Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video
Abstract
In this paper, we present Consistent4D, a novel approach for generating 4D dynamic objects from uncalibrated monocular videos. Uniquely, we cast the 360-degree dynamic object reconstruction as a 4D generation problem, eliminating the need for tedious multi-view data collection and camera calibration. This is achieved by leveraging the object-level 3D-aware image diffusion model as the primary supervision signal for training Dynamic Neural Radiance Fields (DyNeRF). Specifically, we propose a Cascade DyNeRF to facilitate stable convergence and temporal continuity under the supervision signal which is discrete along the time axis. To achieve spatial and temporal consistency, we further introduce an Interpolation-driven Consistency Loss. It is optimized by minimizing the discrepancy between rendered frames from DyNeRF and interpolated frames from a pre-trained video interpolation model. Extensive experiments show that our Consistent4D can perform competitively to prior art alternatives, opening up new possibilities for 4D dynamic object generation from monocular videos, whilst also demonstrating advantage for conventional text-to-3D generation tasks. Our project page is https://consistent4d.github.io/.

1 Introduction
Perceiving dynamic 3D information from visual observations is one of the fundamental yet challenging problems in computer vision, which is the key to a broad range of downstream applications e.g., virtual content creation, autonomous driving simulation, and medical image analysis. However, due to the high complexity nature of dynamic 3D signals, it is rather difficult to recover such information from a single monocular video observation. As a result, existing dynamic object reconstruction approaches usually take synchronized multi-view videos as inputs (Li et al., 2022b; a; Shao et al., 2023), or rely on training data containing effective multi-view cues (e.g., teleporting cameras or quasi-static scenes (Li et al., 2021; Pumarola et al., 2021; Park et al., 2021b; a)). However, current reconstruction approaches often fail in reconstructing regions that were not observed in input sequences (Gao et al., 2022a). Moreover, multi-view data capturing requires synchronized camera rigs and meticulous calibrations, which inevitably limit the methods to potential real-world applications.
On the other hand, given only a video clip of a dynamic object, humans are capable of depicting the appearance, geometry, and movement of the object. This is achieved by prior knowledge of visual appearance accumulated through human life. In contrast to the multi-view video setting, our approach favors such simple and practical input settings of a static monocular video. The static monocular video offers several advantages: ease of collection for handheld cameras, minimizing the risk of motion blur due to camera movement, and obviating the need for camera parameter estimation. As a static monocular video does not provide effective multi-view information for reconstruction, we instead opt for the generation approaches which demonstrates diminished reliance on multi-view information.
In this work, we present a novel video-to-4D generation approach termed Consistent4D. In this approach, we represent dynamic objects through a specially designed Cascade DyNeRF and leverage a pre-trained 2D diffusion model to regulate the DyNeRF optimization, inspired by recent advancements in text-to-3D (Poole et al., 2023; Wang et al., 2022; Chen et al., 2023; Wang et al., 2023) and image-to-3D (Deng et al., 2022; Tang et al., 2023; Melas-Kyriazi et al., 2023) techniques. The challenge is to achieve both spatial and temporal consistency. To tackle this challenge, we introduce an Interpolation-driven Consistency Loss (ICL), which leverages a pre-trained video interpolation model to provide spatiotemporally coherent supervision signals. Notably, the ICL loss not only enhances consistency in 4D generation but also mitigates multi-face issues in 3D generation. Furthermore, we train a lightweight video enhancer to enhance the video generated from dynamic NeRF as a post-processing step.
We have extensively evaluated our approach on both synthetic videos rendered from animated 3D model and in-the-wild videos collected from the Internet. To summarize, the contribution of this work includes:
-
•
We propose a video-to-4D framework for dynamic object generation from a statically captured monocular video. A specially designed Cascade DyNeRF is applied to represent the object, optimized through the Score Distillation Sampling (SDS) loss by a pre-trained 2D diffusion model. Moreover, for the comprehensiveness of the framework, we train a video enhancer to improve the rendering of 4D object as a post-processing step.
-
•
To address the challenge of maintaining temporal and spatial consistency in 4D generation task, we introduce a novel Interpolation-driven Consistency Loss (ICL). The proposed ICL loss can significantly improve consistency, e.g., multi-face problem, in both video-to-4D and text-to-3D generation tasks.
-
•
We extensively evaluate our method on both synthetic and in-the-wild videos collected from the Internet, showing promising results for the new task of video-to-4D generation.
