Comparative Analysis of Multi-Agent Reinforcement Learning Policies for Crop Planning Decision Support
Abstract
In India, the majority of farmers are classified as small or marginal, making their livelihoods particularly vulnerable to economic losses due to market saturation and climate risks. Effective crop planning can significantly impact their expected income, yet existing decision support systems (DSS) often provide generic recommendations that fail to account for real-time market dynamics and the interactions among multiple farmers. In this paper, we evaluate the viability of three multi-agent reinforcement learning (MARL) approaches for optimizing total farmer income and promoting fairness in crop planning: Independent Q-Learning (IQL), where each farmer acts independently without coordination, Agent-by-Agent (ABA), which sequentially optimizes each farmer’s policy in relation to the others, and the Multi-agent Rollout Policy, which jointly optimizes all farmers’ actions for global reward maximization. Our results demonstrate that while IQL offers computational efficiency with linear runtime, it struggles with coordination among agents, leading to lower total rewards and an unequal distribution of income. Conversely, the Multi-agent Rollout policy achieves the highest total rewards and promotes equitable income distribution among farmers but requires significantly more computational resources, making it less practical for large numbers of agents. ABA strikes a balance between runtime efficiency and reward optimization, offering reasonable total rewards with acceptable fairness and scalability. These findings highlight the importance of selecting appropriate MARL approaches in DSS to provide personalized and equitable crop planning recommendations, advancing the development of more adaptive and farmer-centric agricultural decision-making systems.
1 Introduction
India’s agricultural sector faces major challenges. Over half of agricultural households are in debt, often due to crop failures (Statista Research 2024). Effective crop planning is key to improving farmers’ incomes, but existing systems do not adapt well to real-time market supply and demand. This often leads to income loss, especially when recommendations are homogenous, causing market saturation and lower profits. For small-scale farmers, particularly in countries like India, crop planning that adjusts dynamically can significantly boost their earnings (Fabregas, Kremer, and Schilbach 2019).
Crop planning is a crucial challenge for small-scale farmers, especially in developing nations like India, where they face significant risks from climate variability, market fluctuations, and limited resources (Matthan 2023). Decisions on what to plant, when to harvest, and how to manage resources are critical to farmers’ livelihoods, yet traditional decision-support systems (DSS) often fall short of addressing the complexities they face. These systems do not account for the interconnected nature of farming communities, where one farmer’s choices can impact others, especially in shared markets where oversupply can drive down prices. As a result, farmers are left vulnerable to economic instability and are often unable to achieve equitable outcomes (Esteso et al. 2022).
While reinforcement learning (RL) has demonstrated success in agricultural applications such as fertilization management policies (Overweg, Berghuijs, and Athanasiadis 2021), its potential for crop planning remains underexplored, particularly in multi-agent settings. Traditional RL systems primarily focus on optimizing outcomes for a single agent, overlooking the critical role of coordination among multiple farmers. Multi-agent reinforcement learning (MARL) offers a promising framework for addressing this gap, enabling farmers to optimize their actions collectively while managing shared resources and mitigating market risks. Recent advancements in MARL highlight its application in tasks such as spatiotemporal sensing (Tamba 2022) and task offloading and network selection in heterogeneous agricultural networks (Zhu et al. 2023). Additionally, MARL has been used to coordinate UAVs for field coverage and crop monitoring (Marwah et al. 2023). Despite these innovations, existing MARL applications often focus on objectives like spacial coverage or resource allocation, overlooking market saturation and dynamic interdependencies in crop planning. This highlights the need for MARL systems that enhance efficiency, include agent interactions, address market dynamics, and promote economic stability in shared decision-making.
In this paper, we explore how three different MARL algorithms manage joint rewards and fairness in greenhouse crop planning in Telangana, India: (a) Independent Q-Learning (IQL), (b) Agent-by-Agent (ABA), and (c) multi-agent Rollout Policy. Each algorithm has a unique approach: IQL allows each agent to learn independently, optimizing for individual rewards without directly considering the actions of others, which simplifies computation. ABA takes a sequential approach, optimizing the policy of one agent while holding the others constant, improving coordination across agents while maintaining manageable computational complexity. Finally, Rollout takes a more comprehensive approach by considering the joint actions of all agents at each step, aiming to maximize total collective rewards through simultaneous optimization.
