] and differential evolution [30] targeting medium code rate and high code rate .
Thus, the optimized PD-GLDPC code ensembles are constructed while satisfying the typical minimum distance condition to have a minimum distance that grows linearly with the block length of the code.
Comparison of the PD-GLDPC codes is made with the existing state-of-the-art protograph LDPC codes and conventional GLDPC codes [17].
Threshold analysis and shows that the optimized protograph-based PD-GLDPC codes outperform the well known GLDPC and protograph-based LDPC codes and have a competitive asymptotic performance compared to the optimized protograph-based LDPC codes.
To be specific, the optimized protograph PD-GLDPC codes from a random ensemble with a low doping ratio achieves the coding gain over the binary erasure channel (BEC) compared to the optimized GLDPC codes [17] with a relatively higher doping ratio 0.4. In addition, the optimized protograph PD-GLDPC code by the differential evolution outperforms AR4JA codes [31] with coding gains and for code rates and , respectively.
Also, the average VN degree of the optimized PD-GLDPC codes, are only and compared to the state-of-the-art protograph LDPC codes for code rates and , respectively.
Similarly, the frame error rate (FER) results show tangible gain in the waterfall performance compared to the existing protograph-based LDPC codes in [31] without the error floor phenomenon up to FER .
We list the contributions of this paper as follows;
1) We propose a novel doping technique, where the constraints of GC nodes are applied to specific VNs lifted from single protograph node, i.e., partial doping on the VNs after lifting.
2) We propose two design criteria for the optimization of the threshold of the PD-GLDPC codes: the EXIT analysis and the condition for the existence of the typical minimum distance.
3) We propose the optimization method of the asymptotic performances for the PD-GLDPC codes using differential evolution.
4) We show the finite length performance gain of the optimized PD-GLDPC codes over some well known LDPC and GLDPC codes.
The rest of the paper is organized as follows.
In Section II, we introduce some preliminaries on the BEC and protograph-based GLDPC codes.
Section III illustrates the proposed PD-GLDPC code structure and derives its PEXIT analysis and the condition for the typical minimum distance. In addition, the comparison of the proposed PD-GLDPC codes and protograph doped GLDPC codes is given.
The optimization algorithms of PD-GLDPC codes are given in Section IV.
Section V shows the error correcting performance of the proposed codes over the BEC compared with other well known protograph-based LDPC codes.
Section VI concludes the paper with some discussion of the results.
II Backgrounds
| Notation | Explanation | |||
|---|---|---|---|---|
| An base matrix defining the protograph | ||||
| Set of VNs in a protograph | ||||
| Set of CNs in a protograph | ||||
| Set of edges connecting and | ||||
| () | Number of edges incident to (), i.e., variable (check) node degree of () | |||
| () | Set of variable (check) nodes incident to (), i.e., neighborhood of () | |||
| Channel information of | ||||
| Extrinsic information sent from () to () | ||||
| A priori mutual information of () sent from (), where is an SPC node | ||||
| A priori (extrinsic) mutual information of a GC node | ||||
| A posteriori probability of | ||||
| component code | Component code with codelength and information size | |||
| Index set of protograph VNs that are partially doped | ||||
| Lifting factor | ||||
| Doping ratio | ||||
| Extrinsic information from to | ||||
| A priori (extrinsic) mutual information of | ||||
| Optimized protograph of the LDPC code | ||||
| Initial irregular protograph that is used to construct the PD-GLDPC code | ||||
| VN (CN) degree distribution to construct | ||||
|
||||
| Random puncturing ratio of the entire protograph | ||||
| Random puncturing ratio for partially doped VNs in the protograph |
In this section, we introduce some notations and concepts of a binary erasure channel, protograph LDPC codes, and the construction method of protograph doped GLDPC codes. The EXIT analysis and the decoding process of protograph doped GLDPC codes are also briefly introduced. The notations mainly used throughout the paper are summarized in Table 1.
II-A Protograph LDPC Code and BEC
Let be a -bit binary message vector, which is encoded via an linear code, forming an -bit codeword .
The codeword passes through a memoryless BEC, where each bit is either erased with a probability or correctly received.
Protograph LDPC codes [25] are defined by a relatively small bipartite graph representing a protograph, where is a set of VNs and is a set of check nodes (CNs).
Let be a set of edges , where connects a VN and a CN .
The bipartite graph can also be expressed in terms of an -sized base matrix , where and is a set of positive integers less than or equal to a positive integer .
The rows represent the CNs and the columns represent the VNs in the protograph.
Each entry of the base matrix represents the number of edges connected between a VN and a CN.
If there are no edges connected between and , the entry is zero.
The variable (check) node degree () is defined as the number of edges incident to itself.
A protograph LDPC code is constructed by copy-and-permute operation of .
The bipartite graph is copied by the lifting factor and copies of each edge are permuted among copies of and .
In general, the large value of guarantees the sparseness of the code.
II-B Construction of Protograph Doped GLDPC Codes [26]

Conventionally, a protograph doped GLDPC code ensemble is constructed by replacing (doping) a CN of a protograph with a GC node that has a parity-check constraint from an linear code (component code), where () is the code length (dimension) and is the minimum distance of the component code for a CN . The condition for replacement is that the CN degree should be exactly equal to the length of the component code, i.e., . Note that the original CN has the parity-check constraint of an SPC code. The code rate of protograph doped GLDPC codes is , where . While the minimum distance of an SPC node is 2, the VNs connected to the GC node are protected by parity-check constraints of the component code with the minimum distance larger than two. Fig. 1 shows the protograph doped GLDPC code of the code rate by replacing an SPC node with the Hamming code constraints.
II-C PEXIT Analysis and Decoding Process of Protograph Doped GLDPC Codes
| (1) |
The asymptotic performance of the protograph doped GLDPC codes is evaluated by the PEXIT analysis.
The PEXIT analysis tracks down the mutual information of extrinsic messages and a priori error probabilities of the VNs, CNs, and GC nodes of protograph GLDPC codes.
For an exact PEXIT analysis, tracking down each mutual information corresponding to edges of the component code is needed, i.e., multi-dimensional EXIT computation [27].
However, in terms of code optimization, where lots of EXIT computation is required, it is beneficial to reduce the complexity of the EXIT computation in GC nodes by averaging the a priori and extrinsic mutual information of the GC nodes.
