Consistent and Relevant: Rethink the query embedding in
general sound separation
Abstract
The query-based audio separation usually employs specific queries to extract target sources from a mixture of audio signals. Currently, most query-based separation models need additional networks to obtain query embedding. In this way, separation model is optimized to be adapted to the distribution of query embedding. However, query embedding may exhibit mismatches with separation models due to inconsistent structures and independent information. In this paper, we present CaRE-SEP, a consistent and relevant embedding network for general sound separation to encourage a comprehensive reconsideration of query usage in audio separation. CaRE-SEP alleviates the potential mismatch between queries and separation in two aspects, including sharing network structure and sharing feature information. First, a Swin-Unet model with a shared encoder is conducted to unify query encoding and sound separation into one model, eliminating the network architecture difference and generating consistent distribution of query and separation features. Second, by initializing CaRE-SEP with a pretrained classification network and allowing gradient backpropagation, the query embedding is optimized to be relevant to the separation feature, further alleviating the feature mismatch problem. Experimental results indicate the proposed CaRE-SEP model substantially improves the performance of separation tasks. Moreover, visualizations validate the potential mismatch and how CaRE-SEP solves it.
Index Terms— query-based separation, query embedding, consistent structure, relevant features
1 introduction
Audio source separation is a process of separating one or more isolated sound sources from a complex auditory scene [1, 2]. It plays a crucial role in many downstream tasks such as audio extraction, audio transcription, music editing, and speech enhancement [3, 1, 4, 5]. In recent years, the rapid progress in deep learning technologies has largely improved audio source separation performance [6, 7, 8]. Many methods [9, 10, 11] train separate models for different target types of audio sources, which are effective for source separation. However these models require significant computational resources and training data, making it challenging to expand the number of possible audio sources, and so they can only separate the fixed number of sources [2, 12].
To tackle the problem of constrained source types, some query-based separation models [13, 4] have been developed. Lee et al. [13] encoded the specific target source embedding with an extra Query-net, to separate out a target source from an audio mixture. Recently, Chen et al. [4] designed a Transformer-based audio classification model and a CNN-based separation model. They then use these models to extract a target source from an audio mixture given a target source embedding that is obtained from the pre-trained audio classification model, which is trained for audio tagging tasks.
The above query-based audio separation models aim to separate as many sources as possible, but there may be some structural and informational mismatches between query embedding and separation feature. Firstly, these methods require query embedding from an auxiliary model as query. Although these auxiliary models can distinguish different patterns and features in the data to some extent, the auxiliary structure is inconsistent with the encoder of separation network, which may cause a mismatch between the distribution of query embedding and separation feature. For example, Transformer pays attention to global dependencies and CNN focuses more on local features. Besides, it is important to note that the auxiliary network is directly optimized for other tasks, such as audio classification. So the query embedding obtained from it may not be directly relevant to the primary separation task. Thus, query embedding and separation feature might encounter information mismatch.
In this paper, we propose a novel Consistent and Relevant Embedding network for audio source separation (CaRE-SEP) by eliminating structural and informational mismatches from the point that the impact of query embedding in query-based audio separation. Firstly, inspired by [14], we propose a Swin-Unet model incorporating a shared encoder to integrate query encoding and sound separation within a single model. Owing to the shared encoder module, the distribution of generated query embedding and separation feature are also more consistent, which can contribute to the separation task. Subsequently, we initialize the encoder of CaRE-SEP with a pre-trained classification network and dynamically train the query embedding with gradients. This contributes to query embedding being more relevant to the separation task, further boosting the separation performance. Besides, the shared encoder can achieve audio classification, so our CaRE-SEP can jointly train classification and separation tasks. In summary, the main contributions of our CaRE-SEP are as follows:
-
•
Consistent distribution: Since query embedding and separation feature are generated by a shared encoder, their distributions are consistent, which is advantageous for audio separation tasks.
-
•
Relevant information: The query embedding is more relevant to audio source separation with gradient and initialization, which also simplifies the model structure.
