Conditional Randomization Rank Test
Abstract
We propose a new method named the Conditional Randomization Rank Test (CRRT) for testing conditional independence of a response variable and a covariate variable , conditional on the rest of the covariates . The new method generalizes the Conditional Randomization Test (CRT) of [CFJL18] by exploiting the knowledge of the conditional distribution of and is a conditional sampling based method that is easy to implement and interpret. In addition to guaranteeing exact type 1 error control, owing to a more flexible framework, the new method markedly outperforms the CRT in computational efficiency. We establish bounds on the probability of type 1 error in terms of total variation norm and also in terms of observed Kullback–Leibler divergence when the conditional distribution of is misspecified. We validate our theoretical results by extensive simulations and show that our new method has considerable advantages over other existing conditional sampling based methods when we take both power and computational efficiency into consideration.
1 Introduction
We study the problem of testing conditional independence in this paper. To be more specific, let , and be random variables. We consider to test the null hypothesis
| (1) |
i.e., is independent of conditional on the controlling variables . Conditional independence test plays an important role in many statistical problems, like causal inference ([Daw79], [Spi10], [Lec01], [KB07], [Spi10]) and Bayesian networks ([SV95], [CBL98], [Cam06]). For example, consider the case where is a binary variable indicating whether the patient received a treatment, with when the patient received the treatment and otherwise. Let be an outcome associated with the treatment, like the diabetes risk lagged 6 months. Let feature patient’s individual characteristics. Usually, it is of interest to see if or more generally, if the probability distribution of given is the same as that of given so that we can tell whether the treatment is effective.
1.1 Our contributions
In this paper, we propose a versatile and computationally efficient method, called the Conditional Randomization Rank Test (CRRT) to test the null hypothesis (1) . This method generalizes the Conditional Randomization Test (CRT) introduced in [CFJL18]. Like the CRT, the CRRT is built on the conditional version of model-X assumption, which implies that the conditional distribution of is known. Such an assumption is in fact feasible in modern applications. On one hand, it is feasible in practice because usually we have a large amount of unlabeled data (data without ) ([BCS18], [RSC19], [SSC19]), which combined with some domain knowledge, allow us to learn the conditional distribution of quite accurately. On the other hand, as implied in [SP18], domain knowledge is needed to construct non-trivial tests of conditional independence. Since it would be too complicated to know how depends on the covariates when the covariates are high-dimensional, marginal information on the covariates becomes valuable and can be utilized in conditional tests.
Compared with the CRT, we allow the CRRT to be implemented in a more flexible way. It makes the CRRT computationally more efficient than the CRT. It is known that the greatest drawback of the CRT is its restrictive computational burden ([LKJR20]). There are many special forms of the CRT aiming at solving this problem, including the distillation to the CRT (dCRT) in [LKJR20] and the Holdout Randomization Test (HRT) in [TVZ+18]. In addition to having favorable computational efficacy compared to these methods, the CRRT is consistently powerful across a wide range of settings while the HRT suffers from lack of power and the dCRT shows inferior power performance in complicated models. To highlight the advantages of the CRRT, we provide a simple interaction model example here. We consider to test hypothesis (1) when and have a non-ignorable interaction in addition to separate linear effects on . Results are presented in Figure 1. We can see that the CRRT can have comparable power as the CRT and CPT while costing far less computational time; See Section 5 for more details. In addition, we also show that the CRRT is robust to misspecification of the conditional distribution of , both theoretically and empirically.


1.2 Related Work
Conditional tests are ubiquitous in statistical inference. Indeed, many commonly seen statistical problems are essentially conditional independence tests. For example, when we assume a linear model for on covariates :
where and are fixed parameters, and is a random error, it is of interest to test whether , which is equivalent to test (1). If the dimensionality of is relatively small compared with the sample size, we can easily construct a valid test based on classical OLS estimator. In a high-dimensional setting, more conditions on sparsity or design matrix (i.e. on the covariates model when we are considering a random design) or coefficients are needed. For example, see [CL+13], [JM14a], [JM14b], [VdGBR+14], [ZZ14].
To match the complexity in real application, recently many researchers focused more on the assumptions on covariates while allowing flexibility of the response model to the greatest extent. Our method also belongs to this category. Other methods along this line include the CRT ([CFJL18]), the CPT ([BWBS19]), the HRT ([TVZ+18]) and the dCRT ([LKJR20]). These methods can usually control the type 1 error in practice because they totally rely on covariates model (which suffer less from model misspecification) when adequate unlabeled data is accessible. We review the CRT and the CPT for completeness in Section 4. We can naturally relate these model-X methods to semi-supervised learning methods, the key idea of which is also to maximize the use of unlabeled data. There is some recent work developing reliable methods on variable selection solely based on side-information on the covariates; See [BC+15], [GZ18], [BC+19] and the references therein. We discuss connections between the CRRT and these methods in the supplementary material. After finishing our work, we became aware of a concurrent work ([LC21]) where the CRRT was briefly mentioned. Compared with their work, we provide a more in-depth analysis on the CRRT beyond validity.
There are many other nonparametric methods for testing conditional independence which we point out here but we do not intend to compare them with our method in this paper because of some fundamental differences in the framework and assumptions. Roughly speaking, these nonparametric methods can be divided into 4 categories. The first category includes kernel-based methods which require no distributional assumptions ([FGSS08], [ZPJS12], [SZV19]). The Kernel Conditional Independence Test can be viewed as the extension of the Kernel Independence Test ([FGSS08], [GFT+08]). Taking the advantage of the characterization of conditional independence in reproducing kernel Hilbert spaces, one can reduce the original conditional independence test to a low-dimensional test in general. However, kernel-based methods depend on complex asymptotic distributions of the test statistics. Therefore, they have no finite-sample guarantee and show deteriorating performance as the dimension of increases. The second category constructs asymptotically valid tests by measuring the distance between conditional distribution of and ; See, for example, [SW07], [SW14] and [WPH+15]. This approach requires estimating certain point-wise conditional expectations by kernel methods like the Nadaraya-Watson kernel regression. Hence, the number of samples must be extremely large when the dimension of is high. The third category relies on discretization of the conditioning variables, i.e. . They key idea is that holds if and only if holds for all possible . Therefore, if one can discretize the space of , one can test conditional independence on each part and then, can synthesize all test results together ([H+10], [TB10], [DMZS14], [SSS+17], [Run18]). However, it is well-known that discretization of high-dimensional continuous variables is subject to curse of dimensionality and computationally demanding. Note that tests based on within-group permutation also fall in this category because they essentially rely on local independence. The fourth category includes methods testing some weaker null hypothesis ([LG97], [Ber04], [S+09]), where copula estimation would be helpful ([GVO11], [VOG11]).
1.3 Paper Outline
In Section 2, we describe our newly-proposed CRRT in detail and show its effectiveness in controlling finite sample type 1 error. In Section 3, we demonstrate that the CRRT is robust to the misspecification of conditional distribution of . In Section 4, we analyze the connection among several existing methods based on conditional sampling, including the proposed CRRT. In Section 5, we study finite sample performance of the CRRT and show its advantages over other conditional sampling based competitors by extensive simulations. Finally, we conclude our paper by Section 6 with a discussion.
1.4 Notation
The following notation will be used. For a matrix , its th row is denoted by and its th column is denoted by . For any two random variables and , means that they are independent. For two random variables and with i.i.d. copies , if the density of conditional on is , we denote the pdf of conditional on by . When there is no ambiguity, we sometimes suppress the subscript and denote it by .
2 Conditional Randomization Rank Test
Suppose that we have a response variable and predictors . For now, we assume that the conditional distribution of is known and denote the conditional density by throughout this section. Let be an n-dimension i.i.d. realization of , and similarly, let be an dimension matrix with rows i.i.d. drawn from the distribution of . For a given positive integer (usually we can take ), and , let be an n-dimensional vector with elements independently, , where is the th row of . We denote .
Let be any function mapping the enlarged dataset to a -dimension vector. Typically, is a function measuring the importance of to and is a function measuring the importance of to .
Let be the collection of all permutations of . For any , is a matrix with the th column being the th column of , . If is a -dimension vector, is a -dimension vector with the th element being the th element of , . We introduce a property of , which is key to our analysis.
Definition 1.
Let . We say that is -symmetric if for any , .
If is indeed independent with given , we expect that should have similar influence on . Hence, if is a X-symmetric function, should also be stochastically similar.
Proposition 1.
Assume that the null hypothesis is true. If is X-symmetric, then
Further, they are exchangeable. In particular, for any permutation ,
Based on the above exchangeability, a natural choice of p-value for our target test is given by
| (2) |
With this p-value, we will reject at level if . In other words, we will have a strong evidence to believe that Z cannot fully cover X’s influence on Y when is among the largest of . We judge whether to reject based on the rank of . That is why we name the test introduced here Conditional Randomization Rank Test. The following proposition and theorem justifies the use of p-value defined in (2).