The EXIT and PEXIT analyses of the protograph doped GLDPC codes over the BEC in terms of average mutual information are given in [32, 28, 29].
The PEXIT process is given in Alg. 1. Let be the channel information from the erasure channel for the protograph VN . In addition, is the extrinsic information sent from () to () and is the a priori mutual information of () sent from (), where is an SPC node.
For GC nodes, we use the notations and for a priori and extrinsic information.
Let () be a set of variable (check) nodes incident to (), i.e., neighborhood of ().
Finally, is a posteriori probability of .
To explain (1) in Alg. 1, if is a GC node with the Hamming code, the PEXIT of the GC node is computed from a closed form using the property of the simplex code, which is the dual code of a Hamming code.
Also, is the average a priori mutual information for a GC node to compute the PEXIT message.
In (1), we have
For two positive integers and , we also have and , where and .
The PEXIT process searches for the minimum to successfully decode, i.e., for all , in an asymptotic sense.
Now, we briefly explain the decoding process of GLDPC codes over the BEC [13].
The VNs process the conventional message-passing decoding over the BEC by sending correct extrinsic messages to the CNs if any of the incoming bits from their neighborhood is not erased.
The SPC nodes send correct extrinsic messages to the VNs if all of their incoming messages are correctly received, and send erasure messages otherwise.
In this paper, the decoding of GC nodes is processed by the maximum likelihood (ML) decoder.
For each iteration, a GC node with the component code receives the set of erasure locations from .
Let be the parity-check matrix (PCM) of the component code and be the submatrix of indexed with .
The decoder computes the Gaussian-elimination operation of , making it into a reduced row echelon form .
If rank(), the GC node solves all the input erasures and otherwise, the decoder corrects the erasures corresponding to the rows with weight 1 from .
The decoding complexity can be further reduced if the GC node exploits bounded distance decoding; however, the degradation of asymptotic performance is not negligible, as shown in [7].
III The Proposed Protograph-based PD-GLDPC Code



In this section, a new construction method of protograph-based GLDPC codes is proposed. While the conventional protograph GLDPC codes are constructed by replacing some protograph SPC nodes in the original protograph by GC nodes using the component code, the proposed protograph-based PD-GLDPC code is constructed by adding the GC nodes for the subset of variable nodes using component codes after the lifting process of the original protograph, where each GC node is connected to the variable nodes copied from single protograph variable node. A block diagram of the construction process of both codes together with the conventional random GLDPC code is given in Fig. 2.
III-A Construction Method of Protograph-based PD-GLDPC Code
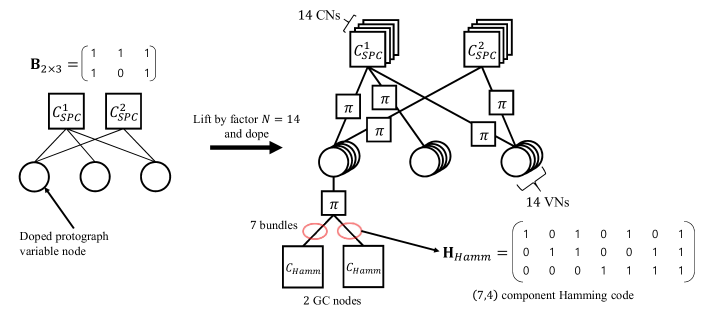
First, we define the partial doping for variable nodes using the addition of GC nodes to a lifted protograph, that is, the addition of rows for the parity check matrix by the component code, where each GC node is incident to variable nodes copied from single protograph variable node. Also, we define a partially doped protograph variable node as a protograph variable node incident to the added GC nodes. While the term doping in conventional GLDPC codes is used in the perspective of check nodes, we use the term partial doping in the perspective of variable nodes. Let be an base matrix, where some protograph variable nodes are partially doped with a component code after the lifting process. Let be the number of the partially doped protograph variable nodes, where each protograph variable node is doped by component codes after the lifting process. Then, a proposed protograph-based PD-GLDPC code is defined with parameters . We assume that the component code used in the paper is the Hamming code and that divides the lifting factor such that , where is a non-negative integer. The variable nodes copied from protograph variable nodes in the base matrix are partially doped by the GC nodes. That is, in the proposed PD-GLDPC code construction, the GC nodes are connected to the variable nodes lifted from each protograph variable node. Thus, the proposed construction method can choose the protograph variable nodes to protect by partial doping. An example of the proposed construction is given in Fig. 3, which illustrates the doping process by a component Hamming code over a base matrix.


The basic concept of the proposed construction is to focus on the protection of VNs lifted from single protograph VN. Although only a portion of VNs from a single protograph VN can be partially doped, for the exactness of EXIT computation and the typical minimum distance analysis, we have limited the doping process over the entire VNs lifted from a single protograph VN.
Since is the multiple of the component code length, all the VNs lifted from single protograph VN can be protected by using GC nodes.
A simple example for the PCM for GC nodes, connected to the VNs lifted from single protograph VN, is shown in Fig. 4(a), where is the PCM of the Hamming code.
Although the PCM of the Hamming code can be applied randomly, a trivial representation of applying generalized constraints sequentially is given.
The constructed PD-GLDPC code has a PCM as in Fig. 4(b), where the upper part is the PCM of the added GC nodes and the lower part refers to the PCM of the LDPC code lifted from the original protograph.
Intuitively, represents the PCM for each partially doped VN in the protograph and thus, the bundles of matrices are diagonally appended to the PCM of the PD-GLDPC code.
Since the doping proceeds after the lifting process, PD-GLDPC codes cannot be expressed in terms of a protograph.
We define the doping ratio as the portion of GC nodes over the entire constraint nodes, i.e.,
Also, we define the doping granularity as the minimum number of protograph VNs needed for doping. For the protograph doped GLDPC codes with component code, the doping granularity is , whereas the proposed PD-GLDPC code has doping granularity 1. The finer doping granularity of the PD-GLDPC codes allows the construction of protograph-based GLDPC codes with the higher rate.
