Thesis \degreeHonours Degree of Bachelor of Science \departmentDepartment of Computer Science
Comparative Analysis of Transfer Learning in Deep Learning Text-to-Speech Models on a Few-Shot, Low-Resource, Customized Dataset
Abstract
Text-to-Speech (TTS) synthesis using deep learning relies on voice quality. Modern TTS models are advanced, but they need large amount of data. Given the growing computational complexity of these models and the scarcity of large, high-quality datasets, this research focuses on transfer learning, especially on few-shot, low-resource, and customized datasets. In this research, "low-resource" specifically refers to situations where there are limited amounts of training data, such as a small number of audio recordings and corresponding transcriptions for a particular language or dialect.
This thesis, is rooted in the pressing need to find TTS models that require less training time, fewer data samples, yet yield high-quality voice output. The research evaluates TTS state-of-the-art model transfer learning capabilities through a thorough technical analysis. It then conducts a hands-on experimental analysis to compare models’ performance in a constrained dataset. This study investigates the efficacy of modern TTS systems with transfer learning on specialized datasets and a model that balances training efficiency and synthesis quality. Initial hypotheses suggest that transfer learning could significantly improve TTS models’ performance on compact datasets, and an optimal model may exist for such unique conditions. This thesis predicts a rise in transfer learning in TTS as data scarcity increases. In the future, custom TTS applications will favour models optimized for specific datasets over generic, data-intensive ones.
A dissertation submitted to the Department of Computer Science
in partial fulfillment of the requirements for the degree of
Bachelor of Science (Honours) in Computer Science
August 2023
Acknowledgements.
I would like to express my deepest appreciation to my supervisor, Dr. Xianta Jiang, whose invaluable guidance, support, and encouragement have been instrumental in the completion of this thesis. His profound knowledge, insightful feedback, and unwavering patience have been a source of constant inspiration, pushing me to explore beyond my limits and fostering a deep sense of curiosity and passion for the field of Computer Science.Table of Contents
List of Tables
List of Figures
Chapter 1 Introduction
In the vast landscape of deep learning, one of the critical challenges faced is the need for vast amounts of data to train effective models. This is especially pertinent in areas like Text-to-Speech (TTS) where the quality of synthesized speech is paramount. Given the ever-increasing computational complexity of modern TTS models and the ever-present challenge of gathering large, quality datasets, it becomes crucial to investigate the efficacy of transfer learning, especially on smaller, customized datasets. This becomes all the more significant in the context of applications that require rapid model deployment with high-quality output, using limited resources.
1.1 Context of the Discipline
Deep Learning-based TTS systems have set the benchmark for voice synthesis, shifting from the traditional concatenative and formant-based methods to neural architectures. These systems, while groundbreaking in their capabilities, are notorious for their hunger for data. As a result, the challenge arises when we deal with few-shot, low-resource, or customized datasets. Can these models, trained on vast general datasets, effectively adapt to smaller, more specialized datasets? Transfer learning promises a solution, allowing models to leverage knowledge acquired from one task to another, potentially offering a shortcut to high-quality synthesis without the need for exhaustive training.
1.2 Objective of the Thesis
Against this backdrop, this thesis titled, "Comparative Analysis of Transfer Learning in Deep Learning Text-to-Speech Models on a Few-Shot, Low-Resource, Customized Dataset," embarks on a journey to:
-
1.
Technical Examination: Systematically analyze leading TTS systems in the context of transfer learning capabilities.
-
2.
Experimental Analysis: Perform hands-on experiments to evaluate the performance of various models on a few-shot, low-resource, customized dataset.
-
3.
Model Identification: Identify a TTS model that strikes the optimal balance between training speed, minimal data requirement, and high-quality voice output.
Research Questions:
-
•
How effective are modern TTS systems when employing transfer learning on small, customized datasets?
-
•
Which model, among the contenders, offers the best trade-off between training speed, dataset size requirement, and synthesis quality?
Hypotheses:
-
•
Transfer learning significantly enhances the capability of TTS models to perform effectively on smaller datasets.
-
•
There exists an optimal TTS model that offers a harmonious blend of rapid training, minimal data dependence, and exemplary voice quality.
Predictions:
-
•
Transfer learning will gain more traction in the TTS domain as data scarcity becomes more prominent.
-
•
Customized TTS applications will lean towards models optimized for performance on specialized datasets rather than generic, data-hungry models.
As we delve deeper into the subsequent chapters, this thesis will unveil the findings from the comparative analysis, providing insights and guidance for future endeavors in the world of TTS, especially in constrained data scenarios.
Chapter 2 Literature Review
2.1 Early TTS Systems
2.1.1 Rule-Based Systems
During the 1980s, rule-based systems were the prevailing approach in the field of Text-to-Speech (TTS), with a strong reliance on linguistic rules as shown by Klatt (\APACyear1980). Phonemic representations of textual content were generated and then used as input for algorithms in order to generate corresponding auditory output, whereby prosodic attributes such as intonation and stress were manually calibrated.
2.1.2 Concatenative Synthesis
During the 1990s, concatenative synthesis gained prominence as the preferred approach Hunt \BBA Black (\APACyear1996). The continuous speech was generated by assembling and storing pre-recorded fragments of human voice. The system’s ability to generate outputs that seem more realistic was limited due to the limited quantity and variety of the database.
2.1.3 Statistical Models
During the early 2000s, there was a surge in the popularity of Hidden Markov Model (HMM)-Based Synthesis, as shown by the work of Tokuda \BOthers. (\APACyear2000). Rather of retaining whole speech fragments, statistical models were used to capture speech characteristics. The aforementioned methodology exhibited adaptability and a reduced memory footprint but sometimes led to the manifestation of "muffled" or "flattened" vocal outputs Tokuda \BOthers. (\APACyear2000).
2.2 Deep Learning Models
WaveNet
WaveNet by DeepMind A\BPBIv\BPBId. Oord \BOthers. (\APACyear2016) improved voice synthesis, making it more realistic. It is raw audio waveforms instead of high-level properties or parameters distinguish WaveNet. It provides precise audio outputs with this fine-grained approach. WaveNet’s conditioning is another trait. This allows the model to generate sounds in multiple languages or impersonate speakers based on input conditions, boosting its application potential. TTS systems produced mechanical audio before WaveNet. WaveNet made speech more natural. It reduced problematic audio splicing in concatenative TTS systems. However, WaveNet had challenges. The model was computationally expensive, especially during generation, hence real-time applications needed robust hardware A\BPBIv\BPBId. Oord \BOthers. (\APACyear2016). To perform successfully, early WaveNet needed lots of high-quality training data. The sample-by-sample audio generation delay was another issue. The model’s various parameters required a lot of computing power to train A\BPBIv\BPBId. Oord \BOthers. (\APACyear2016). WaveNet audio sometimes differs from training data. WaveNet’s speech synthesis achievement was noteworthy despite these challenges. It spurred research and technology to increase its limits while preserving audio quality.
Parallel WaveNet
To solve the problem of WaveNet being too resource intensive, deepMind’s Parallel WaveNet A. Oord \BOthers. (\APACyear2018) and WaveGlow Prenger \BOthers. (\APACyear2019) models are improved models. WaveNet’s quick and simultaneous audio generation makes it more efficient for real-time applications. The original WaveNet produced audio sample-by-sample, rendering it unsuitable for real-time synthesis. To solve this problem, Parallel WaveNet used "Inverse Autoregressive Flow" to create all audio samples simultaneously. Parallel WaveNet increased speed and maintained WaveNet’s high-quality audio. This was a breakthrough since it allowed faster generation without sacrificing sound quality A. Oord \BOthers. (\APACyear2018). This technology enabled real-time voice applications like digital assistants and interactive response systems A. Oord \BOthers. (\APACyear2018). Parallel WaveNet’s success shows that deep learning in speech synthesis may overcome the constraints and challenges of cutting-edge models with refinements and technological improvements A. Oord \BOthers. (\APACyear2018).
WaveGlow
WaveGlow Prenger \BOthers. (\APACyear2019) is a flow-based generative neural network for speech synthesis that replaces WaveNet and Parallel WaveNet. NVIDIA’s WaveGlow combines WaveNet’s greatest features with the Gaussian mixture model-based Parallel WaveNet for quicker, higher-quality speech synthesis Prenger \BOthers. (\APACyear2019). The main benefit of WaveGlow is its simplicity and efficiency. Its flow-based technique offers parallelism and quick audio synthesis while providing WaveNet-like audio quality. This means it can synthesize high-quality audio in real-time without the computational bottlenecks found in some models Prenger \BOthers. (\APACyear2019). WaveGlow combines autoregressive models and normalizing flows to create a single model without probability density distillation or auxiliary models. This simplifies audio generation and training Prenger \BOthers. (\APACyear2019).
Tacotron
Tacotron Y. Wang \BOthers. (\APACyear2017) was developed by Google. Prior to Tacotron, TTS systems had segmented models, each addressing specific synthesis stages. These often produced speech lacking in human-like prosody Y. Wang \BOthers. (\APACyear2017). Tacotron, developed by Google’s research team, aimed to streamline this, targeting natural intonation, and simplifying the intricate TTS pipeline Y. Wang \BOthers. (\APACyear2017). Tacotron employed an end-to-end sequence-to-sequence model, reminiscent of techniques in machine translation. Central to its operation was an attention mechanism, enabling dynamic focus on the input text, thus efficiently learning text-audio alignment Y. Wang \BOthers. (\APACyear2017). It provides numerous valuable contributions:
-
•
End-to-End Learning: Tacotron pioneered in demonstrating direct text-to-speech mapping, eliminating the need for hand-crafted features Y. Wang \BOthers. (\APACyear2017).
-
•
Enhanced Naturalness: With Tacotron, speech synthesis attained a new standard, rivaling contemporary TTS systems. This was amplified when combined with the WaveNet vocoder Y. Wang \BOthers. (\APACyear2017).
-
•
Streamlined TTS Pipeline: Tacotron’s approach drastically reduced TTS complexities Y. Wang \BOthers. (\APACyear2017).
However, Tacotron was not without its challenges. The attention mechanism, while innovative, occasionally introduced speech artifacts such as word repetitions Shen \BOthers. (\APACyear2018). Training the model was another intricate process; stability was an issue that often necessitated meticulous hyperparameter tuning Shen \BOthers. (\APACyear2018). Additionally, achieving real-time synthesis, particularly when integrating with WaveNet, presented significant obstacles. Furthermore, Tacotron had a voracious appetite for vast quantities of high-quality, annotated training data, and it occasionally faltered when confronted with rare words or unconventional pronunciations Shen \BOthers. (\APACyear2018).
Tacotron2
Tacotron 2 Shen \BOthers. (\APACyear2018), a successor to the original Tacotron, brought forth a series of refinements and innovations in the realm of text-to-speech synthesis Shen \BOthers. (\APACyear2018). One of its standout enhancements was in its structural design. The encoder in Tacotron 2 integrated a higher number of convolutional layers Shen \BOthers. (\APACyear2018), allowing it to adeptly capture text features, particularly beneficial for elongated text sequences Shen \BOthers. (\APACyear2018). Additionally, by incorporating WaveNet as its vocoder, the produced speech was significantly more natural and lifelike Shen \BOthers. (\APACyear2018).
In terms of attention mechanisms, while the original Tacotron had pioneered the concept, Tacotron 2 advanced this feature, ensuring more stable outcomes for extended texts Shen \BOthers. (\APACyear2018). This stability was further boosted by Tacotron 2’s simplified symbolic representation for input text, fostering a better text-to-speech mapping Shen \BOthers. (\APACyear2018). Not stopping at that, Tacotron 2 introduced a post-processing network to refine the generated Mel spectrogram, which in turn elevated the overall speech quality Shen \BOthers. (\APACyear2018).
Yet, as with many sophisticated models, Tacotron 2 had its set of challenges. Training stability, especially concerning the attention mechanism, often posed difficulties, more so with extended textual content. And while the integration of WaveNet augmented speech quality, it rendered real-time synthesis quite challenging due to WaveNet’s slower generation pace Shen \BOthers. (\APACyear2018). Achieving optimal performance with Tacotron 2 often mandated vast quantities of high-caliber, annotated training data Shen \BOthers. (\APACyear2018). Furthermore, the model sometimes grappled with rare words or unconventional pronunciations. Lastly, occasional inconsistencies in pronunciation or rhythm were observed in the generated speech Shen \BOthers. (\APACyear2018).
Transformer TTS
To address Conventional RNN and LSTM architectures have difficulties in processing long sequences, leading to inefficient training and long computational delays Li \BOthers. (\APACyear2019). Transformer TTS Li \BOthers. (\APACyear2019) have taken inspiration from the achievements of Transformer designs in natural language processing (NLP) problems and subsequently used them to text-to-speech (TTS) systems. The design in question intrinsically incorporates self-attention processes, which have the potential to provide more stable and accurate alignment compared to the LSTM-based attention mechanism utilized in Tacotron Li \BOthers. (\APACyear2019).
FastSpeech
To address the speed and stability problems of Tacotron 2, FastSpeech Ren \BOthers. (\APACyear2019) was proposed. It uses a non-autoregressive approach and incorporates the structure of the Transformer.
The primary advancements of FastSpeech lie in its speed and determinism. Its non-autoregressive design enables parallelized prediction, hence improving both speed and determinism Ren \BOthers. (\APACyear2019). The robustness of FastSpeech is improved by removing the attention mechanism, which mitigates frequent problems such as the occurrence of missed or repeated audio segments Ren \BOthers. (\APACyear2019). Monotonic Alignment is achieved through the implementation of a teacher-student training strategy in FastSpeech Ren \BOthers. (\APACyear2019). This approach guarantees a consistent pronunciation and rhythm, resulting in a stable alignment between the given text and the corresponding speech output Ren \BOthers. (\APACyear2019).
While the FastSpeech system is considered groundbreaking, it also encounters several challenges and limitations. The training process of dependency parsing is further complicated by its need on a pre-existing model for aligning the data Ren \BOthers. (\APACyear2020). Certain critiques raise the possibility of a trade-off in terms of expressiveness when comparing to attention-based alternatives Ren \BOthers. (\APACyear2020).The implementation of the unique design presents challenges, since it provides a distinct set of difficulties while also addressing some issues Ren \BOthers. (\APACyear2020).
Parallel WaveGAN
The speed of traditional vocoders, such as WaveNet, is quite slow, particularly for real-time synthesis, mostly because of their autoregressive nature, despite their ability to generate speech of high quality Yamamoto \BOthers. (\APACyear2020).
In order to facilitate the integration of waveform generating methods into real-world applications, particularly on devices with constrained processing capabilities, there arose a necessity for enhanced computational efficiency and expedited performance Yamamoto \BOthers. (\APACyear2020).
In contrast to WaveNet, which use a sequential approach by predicting individual samples, Parallel WaveGAN utilizes a non-autoregressive method. This implies that it produces many waveform samples simultaneously, resulting in a significant enhancement of the synthesis speed Yamamoto \BOthers. (\APACyear2020).
The structure of the Generative Adversarial Network (GAN) is characterized by parallel components. The WaveGAN model utilizes a Generative Adversarial Network (GAN) architecture Yamamoto \BOthers. (\APACyear2020). The GAN configuration comprises a generator and a discriminator that engage in a game-theoretic competition. The primary objective of the generator is to generate waveforms that closely resemble genuine waveforms Yamamoto \BOthers. (\APACyear2020), whereas the discriminator’s primary goal is to accurately distinguish between real waveforms and those made by the generator. Over the course of its development, the generator gradually acquires the ability to generate waveforms of exceptional quality Yamamoto \BOthers. (\APACyear2020).
In order to uphold the quality of audio, the Parallel WaveGAN model incorporates a multi-resolution Short-Time Fourier Transform (STFT) loss Yamamoto \BOthers. (\APACyear2020). The preservation of both local and global structures of the audio waveform through this loss contributes to the production of synthetic speech of superior quality Yamamoto \BOthers. (\APACyear2020).
FastSpeech2
FastSpeech 2 was developed to address issues left unanswered by its predecessor. Due to its non-autoregressive and deterministic nature, FastSpeech had limited prosody and expressiveness. Despite its benefits, this deterministic technique produced monotone outputs and lowered voice tone and expressiveness. Even though FastSpeech synthesized speech faster, it still lacked naturalness and quality Ren \BOthers. (\APACyear2020).
FastSpeech 2 addressed these issues with new features. A stronger duration predictor Ren \BOthers. (\APACyear2020) was included to improve speech temporal subtleties Ren \BOthers. (\APACyear2020). Adding pitch and energy predictions Ren \BOthers. (\APACyear2020) improved speech prosody control and made it more natural and dynamic Ren \BOthers. (\APACyear2020). The model’s feed-forward transformers’ layer normalization improved training stability Ren \BOthers. (\APACyear2020). Most importantly, the VarPro (Variational Prosody) Loss allowed FastSpeech 2 to directly learn latent prosody representations from data, enhancing voice synthesis variability and control Ren \BOthers. (\APACyear2020).
These developments brought new obstacles. Due to its more complex architecture, FastSpeech 2 may require more training than its predecessor. The model, like FastSpeech, relied on pre-trained autoregressive TTS model alignments, which could increase training overheads. Furthermore, its improved prosody control has drawbacks. Due to extensive modification, synthesized speech may sound unnatural or introduce artifacts.
MelGAN
MelGAN Kumar \BOthers. (\APACyear2019) emerged as a prominent neural vocoder capable of converting Mel-spectrograms into raw audio waveforms Kumar \BOthers. (\APACyear2019). Setting itself apart from traditional vocoders like WaveNet, one of MelGAN’s standout features is its significantly accelerated speech generation, proficient enough to cater to real-time speech synthesis needs. While it embraces the framework of Generative Adversarial Networks (GANs), MelGAN maintains a simplified structure, rendering it lightweight and user-friendly for both training and deployment phases. Despite its rapid generation capabilities, the quality of the audio output remains uncompromised, especially when synergized with advanced text-to-speech models like Tacotron 2 or FastSpeech Kumar \BOthers. (\APACyear2019). During training, MelGAN demonstrates commendable stability compared to other GAN structures Kumar \BOthers. (\APACyear2019). Notably, it sidesteps the autoregressive steps in audio generation, facilitating parallel processing and swift production of continuous audio Kumar \BOthers. (\APACyear2019). Furthermore, its seamless compatibility with a variety of text-to-speech models adds to its adaptability and versatility Kumar \BOthers. (\APACyear2019). Consequently, with its fusion of speed, high quality, and lightweight characteristics, MelGAN has garnered substantial attention and application within the vocoder domain.
HiFi-GAN
HiFi-GAN, with neural vocoders’ noteworthy advancement, is renowned for its emphasis on high fidelity, producing audio that closely mirrors human speech in clarity and quality Kong \BOthers. (\APACyear2020). This is complemented by its efficient design, tailored for real-time synthesis, making it particularly apt for applications demanding swift voice generation. Its foundation on the Generative Adversarial Network (GAN) framework Kong \BOthers. (\APACyear2020), coupled with a multi-resolution approach, not only ensures stable training but also facilitates the generation of intricate waveforms Kong \BOthers. (\APACyear2020). A significant edge that HiFi-GAN boasts over other vocoders is its reduced audio artifacts, ensuring the output is seamless and natural-sounding Kong \BOthers. (\APACyear2020). Furthermore, its adaptability means it pairs well with a variety of text-to-speech models, enhancing its appeal in diverse speech synthesis architectures. Additionally, its robustness against overfitting, even on constrained datasets, underscores its superior design and utility in the speech synthesis domain Kong \BOthers. (\APACyear2020). HiFi-GAN its sound quality even surpasses WaveNet and MelGAN in some evaluations Kong \BOthers. (\APACyear2020).
FastPitch
FastPitch, which draws inspiration from the fundamental FastSpeech model, presents a paradigm-shifting methodology Łańcucki (\APACyear2021) for the synthesis of text-to-speech (TTS). This approach deviates from conventional text-to-speech (TTS) models by prioritizing autonomy in the process of aligning audio with transcriptions Łańcucki (\APACyear2021). This state of self-sufficiency implies that there is no longer a dependence on external alignment models Łańcucki (\APACyear2021), such as Transformer TTS or Tacotron 2. It is noteworthy that the model possesses an inherent ability to forecast pitch contour Łańcucki (\APACyear2021), a characteristic that enhances the amplification of natural voice modulation in the resulting audio Łańcucki (\APACyear2021). One of the noteworthy characteristics of FastPitch is its efficacy in reducing audio artifacts, hence guaranteeing improved sound quality and accelerated training convergence Łańcucki (\APACyear2021). FastPitch and FastSpeech2 were trained at almost the same time Łańcucki (\APACyear2021).
