Common Information Belief based Dynamic Programs for Stochastic Zero-sum Games with Competing Teams
Abstract
Decentralized team problems where players have asymmetric information about the state of the underlying stochastic system have been actively studied, but games between such teams are less understood. We consider a general model of zero-sum stochastic games between two competing teams. This model subsumes many previously considered team and zero-sum game models. For this general model, we provide bounds on the upper (min-max) and lower (max-min) values of the game. Furthermore, if the upper and lower values of the game are identical (i.e., if the game has a value), our bounds coincide with the value of the game. Our bounds are obtained using two dynamic programs based on a sufficient statistic known as the common information belief (CIB). We also identify certain information structures in which only the minimizing team controls the evolution of the CIB. In these cases, we show that one of our CIB based dynamic programs can be used to find the min-max strategy (in addition to the min-max value). We propose an approximate dynamic programming approach for computing the values (and the strategy when applicable) and illustrate our results with the help of an example.
I Introduction
In decentralized team problems, players collaboratively control a stochastic system to minimize a common cost. The information used by these players to select their control actions may be different. For instance, some of the players may have more information about the system state than others [1]; or each player may have some private observations that are shared with other players with some delay [2]. Such multi-agent team problems with an information asymmetry arise in a multitude of domains like autonomous vehicles and drones, power grids, transportation networks, military and rescue operations, wildlife conservation [3] etc. Over the past few years, several methods have been developed to address decentralized team problems [4, 5, 6, 7, 1]. However, games between such teams are less understood. Many of the aforementioned systems are susceptible to adversarial attacks. Therefore, the strategies used by the team of players for controlling these systems must be designed in such a way that the damage inflicted by the adversary is minimized. Such adversarial interactions can be modeled as zero-sum games between competing teams, and our main goal in this paper is develop a framework that can be used to analyze and solve them.
The aforementioned works [4, 5, 6, 7, 1] on cooperative team problems solve them by first constructing an auxiliary single-agent Markov Decision Process (MDP). The auxiliary state (state of the auxiliary MDP) is the common information belief (CIB). CIB is the belief on the system state and all the players’ private information conditioned on the common (or public) information. Auxiliary actions (actions in the auxiliary MDP) are mappings from agents’ private information to their actions [4]. The optimal values of the team problem and this auxiliary MDP are identical. Further, an optimal strategy for the team problem can be obtained using any optimal solution of the auxiliary MDP with a simple transformation. The optimal value and strategies of this auxiliary MDP (and thus the team problem) can be characterized by dynamic programs (a.k.a. Bellman equations or recursive formulas). A key consequence of this characterization is that the CIB is a sufficient statistic for optimal control in team problems. We investigate whether a similar approach can be used to characterize values and strategies in zero-sum games between teams. This extension is not straightforward. In general games (i.e., not necessarily zero-sum), it may not be possible to obtain such dynamic programs (DPs) and/or sufficient statistics [8, 9]. However, we show that for zero-sum games between teams, the values can be characterized by CIB based DPs. Further, we show that for some specialized models, the CIB based DPs can be used to characterize a min-max strategy as well. A key implication of our result is that this CIB based approach can be used to solve several team problems considered before [4, 1, 7] even in the presence of certain types of adversaries.
A phenomenon of particular interest and importance in team problems is signaling. Players in a team can agree upon their control strategies ex ante. Based on these agreed upon strategies, a player can often make inferences about the system state or the other players’ private information (which are otherwise inaccessible to the player). This implicit form of communication between players is referred to as signaling and can be vital for effective coordination. While signaling is beneficial in cooperative teams, it can be detrimental in the presence of an adversary. This is because the adversary can exploit it to infer sensitive private information and inflict severe damage upon the system. A concrete example that illustrates this trade-off between signaling and secrecy is discussed is Section V. Our framework can be used optimize this trade-off in several stochastic games between teams.
Related Work on Games
Zero-sum games between two individual players with asymmetric information have been extensively studied. In [10, 11, 12, 13, 14, 15], stochastic zero-sum games with varying degrees of generality were considered and dynamic programming characterizations of the value of the game were provided. Various properties of the value functions (such as continuity) were also established and for some specialized information structures, these works also characterize a min-max strategy. Linear programs for computing the values and strategies in certain games were proposed in [16, 17]; and methods based on heuristic search value iteration (HSVI) [18] to compute the value of some games were proposed in [19, 20]. Zero-sum extensive form games in which a team of players competes against an adversary have been studied in [21, 22, 23]. Structured Nash equilibria in general games (i.e. not necessarily zero-sum) were studied in [24, 25, 26] under some assumptions on the system dynamics and players’ information structure. A combination of reinforcement learning and search was used in [27] to solve two-player zero-sum games. While this approach has very strong empirical performance, a better analytical understanding of it is needed. Our work is closely related to [28, 15] and builds on their results. Our novel contributions in this paper over past works are summarized below.
Contributions
(i) In this paper, we study a general class of stochastic zero-sum games between two competing teams of players. Our general model captures a variety of information structures including many previously considered stochastic team [5, 7, 1] and zero-sum game models [15, 19, 20] as well as game models that have not been studied before. Our results provide a unified framework for analyzing a wide class of game models that satisfy some minimal assumptions. (ii) For our general model, we adapt the techniques in [15] to provide bounds on the upper (min-max) and lower (max-min) values of the game. These bounds provide us with fundamental limits on the performance achievable by either team. Furthermore, if the upper and lower values of the game are identical (i.e., if the game has a value), our bounds coincide with the value of the game. Our bounds are obtained using two dynamic programs (DPs) based on a sufficient statistic known as the common information belief (CIB). (iii) We also identify a subclass of game models in which only one of the teams (say the minimizing team) controls the evolution of the CIB. In these cases, we show that one of our CIB based dynamic programs can be used to find the min-max value as well as a min-max strategy111Note that this characterization of a min-max strategy is not present in [15]. A similar result for a very specific model with limited applicability exists in [28]. Our result is substantially more general than that in [28].. (iv) Our result reveals that the structure of the CIB based min-max strategy is similar to the structure of team optimal strategies. Such structural results have been successfully used in prior works [7, 27] to design efficient strategies for significantly challenging team problems. (v) Lastly, we discuss an approximate dynamic programming approach along with key structural properties for computing the values (and the strategy when applicable) and illustrate our results with the help of an example.
Notation
Random variables are denoted by upper case letters, their realizations by the corresponding lower case letters. In general, subscripts are used as time index while superscripts are used to index decision-making agents. For time indices , is the short hand notation for the variables . Similarly, is the short hand notation for the collection of variables . Operators and denote the probability of an event, and the expectation of a random variable respectively. For random variables/vectors and , , and are denoted by , and , respectively. For a strategy , we use (resp. ) to indicate that the probability (resp. expectation) depends on the choice of . For any finite set , denotes the probability simplex over the set . For any two sets and , denotes the set of all functions from to . We define rand to be mechanism that given (i) a finite set , (ii) a distribution over and a random variable uniformly distributed over the interval , produces a random variable with distribution , i.e.,
| (1) |
II Problem Formulation
Consider a dynamic system with two teams. Team 1 has players and Team 2 has players. The system operates in discrete time over a horizon222With a sufficiently large planning horizon, infinite horizon problems with discounted cost can be solved approximately as finite-horizon problems. . Let be the state of the system at time , and let be the action of Player , , in Team , , at time . Let
and be the set of all possible realizations of . We will refer to as Team ’s action at time . The state of the system evolves in a controlled Markovian manner as
| (2) |
where is the system noise. There is an observation process associated with each Player in Team and is given as
| (3) |
where is the observation noise. Let us define
We assume that the sets , and are finite for all and . Further, the random variables (referred to as the primitive random variables) can take finitely many values and are mutually independent.
Remark 1.