Proposition 2.
Assume that is X-symmetric. Denote the ordered statistics of by . When holds, we have
for any pre-defined .
3 Robustness of the CRRT
According to Theorem 1, we know that when the conditional distribution of given is fully known, CRRT can precisely control type 1 error at any desirable level. However, in real applications, this information may not be available. Luckily, however, the following theorems guarantee that the CRRT is robust to moderate misspecification of the conditional distribution. We state two theorems explaining the robustness of the CRRT from two different angles.
Theorem 2.
(Type 1 Error Upper Bound 1.) Assume the true conditional distribution of is . The pseudo variables matrix is generated in the same way described in Section 2 except that the generation is based on a falsely specific or roughly estimated conditional density instead of . The CRRT p-value is defined in (2). Under the null hypothesis , for any given ,
where the total variation distance is defined as .
With the Pinsker’s inequality, we have ([BWBS19]). Combining it with the results in Theorem 2, we know that controlling the Kullback-Leibler divergence is sufficient to guarantee a small deviation from desired type 1 error level.
Example 1.
(Gaussian Model) We now consider that is jointly Gaussian. It implies that there exists and such that conditional on , independently.
Suppose that we know the true variance and can estimate by from a large amount of unlabeled data of size . For example, can be the OLS estimator when is relatively small, or some estimators based on regularization when is of a comparative order as . Without the sparsity assumption, under appropriate conditions, we have ([ZH+08], [BRT+09], [CCD+18]). We may simply assume for convenience. If we additionally assume that uniformly for and , we have
|
|
It implies that if converges to 0 as goes to infinity, the type 1 error control would be asymptotically exact. For other models, the conditions may be more complicated. But in general, with sufficiently large amount of unlabeled data, we are able to make the bias of type 1 error control negligible.
Different from the Theorem 2, the following theorem demonstrate the robustness of CRRT from another angle, where the discrepancy between and will be quantified in the form of observed KL divergence.
Theorem 3.
(Type 1 Error Upper Bound 2.) Assume the true conditional distribution of is . The pseudo variables matrix is generated in the same way described in section 2 except that the generation is based on a falsely specific or roughly estimated conditional density instead of . The CRRT p-value is defined in (2). We define random variables
| (3) |
Denote the ordered statistics of by . For any given , which are independent of and conditional on , and for any given , under the null hypothesis ,
Further, we can obtain the following bound directly controlling type 1 error,
| (4) |
Remark:
-
•
We can see that, when we have the access to the accurate conditional density, i.e. , will be all zero. The last bound for type 1 error in Theorem 4 would be , which is nearly exact when is sufficiently large.
-
•
Though at first glance, it seems that the bound given in (4) may increase with increasing and may even grow to 1 due to the second term on the righthand side, actually we can show that for any small , the bound on the righthand side of (4) can be asymptotically controlled from above, as grows to infinity, by a function , which equals to when . For more details and a generalization of Theorem 4, see the supplement.
- •
Example 2.
(Gaussian Model) We continue to follow the settings and assumptions in Example 1. For , we can simplify as
Denote and for . Besides, denote . Under our assumptions, . We know that , and they are conditionally independent. Now, we assume that converges to as goes to infinity, which is the same as in the Example 1.
First, consider that is bounded, that is, does not go to infinity as goes to infinity. We let , where satisfies that and . Then, according to (4), we have
|
|
The difference between the first term and obviously converges to 0 because converges to . As for the second term, note that
|
|
where . Besides, considering that and is bounded, we can conclude that the second term converges to as . Therefore, we have
as . As for the case of , we relegate it to the supplement.
The above 2 theorems guarantee the robustness of the CRRT. To control the type 1 error at a tolerable level, it is sufficient to control the total variation or the observed KL divergence of and . Then, it is natural to ask a conjugate question. Whether controlling the total variation or the observed KL divergence is necessary? The following 2 theorems give positive answers.
Theorem 4.
(Type 1 Error Lower Bound 1.) Assume the null hypothesis holds. Suppose the true conditional distribution , the proposed conditional density used to sample pseudo variables, and the desired type 1 error level are fixed. Suppose , independently. Suppose that is a continuous variable under both of and . Let such that
For any fixed , when is sufficiently large, we have
where , , and the term decays to 0 exponentially as grows to infinity.
It is easy to see that is bounded from below by . Therefore, the extra error due to misspecification of conditional distribution is at least linear in . It demonstrates that when we apply the CRRT, we need to make sure that we propose a conditional distribution with a small bias. Otherwise, bad choice of -symmetric test function could lead to considerable type 1 error. It is also intuitive that if observed KL divergence is large with high probability, the CRRT would fail to give a good type 1 error control. The following theorem formally demonstrate this point.
Theorem 5.
(Type 1 Error Lower Bound 2.) Assume the null hypothesis holds. Suppose the true conditional distribution , the proposed conditional density used to sample pseudo variables, and the targeted type 1 error level are fixed. Suppose that is a continuous variable under both of and . Denote . Suppose the following inequality holds when , independently,
| (5) |
where and are some nonnegative values, are defined in (3). Then there exists an X-symmetric function and a conditional distribution , such that:
-
1.
If , CRRT has near-exact type 1 error, i.e.,
-
2.
If , independently, we have a lower bound for type 1 error,
Actually, there could be many alternatives way to state the above theorem. We can replace the key condition (5) with a more general form like
where , and then derive a corresponding lower bound for the type 1 error.
4 Connections Among Tests Based on Conditional Sampling
As we have mentioned, model-X methods can effectively use information contained in the (conditional) distribution of covariates and can shift the burden from learning the model of response on covariates to estimating the (conditional) distribution of covariates. They would be a very suitable choice when we have little knowledge about how the response relies on covariates but know more about how the covariates interact with each other. When it comes to the conditional independence testing problem, following the spirit of model-X, there exist several methods based on conditional sampling, including Conditional Randomization Test ([CFJL18]), Conditional Permutation Test ([BWBS19]) and the previously introduced Conditional Randomization Rank Test. For completeness, we also propose Conditional Permutation Rank Test, which will be defined in the current section later soon. In this section, we discuss the connections among them.
To make the structure complete, let us briefly review the CRT and CPT. We still suppose that consists of i.i.d. copies of random variables , where is of dimension , is of dimension and is of dimension . Suppose that we believe the conditional density of is . This conditional distribution is the key to the success of conditional tests. It could be either precisely true or biased. As shown in [BWBS19], as long as has a moderate deviation from the true underlying conditional distribution, say , we are able to control the type 1 error.
Comparing CRRT and CRT
The CRT independently samples pseudo vectors in the same way as the CRRT. For each , is of dimension , with entries independently, . Let be any pre-defined function mapping from to . Here, the requirement of ’pre-defined’ is not strict. only needs to be independent with . Then, the p-values of the CRT is defined as
| (6) |
It is easy to tell that the CRT is essentially a subclass of the CRRT because the CRT requires that the test statistic is same for while the CRRT relaxes such restriction to -symmetry. Compared with the CRT, the CRRT enjoys greater flexibility and therefore can have greater efficiency. We will give some concrete examples to demonstrate this point in our empirical experiments. Here, we show an intuitive toy example. Suppose that we try to use the LASSO estimator as our test statistics for the CRT. Let
where can be given by cross-validation based on or be fixed before analyzing data. For , let . Suppose the dimension of is and the number of pseudo variables . According to Efron, Hastie, Johnstone and Tibshirani (2004), the time complexity of calculating test statistics will be . In contrast, if we apply the CRRT with a similar LASSO statistics, we can see a significant save of time. Let
where can be given by cross-validation based on or be fixed before analyzing data. Then, we can define test statistics
whose calculation would cost time. Hence, the order of time complexity is smaller by a factor of .
In addition to the above LASSO example, there are numerous commonly-seen examples we can use to explain CRRT’s computational advantage. [Lou14] showed that the time complexity of CART is in average case, where is the number of variables and is the number of samples. Suppose and let the number of pseudo variables in both of CRT and CRRT. The total time complexity of CRT is while the complexity of CRRT is . Again, CRRT outperforms CRT by a factor of .
