Connecting Interpretability and Robustness in Decision Trees through Separation
Abstract
Recent research has recognized interpretability and robustness as essential properties of trustworthy classification. Curiously, a connection between robustness and interpretability was empirically observed, but the theoretical reasoning behind it remained elusive. In this paper, we rigorously investigate this connection. Specifically, we focus on interpretation using decision trees and robustness to -perturbation. Previous works defined the notion of -separation as a sufficient condition for robustness. We prove upper and lower bounds on the tree size in case the data is -separated. We then show that a tighter bound on the size is possible when the data is linearly separated. We provide the first algorithm with provable guarantees both on robustness, interpretability, and accuracy in the context of decision trees. Experiments confirm that our algorithm yields classifiers that are both interpretable and robust and have high accuracy. The code for the experiments is available at https://github.com/yangarbiter/interpretable-robust-trees.
1 Introduction
Deploying machine learning (ML) models in high-stakes fields like healthcare, transportation, and law, requires the ML models to be trustworthy. Essential ingredients of trustworthy models are explainability and robustness: if we do not understand the reasons for the model’s prediction, we cannot trust the model; if small changes in the input modifies the model’s prediction, we cannot trust the model. Previous works hypothesized that there is a strong connection between robustness and explainability. They empirically observed that robust models lead to better explanations (Chen et al., 2019; Ross & Doshi-Velez, 2017). In this work, we take a rigorous approach towards understanding the connection between robustness and interpretability.
We focus on binary predictions, where each example has features and the label of each example is in , so an ML model is a hypothesis We want our model to be (i) robust to adversarial perturbations, i.e., for a small distortion, , the model’s response is similar, , for most examples , (ii) interpretable, i.e., the model itself is simple and so self-explanatory, and (iii) have high-accuracy. A common type of interpretable models are decision trees (Molnar, 2019), which we call tree-based explanation and focus on in this paper.
Prior literature (Yang et al., 2020b) showed that data separation is a sufficient condition for a robust and accurate classifier. A data is -separated if the distance between the two closest examples with different labels is at least . Intuitively, if is large, then the data is well-separated. A separated data guarantees that points with opposite labels are far from each other, which is essential to construct a robust model.
In this paper, we examine whether separation implies tree-based explanation. We first show that for a decision tree to have accuracy strictly above (i.e., better than random), the data must be bounded. Henceforth we assume that the data is in We start with a trivial algorithm that constructs a tree-based explanation with complexity (i.e., tree size) . For constant , we show a matching lower bound of Thus, we have a matching lower and upper bound on the explanation size of . Thus, separation implies robustness and interpretability. Unfortunately, for a large number of features, , the explanation size is too high to be useful in practice.
In this paper, we show that designing a simpler explanation is possible with a stronger separability assumption — linear separability with a -margin. This assumption was recently used to gain a better understanding of neural networks (Soudry et al., 2018; Nacson et al., 2019; Shamir, 2020). More formally, this assumption means that there is a vector with such that for each labeled example in the data (Shalev-Shwartz & Ben-David, 2014). Our main building block is a proof that, under the linearity assumption, there is always at least one feature that provides non-trivial information for the prediction. To formalize this, we use the known notion of weak learners (Kearns, 1988), which guarantees the existence of hypothesis with accuracy bounded below by more than .
Our weak-learnability theorem, together with Kearns & Mansour (1999), implies that a popular CART-type algorithm (Breiman et al., 1984) is guaranteed to give a decision tree with size and accuracy . Therefore, under the linearity assumption, we can design a tree with complexity independent of the number of features. Thus, even if the number of features, , is large, the interpretation complexity is not affected. This achieves our first goal of constructing an interpretable model with provable guarantees.
Recently, several research papers gave a theoretical justification for CART’s empirical success (Brutzkus et al., 2020, 2019; Blanc et al., 2019, 2020; Fiat & Pechyony, 2004). Those papers assume that the underlying distribution is uniform or features chosen independently. For many cases, this assumption does not hold. For example, in medical data, there is a strong correlation between age and different diseases. On the other hand, we give a theoretical justification for CART without resorting to the feature-independence assumption. We use, instead, the linear separability assumption. We believe that our method will allow, in the future, proofs with less restrictive assumptions.
So far, we showed how to construct an interpretable model, but we want a model that will not be just interpretable but also robust. Decision trees are not robust by-default (Chen et al., 2019). For example, a small change at the feature at the root of the decision tree leads to an entirely different model (and thus to entirely different predictions): the model defined by the left subtree and the model defined by the right subtree. We are left with the questions: can robustness and interpretability co-exist? How to construct a model that is guaranteed to be both interpretable and robust? To design such a model, we focus on a specific kind of decision tree — risk score (Ustun & Rudin, 2017). A risk score is composed of several conditions (e.g., ) and each matched with a weight, i.e., a small integer. A score of an example is the weighted sum of all the satisfied conditions. The label is then a function of the score . A risk score is a specific case of decision trees, wherein at each level in the tree, the same feature is queried. The number of parameters required to represent a risk score is much smaller than their corresponding decision trees, hence they might be considered more interpretable than decision trees (Ustun & Rudin, 2017).
We design a new learning algorithm, BBM-RS, for learning risk scores that rely on the Boost-by-Majority (BBM) algorithm (Freund, 1995) and our weak learner theorem. It yields a risk score of size and accuracy . Thus, we found an algorithm that creates a risk score with provable guarantees on size and accuracy. As a side effect, note that BBM allows to control the interpretation complexity easily. Importantly, we show that risk scores are also guaranteed to be robust to perturbations, by deliberately adding a small noise to dataset (but not too much noise to make sure that the noisy dataset is still linearly separable). Therefore, we design a model that is guaranteed to have high accuracy and be both interpretable and robust, achieving our final goal.
Finally, in Section 6, we test the validity of the separability assumption and the quality of the new algorithm on real-world datasets that were used previously in tree-based explanation research. On most of the datasets, less than points were removed to achieve an -separation with . For comparison, for binary feature-values , and distance, the best value for is . The added percentage of points required to be removed for the dataset to be linearly separable is less than on average. Thus, we observe that real datasets are close to being separable and even linearly separable. In the next step, we explored the quality of our new algorithm, BBM-RS. Even though it has provable guarantees only if the data is linearly separable, we run it on real datasets that do not satisfy this property. We compare BBM-RS to different algorithms for learning: decision trees (Quinlan, 1986), small risk scores (Ustun & Rudin, 2017), and robust decision trees (Chen et al., 2019). All algorithms try to maximize accuracy, but different algorithms try to, additionally, minimize interpretation complexity or maximize robustness. None of the algorithms aimed to optimize both interpretability and robustness. We compared the (i) interpretation complexity, (ii) robustness, and (iii) accuracy of all four algorithms. We find that our algorithm provides a model with better interpretation complexity and robustness while having comparable accuracy.
To summarize, our main contributions are:
Interpretability under separability: optimal bounds. We show lower and upper bounds on decision tree size for -separable data with , of . Namely, our upper bound proves that for any separable data, there is a tree of size , and the lower bound proves that separability cannot guarantee an explanation smaller than .
