Consolidated Adaptive T-soft Update for Deep Reinforcement Learning
Abstract
Demand for deep reinforcement learning (DRL) is gradually increased to enable robots to perform complex tasks, while DRL is known to be unstable. As a technique to stabilize its learning, a target network that slowly and asymptotically matches a main network is widely employed to generate stable pseudo-supervised signals. Recently, T-soft update has been proposed as a noise-robust update rule for the target network and has contributed to improving the DRL performance. However, the noise robustness of T-soft update is specified by a hyperparameter, which should be tuned for each task, and is deteriorated by a simplified implementation. This study develops adaptive T-soft (AT-soft) update by utilizing the update rule in AdaTerm, which has been developed recently. In addition, the concern that the target network does not asymptotically match the main network is mitigated by a new consolidation for bringing the main network back to the target network. This so-called consolidated AT-soft (CAT-soft) update is verified through numerical simulations.
Index Terms:
Reinforcement Learning, Machine Learning for Robot Control, Deep Learning MethodsI Introduction
As robotic and machine learning technologies remarkably develop, the tasks required of intelligent robots becomes more complex: e.g. physical human-robot interaction [1, 2]; work on disaster sites [3, 4]; and manipulation of various objects [5, 6]. In most cases, these complex tasks have no accurate analytical model. To resolve this difficulty, deep reinforcement learning (DRL) [7] has received a lot of attention as an alternative to classic model-based control. Using deep neural networks (DNNs) as a nonlinear function approximator, DRL can learn the complicated policy and/or value function in a model-free manner [8, 9], or learn the complicated world model for planning the optimal policy in a model-based manner [10, 11].
Since DNNs are nonlinear and especially model-free DRLs must generate pseudo-supervised signals by themselves, making DRL unstable. Techniques to stabilize learning have been actively proposed, such as the design of regularization [5, 9, 12] and the introduction of the model that makes learning conservative [13, 14]. Among them, a target network is one of the current standard techniques in DRL [8, 15]. After generating it as a copy of the main network to be learned by DRL, an update rule is given to make it slowly match the main network at regular intervals or asymptotically. In this case, the pseudo-supervised signals generated from the target network are more stable than those generated from the main network, which greatly contributes to the overall stability of DRL.
The challenge in using the target network is its update rule. It has been reported that too slow update stagnates the whole learning process [16], while too fast update reverts to instability of the pseudo-supervised signals. A new update rule, T-soft update [15], has been proposed to mitigate the latter problem. This method provides a mechanism to limit the amount of updates when the main network deviates unnaturally from the target network, which can be regarded as noise. Such noise robustness enables to stabilize the whole learning process even with the high update rate by appropriately ignoring the unstable behaviors of the main network.
However, the noise robustness of T-soft update is specified as a hyperparameter, which must be set to an appropriate value depending on the task to be solved. In addition, the simplified implementation for detecting noise deteriorates the noise robustness. More sophisticated implementation with the adaptive noise robustness is desired. As another concern, when the update of the target network is restricted like T-soft update does, the target network may not asymptotically match the main network. A new constraint is needed to avoid the situation where the main network deviates from the target network.
Hence, this paper proposes two methods to resolve each of the above two issues: i) the adaptive and sophisticated implementation of T-soft update and; ii) the appropriate consolidation of the main target network to the target network. Specifically, for the issue i), a new update rule, so-called adaptive T-soft (AT-soft) update, is developed based on the recently proposed AdaTerm [17] formulation, which is an adaptively noise-robust stochastic gradient descent method. This allows us to sophisticate the simplified implementation of T-soft update and improve the noise robustness, which can be adaptive to the input patterns. For the issue ii), a new consolidation so that the main network is regularized to the target network when AT-soft update restricts the updates of the target network. By implementing it with interpolation, the parameters in the main network that naturally deviate significantly from that of the target network, are updated to a larger extent. With this consolidation, the proposed method is so-called consolidated AT-soft (CAT-soft) update.