III-B The PEXIT Analysis of Protograph-based PD-GLDPC Codes

The PEXIT of the proposed protograph-based PD-GLDPC codes is similar to that of the conventional protograph GLDPC codes in Alg. 1 except for the EXIT of a GC node. Since the incoming mutual information of each GC node is obtained from only one protograph variable node in the proposed code, the average mutual information sent to each GC node is the same as the extrinsic message of the protograph variable node connected to the GC node. Let be the virtual node representing the set of GC nodes connected to the protograph variable node . An example of the representation of a virtual node over a protograph is given in Fig. 5. Note that although is not a protograph node itself, it is possible to compute the PEXIT of a protograph-based PD-GLDPC code. Also, let be the extrinsic information from to expressed as
Since is solely connected to , the index term for the extrinsic information from to is expressed by the notation of only. In order to compute the EXIT of , let and be the a priori and extrinsic mutual informations of , respectively. Note that the EXIT of each GC node is computed from single a priori mutual information to process single value of extrinsic mutual information for the neighboring variable nodes. For the conventional protograph GLDPC codes, the a priori mutual information of a protograph GC node is computed by averaging the extrinsic mutual information of its neighboring variable nodes. However, for the proposed protograph-based PD-GLDPC codes, since receives the extrinsic mutual information of only, it is clear that . We also compute the extrinsic mutual information from to denoted as using (1), given the a priori mutual information , which is given as
| (2) |
Note that for the proposed protograph-based PD-GLDPC codes, the a priori (extrinsic) EXIT of the GC node is computed from the extrinsic (a priori) EXIT of single protograph variable node. While the EXIT of variable nodes and SPC nodes for the proposed protograph-based PD-GLDPC codes is the same as that of the conventional protograph GLDPC codes described in Alg. 1, the EXIT of the GC nodes in the proposed codes is changed to (2) whereas the conventional protograph GLDPC codes use (1).
In general, as the portion of degree-2 variable nodes in the LDPC codes increases, the asymptotic performance is enhanced [37], but their minimum distance decreases and then the error floor becomes worse.
Although the proposed protograph-based PD-GLDPC code construction method enables the partial doping for any variable nodes in the given protographs, we focus only on partial doping for degree-2 variable nodes as follows.
First, we construct the original base matrix with the large portion of degree-2 variable nodes.
Then, we partially dope some of the protograph variable nodes of degree-2 to increase the minimum distance and improve their performance.
Thus, regular protographs of degree-2 variable nodes and irregular protographs with many degree-2 variable nodes are used for the construction of the proposed protograph-based PD-GLDPC codes.
In terms of irregular ensemble LDPC codes, a large portion of degree-2 variable nodes enables the LDPC code to achieve the capacity approaching performance [38].
On the other hand, by reasonably selecting the number of partially doped variable nodes for degree-2, the property of the linear minimum distance growth with the length of the LDPC code can be guaranteed.
Thus, when we design the proposed protograph-based PD-GLDPC codes, balancing the partial doping over degree-2 variable nodes enables both the existence of a typical minimum distance and a good asymptotic performance.
III-C Condition for Typical Minimum Distance of Protograph-based PD-GLDPC Code
The existence of a typical minimum distance in the given LDPC codes guarantees that their minimum distance grows linearly with the block length of the code in an asymptotic sense [34].
It was proved in [35] that a protograph LDPC code has a typical minimum distance if there is no cycle consisting of only degree-2 variable nodes in the protograph.
Furthermore, in [36], the condition for a typical minimum distance of the conventional protograph GLDPC codes was given as follows.
Assuming that there are no degree-2 variable nodes with double edges, i.e., no type 1 degree-2 variable nodes defined in [36], the neighborhoods of a check node that satisfy are removed along with its edges, where is the number of degree-2 variable nodes among the neighborhoods of .
This process is repeated until no further degree-2 variable nodes remain.
Then, the GLDPC code has a typical minimum distance if all degree-2 variable nodes are removed.
The proposed protograph-based PD-GLDPC code also has a similar approach to that of the conventional protograph GLDPC codes in [36].
However, since a GC node of the proposed protograph-based PD-GLDPC code is not well defined by a protograph node, the derivation of the weight enumerator of the proposed codeword is quite different from that of the conventional GLDPC code.
Thus, the condition for the existence of the typical minimum distance of the proposed protograph-based PD-GLDPC codes is slightly different from that of the conventional protograph LDPC code.
That is, the degree-2 variable nodes to be partially doped are initially excluded before the degree-2 variable node removing process stated in [35], because those variable nodes should be changed to the variable nodes of degrees higher than two by partial doping. Thus, we can regard the degree-2 variable nodes to be partially doped as the variable nodes with higher degrees.
Then, we have the following theorem for the proposed protograph-based PD-GLPDC codes.
Theorem 1.
For a protograph-based PD-GLDPC code, if the undoped degree-2 variable nodes in the protograph have no cycles among themselves, the proposed protograph-based PD-GLDPC code has a typical minimum distance.
Proof.
The proof is given in Appendix A.
The existence of the typical minimum distance of the proposed protograph-based PD-GLDPC code guarantees that the minimum distance of the proposed code grows linearly with the code length of the LDPC code, and thus the proposed code has low error floor for the large code length. In the next section, we use Theorem 1 as the constraint to optimize the protograph in order to guarantee the existence of the typical minimum distance of the proposed protograph-based PD-GLDPC code.
III-D Comparison between the Proposed PD-GLDPC Code and the Conventional Protograph GLDPC Code
The main difference between the proposed protograph-based PD-GLDPC codes and the conventional protograph GLDPC codes is the perspective of doping.
While the conventional protograph GLDPC code replaces an entire row, i.e., a protograph check node by the parity check matrix of the component code, the proposed protograph-based PD-GLDPC code appends some rows incident to the variable nodes copied from single protograph variable node.
The focus of the conventional protograph GLDPC code is to choose a certain protograph check node, whereas the protograph-based PD-GLDPC code is focusing on choosing which protograph variable nodes are further protected by partial doping.
The constraint for the conventional protograph GLDPC code is that the check nodes to be replaced should have the degree equal to the component code length, while the constraint for the proposed protograph-based PD-GLDPC codes is that the lifting size of a protograph should be the multiple of the component code length.
The selection of the check nodes to be replaced in the conventional protograph GLDPC codes is generally difficult since it requires a combinatory search of either the best threshold, minimum distance, or convergence speed.
Also, since many SPC nodes of a given base matrix connect the variable nodes with various degrees, it is very difficult to select the variable nodes to be partially doped for further protection in the conventional protograph GLDPC codes.