Information Structure
At time , Player in Team has access to a subset of all observations and actions generated so far. Let denote the collection of variables (i.e. observations and actions) available to Player in team at time . Then . The set of all possible realizations of is denoted by . Examples of such information structures include which corresponds to the information structure in Dec-POMDPs [5] and wherein each player’s actions are seen by all the players and their observations become public after a delay of time steps.
Information can be decomposed into common and private information, i.e. ; common information is the set of variables known to all players at time . The private information for Player in Team is defined as . Let
We will refer to as Team ’s private information. Let be the set of all possible realizations of common information at time , be the set of all possible realizations of private information for Player in Team at time and be the set of all possible realizations of . We make the following assumption on the evolution of common and private information. This is similar to Assumption 1 of [24, 15].
Assumption 1.
The evolution of common and private information available to the players is as follows: (i) The common information is non-decreasing with time, i.e. . Let be the increment in common information. Thus, . Furthermore,
| (4) |
where is a fixed transformation. (ii) The private information evolves as
| (5) |
where is a fixed transformation and .
Strategies and Values
Players can use any information available to them to select their actions and we allow behavioral strategies for all players. Thus, at time , Player in Team chooses a distribution over its action space using a control law , i.e., The distrubtion is then used to randomly generate the control action as follows. We assume that player of Team has access to i.i.d. random variables that are uniformly distributed over the interval . These uniformly distributed variables are independent of each other and of the primitive random variables. The action is generated using and the randomization mechanism described in (1), i.e.,
| (6) |
The collection of control laws used by the players in Team at time is denoted by and is referred to as the control law of Team at time . Let the set of all possible control laws for Team at time be denoted by . The collection of control laws is referred to as the control strategy of Team , and the pair of control strategies is referred to as a strategy profile. Let the set of all possible control strategies for Team be .
The total expected cost associated with a strategy profile is
| (7) |
where is the cost function at time . Team 1 wants to minimize the total expected cost, while Team 2 wants to maximize it. We refer to this zero-sum game between Team 1 and Team 2 as Game .
Definition 1.
The upper and lower values of the game are respectively defined as
| (8) | ||||
| (9) |
If the upper and lower values are the same, they are referred to as the value of the game and denoted by . The minimizing strategy in (8) is referred to as Team 1’s optimal strategy and the maximizing strategy in (9) is referred to as Team 2’s optimal strategy333The strategy spaces and are compact and the cost is continuous in . Hence, the existence of optimal strategies can be established using Berge’s maximum theorem [30]..
A key objective of this work is to characterize the upper and lower values and of Game . To this end, we will define an expanded virtual game . This virtual game will be used to obtain bounds on the upper and lower values of the original game . These bounds happen to be tight when the upper and lower values of game are equal. For a sub-class of information structures, we will show that the expanded virtual game can be used to obtain optimal strategies for one of the teams.
Remark 2.
An alternative way of randomization is to use mixed strategies wherein a player randomly chooses a deterministic strategy at the beginning of the game and uses it for selecting its actions. According to Kuhn’s theorem, mixed and behavioral strategies are equivalent when players have perfect recall [31].
Remark 3 (Independent and Shared Randomness).
In most situations, the source of randomization is either privately known to the player (as in (6)) or publicly known to all the players in both teams. In this paper, we focus on independent randomization as in (6). In some situations, a shared source of randomness may be available to all players in Team but not to any any of the players in the opposing team. Such shared randomness can help players in a team coordinate better. We believe that our approach can be extended to this case as well with some modifications.
We note that if the upper and lower values of game are the same, then any pair of optimal strategies forms a Team Nash Equilibrium444When players in a team randomize independently, Team Nash equilirbia may not exist in general [32]., i.e., for every and ,
In this case, is the value of the game, i.e. Conversely, if a Team Nash Equilibrium exists, then the upper and lower values are the same [33].
III Expanded Virtual Game
The expanded virtual game is constructed using the methodology in [15]. This game involves the same underlying system model as in game . The key distinction between games and lies in the manner in which the actions used to control the system are chosen. In game , all the players in each team of game are replaced by a virtual player. Thus, game has two virtual players, one for each team, and they operate as follows.
Prescriptions
Consider virtual player associated with Team , . At each time and for each , virtual player selects a function that maps private information to a distribution over the space . Thus, . The set of all such mappings is denoted by . We refer to the tuple of such mappings as virtual player ’s prescription at time . The set of all possible prescriptions for virtual player at time is denoted by . Once virtual player selects its prescription, the action is randomly generated according to the distribution . More precisely,
| (10) |
where the random variable and the mechanism rand are the same as in equation (6).
Strategies
The virtual players in game have access to the common information and all the past prescriptions of both players, i.e., . Virtual player selects its prescription at time using a control law , i.e., Let be the set of all such control laws at time and be the set of all control strategies for virtual player . The total cost for a strategy profile is
| (11) |
The upper and lower values in are defined as
The following theorem establishes the relationship between the upper and lower values of the expanded game and the original game . This result is analogous to Theorem 1 from [15].
Theorem 1 (Proof in App. A).
The lower and upper values of the two games described above satisfy the following: Further, all these inequalities become equalities when a Team Nash equilibrium exists in Game .
III-A The Dynamic Programming Characterization
We describe a methodology for finding the upper and lower values of the expanded game in this subsection. The results (and their proofs) in this subsection are similar to those in Section 4.2 of [15]. However, the prescription spaces in this paper are different (and more general) from those in [15], and thus our results in this paper are more general. Our dynamic program is based on a sufficient statistic for virtual players in game called the common information belief (CIB).
Definition 2.
At time , the common information belief (CIB), denoted by , is defined as the virtual players’ belief on the state and private information based on their information in game . Thus, for each and we have
The belief takes values in the set .
The following lemma describes an update rule that can be used to compute the CIB.
Lemma 1 (Proof in App. B).
For any strategy profile in Game , the common information based belief evolves almost surely as
| (12) |
where is a fixed transformation that does not depend on the virtual players’ strategies. Further, the total expected cost can be expressed as
| (13) |
where the function is as defined in equation (58) in Appendix B.
Values in Game
We now describe two dynamic programs, one for each virtual player in . The minimizing virtual player (virtual player 1) in game solves the following dynamic program. Define for every . In a backward inductive manner, at each time and for each possible common information belief and prescriptions , define the upper cost-to-go function and the upper value function as
| (14) | ||||
| (15) |
The maximizing virtual player (virtual player 2) solves an analogous max-min dynamic program with a lower cost-to-go function and lower value function (See App. C for details).
Lemma 2 (Proof in App. C).
For each , there exists a measurable mapping such that . Similarly, there exists a measurable mapping such that .
Theorem 2 (Proof in App. D).
The upper and lower values of the expanded virtual game are given by and .
Theorem 2 gives us a dynamic programming characterization of the upper and lower values of the expanded game. As mentioned in Theorem 1, the upper and lower values of the expanded game provide bounds on the corresponding values of the original game. If the original game has a Team Nash equilibrium, then the dynamic programs described above characterize the value of the game.
Optimal Strategies in Game
The mappings and obtained from the dynamic programs described above (see Lemma 2) can be used to construct optimal strategies for both virtual players in game in the following manner.
Definition 3.
Define strategies and for virtual players 1 and 2 respectively as follows: for each instance of common information and prescription history , let
where and are the mappings defined in Lemma 2 and (which is a function of ) is obtained in a forward inductive manner using the update rule defined in Lemma 1.
IV Only Virtual Player 1 controls the CIB
In this section, we consider a special class of instances of Game and show that the dynamic program in (15) can be used to obtain a min-max strategy for Team 1, the minimizing team in game . The key property of the information structures considered in this section is that the common information belief is controlled555Note that the players in Team 2 might still be able to control the state dynamics through their actions. only by virtual player 1 in the corresponding expanded game . This is formally stated in the following assumption.
Assumption 2.
