Comparative Analysis of Pooling Mechanisms in LLMs: A Sentiment Analysis Perspective
Abstract
Large Language Models (LLMs) have revolutionized natural language processing (NLP) by delivering state-of-the-art performance across a variety of tasks. Among these, Transformer-based models like BERT and GPT rely on pooling layers to aggregate token-level embeddings into sentence-level representations. Common pooling mechanisms such as Mean, Max, and Weighted Sum play a pivotal role in this aggregation process. Despite their widespread use, the comparative performance of these strategies on different LLM architectures remains underexplored. To address this gap, this paper investigates the effects of these pooling mechanisms on two prominent LLM families – BERT and GPT, in the context of sentence-level sentiment analysis. Comprehensive experiments reveal that each pooling mechanism exhibits unique strengths and weaknesses depending on the task’s specific requirements. Our findings underline the importance of selecting pooling methods tailored to the demands of particular applications, prompting a re-evaluation of common assumptions regarding pooling operations. By offering actionable insights, this study contributes to the optimization of LLM-based models for downstream tasks.
Index Terms:
Large Language Models, Pooling Mechanisms, Sentiment Analysis, Token Embedding AggregationI Introduction
Large Language Models (LLMs) have emerged as transformative tools in natural language processing (NLP), offering unparalleled performance across a broad spectrum of tasks. Among these, BERT (Bidirectional Encoder Representations from Transformers) [1] and GPT (Generative Pre-trained Transformer) [2] stand out as two of the most influential architectures. BERT’s bidirectional attention mechanism enables it to deeply understand contextual relationships within text, making it particularly effective for comprehension-based tasks. On the other hand, GPT’s unidirectional design and autoregressive modeling excel in generating coherent and contextually appropriate text. Together, these models exemplify the state of the art in leveraging transformer-based architectures to tackle diverse linguistic challenges.
The applications of LLMs can be broadly categorized into token-level and sentence-level tasks [3]. Token-level tasks, such as named entity recognition and part-of-speech tagging, require the model to process and predict attributes for individual tokens within a sequence. Sentence-level tasks, including sentiment analysis, entail aggregating token-level information to derive an overall understanding of the text’s meaning. These tasks depend heavily on effective mechanisms to condense token embeddings into coherent sentence-level representations. In this study, we focus on sentence-level tasks, particularly sentiment analysis, as it serves as a fundamental benchmark for evaluating the semantic capabilities of LLMs.
Pooling layers play a critical role in sentence-level tasks by aggregating token embeddings into unified representations [4]. Commonly employed pooling strategies include Mean pooling, which averages embeddings to provide a balanced view, Max pooling, which captures the most salient features, and Weighted Sum pooling, which applies learned weights to emphasize contextually significant tokens. Despite their importance, the comparative effects of these pooling mechanisms on different LLM architectures remain underexplored. To bridge this gap, this paper evaluates the performance of these pooling strategies on BERT and GPT within the context of sentiment analysis. Our contributions are threefold:
-
•
We provide a comprehensive evaluation of Mean, Max, and Weighted Sum pooling mechanisms on BERT and GPT models.
-
•
We identify task-specific strengths and limitations of each pooling method, offering insights into their optimal use cases.
-
•
We present actionable recommendations for practitioners to select appropriate pooling mechanisms based on the specific requirements of downstream tasks.
II Related Work
Deep Learning models, especially the Transformer-based [5, 6, 7] have found innovative applications across various fields like image analysis [8, 9], virtual reality [10], sequences modeling [11], and emotion recognition [12].
The transformer architecture, proposed by Vaswani et al. [13], addressed the sequential computation limitations of RNNs through self-attention mechanisms. This innovation enabled parallel processing of input sequences and more effective modeling of long-range dependencies, establishing the foundation for modern LLMs. The transformer’s encoder-decoder architecture demonstrated superior performance in machine translation tasks and quickly became the de facto standard for neural sequence transduction models [14].
