Complex matrix inversion via real matrix inversions
Abstract.
We study the inversion analog of the well-known Gauss algorithm for multiplying complex matrices. A simple version is when is invertible, which may be traced back to Frobenius but has received scant attention. We prove that it is optimal, requiring fewest matrix multiplications and inversions over the base field, and we extend it in three ways: (i) to any invertible without requiring or be invertible; (ii) to any iterated quadratic extension fields, with over a special case; (iii) to Hermitian positive definite matrices by exploiting symmetric positive definiteness of and . We call all such algorithms Frobenius inversions, which we will see do not follow from Sherman–Morrison–Woodbury type identities and cannot be extended to Moore–Penrose pseudoinverse. We show that a complex matrix with well-conditioned real and imaginary parts can be arbitrarily ill-conditioned, a situation tailor-made for Frobenius inversion. We prove that Frobenius inversion for complex matrices is faster than standard inversion by LU decomposition and Frobenius inversion for Hermitian positive definite matrices is faster than standard inversion by Cholesky decomposition. We provide extensive numerical experiments, applying Frobenius inversion to solve linear systems, evaluate matrix sign function, solve Sylvester equation, and compute polar decomposition, showing that Frobenius inversion can be more efficient than LU/Cholesky decomposition with negligible loss in accuracy. A side result is a generalization of Gauss multiplication to iterated quadratic extensions, which we show is intimately related to the Karatsuba algorithm for fast integer multiplication and multidimensional fast Fourier transform.
1. Introduction
The article is a sequel to our recent work in [14], where we studied the celebrated Gauss multiplication algorithm for multiplying a pair of complex matrices with just three real matrix multiplications. Such methods for performing a complex matrix operation in terms of real matrix operations can be very useful as floating point standards such as the IEEE-754 [1] often do not implement complex arithmetic natively but rely on software to reduce complex arithmetic to real arithmetic [55, p. 55]. Here we will analyze and extend an inversion analogue of Gauss algorithm: Given a complex invertible matrix with , it is straightforward to verify that its inverse is given by
| (1) |
if is invertible, a formula that can be traced back to Georg Frobenius [67]. In our article we will refer to all such algorithms and their variants and extensions as Frobenius inversions. While Gauss multiplication has been thoroughly studied (two representative references are [41, Section 4.6.4] in Computer Science and [32, Section 23.2.4] in Numerical Analysis, with numerous additional references therein), the same cannot be said of Frobenius inversion — we combed through the research literature and found only six references, all from the 1970s or earlier, which we will review in Section 1.3.
Our goal is to vastly extend and thoroughly analyze Frobenius inversion from a modern perspective. We will extend it to the general case where only is invertible but neither nor is (Section 4.2), and to the important special case where is Hermitian positive definite, in a way that exploits the symmetric positive definiteness of and (Section 4.3). We will show (Section 3) that it is easy to find complex matrices with
| (2) |
where the gap between the left- and right-hand side is arbitrarily large, i.e., can be arbitrarily ill-conditioned even when are all well-conditioned — a scenario bespoke for (1).
Frobenius inversion obviously extends to any quadratic fields of the form , i.e., is irreducible over , but we will further extend it to any arbitrary quadratic field, and any iterated quadratic extensions including constructible numbers, multiquadratics, and towers of root extensions (Section 2.4). In fact we show that for iterated quadratic extensions, Frobenius inversion essentially gives the multidimensional fast Fourier transform. We will prove that over any quadratic field Frobenius inversion is optimal in that it requires the least number of matrix multiplications and inversions over its base field (Sections 2.3, 4.3, and 4.2).
For complex matrix inversion, we show that Matlab’s built-in inversion algorithm, i.e., directly inverting a matrix with LU or Cholesky decomposition in complex arithmetic, is slower than applying Frobenius inversion with LU or Cholesky decomposition in real arithmetic (Theorem 4.1, Propositions 4.2 and 4.6). More importantly, we provide a series of numerical experiments in Section 5 to show that Frobenius inversion is indeed faster than Matlab’s built-in inversion algorithm in almost every situation and, despite well-known exhortations to avoid matrix inversion, suffers from no significant loss in accuracy. In fact methods based on Frobenius inversion may be more accurate than standard methods in certain scenarios (Section 5.2).
1.1. Why not invert matrices
Matrix inversion is frown upon in numerical linear algebra, likely an important cause for the lack of interest in algorithms like Frobenius inversion. The usual reason for eschewing inversion [34] is that in solving an nonsingular system , if we compute a solution by inverting through LU factorization and multiplying to , and if we compute a solution directly through the LU factors with backward substitutions , , the latter approach is both faster, with flops for versus for , and more accurate, with backward errors
| (3) |
Here denotes unit roundoff and where and applies componentwise. As noted in [34], usually and so is likely more accurate than when .
Another common rationale for avoiding inversion is the old wisdom that many tasks that appear to require inversion actually do not — an explicit inverse matrix is almost never required because upon careful examination, one would invariably realize that the same objective could be accomplished with a vector like or or a scalar like , , or . These vectors and scalars could be computed with a matrix factorization or approximated to arbitrary accuracy with iterative methods [28], which are often more amenable to updating/downdating [27] or better suited for preserving structures like sparsity.
Caveat
We emphasize that Frobenius inversion, when applied to solve a system of complex linear equations , will not involve actually computing an explicit inverse matrix and then multiplying it to the vector . In other words, we do not use the expression in (1) literally but only apply it in conjunction with various LU decompositions and back substitutions over ; the matrix is never explicitly formed. The details are given in Section 3 alongside discussions of circumstances like (2) where the use of Frobenius inversion gives more accurate results than standard methods, with numerical evidence in Section 5.2.
1.2. Why invert matrices
We do not dispute the reasons in Section 1.1 but numerical linear algebra is a field that benefits from a wide variety of different methods for the same task, each suitable for a different regime. There is no single method that is universally best in every instance. Even the normal equation, frown upon in numerical linear algebra like matrix inversion, can be the ideal method for certain least squares problems.
In fact, if we examine the advantages of computing over in Section 1.1 more closely, we will find that the conclusion is not so clear cut. Firstly, the comparison in (3) assumes that accuracy is quantified by backward error but in reality it is the forward error that is far more important and investigations in [15, 16], both analytical and experimental, show that the forward errors of and are similar. Secondly, if instead of solving a single linear system , we have right-hand sides , then it becomes where and we seek a solution . In this case the speed advantage of computing over disappears when : Note that the earlier flop count for ignores the cost of two backsubstitutions but when there are backsubstitutions, these may no longer be ignored and are in fact dominant, making the cost of computing and comparable. In [15], it is shown that because of data structure complications, computing can be significantly faster than .
Moreover, the old wisdom that one may avoid computing explicit inverse matrices, while largely true, is not always true. There are situations, some of them alluded to in [34, p. 260], where computing an explicit inverse matrix is inevitable or favorable:
- Mimo radios:
-
In such radios, explicit inverse matrices are implemented in hardware [16, 19, 66]. It is straightforward to hardwire or hardcode an explicit inverse matrix but considerably more difficult to do so in the form of “LU factors with permutations and backsubstitutions,” which can require more gates or code space and is more prone to implementation errors.