We conducted experiments to analyze the performance of these algorithms, focusing on key metrics such as runtime, total joint reward, and aggregated welfare, concepts we will define later. Additionally, we adjusted hyperparameters representing long-term reward importance (discount factor, ) and sensitivity to changes in reward distribution (slope coefficient), allowing us to assess stability and fairness across different approaches. The results show that IQL is computationally efficient but struggles to coordinate and maximize joint rewards, while ABA provides a better balance between efficiency and fairness. Rollout achieves the highest joint reward but at the cost of significantly increased runtime. For practitioners seeking an efficient solution with reasonable fairness, the Agent-by-Agent Policy (ABA) offers a balanced approach, whereas those prioritizing maximum joint reward may consider Rollout despite its computational cost. These insights highlight the trade-offs between reward optimization, fairness, and computational complexity in the context of multi-agent crop planning.
2 Related Works
Crop planning is a critical issue for small-scale farmers, particularly in developing nations like India where climate variability and market fluctuations can lead to severe economic losses. Various DSS have been developed to assist farmers in selecting optimal planting and harvesting schedules. Traditional approaches, such as those implemented by (Sarker and Quaddus 2002; Mohamed et al. 2016; Bhatia and Rana 2020), utilize rule-based systems or linear programming techniques to provide generalized crop recommendations based on average weather and market conditions. However, these systems fail to account for the heterogeneity of farmers’ individual circumstances and the non-stationary nature of both environmental and economic factors.
RL offers a more dynamic approach to crop planning by enabling systems to adapt based on continuous feedback from the environment. For example, Yang et al. (2020) applied reinforcement learning to optimize irrigation scheduling, achieving improved water-use efficiency in agriculture. Similarly, Chen et al. (2021) proposed an RL-based system that accounts for weather predictions and soil moisture data to inform farmers’ irrigation practices. While effective for single-agent settings, these systems do not account for the complex interactions between multiple farmers, whose simultaneous actions can influence market prices and resource availability.
While MARL holds promise for addressing challenges in collaborative decision-making, its application in crop planning remains limited. Most existing research explores related but distinct areas, reducing its direct applicability. For example, Kamali, Niksokhan, and Ardestani (2024) developed a multi-agent simulation to evaluate groundwater management policies, where agents negotiate water usage based on local needs. This study highlights MARL’s potential in managing shared resources but does not address crop planning dynamics. Similarly, Li, Zhang, and Wang (2018) applied multi-agent systems in agricultural markets to optimize planting schedules based on market conditions. However, their approach primarily focused on price predictions and overlooked the role of agent interactions in mitigating market saturation. These gaps highlight the need for further exploration of MARL frameworks tailored to the complexities of crop planning.
Our work builds on this existing research by investigating three RL approaches within a multi-agent setting to address critical gaps in crop planning strategies, particularly in optimizing joint rewards among farmers. Conventional systems often rely on uniform recommendations; in contrast, our system dynamically adapts to the actions of other agents (farmers) to mitigate market saturation and promote fair distribution of profits. Each policy is evaluated based on its trade-offs in computational efficiency, coordination, and fairness. This analysis uncovers underexplored dynamics in MARL approaches and offers insights into their potential to advance collaborative decision-making in agricultural systems.
3 Methods
First, we will discuss how we model the problem. We will then describe the objective which our algorithms seek to optimize. Next, we will describe the three algorithms which we have developed to solve our problem.
3.1 Problem Modeling
As mentioned in Section 1, we are investigating greenhouses in Telangana, India. We model the greenhouses as a collection of identical Markov Decision Processes (MDPs). We extend Lu and Prins (2024)’s model of individual greenhouse-agents with a new model to capture interactions between agents. We capture the problem over a finite horizon of discrete timesteps, where a fixed number of days passes with each timestep.
There are agents belonging to the agent set . Every agent owns a greenhouse, whose condition at a given timestep is represented by one of many states. Each state holds information about which crop is planted, and whether it is harvestable. We notate the state of greenhouse at timestep as , and the the joint-state of all agents at timestep as . There exists a common state space such that for all agents and timesteps . Each agent starts at some state , sampled from .
At every timestep, each agent takes some action. We will notate the action of agent at timestep as , and the joint-action of all agents at timestep as . There exists a common state space such that for all agents and timesteps . In particular, there is an action .
Because of crop seasonality, the transition function is non-stationary. Specifically, for every timestep , there is a transition function common to all agents where state transitions are determined as . Here, the transitions are deterministic. Interested readers can refer to Lu and Prins (2024) for detailed descriptions on the states, actions, and transitions for our problem.
We now introduce interactions between agents corresponding to marketplace competition. After every timestep, each agent receives a reward. We notate the reward for agent at timestep as , and the joint-reward of all agents at timestep as . Rewards are non-stationary but not agent-independent. Specifically, for every timestep , there is a reward function where .