2 Related work
3D Generation
3D generation aims to generate 3D content conditionally or unconditionally. Early works mainly make use of GAN, i.e., generate category-specific 3D objects or scenes from random noise after learning the category prior (Schwarz et al., 2020; Chan et al., 2021; Gao et al., 2022b). Recently, general-purpose 3D generation has been enabled by text-to-image diffusion model pre-trained on Internet-scale data, and it also becomes more controllable, e.g., controlled by text prompt or single image. The pioneer work of text-to-3D is DreamFusion (Poole et al., 2023), which proposes Score Distillation Sampling (SDS) loss to leverage the image diffusion model for neural radiance field (NeRF) training. The following works (Lin et al., 2023; Chen et al., 2023; Wang et al., 2023) further enhance the visual quality of the generated object by using mesh representation, Variational Score Distillation, etc. However, the challenging problem, multi-face Janus problem, has not been addressed in the above works. Image is another popular condition for 3D generation. Different from 3D reconstruction, which focuses on the reconstruction of visible regions from multi-view images, 3D generation usually has only a single image and relies much on the image diffusion model to generate invisible regions of the object (Melas-Kyriazi et al., 2023; Tang et al., 2023; Liu et al., 2023). So many works simply translate the image to words using Lora and then exploit text-to-3D methods (Melas-Kyriazi et al., 2023; Tang et al., 2023; Seo et al., 2023). One exception is Zero123 (Liu et al., 2023), which trains a 3D-aware image-to-image model using multi-view data and could generate a novel view of the object in the input image directly. Benefiting from multi-view data training, the multi-face Janus problem has been alleviated to some extent in Zero123.
4D Reconstruction
4D reconstruction, aka dynamic scene reconstruction, is a challenging task. Some early works focus on object-level reconstruction and adopt parametric shape models (Loper et al., 2023; Vo et al., 2020) as representation. In recent years, dynamic neural radiance field become popular, and convenient dynamic scene reconstruction is enabled. These works can be classified into two categories: a deformed scene is directly modeled as a NeRF in canonical space with a time-dependent deformation (Pumarola et al., 2021; Park et al., 2021a; b; Wu et al., 2022b; Tretschk et al., 2021) or time-varying NeRF in the world space (Gao et al., 2021; Li et al., 2021; Xian et al., 2021; Fridovich-Keil et al., 2023; Cao & Johnson, 2023). Some of them require multi-view synchronized data to reconstruct dynamic scenes, however, data collection and calibration is not convenient (Li et al., 2022b; Shao et al., 2023). So, reconstruction from monocular videos gain attention. However, those monocular methods either require teleporting camera or quaic-static scenes (Pumarola et al., 2021; Park et al., 2021a; b), which are not representative of daily life scenarios (Gao et al., 2022a).
4D Generation
4D generation extends 3D generation to space+time domain and thus is more challenging. Early works are mainly category-specific and adopt parametric shape models (Zuffi et al., 2017; 2018; Vo et al., 2020; Kocabas et al., 2020) as representation. They usually take images or videos as conditions and need category-specific 3D templates or per-category training from a collection of images or videos (Ren et al., 2021; Wu et al., 2021; Yang et al., 2022; Wu et al., 2022a). Recently, one zero-shot category-agnostic work, text-to-4D (Singer et al., 2023), achieves general-purpose dynamic scene generation from text prompt. It follows DreamFusion (Poole et al., 2023) and extends it to the time domain by proposing a three-stage training framework. However, the quality of generated scenes is limited due to low-quality video diffusion models.
3 Preliminaries
3.1 Score Distillation Sampling for image-to-3D
Score Distillation Sampling (SDS) is first proposed in DreamFusion (Poole et al., 2023) for text-to-3D tasks. It enables the use of a 2D text-to-image diffusion model as a prior for optimization of a NeRF. We denote the NeRF parameters as , text-to-image diffusion model as , text prompt as , the rendering image and the reimage as and , the SDS loss is defined as:
| (1) |
where is timestamps in diffusion process, denotes noise, and is a weighted function. Intuitively, this loss perturbs with a random amount of noise corresponding to the timestep , and estimates an update direction that follows the score function of the diffusion model to move to a higher density region.
