Constrained Deep Reinforcement Learning for Energy Sustainable Multi-UAV based Random Access IoT Networks with NOMA
Abstract
In this paper, we apply the Non-Orthogonal Multiple Access (NOMA) technique to improve the massive channel access of a wireless IoT network where solar-powered Unmanned Aerial Vehicles (UAVs) relay data from IoT devices to remote servers. Specifically, IoT devices contend for accessing the shared wireless channel using an adaptive -persistent slotted Aloha protocol; and the solar-powered UAVs adopt Successive Interference Cancellation (SIC) to decode multiple received data from IoT devices to improve access efficiency. To enable an energy-sustainable capacity-optimal network, we study the joint problem of dynamic multi-UAV altitude control and multi-cell wireless channel access management of IoT devices as a stochastic control problem with multiple energy constraints. To learn an optimal control policy, we first formulate this problem as a Constrained Markov Decision Process (CMDP), and propose an online model-free Constrained Deep Reinforcement Learning (CDRL) algorithm based on Lagrangian primal-dual policy optimization to solve the CMDP. Extensive simulations demonstrate that our proposed algorithm learns a cooperative policy among UAVs in which the altitude of UAVs and channel access probability of IoT devices are dynamically and jointly controlled to attain the maximal long-term network capacity while maintaining energy sustainability of UAVs. The proposed algorithm outperforms Deep RL based solutions with reward shaping to account for energy costs, and achieves a temporal average system capacity which is higher than that of a feasible DRL based solution, and only lower compared to that of the energy-constraint-free system.
Index Terms:
Constrained Deep Reinforcement Learning, UAV altitude control, Solar-Powered UAVs, Energy Sustainable IoT Networks, -persistent slotted Aloha, Non-Orthogonal Multiple AccessI Introduction
While internet connectivity plays an increasing role in people’s everyday life in densely populated areas, some rural areas and nature fields such as farms, deserts, oceans, and polar regions, typically lack expansive internet coverage. This is because network providers tend to deploy telecommunication infrastructure in areas where providing wireless service is economically profitable. Nevertheless, farmers, environmental agencies, research organizations, defense agencies, and utility companies among many others, have increasing demands for internet connectivity in such under-served areas, to support massive Internet of Things (IoT) based applications ranging from tracking animal health, agricultural growth, and marine life, to surveillance sensors for defense applications and nuclear waste site management, just to name a few. Provisioning wireless internet access for a massive number of IoT devices in under-served areas at cost effective rates is undoubtedly of great interest for governments, businesses, and end customers.
To support emerging IoT based services, new coverage and distributed channel access solutions should be conceived. Unmanned Aerial Vehicle (UAV) based wireless relays have been proposed to facilitate fast and flexible deployment of communication infrastructure due to their high mobility [1, 2, 3, 4, 5, 6, 7, 8, 9]. UAVs equipped with wireless transceivers can fly to a designated area and provision affordable wireless internet connectivity to a massive number of IoT devices, by relaying data to network servers through satellite back-haul links. Moreover, UAVs can dynamically adjust their location in real-time to counter environmental changes and improve system performance.
With the number of IoT devices projected to reach billion by [10], distributed Medium Access Control (MAC) protocols based wireless technologies such as Wi-Fi, Zigbee, and Aloha-based LoRaWAN, are expected to play an important role in provisioning massive IoT access over the unlicensed band in the fifth-generation (G) wireless network era [11, 12, 13]. Non Orthogonal Multiple Access (NOMA), which can improve the spectral efficiency by exploiting Successive Interference Cancellation (SIC) to enable non-orthogonal data transmissions, is yet another promising solution to enable massive machine type communication (mMTC) in G networks and beyond. Recent works propose to apply power-domain NOMA in slotted-Aloha systems to support mMTC of IoT devices [14, 15, 16]. NOMA enabled Aloha-type wireless networks is therefore of significant importance to support massive channel access in UAV-based IoT Networks.
In this work, we consider solar-powered multi-UAV based wireless IoT networks, where UAVs act as wireless Base Stations (BS) for a massive number of IoT devices. IoT devices contend for access to the shared wireless channel using an adaptive -persistent slotted Aloha MAC protocol to send data to the UAVs, which relay the received data to the internet backbone through wireless satellite back-haul links. UAVs on the other hand, are equipped with solar cells to replenish the on-board battery, and exploit power-domain SIC to decode multiple users’ transmissions, thus improving the transmission efficiency. To enable an energy-sustainable and capacity-optimal massive IoT network, we jointly study dynamic multi-UAV altitude control and NOMA-based multi-cell wireless channel access of IoT devices. The objective of the stochastic control problem is to maximize the total network throughput of a massive number of IoT devices, characterized by random uplink channel access and varying wireless channel conditions, and coupled with multiple constraints to ensure energy sustainability of solar-powered UAVs. To the best of our knowledge, our work is the first work to study energy sustainability of a multi-UAV based wireless communication system in support of a massive number of IoT devices with NOMA and random channel access.
The main contributions of our work can be summarized as follows. First, we formulate the joint problem of multi-UAV altitude control and adaptive random channel access of massive IoT devices to attain the maximum capacity under energy sustainability constraints of UAVs over a prespecified operating horizon as a Constrained Markov Decision Process (CMDP). Second, to learn an optimal control policy for the wireless communication system, we design an online model-free Constrained Deep Reinforcement Learning (CDRL) algorithm based on Lagrangian primal-dual policy optimization to solve the CMDP. A cooperative policy is learned among UAVs which ensures energy sustainability of UAVs over an operating horizon, while maximizing the total network capacity with NOMA under the probabilistic mutual interference of IoT devices. Third, we compare the performance of our proposed algorithm to two baseline solutions: 1) unconstrained Deep RL (DRL) approach without energy sustainability constraints, and 2) DRL approach with reward shaping to account for energy costs. Our extensive simulations demonstrate that our proposed algorithm yields feasible policies with higher network capacity, and outperforms baseline solutions which do not guarantee feasible policies. Specifically, the policy learned by our proposed CDRL algorithm achieves a temporal average network capacity that is higher than that of a feasible DRL with reward shaping, and lower than that of the energy-constraint-free system. Last but not least, we demonstrate that the learned policy, which has been efficiently trained on a small network size, can effectively manage networks with a massive number of IoT devices and varying initial network states.
The remainder of this paper is organized as follows. A literature survey of related research work and a background of unconstrained and constrained MDPs is given in Section II. The system model is described in Section III. The problem formulation and the proposed CDRL algorithm is presented in Section IV, followed by the simulation setup and performance evaluation results in Section V. Finally our concluding remarks and future work are given in Section VI.
II Background and Related Works
II-A UAV based Wireless Networks
The deployment and resource allocation of UAV-based wireless networks has been studied in many works. In [1], a polynomial-time algorithm is proposed for successive UAV placement such that the number of UAVs required to provide wireless coverage for a group of ground terminals is minimized and each ground terminal is within the communication range of at least one UAV. The downlink coverage probability for UAVs as a function of the altitude and antenna gain is analyzed in [2]. Based on the circle packing theory, the 3D locations of the UAVs are determined to maximize the total coverage area while ensuring the covered areas of multiple UAVs do not overlap. The work of [3] studies the problem of multiple UAV deployment for on-demand coverage while maintaining connectivity among UAVs. In [4], a distributed coverage-maximizing algorithm for multi UAV deployment subject to the constraint that UAVs maintain communication is proposed for surveillance and monitoring applications.
3D trajectory design and resource allocation in UAV based wireless networks have also been studied in [5, 6, 7, 8, 9]. In [5], a mixed integer non-convex optimization problem is formulated to maximize the minimum downlink throughput of ground users by jointly optimizing multi-user communication scheduling, association, UAVs’ 3D trajectory, and power control. An iterative algorithm based on block coordinate descent and successive convex optimization techniques is proposed to solve the formulated problem. [6] extends on [5] by considering heterogeneous UAVs so that each UAV can be individually controlled. Machine learning based approaches have also been recently considered for UAV 3D trajectory design. In [7], the flight trajectory of the UAV and scheduling of packets are jointly optimized to minimize the sum of Age-of-Information (sum-AoI) at the UAV. The problem is modeled as a finite-horizon Markov Decision Process (MDP) with finite state and action spaces, and a DRL algorithm is proposed to obtain the optimal policy. [8] devises a machine learning based approach to predict users’ mobility information, which is considered in the trajectory design of multiple UAVs. A sense-and-send protocol is designed in [9] to coordinate multiple UAVs, and a multi-UAV Q-learning based algorithm is proposed for decentralized UAV trajectory design. Scheduling based NOMA systems with a UAV-based BS to serve terrestrial users are considered in [17, 18]. In a recent work, the performance of NOMA transmissions in a single-hop random access wireless network is investigated, and an iterative algorithm is proposed to find the optimal transmission probabilities of users to achieve the maximum throughput [19].