BERT, introduced by Devlin et al. [1], marked a breakthrough in NLP by utilizing a bidirectional transformer architecture to generate contextual embeddings for tokens. Unlike unidirectional models, BERT captures relationships between words in both forward and backward directions, enabling superior understanding of text semantics. Numerous variations of BERT have since been developed to enhance its performance and efficiency. For example, RoBERTa [15] optimized BERT’s training process by removing the next sentence prediction task and training on a larger dataset. DistilBERT [16] focuses on reducing model size while retaining most of BERT’s performance, making it suitable for resource-constrained environments. BERT and its variants have been widely adopted for tasks such as sentiment analysis, text classification, and question answering.
GPT, initially proposed by OpenAI [2], pioneered autoregressive modeling for text generation. The model predicts the next word in a sequence based on prior context, making it particularly effective for generative tasks such as text completion and summarization. Its successor, GPT-2 [17], significantly expanded the model’s capacity and demonstrated remarkable versatility across tasks without task-specific fine-tuning. The introduction of GPT-3 [18] and GPT-4 [19] further advanced the state of the art, leveraging billions of parameters to perform complex tasks such as language translation and dialogue generation with minimal instruction. GPT models have found extensive applications in content creation, conversational agents, and zero-shot learning scenarios [20].
Pooling mechanisms are critical for aggregating token embeddings into sentence-level representations. Mean pooling, one of the simplest techniques, computes the average of token embeddings, providing a balanced view of the input. Max pooling, in contrast, captures the most salient features by selecting the maximum value along each dimension. Weighted Sum pooling introduces a learnable weighting mechanism to prioritize contextually important tokens [22, 21]. These pooling strategies have been explored in various contexts [21]. For instance, Justyna et al. [23] incorporated Mean pooling in their work on contextualized embeddings for sentence classification. Max pooling was applied by Conneau et al. [24] in supervised learning tasks to enhance feature selection. Despite these efforts, the comparative impact of pooling operations on LLMs such as BERT and GPT remains underexplored, especially for sentence-level tasks like sentiment analysis.
III Methodology
III-A Attention Mechanism Fundamentals
The attention mechanism serves as the architectural cornerstone of transformer-based Large Language Models (LLMs) [4]. At its core, attention allows models to dynamically weight the importance of different tokens when processing sequential data. The standard attention mechanism can be mathematically formulated as:
| (1) |
where:
-
•
represents query matrices
-
•
represents key matrices
-
•
represents value matrices
-
•
is the dimension of the keys
This mechanism enables models to capture complex contextual relationships by allowing each token to attend to all other tokens in a sequence, generating rich, context-aware representations.
In practice, multi-head attention mechanisms [14], as shown in Figure 1, are employed to enhance model expressiveness and capture diverse token interactions. Multi-head attention involves projecting the input into multiple subspaces, each processed by an independent attention mechanism. The outputs are then concatenated and linearly transformed to produce the final attention output.

III-B Pooling Strategies
The attention mechanism generates token-level embeddings that must be aggregated to form sentence-level representations. Pooling layers play a crucial role in this aggregation process, condensing token embeddings into unified sentence embeddings. We explore three primary pooling strategies: Mean, Max, and Weighted Sum pooling.
Given the token-level embeddings produced by the attention mechanism, where and represents sequence length, we explore three primary pooling strategies:
III-B1 Mean Pooling
| (2) |
Mean pooling provides a balanced representation by averaging token embeddings, offering a uniform perspective across all tokens.
III-B2 Max Pooling
| (3) |
Max pooling captures the most salient features by selecting the maximum values across token dimensions , emphasizing distinctive embedding characteristics.
III-B3 Weighted Sum Pooling
| (4) |
where represents learnable weight parameters. This approach dynamically assigns importance to different tokens through learned weights.
Notably, mean and max pooling emerge as special cases of weighted sum pooling:
-
•
Mean pooling occurs when weights are uniform ()
-
•
Max pooling approximates when weights concentrate on the most significant token
While weighted sum pooling introduces additional parameters, the linear parameter increment remains negligible compared to the model’s overall complexity.
IV Experiments
Our comprehensive evaluation investigates three pooling operations across BERT and GPT2 models for sentiment analysis, providing insights into their differential performance and practical implications.