As it is specific to market dynamics, our model’s reward function is highly structured. First, agents receive rewards only if they make a valid harvest. This means that if and only if is harvestable and .
Secondly, is broken down by crop, and rewards depend only on the number of agents who made a valid harvest of each crop. We will define as the number of agents who made a valid harvest of crop on timestep . For each timestep and crop , there is a pseudo-reward function such that indicates the market price of crop at timestep , when sellers are supplying that crop. is the function which results from assigning the appropriate market price to all agents who made a valid harvest.
is monotonically decreasing on . This is because as the number of sellers of a crop increases, the price of that crop decreases, as the larger number of sellers will bid down the price through supply-demand mechanics. We modeled as a linear function on . We generated the linear fit through a regression of past market data of tuples of the form (crop, kg supplied, price). Specifically, we fitted two parameters , and and set . The slope coefficient is a hyperparameter which adjusts the market impact of each agent.
3.2 Objective
The decision maker’s goal is to develop a policy for each agent, which at each timestep takes in a state and returns an action. Formally, the solution will be a collection of mappings for all agents and timesteps . This indicates that if agent ’s greenhouse in state at time , then we recommend that they take action . We will notate the full collection of policies as a joint-policy .
Farmers cannot observe what is happening in other greenhouses. Therefore, the objective’s type signature is limited to finding independent policies for each agent, meaning that each agent decides actions based only on the state of their own greenhouse, and not on the states of other agents. This choice also has advantages for computational complexity, as there are an exponential order more non-agent-independent policies than agent-independent policies.
We wish to maximize the total welfare of all agents in our system. In order to define total welfare, we will first define returns for each agent as an expectation of the weighted sum of the rewards received over the horizon, parameterized by some discount factor . The discount factor weights how much present rewards are prioritized over future rewards. The return of agent is ). We will notate the joint-returns as , and will sometimes use or , since the returns are fully dependent on .
Now, we will define the total welfare of all agents as ). We choose to optimize the product of returns because it combines a preference for all agents have higher returns, and a preference for returns to be distributed equally. We can also think of this as optimizing . This is motivated since many studies have shown that happiness has a logarithmic relationship with income. We will sometimes use notation.
3.3 Independent Q Learning
IQL adapts single-agent reinforcement learning principles to multi-agent systems (Tan 1993). Each agent independently learns its policy by observing changes in the environment, disregarding the actions of other agents as direct influencing factors. This simplifies the multi-agent problem by treating each agent as if it were operating in a single-agent context, where the focus lies on learning its own Q-function. A Q-function is defined as the expected future rewards for taking a specific action in a given state and following an optimal policy thereafter.
To implement IQL, we construct a Q-table that captures these expected rewards for each possible action in each state. The Q-values in this table are continuously updated as the agent gathers new observations, enabling it to better its decision-making over time. We first choose a learning parameter . Then, for agent , the Q-value update rule is defined as:
| (1) |
Input:State space , action space , transition dynamics , reward function , agent set , time horizon , initial state distribution , discount factor
Parameter: learning rate , exploration probability
Output: Updated Q-values for each state-action pair
The IQLBufferPolicy algorithm is an extension of the IQL approach that introduces two key improvements: optionally initializing the Q-values by solving a Linear Programming (LP) problem using an offline base policy and sampling multiple trajectories for each agent to enhance the policy’s learning process over a longer horizon. Please note that we will use IQL to refer to IQLBufferPolicy from here on. Here’s a brief explanation of the main methods in the IQL code:
-
•
The Q-tables for each agent are initialized, and if the warm start flag is set, the Q-values are “warm-started” using an LPsolver base policy. This offline policy computes the initial Q-values by solving for the agent’s expected reward in each state based on the transition matrices and reward function of the MDP model. This step significantly accelerates the learning process by providing an improved starting point for Q-values. Further information about the LPsolver base policy can be found in Appendix C.
-
•
In this method, the Q-table is updated over multiple episodes, simulating a trajectory of actions and observing the resulting rewards and state transitions. This allows for more robust learning as the agent samples multiple paths and adjusts its Q-values accordingly.
-
•
Choose an action using the epsilon-greedy policy for a specific agent. The epsilon-greedy policy balances exploration and exploitation. With probability , a random action is chosen to explore new actions. Otherwise, the action with the highest Q-value is chosen to exploit known information.
-
•
The Q-value for a state-action pair is updated based on the observed reward and the maximum Q-value of the next state according to the equation shown earlier (following the standard Q-learning update rule). This allows the agent to incrementally improve its policy by considering both immediate and future rewards.