- Superconductivity:
-
In the so-called KKR CPA algorithm [30], one needs to integrate the KKR inverse matrix over the first Brillouin zone, necessitating an explicit inverse matrix.
- Linear modeling:
-
The inverse of a matrix often reveals important statistical properties that could only be discerned when one has access to the full explicit inverse [47, 48], i.e., we do not know which entries of matter until we see all of them. For a specific example, take the ubiquitous model with design matrix and observed values of the dependent variable [48], we understand the regression coefficients through the values its covariance matrix where is the variance of the dependent variable [48]. To see which values are large (positively correlated), small (negatively correlated), or nearly zero (uncorrelated) in relation to other values, we need access to all values of .
- Statistics:
-
For an unbiased estimator of a parameter , its Cramer–Rao lower bound is the inverse of its Fisher information matrix . This is an important quantity that gives a lower bound for the covariance matrix [13, 58] in the sense of where is the Loewner order. In some Gaussian processes, this lower bound could be attained [40]. We need the explicit matrix inverse to understand the limits of certain statistical problems and to design optimal estimators that attain the Cramer–Rao lower bound.
- Graph theory:
- Symbolic computing:
-
Matrix inversions do not just arise in numerical computing with floating point operations. They are routinely performed in finite field arithmetic over a base field of the form in cryptography [36, 65], combinatorics [42], information theory [2], and finite field matrix computations [10]. They are also carried out in rational arithmetic over transcendental fields [20, 21, 26], e.g., with a base field of the form and an extension field of the form , or with finite fields in place of and . With such exact arithmetic, the considerations in Section 1.1 become irrelevant.
In summary, the Frobenius inversion algorithms in this article are useful (i) for problems with well-conditioned , , and but ill-conditioned ; (ii) in situations requiring an explicit inverse matrix; (iii) to applications involving exact finite field or rational arithmetic.
1.3. Previous works
We review existing works that mentioned the inversion formula (1) in the research literature: [22, 23, 62, 64, 67, 70] — we note that this is an exhaustive list, and all predate 1979. We also widened our search to books and the education literature, and found [17, 46] in engineering education publications, [7, pp. 218–219], [32, Exercise 14.8], and [43, Chapter II, Section 20], although they contain no new material.
The algorithm, according to [67], was first discovered by Frobenius and Schur although we are unable to find a published record in their Collected Works [25, 61]. Since “Schur inversion” is already used to mean something unconnected to complex matrices, and calling (1) “Frobenius–Schur inversion” might lead to unintended confusion with Schur inversion, it seems befitting to name (1) after Frobenius alone.
The discussions in [22, 62, 70] are all about deriving Frobenius inversion. From a modern perspective, the key to these derivations is an embedding of into as a subalgebra via
and noting that if is invertible, then corresponds to , given by the standard expression
where denotes the Schur complement of in . The two right blocks of then yield the expression
which is (1). The works in [43, 64] go further in addressing the case when both and are singular [43] and the case when , , or are all singular [64]. However, they require the inversion of a real matrix, wiping out any computational savings that Frobenius inversion affords. The works [23, 70] avoided this pitfall but still compromised the computational savings of Frobenius inversion. Our method in Section 4.2 will cover these cases and more, all while preserving the computational complexity of Frobenius inversion.
1.4. Notations and conventions
Fields are denoted in blackboard bold fonts. We write
for the general linear group of invertible matrices over any field , the orthogonal group over , and the unitary group over respectively. Note that we have written for the transpose and for conjugate transpose for any . Clearly, if . We will also adopt the convention that and for any . Clearly, if .
For or , we write for the spectral norm of and for the spectral condition number of . When we speak of norm or condition number in this article, it will always be the spectral norm or spectral condition number, the only exception is the max norm defined and used in Section 5.
2. Frobenius inversion in exact arithmetic
We will first show that Frobenius inversion works over any quadratic field extension, with over a special case. More importantly, we will show that Frobenius inversion is optimal over any quadratic field extension in that it requires a minimal number of matrix multiplications, inversions, and additions (Theorem 2.5).
The reason for the generality in this section is to show that Frobenius inversion can be useful beyond numerical analysis, applying to matrix inversions in computational number theory [11, 12], computer algebra [51, 52], cryptography [36, 65], and finite fields [49, 50] as well. This section covers the symbolic computing aspects of Frobenius inversion, i.e., in exact arithmetic. Issues related to the numerical computing aspects, i.e., in floating-point arithmetic, including conditioning, positive definiteness, etc, will be treated in Sections 3–5.
Recall that a field is said to be a field extension of another field if . In this case, is automatically a -vector space. The dimension of as a -vector space is called the degree of over and denoted [60]. A degree-two extension is also called a quadratic extension and they are among the most important field extensions. For example, in number theory, two of the biggest achievements in the last decade were the generalizations of Andrew Wiles’ celebrated work to real quadratic fields [24] and imaginary quadratic fields [9]. Let be a quadratic extension of . Then it follows from standard field theory [60] that there exists some monic irreducible quadratic polynomial such that
where denotes the principal ideal generated by and the quotient ring. Let for some . Then, up to an isomorphism, may be written in a normal form:
-
•
: and is not a complete square in ;
-
•
: either and is not a complete square in , or and has no solution in .
2.1. Gauss multiplication over quadratic field extensions
Let be a root of in an algebraic closure . Then , i.e., any element in can be written uniquely as with . Henceforth we will assume that . The product of two elements , is given by
| (4) |
The following result is well-known for but we are unable to find a reference for an arbitrary quadratic extension .
Proposition 2.1 (Complexity of multiplication in quadratic extensions).
Let be as above. Then there exists an algorithm for multiplication in that costs three multiplications in . Moreover, such an algorithm is optimal in the sense of bilinear complexity, i.e., it requires a minimal number of multiplications in .
Proof.
Case I: . The product in (4) can be computed with three -multiplications , , , since
| (5) |
Case II: . The product in (4) can be computed with three -multiplications , , , since
| (6) |
To show optimality in both cases suppose there is an algorithm for computing (4) with two -multiplications and . Then
where in Case I and in Case II. Clearly and are not collinear; thus
and so there exist , , such that
As , at least one of is nonzero. Since is a -multiplication, we must have for some , . Therefore
For Case I, the left equation reduces to and thus as is not a complete square in ; likewise, the right equation gives , a contradiction as cannot be all zero. For Case II, the left equation reduces to . We must have or else will contradict ; but if so, substituting gives , contradicting the assumption that has no solution in . ∎
2.2. Gauss matrix multiplication over quadratic field extensions
We extend the multiplication algorithm in the previous section to matrices. Notations will be as in the last section. Let be the -algebra of matrices over . Since , we have [44, p. 627]. Thus an element in can be written as where .
By following the argument in the proof of Proposition 2.1, we obtain its analogue for matrix multiplication in via matrix multiplications in .
Proposition 2.2 (Gauss matrix multiplication).
2.3. Frobenius matrix inversion over quadratic field extensions
Let with . Then if and only if
| (9) |
from which we may solve for . As we saw in (4), multiplication in and thus that in depends on the form of . So we have to consider two cases corresponding to the two normal forms of .
Lemma 2.3.
Let be as before. Let with .