Furthermore, the conventional protograph GLDPC code construction has two limitations in terms of PEXIT analysis and doping granularity.
First, the PEXIT analysis of the conventional protograph GLDPC codes is not accurate because the PEXIT of the GC node is derived from averaged EXIT of (component code length) protograph variable nodes.
Using a MAP-oriented computation as in Alg. 1, the GC node outputs a single value that represents the extrinsic mutual information for the protograph variable nodes.
Thus, a GC node averages up the a priori mutual information of the neighborhood protograph variable nodes and outputs uniform extrinsic mutual information, which is similar to the EXIT analysis of a random ensemble LDPC code [28].
Since each GC node receives a priori inputs from different protograph variable nodes, the EXIT analysis is not accurate.
Thus, the higher variance of the a priori mutual information from the average, the greater the deviation of the code between the threshold and the actual decoding performance.
On the other hand, since the EXIT of a GC node in the proposed protograph-based PD-GLDPC code requires the a priori mutual information of the same protograph variable node, there is no deviation since the mutual information has the same value, which makes the PEXIT of the proposed code more accurate.
The second limitation is that the conventional protograph GLDPC codes have large doping granularity of protograph variable nodes compared to that of the proposed one.
By replacing a single protograph GC node by a component code with parameters , the protograph variable nodes are doped. Whereas, for every partial doping of GC nodes in the proposed protograph-based PD-GLDPC code, the variable nodes copied from single protograph variable node are partially doped. In other words, the doping granularity is one, which is smaller than the conventional protograph GLDPC codes.
In summary, compared to the conventional protograph GLDPC codes, the proposed protograph-based PD-GLDPC code is more accurate in the PEXIT analysis and has the smaller doping granularity.
IV Optimization of PD-GLDPC Codes
In this section, we introduce two optimization methods for the PD-GLDPC codes. The first subsection illustrates the construction method of protographs from the degree distribution of a random LDPC code ensemble in order to conduct comparison between LDPC codes and PD-GLDPC codes under the same degree distribution. The second subsection shows the optimization method of the protograph using the differential evolution algorithm in order to conduct comparison between LDPC codes and PD-GLDPC codes without any constraints.
IV-A Differential Evolution-Based Code Construction from the Degree Distribution of Random LDPC Code Ensembles
In general, as the portion of degree-2 VNs in the LDPC codes increases, the asymptotic performance is enhanced [37], but their minimum distance decreases and then the error floor becomes worse.
For the construction of PD-GLDPC codes in this subsection, we exploit the balance of the portion of degree-2 VNs, where we focus on the partial doping only for degree-2 VNs. The brief construction method is as follows.
First, we construct the original base matrix with the large portion of degree-2 VNs.
Then, we partially dope some of the protograph VNs of degree-2 to increase the minimum distance and improve their performance.
Thus, irregular protographs with several degree-2 VNs are used for the construction of the proposed PD-GLDPC codes.
In terms of irregular LDPC code ensembles, a large portion of degree-2 VNs enables the LDPC code to achieve the capacity approaching performance [38].
On the other hand, by reasonably selecting the number of partially doped VNs of degree-2, the property of the linear minimum distance growth with the length of the LDPC code can be guaranteed.
Thus, when we design the proposed PD-GLDPC codes, balancing the partial doping over degree-2 VNs enables both the existence of a typical minimum distance and a good asymptotic performance.
Optimization of irregular protograph LDPC code ensembles is made by initially obtaining the degree distribution of the random LDPC code ensemble using differential evolution [30] and constructing the protograph via the progressive edge growth (PEG) [39] algorithm for the construction of the proposed PD-GLPDC codes from
irregular protographs.
In this subsection, in order to make the CN degrees as even as possible, we try to construct the protograph from the degree distribution of a random LDPC code ensemble.
We define as the optimized protograph of the conventional LDPC code and as the initial irregular protograph that is used to construct the PD-GLDPC code.
That is, we can regard as the protograph corresponding to in Fig. 4.
In order to compare FER performances of the conventional LDPC code and the proposed PD-GLDPC code under the same degree distribution, is constructed to have the same VN degree distribution as the PD-GLDPC code constructed from after lifting by .
Let and be the VN and CN degree distributions of an irregular LDPC code ensemble to construct , which is the optimized protograph for the conventional LDPC codes.
In this subsection, we assume the degree distributions and , where and are the portions of edges of VNs and CNs of degree-.
Using the optimized degree distributions of and , a protograph is constructed by the PEG algorithm.
For the description of the protographs that construct the conventional LDPC codes and the proposed PD-GLDPC codes, let be a -sized vector defining the numbers of protograph VNs, where is the number of protograph VNs of degree and is a set of VN degrees that exist in the protograph.
-
(a)
rate constraint
-
(b)
typical minimum distance constraint
-
(c)
existence constraint
In order to make the same VN degree distributions of the LDPC codes constructed from and the PD-GLDPC codes constructed from after lifting by , optimization of and should be constrained by , which is the maximum number of bulks of protograph VNs allowed to be partially doped in .
Although doping granularity for the proposed PD-GLDPC code is 1, we consider doping for bulks of protograph VNs in order to easily match the code rate and degree distribution because the purpose of this subsection is comparing FER performances between the conventional LDPC code and the proposed PD-GLDPC code under the same degree distribution.
A PD-GLDPC code is constructed by partially doping protograph VNs in .
Construction of a PD-GLDPC code from is optimized by ranging the doping bulk , .
That is, we search for the optimal value which maximizes the coding gain between the PD-GLDPC codes constructed from and the conventional protograph LDPC codes constructed from .
Conditions for the degree distributions in order to construct are derived as follows.
The conditions need to guarantee two criteria: i) the VN degree distributions of the protograph LDPC code constructed from and the PD-GLDPC code constructed from after lifting by are the same and ii) a typical minimum distance exists for both code ensembles.
In this subsection, we assume that partial doping is conducted for the first degree-2 protograph VNs without loss of generality due to randomness of the PEG algorithm.
For the bulks of partially doped protograph VNs using the PCM of the Hamming code, the numbers of protograph VNs in should be
Given that is represented as , for the existence constraint, each element of should be non-negative. The parameters are approximated by the PEG construction as
where .