For any strategy profile in Game , the CIB evolves almost surely as
| (16) |
where is a fixed transformation that does not depend on the virtual players’ strategies.
We will now describe some instances of Game that satisfy Assumption 2. We note that two-player zero-sum games that satisfy a property similar to Assumption 2 were studied in [13].
IV-A Game Models Satisfying Assumption 2
All players in Team 2 have the same information
Consider an instance of game in which every player in Team 2 has the following information structure . Further, Team 2’s information is known to every player in Team 1. Thus, the common information . Under this condition, players in Team 2 do not have any private information. Thus, their private information . Any information structure satisfying the above conditions satisfies Assumption 2, see Appendix F-A for a proof. Since Team 1’s information structure is relatively unrestricted, the above model subsumes many previously considered team and game models. Notable examples of such models include: (i) all purely cooperative team problems in [4, 34, 1, 7], and (ii) two-player zero-sum game models where one agent is more informed than the other [16, 13, 19].
Team 2’s observations become common information with one-step delay
Consider an an instance of game where the current private information of Team 2 becomes common information in the very next time-step. More specifically, we have and for each Player in Team 2, . Note that unlike in [16, 19], players in Team 2 have some private information in this model. Any information structure that satisfies the above conditions satisfies Assumption 2, see Appendix F-B for a proof.
Games with symmetric information
Consider the information structure where for every . All the players in this game have the same information and thus, players do not have any private information. Note that this model subsumes perfect information games. It can be shown that this model satisfies Assumption 2 using the same arguments in Appendix F-A. In this case, the CIB is not controlled by both virtual players and thus, we can use the dynamic program to obtain both min-max and max-min strategies.
In addition to the models discussed above, there are other instances of that satisfy Assumption 2. These are included in Appendix E.
IV-B Min-max Value and Strategy in Game
Dynamic Program
Since we are considering special cases of Game , we can use the analysis in Section III to write the min-max dynamic program for virtual player 1. Because of Assumption 2, the belief update in (14) is replaced by . Using Theorems 2 and 3, we can can conclude that the upper value of the expanded game and that the strategy obtained from the DP is a min-max strategy for virtual player 1 in Game . An approximate dynamic programming based approach for solving the dynamic programs is discussed in Appendix H. This discussion includes certain structural properties of the value functions that make their computation significantly more tractable.
Min-max Value and Strategy
The following results provide a characterization of the min-max value and a min-max strategy in game under Assumption 2. Note that unlike the inequality in Theorem 1, the upper values of games and are always equal in this case.
V A Special Case and Numerical Experiments
Consider an instance of Game in which Team 1 has two players and Team 2 has only one player. At each time , Player 1 in Team 1 observes the state perfectly, i.e. , but the player in Team 2 gets an imperfect observation defined as in (3). Player 1 has complete information: at each time , it knows the entire state, observation and action histories of all the players. The player in Team 2 has partial information: at each time , it knows its observation history and action histories of all the players. Player 2 in Team 1 has the same information as that of the player in Team 2. Thus, the total information available to each player at is as follows:
Clearly, . The common and private information for this game can be written as follows: , and . The increment in common information at time is . In the game described above, the private information in includes the entire state history. However, Player 1 in Team 1 can ignore the past states without loss of optimality.
Lemma 3 (Proof in App. I).
There exists a min-max strategy such that the control law at time uses only and to select , i.e.,
The lemma above implies that, for the purpose of characterizing the value of the game and a min-max strategy for Team 1, we can restrict player 1’s information structure to be . Thus, the common and private information become: , and . We refer to this game with reduced private information as Game . The corresponding expanded virtual game is denoted by . A general methodology for reducing private information in decentralized team and game problems can be found in [35]. The information structure in is a special case of the first information structure in Section IV-A, and thus satisfies Assumption 2. Therefore, using the dynamic program in Section IV-B, we can obtain the value function and the min-max strategy .
Numerical Experiments
We consider a particular example of game described above. In this example, there are two entities ( and ) that can potentially be attacked and at any given time, exactly one of the entities is vulnerable. Player 1 of Team 1 knows which of the two entities is vulnerable whereas all the other players do not have this information. Player 2 of Team 1 can choose to defend one of the entities. The attacker in Team 2 can either launch a blanket attack on both entities or launch a targeted attack on one of the entities. When the attacker launches a blanket attack, the damage incurred by the system is minimal if Player 2 in Team 1 happens to be defending the vulnerable entity and the damage is substantial otherwise. When the attacker launches a targeted attack on the vulnerable entity, the damage is substantial irrespective of the defender’s position. But if the attacker targets the invulnerable entity, the attacker becomes passive and cannot attack for some time. Thus, launching a targeted attack involves high risk for the attacker. The state of the attacker (active or passive) and all the players’ actions are public information. The system state thus has two components, the hidden state ( or ) and the state of the attacker ( or ). For convenience, we will denote the states and with 0 and 1 respectively.
The only role of Player 1 in Team 1 in this game is to signal the hidden state using two available actions and . The main challenge is that both the defender and the attacker can see Player 1’s actions. Player 1 needs to signal the hidden state to some extent so that its teammate’s defense is effective under blanket attacks. However, if too much information is revealed, the attacker can exploit it to launch a targeted attack and cause significant damage. In this example, the key is to design a strategy that can balance between these two contrasting goals of signaling and secrecy. A precise description of this model is provided in Appendix J.


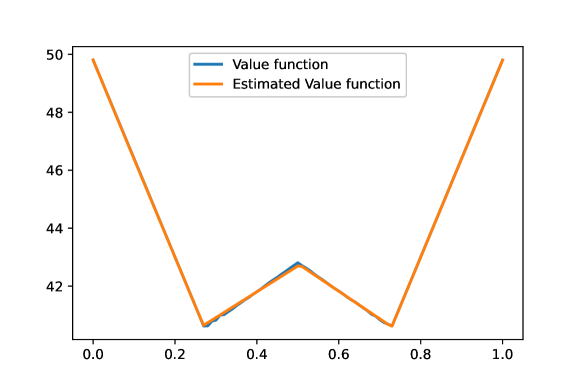
In order to solve this problem, we used the approximate DP approach discussed in Appendix H. The value function thus obtained is shown in Figure 1(a). The tension between signaling and secrecy can be seen in the shape of the value function in Figure 1(a). When the CIB , the value function is concave in its neighborhood and decreases as we move away from 0.5. This indicates that in these belief states, revealing the hidden state to some extent is preferable. However, as the belief goes further away from 0.5, the value function starts increasing at some point. This indicates that the adversary has too much information and is using it to inflict damage upon the system. Figure 1(b) depicts Player 1’s prescriptions leading to non-trivial signaling patterns at various belief states. Notice that the distributions and for hidden states 0 and 1 are quite distinct when (indicating significant signaling) and are nearly identical when (indicating negligible signaling). A more detailed discussion on our experimental results can be found in Appendix J.
VI Conclusions
We considered a general model of stochastic zero-sum games between two competing decentralized teams and provided bounds on their upper and lower values in the form of CIB based dynamic programs. When game has a value, our bounds coincide with the value. We identified several instances of this game model (including previously considered models) in which the CIB is controlled only by one of the teams (say the minimizing team). For such games, we also provide a characterization of the min-max strategy. Under this strategy, each player only uses the current CIB and its private information to select its actions. The sufficiency of the CIB and private information for optimality can potentially be exploited to design efficient strategies in various problems. Finally, we proposed a computational approach for approximately solving the CIB based DPs. There is significant scope for improvement in our computational approach. Tailored forward exploration heuristics for sampling the belief space and adding a policy network can improve the accuracy and tractability of our approach.
References
- [1] Yuxuan Xie, Jilles Dibangoye, and Olivier Buffet, “Optimally solving two-agent decentralized pomdps under one-sided information sharing,” in International Conference on Machine Learning. PMLR, 2020, pp. 10473–10482.
