Combining monte carlo and tensor-network methods for partial differential equations by sketching
Abstract.
In this paper, we propose a general framework for solving high-dimensional partial differential equations with tensor networks. Our approach uses Monte-Carlo simulations to update the solution and re-estimates the new solution from samples as a tensor-network using a recently proposed tensor train sketching technique. We showcase the versatility and flexibility of our approach by applying it to two specific scenarios: simulating the Fokker-Planck equation through Langevin dynamics and quantum imaginary time evolution via auxiliary-field quantum Monte Carlo. We also provide convergence guarantees and numerical experiments to demonstrate the efficacy of the proposed method.
1. Introduction
High-dimensional partial differential equations (PDEs) describe a wide range of phenomena in various fields, including physics, engineering, biology, and finance. However, the traditional finite difference and finite element methods scale exponentially with the number of dimensions. To circumvent the curse of dimensionality, researchers propose to pose various low-complexity ansatz on the solution to control the growth of parameters. For example, [han2018solving, yu2018deep, zhai2022deep] propose to parametrize the unknown PDE solution with deep neural networks and optimize their variational problems instead. [ambartsumyan2020hierarchical, chen2021scalable, chen2023scalable, ho2016hierarchical] approximates the differential operators with data-sparse low-rank and hierarchical matrices. [cao2018stochastic] considers a low-rank matrix approximation to the solution of time-evolving PDE.
The matrix product state (MPS), also known as the tensor train (TT), has emerged as a popular ansatz for representing solutions to many-body Schrödinger equations [white1992density, chan2011density]. Recently, it has also been applied to study statistical mechanics systems where one needs to characterize the evolution of a many-particle system via Fokker-Planck type PDEs [dolgov2011fast, chertkov2021solution, tt_committor]. Despite the inherent high-dimensionality of these PDEs, the MPS/TT representation mitigates the curse-of-dimensionality challenge by representing a -dimensional solution through the contraction of tensor components. Consequently, it achieves a storage complexity of .
To fully harness the potential of MPS/TT in solving high-dimensional PDEs, it is crucial to efficiently perform the following operations:
-
(1)
Fast applications of the time-evolution operator to an MPS/TT represented solution .
-
(2)
Compression of the MPS/TT rank after applying to , as the rank of can be larger than that of .
While these operations can be executed with high numerical precision and time complexity when the PDE problem exhibits a specialized structure (particularly in 1D-like interacting many-body systems), general problems may necessitate exponential running time in dimension to perform these tasks.
On the other hand, Monte-Carlo methods employ a representation of as a collection of random walkers. The application of a time-evolution operator to such a particle representation of can be achieved inexpensively through short-time Monte Carlo simulations. As time progresses, the variance of the particles, or random walkers, may increase, accompanied by a growth in the number of walkers. To manage both the variance and computational cost of the random walkers, it is common to use importance sampling strategies or sparsification of random walkers [greene2019beyond, lim2017fast]. Furthermore, quantum Monte-Carlo methods [Ceperley1995] suffer from an exponentially large variance, resulting from having negative or complex sample weights (a problem commonly known as “sign problem”). Most quantum Monte Carlo methods require adding certain constraints to restrict the space of the random walks, reducing the variance at the expense of introducing a bias. This gives rise to another challenge: how to unbias quantum Monte-Carlo to systematically improve the results [qin2016coupling]?
Our contribution is to combine the best of both worlds. Specifically, we adopt the MPS/TT representation as an ansatz to represent the solution, and we conduct its time evolution by incorporating short-time Monte Carlo simulations. This integration of methodologies allows us to capitalize on the advantages offered by both approaches, leading to improved performance and broader applicability in solving high-dimensional PDEs. The improvement is two-folds,
-
(1)
From the viewpoint of improving tensor network methods, we simplify the application of a semigroup to an MPS/TT via Monte Carlo simulations. While the application of using Monte Carlo is efficient, one needs a fast and accurate method to estimate an underlying MPS/TT from the random walkers. To address this requirement, we employ a recently developed parallel MPS/TT sketching technique, proposed by one of the authors, which enables estimation of the MPS/TT from the random walkers without the need for any optimization procedures.
-
(2)
From the viewpoint of improving Monte Carlo methods, we propose a novel approach to perform walker population control, by reducing the sum of random walkers into a low-rank MPS/TT. In the context of quantum Monte Carlo, we observe a reduced variance in simulations. Furthermore, when it comes to probabilistic modeling, the MPS/TT structure possesses the capability to function as a generative model [ruthotto2021introduction], enabling the generation of fresh samples and conditional samples from the solution.
We demonstrate the success of our algorithm in both statistical and quantum mechanical scenarios for determining the transient solution of parabolic type PDE. In particular, we use our method to perform Langevin dynamics and auxiliary-field quantum Monte Carlo for systems that do not exhibit 1D orderings of the variables, for example, 2D lattice systems. We further provide convergence analysis in the case of solving the Fokker-Planck equation, which demonstrates variance error that does not suffer from the curse-of-dimensionality.
