Conformal Group Recommender System
Abstract
Group recommender systems (GRS) are critical in discovering relevant items from a near-infinite inventory based on group preferences rather than individual preferences, like recommending a movie, restaurant, or tourist destination to a group of individuals. The traditional models of group recommendation are designed to act like a black box with a strict focus on improving recommendation accuracy, and most often, they place the onus on the users to interpret recommendations. In recent years, the focus of Recommender Systems (RS) research has shifted away from merely improving recommendation accuracy towards value additions such as confidence and explanation. In this work, we propose a conformal prediction framework that provides a measure of confidence with prediction in conjunction with a group recommender system to augment the system-generated plain recommendations. In the context of group recommender systems, we propose various nonconformity measures that play a vital role in the efficiency of the conformal framework. We also show that defined nonconformity satisfies the exchangeability property. Experimental results demonstrate the effectiveness of the proposed approach over several benchmark datasets. Furthermore, our proposed approach also satisfies validity and efficiency properties.
keywords:
Group recommender systems , Conformal prediction , Confidence measure1 Introduction
Recommender systems (RS) assist users in decision-making by helping them sift through a huge variety of offered products, such as movies, web pages, articles, and books [1]. These systems exploit past interactions between users and items to make personalized recommendations. RS algorithms are broadly classified into content-based, collaborative, and hybrid filtering, depending on the input used for profiling users and items. Content-based filtering approaches recommend items to a user by considering the similarity between the content or features of items and the user’s profile [2, 3]. On the other hand, the collaborative filtering-based approach recommends items based on the preferences of other users who share similar preferences to the target user [4, 5, 6]. The hybrid approach combines various mechanisms and compositions of different data sources [7, 8]. Group recommender systems (GRS) [9, 10] extend this concept to the user group, wherein it analyses a group of users’ profiles and creates a communal recommendation list. These groups can consist of family members, friends, colleagues, or any collection of individuals who wish to engage with a specific item or application collectively. We observe numerous applications of group recommender systems in our daily lives. For example, a group of friends may plan to dine at a restaurant or organize a tour, while a family may wish to watch a movie together. A Group Recommender System (GRS) can be formally defined as follows. Let represent the set of items, denote the set of users, represent the set of items present in the profile of a user , and indicate a group of users. Given the sets, , , (), and , the goal of a GRS is to recommend the top-k most relevant items from to the user group by considering the individual preferences within the group.
Several approaches in recent years have been proposed to extend personalized recommender systems to group recommender systems, wherein the major focus is to improve the accuracy of recommendations. With the recent algorithmic advancement, the focus of the research has been recently shifted towards creating transparent group recommendation models that prioritize accountability and explainability. These models aim to achieve accuracy while providing additional value through confidence measures, explanations, or sensitivity. Among these enhancements, associating a confidence measure with the recommendation set is a particularly appealing facet. The confidence measures indicate the system’s confidence that the desirable items are present in the recommendation set, which in turn enhance the system’s reliability and help users quickly and correctly identify the products of their choice. Although researchers have thoroughly investigated confidence-based personalized recommender systems [11, 12], only a few methods have been proposed for improving the confidence measure in group recommender systems. Further, considering the individual preferences of the group and providing a delightful recommendation with confidence is not trivial. This paper proposes a confidence-based group recommender system using a conformal prediction framework. The proposed approach represents confidence in connection with the error bound, i.e., if the system exhibits confidence in the recommendation, it implies that the probability of making an error is at most . The concept of conformal prediction forms the basis for the proposed Conformal Group Recommender System (CGRS).
Conformal prediction is a framework for reliable machine learning that measures confidence in the predicted labels on a per-instance basis. A conformal system framework can be implemented alongside any traditional machine learning algorithm, but the implementation largely depends on the underlying algorithm. This paper extends the concept to GRS and defines a nonconformity measure, an essential part of the conformal prediction framework, suitable for group recommendation settings. Given a set of users , items , and a target group of user profiles, and the significance level , the proposed conformal group recommender system returns recommendation set to a group with the confidence of . We demonstrate that the exchangeability property, an essential property for any conformal framework, is satisfied by the proposed nonconformity measure. Furthermore, the proposed approach also satisfies the validity and efficiency properties. Experiment results over several real-world datasets support the efficacy of the proposed conformal group recommender system.
The paper is organized as follows. Section 2 briefly reviews conformity measures in recommender systems and establishes the context for this paper. We cover the foundational concepts of conformal prediction and the algorithm used to build the proposed conformal group recommender systems in Section 3. The proposed algorithm and proof of validity is presented in Section 4. Section 5 presents extensive experimental results on eight benchmark datasets. Finally, Section 6 concludes the paper and offers recommendations for future endeavors.