While several models in the field rely on the distillation of mel-spectrograms with the assistance of a guiding teacher model Łańcucki (\APACyear2021), FastPitch diverges from this approach, simplifying the training process Łańcucki (\APACyear2021). An additional advantage of this system is its capability to undergo training as a multi-speaker model Łańcucki (\APACyear2021), hence enhancing its adaptability. FastPitch offers users a comprehensive range of options for manipulating synthesized speech, including control over prosody, speech pace, and energy levels Łańcucki (\APACyear2021). In order to enhance its capabilities, the model has the ability to accept either graphemes or phonemes as input, hence providing versatility in its potential applications Łańcucki (\APACyear2021).
One notable characteristic of the system is its capacity to perform parallel processing Łańcucki (\APACyear2021). The efficient generation of mel-spectrograms ensures an expedited synthesis procedure. In conclusion, FastPitch is a notable TTS system that demonstrates strength, adaptability, and effectiveness, thereby reshaping the standards within the realm of speech synthesis.
Glow-TTS
The Monotonic Alignment Search (MAS) makes Glow-TTS a cutting-edge text-to-speech model J. Kim \BOthers. (\APACyear2020). This strategy teaches the model how text and spectrogram relate, which trains a Duration Predictor for inference J. Kim \BOthers. (\APACyear2020).
The Glow-TTS encoder maps each character to a Gaussian Distribution, while the decoder uses Glow Layers to convert each spectrogram frame into a latent vector. MAS aligns these processes harmoniously, optimizing model parameters with the most likely alignment. MAS is ignored during inference, so the model only uses the duration predictor J. Kim \BOthers. (\APACyear2020).
Glow-TTS’s encoder architecture is based on the TTS transformer but adds relative positional encoding and a residual Encoder Prenet link J. Kim \BOthers. (\APACyear2020). However, the decoder follows the Glow model J. Kim \BOthers. (\APACyear2020). This model trains solo and multi-speaker models well and is robust to longer sentences J. Kim \BOthers. (\APACyear2020). This durability and its capacity to infer 15 times faster than Tacotron2 make it a leader in its field J. Kim \BOthers. (\APACyear2020).
Glow-TTS’s lack of auto-regressive models and external aligners is a major advantage J. Kim \BOthers. (\APACyear2020). This provides fast, high-quality performance in multi-speaker environments J. Kim \BOthers. (\APACyear2020). Its signature hard monotonic alignments guarantee focused and stable processing. Hard monotonic alignments ensure that the model stays focused on one input segment at each step, making them ideal for consistent voice synthesis J. Kim \BOthers. (\APACyear2020).
OverFlow
OverFlow is an innovative model that leverages the strengths of flow, self-regression, and Neural HMM TTS Mehta \BOthers. (\APACyear2022). At its core, it integrates normalising flows with neural HMM TTS to accurately represent the intricate non-Gaussian distribution patterns observed in speech parameter trajectories Mehta \BOthers. (\APACyear2022).
The primary advantage of OverFlow lies in its hybrid nature. It synergizes the strengths of classical statistical speech synthesis with contemporary neural TTS Mehta \BOthers. (\APACyear2022). This synthesis results in models that need less data and fewer training updates Mehta \BOthers. (\APACyear2022). Furthermore, they substantially reduce the chances of producing nonsensical output, which is a common issue attributed to neural attention failures Mehta \BOthers. (\APACyear2022). Experimental data further bolsters the model’s efficacy. Systems designed on the OverFlow blueprint demand fewer updates than their peers and yet consistently generate speech that rivals the naturalness of human speech Mehta \BOthers. (\APACyear2022).
One of the most salient improvements introduced by OverFlow is the substitution of conventional neural attention with the neural hidden Markov model, or neural HMM. There are several reasons why this substitution is advantageous Mehta \BOthers. (\APACyear2022):
Neural HMM-based models are wholly probabilistic, meaning they can be precisely trained to optimize the sequence likelihood. The introduction of left-to-right no-skip HMMs Mehta \BOthers. (\APACyear2022) ensures strict adherence to the sequence, known as monotonicity Mehta \BOthers. (\APACyear2022). This ensures each phonetic unit in the input is spoken in the right sequence, eliminating the challenge of non-monotonic attention Mehta \BOthers. (\APACyear2022). Such issues are notorious for causing many attention-based neural TTS models to generate incoherent gibberish. Furthermore, these models usually demand vast amounts of data and numerous updates to master proper speec Mehta \BOthers. (\APACyear2022)h. However, it’s worth noting that merely relying on neural HMMs may not unlock their full potential due to their restrictive assumptions. Systems like those detailed in certain research publications posit that state-conditional emission distributions are either Gaussian or Laplace. These assumptions equate to an L2 or L1 loss Mehta \BOthers. (\APACyear2022), respectively. Given the intricate nature of human speech, which follows a highly intricate probability distribution, these assumptions might result in subpar models Mehta \BOthers. (\APACyear2022).
VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
The VITS model presents an advanced approach to Text-to-Speech (TTS) synthesis through its parallel architecture, incorporating several innovative techniques J. Kim \BOthers. (\APACyear2021).
Firstly, VITS employs Normalizing Flows, a method capable of learning and modeling complex probability distributions J. Kim \BOthers. (\APACyear2021). By applying this to their conditional prior distribution, the model can mimic the probability distribution of data more accurately, leading to audio outputs that are closer to genuine speech J. Kim \BOthers. (\APACyear2021).
Additionally, VITS utilizes Adversarial Training J. Kim \BOthers. (\APACyear2021). This approach involves a generator and a discriminator J. Kim \BOthers. (\APACyear2021). The generator strives to produce audio that’s as close to real data as possible, while the discriminator tries to differentiate between genuine and synthesized data J. Kim \BOthers. (\APACyear2021). As training progresses, the generator continuously improves in an attempt to "deceive" the discriminator, thereby producing higher-quality audio J. Kim \BOthers. (\APACyear2021). In VITS, this strategy is applied directly on the audio waveform, aiming for a more natural speech waveform output J. Kim \BOthers. (\APACyear2021).
Beyond generating high-quality audio, VITS also emphasizes the importance of the one-to-many relationship J. Kim \BOthers. (\APACyear2021) . In natural language pronunciation, the same text can be articulated in multiple ways, influenced by factors like pitch and duration J. Kim \BOthers. (\APACyear2021). To capture this diversity, VITS introduces a stochastic duration predictor that can synthesize speech with various rhythms from the same text input J. Kim \BOthers. (\APACyear2021).
In essence, VITS not only focuses on producing fine-grained audio quality but also seeks to simulate the diverse pronunciations of text found in the real world. This allows it to generate rich, natural, and varied voice outputs, meeting the high standards expected of modern TTS systems.
SpeechT5
SpeechT5 has emerged as a groundbreaking framework tailored to handle a spectrum of spoken language tasks Ao \BOthers. (\APACyear2021).
At its core, the model benefits from the strengths of a pre-trained Transformer encoder-decoder architecture Ao \BOthers. (\APACyear2021). To efficiently process both textual and auditory data, SpeechT5 seamlessly integrates pre-nets and post-nets Ao \BOthers. (\APACyear2021). Following its foundational pre-training, the model is further refined and honed to cater to specific tasks, making use of the pertinent pre/post-nets.
Traditional models in this domain often sidelined the importance of textual data when delving into spoken language tasks Ao \BOthers. (\APACyear2021). Additionally, an excessive dependence on pre-trained speech encoders meant that the critical role of decoders was often undervalued Ao \BOthers. (\APACyear2021). Moreover, there was a conspicuous absence of a profound exploration into an encoder-decoder design that synergized both speech and text data sources Ao \BOthers. (\APACyear2021).
Addressing these gaps, SpeechT5 draws inspiration from the esteemed T5 model and pioneers in-depth encoder-decoder pre-training founded on self-supervised learning principles Ao \BOthers. (\APACyear2021). Beyond just its architectural design, SpeechT5 introduces an innovative cross-modal vector quantization technique, creating a harmonious fusion of speech and textual data inputs Ao \BOthers. (\APACyear2021). Testament to its revolutionary design and capabilities, SpeechT5 not only harnesses the power of both unlabeled speech and text data but also sets new benchmarks across multiple spoken language tasks. Whether it’s speech recognition or voice conversion, the model has showcased unparalleled proficiency Ao \BOthers. (\APACyear2021). Furthermore, empirical evaluations underscore the unparalleled effectiveness of the model’s unique approach to joint speech-text pre-training.
VALL-E
VALL-E is a cutting-edge TTS framework that introduces an innovative approach of viewing TTS as a language modeling task. Distinct from other existing systems, what sets VALL-E apart is its use of audio encoder-decoder codes as an intermediate representation, instead of the conventional mel spectrograms. This unique design obviates the need for additional architectural engineering, pre-designed acoustic features, and fine-tuning. Emphasizing the use of a vast amount of semi-supervised data, it employs 60K hours of data for pre-training C. Wang \BOthers. (\APACyear2023), far surpassing prior pre-training endeavors. Another highlight is its powerful context-learning ability akin to GPT-3 C. Wang \BOthers. (\APACyear2023), implying that the model can comprehend and manage intricate contextual information without the need for intricate adjustments C. Wang \BOthers. (\APACyear2023).
Delving deeper into VALL-E, its diverse output emerges as a salient feature. It can generate multiple outputs for a single input text while also retaining the acoustic environment and emotions of a given acoustic cue C. Wang \BOthers. (\APACyear2023). This means that with just a 3-second recording of an unseen speaker C. Wang \BOthers. (\APACyear2023), VALL-E can synthesize high-quality voice with personalized characteristics C. Wang \BOthers. (\APACyear2023). In fact, when compared to other advanced zero-shot TTS systems C. Wang \BOthers. (\APACyear2023), VALL-E showcases significant advantages in terms of voice naturalness and speaker similarity.
In conclusion, VALL-E not only brings forth several disruptive innovations but also presents a plethora of clear advantages, paving the way for future TTS research and applications.
VALL-E X
In recent research, cross-lingual speech synthesis and foreign accents in text-to-speech synthesis have been areas of keen interest Zhang \BOthers. (\APACyear2023). Traditional cross-lingual speech synthesis models often fall short in voice quality when compared to monolingual TTS models due to data scarcity and model capacity constraints Zhang \BOthers. (\APACyear2023). Furthermore, a prevalent challenge is that cross-lingual speech synthesis frequently produces speech tinted with the accent of the source language, a problem that poses noticeable impacts across various scenarios Zhang \BOthers. (\APACyear2023).
To address these issues, researchers developed VALL-E X, a cross-lingual neural encoder-decoder language model trained on a vast amount of multilingual, multi-speaker, multi-domain non-distinct speech data Zhang \BOthers. (\APACyear2023). The central idea of this model is to utilize the source language’s speech and the target language’s text as cues to predict the target language’s acoustic tokens Zhang \BOthers. (\APACyear2023). Distinct from traditional TTS methods, VALL-E X views TTS as a conditional language modeling task, adopting neural encoder-decoder codes as the acoustic intermediate representation Zhang \BOthers. (\APACyear2023).
The most significant advantage of VALL-E X is its capability to produce high-quality cross-lingual speech Zhang \BOthers. (\APACyear2023). It not only preserves the voice, emotion, and acoustic environment of unseen speakers but can also synthesize speech with the native accent for any speaker Zhang \BOthers. (\APACyear2023). This means it has largely addressed the issue of foreign accents in cross-lingual speech synthesis Zhang \BOthers. (\APACyear2023). Empirical tests have shown that, compared to existing baseline methods, VALL-E X stands out noticeably in terms of speaker similarity, voice quality, translation quality, voice naturalness, and human evaluations Zhang \BOthers. (\APACyear2023).
In summary, VALL-E X offers a potent tool to tackle the challenges of cross-lingual speech synthesis, significantly enhancing voice quality and naturalness. This advancement sets an important benchmark for future cross-lingual speech synthesis research.
Meta-MMS
The Massively Multilingual Speech (MMS) project is a groundbreaking initiative that aims to amplify the linguistic coverage of speech technology by 10 to 40 times, contingent on the task Pratap \BOthers. (\APACyear2023). This venture is particularly notable for the introduction of two novel datasets, MMS-lab and MMS-unlab, encompassing labeled speech data from 1,107 languages and unlabeled speech data from 3,809 languages, respectively Pratap \BOthers. (\APACyear2023). The researchers have further developed an encompassing pre-trained wav2vec 2.0 model that covers 1,406 languages Pratap \BOthers. (\APACyear2023), a singular multilingual automatic speech recognition model that caters to 1,107 languages, equivalent voice synthesis models, and a language recognition model that identifies up to 4,017 languages Pratap \BOthers. (\APACyear2023).
One of the standout features of the project is its commitment to large-scale multilingual support Pratap \BOthers. (\APACyear2023). In comparison to existing speech technologies, the models and datasets brought forward by this initiative envelop a broader range of languages, especially those that are resource-scarce and on the brink of extinction Pratap \BOthers. (\APACyear2023). A unique facet in terms of dataset collection was the utilization of publicly available religious texts recitations as the source, a distinctive avenue hitherto untapped for multilingual voice technology Pratap \BOthers. (\APACyear2023).
The advantages presented by Meta-MMS are manifold. Firstly, the sheer linguistic diversity it supports, covering over 1,000 languages Pratap \BOthers. (\APACyear2023), plays a pivotal role in the conservation and fostering of linguistic diversity. Additionally, despite the vast augmentation in linguistic coverage, the project’s models continue to offer high-caliber automatic voice recognition and text-to-speech synthesis.
Addressing long-standing issues, the research mitigates the restrictive linguistic coverage that has marred voice technology. While the past decade has seen significant strides in the field, the technologies could not cater to the majority of the 7,000-plus global languages Pratap \BOthers. (\APACyear2023). The present study expands the linguistic ambit of voice technology by unveiling new datasets and models. Moreover, the extinction risk faced by numerous languages is countered by this project. The constricted linguistic span of current technologies might exacerbate extinction trends, and by bolstering support for more languages, this project serves as a bulwark for these endangered languages.
2.3 Application of Transfer Learning in Various TTS Models
Tacotron2: As mentioned in the literature review, Tacotron2 built upon the original Tacotron model by refining components like the encoder and attention mechanism. Research by \citeAshen2018natural. demonstrated Tacotron2’s ability to leverage transfer learning by initializing the model with pre-trained components. This improved stability and lowered data requirements.
FastSpeech2: This non-autoregressive model relies on alignments from an autoregressive "teacher" model like Tacotron2. \citeAren2020fastspeech showed FastSpeech2 can utilize transfer learning from the teacher to bootstrap its training. Its variance adaptor also aids adaptation to new speakers.
VITS: \citeAkim2021conditional highlighted how VITS leverages normalizing flows and adversarial training to capture complex speech distributions. Its use of normalizing flows is well-suited for adapting to new distributions via fine-tuning, enhancing few-shot transfer capabilities.
Glow-TTS: As a flow-based generative model, Glow-TTS can adapt its prior distribution to new datasets through fine-tuning, as noted by \citeAkim2020glow. Its lightweight design also enables rapid fine-tuning for transfer learning.
OverFlow. \citeAmehta2022overflow emphasized OverFlow’s hybrid design integrating Neural HMM with flows. The probabilistic nature of Neural HMMs suits low-resource scenarios, providing a strong foundation for fine-tuning and transfer Mehta \BOthers. (\APACyear2022).
SpeechT5. \citeAao2021speecht5 showed SpeechT5’s versatility across spoken language tasks via fine-tuning its pre-trained encoder-decoder model. Its ability to perform various downstream tasks highlights SpeechT5’s transfer learning aptitude.
In summary, advancements like attention mechanisms, variance adaptors, normalizing flows, Neural HMMs, and pre-training have expanded TTS models’ capacity to effectively leverage transfer learning, even in low-resource settings. The literature provides encouraging evidence regarding transfer learning’s potential to enable customized TTS with limited data.
2.4 Conclusion
In the domain of text-to-speech the literature review reveals a vibrant and rapidly evolving field. The examination of key technologies, methodologies, and frameworks such as VALL-E highlights the convergence of novel approaches and cutting-edge innovations. A distinctive trend in the literature is the shift towards embracing neural architectures, large-scale data training, and cross-lingual capabilities, reflecting the broader goals of enhancing voice naturalness, speaker similarity, and linguistic diversity. Furthermore, projects such as the Meta-MMS have illuminated the potential to bridge technological gaps, particularly in underserved and endangered languages. Challenges, including the scarcity of data in cross-language voice synthesis, are being addressed through creative solutions and the development of diverse datasets. The integration of TTS as a language modeling task and the application of semi-supervised data have emerged as remarkable innovations, setting the stage for future research. This literature review underscores the dynamism and complexity of the voice cloning field, highlighting not only the achievements but also the areas ripe for exploration, experimentation, and ethical consideration. The convergence of these elements signifies a promising trajectory for voice cloning, with a clear emphasis on accessibility, quality, and the humanization of synthetic speech. It sets the stage for future work, where the synthesis of voices is not merely a technological feat but a nuanced and responsive interplay of science, art, and societal needs.
Chapter 3 Methodology
This section of the thesis delineates the methodological approach undertaken to conduct this research. The overarching objective is to provide a comparative analysis of transfer learning in several state-of-the-art deep learning text-to-speech models on a few-shot, low-resource, customized dataset. The methodology is designed to be thorough, systematic, and replicable, allowing for the validation and verification of the results obtained.
The choice of methodology is intrinsically tied to the research questions, which explore the potential differences in performance and efficiency among the selected models when fine-tuned with a low-resource, customized dataset. The models chosen for this study, namely Tacotron 2, VITS, Glow-TTS, FastSpeech2, OverFlow, FastPitch, and SpeechT5, were selected based on their varying architectures and unique design philosophies that hold the potential for interesting comparative outcomes.
This section is divided into several subsections that cover different aspects of the research process, including the selection of models, detailed description of each model’s architecture and pipeline, and the evaluation metrics used to assess their performance. Furthermore, the processes of data collection, data preprocessing, and model fine-tuning will also be discussed.
Additionally, the crucial aspect of model parameter selection will be addressed. This section will cover the key parameters chosen for each model, the rationale behind their selection, and the importance of these parameters to the model’s overall performance. The importance of selecting suitable parameters cannot be overstated as it significantly influences the performance of each model.
The methodology aims to provide comprehensive and clear explanations of the procedures followed, enabling an understanding of how the research was conducted, and thus, allowing an accurate assessment of its validity and reliability. This ensures that the conclusions drawn are robust, reliable, and contribute significantly to the field of voice cloning using deep learning models.
In the course of our experimentation, we leveraged multiple open-source text-to-speech toolkits to conduct relevant tests and evaluations. The primary toolkits and repositories we made use of are as follows:
-
•
NVIDIA’s Tacotron2111https://github.com/NVIDIA/tacotron2 offered an attention mechanism-based sequence-to-sequence voice synthesis model, giving another powerful baseline for our experiments.
-
•
The VITS model222https://github.com/jaywalnut310/vits, provided by jaywalnut310, represents an efficient TTS system that integrates several cutting-edge technologies.
-
•
SpeechT5 developed by Microsoft333https://github.com/microsoft/SpeechT5, blends the T5 architecture into voice tasks, providing a valuable benchmark for our comparative experiments.
-
•
We also employed FastSpeech2 by ming024444https://github.com/ming024/FastSpeech2, a non-autoregressive voice synthesis method based on the Transformer.
-
•
The TTS toolkit by coqui-ai555https://github.com/coqui-ai/TTS, which encompasses a variety of TTS models and utilities, facilitated our experimental processes.
-
•
An additional version of VITS by Plachtaa666https://github.com/Plachtaa/VITS-fast-fine-tuning was also utilized in certain experimental settings.
By employing the aforementioned tools and repositories, we were able to extensively assess the performance of different models on our specific dataset and pinpoint the optimal solution.
3.1 Model Selection, Architectures and Pipelines
In order to provide a comprehensive comparative analysis of transfer learning in text-to-speech synthesis, a wide array of models were selected, each embodying unique architectural features, training paradigms, and strengths. The following sub-sections provide an overview of these models and the reasoning behind their selection for this study.
3.1.1 Tacotron2
Tacotron2 (Shen et al., 2018) is a highly-regarded model in the field of TTS. Leveraging an end-to-end system, Tacotron2 eliminates the need for intricate text and audio processing pipelines. Its utilization of a recurrent sequence-to-sequence architecture with attention allows us to explore the impact of such features on the model’s ability to adapt to new, low-resource scenarios via transfer learning.
Tacotron2 Architecture
Tacotron 2, as an end-to-end generative text-to-speech model, comprises of two main parts: a recurrent sequence-to-sequence feature prediction network with attention (referred to as Tacotron) and a modified WaveNet model acting as a vocoder.