-
\edefcmrcmr\edefmm\edefitn(i)
If , then whenever .
-
\edefcmrcmr\edefmm\edefitn(ii)
If , then whenever .
Proof.
Let the matrix addition, multiplication, and inversion maps over any field be denoted respectively by
We will now express in terms of , , and .
Lemma 2.4 (Frobenius inversion over quadratic fields).
Let be as before. Let with . If and , then
| (10) |
If and , then
| (11) |
Proof.
We could derive alternative inversion formulas with other conditions on and . For example, in the case , instead of (10), we could have
conditional on ; in the case , instead of (11), we could have
conditional on . There is no single inversion formula that will work universally for all . Nevertheless, in each case, the inversion formula (10) or (11) works almost everywhere except for matrices with or respectively. In Section 4.2, we will see how to alleviate this minor restriction algorithmically for complex matrices.
We claim that (10) and (11) allow to be evaluated by invoking twice, thrice, and once. To see this more clearly, we express them in pseudocode as Algorithms 1 and 2 respectively.
A few words are in order here. A numerical linear algebraist may balk at inverting and then multiplying it to to form instead of solving a linear system with multiple right-hand sides. However, Algorithms 1 and 2 should be viewed in the context of symbolic computing over arbitrary fields. To establish complexity results like Theorem 2.5 and Theorem 2.10, we would have to state the algorithms purely in terms of algebraic operations in , i.e., , , and . The numerical computing aspects specific to and will be deferred to Sections 4–5, where, among other things, we would present several numerical computing variants of Algorithm 1 (see Algorithms 3, 5, 6, 7). We also remind the reader that a term like in the output of these algorithms does not entail matrix addition; here plays a purely symbolic role like the imaginary unit , and and are akin to the ‘real part’ and ‘imaginary part.’
Note that the addition of a fixed constant (i.e., independent of inputs and ) matrix in Step 2 of Algorithm 2 does not count towards the computational complexity of the algorithm [8].
As we mentioned earlier, is a -bimodule. We prove next that Algorithms 1 and 2 have optimal computational complexity in terms of matrix operations in .
Theorem 2.5 (Optimality of Frobenius Inversion).
Proof.
If , then this reduces to Proposition 2.1. So we will assume that . We will restrict ourselves to Algorithm 1 as the argument for Algorithm 2 is nearly identical.
Clearly, we need at least one to compute so Algorithm 1 is already optimal in this regard. We just need to restrict ourselves to the numbers of and , which are invoked twice and thrice respectively in Algorithm 1. We will show that these numbers are minimal. In the following, we pick any that do not commute.
First we claim that it is impossible to compute with fewer than two even with no limit on the number of and . By (10), comprises two matrices and , which we will call its ‘real part’ and ‘imaginary part’ respectively, slightly abusing terminologies. We claim that computing the ‘real part’ alone already takes at least two . If can be computed with just one , then can also be computed with just one as the extra factor involves no inversion. However, if it takes only one , then we must have an expression
for some noncommutative polynomials and . Now observe that
To see that the last two expressions are contradictory, we write and expand them in formal power series, thereby removing negative powers for an easier comparison:
Note that the leftmost expression is purely in powers of , but the rightmost expression must necessarily involve — indeed any term involving a power of must involve to the same or higher power. The remaining possibility that is a power of is excluded since and do not commute. So we arrive at a contradiction. Hence and therefore requires at least two to compute.
Next we claim that it is impossible to compute with fewer than three even with no limit on the number of and . Let the ‘real part’ and ‘imaginary part’ be denoted
Observe that we may express in terms of and in terms of using only and :
So computing both and take the same number of as computing both and . However, as and do not commute, it is impossible to compute both and with just two . Consequently requires at least three to compute. ∎
A more formal way to cast our proof above would involve the notion of a straight-line program [8, Definition 4.2], but we prefer to avoid pedantry given that the ideas involved are the same.
2.4. Frobenius inversion over iterated quadratic extensions
Repeated applications of Algorithms 1 and 2 allow us to extend Frobenius inversion to an iterated quadratic extension:
| (12) |
where , . By our discussion at the beginning of Section 2, for some . Let be the minimal polynomial [60] of . Then is a monic irreducible quadratic polynomial that we may assume is in normal form, i.e.,
Since , any element in may be written as
| (13) |
in multi-index notation with , , and . Moreover, we may regard as a quotient ring of a multivariate polynomial ring or as a tensor product of quotient rings of univariate polynomial ring:
| (14) |
There are many important fields that are special cases of iterated quadratic extensions
Example 2.6 (Constructible numbers).
One of the most famous instance is the special case with the iterated quadratic extension . In which case the positive numbers in are called constructible numbers and they are precisely the lengths that can be constructed with a compass and a straightedge in a finite number of steps. The impossibillity of trisecting an angle, doubling a cube, squaring a circle, constructing -sided regular polygons for , etc, were all established using the notion of constructible numbers.
Example 2.7 (Multiquadratic fields).
Another interesting example is . It is shown in [6] that
is an iterated quadratic extension if the product of any nonempty subset of is not in . In this case, we have and , .
Example 2.8 (Tower of root extensions of non-square).
Yet another commonly occurring example [18, Section 14.7] of iterated quadratic extension is a ‘tower’ of root extensions:
where is not a complete square.
Since and are both free -modules, we have as tensor product of -modules. Hence the expression (13) may be extended to matrices, i.e., any may be written as
| (15) |
with , . Note that the in (13) are scalars and the in (15) are matrices. On the other hand, in an iterated quadratic extension (12), each is an -module, , and thus we also have the tensor product relation
recalling that and . Hence any may also be expressed recursively as
| (16) | ||||||||
with . The relation between the two expressions (15) and (16) is given as follows.
Lemma 2.9.
Proof.
The representation in Lemma 2.9, when combined with Gauss multiplication, gives us a method for fast matrix multiplication in , and, when combined with Frobenius inversion, gives us a method for fast matrix inversion in .
Theorem 2.10 (Gauss multiplication and Frobenius inversion over iterated quadratic extension).
Let be an iterated quadratic extension of of degree . Then
-
\edefcmrcmr\edefmm\edefitn(i)
one may multiply two matrices in with multiplications in ;
-
\edefcmrcmr\edefmm\edefitn(ii)
one may invert a generic matrix in with multiplications and inversions in .
If we write , this multiplication algorithm reduces the complexity of evaluating from to .
Proof.
Slightly abusing terminologies, we will call the multiplication and inversion algorithms in the proof of Theorem 2.10 Gauss multiplication and Frobenius inversion for iterated quadratic extension respectively. Both rely on the general technique of divide-and-conquer. Moreover, Gauss multiplication for iterated quadratic extension is in spirit the same as the Karatsuba algorithm [38] for fast integer multiplication and multidimensional fast Fourier transform [63]. Indeed, all three algorithms may be viewed as fast algorithms for modular polynomial multiplication in a ring
for different choices of . To be more specific, we have
-
\edefcmrcmr\edefmm\edefnn(a)
Karatsuba algorithm: , , .
-
\edefcmrcmr\edefmm\edefnn(b)
Multidimensional fast Fourier transform: , , .