2 Related Work
Group recommender systems assist a group of users who share a common interest. These systems exploit the collective consumption experience of the group to offer them personalized recommendations. However, most of these systems are less transparent than those designed to assist a single user, making it difficult for users to understand why the system recommends a particular item. Despite the enormous application of group recommender systems, there has yet to be a comprehensive analysis of associating confidence with the recommendation in a group context. While confidence measures are well-established in personalized recommender systems [13, 12], their application in group recommender systems is more complex. Group recommender systems have additional complexities in modeling and evaluating preferences due to diverse user preferences. This section reviews related work that focuses on group recommender systems and associating confidence measures with the recommendation set.
The majority of conventional group recommendation models aim to extend personal recommender systems (PRS) to group recommender systems (GRS) by blending individual preferences to form group profiles. MusicFX [14] is among the early proposals in group recommendation, specifically targeting the recommendation of music channels for playing in fitness centers. This system exploits previously specified music preferences of individuals over a wide range of musical genres to recommend music at a particular time. Let’s browse [15] suggests web pages to a group consisting of two or more individuals who are likely to have shared interests.PolyLens [16] employs collaborative filtering and recommends movies to groups of users. Jameson et al. [17] proposed the Travel Decision Forum system, which helps groups plan vacation. The system provides an interface where the group members can view and copy other users’ preferences and combine them using the median strategy once all agree. Garcia et al. [18] proposed intersection and aggregation mechanisms to build a group profile from the individual profiles. Kagita et al.[19] use a virtual user approach with precedence mining to extend PRS to GRS. All the GRS approaches described so far utilize aggregation techniques to determine group profiles or recommendations, and they are inept at associating confidence with the recommendation. In this proposal, we adopt our previous work [19] and propose a conformal group recommender system that furnishes confidence in the recommendations to improve the system’s reliability and user satisfaction. Another difference between the previous work [19] and our current proposal is that we have used coexistence in place of precedence mining, as in many real-world applications, the associations of item consumption are more important than strict precedence relationships.
3 Preliminary Concepts
This section reviews the paper’s foundational concepts, which we use subsequently in our algorithm. We introduce the precursory concepts of conformal prediction in Section 3.1, which serves as the framework for constructing our suggested conformal group recommender system. We then briefly describe the precedence mining and association mining-based personalized recommender systems (PRS) in Sections 3.2 and 3.3, respectively, that we extended to the GRS. Section 3.4 explores the virtual user approach as an efficient method for developing a group recommender system (GRS) from a personalized recommender system (PRS).
3.1 Conformal Prediction
In this section, we offer a concise overview of the conformal prediction principle, presenting relevant information for a comprehensive understanding. Let be a training instance (or an example), where is a -dimensional attribute vector and is the associated class label. Given a dataset, , which contains training instances, the aim of the classification task is to produce a classifier , anticipating that predicts well on any future example , , by optimizing some specific evaluation function. A conformal predictor, on the other hand, associates precise levels of confidence in predictions. Given a method for making a prediction, the conformal predictor offers a set of predicted class labels for an unseen object such that the probability of the correct label not present within this set is no greater than , called prediction region. We assume that the set of all possible labels is known a prior, and all , are in i.i.d. fashion (independently and identically distributed).
The conformal predictor uses a (non)conformity measure designed based on the underlying algorithm to evaluate the difference between a new (test) instance and a training data set. Let , where is tentatively assigned to . The nonconformity measure for an example is a measure of how well conforms to . In other words, the nonconformity measure assesses the likelihood that the label is the correct label for our new example, . The difference in ’s predicted behaviour when is replaced with is then calculated. Let -value be the proportion of with a nonconformity score worse than for all possible values of (all class labels). The -prediction region is formed by labels with -values greater than . Intuitively, the prediction behavior is observed by employing any of the conventional predictors that utilize the training set .
3.2 Precedence Mining based Recommender Systems
The precedence mining (PM) based recommendation model is a type of collaborative filtering (CF) technique that captures the temporal patterns in the user profiles and provides recommendations to the target user based on the sequence of items they have consumed [20]. For example, if a user has seen Toy Story 1, the PM-based CF can recommend Toy Story 2 if it has been seen previously by users who have seen the Toy Story 1. The PM model uses precedence statistics, i.e., the precedence count of item pairs, to estimate the probability of future consumption based on past behavior. It estimates the relevance score of each candidate item for recommendation using precedence statistics.