Character Encoding: The initial step in Tacotron 2 involves the conversion of input text into a sequence of linguistic features. These features, often phonemes or graphemes, are then passed into an embedding layer, which translates these discrete symbols into continuous vectors.
Encoder: The continuous vectors are then fed into the encoder, which in the case of Tacotron 2, is a stack of three convolutional layers followed by a single bidirectional LSTM layer. This encoder processes the input sequence into a higher-level representation that encapsulates the context of each character in the text.
Attention and Decoder: Tacotron 2 uses a location-sensitive attention mechanism to align the encoder outputs with the decoder inputs. The decoder, a stack of LSTM layers, takes this alignment information along with the previously predicted spectrogram frame and generates the next spectrogram frame.
Post-net: After the decoder generates a mel-spectrogram, it is passed through a post-net which is a stack of convolutional layers. This post-net refines the mel-spectrogram prediction, enhancing the output’s quality.
WaveNet Vocoder: Finally, the predicted mel-spectrogram is converted into time-domain waveforms using the WaveNet vocoder. The WaveNet vocoder uses the predicted mel-spectrogram as a local condition to generate high-fidelity speech.
3.1.2 FastSpeech2
In the continuously evolving realm of text-to-speech (TTS) synthesis, the challenge of the one-to-many mapping problem has been a persistent hurdle. FastSpeech2 has paved a transformative path to address this issue. Instead of relying on the over-simplified output typically derived from teacher models, it prioritizes the use of ground-truth targets during training, ensuring a synthesis process that is both genuine and authentic. Additionally, FastSpeech2 uniquely integrates a broader range of speech variation data as conditional inputs. These variations, which envelop crucial speech elements such as pitch, energy, and a refined precision in duration, are extracted directly from the speech waveform. This approach allows FastSpeech2 to adeptly use them during the training phase and employ the predicted values during inference. The results of these innovative changes are nothing short of remarkable. FastSpeech2 has showcased a training speed that surpasses its predecessor, FastSpeech, by a factor of three Ren \BOthers. (\APACyear2020).
FastSpeech2 Architecture and Pipeline