- [2] Ashutosh Nayyar, Aditya Mahajan, and Demosthenis Teneketzis, “Optimal control strategies in delayed sharing information structures,” IEEE Transactions on Automatic Control, vol. 56, no. 7, pp. 1606–1620, 2010.
- [3] Fei Fang, Milind Tambe, Bistra Dilkina, and Andrew J Plumptre, Artificial intelligence and conservation, Cambridge University Press, 2019.
- [4] Ashutosh Nayyar, Aditya Mahajan, and Demosthenis Teneketzis, “Decentralized stochastic control with partial history sharing: A common information approach,” IEEE Transactions on Automatic Control, vol. 58, no. 7, pp. 1644–1658, 2013.
- [5] Frans A Oliehoek and Christopher Amato, A concise introduction to decentralized POMDPs, Springer, 2016.
- [6] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson, “Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning,” in International Conference on Machine Learning. PMLR, 2018, pp. 4295–4304.
- [7] Jakob Foerster, Francis Song, Edward Hughes, Neil Burch, Iain Dunning, Shimon Whiteson, Matthew Botvinick, and Michael Bowling, “Bayesian action decoder for deep multi-agent reinforcement learning,” in International Conference on Machine Learning. PMLR, 2019, pp. 1942–1951.
- [8] Ashutosh Nayyar and Abhishek Gupta, “Information structures and values in zero-sum stochastic games,” in American Control Conference (ACC), 2017. IEEE, 2017, pp. 3658–3663.
- [9] Dengwang Tang, Hamidreza Tavafoghi, Vijay Subramanian, Ashutosh Nayyar, and Demosthenis Teneketzis, “Dynamic games among teams with delayed intra-team information sharing,” arXiv preprint arXiv:2102.11920, 2021.
- [10] Jean-François Mertens, Sylvain Sorin, and Shmuel Zamir, Repeated games, vol. 55, Cambridge University Press, 2015.
- [11] Dinah Rosenberg, Eilon Solan, and Nicolas Vieille, “Stochastic games with a single controller and incomplete information,” SIAM journal on control and optimization, vol. 43, no. 1, pp. 86–110, 2004.
- [12] Jérôme Renault, “The value of repeated games with an informed controller,” Mathematics of operations Research, vol. 37, no. 1, pp. 154–179, 2012.
- [13] Fabien Gensbittel, Miquel Oliu-Barton, and Xavier Venel, “Existence of the uniform value in zero-sum repeated games with a more informed controller,” Journal of Dynamics and Games, vol. 1, no. 3, pp. 411–445, 2014.
- [14] Xiaoxi Li and Xavier Venel, “Recursive games: uniform value, tauberian theorem and the mertens conjecture,” International Journal of Game Theory, vol. 45, no. 1-2, pp. 155–189, 2016.
- [15] Dhruva Kartik and Ashutosh Nayyar, “Upper and lower values in zero-sum stochastic games with asymmetric information,” Dynamic Games and Applications, pp. 1–26, 2020.
- [16] Jiefu Zheng and David A Castañón, “Decomposition techniques for Markov zero-sum games with nested information,” in 52nd IEEE Conference on Decision and Control. IEEE, 2013, pp. 574–581.
- [17] Lichun Li and Jeff Shamma, “LP formulation of asymmetric zero-sum stochastic games,” in 53rd IEEE Conference on Decision and Control. IEEE, 2014, pp. 1930–1935.
- [18] Trey Smith and Reid Simmons, “Heuristic search value iteration for pomdps,” in Proceedings of the 20th conference on Uncertainty in artificial intelligence, 2004, pp. 520–527.
- [19] Karel Horák, Branislav Bošanskỳ, and Michal Pěchouček, “Heuristic search value iteration for one-sided partially observable stochastic games,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2017, vol. 31.
- [20] Karel Horák and Branislav Bošanskỳ, “Solving partially observable stochastic games with public observations,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2019, vol. 33, pp. 2029–2036.
- [21] Bernhard von Stengel and Daphne Koller, “Team-maxmin equilibria,” Games and Economic Behavior, vol. 21, no. 1-2, pp. 309–321, 1997.
- [22] Gabriele Farina, Andrea Celli, Nicola Gatti, and Tuomas Sandholm, “Ex ante coordination and collusion in zero-sum multi-player extensive-form games,” in Conference on Neural Information Processing Systems (NIPS), 2018.
- [23] Youzhi Zhang and Bo An, “Computing team-maxmin equilibria in zero-sum multiplayer extensive-form games,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, vol. 34, pp. 2318–2325.
- [24] Ashutosh Nayyar, Abhishek Gupta, Cedric Langbort, and Tamer Başar, “Common information based Markov perfect equilibria for stochastic games with asymmetric information: Finite games,” IEEE Transactions on Automatic Control, vol. 59, no. 3, pp. 555–570, 2014.
- [25] Yi Ouyang, Hamidreza Tavafoghi, and Demosthenis Teneketzis, “Dynamic games with asymmetric information: Common information based perfect bayesian equilibria and sequential decomposition,” IEEE Transactions on Automatic Control, vol. 62, no. 1, pp. 222–237, 2017.
- [26] Deepanshu Vasal, Abhinav Sinha, and Achilleas Anastasopoulos, “A systematic process for evaluating structured perfect bayesian equilibria in dynamic games with asymmetric information,” IEEE Transactions on Automatic Control, vol. 64, no. 1, pp. 78–93, 2019.
- [27] Noam Brown, Anton Bakhtin, Adam Lerer, and Qucheng Gong, “Combining deep reinforcement learning and search for imperfect-information games,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, Eds. 2020, vol. 33, pp. 17057–17069, Curran Associates, Inc.
- [28] Dhruva Kartik and Ashutosh Nayyar, “Stochastic zero-sum games with asymmetric information,” in 58th IEEE Conference on Decision and Control. IEEE, 2019.
- [29] Panganamala Ramana Kumar and Pravin Varaiya, Stochastic systems: Estimation, identification, and adaptive control, vol. 75, SIAM, 2015.
- [30] A Hitchhiker’s Guide, Infinite dimensional analysis, Springer, 2006.
- [31] Michael Maschler, Eilon Solan, and Shmuel Zamir, Game Theory, Cambridge University Press, 2013.
- [32] Venkat Anantharam and Vivek Borkar, “Common randomness and distributed control: A counterexample,” Systems & control letters, vol. 56, no. 7-8, pp. 568–572, 2007.
- [33] Martin J Osborne and Ariel Rubinstein, A course in game theory, MIT press, 1994.
- [34] Jilles Steeve Dibangoye, Christopher Amato, Olivier Buffet, and François Charpillet, “Optimally solving dec-pomdps as continuous-state mdps,” Journal of Artificial Intelligence Research, vol. 55, pp. 443–497, 2016.
- [35] Hamidreza Tavafoghi, Yi Ouyang, and Demosthenis Teneketzis, “A sufficient information approach to decentralized decision making,” in 2018 IEEE Conference on Decision and Control (CDC). IEEE, 2018, pp. 5069–5076.
- [36] Onésimo Hernández-Lerma and Jean B Lasserre, Discrete-time Markov control processes: basic optimality criteria, vol. 30, Springer Science & Business Media, 2012.
- [37] Dimitri P Bertsekas and John N Tsitsiklis, Neuro-dynamic programming, vol. 5, Athena Scientific Belmont, MA, 1996.
- [38] Tianyi Lin, Chi Jin, and Michael Jordan, “On gradient descent ascent for nonconvex-concave minimax problems,” in International Conference on Machine Learning. PMLR, 2020, pp. 6083–6093.
- [39] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” arXiv preprint arXiv:1706.08500, 2017.
Appendix A Virtual Game and Proof of Theorem 1
A-A Virtual Game
In order to establish the connection between the original game and the expanded game , we construct an intermediate virtual game . Virtual game is very similar to the expanded game . The only difference between games and is that the virtual players in Game have access only to the common information at time . On the other hand, the virtual players in Game have access to the common information as well as the prescription history at time . We formally define virtual game below.