Let be the set of items, be the set of users and be the set of items consumed by . The items for recommendation are chosen based on the criteria that they are not present in the target user’s profile and are likely to be preferred by the target user compared to other items. The PM-based approach keeps and statistics for each item to calculate the recommendation score of an item. is the number of users who has consumed the th item, and the is the number of users who consumed item before item . We use a notation to denote the precedence probability of consuming an item preceding . We define , and as follows.
| (1) |
| (2) |
The objects with high scores are recommended.
Example 1.
Let us consider the movie consumption data of nine users watching six different movies (i.e., Toy Story, Minions, Godfather I, Godfather II, Thor, and Avengers) in the table given below. Let Rob be the target user who has not yet watched Minions and Godfather II. We compute the relevance score for these two candidate items and rank them in decreasing order of the relevance score.
| Users | Movies watched |
|---|---|
| Mark | Minions, Thor, Toy Story, Avengers |
| Christopher | Godfather I, Godfather II, Toy Story, Minions |
| Rob | Thor, Avengers, Godfather I, Toy Story |
| Jacob | Avengers, Godfather I, Godfather II, Thor |
| Rachel | Godfather I, Minions, Godfather II, Toy Story |
| Thomas | Godfather I, Godfather II, Minions |
| Grant | Thor, Avengers, Minions, Toy Story |
| Pamela | Godfather I, Avengers, Thor, Godfather II |
| Holly | Minions, Toy Story, Godfather I, Godfather II |
3.3 Association Mining based Recommender Systems
Although the temporal pattern is important in some real-world applications, the associations of item consumption are more important than strict precedence relationships. For instance, in household product recommendations, device recommendations, or Youtube video recommender systems, more than the sequence, it is crucial to analyze the set of items consumed together. Consider the table given in Example 1 where some movies, such as Minions and Toy Story, are watched together but not necessarily in a particular order. Out of the six users who have watched the movie Minions, five of them have also watched Toy story either before or after it. The opposite is also true. This could be because, while Minions and Toy Story are not as closely related as Godfather I and II, they are both animated children’s films, and it is likely that if a person enjoys Minions, he or she will enjoy Toy Story as well. We consider the number of profiles that consumed two items (say, and ) together in this work rather than the number of profiles that consumed after . In other words, instead of taking the precedence probability of given (), we take the probability of given () while estimating the relevance score of an item to the target user. Thus, Equation 2 is rewritten as
| (3) |
where and is the number of users having consumed item and together. represents the number of users who have consumed item , which is also equal to . denotes the probability of consuming an item given that an item is already consumed. Items with high scores are subsequently recommended to a user. Conversely, if the score is low, it is implausible that the item would interest the user.
We call this formulation as Association Mining based Recommender System. We now consider an example which illustrates the working of the Association Mining based recommender system.
Example 2.
Take into account the Support statistics below, computed based on thirty users’ profiles. over ten items .
Let be the target user and be set of items consumed by . The items which are not consumed by the the user forms the candidate item set for recommendation i.e., . The score of an item which not consumed by user is then calculated as
Similarly, , , , and . Hence, it ranks the items in the order of , and .
Recommender systems that employ Association Mining focus on discovering associations among items that users have consumed. These systems then utilize support statistics to compute a high relevance score for recommending new items. The major advantage of the current model over a traditional CF approach is its ability to account for the frequent pairwise relations among all users. After identifying a subset of similar users, the traditional CF approach narrows down its search to items consumed by the users within the neighborhood. Consequently, certain consumption patterns of items by the entire user group are excluded due to this restriction. The nicety and novelty of this approach lie in its utilization of pairwise relations between items. The current approach is also different from the association rule mining [21] that derives if-then rules using user transactions. In contrast, the present method estimates the relevance score as the likelihood of consuming a candidate item given a set of commodities consumed by a user.
3.4 Virtual User Approach for GRS
The virtual user approach for GRS creates a virtual profile representing the group preferences and utilizes this profile to build the recommendation set [19]. A virtual user profile is created by computing the weight that indicates the group preferences for each item consumed by at least one group member. We compute the weight of an item for a group as follows:
| (4) |
In our previous work, after determining the group weight for all the group items, we proposed two different ways of creating a virtual user profile: 1)Threshold-based virtual user A virtual user profile is made up of items whose weight exceeds a certain threshold. 2) Weighted virtual user The virtual user profile comprises all the items each group member consumes and their weights. This paper adapts both of these techniques and proposes an hybrid approach that relieves the items with significantly less weight and forms a weighted virtual user profile with the remaining items.