-
•
Unified structure: We are the first to propose a unified model that can jointly train classification and separation tasks, which indicates that a single architecture can be simultaneously utilized for classification and separation tasks.
2 Method
In this section, we present the Consistent and Relevant Embedding network for audio source separation (CaRE-SEP). Fig.1 and Fig.2 illustrate the overall and detailed network, respectively.
2.1 Overall architecture
As shown in Fig.1, our CaRE-SEP is composed of shared encoder, connector module and decoder module, where the encoder and connector module are responsible for query embedding, and all of them are trained for the audio source separation.
In Fig.1, we regard query embedding network as a part of separation model and use a shared encoder module to simultaneously obtain query embedding and separation feature, which is different from [4] that uses a frozen extra classification model (ST-SED) to obtain query embedding. When the query embedding module and separation structure are similar, the distribution of generated query embedding and separation feature will be more consistent, leading to optimal performance. Furthermore, we initialize the shared encoder of CaRE-SEP with a pre-trained classification model [15] and perform gradient propagation for query embedding. As a result, the query embedding is optimized to be more relevant to separation task. Next, we will introduce the training process depicted in Fig.1.


We define two audio sources and mix them with energy normalization. To balance classification and separation performance, we do not use mel-spectrograms as input which perform worse in separation. Instead, we use Mel scale-based band-split [16] to split the spectrogram into a series of subband spectrograms. The mixture audio is converted into the spectrogram by Short-time Fourier Transform (STFT) and then split into subband spectrograms. Besides, we use anchor audios to obtain fixed-dimensional query embeddings , which are incorporated into the CaRE-SEP to specify which audio needs to be separated. This process is illustrated by the dashed line in Fig.1. Subsequently, we send two training triplets into the CaRE-SEP model S, respectively. Our separation objective is as follows:
| (1) |
Simultaneously, the linear layer (embedding layer in Fig.1) is applied on the query embedding to unify the feature dimension, and then the queries are added into the audio feature maps of each layer block in the CaRE-SEP model, helping to specify the audio that needs to be separated. As a result, the model will also learn the relationship between the query embedding and mixture, adjusting its weights to adapt to the separation feature. Finally, the output spectrogram is converted into the waveform by inverse STFT (iSTFT). We apply the Mean Absolute Error (MAE) and Source-to-Distortion Ratio (SDR) to compute the loss between separate waveforms and the target source.
2.2 Shared encoder module
As illustrated in the left part of Fig.2, our shared encoder mainly consists of Swin Transformer [17] and Patch Merge [15, 4]. The Patch-Embed CNN splits the input features into different patch tokens inside each window, which more effectively capture the relationship among frequency bins of the same time frame. The transformed patch tokens are sent into three groups of Swin Transformer blocks [17] and Patch-Merge layers to generate hierarchical representations. Within each group, we adopt the more efficient swin transformer block with a shifted window attention to learn feature representation. Specifically, the patch-merge layer is applied to decrease the sequence size at the end of each group.
2.3 Connector module
The connector module contains a swin transformer, token-semantic module [4], and average pooling layer. Hierarchical representations of the swin transformer have the ability to address multiple tasks. Firstly, hierarchical representations can be input into the decoder network to separate isolated audio sources from mixed audio. Besides, they can be processed through the average pooling layer to generate query embedding for separation. Additionally, the token-semantic CNN integrates all frequency bins and maps the feature into the class probabilities. The vectors produced by the token-semantic CNN can accomplish audio tagging tasks by computing binary cross-entropy loss with ground truth labels. So we can simultaneously train tagging and separation tasks in a single model.
2.4 Decoder module
Taking inspiration from U-Net [18], the decoder of our CaRE-SEP is a structure symmetrical to our encoder, which can better accomplish separation tasks. It is composed of three Swin Transformer blocks and three patch expand layers. Different from the patch merge layer, the patch expand layer is devised for up-sampling, which transforms adjacent feature maps into larger feature maps with 2x up-sampling of resolution. Finally, the patch up layer performs 4x up-sampling to restore the feature maps to the original input resolution. The skip connection combines extracted representations of the decoder and multi-scale features from the encoders together, which helps to complement the loss of spatial information resulting from down-sampling.