For the realization of the protograph from the degree distribution using the PEG algorithm, if the summation is lower than , the values of are added by 1 in order starting from the lowest VN degree until the summation is equal to .
If is determined for a given as , where , defined by can be constructed for .
By allowing the PEG algorithm of the VN degree distribution over a base matrix with size , both the code rate and the VN degree distributions for the LDPC codes constructed from and the proposed PD-GLDPC codes constructed from after lifting by are matched.
We search for the value of , which has the best PEXIT threshold while having a typical minimum distance.
The optimized doping value is denoted as . The construction of and the PD-GLDPC code is described in Alg. 2.
| (threshold) |
|
|
Coding gain | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 |
|
|
|
||||||||
| 10 |
|
|
|
||||||||
| 15 |
|
|
|
The protograph of the conventional protograph LDPC code, is made for for the half-rate protograph LDPC code ensemble. The numerical results are summarized in Table II, where the coding gain given for the proposed PD-GLDPC code is compared to the conventional protograph LDPC code with the equal degree distribution.
IV-B Optimization of PD-GLDPC Codes Using Protograph Differential Evolution
In this subsection, we propose the optimization method using the differential evolution algorithm.
Similar to the differential evolution algorithm in [37], we use the differential evolution algorithm to find the protograph with the optimized BEC threshold.
The parameters for the differential evolution are given as follows.
The number of generations of the algorithm is set to . Each entry of the base matrix can have the integer value varying from to a positive integer .
The number of base matrices examined for each generation instance is defined as .
For a given base matrix size , we fix .
The mutation parameter is fixed to and is a uniform random variable with the domain .
Lastly, the crossover probability is fixed to in this paper.
We define the optimized PD-LDPC code ensemble as and the optimization algorithm is given in Alg. 3.
It is clear that while the optimization process is the same as that of the protograph LDPC codes, the indices of the partial doping represented by are included, which show the protograph VNs that are doped by GC nodes.
Although the indices of can be arbitrarily selected for code constructions using the differential evolution algorithms, we fix the number of indices as small as possible. For applications on partially doping over a given protograph, algorithms selecting the indices of can be made to optimize the performance of the code ensemble.
Also, the criterion for the existence of the typical minimum distance derived in Theorem 1 is used during the construction of new trial matrices for the proposed PD-GLDPC codes. The component code used in the following optimization is a Hamming code.
| (3) |
| (4) |
We optimize the protographs for the PD-GLDPC codes for base matrices with size and .
We set and for , and for .
Let be the resulting base matrix of the optimization for both cases. The optimized base matrix result of is given in (3), where the BEC threshold is with the code rate .
Likewise, the result of is given in (4), where the BEC threshold is with the code rate .
The bold parts in the matrix represent VNs that are partially doped.
The results show that the VN with the highest degree is partially doped.
From these optimization results, we can expect that partially doping VNs with high degree and puncturing some portion of them for rate matching can improve the performance of the proposed PD-GLDPC codes.
The approach of partially doping and puncturing is a similar techique to the precoding and puncturing.
Precoding and puncturing high degree VNs in a protograph is a well known technique in order to enhance the threshold of protograph LDPC codes [40].
Precoding takes place by placing a CN between a degree-1 VN and a high degree VN.
In order to compensate for the rate loss, the high degree VN is punctured.
From some intuition of the proposed optimization results and well known concepts of precoding, we apply a similar approach of the precoding technique to the proposed PD-GLDPC codes.
We first define as the portion of random puncturing for VNs that are doped.
For the BEC, we use the concept in [41] to derive . For a target code rate , the random puncturing ratio is .
Thus, is derived as and we use it for the computation of the EXIT during the optimization algorithm.
The channel values for the partially doped VNs become .
Thus, it is possible to construct the PD-GLDPC codes for the target code rate by using the random puncturing method.
For the construction of PD-GLDPC codes with the target code rate , the base matrix is optimized using Alg. 3 for , , and .
Likewise, for the target code rate , the base matrix is optimized for , , and .
Let be the resulting base matrix for the optimized results of the protographs constructed by puncturing partially doped VNs.
The optimized base matrices for both code rates are given as
| (5) |
| (6) |
where resulting base matrix for is given in (5) and the resulting base matrix for is given in (6). The resulting thresholds of the optimized base matrices are and for target code rates and , respectively. The optimization results show that the constructed PD-GLDPC codes have capacity approaching performances and the average VN density is reduced by huge amount compared to . Since the base matrix is driven from the random puncturing of partially doped VNs, we define the constructed PD-GLDPC code ensemble with parameters .
V Numerical Results and Analysis
In this section, we propose the optimized protograph design and show the BLER of the proposed protograph-based PD-GLDPC codes. The performance of the conventional protograph LDPC code is compared with that of the proposed protograph-based PD-GLDPC code. In order to make this comparison, we construct a protograph ensemble that has the same variable node degree distribution as that of the proposed protograph-based PD-GLDPC code.
In this section, we propose the optimized protograph design and show the FER of the proposed PD-GLDPC codes. The performance of the conventional protograph LDPC code is compared with that of the proposed PD-GLDPC code. Two methods of comparison are conducted. The first subsection compares them under the same degree distribution using Alg. 2. The second subsection compares the performance of the PD-GLDPC codes constructed without the degree distribution constraints using Alg. 3 to the state-of-the-art protograph LDPC codes.