Model and Prescriptions
Consider virtual player associated with Team , . At each time , virtual player selects a prescription , where is the set of prescriptions defined in Section III. Once virtual player selects its prescription, the action is randomly generated according to the distribution . More precisely, the system dynamics for this game are given by:
| (17) | |||||
| (18) | |||||
| (19) | |||||
| (20) | |||||
| (21) | |||||
where the functions , and are the same as in .
Strategies
In virtual game , virtual players use the common information to select their prescriptions at time . The th virtual player selects its prescription according to a control law , i.e. . For virtual player , the collection of control laws over the entire time horizon is referred to as its control strategy. Let be the set of all possible control laws for virtual player at time and let be the set of all possible control strategies for virtual player , i.e. . The total cost associated with the game for a strategy profile is
| (22) |
where the function is the same as in Game .
Note that any strategy is equivalent to the strategy that satisfies the following condition: for each time and for each realization of common information ,
| (23) |
Hence, with slight abuse of notation, we can say that the strategy space in the virtual game is a subset of the strategy space in the expanded game .
The following lemma establishes a connection between the original game and the virtual game constructed above.
Lemma 4.
Let and be, respectively, the upper and lower values of the virtual game . Then,
Consequently, if a Team Nash equilibrium exists in the original game , then
Proof.
For a given strategy , let us define a strategy in the following manner. For each time , each instance of common information and player , let
| (24) |
and let . Note that the partial function is a mapping from to . Let
| (25) |
We will denote this correspondence between strategies in Game and with , , i.e., . One can easily verify that the mapping is bijective. Further, for every and , we have
| (26) |
We refer the reader to Appendix A of [24] for a proof of the above statement.
Therefore, for any strategy , we have
| (27) | ||||
| (28) |
Consequently,
| (29) | ||||
| (30) |
This implies that . We can similarly prove that .
Remark 4.
We can also show that a strategy is a min-max strategy in Game if and only if is a min-max strategy in Game . A similar statement holds for max-min strategies as well.
∎
We will now establish the relationship between the upper and lower values of the virtual game and the expanded virtual game . To do so, we define the following mappings between the strategies in games and . To do so, we define the following mappings between the strategies in games and .
Definition 4.
Let be an operator that maps a strategy profile in virtual game to a strategy for virtual player in game as follows: For
| (31) |
where for every and . We denote the ordered pair by .
The mapping is defined in such a way that the strategy profile and the strategy profile induce identical dynamics in the respective games and .
Lemma 5.
Let and be strategy profiles for games and , such that , . Then,
| (32) |
Proof.
Let us consider the evolution of the virtual game under the strategy profile and the expanded virtual game under the strategy profile . Let the primitive variables and the randomization variables in both games be identical. The variables such as the state, action and information variables in the expanded game are distinguished from those in the virtual game by means of a tilde. For instance, is the state in game and is the state in game .
We will prove by induction that the system evolution in both these games is identical over the entire horizon. This is clearly true at the end of time because the state, observations and the common and private information variables are identical in both games. Moreover, since , , the strategies and are identical by definition (see Definition 4). Thus, the prescriptions and actions at are also identical.
For induction, assume that the system evolution in both games is identical until the end of time . Then,
Using equations (3), (5) and (4), we can similarly argue that , and . Since , we also have
| (33) |
Here, equality follows from the construction of the mapping (see Definition 4) and equality follows from the fact that . Further,
| (34) | ||||
| (35) |
Thus, by induction, the hypothesis is true for every . This proves that the virtual and expanded games have identical dynamics under strategy profiles and .
Since the virtual and expanded games have the same cost structure, having identical dynamics ensures that strategy profiles and have the same expected cost in games and , respectively. Therefore, . ∎
A-B Proof of Theorem 1
For any strategy , we have
| (36) |
because . Further,
| (37) | ||||
| (38) | ||||
| (39) |
where the first equality is due to Lemma 5, the second equality is because and the last inequality is due to the fact that for any .
Appendix B Proof of Lemma 1
Definition 5 (Notation for Prescriptions).
For virtual player at time , let be a prescription. We use to denote the probability assigned to action by the distribution . We will also use the following notation:
Here, is the probability assigned to a team action by the prescription when the team’s private information is .
We begin with defining the following transformations for each time . Recall that is the set of all possible common information beliefs at time and is the prescription space for virtual player at time .
Definition 6.
-
1.
Let be defined as
(45) (46) We will use as a shorthand for the probability distribution . The distribution can be viewed as a joint distribution over the variables if the distribution on is and prescriptions are chosen by the virtual players at time .
-
2.
Let be defined as
(47) The distribution is the marginal distribution of the variable obtained from the joint distribution defined above.
-
3.
Let be defined as
(48) where can be any arbitrary measurable mapping. One such mapping is the one that maps every element to the uniform distribution over the finite space .
Let the collection of transformations that can be constructed using the method described in Definition 6 be denoted by . Note that the transformations and do not depend on the strategy profile because the term in (46) depends only on the system dynamics (see equations (17) – (21)) and not on the strategy profile .
Consider a strategy profile . Note that the number of possible realizations of common information and prescription history under is finite. Let be a realization of the common information and prescription history at time with non-zero probability of occurrence under . For this realization of virtual players’ information, the common information based belief on the state and private information at time is given by
| (49) |
Notice that the expression (49) is well-defined, that is, the denominator is non-zero because of our assumption that the realization has non-zero probability of occurrence. Let us consider the numerator in the expression (49). For convenience, we will denote it with . We have
| (50) | |||
| (51) | |||
| (52) |
where is the common information belief on at time given the realization666Note that the belief because , . and is as defined in Definition 6. The equality in (51) is due to the structure of the system dynamics in game described by equations (17) – (21). Similarly, the denominator in (49) satisfies
| (53) |
where is as defined is Definition 6. Thus, from equation (49), we have
| (54) |
where is as defined in Definition 6. Since the relation (54) holds for every realization that has non-zero probability of occurrence under , we can conclude that the common information belief evolves almost surely as
| (55) |
under the strategy profile .
The expected cost at time can be expressed as follows
| (56) | ||||
| (57) |
where the function is as defined as
| (58) |
Therefore, the total cost can be expressed as
| (59) |
Appendix C Domain Extension and Proof of Lemma 2
C-A The Max-min Dynamic Program
The maximizing virtual player (virtual player 2) in game solves the following dynamic program. Define for every . In a backward inductive manner, at each time and for each possible common information belief and prescriptions , define the lower cost-to-go function and the lower value function as
| (60) | ||||
| (61) |
C-B Domain Extension
Recall that is the set of all probability distributions over the finite set . Define
| (62) |
The functions in (58), in (45), in (53) and in (54) were defined for any . We will extend the domain of the argument in these functions to as follows. For any , , and , let
-
1.
-
2.
-
3.
-
4.
where is a zero-vector of size .
Having extended the domain of the above functions, we can also extend the domain of the argument in the functions defined in the dynamic programs of Section III-A. First, for any and , define . We can then define the following functions for every in a backward inductive manner: For any , and , let
| (63) | ||||
| (64) |
Note that when , the above definition of is equal to the definition of in equation (15) of the dynamic program. We can similarly extend and .
Lemma 6.
For any constant and any , we have and .
Proof.