Besides text-to-3D, SDS is also widely used in image-to-3D tasks. Zero123 (Liu et al., 2023) is one prominent representative. It proposes a viewpoint-conditioned image-to-image translation diffusion model fine-tuned from Stable Diffusion (Rombach et al., 2022), and exploits this 3D-aware image diffusion model to optimize a NeRF using SDS loss. This image diffusion model takes one image, denoted by , and relative camera extrinsic between target view and input view, denoted by , as the input, and outputs the target view image. Compared with the original text-to-image diffusion model, text prompt in Equation 1 is not required in this model cause the authors translate the input image and the relative camera extrinsic to text embeddings. Then Equation 1 could be re-written as:
| (2) |
3.2 K-planes
K-planes (Fridovich-Keil et al., 2023) is a simple and effective dynamic NeRF method which factorizes a dynamic 3D volume into six feature planes (i.e., hex-plane), denoted as , where . The first three planes correspond to spatial dimensions, while the last three planes capture spatiotemporal variations. Each of the planes is structured as a tensor in the memory, where represents the size of the plane and is the feature size that encodes scene density and color information. Let denote the timestamp of a video clip, given a point in the 4D space, we normalize the coordinate to the range and subsequently project it onto the six planes using the equation , where is the projection from a space point to a pixel on the ’th plane. The plane feature is extracted via bilinear interpolation. The six plane features are combined using the Hadamard product (i.e., element-wise multiplication), to produce a final feature vector as follows:
| (3) |
Then, the color and density of is calculated as and , where and denotes mlps for color and density, respectively.
4 Method
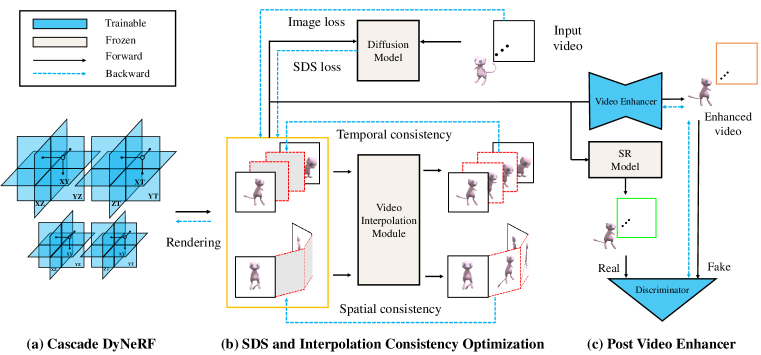
In this work, we target to generate a 360∘ dynamic object from a statically captured monocular video. To achieve this goal, we develop a framework consisting of a DyNeRF and a video enhancer, supervised by the pre-trained 2D diffusion model in Zero123 and a GAN, respectively. As shown in Figure 2, we first train a specially designed cascade DyNeRF using SDS loss and image reconstruction loss. To guarantee spatial and temporal consistency, we propose a novel Interpolation-driven Consistency Loss as the extra regularization for the DyNeRF. For post-processing, we apply GAN to train a lightweight video enhancer, inspired by pix2pix (Isola et al., 2017).To summarize, taking an uncalibrated monocular video as the input, we obtain a DyNeRF from which we can render 360∘ view of the dynamic object, and the rendered results can be further enhanced by the video enhancer.
In the following sections, we will first introduce our design of the Cascade DyNeRF, and then illustrate the Interpolation-driven Consistency loss. At last, we will detail the video enhancer.
4.1 Cascade DyNeRF
Existing DyNeRF methods mainly assume the supervision signals are temporally coherent, however, this assumption does not hold in our task since our main supervision signal is from an image diffusion model. In order to minimize the impact of temporal discontinuity in the supervision signals, we are prone to 4D representations which naturally guarantee a certain level of temporal continuity. Therefore, we build our DyNeRF based on K-planes (Fridovich-Keil et al., 2023) which explots temporal interpolation, an operator naturally inclined to temporal smoothing. Empirically, reducing the time resolution of spatiotemporal planes helps enhance temporal consistency, however, this results in over-smoothed renderings where finer details are lost. In contrast, increasing the time resolution leads to crisp renderings, but the continuity of images within the same time series diminishes. To achieve both temporal continuity and high image quality, we adjust the multi-scale technique in K-planes and introduce Cascade DyNeRF.
Let us denote the scale index by . In K-planes, multi-scale features are exploited by concatenation along feature dimension, then the color and density could be calculated as:
| (4) |
where is the number of scales. In our setting, the experiment results show simple concatenation is hard to balance between image quality and temporal consistency. So we propose to leverage the cascade architecture, which is commonly used in object detection algorithms (Cai & Vasconcelos, 2018; Carion et al., 2020), to first output a coarse yet temporally coherent dynamic object from low-resolution planes and then let the high-resolution planes learn the residual between the coarse and fine results. That is, the color and density of the object after scale is:
| (5) |
where k indicates the scale index. Note that losses are applied to the rendering results of each scale to guarantee that planes with higher resolution learn the residual between results from previous scales and the target object. In this way, we can improve temporal consistency without sacrificing much object quality. But Cascade DyNeRF alone is not enough for spatiotemporal consistency, so we resort to extra regularization, please see in the next section.