V-A Simulation Result for Optimized PD-GLDPC Code from Irregular Random LDPC Code Ensembles

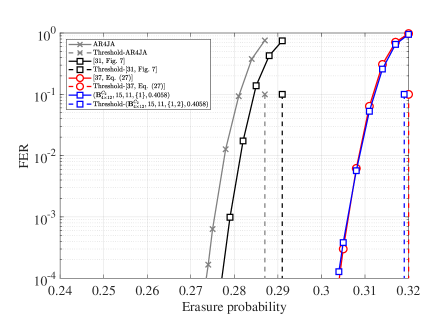
As the performance comparison with the existing GLDPC codes, we use the random GLDPC code ensemble with the threshold in [17] that is represented as and a doping ratio by the Hamming code. Fig. 6 shows performance comparison of four half-rate codes which are AR4JA code [31], the irregular protograph LDPC code constructed from , the random ensemble-based GLDPC code in [17], and the proposed PD-GLDPC code constructed from in Table 2, where . All four codes in Fig. 6 are codes of the half-rate, where is defined as and has the same VN degree distribution as the PD-GLDPC code after lifting by . protograph VNs are partially doped in the PD-GLDPC code. For the constructed PD-GLDPC code, we have . The constructed PD-GLDPC code for has a coding gain of 0.0079 and 0.0039 compared to the GLDPC code in [17] and the irregular protograph LDPC code from , respectively. Fig. 6 shows that the proposed PD-GLDPC code has a good performance both in the waterfall and the low error floor region due to the fact that the code is optimized by increasing the doping as much as possible, and at the same time, the typical minimum distance constraint is satisfied. In terms of the asymptotic analysis, increasing the portion of degree-2 VNs increases the possibility of the code to approach the channel capacity [38]. However, the existence of a typical minimum distance of the protograph is also important, which upper bounds the portion of degree-2 VNs in the LDPC code. Thus, balancing the portion of degree-2 VNs is needed in order to satisfy both a typical minimum distance condition and a good threshold. The proposed PD-GLDPC code guarantees the balance of the degree-2 VNs by carefully choosing the rate of the protograph code and the number of doping on degree-2 VNs.
V-B Simulation Results for PD-GLDPC Code from Optimized Protograph

| Code type | Code rate | Protograph size | Threshold | Average VN degree | Gap to capacity |
| AR4JA [31] | 0.5 | 35 | 0.438 | 3 | 0.062 |
| Protograph [31, Fig. 7] | 0.5 | 48 | 0.468 | 4.25 | 0.032 |
| Protograph [37] | 0.5 | 816 | 0.486 | 5.25 | 0.014 |
| PD-GLDPC | 0.5 | 816 | 0.4857 | 4.58 | 0.0143 |
| AR4JA [31] | 0.67 | 37 | 0.287 | 3.29 | 0.046 |
| Protograph [31, Fig. 7] | 0.67 | 26 | 0.292 | 5 | 0.041 |
| Protograph [37] | 0.67 | 412 | 0.320 | 5.08 | 0.013 |
| PD-GLDPC | 0.67 | 412 | 0.319 | 4.09 | 0.014 |
The proposed PD-GLDPC codes for and are constructed from the ensembles and , respectively.
The protographs are shown in (5) and (6).
The AR4JA [31] and block protograph codes in [31, 37] of the same code rate are used for performance comparison.
We first compare the threshold and average VN degree between the proposed PD-GLDPC code ensembles and the aforementioned protograph LDPC code ensembles in Table 3.
The average VN degree of the PD-GLDPC codes considers both the base matrix and the edges added from the partial doping.
The results show that the asymptotic performance of the proposed PD-GLDPC code ensemble outperforms the AR4JA and block protograph introduced in [31].
The average VN degree of the PD-GLDPC codes is low while having the asymptotic performance comparable to the capacity approaching protographs introduced in [37].
By using the PEG algorithm, the protographs are lifted to construct PD-GLDPC code for . The protograph AR4JA and protographs in [31, 37] are lifted to the same code length. The FER results are shown in Fig. 7(a). Likewise, the protograph of the PD-GLDPC, AR4JA, and [37] are lifted to construct codes for . The protograph in [31, Fig. 7] is lifted to blocklength near .
The FER results are shown in Fig. 7(b).
The doping ratio for the PD-GLDPC codes is for both code rates and .
Also, the FER results of the proposed PD-GLDPC codes for both code rates and show tangible gain compared to the AR4JA code and protograph code in [31].
Also, the performance is comparable to the capacity approaching block LDPC code in [37].
The partial doping and puncturing technique, which is similar to the precoding technique, shows that the capacity approaching PD-GLDPC codes can be constructed with the relatively low average VN degree.
VI Conclusion
We proposed a new class of GLDPC codes called PD-GLDPC codes that has advantages of a finer doping granularity compared to the conventional protograph doped GLDPC codes. Also, we proposed two optimization algorithms for the PD-GLDPC codes: protographs constructed from random LDPC code ensembles and protographs for PD-GLDPC code ensembles constructed from genetic algorithms. Furthermore, we proposed the partially doping and puncturing technique. Using the proposed technique, the constructed PD-GLDPC codes have good FER performances compared to the popular protograph LDPC codes. Since it is possible to partially dope the protograph VNs with a granularity one, the rate loss is reduced from partial doping, and thus, GLDPC codes can have capacity approaching performance in the medium to high code rate regime. For future work, use of other component codes and protographs with degree-1 VNs can be studied. Also, constructions of PD-GLDPC codes by generalizing the partial doping process such as doping over multiple protograph VNs or doping only a portion of a protograph VN can be considered. Furthermore, new constructions of PD-GLDPC codes over additive white Gaussian noise channels can be made.
Abbreviations
| AR4JA | Accumulate-Repeat-4-Jagged-Accumulate |
|---|---|
| BEC | Binary erasure channel |
| CN | Check node |
| EXIT | Extrinsic information transfer |
| FER | Frame error rate |
| GC | Generalized constraint |
| GLDPC | Generalized low-density parity-check |
| LDPC | Low-density parity-check |
| ML | Maximum likelihood |
| PCM | Parity-check matrix |
| PD-GLDPC | Partially doped GLDPC |
| PEG | Progressive edge growth |
| PEXIT | Protograph EXIT |
| SPC | Single parity-check |
| VN | Variable node |
Appendix A Proof of Theorem 1: The Constraint for the Existence of the Typical Minimum Distance of the Proposed Protograph-based PD-GLDPC Codes
A proof for the constraint of the existence of a typical minimum distance for the proposed protograph-based PD-GLDPC codes is given in this appendix.
Similar to that in [36], a typical minimum distance is driven by the weight enumerator analysis over the lifted protograph.
In order to use the notations in [36], we’ve distinguished the indexing notations during the enumeration for the partially doped variable nodes using ′.
Also, the and notations are used for the check nodes and the variable nodes, respectively.
Suppose that the proposed protograph-based PD-GLDPC code is constructed from the protograph defined by and the variable nodes are partially doped, where component codes are identical with the parameters .
We are given a variable node set and a check node set for the protograph.
It is important to note that the GC node set is not defined over a protograph.
However, the codeword enumeration can be made when the protograph is lifted, where is a virtual check node that represents the Hamming check nodes used for partial doping for in the original protograph.