The rest of the paper is organized as follows. First, we introduce some preliminaries for tensor networks, in Section 2. We discuss the proposed framework that combines Monte Carlo and MPS/TT in Section 3. In Section 4, we demonstrate the applications of our proposed framework on two specific evolution systems: the ground state energy problem for quantum many-body system and the density evolution problem by solving the Fokker-Planck equation. In Section 5, we prove the convergence of the proposed method for solving the Fokker-Planck equation. The corresponding numerical experiments for the two applications are provided in Section 6. We conclude the paper with discussions in Section 7.
2. Background and Preliminaries
In order to combine particle-based simulations and tensor-network-based approaches, we need to describe a few basic tools regarding tensor-network.
2.1. Tensor Networks and Notations
Our primary objective in this paper is to obtain an MPS/TT representation of the solution of the initial value problem (3.1) at any time . Since the technique works for at any given , we omit from the expression and use to denote an arbitrary -dimensional function:
| (2.1) |
And the state spaces .
Definition 1.
We say function admits an MPS/TT representation with ranks or bond dimensions , if one can write
| (2.2) |
for all . We call the -tensor the -th tensor core for the MPS/TT.
We present the tensor diagram depicting the MPS/TT representation in Fig. 1(a). In this diagram, each tensor core is represented by a node, and it possesses one exposed leg that represents the degree of freedom associated with the corresponding dimension.
Definition 2.
admits a matrix product operator (MPO) representation with ranks or bond dimensions , if one can write
| (2.3) |
for all , . We call the -tensor the -th tensor core for the MPO.
The tensor network diagram corresponding to the MPO representation is depicted in Fig. 1(b). For more comprehensive discussions on tensor networks and tensor diagrams, we refer interested readers to [tt_committor].


Finally, we introduce some indexing conventions. For two integers where , we use the MATLAB notation to denote the set . When working with high-dimensional functions, it is often convenient to group the variables into two subsets and think of the resulting object as a matrix. We call these matrices unfolding matrices. In particular, for , we define the -th unfolding matrix by or , which is obtained by grouping the first and last variables to form rows and columns, respectively.
2.2. Tensor Network Operations
In this subsection, we introduce several tensor network operations of high importance in our applications using the example of MPS/TT. Similar operators can be extended to more general tensor networks.
2.2.1. Marginalization
To marginalize the MPS/TT representation of defined in Definition 1, one can perform direct operations on each node . For instance, if the goal is to integrate out a specific variable , the operation can be achieved by taking the summation:
| (2.4) |
The overall computational cost of the marginalization process is at most , depending on the number of variables that need to be integrated out.
2.2.2. Normalization
Often, one needs to compute the norm
for a MPS/TT. One can again accomplish this via operations on each node. In particular, one can first form the Hadamard product in terms of two MPS/TTs, and then integrate out all variables of to get using marginalization of MPS/TT as described in Section 2.2.1. The complexity of forming the Hadamard product of two MPS/TTs is , as mentioned in [oseledets2011tensor]. Therefore, the overall complexity of computing using the described approach is also .
2.2.3. Sampling From MPS/TT Parametrized Probability Density
If given a density function in MPS/TT format, it is possible to exploit the linear algebra structure to draw independent and identically distributed (i.i.d.) samples in time [dolgov2020approximation], thereby obtaining a sample . This approach is derived from the following identity:
| (2.5) |
where each
is a conditional distribution of . We note that it is easy to obtain the marginals (hence the conditionals) in time. If we have such a decomposition (2.5), we can draw a sample in complexity as follows. We first draw component . Then we move on and draw . We continue this procedure until we draw .
2.3. Tensor-network sketching
In this subsection, we present a parallel method for obtaining the tensor cores for representing a -dimensional function that is discretely valued, i.e. each takes on finite values in a set , as an MPS/TT. This is done via an MPS/TT sketching technique proposed in [hur2022generative] where the key idea is to solve a sequence of core determining equations. Let be a set of functions such that . In this case, a representation of as Definition 1 can be obtained via solving from the following set of equations
| (2.6) | ||||
| (2.7) | ||||
based on knowledge of ’s.
However (2.6) is still inefficient to solve since each is exponentially sized, moreover, such a size prohibits it to be obtained/estimated in practice. Notice that (2.6) is over-determined, we further reduce the row dimensions by applying a left sketching function to (2.6),
| (2.8) | ||||
where is the left sketching function which compresses over variables .
Now to obtain where , we use a right-sketching by sketching the dimensions , i.e.
| (2.9) |
where is the right sketching function which compresses by contracting out variables . Plugging such a into (2.6), we get
| (2.10) |
where
| (2.11) |
| (2.12) |
and we can readily solve for .
Many different types of sketch functions can be used, e.g. random tensor sketches or cluster basis sketches [ahle2019almost, wang2015fast]. Take a single as an example, we choose a separable form for some (and similarly for ’s) in order to perform fast tensor operations. When the state space is discrete, random tensor sketch amounts to taking to be random vectors of size .
We give special focus to cluster basis sketch, defined as the following:
Definition 3.