IV-A Datasets
We employed the IMDB movie review sentiment analysis dataset, a benchmark corpus for binary sentiment classification. The dataset comprises 50,000 movie reviews meticulously balanced between positive and negative sentiments. Our data partition strategy follows a standard split:
-
•
Training set: 60% (30,000 samples)
-
•
Validation set: 10% (5,000 samples)
-
•
Testing set: 30% (15,000 samples)
The deliberate equal distribution of positive and negative samples mitigates class imbalance, ensuring robust model training and evaluation. This balanced approach prevents potential biases that could arise from skewed class representations. Table I provides a summarization.
| IMDB | #Samples | #Categories | |
|---|---|---|---|
| Train | 30,000 | 16,358 (P) | 13,642 (N) |
| Validation | 5,000 | 2,466 (P) | 2,534 (N) |
| Test | 15,000 | 7,634 (P) | 7,366 (N) |
IV-B Experiment Settings
We selected pretrained BERT-base and GPT2 as our baseline models, implementing a rigorous experimental protocol:
IV-B1 Model Configuration
-
•
Backbone learning rate: 1e-5
-
•
Newly added parameters learning rate: 1e-3
-
•
Remaining hyperparameters: Default configurations as specified in original model papers
IV-B2 Evaluation Metrics
We adopted a comprehensive suite of performance metrics to provide multifaceted model assessment:
-
•
Confusion Matrix: A tabular visualization depicting the model’s prediction accuracy by categorizing outcomes into true positives, true negatives, false positives, and false negatives.
-
•
Precision (): Quantifies the proportion of correctly predicted positive instances among all positive predictions, measuring the model’s exactness.
-
•
Recall (): Represents the proportion of actual positive instances correctly identified, assessing the model’s completeness.
-
•
F1 Score (): Harmonic mean of precision and recall, providing a balanced metric that simultaneously considers both false positives and false negatives.
IV-C Results
IV-C1 Confusion Matrix Analysis
As shown in Figure 2-3, both BERT and GPT2 demonstrated comparable performance across pooling mechanisms, with an aggregate correct prediction rate of approximately 86.07
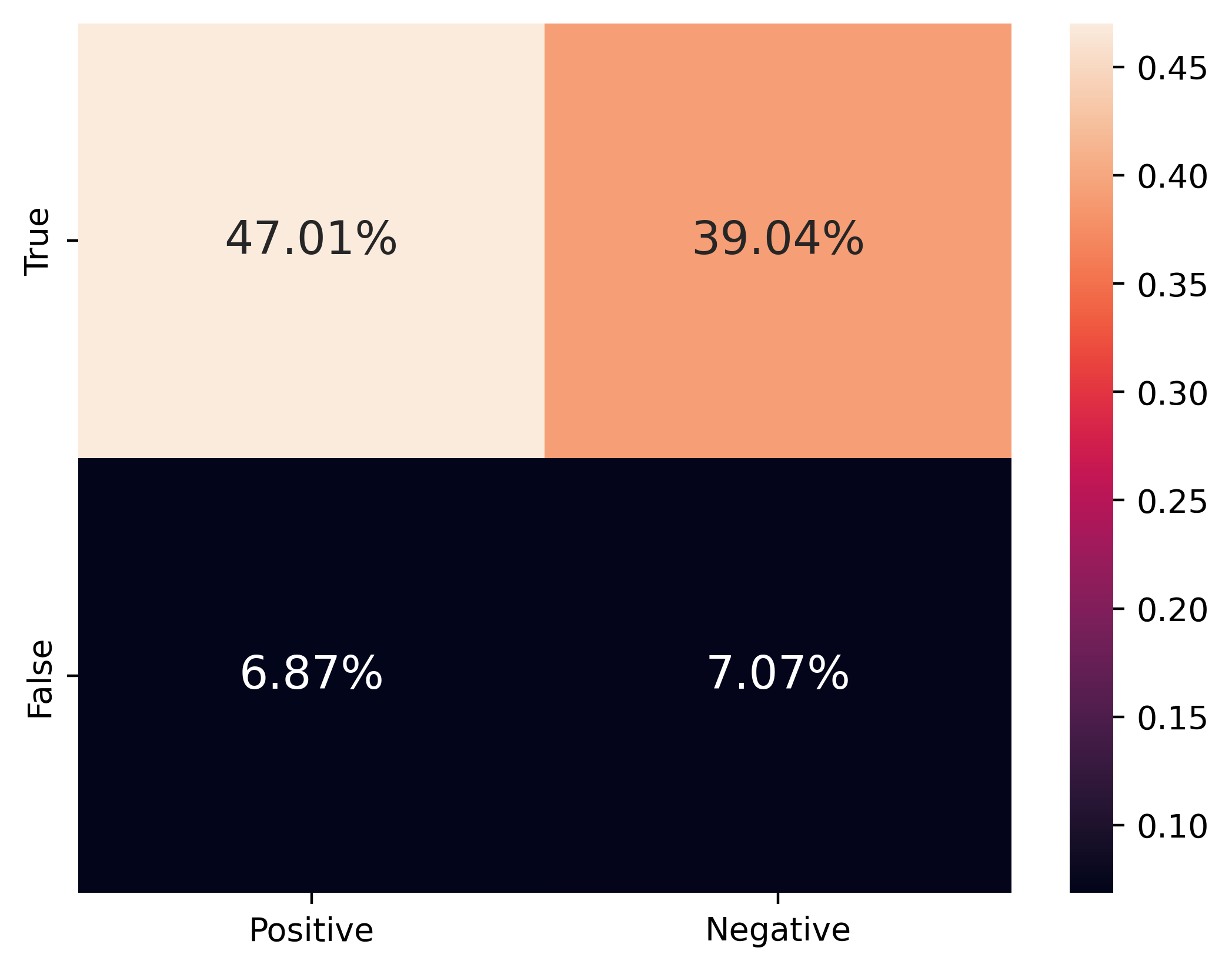





For BERT, Max pooling exhibited distinctive characteristics:
-
•
Highest True Positive rate
-
•
Lowest True Negative rate
-
•
Potentially attributed to the max operation’s tendency to select most prominent features
Mean and Weighted Sum pooling displayed more balanced performance, leveraging comprehensive token consideration. Similar observations can be drawn from GPT2.