To verify CAT-soft update, typical benchmarks implemented by Pybullet [18] are tried using the latest DRL algorithms [12, 19]. It is shown that even though the learning rate is larger than the standard value for DRL, the task performance is improved by CAT-soft update and more stable learning can be achieved. In addition, the developed consolidation successfully suppresses the divergence between the main and target networks.
II Preliminaries
II-A Reinforcement learning
First of all, the basic problem statement of DRL and an actor-critic algorithm, which can handle continuous action space, is natural choice [7] as one of the basic algorithms for robot control. Note that the proposed method can be applied to other algorithms with the target network.
In DRL, an agent interacts with an unknown environment under Markov decision process (MDP) with the current state , the agent’s action , the next state , and the reward from the environment . Specifically, the environment implicitly has its initial randomness and its state transition probability . Since the agent can act on the environment’s state transition through , the goal is to find the optimal policy to reach the desired state. To this end, is sampled from a state-dependent trainable policy, , with its parameters set (a.k.a. weights and biases of DNNs in DRL). The outcome of the interaction between the agent and the environment can be evaluated as .
By repeating the above process, the agent gains the sum of over the future (so-called return), , with discount factor. The main purpose of DRL is to maximize by optimizing (i.e. ). However, cannot be gained due to its future information, hence its expected value is inferred as a trainable (state) value function, , with its parameters set . Finally, DRL optimizes to maximize while increasing the accuracy of .
To learn , a temporal difference (TD) error method is widely used as follows:
| (1) | ||||
| (2) |
where denotes the pseudo-supervised signal generated from the target network with the parameters set (see later). By minimizing , can be optimized to correctly infer the value over .
To learn , a policy-gradient method is applied as follows:
| (3) |
where is sampled from the alternative policy , which is often given by the target network with the parameters set . The sampler change is allowed by the importance sampling, and the likelihood ratio is introduced as in the above loss function. By minimizing , can be optimized to reach the state with higher value.
II-B Target network with T-soft update
The target network with is briefly introduced together with the latest update rule, T-soft update [15]. First, with the initialization phase of the main network, the target network is also created as a copy with . Since the copied is given independently of , and not updated through the minimization problem of eqs. (1) and (3). Therefore, the pseudo-supervised signal has the same value for the same input, which greatly contributes to the stability of learning by making the minimization problem stationary.
However, in practice, if is fixed at its initial value, the correct cannot be generated and the task is never accomplished. Thus, must be updated slowly towards as in alternating optimization [20]. When the target network was first introduced, a technique called hard update was employed [8], where was updated a certain number of times and then copied again as . Afterwards, soft update shown in the following equation has been proposed to make asymptotically match more smoothly.
| (4) |
where denotes the update rate.
The above update rule is given as an exponential moving average, and all new inputs are treated equivalently. As a result, even when is incorrectly updated, its adverse effect as noise is reflected into . This effect is more pronounced when is large, but mitigating this by reducing causes a reduction in learning speed [16].
To tackle this problem, T-soft update that is robust to noise even with relatively large has recently been proposed [15]. It regards the exponential moving average as update of a location parameter of normal distribution, and derives a new update rule by replacing it with student-t distribution that is more robust to noise by specifying degrees of freedom . T-soft update is described in Alg. 1. Note that and must be updated as new internal states.
With mathematical explanations, the issues of T-soft update are again summarized as below.
-
1.
Since must be specified as a constant in advance, it must be tuned for each task to provide the appropriate noise robustness to maximize performance.
-
2.
The larger is, the more the update is suppressed. However, the simple calculation of as mean square error makes it easier to hide the noise hidden in the -th subset.
-
3.
If is frequently close to zero (i.e. no update), there is a risk that will not asymptotically match .