3 experimental setup
3.1 Dataset
AudioSet. Our CaRE-SEP model is trained on AudioSet [19], a large-scale dataset of over two million 10-second audio samples labeled with 527 sound event categories. In the following experiments, we use the full-train set of AudioSet (2M samples) to train our model and evaluate its performance on the evaluation set (22K samples).
ESC-50 [20]. To further evaluate the generalization ability of the separation task, we simulate a mixed audio test dataset based on ESC-50 dataset. The ESC-50 contains 5-second-long recordings distributed across 50 semantic classes. For each audio in a specific category, we randomly select an audio from another category and mix them. As a result, we generate 2,000 simulated mixture samples.
3.2 System Implementation
Implementation details. We use 1024 window size and 320 hop size to compute spectrograms. We use Mel scale-based band-split [16] to compress the spectrogram into 64 bands. For Swin Transformer block, we share the same configuration with [15]. There are two options for latent dimension size D=96 or D=256 corresponding to query embedding of 8D=768 or 8D=2048. Our CaRE-SEP is implemented in Pytorch and trained with AdamW optimizer (=0.9, =0.999, eps=1e-8, decay=5e-4) and a batch size of 96. We utilize a warm-up schedule, initially setting the learning rate at 0.05, 0.1, and 0.2 for the first three epochs. Subsequently, the learning rate is reduced by half every ten epochs until it reaches 0.05.
System evaluation. For the audio tagging task, we use mean average precision (mAP) as the metric. We use Source-to-Distortion Ratio (SDR) as the evaluation metric for audio separation. Similar to [4], we have three SDR metrics for the validation set:
-
•
mixture-SDR:
-
•
clean-SDR:
-
•
silence-SDR:
where the denotes any clip that does not have the same class as the -th clip. The clean SDR aims to confirm the model’s ability to preserve the clean source when provided with the self-source query embedding. The silence SDR is to validate if the model can separate nothing when the given audio lacks a target source.
4 Results and Analyses
4.1 Results on AudioSet
| Model | mAP | SDR(dB) | ||
| Mixture | Clean | Silence | ||
| AudioSet Baseline [19] | 0.314 | - | - | - |
| DeepRes [21] | 0.392 | - | - | - |
| PANN [22] | 0.434 | - | - | - |
| PSLA [23] | 0.444 | - | - | - |
| AST(single) [24] | 0.459 | - | - | - |
| 768-d ST-SED[4] | 0.467 | - | - | - |
| 527-d PANN-SEP [25] | NP | 7.38 | 8.89 | 11.00 |
| 2048-d PANN-SEP [4] | NP | 9.42 | 13.96 | 15.89 |
| 2048-d ST-SED-SEP [4] | 0.459 | 10.55 | 27.83 | 16.64 |
| 768-d CaRE-CLS | 0.463 | - | - | - |
| 768-d CaRE-CLS+SEP | 0.446 | 11.48 | 97.18 | 19.81 |
| 768-d CaRE-SEP | - | 13.14 | 103.16 | 17.72 |
| 2048-d CaRE-SEP | - | 13.84 | 96.1 | 17.38 |
| ID | Model | Configuration | AudioSet Evaluation Set | ||||
| Mixture-SDR(dB) | Clean-SDR(dB) | Silence-SDR(dB) | |||||
| A | 2048-d ST-SED-SEP [4] | ✗ | ✓ | ✗ | 10.55 | 27.83 | 16.64 |
| B | w/ | ✓ | ✓ | ✗ | 10.77 | 31.85 | 13.67 |
| C | 768-d CaRE-SEP | ✓ | ✓ | ✓ | 13.14 | 103.16 | 17.72 |
| D | w/o | ✗ | ✓ | ✓ | 10.09 | 78.13 | 5.85 |
| E | w/o | ✓ | ✗ | ✓ | 11.33 | 100.89 | 15.73 |
| F | w/o | ✗ | ✗ | ✓ | 9.14 | 69.25 | 11.13 |
| G | w/o | ✗ | ✓ | ✗ | 10.34 | 56.7 | 17.59 |
-
•
∗Grad refers to gradient. Init means to initialize the encoder for query embedding. The shared encoder is to unify query encoding and encoder of separation.