Connecting CRRT with CPT
The CPT proposed by [BWBS19] can be viewed as a robust version of the CRT. It inherits the spirit of traditional permutation tests and adopts a pseudo variable generation scheme different from the CRT. Denote the ordered statistics of by , where . Conditional on and , define a conditional distribution induced by :
where and is the collection of all permutations of . Similarly, we can also define induced by . Let be any function from to . The requirements of is same as those in the CRT. The p-values of the CPT is defined in the same way as the CRT. For the CRT, if specifies the true conditional distribution, under the null hypothesis that , we can see that are i.i.d. conditional on and . Such exchangeability guarantees the control of type 1 error. But for the CPT, we need to take a further step to condition on and to ensure exchangeability. As usual, more conditioning, more robustness and correspondingly, less power. [BWBS19] has some good examples to illustrate these points. The following two propositions, combined with the Theorem 5 in [BWBS19] can give us some clues on the robustness provided by the extra conditioning.
Proposition 3.
Assume the null hypothesis holds. Let , conditional on . And, conditional on and , independently. There exists a statistic such that, for the CPT, the following lower bound holds.
as , for a.e. , , where is the set of ordered statistics of .
Proposition 4.
Let , we have
The Proposition 3 indicates that under the misspecification of conditional distribution, if we somehow unluckily choose bad test statistics and a bad type 1 error level , the deviation of type one error may be comparable to the deviation of conditional distribution. Though we cannot directly compare results in Proposition 3 to those in the Theorem 5 of [BWBS19], the Proposition 4 tells us that if is large, so is , which means that if the type 1 error lower bound for the CPT blows up, so does the one for the CRT. Therefore, we can see that the CPT is more robust to the CRT in some sense.
To bridge the CPT and the CRRT, we need to introduce a test incorporating advantages of both, i.e. the conditional permutation rank test (CPRT). The CPRT generalize the CPT, just like that the CRRT is a generalization of the CRT. The CPRT shares a same pseudo variables generation scheme as the CPT. For any prescribed X-symmetric function
where is only required to be independent with , we define the p-value for the CPRT,
It is easy to know that the CPRT can also control the type 1 error if the conditional distribution of given is correctly specified, which can be formalized as the following proposition. We skip its proof since the proof would be basically same as the one of Theorem 1.
Proposition 5.
Assume that the null hypothesis holds. Suppose that is true. For , ’s are independently generated according to conditional distribution induced by . Assume that is -symmetric. Then, the CPRT can successfully control the type 1 error at any given level :

The relationships among 4 conditional tests discussed here can be summarized by figure 2. Actually, permutation is just one of several ways to enhance robustness at the expense of power loss. For example, we can also generate pseudo variables conditional on and , where is the mean of . In general, more conditioning we put, more robustness we gain. The extreme case is that we generate pseudo variables conditioning on and . As a result, all will be identical with and the power will decrease to 0.
When we try to construct a sampling-based conditional test, how much we need to condition on depends on how much we know about the conditional distribution of given . If we are confident that the proposed conditional distribution has slight bias or even no bias, we can try to be more aggressive and apply the CRRT.
5 Empirical Results
In this section, we evaluate the performance of the CRRT proposed in this paper through comparison with other conditional sampling based methods, including CRT, CPT, dCRT, and HRT on simulated data. We also use concrete simulated examples to demonstrate the robustness of the CRRT.
5.1 Some Preliminary Preparations and Explanations
All methods considered in our simulations are conditional resampling based and thus can theoretically control the type 1 error regardless of the number of samplings we take. We know that though a small number of samplings is theoretically valid, a larger can prevent unnecessary conservativeness. At the same time, we do not want to take an extremely large since it will bring prohibitive computational burdens. After some preliminary analysis shown in the supplement, we decide to set across all simulations.
Note that the dCRT is a 2-step test. The first step is distillation, where we extract and compress information in provided by . After distillation, the second step, which we call testing step, can be executed efficiently with a dataset of low dimension. For more details, see [LKJR20]. In the distillation step, it is optional to keep several important elements of and incorporate them in the testing step. In such way, [LKJR20] shows that we can effectively deal with model with slight interactions. We denote the dCRT keeping elements of by . Actually, the dCRT is a special version of the CRT and still enjoys some flexibility because we can take any appropriate approaches in each of the distillation and testing step. In our simulation, we will explicitly specify what methods we use in each step. For example, when we say we use linear Lasso in the distillation step of , it means that we decide which elements would be kept based on the absolute fitted coefficients resulted from linear Lasso regression of on and use the Lasso regression residues as distillation residues. When we say we use least square linear regression in the testing step, it means that we run a simple linear regression of distillation residues on (or its pseudo copies) and important variables kept from the last step and use the corresponding absolute fitted coefficient of (or its pseudo copies) to construct test statistics. Unless specifying additionally, we use least square linear regression in the testing step by default.
The HRT ([TVZ+18]) is also a 2-step test belonging to the family of the CRT. It splits data into training set and testing set. With the training set, we can fit a model, which can be arbitrary, of on and . Then, we use the testing set to generate conditional samplings and feed all copies to the fitted model to obtain predicted errors. These errors work like the test function . In our simulations, when we say we use logistic Lasso in the HRT, it means that we fit a logistic Lasso with the training set.
One-step test, like CRT, CRRT and CPT, would be more simple. As we can see, the test function is flexible. It would be better to choose suitable ’s in different settings. When we say we use the random forest as our test function, it means that we fit a random forest and obtain the feature importance of (or its pseudo copies) to construct test statistics.
We propose a trick in implementing the CRRT. Suppose that and , then would be a matrix. For some given positive integer , say 4, we separate into 4 folds, as . This step can be deterministic or random. For simplicity, in our simulations, we just let be a submatrix consisting of the th column to the th column of , . Then, we apply a -symmetric test function on each and obtain test statistics for and each pseudo variables. Finally, we can construct a p-value based on these test statistics. We call the CRRT equipped with such trick the with mini-batch size , or the with folds. Though after such extra processing, the procedure is no longer a CRRT, it is not hard to show that can promise type 1 error control. When , the degenerates to the .
5.2 The CRRT Shows a Huge Improvement in Computational Efficiency Over the CRT
In this part, we assess the performance of all conditional sampling based tests we have mentioned in the setting of linear regression, which is frequently encountered in theoretical statistical analysis. In particular, we compare their ability to control type 1 error when the null hypothesis is true, their power when the null hypothesis is false, and their computational efficiency. Generally speaking, the CRRT and the dCRT are among the best because they are simultaneously efficient and powerful in our simulations.
We let , and observations are i.i.d.. We perform 200 Monte-Carlo simulations for each specific setting. For , is an i.i.d. realization of , where is a -dimension random vector following a Gaussian process with autoregressive coefficient 0.5. We let
where , , ’s are i.i.d. standard Gaussian, independent of and . We randomly sample a set of size 20 without replacement from , say . For , let if , and if , where is Bernoulli. We consider various values of , including .


Results: Figures 3b exhibits a huge disadvantage of the CRT and the CPT in terms of the computational efficiency. They spend at least 10 times of time than other tests. It validates our assertion in the Section 4 that the CRRT has a great efficiency improvement over the CRT. We should also note that here we just try some simple methods like Lasso. If the methods we use become more complicated, we expect to see a greater computational efficiency discrepancy.
From Figures 3a, we can see that basically all tests included in our simulations show good type 1 error control, which coincides with the theoretical results. When the null hypothesis is true, the HRT always shows markedly low rejection. Meanwhile, its power is significantly lower than other methods’ when the null hypothesis is false. Though setting the proportion of training set to be can reduce conservativeness, it is still overly conservative in practice. The CRT and the CPT stably show greater power than other methods. However, such advantage is slight when compared with the CRRT and the dCRT.
, and exhibit comparable performances in the sense of test effectiveness and computational efficiency. We should note that does not always own computational advantage over with , which can be observed in the Figure 3b. The can be viewed as a conservative version of the . It is no surprise that the gain less power in the above simulations, compared with the and some ’s because there is no interactive effect and methods we use in the distillation step and the testing step basically suit with the nature of models, which make the important variables kept from the distillation step noisy instead.
5.3 The CRRT Outperforms Other Tests in Complicated Settings
In practice, the model of the response variable on covariates is usually not as simple as what we set in the previous subsection. In this subsection, we consider complicated models and assess the performance of CRRT, dCRT and HRT. As impliied by the figure presented in the introduction, the CRT and the CPT spend far more time than the other methods when models get complicated, we do not include them in this subsection. Results show that only the CRRT can remain efficient and powerful in complicated settings.
We set and observations are i.i.d.. We try 200 Monte-Carlo simulations for each specific setting. For , is an i.i.d. realization of , where is a 101-dimension random vector following a Gaussian process with autoregressive coefficient 0.5. We consider the following response model:
where , , ’s are i.i.d. standard Gaussian, independent of and . To construct , we randomly sample 5 indexes without replacement from , say . For , let if , and otherwise, where is Bernoulli. We consider a range of choices of . When , is a function of and random errors in all 3 models, which implies that the null hypothesis of holds. When , is no longer independent of conditional on . We also consider 2 other models with categorical responses, the results of which are provided in the supplement.