Let be a set of single variable basis. A cluster basis sketch with -cluster consists of choosing , and also . For convenience, ’s are chosen to be orthogonal basis.
A similar construct is used in [peng2023generative]. In this case, is of size estimate , and is of size . In principle, we only need for determining a rank- MPS/TT, therefore in practice meets the need. The most important property we look for is that the variance is small, if is an unbiased estimator of . As we shall see in Section 5, when is a density and is an empirical distribution with samples approximating , the choice of such a cluster basis results in the standard deviation of being . In contrast, if one chooses a randomized function that involves all variables as a sketch, the variance would be .
Remark 1 (Rank of the MPS/TT representation).
The rank of the MPS/TT may be too large due to oversketching. For instance, when using a cluster basis sketch with a fixed cluster size, the core determining matrices can grow polynomially with the total number of dimensions. However, the intrinsic rank of the MPS/TT may be small. To address this issue, we can utilize truncated singular value decompositions (SVD) of the matrices to define projectors that reduce the rank of the MPS/TT representation. Let
| (2.13) |
be the truncated SVD with rank for . By solving (2.10) with such a truncation, we obtain an MPS/TT with tensor cores (see Fig. 2(a)). We can further insert projectors between all cores to get the “trimmed” MPS/TT, as shown in Fig. 2(b). We use thick legs to denote dimensions with a large number of indices (’s) and thin legs to denote dimensions with a small number of indices (’s). Then we can redefine the reduced tensor cores by grouping the tensor nodes
| (2.14) |
The regrouping operations are highlighted with red dashed boxes in Fig. 2(b). Now the new tensor core is of shape (Fig. 2(c)). We reduce the bond dimensions of the original MPS/TT to .



3. Proposed Framework
In this section, we present a framework for solving time-evolving systems that arise in both statistical and quantum mechanical systems. In many applications, the evolution of a -dimensional physical system in time is described by a PDE of the form,
| (3.1) |
where is a positive-semidefinite operator and has a semigroup [clifford1961algebraic, hollings2009early, howie1995fundamentals]. is a -dimensional spatial point. Depending on the problem, might be constrained to some sets. The solution of (3.1) can be obtained by applying the semigroup operator to the initial function, i.e. for all . We are especially interested in obtaining the stationary solution . When (3.1) is a Fokker-Planck equation, corresponds to the equilibrium distribution of Langevin dynamics. When (3.1) is the imaginary time evolution of a Schrödinger equation, is the lowest energy state wavefunction.
Our method alternates between the two steps detailed in Alg. 1. Notice that we introduce three versions of the state : is the ground truth state function at time ; is a particle approximation of ; is a tensor-network representation of . The significance of these two operations can be described as follows. In the first step, we use a particle-based simulation to bypass the need of applying exactly, which may have a computational cost that scales unfavorably with respect to the dimensionality. In particular, we generate that can be represented easily as a low-rank TT. In the second step, the use of the sketching algorithm [hur2022generative] bypasses a direct application of recursive SVD-based compression scheme [oseledets2011tensor], which may run into complexity. From a statistical complexity point of view, the variance of an empirical distribution scales exponentially in , therefore one cannot apply a standard tensor compression scheme to directly since it preserves the exponential statistical variance. Hence it is crucial to use the techniques proposed in [hur2022generative], which is designed to control the variance of the sketching procedure.
The method to obtain a Monte-Carlo representation of the time-evolution in Step 1 of Alg. 1 is dependent on the applications, and we present different schemes for many-body Schrödinger and Fokker-Planck equation in Section 4. In this section, we focus on the details of the second step.
| (3.2) |
3.1. MPS/TT Sketching for random walkers represented as a sum of TT
The concept of MPS/TT sketching or general tensor network sketching for density estimations has been extensively explored in [hur2022generative, ren2022high, tang2022generative]. The choice of tensor network representation in practice depends on the problem’s structure. In this work, we demonstrate the workflow using MPS/TT, but the framework can be readily extended to other tensor networks.
A crucial assumption underlying our approach is that each particle exhibits a simple structure and can be efficiently represented or approximated in MPS/TT format. For instance, in the case of a vanilla Markov Chain Monte Carlo (MCMC), we have , which can be expressed as a rank-1 MPS/TT. Consequently, the right-hand side of (3.2) becomes a summation of MPS/TTs. The tensor diagram illustrating this general particle approximation is shown in Fig. 1(a). A naive approach for representing this sum as an MPS/TT consists of directly adding these MPS/TTs, which yields an MPS/TT with a rank of [oseledets2011tensor]. This growth in rank with the number of samples can lead to a high computational complexity of when performing tensor operations.
On the other hand, depending on the problem, if we know that the intrinsic MPS/TT rank of the solution is small, it should be possible to represent the MPS/TT with a smaller size. To achieve this, we apply the method described in Section 2.3 to estimate a low-rank tensor directly from the sum of particles. Specifically, we construct and from the empirical samples and use them to solve for the tensor cores through (2.10), resulting in . This process is illustrated in Fig. 1(b), Fig. 1(c), and Fig. 1(d). It is important to note that we approximate the ground truth using stochastic samples . The estimated tensor cores form an MPS/TT representation of , denoted as .