It is worth to mention that all aforementioned works consider battery powered UAVs with limited energy storage capacity, which constrains the operating horizon. Solar-powered UAVs have great potential to extend the operation time by harvesting solar energy from the sun [20, 21]. [22] studies the optimal trajectory of solar-powered UAVs for maximizing the solar energy harvested. In their design, a higher altitude is preferable to maximize harvested energy. On the other hand, [23] studies the trade-off between solar energy harvesting and communication system performance of a single UAV based wireless network. It is shown that in order to maximize the system throughput, the solar-powered UAV climbs to a high altitude to harvest enough solar energy, and then descends to a lower altitude to improve the communication performance.
The work of [23] considers downlink wireless resource allocation in a centralized scheduling-based and interference-free wireless network with a single UAV. Deploying one solar-powered UAV may lead to a communication outage when the UAV ascends to high altitudes to replenish its on-board battery. On the other hand, scheduling-based networks usually suffer from the curse of dimensionality and do not well scale to massive IoT networks, as signaling overheads scale up with the network size. As such, there is a growing interest in wireless networks with NOMA and decentralized random access MAC protocols, such as Aloha-type MACs adopted in LoRaWAN networks [13]. Analyzing NOMA performance and modeling the probabilistic channel interference caused by uplink transmissions in multi-cell random channel access wireless networks is a very challenging task as it is mathematically intractable. Machine learning provides a data driven approach for system design, and can be used to investigate these challenging wireless systems. Thus motivated, in this work we study energy sustainability of solar-powered multi-UAV based massive IoT networks with random-access and NOMA. We design an online model-free CDRL algorithm for dynamic control of UAVs’ altitude and random wireless channel access management. By deploying multiple UAVs, we demonstrate that is possible to learn a cooperative policy in which multiple UAVs take turns to charge their battery and provision uninterrupted wireless service.
II-B Constrained Deep Reinforcement Learning
One of the primary challenges faced in reinforcement learning is the design of a proper reward function which can efficiently guide the learning process. Many real world problems are multi-objective problems in which conflicting objectives should be optimized. A common approach to handling multi-objective problems in RL is to combine the objectives using a set of coefficients [24]. With this approach, there exist a set of optimal solutions for each set of coefficients, known as the Pareto optimal solutions [25]. In practice, finding the set of coefficients which leads to the desired solutions is not a trivial task. For many problems, it is more natural to specify a single objective and a set of constraints. The CMDP framework is the standard formulation for RL problems involving constraints [26]. Optimal policies for CMDPs can be obtained by solving an equivalent linear programming formulation [26], or via multi time-scale dynamic-programming based algorithms [27, 28, 29, 30, 31]. Such methods may not be applicable to large scale problems or problems with continuous state-action space. Leveraging recent advances in deep learning and policy search methods [32], some works devise multi-time scale algorithms for solving RL problems in presence of constraints [33, 34, 35, 36, 37]. Broadly speaking, these methods are either based on Lagrangian relaxation [33, 34, 35, 36] or constrained policy optimization [37]. In Lagrangian relaxtion based method, primal and dual variables are updated at different time-scales using gradient ascent/descent. In these methods, constraint satisfaction is guaranteed at convergence. On the other hand, in [37] an algorithm is proposed where constraint satisfaction is enforced in every step throughout training. Our proposed algorithm is based on the Proximal Policy Optimization (PPO) [38], which is a highly stable state-of-the-art on-policy model-free RL algorithm that adopts the Lagrangian relaxation based approach to handle multiple constraints. To the best of our knowledge, our work is the first to demonstrate successful policy learning in environments with multiple constraints, and policy transferability among wireless networks of different scales.
II-C Background
In this subsection, unconstrained and constrained MDPs, which are the classical formalization of sequential decision making and define the interaction between a learning agent and its environment in RL and constrained RL, are introduced.
II-C1 Markov Decision Process
An infinite horizon MDP with discounted-returns is defined as a tuple , where and are finite sets of states and actions, respectively, is the model’s state-action-state transition probabilities, and is the initial distribution over the states, , is the immediate reward function which guides the agent through the learning process, and is a discount factor to bound the cumulative rewards and trade-off how far or short sighted the agent is in its decision making. Denote the transition probability from state at time step to state if action is chosen by The transition probability from state to state is therefore, , where is a stochastic policy which maps states to actions. The state-value function of state under policy is long-term expected discounted returns starting in state and following policy thereafter,
|
|
(1) |
Denote the initial distribution over the states by the vector , where . The solution of an MDP is a Markov stationary policy that maximizes the inner product ,
| (2) |
There are several approaches to solve (2), including dynamic programming based methods such as value iteration and policy iteration, [39], in addition to linear programming based methods [40]. When the model’s dynamics, i.e., transition probabilities, are unknown, the Reinforcement Learning (RL) framework can be adopted to find the optimal policies. It is worth to mention that when the agents learns the optimal state-value function and/or the policy as parameterized Deep Neural Networks (DNNs), the agent is commonly referred to as a Deep RL (DRL) agent. There exists a significant body of works with state-of-the-art algorithms to solve the RL problem, which vary by design from value-based methods [41], policy-based methods [42, 32, 38], to hybrid actor-critic type algorithms [43, 44, 45, 46, 47].
II-C2 Constrained Markov Decision Process
In constrained MDPs (CMDPs), additional immediate cost functions are augmented, such that a CMDP is defined by the tuple [26]. The state-value function is defined as in unconstrained MDPs (1). In addition, the infinite-horizon discounted-cost of a state under policy is defined as,
|
. |
(3) |
The solution of a CMDP is a markov stationary policy which maximizes subject to the constraints ,
| (4) | ||||
| (4a) | ||||
Solving for feasible and optimal policies in CMDPs is more challenging compared to unconstrained MDPs, and requires extra mathematical efforts. CMDPs can be solved by defining an appropriate occupation measure and constructing a linear program over this measure, or alternatively by using a Lagrangian relaxation technique in which the CMDP is converted into an equivalent unconstrained problem,
| (5) | ||||
and invoking the minimax theorem,
| (6) |
The right hand side of (6) can be solved on two-time scales: on a faster time scale gradient-ascent is performed on state-values to find the optimal policy for a given set of Lagrangian variables, and on a slower time scale, gradient-descent is performed on the dual variables [26]. Past works explore this primal-dual optimization approach for CMDPs with known model dynamics and tabular-based RL methods with unknown model dynamics [27, 28, 29, 30, 31]. In the realm of deep RL where policies and value functions are parameterized neural networks, recent works which apply primal-dual optimization for generic benchmark problems are emerging [33, 34, 35, 36, 37]. None of these works, however, apply primal-dual optimization techniques in the wireless networking domain. Practical wireless networking systems admit multiple constraints, which might be conflicting. This incurs extra difficulty for policy search and optimization. Applying constrained RL for wireless networking problems is therefore a challenging issue that needs to be investigated.
III System Model
Consider a multi-UAV based IoT network consisting of UAVs and IoT devices, where the UAVs collect data from a massive deployment of IoT devices, as shown in Figure 1(a). Let be the set of UAVs, and be the set of IoT devices. UAVs are connected via wireless back-haul links to a central controller, which controls the altitude of each UAV and manages the access parameters of wireless IoT devices. IoT devices are independently and uniformly distributed (i.u.d.) across a deployment area . Let the locations of IoT devices be . Each IoT device is served by the closest UAV. Denote the subset of IoT devices which are associated with UAV by , , , . Time is slotted into fixed-length discrete time units indexed by . For instance, the -th time slot is , where . Each time slot is further divided into communication sub-slots of length each, as shown in 1(b). Denote the -th communication sub-slot in slot by , . During these communication sub-slots, IoT devices contend for channel access based on an adaptive -persistent slotted Aloha MAC protocol. In this protocol, an IoT device waits until the beginning of a communication sub-slot before attempting to access the channel with probability , which is adapted every time slot by the central controller based on network dynamics. IoT devices transmit uplink data to their associated UAV with a fixed transmission power of watts, and are traffic-saturated, i.e., there is always a data packet ready for transmission.