-
•
Run the Independent Q-learning algorithm for multiple episodes. In each episode, the agents interact with the environment for a fixed number of timesteps (horizon). The state, actions, rewards, and next states are observed, and the Q-values are updated accordingly.
-
•
After the Q-tables are updated, the algorithm computes the best joint policy for the cohort of agents by selecting the action with the highest Q-value for each state and agent. The joint action is computed at each time step, taking into account the current state of all agents.
Time complexity
IQL simplifies multi-agent reinforcement learning by treating each agent independently. For each episode , we loop through all timesteps , where each agent selects an action and observes a reward based on the current state. At each timestep, each agent incurs a cost of where represents action space and the state space. Thus, the overall time complexity, which is linear in the number of agents and timesteps, is . Unfortunately, although this approach is computationally efficient and easy to implement and understand, there is no guarantee of convergence after timesteps. This is due to the non-stationary environment created by the independent learning processes of multiple agents.
3.4 Agent By Agent Policy
The Agent-By-Agent (ABA) algorithm breaks down the global optimization problem of finding a policy for every agent into multiple local optimization problems of finding the best policy for a single agent, while holding the policies of all other agents constant. This allows us to reduce the multi-agent problem into a single-agent problem, where the agents not actively being optimized are treated as if they were part of the environment, simply affecting the reward function. This agent-by-agent optimization is related to the family of coordinate descent algorithms, in which one parameter is optimized at a time until convergence. In our case, the “coordinate” directions are the single-agent policies for each agent .
After initialization, the algorithm loops until a policy convergence threshold is reached. Within this outer loop, a single agent is chosen, and then the algorithm finds the welfare-maximizing policy for agent , according to the currently held policies of all other agents. Formally, we seek to find the single-agent policy such that is maximized. We then update and continue to the next iteration, choosing another agent to optimize.
Dynamic Programming
The most involved portion of this algorithm comes down to solving for the welfare-maximizing policy for a single-agent, given the policies of all other agents. Our solution takes advantage of the acylicity of timesteps, and uses dynamic programming.
For illustration, suppose that we changed our framing of the problem so that we expand our state space to have a state for every () pair for all . The resulting state transition graph would be acyclic, giving us a topological order with which to process states. If we process states in descending order from to , then by the time our algorithm processes a state , we will have already processed all states that can transition to. Further, if we know the value of state for all actions , we can determine the value of each action as a sum of the instantaneous reward and the value of our new state .
Thus, we are yielded the dynamic programming approach. As we are optimizing for some single-agent , we define as the maximal increase to possible from timestep onwards, when agent starts at , and all other agents follow for every timestep. As stated, we will compute values in descending order, so that we have access to values of when calculating values of .
Now, we must find transition equations which relate values. Because welfare is non-linear on returns, it is impossible to determine the actual effect of taking a certain action without knowing the returns of all agents across the entire horizon, which is dependent on the joint-policy. Because the whole point of our dynamic programming approach is to find the best , we do not have access to when we are computing values. Thus, we will have to settle for an approximation of the welfare added from an action, which depends only on the parameters accessible when computing values: namely and . We will do this by linear approximation.
Linear Approximation
Because linearity allows us to isolate the effect of a single reward, the approximation we elect will be a first-order linear approximation of the welfare function evaluated at before the current iteration of single-agent optimization. Specifically, we approximate the change in under some change as . Evaluating the partial derivatives at the previous version of the joint-policy incentives the optimization to improve upon its prior form.
The details of how this is implemented are mathematically involved. Please see the appendix for all of the details on this portion of the algorithm.
Details
Before the main portion of the algorithm, each agent’s policies must be initialized. This can either be done by choosing an arbitrary action and set for all , or by uniformly randomizing the entire policy table.
Additionally, we need a stopping criterion to exit the algorithm’s outer loop. A simple choice is to run the loop for a fixed number of iterations where is a hyperparameter to be optimized empirically. Another option is to set a parameter and terminate when the improvement in welfare from our refined policy is less than .
To choose which agent is selected to optimized, two choices stand out:
-
1.
Cycle through agents in order through until convergence. This approach has the drawback of allowing some systematic limitations; for instance, agent always immediately responds to changes in agent ’s policy, whereas the reverse requires iterating through all other agents.
-
2.
Randomly select one of the agents at each iteration. Randomness often works well in descent-based optimization algorithms, like stochastic gradient descent. If sufficient training iterations are run, agents will be selected roughly equally with high probability.