3.2. Complexity Analysis
In this section, we assume we are given in (3.1) as constant rank MPS/TT. In terms of samples, forming and in (2.11) and (2.12) can be done as
| (3.3) | ||||
is a -tensor of shape . is a matrix of shape . The size of the linear system is independent of the number of dimensions and the total number of particles . The number of sketch functions and are hyperparameters we can control. Let , . First we consider the complexity of forming the core determining equations, i.e. evaluating and . We note that the complexity is dominated by evaluating the tensor contractions between sketch functions ’s, right sketch functions ’s and samples ’s. If the sample and sketch functions , are in low rank MPS/TT representations, then the tensor contractions in the square bracket in (3.3) can be evaluated in time. Each term in the summation can be done independently, potentially even in parallel, giving our final ’s and ’s. Taking all dimensions into account, the total complexity of evaluating ’s and ’s is .
Next, the complexity of solving the linear system (2.10) is . For all dimensions, the total complexity for solving the core determining equations is . Combing everything together, the total computational complexity for MPS/TT sketching for a discrete particle system is
| (3.4) |
Remark 2.
MPS/TT sketching is a method to control the complexity of the solution via estimating an MPS/TT representation in terms of the particles. Another more conventional approach to reduce the rank of MPS/TT is TT-round [tt-decomposition]. With this approach, one can first compute the summation in Fig. 1(a) to form a rank MPS/TT and round the resulting MPS/TT to a constant rank. There are two main drawbacks of this approach. Firstly, the QR decomposition in TT-round has complexity . Secondly, TT-round tries to make , which at the same time makes , and such an error can scale exponentially.




4. Applications
In this section, to demonstrate the generality of the proposed method, we show how it can be used in two applications: quantum Monte Carlo (Section 4.1) and solving Fokker-Planck equation (Section 4.2). For these applications, we focus on discussing how to approximate as a sum of MPS/TT, when is already in an MPS/TT representation, as required in (3.1).
4.1. Quantum Imaginary Time Evolutions
In this subsection, we apply the proposed framework to ground state energy estimation problems in quantum mechanics for the spin system. Statistical sampling-based approaches have been widely applied to these types of problems, see e.g. [lee2022unbiasing]. In this problem, we want to solve
| (4.1) |
where , and is the Hamiltonian operator. Let , where
| (4.2) |
for some , , usually takes the form of or or both. When , gives the lowest eigenvector of . This can be done with the framework detailed in Section 3 with . In what follows, we detail how can be approximated as a sum of functions via a specific version of quantum Monte Carlo, the auxiliary-field quantum Monte Carlo (AFQMC). The AFQMC method [afqmc1, afmc2] is a powerful numerical technique that has been developed to overcome some of the limitations of traditional Monte Carlo simulations. AFQMC is based on the idea of introducing auxiliary fields to decouple the correlations between particles by means of the application of the Hubbard–Stratonovich transformation [hubbard1959calculation]. This reduces the many-body problem to the calculation of a sum or integral over all possible auxiliary-field configurations. The method has been successfully applied to a wide range of problems in statistical mechanics, including lattice field theory, quantum chromodynamics, and condensed matter physics [zhang2013auxiliary, carlson2011auxiliary, shi2021some, qin2016benchmark, lee2022twenty]. However, an issue of AFQMC is that the random walkers are biased towards a mean-field solution [qin2016coupling] in order to reduce the variance caused by the “sign problem”, giving rise to bias when determining the ground state energy. To solve this issue, [qin2016coupling] alternates between running AFQMC and determining a new mean-field solution in order to remove such a bias. Our approach can be regarded as a generalization to the philosophy in [qin2016coupling], where the mean-field is now replaced by a more general MPS/TT representation.
We first focus on how to apply where . We assume is positive semi-definite, which can be easily achieved by adding a diagonal to since . To decouple the interactions through orthogonal transformations, we first perform an eigenvalue decomposition and compute
| (4.3) |
where . The approximation follows from Trotter-decomposition [hatano2005finding]. Using the identity
| (4.4) |
we can write (4.3) as
| (4.5) | ||||
Instead of sampling directly from the spin space, AFQMC approximates the -dimensional integration in (4.5) by a Monte Carlo integration in the -space. Replacing the integration with Monte Carlo samples, we get the following approximation,
| (4.6) | ||||
where is the total number of Monte Carlo samples, is the -th sample for the frequency variable of the -th dimension, and . All samples are drawn from i.i.d. standard normal distribution. The structure of such an approximation to is illustrated in Fig. 1(a), which is a sum of rank-1 MPO. The application of to a function that is already represented as an MPS/TT in the form of Def. 1 can written as
| (4.7) |
Notably, since each is a rank-1 MPO, has the same rank as . Lastly, the application of to some that is represented as an MPS can be done easily, since is a rank-1 MPO.
To summarize, we can approximate the imaginary time propagator with a summation of rank- MPOs. Applying the propagator to many-body wavefunction reduces to MPO-MPS contractions. The corresponding tensor diagram is shown in Fig. 1(b).