Phoneme Embedding: The model begins its processing by taking phonemes as input. These phonemes undergo a transformation via a Phoneme Embedding layer, converting them into continuous-valued vectors. This conversion facilitates better representation and processing in subsequent layers Ren \BOthers. (\APACyear2020).
Positional Encoding Addition: Once we have our phoneme embeddings, it’s essential to provide the model with positional information. Positional Encoding is integrated into these embeddings, ensuring each position (like characters or words in the text) receives a unique encoding, giving the model a clear sense of sequence order Ren \BOthers. (\APACyear2020).
Encoder: These positionally encoded phoneme embeddings are then channeled through the encoder. This stage refines these embeddings, yielding hidden representations that encapsulate both the phonemic and positional nuances of the input Ren \BOthers. (\APACyear2020).
Variance Adaptor: The model then employs a Variance Adaptor, which infuses the hidden sequence with additional variance details, namely duration, pitch, and energy. These metrics are pivotal as they contribute to the naturalness and expressivity of the speech output Ren \BOthers. (\APACyear2020).
Second Positional Encoding: Given the richness and complexity of the hidden representations after the Variance Adaptor, there’s a need to reintroduce positional encoding. This step is crucial as, through multiple transformations, the initial positional data may have become diluted. Re-applying positional encoding ensures a sharp, unambiguous retention of sequence order as the model proceeds Ren \BOthers. (\APACyear2020).
Mel-spectrogram Decoder: Armed with these comprehensive representations, the model progresses to the mel-spectrogram decoder. Here, it translates the processed sequence into a mel-spectrogram, a visual representation of the spectrum of frequencies as they vary with time Ren \BOthers. (\APACyear2020).
Waveform Decoder: The last step before obtaining the audio output involves the waveform decoder. Its primary function is to transform the mel-spectrogram into raw audio waveforms, readying them for playback or storage as audio files Ren \BOthers. (\APACyear2020).
By fusing these carefully designed components and steps, FastSpeech2 establishes itself as a formidable solution in the TTS domain, promising high-quality, natural-sounding speech outputs Ren \BOthers. (\APACyear2020).
3.1.3 FastPitch
FastPitch’s incorporation of two feed-forward Transformer (FFTr) stacks underscores its innovative architecture Łańcucki (\APACyear2021). This design ensures an enhanced processing speed compared to traditional recurrent models. The dual FFTr stacks allow for efficient parallel processing of input data, significantly reducing the time required to generate outputs. Such an architecture not only improves computational efficiency but also aids in capturing intricate patterns in the data. By leveraging the power of FFTr stacks, FastPitch ensures robustness and precision, making it an optimal choice for real-time voice synthesis tasks Łańcucki (\APACyear2021). Furthermore, this dual-stack mechanism can effectively handle longer sequences, ensuring consistency and clarity in the synthesized voice outputs Łańcucki (\APACyear2021). FastPitch and FastSpeech2 were developed at the same time Łańcucki (\APACyear2021).
FastPitch Architecture and Pipeline