4.2 Interpolation-driven Consistency Loss
Video generation methods usually train an inter-frame interpolation module to enhance the temporal consistency between keyframes (Ho et al., 2022; Zhou et al., 2022; Blattmann et al., 2023). Inspired by this, we exploit a pre-trained light-weighted video interpolation model and propose Interpolation-driven Consistency Loss to enhance the spatiotemporal consistency of the 4D generation.
The interpolation model adopted in this work is RIFE (Huang et al., 2022), which takes a pair of consecutive images as well as the interpolation ratio as the input, and outputs the interpolated image. In our case, we first render a batch of images that are either spatially continuous or temporally continuous, denoted by , where is the number of images in a batch. Let us denote the video interpolation model as , the interpolated image as , then we calculate the Interpolation-driven Consistency Loss as:
| (6) | ||||
where , and .
This simple yet effective loss enhances the continuity between frames thus improving the spatiotemporal consistency in dynamic object generation by a large margin. Moreover, we find the spatial version of this loss alleviates the multi-face problem in 3D generation tasks as well. Please refer to the experiment sections to see quantitative and qualitative results. The Interpolation-driven Consistency Loss and some other regularization losses are added with SDS loss in Equation 2, details of which can be found in the experiment section.
4.3 Cross-frame Video Enhancer
Sometimes image sequence rendered from the optimized DyNeRF suffers from artifacts, such as blurry edges, small floaters, and insufficient smoothness, especially when the object motion is abrupt or complex. To further improve the quality of rendered videos, we design a lightweight video enhancer and optimize it via GAN, following pix2pix (Isola et al., 2017). The real images are obtained with image-to-image technique (Meng et al., 2021) using a super-resolution diffusion model, and the fake images are the rendered ones.
To better exploit video information, We add cross-frame attention to the UNet architecture in pix2pix, i.e., each frame will query information from two adjacent frames. We believe this could enable better consistency and image quality. Denote the feature map before and after cross-frame-attention as and , we have:
| (7) | ||||
where , and denotes query, key, and value in attention mechanism, and denotes the concatenation along the width dimension.
Loss for the generator and discriminator are the same as pix2pix.
5 Experiment
We have conducted extensive experiments to evaluate the proposed Consistent4D generator using both synthetic data and in-the-wild data. The experimental setup, comparison with dynamic NeRF baselines, and ablations are provided in the following sections.
5.1 Implementation Details
Data Preparation For each input video, we initially segment the foreground object utilizing SAM (Kirillov et al., 2023) and subsequently sample 32 frames uniformly. The majority of the input videos span approximately 2 seconds, with some variations extending to around 1 second or exceeding 5 seconds. For the ablation study of video sampling, please refer to the appendix A.3.
Training During SDS and interpolation consistency optimization, we utilize zero123-xl trained by Deitke et al. (2023) as the diffusion model for SDS loss. For Cascade DyNeRF, we set , i.e., we have coarse-level and fine-level DyNeRFs.The spatial and temporal resolution of Cascade DyNeRF are configured to 50 and 8 for coarse-level, and 100 and 16 for fine-level, respectively. We first train DyNeRF with batch size 4 and resolution 64 for 5000 iterations. Then we decrease the batch size to 1 and increase the resolution to 256 for the next 5000 iteration training. ICL is employed in the initial 5000 iterations with a probability of 25%, and we sample consecutive temporal frames at intervals of one frame and sample consecutive spatial frames at angular intervals of 5∘-15∘ in azimuth. SDS loss weight is set as 0.01 and reconstruction loss weight is set as 500. In addition to SDS and ICL, we also apply foreground mask loss, normal orientation loss, and 3D smoothness loss. The learning rate is set as 0.1 and the optimizer is Adam. In the post-video enhancing stage, we train the video enhancer with a modified Unet architecture. The learning rate is set as 0.002, the batch size is 16, and the training epoch is 200. The main optimization stage and the video enhancing stage cost about 2.5 hours and 15 minutes on a single V100 GPU. For details, please refer to the appendix A.4.