III Proposal
III-A Adaptive T-soft update
The first two of the three issues mentioned above are resolved by deriving a new update rule, so-called AT-soft update. To develop AT-soft update, the formulation of AdaTerm [17], which is a kind of stochastic gradient descent method with the adaptive noise robustness, is applied. In this method, by assuming that the gradient is generated from student-t distribution, its location, scale, and degrees of freedom parameters, which are utilized for updating the network, can be estimated by approximate maximum likelihood estimation. Instead of the gradient as stochastic variable, the parameters of the main network are considered to be generated from student-t distribution, and its location is mapped to the parameters of the target network. With this assumption, AT-soft update obtains the noise robustness as in the conventional T-soft update. In addition, the degrees of freedom can be estimated at the same time in this formulation, so that the noise robustness can be automatically adjusted according to the faced task.
Specifically, the -th subset of (e.g. a weight matrix in each layer), with the number of dimensions, is assumed to be generated from -dimensional diagonal student-t distribution with three kinds of sample statistics: a location parameter ; a scale parameter ; and degrees of freedom . With and , its density can be described as below.
| (5) |
where denotes the gamma function. Note that the conventional T-soft update simplifies this model as one-dimensional student-t distribution for the mean of , but here we treat it as -dimensional distribution with slightly increased computational cost.
With this assumption, following the derivation of AdaTerm, , , and are optimally inferred to maximize the approximated log-likelihood. The important variable in the derivation is , which indicates the deviation of from , and is calculated as follows:
| (6) |
That is, since represents the pseudo-distance from , the larger is, the closer is to . In addition, the smaller is, the more sensitive is to fluctuations in , leading to higher noise robustness. Using , , which is used only for updating , can be derived as follows:
| (7) |
These are used to calculate the update ratio of the sample statistics, .
| (8) |
where denotes the basic update ratio given as a hyperparameter. To satisfy , the upper bounds of , , are employed.
| (9) |
where means the negative logarithm with the tiny number of float32.
The update amounts for , , and are respectively given as follows:
| (10) | ||||
| (11) | ||||
| (12) |
where denotes the small value for stabilizing the computation and denotes the lower bound of (i.e. the maximum noise robustness) given as a hyperparamter.
Using the update ratios and the update amounts obtained above, , , and can be updated.
| (13) | ||||
| (14) | ||||
| (15) |
As a result, AT-soft update enables to update the parameters set of the target network adaptively (i.e. depending on the deviation of from ), while automatically tuning the noise robustness represented by and .
III-B Consolidation from main to target networks
However, if continues in the above update, will deviate from gradually, and the target network will no longer be able to generate pseudo-supervised signals since the assumption is broken. In such a case, parts of would be updated with the minimization of eqs. (1)–(3) in a wrong direction, causing as outlier. Hence, to stop this fruitless judgement and restart the appropriate updates, reverting to and holding would be the natural effective way. To this end, a heuristic consolidation is designed as below.
Specifically, the update ratio from the main to target networks, , is designed to be larger when the update ratio of is smaller (i.e. when deviates from ).
| (16) |
where adjusts the strength of this consolidation, which should be the same as or weaker than the update speed of the target network.
Next, since consolidating all would interfere with learning, the consolidated subset of outliers, , should be extracted. The simple and popular way is to use the -th quantile with . Since the component that contributes to making small is with large , is defined as follows:
| (17) |
Thus, the following update formula consolidates to the corresponding subset of the target network, .
| (18) |
A rough sketch of this consolidation is shown in Fig. 1. Although loss-function-based consolidations, as proposed in the context of continual learning [21, 22], would be also possible, a more convenient implementation with lower computational cost was employed.
The pseudo-code for the consolidated adaptive T-soft (CAT-soft) update is summarized in Alg. 2. Note that, although must be specified as a new hyperparameter in (C)AT-soft update, specified in T-soft update is already conservatively set for noise, and we can inherit it (i.e. ). Therefore, the additional hyperparameters to be tuned are and . can be given as so that a few parameters in -th subset are consolidated without interfering with learning. can be given as the inverse of the number of parameters to be consolidated. In other words, we can decide whether to make closer to and consolidate fewer parameters tightly, or make smaller and consolidate more parameters slightly.