FastPitch employs a sophisticated feedforward Transformer methodology Łańcucki (\APACyear2021), meticulously designed to transmute raw textual inputs into mel-spectrograms. Remarkably, its design emphasizes parallelism, ensuring that each character within the input text is processed concurrently. This efficient design paradigm ensures that a comprehensive mel-spectrogram is crafted seamlessly within a single forward pass Łańcucki (\APACyear2021).
Delving deeper into its architecture, FastPitch is anchored upon a bidirectional Transformer structure, commonly recognized as a Transformer encoder Łańcucki (\APACyear2021). This foundational component is adeptly complemented with both pitch and duration predictors, emphasizing the model’s adaptability and specificity. As input sequences make their journey through the preliminary N Transformer segments for encoding, they are not merely processed but are enriched with nuanced pitch data, subsequently experiencing discrete upsampling Łańcucki (\APACyear2021). This enriched data is then channeled through another set of N Transformer units Łańcucki (\APACyear2021). Here, the process emphasizes refinement, smoothing out any irregularities in the upsampled signal and culminating in the generation of a polished mel-spectrogram.
FastPitch is inspired by FastSpeech and predominantly incorporates two feed-forward Transformer (FFTr) stacks Łańcucki (\APACyear2021). The first FFTr stack processes the input tokens, while the second manages the output frames. Given an input sequence of lexical units denoted by x and a target sequence of mel-scale spectrogram frames represented by y, the first FFTr stack Łańcucki (\APACyear2021) generates a hidden representation, symbolized as h. This representation, h, then facilitates the prediction of both duration and average pitch for each character via a 1-D CNN Łańcucki (\APACyear2021).
The pitch is adjusted to align with the dimensionality of the hidden representation, h, and then added to it. This modified sum, denoted as g, undergoes discrete upsampling before being input into the output FFTr Łańcucki (\APACyear2021), yielding the final mel-spectrogram sequence. The equation for this can be represented as: g = h + PitchEmbedding(p), .
During training, the model employs the actual values of p and d, while predictions are used during inference. The goal is to minimize the mean-squared error (MSE) between predicted and true values Łańcucki (\APACyear2021).
To encapsulate, FastPitch’s architecture is a testament to the harmonious integration of Transformer prowess, alongside dedicated pitch and duration prediction modules. This symbiosis ensures the creation of a formidable, highly efficient mechanism for text-to-spectrogram conversion.
3.1.4 Glow-TTS
The Glow-TTS model was selected due to its unique structure that includes a text encoder, duration predictor, and flow-based decoder. It has shown strong performance in terms of the quality of synthesized speech and the ability to maintain natural prosody and rhythm of speech. The central algorithm implemented in the Glow-TTS model is the Monotonic Alignment Search. This algorithm significantly influences the model’s ability to generate synthesized speech, thus making it a critical component for evaluation. To effectively assess the impact and performance of the Monotonic Alignment Search, we have opted to select the Glow-TTS model for this study. The model’s structure also makes it less complex than other models, making it a good choice for an initial comparative analysis in this study J. Kim \BOthers. (\APACyear2020).
Glow-TTS Architecture and Pipeline
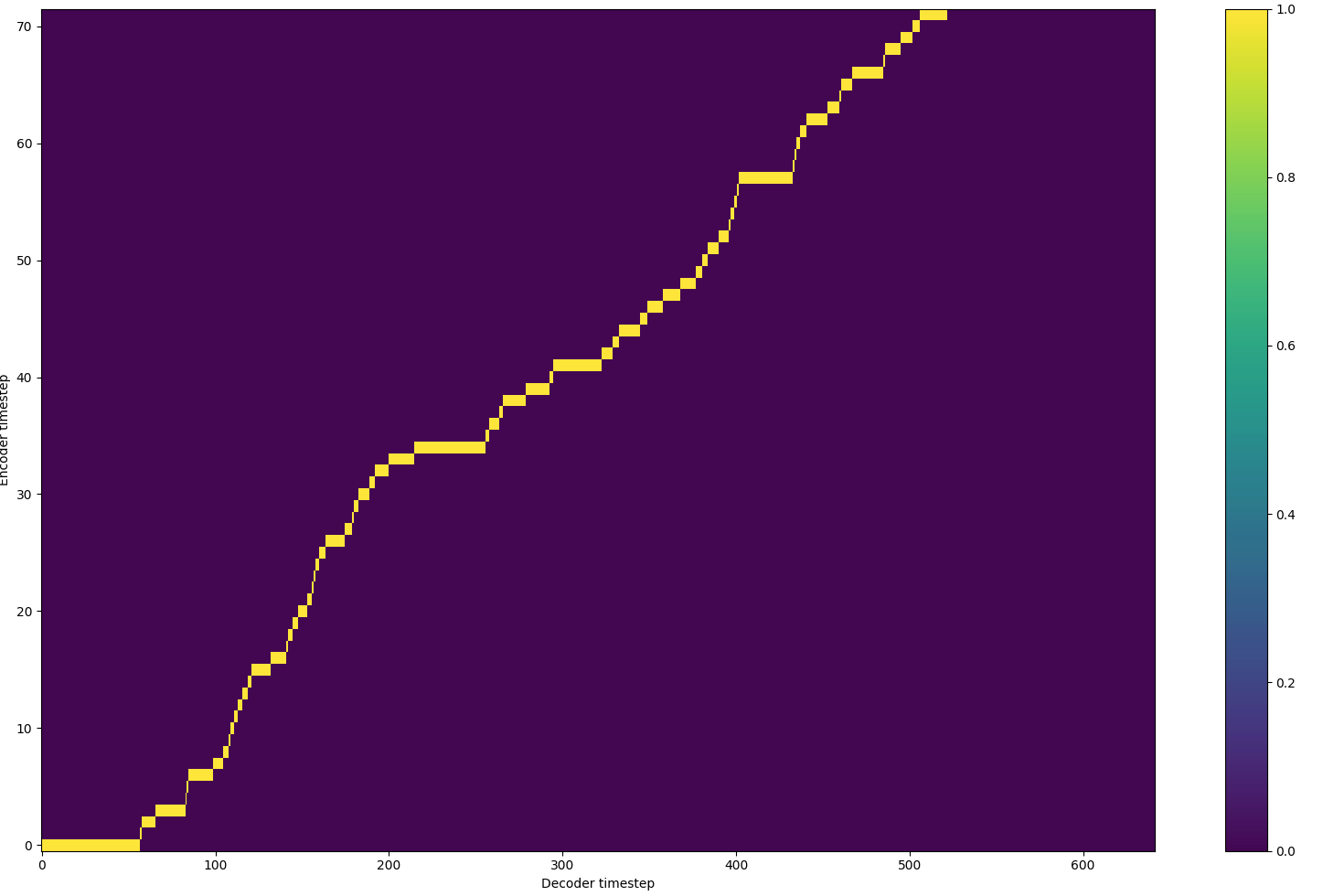
The Glow-TTS model is composed of three main parts: a text encoder, duration predictor, and a flow-based decoder.
Text Encoder: This transforms the input text sequence into a continuous hidden representation. This hidden representation contains information about the phonemes input and its context within the input sequence J. Kim \BOthers. (\APACyear2020).
Duration Predictor: This predicts the duration of each input phoneme. The predicted duration aligns the time each input phoneme expands with the target speech time J. Kim \BOthers. (\APACyear2020).
Flow-Based Decoder: This transforms the outputs of the text encoder and duration predictor into the target speech. The decoder achieves this by sampling a latent variable from the prior distribution and transforming this latent variable into a mel-spectrogram J. Kim \BOthers. (\APACyear2020).
The process of the Glow-TTS model can be split into two phases: the training phase and the inference phase.
Training Phase: The input text is processed through the text encoder to get a hidden representation of each phoneme. These representations are input into the duration predictor to predict the duration of each phoneme. The Monotonic Alignment Search (MAS) algorithm is used to find the most probable hard monotonic alignment J. Kim \BOthers. (\APACyear2020). The alignment and hidden representation are input into the prior encoder to get the statistical properties (mean and variance) of the prior distribution. A latent variable is sampled from the prior distribution and transformed into a mel-spectrogram by the flow decoder J. Kim \BOthers. (\APACyear2020).
Inference Phase: The process during the inference phase is identical to the training phase, except that the durations used to get the alignment are those predicted by the duration predictor, and not the actual durations J. Kim \BOthers. (\APACyear2020).
3.1.5 VITS
The VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech) model J. Kim \BOthers. (\APACyear2021) is selected in this study due to its unique structure and methodology which includes the application of variational inference and normalizing flows. VITS or Variational Inference Text-to-Speech operates by capturing the multimodal nature of speech data via variational inference.
VITS stands out among TTS models due to its ability to generate high-quality speech samples J. Kim \BOthers. (\APACyear2021). Its structure integrates generative modeling with adversarial training, offering robust performance, and versatility. Moreover, it is equipped to handle complex data distributions, something inherently present in speech data. Given these capabilities, it has been selected as part of this study’s comparative analysis.
VITS Architecture and Pipeline

The training procedure and architecture of the VITS model can be described as a series of interconnected components, each performing a specific function in the pipeline. It can be outlined as follows:
Data Preparation: VITS model starts with the extraction of linear and mel spectrograms from speech samples. The linear spectrogram serves as the input to the posterior encoder to be transformed into latent variables, while the mel spectrogram is used to compute reconstruction loss J. Kim \BOthers. (\APACyear2021).
Text Encoding: Phonemes extracted from the input text are fed into a text encoder and transformed into a hidden representation, capturing helpful characteristics of the input text for subsequent speech synthesis J. Kim \BOthers. (\APACyear2021).
Linear Projection Layer: The output of the text encoder is processed by a linear projection layer that converts the hidden text representation into means and variances used for constructing the prior distribution J. Kim \BOthers. (\APACyear2021).
Posterior Encoder: The linear spectrogram, after processing through the posterior encoder, yields latent variables that are sliced and fed into the normalizing flow. The posterior encoder is responsible for converting a sequence of Gaussian noise into two random variables, which are used to represent an approximate posterior distribution. J. Kim \BOthers. (\APACyear2021).
Flow: Referring to the Normalizing Flow, it is a powerful generative model capable of learning complex data distributions. In this model, the flow is applied to the prior encoder to enhance its representational power for the prior distribution, generating more realistic samples J. Kim \BOthers. (\APACyear2021).
Alignment Estimation: Monotonic Alignment Search (MAS) is used to determine the alignment that maximizes the log-likelihood of the latent variables, equivalent to finding the alignment that maximizes the Evidence Lower BOund (ELBO) J. Kim \BOthers. (\APACyear2021).
Stochastic Duration Predictor: This component estimates the duration distribution of the phonemes J. Kim \BOthers. (\APACyear2021).
Adversarial Training: To improve synthetic quality, the model undergoes adversarial training, employing a discriminator to distinguish between real and generated speech samples. Concurrently, the generator (the model) tries to generate speech samples that the discriminator can’t differentiate J. Kim \BOthers. (\APACyear2021).
Optimization: The model is trained to minimize reconstruction loss and adversarial loss, and to maximize the log-likelihood of the latent variables J. Kim \BOthers. (\APACyear2021).
3.1.6 SpeechT5
Choosing SpeechT5 as a model for spoken language processing tasks stems from its multifaceted capabilities. It stands as a unified-modal framework with immense power to handle a plethora of tasks such as automatic speech recognition, speech synthesis, speech translation, voice conversion, speech enhancement, and speaker identification Ao \BOthers. (\APACyear2021). Its versatility is unparalleled, especially when considering that many models are often designed specifically for a single task, while SpeechT5 has the dexterity to span across multiple.
A distinct feature of SpeechT5 is its ability to train without labels Ao \BOthers. (\APACyear2021). It’s grounded on the Transformer encoder-decoder paradigm, allowing it to be pre-trained without the necessity for labeled data. This not only reduces the demands of training data but enhances the model’s adaptability in multitask scenarios.
SpeechT5 Architecture and Pipeline

The architecture of SpeechT5 pivots around a pre-trained Transformer encoder-decoder core, ensuring proficiency in managing both speech and text data. The inclusion of "pre-nets" serves the purpose of transforming the input, be it text or speech, into hidden representations that the Transformer can utilize. On the other side, "post-nets" take the Transformer’s output and reformat it back into text or speech, ensuring a coherent output format Ao \BOthers. (\APACyear2021).
A noteworthy aspect is the model’s adaptability. Post its pre-training phase, the entire encoder-decoder structure can be fine-tuned to cater to individual tasks Ao \BOthers. (\APACyear2021). This fine-tuning leverages specific pre-nets and post-nets tailored for the task in question, which means SpeechT5 can offer specialized solutions while retaining a consistent core architecture.
In essence, SpeechT5 offers not just a robust solution for spoken language processing but presents an adaptable and comprehensive approach, making it a prime choice for a range of applications.
3.1.7 OverFLow
In the quest to delve deeper into text-to-speech systems, the choice of using OverFlow stands out for several pivotal reasons:
OverFlow integrates the Neural HMM, positioning itself as a distinctive and promising model within the TTS domain. Given the contemporary technological landscape, the Neural HMM offers intriguing possibilities for transfer learning in situations characterized by limited samples and resources Mehta \BOthers. (\APACyear2022). Our ambition is to further probe and validate the efficacy of Neural HMM in such specific scenarios .
Beyond merely incorporating Neural HMM, OverFlow amalgamates elements of flow techniques with autoregression, bestowing a more nuanced and comprehensive depiction for TTS Mehta \BOthers. (\APACyear2022). This composite approach stands to bolster the accuracy and stability of the model.
To elaborate further, OverFlow layers normalising flows atop the foundational neural HMM TTS. This design choice equips the model to aptly describe the non-Gaussian distribution intrinsic to speech parameter trajectories Mehta \BOthers. (\APACyear2022). This suggests that the model is adept at precisely capturing the intricate patterns and nuances present in speech data.
In summary, the primary impetus behind our selection of OverFlow is its fusion of multiple cutting-edge techniques, particularly the Neural HMM, coupled with our intrigue about its potential in low-resource transfer learning scenarios Mehta \BOthers. (\APACyear2022).