4.2. Fokker-Planck equation
In this subsection, we demonstrate the application of the proposed framework to numerical simulations of parabolic PDEs, specifically focusing on the overdamped Langevin process and its corresponding Fokker-Planck equations. We consider a particle system governed by the following overdamped Langevin process,
| (4.8) |
where is the state of the system, is a smooth potential energy function, is the inverse of the temperature , and is a -dimensional Wiener processs. If the potential energy function is confining for (see, e.g., [bhattacharya2009stochastic, Definition 4.2]), it can be shown that the equilibrium probability distribution of the Langevin dynamics (4.8) is the Boltzmann-Gibbs distribution,
| (4.9) |
where is the partition function. Moreover, the evolution of the distribution of the particle system can be described by the corresponding time-dependent Fokker-Planck equation,
| (4.10) |
where is the initial distribution. ensures that the . Therefore, (4.10) is the counterpart of (3.1) in our framework.
Now we need to be able to approximate as particle systems. Assuming the current density is a MPS/TT, we use the following procedures to generate a particle approximation :
-
(1)
We apply conditional sampling on the current density estimate (Section 2.2.3) to generate i.i.d. samples .
-
(2)
Then, we simulate the overdamped Langevin dynamics (4.8) using Euler-Maruyama method over time interval for each of the initial stochastic samples . By the end of we have final particle positions , and
(4.11)
by standard Monte Carlo approximation. Note that the only difference between this application and the quantum ground state problem is the conversion of the empirical distribution into an MPS/TT . Here, we employ a version of sketching for continuous distributions instead of discrete distributions as used in quantum ground state energy estimation (Section 4.1). For more detailed information on MPS/TT sketching for continuous distributions, we refer readers to Appendix C of [hur2022generative].
5. Convergence Analysis
In this section, we provide the convergence analysis for the proposed method. We look at the case for the Fokker-Planck equation, in a simplified discretized setting. Let be a Markov-transition kernel of a stochastic process on a discrete state space . Denote the stationary distribution as , which satisfies . We want to show that Alg. 1 converges to . To facilitate the discussion, we define a few new notations. For a -tensor of size , we define its “Frobenius norm” to be
| (5.1) |
Furthermore, when representing as an MPS/TT with cores , we use the notation
| (5.2) |
We are also going to use a standard perturbation theory result for the solution of a linear system.
Lemma 1 (Theorem 3.48, [wendland2017numerical]).
Suppose , . Further . Then with , we have
| (5.3) |
Our main theorem is stated in Theorem 1, which shows that the iterates in Alg. 1 are contracting towards the true solution, perturbed by some error. To prove it, we make the following assumption.
Assumption 1.
Let be a Markov-transition kernel of a stochastic process on a discrete state space . We assume that it has eigenvalues , and therefore has a unique top eigenvector . Furthermore, .
Such an assumption is important to characterize the contraction rate towards in Alg 1:
Lemma 2.
Proof.
In Lemma 2, the error is caused by approximation and variance error associated with representing the iterates of Alg. 1 as MPS/TT. To provide estimates to these errors, we define a notion that characterizes the nearness between a function and an MPS/TT:
Definition 4.
For , we say it is -identifiable with a rank- MPS/TT if each of the associated (defined in (2.13)) can be approximated by . Furthermore, .
This notion of nearness between a function and an MPS/TT can be turned into a bound between them.
Lemma 3.
Proof.
We are now ready to provide a proof of convergence for Alg 1:
Theorem 1.
Proof.
Assuming is -identifiable with some that is of rank-. By Lemma 3, this gives . Suppose for now, the empirical distribution of satisfies . Then (and also ). This means is -identifiable with . Since is the MPS/TT obtained from , by Lemma 3, we have . By triangle inequality, .
In order to complete the proof, we now give the expression of , which is due to the variance of and . We first look at of the form (2.12). Notice that each pair of involves at most variables due to the choice of cluster basis. Therefore, the variance of a single entry comes from a -marginal distribution of for a subset where . Each samples in the empirical distribution is a Bernoulli random variable with probability . Therefore, by Hoeffding’s inequality, for a fixed ,
| (5.10) |
Now we want to bound for every . With a union bound over entries of , this implies
| (5.11) |
Now since consists of applying an orthogonal change of basis to for an (due to our choice of cluster basis in Def. 3), we also have
| (5.12) |
A similar bound on can be obtained likewise. Using (5.12) and applying a union bound over all subsets that contributes to the construction of , and for all time , we get
| (5.13) |
with probability . Letting and identifying completes the proof. ∎
Remark 3.
A few remarks are in order. is the bias error committed by approximating the “true” solution by an MPS/TT (in terms of the notion defined in Def 4), which depends on the underlying physics of the problem. is the variance error of determining an MPS/TT from empirical distribution . From (5.9), it seems like we have surmounted the curse of dimensionality for solving a (discretized) high-dimensional Fokker-Planck equation, since the error of determining the true solution only grows linearly in for . However, while the variance error can be reduced by increasing the number of samples (and we only need samples to have a good approximation), in practice when solving a high-dimensional PDE, the bias (approximation) error could be difficult to reduce. This is where the curse-of-dimensionality could enter.
