Constant Directivity Loudspeaker Beamforming
Abstract
Loudspeaker array beamforming is a common signal processing technique for acoustic directivity control and robust audio reproduction. Unlike their microphone counterpart, loudspeaker constraints are often heterogeneous due to arrayed transducers with varying operating ranges in frequency, acoustic-electrical sensitivity, efficiency, and directivity. This work proposes a frequency-regularization method for generalized Rayleigh quotient directivity specifications and two novel beamformer designs that optimize for maximum efficiency constant directivity (MECD) and maximum sensitivity constant directivity (MSCD). We derive fast converging and analytic solutions from their quadratic equality constrained quadratic program formulations. Experiments optimize generalized directivity index constrained beamformer designs for a full-band heterogeneous array.
Index Terms:
Beamforming, acoustic directivity, regularization, quadratic programming, secular equationI Introduction
Beamformer designs for loudspeaker arrays require constraints atypical to their microphone array counterpart due to greater variations in operating frequency characteristics across loudspeaker transducer elements, acoustic and electric power output limits, and placement restrictions. Traditional frequency-invariant beamforming designs for linear [1], circular [2], spherical [3], differential [4, 5] homogeneous arrays often optimize for directivity factor and white-noise gain (WNG) [6], [7], and beam pattern fit [8]. Such constraints are less applicable for heterogeneous loudspeakers and non-uniform arrays that jointly maximize acoustic/electrical power ratio in a listening window, and satisfy a generalized directivity index (GDI) [9]. The former extends WNG to evaluation regions in spherical coordinates, and transducer dependent penalty factors per electrical power unit over frequency. The latter relaxes beam pattern targets to an acoustic power ratio over two evaluation regions defined by density functions. This work addresses both issues and is organized as follows:
Section II introduces a novel regularization technique for the generalized Rayleigh quotient (GRQ) [10] that penalizing both acoustic and electrical power for heterogeneous arrays without introducing explicit constraints in their formulations. Sections II-A, II-B propose two maximal acoustic efficiency and sensitivity beamformer designs subject to constant GDI equality constraints, and present a pair of iterative and analytic solutions respectively via quadratic programming. Section III solves for the secular equation sub-problem common to both beamformer formulations. Section IV shows several beamformer designs for a sample heterogeneous array and compares convergence rates of the iterative solutions. Section V summarizes the theoretical results and experiments.
II Loudspeaker Directivity Optimization
The GRQ is the power ratio of a beamformer’s responses over two domains specified by weights and so-called ”accept” and ”reject” covariance matrices , and respectively. A beamformer’s GDI equates to the GRQ for covariance matrices specified in the acoustic domain given by
| (1) |
where the expectation samples steering vectors or anechoic frequency responses (conjugate transpose ) over the Cartesian unit-directions . The probability density functions , weight the acoustic power-responses over specifiable directions to boost and attenuate respectively as shown in Fig. 1, and generalize the directivity index [9].


Maximizing GRQ therefore maximizes GDI by reducing GRQ into the normal Rayleigh quotient under a change of variables:
| (2) |
where matrix is the lower-triangular Cholesky factor of . The maximizer of (2) constrained to the unit-circle is therefore the eigenvector of the largest eigenvalue of matrix .
In heterogeneous transducer beamformer design, it is beneficial to mix both acoustic and electric rejection covariance matrices as to penalize components of outside each transducer’s operating frequency ranges. Consider the following generalized Rayleigh penalty quotient (GRPQ) which adds a diagonal positive-definite penalty matrix to the denominator covariance matrix given by
| (3) |
where is unbounded. Inverting the sum of and the identity matrix gives the bounded weighting matrix
| (4) |
which penalizes for smaller . Lowering for frequencies outside transducer ’s operating range has the desired effect on the maximizer and thus generalizes crossover designs to joint frequency-transducer weighted specifications of as shown in Fig. 2.

For computation, also improves the condition number of for maximizing (2) when combined with the following change of variables:
| (5) |
where . The modified GRPQ in (5) is now well-conditioned and bounded above by GRQ as expressed by
| (6) |
where attenuates non-diagonal entries of by .