(a) Network Model

(b) Time Structure
Denote the location of UAV during time slot by . In our system model, , is first determined based on the IoT device distribution on the ground using the popular Lloyd’s K-means clustering algorithm with runtime [48]111Lloyd’s K-means clustering algorithm is an iterative algorithm to determine a set of centroids given a large set of IoT device locations , so as to minimize the within-cluster variance (sum of squared distances to cluster centroid), . The impacts of adopting other schemes for determining on network performance will also be investigated.. Let indicate whether IoT device associates with UAV during time slot . If UAV located at during the -th time slot is the closest to IoT device , , and . The power of the signal transmitted by a wireless IoT device to a UAV is subject to independent Rayleigh channel fading, 222The statistical channel state information, , is assumed to be quasi-static and is fixed during a time slot ., and a distance-dependent free-space path-loss , where is the path-loss exponent, and is the propagation distance between IoT device and UAV , . The received power at UAV from IoT device in a communication sub-slot is,
| (7) |
where is a constant which depends on the wavelength of the transmitted signal, , and is a reference distance. is a Bernoulli random variable with parameter which indicates whether IoT device transmits during communication sub-slot , i.e., with probability . The UAV first decodes the signal with the highest signal power under the interference from all other IoT devices involved in the NOMA transmissions. Without loss of generality, IoT devices are sorted in the descending order of their received signal strength at UAV , such that is the IoT device with the highest received signal to interference plus noise (SNIR) at UAV , and is the IoT device with the second highest received SNIR at UAV 333We consider the two highest received signals to trade-off NOMA gain and SIC decoding complexity for uplink transmissions.. The highest received SNIR at UAV in a communication sub-slot is therefore,
| (8) |
where is the noise floor power. Similarly, the second highest received SNIR at UAV in a communication sub-slot is,
| (9) |
UAV can decode the signal with if
-
1.
user 1 is associated with UAV during communication sub-slot , , and,
-
2.
is larger than the SNIR threshold, i.e., ,
where is a thresholding function to maintain a minimum quality of service,
| (10) |
In addition, UAV can decode the signal with if
-
1.
is successfully decoded,
-
2.
user 2 is associated with UAV during communication sub-slot , , and,
-
3.
is larger than the SNIR threshold, i.e.,
The sum rates of the received data at UAV in communication sub-slot is,
| (11) | ||||
where is the transmission bandwidth, and if and otherwise. The total network capacity in any given system slot ,
| (12) |
UAVs are equipped with solar panels, which harvest solar energy to replenish the on-board battery. The attenuation of solar light passing through a cloud can be modeled based on [23],
| (13) |
where denotes the absorption coefficient of the cloud, and is the distance that the solar light travels through the cloud. Following [23] and the references therein, the solar energy harvested by UAV during time slot can be modeled as,
|
|
(14) |
where is a constant representing the energy harvesting efficiency, is the area of solar panels, and denotes the average solar radiation intensity on earth. and are the altitudes of upper and lower boundaries of the cloud. During time-slot , UAV can cruise upwards or downwards from to . The energy consumed by UAV during time slot [23] is,
| (15) | ||||
where, , is the weight of the UAV, is air density, and is the total area of UAV rotor disks. is the power consumed for maintaining the operation of UAV, and is the power consumed by the receiving antenna. It is worth to mention that cruising upwards consumes more power than cruising downward and hovering.
Denote the battery energy storage of UAV at the beginning of slot by . The battery energy in the next slot is given by,
| (16) |
where , are independent zero-mean gaussian random variables with variance which characterizes the randomness in the battery evolution process, and denotes the positive part.
IV Problem Formulation and Proposed CDRL Algorithm
In this work, we investigate discrete-time UAV altitude control and random channel access management for a multi-UAV based IoT network with NOMA. In order to maximize the total network capacity under stochastic mutual interference of IoT devices while ensuring the energy sustainability of UAVs over the operating horizon , the central controller decides on the altitude of each UAV , at the beginning of each slot , , as well as the channel access probability of IoT devices considering the potential access gain provisioned by NOMA. The channel access probability will be broadcast to IoT devices through beacons at the beginning of each time slot, and IoT devices then adapt their random channel access parameter accordingly.
The problem of maximizing the total network capacity while ensuring energy sustainability of each UAV is a constrained stochastic optimization problem over the operating horizon due to the stochastic channel model and random channel access in the multi-cell IoT network. Offline solutions are generally impractical because it is hard to mathematically track probabilistic mutual interference caused by the uplink transmissions of IoT devices with random access, stochastic channel conditions, and SIC decoding at the UAVs. Hence, we first formulate this problem as a CMDP, and design an online Constrained Deep Reinforcement Learning (CDRL) algorithm, to find an energy sustainable capacity-optimal policy to control the altitude of each UAV and the channel access probability of IoT devices.
IV-A CMDP Formulation
To enable continuous control of UAVs altitudes and channel access probability, we consider parametrized DNN based policies with parameters and state-value function with parameters henceforth. In this subsection, we formulate the joint problem of UAVs altitude control and random channel access of IoT devices as a discrete-time CMDP with continuous state and action spaces as follows,
-
1.
,
i.e., the state space encompasses , the current altitude of UAV along with historical altitudes, current battery energy of UAV along with historical battery energies, probability the highest and second highest received SNIRs from associated users at UAV is greater than or equal to , the mean of the highest and second highest received SNIRs from associated users at UAV given that they are greater than or equal to the SNIR threshold, and the variance of the highest and second highest received SNIRs from associated users at UAV given that they are greater than or equal to the SNIR threshold. Here the mean and variance are calculated over the communication sub-slots.
-
2.
, , where , i.e., the action space encompasses the altitude displacement of each UAV between any two consecutive time slots, and the random channel access probability in the next system slot.
-
3.
, i.e., the immediate reward at the end of each time slot is the total network capacity during slot , normalized by the operating horizon .
-
4.
, , i.e., the immediate cost at the end of each slot is the change in the battery energy between any two consecutive time slots, which is caused by the displacement of each UAV , normalized by the maximum battery energy.
-
5.
, i.e., the upper bound on the long-term expected cost is the negative of the minimum desired battery energy increase at the end of the planning horizon over the initial battery energy.
Based on this formulation, the objective is to find a Markov policy which maximizes the long-term expected discounted total network capacity, while ensuring energy sustainability of each UAV over an operating horizon,
| (17) | ||||
(17) exhibits trade-offs between total system capacity and energy sustainability of UAVs. For instance, a UAV hovering at a higher altitude above the cloud cover can harvest more solar energy to replenish its on-board battery storage, as given by (14). However, at higher altitudes, the received signal power at a UAV from IoT devices will be smaller due to the log-distance path loss model, and consequently, the system capacity will be smaller. The converse is true, that is, when a UAV hovers at lower altitudes, network capacity is improved, yet solar energy harvesting is heavily attenuated. In addition, based on the network topology or the location of the UAVs at any time slot , a certain spatial gain and NOMA overload can be achieved. An optimal stochastic control policy for altitude control of UAVs and channel access management of IoT devices should be therefore learned online. In the following subsection, we propose an online CDRL algorithm to solve (17).
IV-B Proposed CDRL Algorithm
To solve (17) in absence of the state-action-state transition probabilities of the Markov model, we adopt the RL framework in which an autonomous agent learns an optimal policy by repeated interactions with the wireless environment [39]. The wireless environment provides the agent with rewards and costs signals, which the agents exploit to further improve its policy.