OverFlow Architecture and Pipeline
Text Encoder: In the context of TTS acoustic modeling, the neural HMM encoder transforms input vectors, such as phone embeddings, into a sequence of vectors that represent states in a left-to-right, no-skip Hidden Markov Model (HMM). Notably, each input symbol maps to a fixed number of vectors, sometimes two states per symbol Mehta \BOthers. (\APACyear2022).
Autoregressive Left-to-Right Neural HMM Workflow: Neural HMM characterizes sequences, with each frame typically assuming a Gaussian distribution. The technique of Normalizing Flows takes this base distribution and applies an invertible nonlinear transformation , evolving it into a more intricate target distribution. This transformation can be mathematically represented as , where denotes the target distribution, signifies the source distribution, and encapsulates the parameters guiding the transformation. The term "left-to-right" implies a system progression from the sequence’s start to its end without omitting any intermediate steps. In many scenarios, each input symbol might translate into multiple state vectors Mehta \BOthers. (\APACyear2022).
The primary roles of Neural HMMs are probabilistic modeling and serving as an alternative to traditional neural attention. Neural HMMs provide a distributional description of discrete-time sequences, often assuming a Gaussian distribution for each frame. They offer a framework that aligns input values with output observations, standing as an alternative to traditional neural attention Mehta \BOthers. (\APACyear2022).
Decoder: The decoder within the neural HMM (Hidden Markov Model) produces outputs from the provided inputs. Its primary objective is to generate the parameters of the emission distribution and the transition probability. This dual capability aids in delineating how the HMM transitions to the impending state and the output frame that should be produced for each timestep Mehta \BOthers. (\APACyear2022).
The neural HMM decoder accepts two primary inputs: a state-defining vector , corresponding to the HMM state at timestep , and the previously generated acoustic frames , making the model inherently autoregressive. The decoder’s dual outputs are the parameters of the emission distribution and the transition probabilities . The parameter describes the next output frame ’s probability distribution. Most neural HMMs postulate that adheres to a multivariate Gaussian distribution with a diagonal covariance matrix. Under this assumption, the parameter bifurcates into two vectors that respectively correspond to ’s element-wise mean and standard deviation Mehta \BOthers. (\APACyear2022).
The transition probability outlines the probability of the HMM transitioning to a subsequent state. If this transition manifests, then ; otherwise, . Synthesis traditionally commences from and concludes when . To meet the Markov assumption on the concealed states , the decoder’s outputs must remain independent of the input vectors from previous time steps . This independence enables training the model to maximize training data’s log-likelihood using classical HMM’s standard algorithms Mehta \BOthers. (\APACyear2022).
Invertible Post-net: The invertible post-net primarily enhances output quality and ensures compatibility with maximum likelihood training. Many autoregressive TTS systems use a greedy, sequential output generation method during synthesis. To improve this output, a post-net with non-causal CNNs refines the sequence generated by the autoregressive model.
Traditional post-net architectures aren’t compatible with neural HMMs’ maximum likelihood training. But by passing the model output through an invertible post-net, the entire model can be trained to maximize the exact sequence likelihood.
Normalizing flows transform simple latent distributions into more complex target distributions via an invertible nonlinear transformation. The ability to reverse this process allows for the computation of the log-probability of any observed result using the change-of-variables formula. Even when the transformation is slightly non-linear, complex distributions can emerge by chaining several transformations together, often labeled as an invertible neural network Mehta \BOthers. (\APACyear2022).
3.2 Data Collection
For the purpose of examining the model’s ability to generalize on random small datasets Rothauser (\APACyear1969), I read out and record 7 lists from The Harvard Sentences. The Harvard Sentences, sometimes referred to as the Harvard Lines, comprise a set of 720 standardized phrases. These phrases are organized into 10 distinct lists and are specifically designed for testing on systems like Voice over IP, mobile phones, and other telecommunication devices. Phonetically balanced, these sentences reflect the frequency of phoneme occurrences in the English language. As part of the IEEE Recommended Practice for Speech Quality Measurement, these sentences are categorized under the 1965 Revised Speech Balanced Sentence List. Their consistent and standard nature makes them an invaluable tool in the fields of telecommunications, speech, and acoustics research Rothauser (\APACyear1969).
The dataset contains individual sentences like "The birch canoe slid on the smooth planks." To enrich the training set with extended sentences, I merged pairs of these statements. To test transfer learning from a few-shot dataset, my dataset ultimately encompasses 49 sentences, totaling 341 unique words.
I have also created a "metadata.txt" file, which contains the dataset’s transcript to provide labels for training and testing.
3.3 Data Analysis
The total audio duration of all sentences is approximately 266 seconds, with an average duration of 5 seconds per sentence, ranging from 3 to 9 seconds. I employed a sampling rate of 22050Hz, mono audio, with 16 bits per sample, which is a common choice in voice cloning research due to the balance it provides between audio quality and computational efficiency.
3.3.1 Dataset Distribution Analysis
To guarantee the randomness of my dataset and subsequently test the impact of a random dataset on the model’s transfer learning capabilities, I compared both the "text length vs. mean audio duration" and "text length vs. number of instances" in my dataset to those in the LJSpeech Ito \BBA Johnson (\APACyear2017) dataset.
LJSpeech is a renowned public domain dataset that stands out in the realm of voice and speech research. Comprising concise audio recordings, the heart of this dataset lies in its meticulously curated content: passages read aloud by a singular female speaker, sourced from a diverse collection of seven non-fiction English books. These readings encompass a vast array of topics, spanning from profound philosophical discourses and poetic expressions to rigorous scientific analyses Ito \BBA Johnson (\APACyear2017).
Beyond the sheer breadth of content, the dataset’s magnitude is equally impressive, amassing to an aggregate of approximately 24 hours of speech from native speakers Ito \BBA Johnson (\APACyear2017). The dataset contains over 13,000 short audio clips and corresponding transcripts, with the audio clips totaling more than 24 hours in length Ito \BBA Johnson (\APACyear2017). One of LJSpeech’s defining features is its pairing mechanism; each audio snippet is meticulously matched with its corresponding textual transcript Ito \BBA Johnson (\APACyear2017). This characteristic not only anchors the dataset in the realm of supervised machine learning but also makes it an invaluable asset for the intricate processes of speech synthesis, especially for the training of cutting-edge Text-To-Speech (TTS) models.


In speech synthesis research, the relationship between text length and the number of instances within a dataset provides crucial insights into its composition and potential biases. This "Text Length vs Number of Instances" analysis elucidates the distribution of various sentence lengths present in the dataset. A balanced distribution ensures that the model is exposed to a diverse range of sentence structures and lengths during training, facilitating better generalization during real-world applications. In the context of our study, we delve into this relationship not only to understand our dataset’s inherent characteristics but also to ensure its robustness in training models, particularly when evaluating the effects of transfer learning on randomly distributed data.


From the graphical analysis, it’s evident that the distribution of my dataset is highly random. This meets the requirement for a random dataset distribution for testing purposes. In contrast, the LJSpeech dataset exhibits a more uniform distribution, particularly in the "Text Length vs Number of Instances" comparison, which closely aligns with a normal distribution.
3.3.2 Dataset SNR Analysis
Signal-to-Noise Ratio (SNR) is a critical measure in the field of signal processing and communications. It represents the proportion between the power of a signal and the power of background noise. Higher SNR values indicate that the signal is of higher quality, as it’s more distinguishable from the noise. Conversely, a lower SNR suggests that the signal quality is poor because the noise level is relatively high.
The SNR is usually measured in decibels (dB) and is calculated using the formula:
where is the power of the signal and is the power of the noise.
In audio processing, a higher SNR generally indicates clearer, more discernible sounds, while in wireless communications, a higher SNR can lead to more reliable data transfers and fewer errors. Evaluating the SNR is crucial in various applications to ensure the accuracy and quality of signal transmission or retrieval.

According to C. Kim \BBA Stern (\APACyear2008), a Signal-to-Noise Ratio (SNR) less than 20 dB indicates minimal interference from noise in a dataset. In the context of my research, the average SNR was measured at 11.69 dB, suggesting that noise would not significantly influence the outcomes of my model. Thus, there’s no need for additional noise processing on my dataset.
3.4 Data Preprocessing
3.4.1 Data Cleaning
A text cleaner serves as a preprocessing tool in voice and speech processing projects, ensuring that the input text data is standardized and free of anomalies. By removing or modifying inconsistent formatting, punctuations, special characters, and other potential noise factors, a text cleaner aids in creating a uniform dataset. This uniformity is crucial as models often perform better and train faster on consistent and clean data. Furthermore, by converting different textual representations of numbers, dates, or abbreviations to a consistent format, text cleaners enhance the quality of the generated speech in voice cloning or synthesis projects. In essence, a text cleaner ensures the textual data’s integrity, paving the way for better model training and improved speech output quality. The text formatter used in this paper is highly inspired by the work of Yang \BOthers. (\APACyear2021).
The text cleaning procedure is as follows:
Case Normalization: All letters in the text are converted to lowercase to maintain consistency and avoid duplication due to case variations.
Time Conversion: Time representations are converted into textual form to make them comprehensible when read aloud. For instance, "2:30pm" is translated to "two thirty p m", and "2:05" is translated to "two oh five".
Numerical Normalization: Recognizing and removing commas in numbers for a seamless readout. Converting currency symbols followed by numbers into their full textual representation. As an example, "$100" is translated into "one hundred dollars". Decimal numbers are also dealt with, with "3.14" being read as "three point one four". Ordinal numbers like "21st" are transformed into "twenty first". Generic numbers are translated into their word form for clarity.
Abbreviation Expansion: Common abbreviations in the text are expanded to their full form to ensure clarity in speech output. For instance, "co" becomes "company", "gen" transforms into "general", and "mr" is read as "mister".
Symbol Translation: Symbols that can be verbalized are transformed into their respective word forms for clearer interpretation. An example would be the conversion of "&" into "and".
Auxiliary Symbol Removal: Certain symbols that don’t contribute to the semantic meaning, such as "<", ">", "(", and ")", are removed from the text.
Whitespace Normalization: Multiple consecutive whitespace characters, including spaces, tabs, or newline characters, are replaced with a single space. Additionally, any whitespace at the beginning or end of the text is trimmed off.
3.5 Phoneme Conversion
The use of phonemes in speech synthesis and recognition models has become a widespread practice Jurafsky \BBA Martin (\APACyear2008). As the fundamental units of sound in language, phonemes play a pivotal role in achieving multiple key objectives. Firstly, they aid in standardization by reducing disparities across different languages and dialects, enhancing the adaptability of models. Secondly, phonemes increase the flexibility in speech synthesis, enabling the capture of richer vocal nuances, paving the way for more expressive synthesized voices Jurafsky \BBA Martin (\APACyear2008). Furthermore, phonemes enhance the efficiency and accuracy of models, given that they directly map the relationship between text and sound, especially in languages where the relationship between letters and their pronunciation isn’t consistent. Additionally, the multi-language processing capability of phonemes is another reason for their popularity, as many languages share the same phonemes, facilitating the development of multilingual models. Lastly, phonemes assist models in better generalizing when faced with unfamiliar text, as they can more effectively infer the pronunciation of unknown words Jurafsky \BBA Martin (\APACyear2008). Therefore, the use of phonemes not only bolsters the interpretability and accuracy of models but also augments their flexibility. This is the primary reason many modern voice models opt to use phonemes as the basic unit for text processing Jurafsky \BBA Martin (\APACyear2008).
In our research, we utilized an open-source package called Phonemizer Bernard \BBA Titeux (\APACyear2021) to convert our text into the International Phonetic Alphabet (IPA). The IPA is a universally accepted system devised to accurately depict and record phonemes of any human language Association (\APACyear1999). Its primary aim is to provide a unified and unambiguous representation for all human speech sounds. As a widely accepted international standard, the IPA holds significant traction in linguistics and related fields Association (\APACyear1999). One of its core strengths lies in its intricate detailing, allowing for the specific portrayal of almost any conceivable human speech sound, transcending the confines of a particular language or dialect. This system is not only standardized but also scalable, adapting to novel sound descriptions. Contrarily, many languages’ orthographic systems don’t always reflect their actual pronunciation. The IPA offers a way around these orthographic constraints, enabling clear recording of these pronunciations Association (\APACyear1999). For instance, the sentence "I love eating apples," when transcribed in standard American English pronunciation, is represented in IPA as \tipaencoding/aI l\textturnvv \textprimstressitIN \textprimstressæplz /. This method of transcription provides a more precise and granular record of pronunciation, aiding a deeper understanding and description of the sonic structure of languages.
3.6 Forced Alignment
Forced Alignment is a technique employed in the realm of speech processing, primarily aiming to automatically align pronunciations within an audio with its corresponding textual transcription. In essence, this method facilitates the automatic annotation of specific starting and ending time points of pronunciations or phonemes for a given audio segment.
Here are several reasons why Forced Alignment is used:
Data Annotation: During the preparation of training data for speech recognition or synthesis, there’s often a need to label time-specific information for phonemes or words across vast audio data sets. Manual execution of this task is both time-consuming and labor-intensive. In contrast, Forced Alignment accomplishes this process in an automated and expedited manner.
Speech Research: In linguistic or phonetic research, scholars might be intrigued by specific phonetic phenomena, such as the duration of sounds or the placement of stress. Forced Alignment offers researchers a method to swiftly attain precise alignment details for such studies.
Pronunciation Assessment: Within the context of language learning applications, students’ pronunciations can be evaluated by aligning them with standard pronunciations. As a result, learners receive specific feedback concerning deviations in their pronunciation.
Multimodal Data Processing: When handling data that encompasses both audio and text, Forced Alignment ensures synchronization between the audio and the text components.
Enhancing the Accuracy of Speech Applications: By ensuring a precise alignment between audio and text, speech synthesis and recognition systems can be trained with greater accuracy, thereby elevating their overall performance.
Montreal Forced Aligner
I utilized the Montreal Forced Aligner McAuliffe \BOthers. (\APACyear2017) to perform forced alignment for some models. The Montreal Forced Aligner (MFA) stands as a testament to the advancement of open-source tools in the realm of speech processing McAuliffe \BOthers. (\APACyear2017). It offers a platform that researchers and developers can freely utilize and modify. Notably, MFA distinguishes itself with its ability to train on new and diverse data, allowing users to optimize alignment based on specific datasets McAuliffe \BOthers. (\APACyear2017). This adaptability is further highlighted by its use of triphone acoustic models to capture contextual variations in phoneme realization, a marked departure from aligners that predominantly rely on monophone acoustic models McAuliffe \BOthers. (\APACyear2017). The inclusion of speaker adaptation for acoustic features enriches its capacity by simulating differences between speakers. A significant facet of MFA’s prowess is its foundation on Kaldi McAuliffe \BOthers. (\APACyear2017), a renowned open-source automatic speech recognition toolkit. This association provides a suite of benefits such as enhanced portability, the power of parallel processing, and the capability to scale to larger datasets McAuliffe \BOthers. (\APACyear2017). Adding to its versatility, MFA can accommodate multiple transcription formats, making it an adaptable tool for various speech data types McAuliffe \BOthers. (\APACyear2017). Furthermore, its in-built error detection and correction function assists users in pinpointing and rectifying deviations from transcriptions, addressing a common source of alignment errors McAuliffe \BOthers. (\APACyear2017). Evaluation metrics underscore MFA’s superior performance compared to other open-source aligners with simpler architectures McAuliffe \BOthers. (\APACyear2017). Overall, the combination of these features and capabilities firmly positions the Montreal Forced Aligner as a robust and versatile tool in the ever-evolving landscape of speech-text alignment research.
To train Forced Alignment, a lexicon is also required; it provides standard phoneme pronunciations for a given set of vocabulary. Each word might have one or multiple potential phoneme pronunciations, depending on dialects, context, or other factors. Since my dataset is highly similar in format to LJSpeech and both are in English, I utilized the lexicon provided for LJSpeech by the MFA official repository. Additionally, I employed MFA’s pre-trained English acoustic models to execute the forced alignment.
Figure 3.13 is one of the lines from my dataset using MFA’s implementation of Forced Alignment, "The birch canoe slid on the somooth planks ", an aligned image output using the Praat tool. Praat is a computer software specifically designed for speech analysis, developed by Paul Boersma and David Weenink from the University of Amsterdam in the Netherlands Boersma \BBA Weenink (\APACyear2009). It allows users to view spectrograms, pitch, and other speech parameters, and also offers capabilities for speech editing, annotation, and basic speech synthesis functions Boersma \BBA Weenink (\APACyear2009).