When we can’t directly access for future , we approximate it as using observations of past , allowing this algorithm to adapt to real-time market updates. There are many ways to do this which could be explored in future research.
Input: State space , action space , transition dynamics , reward function , agent set , time horizon , initial state distribution , discount factor
Output: Policy
See Appendix B for the pseudocode for the single-agent optimization subroutine.
The time complexity of the entire algorithm is where is the average number of optimizations per agent required for convergence.
3.5 Multi-agent Rollout Policy
The multi-agent rollout algorithm, introduced by Bertsekas (2021), extends the policy iteration (PI) framework to multi-agent systems. Rollout simplifies the optimization process by iteratively improving policies, optimizing each agent’s actions sequentially while considering the fixed decisions of other agents. This sequential optimization significantly reduces computational complexity, making it particularly advantageous for large-scale multi-agent systems. By focusing on one agent at a time, the algorithm leverages the structure of the multi-agent Markov Decision Process (MDP) to approximate near-optimal solutions efficiently.
Traditional PI algorithms face scalability challenges in multi-agent environments due to the exponential growth in complexity when optimizing all agents’ actions simultaneously. The multi-agent rollout method addresses this by performing local optimizations for each agent in a sequential manner, adjusting one agent’s actions at a time while keeping the others fixed. As a result, the computational complexity scales linearly with the number of agents, , enhancing feasibility in systems with many agents.
This approach also supports real-time applications and dynamic replanning, where decisions must adapt to changing conditions continuously. By incorporating the rollout technique into multi-agent settings, we ensure that each agent optimizes its actions while maintaining coordination with others, ultimately producing globally improved policies that enhance system performance over successive iterations.
Single-Agent Rollout Algorithm and Policy Improvement
The standard one-step lookahead single-agent rollout algorithm is a method for improving a given base policy . The base policy refers to an initial policy that guides action selection before any optimization or improvement steps are applied. This base policy serves as a benchmark for evaluating and enhancing the rollout policy. At each time step , given the current state , represents the expected cumulative reward of taking action in state and thereafter following the base policy :
The expected cumulative reward under the base policy , starting from state , is given by:
| (2) |
In this equation:
-
•
The sum calculates the discounted rewards from time to the terminal time ,
-
•
is the terminal reward at time ,
-
•
The expectation is over the sequence of future states generated by following the policy .
The rollout policy is then constructed by selecting, at each time step , the action that maximizes the Q-factor. This is done by choosing:
| (3) |
By selecting actions that maximize , the rollout policy improves upon the base policy, resulting in a higher expected cumulative reward at each stage, as indicated by the inequality:
| (4) |
Multi-Agent Rollout Algorithm with LPSolver Base Policy
The base policy can be derived using various methods that optimize decision-making for each agent. The methods should be designed to minimize the expected cumulative discounted cost and can be chosen based on the specific problem setting. In this work, we use LPSolver policy as the base policy. The policy leverages linear programming to solve each MDP efficiently. Further details on the specific implementation and mechanics of LPSolver policy are provided in Appendix C.
Calculation of for Multiple MDPs
The expected future reward is directly obtained from the value function , precomputed by the LPSolver:
| (5) |
Action Selection
The action for agent is selected by maximizing the expected cumulative reward over the horizon . For each action , a candidate action profile is constructed:
| (6) |
where is the expected cumulative reward starting from time .
The Q-factor for agent is defined as:
| (7) |
subject to:
Time Complexity
The computational complexity of this approach is , where is the planning horizon, is the number of agents, is the action space size, and is the complexity of calling the base policy’s get_next_action() function. This reflects the iterative, multi-agent optimization process, balancing higher computational demands with robust policy improvement.
Input: Initial state , Base policy (implemented via LPSolver with discount factor ), Horizon , State transition function , Reward function
Output: Rollout policy
4 Experiments
In this section, we run simulations to address the challenge of optimizing crop planning for small-scale farmers in India, where traditional systems often lead to income loss by failing to account for real-time market supply and demand. In this study, we evaluate three different reinforcement learning policies (IQL, ABA, and Rollout) to measure how effectively they perform in a multi-agent crop planning environment. We test their impact on runtime, reward distribution, discount factors, and slope coefficients. All policies are aimed at maximizing total farmer income while allowing us to observe fairness outcomes among agents. Testing was conducted on a Ryzen 5600H 3.0 GHz processor, without GPU, and the code was written in Python 3.9.