Algorithm with provable guarantees on interpretability and robustness. Designing algorithms that have provable guarantees both on interpretability, robustness, and accuracy in the context of decision trees is highly sought-after, yet there was no such algorithm before our work. We design the first learning algorithm that has provable guarantees both on interpretability, robustness, and accuracy of the returned model, under the assumption that the data is linearly separable with a margin.
While the CART algorithm is empirically highly effective, its theoretical analysis has been elusive for a long time. As a side effect, we provide an analysis of CART under the assumption of linear separability. To the best of our knowledge, this is the first proof with a distributional assumption that does not include feature independence.
Experiments. We verify the validity of our assumptions empirically and show that for real datasets, if a small percentage of points is removed then we get a linear separable dataset. We also compare our new algorithm to other algorithms that return interpretable models (Quinlan, 1986; Ustun & Rudin, 2017; Chen et al., 2019) and show that if the goal is to design a model that is both interpretable and robust, then our method is preferable.
2 Related Work
Post-hoc explanations. There are two main types of explanations: post hoc explanations (Ribeiro et al., 2016a) and intrinsic explanations (Rudin, 2019b). Algorithms for post hoc explanation take as an input a black-box model and return some form of explanation. Intrinsic explanations are simple models, so the models are self-explanatory. The main advantage of algorithms for post hoc explanations (Lundberg & Lee, 2017; Lundberg et al., 2018; Ribeiro et al., 2016b; Koh & Liang, 2017; Ribeiro et al., 2018; Deutch & Frost, 2019; Li et al., 2020; Boer et al., 2020) is that they can be used on any model. However, they host a variety of problems: they introduce a new source of error stemming from the explanation method (Rudin, 2019b); they can be fooled (Slack et al., 2020); some explanations methods are not robust to common pre-processing steps (Kindermans et al., 2019), and can be independent both of the model and the data generating process (Adebayo et al., 2018). Because of the critics against post hoc explanations, in this paper, we focus on intrinsic explanations.
Explainability and robustness. Different works research the intersection of explanation and robustness of black-box models (Lakkaraju et al., 2020), decision trees (Chen et al., 2019; Andriushchenko & Hein, 2019), and deep neural networks (Szegedy et al., 2013; Goodfellow et al., 2014; Madry et al., 2017; Ross & Doshi-Velez, 2017). Unfortunately, the quality of these methods are only verified empirically. On the theoretical side, most works analyzed explainability and robustness separately. Explainability was researched for supervised learning (Garreau & von Luxburg, 2020b, a; Mardaoui & Garreau, 2020; Hu et al., 2019) and unsupervised learning (Moshkovitz et al., 2020; Frost et al., 2020; Laber & Murtinho, 2021). For robustness, Cohen et al. (2019) showed that the technique of randomized smoothing has robustness guarantees. Ignatiev et al. (2019) connected adversarial examples and a different type of explainability from the point of view of formal logic.
Risk scores. Ustun and Rudin (Ustun & Rudin, 2017) designed a new algorithm for learning risk scores by solving an appropriate optimization problem. They focused on constructing an interpretable model with high accuracy and did not consider robustness, as we do in this work.
3 Preliminaries
We investigate models that are (i) with high-accuracy, (ii) robust, and (iii) interpretable, as formalized next.
High accuracy. We consider the task of binary classification over a domain . Let be an underlying probability distribution111In the paper, we will assume that has additional properties, like separation or linear separation. over labeled examples The input to a learning algorithm consists of a labeled sample , and its output is a hypothesis The accuracy of is equal to . The sample complexity of under the distribution , denoted , is a function mapping desired accuracy and confidence to the minimal positive integer such that for any , with probability at least over the drawn of an i.i.d. sample , the output has accuracy of at least .
Robustness. We focus on the ball, , and denote the -radius ball around a point as . A hypothesis is robust at with radius if for all we have that In (Wang et al., 2018), the notion of astuteness was introduced to measure the robustness of a hypothesis . The astuteness of at radius under a distribution is
For a hypothesis to have high astuteness the positive and negative examples need to be separated. A binary labeled data is -separated if for every two labeled examples ,, it holds that
Interpretability. We focus on intrinsic explanations, also called interpretable models (Rudin, 2019a), where the model itself is the explanation. There are several types of interpretable models, e.g., logistic regression, decision rules, and anchors (Molnar, 2019). One of the most fundamental interpretable models, which we focus on in this paper, is decision trees (Quinlan, 1986). In a decision tree, each leaf corresponds to a label, and each inner node corresponds to a threshold and a feature. The label of an example is the leaf’s label of the corresponding path.
In the paper we also focus on a specific type of decision trees, risk scores (Ustun & Rudin, 2019), see Table 1. It is defined by a series of conditions and a weight for each condition. Each condition compares one feature to a threshold, and the weights should be small integers. A score, , of an example is the number of satisfied conditions out of the conditions, each multiplied by the corresponding weight. The prediction of the risk model is the sign of the score, . A risk score can be viewed as a decision tree where at each level there is the same feature-threshold pair. Since the risk-score model has fewer parameters than the corresponding decision tree, it may be considered more interpretable.
| feature | weights | ||
| LCPA | BBM-RS | ||
| Bias term | -6 | -7 | + … |
| Age 75 | - | 2 | + … |
| Called in Q1 | 1 | 2 | + … |
| Called in Q2 | -1 | - | + … |
| Called before | 1 | 4 | + … |
| Previous call was Successful | 1 | 2 | + … |
| Employment variation rate | 5 | 4 | + … |
| Consumer price index | 1 | - | + … |
| 3 month euribor rate | -2 | - | + … |
| 3 month euribor rate | 5 | - | + … |
| 3 month euribor rate | 2 | - | + … |
| total score = | |||
4 Separation and Interpretability
We want to understand whether separation implies the existence of a small tree-based explanation. Our first observation is that the data has to be bounded for a tree-based explanation to exist. If the data is unbounded, then to achieve a training error slightly better than random, the tree size must depend on the size of the training data, see Section 4.1, Theorem 1.
In Section 4.2 we investigate lower and upper bounds for decision tree’s size, assuming separation. Specifically, in Theorem 2, we show that if the data is bounded, in , then -separability implies a tree based-explanation with tree depth . Importantly, the depth of the tree is independent of the training size, so a tree-based explanation exists. Nevertheless, even for a constant , the size of the tree is exponential in . In Theorem 3, we show that this bound is tight as there is a -separable dataset that requires an exponential size to achieve accuracy even negligibly better than random. The conclusion from this section is that if all we know is that the data is -separability for constant , we understand the interpretation complexity: it is exactly . However, the explanation is of exponential size in . In Section 5, we improve the interpretation complexity by assuming a stronger separability assumption. We will assume linear separability with a margin. All proofs are in Section A.1.
4.1 Bounded
In Theorem 1, we show that the data has to be bounded for a small decision tree to exist. In fact, boundedness is necessarily, even if the data is constrained to be linearly separable. For any tree size and a given accuracy, we can construct a linearly-separable dataset such that any tree of size cannot have the desired accuracy.
Theorem 1.