4 Conformal Group Recommender System
The proposed approach combines conformal prediction and group recommender systems to enrich the system-generated plain group recommendations with the associated confidence value. As discussed previously, the nonconformity measures, a pivotal component of the conformal prediction framework, play a critical role in the efficiency of any conformal model and must be devised carefully after inspecting the underlying model. The nonconformity measure, which essentially measures how strange the new object is in comparison to the training set, is then used to derive a confidence value for a new item. We use the pairwise relations between the items to derive the nonconformity measure in the proposed work.
4.1 Nonconformity Measure for CGRS
Let be the virtual user representing the group profile and be the set of weighted items in the virtual user profile. We randomly divide the virtual user profile into and , where is the training set that holds items known to be consumed and contains the candidate set of items that are consumed by the user but are not part of the training dataset. Given a new candidate item , CGRS measures its strangeness with respect to the items in the training set. We define the nonconformity of an item as the relevance score of a candidate item with a profile excluding . We compute the nonconformity value for each item in the extended training set . To compute the nonconformity score of an item , we use the profile . The nonconformity value of , indicated as , concerning the recommendability of an item is defined as follows.
| (5) |
Lemma 1.
Nonconformity of items remains consistent regardless of the permutation of the items, i.e.,
Proof.
The nonconformity computation given in Equation 5 considers the pairwise probability of a recommendable item concerning all the items of in the product term. One can easily see that the result is invariant of the order of the items in . Hence, the nonconformity scores remain unaffected even when the training set is permuted. Hence, it is proved that the proposed nonconformity measure yields consistent results regardless of the permutation of the items. ∎
4.2 Recommendation using - values
The -value of a new item is defined as the proportion of ’s in such that the score is greater than or equal to .
| (6) |
It can also be seen that the disagreement between and for is proportional to the difference between probabilities and . Formally, if and only if .
Lemma 2.
if and only if
Proof.
Similarly,
The only term missing in computation is and similarly, for computation is . The rest of the terms are the same in both and computation. Hence, if and only if . ∎
Hence, comparing the weighted probabilities is better choice than comparing the scores directly to streamline the computation. Thus we redefine given in Equation 6 as follows.
| (7) |
The final -value is then computed by taking an average of -values concerning each candidate item in the set . A higher average -value of an item implies a greater chance of being recommended.
| (8) |
Recommendation set with confidence: We determine -value for each candidate item, and if -value is more than , we include it in the recommendation set; otherwise, we do not.
The proposed conformal group recommender algorithm is outlined in Algorithm 1.
Input:
Output: Recommendation set ()
split into two sets and
for each in do
4.3 Validity and Efficiency
The property of validity ensures that the probability of committing an error will not surpass for the recommendation set . This indicates that the possibility of not recommending user’s interesting item is bounded to , i.e., . Lemma 1 discussed in the previous subsection forms the basis for proving the validity of the proposed approach. The following lemma establishes the fulfillment of the validity property by the proposed CGRS by employing the line of reasoning provided by Vovk et al. [22].
Lemma 3.
Assuming that objects are distributed independently and identically concerning their precedence relations with the training data, the probability of the error that does not belong to will be at most , i.e., .
Proof.
When the -value of a new item to be recommended is less than or equal to , i.e., , we regard that as an error. The -value is lower than when the expression holds. To determine the probability of for all , we consider the case where is among the largest elements of the set . When all objects () are independently and identically distributed with respect to their precedence relations with , all permutations of the set are equiprobable. Thus, the probability that is among the largest elements does not exceed . Consequently, . In the scenario where the -values, i.e., , are uniformly distributed, the mean of these -values, denoted as , will not exceed . Hence, , which represents the probability of error. ∎
Apart from meeting the validity property, possessing an efficient recommendation set is desirable. Within the conformal framework, an efficient set is characterized by narrower intervals and higher confidence levels. We experimentally investigate the efficiency aspects in Section 5 using standard performance metrics.