- \edefcmrcmr\edefmm\edefnn(c)
2.5. Moore–Penrose and Sherman–Morrison
One might ask if Frobenius inversion extends to pseudoinverse. In particular, does (10) hold if matrix inverse is replaced by Moore–Penrose inverse? The answer is no, which can be seen by taking , , in which case (10) is just (1). Let
where denotes the right-hand side of (1) with Moore–Penrose inverse in place of matrix inverse. Clearly .
3. Solving linear systems with Frobenius inversion
We remind the reader that the previous section is the only one about Frobenius inversion over arbitrary fields. In this and all subsequent sections we return to the familiar setting of real and complex fields. In this section we discuss the solution of a system of complex linear equations
| (17) |
for with Frobenius inversion in a way that does not require computing explicit inverse and the circumstances under which this method is superior. For the sake of discussion, we will assume throughout this section that we use LU factorization, computed using Gaussian Elimination with Partial Pivoting, as our main tool, but one may easily substitute it with any other standard matrix decomposition.
The most straightforward way to solve (17) would be directly as a complex linear system with coefficient matrix . As we mentioned at the beginning of this article, the IEEE-754 floating point standard [1] does not support complex floating point arithmetic and relies on software to convert them to real floating point arithmetic [55, p. 55]. For greater control, we might instead transform (17) into a real linear system with coefficient matrix . Note that the condition numbers of the coefficient matrices are identical:
However, an alternative that takes advantage of Frobenius inversion (1) would be Algorithm 3. For simplicity, we assume that is invertible below but if not, this can be easily addressed with a simple trick in Section 4.2.
One may easily verify that Algorithm 3 gives the solution as claimed, by virtue of the expression (1) for Frobenius inversion. Observe that Algorithm 3 involves only the matrices , , and , unsurprising since these are the matrices that appear in (1). In the rest of this section, we will establish that there is an open subset of matrices with
| (18) |
A consequence is that ill-conditioned complex matrices with well-conditioned real and imaginary parts are common; in particular, there are uncountably many and they occur with positive probability with respect to any reasonable probability measure (e.g., Gaussian) on . In fact we will show in Theorems 3.3 and 3.3 that or can be arbitrarily ill-conditioned when and are well-conditioned or even perfectly conditioned, a situation that is tailor-made for Algorithm 3.
Lemma 3.1.
Let with for some . Let . Then
Proof.
Choosing specific matrix decompositions and imposing conditions on in Lemma 3.1 allows us to deduce better bounds for .
Corollary 3.2.
Let and . Let be a QR decomposition with and upper triangular. If is a normal matrix with eigenvalues , then
Proof.
It suffices to observe that , , and is unitarily diagonalizable. ∎
We may now show that for any well-conditioned , there is a well-conditioned such that is arbitrarily ill-conditioned (i.e., ).
Theorem 3.3 (Ill-conditioned matrices with well-conditioned real and imaginary parts).
Let and . Then there exists such that
Proof.
Consider the normal matrix
where is a real parameter to be chosen later. The eigenvalues of are and so . Let be the QR decomposition of and set . Then . By Corollary 3.2, we have . Hence if is chosen in the interval , we get . ∎
Interestingly, we may use the Frobenius inversion formula to push Theorem 3.3 to the extreme, constructing an arbitrarily ill-conditioned complex matrix with perfectly conditioned real and imaginary parts.
Proposition 3.4.
Let . There exists with and .
Proof.
Let . The Frobenius inversion formula (1) gives
An orthogonal matrix must have an eigenvalue decomposition of the form for some and with . Therefore and
Since the spectral norm is unitarily invariant,
from which we deduce that
The last inequality follows from the fact that ’s are unit complex numbers. Now observe that if we choose to be sufficiently close to , then can be made arbitrarily large. ∎
Note that Frobenius inversion (1) and Algorithm 3 avoids and work instead with the matrices , , and . It is not difficult to tweak Theorem 3.3 to add to the mix.
Theorem 3.5 (Ill-conditioned matrices for Frobenius inversion).
Let and . Then there exists such that
In other words, for any invertible matrix there exists a well-conditioned such that is well-conditioned but is arbitrarily ill-conditioned.
Proof.
Consider the skew-symmetric (and therefore normal) matrix
where is a real parameter to be chosen later. The eigenvalues of are so . Let be the QR decomposition of and set . Then . By Corollary 3.2, we have . Hence if is chosen in the interval , we get . We also have
and as , we see that and so
Theorems 3.3 and 3.5 show the existence of arbitrarily ill-conditioned complex matrices with well-conditioned real and imaginary parts (and also in the case of Theorem 3.5). We next show that such matrices exist in abundance — not only are there uncountably many of them, they occur with nonzero probability, showing that there is no shortage of matrices where Algorithm 3 provides an edge by avoiding the ill-conditioning of or, equivalently, of .
Proposition 3.6.
Let . For any ,
have nonempty interiors in and respectively.
Proof.
Consider the maps and defined by
respectively. These are continuous since the condition number is a continuous function on invertible matrices. For any , the preimage by Theorem 3.3 and by Theorem 3.5. Note that these preimages are precisely the required sets in question and by continuity of and they must have nonempty interiors. ∎
One may wonder if there is a flip side to Theorems 3.3 and 3.5, i.e., are there complex matrices whose condition numbers are controlled by their real and imaginary parts? We conclude this section by giving a construction of such matrices.
Proposition 3.7.
Let . If for some , then
In particular, if is well-conditioned and , then is also well-conditioned.
Proof.
We first show a more generally inequality that holds for arbitrary . Recall that singular values satisfy
In particular, we have and , and therefore
Also, we have and , and therefore
If , then
Rewriting in terms of condition number,
Hence
Since , we have
and so . If we set , , and substitute , the required inequality follows. ∎
4. Computing explicit inverse with Frobenius inversion
We have discussed at length in Section 1.2 why computing an explicit inverse for a matrix is sometimes an inevitable or desirable endeavor. Here we will discuss the numerical properties of inverting a complex matrix using Frobenius inversion. The quadratic extension over falls under Algorithm 1 (as opposed to Algorithm 2) and here we will compare its computational complexity with the complex matrix inversion algorithm based on LU decomposition, the standard method of choice for computing explicit inverse in Matlab, Maple, Julia, and Python.
Strictly speaking, Algorithm 4 computes the left inverse of the input matrix , i.e., . We may also compute its right inverse, i.e., , by swapping the order of backward and forward substitutions. Even though the left and right inverse of a matrix are always equal mathematically, i.e., in exact arithmetic, they can be different numerically, i.e., in floating-point arithmetic [34]. Any subsequent mentions of Algorithm 4 would also hold with its right inverse variant.
4.1. Floating point complexity
In Section 2, we discussed computational complexity of Frobenius inversion for in units of , , , which are in turn treated as black boxes. Here, for the case of and , we will count actual real flops, i.e., real floating point operations; we will not distinguish between the cost of real addition and real multiplication since there is no noticeable difference in their latency on modern processors — each would count as a single flop. With this in mind, we do not use Gauss multiplication for complex numbers since it trades one real multiplication for three real additions, i.e., more expensive if real addition costs the same as real multiplication. We caution our reader that this says nothing about Gauss multiplication for complex matrices since real matrix addition ( flops) is still much cheaper than real matrix multiplication ( flops).