For any tree size and , there is a dataset in that is linearly separable, and any decision tree with size has accuracy less than
4.2 Upper and lower bounds
Assuming the data in is -separated, Theorem 2 tells us that one can construct a decision tree with depth and training error (and from standard VC-arguments also accuracy , with enough examples) . Importantly, the depth of the tree is independent of the training size . Nevertheless, it means the size of the tress is exponential in . The idea of the proof is to fine-grain the data to bins of size about , in each coordinate. From this construction, it is clear that the returned model is robust at any training data.
Theorem 2.
For any labeled data in that is -separated, there is a decision tree of depth at most which has a training error .
Theorem 3 proves a matching lower bound by constructing a dataset such that any tree that achieves error better than random, the tree size must be exponential in . The dataset proving this lower bound is parity. More specifically, it contains the points and the label of each point is the xor of all of its coordinates.
Theorem 3.
There is a labeled dataset in which is -separated and has the following property. For any and any decision tree that achieves accuracy , the size of is at least
5 Linear Separability
In the previous section, we showed that -separability implies a decision tree with size exponential in , and we showed a matching lower bound. This section explores a stronger assumption than separability that will guarantee a smaller tree, i.e., a simpler explanation. This assumption is that the data is linearly separable with a margin. More formally, data is -linearly separable if there is , , such that for each positive example it holds that and for each negative example it holds that Note that without loss of generality (if the inequality does not hold, multiply the -th feature in each example by ). Thus, we can interpret as a distribution over all the features. One might interpret the highest as the most important feature. However, this will be misleading. For example, if all that data has the same value at the -th feature, this feature is meaningless. In the experimental section, Section 6, we show that real datasets are close to being linearly separable.
The key step in designing a model which is both interpretable and robust is to show that one feature can provide a nontrivial prediction. In particular, in Section 5.1 we show that the hypotheses class, , is a weak learner, where
This class is similar to the known decision stumps class, but it does not contain hypotheses of the form “if then else ”. The reason will become apparent in Section 5.3, but for now, we will hint that it helps achieve robustness.
In Section 5.2, we observe that weak learnability immediately implies that the known CART algorithm constructs a tree of size independent of (Kearns & Mansour, 1999). Unfortunately, decision trees are not necessarily robust. To overcome this difficulty, we focus on one type of decision trees, risk scores, which are interpretable models on their own. In Section 5.3 we show how to use (Freund, 1995) together with our weak learnability theorem to construct a risk score model. We also show that this model is robust. This concludes our quest of finding a model that is guaranteed to be robust, interpretable, and have high-accuracy under the linearity separable assumption. In Section 6 we will evaluate the model on several real datasets.
5.1 Weak learner
This section shows that under the linearity assumption, we can always find a feature that gives nontrivial information, which is formally defined using the concept of a weak learner class. We say that a class is a weak learner if for every function that is -linearly separable and for every distribution over the examples, there is hypothesis such that is strictly bigger than , preferably at least . Finding the best hypothesis in can be done efficiently using dynamic programming (Shalev-Shwartz & Ben-David, 2014). The interesting question is how to prove that there must be a weak learner in . This will be the focus of the current section.
One might suspect that if the data is linearly separable by the vector (i.e., for each labeled example it holds that ), then which corresponds to the highest is a weak learner. Conversely, if is small, then the corresponding hypotheses will have a low accuracy. These claims are not true. To illustrate this, think about the extreme example where but completely predicts the output of any example . From the viewpoint of , the first feature is irrelevant, as it does not contribute to the term , but the first feature is a perfect predictor.
To prove that there is always a hypothesis in with accuracy , we view as a graph. Namely, define a bipartite graph where the vertices are the examples and the hypotheses and there is an edge between a hypothesis and example if correctly predicts . The edges of the graph are defined so that (i) the degree of the hypotheses vertices corresponds to its accuracy and (ii) the linearity assumption ensures that the degree of the example vertices is high. These two properties of the graph proves the theorem. All proofs are in Section A.2.
Theorem 4.
Fix . For any data in that is labeled by a -linearly separable hypothesis and for any distribution on the examples, there is a hypothesis such that
As a side note, in (Shalev-Shwartz & Singer, 2008), a different connection between linear separability and weak learning was formed. They view each example in the hypotheses basis, and on this basis, the famous minimax theorem implies that linearity is equivalent to weak learnability. In this paper, we focus on the case that the data, in its original form, is linearly separable. Nonetheless, in the case where the features are binary, the two views, the original and hypotheses basis, coincide. However, our method also holds for the nonbinary case.
So far, we showed the existence of hypothesis in with accuracy . Standard arguments in learning theory imply that the hypothesis that maximizes the accuracy on a sample also has accuracy . Specifically, for any sample , denote by the best hypothesis in on the sample . Basic arguments in learning theory shows that for a sample of size , the hypothesis has a good accuracy, as the following theorem proves.
Theorem 5 (weak-learner).
Fix . For any distribution over that satisfies linear separability with a -margin, and for any there is , such that with probability at least over the sample of size , it holds that
5.2 Decision tree using CART
CART is a popular algorithm for learning decision trees. In (Kearns & Mansour, 1999) it was shown that if the internal nodes define a -weak learner and number of samples is some polynomial of , then a CART-type algorithm returns a tree with size and accuracy at least , with probability at least Under the linearity assumption, we know that the internal nodes indeed define a -weak learner by Theorem 5. Thus, we get a model with a tree size independent of the training size and the dimension. But the model is not necessarily robust.
The above results can be interrupted as a proof for the CART’s algorithm success. This proof does not use the strong assumption of feature independence, which is assumed in recent works (Brutzkus et al., 2020, 2019; Blanc et al., 2019, 2020; Fiat & Pechyony, 2004).
Designing robust decision trees is inherently a difficult task. The reason is that, generally, the model defined by the right and left subtrees can be completely different. The feature in the root determines if the model uses the right or left subtrees. Thus, a small change in the -th feature completely changes the model. To overcome this difficulty we focus on a specific type of decision tree, risk scores (Ustun & Rudin, 2019), see Table 1 for an example. In the decision tree that corresponds to the risk score, the right and left subtrees are the same. In the next section, we design risk scores that have guarantees on the robustness and the accuracy.
5.3 Risk score
This section designs an algorithm that returns a risk score model with provable guarantees on its accuracy and robustness, assuming that the data is linearly separable. In the previous section, we used (Kearns & Mansour, 1999) that viewed CART as a boosting method. This section uses a more traditional boosting method — the Boost-by-Majority algorithm (BBM) (Freund, 1995). This boosting algorithm gets as an input training data and an integer , and at each step it reweigh the examples and apply a -weak learner that returns a hypothesis . At the end, after steps, BBM returns In (Freund, 1995; Schapire & Freund, 2013) it was shown that BBM returns hypothesis with accuracy at least after at most rounds.
The translation from BBM, which uses as a weak learner, to a risk score model, is straightforward. The hypotheses in exactly correspond to the conditions in the risk score. Each condition has weight of . If the number of conditions that hold is at least then our risk model returns , else it returns Together with Theorem 4 and (Freund, 1995) we get that BBM returns a risk score with accuracy at least and with conditions.