Our first experiment was total joint reward, which is the sum of farmer rewards. Experiments were set up with 5, 10, 15, and 20 agents, and we measured how much total reward each policy generated. Unless otherwise noted, 14 days passes with each timestep for a total of timesteps. We set the parameter to 0.1 and the slope coefficient to 500.

The results showed that both ABA and Rollout produced significantly higher total rewards, each reaching approximately 500,000 rupees, while IQL achieved much lower rewards. For Rollout, the rewards per agent were relatively consistent, with each agent making around 100,000 rupees, which indicates a strong distributional balance. ABA also showed relatively fair reward distribution but had one agent with zero rewards, suggesting only partial fairness. Here, we define “fairness” as equal distribution of rewards across agents, a common metric for equity in MARL applications. This concept of fairness has been explored by researchers as a benchmark to measure equitable outcomes among agents, particularly in settings where agents are interdependent (Ju, Ghosh, and Shroff 2024).
IQL was the least effective in reward distribution, with some agents even experiencing negative rewards. This result reflects IQL’s non-stationarity, where each agent optimizes based solely on its individual states and rewards, while other agents’ actions continuously alter the environment. As a result, agents lack sufficient time to learn and converge on optimal joint actions. In contrast, ABA uses dynamic programming to work backward from the horizon, capturing the true value of each state with a comprehensive cost function. Rollout, by using an LPSolver as its base, shows some limitations; since the LPSolver optimizes for single-agent policies, Rollout mostly coordinates all agents to take similar actions. While this alignment maximizes reward within the simulation’s parameters, it risks oversaturating the market if applied without such constraints in practice.

For the runtime analysis, we used a general MDP model to avoid the complexities of greenhouse-specific details. This allowed us to focus on core performance and scalability, providing a clearer and faster comparison of how each policy handles multiple agents without the added complexity of the Greenhouse constraints, such as crop maturity, market interactions, or seasonal factors.
The simulation results indicate that Rollout required significantly more runtime as the number of agents increased, reaching over 3500 seconds for 20 agents, as shown in Figure 2. This extended runtime makes Rollout less practical for large-scale applications. In contrast, IQL and ABA (ABA) completed their tasks much faster. IQL exhibited time complexity, scaling linearly with the number of agents. ABA also showed a manageable runtime with time complexity, where is the number of states, reflecting its stepwise optimization of each agent’s policy through dynamic programming. This complexity is consistent with the results shown, where ABA scales efficiently with increasing agent numbers while balancing computational demand. In summary, while Rollout achieves the highest rewards, its larger time complexity limits scalability. IQL is efficient but sacrifices reward performance, whereas ABA achieves a balance of decent rewards with a reasonable runtime.

Finally, we examined the effect of different slope coefficients—values ranging from 500 to 1,500—on the total joint reward across 26 horizons, 14 timesteps, and 2 agents. The slope coefficient reflects how sensitive the market is to oversupply; as more agents harvest the same crop, prices drop more sharply with higher slope values. This coefficient directly impacts total reward: if agent follows the same policy but under different slope coefficients, the total reward can vary because the market price adjusts differently depending on supply sensitivity. Therefore, we interpret each point on the plot in light of this supply sensitivity.
With IQL, the reward remains flat across all slope coefficients, showing that IQL’s independent agent actions make it unable to adapt to supply-driven price sensitivity. This flat result indicates that the slope coefficient does not influence IQL’s total reward outcome. By contrast, ABA shows a steady increase in reward as the slope coefficient rises. This upward trend suggests that ABA can effectively adapt to market conditions, likely by spreading out agents’ harvest times to avoid market oversaturation. Rollout, meanwhile, displays a slight dip around a slope coefficient of 1,000, possibly due to challenges in coordinating actions at this particular sensitivity. However, Rollout recovers as the slope coefficient increases, which indicates that it can adjust agents’ actions to balance market supply and demand at higher sensitivity values. Overall, ABA and Rollout better handle market dynamics by leveraging coordination, making them more effective in scenarios where agents must balance their actions to avoid oversupply and maintain favorable prices.