4.4 Time complexity analysis
In this section, we analyze the time complexity of the proposed approach. The time complexity of creating the virtual user profile is , where is the total number of items, is the group size, and is the number of items in each group member111If each member has consumed a different number of items, in the time complexity expression will be maximum among all the individual profile sizes.. Assuming items in the virtual user profile, items in and k items in , the time complexity of the -value computation for each item is . To make a recommendation set, we need to compute -value for all the candidate items. Hence, the total complexity is
5 Emperical Study
This section reports the empirical assessment of our proposed conformal group recommender system (CGRS). Experiments were carried out on eight benchmark datasets demonstrating that CGRS could achieve higher prediction accuracy than the baseline GRS model [19]. Table 1 presents the details of the experiments used for experiments.
| Dataset | Users | Items | Records |
|---|---|---|---|
| MovieLens 100K | 943 | 1,682 | 100,000 |
| MovieLens-latest-small | 707 | 8,553 | 100,024 |
| MovieLens 1M | 6,040 | 3,952 | 1,000,209 |
| Personality-2018 | 1,820 | 35,196 | 1,028,752 |
| MovieLens 10M | 71,567 | 10,681 | 10,000,054 |
| MovieLens 20M | 138,494 | 26,745 | 20,000,262 |
| MovieLens-latest | 229,061 | 26,780 | 21,063,128 |
| MovieLens 25M | 162,000 | 62,000 | 25,000,096 |
In the preprocessing stage, the items available in a user’s profile are ordered according to their timestamp. We remove the user profiles having fewer than 20 ratings and perform train and test division for each user in a 6:4 ratio. The virtual user profile is constructed using the data available in the training sets. Further, in the case of CGRS, for splitting the virtual user profile into two groups, we fine-tuned with different combinations of sizes and selected 75% of the virtual user profile as and the remaining as the . We analyzed the results in two different kinds of group settings, namely homogeneous and random. In the homogeneous group setting, the candidates for forming a group are chosen in a way such that they jointly share at least some percentage of common items. Given the size of group , we form a homogeneous group if each user has at least percent of common items.
In the random group setting, the candidates for forming a group are chosen randomly from the list of users.
Performance Metrics: To assess the effectiveness of the proposed CGRS approach, we used the following evaluation metrics in our experiments
Precision: Precision represents the proportion of items recommended by a system that are relevant to the user’s interests.
where is the set of all items recommended by the system, and is the set of relevant items that the user used or interacted with.
Recall: Recall measures the proportion of relevant items that were actually recommended out of all the relevant items that exist for the user.
F1-score: The F1-score is defined as the harmonic mean of precision and recall, and ranges from 0 to 1, where a higher score indicates a better performance.
Normalized Discounted Cumulative Gain (NDCG): NDCG is a widely used ranking quality metric that measures a recommendation system’s effectiveness based on the recommended items’ graded relevance. NDCG calculates the ratio of the Discounted Cumulative Gain (DCG) of the recommended order to the Ideal DCG (iDCG) of the order. DCG measures the relevance and position of the recommended items, while iDCG represents the highest possible DCG that can be obtained for a given set of relevant items.
where DCG is calculated as
and iDCG is calculated by sorting the set of relevant items in decreasing order of their relevance scores.
Reverse Reciprocal (RR): RR calculates the reciprocal rank of the first item in the recommendation set that the user actually consumes. The reciprocal rank of a user is defined as the relevance score of the top-most relevant item. The RR score is then calculated by taking the reciprocal of the rank of the first item in the recommendation set. A higher RR score indicates a higher ranking quality of the recommended items.
Average Precision (AP): AP measures the quality of ranked lists. It is calculated as the average of precision values at each point in the ranked list where a relevant item is found. Given N number of items in the recommendation set and m number of items actually consumed by the user, the average precision score is calculated as follows
where P(k) is the precision at top-k items in recommendation set. The value of rel(k) is 1 if the item at kth position in the recommendation set is actually consumed by the user, otherwise 0.
Area Under Curve (AUC): AUC measures the probability that a random relevant item will be ranked higher than a random irrelevant item. The higher value of AUC score implies a better recommendation system. AUC ranges between 0 and 1, with a higher value indicating a better ranking performance of the recommendation system.
5.1 Experimental Results
This section reports the experimental analysis to study the performance of CGRS. The experiments are conducted on standard benchmark datasets mentioned in Table 1. The evaluation is based on traditional metrics such as Precision, Recall, F1-score, NDCG, RR, AP, and AUC. We also analyze the proposed approach by varying the group sizes. All the results reported here are the average of 500 randomly generated instances.
5.1.1 Performance over different datasets
We evaluated the Conformal Group Recommender System (CGRS) against the Group Recommender System (GRS) [7], using
the performance metrics mentioned earlier in this section. GRS [7] serves as the foundation for our proposed CGRS. We conducted experiments using various datasets listed in Table 1, and the results indicate that the conformal approach improves recommendation accuracy and reliability by providing confidence. Although we present the results for a group size of 2, we observed similar outcomes for other group sizes.