| Pistol | Guppie | Crocodile | Monster | Skull | Trump | Aurorus | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LPIPS | CLIP | LPIPS | CLIP | LPIPS | CLIP | LPIPS | CLIP | LPIPS | CLIP | LPIPS | CLIP | LPIPS | CLIP | LPIPS | CLIP | |
| D-NeRF | 0.52 | 0.66 | 0.32 | 0.76 | 0.54 | 0.61 | 0.52 | 0.79 | 0.53 | 0.72 | 0.55 | 0.60 | 0.56 | 0.66 | 0.51 | 0.68 |
| K-planes | 0.40 | 0.74 | 0.29 | 0.75 | 0.19 | 0.75 | 0.47 | 0.73 | 0.41 | 0.72 | 051 | 0.66 | 0.37 | 0.67 | 0.38 | 0.72 |
| ours | 0.10 | 0.90 | 0.12 | 0.90 | 0.12 | 0.82 | 0.18 | 0.90 | 0.17 | 0.88 | 0.23 | 0.85 | 0.17 | 0.85 | 0.16 | 0.87 |

5.2 Comparisons with Other Methods
To date, few methods have been developed for 4D generation utilizing video obtained from a static camera, so we only manage to compare our method with D-NeRF (Pumarola et al., 2021) and K-planes (Fridovich-Keil et al., 2023).
Quantitative Results To quantitatively evaluate the proposed video-4D generation method, we select and download seven animated models, namely Pistol, Guppie, Crocodie, Monster, Skull, Trump, Aurorus, from Sketchfab (ske, 2023) and render the multi-view videos by ourselves, as shown in Figure 3 and appendix A.2. We render one input view for scene generation and 4 testing views for our evaluation. The per-frame LPIPS (Zhang et al., 2018) score and the CLIP (Radford et al., 2021) similarity are computed between testing and rendered videos. We report the scores averaged over the four testing views in Table. 1. Note that the commonly used PSNR and SSIM scores were not applied in our scenario as the pixel- and patch-wise similarities are too sensitive to the reconstruction difference, which does not align with the generation quality usually perceived by humans. As shown in Table 1, our dynamic 3D generation produces the best quantitative results over the other two methods on both the LPIPS and CLIP scores, which well aligns with the qualitative comparisons shown in Figure 3.
Qualitative Results The outcomes of our method and those of dyNeRFs are illustrated in Figure 3. It is observable that both D-NeRF and HyperNeRF methods struggle to achieve satisfactory results in novel views, owing to the absence of multi-view information in the training data. In contrast, leveraging the strengths of the generation model, our method proficiently generates a 360∘ representation of the dynamic object. For additional results, please refer to the appendix A.1.
5.3 Ablations
We perform ablation studies for every component within our framework. For clarity, the video enhancer is excluded when conducting ablations for SDS and interpolation consistency optimization.

| w/o ICL | w/ ICL | |
| preference rate(%) | 24.5 | 75.5 |
| w/o ICL | w/ ICL | |
| success rate(%) | 19.3 | 28.6 |
Cascade DyNeRF In Figure 4, we conduct an ablation study for Cascade DyNeRF. Specifically, we substitute Cascade DyNeRF with the original K-planes architecture, maintaining all other settings unchanged. In the absence of the cascade architecture, the training proves to be unstable, occasionally yielding incomplete or blurry objects, as demonstrated by the first and second objects in Figure 4. In some cases, while the model manages to generate a complete object, the moving parts of the object lack clarity, exemplified by the leg and beak of the bird. Conversely, the proposed Cascade DyNeRF exhibits stable training, leading to relatively satisfactory generation results.
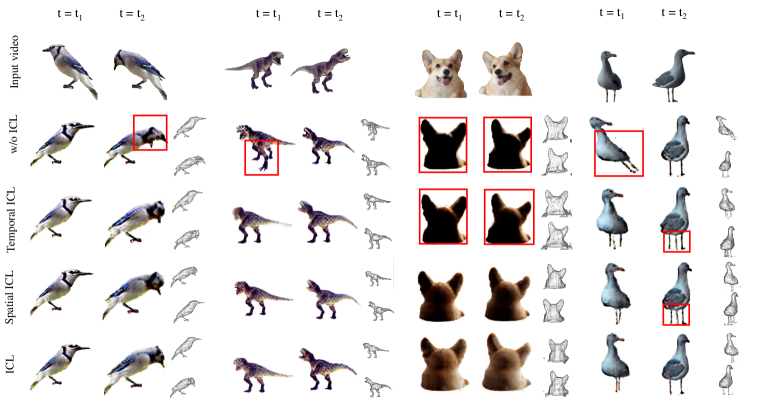
Interpolation-driven Consistency Loss The introduction of Interpolation-driven Consistency Loss (ICL) stands as a significant contribution of our work. Therefore, we conduct extensive experiments to investigate both its advantages and potential limitations. Figure 5(a) illustrates the ablation of both spatial and temporal Interpolation-driven Consistency Loss (ICL) in the video-to-4D task. Without ICL, the objects generated exhibit spatial and temporal inconsistency, as evidenced by the multi-face/foot issue in the blue jay and T-rex, and the unnatural pose of the seagull. Additionally, color discrepancies, such as the black backside of the corgi, are also noticeable. Employing either spatial or temporal ICL mitigates the multi-face issue, and notably, the use of spatial ICL also alleviates the color defect problem. Utilizing both spatial and temporal ICL concurrently yields superior results. We further perform a user study, depicted in Figure 2(a), which includes results w/ and w/o ICL for 20 objects. For efficiency in evaluation, cases in which both methods fail are filtered out in this study. 20 users participate in this evaluation, and the results unveiled a preference for results w/ ICL in 75% of the cases.