∗w/ is with and w/o is without.
In this experiment, we train our CaRE-SEP model on AudioSet and evaluate the performance, with the results presented in Table 1. The hidden dimensions of the separation model have different sizes, including 527-d, 768-d, and 2048-d.
For the audio classification task, when we only train audio tagging with CaRE-CLS, the performance is almost close to the best result. The difference between them is that 768d ST-SED uses mel-spectrogram while we use subband spectrogram as input. When we perform joint training in CaRE-CLS+CEP, the classification performance is slightly worse, the separation performance is better than the AudioSet baseline but not as good as our CaRE-SEP, indicating that there are some conflicts between the classification feature and the separation feature. We will further explain this in Section 4.2
For the separation task, we could clearly figure out that our CaRE-SEP models trained at 768-d and 2048-d embeddings achieve optimal performance. Compared to the baseline (2048-d ST-SED-SEP), our best mixture-SDR increases by more than 3 dB, and the improvement of clean-SDR is quite significant, demonstrating that our model can maintain the audio features very well. All of these results demonstrate the effectiveness of our proposed model.
It is worth noting that our model exhibits a similar performance in both the 768-d and 2048-d dimensions. A possible reason is that the larger embedding space may have some redundancy, and the 768-d query embedding space can already help the model better capture the audio features and provide more discriminative embeddings for more accurate separation.
4.2 The distribution of embedding

(a) Separation feature from
2048-d ST-SED-SEP

(b) Query embedding from
2048-d ST-SED-SEP
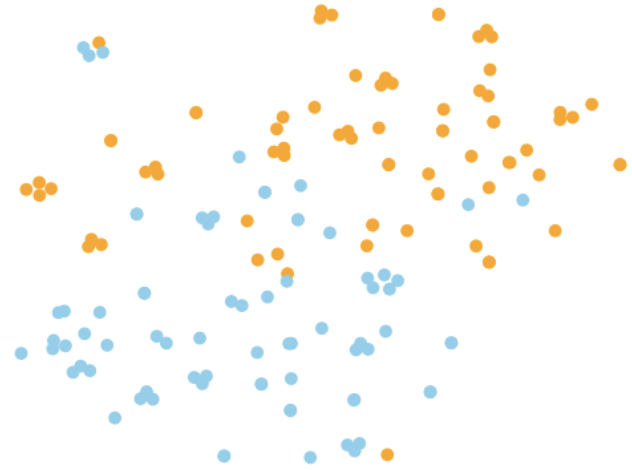
(c) Separation feature from
our 2048-d CaRE-SEP

(d) Query embedding from
our 2048-d CaRE-SEP
In this section, we aim to analyze the effectiveness of our proposed model from the perspective of feature distribution. We randomly sample 70 audio samples from each of 2 categories in the AudioSet evaluation set and extract separation feature and query embedding from different models. As shown in Fig.3, we use t-SNE [26] to visualize the distribution of embeddings, with different colors indicating individual categories. In the 2048-d ST-SED-SEP (baseline) and our CaRE-SEP, we extract output of the final block in the connector module as the separation feature.
Fig.3(a) and Fig.3(c) indicate that separation feature can slightly discriminate categories, with a small inter-class difference. However, the query embedding shows more apparent class discriminability in Fig.3(b), which validates the conjecture that a mismatch exists between the query embedding and separation feature in the baseline. Fig.3(d) is almost consistent with Fig.3(c), which further suggests that our model can generate consistent and relevant query embedding with separation feature. In addition, we also calculate the KL divergence between the embeddings of two categories. The four KL divergences in Fig.3 are (a)4.34, (b)10.37, (c)5.08, (d)5.77, respectively. This metric analysis indicates that the distribution between separation feature and query embedding exists mismatches in baseline. While in our CaRE-SEP, their distribution is closer.