Homogeneous Groups: In the first set of experiments, we assessed the effectiveness of our proposed approach in the homogeneous group setting. The performance results for the homogeneous group setting are presented in Table 2.
| AP | RR | AUC | NDCG | |||||
| Dataset | GRS | CGRS | GRS | CGRS | GRS | CGRS | GRS | CGRS |
| ML 100K | 0.20563 | 0.22068 | 0.74760 | 0.74972 | 0.88378 | 0.89307 | 0.56149 | 0.57118 |
| ML-LS | 0.18439 | 0.25334 | 0.75768 | 0.80948 | 0.94065 | 0.95401 | 0.55016 | 0.58754 |
| ML 1M | 0.20712 | 0.21363 | 0.81423 | 0.81464 | 0.88204 | 0.88616 | 0.60240 | 0.60578 |
| ML 10M | 0.21730 | 0.21929 | 0.74704 | 0.74891 | 0.97131 | 0.97307 | 0.55389 | 0.55569 |
| ML 20M | 0.19713 | 0.19925 | 0.70836 | 0.70961 | 0.98494 | 0.98589 | 0.54107 | 0.54267 |
| ML 25M | 0.18300 | 0.18455 | 0.75612 | 0.75612 | 0.99177 | 0.99231 | 0.54850 | 0.54979 |
| ML Latest | 0.19361 | 0.19494 | 0.66250 | 0.66250 | 0.98810 | 0.98850 | 0.52236 | 0.52341 |
| Per-2018 | 0.21536 | 0.27154 | 0.89691 | 0.90925 | 0.96067 | 0.96489 | 0.63456 | 0.65580 |
In Figure 1, we present a comprehensive comparison of precision scores for different datasets, while varying the top-K parameter. The results indicate that our proposed CGRS outperforms the underlying GRS in terms of precision scores. It is noteworthy that we obtained similar results for recall and F1-score as well, which are presented in Figures 2 and 3, respectively. These findings demonstrate that the proposed CGRS can deliver better recommendation accuracy compared to the traditional GRS, and can be particularly useful in applications where precise recommendations are crucial.





















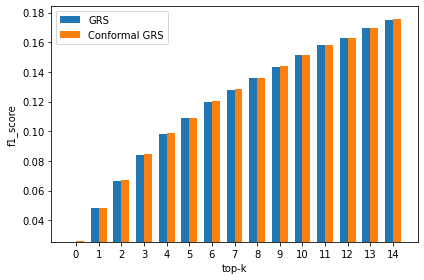


Random Groups: In this experimental section, we focus on the performance results for the random group setting. Table 3 displays the AP, RR, AUC, and NDCG values of the CGRS and GRS. Our findings indicate that the CGRS approach continues to outperform the GRS approach, and we observe a similar trend in the random group setting. Additionally, we have included visual representations of the Precision, Recall, and F1-score metrics for each dataset in the Figures 4, 5, and 6, respectively.
| AP | RR | AUC | NDCG | |||||
| Dataset | GRS | CGRS | GRS | CGRS | GRS | CGRS | GRS | CGRS |
| ML 100K | 0.18899 | 0.20271 | 0.62167 | 0.63175 | 0.87293 | 0.87784 | 0.54847 | 0.55597 |
| ML-LS | 0.12772 | 0.19950 | 0.51417 | 0.57387 | 0.91507 | 0.92548 | 0.50005 | 0.53692 |
| ML 1M | 0.14462 | 0.14849 | 0.52104 | 0.52397 | 0.87487 | 0.87733 | 0.52774 | 0.53016 |
| ML 10M | 0.12972 | 0.20035 | 0.52734 | 0.58781 | 0.91666 | 0.92339 | 0.50428 | 0.54104 |
| ML 20M | 0.14143 | 0.14143 | 0.50034 | 0.50107 | 0.97454 | 0.97538 | 0.50591 | 0.50745 |
| ML 25M | 0.13341 | 0.13665 | 0.52560 | 0.52754 | 0.98546 | 0.98603 | 0.51164 | 0.51330 |
| ML Latest | 0.10681 | 0.10915 | 0.36672 | 0.36697 | 0.98266 | 0.98297 | 0.41387 | 0.41514 |
| Per-2018 | 0.18746 | 0.23878 | 0.77307 | 0.79475 | 0.95812 | 0.96218 | 0.59667 | 0.61593 |
5.1.2 Effect of Varying Group Sizes on Performance of CGRS
This subsection presents the comparative performance analysis of CGRS and GRS for homogeneous and random groups with varying group sizes. The CGRS method consistently outperforms GRS, as shown in the previous section.