We remark that other boosting methods, e.g., (Freund & Schapire, 1997; Kanade & Kalai, 2009), cannot replace BBM in the suggested scheme, since the final combination has to be a simple sum of the weak learners and not arbitrary linear combination. The letter corresponds to a risk score where the weights are in and not a small integer, as desired.
Our next and final goal is to prove that our risk score model is also robust. For that, we use the concept of monotonicity. For , we say that if and only if for all it holds that . A model is monotone if for all it holds that We will show that BBM with weak learners from yields a monotone model. The reasons being (i) all conditions are of the form “”, (ii) all weights are non-negative, except the bias term, and (iii) classification of a risk score is detriment by the score’s sign. All proofs appear in Section A.3.
Claim 6.
If every condition in a risk-score model is of the form “” and all weights are positive, except the bias term, then is a monotone model.
In Claim 7 we show that, by carefully adding a small noise to each feature, we can transform any algorithm that returns a monotone model to one that returns a robust model.
Claim 7.
Assume a learning algorithm gets as an input -linearly separable and returns a monotone model with accuracy . Then, there is an algorithm that returns a model with astuteness at least at radius
To summarize, in Algorithm 1 we show the pseudocode of our new algorithm, BBM-RS. In the first step we add noise to each example by replacing each example by , where is a parameter that defines the noise level and is the all-one vector. In other words, we add noise to each feature. In the second step, the algorithm iteratively adds conditions to the risk score. At each iteration, we first find the distribution defined by BBM (Freund, 1995). Then, we find the best hypothesis in , according to We add to the risk score a condition “”. Finally, we add a bias term of , to check if at least half of the conditions are satisfied.
6 Experiments
In previous sections, we designed new algorithms and gave provable guarantees for separated data. We next investigate these results on real datasets. Concretely, we ask the following questions:
-
•
How separated are real datasets?
-
•
How well does BBM-RS perform compared with other interpretable methods?
-
•
How do interpretability, robustness, and accuracy trade-off with one another in BBM-RS?
Datasets. To maintain compatibility with prior work on interpretable and robust decision trees (Ustun & Rudin, 2019; Lin et al., 2020), we use the following pre-processed datasets from their repositories – adult, bank, breastcancer, mammo, mushroom, spambase, careval, ficobin, and campasbin. We also use some datasets from other sources such as LIBSVM (Chang & Lin, 2011) datasets and Moro et al. (2014). These include diabetes, heart, ionosphere, and bank2. All features are normalized to . More details can be found in Appendix B. The dataset statistics are shown in Table 2.
| dataset statistics | -separation | -linear separation | ||||||
| # samples | # features | # binary features | portion of positive label | sep. | sep. | |||
|---|---|---|---|---|---|---|---|---|
| adult | 32561 | 36 | 36 | 0.24 | 0.88 | 1.00 | 0.84 | 0.001 |
| bank | 41188 | 57 | 57 | 0.11 | 0.97 | 1.00 | 0.90 | 0.33 |
| bank2 | 41188 | 63 | 53 | 0.11 | 1.00 | 0.0004 | 0.91 | 0.00002 |
| breastcancer | 683 | 9 | 0 | 0.35 | 1.00 | 0.11 | 0.97 | 0.0003 |
| careval | 1728 | 15 | 15 | 0.30 | 1.00 | 1.00 | 0.96 | 0.003 |
| compasbin | 6907 | 12 | 12 | 0.46 | 0.68 | 1.00 | 0.65 | 0.20 |
| diabetes | 768 | 8 | 0 | 0.65 | 1.00 | 0.11 | 0.77 | 0.0008 |
| ficobin | 10459 | 17 | 17 | 0.48 | 0.79 | 1.00 | 0.70 | 0.33 |
| heart | 270 | 20 | 13 | 0.44 | 1.00 | 0.13 | 0.89 | 0.0003 |
| ionosphere | 351 | 34 | 1 | 0.64 | 1.00 | 0.80 | 0.95 | 0.0007 |
| mammo | 961 | 14 | 13 | 0.46 | 0.83 | 0.33 | 0.79 | 0.14 |
| mushroom | 8124 | 113 | 113 | 0.48 | 1.00 | 1.00 | 1.00 | 0.02 |
| spambase | 4601 | 57 | 0 | 0.39 | 1.00 | 0.000063 | 0.94 | 0.000002 |
6.1 Separation of real datasets
To understand how separated they are, we measure the closeness of each dataset to being - or linearly separated. The separateness of a dataset is one minus the fraction of examples needed to be removed for it to be - or linearly separated.
For -separation, we use the algorithm designed by Yang et al. (2020a) that calculates the minimum number of examples needed to be removed for a dataset to be -separated with . This ensures that after removal, there will be no pair of examples that are very similar but with different labels. Finding the optimal separateness for linear separation is NP-hard (Ben-David et al., 2003), thus we run a regularized linear SVM with regularization terms and record the lowest training error as an approximation to one minus the optimal separateness.
The separation results are shown in Table 2. Eight datasets are already -separated (separateness ). In the five datasets with separateness 100%, there are examples with very similar features but different labels. This occurs mostly in binarized datasets; see Appendix C for an example. Three datasets are almost separated with separateness equal to , , and , and two have separateness and . To summarize, of the datasets are -separated with , after removing at most of the points.
Linear separation is a stricter property than -separation, so the separateness for linear separation is smaller or equal to the separateness for -separation. Seven datasets have separateness , three separateness between and , and the remaining three have separateness . After removing the points, all datasets are -linearly separable and nine datasets have To summarize, (i) of the datasets are close to being linearly separated (ii) requiring linear-separability reduces the separateness of the -separated dataset by only an average of . From this we conclude that for these datasets at least, the assumption of or linear-separability is approximately correct.
| IC (lower=better) | test accuracy (higher=better) | ER (higher=better) | ||||||||||
| DT | RobDT | LCPA | BBM-RS | DT | RobDT | LCPA | BBM-RS | DT | RobDT | LCPA | BBM-RS | |
| adult | ||||||||||||
| bank | ||||||||||||
| bank2 | ||||||||||||
| breastcancer | ||||||||||||
| careval | ||||||||||||
| compasbin | ||||||||||||
| diabetes | ||||||||||||
| ficobin | ||||||||||||
| heart | ||||||||||||
| ionosphere | ||||||||||||
| mammo | ||||||||||||
| mushroom | ||||||||||||
| spambase | ||||||||||||
6.2 Performance of BBM-RS
Next, we want to understand how our proposed BBM-RS performs on real datasets. We compare the performance of BBM-RS with three different baselines on three evaluation criteria: interpretability, accuracy, and robustness.
Baselines. We compare BBM-RS with three baselines: (i) LCPA (Ustun & Rudin, 2019), an algorithm for learning risk scores, (ii) DT (Breiman et al., 1984), standard algorithm for learning decision trees, and (iii) Robust decision tree (RobDT) (Chen et al., 2019), an algorithm for learning robust decision trees.
We use a -fold cross-validation based on accuracy for hyperparameters selection. For DT and RobDT, we search through for the maximum depth of the tree. For BBM-RS, we search through for the maximum number of weak learners (). The algorithm stops when it reaches iterations or if no weak learner can produce a weighted accuracy . For LCPA, we search through for the maximum norm of the weight vector. We set the robust radius for RobDT and the noise level for BBM-RS to . More details about the setup of the algorithms can be found in Appendix B.