Moreover, Fig.3(b) is obtained from the extra classification model. Fig.3(b) and Fig.3(a) can indicate the classification features are inconsistent with the separation feature. This can also explain the reason for the slight decrease in classification performance when jointly training classification and separation in Section 4.1.
4.3 Ablation Study
As demonstrated in Table 2, we investigate the impact of query embedding on the performance of separation models from three perspectives. refers to the gradient backpropagation during the training (not freezing). is to initialize the shared encoder with a pre-trained classification model. means that the separation encoder can simultaneously generate query embedding.
We validate the effectiveness of the proposed swin-unet architecture, shared encoder, classification initialization, and gradient backpropagation sequentially. First, the proposed swin-unet architecture is tested by comparing models A and G, each of which has an extra classification network [4]. Model G gets comparable results with the baseline, demonstrating the effectiveness of our proposed model structure. Second, the shared encoder is tested by comparing models B and C. Model B trains the query embedding with gradients in the extra network and performs worse than model C, indicating the importance of encoder sharing. Third, the initialization of the shared encoder is evaluated by comparing models D and F. Model D uses a pre-trained classification model to initialize the shared encoder, which improves the performance by nearly 1 dB compared with model F. This confirms that the classification embedding can help audio source separation. Fourth, we train the query embedding with gradients in the shared encoder to validate the gradient backpropagation. Model E demonstrates a significant increase in mixture SDR when compared to models F and D, indicating that gradient backpropagation is crucial for query embedding. Moreover, we test model F with a shared encoder to directly generate query embedding, which results in the worst mixture SDR. This suggests that and are indispensable for the shared encoder.
4.4 Results on ESC-50
| Model | Mixture-SDR(dB) |
|---|---|
| 2048-d ST-SED-SEP [4] | 9.03 |
| 768-d CaRE-SEP | 9.83 |
| 768-d CaRE-CLS+SEP | 10.34 |
To verify generalization ability, we further evaluate the zero-shot performance on ESC-50. Table 3 shows our CaRE performs better than baseline, they can both demonstrate the effectiveness of consistent and relevant embeddings. The performance of joint training is better than CaRE-SEP, which is different from the results on AudioSet. This can be explained by that these two datasets are inconsistent. The models trained on AudioSet train set perform well in its evaluation set. While directly testing the zero-shot performance on ESC-50, the performance of CLS+SEP is better, indicating labels play an important role in zero-shot generalization.
5 conclusions
In this study, we propose CaRE-SEP, a consistent and relevant embedding network for general sound separation. Different from previous query-based audio separation models which need auxiliary networks to generate query embedding, our CaRE-SEP can make the query embedding and separation feature more consistent and relevant by eliminating structural and informational mismatches in a single model. Extensive experiments show the influence of query embedding on separation tasks, as well as significant separation performance achieved by our method. Moreover, CaRE-SEP can simultaneously train classification and separation tasks, demonstrating that joint multi-task training is a promising direction in the future.
References
- [1] Aditya Arie Nugraha, Antoine Liutkus, and Emmanuel Vincent, “Multichannel audio source separation with deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 9, pp. 1652–1664, 2016.
- [2] Prem Seetharaman, Gordon Wichern, Shrikant Venkataramani, and Jonathan Le Roux, “Class-conditional embeddings for music source separation,” in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 301–305.
- [3] Emmanuel Vincent, Rémi Gribonval, and Cédric Févotte, “Performance measurement in blind audio source separation,” IEEE transactions on audio, speech, and language processing, vol. 14, no. 4, pp. 1462–1469, 2006.