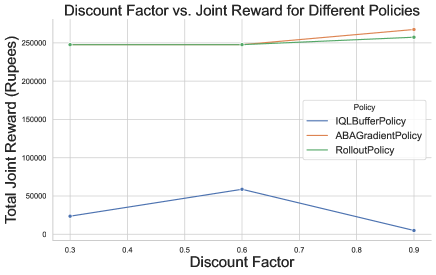
Next, we observed how discount factors (ranging from 0.3 to 0.9) impact the total joint reward for the three policies across 26 horizons, 14 timesteps, and 2 agents. A discount factor represents how much weight the policies place on future rewards compared to immediate ones. ABA and Rollout maintain consistently high rewards, with a slight upward trend as the discount factor increases. These policies, which optimize for joint rewards, are better at managing the long-term impact of actions and coordinating between agents, ensuring that they continue to maximize total rewards even as future rewards become more important. In contrast, IQL reaches its highest performance at a discount factor of around 0.6 but then drops off as the discount factor increases. This behavior likely occurs because IQL operates independently for each agent, meaning that agents do not coordinate their actions. As the discount factor increases, agents focus more on long-term rewards, but since they are not considering the actions of other agents, their decisions negatively affect overall outcomes. This leads to lower joint rewards, particularly at higher discount factors.
5 Conclusion
In this study, we explored the distinct trade-offs among computational efficiency, reward optimization, and fairness in multi-agent crop planning using different MARL algorithms. IQL initially appeared advantageous due to its computational efficiency; however, as the number of agents increases, IQL’s performance declines due to coordination challenges, resulting in lower overall rewards and a less equitable outcome distribution. This difficulty with coordination limits IQL’s suitability for multi-agent contexts where fairness is a priority.
The ABA policy, which plans actions for each agent in advance, offers a compromise between coordination and computational demand. Unlike IQL, ABA enhances agent coordination by optimizing sequentially, which improves fairness and reward distribution. However, its moderate computational overhead must be weighed against its performance benefits.
Conversely, the multi-agent Rollout policy achieves the highest rewards and equitable outcomes by optimizing joint agent actions simultaneously. This approach, however, significantly increases runtime, making it less feasible for large-scale applications. This trade-off implies that Rollout may only be practical in scenarios with fewer agents or lower computational constraints.
The experimental analysis was crucial in clarifying these trade-offs, providing insights into each algorithm’s strengths and limitations under varying conditions. Ultimately, these findings underscore that selecting an appropriate MARL approach for agricultural decision-support systems requires balancing efficiency, reward optimization, and fairness according to specific needs. To address the scalability of these algorithms, we recommend further exploration into enhancing MARL policies that can balance fairness and efficiency in resource-constrained environments, ensuring sustainable support for farmers.
References
- Bertsekas (2021) Bertsekas, D. 2021. Multiagent Reinforcement Learning: Rollout and Policy Iteration. IEEE/CAA Journal of Automatica Sinica, 8(2): 249–272.
- Bhatia and Rana (2020) Bhatia, M.; and Rana, A. 2020. A Mathematical Approach to Optimize Crop Allocation – A Linear Programming Model. International Journal of Design & Nature and Ecodynamics, 15(2): 245–252. Available online: 30 April 2020.
- Chen et al. (2021) Chen, M.; Cui, Y.; Wang, X.; Xie, H.; Liu, F.; Luo, T.; Zheng, S.; and Luo, Y. 2021. A reinforcement learning approach to irrigation decision-making for rice using weather forecasts. Agricultural Water Management, 250: 106838.
- Esteso et al. (2022) Esteso, A.; Alemany, M.; Ortiz, A.; and Liu, S. 2022. Optimization model to support sustainable crop planning for reducing unfairness among farmers. Central European Journal of Operations Research, 30(3): 1101–1127.
- Fabregas, Kremer, and Schilbach (2019) Fabregas, R.; Kremer, M.; and Schilbach, F. 2019. Realizing the Potential of Digital Development: The Case of Agricultural Advice. Science, 366(eaay3038).
- Ju, Ghosh, and Shroff (2024) Ju, P.; Ghosh, A.; and Shroff, N. B. 2024. Achieving Fairness in Multi-Agent MDP using Reinforcement Learning. In Proceedings of the 12th International Conference on Learning Representations (ICLR 2024). Hybrid, Vienna, Austria.
- Kamali, Niksokhan, and Ardestani (2024) Kamali, A.; Niksokhan, M. H.; and Ardestani, M. 2024. Multi-agent system simulation and centralized optimal model for groundwater management considering evaluating the economic and environmental effects of varied policy instruments implemented. Journal of Hydroinformatics, 26(9): 2353–2374.
- Li, Zhang, and Wang (2018) Li, X.; Zhang, Y.; and Wang, J. 2018. Designing Price-Contingent Vegetable Rotation Schedules Using Agent-Based Simulation. Agricultural Systems, 166: 24–34.
- Lu and Prins (2024) Lu, T.; and Prins, A. 2024. An Online Optimization-Based Decision Support Tool for Small Farmers in India: Learning in Non-stationary Environments. 3rd Annual AAAI Workshop on AI to Accelerate Science and Engineering (AI2ASE).