Homogeneous Groups: The results in Table 4 show the performance metrics values for the varying group size. We present results specific to the Personality-2018 dataset in the table. Similar outcomes have been observed over the other datasets.
| AP | RR | AUC | NDCG | |||||
| Group size | GRS | CGRS | GRS | CGRS | GRS | CGRS | GRS | CGRS |
| 2 | 0.21536 | 0.27154 | 0.89691 | 0.90925 | 0.96067 | 0.96489 | 0.63456 | 0.65580 |
| 3 | 0.15776 | 0.19241 | 0.90760 | 0.92286 | 0.95538 | 0.95840 | 0.52325 | 0.53786 |
| 4 | 0.10855 | 0.13315 | 0.87872 | 0.88972 | 0.95073 | 0.95301 | 0.43393 | 0.44459 |
| 5 | 0.07871 | 0.09692 | 0.80740 | 0.82353 | 0.94608 | 0.94773 | 0.36742 | 0.37538 |
| 6 | 0.06259 | 0.07651 | 0.78733 | 0.81640 | 0.94102 | 0.94229 | 0.32410 | 0.33045 |
We also provide visual comparisons of the Precision, Recall, and F1-score metrics for different group sizes using Figures 7, 8 and 9, respectively. Our results show that the proposed CGRS method outperforms GRS in terms of precision, recall, and F1-score for homogeneous groups with various group sizes. The improvement is particularly noticeable in the precision metric.















Random groups: In this series of experiments, we investigate the performance of the proposed CGRS compared to the base method for random groups by varying the group sizes. Table 5 shows the results we obtained for the Personality-2018 dataset. Our findings indicate that the CGRS approach continues to outperform the GRS approach, and we observe a similar trend in the random group setting.
| AP | RR | AUC | NDCG | |||||
| Group size | GRS | CGRS | GRS | CGRS | GRS | CGRS | GRS | CGRS |
| 2 | 0.18746 | 0.23878 | 0.77307 | 0.79475 | 0.95811 | 0.96218 | 0.59667 | 0.61593 |
| 3 | 0.14278 | 0.17449 | 0.70996 | 0.73890 | 0.95421 | 0.95736 | 0.51699 | 0.52834 |
| 4 | 0.11274 | 0.13342 | 0.65856 | 0.67120 | 0.94705 | 0.94906 | 0.44609 | 0.4519 |
| 5 | 0.09147 | 0.11074 | 0.63788 | 0.65718 | 0.94661 | 0.94793 | 0.40132 | 0.40617 |
| 6 | 0.07448 | 0.08751 | 0.58739 | 0.59873 | 0.93640 | 0.93714 | 0.35557 | 0.35651 |
Figures 10, 11, and 12 depict a comparison between the Precision, Recall, and F1-score of the proposed CGRS and the base method for random group settings. The results indicate that the proposed CGRS method achieves better precision values compared to the base method for random groups with different group sizes. While CGRS demonstrates better recall and f1-score for random groups of size 2, GRS yields better values for other group sizes. In summary, our findings confirm the proposed CGRS achieves better performance accuracy than its counterparts while making the recommendation more transparent with the added confidence value.
6 Conclusions and Discussion
This paper introduces a conformal framework to the group recommendation scenario for a reliable recommendation. The theoretical facets in the article demonstrate the likelihood that the proposed CGRS makes an error is bounded by the given significance level , and hence the system exhibits a confidence of (). In addition to furnishing a confidence measure of reliability, the proposed method also improves the quality of recommendations. Our experimental analysis of various benchmark datasets corroborates that the proposed CGRS performs better than the baseline GRS approach in terms of different standard performance metrics assessing recommendation quality. Extension of the proposed framework to various group recommendation algorithms is a goal worth pursuing in the future. Further, investigating a conformal framework that efficiently furnishes confidence to the complex group recommender algorithms, such as deep learning-based models, is also an exciting direction for vigorous research.
References
- [1] Francesco Ricci, Lior Rokach, and Bracha Shapira. Introduction to recommender systems handbook. In Recommender systems handbook, pages 1–35. Springer, 2011.
- [2] Michael J Pazzani and Daniel Billsus. Content-based recommendation systems. In The adaptive web: methods and strategies of web personalization, pages 325–341. Springer, 2007.