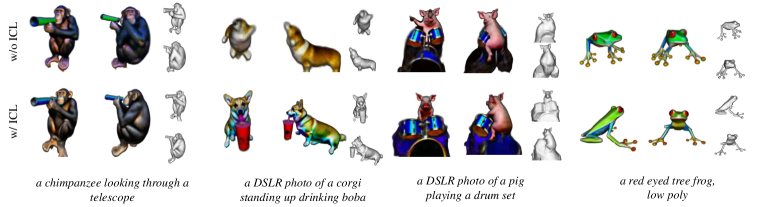
We further explore whether ICL could alleviate multi-face problems for text-to-3D tasks. We compared the success rate of DreamFusion implemented w/ and w/o the proposed ICL loss. For the sake of fairness and rigor, we collect all prompts related to animals from the official DreamFusion project page, totaling 230. 20 users are asked to participate in this non-cherry-pick user study, where we establish three criteria for a successful generation: alignment with the text prompt, absence of multi-face issues, and clarity in geometry and texture. We visualize the statistics in Table 2(b) and Table 2. The results show that although users have different understandings of successful generation, results w/ ICL always outperform results w/o it. For a comprehensive understanding, qualitative comparisons are presented in Figure 5(b), which indicates the proposed technique effectively alleviates the multi-face Janus problem and thus promotes the success rate. Implementation details about text-to-3D can be found in the appendix A.4, and we also analyze the failure cases and limitations of ICL in A.5.
Cross-frame Video Enhancer In Figure 11 (see in appendix), we show the proposed cross-frame video enhancer could improve uneven color distribution and smooth out the rough edges, as shown in almost all figures, and remove some floaters, as indicated by the cat in the red and green box.
6 Conclusion
We introduce a novel video-to-4D framework, named Consistent4D, aimed at generating 360∘ 4D objects from uncalibrated monocular videos captured by a stationary camera. Specifically, we first optimize a Cascade DyNeRF which is specially designed to facilitate stable training under the discrete supervisory signals from an image-to-image diffusion model. More crucially, we introduce an Interpolation-driven Consistency Loss to enhance spatial and temporal consistency, the main challenge in this task. For comprehensiveness, we train a lightweight video enhancer to rectify scattered color discrepancies and eliminate minor floating artifacts, as a post-processing step. Extensive experiments conducted on both synthetic and in-the-wild data demonstrate the effectiveness of our method.
References
- dee (2023) Deepfloyd. https://huggingface.co/DeepFloyd, 2023.
- ske (2023) Sketchfab. https://sketchfab.com/3d-models, 2023.
- Blattmann et al. (2023) Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In CVPR, 2023.
- Cai & Vasconcelos (2018) Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In CVPR, 2018.
- Cao & Johnson (2023) Ang Cao and Justin Johnson. Hexplane: A fast representation for dynamic scenes. In arXiv preprint, 2023.
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- Chan et al. (2021) Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In CVPR, 2021.
- Chen et al. (2023) Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In arXiv preprint, 2023.
- Deitke et al. (2023) Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. In arXiv preprint, 2023.
- Deng et al. (2022) Congyue Deng, Chiyu Jiang, Charles R Qi, Xinchen Yan, Yin Zhou, Leonidas Guibas, Dragomir Anguelov, et al. Nerdi: Single-view nerf synthesis with language-guided diffusion as general image priors. In arXiv preprint, 2022.
- Fridovich-Keil et al. (2023) Sara Fridovich-Keil, Giacomo Meanti, Frederik Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. In arXiv preprint, 2023.
- Gao et al. (2021) Chen Gao, Ayush Saraf, Johannes Kopf, and Jia-Bin Huang. Dynamic view synthesis from dynamic monocular video. In ICCV, 2021.
- Gao et al. (2022a) Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthesis: A reality check. In NeurIPS, 2022a.
- Gao et al. (2022b) Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d textured shapes learned from images. In NeurIPS, 2022b.