Although is not a protograph check node, we define it for the enumeration of the partially doped protograph variable nodes.
The protograph-based PD-GLDPC code is constructed by lifting the graph by times and permuting the replicated edges.
Each () has degree () and each has degree .
For the enumeration of the GC node , we can think of it as a protograph node of degree that is lifted by a factor of .
The upper bound of the weight enumerator of the proposed protograph-based PD-GLDPC code with weight , denoted as is derived as follows.
Let be the th edge weight from a variable node .
For a partially doped variable node , there are weights sent towards the incident GC node, where the th weight is defined as .
For a given input weight vector , we need to calculate and sum it over every instance of that satisfies . For input , it is clear that because the extrinsic weight consists of weights solely from .
We introduce the following notations:
-
•
is the vector weight enumerator for a variable node of the protograph [36].
-
•
is the vector weight enumerator for a check node of the original protograph, for the incoming weight vector [36].
-
•
is the vector weight enumerator for partially doped variable nodes .
-
•
is the vector weight enumerator for check nodes that are created during the lifting process given the weight vector . is the summation of enumerators over all possible values given that satisfying
where such that
Then, the weight enumerator is given as
where
The solution to the equation is given as . The term is lower bounded by . Then, can be upper bounded as
| (7) |
where is the total weight of the partially doped variable nodes. Then is used for the second and the third inequalities in (7). It was shown in (18) of [36] that the inequality
holds, where is the minimum distance of an SPC component code for the original protograph and is the maximum number of codewords of an SPC component code. Using the similar notations in [36], let and be the minimum distance and the number of codewords of the component code for the GC nodes. Then, is upper bounded as
| (8) |
For the inequality in the third line of (8), we use the fact that with , which is clear by using the derivative on the multivariable function that consists of independent ’s. The equality is satisfied when all values are the same. Going back to (7), let for convenience. Then we have
| (9) |
We classify the variable nodes in the protograph into three groups before doping:
-
•
Protograph variable nodes of degrees higher than 2
-
•
Protograph variable nodes of degree 2 to be partially doped
-
•
Protograph other variable nodes of degree 2.
We also separate the weights of codewords after lifting into three parts according to the three groups of variable nodes: , , and , where is the weight of the sub-codeword corresponding to a protograph variable node of degree higher than 2 and and are the weights of codewords of each partially doped and undoped protograph variable node and of degree 2 from the protograph, respectively. The sum of sub-codeword weights for each group of variable nodes is given as , , and . It is clear that for the total codeword weight , . Then, the upper bound of the first term in (9) is written as
| (10) |
which is derived by using three weight groups of codewords similar to (20) of [36]. We share the same inequality over the given codeword weight as in [36]. Using the derivation in [36], the upper bound of the second term of (9) can be derived as
| (11) |
Using (10) and (11), the upper bound of is derived in terms of as follows:
| (12) |
Let be the parameter satisfying . Then, from the upper bound in (12), is given as
Assuming that there are no type 1 degree-2 variable nodes defined in [36] and there are no cycles consisting only of undoped variable nodes of degree-2, we use the result of (22) in [36] such that the inequality is satisfied for all , where is the weight of the degree-2 undoped variable node of and the total weight of them is denoted as for check node . Similar to the result in [36], we can derive the upper bound , which is the same as . Now, the upper bound of needs to be derived for independent values and . The first and second partial derivatives of by are given as
Since the first derivative over is negative and the second derivative is positive, is upper bounded by
Since the resulting upper bound of is the same as (37) in [36], the rest of the proof is the same as that in [36] and thus the proposed constraint guarantees the existence of typical minimum distance of the proposed protograph-based PD-GLDPC code.
Acknowledgment
The authors would like to thank…
References
- [1] R. G. Gallager, “Low-density parity-check codes,” IRE Trans. Inf. Theory, vol. 8, no. 1, pp. 21–28, Jan. 1962.
- [2] D. J. C. MacKay and R. M. Neal, “Near shannon limit performance of low density parity check codes,” IEEE Electron. Lett., vol. 32, no. 18, pp. 1645–1646, 1996.
- [3] R. M. Tanner, “A recursive approach to low complexity codes,” IEEE Trans. Inf. Theory, vol. 27, no. 5, pp. 533–547, Sep. 1981.
- [4] G. Liva and W. E. Ryan, “Short low-error-floor Tanner codes with Hamming nodes,” in Proc. IEEE MILCOM, 2005.
- [5] S. Abu-Surra, D. Divsalar, and W. E. Ryan, “Enumerators for protograph-based ensembles of LDPC and generalized LDPC codes,” IEEE Trans. Inf. Theory, vol. 57, no. 2, pp. 858–886, Feb. 2011.
- [6] I. P. Mulholland, E. Paolini, and M. F. Flanagan, “Design of LDPC code ensembles with fast convergence properties,” in Proc. IEEE BlackSeaCom, 2015.
- [7] Y. Liu, P. M. Olmos, and T. Koch, “A probabilistic peeling decoder to efficiently analyze generalized LDPC codes over the BEC,” IEEE Trans. Inf. Theory, vol. 65, no. 8, pp. 4831–4853, Aug. 2019.
- [8] M. Lentmaier and K. S. Zigangirov, “On generalized low-density parity-check codes based on Hamming component codes,” IEEE Commun. Lett., vol. 3, no. 8, pp. 248–250, Aug. 1999.
- [9] G. Yue, L. Ping, and X. Wang, “Generalized low-density parity-check codes based on Hadamard constraints,” IEEE Trans. Inf. Theory, vol. 53, no. 3, pp. 1058–1079, Mar. 2007.
- [10] N. Miladinovic and M. Fossorier, “Generalized LDPC codes with Reed-Solomon and BCH codes as component codes for binary channels,” in Proc. IEEE GLOBECOM, 2005.
- [11] D. G. M. Mitchell, M. Lentmaier, and D. J. Costello, “On the minimum distance of generalized spatially coupled LDPC codes,” in Proc. IEEE ISIT, Jul. 2013.
- [12] P. M. Olmos, D. G. M. Mitchell, and D. J. Costello, “Analyzing the finite-length performance of generalized LDPC codes,” in Proc. IEEE ISIT, Jun. 2015.