The proof can be easily obtained from the above definitions of the extended functions. ∎
C-C Proof of Lemma 2
We will first prove inductively that the function is continuous. Let us as assume that value function is continuous for some . Note that this assumption clearly holds at . At time , we have
| (65) | ||||
| (66) | ||||
| (67) |
where the last inequality follows from the homogeneity property of the value functions in Lemma 6 and the structure of the belief update in (54). The first term in (67) is clearly continuous (see 58). Also, the transformation defined in (45) is a continuous function. Therefore, by our induction hypothesis, the composition is continuous in for every common observation . Thus, is continuous in its arguments. To complete our inductive argument, we need to show that is a continuous function and to this end, we will use the Berge’s maximum theorem (Lemma 17.31) in [30]. Since is continuous and is compact, we can use the maximum theorem to conclude that the following function
| (68) |
is continuous in . Once again, we can use the maximum theorem to conclude that
| (69) |
is continuous in . This concludes our inductive argument. Also, because of the continuity of in (68), we can use the measurable selection condition (see Condition 3.3.2 in [36]) to prove the existence of the measurable mapping as defined in Lemma 2. A similar argument can be made to establish the existence of a maxminimizer and a measurable mapping as defined in Lemma 2. This concludes the proof of Lemma 2.
Appendix D Proof of Theorem 2
Let us first define a distribution over the space in the following manner. The distribution , given , is recursively obtained using the following relation
| (70) | ||||
| (71) |
where is as defined in Definition 6 in Appendix B. We refer to this distribution as the strategy-independent common information belief (SI-CIB).
Let be any strategy for virtual player 1 in game . Consider the problem of obtaining virtual player 2’s best response to the strategy with respect to the cost defined in (11). This problem can be formulated as a Markov decision process (MDP) with common information and prescription history as the state. The control action at time in this MDP is , which is selected based on the information using strategy . The evolution of the state of this MDP is as follows
| (72) |
where
| (73) |
almost surely. Here, and the transformation is as defined in Definition 6 in Appendix B. Notice that due to Lemma 1, the common information belief associated with any strategy profile is equal to almost surely. This results in the state evolution equation in (73). The objective of this MDP is to maximize, for a given , the following cost
| (74) |
where is as defined in equation (58). Due to Lemma 1, the total expected cost defined above is equal to the cost defined in (11).
The MDP described above can be solved using the following dynamic program. For every realization of virtual players’ information , define
In a backward inductive manner, for each time and each realization , define
| (75) |
where and is the SI-CIB associated with the information . Note that the measurable selection condition (see condition 3.3.2 in [36]) holds for the dynamic program described above. Thus, the value functions are measurable and there exists a measurable best-response strategy for player 2 which is a solution to the dynamic program described above. Therefore, we have
| (76) |
Claim D.1.
For any strategy and for any realization of virtual players’ information , we have
| (77) |
where is as defined in (15) and is the SI-CIB belief associated with the instance . As a consequence, we have
| (78) |
Proof.
The proof is by backward induction. Clearly, the claim is true at time . Assume that the claim is true for all times greater than . Then we have
The first equality follows from the definition in (75) and the inequality after that follows from the induction hypothesis. The last inequality is a consequence of the definition of the value function . This completes the induction argument. Further, using Claim D.1 and the result in (76), we have
∎
We can therefore say that
| (79) |
Further, for the strategy defined in Definition 3, the inequalities (77) and (78) hold with equality. We can prove this using an inductive argument similar to the one used to prove Claim D.1. Therefore, we have
| (80) |
Combining (79) and (80), we have
Thus, the inequality in (80) holds with equality which leads us to the result that the strategy is a min-max strategy in game . A similar argument can be used to show that
and that the strategy defined in Definition 3 is a max-min strategy in game .
Appendix E Information Structures
E-A Team 2 does not control the state
Consider an instance of Game in which the state evolution and the players’ observations are given by
Further, let the information structure of the players be such that the common and private information evolve as
| (81) | ||||
| (82) |
In this model, Team 2’s actions do not affect the system evolution and Team 2’s past actions are not used by any of the players to select their current actions. Any information structure that satisfies these conditions satisfies Assumption 2, see Appendix F-C for a proof.
E-B Global and local states
Consider a system in which the system state comprises of a global state and a local state for Team . The state evolution is given by
| (83) | ||||
| (84) | ||||
| (85) |
Note that Team 2’s current local state does not affect the state evolution. Further, we have
| (86) | ||||
| (87) | ||||
| (88) |
Under this system dynamics and information structure, we can prove that Assumption 2 holds. The proof of this is provided in Appendix F-D.
Appendix F Information Structures that Satisfy Assumption 2: Proofs
For each model in IV-A, we will accordingly construct transformations and at each time such that
| (89a) | ||||
| (89b) | ||||
Note that the transformations and do not make use of virtual player 2’s prescription . Following the methodology in Definition 6, we define as
| (90) |
where the transformation is chosen to be
| (91) |
where is the uniform distribution over the space . Since the transformations and satisfy (89a) and (89b), we can simplify the expression for the transformation in (90) to obtain the following
| (92) |
This concludes the construction of an update rule in the class that does not use virtual player 2’s prescription . We will now describe the the construction of the transformations and for each information structure in Section IV-A.
F-A All players in Team 2 have the same information
In this case, Team 2 does not have any private information and any instance of the common observation includes Team 2’s action at time (denote it with ). The corresponding transformation (see Definition 6) has the following form.
| (93) | ||||
| (94) | ||||
| (95) | ||||
| (96) |
Here, we use the fact that Team 2 does not have any private information and is a part of the common observation . Similarly, the corresponding transformation (see Definition 6) has the following form.
| (97) | ||||
| (98) |
Using the results (96) and (98), we can easily conclude that the transformations and defined above satisfy the conditions (89a) and (89b).
F-B Team 2’s observations become common information with a delay of one-step
In this case, any instance of the common observation includes Team 2’s private information at time (denote it with ) and Team 2’s action at time (denote it with ). The corresponding transformation (see Definition 6) has the following form.
| (99) | ||||
| (100) | ||||
| (101) | ||||
| (102) |
Here, we use the fact that both and are part of the common observation . Similarly, the corresponding transformation (see Definition 6) has the following form.
| (103) | ||||
| (104) |
Using the results (102) and (104), we can conclude that the transformations and defined above satisfy the conditions (89a) and (89b).
F-C Team 2 does not control the state
In this case, the corresponding transformation (see Definition 6) has the following form.
| (105) | ||||
| (106) | ||||
| (107) | ||||
| (108) | ||||
| (109) |
Note that (107) holds because does not influence the evolution of state, common and private information and (108) follows by summing over . Similarly, the corresponding transformation (see Definition 6) has the following form.
| (110) | ||||
| (111) |
Using the results (109) and (111), we can conclude that the transformations and satisfy the conditions (89a) and (89b).
F-D Global and local states
In this case, the private information variables of each player are part of the system state because and . Therefore, the common information belief is formed only on the system state. Let us first define a collection of beliefs with a particular structure
| (112) |
where and denote the respective conditional and marginal distributions formed using the joint distribution , and is some realization of the global state . Under the dynamics and information structure in this case, we can show that the belief computed recursively using the transformation as in (54) always lies in (for an appropriate initial distribution on the state ). Therefore, we restrict our attention to beliefs in the restricted set . Let such that
| (113) |
In this case, any instance of the common observation comprises of the global state and players’ actions (denoted by for Teams 1 and 2 respectively). The corresponding transformation (see Definition 6) has the following form.
| (114) | ||||
| (115) | ||||
| (116) | ||||
| (117) | ||||
| (118) |
Similarly, the corresponding transformation (see Definition 6) has the following form.
| (119) | ||||
| (120) |
Using the results (118) and (120), we can conclude that the transformations and satisfy the conditions (89a) and (89b).
Appendix G Proof of Theorem 5
Let be the min-max strategy for virtual player 1 in the expanded virtual game as described in Section IV-B. Note that the strategy uses only the common information and virtual player 1’s past prescriptions . This is because the CIB update in Assumption 2 does not depend on virtual player 2’s prescription . Let us define a strategy for virtual player 1 in the virtual game defined in Appendix A. At each time and for each instance ,
| (121) |
Here, is the mapping obtained by solving the min-max dynamic program (see Lemma 2) and is computed using the following relation
| (122) | ||||
| (123) |
where is the belief update transformation in Assumption 2. Note that the prescription is the same as the one obtained in the “Get prescription” step in Algorithm 1 for common information in the -th iteration.