IV-C2 Performance Metrics Evaluation
Precision, Recall, and F1 score analyses depicted in Figure 4 revealed nuanced insights:
-
•
BERT achieved peak performance (87.22%) with Mean pooling
-
•
GPT2 optimized performance (88.38%) using Weighted Sum pooling


These results underscore the model-specific nature of pooling mechanism effectiveness. Key observations include:
-
•
Mean pooling offers computational efficiency and balanced representation
-
•
Weighted Sum provides enhanced flexibility for complex tasks
-
•
Model architecture significantly influences pooling mechanism performance
IV-C3 Practical Recommendations
-
•
For computational constraints: Utilize Mean pooling
-
•
For complex, adaptable applications: Employ Weighted Sum
-
•
When maximum positive detection is crucial: Consider Max pooling
The findings emphasize that pooling mechanism selection should be tailored to specific model architectures, downstream tasks, and computational resources.
V Conclusion
This paper provides a systematic evaluation of pooling mechanisms – Mean, Max, and Weighted Sum on two leading LLM families, BERT and GPT, with a focus on sentiment analysis as a representative sentence-level task. Our findings highlight the distinctive contributions of each pooling strategy: Mean pooling excels in general scenarios by providing stable and robust embeddings, Max pooling emphasizes salient features but may overfit to extremes, and Weighted Sum pooling offers flexibility but requires careful optimization. These results emphasize the importance of tailoring pooling mechanisms to align with task-specific requirements and model architectures.
By delving into the interplay between pooling strategies and LLM performance, this research fosters a deeper understanding of the design choices in pooling layers and their impact on downstream applications. Practical recommendations drawn from our analysis aim to guide researchers and practitioners in selecting appropriate pooling methods for their needs. Looking ahead, extending this investigation to additional architectures, tasks, and pooling variations holds promise for further refining the use of LLMs in NLP.
References
- [1] Devlin, Jacob. ”Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
- [2] Radford, Alec. ”Improving language understanding by generative pre-training.” (2018).
- [3] Floridi, Luciano, and Massimo Chiriatti. ”GPT-3: Its nature, scope, limits, and consequences.” Minds and Machines 30 (2020): 681-694.