6. Numerical Experiments
6.1. Quantum Ground State Energy Estimations
In this subsection, we consider the ground state energy estimation problem using the transverse-field Ising model of the following quantum Hamiltonian,
| (6.1) |
where , are the Pauli matrices [gull1993imaginary],
| (6.2) | |||
| (6.3) |
and is the identity matrix. When , and is the adjacency matrix of a 1D cycle graph, the system undergoes a quantum phase transition. We consider three models under this category: (a) sites, (b) sites, and (c) sites. We also consider a 2D Ising system which is configured as (d) sites with , and the adjacency matrix of a 2D periodic square lattice. For the 1D model, the dimensions of the MPS/TT are naturally ordered according to the sites on the 1D chain. In the 2D Ising model case, we use a space-filling curve [sagan2012space] to order the dimensions. For example, we show the space-filling curve and the ordering of MPS/TT dimensions in a lattices in Fig. 6.1.

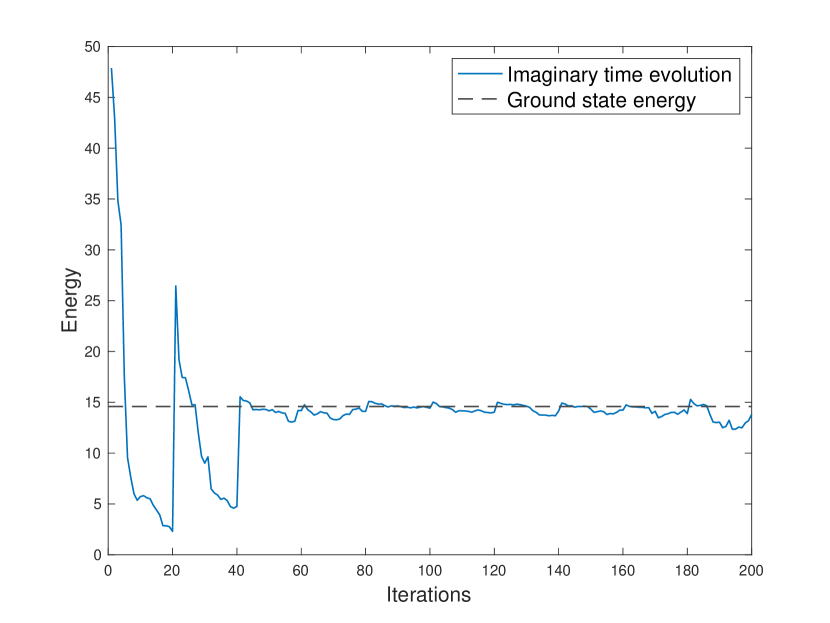
We set the infinitesimal time step to be , and use samples in each power method iteration to approximate the propagator . The rest of the parameters are set as follows: we use a (size of ) random tensor sketches (Section 2.3) for sketching and we use as the singular value threshold to solve the core determining equations (2.10). We initialize the initial wavefunction as a random MPS/TT. The imaginary time evolution energy is shown in Fig. 6.2. Here we use the symmetric energy estimator given by
| (6.4) |
where is the wavefunction of the -th iteration. Theoretically, the energy given by the symmetric estimator can only be larger than the ground state energy. Often in quantum Monte-Carlo, mixed estimators
| (6.5) |
where is a fixed reference wavefunction is used to reduce the bias error originating from the variance in [zhang2013auxiliary, shi2021some]. The variance can be further reduced by taking the average of the mixed energy estimators over several iterations.




We report the energies based on the symmetric estimator in Fig. 6.2 and compare with the ground truth energy for the quantum Hamiltonian. The ground state energy in 1D Ising model with , , and sites is reported in [sandvik2007variational]. For the 2D Ising model, we are still able to store the Hamiltonian exactly in memory so we solve the ground state energy by exact eigendecomposition.
For the 1D Ising model with sites, the ground-state energy per spin is and our approach converges to energy , with a relative error of . For the 1D Ising model with sites, the ground-state energy per spin is and our approach converges to energy , with a relative error of . For the 1D Ising model with sites, the ground-state energy per spin is and our approach converges to energy , with a relative error of . In the 2D case, the ground-state energy per spin is and our approach converges to energy , with a relative error of . Our approach has already achieved stable convergence and very accurate ground state energy estimation with only the symmetric estimators.