Our implementation of Frobenius inversion in Algorithm 1 requires real matrix multiplication and real matrix inversion as subroutines. Let and be respectively any two algorithms for real matrix inversion and real matrix multiplication, with real flop counts and on real matrix inputs. There is little loss of generality in making two mild assumptions about the inversion algorithm :
-
\edefcmrcmr\edefmm\edefnn(i)
also works for complex matrix inputs at the cost of a multiple of , the multiple being the cost of a complex flop in terms of real flops;
-
\edefcmrcmr\edefmm\edefnn(ii)
the number of complex additions and the number of complex multiplications in applied to complex matrix inputs both take the form lower order terms, i.e., same dominant term but lower order terms may differ.
Note that these assumptions are satisfied if is chosen to be Algorithm 4, even if we replace the LU decomposition in them by other decompositions like QR or Cholesky (if applicable).
Theorem 4.1 (Frobenius inversion versus standard inversion).
Let be such that the cost of computing for any , is bounded by . Algorithm 1 with subroutines and on real inputs and is asymptotically faster than directly applying on complex input if and only if
Proof.
The first two steps of Algorithm 1 computes , which costs operations. Thereafter, computing costs one matrix multiplication, one matrix addition, one matrix inversion, and finally one matrix multiplication. We disregard matrix addition since it takes flops and does not contribute to the dominant term. So the cost in real flops of Algorithm 1 is dominated by for sufficiently large.
Now suppose we apply directly to the complex matrix . Each complex addition costs two real flops (real additions) and each complex multiplication costs six real flops (four real multiplications and two real additions). Also, by assumption ii, has the same number of real additions and real multiplications, ignoring lower order terms. So the cost in real flops of applied directly to is dominated by for sufficiently large, i.e., the ‘multiple’ in assumption i is .
As we discussed in Section 2.3, Algorithm 1 is written in a general form that applies over arbitrary fields and to both symbolic and numerical computing. However, when restricted to , , and with numerical computing in mind, we may state a more specific version Algorithm 5 involving LU decomposition and backsubstitutions for .
Note that Steps 2 and 3 in Algorithm 5 are essentially just Algorithm 4 with a different right-hand side, and likewise for Steps 5 and 6. Hence we may regard Algorithm 5 as Algorithm 1 with given by Algorithm 4 and given by standard matrix multiplication. These choices allow us to assign flop counts to illustrate Theorem 4.1.
Proposition 4.2 (Flop counts).
Proof.
These come from a straightforward flop count of the respective algorithms, dropping lower order terms. ∎
With these choices for and , the cost of computing is asymptotically bounded by — one LU decomposition plus forward and backward substitutions. So and . Hence inverting a complex matrix via Algorithm 5 is indeed faster than inverting it directly with Algorithm 4, as predicted by Theorem 4.1; we will also present numerical evidence that supports this in Section 5.
Proposition 4.2 also tells us that variations of Frobenius inversion formula like the one proposed in [70] can obliterate the computational savings afforded by Frobenius inversion. These variants all take the form for some and the extra matrix multiplications incur additional costs. As a result, the variant in [70] takes real flops, which exceeds even the by standard methods (e.g., Algorithm 4).
4.2. Almost sure Frobenius inversion
One obvious shortcoming of Frobenius inversion is that (1) requires the real part to be invertible. It is easy to modify (1) to
if is invertible. Nevertheless we may well have circumstances where is invertible but neither nor is, e.g., . Here we will extend Frobenius inversion to any invertible in a way that preserves its computational complexity — this last qualification is important. As we saw in Proposition 4.2, the speed improvement of Frobenius inversion comes from the constants, i.e., it inverts an complex matrix with real flops whereas Algorithm 4 takes real flops. As we noted in Section 1.3, prior attempts such as those in [70, 23] at extending Frobenius inversion to all invariably require the inversion of a real matrix of size , thereby obliterating any speed improvement afforded by Frobenius inversion.
Our approach avoids any matrices of larger dimension by adding a simple randomization step that in turns depend on the following observation.
Lemma 4.3.
Let with . Then there exist at most values of such that is singular.
Proof.
As is a polynomial of degree at most and , has at most zeros in . So is invertible for all but at most values of . ∎
Algorithm 6 is essentially Frobenius inversion applied to for some random . Note that is exactly the real part of and therefore invertible for all but at most values of by Lemma 4.3. The interval is chosen so that we may generate from the uniform distribution but we could have also used with standard normal distribution, both of which are standard implementations in numerical packages.
Note that Algorithm 5 fails on a set of real dimension , i.e., when the real part of the input is singular, but Algorithm 6 has reduced this to a set of dimension zero.
Proposition 4.4.
4.3. Hermitian positive definite matrices
The case of Hermitian positive definite deserves special consideration given their ubiquity. We will propose and analyze a new variant of Frobenius inversion that exploits this special structure of . The happy coincidence is that a Hermitian positive definite must necessarily have symmetric positive definite and as well as a skew-symmetric — precisely the matrices we need in Frobenius inversion. Various required quantities may thus be computed via Cholesky decompositions and :
| (22) | ||||
Lemma 4.5.
Let be a Hermitian positive definite matrix with . Then
-
\edefcmrcmr\edefmm\edefitn(i)
is symmetric positive definite and is skew-symmetric;
-
\edefcmrcmr\edefmm\edefitn(ii)
is symmetric positive definite.
In particular, is always invertible and so there is no need for an analogue of Algorithm 6.
Proof.
Let and write to indicate positive definiteness. Then since and , is symmetric and is skew-symmetric given that is Hermitian. Since , for any ,
with equality if and only if , showing that is positive definite. Again since , for any ,
with equality if and only if ; so is also Hermitian positive definite. Now observe that and
Therefore it suffices to establish ii for . As
it follows that . An alternative way to show ii is to use Lemma 2.4, which informs us that is the real part of , allowing us to invoke i. Then . ∎
With Lemma 4.5 established, we may turn (22) into Algorithm 7, which essentially replaces the LU decompositions in Algorithm 5 with Cholesky decompositions, taking care to preserve symmetry and positive definiteness.
The standard method for inverting a Hermitian positive definite matrix is to simply replace LU decomposition in Algorithm 4 by Cholesky decomposition, given in Algorithm 8 for easy reference.
With this, we obtain an analogue of Proposition 4.2. The flop counts below show that Algorithm 7 provides a 22% speedup over Algorithm 8. The experiments in Section 5.6 will attest to this improvement.
Proposition 4.6 (Flop counts).
Proof.
Algorithm 8 performs one Cholesky decomposition, backward substitutions, and forward substitutions, all over . So its flop complexity is dominated by complex flops and thus, by the same reasoning in the proof of Theorem 4.1, real flops. On the other hand, Algorithm 7 performs two Cholesky decompositions, backward substitutions, forward substitutions, and two matrix multiplications, all over . Moreover, the symmetry in allows the matrix multiplication in Step 5 to have a reduced complexity of real flops. Hence its flop complexity is dominated by real flops. ∎
We end with an observation that the discussions in this section apply as long as and . Indeed, another important class of matrices with this property are the with symmetric positive definite real and imaginary parts, i.e., and [32, p. 209]. By Lemma 4.5, such matrices are not Hermitian positive definite except in the trivial case when . However, since such matrices must clearly satisfy , Algorithm 7 and Proposition 4.6 will apply verbatim to them.