6.2.1 Evaluation
We evaluate interpretability, accuracy, and robustness of each baseline. The data is randomly split into training and testing sets by 2:1. The experiment is repeated times with different training and testing splits. The mean and standard error of the evaluation criteria are recorded.
Interpretability. We measure a model’s interpretability by evaluating its Interpretation Complexity (IC), which is the number of parameters in the model. For decision trees (DT and RobDT) the IC is the number of internal nodes in the tree, and for risk scores (LCPA and BBM-RS) it is the number non-zero terms in the weight vector. The lower the IC is, the more interpretable the model is.
Robustness. We measure model’s robustness by evaluating its Empirical robustness (ER) (Yang et al., 2020a). ER on a classifier at an input is . We evaluate ER on randomly chosen correctly predicted examples in the test set. The larger ER is, the more robust the classifier is.
6.2.2 Results
The results are shown in Table 3 (only the means are shown, the standard errors can be found in Appendix C). We see that BBM-RS performs well in terms of interpretability and robustness. BBM-RS performs the best on nine and eleven out of thirteen datasets in terms of interpretation complexity and robustness, respectively. In terms of accuracy, in nine out of the thirteen datasets, BBM-RS is the best or within to the best. These results show that on most datasets, BBM-RS is better than other algorithms in IC and ER while being comparable in accuracy.
6.3 Tradeoffs in BBM-RS
The parameter gives us the opportunity to explore the tradeoff between interpretability, robustness, and accuracy within BBM-RS. Figure 1 shows that for small , BBM-RS’s IC is high, and its ER is low, and when is high, IC is low, and ER is high. This empirical observation strengthens the claim that interpretability and robustness are correlated. See Appendix C for experiments on other datasets and experiments on the tradeoffs between IC and accuracy.

7 Conclusion
We found that linear separability is a hidden property of the data that guarantees both interpretability and robustness. We designed an efficient algorithm, BBM-RS, that returns a model, risk-score, which we prove is interpretable, robust, and have high-accuracy. An interesting open question is whether a weaker notion than linear separability can give similar guarantees.
Acknowledgements
Kamalika Chaudhuri and Yao-Yuan Yang thank NSF under CIF 1719133 and CNS 1804829 for research support.
References
- Adebayo et al. (2018) Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., and Kim, B. Sanity checks for saliency maps. Advances in neural information processing systems, 31:9505–9515, 2018.
- Alon & Spencer (2004) Alon, N. and Spencer, J. H. The probabilistic method. John Wiley & Sons, 2004.
- Andriushchenko & Hein (2019) Andriushchenko, M. and Hein, M. Provably robust boosted decision stumps and trees against adversarial attacks. In Advances in Neural Information Processing Systems, pp. 13017–13028, 2019.
- Ben-David et al. (2003) Ben-David, S., Eiron, N., and Long, P. M. On the difficulty of approximately maximizing agreements. Journal of Computer and System Sciences, 66(3):496–514, 2003.
- Blanc et al. (2019) Blanc, G., Lange, J., and Tan, L.-Y. Top-down induction of decision trees: rigorous guarantees and inherent limitations. arXiv preprint arXiv:1911.07375, 2019.
- Blanc et al. (2020) Blanc, G., Lange, J., and Tan, L.-Y. Provable guarantees for decision tree induction: the agnostic setting. arXiv preprint arXiv:2006.00743, 2020.
- Boer et al. (2020) Boer, N., Deutch, D., Frost, N., and Milo, T. Personal insights for altering decisions of tree-based ensembles over time. Proceedings of the VLDB Endowment, 13(6):798–811, 2020.
- Breiman et al. (1984) Breiman, L., Friedman, J., Stone, C. J., and Olshen, R. A. Classification and regression trees. CRC press, 1984.
- Brutzkus et al. (2019) Brutzkus, A., Daniely, A., and Malach, E. On the optimality of trees generated by id3. arXiv preprint arXiv:1907.05444, 2019.
- Brutzkus et al. (2020) Brutzkus, A., Daniely, A., and Malach, E. Id3 learns juntas for smoothed product distributions. In Conference on Learning Theory, pp. 902–915. PMLR, 2020.
- Chang & Lin (2011) Chang, C.-C. and Lin, C.-J. Libsvm: a library for support vector machines. ACM transactions on intelligent systems and technology (TIST), 2(3):1–27, 2011.
- Chen et al. (2019) Chen, H., Zhang, H., Boning, D., and Hsieh, C.-J. Robust decision trees against adversarial examples. arXiv preprint arXiv:1902.10660, 2019.
- Cohen et al. (2019) Cohen, J. M., Rosenfeld, E., and Kolter, J. Z. Certified adversarial robustness via randomized smoothing. arXiv preprint arXiv:1902.02918, 2019.
- Deutch & Frost (2019) Deutch, D. and Frost, N. Constraints-based explanations of classifications. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 530–541. IEEE, 2019.
- Fiat & Pechyony (2004) Fiat, A. and Pechyony, D. Decision trees: More theoretical justification for practical algorithms. In International Conference on Algorithmic Learning Theory, pp. 156–170. Springer, 2004.
- Freund (1995) Freund, Y. Boosting a weak learning algorithm by majority. Information and computation, 121(2):256–285, 1995.
- Freund & Schapire (1997) Freund, Y. and Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences, 55(1):119–139, 1997.
- Frost et al. (2020) Frost, N., Moshkovitz, M., and Rashtchian, C. Exkmc: Expanding explainable -means clustering. arXiv preprint arXiv:2006.02399, 2020.
- Garreau & von Luxburg (2020a) Garreau, D. and von Luxburg, U. Explaining the explainer: A first theoretical analysis of lime. arXiv preprint arXiv:2001.03447, 2020a.
- Garreau & von Luxburg (2020b) Garreau, D. and von Luxburg, U. Looking deeper into lime. arXiv preprint arXiv:2008.11092, 2020b.
- Goodfellow et al. (2014) Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Hu et al. (2019) Hu, X., Rudin, C., and Seltzer, M. Optimal sparse decision trees. In Advances in Neural Information Processing Systems, pp. 7267–7275, 2019.
- Ignatiev et al. (2019) Ignatiev, A., Narodytska, N., and Marques-Silva, J. On relating explanations and adversarial examples. In Advances in Neural Information Processing Systems, pp. 15883–15893, 2019.
- Kanade & Kalai (2009) Kanade, V. and Kalai, A. Potential-based agnostic boosting. Advances in neural information processing systems, 22:880–888, 2009.
- Kantchelian et al. (2016) Kantchelian, A., Tygar, J. D., and Joseph, A. Evasion and hardening of tree ensemble classifiers. In International Conference on Machine Learning, pp. 2387–2396, 2016.
- Kearns (1988) Kearns, M. Learning boolean formulae or finite automata is as hard as factoring. Technical Report TR-14-88 Harvard University Aikem Computation Laboratory, 1988.