Next, we fix and test the performance of our proposed algorithm with a range of magnetic fields . The results for Ising model with , sites and Ising model with sites are summarized in Table 1, Table 2 and Table 3, respectively. The ground-state energy for 1D models can be exactly computed following [burkhardt1985finite, lieb1961two] and the energy for the 2D Ising model is computed by exact eigendecomposition. For all magnetic fields, our algorithm achieves stable convergence (not shown) and relative error in energy of order .
| Ground-state energy per site | -1.0100 | -1.0922 | -1.2738 | -1.5852 | -1.9418 |
| AFQMC+TT | -1.0100 | -1.0921 | -1.2726 | -1.5846 | -1.9411 |
| Relative error |
| Ground-state energy per site | -1.0100 | -1.0922 | -1.2734 | -1.5852 | -1.9418 |
| AFQMC+TT | -1.0100 | -1.0918 | -1.2712 | -1.5797 | -1.9404 |
| Relative error |
| h=0.2 | h=0.6 | h=1.0 | h=1.4 | h=1.8 | |
| Ground-state energy per site | -1.5071 | -1.5640 | -1.6788 | -1.8537 | -2.0954 |
| AFQMC+TT | -1.5071 | -1.5639 | -1.6786 | -1.8531 | -2.0945 |
| Relative error |
Tensor network sketching makes it possible to work with large number of samples while maintaining an algorithm with memory complexity that is independent of the number of samples. To demonstrate the advantage of tensor network sketching over other recompression methods, we consider a natural alternative that has constant memory usage. One can first add up the samples by performing addition in terms of MPS/TT into a high-rank tensor and truncate the rank. While doing addition, as the rank increases, if the rank hits 100 we apply the SVD-based TT-rounding procedure [oseledets2011tensor] to reduce the rank. The energy (computed by both the symmetric and mixed estimators) for 1D model and 2D Ising model are shown in Fig. 6.3. We can clearly observe that the energy convergence is more stable with the proposed sketching method.



6.2. Fokker-Planck Equation
In this numerical experiment, we solve the Fokker-Planck equation by parameterizing the density with MPS/TT. We consider two systems in this subsection, one with a simple double-well potential that takes a separable form, which is intrinsically a 1D potential, and the other one being the Ginzburg-Landau potential, where we only compare the obtained marginals with the ground truth marginals since the true density is exponentially sized.
6.2.1. Double-well Potential
We consider the following double-well potential
| (6.6) |
and the particle dynamics governed by overdamped Langevin equation (4.8). Since the potential function is easily separable, the equilibrium Boltzmann density is a product of univariate densities for each dimension, i.e.
| (6.7) |
In this example, we use and . The support of the domain is a hypercube where . To obtain a continuous MPS/TT approximation, we use the Gaussian kernel function as univariate basis functions , where
| (6.8) |
to form cluster basis for spanning the PDE solution, as mentioned in Section 2.3. In terms of the sketching function, we use cluster basis functions with as mentioned in 3. This results in tensor sketches. After sketching, we obtain a continuous analog of (2.10) (where each is a set of continuous univariate functions), and we solve this linear least-squares in function space using the same set of univariate basis functions. We visualize all the basis functions in Fig. 6.4.

We start from the uniform distribution over the hypercube and evolve the distribution towards equilibrium. To approximate the given solution at each time as an MPS/TT, we first sample from this distribution via a conditional sampling Section 2.2.3. Then we simulate the overdamped Langevin process forward for the sampled particles up to time , as detailed in Section 4.2. Then we estimate a new MPS/TT representation . We choose time and we use samples for all iterations.






In Fig. 6.5 we visualize the simulated Langevin particles, the fitted continuous MPS/TT density and the target equilibrium density for the first dimension at iteration and . We can observe that the particle distribution gets evolved effectively by the Langevin dynamics and the fitted continuous MPS/TT density accurately captures the histograms of the particle samples. The low-complexity continuous MPS/TT format also serves as an extra regularization and as a result, is not prone to overfitting. To quantify the performance of our algorithm, we evaluate the relative error metric where and are the first marginal distribution of the ground truth and MPS/TT represented distribution, respectively. At iteration , the relative error . We can further improve the performance of the algorithm by choosing more basis functions and generating more stochastic samples.
6.2.2. 1D Ginzburg-Landau Potential
The Ginzburg-Landau theory was developed to provide a mathematical description of phase transition [GL-model]. In this numerical example, we consider a simplified Ginzburg-Landau model, in which the potential energy is defined as
| (6.9) |
where , . We fix , and the temperature . We use the same set of basis function for all dimensions as shown in Fig. 6.4. We use the cluster basis with as sketching tensor, which results in a tensor rank . For this example, we solve the Fokker-Planck equation starting from the initial uniform distribution over the hypercube and evolve the distribution with time and samples.






In Fig. 6.6 we visualize the 8-th marginal distribution of the particle dynamics, the MPS/TT density, and the equilibrium density, at iteration and . At iteration , the relative error of the 8-th marginal distribution is .