II-A Maximum Efficiency Constant Directivity Beamformer
In speaker array beamforming design, we can consider the following constant GRQ optimization s.t. , which maximizes an array’s efficiency defined by the ratio of the acoustic output power for covariance matrix , to electric output power s.t. constant GDI . The constraint is feasible for between the smallest and largest generalized eigenvalues of , , and the solutions are not generally unique; consider diagonalizing matrix in (2):
| (7) |
where is the column matrix of eigenvectors and s.t. the ascending real-valued eigenvalues. For constrained to the unit-circle, is satisfied by multiple non-negative weighting of except at the extrema . For the open interval , we express GRQs (2), (7) as the quadratic equality constraint via substitution for the Hermitian matrix , which is shown to be indefinite:
| (8) |
where .
We now formally define the maximum efficiency constant directivity MECD beamformer design as a quadratic equality constrained quadratic program given by
| (9) |
where Hermitian matrix is the speaker covariances over a separate evaluation density as in (1), and indefinite matrix constrains the GDI to . The necessary conditions for optimality are expressed via the Lagrangian function :
| (10) |
where and are the Lagrangian multipliers and it suffices to restrict both for Hermitian . Substituting in (10) into the constraints yields the critical points of :
| (11) |
which are bounded between smallest and largest eigenvalues of . The stationary points of can be found via iterative methods such the differential multipliers (DM) [11], which at each iteration sets , performs a round of gradient ascent and descent on , via (10), (11) with fixed step-sizes , respectively, and lastly normalizes to the unit-circle.
We can greatly improve the convergence rate of the gradient method by directly solving for via projecting along an unknown direction onto the nearest feasible point satisfying the quadratic equality constraints given by
| (12) |
before normalizing the projection to the unit-circle.
This is expressed in the proposed MECD projected ascent (PA) Algorithm (1), which iterates between moving along the gradient of the objective in (9), solving for the minimum norm projection vector for (12), and normalizing the projection to . The minimum norm projection to (12) is a variant of the quadratic constrained least-squares problem in [12] that we generalize for indefinite . Its feasible surface is the intersection of two hyper-ellipsoids characterized by and with necessary conditions satisfying the Lagrangian and multiplier :
| (13) |
where it suffices to restrict . It is useful to express Hermitian along the column matrix of eigenvectors and diagonal matrix of real-valued eigenvalues so that deflates the latter:
| (14) |
where . Substituting into the constraints yields the critical points which are the roots of a quadratic secular equation variant [13]:
| (15) |
where and the inner terms are diagonal matrices. is therefore a sum of rational quadratic functions.
We can further characterize the minimizer via a slight modification of the first two theorems in the quadratic constrained least-squares solution [12] to support indefinite for the squared norm (see Appendix derivations). Given a pair of critical points and solutions and satisfying (14), (15), the difference of the squared norms between vectors relates to the difference in multipliers :
| (16) |
and the squared norm of the vector difference relates to the sum of multipliers :
| (17) |
Unlike [12], the term may be negative for indefinite such that choosing the via (16) is insufficient for determining the smaller norm between . Conversely, (17) no longer ensures that there is at most one solution . Taking the product of the left and right-hand sides of (16), (17) however gives
| (18) |
which implies that picking the gives the smaller norm between . Therefore, the multiplier nearest to and its corresponding vector after substitution into (14) is the minimum norm solution under projection to (12). Methods for finding are discussed in Section III.
We note that a semi-definite program (SDP) and its relaxation of MECD in (9) is also possible as the number constraints tightly bounds the rank of the solution [14, 15, 16]. Formally, the MECD-SDP for unknown Hermitian and semi-definite matrix and the matrix trace operator is given by
| (19) |
which for Hermitian matrices , ensures a real-valued trace of two constraints, and a rank- solution . The interior-point method (IPM) therefore finds the maximizer within polynomial time as the problem is convex.