- [4] Ke Chen, Xingjian Du, Bilei Zhu, Zejun Ma, Taylor Berg-Kirkpatrick, and Shlomo Dubnov, “Zero-shot audio source separation through query-based learning from weakly-labeled data,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022, vol. 36, pp. 4441–4449.
- [5] Helin Wang, Dongchao Yang, Chao Weng, Jianwei Yu, and Yuexian Zou, “Improving target sound extraction with timestamp information,” InterSpeech, 2022.
- [6] Andreas Jansson, Eric Humphrey, Nicola Montecchio, Rachel Bittner, Aparna Kumar, and Tillman Weyde, “Singing voice separation with deep u-net convolutional networks,” 2017.
- [7] Daniel Stoller, Sebastian Ewert, and Simon Dixon, “Wave-u-net: A multi-scale neural network for end-to-end audio source separation,” arXiv preprint arXiv:1806.03185, 2018.
- [8] Yi Luo and Nima Mesgarani, “Tasnet: Time-domain audio separation network for real-time, single-channel speech separation,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 696–700.
- [9] Aditya Arie Nugraha, Antoine Liutkus, and Emmanuel Vincent, “Multichannel music separation with deep neural networks,” in 2016 24th European Signal Processing Conference (EUSIPCO), 2016, pp. 1748–1752.
- [10] Stefan Uhlich, Marcello Porcu, Franck Giron, Michael Enenkl, Thomas Kemp, Naoya Takahashi, and Yuki Mitsufuji, “Improving music source separation based on deep neural networks through data augmentation and network blending,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 261–265.
- [11] Naoya Takahashi, Nabarun Goswami, and Yuki Mitsufuji, “Mmdenselstm: An efficient combination of convolutional and recurrent neural networks for audio source separation,” in 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), 2018, pp. 106–110.
- [12] Olga Slizovskaia, Leo Kim, Gloria Haro, and Emilia Gomez, “End-to-end sound source separation conditioned on instrument labels,” in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 306–310.
- [13] Jie Hwan Lee, Hyeong-Seok Choi, and Kyogu Lee, “Audio query-based music source separation,” arXiv preprint arXiv:1908.06593, 2019.
- [14] Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang, “Swin-unet: Unet-like pure transformer for medical image segmentation,” in European conference on computer vision. Springer, 2022, pp. 205–218.
- [15] Ke Chen, Xingjian Du, Bilei Zhu, Zejun Ma, Taylor Berg-Kirkpatrick, and Shlomo Dubnov, “Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 646–650.
- [16] Hangting Chen, Jianwei Yu, Yi Luo, Rongzhi Gu, Weihua Li, Zhuocheng Lu, and Chao Weng, “Ultra Dual-Path Compression For Joint Echo Cancellation And Noise Suppression,” in Proc. INTERSPEECH 2023, 2023, pp. 2523–2527.
- [17] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012–10022.
- [18] Olaf Ronneberger, Philipp Fischer, and Thomas Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 2015, pp. 234–241.
- [19] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780.
- [20] Karol J Piczak, “Esc: Dataset for environmental sound classification,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 1015–1018.
- [21] Logan Ford, Hao Tang, François Grondin, and James R Glass, “A deep residual network for large-scale acoustic scene analysis.,” in InterSpeech, 2019, pp. 2568–2572.
- [22] Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, and Mark D Plumbley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020.
- [23] Yuan Gong, Yu-An Chung, and James Glass, “Psla: Improving audio tagging with pretraining, sampling, labeling, and aggregation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021.
- [24] Yuan Gong, Yu-An Chung, and James Glass, “AST: Audio Spectrogram Transformer,” in Proc. Interspeech 2021, 2021, pp. 571–575.
- [25] Qiuqiang Kong, Yuxuan Wang, Xuchen Song, Yin Cao, Wenwu Wang, and Mark D. Plumbley, “Source separation with weakly labelled data: an approach to computational auditory scene analysis,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 101–105.
- [26] Laurens Van der Maaten and Geoffrey Hinton, “Visualizing data using t-sne.,” Journal of machine learning research, vol. 9, no. 11, 2008.