IV Simulations
| Symbol | Meaning | Value |
|---|---|---|
| #Hidden layer | ||
| #Neuron for each layer | ||
| Discount factor | ||
| For AdaTerm [17] | ||
| For PPO-RPE [12] | ||
| For PER [19] | ||
| For L2C2 [23] |
IV-A Setup
For the statistical verification of the proposed method, the following simulations are conducted. As simulation environments, Pybullet [18] with OpenAI Gym [24] is employed. From it, InvertedDoublePendulumBulletEnv-v0 (DoublePendulum), HopperBulletEnv-v0 (Hopper), and AntBulletEnv-v0 (Ant) are chosen as tasks. To make the tasks harder, the observations from them are with white noises, scale of which is . With 18 random seeds, each task is tried to be accomplished by each method. After training, the learned policy is run 100 times for evaluating the sum of rewards as a score (larger is better).
The implementation of the base network architecture and DRL algorithm is basically the same as in the literature [23]. However, it is noticeable that the stochastic policy function is modeled by student-t distribution for conservative learning and efficient exploration [14], instead of normal distribution. Hyperparamters for the implementation are summarized in Table I. Note that the learning difficulty is higher because the specified value of the learning rate is higher than one suitable for DRL, revealing the effectiveness of the target network for stabilizing learning.
The following three methods are compared.
-
•
T-soft update:
-
•
AT-soft update:
-
•
CAT-soft update:
Here, is designed to consolidate only one parameter in each subset as the simplest implementation. Correspondingly, is given as the inverse of the (maximum) number of consolidated parameters. is set smaller than one in the literature [15], but this is to counteract the negative effects of the high learning rate (i.e. ) set above.


| Method | DoublePendulum | Hopper | Ant |
|---|---|---|---|
| T-soft | 6427.1 3357.8 | 1852.8 900.9 | 2683.8 249.3 |
| AT-soft | 6379.7 3299.7 | 1662.7 897.4 | 2764.1 265.5 |
| CAT-soft | 7129.2 2946.0 | 1971.2 812.9 | 2760.0 312.2 |
IV-B Result
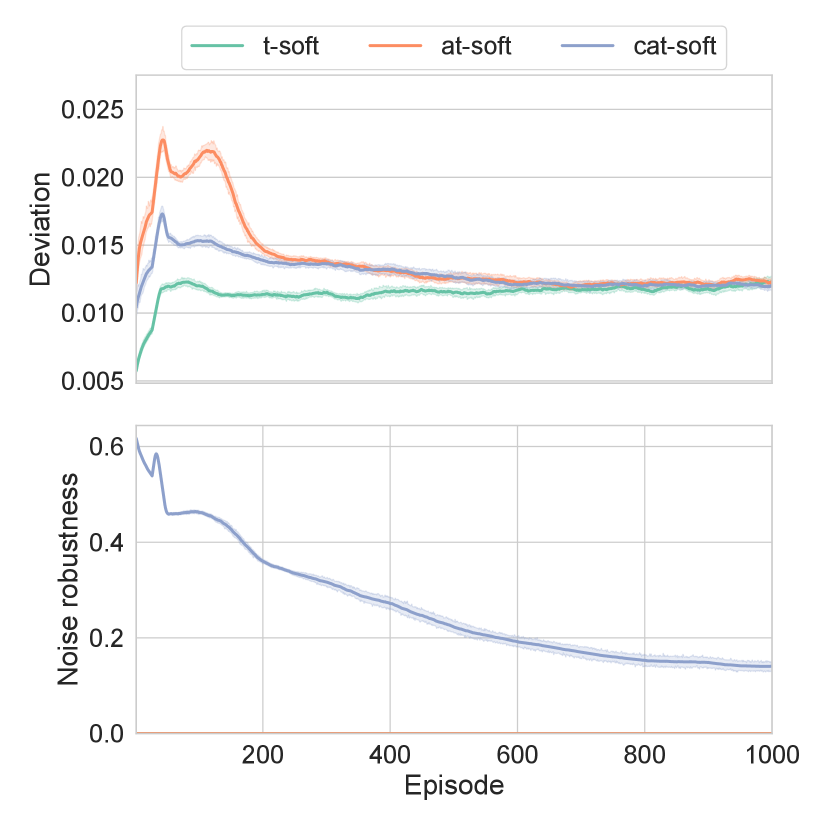
The learning behaviors are depicted in Fig. 2. As pointed out, the deviation by (C)AT-soft updates were larger than that of the conventional T-soft update since (C)AT-soft update have better outlier and noise detection performance and the target network update is easily suppressed. This was pronounced in the early stage of training when the noise robustness is high and the update of the main network is unstable. However, CAT-soft update suppressed the deviation in the early stage of training. As the learning progresses, CAT-soft update converged to roughly the same level of deviation as AT-soft update because the consolidation was relaxed with the weakened noise robustness.