Our proposed algorithm is based on the state-of-the-art Proximal Policy Optimization (PPO) algorithm [38], and leverages the technique of primal-dual optimization [34]. The architecture of our proposed algorithm is shown in Figure 2.
In the proposed CDRL algorithm, parameterized DNN of the policy is learned by maximizing the PPO-clip objective function, which is a specially designed clipped surrogate advantage objective that ensures constructive policy updates,
| (18) |
where are the policy neural network parameters, is a clip fraction, and is the generalized advantage estimator (GAE) [49]444The advantage function is defined as the difference between the state-action value function and the value function, . GAE makes a compromise between bias and variance in estimating the advantage.,
| (19) |
Clipping in (18) acts as a regularizer which controls how much the new policy can go away from the old one while still improving the training objective. In order to further ensure reasonable policy updates, we adopt a simple early stopping method in which gradient optimization on (18) is terminated when the mean KL-divergence between the new and old policy reaches a predefined threshold . In (19), is a Lagrangian penalized reward signal [33],
| (20) |
In our proposed algorithm, the Lagrangian penalty multipliers are updated adaptively according to policy feasibility by performing gradient descent on the original constraints. Towards this end, we define the following loss function which is minimized with respect to ,
|
|
(21) |
Finally, the state-value function is learned by minimizing the mean squared error loss against the policy’s discounted rewards-to-go,
| (22) |
The optimization in our proposed algorithm is performed over three time-scales, on the fastest time scale, the state-value function is updated by minimizing (22), then the policy is updated by maximizing (18) on the intermediate time-scale, and finally, the Lagrangian multipliers are updated on the slowest time-scale by minimizing (21). Optimization time-scales are controlled by choosing the maximum learning rate of the stochastic gradient optimizer used, e.g., ADAM [50], as well as the number of gradient steps performed at the end of each training epoch. The full algorithmic procedure for training the CDRL agent is outlined in Algorithm .
The adopted policy is a parameterized stochastic Gaussian policy,
| (23) |
where are the DNN parameters for the mean of the policy, and are the DNN parameters for the variance of the policy. At the beginning of training, the variance of the policy network encourages exploration. As training progresses, the variance of the policy is reduced due to maximizing (18) and the policy shifts slowly towards a deterministic policy.
CDRL Implementation and Training: A fully connected multi-layer perceptron network with three hidden layers for both the policy and value networks are used. Each hidden layer has neurons. activation units are used in all neurons. The range of output neurons responsible for the altitude displacement of each UAV is linearly scaled to in order to limit the maximum cruising velocity, while the range of the output neuron in charge of the random channel access probability is linearly scaled to . The weights of the policy network are heuristically initialized to generate a feasible policy. The variance of the Gaussian policy is state-independent, , with initial value . Training has been performed over epochs, where each epoch corresponds to episodes, and each episode corresponds to trajectories of length time steps. At the end of each episode, the trajectory is cut-off and the wireless system is reinitialized. Episodes in each epoch are rolled-out in parallel by Message Passing Interface (MPI) ranks. After each MPI rank completes its episodic roll-out, Lagrangian primal-dual policy optimization is performed locally as outlined in Algorithm , based on the averaged gradients of the MPI ranks, such that the DNN parameters , , and the Lagrange multipliers , are synchronized among the MPI ranks during training. At the end of training, the trained policy network corresponding to the mean of the learned Gaussian policy, , is used to test its performance through the simulated environment.
V Performance Evaluation
We have developed a simulator in Python for the solar-powered multi-UAV based Wireless IoT network with NOMA described in section III, and implemented the proposed CDRL algorithm based on OpenAI’s implementation of PPO [51]. We trained the proposed CDRL agent in a multi-cell wireless IoT network of solar-powered UAVs and IoT devices. IoT devices were deployed independently and uniformly within a grid of m. The two UAVs were initially deployed at m and m with initial battery energy, i.e., Wh. Although we have investigated the impacts of different initial UAV deployments on network performance, note that the and coordinates of the two UAVs, i.e., m and m, are minimizers of the sum of squared planar distances between IoT devices and the closest UAV, as determined by Lloyd’s K-means clustering algorithm for the uniform random deployment of IoT devices on the ground. UAVs were allowed to cruise vertically between m and m. As a baseline for comparison, we have compared the performance of the proposed CDRL algorithm with unconstrained PPO agent without energy sustainability constraints, and unconstrained PPO agents that accounts for energy costs via fixed reward shaping (RLWS), where the reward signal was , and or . The main simulation parameters for the experiments are outlined in Table I.
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Wh | |||
| MHz | |||
| watts | |||
| (1hr) | |||
| km | |||
| km | |||
| Wh | |||
The output energy of the solar panels as a function of the altitude according to (14) is shown in Figure 3. It can be seen that above the cloud cover at m, the output solar energy reaches the highest, and it attenuates exponentially through the cloud until m is reached. Below m, the output solar energy is zero. UAVs cruising above m harvest the most solar energy, while UAVs cruising below m drain their battery energy the fastest. Note that hovering at low altitudes reduces distance-dependant path-loss and improves the wireless communication rates, however, it is not energy sustainable for UAVs.