Results: Based on the Figure 4a, we can see that the CRRT’s have dominating power over the dCRT’s and the HRT’s. In particular, the CRRT with batch size 50 (i.e. CRRT_4_rf) has the most power among all tests considered here. Basically all tests can control the observed type 1 error when the effect size is 0. Figure 4b shows that the CRRT’s do not sacrifice much computational efficiency. It is worth mentioning that does not gain more power than , which demonstrate that the strategy of keeping important features after the distillation step could fail to alleviate the problem brought by interactions when the model is complicated.
5.4 The CRRT Is More Robust to Conditional Distribution Misspecification Than the dCRT
We prove in the Section 3 that the CRRT is robust to misspecification of conditional density, i.e. . In this subsection, we demonstrate it with simulations covering 3 sources of misspecification, including the misspecification from non data-dependent estimation, from using unlabeled data and from reusing labeled data. Note that when the misspecification originates from reusing labeled data, currently there is no theoretical results on robustness. We consider the CRRT and the dCRT, which shows relatively good performance in previous experiments.
5.4.1 Misspecification From Non Data-Dependent Estimation
One source of conditional distribution misspecification comes from domain knowledge or some conventions, which does not depend on labeled data or unlabeled data. We consider the following 3 response models. For each specific setting, we run 500 Monte-Carlo simulations.




linear regression: We set , and observations are i.i.d.. For , is an i.i.d. realization of , where is a -dimension random vector. follows a Gaussian process with autoregressive coefficient 0.5 and , where and will be specified shortly. We let
where , ’s are i.i.d. standard Gaussian, independent of and . is constructed as follows. We randomly sample a set of size 20 without replacement from , say S. For , let if , and if , where is Bernoulli.
linear regression: Basically everything is same as the linear regression setting, except that the dimension of is increased from 100 to 400 while the sparsity of remains to be 20.
logistic regression: and are generated in the same way as the previous model, where . We consider a binary model,
where . ’s and are constructed in a same way as the linear regression model.
Suppose that is from a Gaussian AR(1) process with autoregressive coefficient 0.5. The conditional distribution of given must be Gaussian in the form of . For , we let and mentioned above be and respectively. For , we set the conditional distribution of pseudo variable given be . When is exactly 0, the conditional distribution of given would be also and there is no misspecification. As the value of increases, the degree of misspecification increases.
Results: Figures 5(a) and 5(b) display results for the linear regression model. Increasing misspecification of conditional distribution can inflate the type 1 error. Besides, it can be seen that the CRT’s are always more robust than corresponding dCRT’s with same type of test function. In particular, the CRRT’s with linear Lasso as the test function are the least sensitive. Even when , the CRRT_lasso_1 can still control the type 1 error below 0.1 while the dCRT_lasso_12 has a type 1 error reaching 0.25.
When we turn to the Figure 5(c), where results for the linear regression model are shown, we can see that the CRRT’s show a more pronounced advantage in robustness to misspecification over the dCRT’s. The performances of the CRRT’s vary little among different choices of batch size.
From the Figure 5(d), where results for the logistic regression model are shown, we can see that the CRRT’s still behave more robustly than the dCRT’s and successfully control the observed type 1 error under 0.1 as in the previous setting.
In summary, the CRRT is more robust to the current misspecification type than the dCRT across several models. Besides, the CRRT has comparable computational efficiency as the dCRT, which is not shown directly here but can be inferred from previous results since the misspecification has no impact on computation. We should note that, unlike the monotonic trend shown here, the misspecification of conditional distribution may have involved influence on the type 1 error. For more details, see the supplement.
5.4.2 Misspecification From Using Unlabeled Data
Estimating the conditional distribution by using unlabeled data is an effective and popular approach without sacrificing theoretical validity ([CFJL18], [HJ19], [RSC19], [SSC19]). Being able to utilize unlabeled data is also a main reason why model-X methods become more and more attractive. Usually, we propose a parametric family for the target conditional distribution and estimates parameters with unlabeled data. When the proposed parametric family is correct, the estimated conditional distribution would be more closed to the true one as we have unlabeled data of larger size. Of course, we can also consider to use unlabeled data in a nonparametric way with some kernel methods. But here, we only show simulations of parametric estimations.
We still consider same response models as in the previous part, i.e. linear regression, linear regression and logistic regression. Here, we fix and such that follows a Gaussian AR(1) process with autoregressive coefficient 0.5. However, we will not use the exact conditional distribution to generate pseudo variables. Instead, we assume a Gaussian model and get estimators and with unlabeled dataset , where and by using scaled Lasso ([SZ12]). Note that each row of the unlabeled dataset is a realization of . Then, we generate pseudo variables based on the estimated conditional distribution .




Results: The plots in the Figure 6 exhibit en encouraging phenomenon that both of the CRRT and the dCRT can basically control the type 1 error under 0.05 when there is a misspecification from unlabeled data estimation. The CRRT apparently has a more stable performance than the dCRT. The dCRT could be too conservative when , the sample size of unlabeled data is relatively small. Besides, in the logistic regression setting, the dCRT’s have observed type 1 error slightly exceeding the threshold.
5.4.3 Misspecification From Reusing Data
Though losing theoretical guarantee, when we do not have abundant unlabeled data, we can estimate the conditional distribution by reusing data. We consider similar procedures as in the last part except that we estimate on labeled data instead of unlabeled data. In such case, is no longer independent with our data for constructing test statistics and hence theoretical results on robustness proposed before fail to work here.


Results: We consider linear regression model and logistic regression model, with results shown in the Figure 7. It is hard to tell whether the CRRT outperforms the dCRT here. They have similar performance while the dCRT is relatively more aggressive. Good news is that, both of these 2 types of test can basically control the observed type 1 error around the desired level. We can also see that their performances are not dependent on , the sample size of data.
6 Discussions
This paper propose the CRRT, a new method for testing conditional independence, generalizing the CRT proposed in [CFJL18]. It is more flexible, more efficient and comparably powerful with theoretically well grounded type 1 error control and robustness guarantee. We only discuss the case when the response variable is univariate. But, we can trivially extend results presented in this paper to multi-dimensional settings.
Again, conditional independence is not a testable test if the control variable is continuous ([Ber04], [SP18]). Therefore, we need some pre-known information on the covariates model or the response model. The CRRT focuses on the former, like other model-X methods. However, usually knowledge concerning the response model is not completely absent. It would be pragmatically attractive to develop conditional sampling based methods that can incorporate information from both of the covariates model side and the response model side.
Reusing data is a commonly used approach in practice though usually leading to overfitting. It would be interesting to develop theories to theoretically justify the use of the CRRT combined with this approach, in terms of type 1 error control and robustness. Splitting data is a popular option when we have to perform estimation and testing on a same copy of data ([WR09]). However, it is well known that simple splitting can cause tremendous power loss. Some cross-splitting approaches are proposed as remedies ([CCD+18], [BC+19]). It seems promising to combine these approaches with the CRRT.
References and Notes
- [BC+13] Alexandre Belloni, Victor Chernozhukov, et al. Least squares after model selection in high-dimensional sparse models. Bernoulli, 19(2):521–547, 2013.
- [BC+15] Rina Foygel Barber, Emmanuel J Candès, et al. Controlling the false discovery rate via knockoffs. The Annals of Statistics, 43(5):2055–2085, 2015.
- [BC+19] Rina Foygel Barber, Emmanuel J Candès, et al. A knockoff filter for high-dimensional selective inference. The Annals of Statistics, 47(5):2504–2537, 2019.
- [BCS18] Rina Foygel Barber, Emmanuel J Candès, and Richard J Samworth. Robust inference with knockoffs. arXiv preprint arXiv:1801.03896, 2018.
- [Ber04] Wicher Pieter Bergsma. Testing conditional independence for continuous random variables. Eurandom, 2004.
- [BM+58] GEP Box, Mervin E Muller, et al. A note on the generation of random normal deviates. The Annals of Mathematical Statistics, 29(2):610–611, 1958.
- [Bre01] Leo Breiman. Random forests. Machine learning, 45(1):5–32, 2001.
- [BRT+09] Peter J Bickel, Ya’acov Ritov, Alexandre B Tsybakov, et al. Simultaneous analysis of lasso and dantzig selector. The Annals of statistics, 37(4):1705–1732, 2009.
- [BSSC20] Stephen Bates, Matteo Sesia, Chiara Sabatti, and Emmanuel Candes. Causal inference in genetic trio studies. arXiv preprint arXiv:2002.09644, 2020.
- [BWBS19] Thomas B Berrett, Yi Wang, Rina Foygel Barber, and Richard J Samworth. The conditional permutation test for independence while controlling for confounders. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 2019.