The scores of 100 runs after learning are summarized in Table II. AT-soft update slightly increased the performance of T-soft update on Ant, but decreased it on Hopper. In contrast, CAT-soft update outperformed T-soft update in all tasks.
IV-C Demonstration
| Argument | Default | Modified |
| motor_velocity_limit | 100 | |
| pd_control_enabled | False | True |
| accurate_motor_model_enabled | True | False |
| action_repeat | 1 | 4 |
| observation_noise_stdev | 0 | |
| hard_reset | True | False |
| env_randomizer | Uniform | None |
| distance_weight | 1 | 100 |
| energy_weight | 0.005 | 1 |
| shake_weight | 0 | 1 |


As a demonstration, a simulation closer to the real robot experiment, MinitaurBulletDuckEnv-v0 (Minitaur) in Pybullet, is tried. The task is to move a duck on top of a Ghost Minitaur, a quadruped robot developed by Ghost Robotics. Since this duck is not fixed, careful locomotion is required, and its states (e.g. position) are unobserved, making this task a partially observed MDP (POMDP). Note that the default setting for Minitaur tasks is unrealistic, as pointed out in the literature [25]. Therefore, it was modified as shown in Table III (arguments not listed are left at default).
T-soft and CAT-soft updates are compared under the same conditions as in the above simulations. The learning curves of the scores for 8 trials and the test results of the trained policies are depicted in Fig. 3. The best behaviors on the tests can be found in the attached video. As can be seen from Fig. 3, only the proposed CAT-soft update was able to acquire the successful cases of the task (walking without dropping the duck). Thus, it is suggested that CAT-soft update can contribute to the success of the task by steadily improving the learning performance even for more practical tasks.
V Conclusion
This paper proposed a new update rule for the target network, CAT-soft update, which stabilizes DRL. In order to adaptively adjust the noise robustness, the update rule inspired by AdaTerm, which has been developed recently, was derived. In addition, a heuristic consolidation from the main to target networks was developed to suppress the deviation between them, which may occur when updates are continuously limited due to noise. The developed CAT-soft update was tested on the DRL benchmark tasks, and succeeded in improving and stabilizing the learning performance over the conventional T-soft update.
Actually, the target network should not deviate from the main network in terms of its outputs, not in terms of its parameters. A new consolidation and a noise-robust update based on the output space are expected to contribute to further performance improvements. These efforts to stabilize DRL will lead to its practical use in the near future.
ACKNOWLEDGMENT
This work was supported by JSPS KAKENHI, Grant-in-Aid for Scientific Research (B), Grant Number JP20H04265.
References
- [1] H. Modares, I. Ranatunga, F. L. Lewis, and D. O. Popa, “Optimized assistive human–robot interaction using reinforcement learning,” IEEE transactions on cybernetics, vol. 46, no. 3, pp. 655–667, 2015.
- [2] T. Kobayashi, E. Dean-Leon, J. R. Guadarrama-Olvera, F. Bergner, and G. Cheng, “Whole-body multicontact haptic human–humanoid interaction based on leader–follower switching: A robot dance of the “box step”,” Advanced Intelligent Systems, p. 2100038, 2021.