The learning curves of the trained CDRL agent are shown in Figure 4. It can be seen in Figure 4(a) that the CDRL agent becomes more experienced as training progresses, collecting higher expected total rewards. In addition, the CDRL agent becomes more experienced in satisfying energy constraints, learning policies whose expected costs fall bellow , which means that the learned policy results in energy increase in the battery of each UAV by at least at the end of the flight horizon. On the other hand, the convergence of the Lagrangian multipliers to non-negative values during the training of the proposed CDRL algorithm is shown in Figure 4(b). It can be observed that the two cost constraints are penalized differently, which is primarily due to the different initial conditions and different terminal states. The Lagrangian multiplier of the energy constraint corresponding to UAV 1 is larger than that of UAV 2, which means that the energy constraint of UAV 1 is satisfied farther from the constraint boundary compared to that of UAV 2. Based on this observation, it is therefore expected that UAV 1 will end up its flight with more harvested energy in its battery compared to UAV 2.

(a) Learning Curves

(b) Lagrange Multipliers
The learned policy by our proposed CDRL algorithm is shown in Figure 5. It can be seen from Figures 5(a) and 5(b) that the CDRL agent learns a policy in which the two UAVs take turns in cruising upwards to recharge their on-board batteries, and in serving IoT devices deployed on the ground. UAV first climbs up to recharge its battery, while UAV descends down to improve communication performance for IoT devices on the ground. Since IoT devices are associated with the closest UAV, in this case, all IoT devices are associated with UAV . When UAV ’s battery is fully charged, it descends down gradually to switch roles with UAV : UAV becomes the BS with which all IoT devices are associated, while UAV climbs up to recharge its battery. Such a policy ensures that the battery energy of the two UAVs is not drained throughout the operating horizon as can be seen from Figure 5(c). Note that the terminal energy in UAV’s 1 battery is higher than that of UAV 2, which is expected based on the observation that the Lagrange multiplier corresponding to UAV’s 1 energy constraint is larger than that of UAV 2. In Figure 5(d), the random channel access probability based on the learned CDRL policy is shown. It can be observed that when either of the two UAVs is fully serving all the IoT devices, the wireless networking system is overloaded with , thanks to NOMA. Note that is the optimal transmission probability in single-cell -persistent slotted Aloha systems without NOMA. The channel access probability is dynamically adapted when the two UAVs cruise upward and downward to exchange roles in the wireless system. At times when both UAVs have associated users, the channel access probability can be seen to spike higher to maintain NOMA overload, as can be observed from Figures 6(a)-(b). It can be seen from these two figures that NOMA’s gain is higher in steady states when all IoT devices are associated with the same UAV, compared to transient states when the two UAVs exchange roles and are both serving IoT devices. This is because it is less likely that the second highest received SINR to a UAV is from within the same cell at times when both UAVs provision wireless service. By deploying multiple UAVs, it is therefore possible to learn a cooperative policy in which UAVs take turns to charge their battery and provision uninterrupted wireless service as Figure 6(b) shows.

(a) UAV Altitudes vs Time

(b) UAV IoT Device Association vs Time
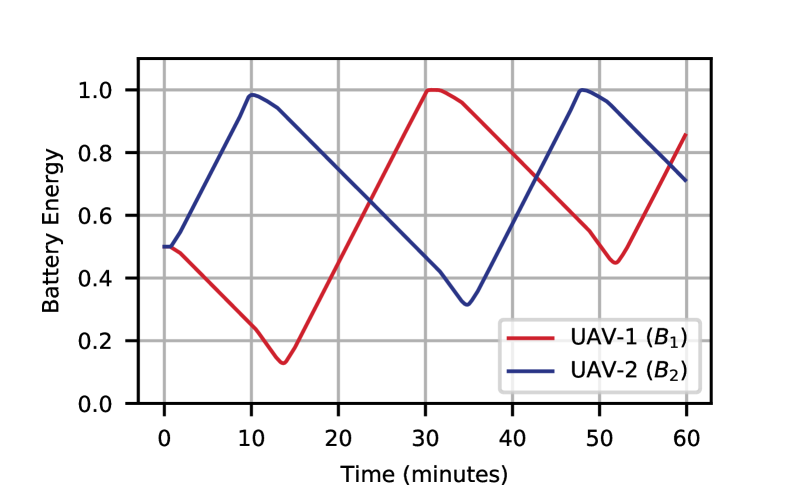
(c) UAV Battery Energy vs Time