- [Cam06] Luis M de Campos. A scoring function for learning bayesian networks based on mutual information and conditional independence tests. Journal of Machine Learning Research, 7(Oct):2149–2187, 2006.
- [CBL98] Jie Cheng, David Bell, and Weiru Liu. Learning bayesian networks from data: An efficient approach based on information theory. On World Wide Web at http://www. cs. ualberta. ca/~ jcheng/bnpc. htm, 1998.
- [CCD+18] Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters, 2018.
- [CFJL18] Emmanuel Candès, Yingying Fan, Lucas Janson, and Jinchi Lv. Panning for gold:‘model-x’knockoffs for high dimensional controlled variable selection. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 80(3):551–577, 2018.
- [CG16] Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016.
- [CL+13] Arindam Chatterjee, Soumendra N Lahiri, et al. Rates of convergence of the adaptive lasso estimators to the oracle distribution and higher order refinements by the bootstrap. The Annals of Statistics, 41(3):1232–1259, 2013.
- [CLL11] Tony Cai, Weidong Liu, and Xi Luo. A constrained l1 minimization approach to sparse precision matrix estimation. Journal of the American Statistical Association, 106(494):594–607, 2011.
- [Daw79] A Philip Dawid. Conditional independence in statistical theory. Journal of the Royal Statistical Society: Series B (Methodological), 41(1):1–15, 1979.
- [DMZS14] Gary Doran, Krikamol Muandet, Kun Zhang, and Bernhard Schölkopf. A permutation-based kernel conditional independence test. In UAI, pages 132–141, 2014.
- [EHJ+04] Bradley Efron, Trevor Hastie, Iain Johnstone, Robert Tibshirani, et al. Least angle regression. The Annals of statistics, 32(2):407–499, 2004.
- [FGSS08] Kenji Fukumizu, Arthur Gretton, Xiaohai Sun, and Bernhard Schölkopf. Kernel measures of conditional dependence. In Advances in neural information processing systems, pages 489–496, 2008.
- [FHT08] Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Sparse inverse covariance estimation with the graphical lasso. Biostatistics, 9(3):432–441, 2008.
- [GFT+08] Arthur Gretton, Kenji Fukumizu, Choon H Teo, Le Song, Bernhard Schölkopf, and Alex J Smola. A kernel statistical test of independence. In Advances in neural information processing systems, pages 585–592, 2008.
- [GHS+05] Arthur Gretton, Ralf Herbrich, Alexander Smola, Olivier Bousquet, and Bernhard Schölkopf. Kernel methods for measuring independence. Journal of Machine Learning Research, 6(Dec):2075–2129, 2005.
- [GVO11] Irène Gijbels, Noël Veraverbeke, and Marel Omelka. Conditional copulas, association measures and their applications. Computational Statistics & Data Analysis, 55(5):1919–1932, 2011.
- [GZ18] Jaime Roquero Gimenez and James Zou. Improving the stability of the knockoff procedure: Multiple simultaneous knockoffs and entropy maximization. arXiv preprint arXiv:1810.11378, 2018.
- [H+10] Tzee-Ming Huang et al. Testing conditional independence using maximal nonlinear conditional correlation. The Annals of Statistics, 38(4):2047–2091, 2010.
- [HJ19] Dongming Huang and Lucas Janson. Relaxing the assumptions of knockoffs by conditioning. arXiv preprint arXiv:1903.02806, 2019.
- [HL10] Radoslav Harman and Vladimír Lacko. On decompositional algorithms for uniform sampling from n-spheres and n-balls. Journal of Multivariate Analysis, 101(10):2297–2304, 2010.
- [JM14a] Adel Javanmard and Andrea Montanari. Confidence intervals and hypothesis testing for high-dimensional regression. The Journal of Machine Learning Research, 15(1):2869–2909, 2014.
- [JM14b] Adel Javanmard and Andrea Montanari. Hypothesis testing in high-dimensional regression under the gaussian random design model: Asymptotic theory. IEEE Transactions on Information Theory, 60(10):6522–6554, 2014.
- [KB07] Markus Kalisch and Peter Bühlmann. Estimating high-dimensional directed acyclic graphs with the pc-algorithm. Journal of Machine Learning Research, 8(Mar):613–636, 2007.
- [LC21] Shuangning Li and Emmanuel J Candès. Deploying the conditional randomization test in high multiplicity problems. arXiv preprint arXiv:2110.02422, 2021.
- [Lec01] Michael Lechner. Identification and estimation of causal effects of multiple treatments under the conditional independence assumption. In Econometric evaluation of labour market policies, pages 43–58. Springer, 2001.
- [LF16] Lihua Lei and William Fithian. Power of ordered hypothesis testing. In International Conference on Machine Learning, pages 2924–2932, 2016.
- [LF18] Lihua Lei and William Fithian. Adapt: an interactive procedure for multiple testing with side information. Journal of the Royal Statistical Society, 2018.
- [LG97] Oliver Linton and Pedro Gozalo. Conditional independence restrictions: testing and estimation. V Cowles Foundation Discussion Paper, 1140, 1997.
- [LKJR20] Molei Liu, Eugene Katsevich, Lucas Janson, and Aaditya Ramdas. Fast and powerful conditional randomization testing via distillation. arXiv preprint arXiv:2006.03980, 2020.
- [Lou14] Gilles Louppe. Understanding random forests: From theory to practice. arXiv preprint arXiv:1407.7502, 2014.
- [LRF17] Lihua Lei, Aaditya Ramdas, and William Fithian. Star: A general interactive framework for fdr control under structural constraints. arXiv preprint arXiv:1710.02776, 2017.
- [M+46] Frederick Mosteller et al. On some useful” inefficient” statistics. The Annals of Mathematical Statistics, 17(4):377–408, 1946.
- [Pea88] Judea Pearl. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann, 1988.
- [RBL+08] Adam J Rothman, Peter J Bickel, Elizaveta Levina, Ji Zhu, et al. Sparse permutation invariant covariance estimation. Electronic Journal of Statistics, 2:494–515, 2008.
- [Ros02] Paul Rosenbaum. Observational studies. Springer, 2 edition, 2002.
- [RSC19] Yaniv Romano, Matteo Sesia, and Emmanuel Candès. Deep knockoffs. Journal of the American Statistical Association, pages 1–12, 2019.
- [Run18] Jakob Runge. Conditional independence testing based on a nearest-neighbor estimator of conditional mutual information. In International Conference on Artificial Intelligence and Statistics, pages 938–947, 2018.
- [RWL+10] Pradeep Ravikumar, Martin J Wainwright, John D Lafferty, et al. High-dimensional ising model selection using -regularized logistic regression. The Annals of Statistics, 38(3):1287–1319, 2010.
- [S+09] Kyungchul Song et al. Testing conditional independence via rosenblatt transforms. The Annals of Statistics, 37(6B):4011–4045, 2009.
- [SGSH00] Peter Spirtes, Clark N Glymour, Richard Scheines, and David Heckerman. Causation, prediction, and search. MIT press, 2000.
- [SKB+20] Matteo Sesia, Eugene Katsevich, Stephen Bates, Emmanuel Candès, and Chiara Sabatti. Multi-resolution localization of causal variants across the genome. Nature communications, 11(1):1–10, 2020.
- [SP18] Rajen D Shah and Jonas Peters. The hardness of conditional independence testing and the generalised covariance measure. arXiv preprint arXiv:1804.07203, 2018.
- [Spi10] Peter Spirtes. Introduction to causal inference. Journal of Machine Learning Research, 11(5), 2010.
- [SSC19] Matteo Sesia, Chiara Sabatti, and Emmanuel J Candès. Gene hunting with hidden markov model knockoffs. Biometrika, 106(1):1–18, 2019.
- [SSS+17] Rajat Sen, Ananda Theertha Suresh, Karthikeyan Shanmugam, Alexandros G Dimakis, and Sanjay Shakkottai. Model-powered conditional independence test. In Advances in neural information processing systems, pages 2951–2961, 2017.
- [SV95] Moninder Singh and Marco Valtorta. Construction of bayesian network structures from data: a brief survey and an efficient algorithm. International journal of approximate reasoning, 12(2):111–131, 1995.
- [SW07] Liangjun Su and Halbert White. A consistent characteristic function-based test for conditional independence. Journal of Econometrics, 141(2):807–834, 2007.
- [SW08] Liangjun Su and Halbert White. A nonparametric hellinger metric test for conditional independence. Econometric Theory, pages 829–864, 2008.
- [SW14] Liangjun Su and Halbert White. Testing conditional independence via empirical likelihood. Journal of Econometrics, 182(1):27–44, 2014.