The display showcases, from top to bottom, the waveform of my voice, the derived spectrogram, and the phoneme representation. Within the spectrogram, the yellow line indicates intensity, and the blue line represents pitch.
3.7 Transfer Learning and Model Fine-Tuning
3.7.1 Understanding Transfer Learning
Transfer learning is a machine learning strategy where a pre-trained model is used on a new, related task. It’s the idea of overcoming the isolated learning paradigm and leveraging knowledge acquired from related tasks to improve the learning performance. In the context of deep learning for voice synthesis, models are typically pre-trained on large datasets, learning a rich understanding of the task which can then be adapted for more specific applications.
3.7.2 Fine-Tuning and Its Advantages
Fine-tuning is a form of transfer learning. Once a model has been pre-trained, fine-tuning adjusts the model parameters to the new task using the new task-specific dataset. This is especially advantageous when dealing with smaller datasets, as is the case in this research. Rather than training a model from scratch, which would require a substantial amount of data, fine-tuning allows us to leverage existing learned features and adjust them to our specific task. This can result in significant savings in both time and computational resources while potentially achieving a higher model performance than training from scratch.
3.7.3 Application of Transfer Learning and Fine-Tuning in This Research
In this study, we leverage models that have been pre-trained on the LJSpeech dataset, a large-scale English speech dataset. The sentences read by the speaker are sourced from public domain books available on Project Gutenberg, and they cover a variety of topics and genres, providing a rich set of different phonemes and phoneme sequences. This makes LJSpeech a versatile dataset for training text-to-speech models. The high quality and consistency of the recordings, along with the variety of sentence content, makes the LJSpeech dataset a valuable resource for training and evaluating speech synthesis systems.
These models have a comprehensive understanding of the task of text-to-speech synthesis. We then apply the strategy of fine-tuning to adapt these pre-existing deep learning text-to-speech models to our few-shot, low-resource, customized dataset.
By using transfer learning and fine-tuning, we aim to achieve high-quality voice cloning on a smaller dataset than these models were originally trained on. It is crucial to note that all the selected models have their base learning from the same LJSpeech dataset, which ensures a level of uniformity in the base knowledge. This uniformity aids in providing a more reliable comparison of their performance post fine-tuning on our specific dataset.
This strategy not only enables a comparison of how different architectures respond to fine-tuning on a small, specific dataset, but it also contributes to our understanding of their suitability for low-resource voice cloning applications.
Chapter 4 Experiments
4.1 Hyper-parameter Selection
This study fine-tuned pre-trained models of Tacotron2, FastSpeech2, FastPitch, Glow-TTS, VITS, SpeechT5, and OverFlow on the LJSpeech Dataset. The training was conducted on Google Colab, where the setup included 83.5 GB of RAM and an NVIDIA A100 GPU with CUDA support. In the course of the research, the primary objective was to strike a balance between producing high-quality audio outputs and maintaining computational efficiency, especially under constraints of limited resources. To guarantee a consistent and unbiased comparison amongst various models, specific key hyperparameters were standardized.
-
•
Learning Rate: The selected learning rate was . The orginal learning rate was , however, through experimentation, it was found that the fine-tuning speed for Tacotron2 was overly slow.
-
•
Epoch: Initial experiments with longer epochs, 1,000 and 500, produced Tacotron2 models of subpar quality. The synthesized speech was indistinguishable and overwhelmed with noise. Furthermore, these settings resulted in prolonged training durations. Therefore, after empirical evaluation, we decided on 250 epochs.
-
•
Data Splitting: Out of 49 samples, 45 were allocated for training and 5 for validation. Considering the limited size of our training dataset (45 samples), a smaller batch size was adopted. This decision ensures a sufficient number of weight updates during each epoch, allowing the model to adapt optimally to the data. Larger batch sizes might impede the frequency of weight updates, especially with such a limited dataset.
-
•
Batch Size: Given the limited size of my training dataset, comprising only 45 samples, I opted for a smaller batch size. This decision ensures that the model undergoes sufficient weight updates in each epoch, enabling it to better learn from and adapt to the data. Using a larger batch size might restrict the frequency of weight adjustments, especially in the context of such a constrained dataset.
-
•
Iteration Count: The model was trained for 3,000 iterations.
-
•
Warm-up Steps: The warm-up phase was set to 200 steps. Given an iteration count of 3,000, this warm-up period offers a gradual learning rate adjustment phase, ensuring stability early in training. The model begins with a subdued learning rate, mitigating potential oscillations or instabilities. As the 200-step threshold nears, the learning rate gradually reaches its peak, adjusting as per the set strategy for the remainder of the training. This method enhances training stability and final model performance.
-
•
Weight Decay: A decay rate of 0.01 was chosen for L2 regularization. Given the small dataset size, a higher penalty is applied to prevent model over-complication and overfitting.
-
•
Precision: We adopted mixed-precision training using fp16 to strike a balance between computation efficiency and training stability.
-
•
Vocoder: The choice for the vocoder was HiFi-GAN, a model optimized for high-fidelity speech synthesis and based on GANs. Given its commendable audio quality and considering the time costs, we opted not to train a vocoder from scratch for this research.
| Hyper-parameter | Value/Description |
|---|---|
| Learning Rate | |
| Epoch | 250 |
| Data Splitting | 45 training samples, 5 validation samples |
| Batch Size | 4 |
| Warm-up Steps | 200 |
| Weight Decay (L2 regularization) | 0.01 |
| Precision | Mixed-precision (fp16) |
| Vocoder | HiFi-GAN |
4.2 Model Performance and Evaluation
4.2.1 Training and Validation Losses
The training and validation losses serve as primary indicators of a model’s performance throughout the learning process. As the model iteratively refines its parameters in response to the data, these losses provide insights into its progression, convergence behavior, and generalization capability. Training loss assesses the model’s fit to the data it directly learns from, while validation loss offers a perspective on its performance with unseen data. A comparative examination of these losses aids in diagnosing potential issues such as overfitting, underfitting, or other convergence anomalies. In this section, we delve into the trajectory of these losses during the training of the VITS model and discuss their implications for model evaluation.
Tacotron2 Losses
From the visual representations of Tacotron2’s training and validation loss, it’s evident that the model’s loss metric performs favorably. The loss consistently decreases, reaching an approximate value of 0.1 around the 2,000-step mark. This observation suggests that further training may be unnecessary beyond this point. The loss drops to a point and then smoothes out, this may mean that the model has reached convergence, i.e. the model may not benefit from further training.


The model’s training and validation losses both exhibit consistent reductions. This indicates that the model’s architecture is well-suited for transfer learning, especially given the limited data at hand. The model’s success in fine-tuning from its pre-trained state implies that its inherent design and initialization methods are conducive to transfer learning. In situations with limited data, there’s an increased risk of model overfitting. However, the steady decrease in validation loss suggests that this model effectively mitigates the risk of overfitting.
FastSpeech2 Losses


FastSpeech2 incorporates multiple loss functions, ensuring the model’s optimization across various aspects. Below is a brief explanation of these losses:
-
•
Duration loss: This loss accounts for the discrepancy between the model’s predicted duration and the actual duration. FastSpeech2 uses this loss to correctly align the input text with the output spectrogram.
-
•
Energy loss: This is related to the energy (or loudness) of the sound. The model aims to predict the energy for each frame and computes the loss against the actual energy values.
-
•
Mel loss: This loss measures the difference between the model’s predicted Mel-scaled spectrogram and the target spectrogram. It ensures that the generated speech content aligns with the intended content.
-
•
Mel postnet loss: FastSpeech2 employs a post-processing network (postnet) to further refine the produced spectrogram. This loss measures the variance between the spectrogram outputted by the postnet and the target spectrogram.
-
•
Pitch loss: Pertaining to pitch prediction, the model seeks to predict the pitch for each frame and calculates the loss against actual pitch values.
-
•
Total loss: This represents the summation or combination of all the aforementioned losses. Minimizing this composite loss during training ensures the model’s holistic optimization across all relevant aspects.
Despite the continuous decline and eventual convergence of the Training Loss to a minimum value, the Validation Loss has been observed to increase within a confined range. A continuous decline in the loss on the training set, coupled with a rise in the loss on the test (or validation) set, typically signals overfitting. Overfitting can stem from an overly complex model that memorizes the training data instead of discerning useful patterns from it. Such a scenario hampers performance on the test set as the model fails to generalize to unfamiliar data, may represent poor learning for the few-shots dataset.
FastPitch Losses
FastPitch, being a sophisticated neural network model, incorporates multiple loss components to ensure a comprehensive training regime that captures various aspects of speech synthesis. Each of these losses targets specific features of the voice generation process.

The principal losses associated with FastPitch include:
-
•
avg duration error: This represents the average discrepancy between the predicted speech duration by the model and the actual duration, ensuring that the generated voice aligns temporally with the original text.
-
•
avg loader time: Not strictly a loss, this metric relates to the average time taken to load training samples, indicative of data throughput efficiency.
-
•
avg loss: Likely an amalgamation or average of all other loss components, acting as the primary objective to minimize during training.
-
•
avg loss aligner: This loss pertains to the alignment between text and voice, ensuring synchronization over time.
-
•
avg loss binary alignment: A finer alignment metric between text and voice, likely capturing more granular alignment details.
-
•
avg loss dur: Analogous to avg_duration_error, it focuses on the alignment of voice duration.
-
•
avg loss pitch: Relates to the error between the model’s predicted pitch and the actual pitch. Pitch is pivotal in both music and voice, ensuring the produced voice matches the original recording’s tonality.
-
•
avg loss spec: Assesses the discrepancy between the produced and target spectrograms, guaranteeing that the synthesized voice content matches the target.
-
•
avg grad norm: In training deep learning models, the phenomenon of gradient explosion and vanishing can be encountered. On the other hand, minuscule gradients might halt the training progress, leading to gradient vanishing. To combat frequent occurrences of gradient explosions, gradient clipping is applied, ensuring the gradient values don’t surpass a set threshold. Observations of gradient behaviors are pivotal as they can suggest necessary adjustments to the learning rate. Furthermore, regularization methods, such as weight decay or dropout, influence the gradient’s magnitude. Hence, keeping an eye on the avg grad norm becomes essential to understand how these regularization techniques are affecting the training process.
The avg loss binary alignment, either during training or validation, plummet suddenly and then converge, is intriguing. Particularly, the abrupt drop followed by a surge in avg loss binary alignment suggests that this module, might be more challenging to minimize than other losses. As the model increasingly tailors itself to the training data, it’s plausible that at some juncture, it over-optimizes for a specific loss, neglecting others in the process.
In conclusion, understanding and monitoring these loss components and metrics is vital for an effective training regime, aiding in model diagnostics, improvements, and achieving robust voice synthesis.
Glow-TTS Losses


The avg amp scalar is associated with mixed precision training of the model to ensure numerical stability. In mixed precision training, a combination of single and half precision is utilized to expedite training and reduce memory consumption. To circumvent potential numerical stability issues introduced by half-precision computations, particularly during weight updates, a dynamically adjusted amp scalar (automatic mixed precision scalar) is introduced to scale the model’s loss. The avg amp scalar represents the average value of this scaling factor throughout the training process, offering insights into the model’s numerical stability and behavior during mixed precision training.
Avg loss dur refers to the average loss associated with duration predictions in speech synthesis models. Specifically, it measures the discrepancy between the model’s predicted durations for phonemes or words and their actual durations in the training data. This loss is crucial because the rhythmic flow and pace of the synthesized speech depend on accurate duration predictions. Monitoring avg loss dur helps in ensuring that the synthesized speech aligns temporally with the original text and maintains a natural rhythm.
In our observations from the plots, the average loss during training demonstrates a gradual descent. However, conspicuous spikes or "surges" are evident in the avg loss dur and avg loss on the test set. A potential explanation for this disparity could be the diminutive size of our test dataset, comprising merely five samples, which could lead to a considerable distribution gap compared to the training data, consequently affecting the inference outcomes adversely. Another plausible cause could be overfitting, where the model might have excessively adapted to the training data, compromising its generalization capabilities. Furthermore, the oscillations in loss might also be attributed to the inherent variability introduced by the mini-batch training approach.
OverFlow TTS Losses
In the OverFlow model, the log-likelihood loss is employed as the primary evaluation metric. Consequently, negative loss values are expected, as they represent the negative logarithm of the probability.


Given that the loss is negative, it signifies that the gap between the predicted probability distribution of the model and the actual distribution is decreasing. A lesser negative log-likelihood value (closer to 0) indicates a more accurate prediction by the model. The transition of the loss from -8.95 to -9.25 suggests increased uncertainty in the model’s predictions. In the context of log-likelihood loss, a smaller negative value represents a lower prediction probability, possibly indicating a decline in the model’s confidence for certain samples. This phenomenon suggests that the OverFlow model may not be well-suited for few-shot, low-resource transfer learning scenarios.
VITS Losses


The definition of final loss for training the conditional VAE (Variational Autoencoder) in VITS J. Kim \BOthers. (\APACyear2021) is expressed as:
Where:
-
•
is the reconstruction loss.
-
•
is the KL divergence loss.
-
•
is the duration loss.
-
•
is the adversarial loss for the generator.
-
•
is the feature-matching loss for the generator.
The discriminator loss is given by:
This loss function is used to train the discriminator to distinguish between the real waveform y and the generated waveform G(z).
The generator losses is given by:
-
•
Adversarial Loss for the Generator:
This loss function encourages the generator to produce waveforms that the discriminator cannot easily distinguish from real waveforms.
-
•
Feature-Matching Loss:
This loss ensures that the generated output matches the features of the real data, where T denotes the total number of layers in the discriminator, and represents the l-th layer’s output.
In the context of the VITS model, the terms and denote the generator loss and the discriminator loss respectively. Throughout the training process, rapid fluctuations in the loss values can be observed. According to feedback from a discussion on this GitHub issue, such behavior is typical during the training of the VITS model. Given the non-intuitive nature of these loss values, it’s challenging to directly infer the model’s performance or its adaptability to the dataset based on them alone.
SpeechT5 Losses


During the training process of the model, we observed that the loss steadily decreased and eventually converged to a specific value. Although there were sawtooth-like fluctuations during training, such oscillations are within expected norms. Several factors might contribute to these fluctuations: on one hand, a relatively high learning rate and a small batch size could cause the model to jump during optimization; on the other hand, an excessively high momentum when using the Adam optimizer might lead to similar outcomes. Moreover, other factors could also impact the stability of the model’s training.
In the testing phase, the model’s loss exhibited significant oscillations. We hypothesize that this is directly related to the small size of our test set. A smaller test set might cause the model’s evaluation to be influenced by individual or a few samples, leading to substantial changes in the loss value. To further stabilize the model’s testing performance in future work, we might need to increase the size of the testing data or make other related adjustments.
Chapter 5 Result
5.1 Alignment Chart and Mel-Spectrogram Chart
In the world of sequence-to-sequence deep learning models, an alignment chart serves as a critical visualization tool, providing a pictorial representation of the correspondence between input and output sequences. Such charts are of paramount importance in applications like machine translation or speech synthesis. By closely observing these charts, one can gain insights into how the model correlates with the input sequence during the generation of each output segment. This visualization is not just an academic exercise; it provides researchers with a valuable perspective on the model’s internal processes, simultaneously facilitating the identification and resolution of potential alignment glitches. Predominantly, alignment charts have become synonymous with attention mechanisms, given that the latter’s weights transparently showcase the alignment dynamics.
FastSpeech2, it stands apart as a non-autoregressive speech synthesis model Ren \BOthers. (\APACyear2020). Unlike Tacotron-like models underpinned by attention, FastSpeech2 abstains from generating a conventional alignment chart to represent text-audio alignments Ren \BOthers. (\APACyear2020). Its design is engineered to mitigate potential alignment issues inherent to attention mechanisms, especially in the initial training phases. Achieving this requires the model to utilize pre-computed durations for text-to-audio, rather than dynamically determining these via attention mechanisms Ren \BOthers. (\APACyear2020). These durations are generally computed beforehand by models like Tacotron2 and fed into FastSpeech2 Ren \BOthers. (\APACyear2020). Thus, while FastSpeech2 doesn’t intrinsically generate an alignment chart, the Tacotron2 model used to furnish durations can provide corresponding attention weights that can serve as a visual alignment guide. Beyond this, FastSpeech2 predicts mel-spectrogram charts and other features, including f0 (fundamental frequency) and energy Ren \BOthers. (\APACyear2020), enhancing the naturalness and intonation of the produced voice.