- Kearns & Mansour (1999) Kearns, M. and Mansour, Y. On the boosting ability of top–down decision tree learning algorithms. Journal of Computer and System Sciences, 58(1):109–128, 1999.
- Kindermans et al. (2019) Kindermans, P.-J., Hooker, S., Adebayo, J., Alber, M., Schütt, K. T., Dähne, S., Erhan, D., and Kim, B. The (un) reliability of saliency methods. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, pp. 267–280. Springer, 2019.
- Koh & Liang (2017) Koh, P. W. and Liang, P. Understanding black-box predictions via influence functions. arXiv preprint arXiv:1703.04730, 2017.
- Laber & Murtinho (2021) Laber, E. and Murtinho, L. On the price of explainability for some clustering problems. arXiv preprint arXiv:2101.01576, 2021.
- Lakkaraju et al. (2020) Lakkaraju, H., Arsov, N., and Bastani, O. Robust and stable black box explanations. In International Conference on Machine Learning, pp. 5628–5638. PMLR, 2020.
- Li et al. (2020) Li, X.-H., Shi, Y., Li, H., Bai, W., Song, Y., Cao, C. C., and Chen, L. Quantitative evaluations on saliency methods: An experimental study. arXiv preprint arXiv:2012.15616, 2020.
- Lin et al. (2020) Lin, J., Zhong, C., Hu, D., Rudin, C., and Seltzer, M. Generalized and scalable optimal sparse decision trees. In International Conference on Machine Learning, pp. 6150–6160. PMLR, 2020.
- Lundberg & Lee (2017) Lundberg, S. M. and Lee, S.-I. A unified approach to interpreting model predictions. In Advances in neural information processing systems, pp. 4765–4774, 2017.
- Lundberg et al. (2018) Lundberg, S. M., Erion, G. G., and Lee, S.-I. Consistent individualized feature attribution for tree ensembles. arXiv preprint arXiv:1802.03888, 2018.
- Madry et al. (2017) Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Mardaoui & Garreau (2020) Mardaoui, D. and Garreau, D. An analysis of lime for text data. arXiv preprint arXiv:2010.12487, 2020.
- Molnar (2019) Molnar, C. Interpretable Machine Learning. 2019. https://christophm.github.io/interpretable-ml-book/.
- Moro et al. (2014) Moro, S., Cortez, P., and Rita, P. A data-driven approach to predict the success of bank telemarketing. Decision Support Systems, 62:22–31, 2014.
- Moshkovitz et al. (2020) Moshkovitz, M., Dasgupta, S., Rashtchian, C., and Frost, N. Explainable k-means and k-medians clustering. In International Conference on Machine Learning, pp. 7055–7065. PMLR, 2020.
- Nacson et al. (2019) Nacson, M. S., Lee, J., Gunasekar, S., Savarese, P. H. P., Srebro, N., and Soudry, D. Convergence of gradient descent on separable data. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 3420–3428. PMLR, 2019.
- Pedregosa et al. (2011) Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- Quinlan (1986) Quinlan, J. R. Induction of decision trees. Machine learning, 1(1):81–106, 1986.
- Ribeiro et al. (2016a) Ribeiro, M. T., Singh, S., and Guestrin, C. Model-agnostic interpretability of machine learning. arXiv preprint arXiv:1606.05386, 2016a.
- Ribeiro et al. (2016b) Ribeiro, M. T., Singh, S., and Guestrin, C. ” why should i trust you?” explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1135–1144, 2016b.
- Ribeiro et al. (2018) Ribeiro, M. T., Singh, S., and Guestrin, C. Anchors: High-precision model-agnostic explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Ross & Doshi-Velez (2017) Ross, A. S. and Doshi-Velez, F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. arXiv preprint arXiv:1711.09404, 2017.
- Rudin (2019a) Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1:206–215, May 2019a.
- Rudin (2019b) Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1(5):206–215, 2019b.
- Schapire & Freund (2013) Schapire, R. E. and Freund, Y. Boosting: Foundations and algorithms. Kybernetes, 2013.
- Shalev-Shwartz & Ben-David (2014) Shalev-Shwartz, S. and Ben-David, S. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.
- Shalev-Shwartz & Singer (2008) Shalev-Shwartz, S. and Singer, Y. On the equivalence of weak learnability and linear separability: New relaxations and efficient boosting algorithms. In 21st Annual Conference on Learning Theory, COLT 2008, 2008.
- Shamir (2020) Shamir, O. Gradient methods never overfit on separable data. arXiv preprint arXiv:2007.00028, 2020.
- Slack et al. (2020) Slack, D., Hilgard, S., Jia, E., Singh, S., and Lakkaraju, H. Fooling lime and shap: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pp. 180–186, 2020.
- Soudry et al. (2018) Soudry, D., Hoffer, E., Nacson, M. S., Gunasekar, S., and Srebro, N. The implicit bias of gradient descent on separable data. The Journal of Machine Learning Research, 19(1):2822–2878, 2018.
- Szegedy et al. (2013) Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., and Fergus, R. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Ustun & Rudin (2017) Ustun, B. and Rudin, C. Optimized risk scores. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1125–1134, 2017.
- Ustun & Rudin (2019) Ustun, B. and Rudin, C. Learning optimized risk scores. Journal of Machine Learning Research, 20(150):1–75, 2019.
- Wang et al. (2018) Wang, Y., Jha, S., and Chaudhuri, K. Analyzing the robustness of nearest neighbors to adversarial examples. In International Conference on Machine Learning, pp. 5133–5142. PMLR, 2018.
- Yang et al. (2020a) Yang, Y.-Y., Rashtchian, C., Wang, Y., and Chaudhuri, K. Robustness for non-parametric classification: A generic attack and defense. In International Conference on Artificial Intelligence and Statistics, pp. 941–951. PMLR, 2020a.
- Yang et al. (2020b) Yang, Y.-Y., Rashtchian, C., Zhang, H., Salakhutdinov, R., and Chaudhuri, K. Adversarial robustness through local lipschitzness. arXiv preprint arXiv:2003.02460, 2020b.
Appendix A Proofs
A.1 Separation and interpretability
See 1
Proof.
Fix an integer and We will start by describing the dataset and prove it is linearly separable. We will then show that any decision tree of size must have accuracy smaller than
Dataset.
The dataset size is , to be fixed later. The dataset includes, for any , a group, , of four points: two points that are labeled positive and two points that are labeled negative for some small , see Figure 2.

To prove that the dataset is linearly separable focus on the vector with . For each labeled examples in the dataset, the inner product is equal to .
Accuracy.
We will prove by induction that the points arriving in each node are a series of consecutive groups, perhaps except a few points that are in the “tails”. In each node, the number of positive and negative examples is about the same, so one cannot predict well. See intuition in Figure 3.

More formally, a tail is a subset of , i.e., , where is the power set. We prove the following claim.
Claim. For each inner node , there are integers such that the points arriving to this node, , satisfy
where and In other words, contains a series of consecutive groups and a few points from the group after and before the series.
Proof.