Using Definition 4, we have
| (124) |
for any strategy . Based on this observation and the fact that for a given , for every , we have
| (125) |
Further, due to Theorem 1, we have
| (126) | ||||
| (127) | ||||
| (128) | ||||
| (129) | ||||
| (130) |
where the equality in is because is a min-max strategy of . Inequality holds because . Equality in is a consequence of the result in (125) and Lemma 5 in Appendix A. The last inequality simply follows from the definition of the upper value of the virtual game. Therefore, all the inequalities in the display above must hold with equality. Hence, must be a min-max strategy of game and .
From Lemma 4 in Appendix A, we know that and thus, . Further, we can verify from the description of the strategy in Algorithm 1 that , where is the transformation defined in the proof of Lemma 4 in Appendix A. Based on the argument in Remarks 4 in Appendix A, we can conlude that the strategy is a min-max strategy in Game .
Appendix H Solving the DP: Methods and Challenges
In the previous section, we provided a dynamic programming characterization of the upper value and a min-max strategy in the original game . We now describe an approximate dynamic programming methodology [37] that can be used to compute them. The methodology we propose offers broad guidelines for a computational approach. We do not make any claim about the degree of approximation achieved by the proposed methodology. In Section H-A, we discuss some structural properties of the cost-to-go and value functions in the dynamic program that may be useful for computational simplification. We illustrate our approach and the challenges involved with the help of an example in Section V.
At each time , let be a an approximate representation of the upper value function in a suitable parametric form, where is a vector representing the parameters. We proceed as follows.
Sampling the belief space
At time , we sample a set of belief points from the set (the set of all CIBs). A simple sampling approach would be to uniformly sample the space . Using the arguments in Appendix 5 of [15], we can say that the value function is uniformly continuous in the CIB . Thus, if the set is sufficiently large, computing the value function only at the belief points in may be enough for obtaining an -approximation of the value function. It is likely that the required size of to ensure an -approximation will be prohibitively large. For solving POMDPs, more intelligent strategies for sampling the belief points, known as forward exploration heuristics, exist in literature [18, 19, 1]. While these methods rely on certain structural properties of the value functions (such as convexity), it may be possible to adapt them for our dynamic program and make the CIB sampling process more efficient. A precise understanding of such exploration heuristics and the relationship between the approximation error and the associated computational burden is needed. This is a problem for future work.
Compute value function at each belief point
Once we have a collection of points , we can then approximately compute the value for each For each belief vector , we will compute which is given by
| (131) | ||||
| (132) |
For a given belief point , one approach for solving the min-max problem in (132) is to use the Gradient Descent Ascent (GDA) method [38, 39]. This can however lead to local optima because in general, the cost is neither convex nor concave in the respective prescriptions. In some cases such as when Team 2 has only one player, the inner maximizing problem in (132) can be substantially simplified and we will discuss this in Section H-A.
Interpolation
For solving a particular instance of the min-max problem in (132), we need an estimate of the value function . Generally, knowing just the value of the function at different points may be insufficient and we may need additional information like the first derivatives/gradients especially when we are using gradient based methods like GDA. In that case, it will be helpful to choose an appropriate parametric form (such as neural networks) for that has desirable properties like continuity or differentiability. The parameters can be obtained by solving the following regression problem.
| (133) |
Standard methods such as gradient descent can be used to solve this regression problem.
H-A Structural Properties of the DP
We will now prove that under Assumption 2, the cost-to-go function (see (14)) in the min-max dynamic program defined in Section IV-B is linear in virtual player 2’s prescription in its product form (see Definition 5 in Appendix B).
Lemma 7.
Proof.
We have
| (134) | ||||
| (135) | ||||
| (136) |
where the last equality uses the fact that the belief update does not depend on and both (see (58)) and (see (53)) are linear in . We then rearrange terms in (135) and appropriately define to obtain (136). Here, represents the marginal distribution of the second player’s private information with respect to the common information based belief . ∎
Remark 5.
When there is only one player in Team 2, then the prescription coincides with its product form in Definition 5. Then the cost-to-go is linear in as well.
At any given time , a pure prescription for virtual player 2 in Game is a prescription such that for every and every instance , the distribution is degenerate. Let be the set of all such pure prescriptions at time for virtual player 2.
Proof.
Using Lemma 7, for a fixed value of CIB and virtual player 1’s prescription , the inner maximization problem in (15) can be viewed as a single-stage team problem. In this team problem, the are players and the state of the system is which is distributed according to . Player ’s information in this team is . Using this information, the player selects a distribution which is then used to randomly generate an action . The reward for this team is given by defined in Lemma 7. It can be easily shown that for a single-stage team problem, we can restrict to deterministic strategies without loss of optimality. It is easy to see that the set of all deterministic strategies in the single-stage team problem described above corresponds to the collection of pure prescriptions . This concludes the proof of Lemma 8. ∎
Lemma 8 allows us to transform a non-concave maximization problem over the continuous space in (15) and (132) into a maximization problem over a finite set . This is particularly useful when players in Team 2 do not have any private information because in that case, has the same size as the action space . Other structural properties and simplifications are discussed in Appendix 7.
Appendix I Proof of Lemma 3
For proving Lemma 3, it will be helpful to split Team 1’s strategy into two parts where and . The set of all such strategies for Player in Team 1 will be denoted by . We will prove the lemma using the following claim.
Claim I.1.
Consider any arbitrary strategy for Team 1. Then there exists a strategy for Player 1 in Team 1 such that, for each , is a function of and and
Suppose that the above claim is true. Let be a min-max strategy for Team 1. Due to Claim I.1, there exists a strategy for Player 1 in Team 1 such that, for each , is a function only of and and
for every strategy . Therefore, we have that
Thus, is a min-max strategy for Team 1 wherein Player 1 uses only the current state and Player 2’s information.
Proof of Claim I.1: We now proceed to prove Claim I.1. Consider any arbitrary strategy for Team 1. Let be a realization of Team 2’s information (which is the same as Player 2’s information in Team 1). Define the distribution over the space as follows:
if is feasible, that is , under the open-loop strategy for Team 2. Otherwise, define to be the uniform distribution over the space .
Lemma 9.
Let be Team 1’s strategy and let be an arbitrary strategy for Team 2. Then for any realization of the variables , we have
almost surely.
Proof.
From Team 2’s perspective, the system evolution can be seen in the following manner. The system state at time is . Team 2 obtains a partial observation of the state at time . Using information , Team 2 then selects an action . The state then evolves in a controlled Markovian manner (with dynamics that depend on ). Thus, from Team 2’s perspective, this system is a partially observable Markov decision process (POMDP). The claim in the Lemma then follows from the standard result in POMDPs that the belief on the state given the player’s information does not depend on the player’s strategy [29]. ∎
For any instance of Team 2’s information , define the distribution over the space as follows
| (137) |
Define strategy for Player 1 in Team 1 such that for any realization of state and Player 2’s information at time , the probability of selecting an action at time is
| (138) |
where denotes the uniform distribution over the action space . Notice that the construction of the strategy does not involve Team 2’s strategy .
Lemma 10.
For any strategy for Team 2, we have
almost surely for every .
Proof.
Let be a realization that has a non-zero probability of occurrence under the strategy profile . Then using Lemma 9, we have
| (139) |
for every realization of states and of action . Summing over all and using (137) and (139), we have
| (140) |
The left hand side of the above equation is positive since is a realization of positive probability under the strategy profile .
Let us define , where is as defined in (138). We can now show that the strategy satisfies
for every strategy . Because of the structure of the cost function in (7), it is sufficient to show that for each time , the random variables have the same joint distribution under strategy profiles and . We prove this by induction. It is easy to verify that at time , have the same joint distribution under strategy profiles and .