II-B Maximum Sensitivity Constant Directivity Beamformer
If the evaluation region is conventional111Speaker’s acoustic response is measured at single point at m distance, then MECD maximizes the loudspeaker sensitivity [17] which we show has an analytic secular equation solution. Constraining the acoustic response to also be distortionless at the measurement point reduces MECD into the proposed maximum sensitivity constant directivity MSCD quadratic program with both quadratic and linear constraint beamformer:
| (20) |
whereby and the acoustic output at is constrained to unity and therefore has unit acoustic power for . This problem is a variant of [13, 18] where the latter’s quadratic equality is set to unity instead of zero. The MSCD extrema are found at the critical points of the Lagrangian function and multipliers and :
| (21) |
where it suffices to restrict for Hermitian . Substituting into the constraints yields the critical points:
| (22) |
which restricts as the eigenvalues of are also real. The critical points are the real-valued roots of in (22), analogous to that of (15) and given by
| (23) |
where , column eigenvector matrix and diagonal matrix of real-valued eigenvalues of . The minimizer is therefore found at the root nearest to .
III Quadratic Secular Equation Root-Finding
The secular equations in (15), (23) can be expressed in rational form w.r.t. reciprocal eigenvalue poles :
| (24) |
where and are the th elements of and from (15), (23) respectively, and . It is also useful to express and its first derivative in terms of the set of negative and positive poles and respectively given by
| (25) |
Unlike the linear and quadratic secular equations in [13], is not monotonic in most intervals between consecutive poles due to the presence of different signed in the numerator terms. The one exception is the tightest interval bounding which contains the smallest magnitude negative and positive poles , respectively. This is a consequence of (25) where the first derivatives given by
| (26) |
in the intervals outside these poles are bounded and positive.

Moreover, we show as in Fig. 3 that the intersecting interval contains exactly one real-valued root that is also the root nearest to and therefore equivalent to the critical point and solutions to (12), (20). The proof is as follows:
The function where , is continuous and so the intermediate value theorem guarantees the existence of at least one real-valued root in the interval. Its first derivative is strictly positive in the interval via (26) and therefore contains exactly one root that can easily be found via bracketing methods such as [19]. To show that is indeed the nearest to , observe that reflecting over or in the interval moves closer to the remaining poles in , respectively:
| (27) |
which with (26) places bounds on , given by
| (28) |
and as a result induces bounds on after summation:
| (29) |
This implies there are no roots in the regions reflected across and given by and respectively and that must be nearest to .
IV Experiments
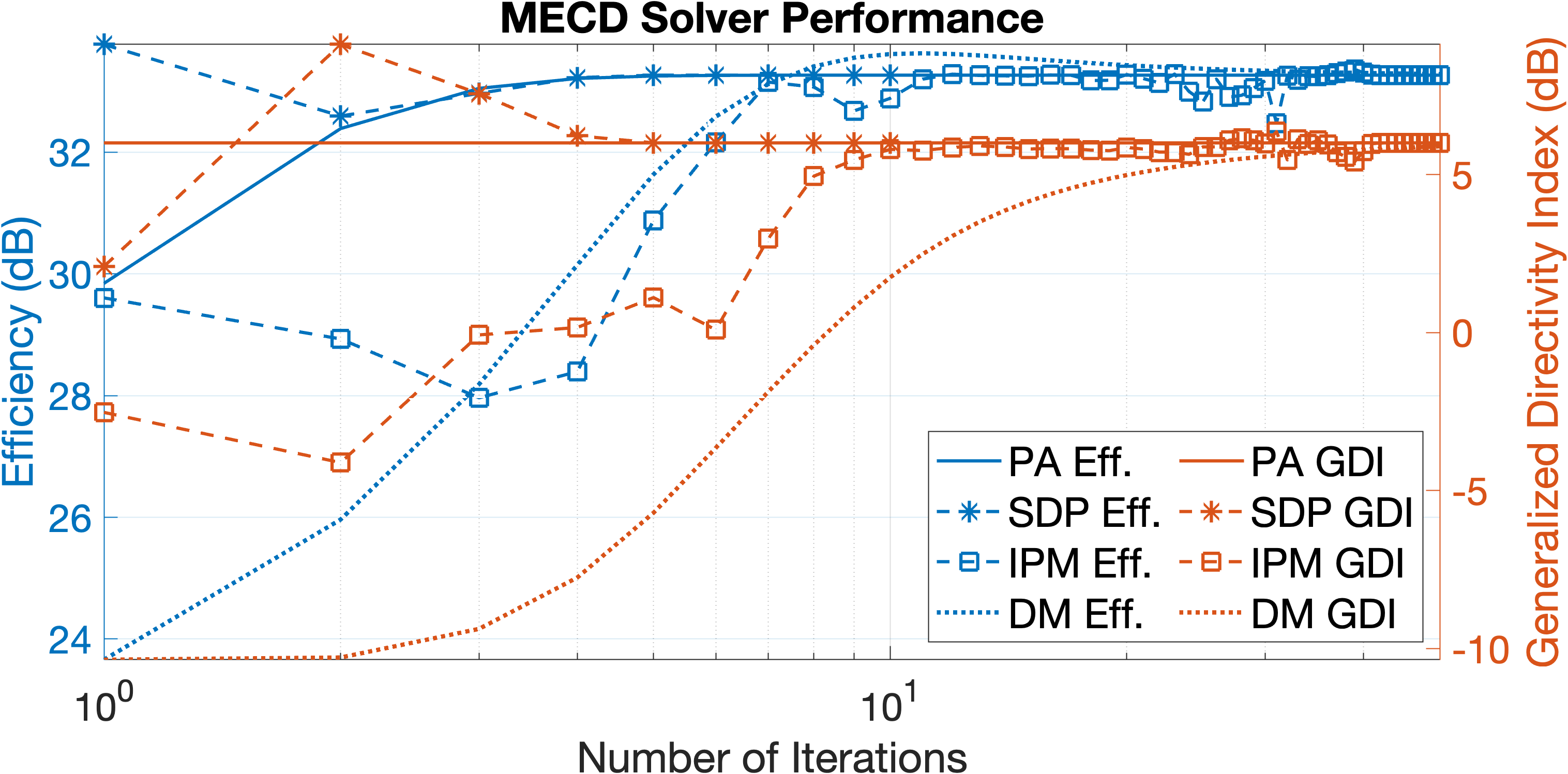
We first compare MECD solver performance for elements with randomized complex-valued covariances in Fig. 4. Our PA method reduces the number of iterations to convergence of the baseline DM method from to . Larger step-sizes in the latter cause oscillations between the objective and constraint, and also exhibit to a lesser degree in Matlab’s fmincon IPM solver. SDPT3 [20] for SDP shows similar convergence rates of the objective to PA but requires more compute in solving for number of variables instead of .
We then compare GRQ to GRPQ beamformer designs for a measured sample mid-range, full-range, and tweeter array with integrated over densities from Fig. 1, frequency weighting from Fig. 2, and constant GDI for MECD and MSCD. GRPQ beam patterns shown in Fig. 5 exhibit more regular responses inline with expected transducer operating frequency ranges; directivity grows increasingly omni-directional in low-frequency as only the mid-range is active. MECD beam patterns exhibit less lobing than MSCD and their maximum GDI counterparts.






V Conclusion
We introduced an electrical power penalty term to GRQ for regularizing frequency-dependent heterogeneous speaker array beamformer designs such as MECD and MSCD. Characterizing the projection sub-problem in MECD-PA and MSCD yielded a fast quadratic secular equation root-finding solution. The PA method accelerated convergence rates over the baseline DM, IPM, and SDP methods. GRPQ solutions exhibited more regular beam patterns than GRQ for a sample -way system. Inequality constrained GDI can be considered in future works.
The necessary conditions for in (12) are given by
| (30) |
where several useful relations are derived for characterizing the minimizer. Expanding the equality constraint in (30) relates the sum of symmetric terms to the sum of mixed terms:
| (31) |
It is possible to relate the squared norm of from (30) to the difference in squared norms under via (31):
| (32) |
For , , the mixed products from (30) are given:
| (33) |
where their arithmetic mean is equivalent under conjugation and :
| (34) |
Summing (34) and substituting (31) gives
| (35) |
Subtracting (35) from the sum of , substituted into (32) gives which verifies (17). Next, observe that the arithmetic difference is equivalent under conjugation:
| (36) |
whereby taking the summation and substituting (31) gives
| (37) |
Subtracting (37) from the difference after substitution into (32) verifies (16) after combining the terms.