- [SZ12] Tingni Sun and Cun-Hui Zhang. Scaled sparse linear regression. Biometrika, 99(4):879–898, 2012.
- [SZV19] Eric V Strobl, Kun Zhang, and Shyam Visweswaran. Approximate kernel-based conditional independence tests for fast non-parametric causal discovery. Journal of Causal Inference, 7(1), 2019.
- [TB10] Ioannis Tsamardinos and Giorgos Borboudakis. Permutation testing improves bayesian network learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 322–337. Springer, 2010.
- [TVZ+18] Wesley Tansey, Victor Veitch, Haoran Zhang, Raul Rabadan, and David M Blei. The holdout randomization test: Principled and easy black box feature selection. arXiv preprint arXiv:1811.00645, 2018.
- [VdGBR+14] Sara Van de Geer, Peter Bühlmann, Ya’acov Ritov, Ruben Dezeure, et al. On asymptotically optimal confidence regions and tests for high-dimensional models. The Annals of Statistics, 42(3):1166–1202, 2014.
- [VGS17] Aaron R Voelker, Jan Gosmann, and Terrence C Stewart. Efficiently sampling vectors and coordinates from the n-sphere and n-ball. Technical report, Tech. Rep.) Waterloo, ON: Centre for Theoretical Neuroscience. doi: 10.13140 …, 2017.
- [VOG11] Noël Veraverbeke, Marek Omelka, and Irene Gijbels. Estimation of a conditional copula and association measures. Scandinavian Journal of Statistics, 38(4):766–780, 2011.
- [WPH+15] Xueqin Wang, Wenliang Pan, Wenhao Hu, Yuan Tian, and Heping Zhang. Conditional distance correlation. Journal of the American Statistical Association, 110(512):1726–1734, 2015.
- [WR09] Larry Wasserman and Kathryn Roeder. High dimensional variable selection. Annals of statistics, 37(5A):2178, 2009.
- [YL07] Ming Yuan and Yi Lin. Model selection and estimation in the gaussian graphical model. Biometrika, 94(1):19–35, 2007.
- [ZH+08] Cun-Hui Zhang, Jian Huang, et al. The sparsity and bias of the lasso selection in high-dimensional linear regression. The Annals of Statistics, 36(4):1567–1594, 2008.
- [Zhu05] Xiaojin Jerry Zhu. Semi-supervised learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences, 2005.
- [ZPJS12] Kun Zhang, Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Kernel-based conditional independence test and application in causal discovery. arXiv preprint arXiv:1202.3775, 2012.
- [ZZ14] Cun-Hui Zhang and Stephanie S Zhang. Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society: Series B: Statistical Methodology, pages 217–242, 2014.
Appendix
Appendix A Supplementary Analysis on the Robustness of CRRT
A.1 Continuous Analysis on the Example 2
Here, we assume that . According to the result provided in Theorem 3, for any measurable functions of , , the following inequality holds,
| (7) |
We work with the second term on the righthand side firstly:
| (8) |
where the third step is based on that . Next, we have
| (9) |
where is the empirical CDF of and is the true CDF of . Denote , , where satisfies that and , and set
Under such settings, when . Hence, based on (9), we have
|
|
(10) |
where the last step is based on the Dvoretzky–Kiefer–Wolfowitz inequality. Combining results in (10) and (8), we know that as . Denote . Then, for ,
|
|
(11) |
where the first result is based on the concentration inequality. Under the current settings of ’s, we have
|
|
(12) |
as . We can see that depends only on and therefore ’s are independent of and conditional on . Thus, combining results in (12), (7) and that as , we can conclude that as .
A.2 The Impact of Large , the Number of Conditional Samplings
For convenience, we restate the last bound in the Theorem 4 here:
| (13) |
It appears that is monotonically increasing with . It is true when all are identical and fixed. Such phenomenon is counterintuitive and may make this upper bound meaningless in practice. Luckily, are adjustable and can vary with . We roughly show that for any given small , there exist a function such that
|
|
and
It’s true that the above conclusion cannot demonstrate that the bound in (13) is monotonically decreasing with . But, at least it implies that large won’t have severe negative impact when the conditional distribution is misspecified. We don’t intend to give a thorough and rigorous proof. We just roughly sketch our ideas here. For , let
where and . Denote the ordered statistics of by . We observe that the marginal distributions of do not vary with . Besides, conditional on , are i.i.d. and independent of . Denote the distribution of conditional on by and the distribution of conditional on by . Denote the quantile function associated with and by and respectively. For any fixed positive integer , let , if for some integer , and
where can be any measure of the distance between and such that when and are identical. Then, we have
| (14) |
where the 4th step is based on the asymptotic results of ordered statistics given in Mosteller (1946). For any given ,
as . Hence, under mild conditions, for any given small , there exists , such that and
holds uniformly for . Next, we have
| (15) |
which will be when and are identical as . Results in (14) and (15) combined together can lead to our claim at the beginning.
A.3 A Generalization of Theorem 4
Here, we give a general type 1 error upper bound control result, with the Theorem 4 being its special form.
Theorem 6.
(Type 1 Error Upper Bound 3.) Suppose conditions in the Theorem 4 hold. Let be the unordered set of . Denote . For a given , we denote the ordered statistics of by . For any given measurable functions
and any given , suppose the null hypothesis holds. For conciseness, we denote
Then,
| (16) |
This leads to that,
Since are arbitrary, we can obtain the following bound directly controlling type 1 error,
Proof of Theorem 6.
We use same notations and similar ideas as in the proof of Theorem 4. For any ,
|
|
(17) |
where the last step holds based on (26). Actually, we have,
| (18) |
where the definition of is given in the proof of Theorem 4. Combining results in (17) and (18), we have
| (19) |
For any given , we have
|
|
(20) |
where the third step is based on (19) and the last step is legitimate due to ’s one-to-one property, . Therefore, we have
| (21) |
∎
Appendix B Connections Between CRRT and Knockoffs
The CRRT is deeply influenced by the spirit of knockoffs ([BC+15]; [CFJL18]; [BC+19]) that utilizing information on the covariates sides can help us avoid the uncertainty of the relationship between the response variable and covariates. In this section, we make this connection more concrete. Specifically speaking, we show that there’s a direct comparison between the CRRT and multiple knockoffs ([GZ18]), which is a variant of the original knockoffs. After comparison, we point out that the version of multiple knockoffs given in [GZ18] may be too conservative. We provide a modified version that can own greater power and at the same time, maintain finite sample FDR control at a same level.
Suppose that we have original data , where is a vector, is a matrix, which sometimes is denoted by alternatively. Each row of , a realization of , is independently and identically generated from some distribution . Just be careful that the in this section is different from those in previous sections. For a given positive integer , we generate a -knockoff copy of , denoted by , where is an matrix, for . We call a -knockoff copy of if satisfies the extended exchangeability defined below and .
Definition 2.
If , where is the collection of all permutations of , we define , where , for and . We say that is extended exchangeable, if for any ,
where .
To construct multiple knockoffs selection, we can use any test function satisfying that for any ,
| (24) |
where for . For , denote the ordered statistics of by and define . As like [GZ18], for simplicity, we assume that
Then, for , we can define
In [GZ18], for any given desired FDR level , the selection set is defined as
where . They prove that this multiple knockoffs selection procedure can control the FDR at level .
Now, let’s take a look at a special case of their multiple-knockoff procedure. Assume that , the first element of , is our main target and we want to check whether holds, where . For , let , where are sampled i.i.d. from distribution of , independent of . It’s easy to check that under such construction, is extended exchangeable. For any qualified multiple knockoffs test function satisfying the property stated in (24), we define a function , which is essentially a function of . In fact, is -symmetric if we view it as a test function for testing conditional independence. For any given , the definition of can be simplified as
If , we always have , and hence we’ll select the first covariate if and only if . If , we have and hence we select no variable. If , we select the first variable if and only if .
As comparison, the CRRT based on rejects the null hypothesis and select the first variable if and only if ranks at least th among . Thus, when , decision rules given by the multiple knockoffs and the CRRT are basically identical. To be more specific, when , the CRRT select no vairable. When , is selected. However, there’s a great difference when that the special multiple knockoffs procedure rejects only if is the largest one while the CRRT rejects when ranks high enough. When gets larger, the above special multiple knockoffs procedure exhibits greater conservativeness, which is unnecessary. Though such comparison is unfair because the multiple knockoffs doesn’t specialize in conditional independence testing, it still gives us some hint to improve the multiple knockoffs. Trying to eliminate such redundant conservativeness, we provide a modified definition of the threshold:
|
|
(25) |
where , , and further we let the selected set be . This modified multiple knockoffs procedure roughly matches the CRRT in single variable testing problem. Since , the modified selection procedure selects if and only if , which is close to when is small. We conjecture that this modified version would be more powerful in general model selection problem. But we don’t pursue to show it here because we want to focus on the conditional testing problem. In fact, the modified multiple knockoffs procedure can also control finite sample FDR like the original procedure.