- [3] T. Kobayashi, T. Aoyama, K. Sekiyama, and T. Fukuda, “Selection algorithm for locomotion based on the evaluation of falling risk,” IEEE Transactions on Robotics, vol. 31, no. 3, pp. 750–765, 2015.
- [4] J. Delmerico, S. Mintchev, A. Giusti, B. Gromov, K. Melo, T. Horvat, C. Cadena, M. Hutter, A. Ijspeert, D. Floreano et al., “The current state and future outlook of rescue robotics,” Journal of Field Robotics, vol. 36, no. 7, pp. 1171–1191, 2019.
- [5] Y. Tsurumine, Y. Cui, E. Uchibe, and T. Matsubara, “Deep reinforcement learning with smooth policy update: Application to robotic cloth manipulation,” Robotics and Autonomous Systems, vol. 112, pp. 72–83, 2019.
- [6] O. Kroemer, S. Niekum, and G. Konidaris, “A review of robot learning for manipulation: Challenges, representations, and algorithms,” Journal of Machine Learning Research, vol. 22, no. 30, pp. 1–82, 2021.
- [7] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [8] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [9] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning. PMLR, 2018, pp. 1861–1870.
- [10] K. Chua, R. Calandra, R. McAllister, and S. Levine, “Deep reinforcement learning in a handful of trials using probabilistic dynamics models,” in Advances in Neural Information Processing Systems, 2018, pp. 4754–4765.
- [11] M. Okada, N. Kosaka, and T. Taniguchi, “Planet of the bayesians: Reconsidering and improving deep planning network by incorporating bayesian inference,” in IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2020, pp. 5611–5618.
- [12] T. Kobayashi, “Proximal policy optimization with relative pearson divergence,” in IEEE international conference on robotics and automation. IEEE, 2021, pp. 8416–8421.
- [13] I. Osband, C. Blundell, A. Pritzel, and B. Van Roy, “Deep exploration via bootstrapped dqn,” Advances in neural information processing systems, vol. 29, pp. 4026–4034, 2016.
- [14] T. Kobayashi, “Student-t policy in reinforcement learning to acquire global optimum of robot control,” Applied Intelligence, vol. 49, no. 12, pp. 4335–4347, 2019.
- [15] T. Kobayashi and W. E. L. Ilboudo, “t-soft update of target network for deep reinforcement learning,” Neural Networks, 2021.
- [16] S. Kim, K. Asadi, M. Littman, and G. Konidaris, “Deepmellow: removing the need for a target network in deep q-learning,” in International Joint Conference on Artificial Intelligence. AAAI Press, 2019, pp. 2733–2739.
- [17] W. E. L. Ilboudo, T. Kobayashi, and K. Sugimoto, “Adaterm: Adaptive t-distribution estimated robust moments towards noise-robust stochastic gradient optimizer,” arXiv preprint arXiv:2201.06714, 2022.
- [18] E. Coumans and Y. Bai, “Pybullet, a python module for physics simulation for games, robotics and machine learning,” GitHub repository, 2016.
- [19] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv:1511.05952, 2015.
- [20] J. C. Bezdek and R. J. Hathaway, “Convergence of alternating optimization,” Neural, Parallel & Scientific Computations, vol. 11, no. 4, pp. 351–368, 2003.
- [21] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- [22] F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” in International Conference on Machine Learning. PMLR, 2017, pp. 3987–3995.
- [23] T. Kobayashi, “L2c2: Locally lipschitz continuous constraint towards stable and smooth reinforcement learning,” arXiv preprint arXiv:2202.07152, 2022.
- [24] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “Openai gym,” arXiv preprint arXiv:1606.01540, 2016.
- [25] T. Kobayashi, “Optimistic reinforcement learning by forward kullback-leibler divergence optimization,” arXiv preprint arXiv:2105.12991, 2021.