References
- [1] D. B. Ward, R. A. Kennedy, and R. C. Williamson, Constant directivity beamforming. Springer, 2001, pp. 3–17.
- [2] G. Huang, J. Chen, and J. Benesty, “Insights into frequency-invariant beamforming with concentric circular microphone arrays,” IEEE/ACM Trans. Audio, Speech, Language Process., vol. 26, no. 12, 2018.
- [3] F. Zotter, H. Pomberger, and A. Schmeder, “Efficient directivity pattern control for spherical loudspeaker arrays,” Journal of the Acoustical Society of America, vol. 123, no. 5, p. 3643, 2008.
- [4] J. Wang, W. Zhang, C. Pan, J. Chen, and J. Benesty, “On the design of differential loudspeaker arrays with broadside radiation patterns,” JASA Express Letters, vol. 1, no. 8, 2021.
- [5] F. Miotello, A. Bernardini, D. Albertini, F. Antonacci, and A. Sarti, “Steerable first-order differential loudspeaker arrays with monopole and dipole elements,” in Convention of the European Acoustics Association, Forum Acusticum, 2023, pp. 11–15.
- [6] R. Berkun, I. Cohen, and J. Benesty, “Combined beamformers for robust broadband regularized superdirective beamforming,” IEEE/ACM Trans. Audio, Speech, Language Process., vol. 23, no. 5, 2015.
- [7] M. Crocco and A. Trucco, “Design of robust superdirective arrays with a tunable tradeoff between directivity and frequency-invariance,” IEEE Trans. Signal Process., vol. 59, no. 5, 2011.
- [8] L. C. Parra, “Steerable frequency-invariant beamforming for arbitrary arrays,” The Journal of the Acoustical Society of America, vol. 119, no. 6, pp. 3839–3847, 2006.
- [9] Y. Luo, “Spherical harmonic covariance and magnitude function encodings for beamformer design,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2021, pp. 1–17, 2021.
- [10] R. Horn and C. Johnson, Matrix Analysis. Cambridge University Press, 1990.
- [11] J. Platt and A. Barr, “Constrained differential optimization,” in Neural Information Processing Systems, D. Anderson, Ed., vol. 0. American Institute of Physics, 1987.
- [12] W. Gander, “Least squares with a quadratic constraint,” Numerische Mathematik, vol. 36, pp. 291–307, 1980.
- [13] G. H. Golub, “Some modified matrix eigenvalue problems,” SIAM Review, vol. 15, no. 2, p. 330, 1973.
- [14] A. Shapiro, “Rank-reducibility of a symmetric matrix and sampling theory of minimum trace factor analysis,” Psychometrika, vol. 47, pp. 187–199, 1982.
- [15] A. I. Barvinok, “Problems of distance geometry and convex properties of quadratic maps,” Discrete & Computational Geometry, vol. 13, pp. 189–202, 1995.
- [16] G. Pataki, “On the rank of extreme matrices in semidefinite programs and the multiplicity of optimal eigenvalues,” Mathematics of Operations Research, vol. 23, 05 1998.
- [17] D. Davis, E. Patronis, and P. Brown, Sound System Engineering 4e. Taylor & Francis, 2013, pp. 365–366.
- [18] W. Gander, G. H. Golub, and U. Von Matt, “A constrained eigenvalue problem,” Linear Algebra and its applications, vol. 114, pp. 815–839, 1989.
- [19] R. P. Brent, “An algorithm with guaranteed convergence for finding a zero of a function,” The Computer Journal, vol. 14, no. 4, 1971.
- [20] K.-C. Toh, M. J. Todd, and R. H. Tütüncü, “SDPT3 — a matlab software package for semidefinite programming, version 1.3,” Optimization methods and software, vol. 11, no. 1-4, pp. 545–581, 1999.