(d) Channel Access Probability vs Time

(a) Probability SNIR is equal or larger than

(b) Conditional Expected SNIR
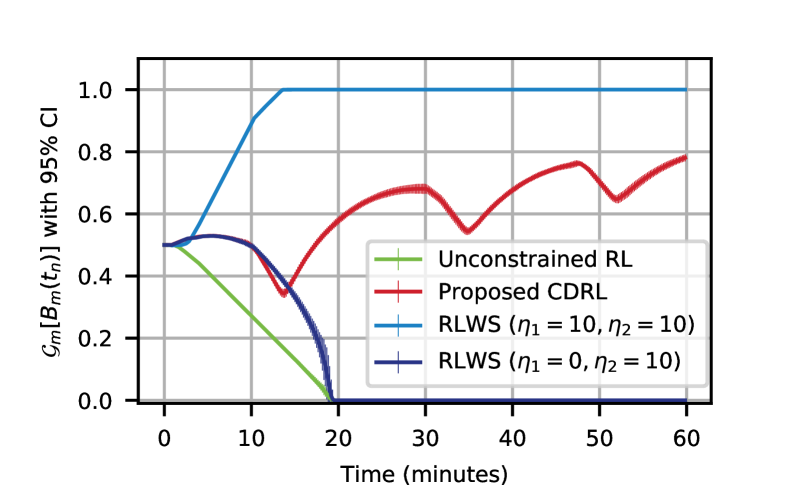
The performance comparison of our proposed CDRL algorithm with two other baseline schemes in terms of the achieved mean total network capacity with confidence interval versus flight time is shown in Figure 7(a). The statistical results are based on roll-outs of the learned policy in the simulated wireless IoT environment with NOMA. It can be seen that the proposed CDRL agent learns a policy whose achieved temporal average network capacity is higher compared to the policy learned by the conservative RLWS agent with . Compared to the RL agent without energy constraints, only of the achievable temporal average system capacity is sacrificed in order to maintain energy sustainability of UAVs. In Figure 7(b), the geometric mean of the battery energy of the two UAVs, defined as , is plotted versus flight time. Note that the geometric mean is chosen as a single measure to characterize battery energy of the UAVs. If the battery of any UAV is exhausted, , the geometric mean will be . It can be seen that the policy learned by the RLWS agent with is the most conservative, fully recharging the batteries of both UAVs by the -th minute. On the other hand, the unconstrained agent learns a policy which is indifferent to battery energy, leading to energy depletion of at least one UAV by the -th minute. This is reflected in Figure 8, where the altitude trajectories based on the policies learned by the unconstrained RL agent and the RLWS agents are shown. The policy of the unconstrained agent descends the two UAVs to the lowest allowable altitude of m. This policy is communication-performance bound, achieving the highest network capacity as shown in Figure 7(a). On the other hand, the policy of the RLWS agent with attempts to minimize the energy costs and maintain a high battery energy at all times. Hence, the two UAVs hover at the altitude at which solar energy harvesting is the highest. For the RLWS agent with , UAV ascends to m where the most solar energy can be harvested to maintain energy sustainability, while UAV descends down to m to provision wireless service, indifferent to energy sustainability, which leads to its battery depletion by the -th minute as can be seen from Figure 7(b). This is expected as the reward signal for training this agent does not penalize energy costs of UAV . In contrast, the policy learned by the proposed CDRL agent strikes a balance: it ensures energy sustainability while slightly sacrificing the network capacity performance.

(a) System Capacity vs Time
(b) Sum Battery Energy vs Time

Policy Generalizability: To demonstrate the generalizability and robustness of the learned CDRL policy, we test its performance on networks with different initial states and varying number of IoT devices. Note that the CDRL policy has been trained given that IoT devices are uniformly deployed on ground, and that the two UAVs are initially present at altitudes of m and m. In Figure 9(a), we demonstrate the learned policy performance given different initial altitudes of UAVs. Specifically, we consider two extreme cases: both UAVs are initially deployed at the altitude of m (case A), or at m (case B). For those two cases, Figure 9(a) shows that the two UAVs tend to fully de-synchronize their vertical flight trajectories, such that when one of them is charging its battery at m, the other is provisioning wireless service at m. The temporal average system capacity for cases A and B are bit per second (bps) and bps, respectively. Notice that case B achieves a slightly lower temporal average network capacity because both UAVs are initially farther away from IoT devices. In the legend, the temporal geometric mean of the battery energy of each UAV, defined as , is reported to demonstrate energy sustainability of UAVs throughout the operating horizon.
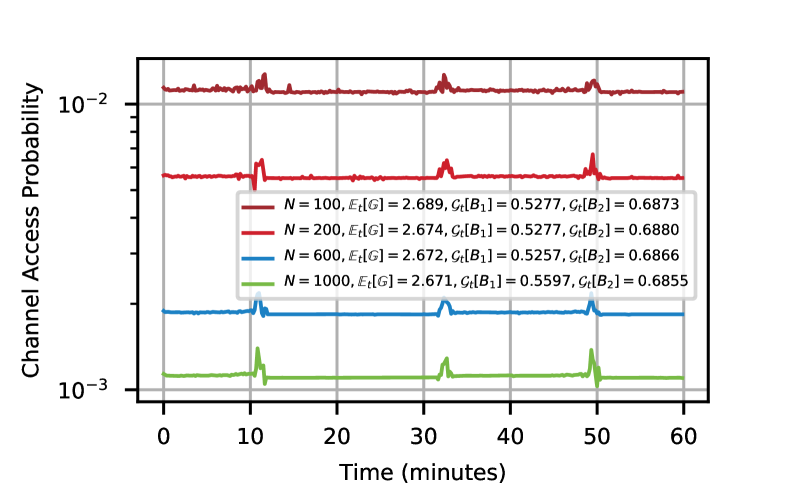
In Figure 9(b), we test how the learned CDRL policy scales with varying number of IoT devices. As can be seen from Figure 9(b), the channel access probability is scaled appropriately given the number of IoT devices vary in , maintaining comparable temporal average network capacity around bps. In addition, the temporal geometric mean of the battery energy of each UAV is also reported in the legend to demonstrate energy sustainability of UAVs. Last but not least, in Figure 9(c), we test the performance of the learned policy given different horizontal deployment of the two UAVs. We consider three cases: (A) the two UAVs are deployed at m and m, as determined by the K-means clustering algorithm, (B) the two UAVs are deployed farthest from each other at m and m, and (C) the two UAVs are randomly deployed on the xy-plane. It can be observed from Figure 9(c) that the mean network capacity is highest when the K-means algorithm is employed to determine the xy-planar deployment of the two UAVs. In addition, it is shown that randomly deploying the two UAVs in the xy-plane, case (C), is slightly lower than that in case (A), whereas the extreme case of deploying the two UAVs on the diagonal, case (B), achieves the lowest network capacity. In all cases, the learned policy still ensures energy sustainability of the two UAVs as indicated by the temporal geometric mean of the battery energy of each UAV, which is reported in the legend.