- Marwah et al. (2023) Marwah, N.; Singh, V. K.; Kashyap, G. S.; and Wazir, S. 2023. An analysis of the robustness of UAV agriculture field coverage using multi-agent reinforcement learning. International Journal of Information Technology, 15: 2317–2327.
- Matthan (2023) Matthan, T. 2023. Beyond bad weather: Climates of uncertainty in rural India. In Climate Change and Critical Agrarian Studies, 164–185. Routledge.
- Mohamed et al. (2016) Mohamed, H.; Mahmoud, M.; Elramlawi, H.; and Ahmed, S. 2016. Development of mathematical model for optimal planning area allocation of multi crop farm. International Journal of Science and Engineering Investigations, 5(59): 7.
- Overweg, Berghuijs, and Athanasiadis (2021) Overweg, H.; Berghuijs, H. N. C.; and Athanasiadis, I. N. 2021. CropGym: A reinforcement learning environment for crop management. arXiv preprint arXiv:2104.04326.
- Sarker and Quaddus (2002) Sarker, R.; and Quaddus, M. 2002. Modelling a nationwide crop planning problem using a multiple criteria decision-making tool. Computers & Industrial Engineering, 42(2-4): 541–553.
- Statista Research (2024) Statista Research. 2024. India: Agricultural Households in Debt. Accessed: 2024-11-18.
- Tamba (2022) Tamba, T. A. 2022. A Multi-Agent Reinforcement Learning Approach for Spatiotemporal Sensing Application in Precision Agriculture. In Industry 4.0 in Small and Medium-Sized Enterprises (SMEs), 71–84. CRC Press.
- Tan (1993) Tan, M. 1993. Multi-agent reinforcement learning: Independent vs. cooperative agents. In Proceedings of the Tenth International Conference on Machine Learning, 330–337. San Francisco, CA: Morgan Kaufmann.
- Yang et al. (2020) Yang, Y.; Hu, J.; Porter, D.; Marek, T.; Heflin, K.; and Kong, H. 2020. Deep Reinforcement Learning-Based Irrigation Scheduling. Transactions of the ASABE, 63(3): 549–556.
- Zhu et al. (2023) Zhu, A.; Zeng, Z.; Guo, S.; Lu, H.; Ma, M.; and Zhou, Z. 2023. Game-theoretic robotic offloading via multi-agent learning for agricultural applications in heterogeneous networks. Computers and Electronics in Agriculture, 211: 108017.
Appendix A Details On Linear Approximation for Agent by Agent Algorithm
Here, we will cover in more detail how we obtain a linear approximation for the effect of a change in a single reward for a single agent. Specifically, we approximate the change in under some change as .
We expand out the partial derivative using the multi-variable chain rule. Since only has an effect on , we are left with only one term. We can calculate each of these partial derivatives by consulting their definition equations, and can then combine the entire linear approximation into one concise equation. Again, we will use and values derived from previous values of .
| (8) | ||||
| (9) | ||||
| (10) | ||||
| (11) |
Now, we have an approximation for the change in based on some change in for some agent and timestep . We now must turn this into an approximation for the instantaneous change in based on some change in and for some . We do this by calculating the effect of the action change on for all agents , and multiplying each of these terms by the previously calculated effect of on , and then taking the sum of these products. We can then manipulate the algebra, to derive defined as the the effect on of changing and .
| (12) | ||||
| (13) | ||||
| (14) | ||||
| (15) |
The above expression is now dependent only on the state and action trajectories, which can be simulated using the previous version of the joint-policy before computing values. Putting this altogether, we get the transitions we need.
| (16) |
As a base case, values for should have no term represent future welfare improvement, because the MDP is at the last step of the horizon. The transitions here are thus simply:
| (17) |
Once we have calculated all values, we can easily recover the single-agent-optimized policy by from each timestep choosing the action that yielded the best improvement according to the transition equation. Specifically, we will take
| (18) |
Appendix B Pseudocode For Single-Agent Optimization Subroutine in Agent by Agent Algorithm
The following pseudocode is the implementation of line 18 in Algorithm 2.
Input: agent , linear approximator
Output: Optimized policy for agent i
Appendix C Details of LPSolver Base Policy
LPSolver Base Policy for Multiple MDPs.
The LPSolver policy is a specific implementation of the base policy, solving each MDP as a linear program to minimize expected cumulative discounted cost. The value function for each state and agent is obtained by solving:
| Minimize | (19) | |||
| Subject to | (20) |
The stationary policy is then:
| (21) |