5. Numerical experiments
We present results from numerical experiments comparing the speed and accuracy of Frobenius inversion (Algorithms 3, 5, 7) with standard methods via LU and Cholesky decompositions (Algorithms 4, 8). We begin by comparing Algorithms 4 and 5, followed by a variety of common tasks: linear systems, matrix sign function, Sylvester equations, Lyapunov equations, polar decomposition, and rounding up with a comparison of Algorithms 7 and 8 on the inversion of Hermitian positive matrices. These results show that algorithms based on Frobenius inversion are more efficient than standard ones based on LU or Cholesky decompositions, with negligible loss in accuracy, confirming Theorem 4.1, Propositions 4.2 and 4.6. In all experiments, we repeat our random trials ten times and record average time taken and average forward or backward error. All codes are available at https://github.com/zhen06/Complex-Matrix-Inversion.
5.1. Matrix inversion
For our speed experiments, we generate with entries of sampled uniformly from and from to .


Figure 1 shows the times taken for Matlab’s built-in inversion (Algorithm 4), i.e., directly performing LU decomposition in complex arithmetic, and Frobenius inversion with LU decomposition in real arithmetic (Algorithm 5). They are plotted against matrix dimension , using two different scales for the horizontal axis. As predicted by Proposition 4.2, Frobenius inversion is indeed faster than Matlab’s inversion, with a widening gap as grows bigger.
For our accuracy experiments, we want some control over the condition numbers of our random matrices to reduce conditioning as a factor affecting accuracy. We generate a random with condition number : first generate a random orthogonal by QR factoring a random with entries sampled uniformly from ; next generate a random diagonal with , , signs assigned randomly, and sampled uniform randomly; then set . We generate in the same way. So . We also check that is on the same order of magnitude as or otherwise discard . In the plots below, we set and increase from through .
Accuracy is measured by left and right relative residuals defined respectively as
| (23) |
where is the computed inverse of and the max norm is
| (24) |
Figure 2 shows the left and right relative residuals computed by Matlab’s built-in inversion (Algorithm 4) and Frobenius inversion (Algorithm 5), plotted against matrix dimension . At first glance, Frobenius inversion is less accurate than Matlab’s inversion. But one needs to look at the scale of the vertical axis — the two algorithms give essentially the same results to machine precision ( decimal digits of accuracy), any difference can be safely ignored for all intents and purposes.


5.2. Solving linear systems
It is remarkable that Frobenius inversion shows nearly no loss in accuracy as measured by backward error. For the matrix dimensions in Section 5.1, forward error experiments are too expensive due to the cost of finding exact inverse. To get a sense of the forward errors, we look at a problem intimately related to matrix inversion — solving linear systems.
We use the same matrices generated in Section 5.1 and generate two vectors with entries sampled uniformly from . We set and solve the complex linear system to get a computed solution using three methods: (i) Frobenius inversion (Algorithm 3), (ii) complex LU factorization, and (iii) augmented system ; we rely on Matlab’s mldivide (i.e., the ‘backslash’ operator) for the last two.

Figure 3 shows the relative forward errors plotted against matrix dimension. The conclusion is clear: Frobenius inversion gives the most accurate result.
5.3. Matrix sign function
The matrix sign function appears in a wide range of problems such as algebraic Riccati equation [59], Sylvester equation [33, 59], polar decomposition [33], and spectral decomposition [3, 4, 5, 37, 45]. For with Jordan decomposition where its Jordan canonical form is partitioned into with positive real part and with negative real part, its matrix sign function is defined to be
| (25) |
Since the Jordan decomposition cannot be determined in finite precision [29], its definition does not offer a viable way of computation. The standard way to evaluate the matrix sign function is to use Newton iterations [35, 59]:
| (26) |
This affords a particularly pertinent test for Frobenius inversion as it involves repeated inversion. Our stopping condition is given by the relative change in : We stop when or when .
The definition via Jordan decomposition is useful for generating random examples for our tests: We generate a random diagonal whose first diagonal entries have positive real parts and the rest have negative real parts, avoiding near zero values, and with from to . We generate a random with real and imaginary parts of its entries sampled uniformly from . We set . In this way we obtain via (25) as well.
In each iteration of (26), we compute with Matlab’s inversion in complex arithmetic (Algorithm 4) and Frobenius inversion in real arithmetic (Algorithm 5). Accuracy is measured by relative forward error . From Figure 4, we see that Frobenius inversion offers an improvement in speed at the cost of slightly less accurate results.


5.4. Sylvester and Lyapunov equations
One application of the matrix sign function is to seek, for given , , and , a solution for the Sylvester equation:
or its special case with , the Lyapunov equation [34]. As noted in [33, 59], if and , then
Thus the Newton iterations (26) applied to will converge to , yielding the solution of Sylvester equation in the limit.
As usual, we ‘work backwards’ to generate with , with , and with and taking values between and . First we generate a random by sampling the real and imaginary parts of its entries in uniformly; next we generate a random diagonal whose diagonal entries have positive real parts sampled from the interval ; then we set . We generate in the same way. We generate a random with real and imaginary parts of its entries sampled uniformly from and set .
Using the same stopping condition in Section 5.3 with a tolerance of and maximum iterations, we compute a solution with the Newton iterations (26). Accuracy is measured by relative forward error .
Figure 5 gives the results for Sylvester and Lyapunov equations, showing that in both cases Frobenius inversion is faster than Matlab’s inversion with no difference in accuracy. Indeed, at a scale of for the vertical axis, the two graphs in the accuracy plot for Lyapunov equation (bottom right plot of Figure 5) are indistinguishable. The accuracy plot for Sylvester equation (top right plot of Figure 5) uses a finer vertical scale of ; but had we used a scale of , the two graphs therein would also have been indistinguishable.




5.5. Polar decomposition
Another application of the matrix sign function is to polar decompose a given into with and Hermitian positive semidefinite. This is based on the observation [31, 33, 39] that
Here the Newton iterations (26) take a slightly different form
| (27) |
We generate random with real and imaginary parts of its entries sampled uniformly from . We then QR factorize and l set and . The value of runs from to .
Using the same stopping condition in Section 5.3 with a tolerance of and maximum iterations, we compute a solution with the Newton iterations (27), with computed by either Frobenius inversion or Matlab’s inversion. We then set . Accuracy is measured by relative forward errors and .