(a) Policy Performance with Varying Initial Altitudes
(b) Policy Performance with Varying Number of IoT Devices

(C) Policy Performance with Different Selection Schemes
VI Conclusion
In this paper, we have applied constrained deep reinforcement learning to study the joint problem of dynamic multi-UAV altitude control and random channel access management of a multi-cell UAV-based wireless network with NOMA, in support of a massive number of IoT devices. To enable an energy-sustainable capacity-optimal IoT network, we have formulated this constrained stochastic control problem as a constrained markov decision process, and proposed an online model-free constrained deep reinforcement learning algorithm to learn an optimal control policy for wireless network management. Our extensive simulations have demonstrated that the proposed algorithm learns a cooperative policy in which the altitude of UAVs and channel access probability of IoT devices are dynamically adapted to maximize the long-term total network capacity while maintaining energy sustainability of UAVs. The policy learned by the proposed algorithm ensures energy sustainable operation of UAVs, and outperforms baseline solutions. In our future work, we will study the design of a constrained multi-agent RL framework to tackle resource management problems in spatially distributed massive wireless networks.
Acknowledgment
This work was supported in part by the NSF grants ECCS1554576, ECCS-1610874, and CNS-1816908. We gratefully acknowledge the computing resources provided on Bebop, a high-performance computing cluster operated by the Laboratory Computing Resource Center at Argonne National Laboratory.
References
- [1] J. Lyu, Y. Zeng, R. Zhang, and T. J. Lim, “Placement optimization of UAV-mounted mobile base stations,” IEEE Communications Letters, vol. 21, no. 3, pp. 604–607, 2016.
- [2] M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Efficient deployment of multiple unmanned aerial vehicles for optimal wireless coverage,” IEEE Communications Letters, vol. 20, no. 8, pp. 1647–1650, 2016.
- [3] H. Zhao, H. Wang, W. Wu, and J. Wei, “Deployment algorithms for UAV airborne networks toward on-demand coverage,” IEEE Journal on Selected Areas in Communications, vol. 36, no. 9, pp. 2015–2031, 2018.
- [4] A. V. Savkin and H. Huang, “A method for optimized deployment of a network of surveillance aerial drones,” IEEE Systems Journal, 2019.
- [5] Q. Wu, Y. Zeng, and R. Zhang, “Joint trajectory and communication design for multi-UAV enabled wireless networks,” IEEE Transactions on Wireless Communications, vol. 17, no. 3, pp. 2109–2121, 2018.
- [6] Y. Xu, L. Xiao, D. Yang, Q. Wu, and L. Cuthbert, “Throughput maximization in multi-UAV enabled communication systems with difference consideration,” IEEE Access, vol. 6, pp. 55 291–55 301, 2018.
- [7] M. A. Abd-Elmagid, A. Ferdowsi, H. S. Dhillon, and W. Saad, “Deep reinforcement learning for minimizing age-of-information in UAV-assisted networks,” arXiv preprint arXiv:1905.02993, 2019.
- [8] X. Liu, Y. Liu, Y. Chen, and L. Hanzo, “Trajectory design and power control for multi-UAV assisted wireless networks: A machine learning approach,” IEEE Transactions on Vehicular Technology, 2019.
- [9] J. Hu, H. Zhang, and L. Song, “Reinforcement learning for decentralized trajectory design in cellular UAV networks with sense-and-send protocol,” IEEE Internet of Things Journal, 2018.
- [10] Cisco, “Cisco visual networking index: Global mobile data traffic forecast update, 2016-2021,” Feb. 2017.
- [11] S. Khairy, M. Han, L. X. Cai, Y. Cheng, and Z. Han, “A renewal theory based analytical model for multi-channel random access in ieee 802.11 ac/ax,” IEEE Transactions on Mobile Computing, vol. 18, no. 5, pp. 1000–1013, 2018.
- [12] S. Khairy, M. Han, L. X. Cai, and Y. Cheng, “Sustainable wireless IoT networks with RF energy charging over Wi-Fi (CoWiFi),” IEEE Internet of Things Journal, 2019.
- [13] C. El Fehri, M. Kassab, S. Abdellatif, P. Berthou, and A. Belghith, “Lora technology mac layer operations and research issues,” Procedia computer science, vol. 130, pp. 1096–1101, 2018.
- [14] J. Choi, “NOMA-based random access with multichannel ALOHA,” IEEE Journal on Selected Areas in Communications, vol. 35, no. 12, pp. 2736–2743, 2017.
- [15] J.-B. Seo, B. C. Jung, and H. Jin, “Nonorthogonal random access for 5G mobile communication systems,” IEEE Transactions on Vehicular Technology, vol. 67, no. 8, pp. 7867–7871, 2018.
- [16] J. Choi, “A game-theoretic approach for NOMA-ALOHA,” in 2018 European Conference on Networks and Communications (EuCNC). IEEE, 2018, pp. 54–9.
- [17] N. Zhao, X. Pang, Z. Li, Y. Chen, F. Li, Z. Ding, and M.-S. Alouini, “Joint trajectory and precoding optimization for UAV-assisted NOMA networks,” IEEE Transactions on Communications, vol. 67, no. 5, pp. 3723–3735, 2019.
- [18] A. A. Nasir, H. D. Tuan, T. Q. Duong, and H. V. Poor, “UAV-enabled communication using NOMA,” IEEE Transactions on Communications, 2019.
- [19] Z. Chen, Y. Liu, S. Khairy, L. X. Cai, Y. Cheng, and R. Zhang, “Optimizing non-orthogonal multiple access in random access networks,” in 2020 IEEE 91st Vehicular Technology Conference (VTC-Spring). IEEE, 2020, pp. 1–5.
- [20] S. Morton, R. D’Sa, and N. Papanikolopoulos, “Solar powered UAV: Design and experiments,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2015, pp. 2460–2466.
- [21] P. Oettershagen, A. Melzer, T. Mantel, K. Rudin, T. Stastny, B. Wawrzacz, T. Hinzmann, K. Alexis, and R. Siegwart, “Perpetual flight with a small solar-powered UAV: Flight results, performance analysis and model validation,” in 2016 IEEE Aerospace Conference. IEEE, 2016, pp. 1–8.
- [22] J.-S. Lee and K.-H. Yu, “Optimal path planning of solar-powered UAV using gravitational potential energy,” IEEE Transactions on Aerospace and Electronic Systems, vol. 53, no. 3, pp. 1442–1451, 2017.
- [23] Y. Sun, D. Xu, D. W. K. Ng, L. Dai, and R. Schober, “Optimal 3d-trajectory design and resource allocation for solar-powered UAV communication systems,” IEEE Transactions on Communications, 2019.
- [24] S. Mannor and N. Shimkin, “A geometric approach to multi-criterion reinforcement learning,” Journal of machine learning research, vol. 5, no. Apr, pp. 325–360, 2004.
- [25] K. Van Moffaert and A. Nowé, “Multi-objective reinforcement learning using sets of pareto dominating policies,” The Journal of Machine Learning Research, vol. 15, no. 1, pp. 3483–3512, 2014.
- [26] E. Altman, Constrained Markov decision processes. CRC Press, 1999, vol. 7.
- [27] S. Bhatnagar and K. Lakshmanan, “An online actor–critic algorithm with function approximation for constrained markov decision processes,” Journal of Optimization Theory and Applications, vol. 153, no. 3, pp. 688–708, 2012.
- [28] S. Bhatnagar, “An actor–critic algorithm with function approximation for discounted cost constrained markov decision processes,” Systems & Control Letters, vol. 59, no. 12, pp. 760–766, 2010.
- [29] V. S. Borkar, “An actor-critic algorithm for constrained markov decision processes,” Systems & control letters, vol. 54, no. 3, pp. 207–213, 2005.