Proposition 6.
From the proof of the above proposition, we can see that actually in (25), we can replace with some other conditions based on ordered statistics while remaining the FDR control, which means that we can generalize the multiple knockoffs framework to make it more flexible. We didn’t study this generalization in this paper. There could be some alternative conditions enjoying optimal properties in some sense.
Appendix C Proofs
Proof of Proposition 1.
We first to show that, for any
Under the null hypothesis , are i.i.d.. Therefore, we have . Further, we have . Thus,
which is our desired result. This result directly implies that
∎
Proof of Proposition 2.
According to Proposition 1, for any ,
Since the ordered statistics of is also , we have
It implies that
where is the -th element of , . Because is arbitrary, we know that conditional on , is uniformly distributed on
Based on such symmetry, we can easily know that
for any given . ∎
Proof of Theorem 2.
Let be a n-dimension vector with elements independently, , independent of and of .
Recall that , which is a function of . Define . For given and , define
Then,
Since is sampled based on , are i.i.d. conditional on and . According to Theorem 1, .
As for the second part, for given , we define . Then,
Combining the results above, we have
Taking expectation with respect to and on both sides completes the proof. ∎
Proof of Theorem 4.
In the following proof, sometimes we use to denote alternatively. When we say ranks th, we mean that is the th largest value among . Recall that
Based on the above definition, we know that is roughly equivalent to that is among the largest of . When all ’s are distinct, such equivalence is exact. When there are some ’s, tied with , our rule in fact assigns a lower rank (smaller the value, lower the rank) and hence tends to be conservative. And we can see that whether there are repeated values among doesn’t affect ’s rank. Thus, without loss of generality, we may assume that all ’s are distinct with probability 1, conditional on and . That is,
Denote the unordered set of by . According to our assumption, with probability 1, conditional on and , are distinct with probability 1 (no typo here). We have the following claim.
Claim 1 With probability 1, there exists a one-to-one map , such that ranks th if and only if , . Such map depends on the unordered set and the test function , and . The proof of this claim is given immediately after the current proof.
Given , according to Claim 1, without loss of generality, we assume that ranks th if and only if , for . We are going to show that for any and ,
| (26) |
Actually, based on our assumption, we have
To prove (26), it suffices to show that for any . We have the following observation,
| (27) |
It’s obvious that there’s a one-to-one map from to such that if , for some , then , for . If ,
where . Given the above results and that is one-to-one, we have
|
|
which, combined with (27), results in
And this implies (26) is validate. Denote , for . Denote the ordered statistics of by . For a given , we denote the ordered statistics of by . Next, for any ,
|
|
(28) |
where the 3rd step is valid because we previously assume that ranks th if and only if , the second to the last step is valid due to the fact that is a function of , the last step holds based on (26). For any given s, it’s obvious that there’s a one-to-one map from to such that , . Then, we can resume our previous derivation,
Plugging it back to (28), we have
With the above results, for any given , we have
|
|
where the last step is true due to ’s one-to-one property, . Based on this result, we have
By taking expectations on both sides, the above result immediately gives us the desired conclusions stated in Theorem 4.
Proof of Claim 1 First, we show that with probability 1, for fixed and , for any , there exists , such that sufficiently lead to that ranks th. We only need to focus on such that for any , . Such event happens with probability 1 based on our assumption mentioned at the beginning of the proof. Let permutation satisfy that when , ranks th. (Such permutation does exist. Suppose that when , ranks th, and ranks th. We just need to let and . Based on ’s X-symmetry, now ranks th.)
For any such that , there exists a such that
Then,
Since permutation doesn’t change the 1st element, we have
which implies that still ranks th among as . Hence, due to the arbitrariness of , is a sufficient condition that ranks th.
Next, we show that for any permutations , if , the rank of , denoted by , is different from the rank of , denoted by . Suppose on the contrary that, . There exists , such that . Let satisfying that , , and , . Then, based on what’ve just shown, the rank of , denoted by , equals . Because, , now we have , which is impossible, since if we switch and , we also switch the rank of and . Combining 2 parts shown above, we can conclude that Claim 1 is true. ∎
Proof of Theorem 4.
For brevity, we denote by . According to the definition of , there exists a set such that
and
Denote by . Let’s first to consider the case when . Let such that , and
Such exists a.s. due to the assumption that is conditionally continuous under conditional distribution and a.s.. Then, it’s not hard to know that
Because and independently, we have
For , let , and . Define as in (2). Then, denoting , as goes to infinity, we have
where we use the conditional independence of in the 3rd step, we apply the Bennett’s inequality in the 5th step and require to be sufficiently large such that .
In the case when , we proceed in a similar way. Let such that , and
Then, we have
For , let , and . Similarly, we can show that
We want to point out that though the definitions of in the above two situations are different, they depend only on and . We can summarize a compact definition of as follows,
For , let , , and defined as in (2). It’s easy to check that is -symmetric. Combining the above results together, we have
Note that the definition of doesn’t depend on . If we allow to depend on , we can replace with some other functions of like and can have a tighter asymptotic bound. ∎
Proof of Theorem 5.
In the following proof, sometimes we use to denote alternatively. When we say ranks th, we mean that is the th largest value among . Since the main condition is a function of , it’s natural to consider
It’s easy to see that is -symmetric. As before, we denote the unordered set of by . Based on the assumption that is a continuous variable under both of and , are distinct with probability 1.
We’ll frequently use equation (26). Therefore, we restate it here. For any and ,
| (29) |
In the first setting, that is, when , since are distinct with probability 1, events are of equal probability. Therefore,
Next, we show that if , independently, we can promise a nontrivial lower bound for the type 1 error. Denote the ordered statistics of , by . We start from our probability condition,
| (30) |
where and the last step is based on (29). Next,
based on which, we further have
| (31) |
Actually, we can see that
Based on this result, we can proceed (31) as
where the last step holds based on (30).
∎
Proof of Proposition 4.
For given and , let be the set satisfying that
|
|
Let . Denote . Denote . Then we have
|
|
where the last step is valid because
and similar result holds for . ∎
Proof of Proposition 6.
Since tied values can only make the given modified multiple knockoffs procedure more conservative, for simplicity, we assume that for , . Then, we can make a claim similar to the Lemma 3.2 in Gemenez and Zou (2018):
Claim 2: The ranks corresponding to null variables, , are i.i.d. uniformly on the set , and are independent of the other ranks , and of .
We skip the proof of this claim because we can show it in an almost same way as in the Lemma 3.2 of Gemenez and Zou (2018). Recall that
Similar to Barber and Candès (2015) and Gemenez and Zou (2018), we construct one-bit p-values for :
Based on the Claim 2, for , we have
which implies that . Since for , is a function of , based on the Claim 2, all ’s corresponding to null variables are mutually independent and are independent from the nonnulls, conditional on .
Before defining a Selective SeqStep+ sequential test, we adjust the order of variables. Because all of our arguments are conditional on , it’s legitimate to rearrange the order of based on some functions of . In particular, we can adjust the order of variables based on . Hence, we can directly assume that
Next, we define a Selective SeqStep+ threshold
and . Noting that , we can assert that
by applying the Theorem 3 in Barber and Candès (2015). Our last job is to show that is identical with . We have
from which we can tell . Hence,
Thus,
which concludes the proof. ∎
Appendix D Supplementary Simulations
D.1 Impact of the Number of Conditional Samplings
In this part, we inspect the impact of , the number of conditional samplings on the performance of the CRT and the dCRT, which are 2 main competitors of our method, in several different model settings. Based on the Theorem 1, we know that the choice of doesn’t affect the validity of type 1 error control of the CRRT. Actually, this conclusion also applies to other conditional sampling based methods considered in this paper, like CRT and dCRT. As mentioned in the first remark of the Theorem 4, larger leads to less conservative tests. We demonstrate by the following simulations that is sufficiently large for the CRT and the dCRT in the sense that the amount of removable conservativeness is negligible. Based on results in this subsection, we fix in further simulations for all conditional sampling based methods.