- [13] D. G. M. Mitchell, P. M. Olmos, M. Lentmaier, and D. J. Costello, “Spatially coupled generalized LDPC codes: Asymptotic analysis and finite length scaling,” IEEE Trans. Inf. Theory, vol. 67, no. 6, pp. 3708–3723, Jun. 2021.
- [14] E. Paolini, M. P. C. Fossorier, and M. Chiani, “Generalized and doubly generalized LDPC codes with random component codes for the binary erasure channel,” IEEE Trans. Inf. Theory, vol. 56, no. 4, pp. 1651–1672, Apr. 2010.
- [15] Y. Wang and M. Fossorier, “Doubly generalized LDPC codes,” in Proc. IEEE ISIT. 2006.
- [16] Y. Wang and M. Fossorier, “Doubly generalized LDPC codes over the AWGN channel,” IEEE Trans. Commun., vol. 57, no. 5, pp. 1312–1319, May 2009.
- [17] R. Guan and L. Zhang, “Hybrid Hamming GLDPC codes over the binary erasure channel,” in Proc. IEEE ASID, 2017.
- [18] Y. Fang, G. Bi, Y. L. Guan, and F. C. M. Lau, “A survey on protograph LDPC codes and their applications,” IEEE Commun. Surveys Tuts., vol. 17, no. 4, pp. 1989–2016, Fourthquarter 2015.
- [19] M. Stinner and P. M. Olmos, “On the waterfall performance of finite-length SC-LDPC codes constructed from protographs,” IEEE J. Sel. Areas Commun., vol. 34, no. 2, pp. 345–361, Feb. 2016.
- [20] Z. Yang, Y. Fang, G. Cai, G. Zhang, and P. Chen, “Design and optimization of tail-biting spatially coupled protograph LDPC codes under shuffled belief-propagation decoding,” IEEE Commun. Lett., vol. 24, no. 7, pp. 1378–1382, Jul. 2020.
- [21] P. W. Zhang, F. C. M. Lau, and C. -W. Sham, “Spatially coupled PLDPC-Hadamard convolutional codes,” IEEE Trans. Commun., Early Access, 2022.
- [22] P. -W. Zhang, F. C. M. Lau, and C. -W. Sham, “Protograph-based LDPC Hadamard codes,” IEEE Trans. Commun., vol. 69, no. 8, pp. 4998–5013, Aug. 2021.
- [23] P. W. Zhang, F. C. M. Lau, and C. -W. Sham, “Layered decoding for protograph-based low-density parity-check Hadamard codes,” IEEE Commun. Lett., vol. 25, no. 6, pp. 1776–1780, Jun. 2021.
- [24] A. K. Pradhan and A. Thangaraj, “Protograph LDPC codes with block thresholds: extension to degree-one and generalized nodes,” IEEE Trans. Commun., vol. 66, no. 12, pp. 5876–5887, Dec. 2018.
- [25] J. Thorpe, “Low-density parity-check (LDPC) codes constructed from protographs,” Jet Propulsion Lab., Pasadena, CA, INP Progress Rep. 42–154, 2003.
- [26] G. Liva, W. E. Ryan, and M. Chiani, “Quasi-cyclic generalized LDPC codes with low error floors,” IEEE Trans. Commun., vol. 56, no. 1, pp. 49–57, Jan. 2008.
- [27] M. Lentmaier, M. B. S. Tavares, and G. P. Fettweis, “Exact erasure channel density evolution for protograph-based generalized LDPC codes,” in Proc. IEEE ISIT, 2009.
- [28] A. Ashikhmin, G. Kramer, and S. ten Brink, “Extrinsic information transfer functions: Model and erasure channel properties,” in IEEE Tran. Inf. Theory, vol. 50, no. 11, pp. 2657–2673, Nov. 2004.
- [29] G. Liva and M. Chiani, “Protograph LDPC codes design based on EXIT analysis,” in Proc. IEEE GLOBECOM, 2007.
- [30] A. Shokrollahi and R. Storn, “Design of efficient erasure codes with differential evolution,” in Proc. IEEE ISIT, 2000.
- [31] D. Divsalar, S. Dolinar, and C. Jones, “Construction of protograph LDPC codes with linear minimum distance,” in Proc. IEEE ISIT, 2006.
- [32] Y. Yu, Y. Han, and L. Zhang, “Hamming-GLDPC codes in BEC and AWGN channel,” in Proc. IEEE ICWMMN, 2015.
- [33] C. Di, A. Montanari, and R. Urbanke, “Weight distributions of LDPC code ensembles: Combinatorics meets statistical physics,” in Proc. ISIT, 2004.
- [34] R. G. Gallager, Low-density parity-check codes. Cambridge, MA: MIT Press, 1963.
- [35] S. Abu-Surra, D. Divsalar, and W. E. Ryan, “On the existence of typical minimum distance for protograph-based LDPC codes,” in Proc. IEEE ITA, 2010.
- [36] S. Abu-Surra, D. Divsalar, and W. E. Ryan, “On the typical minimum distance of protograph-based generalized LDPC codes,” in Proc. IEEE ISIT, 2010.
- [37] A. K. Pradhan, A. Thangaraj, and A. Subramanian, “Construction of near-capacity protograph LDPC code sequences with block-error thresholds,” IEEE Trans. Commun., vol. 64, no. 1, pp. 27–37, Jan. 2016.
- [38] C. Di, T. J. Richardson, and R. L. Urbanke, “Weight distribution of low-density parity-check codes,” IEEE Trans. Inf. Theory, vol. 52, no. 11, pp. 4839–4855, Nov. 2006.
- [39] Xiao-Yu Hu, E. Eleftheriou, and D. M. Arnold, “Regular and irregular progressive edge-growth Tanner graphs,” IEEE Trans. Inf. Theory, vol. 51, no. 1, pp. 386–398, Jan. 2005.
- [40] D. Divsalar, C. Jones, S. Dolinar, and J. Thorpe, “Protograph based LDPC codes with minimum distance linearly growing with block size,” in Proc. IEEE GLOBECOM, 2005.
- [41] D. G. M. Mitchell, M. Lentmaier, A. E. Pusane, and D. J. Costello, “Randomly punctured LDPC codes,” IEEE J. Sel. Areas Commun., vol. 34, no. 2, pp. 408–421, Feb. 2016.