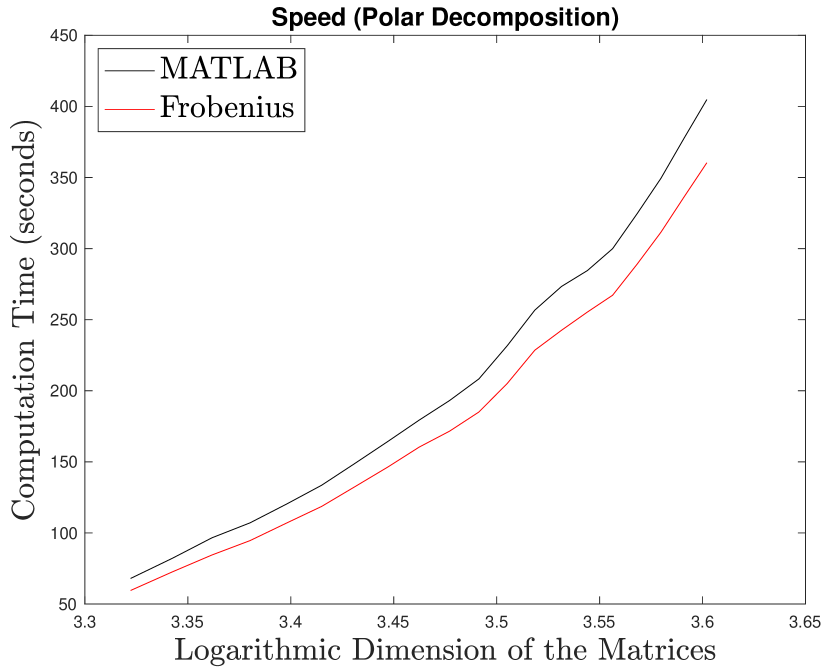

5.6. Hermitian positive definite matrix inversion
We repeat experiments in Section 5.1 on Hermitian positive definite matrices for our variant of Frobenius inversion (Algorithm 7) and Matlab’s built-in inversion based on Cholesky decomposition (Algorithm 8). For comparison, we also include Algorithms 4 and 5 that do not exploit Hermitian positive definiteness.
For our speed experiments, we generate a random Hermitian positive definite with sampled uniformly from and from to . We plot the results in Figure 7, with two different scales for the horizontal axis.


For our accuracy experiments, we control the condition numbers of our matrices to reduce conditioning as a factor affecting accuracy. To generate a random Hermitian positive definite with condition number , first we generate a random unitary by QR factoring a random with real and imaginary parts of its entries sampled uniformly from ; next we generate a random diagonal with , , and sampled uniform randomly; then we set . So . In the plots below, we set and increase from through .


Accuracy is measured by left and right relative residuals as defined in equation (23), with results plotted in Figure 8, which shows the left and right relative residuals computed by Algorithms 4, 5, 7, 8 plotted against matrix dimension . The important thing to note is the scale of the vertical axes — all four algorithms give essentially the same results up to machine precision.
6. Conclusion
We hope our effort here will rekindle interest in this beautiful algorithm. In future work, we plan to provide rounding error analysis for Frobenius inversion, discuss its relation with Strassen-style algorithms, and its advantage in solving linear systems with a large number of right-hand sides.
Acknowledgment
ZD acknowledges the support of DARPA HR00112190040 and NSF ECCF 2216912. LHL acknowledges the support of DARPA HR00112190040, NSF DMS 1854831, and a Vannevar Bush Faculty Fellowship ONR N000142312863. KY acknowledges the support of CAS Project for Young Scientists in Basic Research, Grant No. YSBR-008, National Key Research and Development Project No. 2020YFA0712300, and National Natural Science Foundation of China Grant No. 12288201.
References
- [1] IEEE standard for floating-point arithmetic. In IEEE Std 754-2019 (Revision of IEEE 754-2008), pages 1–84. IEEE, New York, NY, 2019.
- [2] H. Althaus and R. Leake. Inverse of a finite-field Vandermonde matrix (corresp.). IEEE Trans. Inform. Theory, 15(1):173–173, 1969.
- [3] Z. Bai, J. Demmel, J. Dongarra, A. Petitet, H. Robinson, and K. Stanley. The spectral decomposition of nonsymmetric matrices on distributed memory parallel computers. SIAM J. Sci. Comput., 18(5):1446–1461, 1997.
- [4] Z. Bai and J. W. Demmel. Design of a parallel nonsymmetric eigenroutine toolbox. University of Kentucky, Lexington, KY, 1992.
- [5] A. N. Beavers, Jr. and E. D. Denman. A computational method for eigenvalues and eigenvectors of a matrix with real eigenvalues. Numer. Math., 21:389–396, 1973.
- [6] A. S. Besicovitch. On the linear independence of fractional powers of integers. J. Lond. Math. Soc., 15:3–6, 1940.
- [7] E. Bodewig. Matrix calculus. North-Holland, Amsterdam, enlarged edition, 1959.
- [8] P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic complexity theory, volume 315 of Grundlehren der mathematischen Wissenschaften. Springer-Verlag, Berlin, 1997.
- [9] A. Caraiani and J. Newton. On the modularity of elliptic curves over imaginary quadratic fields. arXiv:2301.10509, 2023.
- [10] S. Casacuberta and R. Kyng. Faster sparse matrix inversion and rank computation in finite fields. In 13th Innovations in Theoretical Computer Science Conference, ITCS 2022, pages 33:1–33:24. Dagstuhl Publishing, Germany, 2022.
- [11] H. Cohen. A course in computational algebraic number theory, volume 138 of Graduate Texts in Mathematics. Springer-Verlag, Berlin, 1993.
- [12] H. Cohen. Advanced topics in computational number theory, volume 193 of Graduate Texts in Mathematics. Springer-Verlag, New York, NY, 2000.
- [13] H. Cramér. Mathematical Methods of Statistics, volume 9 of Princeton Mathematical Series. Princeton University Press, Princeton, NJ, 1946.
- [14] Z. Dai and L.-H. Lim. Numerical stability and tensor nuclear norm. Numer. Math., to appear, 2023.
- [15] A. Ditkowski, G. Fibich, and N. Gavish. Efficient solution of using . J. Sci. Comput., 32(1):29–44, 2007.
- [16] A. Druinsky and S. Toledo. How accurate is ? arXiv:1201.6035, 2012.
- [17] K. Dudeck. Solving complex systems using spreadsheets: A matrix decomposition approach. In Proceedings of the 2005 ASEE Annual Conference and Exposition: The Changing Landscape of Engineering and Technology Education in a Global World, pages 12875–12880. ASEE, Washington, DC, 2005.
- [18] D. S. Dummit and R. M. Foote. Abstract algebra. John Wiley, Hoboken, NJ, third edition, 2004.
- [19] S. Eberli, D. Cescato, and W. Fichtner. Divide-and-conquer matrix inversion for linear MMSE detection in SDR MIMO receivers. In Proceedings of the 26th IEEE Norchip Conference, pages 162–167. IEEE, New York, NY, 2008.
- [20] W. Eberly. Processor-efficient parallel matrix inversion over abstract fields: Two extensions. In Proceedings of the 2nd International Symposium on Parallel Symbolic Computation, PASCO ’97, page 38–45. ACM, New York, NY, 1997.
- [21] W. Eberly, M. Giesbrecht, P. Giorgi, A. Storjohann, and G. Villard. Faster inversion and other black box matrix computations using efficient block projections. In Proceedings of the 2007 International Symposium on Symbolic and Algebraic Computation, ISSAC ’07, page 143–150, New York, NY, USA, 2007. ACM, New York, NY.
- [22] L. W. Ehrlich. Complex matrix inversion versus real. Comm. ACM, 13:561–562, 1970.
- [23] M. El-Hawary. Further comments on “a note on the inversion of complex matrices”. IEEE Trans. Automat. Contr., 20(2):279–280, 1975.