D.1.1 Impact of the Number of Conditional Samplings on the Performance of Distillation-Based Tests
Here, we assess the impact of on the performance of distillation-based tests (Liu, Katsevich, Janson and Ramdas, 2020), including , and . We consider 3 settings, including linear regression, linear regression and logistic regression. For each specific setting, we run 100 Monte-Carlo simulations.
linear regression: We set , and observations are i.i.d.. For , is an i.i.d. realization of , where is a -dimension random vector following a Gaussian process with autoregressive coefficient 0.5. We let
where , , ’s are i.i.d. standard Gaussian, independent of and . For simplicity, we fix by letting and elsewhere. We consider various values of , including . We use linear Lasso in the distillation step, with regularized parameter tuned by cross-validation, and use linear least square regression in the testing step.
linear regression: Basically all things are same as those in the previous setting except that the dimension of is 500 instead of 100.
logistic regression: Models for covariates are same as those in the first setting while the model for response variable is different. We let
where , , ’s are i.i.d. standard Gaussian, independent of and . We use logistic Lasso in the distillation step, with regularized parameter tuned by cross-validation, and use linear least square regression in the testing step.









Results: From Figure 8, 9 and 10, we can observe that each of the 3 distillation-based tests considered here show similar performance under different choices of varying from 100 to 50000. In most cases, leads to desirable observed type 1 error, which is less than 0.05, while sometimes brings type 1 error exceeding the threshold. There’s no obvious evidence showing that we can gain much greater power by increasing from 200 to 50000. Hence, we decide to take in subsequent analysis.
D.1.2 Impact of the Number of Conditional Samplings on the Performance of the CRT
We also assess the impact of on the performance of the CRT with same simulation settings as those for distillation-based tests. Unlike distillation-based tests, the original CRT introduced in Candès, Fan, Janson and Lv (2018) is not a two-stage test. In the 2 linear regression settings, we evaluate the importance of variables (i.e. test statistics) by linear Lasso fitted coefficients. In the logistic regression settings, we obtain the variables importance by logistic Lasso fitted coefficients. Due to the limitation of computation, we are not able to simulate the CRT with extremely large . For each specific setting, we run 100 Monte-Carlo simulations.



Results: From Figure 11, we can see that there’s no significant difference in performance among 3 choices of in 3 considered settings. In particular, no matter what’s the value of , the CRT always shows observed type 1 error control under the null hypothesis of conditional independence, which is encouraging. Of course, as mentioned in Candès, Fan, Janson and Lv (2018), there could be some settings in which we need an extremely large to guarantee that the CRT has good observed type 1 error control in practice. Besides, the CRT under larger doesn’t show obvious advantage in power. Therefore, out of simultaneous consideration of theoretical power and computational burden, we set for further simulations.
D.2 More Complicated Models
In the main content, we consider the case of continuous response variable. Here, we provide further investigations in cases of categorical response variable.
Recall that and the number of Monte-Carlo simulations is 200 for each specific setting. For , is an i.i.d. realization of , where is a 101-dimension random vector following a Gaussian process with autoregressive coefficient 0.5. We consider the following categorical response model with different forms of interactions:
|
|
where , , ’s are i.i.d. standard Gaussian, independent of and . To construct , we randomly sample a set of size 5 without replacement from , say . For , let if , and if , where is Bernoulli. and are also constructed in the same way independently. We consider various values of for different models. The difference between the 3rd and the 2nd model is that, in the 3rd one, covariates entangle with each other in a more involved way.




Results: Results under the Interaction Model 2 and 3 are provided in Figure 12 and 13, where the response variable is categorical. Because results under these 2 models are similar, we analyze them together. The CRRT’s and the dCRT_12_rf are among the most powerful tests. However, the dCRT_12_rf is in average at least 4 times slower than the CRRT_4_rf, which is consistently the most powerful test. Again, increasing the number of important variables kept from the distillation step doesn’t help to improve power while costing more computations. Taking both power and efficiency into consideration, the CRRT with batch size 50 is obviously the best one.
D.3 Supplementary Results to the Subsection 5.4
It’s well comprehensible that misspecification of the conditional distribution of can not only inflate type 1 error like what we’ve shown in the Subsection 5.4, but can sometimes drive it downwards. This could happen and we can easily construct simple intuitive example as follows. Suppose that , where both and are scalars and . Let , independent of and while for . As long as , pseudo variables are more related with than and most methods would tend to believe that pseudo variables are more conditionally important, which brings the type 1 error downwards. Here, we give more examples under non data-dependent misspecification to show the mixed influence of conditional distribution misspecification. We consider the following 4 models.
linear regression: We set , and observations are i.i.d.. For , is an i.i.d. realization of , where is a -dimension random vector. follows a Gaussian process with autoregressive coefficient 0.5 and , where the definition of and will be given shortly. We let
where , ’s are i.i.d. standard Gaussian, independent of and . is constructed as follows. We randomly sample a set of size 20 without replacement from , say S. For , let if , and if , where is Bernoulli.
cubic regression: and are generated in the same way as the previous model. Instead of assuming a linear model, we let
where . ’s and are constructed in a same way as the previous model.
linear regression: We set , and observations are i.i.d.. For , is an i.i.d. realization of , where is a -dimension random vector. follows a Gaussian process with autoregressive coefficient 0.5 and . We let
where , ’s are i.i.d. standard Gaussian, independent of and . is constructed as follows. We randomly sample a set of size 20 without replacement from , say S. For , let if , and if , where is Bernoulli.
logistic regression: and are generated in the same way as the previous model, where . We consider a binary model,
where . ’s and are constructed in a same way as the linear regression model.













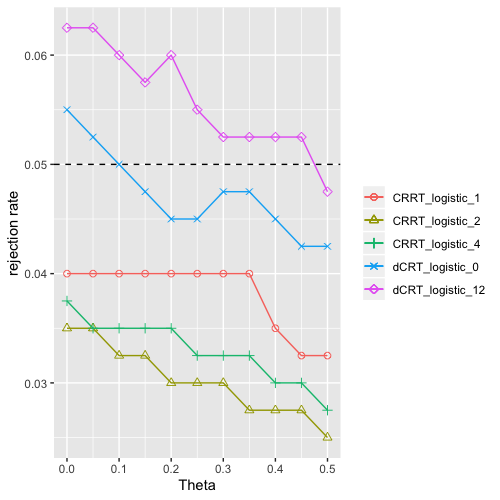
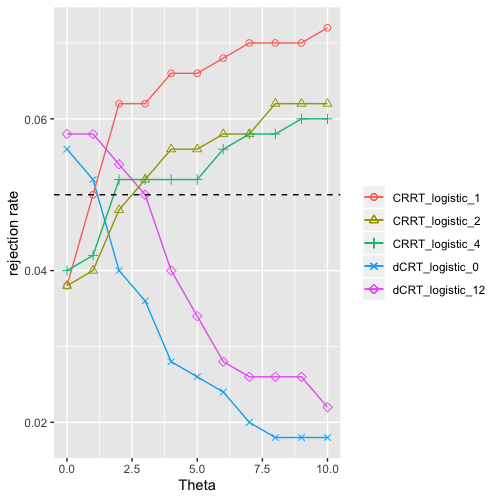
For each pseudo variable , we let its conditional distribution such that follows a Gaussian process with autoregressive coefficient 0.5. This is also the we’ve mentioned above. We consider 3 types of non data-dependent conditional distribution misspecification by assigning different from , which are same as the Berrett, Wang, Barber and Samworth (2019):
-
•
Quadratic: ,
-
•
Cubic: ,
-
•
Tanh: ,
where can reflect the degree of misspecification.
Results: Results for the linear regression model are given in Figures 14 and 15. When we adopt OLS-based CRT’s or dCRT’s, we get more and more conservative results in general as deviates more from . Lasso-based dCRT’s also show similar behaviors while Lasso-based CRT’s have increasing type 1 error as misspecification is enlarged.
Results for the cubic regression model are given in Figure 16. We can see quite different phenomenon in different misspecification settings. When the misspecification is quadratic, the impact of misspecification seems to be non-monotonic. When the misspecification is cubic, dCRT_lasso_12 gets more conservative while other tests show opposite behaviors as increases. When the misspecification is tanh, the dCRT’s get more conservative while the CRRT’s get more aggressive as increases.
Results for the linear regression model are given in Figure 17. No matter under which type of misspecification, the dCRT’s always grow conservative as increases. The CRT’s have slight increase in type 1 error as increases under quadratic and cubic misspecification and exhibit a relatively more obvious increase under the tanh misspecification.
Results for the logistic regression model are given in Figure 18. Still, the dCRT’s become more conservative as increases. The CRT’s remain stable under the quadratic misspecification, have decreasing type 1 error under the cubic misspecification and have increasing type 1 error under the tanh misspecification.
To sum up, what we can see here is totally different from what’s been shown in the Subsection 5.4, where both of the CRT and the dCRT have monotonically increasing rejection rate as the degree of misspecification increases. Results demonstrate that how misspecification of conditional distribution would affect the type 1 error is quiet complicated and unpredictable. It depends on the joint model, the test we use and the type of misspecification.