6.2.3. 2D Ginzburg-Landau Potential
In this section, we consider an analogous Ginzburg-Landau-type model on a two-dimensional square lattice space. The 2D Ginzburg-Landau example cannot be easily done with the traditional tensor-network method, which requires the compression of the semigroup operator into an MPO. Such a compression is difficult when the variables cannot be ordered along a 1D line. This, however, is not an issue for us, since we never compress any operator in our framework. Similarly, we define the value of the scalar field at lattice points as , , and define the potential energy,
| (6.10) |
with boundary conditions
| (6.11) |
Here the total number of dimensionality is . We set , , and the inverse temperature for this example. All other settings remain the same as in the 1D case (Section 6.2.3). We use the same set of basis functions for all dimensions as shown in Fig. 6.4 and we use the same cluster basis with as in the previous section. We solve the Fokker-Planck equation starting from the initial uniform distribution over the hypercube and evolve the distribution with time and samples. To order the dimensions in a 2D lattice into a chain-like structure, we use the space-filling curve (Fig. 6.1).


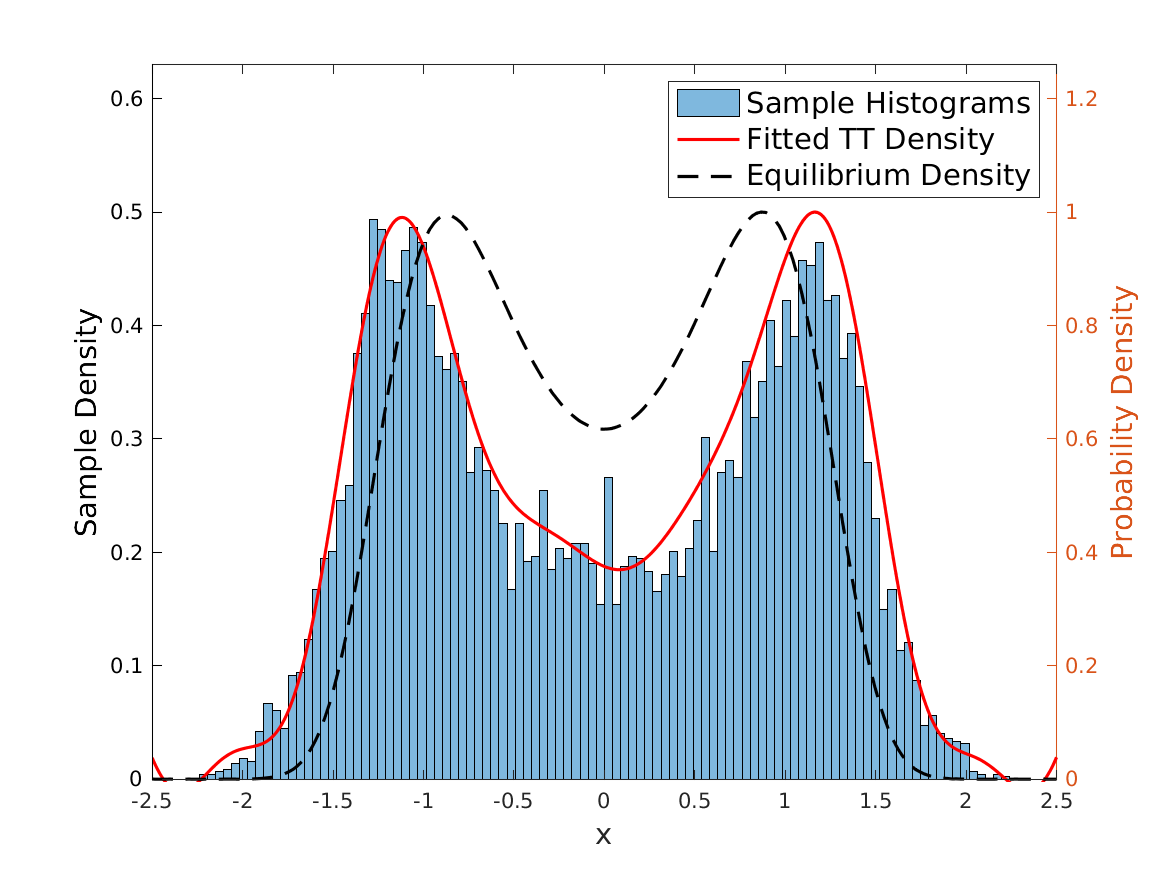



In Fig. 6.7 we visualize the 8-th marginal distribution of the particle dynamics, the MPS/TT density, and the equilibrium density, at iteration and . At iteration , the relative error of the 8-th marginal distribution is .
7. Conclusion
In this paper, we propose a novel and general framework that combines Monte-Carlo simulation with an MPS/TT ansatz. By leveraging the advantages of both approaches, our method offers an efficient way to apply the semigroup/time-evolution operator and control the variance and population of random walkers using tensor-sketching techniques.
The performance of our algorithm is determined by two factors: the number of randomized sketches and the number of samples used. Our algorithm is expected to succeed when we can employ samples to determine a low-rank MPS/TT representation based on estimating certain low-order moments. Hence, it is crucial to investigate the function space under time evolution and understand how the MPS/TT representation of the solution can be efficiently determined using Monte-Carlo method in a statistically optimal manner.
8. Acknowledgements
Y.C. and Y.K. acknowledge partial support from NSF Award No. DMS-211563 and DOE Award No. DE-SC0022232. The authors also thank Michael Lindsey and Shiwei Zhang regarding discussions on potential improvements for the proposed method.