- [30] P. Geibel and F. Wysotzki, “Learning algorithms for discounted mdps with constraints,” International Journal of Mathematics, Game Theory, and Algebra, vol. 21, no. 2/3, p. 241, 2012.
- [31] P. Geibel and F. Wysotzki, “Risk-sensitive reinforcement learning applied to control under constraints,” Journal of Artificial Intelligence Research, vol. 24, pp. 81–108, 2005.
- [32] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” in International conference on machine learning, 2015, pp. 1889–1897.
- [33] C. Tessler, D. J. Mankowitz, and S. Mannor, “Reward constrained policy optimization,” arXiv preprint arXiv:1805.11074, 2018.
- [34] Q. Liang, F. Que, and E. Modiano, “Accelerated primal-dual policy optimization for safe reinforcement learning,” arXiv preprint arXiv:1802.06480, 2018.
- [35] M. Fu et al., “Risk-sensitive reinforcement learning: A constrained optimization viewpoint,” arXiv preprint arXiv:1810.09126, 2018.
- [36] Y. Chow, M. Ghavamzadeh, L. Janson, and M. Pavone, “Risk-constrained reinforcement learning with percentile risk criteria,” The Journal of Machine Learning Research, vol. 18, no. 1, pp. 6070–6120, 2017.
- [37] J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 22–31.
- [38] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [39] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [40] L. Kallenberg, “Markov decision processes,” Lecture Notes. University of Leiden, 2011.
- [41] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013.
- [42] R. S. Sutton, D. A. McAllester, S. P. Singh, and Y. Mansour, “Policy gradient methods for reinforcement learning with function approximation,” in Advances in neural information processing systems, 2000, pp. 1057–1063.
- [43] D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, “Deterministic policy gradient algorithms,” 2014.
- [44] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv:1509.02971, 2015.
- [45] S. Fujimoto, H. van Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” arXiv preprint arXiv:1802.09477, 2018.
- [46] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in International conference on machine learning, 2016, pp. 1928–1937.
- [47] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” arXiv preprint arXiv:1801.01290, 2018.
- [48] S. Lloyd, “Least squares quantization in pcm,” IEEE transactions on information theory, vol. 28, no. 2, pp. 129–137, 1982.
- [49] J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,” arXiv preprint arXiv:1506.02438, 2015.
- [50] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [51] “OpenAI spinning up in deep RL repository,” https://github.com/openai/spinningup/tree/master/spinup/algos/ppo/, [Online; accessed January 15, 2020].
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a6b73013-bd5e-4ac6-8219-013d635b9b04/sammy.jpg) |
Sami Khairy (S’16) received the B.S. degree in Computer Engineering from the University of Jordan, Amman, Jordan, in 2014 and the M.S. degree in Electrical Engineering from Illinois Institute of Technology, Chicago, IL, USA, in 2016. He is currently working towards the Ph.D. degree in Electrical Engineering at Illinois Institute of Technology. His research interests span the broad areas of analysis and protocol design for next generation wireless networks, AI powered wireless networks resource management, reinforcement learning, statistical learning, and statistical signal processing. He received a Fulbright Predoctoral Scholarship from JACEE and the U.S. Department of State in 2015, and the Starr/Fieldhouse Research Fellowship from IIT in 2019. He is an IEEE student member and a member of IEEE ComSoc and IEEE HKN. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a6b73013-bd5e-4ac6-8219-013d635b9b04/prasanna.png) |
Prasanna Balaprakash is a computer scientist at the Mathematics and Computer Science Division with a joint appointment in the Leadership Computing Facility at Argonne National Laboratory. His research interests span the areas of artificial intelligence, machine learning, optimization, and high-performance computing. Currently, his research focuses on the development of scalable, data-efficient machine learning methods for scientific applications. He is a recipient of U.S. Department of Energy 2018 Early Career Award. He is the machine-learning team lead and data-understanding team co-lead in RAPIDS, the SciDAC Computer Science institute. Prior to Argonne, he worked as a Chief Technology Officer at Mentis Sprl, a machine learning startup in Brussels, Belgium. He received his PhD from CoDE-IRIDIA (AI Lab), Université Libre de Bruxelles, Brussels, Belgium, where he was a recipient of Marie Curie and F.R.S-FNRS Aspirant fellowships. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a6b73013-bd5e-4ac6-8219-013d635b9b04/lin.png) |
Lin X. Cai (S’09–M’11–SM’19) received the M.A.Sc. and Ph.D. degrees in Electrical and Computer Engineering from the University of Waterloo, Waterloo, Canada, in 2005 and 2010, respectively. She is currently an Associate Professor with the Department of Electrical and Computer Engineering, Illinois Institute of Technology, Chicago, Illinois, USA. Her research interests include green communication and networking, intelligent radio resource management, and wireless Internet of Things. She received a Postdoctoral Fellowship Award from the Natural Sciences and Engineering Research Council of Canada (NSERC) in 2010, a Best Paper Award from the IEEE Globecom 2011, an NSF Career Award in 2016, and the IIT Sigma Xi Research Award in the Junior Faculty Division in 2019. She is an Associated Editor of IEEE Transaction on Wireless Communications, IEEE Network Magazine, and a co-chair for IEEE conferences. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a6b73013-bd5e-4ac6-8219-013d635b9b04/cheng.png) |
Yu Cheng (S’01–M’04–SM’09) received the B.E. and M.E. degrees in electronic engineering from Tsinghua University, Beijing, China, in 1995 and 1998, respectively, and the Ph.D. degree in electrical and computer engineering from the University of Waterloo, Waterloo, ON, Canada, in 2003. He is currently a Full Professor with the Department of Electrical and Computer Engineering, Illinois Institute of Technology, Chicago, IL, USA. His current research interests include wireless network performance analysis, network security, big data, cloud computing, and machine learning. Dr. Cheng was a recipient of the Best Paper Award at QShine 2007, the IEEE ICC 2011, the Runner-Up Best Paper Award at ACM MobiHoc 2014, the National Science Foundation CAREER Award in 2011, and the IIT Sigma Xi Research Award in the Junior Faculty Division in 2013. He has served as several Symposium Co-Chairs for IEEE ICC and IEEE GLOBECOM, and the Technical Program Committee Co-Chair for WASA 2011 and ICNC 2015. He was a founding Vice Chair of the IEEE ComSoc Technical Subcommittee on Green Communications and Computing. He was an IEEE ComSoc Distinguished Lecturer from 2016 to 2017. He is an Associate Editor for the IEEE Transactions on Vehicular Technology, IEEE Internet of Things Journal, and IEEE Wireless Communications. |