- Guo et al. (2023) Yuan-Chen Guo, Ying-Tian Liu, Ruizhi Shao, Christian Laforte, Vikram Voleti, Guan Luo, Chia-Hao Chen, Zi-Xin Zou, Chen Wang, Yan-Pei Cao, and Song-Hai Zhang. threestudio: A unified framework for 3d content generation. https://github.com/threestudio-project/threestudio, 2023.
- Ho et al. (2022) Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. In arXiv preprint, 2022.
- Huang et al. (2022) Zhewei Huang, Tianyuan Zhang, Wen Heng, Boxin Shi, and Shuchang Zhou. Real-time intermediate flow estimation for video frame interpolation. In ECCV, 2022.
- Isola et al. (2017) Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017.
- Kirillov et al. (2023) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In arXiv preprint, 2023.
- Kocabas et al. (2020) Muhammed Kocabas, Nikos Athanasiou, and Michael J Black. Vibe: Video inference for human body pose and shape estimation. In CVPR, 2020.
- Li et al. (2022a) Ruilong Li, Julian Tanke, Minh Vo, Michael Zollhöfer, Jürgen Gall, Angjoo Kanazawa, and Christoph Lassner. Tava: Template-free animatable volumetric actors. In ECCV, 2022a.
- Li et al. (2022b) Tianye Li, Mira Slavcheva, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, et al. Neural 3d video synthesis from multi-view video. In CVPR, 2022b.
- Li et al. (2021) Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. In CVPR, 2021.
- Lin et al. (2023) Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In CVPR, 2023.
- Liu et al. (2023) Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. In arXiv preprint, 2023.
- Loper et al. (2023) Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, 2023.
- Melas-Kyriazi et al. (2023) Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. Realfusion: 360 deg reconstruction of any object from a single image. In arXiv preprint, 2023.
- Meng et al. (2021) Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. In ICLR, 2021.
- Park et al. (2021a) Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. In CVPR, 2021a.
- Park et al. (2021b) Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M Seitz. Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields. In arXiv preprint, 2021b.
- Poole et al. (2023) Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In ICLR, 2023.
- Pumarola et al. (2021) Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. In CVPR, 2021.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
- Ren et al. (2021) Zhongzheng Ren, Xiaoming Zhao, and Alex Schwing. Class-agnostic reconstruction of dynamic objects from videos. In NeurIPS, 2021.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Schwarz et al. (2020) Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis. In NeurIPS, 2020.
- Seo et al. (2023) Junyoung Seo, Wooseok Jang, Min-Seop Kwak, Jaehoon Ko, Hyeonsu Kim, Junho Kim, Jin-Hwa Kim, Jiyoung Lee, and Seungryong Kim. Let 2d diffusion model know 3d-consistency for robust text-to-3d generation. In arXiv preprint, 2023.
- Shao et al. (2023) Ruizhi Shao, Zerong Zheng, Hanzhang Tu, Boning Liu, Hongwen Zhang, and Yebin Liu. Tensor4d: Efficient neural 4d decomposition for high-fidelity dynamic reconstruction and rendering. In CVPR, 2023.
- Singer et al. (2023) Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, et al. Text-to-4d dynamic scene generation. In arXiv preprint, 2023.
- Tang et al. (2023) Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. In arXiv preprint, 2023.
- Tretschk et al. (2021) Edgar Tretschk, Ayush Tewari, Vladislav Golyanik, Michael Zollhöfer, Christoph Lassner, and Christian Theobalt. Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video. In ICCV, 2021.
- Verbin et al. (2022) Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T Barron, and Pratul P Srinivasan. Ref-nerf: Structured view-dependent appearance for neural radiance fields. In CVPR, 2022.
- Vo et al. (2020) Minh Vo, Yaser Sheikh, and Srinivasa G Narasimhan. Spatiotemporal bundle adjustment for dynamic 3d human reconstruction in the wild. In IEEE TPAMI, 2020.
- Wang et al. (2022) Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In arXiv preprint, 2022.
- Wang et al. (2023) Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. In arXiv preprint, 2023.
- Wu et al. (2021) Shangzhe Wu, Tomas Jakab, Christian Rupprecht, and Andrea Vedaldi. Dove: Learning deformable 3d objects by watching videos. In arXiv preprint, 2021.
- Wu et al. (2022a) Shangzhe Wu, Ruining Li, Tomas Jakab, Christian Rupprecht, and Andrea Vedaldi. Magicpony: Learning articulated 3d animals in the wild. In arXiv preprint, 2022a.
- Wu et al. (2022b) Tianhao Wu, Fangcheng Zhong, Andrea Tagliasacchi, Forrester Cole, and Cengiz Oztireli. D 2 nerf: Self-supervised decoupling of dynamic and static objects from a monocular video. In arXiv preprint, 2022b.