We will prove the claim by induction on the level of the tree. The claim is correct for the root with and . To prove the claim by induction, suppose an inner node uses a threshold and the first feature. Denote the closest integer to by . The points reaching the left son are
and the nodes reaching the right son are
A similar argument also hold if uses the second feature, which proves our claim. ∎
To finish the proof of Theorem 1, first note that the number of positive and negative examples in each is exactly equal. Together with the claim that we just proved, for each leaf , the number of points that are correctly classified out of the points, , reaching , is at most Thus the total number of points correctly classified by the entire tree is at most Thus, the accuracy of the tree is at most We take and get that the accuracy is smaller than which is what we wanted to prove.
∎
See 2
Proof.
Each feature is in , so Fix and We can bound by
Take two data points, one labeled positive, , and one negative . By the -separation, we know that there is a feature such that
This means that we can find a threshold among the thresholds that distinguishes the examples and , i.e., there is , such that
We focus on the decision tree with all possible features and the thresholds. All examples reaching the same leaf, has the same label. In other words, the training error is Since there are pairs of feature and thresholds, the depth of the tree is at most .
∎
See 3
Proof.
We start with describing the dataset, then we will show that any decision tree must be large if we want to achieve accuracy.
The dataset.
The inputs are all strings in The hypothesis is the parity function, i.e., and
Each node has equal number of positive and negative examples.
The main idea is that as long as the depth of a node is not , it has exactly the same number of positive and negative examples reaching it. This is true since as long as at most features are fixed, there exactly the same number of positive and negative examples that agree on these features.
Large size.
Denote by the set of all nodes that exactly one example reach them. Denote this set size by We want to prove that is large. So far, we proved that for each node that contains more than one example, exactly half of the examples are labeled positive and half negative. Number of examples correctly classified is half of all the examples not in plus . There are examples in total. So the accuracy is equal to . The latter should be at least . Therefore, the size of the tree is at least
∎
A.2 Linear separability: weak learner
We start with the more restricted case where the features are binary. This will give the necessary foundations for the general case, where features are in . In this case is simplified to the set
Theorem 8.
For any data in that is labeled by a -linearly separable a hypothesis and for any distribution on the examples, there is hypothesis such that
Proof.
The proof’s high-level idea is to represent the class as a bipartite graph and lower bound the weighted density of this graph. The high lower-bound leads to a high degree vertex, which will correspond to our desired weak learner.
Recall that by the fact that the data is -linearly separable, we know that there is a vector with such that for eac labeled example it holds that
| (1) |
Bipartite graph description.
Consider the following bipartite graph. The vertices are the examples in the training data and the hypotheses in the binary version of . There is an edge between an example and hypothesis , if it correctly classify , i.e., if . Each vertex is given a weight: example gets weight and a hypothesis gets weight , where is in Equation (1).
Assumption: .
We assume without loss of generality that , otherwise if there is , we can multiply the -th feature in all the examples by . After this multiplication, the linearity assumption still holds. We know that , and since , we get that .
Lower bound weighted-density.
The main idea is to lower bound the weighted density of the bipartite graph, which is the sum over all edges in the graph, each with weight :
To prove a lower bound on , we focus on one labeled example From the linearity assumption, Equation (1), we know that Recall that is equal to or , since we are in the binary case. We can separate the sum depending on whether is equal to or and get that
We know that , thus , and the inequality can be rewritten as
Notice that . Thus, the inequality can be further rewritten as
This inequality holds for any labeled example, so we can sum all these inequalities, each with weight and get that
Finding a weak learner.
Since is a probability distribution, we can rewrite and get
From the probabilistic method (Alon & Spencer, 2004), there is a hypothesis such that
By the definition of the graph, . Thus, we get that
which is exactly what we wanted to prove.
∎
Theorem 9 (binary weak-learner).
For any distribution over labeled examples that satisfies linear separability with a -margin, and for any there is , such that with probability at least over the sample of size , it holds that
Proof.
We start with a known fact222To bound the note that for any points in there is at least one point , where in each coordinate it is not the largest one among the points. Thus, it’s impossible that is labeled while all the rest of the points are labeled . that
Denote the best hypothesis in the binary version in as . From Theorem 8, we know that For every sample , denote by the hypothesis in the binary version of that optimizes the accuracy on the sample From the fundamental theorem of statistical learning (Shalev-Shwartz & Ben-David, 2014), we know that for , with probability at least over the sample of size , it holds that
∎
See 4
Proof.
The proof is similar in spirit to the proof of Theorem 8. The main difference is the technique to lower bound , the weighted density. In the current proof we use the fact that if for some positive example , its -th feature, , is high, then it contains many edges in the graph. For a negative example , if its -th feature, , is low, then it contains many edges in the graph.
Bipartite graph description.
We first discretize the segment to values with :
The value of was chosen such that We focus on the following subclass of which is a discretization of
We use a similar bipartite graph as in the proof of Theorem 8 for the subclass : the vertices are the examples and the hypotheses in ; and there is an edge between an example with label and hypothesis whenever , i.e., when correctly classify .
Recall that by the fact that the data is -linearly separable, we know that there is a vector with and for any labeled example it holds that
| (2) |
From the same argument as in Theorem 8, we assume that
We are now ready to give each vertex in the bipartite graph a weight: example gets weight and a hypothesis gets weight , where is as in Equation (2). The weights on the hypotheses were chosen such that they will sum up to :
| (3) |
Lower bound weighted-density.
We will lower bound the weighted density of the bipartite graph, which is the sum over all edges in the graph, each with weight :
To show a lower bound on , we focus on one labeled example and one feature and we will lower bound the following sum
| (4) |
The sum in the RHS is equal to the number of ’s such that :
| (5) |
To lower bound we separate the analysis depending on the label . If is a positive example, i.e., , we have that
For a negative example , we can lower bound by
To summarize these two equations we get that
Going back to Equation (4),
Summing over all features
| (6) | |||||
| (7) |
Weighted sum over all examples yields the desired lower bound on
Finding a weak learner.
The proof now continues similarly to the proof of Theorem 8. Since is a probability distribution over all hypotheses in (see Equation 3), we can rewrite and get
From the probabilistic method (Alon & Spencer, 2004), there is hypothesis such that
By the definition of the graph, . Thus, we get that
which is exactly what we wanted to prove.
∎
See 5
Proof.
Proof is similar to Theorem 9. ∎
A.3 Linear separability: risk scores
See 6
Proof.
Fix a risk score model which is defined by a series of conditions and weights . The score, , of an example is the weighted-sum of all satisfied conditions,
where if is true, and otherwise. The prediction of the model is equal to
Fix examples with Our goal is to show that The key observation is that any condition satisfied by is also satisfied by because by our assumption that In different words we have that
| (8) |
This implies that the score of is at least the score of , since it holds that
Thus, we get exactly what we wanted to prove
As an aside, at this point, it should become apparent why we restricted our conditions to be of the form and did not allow natural conditions of the form , such conditions will not be monotone and Inequality (8) will not hold. ∎
See 7
Proof.
The high-level idea is to focus on a noisier distribution than the original one. The noise is small enough so that the new data will remain linearly separable with a (slightly worse) margin. Therefore, the learning algorithm can be applied. We call the learning algorithm with a sample from the noisy distribution and return its result. We will prove that a point correctly classified in the noisy dataset implies that the noiseless point is robust to adversarial examples.