Now assume that at time ,
| (141) |
for any realization of state, actions and Team 2’s information . Let . Then we have
| (142) | ||||
| (143) |
The equality in (142) is due to the induction hypothesis. Note that the conditional distribution does not depend on players’ strategies (see equations (2) and (3)).
At , for any realization that has non-zero probability of occurrence under the strategy profile , we have
| (144) | ||||
| (145) | ||||
| (146) | ||||
| (147) | ||||
| (148) | ||||
| (149) |
where the equality in (144) is a consequence of the chain rule and the manner in which players randomize their actions. Equality in (146) follows from Lemma 10 and the equality in (147) follows from the result in (143). Therefore, by induction, the equality in (141) holds for all . This concludes the proof of Claim I.1. ∎
Appendix J Numerical Experiments: Details
J-A Game Model
States
There are two players in Team 1 and one player in Team 2. We will refer to Player 2 in Team 1 as the defender and the Player in Team 2 as the attacker. Player 1 in Team 1 will be referred to as the signaling player. The state space of the system is . For convenience, we will denote these four states with in the same order. Recall that and represent the two entities and and denote the active and passive states of the attacker. Therefore, if the state , this means that the vulnerable entity is and the attacker is active. Similar interpretation applies for other states.
Actions
Each player in Team 1 has two actions and let . Player 2’s action corresponds to defending entity and corresponds to defending entity . Player 1’s actions are meant only for signaling. The player (attacker) in Team 2 has three actions, . For the attacker, represents the targeted attack on entity , represents the targeted attack on entity and represents the blanket attack on both entities.
Dynamics
In this particular example, the actions of the players in Team 1 do not affect the state evolution. Only the attacker’s actions affect the state evolution. We consider this type of setup for simplicity and one can let the players in Team 1 control the state evolution as well. On the other hand, note that the evolution of the CIB is controlled only by Team 1 (the signaling player) and not by Team 2 (attacker). The transition probabilities are provided in Table I. We interpret these transitions below.
Whenever the attacker is passive, i.e. or 3, then the attacker will remain passive with probability 0.7. In this case, the system state does not change. With probability 0.3, the attacker will become active. Given that the attacker becomes active, the next state may either be 0 or 1 with probability 0.5 each. In this state, even the attacker’s actions do not affect the transitions.
When the current state , the following cases are possible:
-
1.
Attacker plays : In this case, the attacker launches a successful targeted attack. The next state is either 0 or 1 with probability 0.5.
-
2.
Attacker plays : The next state is 2 with probability 1. Thus, the attacker becomes passive if it targets the invulnerable entity.
-
3.
Attacker plays : The state does not change with probability . With probability 0.3, .
The attacker’s actions can be interpreted similarly when the state .
| (0.5,0.5,0.0,0.0) | (0.0,0.0,0.0,1.0) | (0.15,0.15,0.7,0.0) | (0.15,0.15,0.0,0.7) | |
| (0.0,0.0,1.0,0.0) | (0.5,0.5,0.0,0.0) | (0.15,0.15,0.7,0.0) | (0.15,0.15,0.0,0.7) | |
| (0.7,0.0,0.3,0.0) | (0.0,0.7,0.0,0.3) | (0.15,0.15,0.7,0.0) | (0.15,0.15,0.0,0.7) |
Cost
Player 1’s actions in Team 1 do not affect the cost in this example (again for simplicity). The cost as a function of the state and the other players’ actions is provided in Table II.
| 15 | 0 | 0 | 0 | |
| 0 | 15 | 0 | 0 | |
| 10 | 20 | 0 | 0 | |
| 15 | 0 | 0 | 0 | |
| 0 | 15 | 0 | 0 | |
| 20 | 10 | 0 | 0 |
Note that when the attacker is passive, the system does not incur any cost. If the attacker launches a successful targeted attack, then the cost is 15. If the attacker launches a failed targeted attack, then the cost is 0. When the attacker launches a blanket attack, if the defender happens to be defending the vulnerable entity, the cost incurred is 10. Otherwise, the cost incurred is 20.
We consider discounted cost with a horizon of . Therefore, the cost function at time , where the function is defined in Table II. The discount factor in our problem is .
J-B Architecture and Implementation
At any time , we represent the value functions using a deep fully-connected ReLU network. The network (denoted by with parameters ) takes the CIB as input and returns the value . The state in our example takes only four values and thus, we sample the CIB belief space uniformly. For each CIB point in the sampled set, we compute an estimate of the value function as in (132). Since Team 2 has only one player, we can use the structural result in Section H-A to simplify the inner maximization problem in (132) and solve the outer minimization problem in (132) using gradient descent. The neural network representation of the value function is helpful for this as we can compute gradients using backpropagation. Since this minimization is not convex, we may not converge to the global optimum. Therefore, we use multiple initializations and pick the best solution. Finally, the interpolation step is performed by training the neural network with loss.
We illustrate this iterative procedure in Section J-D. For each time , we compute the upper value functions at the sampled belief points using the estimated value function . In the figures in Section J-D, these points are labeled “Value function” and plotted in blue. The weights of the neural network are then adjusted by regression to obtain an approximation. This approximated value function is plotted in orange. For the particular example discussed above, we can obtain very close approximations of the value functions. We can also observe that the value function converges due to discounting as the horizon of the problem increases.
J-C The Value Function and Team 1’s Strategy
The value function computed using the methodology described above is depicted in Figure 1(a). Since the the initial belief is given by , we can conclude that the min-max value of the game is 65.2. We note that the value function in Figure 1(a) is neither convex nor concave. As discussed earlier in Section V, the trade-off between signaling and secrecy can be understood from the value function. Clearly, revealing too much (or too little) information about the hidden state is unfavorable for Team 1. The most favorable belief according to the value function seems to be (or 0.72).
We also compute a min-max strategy for Team 1 and the corresponding best-response777This is not to be confused with the max-min strategy for the attacker. for the attacker in Team 2. The min-max strategy is computed using Algorithm 1.
-
1.
In the best-response, the attacker decides to launch a targeted attack (while it is active) on entity if and on entity if . For all other belief-states it launches a blanket attack. Clearly, the attacker launches a targeted attack only if it is confident enough.
-
2.
According to our computed min-max strategy, Player 2 in Team 1 simply computes the CIB and chooses to defend the entity that is more likely to be vulnerable.
-
3.
The signaling strategy for Player 1 in Team 1 is more complicated. This can be seen from the strategy depicted in Figure 1(b). The signaling strategy can be divided into three broad regions as shown in Figure 1(b).
-
(a)
The grey region is where the signaling can be arbitrary. This is because the attacker in these belief states is confident enough about which entity is vulnerable and will decide to launch a targeted attack immediately.
-
(b)
In the brown region, the signaling is negligible. This is because even slight signaling might make the attacker confident enough to launch a targeted attack.
-
(c)
In the yellow region, there is substantial signaling. In this region, the attacker uses the blanket attack and signaling can help Player 2 in Team 1 defend better.
-
(a)
We also observe an interesting pattern in the signaling strategy. Consider the CIB in Figure 1(b). Let the true state be 0. In this scenario, Player 1 in Team 1 knows that the state is 0 while Player 2 believes that state 1 is more likely. Therefore, Player 1’s signaling strategy must be such that it quickly resolves this mismatch between the state and Player 2’s belief. However, when the true state is 1, Player 2’s belief is consistent with the state. Too much signaling in this case can make the attacker more confident about the system state. We note that there is an asymmetry w.r.t. the state in the signaling requirement, i.e., signaling is favorable when the state is 0 but unfavorable when the state is 1. The asymmetric signaling strategy for states 0 and 1 depicted in Figure 1(b) achieves this goal of asymmetric signaling efficiently.
J-D Value Function Approximations
In this Section, we present successive approximations of the value functions obtained using our methodology in Section H.