- Xian et al. (2021) Wenqi Xian, Jia-Bin Huang, Johannes Kopf, and Changil Kim. Space-time neural irradiance fields for free-viewpoint video. In CVPR, 2021.
- Yang et al. (2022) Gengshan Yang, Minh Vo, Natalia Neverova, Deva Ramanan, Andrea Vedaldi, and Hanbyul Joo. Banmo: Building animatable 3d neural models from many casual videos. In CVPR, 2022.
- Zhang et al. (2018) Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In cvpr, 2018.
- Zhou et al. (2022) Daquan Zhou, Weimin Wang, Hanshu Yan, Weiwei Lv, Yizhe Zhu, and Jiashi Feng. Magicvideo: Efficient video generation with latent diffusion models. In arXiv preprint, 2022.
- Zuffi et al. (2017) Silvia Zuffi, Angjoo Kanazawa, David W Jacobs, and Michael J Black. 3d menagerie: Modeling the 3d shape and pose of animals. In CVPR, 2017.
- Zuffi et al. (2018) Silvia Zuffi, Angjoo Kanazawa, and Michael J. Black. Lions and tigers and bears: Capturing non-rigid, 3d, articulated shape from images. In CVPR, 2018.
Appendix A Appendix
A.1 Additional Visualization Results

In Figure 6, we present the result of our method on four in-the-wild videos. For clarity, we describe the input videos as follows: robot dancing, squirrel feeding, toy-spiderman dancing, toy-rabbit deforming. Due to limited space, the reviewers are strongly recommended to watch the video in the attached files to see various visualization results.
A.2 Data Used in Video-to-4D Quantitative Evaluation

Sin three dynamic objects are shown in Figure 7, we only visualize the rest four here, as shown in Figure 7. The observation is similar to the results in the main paper.
We demonstrate the effectiveness of video enhancer in Figure 11. The analysis can be found in the main paper.
A.3 The Number of Frames

For simplicity, we sample each input video to 32 frames in all experiments. However, we find input videos without sampling sometimes give slightly better results, as shown in Figure 8.
A.4 Implementation Details
Loss Function in Video-to-4D Besides SDS loss , Interpolation-driven consistency loss , we also apply reconstruction loss and mask loss for the input view. 3D normal smooth loss and orientation loss (Verbin et al., 2022) are also applied. Therefore, the final loss is calculated as , where , , , , , and is initially 1 and increased to 20 linearly until 5000 iterations. Note that the reconstruction loss and SDS loss are applied alternatively.
Video Enhancer For video enhancer architecture, we follow pix2pix (Isola et al., 2017) except for that we modify the unet256 architecture to a light-weighted version, with only three up/down layers and one cross-frame attention layer. The feature dimensions for the unet layers are set as 64, 128, and 256. Besides, we inject a cross-attention layer in the inner layer of the unet to enable the current frame to query information from adjacent frames. For real images, we use DeepFloyd-IF stage II (dee, 2023), which is a diffusion model for super-resolution tasks. The input image, i.e., the rendered image, is resized to and the output resolution is . The prompt needed by the diffusion model is manually set, i.e., we use the ”a ” as the prompt, in which is the category of the dynamic object. For example, the prompts for dynamic objects in Figure 11 are a bird, a cat, a minions. The prompt cloud also be obtained from image or video caption models, or large language models.
Text-to-3D Details We choose Threestudio built by (Guo et al., 2023) as the codebase since it is the best public implementation we could find. DeepFloy-IF (dee, 2023) is employed as the diffusion model, and all default tricks in Threestudio are utilized. The hyper-parameters for results w/ and w/o ICL, such as batch size and learning rate, are kept consistent between the implementations w/ and w/o ICL, except for those related to ICL. We train the model for 5000 iterations, the first 1000 iterations with batch size 8 and resolution 64, and the rest 4000 with batch size 2 and resolution 256. The learning rate is 0.01 and the optimizer is Adam, the same as the default setting in Threestudio. The ICL loss is applied in the first 1000 iterations with probability 30% and weight 2000.
A.5 Failure Cases


Video-to-4D Since the video-to-4D task in this paper is very challenging, our method actually has many failure cases. For example, we fail to generate the dynamic object when the motion is complex or abrupt, as shown in Figure 10. In Figure 10, the dog’s tail disappears in the second image because the tail is occluded in the input image when . The frog, which is jumping up and down fast, gets blurry when .
Text-to-3D When applying ICL in text-to-3D, we find some multi-face cases that could not be alleviated, and we show them in Figure 10.