- [3] Pasquale Lops, Marco De Gemmis, and Giovanni Semeraro. Content-based recommender systems: State of the art and trends. Recommender systems handbook, pages 73–105, 2011.
- [4] Yehuda Koren, Steffen Rendle, and Robert Bell. Advances in collaborative filtering. Recommender systems handbook, pages 91–142, 2021.
- [5] Vikas Kumar, Arun K Pujari, Sandeep Kumar Sahu, Venkateswara Rao Kagita, and Vineet Padmanabhan. Collaborative filtering using multiple binary maximum margin matrix factorizations. Information Sciences, 380:1–11, 2017.
- [6] KH Salman, Arun K Pujari, Vikas Kumar, and Sowmini Devi Veeramachaneni. Combining swarm with gradient search for maximum margin matrix factorization. In PRICAI 2016: Trends in Artificial Intelligence: 14th Pacific Rim International Conference on Artificial Intelligence, Phuket, Thailand, August 22-26, 2016, Proceedings 14, pages 167–179. Springer, 2016.
- [7] Robin Burke. Hybrid recommender systems: Survey and experiments. User modeling and user-adapted interaction, 12:331–370, 2002.
- [8] Svetlin Bostandjiev, John O’Donovan, and Tobias Höllerer. Tasteweights: a visual interactive hybrid recommender system. In Proceedings of the sixth ACM conference on Recommender systems, pages 35–42, 2012.
- [9] Venkateswara Rao Kagita, Arun K Pujari, and Vineet Padmanabhan. Group recommender systems: A virtual user approach based on precedence mining. In AI 2013: Advances in Artificial Intelligence: 26th Australasian Joint Conference, Dunedin, New Zealand, December 1-6, 2013. Proceedings 26, pages 434–440. Springer, 2013.
- [10] Venkateswara Rao Kagita, Vineet Padmanabhan, and Arun K Pujari. Precedence mining in group recommender systems. In Pattern Recognition and Machine Intelligence: 5th International Conference, PReMI 2013, Kolkata, India, December 10-14, 2013. Proceedings 5, pages 701–707. Springer, 2013.
- [11] Venkateswara Rao Kagita, Arun K Pujari, Vineet Padmanabhan, Sandeep Kumar Sahu, and Vikas Kumar. Conformal recommender system. Information Sciences, 405:157–174, 2017.
- [12] Venkateswara Rao Kagita, Arun K Pujari, Vineet Padmanabhan, and Vikas Kumar. Inductive conformal recommender system. Knowledge-Based Systems, 250:109108, 2022.
- [13] Venkateswara Rao Kagita, Arun K Pujari, Vineet Padmanabhan, Sandeep Kumar Sahu, and Vikas Kumar. Conformal recommender system. Information Sciences, 405:157–174, 2017.
- [14] Joseph F McCarthy and Theodore D Anagnost. Musicfx: an arbiter of group preferences for computer supported collaborative workouts. In Proceedings of the 1998 ACM conference on Computer supported cooperative work, pages 363–372, 1998.
- [15] Henry Lieberman, Neil W Van Dyke, and Adrian S Vivacqua. Let’s browse: a collaborative web browsing agent. In Proceedings of the 4th international conference on Intelligent user interfaces, pages 65–68, 1998.
- [16] Mark O’connor, Dan Cosley, Joseph A Konstan, and John Riedl. Polylens: A recommender system for groups of users. In ECSCW 2001, pages 199–218. Springer, 2001.
- [17] Anthony Jameson. More than the sum of its members: challenges for group recommender systems. In Proceedings of the working conference on Advanced visual interfaces, pages 48–54, 2004.
- [18] Inma Garcia, Laura Sebastia, Eva Onaindia, and Cesar Guzman. A group recommender system for tourist activities. In International conference on electronic commerce and web technologies, pages 26–37. Springer, 2009.
- [19] Venkateswara Rao Kagita, Arun K Pujari, and Vineet Padmanabhan. Virtual user approach for group recommender systems using precedence relations. Information Sciences, 294:15–30, 2015.
- [20] Aditya G Parameswaran, Georgia Koutrika, Benjamin Bercovitz, and Hector Garcia-Molina. Recsplorer: recommendation algorithms based on precedence mining. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data, pages 87–98, 2010.
- [21] Yong Soo Kim and Bong-Jin Yum. Recommender system based on click stream data using association rule mining. Expert Systems with Applications, 38(10):13320–13327, 2011.
- [22] Glenn Shafer and Vladimir Vovk. A tutorial on conformal prediction. Journal of Machine Learning Research, 9(3), 2008.