Noisy data.
Fix a data and a distribution on . We will create a noisy distribution on the labeled examples by mapping each example to a new labeled example where
where is the vector of all Thus, if is a positive labeled example () then . This means that from each coordinate we decrease . Intuitively, we make looks more negative. Similarly, if is a negative labeled example () we create a new example , intuitively, making looks more positive by adding to each coordinate.
If we have a samples from , then we can easily sample from by subtracting from each labeled example in the sample.
Noisy data is -linearly separable.
Suppose that the original data is -separable. This means that there is a vector with such that for every labeled example in it holds that We know that the corresponding example in the noisy data is equal to . We will prove a lower bound on and this will prove that the noisy input is also linearly separable with a margin. We will use the fact that for any label and get that
Recall that , which means that This means that Together with the fact that , we can now give the desired lower bounds on
In different words, the new data is -linearly separable.
Model is robust.
In order to construct a robust model, we take our sample from . Then we transform it to a sample from by subtracting noise of to each labeled example , and then we call algorithm with the noisy training data. From our assumption, the resulting model has accuracy . We will show that the returned model has astuteness of at radius with respect to We do this by proving that if is correctly classified than the model is robust at with radius
Fix a noisy labeled example and an example that is close to , in , i.e., . If is positively labeled then is also positively labeled, and from the construction of the noisy dataset it holds that
Hence, from the monotone property of the model, if is labeled correctly then so is . A similar argument holds if is negatively labeled.
∎
Appendix B Additional Experiment Details
B.1 Setups
The experiments are performed on a Intel Core i9 9940X machine with 128GB of RAM. The code for the experiments is available at https://github.com/yangarbiter/interpretable-robust-trees.
Additional dataset details.
The adult, bank, breastcancer, mammo, mushroom, and spambase datasets are retrieved from a publicly available repository 333https://github.com/ustunb/risk-slim/tree/master/examples/data, and these datasets are used by Ustun & Rudin (2019). The careval, ficobin, and campasbin datasets are also retrieved from a publicly available source444https://github.com/Jimmy-Lin/GeneralizedOptimalSparseDecisionTrees/tree/master/experiments/datasets and used by Lin et al. (2020). We also added the diabetes, heart, and ionosphere dataset from 555https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/ and bank2 dataset from Moro et al. (2014). All features are scaled to by the following formula , where represents the feature value, and and represents the minimum and maximum value of the given feature across the entire data.
In the adult dataset, the target is to predict whether the person’s income is greater then . For bank and bank2 datasets, we want to predict whether the client opens a bank account after a marketing call. In the breastcancer dataset, we want to predict whether the given sample is benign. In the heart dataset, we want to detect the presence of heart disease in a patient. In the mammo dataset, we want to predict whether the sample from the mammography is malignant. In the mushroom dataset, we want to predict whether the mushroom is poisonous. In the spambase dataset, we want to predict whether an email is a spam. In the careval dataset, the goal is to evaluate cars. In the ficobin dataset, we want to predict a person credit risk. In the campasbin dataset, we want to predict whether a convicted criminal will re-offend again. In the diabetes dataset, we want to predict whether or not the patients in the dataset have diabetes. In the ionosphere dataset, we want to predict whether the radar data are showing some evidence of some type of structure in the ionosphere.
Baseline implementations
For DT, we use the implementation from scikit-learn (Pedregosa et al., 2011) and set the splitting criteria to entropy. For LCPA and RobDT, we use the implementation from their original authors666https://github.com/ustunb/risk-slim and https://github.com/chenhongge/RobustTrees.
Measure empirical robustness.
Appendix C Additional Results
C.1 Examples that are similar but labeled differently
The compasbin dataset has the lowest -separateness. Its binary features are:
-
•
sex:Female
-
•
age:
-
•
age:
-
•
age:
-
•
age:
-
•
juvenile-felonies:=0
-
•
juvenile-misdemeanors:=0
-
•
juvenile-crimes:=0
-
•
priors:=0
-
•
priors:=1
-
•
priors:2-3
-
•
priors:3
There are people who are: male, age between to , did not commit any juvenile felonies, misdemeanors, and crimes, and have more than previous criminal conviction. These people will have the same feature vector while for their labels, recidivate within two years while people did not.
C.2 Relationship between explainability, accuracy, and robustness in BBM-RS
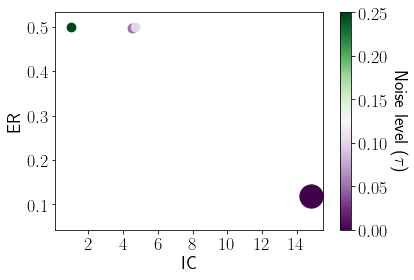
To understand the interaction between explainability, accuracy, and robustness, we measure these criteria of BBM-RS with different noise levels . The results are shown in Figure 4. We observed that, by changing the noise level, that robustness and the explanation complexity go hand in hand. For higher noise levels, we have a higher robustness and lower explanation complexity and accuracy. The shows that by making the model simpler, we can have better robustness and explainability while loosing some accuracy.











C.3 Trade-off between explanation complexity and accuracy for BBM-RS
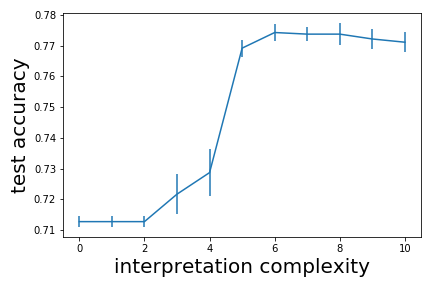
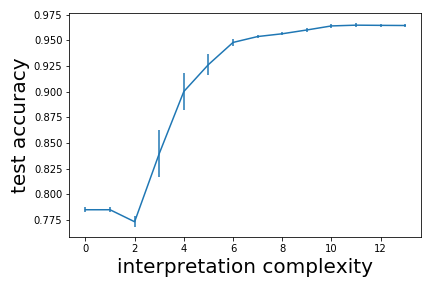
To understand how explanation complexity effects accuracy, we first train a BBM-RS classifier. The learned BBM-RS classifier consists of weak learners. We then measure the test accuracy of using only weak learners for prediction, where . Finally, we plot out the figure of accuracy versus explanation complexity (number of unique weak learners) in Table 5. Note that for the same explanation complexity, there may be more then one test accuracy. In this case we show the highest test accuracy. In Table 5, we see that with the increase of explanation complexity, generally the test accuracy also increases.











| EC | test accuracy | ER | ||||||||||
| DT | RobDT | LCPA | BBM-RS | DT | RobDT | LCPA | BBM-RS | DT | RobDT | LCPA | BBM-RS | |
| adult | ||||||||||||
| bank | ||||||||||||
| bank2 | ||||||||||||
| breastcancer | ||||||||||||
| careval | ||||||||||||
| compasbin | ||||||||||||
| diabetes | ||||||||||||
| ficobin | ||||||||||||
| heart | ||||||||||||
| ionosphere | ||||||||||||
| mammo | ||||||||||||
| mushroom | ||||||||||||
| spambase | ||||||||||||