5.1.1 Analysis of Alignment and Mel-Spectrogram Graphs
By scrutinizing alignment charts, one can glean intuitive insights about the model’s attention and alignment. The following are key indicators that can guide researchers in evaluating a model based on its alignment chart:
Clear Diagonal Lines: A quintessential alignment chart predominantly exhibits a distinct diagonal line, signifying a consistent alignment between input and output sequences. This indicates that the model is sequentially processing the input and generating the output in the anticipated manner. Disjointed or Scrambled Lines: Instances where the alignment chart manifests disjointed, scrambled, or any other irregular patterns signal potential alignment challenges. Such discrepancies could arise from inconsistencies in training data, parts of the model not learning aptly, among other issues. Diving deeper into specific models, FastPitch is a Transformer-based text-to-speech synthesis model that diverges from the standard Transformer architecture by incorporating unique features to enhance its performance and efficiency. Within FastPitch, two distinct alignment charts can be discerned:
Alignment: Representing the traditional alignment chart, it delineates the relationship between input text (like words or phonemes) and the generated acoustic features (e.g., mel-spectrogram). This alignment is a direct output of FastPitch’s attention mechanism, indicating how the model aligns the input text during the generation of each acoustic feature segment. Alignment Head: With multiple attention heads, FastPitch learns diverse attention patterns. One specific head, known as the “alignment head”, is tailored to learn the alignment dynamics between the text and acoustic features. Its specialized design often results in more explicit and coherent outputs, offering users a clearer alignment perspective.
From the various alignment graphs of different models, a multifaceted analysis and prediction can be deduced. In the graph of Tacotron2, there are noticeable discontinuities. Such interruptions might lead to moments of ambiguity during the text-to-speech conversion process, thereby affecting the fluency of the sound. Compared to the original FastPitch Alignment, the FastPitch with head showcases a more accurate alignment, indicating superior performance. FastPitch with multi-head attention should produce the best results among selected models.
Upon examining the Glow-TTS graph, it becomes evident that the lines do not fully reach the diagonal. This suggests potential alignment issues when the model processes certain data, possibly resulting in a suboptimal voice output. The alignment graph of OverFlow is particularly unsatisfactory. Such alignment discrepancies could lead to discontinuous and muffled sound, severely compromising the final synthesized voice quality.
The alignment patterns observed in VITS are notably coherent and consistent, suggesting a strong correlation between the input and output sequences. Given this efficient alignment, it’s anticipated that VITS would deliver high-quality and accurate results in its speech synthesis tasks.
In contrast to the aforementioned models, FastSpeech2 demonstrates formidable capability in spectrogram synthesis. The generated Mel-spectrogram aligns closely with the ground-truth spectrogram. Moreover, the comparison of f0 and Energy also reveals high consistency. This high degree of alignment suggests that FastSpeech2 is likely to produce excellent synthesized voice outcomes.
SpeechT5, akin to other pure Transformer-based models, does not produce an explicit, interpretable alignment chart. This stems from their reliance on the inherent attention mechanism to implicitly align input-output, as opposed to explicit alignments. The self-attention mechanism in these models captures and encodes alignment relations within hidden states, thereby not necessitating a distinct alignment chart.
5.1.2 Prediction from the Graphs
Regarding the SpeechT5 model, direct assessments based on alignment visualizations prove challenging, as it doesn’t generate interpretable alignment charts. However, when comparing the models for which we do have visual insights, our analysis leads us to the following qualitative ranking in terms of expected performance: FastPitch appears to be at the forefront, followed closely by VITS. FastSpeech2 then comes next, displaying strong correspondence, but not as pronounced as the previous two. Tacotron2 seems to show some potential misalignments, placing it behind the aforementioned models. Glow-TTS, while possessing a distinct alignment pattern, doesn’t seem to align perfectly diagonally, hinting at potential synthesis challenges. Finally, OverFlow appears to have the most irregular patterns, which might indicate significant alignment issues that could affect its output quality.
5.2 Model Fine-tuning Time
Table 5.1 presents the training durations for various state-of-the-art speech synthesis models. These times provide insight into the computational effort required to train each model. Tacotron2, for instance, has one of the lengthier training periods, spanning almost two hours. On the other end of the spectrum, SpeechT5 exhibits a surprisingly swift training duration of just 15 minutes. Such differences can be attributed to various factors including model complexity, dataset size, and optimization techniques employed.
| Model | Training Time |
|---|---|
| Tacotron2 | 1.803 hours |
| FastSpeech2 | 51m26s |
| FastPitch | 43m31s |
| GlowTTS | 20.31 min |
| OverFlow | 32 min |
| VITS | 4 hours 25 min |
| SpeechT5 | 15 min |
5.3 MOS Evaluation
In the realm of Text-to-Speech (TTS) research, evaluating the quality and naturalness of the generated speech is of paramount importance. To this end, we employ the Mean Opinion Score (MOS) as our primary metric of assessment. MOS is a widely-accepted subjective evaluation method, wherein participants are tasked with rating specific speech samples based on their perceptual experience. The scoring typically spans from 1 to 5, where 1 indicates "Poor" quality, and 5 denotes "Excellent". This scoring mechanism provides us with an intuitive and quantifiable means to gauge the performance of our TTS system. By aggregating a series of MOS scores, we can attain a comprehensive, objective feedback on the produced speech, thus aiding in further model and technique refinement. However, it’s essential to note that while MOS is a potent tool, it is still anchored in human subjectivity, which may vary based on listeners’ backgrounds, experiences, and expectations Shirali-Shahreza \BBA Penn (\APACyear2018).
In the evaluation phase of my text-to-speech model, I used each fine-tuned model to generate a 5-second audio clip for testing with the phrase: ’Here is Ze, and this is my honour project testing’." I conducted a subjective listening test involving 38 participants who were familiar with my voice. The primary objective of this test was to ascertain the verisimilitude of the generated voice to my own. The participants were tasked with rating the samples across four key dimensions:
-
1.
Timbral Similarity: Participants assessed the degree of resemblance between the synthesized voice and my natural voice. This dimension gauges how well the TTS system has been able to capture and replicate the unique characteristics inherent to my vocal identity.
-
2.
Naturalness: This metric evaluates the lifelikeness of the synthesized speech. Here, listeners determined whether the output sounded authentically human or exhibited artifacts typical of machine-generated voices.
-
3.
Fluency: Under this criterion, the smoothness and continuity of the speech were examined. Participants listened for any stutters, hesitations, or unnatural breaks that might disrupt the flow, making the speech sound less fluid.
-
4.
Pitch and Emotion: This metric is concerned with the tonal quality and emotional expressiveness of the speech. Participants judged if the voice conveyed varied emotions and intonations or if it sounded monotonous, akin to the flat tonality often associated with robotic voices.
These subjective evaluations provided valuable insights into the strengths and potential areas of improvement for my text-to-speech system, ensuring its ability to produce outputs that are both high-fidelity and emotionally resonant.
| Model | Timbral Similarity | Naturalness | Fluency | Pitch and Emotion |
|---|---|---|---|---|
| Tacotron2 | 4.605 ± 0.85 | 4.395 ± 0.089 | 3.211 ± 0.106 | 3.605 ± 0.100 |
| VITS | 4.447 ± 0.081 | 4.289 ± 0.108 | 3.263 ± 0.129 | 3.263 ± 0.098 |
| Glow-TTS | 2.579 ± 0.123 | 2.026 ± 0.026 | 3.237 ± 0.070 | 2.842 ± 0.144 |
| FastSpeech2 | 2.000 ± 0.084 | 1.579 ± 0.081 | 1.816 ± 0.091 | 1.711 ± 0.106 |
| OverFlow | 1.132 ± 0.056 | 3.342 ± 0.078 | 4.237 ± 0.070 | 2.605 ± 0.080 |
| FastPitch | 4.263 ± 0.072 | 4.474 ± 0.082 | 3.947 ± 0.075 | 3.789 ± 0.108 |
| SpeechT5 | 4.132 ± 0.120 | 4.289 ± 0.075 | 4.526 ± 0.118 | 4.447 ± 0.105 |
The table showcases the performance of various text-to-speech models across four metrics: Timbral Similarity, Naturalness, Fluency, and Pitch & Emotion. Each model’s scores were measured relative to the familiarity of the speaker’s voice, with higher scores indicating better performance.
Timbral Similarity: This metric gauges the degree of resemblance between the synthesized voice and the original speaker’s voice. Tacotron2 and VITS exhibit superior performance in this area, scoring 4.605 and 4.447, respectively. This indicates that both models are adept at capturing the specific characteristics of the original voice. On the contrary, OverFlow seems to struggle in this metric with a score of 1.132.
Naturalness: Referring to how lifelike and real the synthesized voice sounds, the highest performance is noted from FastPitch at 4.474. This suggests that its generated voice is almost indistinguishable from a real human voice. In contrast, FastSpeech2 possesses a score of 1.579, implying that its output might sound more mechanical or artificial.
Fluency: This metric evaluates the smoothness of the synthesized speech, ensuring there are no stutters or breaks. SpeechT5 takes the lead in this domain, securing a score of 4.526. This highlights its proficiency in delivering speech that flows seamlessly. Conversely, FastSpeech2 trails behind other models with a score of 1.816.
Pitch and Emotion: A critical factor, as it pertains to the emotional expressiveness and tonal variations in the voice. SpeechT5 again leads the pack with 4.447, meaning its output contains varied and human-like emotional tones. In contrast, FastSpeech2 and OverFlow score lower, hinting at potential monotony or lack of emotional depth in their outputs.
An overall score can be calculated as an average across all four metrics for each model.
| Model | Average Score |
|---|---|
| Tacotron2 | 3.954 |
| VITS | 3.816 |
| Glow-TTS | 2.671 |
| FastSpeech2 | 1.777 |
| OverFlow | 2.829 |
| FastPitch | 4.118 |
| SpeechT5 | 4.349 |
Based on those scores, SpeechT5 has the highest overall score of 4.349, making it the top-performing model in this comparison.
FastSpeech2 holds the lowest average score of 1.777, suggesting it might be the least effective in replicating voice characteristics as per the chosen metrics.
Remember, these averages provide a summarized perspective and may not account for nuances in specific use-cases.
Chapter 6 Discussion
6.1 Interpreting the Findings
Based on the feedback and synthesized audio results I received, OverFlow was unable to capture the timbre of my voice. Considering that the pre-trained model was based on LJSpeech, the generated voice remained feminine. However, the pauses and intonation did bear some resemblance to mine, suggesting that its capability for transfer learning with a small dataset is lacking. In contrast, the VITS model supports seamless interchange among Chinese, English, and Japanese languages. The ability to input in any of these three languages and obtain outputs in all three is truly remarkable.
SpeechT5 can handle a variety of spoken language tasks, including automatic speech recognition, speech synthesis, speech translation, voice conversion, speech enhancement, and speaker identification, as cited from Ao \BOthers. (\APACyear2021). Furthermore, the fact that it requires only a mere 15 minutes of training to achieve this is astonishing. The significance of Tacotron2’s work cannot be understated, as many subsequent models were inspired and improved upon its foundational ideas.
Upon evaluation of the selected Text-to-Speech models, it became evident that the application of transfer learning in a few-shot, low-resource setting varied significantly across models. While some models exhibited a commendable ability to harness pre-existing knowledge and apply it effectively to the limited dataset, others struggled to maintain their previously acclaimed high performance.
6.2 Hypotheses Verification
6.2.1 Effectiveness of Transfer Learning
Our first hypothesis posited that transfer learning significantly enhances the capability of TTS models to perform effectively on smaller datasets. The experiments largely verified this, with a marked improvement in voice quality, fluency, and naturalness in models leveraging transfer learning compared to those trained from scratch on the small dataset.
6.2.2 Optimal TTS Model Identification
Our second hypothesis suggested the existence of an optimal TTS model that offers a harmonious blend of rapid training, minimal data dependence, and exemplary voice quality. From our experiments, SpeechT5 emerged as a potential contender for this title, showcasing a promising balance of the stated criteria.
6.3 Comparison with Prior Work
Comparing our findings with previous research, we observed a consistent trend. Earlier studies, such as those by Tits \BOthers. (\APACyear2020) and Jia \BOthers. (\APACyear2018), also highlighted the challenges and potential of transfer learning in TTS. However, our study offers a more extensive comparison, especially in the context of the few-shot, low-resource scenario.
6.4 Limitations
While our research provides crucial insights, it comes with its set of limitations. One of the limitations of this study is that cannot guarantee that every parameter chosen is optimal for each individual model. The choice of the dataset, though customized, might not represent all types of low-resource scenarios. Additionally, the models evaluated were bound by our computational constraints, and there could be newer models in the horizon that offer even better transfer learning capabilities.
6.5 Ethical Considerations
The rise of voice synthesis technology has inadvertently given a boost to the nefarious activities of scammers. Recently, there has been a surge in incidents where fraudsters clone the voices of family members or friends to deceive unsuspecting individuals. With advancements in technology, it is now possible to replicate a person’s voice with just a few samples of their speech. Additionally, the digital realm is witnessing the emergence of AI-driven artists, such as the famed "Fake Drake". A song titled "Heart on my Sleeve 111https://www.youtube.com/watch?v=7HZ2ie2ErFI" featuring both AI Drake and the singer The Weeknd gained immense popularity online, racking up a staggering 4.3 million plays. This collaboration between artificial and human voices has sparked widespread interest and debate among netizens.
Text-to-Speech (TTS) technologies have several ethical considerations that change as the technology advances. As TTS systems improve, they can accurately mimic a person’s voice with a few samples. This feature raises worries about cloned voices being used for identity theft or misinformation operations.
Who owns a voice? Have they given explicit permission if a person’s voice is cloned and used in media, advertisements, or other commercial activities? Informed permission for voice cloning is essential to prevent legal and ethical issues. TTS can make "deepfake" audio recordings of people saying things they never did. Fake recordings may defame, manipulate public opinion, and even influence elections.
As AI-generated voices grow more common, voice-over artists, narrators, and vocalists may struggle. The economic effects of replacing human talent with AI voices must be considered. In music and entertainment, AI-driven musicians like "Fake Drake" raise doubts about authenticity. Can an AI-generated song ever be as emotive as a human-written and performed one? TTS’s capacity to alter speech tones might be used to emotionally manipulate listeners. In advertising, an AI may change its pitch or tone to evoke trust or urgency, posing ethical questions about autonomy and manipulation.
Should listeners know the difference between TTS and human voices? News reporting and education need transparency because trust and authenticity matter. TTS technologies have the potential to disrupt many industries, but they also bring ethical issues. As with many innovative technology, safe usage requires continuing discourse, strict laws, and public awareness efforts.
Bibliography
References
- Ao \BOthers. (\APACyear2021) \APACinsertmetastarao2021speecht5{APACrefauthors}Ao, J., Wang, R., Zhou, L., Wang, C., Ren, S., Wu, Y.\BDBLothers \APACrefYearMonthDay2021. \BBOQ\APACrefatitleSpeecht5: Unified-modal encoder-decoder pre-training for spoken language processing Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2110.07205. \PrintBackRefs\CurrentBib
- Association (\APACyear1999) \APACinsertmetastarinternational1999handbook{APACrefauthors}Association, I\BPBIP. \APACrefYear1999. \APACrefbtitleHandbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet Handbook of the international phonetic association: A guide to the use of the international phonetic alphabet. \APACaddressPublisherCambridge University Press. \PrintBackRefs\CurrentBib
- Bernard \BBA Titeux (\APACyear2021) \APACinsertmetastarBernard2021{APACrefauthors}Bernard, M.\BCBT \BBA Titeux, H. \APACrefYearMonthDay2021. \BBOQ\APACrefatitlePhonemizer: Text to Phones Transcription for Multiple Languages in Python Phonemizer: Text to phones transcription for multiple languages in python.\BBCQ \APACjournalVolNumPagesJournal of Open Source Software6683958. {APACrefURL} https://doi.org/10.21105/joss.03958 {APACrefDOI} 10.21105/joss.03958 \PrintBackRefs\CurrentBib
- Boersma \BBA Weenink (\APACyear2009) \APACinsertmetastarBoersma2009{APACrefauthors}Boersma, P.\BCBT \BBA Weenink, D. \APACrefYearMonthDay2009. \APACrefbtitlePraat: doing phonetics by computer (Version 5.1.13). Praat: doing phonetics by computer (version 5.1.13). {APACrefURL} http://www.praat.org \PrintBackRefs\CurrentBib
- Hunt \BBA Black (\APACyear1996) \APACinsertmetastarhunt1996unit{APACrefauthors}Hunt, A\BPBIJ.\BCBT \BBA Black, A\BPBIW. \APACrefYearMonthDay1996. \BBOQ\APACrefatitleUnit selection in a concatenative speech synthesis system using a large speech database Unit selection in a concatenative speech synthesis system using a large speech database.\BBCQ \BIn \APACrefbtitle1996 IEEE international conference on acoustics, speech, and signal processing conference proceedings 1996 ieee international conference on acoustics, speech, and signal processing conference proceedings (\BVOL 1, \BPGS 373–376). \PrintBackRefs\CurrentBib
- Ito \BBA Johnson (\APACyear2017) \APACinsertmetastarljspeech17{APACrefauthors}Ito, K.\BCBT \BBA Johnson, L. \APACrefYearMonthDay2017. \APACrefbtitleThe LJ Speech Dataset. The lj speech dataset. \APAChowpublishedhttps://keithito.com/LJ-Speech-Dataset/. \PrintBackRefs\CurrentBib
- Jia \BOthers. (\APACyear2018) \APACinsertmetastartransfer_learning_2{APACrefauthors}Jia, Y., Zhang, Y., Weiss, R., Wang, Q., Shen, J., Ren, F.\BDBLothers \APACrefYearMonthDay2018. \BBOQ\APACrefatitleTransfer learning from speaker verification to multispeaker text-to-speech synthesis Transfer learning from speaker verification to multispeaker text-to-speech synthesis.\BBCQ \APACjournalVolNumPagesAdvances in neural information processing systems31. \PrintBackRefs\CurrentBib
- Jurafsky \BBA Martin (\APACyear2008) \APACinsertmetastarNLPbook{APACrefauthors}Jurafsky, D.\BCBT \BBA Martin, J. \APACrefYear2008. \APACrefbtitleSpeech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition Speech and language processing: An introduction to natural language processing, computational linguistics, and speech recognition (\BVOL 2). \PrintBackRefs\CurrentBib
- C. Kim \BBA Stern (\APACyear2008) \APACinsertmetastarkim2008robust{APACrefauthors}Kim, C.\BCBT \BBA Stern, R\BPBIM. \APACrefYearMonthDay2008. \BBOQ\APACrefatitleRobust signal-to-noise ratio estimation based on waveform amplitude distribution analysis Robust signal-to-noise ratio estimation based on waveform amplitude distribution analysis.\BBCQ \BIn \APACrefbtitleNinth Annual Conference of the International Speech Communication Association. Ninth annual conference of the international speech communication association. \PrintBackRefs\CurrentBib
- J. Kim \BOthers. (\APACyear2020) \APACinsertmetastarkim2020glow{APACrefauthors}Kim, J., Kim, S., Kong, J.\BCBL \BBA Yoon, S. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleGlow-tts: A generative flow for text-to-speech via monotonic alignment search Glow-tts: A generative flow for text-to-speech via monotonic alignment search.\BBCQ \APACjournalVolNumPagesAdvances in Neural Information Processing Systems338067–8077. \PrintBackRefs\CurrentBib
- J. Kim \BOthers. (\APACyear2021) \APACinsertmetastarkim2021conditional{APACrefauthors}Kim, J., Kong, J.\BCBL \BBA Son, J. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleConditional variational autoencoder with adversarial learning for end-to-end text-to-speech Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.\BBCQ \BIn \APACrefbtitleInternational Conference on Machine Learning International conference on machine learning (\BPGS 5530–5540). \PrintBackRefs\CurrentBib
- Klatt (\APACyear1980) \APACinsertmetastarklatt1980software{APACrefauthors}Klatt, D\BPBIH. \APACrefYearMonthDay1980. \BBOQ\APACrefatitleSoftware for a cascade/parallel formant synthesizer Software for a cascade/parallel formant synthesizer.\BBCQ \APACjournalVolNumPagesthe Journal of the Acoustical Society of America673971–995. \PrintBackRefs\CurrentBib
- Kong \BOthers. (\APACyear2020) \APACinsertmetastarkong2020hifi{APACrefauthors}Kong, J., Kim, J.\BCBL \BBA Bae, J. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleHifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis.\BBCQ \APACjournalVolNumPagesAdvances in Neural Information Processing Systems3317022–17033. \PrintBackRefs\CurrentBib
- Kumar \BOthers. (\APACyear2019) \APACinsertmetastarkumar2019melgan{APACrefauthors}Kumar, K., Kumar, R., De Boissiere, T., Gestin, L., Teoh, W\BPBIZ., Sotelo, J.\BDBLCourville, A\BPBIC. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleMelgan: Generative adversarial networks for conditional waveform synthesis Melgan: Generative adversarial networks for conditional waveform synthesis.\BBCQ \APACjournalVolNumPagesAdvances in neural information processing systems32. \PrintBackRefs\CurrentBib
- Łańcucki (\APACyear2021) \APACinsertmetastarlancucki2021fastpitch{APACrefauthors}Łańcucki, A. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleFastpitch: Parallel text-to-speech with pitch prediction Fastpitch: Parallel text-to-speech with pitch prediction.\BBCQ \BIn \APACrefbtitleICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Icassp 2021-2021 ieee international conference on acoustics, speech and signal processing (icassp) (\BPGS 6588–6592). \PrintBackRefs\CurrentBib
- Li \BOthers. (\APACyear2019) \APACinsertmetastartransformer{APACrefauthors}Li, N., Liu, S., Liu, Y., Zhao, S.\BCBL \BBA Liu, M. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleNeural speech synthesis with transformer network Neural speech synthesis with transformer network.\BBCQ \BIn \APACrefbtitleProceedings of the AAAI conference on artificial intelligence Proceedings of the aaai conference on artificial intelligence (\BVOL 33, \BPGS 6706–6713). \PrintBackRefs\CurrentBib
- McAuliffe \BOthers. (\APACyear2017) \APACinsertmetastarmcauliffe2017montreal{APACrefauthors}McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M.\BCBL \BBA Sonderegger, M. \APACrefYearMonthDay2017. \BBOQ\APACrefatitleMontreal forced aligner: Trainable text-speech alignment using kaldi. Montreal forced aligner: Trainable text-speech alignment using kaldi.\BBCQ \BIn \APACrefbtitleInterspeech Interspeech (\BVOL 2017, \BPGS 498–502). \PrintBackRefs\CurrentBib
- Mehta \BOthers. (\APACyear2022) \APACinsertmetastarmehta2022overflow{APACrefauthors}Mehta, S., Kirkland, A., Lameris, H., Beskow, J., Székely, É.\BCBL \BBA Henter, G\BPBIE. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleOverFlow: Putting flows on top of neural transducers for better TTS Overflow: Putting flows on top of neural transducers for better tts.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2211.06892. \PrintBackRefs\CurrentBib
- A. Oord \BOthers. (\APACyear2018) \APACinsertmetastar2018parallel{APACrefauthors}Oord, A., Li, Y., Babuschkin, I., Simonyan, K., Vinyals, O., Kavukcuoglu, K.\BDBLothers \APACrefYearMonthDay2018. \BBOQ\APACrefatitleParallel wavenet: Fast high-fidelity speech synthesis Parallel wavenet: Fast high-fidelity speech synthesis.\BBCQ \BIn \APACrefbtitleInternational conference on machine learning International conference on machine learning (\BPGS 3918–3926). \PrintBackRefs\CurrentBib
- A\BPBIv\BPBId. Oord \BOthers. (\APACyear2016) \APACinsertmetastarwavenet{APACrefauthors}Oord, A\BPBIv\BPBId., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A.\BDBLKavukcuoglu, K. \APACrefYearMonthDay2016. \BBOQ\APACrefatitleWavenet: A generative model for raw audio Wavenet: A generative model for raw audio.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:1609.03499. \PrintBackRefs\CurrentBib
- Pratap \BOthers. (\APACyear2023) \APACinsertmetastarmeta-mms{APACrefauthors}Pratap, V., Tjandra, A., Shi, B., Tomasello, P., Babu, A., Kundu, S.\BDBLothers \APACrefYearMonthDay2023. \BBOQ\APACrefatitleScaling speech technology to 1,000+ languages Scaling speech technology to 1,000+ languages.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2305.13516. \PrintBackRefs\CurrentBib
- Prenger \BOthers. (\APACyear2019) \APACinsertmetastar2019waveglow{APACrefauthors}Prenger, R., Valle, R.\BCBL \BBA Catanzaro, B. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleWaveglow: A flow-based generative network for speech synthesis Waveglow: A flow-based generative network for speech synthesis.\BBCQ \BIn \APACrefbtitleICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Icassp 2019-2019 ieee international conference on acoustics, speech and signal processing (icassp) (\BPGS 3617–3621). \PrintBackRefs\CurrentBib
- Ren \BOthers. (\APACyear2020) \APACinsertmetastarren2020fastspeech{APACrefauthors}Ren, Y., Hu, C., Tan, X., Qin, T., Zhao, S., Zhao, Z.\BCBL \BBA Liu, T\BHBIY. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleFastspeech 2: Fast and high-quality end-to-end text to speech Fastspeech 2: Fast and high-quality end-to-end text to speech.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2006.04558. \PrintBackRefs\CurrentBib
- Ren \BOthers. (\APACyear2019) \APACinsertmetastarren2019fastspeech{APACrefauthors}Ren, Y., Ruan, Y., Tan, X., Qin, T., Zhao, S., Zhao, Z.\BCBL \BBA Liu, T\BHBIY. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleFastspeech: Fast, robust and controllable text to speech Fastspeech: Fast, robust and controllable text to speech.\BBCQ \APACjournalVolNumPagesAdvances in neural information processing systems32. \PrintBackRefs\CurrentBib
- Rothauser (\APACyear1969) \APACinsertmetastarrothauser1969ieee{APACrefauthors}Rothauser, E. \APACrefYearMonthDay1969. \BBOQ\APACrefatitleIEEE recommended practice for speech quality measurements Ieee recommended practice for speech quality measurements.\BBCQ \APACjournalVolNumPagesIEEE Transactions on Audio and Electroacoustics173225–246. \PrintBackRefs\CurrentBib
- Shen \BOthers. (\APACyear2018) \APACinsertmetastarshen2018natural{APACrefauthors}Shen, J., Pang, R., Weiss, R\BPBIJ., Schuster, M., Jaitly, N., Yang, Z.\BDBLothers \APACrefYearMonthDay2018. \BBOQ\APACrefatitleNatural tts synthesis by conditioning wavenet on mel spectrogram predictions Natural tts synthesis by conditioning wavenet on mel spectrogram predictions.\BBCQ \BIn \APACrefbtitle2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) 2018 ieee international conference on acoustics, speech and signal processing (icassp) (\BPGS 4779–4783). \PrintBackRefs\CurrentBib
- Shirali-Shahreza \BBA Penn (\APACyear2018) \APACinsertmetastarMOS{APACrefauthors}Shirali-Shahreza, S.\BCBT \BBA Penn, G. \APACrefYearMonthDay2018. \BBOQ\APACrefatitleMOS Naturalness and the Quest for Human-Like Speech Mos naturalness and the quest for human-like speech.\BBCQ \BIn \APACrefbtitle2018 IEEE Spoken Language Technology Workshop (SLT) 2018 ieee spoken language technology workshop (slt) (\BPG 346-352). {APACrefDOI} 10.1109/SLT.2018.8639599 \PrintBackRefs\CurrentBib
- Tits \BOthers. (\APACyear2020) \APACinsertmetastartransfer_learning_1{APACrefauthors}Tits, N., El Haddad, K.\BCBL \BBA Dutoit, T. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleExploring transfer learning for low resource emotional tts Exploring transfer learning for low resource emotional tts.\BBCQ \BIn \APACrefbtitleIntelligent Systems and Applications: Proceedings of the 2019 Intelligent Systems Conference (IntelliSys) Volume 1 Intelligent systems and applications: Proceedings of the 2019 intelligent systems conference (intellisys) volume 1 (\BPGS 52–60). \PrintBackRefs\CurrentBib
- Tokuda \BOthers. (\APACyear2000) \APACinsertmetastartokuda2000speech{APACrefauthors}Tokuda, K., Yoshimura, T., Masuko, T., Kobayashi, T.\BCBL \BBA Kitamura, T. \APACrefYearMonthDay2000. \BBOQ\APACrefatitleSpeech parameter generation algorithms for HMM-based speech synthesis Speech parameter generation algorithms for hmm-based speech synthesis.\BBCQ \BIn \APACrefbtitle2000 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 00CH37100) 2000 ieee international conference on acoustics, speech, and signal processing. proceedings (cat. no. 00ch37100) (\BVOL 3, \BPGS 1315–1318). \PrintBackRefs\CurrentBib
- C. Wang \BOthers. (\APACyear2023) \APACinsertmetastarvalle{APACrefauthors}Wang, C., Chen, S., Wu, Y., Zhang, Z., Zhou, L., Liu, S.\BDBLothers \APACrefYearMonthDay2023. \BBOQ\APACrefatitleNeural codec language models are zero-shot text to speech synthesizers Neural codec language models are zero-shot text to speech synthesizers.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2301.02111. \PrintBackRefs\CurrentBib
- Y. Wang \BOthers. (\APACyear2017) \APACinsertmetastarwang2017tacotron{APACrefauthors}Wang, Y., Skerry-Ryan, R., Stanton, D., Wu, Y., Weiss, R\BPBIJ., Jaitly, N.\BDBLothers \APACrefYearMonthDay2017. \BBOQ\APACrefatitleTacotron: Towards end-to-end speech synthesis Tacotron: Towards end-to-end speech synthesis.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:1703.10135. \PrintBackRefs\CurrentBib
- Yamamoto \BOthers. (\APACyear2020) \APACinsertmetastaryamamoto2020parallel{APACrefauthors}Yamamoto, R., Song, E.\BCBL \BBA Kim, J\BHBIM. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleParallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram.\BBCQ \BIn \APACrefbtitleICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Icassp 2020-2020 ieee international conference on acoustics, speech and signal processing (icassp) (\BPGS 6199–6203). \PrintBackRefs\CurrentBib
- Yang \BOthers. (\APACyear2021) \APACinsertmetastaryang2021torchaudio{APACrefauthors}Yang, Y\BHBIY., Hira, M., Ni, Z., Chourdia, A., Astafurov, A., Chen, C.\BDBLShi, Y. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleTorchAudio: Building Blocks for Audio and Speech Processing Torchaudio: Building blocks for audio and speech processing.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2110.15018. \PrintBackRefs\CurrentBib
- Zhang \BOthers. (\APACyear2023) \APACinsertmetastarvall_ex{APACrefauthors}Zhang, Z., Zhou, L., Wang, C., Chen, S., Wu, Y., Liu, S.\BDBLothers \APACrefYearMonthDay2023. \BBOQ\APACrefatitleSpeak foreign languages with your own voice: Cross-lingual neural codec language modeling Speak foreign languages with your own voice: Cross-lingual neural codec language modeling.\BBCQ \APACjournalVolNumPagesarXiv preprint arXiv:2303.03926. \PrintBackRefs\CurrentBib