- [4] Yao, Yifan, et al. ”A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.” High-Confidence Computing (2024): 100211.
- [5] Yang, Xiaoran, Zhen Guo, and Zetian Mai. ”Botnet detection based on machine learning.” In 2022 International Conference on Blockchain Technology and Information Security (ICBCTIS), pp. 213-217. IEEE, 2022.
- [6] Lin, Chengrong, Shaofan Chen, Xiaoran Yang, Caimao Li, Cong Qu, and Qiuhong Chen. ”Research and application of knowledge graph technology for intelligent question answering.” In 2021 12th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), pp. 152-156. IEEE, 2021.
- [7] Yang, Xiaoran. ”Research on automatic composition based on multiple machine learning models.” In 2021 3rd International Conference on Artificial Intelligence and Advanced Manufacture, pp. 1206-1209. 2021.
- [8] Zhao, Sihao, Jiahui Xie, Chu Lin, Xiaolan Nie, Jun Ye, Xiaoran Yang, and Pengzhi Xu. ”Image Retrieval Based on Blockchain.” In 2022 International Conference on Blockchain Technology and Information Security (ICBCTIS), pp. 210-212. IEEE, 2022.
- [9] Liu, Juncheng, Xiaoran Yang, Jing-Chen Hong, and Hiroyasu Iwata. ”Analysis of Lifting Posture by Two Inertial Measurement Units and a Classification Model Based on a Convolutional Neural Network.” In 2024 10th IEEE RAS/EMBS International Conference for Biomedical Robotics and Biomechatronics (BioRob), pp. 383-388. IEEE, 2024.
- [10] Yang, Xiaoran, Yang Zhan, Yukiko Iwasaki, Miaohui Shi, Shijie Tang, and Hiroyasu Iwata. ”Balancing Real-world Interaction and VR Immersion with AI Vision Robotic Arm.” In 2023 IEEE International Conference on Mechatronics and Automation (ICMA), pp. 2051-2057. IEEE, 2023.
- [11] Deng, Xiaoru, Hui Zhou, Xiaoran Yang, and Chunyang Ye. ”Short-Term Traffic Condition Prediction Based on Multi-source Data Fusion.” In International Conference on Data Mining and Big Data, pp. 327-335. Singapore: Springer Singapore, 2021.
- [12] Yang, Xiaoran, Shuhan Yu, and Wenxi Xu. ”Improvement and Implementation of a Speech Emotion Recognition Model Based on Dual-Layer LSTM.” arXiv preprint arXiv:2411.09189 (2024).
- [13] Vaswani, A. ”Attention is all you need.” Advances in Neural Information Processing Systems (2017).
- [14] Xing, Jinming. ”Enhancing Link Prediction with Fuzzy Graph Attention Networks and Dynamic Negative Sampling.” arXiv preprint arXiv:2411.07482 (2024).
- [15] Liu, Yinhan. ”Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 364 (2019).
- [16] Sanh, V. ”DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019).
- [17] Radford, Alec, et al. ”Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
- [18] Brown, Tom B. ”Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 (2020).
- [19] Achiam, Josh, et al. ”Gpt-4 technical report.” arXiv preprint arXiv:2303.08774 (2023).
- [20] Lund, Brady D., and Ting Wang. ”Chatting about ChatGPT: how may AI and GPT impact academia and libraries?.” Library hi tech news 40.3 (2023): 26-29.
- [21] Xing, Jinming, Can Gao, and Jie Zhou. ”Weighted fuzzy rough sets-based tri-training and its application to medical diagnosis.” Applied Soft Computing 124 (2022): 109025.
- [22] Gao, Can, et al. ”Parameterized maximum-entropy-based three-way approximate attribute reduction.” International Journal of Approximate Reasoning 151 (2022): 85-100.
- [23] Sarzynska-Wawer, Justyna, et al. ”Detecting formal thought disorder by deep contextualized word representations.” Psychiatry Research 304 (2021): 114135.
- [24] Conneau, Alexis, et al. ”Supervised learning of universal sentence representations from natural language inference data.” arXiv preprint arXiv:1705.02364 (2017).