- [24] N. Freitas, B. V. Le Hung, and S. Siksek. Elliptic curves over real quadratic fields are modular. Invent. Math., 201(1):159–206, 2015.
- [25] F. G. Frobenius. Gesammelte Abhandlungen. Bände I, II, III. Springer-Verlag, Berlin, 1968.
- [26] M. Giesbrecht. Nearly optimal algorithms for canonical matrix forms. SIAM J. Comput., 24(5):948–969, 1995.
- [27] P. E. Gill, G. H. Golub, W. Murray, and M. A. Saunders. Methods for modifying matrix factorizations. Math. Comp., 28:505–535, 1974.
- [28] G. H. Golub. Matrix computation and the theory of moments. In Proceedings of the International Congress of Mathematicians, volume 2, pages 1440–1448. Birkhäuser, Basel, 1995.
- [29] G. H. Golub and J. H. Wilkinson. Ill-conditioned eigensystems and the computation of the Jordan canonical form. SIAM Rev., 18(4):578–619, 1976.
- [30] M. T. Heath, G. A. Geist, and J. B. Drake. Early experience with the Intel iPSC/860 at Oak Ridge National Laboratory. Int. J. High Perform. Comput. Appl., 5(2):10–26, 1991.
- [31] N. J. Higham. Computing the polar decomposition—with applications. SIAM J. Sci. Statist. Comput., 7(4):1160–1174, 1986.
- [32] N. J. Higham. Stability of a method for multiplying complex matrices with three real matrix multiplications. SIAM J. Matrix Anal. Appl., 13(3):681–687, 1992.
- [33] N. J. Higham. The matrix sign decomposition and its relation to the polar decomposition. Linear Algebra Appl., 212/213:3–20, 1994.
- [34] N. J. Higham. Accuracy and stability of numerical algorithms. SIAM, Philadelphia, PA, second edition, 2002.
- [35] N. J. Higham. Functions of matrices. SIAM, Philadelphia, PA, 2008.
- [36] J. Hoffstein, J. Pipher, and J. H. Silverman. An introduction to mathematical cryptography. Undergraduate Texts in Mathematics. Springer, New York, second edition, 2014.
- [37] J. L. Howland. The sign matrix and the separation of matrix eigenvalues. Linear Algebra Appl., 49:221–232, 1983.
- [38] A. A. Karatsuba. The complexity of computations. Trudy Mat. Inst. Steklov., 211:186–202, 1995.
- [39] C. Kenney and A. J. Laub. On scaling Newton’s method for polar decomposition and the matrix sign function. SIAM J. Matrix Anal. Appl., 13(3):698–706, 1992.
- [40] A. Klein and G. Mélard. Computation of the Fisher information matrix for time series models. J. Comput. Appl. Math., 64(1-2):57–68, 1995.
- [41] D. E. Knuth. The art of computer programming. Vol. 2. Addison-Wesley, Reading, MA, third edition, 1998.
- [42] C. Krattenthaler. A new matrix inverse. Proc. Amer. Math. Soc., 124(1):47–59, 1996.
- [43] C. Lanczos. Applied analysis. Prentice-Hall, Englewood Cliffs, NJ, 1956.
- [44] L.-H. Lim. Tensors in computations. Acta Numer., 30:555–764, 2021.
- [45] C.-C. Lin and E. Zmijewski. A parallel algorithm for computing the eigenvalues of an unsymmetric matrix on an SIMD mesh of processors. University of California, Santa Barbara, CA, 1991.
- [46] K. Lo. Several numerical methods for matrix inversion. Int. J. Electr. Eng. Educ., 15(2):131–141, 1978.
- [47] J. H. Maindonald. Statistical computation. Series in Probability and Mathematical Statistics: Applied Probability and Statistics. John Wiley, New York, NY, 1984.
- [48] P. McCullagh and J. A. Nelder. Generalized linear models. Monographs on Statistics and Applied Probability. Chapman & Hall, London, 1989.
- [49] R. J. McEliece. Finite fields for computer scientists and engineers, volume 23 of International Series in Engineering and Computer Science. Kluwer, Boston, MA, 1987.
- [50] A. J. Menezes, I. F. Blake, X. Gao, R. C. Mullin, S. A. Vanstone, and T. Yaghoobian. Applications of finite fields, volume 199 of International Series in Engineering and Computer Science. Kluwer, Boston, MA, 1993.
- [51] M. Mignotte. Mathematics for computer algebra. Springer-Verlag, New York, NY, 1992.
- [52] B. Mishra. Algorithmic algebra. Texts and Monographs in Computer Science. Springer-Verlag, New York, NY, 1993.
- [53] P. Mukherjee and L. Satish. On the inverse of forward adjacency matrix. arXiv:1711.09216, 2017.
- [54] I. Munro. Some results concerning efficient and optimal algorithms. In Proceedings of the Third Annual ACM Symposium on Theory of Computing, STOC ’71, page 40–44. ACM, New York, NY, 1971.
- [55] M. L. Overton. Numerical computing with IEEE floating point arithmetic. SIAM, Philadelphia, PA, 2001.
- [56] S. K. Panda. Inverses of bicyclic graphs. Electron. J. Linear Algebra, 32:217–231, 2017.
- [57] S. Pavlíková. A note on inverses of labeled graphs. Australas. J. Combin., 67:222–234, 2017.
- [58] C. R. Rao. Information and the accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc., 37:81–91, 1945.
- [59] J. D. Roberts. Linear model reduction and solution of the algebraic Riccati equation by use of the sign function. Internat. J. Control, 32(4):677–687, 1980.
- [60] S. Roman. Field theory, volume 158 of Graduate Texts in Mathematics. Springer, New York, NY, second edition, 2006.
- [61] I. Schur. Gesammelte Abhandlungen. Band I, II, III. Springer-Verlag, Berlin, 1973.
- [62] J. Schur. Über potenzreihen, die im innern des einheitskreises beschränkt sind. J. Reine Angew. Math., 148:122–145, 1918.
- [63] W. W. Smith and J. Smith. Handbook of real-time fast Fourier transforms. IEEE, New York, NY, 1995.
- [64] W. W. Smith, Jr. and S. Erdman. A note on the inversion of complex matrices. IEEE Trans. Automatic Contol, AC-19:64, 1974.
- [65] D. R. Stinson and M. B. Paterson. Cryptography. Textbooks in Mathematics. CRC Press, Boca Raton, FL, fourth edition, 2019.
- [66] C. Studer, S. Fateh, and D. Seethaler. ASIC implementation of soft-input soft-output MIMO detection using MMSE parallel interference cancellation. IEEE J. Solid-State Circuits, 46(7):1754–1765, 2011.
- [67] L. Tornheim. Inversion of a complex matrix. Comm. ACM, 4:398, 1961.
- [68] S. Winograd. On the number of multiplications necessary to compute certain functions. Comm. Pure Appl. Math., 23:165–179, 1970.
- [69] D. Ye, Y. Yang, B. Mandal, and D. J. Klein. Graph invertibility and median eigenvalues. Linear Algebra Appl., 513:304–323, 2017.
- [70] A. Zielinski. On inversion of complex matrices. Internat. J. Numer. Methods Engrg., 14(10):1563–1566, 1979.